
Redes neurais de maneira fácil (Parte 64): Método de clonagem de comportamento ponderada conservadora (CWBC)

Introdução
O transformador de decisões e todas as suas modificações, que nos foram apresentadas nos últimos artigos, são métodos de clonagem de comportamento (behavioral cloning — BC). Treinamos modelos para repetir as ações de "trajetórias especialistas" dependendo do estado do ambiente e dos objetivos estabelecidos. Dessa forma, ensinamos o modelo a imitar o comportamento do especialista no estado atual do ambiente para alcançar um objetivo definido.
Entretanto, na vida real, as avaliações de diferentes especialistas do mesmo estado ambiental podem variar significativamente. E às vezes até o oposto completo. Além disso, gostaria de lembrar que em trabalhos anteriores não envolvemos especialistas para criar nossa amostra de treinamento. Usamos diferentes métodos para amostrar as ações do agente e selecionamos as melhores trajetórias, que nem sempre foram ótimas.
Aqui temos de reconhecer que, durante a amostragem de trajetórias em um espaço contínuo de ações e episódios, é praticamente impossível manter todas as opções possíveis. E apenas uma pequena parte das trajetórias amostradas pode pelo menos parcialmente atender às nossas exigências. Tais trajetórias são mais parecidas com valores atípicos, que o modelo pode simplesmente descartar durante o treinamento.
Como forma de sair dessa situação, usamos abordagens do método Go-Explore. Desse modo, compusemos uma trajetória de sucesso a partir de pequenos pedaços, sequencialmente. Essas trajetórias podem ser chamadas de subótimas. Elas estão próximas das nossas expectativas, mas sua qualidade permanece não comprovada.
E, claro, podemos rotular "manualmente" uma trajetória ótima com base em dados históricos. Esta abordagem nos aproxima do aprendizado supervisionado com todos os prós e contras desse método.
Ao mesmo tempo, a seleção de passagens ótimas coloca o modelo em condições ideais, o que pode levar ao superajuste do modelo. Isso acontece quando o modelo, após memorizar a rota da amostra de treinamento, não consegue generalizar a experiência adquirida para novos estados do ambiente.
O segundo problema dos métodos de clonagem de comportamento é a definição de objetivos para o modelo (Return To Go). Já abordamos essa questão em trabalhos anteriores. Em alguns artigos, recomenda-se usar um coeficiente para o resultado máximo da amostra de treinamento, o que muitas vezes permite obter melhores resultados. Mas esse método só é aplicável para resolver problemas estáticos. E o coeficiente é ajustado para cada problema individualmente. O método Dichotomy of Control nos oferece outra maneira de resolver esse problema. Existem também outras abordagens.
Os problemas mencionados acima são explorados pelos autores do artigo «Reliable Conditioning of Behavioral Cloning for off-line Reinforcement Learning». E para resolver esses problemas, é proposto um método bastante interessante chamado ConserWeightive Behavioral Cloning (CWBC), que é aplicável não apenas para modelos da família transformador de decisões.
1. Algoritmo
Com o objetivo de identificar fatores que afetam a confiabilidade dos métodos de aprendizado por reforço que dependem de recompensas alvo, os autores do artigo «Reliable Conditioning of Behavioral Cloning for off-line Reinforcement Learning» realizaram dois experimentos ilustrativos.
No primeiro experimento, modelos de diferentes arquiteturas foram executados em conjuntos de trajetórias de diferentes níveis de rentabilidade, variando de quase aleatório a especialista e subótimo. Os resultados do experimento mostraram que a confiabilidade do modelo depende significativamente da qualidade dos dados na amostra de treinamento. Ao treinar modelos com dados de trajetórias de rentabilidade média e especialista, o modelo tem um desempenho confiável sob a condição de alvos altos. Por outro lado, ao treinar o modelo com trajetórias de baixo desempenho, este diminui rapidamente após um certo ponto de aumento do RTG. Isso se deve ao fato de que os dados de baixa qualidade não fornecem informações suficientes para treinar uma política condicionada a grandes recompensas. E isso afeta a confiabilidade do modelo obtido.
