MQL5 开发的自动交易示例的文章
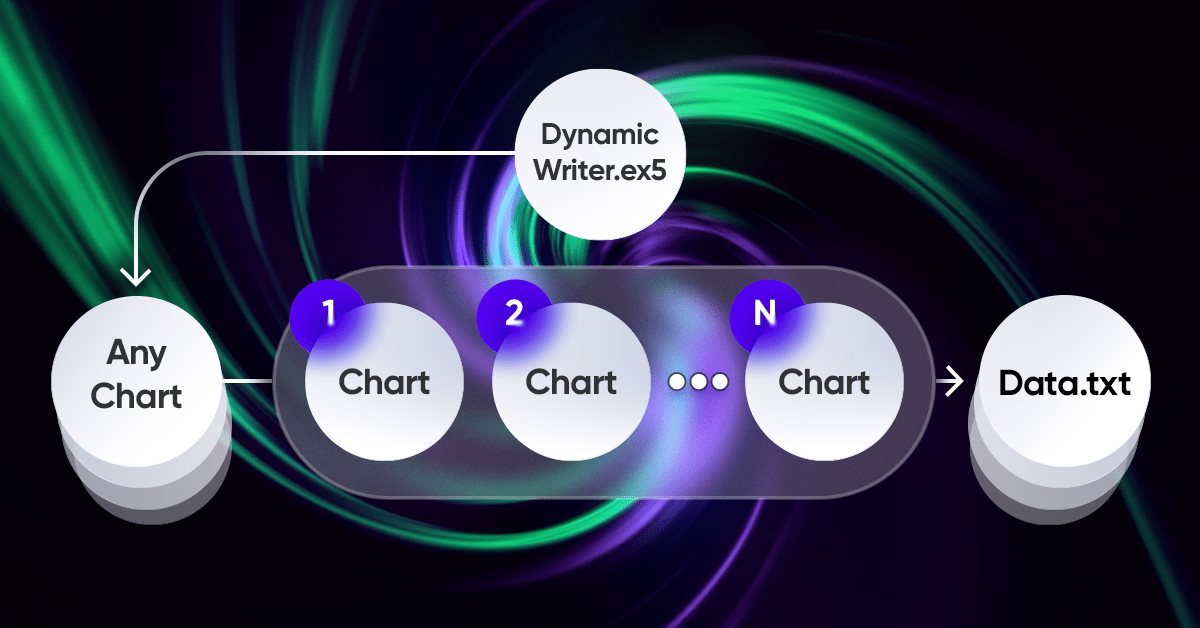
模式搜索的暴力方法(第六部分):循环优化
在这篇文章中,我将展示改进的第一部分,这些改进不仅使我能够使MetaTrader 4和5交易的整个自动化链闭环,而且还可以做一些更有趣的事情。从现在起,这个解决方案使我能够完全自动化创建EA和优化,并最大限度地降低寻找有效交易配置的劳动力成本。

神经网络变得轻松(第五十二部分):研究乐观情绪和分布校正
由于模型是基于经验复现缓冲区进行训练,故当前的扮演者政策会越来越远离存储的样本,这会降低整个模型的训练效率。在本文中,我们将查看一些能在强化学习算法中提升样本使用效率的算法。


神经网络变得轻松(第二十八部分):政策梯度算法
我们继续研究强化学习方法。 在上一篇文章中,我们领略了深度 Q-学习方法。 按这种方法,已训练模型依据在特定情况下采取的行动来预测即将到来的奖励。 然后,根据政策和预期奖励执行动作。 但并不总是能够近似 Q-函数。 有时它的近似不会产生预期的结果。 在这种情况下,近似方法不应用于功用函数,而是应用于动作的直接政策(策略)。 其中一种方法是政策梯度。

为EA交易提供指标的现成模板(第2部分):交易量和比尔威廉姆斯指标
在本文中,我们将研究交易量和比尔威廉姆斯指标类别的标准指标。我们将创建现成的模板,用于EA中的指标使用——声明和设置参数、指标初始化和析构,以及从EA中的指示符缓冲区接收数据和信号。


将ML模型与策略测试器集成(结论):实现价格预测的回归模型
本文描述了一个基于决策树的回归模型的实现。该模型应预测金融资产的价格。我们已经准备好了数据,对模型进行了训练和评估,并对其进行了调整和优化。然而,需要注意的是,该模型仅用于研究目的,不应用于实际交易。

MQL5 中的范畴论 (第 10 部分):幺半群组
本文是以 MQL5 实现范畴论系列的延续。 在此,我们将”幺半群-组“视为常规化幺半群集的一种手段,令它们在更广泛的幺半群集和数据类型中更具可比性。


