
Нейросети — это просто (Часть 64): Метод Консервативного Весового Поведенческого Клонирования (CWBC)

Введение
Трансформер решений и все его модификации, с которыми мы познакомились в последних статьях, относятся к методам Клонирования Поведения (Behavioral Сloning — BC). Мы обучаем модели повторять действия из "экспертных" траекторий в зависимости от состояния окружающей среды и поставленных целей. Тем самым учим модель имитировать поведение эксперта в сложившемся состоянии окружающей среды для достижения поставленной цели.
Однако в реальных условиях оценки различных экспертов одного и того же состояния окружающей среды довольно сильно расходятся. И порой до абсолютно противоположных. Более того, я хочу напомнить, что в предыдущих работах мы не привлекали экспертов для создания нашей обучающей выборки. Мы использовали различные методы сэмплирования действий Агента и отбирали лучшие траектории. Которые далеко не всегда были оптимальными.
Тут надо признать, что в процессе сэмплирования траекторий в условиях непрерывного пространства действий и эпизодов практически невозможно сохранить все возможные варианты. И только малая часть сэмплированных траекторий может хотя бы отчасти удовлетворять нашим требованиям. Такие траектории больше похожи на выбросы, которые модель может просто отбросить в процессе обучения.
Как вариант выхода из подобной ситуации мы использовали подходы метода Go-Explore. И последовательно из маленьких кусочков составляли успешную траекторию. Такие траектории можно назвать субоптимальными. Они близки к нашим ожиданиям, но их оптимальность остается не доказанной.
И, конечно, мы можем разметить "руками" оптимальную траекторию на исторических данных. Такой подход приближает нас к обучению с учителем со всеми плюсами и минусами этого подхода.
В то же время отбор оптимальных проходов ставит модель в идеальные условия, что может привести к переобучению модели. Когда модель, заучив маршрут обучающей выборки, не сможет обобщить полученный опыт на новые состояния окружающей среды.
Второй проблемный момент методов клонирования поведения — постановка целей перед моделью (Return To Go). Данный вопрос мы уже затрагивали в предыдущих работах. В некоторых работах рекомендуется использовать коэффициент к максимальному результату из обучающей выборке, что часто позволяет получить более высокие результаты. Но такой подход применим только для решения статичных задач. И коэффициент подбирается для каждой задачи отдельно. Метод Dichotomy of Control предлагает нам ещё один вариантов решения данной проблемы. Существуют и другие подходы.
Озвученные выше проблемы исследуются авторами статьи «Reliable Conditioning of Behavioral Cloning for Offline Reinforcement Learning». И для их решения предлагается довольно интересный метод ConserWeightive Behavioral Cloning (CWBC), который применим не только для моделей семейства Decision Transformer.
1. Алгоритм
C целью выявления факторов, влияющих на надежность методов обучения с подкреплением, зависящих от целевых вознаграждений, авторами статьи «Reliable Conditioning of Behavioral Cloning for Offline Reinforcement Learning» было проведено два иллюстративных эксперимента.
В первом эксперименте модели различной архитектуры запускались на наборах траекторий различного уровня доходности. От практически случайных до экспертных и субоптимальных. Результаты эксперимента продемонстрировали, что надежность модели в значительной мере зависит от качества данных в обучающей выборке. При обучении моделей на данных траекторий средней и экспертной доходности надежные результаты модель демонстрирует при условии высоких целей. В то же время при обучении модели на траекториях с низким результатом её производительность быстро снижается после определенного момента увеличения RTG. Это связано с тем, что данные низкого качества не предоставляют достаточно информации для обучения политики, обусловленной на большие вознаграждения. И это отрицательно сказывается на надежности полученной модели.
Качество данных не единственная причина надежности модели. Архитектура модели также играет важную роль. В проводимых экспериментах DT проявляет надежность во всех трех наборах данных. Предполагается, что надежность DT достигается использованием архитектуры Трансформера. Поскольку политика прогнозирования следующего действия Агента строится на последовательности состояний окружающей среды и меток RTG, слои внимания могут игнорировать метки RTG вне распределения обучающей выборки. При этом достигается хорошая точность прогнозирования. В то же время модели, построенные на архитектуре MLP, получая текущее состояние и целевой возврат в качестве исходных данных для генерации действий не могут игнорировать информацию о желаемом вознаграждении. Для проверки этой гипотезы авторы экспериментируют с немного измененной версией DT, в которой конкатенируются векторы состояния окружающей среды и RTG на каждом временном шаге. Таким образом модель не может игнорировать информацию о RTG в последовательности. Результаты эксперимента демонстрируют быстрое снижение надежности такой модели после выхода RTG за пределы распределения обучающей выборки. Что подтверждает сделанное выше предположение.
Для оптимизации процесса обучения моделей и минимизации влияния выше указанных факторов авторы статьи предлагают использовать фреймворк ConserWeightive Behavioral Cloning (CWBC), который является довольно простым и эффективный способом улучшения надежности существующих методов обучения моделей клонирования поведения. CWBC состоит из двух компонентов:
- Взвешивание траекторий.
- Консервативная регуляризация RTG
Взвешивание траекторий предоставляет системный способ преобразования субоптимального распределения данных для более точной оценки оптимального распределения путем увеличения веса высокодоходных траекторий. А консервативный регуляризатор потерь побуждает политику оставаться близкой к исходному распределению данных при условии больших целей.
1.1 Взвешивание траекторий
Мы знаем, что оптимальное оффлайн распределение траекторий просто является распределением демонстраций, сгенерированных оптимальной политикой. Обычно оффлайн распределение траекторий будет смещено относительно оптимального. Во время обучения это приводит к разрыву между обучением и тестированием, поскольку мы хотим обусловить нашего Агента на максимальную доходность при оценке и эксплуатации модели, но вынуждены минимизировать эмпирический риск на смещенном распределении данных во время обучения.
Основная идея метода заключается в преобразовании обучающей выборки траекторий в новое распределение, которое лучше оценивает оптимальную траекторию. Новое распределение должно сосредотачиваться на траекториях с высоким доходом, что интуитивно смягчает разрыв между обучением и тестированием. И поскольку мы ожидаем, что оригинальный набор данных будет содержать очень мало траекторий с высоким доходом, то простое отсеивание траекторий с низким результатом приведет к удалению большинства обучающих данных. А это приведет к снижению обобщающей способности обученной модели. И авторы метода предлагают взвешивать траектории на основе их доходов.