A qualidade dos dados não é a única razão para creditar a confiabilidade no modelo. A arquitetura do modelo também desempenha um papel importante. Nos experimentos realizados, o DT mostrou ser confiável em todos os três conjuntos de dados. Supõe-se que a confiabilidade do DT seja alcançada usando a arquitetura do transformador. Como a política de previsão da próxima ação do Agente é construída com base na sequência de estados do ambiente e nos rótulos RTG, as camadas de atenção podem ignorar os rótulos RTG fora da distribuição da amostra de treinamento. Isso proporciona uma boa precisão de previsão. Ao mesmo tempo, modelos construídos com base na arquitetura MLP, que recebem o estado atual e o retorno alvo como dados de entrada para geração de ações, não podem ignorar informações sobre a recompensa desejada. Para verificar essa hipótese, os autores experimentam com uma versão ligeiramente modificada do DT, que concatena vetores de estado do ambiente e RTG em cada etapa temporal. Assim, o modelo não pode ignorar as informações do RTG na sequência. Os resultados do experimento mostram uma rápida diminuição na confiabilidade desse modelo após o RTG exceder os limites da distribuição da amostra de treinamento. Isso confirma a suposição feita anteriormente.
Para otimizar o processo de treinamento de modelos e minimizar a influência dos fatores mencionados acima, os autores do artigo propõem o uso do framework ConserWeightive Behavioral Cloning (CWBC), que é uma maneira simples e eficaz de melhorar a confiabilidade dos métodos existentes de treinamento de modelos de clonagem de comportamento. O CWBC consiste em dois componentes:
- Ponderação de trajetórias
- Regularização conservadora do RTG
A ponderação de trajetórias oferece um método sistemático de transformar a distribuição subótima de dados para uma avaliação mais precisa da distribuição ótima por meio do aumento do peso das trajetórias de alta rentabilidade. Um regularizador conservador de perdas incentiva a política a permanecer próxima à distribuição original dos dados, condicionada a grandes objetivos.
1.1 Ponderação de trajetórias
Sabemos que a distribuição ótima off-line de trajetórias é simplesmente a distribuição de demonstrações geradas pela política ótima. Normalmente, a distribuição off-line de trajetórias será enviesada em relação à ótima. Durante o treinamento, isso leva a uma discrepância entre treinamento e teste, já que queremos condicionar nosso Agente à máxima rentabilidade ao avaliar e utilizar o modelo, mas somos forçados a minimizar o risco empírico numa distribuição de dados enviesada durante o treinamento.
A ideia principal do método consiste em transformar o conjunto de treinamento de trajetórias em uma nova distribuição que melhor avalie a trajetória ótima. A nova distribuição deve focar em trajetórias de alta rentabilidade, o que intuitivamente suaviza a discrepância entre treinamento e teste. E, como esperamos que o conjunto original de dados contenha muito poucas trajetórias de alta rentabilidade, simplesmente filtrar trajetórias de baixo desempenho resultará na eliminação da maioria dos dados de treinamento. Isso levará a uma redução na capacidade de generalização do modelo treinado. E os autores do método propõem ponderar as trajetórias com base em seus retornos.
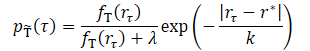
onde λ, k são dois hiperparâmetros que definem a forma da distribuição transformada.
O parâmetro de suavização k controla a ponderação das trajetórias de acordo com seu desempenho. Intuitivamente, um k menor atribui maior peso às trajetórias com altos resultados. E, ao aumentar o valor do parâmetro, a distribuição transformada se torna mais uniforme. Os autores sugerem definir o valor de k como a diferença entre o valor máximo e o valor do percentil z dos resultados na amostra de treinamento.
![]()
Isso permite que o valor real de k se adapte a diferentes conjuntos de dados. Os autores do método testaram quatro valores de z do conjunto {99, 90, 50, 0}, que correspondem a quatro valores crescentes de k. Pelos resultados dos experimentos, para cada conjunto de dados, a distribuição transformada usando um pequeno k se concentra fortemente em recompensas altas. À medida que k aumenta, a densidade de trajetórias com baixa recompensa aumenta, e a distribuição se torna mais uniforme. No entanto, valores relativamente pequenos de k baseados no percentil do conjunto {99, 90, 50} mostram bom desempenho em todos os conjuntos de dados. No entanto, valores maiores de k baseados no percentil 0 pioram o desempenho para o conjunto de dados com trajetórias especialistas.
O parâmetro λ também afeta a distribuição transformada. Com λ = 0, a distribuição transformada se concentra em recompensas altas. À medida que λ aumenta, a distribuição transformada tende para a original, mas ainda ponderada em favor da área de altas recompensas devido ao efeito do termo exponencial. O desempenho real dos modelos com diferentes valores de λ mostra resultados semelhantes, que são melhores ou comparáveis ao treinamento no conjunto de dados original.
