Algorithmen zur Optimierung mit Populationen: Der Affen-Algorithmus (Monkey Algorithmus, MA)
Andrey Dik | 3 Mai, 2023
Inhalt:
1. Einführung
2. Algorithmus
3. Testergebnisse
1. Einführung
Der Affen-Algorithmus (MA) ist ein metaheuristischer Suchalgorithmus. In diesem Artikel werden die wichtigsten Komponenten des Algorithmus beschrieben und Lösungen für das Klettern (Aufwärtsbewegung), den lokalen Sprung und den globalen Sprung vorgestellt. Der Algorithmus wurde von R. Zhao und W. Tang im Jahr 2007 vorgeschlagen. Der Algorithmus simuliert das Verhalten von Affen, die sich auf der Suche nach Nahrung über Berge bewegen und springen. Es wird vermutet, dass die Affen denken, dass je höher der Berg ist, desto mehr Nahrung gibt es auf seinem Gipfel.
Das von den Affen erkundete Gebiet ist eine Fitnessfunktionslandschaft, sodass der höchste Berg der Lösung des Problems entspricht (wir betrachten das Problem der globalen Maximierung). Von seiner aktuellen Position aus bewegt sich jeder der Affen nach oben, bis er die Spitze des Berges erreicht. Das Klettern ist so konzipiert, dass der Wert der Zielfunktion schrittweise verbessert wird. Dann macht der Affe eine Reihe von lokalen Sprüngen in eine zufällige Richtung, in der Hoffnung, einen höheren Platz zu finden, und die Kletterbewegung wird wiederholt. Nach einer bestimmten Anzahl von Klettervorgängen und lokalen Sprüngen glaubt der Affe, dass er die Landschaft in der Nähe seiner Ausgangsposition ausreichend erkundet hat.
Um einen neuen Bereich des Suchraums zu erkunden, führt der Affe einen langen globalen Sprung durch. Die oben genannten Schritte werden in den Algorithmusparametern eine bestimmte Anzahl von Malen wiederholt. Die Lösung des Problems wird als der höchste der von der gegebenen Affenpopulation gefundenen Scheitelpunkt erklärt. Allerdings verbringt die MA viel Rechenzeit mit der Suche nach lokalen optimalen Lösungen während des Kletterns. Der globale Sprungprozess kann die Konvergenzrate des Algorithmus beschleunigen. Der Zweck dieses Prozesses ist es, die Affen zu zwingen, neue Suchmöglichkeiten zu finden, um nicht in die lokale Suche zu verfallen. Der Algorithmus hat Vorteile wie eine einfache Struktur, relativ hohe Zuverlässigkeit und eine gute Suche nach lokalen optimalen Lösungen.
Der MA ist eine neue Art von evolutionärem Algorithmus, der viele komplexe Optimierungsprobleme lösen kann, die durch Nichtlinearität, Nichtdifferenzierbarkeit und hohe Dimensionalität gekennzeichnet sind. Der Unterschied zu anderen Algorithmen besteht darin, dass der Zeitaufwand des MA hauptsächlich auf den Einsatz des Kletterverfahrens zurückzuführen ist, um lokale optimale Lösungen zu finden. Im nächsten Abschnitt beschreibe ich die Hauptkomponenten des Algorithmus, die vorgestellten Lösungen, die Initialisierung, das Klettern, die Beobachtung und den Sprung.
2. Algorithmus
Zum besseren Verständnis des Affen-Algorithmus ist es sinnvoll, mit Pseudocode zu beginnen.
Der Pseudocode des MA-Algorithmus:
1. Verteilen der Affen zufällig über den Suchraum.
2. Messen der Höhe der Affenposition.
3. Ausführen einer bestimmte Anzahl von lokalen Sprüngen.
4. Wenn der in Schritt 3 erhaltene neue Scheitelpunkt höher liegt, sollten von dieser Stelle aus lokale Sprünge gemacht werden.
5. Wenn die Anzahl der lokalen Sprünge erschöpft ist und kein neuer Scheitelpunkt gefunden wird, wird ein globaler Sprung durchgeführt.
6. Nach Schritt 5, Schritt 3 wiederholen
7. Wiederholen des Vorgangs ab Schritt 2, bis das Stoppkriterium erfüllt ist.
Analysieren wir die einzelnen Punkte des Pseudocodes genauer.
1. Zu Beginn der Optimierung ist der Suchraum für die Affen unbekannt. Die Tiere befinden sich zufällig in unbekanntem Terrain, da die Wahrscheinlichkeit, Nahrung zu finden, an jedem Ort gleich groß ist.
2. Der Prozess der Messung der Höhe der Affenposition ist die Erfüllung der Aufgabe der Fitnessfunktion.
3. Bei lokalen Sprüngen ist die Anzahl der Sprünge in den Algorithmusparametern begrenzt. Das bedeutet, dass der Affe versucht, seine derzeitige Position zu verbessern, indem er kleine lokale Sprünge im Lebensmittelbereich macht. Wenn die neu gefundene Nahrungsquelle besser ist, gehe zu Schritt 4.
