Practical advice, please.
Question: How do I evaluate the results correctly?
The error of each module is given as a percentage. 0% is the ideal result.
| ________________ PARAMETERS ________________ | Mod 1 | Mod 2 | Mod 3 | Mode 4 | Mode 5 | (vi) Mode 6 | (vi) Mode 7 | (vi) Mode 8 | (vi) Mod 9 | (vi) Mod 10 | (vi) Mod 11 | (vi) Mod 12 | (viii) mod 13 | (vi) 14 | Mode 15 | Average error | From the attempts |
| 2_48_24_2160_12_VECTOR_UP_HIDDEN_LAYERS_HAND | 4,43 | 17,09 | 15,82 | 2,53 | 0,63 | 17,72 | 28,48 | 5,70 | 13,29 | 5,70 | 8,23 | 6,33 | 0,63 | 3,16 | 6,96 | 9,11 | 158,00 |
| 2_48_24_2160_12_VECTOR_UP_HIDDEN_LAYERS_MT1 | 5,06 | 17,72 | 12,66 | 3,80 | 0,63 | 19,62 | 29,11 | 4,43 | 9,49 | 5,06 | 6,33 | 6,33 | 1,90 | 1,90 | 6,33 | 8,69 | 158,00 |
| 2_48_24_2160_12_VECTOR_UP_HIDDEN_LAYERS_MT2 | 4,43 | 20,25 | 16,46 | 4,43 | 0,63 | 17,72 | 29,75 | 6,33 | 5,06 | 8,23 | 10,13 | 5,06 | 0,63 | 1,27 | 4,43 | 8,99 | 158,00 |
I want the error of each module to be minimal, but I also want the spread to be minimal.
product of logarithms
ZS: not really sure what is required, but the logarithm will allow errors to be treated progressively, it will give better results in single cases (individual modules). And multiplication is an attempt to reduce dispersionproduct of logarithms
ZS: I don't really understand what exactly is required, but logarithm will allow errors to be treated progressively, it will give better results in single cases (individual modules). And multiplication is an attempt to reduce the spreadThank you. Andpractically how is it?
Thank you. Andpractically how is that?
Probably just the product of
Option1 ) Translate each module into the style (1-x%) and multiply them..... the answer is also subtracted from the unit.
x% is the cell value
Option2
With logarithms we simply take value of a cell and count logarithm from it)))) the closer to zero value is to progressive evaluation i.e. with some base setting 0.1 is better than 0.01 and also 0.1 is better than 1. There will only be a base parameter for the logarithm which is worth playing around with.
Perhaps a simple product would do.
Option1 ) Translate each module into the style (1-x%) and multiply them..... The answer is also subtracted from the unit.
x% is the cell value
Option2
With logarithms we simply take value of a cell and count logarithm from it)))) the closer to zero value is to progressive evaluation i.e. with some base setting 0.1 is better than 0.01 and also 0.1 is better than 1. There will only be a basis parameter of the logarithm which is worth playing around with.
Option 1
| -3,43 | -16,09 | -14,82 | -1,53 | 0,37 | -16,72 | -27,48 | -4,70 | -12,29 | -4,70 | -7,23 | -5,33 | 0,37 | -2,16 | -5,96 | 10601305851,38 |
| -4,06 | -16,72 | -11,66 | -2,80 | 0,37 | -18,62 | -28,11 | -3,43 | -8,49 | -4,06 | -5,33 | -5,33 | -0,90 | -0,90 | -5,33 | -6223799946,09 |
| -3,43 | -19,25 | -15,46 | -3,43 | 0,37 | -16,72 | -28,75 | -5,33 | -4,06 | -7,23 | -9,13 | -4,06 | 0,37 | -0,27 | -3,43 | 1237520122,21 |
What does this tell me?
Option 2
| -0,64640373 | -1,23274206 | -1,19920648 | -0,40312052 | 0,200659451 | -1,24846372 | -1,45453998 | -0,75587486 | -1,12352498 | -0,75587486 | -0,91539984 | -0,80140371 | 0,200659451 | -0,49968708 | -0,84260924 |
| -0,70415052 | -1,24846372 | -1,10243371 | -0,5797836 | 0,200659451 | -1,292699 | -1,46404221 | -0,64640373 | -0,97726621 | -0,70415052 | -0,80140371 | -0,80140371 | -0,2787536 | -0,2787536 | -0,80140371 |
| -0,64640373 | -1,30642503 | -1,21642983 | -0,64640373 | 0,200659451 | -1,24846372 | -1,47348697 | -0,80140371 | -0,70415052 | -0,91539984 | -1,00560945 | -0,70415052 | 0,200659451 | -0,10380372 | -0,64640373 |
This is the logarithm with base 0.1
What should I do with it?