1.2 Regulação conservadora
Como mencionado anteriormente, a arquitetura também desempenha um papel importante na confiabilidade do modelo treinado. O cenário ideal é difícil de ser alcançado, e às vezes até impossível. No entanto, os autores do CWBC se esforçam para obter uma política próxima à distribuição original dos dados para evitar perdas catastróficas quando o RTG é especificado fora da distribuição. Em outras palavras, a política deve ser conservadora. No entanto, o conservadorismo não precisa necessariamente vir da arquitetura, mas também pode surgir da função de perda correta durante o treinamento do modelo, como é típico em métodos conservadores baseados na avaliação de custos de estados e transições.
Os autores propõem um novo regulador conservador para métodos de clonagem comportamental que dependem de RTG, que explicitamente incentiva a política a permanecer próxima à distribuição original dos dados. A ideia é garantir a previsão de ações próximas à distribuição original mesmo quando grandes valores de RTG são especificados fora da distribuição de amostra de treinamento. Isso é alcançado adicionando ruído positivo ao RTG para trajetórias com alta recompensa real e punindo com distâncias L2 entre a ação prevista e a real da amostra de treinamento. Para garantir a geração de grandes valores de RTG fora da distribuição, geramos ruído de maneira que o valor ajustado de RTG não seja inferior à recompensa mais alta na amostra de treinamento.
A regulação conservadora é aplicada às trajetórias cujos retornos excedem o percentil q de recompensas na amostra de treinamento. Isso garante que, quando RTG é especificado fora da distribuição de treinamento, a política se comporta de maneira semelhante às trajetórias de alta recompensa, e não a uma trajetória aleatória. Adicionamos ruído e deslocamos o RTG a cada etapa de tempo.
Os experimentos realizados pelos autores do método mostram que o uso do percentil 95 geralmente funciona bem em diferentes ambientes e conjuntos de dados.
Os autores notam que o regulador conservador proposto difere de outros componentes conservadores para métodos de RL off-line, que são baseados na avaliação de custos de estados e transições. Enquanto os últimos geralmente tentam regular a avaliação da função de custo para prevenir o erro de extrapolação, o método proposto distorce as recompensas alvo para criar condições fora da distribuição e é regulado pela previsão de ações.
Ao usar a ponderação de trajetórias juntamente com a regulação conservadora, obtemos o ConserWeightive Behavioral Cloning (CWBC), que combina o melhor de ambos os componentes.
2. Implementação com MQL5
Após discutir os aspectos teóricos do método ConserWeightive Behavioral Cloning, passamos à implementação de nossa interpretação dos métodos propostos. Neste trabalho, treinaremos 2 modelos:
- Agente (transformador de decisões) para prever ações.
- Modelo de avaliação de custo do estado atual do ambiente para geração de RTG.
Neste processo, adicionaremos a ponderação de trajetórias e a regulação conservadora para otimizar o processo de treinamento. Os autores do CWBC afirmam que os algoritmos propostos permitem aumentar a eficácia do treinamento do DT em média em 8%.
Note que o processo de treinamento dos modelos é independente. E há a possibilidade de implementar seu treinamento paralelo. E é isso que vamos fazer. Mas primeiro vamos descrever a arquitetura dos modelos. Aqui, dividimos o processo de descrição da arquitetura em 2 métodos separados. No método CreateDescriptions, criaremos a descrição da arquitetura do Agente, que recebe como entrada uma etapa da sequência analisada composta por 5 entidades:
- dados históricos de movimento de preços e indicadores analisados;
- estados de conta e posições abertas;
- rótulo temporal;
- última ação do Agente;
- RTG.
Isso é refletido na camada de dados de entrada do modelo.
bool CreateDescriptions(CArrayObj *agent) { //--- CLayerDescription *descr; //--- if(!agent) { agent = new CArrayObj(); if(!agent) return false; } //--- Agent agent.Clear(); //--- Input layer if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBaseOCL; int prev_count = descr.count = (BarDescr * NBarInPattern + AccountDescr + TimeDescription + NActions + NRewards); descr.activation = None; descr.optimization = ADAM; if(!agent.Add(descr)) { delete descr; return false; }
Como de costume, os dados recebidos passam por um pré-processamento na camada de normalização em lote.