4. Eine neue Nahrungsquelle wurde gefunden, die Anzahl der lokalen Sprünge wird zurückgesetzt. Nun wird von diesem Ort aus nach einer neuen Nahrungsquelle gesucht.
5. Wenn lokale Sprünge nicht zur Entdeckung einer besseren Nahrungsquelle führen, kommt der Affe zu dem Schluss, dass das aktuelle Gebiet vollständig erforscht ist und es an der Zeit ist, nach einem neuen, weiter entfernten Ort zu suchen. An dieser Stelle stellt sich die Frage nach der Richtung der weiteren Sprünge? Die Idee des Algorithmus besteht darin, den Koordinatenmittelpunkt aller Affen zu verwenden und so für eine gewisse Kommunikation zu sorgen - Kommunikation zwischen Affen in einer Herde: Affen können laut schreien und sind durch ihr gutes räumliches Gehör in der Lage, die genaue Position ihrer Verwandten zu bestimmen. Wenn man die Position der Verwandten kennt (die Verwandten werden sich nicht an Orten aufhalten, an denen es keine Nahrung gibt), ist es möglich, die optimale neue Position der Nahrung annähernd zu berechnen, daher ist es notwendig, einen Sprung in diese Richtung zu machen.
Im ursprünglichen Algorithmus macht der Affe einen globalen Sprung entlang einer Linie, die durch das Zentrum der Koordinaten aller Affen und die aktuelle Position des Tieres verläuft. Die Richtung des Sprungs kann entweder in Richtung des Koordinatenzentrums oder in die entgegengesetzte Richtung vom Zentrum aus erfolgen. Ein Sprung in die entgegengesetzte Richtung des Zentrums widerspricht der eigentlichen Logik der Nahrungssuche mit angenäherten Koordinaten für alle Affen, was durch meine Experimente mit dem Algorithmus bestätigt wurde - in der Tat ist dies eine 50%ige Wahrscheinlichkeit, dass es eine Entfernung vom globalen Optimum geben wird.
Die Praxis hat gezeigt, dass es vorteilhafter ist, über das Koordinatenzentrum hinaus zu springen, als nicht zu springen oder in die entgegengesetzte Richtung zu springen. Die Konzentration aller Affen an einem Punkt findet nicht statt, obwohl eine solche Logik dies auf den ersten Blick unvermeidlich erscheinen lässt. Wenn die Affen die Grenze der lokalen Sprünge ausgeschöpft haben, springen sie weiter als das Zentrum, wodurch sich die Position aller Affen in der Population dreht. Wenn wir uns höhere Affen vorstellen, die diesem Algorithmus gehorchen, sehen wir ein Rudel von Tieren, das von Zeit zu Zeit über den geometrischen Mittelpunkt des Rudels springt, während sich das Rudel selbst zu einer reicheren Nahrungsquelle bewegt. Dieser Effekt der „Rudelbewegung“ ist in der Animation des Algorithmus deutlich zu sehen (der ursprüngliche Algorithmus hat diesen Effekt nicht und die Ergebnisse sind schlechter).
6. Nachdem der Affe einen globalen Sprung gemacht hat, beginnt er, die Position der Nahrungsquelle am neuen Ort zu bestimmen. Der Prozess wird fortgesetzt, bis das Stoppkriterium erfüllt ist.
Die gesamte Idee des Algorithmus lässt sich leicht in einem einzigen Diagramm darstellen. Die Bewegung des Affen ist in Abbildung 1 durch Kreise mit Zahlen gekennzeichnet. Jede Zahl ist eine neue Position für den Affen. Die kleinen gelben Kreise stehen für gescheiterte lokale Sprungversuche. Die Zahl 6 gibt die Position an, bei der die Grenze der lokalen Sprünge ausgeschöpft ist und keine neue beste Position gefunden wurde. Die Kreise ohne Zahlen stellen die Standorte der übrigen Teilnehmer dar. Der geometrische Mittelpunkt des Pakets wird durch einen kleinen Kreis mit den Koordinaten (x,y) angezeigt.

Bild 1. Schematische Darstellung der Bewegung eines Affen im Rudel
Werfen wir einen Blick auf den MA-Code.
Es ist praktisch, einen Affen in einem Rudel mit der Struktur S_Monkey zu beschreiben. Die Struktur enthält das Array c[] mit den aktuellen Koordinaten, das Array cB[] mit den besten Nahrungskoordinaten (von der Position mit diesen Koordinaten erfolgen lokale Sprünge), h und hB — der Höhenwert des aktuellen Punktes bzw. der Wert des höchsten Punktes. lCNT — lokaler Sprungzähler, der die Anzahl der Versuche zur Verbesserung einer Position begrenzt.