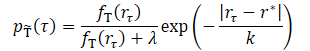
где λ, k являются двумя гиперпараметрами, определяющими форму преобразованного распределения.
Параметр сглаживания k управляет взвешиванием траекторий в зависимости от их результативности. Интуитивно понятно, что меньший k придает больший вес траекториям с высокими результатом. А при увеличении значения параметра преобразованное распределение становится более равномерным. Авторы предлагают устанавливать значение k как разницу между максимальным и значение z-го перцентиля результатов в обучающей выборке.
![]()
Это позволяет фактическому значению k адаптироваться к различным наборам данных. Авторы метода провели тестирование четырех значения z из множества {99, 90, 50, 0}, которые соответствуют четырем увеличивающимся значениям k. По результатам экспериментов для каждого датасета преобразованное распределение с использованием маленького k сильно концентрируется на высоких вознаграждениях. С увеличением k плотность траекторий с низким вознаграждением увеличивается, и распределение становится более равномерным. При этом относительно небольшие значения k на основе перцентиля из множества {99, 90, 50} модель демонстрирует хорошую производительность на всех датасетах. Однако, большие значения k на основе перцентиля 0 ухудшают производительность для датасета с экспертными траекториями.
Параметр λ также оказывает влияние на преобразованное распределение. При λ = 0 преобразованное распределение концентрируется на высоких вознаграждениях. С увеличением λ преобразованное распределения стремится к оригинальному, но по-прежнему взвешенно в сторону области высоких вознаграждений из-за влияния экспоненциального члена. Фактическая производительность моделей при различных значения λ демонстрирует схожие результаты, которые лучше или сравнимы с обучением на исходном наборе данных.
1.2 Консервативная регуляризация
Как было отмечено выше, архитектура также играет важную роль в надежности обученной модели. Идеальный сценарий реализовать трудно, а порой даже невозможно. Но авторы метода CWBC стремятся получить политику близкой к исходному распределению данных, чтобы избежать катастрофической потери при указании RTG вне распределения. Другими словами, политика должна быть консервативной. Тем не менее консерватизм не обязательно должен происходить от архитектуры, а может также возникнуть из правильной функции потерь обучения модели, как это обычно делается в консервативных методах, основанных на оценке стоимости состояний и переходов.
Авторы метода предлагают новый консервативный регуляризатор для методов поведенческого клонирования, зависящих от RTG, который явно побуждает политику оставаться близкой к исходному распределению данных. Идея заключается в обеспечении прогнозирования действий близких к исходному распределению даже при указании больших значений RTG вне распределения обучающей выборки. Что достигается добавлением положительного шума к RTG для траекторий с высоким фактическим вознаграждением и наказываем L2-расстояния между прогнозируемым действием и фактическим из обучающей выборки. Для гарантирования генерации больших значений RTG вне распределения мы генерируем шум таким образом, чтобы скорректированное значение RTG было не менее самого высокого вознаграждения в обучающей выборке.
Предлагается применять консервативную регуляризацию к траекториям, возвраты которых превышают q-й перцентиль вознаграждений в обучающей выборке. Это гарантирует, что при указании RTG вне обучающего распределения политика ведет себя аналогично траекториям с высоким вознаграждением, а не случайной траектории. Мы добавляем шум и смещаем RTG на каждом временном шаге.
Проведенные авторами метода эксперименты демонстрируют, что использование 95-го перцентиля обычно хорошо работает в различных средах и наборах данных.
Авторы метода отмечают, что предложенный консервативный регуляризатор отличается от других консервативных компонентов для методов оффлайн RL, основанных на оценке стоимости состояний и переходов. В то время как последние обычно пытаются регулировать оценку функции стоимости, чтобы предотвратить ошибку экстраполяции, предложенный метод искажает целевые вознаграждения для создания условий вне распределения и регулируется прогнозирование действий.
При использовании взвешивания траекторий вместе с консервативным регуляризатором мы получаем "ConserWeightive Behavioral Cloning" (CWBC), который объединяет лучшее из обеих компонентов.
2. Реализация средствами MQL5
После рассмотрения теоретическим аспектов метода ConserWeightive Behavioral Cloning мы переходим к реализации своей интерпретации предложенных подходов. В данной работе мы будем обучать 2 модели:
- Агента (Decision Transformer) для прогнозирования действий.
- Модель оценки стоимости текущего состояния окружающей среды для генерации RTG.
При этом мы добавим взвешивание траекторий и консервативную регуляризацию для оптимизации процесса обучения. Авторы метода CWBC утверждают, что предложенные алгоритмы позволяют повысить эффективность обучения DT в среднем на 8%.
Сразу надо отметить, что процесс обучение моделей независим. И существует возможность организовать их параллельное обучение. Чем мы и воспользуемся. Но сначала опишем архитектуру моделей. И здесь мы разделим процесс описания архитектуры на 2 отдельных метода. В методе CreateDescriptions мы создадим описание архитектуры Агента, который получает на вход один шаг анализируемой последовательности, состоящий из 5 сущностей:
- исторические данные ценового движения и анализируемых индикаторов;
- состояния счета и открытых позиций;
- метка времени;
- последнее действие Агента;
- RTG.
Это мы и отражаем в слое исходных данных модели.
bool CreateDescriptions(CArrayObj *agent) { //--- CLayerDescription *descr; //--- if(!agent) { agent = new CArrayObj(); if(!agent) return false; } //--- Agent agent.Clear(); //--- Input layer if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBaseOCL; int prev_count = descr.count = (BarDescr * NBarInPattern + AccountDescr + TimeDescription + NActions + NRewards); descr.activation = None; descr.optimization = ADAM; if(!agent.Add(descr)) { delete descr; return false; }
Как обычно, полученные данные проходят предварительную обработку в слое пакетной нормализации.
//--- layer 1 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBatchNormOCL; descr.count = prev_count; descr.batch = 1000; descr.activation = None; descr.optimization = ADAM; if(!agent.Add(descr)) { delete descr; return false; }
Далее мы приводим все сущности в сопоставимый вид. Для этого мы сначала используем слой эмбединга, который переносит все данное в единое N-мерное пространство. Здесь я хочу напомнить, что созданный нами слой эмбединга содержит в памяти полученные ранее данные на глубину анализируемой истории. И новые данные добавляются к собранной последовательности.