//--- layer 1 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBatchNormOCL; descr.count = prev_count; descr.batch = 1000; descr.activation = None; descr.optimization = ADAM; if(!agent.Add(descr)) { delete descr; return false; }
Em seguida, todas as entidades são transformadas em uma forma comparável. Para isso, primeiro usamos uma camada de incorporação, que transfere todos os dados para um espaço unidimensional N. Quero lembrar que a camada de incorporação que criamos contém dados previamente obtidos sobre a profundidade do histórico analisado. E novos dados são adicionados à sequência coletada.
//--- layer 2 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronEmbeddingOCL; prev_count = descr.count = HistoryBars; { int temp[] = {BarDescr * NBarInPattern, AccountDescr, TimeDescription, NActions, NRewards}; ArrayCopy(descr.windows, temp); } int prev_wout = descr.window_out = EmbeddingSize; if(!agent.Add(descr)) { delete descr; return false; }
Então, com uma camada SoftMax, convertemos todas as incorporações para uma distribuição comparável. Note que o SoftMax é aplicado individualmente para cada incorporação.
//--- layer 3 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronSoftMaxOCL; descr.count = EmbeddingSize; descr.step = prev_count * 5; descr.activation = None; descr.optimization = ADAM; if(!agent.Add(descr)) { delete descr; return false; }
Depois de reunir todas as incorporações em uma forma comparável, usamos um bloco de atenção que analisará a sequência obtida.
//--- layer 4 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronMLMHAttentionOCL; prev_count = descr.count = prev_count * 5; descr.window = EmbeddingSize; descr.step = 8; descr.window_out = 32; descr.layers = 4; descr.optimization = ADAM; if(!agent.Add(descr)) { delete descr; return false; }
O próximo passo é um bloco de dois camadas convolucionais que procura padrões estáveis nos dados e ao mesmo tempo reduz pela metade a dimensionalidade dos dados.
//--- layer 5 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronConvOCL; prev_count = descr.count = prev_count; descr.window = EmbeddingSize; descr.step = EmbeddingSize; prev_wout = descr.window_out = EmbeddingSize; descr.optimization = ADAM; descr.activation = LReLU; if(!agent.Add(descr)) { delete descr; return false; } //--- layer 6 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronConvOCL; prev_count = descr.count = prev_count; descr.window = prev_wout; descr.step = prev_wout; prev_wout = descr.window_out = prev_wout / 2; descr.optimization = ADAM; descr.activation = LReLU; if(!agent.Add(descr)) { delete descr; return false; }
Observe que até agora processamos os dados dentro de uma única incorporação. E terminaremos esta etapa de transformar todas as entidades em uma forma comparável usando a função SoftMax, que também aplicamos a cada entidade na sequência individualmente.
//--- layer 7 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronSoftMaxOCL; descr.count = prev_count; descr.step = prev_wout; descr.activation = None; descr.optimization = ADAM; if(!agent.Add(descr)) { delete descr; return false; }
Dados assim processados e completamente comparáveis são transmitidos para o bloco de tomada de decisão, que consiste em camadas totalmente conectadas, com a geração de ações preditivas do Agente na saída.
//--- layer 8 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBaseOCL; descr.count = LatentCount; descr.optimization = ADAM; descr.activation = LReLU; if(!agent.Add(descr)) { delete descr; return false; } //--- layer 9 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBaseOCL; prev_count = descr.count = LatentCount; descr.activation = LReLU; descr.optimization = ADAM; if(!agent.Add(descr)) { delete descr; return false; } //--- layer 10 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBaseOCL; descr.count = LatentCount; descr.activation = LReLU; descr.optimization = ADAM; if(!agent.Add(descr)) { delete descr; return false; } //--- layer 11 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBaseOCL; descr.count = NActions; descr.activation = SIGMOID; descr.optimization = ADAM; if(!agent.Add(descr)) { delete descr; return false; } //--- return true; }
O próximo passo é criar a descrição da arquitetura do modelo de avaliação de custo do estado ambiental no método CreateRTGDescriptions. Este modelo recebe como entrada uma sequência de dados históricos de mudança de preços e indicadores analisados. Vale ressaltar que neste caso estamos falando de uma sequência de várias barras.
bool CreateRTGDescriptions(CArrayObj *rtg) { //--- CLayerDescription *descr; //--- if(!rtg) { rtg = new CArrayObj(); if(!rtg) return false; } //--- RTG rtg.Clear(); //--- Input layer if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBaseOCL; int prev_count = descr.count = ValueBars * BarDescr; descr.activation = None; descr.optimization = ADAM; if(!rtg.Add(descr)) { delete descr; return false; }
Os dados recebidos também passam por um processamento primário na camada de normalização em lote.
