Статьи по программированию и использованию торговых роботов на языке MQL5
Эксперты, созданные для платформы MetaTrader, выполняют самые разнообразные функции, задуманные их разработчиками. Торговые роботы могут отслеживать множество финансовых инструментов 24 часа в сутки, копировать сделки, создавать и отсылать отчеты, анализировать новости и даже предоставлять трейдеру собственный графический интерфейс, разработанный по его заказу.
В статьях предлагаются приемы программирования, математические идеи по обработке данных, советы по созданию и заказу торговых роботов.
Новая статья

Вы упускаете торговые возможности:
- Бесплатные приложения для трейдинга
- 8 000+ сигналов для копирования
- Экономические новости для анализа финансовых рынков
Регистрация
Вход
Вы принимаете политику сайта и условия использования
Если у вас нет учетной записи, зарегистрируйтесь
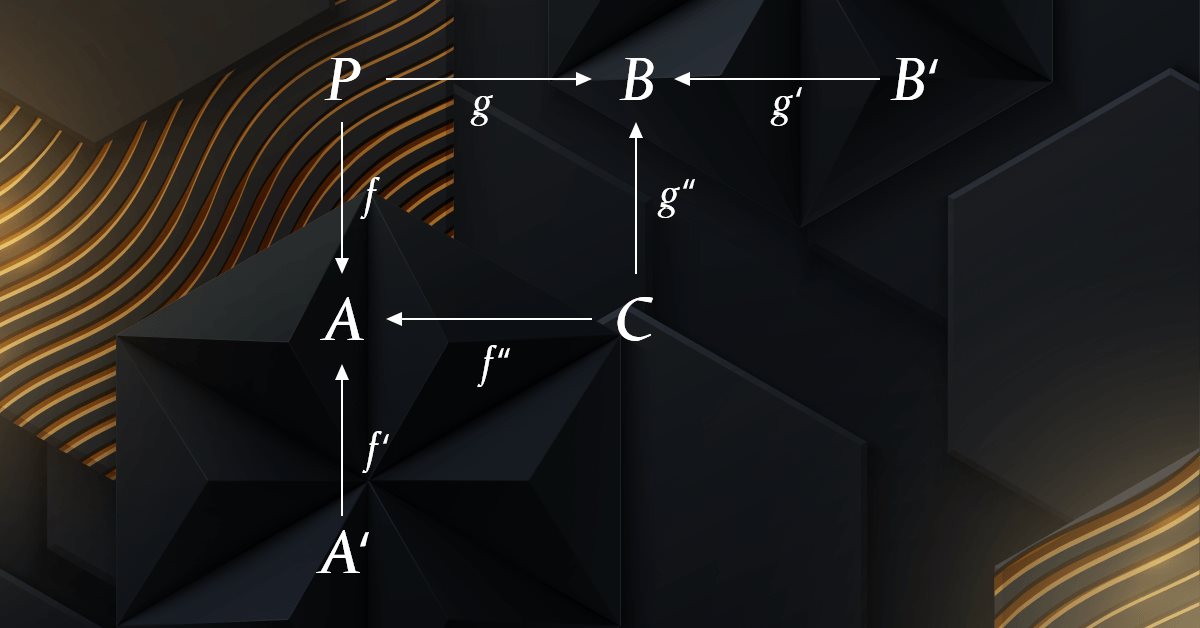
Теория категорий в MQL5 (Часть 4): Интервалы, эксперименты и композиции
Теория категорий представляет собой разнообразный и расширяющийся раздел математики, который пока относительно не освещен в MQL5-сообществе. Эта серия статей призвана описать некоторые из ее концепций для создания открытой библиотеки и дальнейшему использованию этого замечательного раздела в создании торговых стратегий.

