
Разметка данных в анализе временных рядов (Часть 4): Декомпозиция интерпретируемости с использованием разметки данных

Введение
В прошлой статье мы говорили о модели NHITS, в которой мы проверяли прогноз цен закрытия только для одной входной переменной. В этой статье мы обсудим интерпретируемость модели и использование нескольких ковариат для прогнозирования цен закрытия. В этот раз для демонстрации будем использовать другую модель, которая предоставляет еще больше возможностей — NBEATS. Основное внимание в статье будет уделено интерпретируемости модели. Также мы увидим, для чего вводится тема ковариат. В итоге вы должны научиться использовать разные модели для проверки своих идей в любое нужное время. Конечно, эти две модели по сути являются качественными интерпретируемыми моделями. Идеи можно расширить до других моделей и проверять их с помощью библиотек, о которых говорится в статье. Обратите внимание, что эта серия статей направлена исключительно на решение поставленной задачи. Вы должны трезво оценить все риски, прежде чем применять какие-либо идеи, в том числе упомянутые в статье, непосредственно в реальной торговле. Реализация торговых возможностей требует дополнительных настроек параметров и дополнительных методов оптимизации для обеспечения надежных и стабильных результатов.Ссылки на предыдущие три статьи:
- Разметка данных в анализе временных рядов (Часть 1): Создаем набор данных с маркерами тренда с помощью графика советника
- Разметка данных в анализе временных рядов (Часть 2): Создаем наборы данных с маркерами тренда с помощью Python
- Разметка данных в анализе временных рядов (Часть 3): Пример использования разметки данных
Содержание:
- Введение
- О модели NBEATS
- Импорт библиотек
- Переписываем класс TimeSeriesDataSet
- Обработка данных
- Получение скорости обучения
- Определение функции обучения
- Обучение и тестирование модели
- Интерпретация модели
- Заключение
О модели NBEATS
Эту модель широко обсуждали и объясняли в различных журналах и на сайтах. Чтобы вам не пришлось ходить по различным сайтами и прочим источникам информации, я приведу здесь простое введение в эту модель. Модель NBEATS может обрабатывать входные и выходные последовательности любой длины и не зависит от разработки конкретных функций или масштабирования входных данных для временных рядов. Модель также может использовать полиномы и ряды Фурье в качестве базовых функций для интерпретируемых конфигураций при моделировании трендов и сезонного разложения. Кроме того, в модели используется топология двойного суммирования остатков, так что каждый строительный блок имеет две остаточные ветви: одну по обратному предсказанию, а другую по прямому предсказанию, что значительно улучшает обучаемость и интерпретируемость модели. Выглядит впечатляюще!Оригинальная статья опубликована здесь: https://arxiv.org/pdf/1905.10437.pdf
1. Архитектура модели
2. Процесс реализации модели
Входной временной ряд представляется в виде вектора низкой размерности, а вторая часть переводит вектор обратно во временной ряд. Этот шаг также на AutoEncoder, где происходит маппинг временного ряда с вектором низкой размерности для сохранения базовой информации, а затем идет его восстановление. Упрощенно этот процесс можно представить так: 
Модуль сгенерирует два набора коэффициентов расширения: один для прогнозирования будущего (forecast), а другой — для прогнозирования прошлого (backcast). Этот процесс можно представить следующей формулой:

3.Интерпретируемость
Декомпозиция модели интерпретируема. Модель NBEATS вводит некоторые предварительные знания на каждом уровне, благодаря чему уровням приходится изучать определенные характеристики временных рядов. Это дает нам интерпретируемую декомпозицию временных рядов. Метод реализации заключается в ограничении коэффициентов расширения функциональной формой выходной последовательности. Например, если нужно, чтобы определенный блок слоев прогнозировал сезонность временного ряда, можно использовать следующую формулу, чтобы выходной слой показывал именно сезонные данные:


4. Ковариаты
В этой статье мы также знакомимся с ковариатами, которые помогут спрогнозировать целевое значение. Какие у нас есть ковариаты:- static_categoricals — список категориальных переменных, которые со временем не меняются.