//—————————————————————————————————————————————————————————————————————————————— struct S_Monkey { double c []; //coordinates double cB []; //best coordinates double h; //height of the mountain double hB; //best height of the mountain int lCNT; //local search counter }; //——————————————————————————————————————————————————————————————————————————————
Die Klasse des Affen-Algorithmus C_AO_MA unterscheidet sich nicht von den zuvor besprochenen Algorithmen. Ein Rudel Affen wird in der Klasse als Array m[] der Affen-Struktur dargestellt. Die Deklarationen in der Klasse der Methoden und Mitglieder sind vom Codevolumen her gering. Da der Algorithmus prägnant ist, wird im Gegensatz zu vielen anderen Optimierungsalgorithmen hier nicht sortiert. Wir benötigen Arrays, um das Maximum, das Minimum und den Schritt der optimierten Parameter festzulegen, sowie konstante Variablen, um die externen Parameter des Algorithmus an sie zu übergeben. Gehen wir nun zur Beschreibung der Methoden über, die die Hauptlogik von MA enthalten.
//—————————————————————————————————————————————————————————————————————————————— class C_AO_MA { //---------------------------------------------------------------------------- public: S_Monkey m []; //monkeys public: double rangeMax []; //maximum search range public: double rangeMin []; //minimum search range public: double rangeStep []; //step search public: double cB []; //best coordinates public: double hB; //best height of the mountain public: void Init (const int coordNumberP, //coordinates number const int monkeysNumberP, //monkeys number const double bCoefficientP, //local search coefficient const double vCoefficientP, //jump coefficient const int jumpsNumberP); //jumps number public: void Moving (); public: void Revision (); //---------------------------------------------------------------------------- private: int coordNumber; //coordinates number private: int monkeysNumber; //monkeys number private: double b []; //local search coefficient private: double v []; //jump coefficient private: double bCoefficient; //local search coefficient private: double vCoefficient; //jump coefficient private: double jumpsNumber; //jumps number private: double cc []; //coordinate center private: bool revision; private: double SeInDiSp (double In, double InMin, double InMax, double Step); private: double RNDfromCI (double min, double max); private: double Scale (double In, double InMIN, double InMAX, double OutMIN, double OutMAX, bool revers); }; //——————————————————————————————————————————————————————————————————————————————
Die öffentliche Methode Init() dient der Initialisierung des Algorithmus. Hier legen wir die Größe der Arrays fest. Wir initialisieren die Qualität des besten vom Affen gefundenen Gebiets mit dem kleinstmöglichen „double“-Wert, und wir werden dasselbe mit den entsprechenden Variablen der MA-Struktur-Arrays tun.
//—————————————————————————————————————————————————————————————————————————————— void C_AO_MA::Init (const int coordNumberP, //coordinates number const int monkeysNumberP, //monkeys number const double bCoefficientP, //local search coefficient const double vCoefficientP, //jump coefficient const int jumpsNumberP) //jumps number { MathSrand ((int)GetMicrosecondCount ()); // reset of the generator hB = -DBL_MAX; revision = false; coordNumber = coordNumberP; monkeysNumber = monkeysNumberP; bCoefficient = bCoefficientP; vCoefficient = vCoefficientP; jumpsNumber = jumpsNumberP; ArrayResize (rangeMax, coordNumber); ArrayResize (rangeMin, coordNumber); ArrayResize (rangeStep, coordNumber); ArrayResize (b, coordNumber); ArrayResize (v, coordNumber); ArrayResize (cc, coordNumber); ArrayResize (m, monkeysNumber); for (int i = 0; i < monkeysNumber; i++) { ArrayResize (m [i].c, coordNumber); ArrayResize (m [i].cB, coordNumber); m [i].h = -DBL_MAX; m [i].hB = -DBL_MAX; m [i].lCNT = 0; } ArrayResize (cB, coordNumber); } //——————————————————————————————————————————————————————————————————————————————
Die erste öffentliche Methode Moving(), die bei jeder Iteration ausgeführt werden muss, implementiert die Logik des Affensprungs. Bei der ersten Iteration, wenn die „revision“-Flags „false“ ist, müssen die Agenten mit zufälligen Werten im Koordinatenbereich des untersuchten Raums initialisiert werden, was der zufälligen Position der Affen im Lebensraum des Rudels entspricht. Um mehrfach wiederholte Operationen wie die Berechnung der Koeffizienten von globalen und lokalen Sprüngen zu reduzieren, speichern wir die Werte für die entsprechenden Koordinaten (jede der Koordinaten kann eine eigene Dimension haben) in den Arrays v[] und b[]. Wir setzen den Zähler der lokalen Sprünge von jedem Affen auf Null zurück.
//---------------------------------------------------------------------------- if (!revision) { hB = -DBL_MAX; for (int monk = 0; monk < monkeysNumber; monk++) { for (int c = 0; c < coordNumber; c++) { m [monk].c [c] = RNDfromCI (rangeMin [c], rangeMax [c]); m [monk].c [c] = SeInDiSp (m [monk].c [c], rangeMin [c], rangeMax [c], rangeStep [c]); m [monk].h = -DBL_MAX; m [monk].hB = -DBL_MAX; m [monk].lCNT = 0; } } for (int c = 0; c < coordNumber; c++) { v [c] = (rangeMax [c] - rangeMin [c]) * vCoefficient; b [c] = (rangeMax [c] - rangeMin [c]) * bCoefficient; } revision = true; }
Um den Koordinatenmittelpunkt aller Affen zu berechnen, verwenden wir das Array cc[], dessen Dimension der Anzahl der Koordinaten entspricht. Die Idee dabei ist, die Koordinaten der Affen zu addieren und die resultierende Summe durch die Größe der Population zu dividieren. Der Mittelpunkt der Koordinaten ist also das arithmetische Mittel der Koordinaten.
