
Нейросети — это просто (Часть 83): Алгоритм пространственно-временного преобразователя постоянного внимания (Conformer)

Введение
Непредсказуемость поведения финансовых рынков можно сравнить, наверное, с изменчивостью погоды. Однако в области прогнозирования погодных явлений человечество сделало довольно много. И в настоящее время мы с достаточной долей уверенности смотрим на прогнозы погоды, представленные метеорологами. А можем ли мы использовать их наработки для прогнозирования "погоды" финансовых рынков? В данной статье я предлагаю Вам познакомиться с комплексным алгоритмом пространственно-временного преобразователя постоянного внимания Conformer, который был разработан для целей прогнозирования погоды и представлен в статье "Conformer: Embedding Continuous Attention in Vision Transformer for Weather Forecasting". В своей работе авторы метода предлагают алгоритм Continuous Attention. И комбинируют его с рассмотренными нами в предыдущей статье Neural ODE.
1. Алгоритм Conformer
Conformer предназначен для изучения непрерывного изменения погоды с течением времени путем реализации непрерывности в механизме внимания с несколькими головками. Механизм внимания закодирован как дифференцируемая функция в архитектуре преобразователя для моделирования сложной динамики погоды.
Изначально, перед авторами метода стояла задача построение модели, которая получает данные о погоде в качестве исходных данных в форме (XN*W*H, T). Здесь N — количество погодных переменных, таких как температура, скорость ветра, давление и т. д. А W*H относится к пространственному разрешению переменной. T — это время, в течение которого система развивается. Модель принимает погодные переменные во времени t, изучает эволюцию пространственно-временной системы и прогнозирует погоду на следующем временном шаге t+1.
![]()
Поскольку погода постоянно меняется с течением времени, также важно фиксировать постоянные изменения в пределах предоставленных данных за фиксированное время. Идея состоит в том, чтобы изучить непрерывное скрытое представление данных о погоде с помощью решателей дифференциальных уравнений. Таким образом, модель не только прогнозирует значение погодной переменной в момент времени «T», но и определенный интеграл также изучает изменения погодной переменной, такой как температура, от начального момента времени до момента «T». Систему можно представить как:
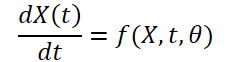
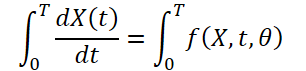
![]()
Информация о погоде весьма изменчива и сложно предсказуема как на временном, так и на пространственном уровне. Временные производные каждой погодной переменной рассчитываются для сохранения динамики погоды и обеспечения лучшего извлечения признаков из дискретных данных. Авторы метода выполняют выборочное дифференцирование на уровне пикселей, чтобы фиксировать непрерывные изменения погодных явлений с течением времени.
Нормализация производных — один из важнейших шагов для обеспечения стабильности поведения модели глубокого обучения. Авторы метода в своей работе расширяют идею нормализации, как отдельных элементов архитектуры модели. Они исследуют роль нормализации при ее непосредственном применении к производным. В авторской работе исследуется влияние на результат работы модели двух наиболее распространенных методов нормализации и слоя предварительного дифференцирования, чтобы продемонстрировать их преимущества в непрерывных системах.
Внимание — один из ключевых компонентов архитектуры Трансформер. Он основан на идее определения наиболее важных блоков исходных данных на заключительном этапе прогнозирования. Несмотря на успех в решении различных задач, Трансформер по-прежнему ограничен в своих возможностях обучения встраиванию информации для таких высоко динамичных систем, как прогноз погоды. Авторы метода Conformer разрабатывают механизм Continuous Attention для моделирования непрерывного изменения состояния погодных переменных. Во-первых, авторы метода заменяют анализ зависимостей между элементами исходного состояния на внимание между соответствующими параметрами различных состояний окружающей среды. Это позволяет вычислить контекстное пространство встраивания для каждой погодной переменной, меняющейся со временем. Такой шаг гарантирует, что модель будет обрабатывать одну и ту же переменную в разных состояниях в пакете вместо того, чтобы обращаться к блокам в одном и том же состоянии окружающей среды. Преобразование переменных изучается путем присвоения каждой переменной собственного Query, Key и Value для каждого образца исходных данных, аналогично тому, как это делается в одном состоянии окружающей среды. Механизм внимания вычисляет оценки зависимости между переменными разных выборок (в одних и тех же позициях переменных). Подобно традиционным механизмам внимания, веса зависимостей, полученные для разных пакетов, можно использовать для агрегирования или взвешивания информации, связанной с этими переменными.
Эта модификация позволяет модели фиксировать взаимосвязи или зависимости между одними и теми же погодными переменными в разных состояниях окружающей среды. Это оказалось полезным в сценарии прогнозирования погоды, когда модель способна отображать непрерывно развивающиеся характеристики каждой погодной переменной. Чтобы обеспечить непрерывное обучение, авторы метода вводят производные в механизм Continuous Attention. Дифференциальные уравнения представляют динамику физической системы во времени и учитывают недостающие значения данных. Авторы метода объединили механизм внимания с парадигмой обучения на основе дифференциальных уравнений, чтобы смоделировать изменение атмосферы как по пространственным, так и по временным характеристикам. Более того, этот подход снимает ограничение моделирования сложных физических уравнений в моделях. И вместо того, чтобы делать прогнозы только для определенной отметки времени, Conformer изучает переходные изменения от одного временного шага к другому, что важно для фиксации беспрецедентных изменений погоды.
Для вычисления Continuous Attention, авторы метода предлагают вычислить производные сходства для одних и тех же переменных в каждой выборке данных. Предположим, у нас есть 2 выборки исходных данных размером (N*W*H). Обозначим их как X0 и X1 для времени t0 и t1, соответственно. Каждая переменная имеет свои собственные тензоры Q, K и V в обеих выборках. Continuous Attention рассчитывается следующим образом:
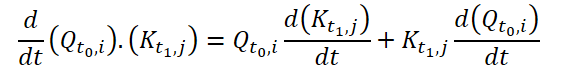
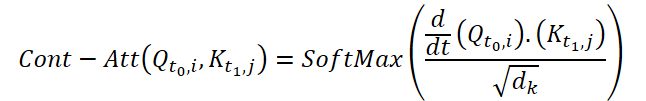
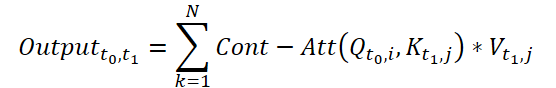
Полученный результат представляет собой взвешенную по вниманию сумму значений аналогичных переменных в исходных данных в определенный момент времени t0 и t1. Представленный процесс рассчитывает внимание между схожими переменными в исходных данных на всех временных шагах, позволяя модели фиксировать взаимосвязи или взаимодействия между переменными во всей последовательности исходных выборок.
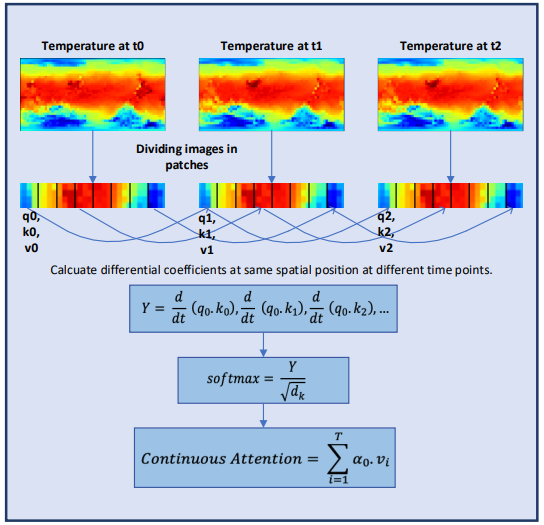
Для еще лучшего изучения непрерывных характеристик метеорологической информации авторы Conformer добавляют в модель слои Neural ODE. Поскольку решатели с адаптивным размером имеют более высокую точность, чем с фиксированным размером, авторы метода выбрали метод Дорманда-Принса (Dopri5). Это позволяет изучать минимально возможные изменения погоды во времени. Полный рабочий процесс Conformer и размещение слоев Neural ODE показан в авторской визуализации метода ниже.