- static_reals — список непрерывных переменных, которые со временем не меняются.
- time_varying_known_categoricals — список категориальных переменных, которые меняются со временем и известны в будущем, например, информация о выходных.
- time_varying_known_reals — список непрерывных переменных, которые изменяются со временем и известны в будущем, например даты.
- time_varying_unknown_categoricals — список категориальных переменных, которые меняются со временем и неизвестны в будущем, например, тренд.
- time_varying_unknown_reals — список непрерывных переменных, которые меняются со временем и неизвестны в будущем, например, рост или радение.
5. Внешние переменные
Модель NBEATS позволяет вводить внешние переменные, которые вроде и не связаны с выборкой, но при этом модель меняется. Команда исследователей назвала расширение модели за счет экзогенных переменных NBEATSx, но не будем говорить о ней в нашей статье.Импорт библиотек
Пояснения здесь не нужны. Берем и импортируем.
import lightning.pytorch as pl import os from lightning.pytorch.callbacks import EarlyStopping,ModelCheckpoint import matplotlib.pyplot as plt import numpy as np import pandas as pd from pytorch_forecasting import TimeSeriesDataSet,NBeats from pytorch_forecasting.data import NaNLabelEncoder from pytorch_forecasting.metrics import MQF2DistributionLoss from pytorch_forecasting.data.samplers import TimeSynchronizedBatchSampler from lightning.pytorch.tuner import Tuner import MetaTrader5 as mt import warnings import json
Переписываем класс TimeSeriesDataSet
Здесь также не нужны лишние объяснения. Все уже описывалось раньше. Так что вы можете почитать о том, что делается и зачем, в предыдущих статьях из этой серии.
class New_TmSrDt(TimeSeriesDataSet): ''' rewrite dataset class ''' def to_dataloader(self, train: bool = True, batch_size: int = 64, batch_sampler: Sampler | str = None, shuffle:bool=False, drop_last:bool=False, **kwargs) -> DataLoader: default_kwargs = dict( shuffle=shuffle, # drop_last=train and len(self) > batch_size, drop_last=drop_last, # collate_fn=self._collate_fn, batch_size=batch_size, batch_sampler=batch_sampler, ) default_kwargs.update(kwargs) kwargs = default_kwargs # print(kwargs['drop_last']) if kwargs["batch_sampler"] is not None: sampler = kwargs["batch_sampler"] if isinstance(sampler, str): if sampler == "synchronized": kwargs["batch_sampler"] = TimeSynchronizedBatchSampler( SequentialSampler(self), batch_size=kwargs["batch_size"], shuffle=kwargs["shuffle"], drop_last=kwargs["drop_last"], ) else: raise ValueError(f"batch_sampler {sampler} unknown - see docstring for valid batch_sampler") del kwargs["batch_size"] del kwargs["shuffle"] del kwargs["drop_last"] return DataLoader(self,**kwargs)
Обработка данных
Мы не будем здесь повторять загрузку и предварительную обработку данных. Полные описания уже приводились в предыдущих трех статьях, поэтому я рекомендую почитать их. В этой же статье мы рассмотрим только соответствующие изменения по месту.
1. Сбор данных
def get_data(mt_data_len:int): if not mt.initialize(): print('initialize() failed!') else: print(mt.version()) sb=mt.symbols_total() rts=None if sb > 0: rts=mt.copy_rates_from_pos("GOLD_micro",mt.TIMEFRAME_M15,0,mt_data_len) mt.shutdown() # print(len(rts)) rts_fm=pd.DataFrame(rts) rts_fm['time']=pd.to_datetime(rts_fm['time'], unit='s') rts_fm['time_idx']= rts_fm.index%(max_encoder_length+2*max_prediction_length) rts_fm['series']=rts_fm.index//(max_encoder_length+2*max_prediction_length) return rts_fm
2.Предварительная обработка
В отличие от того, как мы делали это ранее, сейчас мы поговорим о ковариатах. Почему мы их используем? На самом деле существуют и другие варианты этой модели: NBEATSx и GAGA. Если вас интересуют эти модели или какие-либо другие, включенные в библиотеку прогнозирования pytorch, которую мы используем, важно понимать ковариаты. Давайте попробуем разобраться, не вдаваясь в излишние подробности.