//--- layer 1 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBatchNormOCL; descr.count = prev_count; descr.batch = 1000; descr.activation = None; descr.optimization = ADAM; if(!rtg.Add(descr)) { delete descr; return false; }
Em seguida, criaremos a incorporação de cada barra usando uma camada convolucional e a função SoftMax. Neste caso, não usamos uma camada de incorporação, pois a estrutura de dados de cada barra é uniforme e não precisamos acumular dados obtidos.
//--- layer 2 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronConvOCL; prev_count = descr.count = (prev_count + BarDescr - 1) / BarDescr; descr.window = BarDescr; descr.step = BarDescr; int prev_wout = descr.window_out = EmbeddingSize; descr.optimization = ADAM; descr.activation = LReLU; if(!rtg.Add(descr)) { delete descr; return false; } //--- layer 3 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronSoftMaxOCL; descr.count = prev_count; descr.step = EmbeddingSize; descr.activation = None; descr.optimization = ADAM; if(!rtg.Add(descr)) { delete descr; return false; }
Os dados processados são transmitidos para um bloco de atenção.
//--- layer 4 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronMLMHAttentionOCL; descr.count = prev_count; descr.window = EmbeddingSize; descr.step = 8; descr.window_out = 32; descr.layers = 4; descr.optimization = ADAM; if(!rtg.Add(descr)) { delete descr; return false; }
Então os dados são encaminhados para um bloco de camadas convolucionais e subsequente normalização com SoftMax, semelhante ao modelo discutido anteriormente.
//--- layer 5 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronConvOCL; prev_count = descr.count = prev_count; descr.window = EmbeddingSize; descr.step = EmbeddingSize; prev_wout = descr.window_out = EmbeddingSize; descr.optimization = ADAM; descr.activation = LReLU; if(!rtg.Add(descr)) { delete descr; return false; } //--- layer 6 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronConvOCL; prev_count = descr.count = prev_count; descr.window = prev_wout; descr.step = prev_wout; prev_wout = descr.window_out = prev_wout / 2; descr.optimization = ADAM; descr.activation = LReLU; if(!rtg.Add(descr)) { delete descr; return false; } //--- layer 7 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronSoftMaxOCL; descr.count = prev_count; descr.step = prev_wout; descr.activation = None; descr.optimization = ADAM; if(!rtg.Add(descr)) { delete descr; return false; }
Depois disso, criamos um bloco de tomada de decisões de camadas totalmente conectadas.
//--- layer 8 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBaseOCL; descr.count = LatentCount; descr.optimization = ADAM; descr.activation = LReLU; if(!rtg.Add(descr)) { delete descr; return false; } //--- layer 8 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBaseOCL; prev_count = descr.count = LatentCount; descr.activation = TANH; descr.optimization = ADAM; if(!rtg.Add(descr)) { delete descr; return false; }
Na saída do modelo, criamos a estocasticidade da política de geração de RTG usando um bloco de autocodificador variacional. Assim, simulamos a estocasticidade do ambiente e o custo das possíveis transições dentro da distribuição aprendida.
//--- layer 9 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBaseOCL; descr.count = 2 * NRewards; descr.activation = None; descr.optimization = ADAM; if(!rtg.Add(descr)) { delete descr; return false; } //--- layer 10 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronVAEOCL; descr.count = NRewards; descr.activation = None; descr.optimization = ADAM; if(!rtg.Add(descr)) { delete descr; return false; } //--- return true; }
Após criar a descrição da arquitetura dos modelos, passamos ao trabalho com os Expert Advisors para treinamento dos modelos. Para a coleta inicial da amostra de treinamento, selecionaremos as melhores trajetórias aleatórias, amostradas com o auxílio do EA "...\CWBC\Faza1.mq5". O algoritmo deste EA e os princípios de coleta de dados são descritos no artigo dedicado ao Control Transformer.