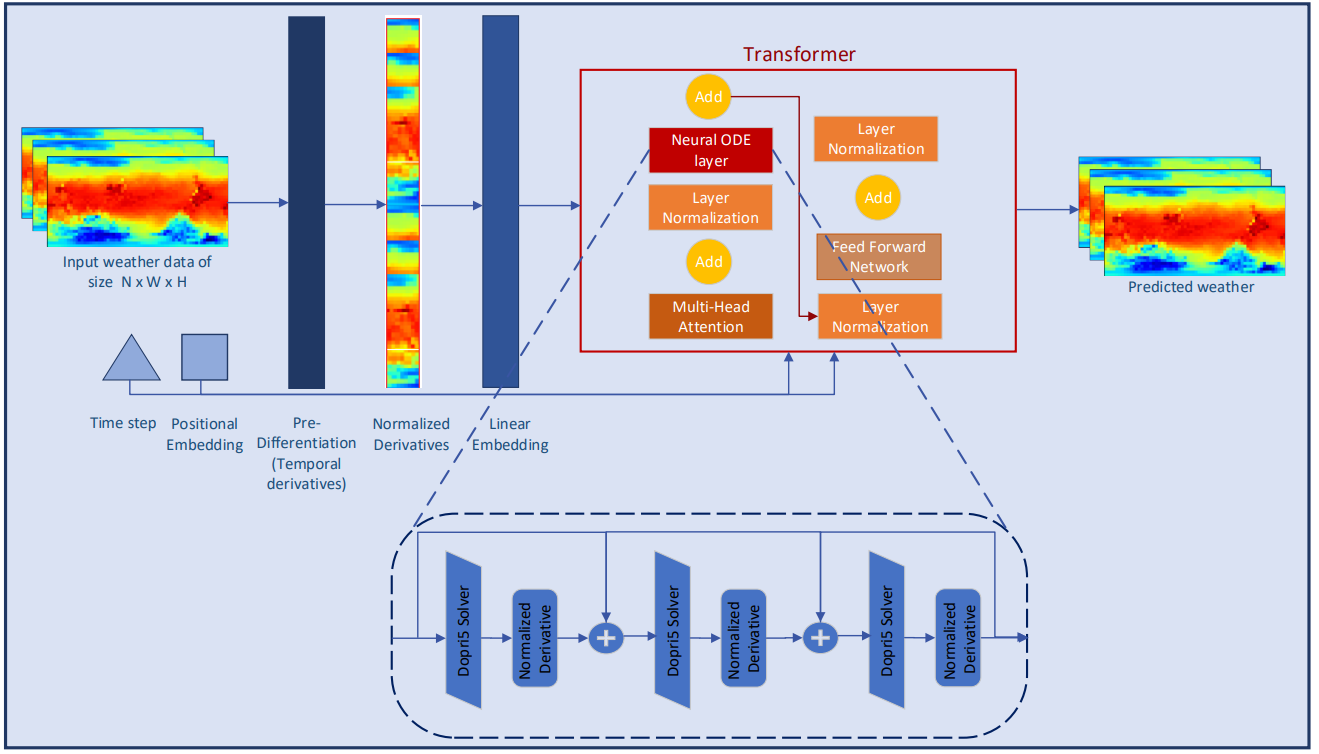
2. Реализация средствами MQL5
После рассмотрения теоретических аспектов методов Conformer мы переходим к практической реализации предложенных подходов средствами MQL5. Основной функционал мы реализуем в новом классе CNeuronConformer, который мы создадим наследником базового класса нейронного слоя CNeuronBaseOCL.
2.1 Архитектура класса CNeuronConformer
В структуре класса CNeuronConformer мы наблюдаем уже привычные методы, переопределяемые во всех классах реализации методов внимания. Однако Continuous Attention настолько отличается от рассмотренных ранее методов внимания, что было принято решение полностью реализовать алгоритм с "чистого листа". Тем не менее в данной реализации мы будем использовать наработки из прошлых работ.
Для записи основных параметров архитектуры слоя мы вводим 5 переменных:
- iWindow — размер вектора описания одного параметра в тензоре исходных данных;
- iDimension — размерность вектора одной сущности Query, Key, Value;
- iHeads — количество голов внимания;
- iVariables — количество параметров описания одного состояния окружающей среды;
- iCount — количество анализируемых состояний окружающей среды (длина последовательности исходных данных).
Для генерации сущностей Query, Key и Value мы, как и ранее в подобных случаях, воспользуемся сверточным слоем cQKV. Такой подход позволяет нам осуществить параллельную всех 3 сущностей. Производные сущностей по времени мы будем записывать в базовый нейронный слой cdQKV.
Коэффициенты зависимостей, по аналогии с нативным алгоритмом Трансформера, мы будем сохранять в матрице Score. Но в данной реализации мы не будем создавать копию матрицы на стороне основной программы. Создадим лишь буфер в контексте OpenCL. А в локальной переменной iScore класса CNeuronConformer сохраним указатель на буфер.
Результаты много-голового внимания мы сохраним в буферах базового нейронного слоя cAttentionOut. И понизим размерность полученных данных с помощью сверточного слоя cW0.
Согласно алгоритму Conformer, за блоком внимания идет блок из нейронных слоев обычных дифференциальных уравнений. Для них мы создадим массив cNODE. Аналогично, для блока FeedForward создадим массив cFF.
class CNeuronConformer : public CNeuronBaseOCL { protected: //--- int iWindow; int iDimension; int iHeads; int iVariables; int iCount; //--- CNeuronConvOCL cQKV; CNeuronBaseOCL cdQKV; int iScore; CNeuronBaseOCL cAttentionOut; CNeuronConvOCL cW0; CNeuronNODEOCL cNODE[3]; CNeuronConvOCL cFF[2]; //--- virtual bool feedForward(CNeuronBaseOCL *NeuronOCL); virtual bool attentionOut(void); //--- virtual bool AttentionInsideGradients(void); virtual bool updateInputWeights(CNeuronBaseOCL *NeuronOCL); public: CNeuronConformer(void) {}; ~CNeuronConformer(void) {}; //--- virtual bool Init(uint numOutputs, uint myIndex, COpenCLMy *open_cl, uint window, uint window_key, uint heads, uint variables, uint units_count, ENUM_OPTIMIZATION optimization_type, uint batch); //--- virtual bool calcInputGradients(CNeuronBaseOCL *prevLayer); //--- virtual int Type(void) const { return defNeuronConformerOCL; } //--- methods for working with files virtual bool Save(int const file_handle); virtual bool Load(int const file_handle); //--- virtual void SetOpenCL(COpenCLMy *obj); virtual CLayerDescription* GetLayerInfo(void); };
Все внутренние объекты класса мы объявляем статические. И это позволяет нам оставить "пустыми" конструктор и деструктор класса. А инициализация объекта класса в соответствии с требованиями пользователя осуществляется в методе Init. В параметрах метода мы будем передавать основные параметры архитектуры объекта.
bool CNeuronConformer::Init(uint numOutputs, uint myIndex, COpenCLMy *open_cl, uint window, uint window_key, uint heads, uint variables, uint units_count, ENUM_OPTIMIZATION optimization_type, uint batch) { if(!CNeuronBaseOCL::Init(numOutputs, myIndex, open_cl, window * variables * units_count, optimization_type, batch)) return false;
В теле же метода мы сразу вызываем одноименный метод родительского класса, в котором осуществляется минимально необходимый контроль полученных параметров и инициализация унаследованных объектов. О результатах прохождения контролей и инициализации мы узнаем по возвращаемому методом логическому результату.
Далее мы инициализируем внутренний слой cQKV, который служит для генерируем сущности Query, Key и Value. Обратите внимание, что методом Conformer предусмотрено создание сущностей для каждой отдельной переменной. Поэтому размер окна и шага свертки равны длине вектора эмбединга одной переменной. При этом количество элементов свертки равно произведению количества переменных описания одного состояния окружающей среды на количество анализируемых таких состояний. Количество фильтров свертки равно 3 произведениям длины одной сущности на количество голов внимания.
if(!cQKV.Init(0, 0, OpenCL, window, window, 3 * window_key * heads, variables * units_count, optimization, iBatch)) return false;
После успешного прохождения 2 выше указанных методов мы сохраним полученные параметры во внутренних переменных.
iWindow = int(fmax(window, 1)); iDimension = int(fmax(window_key, 1)); iHeads = int(fmax(heads, 1)); iVariables = int(fmax(variables, 1)); iCount = int(fmax(units_count, 1));
Инициализируем внутренний слой для записи частных производных по времени.
if(!cdQKV.Init(0, 1, OpenCL, 3 * iDimension * iHeads * iVariables * iCount, optimization, iBatch)) return false;
И создадим буфер коэффициентов внимания.
iScore = OpenCL.AddBuffer(sizeof(float) * iCount * iHeads * iVariables * iCount, CL_MEM_READ_WRITE); if(iScore < 0) return false;
Инициализацией внутренних слоев cAttentionOut и cW0 мы завершаем работу по подготовке объектов блока внимания.
if(!cAttentionOut.Init(0, 2, OpenCL, iDimension * iHeads * iVariables * iCount, optimization, iBatch)) return false; if(!cW0.Init(0, 3, OpenCL, iDimension * iHeads, iDimension * iHeads, iWindow, iVariables * iCount, optimization, iBatch)) return false;
Здесь следует обратить внимание, что на выходе блока внимания размерность данных должна соответствовать размерности полученных исходных данных. При этом, так как алгоритмом Conformer предусмотрен анализ зависимостей в рамках одной переменной, но в разных состояниях окружающей среды, то и понижение размерности мы осуществляем в рамках отдельных переменных.