//--- layer 2 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronEmbeddingOCL; prev_count = descr.count = HistoryBars; { int temp[] = {BarDescr * NBarInPattern, AccountDescr, TimeDescription, NActions, NRewards}; ArrayCopy(descr.windows, temp); } int prev_wout = descr.window_out = EmbeddingSize; if(!agent.Add(descr)) { delete descr; return false; }
А затем слоем SoftMax приведем все эмбединги в сопоставимое распределение. Обратите внимание, что SoftMax применяется в разрезе каждого отдельного эмбединга.
//--- layer 3 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronSoftMaxOCL; descr.count = EmbeddingSize; descr.step = prev_count * 5; descr.activation = None; descr.optimization = ADAM; if(!agent.Add(descr)) { delete descr; return false; }
После приведения всех эмбедингов в сопоставимый вид мы используем блок внимания, который проанализирует полученную последовательность.
//--- layer 4 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronMLMHAttentionOCL; prev_count = descr.count = prev_count * 5; descr.window = EmbeddingSize; descr.step = 8; descr.window_out = 32; descr.layers = 4; descr.optimization = ADAM; if(!agent.Add(descr)) { delete descr; return false; }
Далее следует блок из 2 сверточных слоёв, который ищет в данных устойчивые паттерны и одновременно снижает размерность данных в 2 раза.
//--- layer 5 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronConvOCL; prev_count = descr.count = prev_count; descr.window = EmbeddingSize; descr.step = EmbeddingSize; prev_wout = descr.window_out = EmbeddingSize; descr.optimization = ADAM; descr.activation = LReLU; if(!agent.Add(descr)) { delete descr; return false; } //--- layer 6 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronConvOCL; prev_count = descr.count = prev_count; descr.window = prev_wout; descr.step = prev_wout; prev_wout = descr.window_out = prev_wout / 2; descr.optimization = ADAM; descr.activation = LReLU; if(!agent.Add(descr)) { delete descr; return false; }
Обратите внимание, что до сих пор мы осуществляли обработку данных в рамках отдельно взятого эмбединга. И завершим этот этап приведение всех сущностей в сопоставимый вид с использование функции SoftMax, которую мы также применяем к каждой сущности в последовательности отдельно.
//--- layer 7 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronSoftMaxOCL; descr.count = prev_count; descr.step = prev_wout; descr.activation = None; descr.optimization = ADAM; if(!agent.Add(descr)) { delete descr; return false; }
Обработанные таким образом и полностью сопоставимые данные передаются в блок принятия решения, состоящий из полносвязных слоев, с генераций прогнозных действий Агента на выходе.
//--- layer 8 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBaseOCL; descr.count = LatentCount; descr.optimization = ADAM; descr.activation = LReLU; if(!agent.Add(descr)) { delete descr; return false; } //--- layer 9 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBaseOCL; prev_count = descr.count = LatentCount; descr.activation = LReLU; descr.optimization = ADAM; if(!agent.Add(descr)) { delete descr; return false; } //--- layer 10 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBaseOCL; descr.count = LatentCount; descr.activation = LReLU; descr.optimization = ADAM; if(!agent.Add(descr)) { delete descr; return false; } //--- layer 11 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBaseOCL; descr.count = NActions; descr.activation = SIGMOID; descr.optimization = ADAM; if(!agent.Add(descr)) { delete descr; return false; } //--- return true; }
Следующим этапом мы создадим описание архитектуры модели оценки стоимости состояния окружающей среды в методе CreateRTGDescriptions. Данная модель получает на вход некоторую последовательность исторических данных изменения цены и анализируемых индикаторов. Стоит отметить, что в данном случае мы говорим о последовательности нескольких баров.
bool CreateRTGDescriptions(CArrayObj *rtg) { //--- CLayerDescription *descr; //--- if(!rtg) { rtg = new CArrayObj(); if(!rtg) return false; } //--- RTG rtg.Clear(); //--- Input layer if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBaseOCL; int prev_count = descr.count = ValueBars * BarDescr; descr.activation = None; descr.optimization = ADAM; if(!rtg.Add(descr)) { delete descr; return false; }
Полученные данные также проходят первичную обработку в слое пакетной нормализации.
//--- layer 1 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBatchNormOCL; descr.count = prev_count; descr.batch = 1000; descr.activation = None; descr.optimization = ADAM; if(!rtg.Add(descr)) { delete descr; return false; }
Далее мы создадим эмбединг каждого бара с использованием сверточного слоя и функции SoftMax. В данном случае мы не используем слой эмбединга, так как структура данных каждого бара одинаковая и нам не нужно осуществлять накопление полученных данных.
//--- layer 2 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronConvOCL; prev_count = descr.count = (prev_count + BarDescr - 1) / BarDescr; descr.window = BarDescr; descr.step = BarDescr; int prev_wout = descr.window_out = EmbeddingSize; descr.optimization = ADAM; descr.activation = LReLU; if(!rtg.Add(descr)) { delete descr; return false; } //--- layer 3 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronSoftMaxOCL; descr.count = prev_count; descr.step = EmbeddingSize; descr.activation = None; descr.optimization = ADAM; if(!rtg.Add(descr)) { delete descr; return false; }
Обработанные данные передаются в блок внимания.
//--- layer 4 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronMLMHAttentionOCL; descr.count = prev_count; descr.window = EmbeddingSize; descr.step = 8; descr.window_out = 32; descr.layers = 4; descr.optimization = ADAM; if(!rtg.Add(descr)) { delete descr; return false; }
А затем данные попадают в блок сверточных слоёв и последующей нормализацией SoftMax, аналогично выше рассмотренной модели.