I have tried other functions. Only how do I understand them too? ....
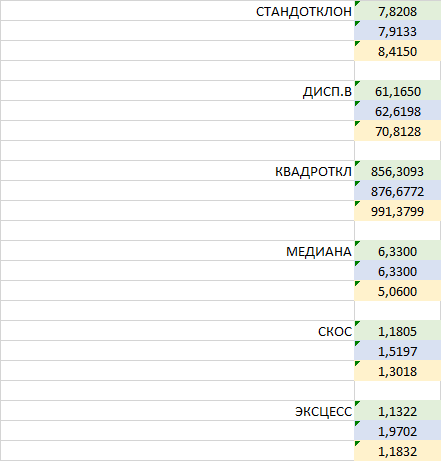
| STANDOTCLONE | 7,8208 |
| 7,9133 | |
| 8,4150 | |
| DISP.B | 61,1650 |
| 62,6198 | |
| 70,8128 | |
| QUADROTKL | 856,3093 |
| 876,6772 | |
| 991,3799 | |
| MEDIANA | 6,3300 |
| 6,3300 | |
| 5,0600 | |
| SCOS | 1,1805 |
| 1,5197 | |
| 1,3018 | |
| EXCESS | 1,1322 |
| 1,9702 | |
| 1,1832 |
Find the maximum in each row, then choose the row with the minimum maximum. Pardon the pun))
Maximum maximum in line 3, minimum maximum in line 1. И? )))
Maximum maximum in line 3, minimum maximum in line 1. И? )))
Choose the first line.
Option 1
| -3,43 | -16,09 | -14,82 | -1,53 | 0,37 | -16,72 | -27,48 | -4,70 | -12,29 | -4,70 | -7,23 | -5,33 | 0,37 | -2,16 | -5,96 | 10601305851,38 |
| -4,06 | -16,72 | -11,66 | -2,80 | 0,37 | -18,62 | -28,11 | -3,43 | -8,49 | -4,06 | -5,33 | -5,33 | -0,90 | -0,90 | -5,33 | -6223799946,09 |
| -3,43 | -19,25 | -15,46 | -3,43 | 0,37 | -16,72 | -28,75 | -5,33 | -4,06 | -7,23 | -9,13 | -4,06 | 0,37 | -0,27 | -3,43 | 1237520122,21 |
What does this tell me?
Option 2
| -0,64640373 | -1,23274206 | -1,19920648 | -0,40312052 | 0,200659451 | -1,24846372 | -1,45453998 | -0,75587486 | -1,12352498 | -0,75587486 | -0,91539984 | -0,80140371 | 0,200659451 | -0,49968708 | -0,84260924 |
| -0,70415052 | -1,24846372 | -1,10243371 | -0,5797836 | 0,200659451 | -1,292699 | -1,46404221 | -0,64640373 | -0,97726621 | -0,70415052 | -0,80140371 | -0,80140371 | -0,2787536 | -0,2787536 | -0,80140371 |
| -0,64640373 | -1,30642503 | -1,21642983 | -0,64640373 | 0,200659451 | -1,24846372 | -1,47348697 | -0,80140371 | -0,70415052 | -0,91539984 | -1,00560945 | -0,70415052 | 0,200659451 | -0,10380372 | -0,64640373 |
This is the logarithm with base 0.1
What should I do with it?
I have tried other functions. But how do I understand them too?