В отношении форекс-данных в качестве ковариат мы используем значения open, high и low. Разумеется, можно использовать и другие данные в качестве ковариат, например MACD, ADX, RSI и другие индикаторы, но помните, что они обязательно должны быть связаны с нашими данными. Нельзя добавлять несоответствующие внешние переменные, скажем, протоколы заседаний Федеральной резервной системы, решения по процентным ставкам, несельскохозяйственные данные и т. д., в качестве входных ковариат, поскольку модель не имеет функций для анализа этих данных. Возможно, однажды я напишу статью, посвященную тому, как добавлять внешние переменные в модель.
Теперь давайте посмотрим, как добавлять ковариаты в класс New_TmSrDt(). В классе предусмотрены следующие определения переменных:
- static_categoricals (List[str])
- static_reals (List[str])
- timevaryingknown_categoricals (List[str])
- timevaryingknown_reals (List[str])
- timevaryingunknown_categoricals (List[str])
- timevaryingunknown_reals (List[str])
- timevaryingknown_categoricals
- timevaryingknown_reals
- timevaryingunknown_categoricals
- timevaryingunknown_reals
Поскольку переменные open, high и low вообще не являются категориями, на выбор остаются только time_varying_known_reals и time_varying_unknown_reals. Кто-то может сказать, что если нужно спрогнозировать значения close, и значения open, high и low каждого бара можно получить в реальном времени, то почему их нельзя добавить в time_varying_known_reals? Давайте посмотрим внимательно: если мы прогнозируем значение только одного бара, это уже очно известно, тогда можно полностью классифицировать их как time_variing_known_reals. Но что, если мы хотим предсказать значения нескольких баров? Мы можем узнать только данные текущего бара, а следующие за ним значения совершенно неизвестны, поэтому они не подходят для среды, обсуждаемой в нашей статье. Получается, их нужно добавить в категорию time_varying_unknown_reals. Но если вы предсказываете значение close только одного бара, определенно можете добавить его в time_varying_known_reals, поэтому важно внимательно рассмотреть конкретный вариант использования. Существует также особый случай для time_variing_known_reals. Фактически, каждый из наших баров имеет фиксированный цикл, например M15, H1, H4, D1 и т.д. Благодаря этому мы можем полностью вычислить время, к которому относятся прогнозируемые бары. Так что вы вполне можете добавить время как time_variing_known_reals. Мы сейчас не будем на этом останавливаться, но если вам интересно, вы сможете сами добавить. Если вы хотите использовать ковариаты, можно изменить time_varying_unknown_reals=["close"] на time_varying_unknown_reals=["close","high","open","low"]". Наша версия NBEATS не поддерживает эту функцию!
Итак, мы имеем такой код:
def spilt_data(data:pd.DataFrame, t_drop_last:bool, t_shuffle:bool, v_drop_last:bool, v_shuffle:bool): training_cutoff = data["time_idx"].max() - max_prediction_length #max:95 context_length = max_encoder_length prediction_length = max_prediction_length training = New_TmSrDt( data[lambda x: x.time_idx <= training_cutoff], time_idx="time_idx", target="close", categorical_encoders={"series":NaNLabelEncoder().fit(data.series)}, group_ids=["series"], time_varying_unknown_reals=["close"], max_encoder_length=context_length, max_prediction_length=prediction_length, ) validation = New_TmSrDt.from_dataset(training, data, min_prediction_idx=training_cutoff + 1) train_dataloader = training.to_dataloader(train=True, shuffle=t_shuffle, drop_last=t_drop_last, batch_size=batch_size, num_workers=0,) val_dataloader = validation.to_dataloader(train=False, shuffle=v_shuffle, drop_last=v_drop_last, batch_size=batch_size, num_workers=0) return train_dataloader,val_dataloader,training
Получение скорости обучения
Пояснения здесь не нужны. Все уже описывалось раньше. Так что вы можете почитать о том, что делается и зачем, в предыдущих статьях из этой серии.