//calculate the coordinate center of the monkeys---------------------------- for (int c = 0; c < coordNumber; c++) { cc [c] = 0.0; for (int monk = 0; monk < monkeysNumber; monk++) { cc [c] += m [monk].cB [c]; } cc [c] /= monkeysNumber; }
Laut Pseudocode springt der Affe von seinem Standort mit gleicher Wahrscheinlichkeit in alle Richtungen, wenn die Grenze der lokalen Sprünge nicht erreicht wird. Der Radius des Kreises der lokalen Sprünge wird durch den Koeffizienten der lokalen Sprünge bestimmt, der entsprechend der Dimension der Koordinaten des Arrays b[] neu berechnet wird.
//local jump-------------------------------------------------------------- if (m [monk].lCNT < jumpsNumber) //local jump { for (int c = 0; c < coordNumber; c++) { m [monk].c [c] = RNDfromCI (m [monk].cB [c] - b [c], m [monk].cB [c] + b [c]); m [monk].c [c] = SeInDiSp (m [monk].c [c], rangeMin [c], rangeMax [c], rangeStep [c]); } }
Kommen wir nun zu einem sehr wichtigen Teil der MA-Logik - die Leistung des Algorithmus hängt weitgehend von der Implementierung globaler Sprünge ab. Verschiedene Autoren nähern sich diesem Thema aus unterschiedlichen Blickwinkeln und bieten alle möglichen Lösungen an. Den Untersuchungen zufolge haben lokale Sprünge kaum Auswirkungen auf die Konvergenz des Algorithmus. Es sind die globalen Sprünge, die die Fähigkeit des Algorithmus bestimmen, von lokalen Extrema zu „springen“. Meine Experimente mit globalen Sprüngen haben nur einen brauchbaren Ansatz für diesen speziellen Algorithmus ergeben, der die Ergebnisse verbessert.
Oben haben wir besprochen, dass es ratsam ist, zum Mittelpunkt der Koordinaten zu springen, und dass es besser ist, wenn der Endpunkt hinter dem Mittelpunkt liegt und nicht zwischen dem Mittelpunkt und den aktuellen Koordinaten. Dieser Ansatz wendet die Levy-Fluggleichungen an, die wir in dem Artikel über den Kuckucks-Optimierungsalgorithmus (COA) ausführlich beschrieben haben.

Bild 2. Graphen der Levy-Flugfunktion in Abhängigkeit vom Gleichungsgrad
Die Affenkoordinaten werden anhand der folgenden Gleichung berechnet:
m [monk].c [c] = cc [c] + v [c] * pow (r2, -2.0);
wobei:
cc [c] — Koordinate des Zentrums der Koordinaten,
v [c] — Koeffizient des auf die Dimension des Suchraums umgerechneten Sprungradius,
r2 — Zahl im Bereich von 1 bis 20.
Durch die Anwendung des Levy'schen Fluges bei dieser Operation erreichen wir eine höhere Wahrscheinlichkeit, dass der Affe in der Nähe des Koordinatenzentrums auftrifft, und eine geringere Wahrscheinlichkeit, dass er sich weit außerhalb des Zentrums befindet. Auf diese Weise schaffen wir ein Gleichgewicht zwischen Forschen und Nutzen der Suche und entdecken gleichzeitig neue Nahrungsquellen. Liegt die empfangene Koordinate außerhalb der unteren Grenze des zulässigen Bereichs, so wird die Koordinate auf die entsprechende Entfernung zur oberen Grenze des Bereichs übertragen. Das Gleiche gilt, wenn die Obergrenze überschritten wird. Am Ende der Koordinatenberechnungen überprüfen wir den erhaltenen Wert auf Übereinstimmung mit den Grenzen und dem Forschungsschritt.
//global jump------------------------------------------------------------- for (int c = 0; c < coordNumber; c++) { r1 = RNDfromCI (0.0, 1.0); r1 = r1 > 0.5 ? 1.0 : -1.0; r2 = RNDfromCI (1.0, 20.0); m [monk].c [c] = cc [c] + v [c] * pow (r2, -2.0); if (m [monk].c [c] < rangeMin [c]) m [monk].c [c] = rangeMax [c] - (rangeMin [c] - m [monk].c [c]); if (m [monk].c [c] > rangeMax [c]) m [monk].c [c] = rangeMin [c] + (m [monk].c [c] - rangeMax [c]); m [monk].c [c] = SeInDiSp (m [monk].c [c], rangeMin [c], rangeMax [c], rangeStep [c]); }
Nach lokalen/globalen Sprüngen erhöhen wir den Sprungzähler um eins.
m [monk].lCNT++;
Revision() ist die zweite öffentliche Methode, die bei jeder Iteration aufgerufen wird, nachdem die Fitnessfunktion berechnet wurde. Diese Methode aktualisiert die globale Lösung, wenn eine bessere Lösung gefunden wird. Die Logiken der Verarbeitung der Ergebnisse nach lokalen und globalen Sprüngen unterscheiden sich voneinander. Bei lokalen Sprüngen muss geprüft werden, ob sich die aktuelle Position verbessert hat, und diese aktualisiert werden (in den nächsten Iterationen wird von dieser neuen Position aus gesprungen), während bei globalen Sprüngen nicht geprüft wird, ob sich die Position verbessert hat - neue Sprünge werden in jedem Fall von dieser Position aus gemacht.