Создаем простой мультивалютный советник с использованием MQL5 (Часть 3): Префиксы/суффиксы символов и торговая сессия
Я получил комментарии от нескольких коллег-трейдеров о том, как использовать рассматриваемый мной мультивалютный советник у брокеров, использующих префиксы и/или суффиксы с именами символов, а также о том, как реализовать в советнике торговые часовые пояса или торговые сессии.
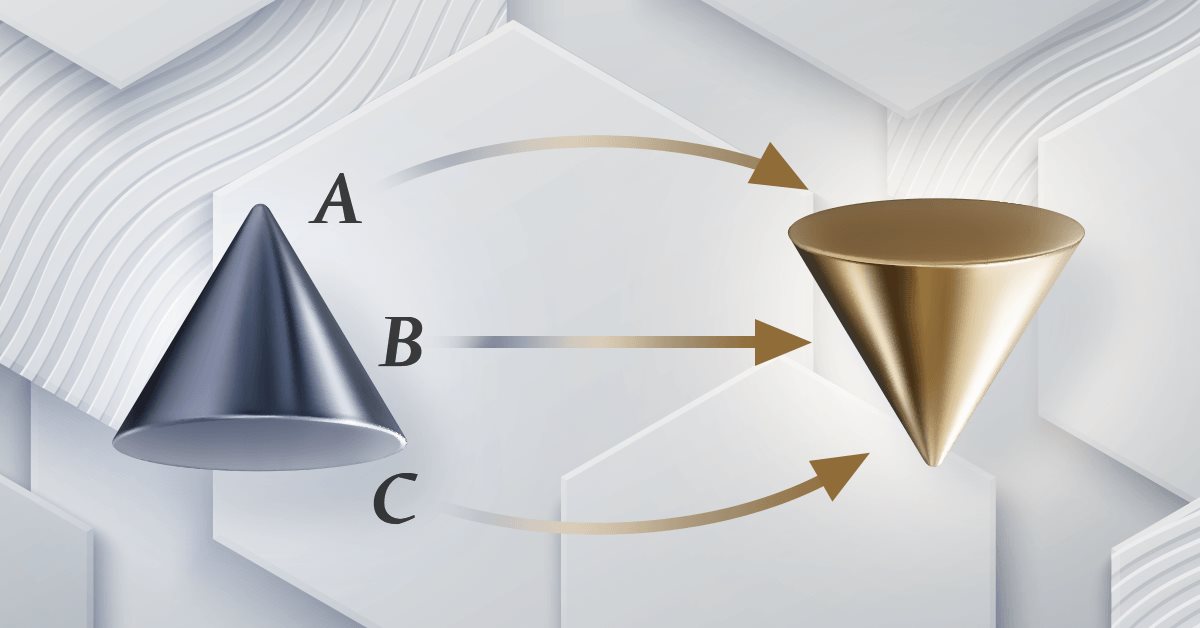
Теория категорий в MQL5 (Часть 22): Другой взгляд на скользящие средние
В этой статье мы попытаемся упростить описание концепций, рассматриваемых в этой серии, остановившись только на одном индикаторе - наиболее распространенном и, вероятно, самом легком для понимания. Речь идет о скользящей средней. Также мы рассмотрим значение и возможные применения вертикальных естественных преобразований.

Разрабатываем мультивалютный советник (Часть 5): Переменный размер позиций
В предыдущих частях разрабатываемый советник имел возможность использовать только фиксированный размер позиций для торговли. Это допустимо для тестирования, но нежелательно при торговле на реальном счёте. Давайте обеспечим возможность торговли с переменным размером позиций.
Альтернативные показатели риска и доходности в MQL5
В этой статье мы представим реализацию нескольких показателей доходности и риска, рассматриваемых как альтернативы коэффициенту Шарпа, и исследуем гипотетические кривые капитала для анализа их характеристик.

Нейросети — это просто (Часть 87): Сегментация временных рядов
Прогнозирование играет важную роль в анализе временных рядов. В новой статье мы поговорим о преимуществах сегментации временных рядов.

Шаблоны проектирования в MQL5 (Часть 2): Структурные шаблоны
В этой статье мы продолжим изучать шаблоны проектирования, которые позволяют разработчикам создавать расширяемые и надежные приложений не только на MQL5, но и на других языках программирования. В этот раз мы поговорим о другом типе — о структурных шаблонах. Будем учиться проектировать системы, используя имеющиеся классы для формирования более крупных структур.