//--- layer 5 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronConvOCL; prev_count = descr.count = prev_count; descr.window = EmbeddingSize; descr.step = EmbeddingSize; prev_wout = descr.window_out = EmbeddingSize; descr.optimization = ADAM; descr.activation = LReLU; if(!rtg.Add(descr)) { delete descr; return false; } //--- layer 6 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronConvOCL; prev_count = descr.count = prev_count; descr.window = prev_wout; descr.step = prev_wout; prev_wout = descr.window_out = prev_wout / 2; descr.optimization = ADAM; descr.activation = LReLU; if(!rtg.Add(descr)) { delete descr; return false; } //--- layer 7 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronSoftMaxOCL; descr.count = prev_count; descr.step = prev_wout; descr.activation = None; descr.optimization = ADAM; if(!rtg.Add(descr)) { delete descr; return false; }
После чего мы создаем блок принятия решений из полносвязных слоем.
//--- layer 8 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBaseOCL; descr.count = LatentCount; descr.optimization = ADAM; descr.activation = LReLU; if(!rtg.Add(descr)) { delete descr; return false; } //--- layer 8 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBaseOCL; prev_count = descr.count = LatentCount; descr.activation = TANH; descr.optimization = ADAM; if(!rtg.Add(descr)) { delete descr; return false; }
На выходе модели мы создаем стохастичность политики генерации RTG с использованием блока вариационного автоэнкодера. Тем самым мы имитируем стохастичность окружающей среды и стоимости возможных переходов в рамках выученного распределения.
//--- layer 9 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBaseOCL; descr.count = 2 * NRewards; descr.activation = None; descr.optimization = ADAM; if(!rtg.Add(descr)) { delete descr; return false; } //--- layer 10 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronVAEOCL; descr.count = NRewards; descr.activation = None; descr.optimization = ADAM; if(!rtg.Add(descr)) { delete descr; return false; } //--- return true; }
После создания описания архитектуры моделей мы переходим к работе над советниками обучения моделей. Для первичного сбора обучающей выборки мы отберем лучшие случайные траектории, сэмплированные с помощью советника "...\CWBC\Faza1.mq5". Алгоритм данного советника и принципы сбора данных описаны в статье, посвященной Control Transformer.
Далее мы создадим советник обучения нашего Агента "...\CWBC\StudyAgent.mq5". Надо сказать, что данные советник во многом унаследовал структуру советника обучения оригинального Decision Transformer. Однако мы дополнили его подходами метода CWBC. Вначале мы создадим метод взвешивания траекторий GetProbTrajectories, который вернет нам вектор с накопительными суммами вероятностей для семплирования траекторий. И сразу в теле метода мы определим максимальное вознаграждение в буфере воспроизведения опыта, уровень необходимого квантиля и вектор среднеквадратических отклонений вознаграждений. Эти данные нам потребуются для последующей консервативной регуляризации.
В параметрах методу мы будем передавать буфер воспроизведения опыта и необходимые переменные.
vector<float> GetProbTrajectories(STrajectory &buffer[], float &max_reward, float &quantile, vector<float> &std, double quant, float lanbda) { ulong total = buffer.Size();
В теле метода мы сразу определяем количество траекторий в буфере воспроизведения и подготовим матрицу для сбора вознаграждений в проходах.
matrix<float> rewards = matrix<float>::Zeros(total, NRewards); vector<float> result;
Здесь следует вспомнить, что при сохранении траектории в буфер воспроизведения мы пересчитываем накопительное вознаграждение до конца прохода. Следовательно, суммарное вознаграждение за весь проход будет храниться в элементе с индексом 0. Мы организуем цикл и скопируем суммарное вознаграждение каждого прохода в подготовленную нами матрицу.
for(ulong i = 0; i < total; i++) { result.Assign(buffer[i].States[0].rewards); rewards.Row(result, i); }
С использование матричных операций мы получаем среднеквадратическое отклонение по каждому элементу вектора вознаграждений.
std = rewards.Std(0);
Вектор суммарных вознаграждений каждого прохода и значение максимального вознаграждения.
result = rewards.Sum(1);
max_reward = result.Max();
Обратите внимание, что я использовал простое суммирование вектора вознаграждений в каждом проходе. Однако возможны варианты среднего значения декомпозированных вознаграждений. А также взвешенных вариантов суммы или среднего. Использование подхода зависит от конкретной задачи.
Далее нам предстоит определить уровень необходимого квантиля. В документации MQL5 по векторной операции Quantile указано, что для корректного вычисления необходим отсортированный вектор последовательности. Создадим копию вектора суммарных вознаграждений и отсортируем его по возрастанию.
vector<float> sorted = result; bool sort = true; int iter = 0; while(sort) { sort = false; for(ulong i = 0; i < sorted.Size() - 1; i++) if(sorted[i] > sorted[i + 1]) { float temp = sorted[i]; sorted[i] = sorted[i + 1]; sorted[i + 1] = temp; sort = true; } iter++; } quantile = sorted.Quantile(quant);
Далее мы вызываем векторную функцию Quantile и сохраняем полученный результат.
После сбора данных, необходимых для последующих операций мы переходим непосредственно к определению весов для каждой траектории. И тут надо понимать, что для унификации использования коэффициента λ нам необходим алгоритм для приведения всех возможных выборок вознаграждений к единому распределению. Для этого мы нормализуем все вознаграждения в диапазоне (0, 1].
Обратите внимание, мы не включаем "0" в диапазон нормализованных значений, т.к. каждая траектория должна иметь вероятность отличную от "0". Поэтому мы занижаем минимальное значение диапазона вознаграждений на 10% от среднеквадратического вознаграждения.
Максимальное использование относительных значений позволяет сделать наш расчет поистине унифицированным.
float min = result.Min() - 0.1f * std.Sum();
Однако, остается небольшая вероятность получения идентичных значений вознаграждений во всех проходах. Причины тому могут быть различные. Но несмотря на низкую вероятность такого события, мы все же создадим проверку. И в основной ветке нашего алгоритма мы сначала рассчитаем экспоненциальную составляющую. А затем нормализуем вознаграждения и пересчитаем весовые коэффициенты траекторий.
if(max_reward > min) { vector<float> multipl=exp(MathAbs(result - max_reward) / (result.Percentile(90)-max_reward)); result = (result - min) / (max_reward - min); result = result / (result + lanbda) * multipl; result.ReplaceNan(0); }
Для частного случая равных вознаграждений мы заполним вектор вероятностей константным значением.
else result.Fill(1);
Затем мы приведем сумму всех вероятностей к "1" и посчитаем вектор накопительных сумм.
result = result / result.Sum(); result = result.CumSum(); //--- return result; }
Для сэмплирования траектории на каждой итерации мы будем использовать метод SampleTrajectory, в параметрах которому мы будем передавать вектор накопительных вероятностей, полученный выше. А результатом итераций будет индекс траектории в буфере воспроизведения опыта.
int SampleTrajectory(vector<float> &probability) { //--- check ulong total = probability.Size(); if(total <= 0) return -1;
В теле метода мы проверяем размер полученного вектора вероятностей и если он пуст, то сразу возвращаем неверный индекс "-1".