//—————————————————————————————————————————————————————————————————————————————— void C_AO_MA::Revision () { for (int monk = 0; monk < monkeysNumber; monk++) { if (m [monk].h > hB) { hB = m [monk].h; ArrayCopy (cB, m [monk].c, 0, 0, WHOLE_ARRAY); } if (m [monk].lCNT <= jumpsNumber) //local jump { if (m [monk].h > m [monk].hB) { m [monk].hB = m [monk].h; ArrayCopy (m [monk].cB, m [monk].c, 0, 0, WHOLE_ARRAY); m [monk].lCNT = 0; } } else //global jump { m [monk].hB = m [monk].h; ArrayCopy (m [monk].cB, m [monk].c, 0, 0, WHOLE_ARRAY); m [monk].lCNT = 0; } } } //——————————————————————————————————————————————————————————————————————————————
Wir können die Ähnlichkeit der Ansätze dieses Algorithmus mit einer Gruppe von Schwarmintelligenz-Algorithmen feststellen, wie z.B.Partikelschwarm (PSO) und andere mit einer ähnlichen Suchstrategie-Logik.
3. Testergebnisse
MA-Prüfstandsergebnisse:
2023.02.22 19:36:21.841 Test_AO_MA (EURUSD,M1) C_AO_MA:50;0.01;0.9;50
2023.02.22 19:36:21.841 Test_AO_MA (EURUSD,M1) =============================
2023.02.22 19:36:26.877 Test_AO_MA (EURUSD,M1) 5 Rastrigin; Funktionsdurchläufe 10000 Ergebnis: 64.89788419898215
2023.02.22 19:36:26.878 Test_AO_MA (EURUSD,M1) Score: 0.80412
2023.02.22 19:36:36.734 Test_AO_MA (EURUSD,M1) 25 Rastrigin; Funktionsdurchläufe 10000 Ergebnis: 55.57339368461394
2023.02.22 19:36:36.734 Test_AO_MA (EURUSD,M1) Score: 0.68859
2023.02.22 19:37:34.865 Test_AO_MA (EURUSD,M1) 500 Rastrigin; Funktionsdurchläufe 10000 Ergebnis: 41.41612351844293
2023.02.22 19:37:34.865 Test_AO_MA (EURUSD,M1) Score: 0.51317
2023.02.22 19:37:34.865 Test_AO_MA (EURUSD,M1) =============================
2023.02.22 19:37:39.165 Test_AO_MA (EURUSD,M1) 5 Forest; Funktionsdurchläufe 10000 Ergebnis: 0.4307085210424681
2023.02.22 19:37:39.165 Test_AO_MA (EURUSD,M1) Score: 0.24363
2023.02.22 19:37:49.599 Test_AO_MA (EURUSD,M1) 25 Forest; Funktionsdurchläufe 10000 Ergebnis: 0.19875891413613866
2023.02.22 19:37:49.599 Test_AO_MA (EURUSD,M1) Score: 0.11243
2023.02.22 19:38:47.793 Test_AO_MA (EURUSD,M1) 500 Forest; Funktionsdurchläufe 10000 Ergebnis: 0.06286212143582881
2023.02.22 19:38:47.793 Test_AO_MA (EURUSD,M1) Score: 0.03556
2023.02.22 19:38:47.793 Test_AO_MA (EURUSD,M1) =============================
2023.02.22 19:38:53.947 Test_AO_MA (EURUSD,M1) 5 Megacity; Funktionsdurchläufe 10000 Ergebnis: 2.8
2023.02.22 19:38:53.947 Test_AO_MA (EURUSD,M1) Score: 0.23333
2023.02.22 19:39:03.336 Test_AO_MA (EURUSD,M1) 25 Megacity; Funktionsdurchläufe 10000 Ergebnis: 0.96
2023.02.22 19:39:03.336 Test_AO_MA (EURUSD,M1) Score: 0.08000
2023.02.22 19:40:02.068 Test_AO_MA (EURUSD,M1) 500 Megacity; Funktionsdurchläufe 10000 Ergebnis: 0.34120000000000006
2023.02.22 19:40:02.068 Test_AO_MA (EURUSD,M1) Score: 0.02843
Betrachtet man die Visualisierung des Algorithmus auf Testfunktionen, so ist festzustellen, dass es keine Muster im Verhalten gibt, das dem des RND-Algorithmus sehr ähnlich ist. Es gibt eine kleine Konzentration von Agenten in lokalen Extremen, was auf Versuche hinweist, die Lösung durch den Algorithmus zu verfeinern, aber es gibt keine offensichtlichen Staus.