Шаблоны проектирования в программировании на MQL5 (Часть 3): Поведенческие шаблоны 1
В новая статье серии, посвященной шаблонам проектирования, мы рассмотрим поведенческие шаблоны, чтобы понять, как эффективно создавать методы взаимодействия между созданными объектами. Спроектировав эти шаблоны поведения, мы сможем понять, как создавать многоразовое, расширяемое и тестируемое программное обеспечение.
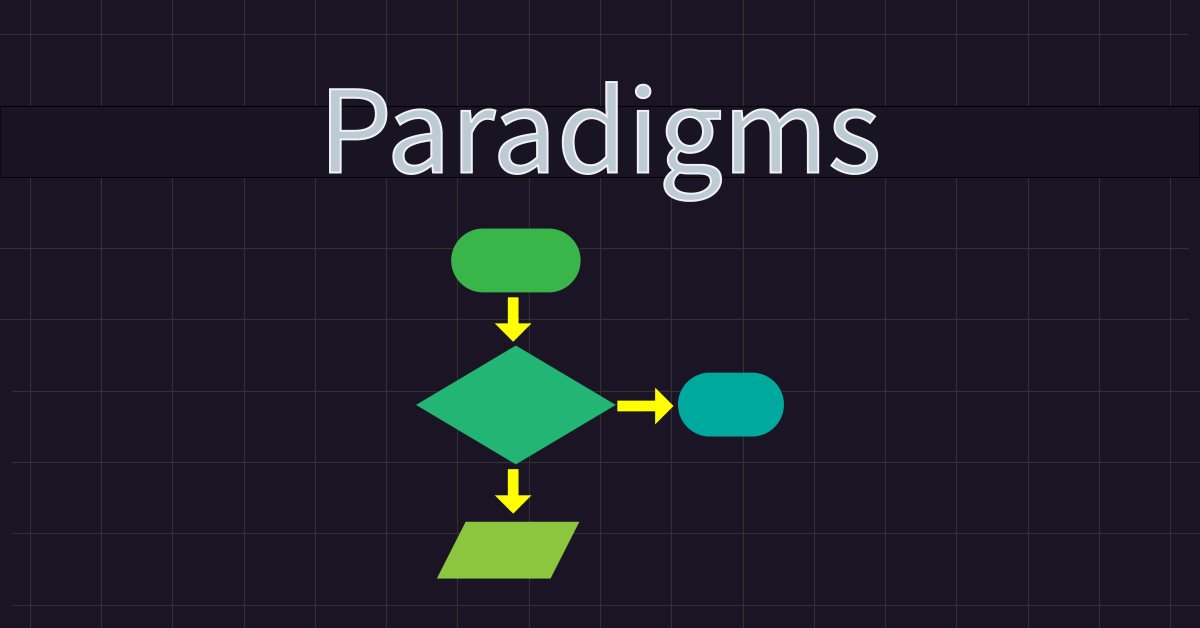
Парадигмы программирования (Часть 1): Процедурный подход к разработке советника на основе ценовой динамики
Узнайте о парадигмах программирования и их применении в коде MQL5. В этой статье исследуются особенности процедурного программирования, а также предлагаются практические примеры. Вы узнаете, как разработать советник на основе ценовой динамики (Price Action), используя индикатор EMA и свечные данные. Кроме того, статья знакомит с парадигмой функционального программирования.

Популяционные алгоритмы оптимизации: Искусственные мультисоциальные поисковые объекты (artificial Multi-Social search Objects, MSO)
Продолжение предыдущей статьи как развитие идеи социальных групп. В новой статье исследуется эволюция социальных групп с использованием алгоритмов перемещения и памяти. Результаты помогут понять эволюцию социальных систем и применить их в оптимизации и поиске решений.

Возможности Мастера MQL5, которые вам нужно знать (Часть 07): Дендрограммы
Классификация данных для анализа и прогнозирования — очень разнообразная область машинного обучения с большим количеством подходов и методов. В этой статье рассматривается один из таких подходов, а именно агломеративная иерархическая классификация (Agglomerative Hierarchical Classification).