def get_learning_rate(): pl.seed_everything(42) trainer = pl.Trainer(accelerator="cpu", gradient_clip_val=0.1,logger=False) net = NBeats.from_dataset( training, learning_rate=3e-2, weight_decay=1e-2, backcast_loss_ratio=0.0, optimizer="AdamW", ) res = Tuner(trainer).lr_find( net, train_dataloaders=t_loader, val_dataloaders=v_loader, min_lr=1e-5, max_lr=1e-1 ) # print(f"suggested learning rate: {res.suggestion()}") lr_=res.suggestion() return lr_
Примечание. Есть несколько отличий между этой функцией и Nbits: функция NBeats.from_dataset() не имеет параметров hidden_size. А параметр потерь не может использовать метод MQF2DistributionLoss().
Определение функции обучения
Пояснения здесь не нужны. Все уже описывалось раньше. Так что вы можете почитать о том, что делается и зачем, в предыдущих статьях из этой серии.
def train():
early_stop_callback = EarlyStopping(monitor="val_loss",
min_delta=1e-4,
patience=10,
verbose=True,
mode="min")
ck_callback=ModelCheckpoint(monitor='val_loss',
mode="min",
save_top_k=1,
filename='{epoch}-{val_loss:.2f}')
trainer = pl.Trainer(
max_epochs=ep,
accelerator="cpu",
enable_model_summary=True,
gradient_clip_val=1.0,
callbacks=[early_stop_callback,ck_callback],
limit_train_batches=30,
enable_checkpointing=True,
)
net = NBeats.from_dataset(
training,
learning_rate=lr,
log_interval=10,
log_val_interval=1,
weight_decay=1e-2,
backcast_loss_ratio=0.0,
optimizer="AdamW",
stack_types = ["trend", "seasonality"],
)
trainer.fit(
net,
train_dataloaders=t_loader,
val_dataloaders=v_loader,
# ckpt_path='best'
)
return trainer
Примечание. Здесь для NBeats.from_dataset() требуется добавить интерпретируемую переменную типа декомпозиции stack_types. Мы используем значение по умолчанию. Помимо этих двух значений по умолчанию, существует также "общий" вариант.
Обучение и тестирование модели
Далее мы реализуем логику обучения и прогнозирования модели, которая была объяснена в предыдущей статье. Изменений здесь нет, поэтому я не буду останавливаться на ней подробно.
if __name__=='__main__': ep=200 __train=False mt_data_len=200000 max_encoder_length = 2*96 max_prediction_length = 30 batch_size = 128 info_file='results.json' warnings.filterwarnings("ignore") dt=get_data(mt_data_len=mt_data_len) if __train: # print(dt) # dt=get_data(mt_data_len=mt_data_len) t_loader,v_loader,training=spilt_data(dt, t_shuffle=False,t_drop_last=True, v_shuffle=False,v_drop_last=True) lr=get_learning_rate() trainer__=train() m_c_back=trainer__.checkpoint_callback m_l_back=trainer__.early_stopping_callback best_m_p=m_c_back.best_model_path best_m_l=m_l_back.best_score.item() # print(best_m_p) if os.path.exists(info_file): with open(info_file,'r+') as f1: last=json.load(fp=f1) last_best_model=last['last_best_model'] last_best_score=last['last_best_score'] if last_best_score > best_m_l: last['last_best_model']=best_m_p last['last_best_score']=best_m_l json.dump(last,fp=f1) else: with open(info_file,'w') as f2: json.dump(dict(last_best_model=best_m_p,last_best_score=best_m_l),fp=f2) best_model = NHiTS.load_from_checkpoint(best_m_p) predictions = best_model.predict(v_loader, trainer_kwargs=dict(accelerator="cpu",logger=False), return_y=True) raw_predictions = best_model.predict(v_loader, mode="raw", return_x=True, trainer_kwargs=dict(accelerator="cpu",logger=False)) for idx in range(10): # plot 10 examples best_model.plot_prediction(raw_predictions.x, raw_predictions.output, idx=idx, add_loss_to_title=True) plt.show() else: with open(info_file) as f: best_m_p=json.load(fp=f)['last_best_model'] print('model path is:',best_m_p) best_model = NHiTS.load_from_checkpoint(best_m_p) offset=1 dt=dt.iloc[-max_encoder_length-offset:-offset,:] last_=dt.iloc[-1] # print(len(dt)) for i in range(1,max_prediction_length+1): dt.loc[dt.index[-1]+1]=last_ dt['series']=0 # dt['time_idx']=dt.apply(lambda x:x.index,args=1) dt['time_idx']=dt.index-dt.index[0] # dt=get_data(mt_data_len=max_encoder_length) predictions = best_model.predict(dt, mode='raw',trainer_kwargs=dict(accelerator="cpu",logger=False),return_x=True) best_model.plot_prediction(predictions.x,predictions.output,show_future_observed=False) plt.show()
Примечание. Прежде чем запускать, убедитесь, что у вас установлен TensorBoard! Это важно, иначе произойдут непонятные ошибки.