神经网络变得轻松(第四十八部分):降低 Q-函数高估的方法
在上一篇文章中,我们概述了 DDPG 方法,它允许在连续动作空间中训练模型。然而,与其它 Q-学习方法一样,DDPG 容易高估 Q-函数的数值。这个问题往往会造成训练代理者时选择次优策略。在本文中,我们将研究一些克服上述问题的方式。
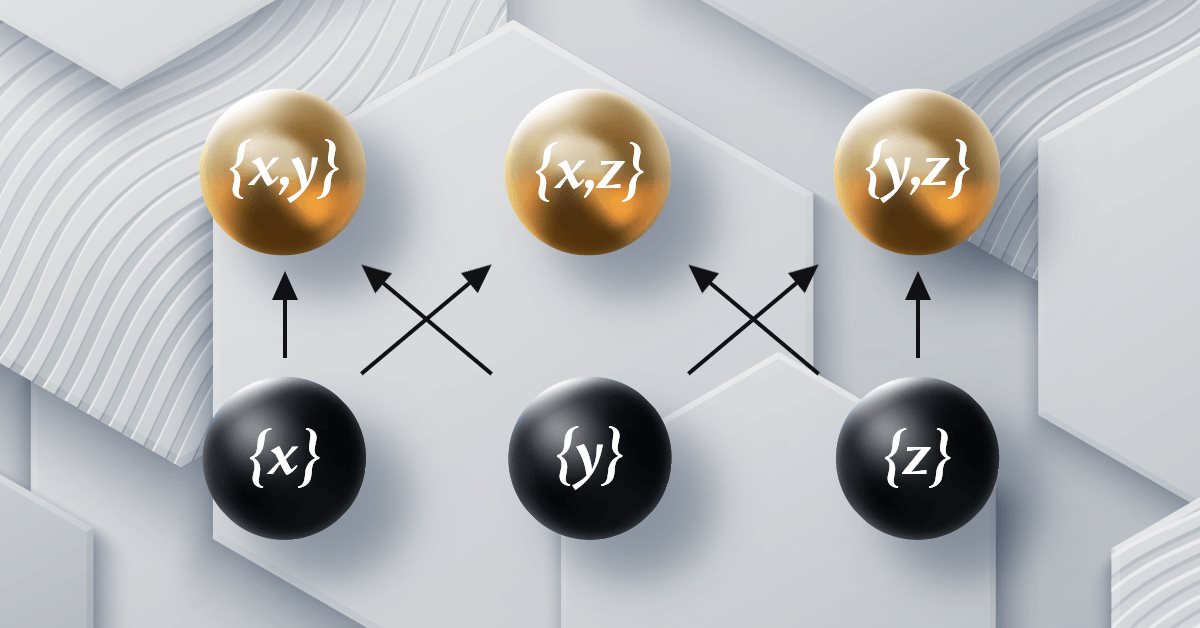
MQL5 中的范畴论 (第 12 部分):秩序(Orders)
本文是范畴论系列文章之以 MQL5 实现图论的部分,深入研讨秩序(Orders)。我们通过研究两种主要的秩序类型,实测秩序论的概念如何支持幺半群集合,从而为交易决策提供信息。

神经网络变得轻松(第五十三部分):奖励分解
我们已经不止一次地讨论过正确选择奖励函数的重要性,我们通过为单独动作添加奖励或惩罚来刺激代理者的预期行为。但是关于由代理者解密我们的信号的问题仍旧悬而未决。在本文中,我们将探讨将单独信号传输至已训练代理者时的奖励分解。

神经网络变得轻松(第四十九部分):软性扮演者-评价者
我们继续讨论解决连续动作空间问题的强化学习算法。在本文中,我将讲演软性扮演者-评论者(SAC)算法。SAC 的主要优点是拥有查找最佳策略的能力,不仅令预期回报最大化,而且拥有最大化的动作熵(多样性)。

神经网络变得轻松(第五十一部分):行为-指引的扮演者-评论者(BAC)
最后两篇文章研究了软性扮演者-评论者算法,该算法将熵正则化整合到奖励函数当中。这种方式在环境探索和模型开发之间取得平衡,但它仅适用于随机模型。本文提出了一种替代方式,能适用于随机模型和确定性模型两者。