Пишем первую модель стеклянного ящика (Glass Box) на Python и MQL5
Модели машинного обучения трудно интерпретировать, и понимание того, почему модели не совпадают с нашими ожиданиями, может очень сильно помочь в конечном итоге достичь нужного результата от использования таких современных методов. Без всестороннего понимания внутренней работы модели может быть сложно найти ошибки, которые ухудшают производительность. При этом можно тратить время на создание функций, которые не влияют на качество прогноза. В итоге, какой бы хорошей ни была модель, мы упускаем все ее основные преимущества из-за собственных ошибок. К счастью, существует сложное, но при этом хорошо разработанное решение, которое позволяет ясно увидеть, что происходит под капотом модели.

Возможности Мастера MQL5, которые вам нужно знать (Часть 09): Сочетание кластеризации k-средних с фрактальными волнами
Кластеризация k-средних использует подход к группировке точек данных в виде процесса, изначально фокусирующегося на макропредставлении набора данных, в котором применяются случайно сгенерированные центроиды кластера. Затем эти центроиды масштабируются и настраиваются для точного представления набора данных. В статье рассматриваются кластеризация и несколько вариантов ее использования.

Разработка и тестирование торговых систем Aroon
В этой статье мы узнаем, как построить торговую систему Aroon, изучив основы индикаторов и необходимые шаги для создания торговой системы на основе индикатора Aroon. После создания этой торговой системы мы проверим, может ли она быть прибыльной или требует дополнительной оптимизации.

Добавляем пользовательскую LLM в торгового робота (Часть 2): Пример развертывания среды
Языковые модели (LLM) являются важной частью быстро развивающегося искусственного интеллекта, поэтому нам следует подумать о том, как интегрировать мощные LLM в нашу алгоритмическую торговлю. Большинству людей сложно настроить эти модели в соответствии со своими потребностями, развернуть их локально, а затем применить к алгоритмической торговле. В этой серии статей будет рассмотрен пошаговый подход к достижению этой цели.

Разработка системы репликации (Часть 31): Проект советника — класс C_Mouse (V)
Разрабатывать способ установки таймера необходимо таким образом, чтобы во время репликации/моделирования он мог сообщить нам, сколько времени осталось, что может показаться на первый взгляд простым и быстрым решением. Многие просто пытаются приспособиться и использовать ту же систему, что и в случае с торговым сервером. Но есть один момент, который многие не учитывают, когда думают о таком решении: при репликации, и это не говоря уже о моделировании, часы работают по-другому. Всё это усложняет создание подобной системы.

Теория категорий в MQL5 (Часть 20): Самовнимание и трансформер
Немного отвлечемся от наших постоянных тем и рассмотрим часть алгоритма ChatGPT. Есть ли у него какие-то сходства или понятия, заимствованные из естественных преобразований? Попытаемся ответить на эти и другие вопросы, используя наш код в формате класса сигнала.

Комбинаторно-симметричная перекрестная проверка в MQL5
В статье показана реализация комбинаторно-симметричной перекрестной проверки на чистом MQL5 для измерения степени подгонки после оптимизации стратегии с использованием медленного полного алгоритма тестера стратегий.

Разработка системы репликации (Часть 30): Проект советника — класс C_Mouse (IV)
Сегодня мы изучим технику, которая может очень сильно помочь нам на разных этапах нашей профессиональной жизни в качестве программиста. Вопреки мнению многих, ограничена не сама платформа, а знания человека, который говорит об ограничениях. В данной статье будет рассказано о том, что с помощью здравого смысла и творческого подхода можно сделать платформу MetaTrader 5 гораздо более интересной и универсальной, не прибегая к созданию безумных программ или чего-то подобного, и создать простой, но безопасный и надежный код. Мы будем использовать свою изобретательность, чтобы изменить уже существующий код, не удаляя и не добавляя ни одной строки в исходный код.

Разметка данных в анализе временных рядов (Часть 4): Декомпозиция интерпретируемости с использованием разметки данных
В этой серии статей представлены несколько методов разметки временных рядов, которые могут создавать данные, соответствующие большинству моделей искусственного интеллекта (ИИ). Целевая разметка данных может сделать обученную модель ИИ более соответствующей пользовательским целям и задачам, повысить точность модели и даже помочь модели совершить качественный скачок!