Результат обучения (при запуске кода появится 10 изображений, в качестве примера приведено случайное):

Результаты тестирования:

Интерпретация модели
Существует много способов интерпретации данных, но модель NBEATS уникальна тем, что разбивает прогнозы на сезонность и тенденции (конечно, поскольку в этой статье выбраны эти два фактора, результаты можно разбить только на эти два, но может быть много других комбинаций).
Если вы закончили обучение и хотите разложить прогноз, нужно добавить такой код:
for idx in range(10): # plot 10 examples best_model.plot_interpretation(x, raw_predictions, idx=idx)
Если вы хотите разложить прогноз при запуске прогноза, можно добавить следующий код:
best_model.plot_interpretation(predictions.x,predictions.output,idx=0) Результат будет такой:
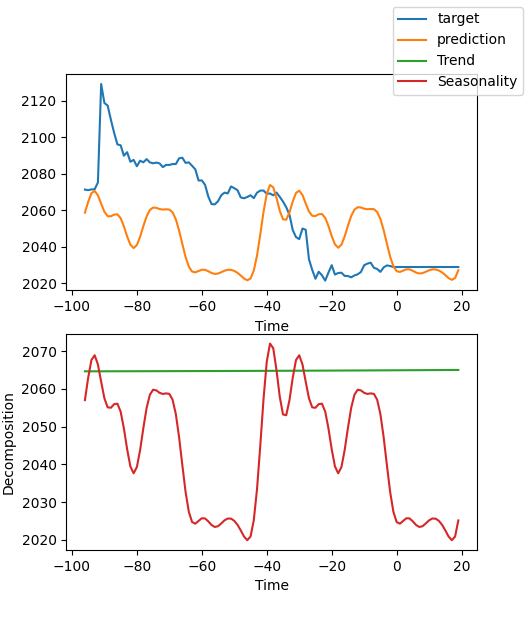
На этом рисунке результаты не очень хорошие. Но это лишь грубый пример, я не оптимизировал тщательно нашу модель, а ключевые показатели данных до сих пор не уточнены с научной точки зрения. Более того, большинство параметров модели используются только по умолчанию и не настраиваются, поэтому есть много возможностей для оптимизации.
Заключение
В этой статье мы обсуждали, как использовать размеченные данные для прогнозирования будущих цен с помощью модели NBEATS. Также, в статье представлена специальная функция разложения интерпретируемости для модели NBEATS. Хотя изменения в коде не существенны, обратите внимание на обсуждение ковариат в тексте. Если вы хорошо разобрались в использовании различных ковариат, можете распространить эту модель на другие сценарии применения. Думаю, это поможет повысить точность советника и точнее выполнять необходимые задачи. Конечно, эта статья — всего лишь пример. Здесь приведены лишь грубые данные, которые, в текущем виде, не подходят для использования в реальной торговле. В коде есть много мест, которые нуждаются в дальнейшей оптимизации, поэтому не используйте его непосредственно в торговле! Также в статье упоминаются внешние переменные. Не знаю, интересно ли кому-то это направление. Если я смогу получить достаточно информации, возможно, опишу, как ее реализовать, в этой серии статей в будущем.