Все используемые нейронные слои обычных дифференциальных уравнений имеют одинаковую архитектуру. Это позволяет нам осуществить их инициализацию в цикле.
for(int i = 0; i < 3; i++) if(!cNODE[i].Init(0, 4 + i, OpenCL, iWindow, iVariables, iCount, optimization, iBatch)) return false;
И нам остается инициализировать объекты блока FeedForward.
if(!cFF[0].Init(0, 7, OpenCL, iWindow, iWindow, 4 * iWindow, iVariables * iCount, optimization, iBatch)) return false; if(!cFF[1].Init(0, 8, OpenCL, 4 * iWindow, 4 * iWindow, iWindow, iVariables * iCount, optimization, iBatch)) return false;
Перед завершением работы метода мы организуем подмену указателя буфера градиентов нашего класса на буфер градиентов последнего слоя блока FeedForward. Подобный прием позволяет нам исключить излишнее копирование данных, и мы не раз его использовали ранее в реализации многих методов.
if(getGradientIndex() != cFF[1].getGradientIndex()) SetGradientIndex(cFF[1].getGradientIndex()); //--- return true; }
2.2 Реализация прямого прохода
После инициализации экземпляра класса мы переходим к реализации алгоритма прямого прохода. И здесь следует обратить внимание на предложенный авторами метода Conformer алгоритм Continuous Attention. В нем используются частные производные сущностей Query и Key по времени.
Очевидно, что на стадии обучения модели мы не имеем далее ближайшего приближения функции зависимости данных сущностей от времени. Поэтому к вопросу определения производных мы подойдем с другой стороны. Вначале давайте вспомним геометрический смысл производной функции. А он гласит, что производной функции по аргументу в конкретной точке является угол наклона касательной к графику функции в данной точке и показывает приближенное (для линейной функции точное) изменение значения функции при изменении аргумента на 1.
В наших исходных данных мы получаем состояния окружающей среды с фиксированным временным шагом, который равен анализируемому тайм-фрейму. Для целей упрощения нашей реализации мы пренебрежём конкретным тайм-фреймом и приравняем шаг времени между 2 последующими состояниями к "1". Таким образом, мы можем получить некоторое приближение производной функции аналитическим путем, взяв среднее изменение значения функции за 2 последующих перехода между состояниями из предыдущего к текущему и из текущего в последующее.
Предложенный механизм мы реализуем на стороне контекста OpenCL в кернеле TimeDerivative. В параметрах кернела мы будем передавать указатели 2 буфера: исходных данных и результатов. А так же размерность одной сущности.
__kernel void TimeDerivative(__global float *qkv, __global float *dqkv, int dimension) { const size_t pos = get_global_id(0); const size_t variable = get_global_id(1); const size_t head = get_global_id(2); const size_t total = get_global_size(0); const size_t variables = get_global_size(1); const size_t heads = get_global_size(2);
Запуск кернела мы планируем осуществлять в 3 размерностях:
- Количество анализируемых состояний окружающей среды;
- Количество переменных описания одного состояния окружающей среды;
- Количество голов внимания.
В теле кернела мы сразу идентифицируем текущий поток во всех 3 измерениях. После чего мы определяем смещения в буферах до обрабатываемых сущностей. Для удобства мы используем буфер исходных данных и результатов одного размера. Следовательно, и смещения будут идентичными.
const int shift = 3 * heads * variables * dimension; const int shift_query = pos * shift + (3 * variable * heads + head) * dimension; const int shift_key = shift_query + heads * dimension;
Далее мы организуем вычисление отклонений в цикле с перебором всех элементов одной сущности. Вначале мы аналитическим путем определяем производную для Query.
for(int i = 0; i < dimension; i++) { //--- dQ/dt { int count = 0; float delta = 0; float value = qkv[shift_query + i]; if(pos > 0) { delta = value - qkv[shift_query + i - shift]; count++; } if(pos < (total - 1)) { delta += qkv[shift_query + i + shift] - value; count++; } if(count > 0) dqkv[shift_query + i] = delta / count; }
Здесь следует обратить внимание на частные случаи первого и последнего элементов последовательность. В указанных состояниях мы имеем только один переход. Мы не будем усложнять алгоритм и воспользуемся только имеющимися данными.
Аналогичным образом вычисляем производные и для Key.
//--- dK/dt { int count = 0; float delta = 0; float value = qkv[shift_key + i]; if(pos > 0) { delta = value - qkv[shift_key + i - shift]; count++; } if(pos < (total - 1)) { delta += qkv[shift_key + i + shift] - value; count++; } if(count > 0) dqkv[shift_key + i] = delta / count; } } }
После определения частных производных по времени мы имеем все необходимые данные для выполнения Continuous Attention. На стороне контекста OpenCL мы реализуем предложенный алгоритм в кернеле FeedForwardContAtt. В параметрах кернела мы будем передавать указатели на 4 буфера данных: 2 буфера исходных данных (сущностей и их производных), буфер матрицы коэффициентов зависимости и буфер результатов много-голового внимания. Кроме того, в параметрах кернела мы передадим 2 константы: размерность вектора одной сущности и количество голов внимания.
__kernel void FeedForwardContAtt(__global float *qkv, __global float *dqkv, __global float *score, __global float *out, int dimension, int heads) { const size_t query = get_global_id(0); const size_t key = get_global_id(1); const size_t variable = get_global_id(2); const size_t queris = get_global_size(0); const size_t keis = get_global_size(1); const size_t variables = get_global_size(2);
В теле кернела мы, как всегда, сначала идентифицируем текущий поток во всех измерениях пространства задач. В данном случае используется 3 мерное пространство задач с созданием локальных групп в рамках одного запроса для одной переменной.
Тут же мы объявляем локальный массив для промежуточных данных.
const uint ls_score = min((uint)keis, (uint)LOCAL_ARRAY_SIZE); __local float local_score[LOCAL_ARRAY_SIZE];
И затем организовываем цикл с итерациями по числу голов внимания. В теле цикла мы последовательно выполним анализ данных по всем головам внимания.
for(int head = 0; head < heads; head++) { const int shift = 3 * heads * variables * dimension; const int shift_query = query * shift + (3 * variable * heads + head) * dimension; const int shift_key = key * shift + (3 * variable * heads + heads + head) * dimension; const int shift_out = dimension * (heads * (query * variables + variable) + head); int shift_score = keis * (heads * (query * variables + variable) + head) + key;
Здесь мы сначала определяем смещение в буферах данных до анализируемых элементов. После чего мы посчитаем коэффициенты зависимости. Определение указанных коэффициентов осуществляется в 3 этапа. Сначала мы посчитаем экспоненциальные значения d/dt(Q.K) и сохраним их в соответствующие элементу буфера коэффициентов зависимости. Вычисления осуществляются в параллельных потоках одной рабочей граппы.
//--- Score float scr = 0; for(int d = 0; d < dimension; d++) scr += qkv[shift_query + d] * dqkv[shift_key + d] + qkv[shift_key + d] * dqkv[shift_query + d]; scr = exp(min(scr / sqrt((float)dimension), 30.0f)); score[shift_score] = scr; barrier(CLK_LOCAL_MEM_FENCE);
Вторым этапом мы соберем сумму всех полученных значений.
if(key < ls_score) { local_score[key] = scr; for(int k = ls_score + key; k < keis; k += ls_score) local_score[key] += score[shift_score + k]; } barrier(CLK_LOCAL_MEM_FENCE); //--- int count = ls_score; do { count = (count + 1) / 2; if(key < count) { if((key + count) < keis) { local_score[key] += local_score[key + count]; local_score[key + count] = 0; } } barrier(CLK_LOCAL_MEM_FENCE); } while(count > 1);
И на третьем этапе нормализуем коэффициенты зависимости.
score[shift_score] /= local_score[0];
barrier(CLK_LOCAL_MEM_FENCE);
И в завершении итераций цикла мы посчитаем значение результатов блока внимания в соответствии с определенными выше коэффициентами зависимости.
shift_score -= key; for(int d = key; d < dimension; d += keis) { float sum = 0; int shift_value = (3 * variable * heads + 2 * heads + head) * dimension + d; for(int v = 0; v < keis; v++) sum += qkv[shift_value + v * shift] * score[shift_score + v]; out[shift_out + d] = sum; } barrier(CLK_LOCAL_MEM_FENCE); } //--- }
После создания кернелов реализации алгоритма Continuous Attention на стороне OpenCL контекста нам предстоит реализовать вызов выше созданных кернелов из основной программы. Для этого в наш класс CNeuronConformer мы добавим метод attentionOut.