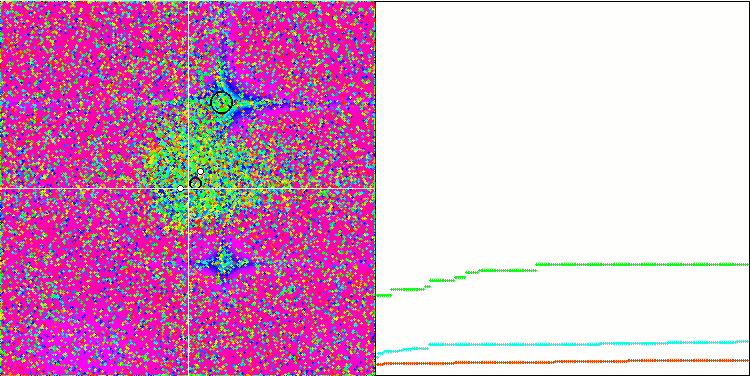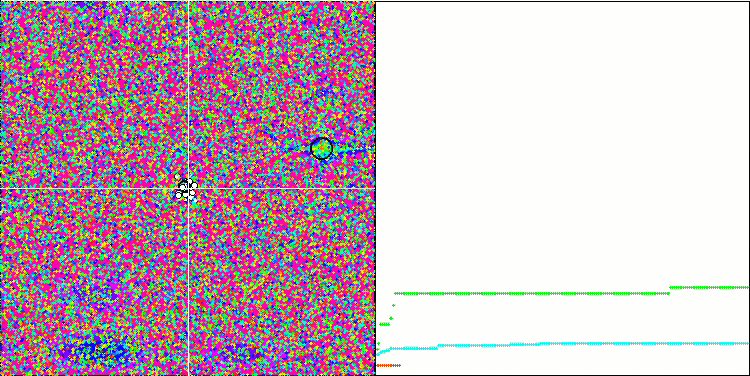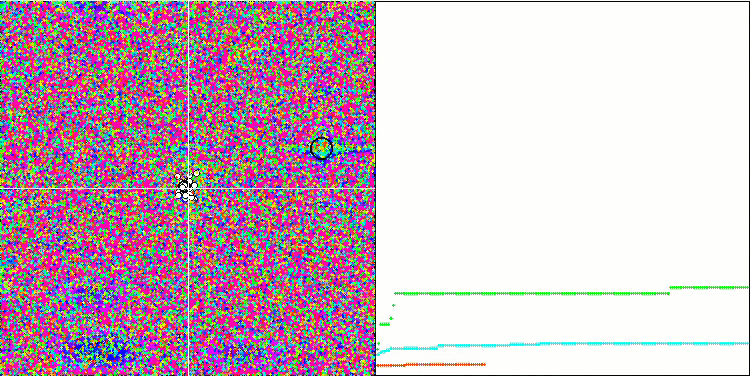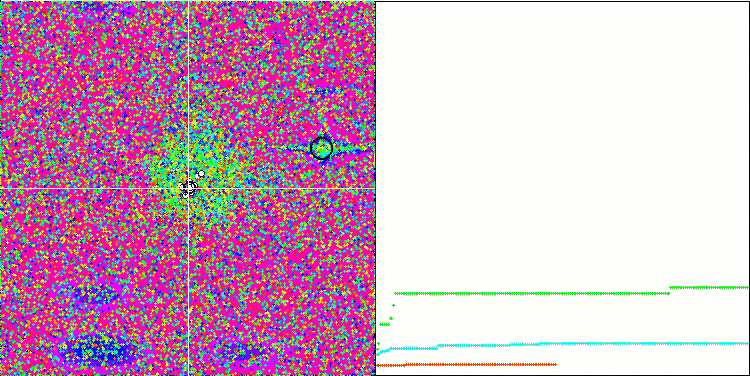
MA mit der Rastrigin-Testfunktion.

MA mit der Forest-Testfunktion.
MA mit der Megacity-Testfunktion.
Kommen wir nun zur Analyse der Testergebnisse. Auf der Grundlage der Bewertungsergebnisse rangiert der MA-Algorithmus am Ende der Tabelle zwischen GSA und FSS. Da die Prüfung der Algorithmen auf dem Prinzip der vergleichenden Analyse beruht, bei der die Bewertungen der Ergebnisse relative Werte zwischen dem besten und dem schlechtesten Ergebnis sind, führt das Auftreten eines Algorithmus mit hervorragenden Ergebnissen in einem Test und schlechten Ergebnissen in anderen Tests manchmal zu einer Änderung der Parameter anderer Testteilnehmer.