На этом статья подошла к концу, надеюсь, она окажется полезной.
Весь код целиком:
# Copyright 2021, MetaQuotes Ltd. # https://www.mql5.com import lightning.pytorch as pl import os from lightning.pytorch.callbacks import EarlyStopping,ModelCheckpoint import matplotlib.pyplot as plt import pandas as pd from pytorch_forecasting import TimeSeriesDataSet,NBeats from pytorch_forecasting.data import NaNLabelEncoder from pytorch_forecasting.data.samplers import TimeSynchronizedBatchSampler from lightning.pytorch.tuner import Tuner import MetaTrader5 as mt import warnings import json from torch.utils.data import DataLoader from torch.utils.data.sampler import Sampler,SequentialSampler class New_TmSrDt(TimeSeriesDataSet): ''' rewrite dataset class ''' def to_dataloader(self, train: bool = True, batch_size: int = 64, batch_sampler: Sampler | str = None, shuffle:bool=False, drop_last:bool=False, **kwargs) -> DataLoader: default_kwargs = dict( shuffle=shuffle, # drop_last=train and len(self) > batch_size, drop_last=drop_last, # collate_fn=self._collate_fn, batch_size=batch_size, batch_sampler=batch_sampler, ) default_kwargs.update(kwargs) kwargs = default_kwargs # print(kwargs['drop_last']) if kwargs["batch_sampler"] is not None: sampler = kwargs["batch_sampler"] if isinstance(sampler, str): if sampler == "synchronized": kwargs["batch_sampler"] = TimeSynchronizedBatchSampler( SequentialSampler(self), batch_size=kwargs["batch_size"], shuffle=kwargs["shuffle"], drop_last=kwargs["drop_last"], ) else: raise ValueError(f"batch_sampler {sampler} unknown - see docstring for valid batch_sampler") del kwargs["batch_size"] del kwargs["shuffle"] del kwargs["drop_last"] return DataLoader(self,**kwargs) def get_data(mt_data_len:int): if not mt.initialize(): print('initialize() failed!') else: print(mt.version()) sb=mt.symbols_total() rts=None if sb > 0: rts=mt.copy_rates_from_pos("GOLD_micro",mt.TIMEFRAME_M15,0,mt_data_len) mt.shutdown() # print(len(rts)) rts_fm=pd.DataFrame(rts) rts_fm['time']=pd.to_datetime(rts_fm['time'], unit='s') rts_fm['time_idx']= rts_fm.index%(max_encoder_length+2*max_prediction_length) rts_fm['series']=rts_fm.index//(max_encoder_length+2*max_prediction_length) return rts_fm def spilt_data(data:pd.DataFrame, t_drop_last:bool, t_shuffle:bool, v_drop_last:bool, v_shuffle:bool): training_cutoff = data["time_idx"].max() - max_prediction_length #max:95 context_length = max_encoder_length prediction_length = max_prediction_length training = New_TmSrDt( data[lambda x: x.time_idx <= training_cutoff], time_idx="time_idx", target="close", categorical_encoders={"series":NaNLabelEncoder().fit(data.series)}, group_ids=["series"], time_varying_unknown_reals=["close"], max_encoder_length=context_length, # min_encoder_length=max_encoder_length//2, max_prediction_length=prediction_length, # min_prediction_length=1, ) validation = New_TmSrDt.from_dataset(training, data, min_prediction_idx=training_cutoff + 1) train_dataloader = training.to_dataloader(train=True, shuffle=t_shuffle, drop_last=t_drop_last, batch_size=batch_size, num_workers=0,) val_dataloader = validation.to_dataloader(train=False, shuffle=v_shuffle, drop_last=v_drop_last, batch_size=batch_size, num_workers=0) return train_dataloader,val_dataloader,training def get_learning_rate(): pl.seed_everything(42) trainer = pl.Trainer(accelerator="cpu", gradient_clip_val=0.1,logger=False) net = NBeats.from_dataset( training, learning_rate=3e-2, weight_decay=1e-2, backcast_loss_ratio=0.1, optimizer="AdamW", ) res = Tuner(trainer).lr_find( net, train_dataloaders=t_loader, val_dataloaders=v_loader, min_lr=1e-5, max_lr=1e-1 ) # print(f"suggested learning rate: {res.suggestion()}") lr_=res.suggestion() return lr_ def train(): early_stop_callback = EarlyStopping(monitor="val_loss", min_delta=1e-4, patience=10, verbose=True, mode="min") ck_callback=ModelCheckpoint(monitor='val_loss', mode="min", save_top_k=1, filename='{epoch}-{val_loss:.2f}') trainer = pl.Trainer( max_epochs=ep, accelerator="cpu", enable_model_summary=True, gradient_clip_val=1.0, callbacks=[early_stop_callback,ck_callback], limit_train_batches=30, enable_checkpointing=True, ) net = NBeats.from_dataset( training, learning_rate=lr, log_interval=10, log_val_interval=1, weight_decay=1e-2, backcast_loss_ratio=0.0, optimizer="AdamW", stack_types=["trend", "seasonality"], ) trainer.fit( net, train_dataloaders=t_loader, val_dataloaders=v_loader, # ckpt_path='best' ) return trainer if __name__=='__main__': ep=200 __train=False mt_data_len=80000 max_encoder_length = 96 max_prediction_length = 20 # context_length = max_encoder_length # prediction_length = max_prediction_length batch_size = 128 info_file='results.json' warnings.filterwarnings("ignore") dt=get_data(mt_data_len=mt_data_len) if __train: # print(dt) # dt=get_data(mt_data_len=mt_data_len) t_loader,v_loader,training=spilt_data(dt, t_shuffle=False,t_drop_last=True, v_shuffle=False,v_drop_last=True) lr=get_learning_rate() # lr=3e-3 trainer__=train() m_c_back=trainer__.checkpoint_callback m_l_back=trainer__.early_stopping_callback best_m_p=m_c_back.best_model_path best_m_l=m_l_back.best_score.item() # print(best_m_p) if os.path.exists(info_file): with open(info_file,'r+') as f1: last=json.load(fp=f1) last_best_model=last['last_best_model'] last_best_score=last['last_best_score'] if last_best_score > best_m_l: last['last_best_model']=best_m_p last['last_best_score']=best_m_l json.dump(last,fp=f1) else: with open(info_file,'w') as f2: json.dump(dict(last_best_model=best_m_p,last_best_score=best_m_l),fp=f2) best_model = NBeats.load_from_checkpoint(best_m_p) predictions = best_model.predict(v_loader, trainer_kwargs=dict(accelerator="cpu",logger=False), return_y=True) raw_predictions = best_model.predict(v_loader, mode="raw", return_x=True, trainer_kwargs=dict(accelerator="cpu",logger=False)) for idx in range(10): # plot 10 examples best_model.plot_prediction(raw_predictions.x, raw_predictions.output, idx=idx, add_loss_to_title=True) plt.show() else: with open(info_file) as f: best_m_p=json.load(fp=f)['last_best_model'] print('model path is:',best_m_p) best_model = NBeats.load_from_checkpoint(best_m_p) offset=1 dt=dt.iloc[-max_encoder_length-offset:-offset,:] last_=dt.iloc[-1] # print(len(dt)) for i in range(1,max_prediction_length+1): dt.loc[dt.index[-1]+1]=last_ dt['series']=0 # dt['time_idx']=dt.apply(lambda x:x.index,args=1) dt['time_idx']=dt.index-dt.index[0] # dt=get_data(mt_data_len=max_encoder_length) predictions = best_model.predict(dt, mode='raw',trainer_kwargs=dict(accelerator="cpu",logger=False),return_x=True) # best_model.plot_prediction(predictions.x,predictions.output,show_future_observed=False) best_model.plot_interpretation(predictions.x,predictions.output,idx=0) plt.show()
Перевод с английского произведен MetaQuotes Ltd.
Оригинальная статья: https://www.mql5.com/en/articles/13218
- Бесплатные приложения для трейдинга
- 8 000+ сигналов для копирования
- Экономические новости для анализа финансовых рынков
Вы принимаете политику сайта и условия использования