Мы не стали разделять вызов кернелов на отдельные методы. Ведь их вызов осуществляется последовательно. А разделение алгоритма на стороне OpenCL программы вызвано различием в пространстве задач.
Так как данный метод создан только для вызова внутри класса, то и его алгоритм построен полностью на использовании внутренних объектов и переменных. Это позволило полностью исключить параметры метода.
bool CNeuronConformer::attentionOut(void) { if(!OpenCL) return false;
В теле метода мы проверяем актуальность указателя на контекст OpenCL. После чего осуществляем подготовку к вызову первого кернела определения производных сущностей.
Мы сначала определяем пространство задач.
bool CNeuronConformer::attentionOut(void) { if(!OpenCL) return false; //--- Time Derivative { uint global_work_offset[3] = {0, 0, 0}; uint global_work_size[3] = {iCount, iVariables, iHeads};
Затем передаем параметры кернелу.
ResetLastError(); if(!OpenCL.SetArgumentBuffer(def_k_TimeDerivative, def_k_tdqkv, cQKV.getOutputIndex())) { printf("Error of set parameter kernel %s: %d; line %d", __FUNCTION__, GetLastError(), __LINE__); return false; } if(!OpenCL.SetArgumentBuffer(def_k_TimeDerivative, def_k_tddqkv, cdQKV.getOutputIndex())) { printf("Error of set parameter kernel %s: %d; line %d", __FUNCTION__, GetLastError(), __LINE__); return false; } if(!OpenCL.SetArgument(def_k_TimeDerivative, def_k_tddimension, int(iDimension))) { printf("Error of set parameter kernel %s: %d; line %d", __FUNCTION__, GetLastError(), __LINE__); return false; }
И осуществляем постановку кернела в очередь выполнения.
if(!OpenCL.Execute(def_k_TimeDerivative, 3, global_work_offset, global_work_size)) { printf("Error of execution kernel %s: %d", __FUNCTION__, GetLastError()); return false; } }
Общий алгоритм постановки второго кернела в очередь выполнения аналогичен. Только добавляем пространство задач рабочей группы.
//--- MH Attention Out { uint global_work_offset[3] = {0, 0, 0}; uint global_work_size[3] = {iCount, iCount, iVariables}; uint local_work_size[3] = {1, iCount, 1};
Кроме того, увеличивается число передаваемых параметров.
ResetLastError(); if(!OpenCL.SetArgumentBuffer(def_k_FeedForwardContAtt, def_k_caqkv, cQKV.getOutputIndex())) { printf("Error of set parameter kernel %s: %d; line %d", __FUNCTION__, GetLastError(), __LINE__); return false; } if(!OpenCL.SetArgumentBuffer(def_k_FeedForwardContAtt, def_k_cadqkv, cdQKV.getOutputIndex())) { printf("Error of set parameter kernel %s: %d; line %d", __FUNCTION__, GetLastError(), __LINE__); return false; } if(!OpenCL.SetArgumentBuffer(def_k_FeedForwardContAtt, def_k_cascore, iScore)) { printf("Error of set parameter kernel %s: %d; line %d", __FUNCTION__, GetLastError(), __LINE__); return false; } if(!OpenCL.SetArgumentBuffer(def_k_FeedForwardContAtt, def_k_caout, cAttentionOut.getOutputIndex())) { printf("Error of set parameter kernel %s: %d; line %d", __FUNCTION__, GetLastError(), __LINE__); return false; } if(!OpenCL.SetArgument(def_k_FeedForwardContAtt, def_k_cadimension, int(iDimension))) { printf("Error of set parameter kernel %s: %d; line %d", __FUNCTION__, GetLastError(), __LINE__); return false; } if(!OpenCL.SetArgument(def_k_FeedForwardContAtt, def_k_caheads, int(iHeads))) { printf("Error of set parameter kernel %s: %d; line %d", __FUNCTION__, GetLastError(), __LINE__); return false; }
После выполнения подготовительной работы осуществляем постановку кернела в очередь выполнения.
if(!OpenCL.Execute(def_k_FeedForwardContAtt, 3, global_work_offset, global_work_size, local_work_size)) { printf("Error of execution kernel %s: %d", __FUNCTION__, GetLastError()); return false; } } //--- return true; }
Однако вызов 2 кернелов реализует лишь часть предложенного метода Conformer. Точнее основную часть Continuous Attention. Полный же алгоритм прямого прохода нашего класса мы опишем в методе CNeuronConformer::feedForward. Аналогично одноименным методам ранее созданных классов, в параметрах метод feedForward получает указатель на объект предшествующего слоя, который содержит исходные данные для нашего класса.
bool CNeuronConformer::feedForward(CNeuronBaseOCL *NeuronOCL) { //--- Generate Query, Key, Value if(!cQKV.FeedForward(NeuronOCL)) return false;
В теле метода мы сначала вызываем метод прямого прохода внутреннего слоя cQKV для формирования тензоров сущностей Query, Key и Value. После чего вызываем выше созданный метод вызова кернелов механизма Continuous Attention.
//--- MH Continuas Attention if(!attentionOut()) return false;
Затем мы понижаем размерность полученных результатов много-голового внимания. Полученный тензор складываем с исходными данными и нормализуем в пределах отдельных переменных.
if(!cW0.FeedForward(GetPointer(cAttentionOut))) return false; if(!SumAndNormilize(NeuronOCL.getOutput(), cW0.getOutput(), cW0.getOutput(), iDimension, true, 0, 0, 0, 1)) return false;
За блоком Continuous Attention алгоритмом Conformer предусмотрен блок решателей обыкновенных дифференциальных уравнений. Мы организуем их вызов в цикле. После чего суммируем тензора на входе и выходе блока. А результат нормализуем.
//--- Neural ODE CNeuronBaseOCL *prev = GetPointer(cW0); for(int i = 0; i < 3; i++) { if(!cNODE[i].FeedForward(prev)) return false; prev = GetPointer(cNODE[i]); } if(!SumAndNormilize(prev.getOutput(), cW0.getOutput(), prev.getOutput(), iDimension, true, 0, 0, 0, 1)) return false;
В завершении метода прямого прохода мы осуществляем прямой проход блока FeedForward с последующим суммированием и нормализацией результатов.
//--- Feed Forward for(int i = 0; i < 2; i++) { if(!cFF[i].FeedForward(prev)) return false; prev = GetPointer(cFF[i]); } if(!SumAndNormilize(prev.getOutput(), cNODE[2].getOutput(), getOutput(), iDimension, true, 0, 0, 0, 1)) return false; //--- return true; }
На этом мы завершаем работу по реализации алгоритма прямого прохода. Но для обучения моделей нам так же необходимо реализовать обратный проход с распределением градиента ошибки до всех элементов в соответствии с их влиянием на конечный результат и корректировкой параметров модели в сторону снижения общей ошибки работы модели.
2.3 Организация обратного прохода
Реализация алгоритма обратного прохода нам так же потребует создания новых кернелов. И прежде всего нам предстоит создать кернел распределения градиентов ошибки через блок Continuous Attention — HiddenGradientContAtt. В параметрах кернела мы будем передавать указатели на 6 буферов данных и 1 константу.
__kernel void HiddenGradientContAtt(__global float *qkv, __global float *qkv_g, __global float *dqkv, __global float *dqkv_g, __global float *score, __global float *out_g, int dimension) { const size_t pos = get_global_id(0); const size_t variable = get_global_id(1); const size_t head = get_global_id(2); const size_t total = get_global_size(0); const size_t variables = get_global_size(1); const size_t heads = get_global_size(2);
Аналогично кернелу прямого прохода, обратный проход мы реализуем в 3 мерном пространстве задач, но без группировки на рабочие группы. В теле кернела мы сразу идентифицируем поток во всех измерениях пространства задач.