Die Ergebnisse von MA haben jedoch nicht zu einer Neuberechnung der Ergebnisse anderer Testteilnehmer in der Tabelle geführt. MA hat kein einziges Testergebnis, das am schlechtesten wäre, obwohl es Algorithmen mit null relativen Ergebnissen und einer höheren Bewertung gibt (z. B. GSA). Obwohl sich der Algorithmus also eher bescheiden verhält und die Suchfähigkeit nicht gut genug zum Ausdruck kommt, zeigt der Algorithmus stabile Ergebnisse, was eine positive Eigenschaft für Optimierungsalgorithmen ist.
| AO | Beschreibung | Rastrigin | Rastrigin final | Forest | Forest final | Megacity (diskret) | Megacity final | Endergebnis | ||||||
| 10 Parameter (5 F) | 50 Parameter (25 F) | 1000 Parameter (500 F) | 10 Parameter (5 F) | 50 Parameter (25 F) | 1000 Parameter (500 F) | 10 Parameter (5 F) | 50 Parameter (25 F) | 1000 Parameter (500 F) | ||||||
| HS | Harmoniesuche | 1.00000 | 1.00000 | 0.57048 | 2.57048 | 1.00000 | 0.98931 | 0.57917 | 2.56848 | 1.00000 | 1.00000 | 1.00000 | 3.00000 | 100.000 |
| ACOm | Ameisen-Kolonie-Optimierung M | 0.34724 | 0.18876 | 0.20182 | 0.73782 | 0.85966 | 1.00000 | 1.00000 | 2.85966 | 1.00000 | 0.88484 | 0.13497 | 2.01981 | 68.094 |
| IWO | Optimierung mit invasiven Unkräutern | 0.96140 | 0.70405 | 0.35295 | 2.01840 | 0.68718 | 0.46349 | 0.41071 | 1.56138 | 0.75912 | 0.39732 | 0.80145 | 1.95789 | 67.087 |
| COAm | Kuckuck-Optimierungsalgorithmus M | 0.92701 | 0.49111 | 0.30792 | 1.72604 | 0.55451 | 0.34034 | 0.21362 | 1.10847 | 0.67153 | 0.30326 | 0.41127 | 1.38606 | 50.422 |
| FAm | Firefly-Algorithmus M | 0.60020 | 0.35662 | 0.20290 | 1.15972 | 0.47632 | 0.42299 | 0.64360 | 1.54291 | 0.21167 | 0.25143 | 0.84884 | 1.31194 | 47.816 |
| BA | Fledermaus-Algorithmus | 0.40658 | 0.66918 | 1.00000 | 2.07576 | 0.15275 | 0.17477 | 0.33595 | 0.66347 | 0.15329 | 0.06334 | 0.41821 | 0.63484 | 39.711 |
| ABC | Künstliches Bienenvolk (Artificial Bee Colony, ABC) | 0.78424 | 0.34335 | 0.24656 | 1.37415 | 0.50591 | 0.21455 | 0.17249 | 0.89295 | 0.47444 | 0.23609 | 0.33526 | 1.04579 | 38.937 |
| BFO | Optimierung der bakteriellen Futtersuche | 0.67422 | 0.32496 | 0.13988 | 1.13906 | 0.35462 | 0.26623 | 0.26695 | 0.88780 | 0.42336 | 0.30519 | 0.45578 | 1.18433 | 37.651 |
| GSA | Algorithmus für die Schwerkraftsuche | 0.70396 | 0.47456 | 0.00000 | 1.17852 | 0.26854 | 0.36416 | 0.42921 | 1.06191 | 0.51095 | 0.32436 | 0.00000 | 0.83531 | 35.937 |
| MA | Affen-Algorithmus | 0.33300 | 0.35107 | 0.17340 | 0.85747 | 0.03684 | 0.07891 | 0.11546 | 0.23121 | 0.05838 | 0.00383 | 0.25809 | 0.32030 | 14.848 |
| FSS | Fischschulsuche | 0.46965 | 0.26591 | 0.13383 | 0.86939 | 0.06711 | 0.05013 | 0.08423 | 0.20147 | 0.00000 | 0.00959 | 0.19942 | 0.20901 | 13.215 |
| PSO | Partikelschwarmoptimierung | 0.20515 | 0.08606 | 0.08448 | 0.37569 | 0.13192 | 0.10486 | 0.28099 | 0.51777 | 0.08028 | 0.21100 | 0.04711 | 0.33839 | 10.208 |
| RND | zufällig | 0.16881 | 0.10226 | 0.09495 | 0.36602 | 0.07413 | 0.04810 | 0.06094 | 0.18317 | 0.00000 | 0.00000 | 0.11850 | 0.11850 | 5.469 |
| GWO | Grauer-Wolf-Optimierung | 0.00000 | 0.00000 | 0.02672 | 0.02672 | 0.00000 | 0.00000 | 0.00000 | 0.00000 | 0.18977 | 0.03645 | 0.06156 | 0.28778 | 1.000 |
Zusammenfassung
Der klassische MA-Algorithmus besteht im Wesentlichen darin, ein Kletterverfahren zu nutzen, um lokale optimale Lösungen zu finden. Der Kletterschritt spielt eine entscheidende Rolle für die Genauigkeit der Annäherung an die lokale Lösung. Je kleiner der Kletterschritt für lokale Sprünge ist, desto höher ist die Genauigkeit der Lösung, aber es sind mehr Iterationen erforderlich, um das globale Optimum zu finden. Um die Rechenzeit durch eine geringere Anzahl von Iterationen zu reduzieren, empfehlen viele Forscher, in den ersten Phasen der Optimierung andere Optimierungsmethoden wie ABC, COA, IWO zu verwenden und die globale Lösung mit MA zu verfeinern. Ich bin mit diesem Ansatz nicht einverstanden. Ich glaube, dass es sinnvoller ist, die beschriebenen Algorithmen sofort zu verwenden als MA, obwohl MA das Entwicklungspotenzial hat, das es zu einem guten Objekt für weitere Experimente und Studien macht.