Далее мы генерируем случайное число в диапазоне [0, 1] из равномерного распределения и ищем элемент, в диапазон вероятности выбора которого попадает полученное случайное значение.
Вначале мы проверяем экстремумы (первый и последний элемент вектора вероятностей.
//--- randomize float rnd = float(MathRand() / 32767.0); //--- search if(rnd <= probability[0] || total == 1) return 0; if(rnd > probability[total - 2]) return int(total - 1);
Если сэмплированное значение не попадает в диапазоны экстремумов, то нам предстоит перебрать элементы вектора в поисках необходимого значения.
Интуитивно можно предположить, что распределение вероятностей траекторий будет стремиться к равномерному. Да и начиная перебор элементов из средины вектора при движении в нужном направлении будет гораздо быстрее перебора всего массива от начала. Поэтому мы умножаем сэмплированное значение на размер вектора и получаем некоторый индекс элемента. Мы проверяем вероятность выбранного элемента на соответствие сэмплированному значению. И если его вероятность ниже, то в цикле увеличиваем индекс до нахождения необходимого элемента. В противном случае делаем все то же самое, только уменьшаем индекс.
int result = int(rnd * total); if(probability[result] < rnd) while(probability[result] < rnd) result++; else while(probability[result - 1] >= rnd) result--; //--- return result return result; }
Результат возвращаем вызывающей программе.
Ещё одна вспомогательная функция, которая нам потребуется в процессе реализации метода CWBC — это функция генерации шума Noise. В параметрах функции мы будем передавать вектор среднеквадратических отклонений элементов вектора вознаграждений и скалярный коэффициент, определяющий максимальный уровень шума. Возвращает функция вектор шума.
vector<float> Noise(vector<float> &std, float multiplyer) { //--- check ulong total = std.Size(); if(total <= 0) return vector<float>::Zeros(0);
В теле функции мы сначала проверяем размер вектора среднеквадратических отклонений. И если он пустой, то и мы возвращаем пустой вектор шума.
После успешного прохождения блока контролей мы создаем вектор нулевых значений. И далее в цикле генерируем отдельное значение шума для каждого элемента вектора вознаграждений.
vector<float> result = vector<float>::Zeros(total); for(ulong i = 0; i < total; i++) { float rnd = float(MathRand() / 32767.0); result[i] = std[i] * rnd * multiplyer; } //--- return result return result; }
Мы создали отдельные блоки для реализации метода CWBC и теперь переходим к реализации полного алгоритма обучения модели Агента, который реализован в методе Train.
В теле метода мы объявляем необходимые локальные переменные и вызываем метод взвешивания траекторий GetProbTrajectories.
void Train(void) { float max_reward = 0, quantile = 0; vector<float> std; vector<float> probability = GetProbTrajectories(Buffer, max_reward, quantile, std, 0.95, 0.1f); uint ticks = GetTickCount();
После чего организовываем систему циклов обучения модели. В теле цикла мы сначала вызываем метод SampleTrajectory для сэмплирования траектории, а затем случайным образом выбираем состояние на выбранной траектории для старта процесса обучения.
bool StopFlag = false; for(int iter = 0; (iter < Iterations && !IsStopped() && !StopFlag); iter ++) { int tr = SampleTrajectory(probability); int i = (int)((MathRand() * MathRand() / MathPow(32767, 2)) * MathMax(Buffer[tr].Total - 2 * HistoryBars - ValueBars, MathMin(Buffer[tr].Total, 20))); if(i < 0) { iter--; continue; }
Далее мы организовываем вложенный цикл, в котором осуществляется непосредственное обучение модели на последовательных состояниях окружающей среды. Напомню, что для корректного обучения и функционирования модели Decision Transformer нам необходимо использовать события в строгом соответствии с их исторической последовательностью. Модель собирает полученные данные по мере их поступления во внутреннем буфере и формирует историческую последовательность для анализа.
Actions = vector<float>::Zeros(NActions); Agent.Clear(); for(int state = i; state < MathMin(Buffer[tr].Total - 1 - ValueBars, i + HistoryBars * 3); state++) { //--- History data State.AssignArray(Buffer[tr].States[state].state);
В теле цикла мы собираем данные в буфер исходных данных. Первыми загружаем исторические данные ценового движения и показателей анализируемых индикаторов.
За ними следует информация о состоянии счета и открытых позициях.
//--- Account description float PrevBalance = (state == 0 ? Buffer[tr].States[state].account[0] : Buffer[tr].States[state - 1].account[0]); float PrevEquity = (state == 0 ? Buffer[tr].States[state].account[1] : Buffer[tr].States[state - 1].account[1]); State.Add((Buffer[tr].States[state].account[0] - PrevBalance) / PrevBalance); State.Add(Buffer[tr].States[state].account[1] / PrevBalance); State.Add((Buffer[tr].States[state].account[1] - PrevEquity) / PrevEquity); State.Add(Buffer[tr].States[state].account[2]); State.Add(Buffer[tr].States[state].account[3]); State.Add(Buffer[tr].States[state].account[4] / PrevBalance); State.Add(Buffer[tr].States[state].account[5] / PrevBalance); State.Add(Buffer[tr].States[state].account[6] / PrevBalance);
После чего мы формируем метку времени.
//--- Time label double x = (double)Buffer[tr].States[state].account[7] / (double)(D'2024.01.01' - D'2023.01.01'); State.Add((float)MathSin(2.0 * M_PI * x)); x = (double)Buffer[tr].States[state].account[7] / (double)PeriodSeconds(PERIOD_MN1); State.Add((float)MathCos(2.0 * M_PI * x)); x = (double)Buffer[tr].States[state].account[7] / (double)PeriodSeconds(PERIOD_W1); State.Add((float)MathSin(2.0 * M_PI * x)); x = (double)Buffer[tr].States[state].account[7] / (double)PeriodSeconds(PERIOD_D1); State.Add((float)MathSin(2.0 * M_PI * x));
И дописываем в буфер вектора последних действий Агента.