Дальнейший алгоритм кернела можно разделить на 3 части по объекту отнесения градиента ошибки. В первом блоке мы распределим градиент ошибки до сущности Value.
//--- Value gradient { const int shift_value = dimension * (heads * (3 * variables * pos + 3 * variable + 2) + head); const int shift_out = dimension * (head + variable * heads); const int shift_score = total * (variable * heads + head); const int step_out = variables * heads * dimension; const int step_score = variables * heads * total; //--- for(int d = 0; d < dimension; d++) { float sum = 0; for(int g = 0; g < total; g++) sum += out_g[shift_out + g * step_out + d] * score[shift_score + g * step_score]; qkv_g[shift_value + d] = sum; } }
Здесь мы сначала определяем смещение в буферах данных до анализируемых элементов. А затем в системе циклов собираем градиенты ошибки во всех зависимых элементов и по всем элементам вектора сущности.
Во втором блоке мы распределяем градиенты ошибки до Query. Однако здесь алгоритм немного сложнее.
//--- Query gradient { const int shift_out = dimension * (heads * (pos * variables + variable) + head); const int step = 3 * variables * heads * dimension; const int shift_query = dimension * (3 * heads * variable + head) + pos * step; const int shift_key = dimension * (heads * (3 * variable + 1) + head); const int shift_value = dimension * (heads * (3 * variable + 2) + head); const int shift_score = total * (heads * (pos * variables + variable) + head);
Как и в первом блоке, мы сначала определяем смещение до анализируемых элементов в буферах данных. После чего нам сначала предстоит распределить градиент на матрицу коэффициентов зависимости и скорректировать его на производную функции SoftMax.
//--- Score gradient for(int k = 0; k < total; k++) { float score_grad = 0; float scr = score[shift_score + k]; for(int v = 0; v < total; v++) { float grad = 0; for(int d = 0; d < dimension; d++) grad += qkv[shift_value + v * step + d] * out_g[shift_out + d]; score_grad += score[shift_score + v] * grad * ((float)(pos == v) - scr); } score_grad /= sqrt((float)dimension);
И только потом мы можем распределить градиент ошибки до сущности Query. Однако в отличии от алгоритма нативного Трансформер, в данном случае мы распределяем градиент ошибки ещё и на соответствующие производные сущности Query по времени.
//--- Query gradient for(int d = 0; d < dimension; d++) { if(k == 0) { dqkv_g[shift_query + d] = score_grad * qkv[shift_key + k * step + d]; qkv_g[shift_query + d] = score_grad * dqkv[shift_key + k * step + d]; } else { dqkv_g[shift_query + d] += score_grad * qkv[shift_key + k * step + d]; qkv_g[shift_query + d] += score_grad * dqkv[shift_key + k * step + d]; } } } }
Аналогичным образом осуществляется распределение градиента ошибки на сущность Key и её частную производную. Только в матрице коэффициентов зависимости мы проходим по другому измерению.
//--- Key gradient { const int shift_key = dimension * (heads * (3 * variables * pos + 3 * variable + 1) + head); const int shift_out = dimension * (heads * variable + head); const int step_out = variables * heads * dimension; const int step = 3 * variables * heads * dimension; const int shift_query = dimension * (3 * heads * variable + head); const int shift_value = dimension * (heads * (3 * variable + 2) + head) + pos * step; const int shift_score = total * (heads * variable + head); const int step_score = variables * heads * total; //--- Score gradient for(int q = 0; q < total; q++) { float score_grad = 0; float scr = score[shift_score + q * step_score]; for(int g = 0; g < total; g++) { float grad = 0; for(int d = 0; d < dimension; d++) grad += qkv[shift_value + d] * out_g[shift_out + d + g * step_out]; score_grad += score[shift_score + q * step_score + g] * grad * ((float)(q == pos) - scr); } score_grad /= sqrt((float)dimension); //--- Key gradient for(int d = 0; d < dimension; d++) { if(q == 0) { dqkv_g[shift_key + d] = score_grad * qkv[shift_query + q * step + d]; qkv_g[shift_key + d] = score_grad * dqkv[shift_query + q * step + d]; } else { qkv_g[shift_key + d] += score_grad * dqkv[shift_query + q * step + d]; dqkv_g[shift_key + d] += score_grad * qkv[shift_query + q * step + d]; } } } } }
Как можно заметить, в предыдущем кернеле мы распределили градиент ошибки как на сами сущности, так и на их производные. Напомню, что частные производные по времени мы считали аналитическим путем на основе значений самих сущностей для различных состояний окружающей среды. Логично, что и градиент ошибки мы можем передать аналогичным путем. Такой алгоритм мы реализуем в кернеле HiddenGradientTimeDerivative.
__kernel void HiddenGradientTimeDerivative(__global float *qkv_g, __global float *dqkv_g, int dimension) { const size_t pos = get_global_id(0); const size_t variable = get_global_id(1); const size_t head = get_global_id(2); const size_t total = get_global_size(0); const size_t variables = get_global_size(1); const size_t heads = get_global_size(2);
Параметры кернела и пространство задач аналогичны прямому проходу. Только вместо буферов результатов мы используем буферы градиентов ошибки.
В теле метода мы сразу идентифицируем поток во всех измерениях используемого пространства задач. После чего определяем смещение в буферах данных.
const int shift = 3 * heads * variables * dimension; const int shift_query = pos * shift + (3 * variable * heads + head) * dimension; const int shift_key = shift_query + heads * dimension;
Аналогично вычислению производных осуществляем распределение градиентов ошибки.
for(int i = 0; i < dimension; i++) { //--- dQ/dt { int count = 0; float grad = 0; float current = dqkv_g[shift_query + i]; if(pos > 0) { grad += current - dqkv_g[shift_query + i - shift]; count++; } if(pos < (total - 1)) { grad += dqkv_g[shift_query + i + shift] - current; count++; } if(count > 0) grad /= count; qkv_g[shift_query + i] += grad; }
//--- dK/dt { int count = 0; float grad = 0; float current = dqkv_g[shift_key + i]; if(pos > 0) { grad += current - dqkv_g[shift_key + i - shift]; count++; } if(pos < (total - 1)) { grad += dqkv_g[shift_key + i + shift] - current; count++; } if(count > 0) grad /= count; qkv_g[shift_key + i] += dqkv_g[shift_key + i] + grad; } } }
Вызов данных кернелов на стороне основной программы осуществляется в методе CNeuronConformer::AttentionInsideGradients. Алгоритм его построения аналогичен соответствующему методу прямого прохода. Только вызов кернелов осуществляется в обратном порядке. Сначала мы осуществляем постановку в очередь выполнения кернела распределения градиента через блок Continuous Attention.
bool CNeuronConformer::AttentionInsideGradients(void) { if(!OpenCL) return false; //--- MH Attention Out Gradient { uint global_work_offset[3] = {0, 0, 0}; uint global_work_size[3] = {iCount, iVariables, iHeads};
ResetLastError(); if(!OpenCL.SetArgumentBuffer(def_k_HiddenGradientContAtt, def_k_hgcaqkv, cQKV.getOutputIndex())) { printf("Error of set parameter kernel %s: %d; line %d", __FUNCTION__, GetLastError(), __LINE__); return false; } if(!OpenCL.SetArgumentBuffer(def_k_HiddenGradientContAtt, def_k_hgcaqkv_g, cQKV.getGradientIndex())) { printf("Error of set parameter kernel %s: %d; line %d", __FUNCTION__, GetLastError(), __LINE__); return false; } if(!OpenCL.SetArgumentBuffer(def_k_HiddenGradientContAtt, def_k_hgcadqkv, cdQKV.getOutputIndex())) { printf("Error of set parameter kernel %s: %d; line %d", __FUNCTION__, GetLastError(), __LINE__); return false; } if(!OpenCL.SetArgumentBuffer(def_k_HiddenGradientContAtt, def_k_hgcadqkv_g, cdQKV.getGradientIndex())) { printf("Error of set parameter kernel %s: %d; line %d", __FUNCTION__, GetLastError(), __LINE__); return false; } if(!OpenCL.SetArgumentBuffer(def_k_HiddenGradientContAtt, def_k_hgcascore, iScore)) { printf("Error of set parameter kernel %s: %d; line %d", __FUNCTION__, GetLastError(), __LINE__); return false; } if(!OpenCL.SetArgumentBuffer(def_k_HiddenGradientContAtt, def_k_hgcaout_g, cAttentionOut.getGradientIndex())) { printf("Error of set parameter kernel %s: %d; line %d", __FUNCTION__, GetLastError(), __LINE__); return false; } if(!OpenCL.SetArgument(def_k_HiddenGradientContAtt, def_k_hgcadimension, int(iDimension))) { printf("Error of set parameter kernel %s: %d; line %d", __FUNCTION__, GetLastError(), __LINE__); return false; }
if(!OpenCL.Execute(def_k_HiddenGradientContAtt, 3, global_work_offset, global_work_size)) { printf("Error of execution kernel %s: %d", __FUNCTION__, GetLastError()); return false; } }
А затем добавим градиент ошибки от частных производных.