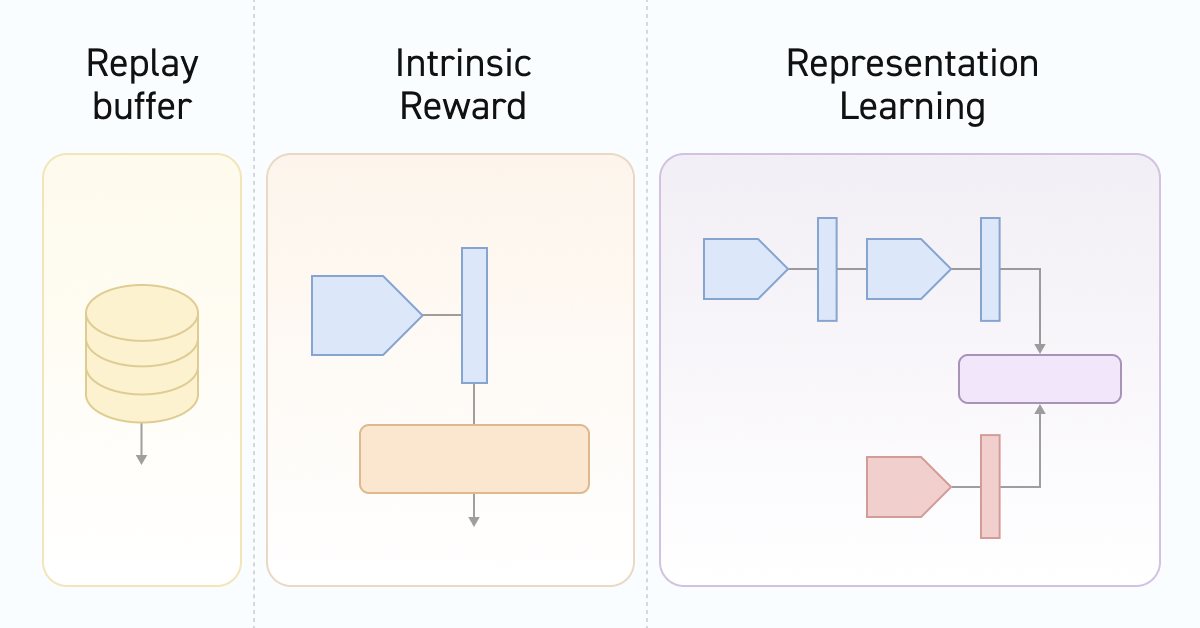
神经网络变得轻松(第五十五部分):对比内在控制(CIC)
对比训练是一种无监督训练方法表象。它的目标是训练一个模型,突显数据集中的相似性和差异性。在本文中,我们将谈论使用对比训练方式来探索不同的扮演者技能。

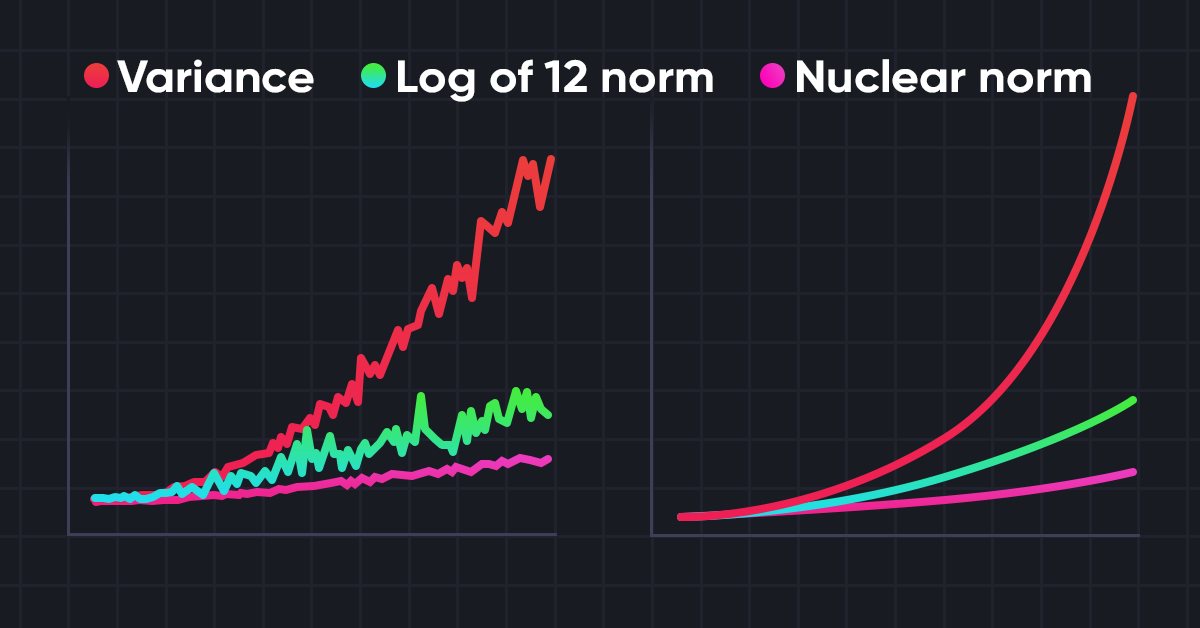
神经网络变得简单(第 56 部分):利用核范数推动研究
强化学习中的环境研究是一个紧迫的问题。我们之前已视察过一些方式。在本文中,我们将讲述另一种基于最大化核范数的方法。它允许智能体识别拥有高度新颖性和多样性的环境状态。
如何利用 MQL5 创建简单的多币种智能交易系统(第 2 部分):指标信号:多时间帧抛物线 SAR 指标
本文中的多币种智能交易系统是智能交易系统或交易机器人,它仅在一个品种图表上就能交易(开单、平单、和管理订单,例如:尾随停损和止盈)超过 1 个交易品种对。这次我们只用 1 个指标,即抛物线 SAR 或 iSAR, 将其应用在 PERIOD_M15 到 PERIOD_D1 的多个时间帧。


神经网络变得简单(第 59 部分):控制二分法(DoC)
在上一篇文章中,我们领略了决策变换器。但是,外汇市场复杂的随机环境不允许我们充分发挥所提议方法的潜能。在本文中,我将讲述一种算法,旨在提高在随机环境中的性能。