//--- Prev action if(state > 0) State.AddArray(Buffer[tr].States[state - 1].action); else State.AddArray(vector<float>::Zeros(NActions));
Далее нам остается добавить в буфер целеуказание в виде RTG. В этом блоке мы будем использовать целеуказание не до конца прохода, а только на небольшой локальный отрезок. И здесь же мы добавим процесс консервативной регуляризации. Для этого мы сначала проверим доходность используемой траектории и, при необходимости, сформируем вектор шума. Напомню, что согласно методу CWBC шум добавляется только к наиболее прибыльным проходам.
//--- Return to go vector<float> target, result; vector<float> noise = vector<float>::Zeros(NRewards); target.Assign(Buffer[tr].States[0].rewards); if(target.Sum() >= quantile) noise = Noise(std, 100);
Далее мы вычисляем фактическую доходность на локальном историческом отрезке. Добавляем полученный вектор шума. И добавляем полученные значения в буфер исходных данных.
target.Assign(Buffer[tr].States[state + 1].rewards); result.Assign(Buffer[tr].States[state + ValueBars].rewards); target = target - result * MathPow(DiscFactor, ValueBars) + noise; State.AddArray(target);
Теперь, когда мы сформировали полный набор необходимых данных мы осуществляем прямой проход Агента для формирования вектора действий.
//--- Feed Forward if(!Agent.feedForward(GetPointer(State), 1, false, (CBufferFloat*)NULL)) { PrintFormat("%s -> %d", __FUNCTION__, __LINE__); StopFlag = true; break; }
После успешного прохождения прямого прохода мы вызываем метод обратного прохода Агента с целью минимизации расхождений между прогнозируемыми и фактическими действиями Агента. Этот процесс аналогичен обучению оригинального DT.
//--- Policy study Result.AssignArray(Buffer[tr].States[state].action); if(!Agent.backProp(Result, (CBufferFloat*)NULL)) { PrintFormat("%s -> %d", __FUNCTION__, __LINE__); StopFlag = true; break; }
Нам остается лишь проинформировать пользователя о ходе процесса обучения модели и перейти к следующей итерации нашей системы циклов обучения модели.
//--- if(GetTickCount() - ticks > 500) { string str = StringFormat("%-15s %5.2f%% -> Error %15.8f\n", "Agent", iter * 100.0 / (double)(Iterations), Agent.getRecentAverageError()); Comment(str); ticks = GetTickCount(); } } }
После завершения полного цикла итераций обучения модели мы очищаем поле комментариев на графике. Выводим результаты обучения в лог и инициируем завершение работы советника.
Comment(""); //--- PrintFormat("%s -> %d -> %-15s %10.7f", __FUNCTION__, __LINE__, "Agent", Agent.getRecentAverageError()); ExpertRemove(); //--- }
На этом мы завершаем знакомство с алгоритмом обучения Агента. Обучение модели оценки стоимости состояния окружающей среды построено по аналогичному принципу в советнике "...\CWBC\StudyRTG.mq5" и я предлагаю Вам самостоятельно с ним ознакомиться во вложении. Там же вы найдете и все программы, используемые в данной статье.
А я бы хотел остановиться ещё на одном моменте. Мы сформировали первичную обучающую выборку путем выбора лучших из сэмплированных траекторий. Их можно условно отнести к субоптимальным, так как они удовлетворяют некоторым нашим требованиям. И далее нам бы хотелось оптимизировать политику Агента, обученного на подобных данных. Для этого нам нужно проверить работу обученной модели на исторических данных и параллельно собрать информацию о возможности оптимизации политики. С этой целью при очередном проходе в тестере стратегий на историческом отрезке обучающей выборки мы будем совершать действиям в некотором доверительном интервале от спрогнозированных Агентом и добавим результаты таких проходов в наш буфер воспроизведения опыта. После чего проведем итерацию дообучения моделей.
Функционал сбора дополнительных проходов мы реализуем в советнике "...\CWBC\Research.mq5". В рамках данной статьи мы не будем подробно останавливаться на всех методах советника. Рассмотрим лишь метод обработки тиков OnTick, в котором реализовано взаимодействие с окружающей средой.
В теле метода мы, как обычно, проверяем наступление события открытия нового бара и, при необходимости, загружаем исторические данные.
void OnTick() { //--- if(!IsNewBar()) return; //--- int bars = CopyRates(Symb.Name(), TimeFrame, iTime(Symb.Name(), TimeFrame, 1), History, Rates); if(!ArraySetAsSeries(Rates, true)) return; //--- RSI.Refresh(); CCI.Refresh(); ATR.Refresh(); MACD.Refresh(); Symb.Refresh(); Symb.RefreshRates();
Из полученных данных мы сначала формируем вектор исходных данных для оценки стоимости состояния и вызываем прямой проход соответствующей модели.
//--- History data float atr = 0; bState.Clear(); for(int b = ValueBars - 1; b >= 0; b--) { float open = (float)Rates[b].open; float rsi = (float)RSI.Main(b); float cci = (float)CCI.Main(b); atr = (float)ATR.Main(b); float macd = (float)MACD.Main(b); float sign = (float)MACD.Signal(b); if(rsi == EMPTY_VALUE || cci == EMPTY_VALUE || atr == EMPTY_VALUE || macd == EMPTY_VALUE || sign == EMPTY_VALUE) continue; //--- bState.Add((float)(Rates[b].close - open)); bState.Add((float)(Rates[b].high - open)); bState.Add((float)(Rates[b].low - open)); bState.Add((float)(Rates[b].tick_volume / 1000.0f)); bState.Add(rsi); bState.Add(cci); bState.Add(atr); bState.Add(macd); bState.Add(sign); } if(!RTG.feedForward(GetPointer(bState), 1, false)) return;
Далее мы формируем тензор исходных данных нашего Агента. При этом соблюдаем последовательность данных, используемую при обучении модели. Только вместо буфера воспроизведения опыта мы используем данные от окружающей среды.