//--- Time Derivative Gradient { uint global_work_offset[3] = {0, 0, 0}; uint global_work_size[3] = {iCount, iVariables, iHeads};
ResetLastError(); if(!OpenCL.SetArgumentBuffer(def_k_HGTimeDerivative, def_k_tdqkv, cQKV.getGradientIndex())) { printf("Error of set parameter kernel %s: %d; line %d", __FUNCTION__, GetLastError(), __LINE__); return false; } if(!OpenCL.SetArgumentBuffer(def_k_HGTimeDerivative, def_k_tddqkv, cdQKV.getGradientIndex())) { printf("Error of set parameter kernel %s: %d; line %d", __FUNCTION__, GetLastError(), __LINE__); return false; } if(!OpenCL.SetArgument(def_k_HGTimeDerivative, def_k_tddimension, int(iDimension))) { printf("Error of set parameter kernel %s: %d; line %d", __FUNCTION__, GetLastError(), __LINE__); return false; }
if(!OpenCL.Execute(def_k_HGTimeDerivative, 3, global_work_offset, global_work_size)) { printf("Error of execution kernel %s: %d", __FUNCTION__, GetLastError()); return false; } } //--- return true; }
После завершения подготовительной работы мы соберем весь алгоритм распределения градиента ошибки в методе CNeuronConformer::calcInputGradients, в параметрах которого мы получаем указатель на объект предшествующего слоя. Именно в него нам предстоит передать градиент ошибки.
bool CNeuronConformer::calcInputGradients(CNeuronBaseOCL *prevLayer) { //--- Feed Forward Gradient if(!cFF[1].calcInputGradients(GetPointer(cFF[0]))) return false; if(!cFF[0].calcInputGradients(GetPointer(cNODE[2]))) return false; if(!SumAndNormilize(Gradient, cNODE[2].getGradient(), cNODE[2].getGradient(), iDimension, false)) return false;
Благодаря организованной нами подмене буферов градиентов последующий слой передал нам градиент ошибки непосредственно в буфер последнего внутреннего слоя в блоке FeedForward. И теперь, без излишних операций копирования мы последовательно вызывает методы обратного прохода объектов блока FeedForward.
Напомню, что при прямом проходе мы складывали значение буферов на входе и выходе блока FeedForward. Аналогично мы складываем градиенты ошибки. И передаем полученный результат на выход блока слоев обычных дифференциальных уравнений. После чего организовываем цикл с обратным перебором внутренних слоев блока Neural ODE и распределением в них градиента ошибки.
//--- Neural ODE Gradient CNeuronBaseOCL *prev = GetPointer(cNODE[1]); for(int i = 2; i > 0; i--) { if(!cNODE[i].calcInputGradients(prev)) return false; prev = GetPointer(cNODE[i - 1]); } if(!cNODE[0].calcInputGradients(GetPointer(cW0))) return false; if(!SumAndNormilize(cW0.getGradient(), cNODE[2].getGradient(), cW0.getGradient(), iDimension, false)) return false;
Здесь мы также суммируем градиенты ошибки на входе и выходе блока.
Первый при прямом проходе и последний при обратном проходе блок Continuous Attention. Мы сначала распределяем градиент ошибки между головами внимания.
//--- MH Attention Gradient if(!cW0.calcInputGradients(GetPointer(cAttentionOut))) return false;
Затем распределим градиент ошибки через блок внимания.
if(!AttentionInsideGradients()) return false;
И спустим градиент ошибки до уровня предыдущего слоя.
//--- Query, Key, Value Graddients if(!cQKV.calcInputGradients(prevLayer)) return false;
В завершении метода мы суммируем градиент ошибки на входе и выходе блока внимания.
if(!SumAndNormilize(cW0.getGradient(), prevLayer.getGradient(), prevLayer.getGradient(), iDimension, false)) return false; //--- return true; }
После распределения градиента ошибки между всеми объектами в соответствии с их влиянием на конечный результат мы переходим к оптимизации параметров с целью снижения общей ошибки работы моделей.
Здесь надо сказать, что все обучаемые параметры нашего класса CNeuronConformer содержатся во внутренних нейронных слоях. Поэтому для обновления параметров модели нам достаточно поочередно вызвать одноименные методы внутренних объектов.
bool CNeuronConformer::updateInputWeights(CNeuronBaseOCL *NeuronOCL) { //--- MH Attention if(!cQKV.UpdateInputWeights(NeuronOCL)) return false; if(!cW0.UpdateInputWeights(GetPointer(cAttentionOut))) return false;
//--- Neural ODE CNeuronBaseOCL *prev = GetPointer(cW0); for(int i = 0; i < 3; i++) { if(!cNODE[i].UpdateInputWeights(prev)) return false; prev = GetPointer(cNODE[i]); }
//--- Feed Forward for(int i = 0; i < 2; i++) { if(!cFF[i].UpdateInputWeights(prev)) return false; prev = GetPointer(cFF[i]); } //--- return true; }
На этом мы завершаем рассмотрение методов нового класса CNeuronConformer, в котором мы реализовали основные подходы, предложенные авторами метода Conformer. К сожалению, формат статьи не позволяет более подробно остановиться на вспомогательных методах класса. Я предлагаю Вам самостоятельно познакомиться с ними во вложении. Так же вы найдете полный код всех программ, используемых при подготовке статьи. А мы движемся дальше.
2.4 Архитектура обучаемых моделей
И прежде, чем перейти к рассмотрению архитектуры обучаемых моделей, я бы хотел напомнить, что методом Conformer предусматривается анализ в разрезе отдельных параметров описания окружающей среды. Следовательно, при первичной обработке исходных данных нам предстоит создать эмбединг для каждого анализируемого параметра.
Вначале, давайте посмотрим на структуру анализируемых данных.
......... ......... sState.state[shift] = (float)(Rates[b].close - open); sState.state[shift + 1] = (float)(Rates[b].high - open); sState.state[shift + 2] = (float)(Rates[b].low - open); sState.state[shift + 3] = (float)(Rates[b].tick_volume / 1000.0f); sState.state[shift + 4] = rsi; sState.state[shift + 5] = cci; sState.state[shift + 6] = atr; sState.state[shift + 7] = macd; sState.state[shift + 8] = sign; ........ ........
В своей реализации я разделил исходные данные следующим образом:
- Описание последней свечи (4 элемента)
- RSI (1 элемент)
- CCI (1 элемент)
- ATF (1 элемент)
- MACD (2 элемента)
Подобное деление — это лишь мое видение. И в своей работе Вы можете использовать иное разделение. Однако оно должно найти отражение в архитектуре обучаемых моделей.
И так, архитектура обучаемых моделей описана в методе CreateDescriptions. В параметрах метод получает 3 указателя на динамические массивы, для передачи архитектуры 3 моделей.
В теле метода мы сначала проверяем полученные указатели и, при необходимости, создаем новые объекты динамических массивов.
bool CreateDescriptions(CArrayObj *encoder, CArrayObj *actor, CArrayObj *critic) { //--- CLayerDescription *descr; //--- if(!encoder) { encoder = new CArrayObj(); if(!encoder) return false; } if(!actor) { actor = new CArrayObj(); if(!actor) return false; } if(!critic) { critic = new CArrayObj(); if(!critic) return false; }
Не обработанные данные описания текущего состояния окружающей среды мы передаем на вход модели Энкодера.
//--- Encoder encoder.Clear(); //--- Input layer if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBaseOCL; int prev_count = descr.count = (HistoryBars * BarDescr); descr.activation = None; descr.optimization = ADAM; if(!encoder.Add(descr)) { delete descr; return false; }
Полученные данные проходят первичную обработку в слое пакетной нормализации.
//--- layer 1 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBatchNormOCL; descr.count = prev_count; descr.batch = MathMax(1000, GPTBars); descr.activation = None; descr.optimization = ADAM; if(!encoder.Add(descr)) { delete descr; return false; }
После чего мы создаем Эмбединги параметров текущего состояния в соответствии с выше представленной структурой.