It's a bitch."Error of each module is given as a percentage. 0% is the ideal result." Number 1 means 100% - x% or 1-X*0.01

| TOTAL | ||||||||||||||||
| 0,9557 | 0,8291 | 0,8418 | 0,9747 | 0,9937 | 0,8228 | 0,7152 | 0,943 | 0,8671 | 0,943 | 0,9177 | 0,9367 | 0,9937 | 0,9684 | 0,9304 | 0,77439 | |
| 0,9494 | 0,8228 | 0,8734 | 0,962 | 0,9937 | 0,8038 | 0,7089 | 0,9557 | 0,9051 | 0,9494 | 0,9367 | 0,9367 | 0,981 | 0,981 | 0,9367 | 0,758606 | |
| 0,9557 | 0,7975 | 0,8354 | 0,9557 | 0,9937 | 0,8228 | 0,7025 | 0,9367 | 0,9494 | 0,9177 | 0,8987 | 0,9494 | 0,9937 | 0,9873 | 0,9557 | 0,771806 |
the second line is the best, and the first and the third are very similar
the total subtracted from the unit, i.e. the closer to 0 the total, the better the results..... in other words, the results so far are not very good because 0.75 is your 75, although it depends on what to compare it with..... the worst score would be 1 (100%) the best score 0
You have to understand that a score of 90 is ten times better than a score of 99.... a score of 99 is ten times better than a score of 99.9... 100 is in fact possible only when all modules have an error score of 100... i.e. a score of 0.1 is ten times worse than a score of 0.01. At the same time, a score of 10 is ten times worse than a score of 1.
with the logarithm over think..... the answer should be exclusively positive values... usually a logarithm of 1.1... in the range of 1 to 2, not 0 to 1.... if they want to increase the number and from 2 if they want to decrease it progressively
The quadratic deviation method is definitely out of the question. So are all the others that count deviations. Because ideally the quadratic deviation from a linear regression would be used in order to understand the variance. But then we get an estimate of these deviations without any average of the numbers themselves.....
Question: How do I evaluate the results correctly?
The error of each module is given as a percentage. 0% is the ideal result.
| ________________ PARAMETERS ________________ | Mod 1 | Mod 2 | Mod 3 | Mode 4 | Mode 5 | (vi) Mode 6 | (vi) Mode 7 | (vi) Mode 8 | (vi) Mod 9 | (vi) Mod 10 | (vi) Mod 11 | (vi) Mod 12 | (viii) mod 13 | (vi) 14 | Mode 15 | Average error | From the attempts |
| 2_48_24_2160_12_VECTOR_UP_HIDDEN_LAYERS_HAND | 4,43 | 17,09 | 15,82 | 2,53 | 0,63 | 17,72 | 28,48 | 5,70 | 13,29 | 5,70 | 8,23 | 6,33 | 0,63 | 3,16 | 6,96 | 9,11 | 158,00 |
| 2_48_24_2160_12_VECTOR_UP_HIDDEN_LAYERS_MT1 | 5,06 | 17,72 | 12,66 | 3,80 | 0,63 | 19,62 | 29,11 | 4,43 | 9,49 | 5,06 | 6,33 | 6,33 | 1,90 | 1,90 | 6,33 | 8,69 | 158,00 |
| 2_48_24_2160_12_VECTOR_UP_HIDDEN_LAYERS_MT2 | 4,43 | 20,25 | 16,46 | 4,43 | 0,63 | 17,72 | 29,75 | 6,33 | 5,06 | 8,23 | 10,13 | 5,06 | 0,63 | 1,27 | 4,43 | 8,99 | 158,00 |
I want the error of each module to be minimal, but I also want the scatter to be minimal.
It is probably better to get the sum of squares for the module errors, and extract the root.
Thus, we will get the total module error estimate.
The closer to zero this value is, the better.
So it goes like this.