for(int b = 0; b < (int)NBarInPattern; b++) { float open = (float)Rates[b].open; float rsi = (float)RSI.Main(b); float cci = (float)CCI.Main(b); atr = (float)ATR.Main(b); float macd = (float)MACD.Main(b); float sign = (float)MACD.Signal(b); if(rsi == EMPTY_VALUE || cci == EMPTY_VALUE || atr == EMPTY_VALUE || macd == EMPTY_VALUE || sign == EMPTY_VALUE) continue; //--- int shift = b * BarDescr; sState.state[shift] = (float)(Rates[b].close - open); sState.state[shift + 1] = (float)(Rates[b].high - open); sState.state[shift + 2] = (float)(Rates[b].low - open); sState.state[shift + 3] = (float)(Rates[b].tick_volume / 1000.0f); sState.state[shift + 4] = rsi; sState.state[shift + 5] = cci; sState.state[shift + 6] = atr; sState.state[shift + 7] = macd; sState.state[shift + 8] = sign; } bState.AssignArray(sState.state);
Параллельно мы собираем используемые данные в структуру для сохранения в буфере воспроизведения опыта.
Тут же мы проводим опрос окружающей среды (запросы к терминалу) для сбора информации о состоянии счета и открытых позициях.
//--- Account description sState.account[0] = (float)AccountInfoDouble(ACCOUNT_BALANCE); sState.account[1] = (float)AccountInfoDouble(ACCOUNT_EQUITY); //--- double buy_value = 0, sell_value = 0, buy_profit = 0, sell_profit = 0; double position_discount = 0; double multiplyer = 1.0 / (60.0 * 60.0 * 10.0); int total = PositionsTotal(); datetime current = TimeCurrent(); for(int i = 0; i < total; i++) { if(PositionGetSymbol(i) != Symb.Name()) continue; double profit = PositionGetDouble(POSITION_PROFIT); switch((int)PositionGetInteger(POSITION_TYPE)) { case POSITION_TYPE_BUY: buy_value += PositionGetDouble(POSITION_VOLUME); buy_profit += profit; break; case POSITION_TYPE_SELL: sell_value += PositionGetDouble(POSITION_VOLUME); sell_profit += profit; break; } position_discount += profit - (current - PositionGetInteger(POSITION_TIME)) * multiplyer * MathAbs(profit); } sState.account[2] = (float)buy_value; sState.account[3] = (float)sell_value; sState.account[4] = (float)buy_profit; sState.account[5] = (float)sell_profit; sState.account[6] = (float)position_discount; sState.account[7] = (float)Rates[0].time; //--- bState.Add((float)((sState.account[0] - PrevBalance) / PrevBalance)); bState.Add((float)(sState.account[1] / PrevBalance)); bState.Add((float)((sState.account[1] - PrevEquity) / PrevEquity)); bState.Add(sState.account[2]); bState.Add(sState.account[3]); bState.Add((float)(sState.account[4] / PrevBalance)); bState.Add((float)(sState.account[5] / PrevBalance)); bState.Add((float)(sState.account[6] / PrevBalance));
Метка времени формируется с полным соблюдением алгоритма процесса обучения.
//--- Time label double x = (double)Rates[0].time / (double)(D'2024.01.01' - D'2023.01.01'); bState.Add((float)MathSin(2.0 * M_PI * x)); x = (double)Rates[0].time / (double)PeriodSeconds(PERIOD_MN1); bState.Add((float)MathCos(2.0 * M_PI * x)); x = (double)Rates[0].time / (double)PeriodSeconds(PERIOD_W1); bState.Add((float)MathSin(2.0 * M_PI * x)); x = (double)Rates[0].time / (double)PeriodSeconds(PERIOD_D1); bState.Add((float)MathSin(2.0 * M_PI * x));
В завершении процесса сбора вектора исходных данных и добавляем последние действия Агента и целеуказания, сформированные нашей моделью.
//--- Prev action bState.AddArray(AgentResult); //--- Latent representation RTG.getResults(Result); bState.AddArray(Result);
Собранные данные передаются в метод прямого прохода нашего Агента для формирования вектора последующих действий.
//--- if(!Agent.feedForward(GetPointer(bState), 1, false, (CBufferFloat *)NULL)) return;
Вектор прогнозных действий Агента мы немного искажаем путем добавления случайного шума. Тем самым мы стимулирование исследование окружающей среды в некотором окружении спрогнозированных действий.
Agent.getResults(AgentResult); for(ulong i = 0; i < AgentResult.Size(); i++) { float rnd = ((float)MathRand() / 32767.0f - 0.5f) * 0.03f; float t = AgentResult[i] + rnd; if(t > 1 || t < 0) t = AgentResult[i] - rnd; AgentResult[i] = t; } AgentResult.Clip(0.0f, 1.0f);
После чего мы сохраняем в локальные переменные данные, необходимые на последующих свечах.
PrevBalance = sState.account[0]; PrevEquity = sState.account[1];
Скорректируем перекрывающиеся объемы разнонаправленных позиций.
double min_lot = Symb.LotsMin(); double step_lot = Symb.LotsStep(); double stops = MathMax(Symb.StopsLevel(), 1) * Symb.Point(); if(AgentResult[0] >= AgentResult[3]) { AgentResult[0] -= AgentResult[3]; AgentResult[3] = 0; } else { AgentResult[3] -= AgentResult[0]; AgentResult[0] = 0; }
И дешифруем полученный вектор действий Агента. После чего осуществим их в окружающей среде.