Der Affen-Algorithmus ist ein populationsbasierter Algorithmus, der seine Wurzeln in der Natur hat. Wie viele andere metaheuristische Algorithmen ist dieser Algorithmus evolutionär und in der Lage, eine Reihe von Optimierungsproblemen, einschließlich Nichtlinearität, Nichtdifferenzierbarkeit und hoher Dimensionalität des Suchraums, mit einer hohen Konvergenzrate zu lösen. Ein weiterer Vorteil des Affen-Algorithmus besteht darin, dass dieser Algorithmus durch eine geringe Anzahl von Parametern gesteuert wird, wodurch er recht einfach zu implementieren ist. Trotz der Stabilität der Ergebnisse erlaubt die geringe Konvergenzrate nicht, den Affen-Algorithmus für die Lösung von Problemen mit hoher Rechenkomplexität zu empfehlen, da er eine beträchtliche Anzahl von Iterationen erfordert. Es gibt viele andere Algorithmen, die die gleiche Arbeit in kürzerer Zeit (Anzahl der Iterationen) erledigen.
Trotz meiner zahlreichen Experimente kam die klassische Version des Algorithmus nicht über die dritte Zeile der Bewertungstabelle hinaus, blieb in lokalen Extremen stecken und funktionierte extrem schlecht bei diskreten Funktionen. Ich hatte keine besondere Lust, einen Artikel darüber zu schreiben, also habe ich versucht, ihn zu verbessern. Einer dieser Versuche zeigte einige Verbesserungen bei den Konvergenzindikatoren und erhöhte die Stabilität der Ergebnisse durch die Verwendung eines Bias‘ der Wahrscheinlichkeit bei globalen Sprüngen sowie durch die Überarbeitung des Prinzips der globalen Sprünge selbst. Viele MA-Forscher weisen auf die Notwendigkeit hin, den Algorithmus zu modernisieren, weshalb es viele Änderungen am Affen-Algorithmus gibt. Es war nicht meine Absicht, alle Arten von Modifikationen von MA zu berücksichtigen, da der Algorithmus selbst nicht außergewöhnlich ist, sondern eine Variation des Partikelschwarms (PSO) darstellt. Das Ergebnis der Experimente war die endgültige Version des in diesem Artikel vorgestellten Algorithmus ohne die zusätzliche Markierung „m“ (modifiziert).
Das Histogramm der Testergebnisse des Algorithmus ist unten dargestellt.
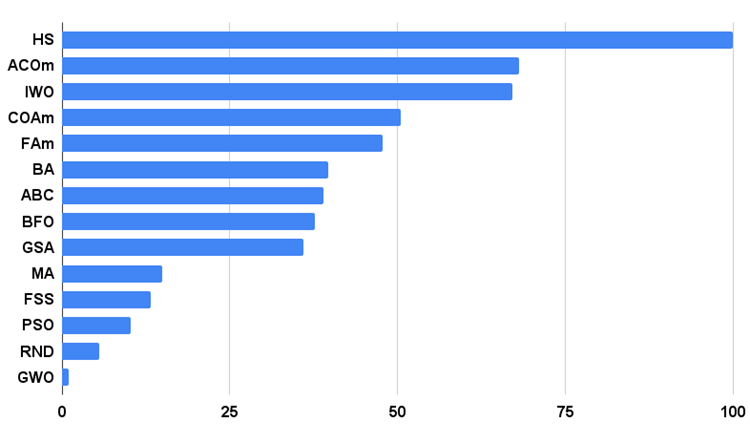
Abb. 3. Histogramm der Testergebnisse der Algorithmen
MA Pro und Kontra:
1. Einfache Implementierung.
2. Gute Skalierbarkeit trotz niedriger Konvergenzrate.
3. Gute Leistung bei diskreten Funktionen.
4. Geringe Anzahl von externen Parametern.
Nachteile
1. Niedrige Konvergenzrate.
2. Erfordert eine große Anzahl von Iterationen für eine Suche.
3. Geringer Gesamtwirkungsgrad.
Jeder Artikel verfügt über ein Archiv, das aktualisierte aktuelle Versionen der Algorithmuscodes für alle früheren Artikel enthält. Der Artikel basiert auf den gesammelten Erfahrungen des Autors und stellt seine persönliche Meinung dar. Die Schlussfolgerungen und Urteile beruhen auf den Experimenten.