//+------------------------------------------------------------------+ //| EstimateError.mq5 | //| Copyright 2020, MetaQuotes Software Corp. | //| https://www.mql5.com | //+------------------------------------------------------------------+ #property copyright "Copyright 2020, MetaQuotes Software Corp." #property link "https://www.mql5.com" #property version "1.00" double ModN[15][3] = {{4.43, 5.06, 4.43}, {17.09, 17.72, 20.25}, {15.82, 12.66, 16.46}, {2.53, 3.80, 4.43}, {0.63, 0.63, 0.63}, {17.72, 19.62, 17.72}, {28.48, 29.11, 29.75}, {5.70, 4.43, 6.33}, {13.29, 9.49, 5.06}, {5.70, 5.06, 8.23}, {8.23, 6.33, 10.13}, {6.33, 6.33, 5.06}, {0.63, 6.33, 0.63}, {3.16, 1.90, 1.27}, {6.96, 6.33, 4.43}}; //+------------------------------------------------------------------+ //| Script program start function | //+------------------------------------------------------------------+ void OnStart() { double ModX[]; ArrayResize(ModX, 3); ZeroMemory(ModX); int num = 1; double est = 0.0; for(int i=0; i<15; i++) { for(int j=0; j<3; j++) { ModX[j] = ModN[i][j]; } est = EstimateError(ModX); PrintFormat("Mod"+(string)num+" EstimateError: %.3f", est); num++; } }// End OnStart //+------------------------------------------------------------------+ double EstimateError(double & arr[]) { int size = ArraySize(arr); if(size == 0 || size < 3) return(0.0); //double avg = ArrayMean(arr); double max = ArrayMax(arr); double min = ArrayMin(arr); double sum_sqr_e = 0.0; double est_e = 0.0; for(int i=0; i<size; i++) sum_sqr_e += MathPow(arr[i] - (max-min)/* или avg*/, 2.0) / (size - 2.0); est_e = MathSqrt(sum_sqr_e); return(est_e); } //+------------------------------------------------------------------- //Возвращает максимальное значение элементов массива double ArrayMax(double & arrIn[]) { uint size = ArraySize(arrIn); if(size == 0) return(0.0); double max = arrIn[0]; for(uint i=1; i<size; i++) if(arrIn[i] > max) max = arrIn[i]; return(max); } //-------------------------------------------------------------------- //Возвращает минимальное значение элементов массива double ArrayMin(double & arrIn[]) { uint size = ArraySize(arrIn); if(size == 0) return(0.0); double min = arrIn[0]; for(uint i=1; i<size; i++) if(arrIn[i] < min) min = arrIn[i]; return(min); } //-------------------------------------------------------------------- //Возвращает средне арефметическое значение элементов массива double ArrayMean(double & arrIn[]) { uint size = ArraySize(arrIn); if(size == 0) return(0.0); double sum = 0.0; for(uint i=0; i<size; i++) sum += arrIn[i]; return(sum/size); } //--------------------------------------------------------------------
2020.06.07 04:59:23.227 EstimateError (AUDUSD,M5) Mod1 EstimateError: 6.965 2020.06.07 04:59:23.227 EstimateError (AUDUSD,M5) Mod2 EstimateError: 26.422 2020.06.07 04:59:23.227 EstimateError (AUDUSD,M5) Mod3 EstimateError: 19.577 2020.06.07 04:59:23.227 EstimateError (AUDUSD,M5) Mod4 EstimateError: 3.226 2020.06.07 04:59:23.227 EstimateError (AUDUSD,M5) Mod5 EstimateError: 1.091 2020.06.07 04:59:23.227 EstimateError (AUDUSD,M5) Mod6 EstimateError: 28.540 2020.06.07 04:59:23.227 EstimateError (AUDUSD,M5) Mod7 EstimateError: 48.234 2020.06.07 04:59:23.227 EstimateError (AUDUSD,M5) Mod8 EstimateError: 6.361 2020.06.07 04:59:23.227 EstimateError (AUDUSD,M5) Mod9 EstimateError: 6.102 2020.06.07 04:59:23.227 EstimateError (AUDUSD,M5) Mod10 EstimateError: 5.965 2020.06.07 04:59:23.227 EstimateError (AUDUSD,M5) Mod11 EstimateError: 8.130 2020.06.07 04:59:23.227 EstimateError (AUDUSD,M5) Mod12 EstimateError: 8.098 2020.06.07 04:59:23.227 EstimateError (AUDUSD,M5) Mod13 EstimateError: 7.198 2020.06.07 04:59:23.227 EstimateError (AUDUSD,M5) Mod14 EstimateError: 1.413 2020.06.07 04:59:23.227 EstimateError (AUDUSD,M5) Mod15 EstimateError: 6.138
The estimate shows that Mod5 has the smallest error.
- Free trading apps
- Over 8,000 signals for copying
- Economic news for exploring financial markets
You agree to website policy and terms of use
Question: How do I evaluate the results correctly?
The error of each module is given as a percentage. 0% is the ideal result.
I would like the error of each module to be minimal, but I would also like the spread to be minimal.