//--- layer 2 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronEmbeddingOCL; { int temp[] = {4, 1, 1, 1, 2}; ArrayCopy(descr.windows, temp); }
Обратите внимание, что в ранее рассмотренных архитектурах для эмбединга мы указывали размер окна равный размеру исходных данных. Тем самым мы создавали эмбединг отдельного состояния. Однако в данном случае мы исходим из анализа описания последнего бара с разбиением параметром на указанные выше блоки. В случае же анализа более 1 бара или иной конфигурации данных, это должно найти отражение в размере окон анализируемых данных.
prev_count = descr.count = GPTBars; int prev_wout = descr.window_out = EmbeddingSize / 2; if(!encoder.Add(descr)) { delete descr; return false; }
Последующий сверточный слой завершает процесс генерирования эмбедингов исходных данных.
//--- layer 3 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronConvOCL; descr.count = prev_count * 5; descr.step = descr.window = prev_wout; prev_wout = descr.window_out = EmbeddingSize; if(!encoder.Add(descr)) { delete descr; return false; }
Добавим к эмбедингам гармоники позиционного кодирования.
//--- layer 4 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronPEOCL; descr.count = prev_count; descr.window = prev_wout * 5; if(!encoder.Add(descr)) { delete descr; return false; }
И в завершении модели энкодера создадим блок из 5 последовательных слоем Conformer. Параметры слоя мы указываем аналогично другим слоям внимания. А количество анализируемых переменных укажем в descr.layers.
for(int i = 0; i < 5; i++) { if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronConformerOCL; descr.count = prev_count; descr.window = prev_wout; descr.step = 4; descr.window_out = EmbeddingSize; descr.layers = 5; if(!encoder.Add(descr)) { delete descr; return false; } }
В основе модели Актера, как и ранее, лежит слой кросс-внимания, который оценивает зависимости между текущим состоянием счета и сжатым представлением текущего состояния окружающей среды, полученным от Экодера.
На вход модели мы сначала подаем описание состояния счета.
//--- Actor actor.Clear(); //--- Input layer if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBaseOCL; prev_count = descr.count = AccountDescr; descr.activation = None; descr.optimization = ADAM; if(!actor.Add(descr)) { delete descr; return false; }
Преобразовываем его в эмбединг.
//--- layer 1 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBaseOCL; prev_count = descr.count = EmbeddingSize; descr.activation = SIGMOID; descr.optimization = ADAM; if(!actor.Add(descr)) { delete descr; return false; }
И добавляем блок из 3 слоев кросс-внимания.
//--- layer 2-4 for(int i = 0; i < 3; i++) { if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronCrossAttenOCL; { int temp[] = {1, GPTBars * 5}; ArrayCopy(descr.units, temp); } { int temp[] = {EmbeddingSize, EmbeddingSize}; ArrayCopy(descr.windows, temp); } descr.window_out = 16; descr.step = 4; descr.activation = None; descr.optimization = ADAM; if(!actor.Add(descr)) { delete descr; return false; } }
На основании данных, полученных из блока кросс-внимания формируем стохастическую политику Актера.
//--- layer 5 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBaseOCL; descr.count = LatentCount; descr.activation = SIGMOID; descr.optimization = ADAM; if(!actor.Add(descr)) { delete descr; return false; } //--- layer 6 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBaseOCL; descr.count = 2 * NActions; descr.activation = None; descr.optimization = ADAM; if(!actor.Add(descr)) { delete descr; return false; } //--- layer 7 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronVAEOCL; descr.count = NActions; descr.optimization = ADAM; if(!actor.Add(descr)) { delete descr; return false; }
Модель Критика построена по аналогичной структуре. Только вместо состояния счета, она сопоставляет действия Актера с состоянием окружающей среды.
На вход модели подаем сгенерированные действия Актера.
//--- Critic critic.Clear(); //--- Input layer if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBaseOCL; prev_count = descr.count = NActions; descr.activation = None; descr.optimization = ADAM; if(!critic.Add(descr)) { delete descr; return false; }
Которые преобразовываются в Эмбединг.
//--- layer 1 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBaseOCL; prev_count = descr.count = EmbeddingSize; descr.activation = SIGMOID; descr.optimization = ADAM; if(!critic.Add(descr)) { delete descr; return false; }
И далее идет блок кросс-внимания из 3 слоев.
//--- layer 2-4 for(int i = 0; i < 3; i++) { if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronCrossAttenOCL; { int temp[] = {1, GPTBars * 5}; ArrayCopy(descr.units, temp); } { int temp[] = {EmbeddingSize, EmbeddingSize}; ArrayCopy(descr.windows, temp); } descr.window_out = 16; descr.step = 4; descr.activation = None; descr.optimization = ADAM; if(!critic.Add(descr)) { delete descr; return false; } }
Непосредственно оценка действий осуществляется в блоке перцептрона.
//--- layer 5 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBaseOCL; descr.count = LatentCount; descr.activation = SIGMOID; descr.optimization = ADAM; if(!critic.Add(descr)) { delete descr; return false; } //--- layer 6 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBaseOCL; descr.count = LatentCount; descr.activation = SIGMOID; descr.optimization = ADAM; if(!critic.Add(descr)) { delete descr; return false; } //--- layer 7 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBaseOCL; descr.count = NRewards; descr.activation = None; descr.optimization = ADAM; if(!critic.Add(descr)) { delete descr; return false; } //--- return true; }
2.5 Обучение моделей
Внесенные нами изменения не отразились на процессе взаимодействия с окружающей средой. Это позволило нам использовать без изменения советник "...\Conformer\Research.mq5" для сбора первичных обучающих данных и последующего обновления обучающей выборки. Кроме того, несмотря на изменения в подходе к анализу исходных данных, мы оставили без изменения их структуру. Что позволяет нам использовать собранные ранее обучающие выборки в процессе обучения модели.
Тем не менее, мы внесли некоторые изменения в процесс обучения моделей, которые нашли свое отражение в алгоритме советника "...\Conformer\Study.mq5". В рамках данной статьи мы рассмотрим лишь метод непосредственного обучения моделей Train.
Как и ранее, в начале метода мы генерируем вектор вероятностей выбора траекторий в зависимости от их доходности. Наиболее прибыльные проходы получают большую вероятность при семплировании в процессе обучения моделей.
void Train(void) { //--- vector<float> probability = GetProbTrajectories(Buffer, 0.9);
Затем мы инициализируем локальные переменные.
vector<float> result, target; bool Stop = false; //--- uint ticks = GetTickCount();
И создаем систему вложенных циклов обучения моделей. В теле внешнего цикла мы сэмплируем траекторию из буфера воспроизведения опыта и начальное состояние обучения на ней.
int tr = SampleTrajectory(probability); int batch = GPTBars + 48; int state = (int)((MathRand() * MathRand() / MathPow(32767, 2)) * (Buffer[tr].Total - 2 - PrecoderBars - batch)); if(state <= 0) { iter--; continue; }
После чего очищаем рекуррентные буферы Энкодера и определяем конечное состояние обучающего паркета.
Encoder.Clear(); int end = MathMin(state + batch, Buffer[tr].Total - PrecoderBars);
После проведения подготовительной работы мы организовываем вложенный цикл непосредственного перебора обучающих состояний.
for(int i = state; i < end; i++) { bState.AssignArray(Buffer[tr].States[i].state); //--- State Encoder if(!Encoder.feedForward((CBufferFloat*)GetPointer(bState), 1, false, (CBufferFloat*)NULL)) { PrintFormat("%s -> %d", __FUNCTION__, __LINE__); Stop = true; break; }
В теле цикла мы сначала загружаем из буфера воспроизведения опыта состояние окружающей среды и осуществляем его анализ в нашем Энкодере, путем вызова метода прямого прохода.
Далее мы загружаем действия Актера из буфера воспроизведения опыта и оцениваем их нашим Критиком.
//--- Critic bActions.AssignArray(Buffer[tr].States[i].action); if(bActions.GetIndex() >= 0) bActions.BufferWrite(); if(!Critic.feedForward((CBufferFloat*)GetPointer(bActions), 1, false, GetPointer(Encoder))) { PrintFormat("%s -> %d", __FUNCTION__, __LINE__); Stop = true; break; }
И сразу корректируем оценку Критика в сторону фактического вознаграждения из буфера воспроизведения опыта.
result.Assign(Buffer[tr].States[i + 1].rewards); target.Assign(Buffer[tr].States[i + 2].rewards); result = result - target * DiscFactor; Result.AssignArray(result); Critic.TrainMode(true); if(!Critic.backProp(Result, (CNet *)GetPointer(Encoder)) || !Encoder.backPropGradient((CBufferFloat*)NULL)) { PrintFormat("%s -> %d", __FUNCTION__, __LINE__); Stop = true; break; }
Градиент ошибки Критика мы так же передаем Энкодеру, с целью оптимизация анализа состояния окружающей среды.