Разработка системы репликации (Часть 29): Проект советника — класс C_Mouse (III)
После улучшения класса C_Mouse, мы можем сосредоточиться на создании класса, призванного создать совершенно новую основу для обучения. Как уже упоминалось в начале статьи, мы не будем использовать наследование или полиморфизм для создания этого нового класса. Вместо этого мы изменим, а точнее, добавим новые объекты в ценовую линию. Именно этим мы и займемся в данный момент, а в следующей статье мы рассмотрим, как изменить исследования. Но мы сделаем всё это, не меняя код класса C_Mouse. Признаюсь, на практике было бы легче достичь этого с помощью наследования или полиморфизма. однако существуют и другие методы достижения такого же результата.

Разметка данных в анализе временных рядов (Часть 5):Применение и тестирование советника с помощью Socket
В этой серии статей представлены несколько методов разметки временных рядов, которые могут создавать данные, соответствующие большинству моделей искусственного интеллекта (ИИ). Целевая разметка данных может сделать обученную модель ИИ более соответствующей пользовательским целям и задачам, повысить точность модели и даже помочь модели совершить качественный скачок!

Нейросети — это просто (Часть 89): Трансформер частотного разложения сигнала (FEDformer)
Все рассмотренные нами ранее модели анализируют состояние окружающей среды в виде временной последовательности. Однако, тот же временной ряд можно представить и в виде частотных характеристик. В данной статье я предлагаю вам познакомиться с алгоритмом, который использует частотные характеристики временной последовательности для прогнозирования будущих состояний.

Разрабатываем мультивалютный советник (Часть 11): Начало автоматизации процесса оптимизации
Для получения хорошего советника нам надо подобрать для него множество хороших наборов параметров экземпляров торговых стратегий. Это можно делать вручную, запуская оптимизацию на разных символах, и затем отбирая лучшие результаты. Но лучше поручить эту работу программе и заняться более продуктивной деятельностью.

Возможности Мастера MQL5, которые вам нужно знать (Часть 10): Нетрадиционная RBM
Ограниченные машины Больцмана (Restrictive Boltzmann Machines, RBM) представляют собой на базовом уровне двухслойную нейронную сеть, способную выполнять неконтролируемую классификацию посредством уменьшения размерности. Мы используем ее основные принципы и посмотрим что случится, если мы перепроектируем и обучим ее нестандартно. Сможем ли мы получить полезный фильтр сигналов?

Разметка данных в анализе временных рядов (Часть 6):Применение и тестирование советника с помощью ONNX
В этой серии статей представлены несколько методов разметки временных рядов, которые могут создавать данные, соответствующие большинству моделей искусственного интеллекта (ИИ). Целевая разметка данных может сделать обученную модель ИИ более соответствующей пользовательским целям и задачам, повысить точность модели и даже помочь модели совершить качественный скачок!

Прогнозирование на основе глубокого обучения и открытие ордеров с помощью пакета MetaTrader 5 python и файла модели ONNX
Проект предполагает использование Python для прогнозирования на финансовых рынках на основе глубокого обучения. Мы изучим тонкости тестирования производительности модели с использованием таких ключевых показателей, как средняя абсолютная ошибка (MAE), средняя квадратичная ошибка (MSE) и R-квадрат (R2), а также научимся объединять это всё в исполняемом файле. Мы также создадим файл модели ONNX и советник.

Разрабатываем мультивалютный советник (Часть 10): Создание объектов из строки
План разработки советника предусматривает несколько этапов с сохранением промежуточных результатов в базе данных. Заново достать их оттуда можно только в виде строк или чисел, а не объектов. Поэтому нам нужен способ воссоздания в советнике нужных объектов из строк, прочитанных из базы данных.

Нейросети — это просто (Часть 90): Частотная интерполяция временных рядов (FITS)
При изучении метода FEDformer мы приоткрыли дверь в частотную область представления временного ряда. В новой статье мы продолжим начатую тему. И рассмотрим метод, позволяющий не только проводить анализ, но и прогнозировать последующие состояния в частной области.
Нейросети — это просто (Часть 91): Прогнозирование в частотной области (FreDF)
Мы продолжаем рассмотрение темы анализ и прогнозирования временных рядов в частотной области. И в данной статье мы познакомимся с новым методом прогнозирования в частотной области, который может быть добавлен к многим, изученным нами ранее, алгоритмам.