//--- buy control if(AgentResult[0] < 0.9*min_lot || (AgentResult[1] * MaxTP * Symb.Point()) <= stops || (AgentResult[2] * MaxSL * Symb.Point()) <= stops) { if(buy_value > 0) CloseByDirection(POSITION_TYPE_BUY); } else { double buy_lot = min_lot + MathRound((double)(AgentResult[0] - min_lot) / step_lot) * step_lot; double buy_tp = Symb.NormalizePrice(Symb.Ask() + AgentResult[1] * MaxTP * Symb.Point()); double buy_sl = Symb.NormalizePrice(Symb.Ask() - AgentResult[2] * MaxSL * Symb.Point()); if(buy_value > 0) TrailPosition(POSITION_TYPE_BUY, buy_sl, buy_tp); if(buy_value != buy_lot) { if(buy_value > buy_lot) ClosePartial(POSITION_TYPE_BUY, buy_value - buy_lot); else Trade.Buy(buy_lot - buy_value, Symb.Name(), Symb.Ask(), buy_sl, buy_tp); } }
//--- sell control if(AgentResult[3] < 0.9*min_lot || (AgentResult[4] * MaxTP * Symb.Point()) <= stops || (AgentResult[5] * MaxSL * Symb.Point()) <= stops) { if(sell_value > 0) CloseByDirection(POSITION_TYPE_SELL); } else { double sell_lot = min_lot + MathRound((double)(AgentResult[3] - min_lot) / step_lot) * step_lot;; double sell_tp = Symb.NormalizePrice(Symb.Bid() - AgentResult[4] * MaxTP * Symb.Point()); double sell_sl = Symb.NormalizePrice(Symb.Bid() + AgentResult[5] * MaxSL * Symb.Point()); if(sell_value > 0) TrailPosition(POSITION_TYPE_SELL, sell_sl, sell_tp); if(sell_value != sell_lot) { if(sell_value > sell_lot) ClosePartial(POSITION_TYPE_SELL, sell_value - sell_lot); else Trade.Sell(sell_lot - sell_value, Symb.Name(), Symb.Bid(), sell_sl, sell_tp); } }
Далее нам остается получить вознаграждение от окружающей среды за переход в текущее состояние (предыдущие действия Агента) и передать собранные данные в буфер воспроизведения опыта.
int shift = BarDescr * (NBarInPattern - 1); sState.rewards[0] = bState[shift]; sState.rewards[1] = bState[shift + 1] - 1.0f; if((buy_value + sell_value) == 0) sState.rewards[2] -= (float)(atr / PrevBalance); else sState.rewards[2] = 0; for(ulong i = 0; i < NActions; i++) sState.action[i] = AgentResult[i]; if(!Base.Add(sState)) ExpertRemove(); }
С полным кодом советника и всех его методов вы можете ознакомиться во вложении.
Советник тестирования обученной модели "...\CWBC\Test.mq5" создан по аналогичному алгоритму за исключением искажения вектора действий, спрогнозированных Агентом. Его код так же приведен во вложении к статье.
И после создания всех необходимых программ мы переходим к тестированию проделанной работы.
3. Тестирование
В практической части нашей статьи мы провели довольно объемную работу по реализации нашего видения метода ConserWeightive Behavioral Cloning средствами MQL5. И теперь настало время на практике оценить результат наших трудов. Как всегда, обучать и тестировать наши модели мы будем на исторических данных инструмента EURUSD тайм-фрейм H1. В качестве обучающих данных мы будем использовать исторический период в первые 7 месяцем 2023 года. А тестирование проведем на данных Августа 2023 года.
Как уже было сказано выше, первичное обучение мы проведем на данных, сэмплированных в статье Control Transformer. Поэтому мы опускаем данный процесс и сразу переходим к процессу обучения моделей.
Выше нами было создано 2 советника для обучения двух моделей. Это позволяет нам осуществить параллельное обучение 2 моделей. При этом процесс можно осуществлять на различных устройствах независимо.
После первичного обучения моделей мы проверяем результативность работы обученной модели на обучающей выборке и осуществляем сбор дополнительных траекторий, путем запуска советников "...\CWBC\Research.mq5" и "...\CWBC\Test.mq5" в тестере стратегий на историческом периоде обучающей выборки. Последовательность запуска советников в данном случае не оказывает влияние на процесс обучения моделей.
Затем мы осуществляем дообучение моделей на данных обновленного буфера воспроизведения опыта.
Здесь надо отметить, что в моем случае повышение производительности модели наблюдалось только после первой итерации дообучения. Последующие итерации сбора дополнительных траекторий и дообучения модели не дали результата. Но это может быть частным случаем.
В процессе обучения мне удалось получить модель генерирующую прибыль на историческом отрезке обучающей выборки.


За период обучения модель совершила 141 сделку. Около 40% было закрыто с прибылью. Максимальная прибыльная сделка более чем в 4 раза превышает максимальный убыток. А средняя прибыльная сделка почти в 2 раза превышает средний убыток. Более того, средняя прибыльная сделка на 13% превышает максимальный убыток. Все это дало профит-фактор на уровне 1.11. Подобные результаты наблюдаются и на новых данных.
Но в полученных результатах есть и "лошка дегтя". Модель совершила только длинные позиции, что в целом соответствует глобальному тренду на данном историческом интервале. Как следствие, линия баланса очень напоминает график инструмента.


Детальный анализ тестирования демонстрирует убытки в феврале и мае 2023 года, которые перекрываются в последующие месяцы. Наиболее прибыльным оказался март месяц. А в разрезе недели максимальную доходность продемонстрировала среда.
Заключение
В данной статье мы познакомились с методов ConserWeightive Behavioral Cloning (CWBC), который комбинирует траекторное взвешивание и консервативную регуляризацию для повышения надежности обучаемых стратегий. Мы реализовали предложенный метод средствами MQL5 и провели тестирование на реальных исторических данных.
Наши результаты показывают, что CWBC демонстрирует довольно высокую степень стабильности офлайн обучения моделей. В частности, метод успешно справляется с условиями, когда траектории с высокими возвращениями составляют небольшую часть обучающего набора данных. При этом стоит отметить важность тщательного подпора необходимых гиперпараметров, что играет важную роль в эффективности CWBC.
Ссылки
Программы, используемые в статье
| # | Имя | Тип | Описание |
|---|---|---|---|
| 1 | Faza1.mq5 | Советник | Советник сбора примеров |
| 2 | Research.mq5 | Советник | Советник сбора дополнительных траекторий |
| 3 | StudyAgentmq5 | Советник | Советник обучения модели локальной политики |
| 4 | StudyRTG.mq5 | Советник | Советник обучения Функции стоимости |
| 5 | Test.mq5 | Советник | Советник для тестирования модели |
| 6 | Trajectory.mqh | Библиотека класса | Структура описания состояния системы |
| 7 | NeuroNet.mqh | Библиотека класса | Библиотека классов для создания нейронной сети |
| 8 | NeuroNet.cl | Библиотека | Библиотека кода программы OpenCL |
- Бесплатные приложения для трейдинга
- 8 000+ сигналов для копирования
- Экономические новости для анализа финансовых рынков
Вы принимаете политику сайта и условия использования