Следующим шагом мы загружаем из буфера воспроизведения опыта описание состояния счета, соответствующее анализируемому состоянию окружающей среды.
//--- Policy float PrevBalance = Buffer[tr].States[MathMax(i - 1, 0)].account[0]; float PrevEquity = Buffer[tr].States[MathMax(i - 1, 0)].account[1]; bAccount.Clear(); bAccount.Add((Buffer[tr].States[i].account[0] - PrevBalance) / PrevBalance); bAccount.Add(Buffer[tr].States[i].account[1] / PrevBalance); bAccount.Add((Buffer[tr].States[i].account[1] - PrevEquity) / PrevEquity); bAccount.Add(Buffer[tr].States[i].account[2]); bAccount.Add(Buffer[tr].States[i].account[3]); bAccount.Add(Buffer[tr].States[i].account[4] / PrevBalance); bAccount.Add(Buffer[tr].States[i].account[5] / PrevBalance); bAccount.Add(Buffer[tr].States[i].account[6] / PrevBalance); double time = (double)Buffer[tr].States[i].account[7]; double x = time / (double)(D'2024.01.01' - D'2023.01.01'); bAccount.Add((float)MathSin(x != 0 ? 2.0 * M_PI * x : 0)); x = time / (double)PeriodSeconds(PERIOD_MN1); bAccount.Add((float)MathCos(x != 0 ? 2.0 * M_PI * x : 0)); x = time / (double)PeriodSeconds(PERIOD_W1); bAccount.Add((float)MathSin(x != 0 ? 2.0 * M_PI * x : 0)); x = time / (double)PeriodSeconds(PERIOD_D1); bAccount.Add((float)MathSin(x != 0 ? 2.0 * M_PI * x : 0)); if(bAccount.GetIndex() >= 0) bAccount.BufferWrite();
На этих данных мы генерируем действие Актера в соответствии с его текущей политикой.
//--- Actor if(!Actor.feedForward((CBufferFloat*)GetPointer(bAccount), 1, false, GetPointer(Encoder))) { PrintFormat("%s -> %d", __FUNCTION__, __LINE__); Stop = true; break; }
И оцениваем их нашим Критиком.
if(!Critic.feedForward((CNet *)GetPointer(Actor), -1, (CNet*)GetPointer(Encoder))) { PrintFormat("%s -> %d", __FUNCTION__, __LINE__); Stop = true; break; }
Корректировка политики Актера осуществляется в 2 этапа. Вначале мы корректируем политику минимизировать отклонение от фактических действий Агента. Это позволяет нам удерживать политику Актера в распределении близком к нашей обучающей выборке.
if(!Actor.backProp(GetPointer(bActions), GetPointer(Encoder)) || !Encoder.backPropGradient((CBufferFloat*)NULL)) { PrintFormat("%s -> %d", __FUNCTION__, __LINE__); Stop = true; break; }
На втором этапе мы корректируем политику Актера в соответствии с оценкой его действий Критиком. Для этого мы отключаем режим обучения Критика и пропускаем через него градиент ошибки до Актера. После чего корректируем политику в направлении полученного градиента ошибки.
Critic.TrainMode(false); if(!Critic.backProp(Result, (CNet *)GetPointer(Encoder)) || !Actor.backPropGradient((CNet *)GetPointer(Encoder), -1, -1, false) || !Encoder.backPropGradient((CBufferFloat*)NULL)) { PrintFormat("%s -> %d", __FUNCTION__, __LINE__); Stop = true; break; }
Обратите внимание, что в обоих случаях корректировки политики Актера мы передаем градиент ошибки нашему Энкодеру и корректируем "его представление" об окружающей среде. Таким образом мы стремимся сделать анализ окружающей среды максимально информативным.
После обновления параметров всех моделей нам остается лишь проинформировать пользователя о ходе процесса обучения и перейти к следующей итерации системы циклов.
if(GetTickCount() - ticks > 500) { double percent = (double(i - state) / ((end - state)) + iter) * 100.0 / (Iterations); string str = StringFormat("%-14s %6.2f%% -> Error %15.8f\n", "Actor", percent, Actor.getRecentAverageError()); str += StringFormat("%-14s %6.2f%% -> Error %15.8f\n", "Critic", percent, Critic.getRecentAverageError()); Comment(str); ticks = GetTickCount(); } } }
Процесс обучения повторяется до полного перебора всех итераций системы циклов. И после успешного завершения процесса обучения мы очищаем поле комментариев на графике.
Comment(""); //--- PrintFormat("%s -> %d -> %-15s %10.7f", __FUNCTION__, __LINE__, "Actor", Actor.getRecentAverageError()); PrintFormat("%s -> %d -> %-15s %10.7f", __FUNCTION__, __LINE__, "Critic", Critic.getRecentAverageError()); ExpertRemove(); //--- }
Выводим в журнал результаты процесса обучения моделей и инициализируем завершение работы советника обучения.
На этом мы завершаем анализ алгоритмов, используемых в статье программ. А с полным их кодом Вы можете познакомиться во вложении.
3. Тестирование
В рамках данной статьи мы познакомились с методом Conformer и реализовали предложенные подходы средствами MQL5. И теперь у нас есть возможность обучить модель, предложенным методом и провести его тестирование на реальных данных.
Как обычно, обучение и тестирование модели мы проведем с использование тестера стратегий MetaTrader 5 на реальных исторических данных инструмента EURUSD тайм-фрейм H1. Для обучения моделей мы используем исторические данные за первые 7 месяцев 2023 года. А тестирование обученной модели провели на исторических данных Августа 2023 года.
При подготовке данной статьи я обучал модель на выборке, собранной для обучения моделей из предыдущих статей данной серии.
Должен сказать, что изменение архитектуры моделей и алгоритма процесса обучения несколько увеличило затраты на одну итерацию. Однако предложенные подходы демонстрируют стабильность процесса обучения, что, по моим ощущениям, снижает количество необходимых повторений для обучения модели.
В процессе обучения мне удалось получить модель, способную генерировать прибыль как на обучающих, так и на тестовых данных.


За период тестирования модель совершила 34 сделки, 18 из которых закрылись с прибылью. Что составляет 52.94% прибыльных сделок. При этом средняя прибыльная сделка на 52.47% превышает среднюю убыточную. А максимальная прибыльная более чем в 2 раза превышает аналогичный убыточный показатель. В целом модель продемонстрировала профит-фактор на уровне 1.72 и на графике баланса мы видим тенденцию к росту. Максимальная просадка по Equity составила 17.12%, а по балансу 8.96%.
Заключение
В данной статье мы познакомились с комплексным алгоритмом пространственно-временного преобразователя постоянного внимания Conformer, который был разработан для целей прогнозирования погоды и представлен в статье "Conformer: Embedding Continuous Attention in Vision Transformer for Weather Forecasting". Авторы метода предлагают алгоритм Continuous Attention и комбинируют его с Neural ODE.
В практической части нашей статьи мы реализовали предложенные подходы средствами MQL5. Провели обучение и тестирование созданных моделей. Результаты тестирования довольно обнадеживающие. Модель позволила сгенерировать прибыль как на обучающей, так и на тестовой выборке.
Однако хочу напомнить, что все программы, представленные в статье, носят только информативный характер и предназначены для демонстрации предложенных подходов.
Ссылки
Программы, используемые в статье
| # | Имя | Тип | Описание |
|---|---|---|---|
| 1 | Research.mq5 | Советник | Советник сбора примеров |
| 2 | ResearchRealORL.mq5 | Советник | Советник сбора примеров методом Real-ORL |
| 3 | Study.mq5 | Советник | Советник обучения Моделей |
| 4 | Test.mq5 | Советник | Советник для тестирования модели |
| 5 | Trajectory.mqh | Библиотека класса | Структура описания состояния системы |
| 6 | NeuroNet.mqh | Библиотека класса | Библиотека классов для создания нейронной сети |
| 7 | NeuroNet.cl | Библиотека | Библиотека кода программы OpenCL |
- Бесплатные приложения для трейдинга
- 8 000+ сигналов для копирования
- Экономические новости для анализа финансовых рынков
Вы принимаете политику сайта и условия использования