Em seguida, criaremos o EA de treinamento do nosso Agente "...\CWBC\StudyAgent.mq5". É importante mencionar que este EA herda em grande parte a estrutura do EA de treinamento do original Decision Transformer. No entanto, complementamos isso com as abordagens do CWBC. Inicialmente, criaremos o método de ponderação de trajetórias GetProbTrajectories, que nos retornará um vetor com somas acumulativas de probabilidades para amostragem de trajetórias. E imediatamente no corpo do método definimos a recompensa máxima no buffer de reprodução de experiências, o nível de quantil necessário e o vetor de desvios padrão das recompensas. Esses dados serão necessários para a regulação conservadora subsequente.
Nos parâmetros do método passaremos o buffer de reprodução de experiência e as variáveis necessárias.
vector<float> GetProbTrajectories(STrajectory &buffer[], float &max_reward, float &quantile, vector<float> &std, double quant, float lanbda) { ulong total = buffer.Size();
No corpo do método, definimos imediatamente o número de trajetórias no buffer de reprodução e preparamos uma matriz para coletar recompensas nas passagens.
matrix<float> rewards = matrix<float>::Zeros(total, NRewards); vector<float> result;
Aqui, vale lembrar que ao salvar uma trajetória no buffer de reprodução, recalculamos a recompensa acumulada até o final da passagem. Consequentemente, a recompensa total por toda a passagem será armazenada no elemento com índice 0. Fazemos um laço e copiamos a recompensa total de cada passagem para a matriz que preparamos.
for(ulong i = 0; i < total; i++) { result.Assign(buffer[i].States[0].rewards); rewards.Row(result, i); }
Com o uso de operações matriciais, obtemos o desvio padrão para cada elemento do vetor de recompensas.
std = rewards.Std(0);
Vetor das recompensas totais de cada passagem e o valor da recompensa máxima.
result = rewards.Sum(1);
max_reward = result.Max();
Note que eu usei a simples soma do vetor de recompensas em cada passagem. No entanto, são possíveis variantes de média de recompensas decompostas. Bem como opções ponderadas de soma ou média. A escolha do método depende da tarefa específica.
Em seguida, precisamos definir o nível do quantil necessário. Na documentação MQL5 sobre a operação vetorial Quantile, é mencionado que para um cálculo correto é necessário um vetor de sequência ordenado. Criaremos uma cópia do vetor de recompensas totais e o ordenaremos em ordem crescente.
vector<float> sorted = result; bool sort = true; int iter = 0; while(sort) { sort = false; for(ulong i = 0; i < sorted.Size() - 1; i++) if(sorted[i] > sorted[i + 1]) { float temp = sorted[i]; sorted[i] = sorted[i + 1]; sorted[i + 1] = temp; sort = true; } iter++; } quantile = sorted.Quantile(quant);
Depois, chamamos a função vetorial Quantile e salvamos o resultado obtido.
Após coletar os dados necessários para as operações subsequentes, passamos diretamente à definição dos pesos para cada trajetória. E aqui é importante entender que, para a unificação do uso do coeficiente λ, precisamos de um algoritmo para converter todas as amostras possíveis de recompensas em uma distribuição única. Para isso, normalizamos todas as recompensas no intervalo (0, 1].
Observe que não incluímos "0" no intervalo de valores normalizados, pois cada trajetória deve ter uma probabilidade diferente de "0". Portanto, subestimamos o valor mínimo da faixa de recompensas em 10% do desvio padrão da recompensa.
O uso máximo de valores relativos permite que nosso cálculo seja verdadeiramente unificado.
float min = result.Min() - 0.1f * std.Sum();
No entanto, ainda há uma pequena probabilidade de obter valores idênticos de recompensas em todas as passagens. As razões para isso podem ser diversas. Mas, apesar da baixa probabilidade de tal evento, ainda criaremos uma verificação. E no ramo principal do nosso algoritmo, primeiro calcularemos o componente exponencial. E então normalizaremos as recompensas e recalcularemos os coeficientes de peso das trajetórias.
if(max_reward > min) { vector<float> multipl=exp(MathAbs(result - max_reward) / (result.Percentile(90)-max_reward)); result = (result - min) / (max_reward - min); result = result / (result + lanbda) * multipl; result.ReplaceNan(0); }
Para o caso especial de recompensas iguais, preencheremos o vetor de probabilidades com um valor constante.
else result.Fill(1);
Então, faremos a soma de todas as probabilidades igual a "1" e calcularemos o vetor de somas acumuladas.
result = result / result.Sum(); result = result.CumSum(); //--- return result; }
Para amostrar uma trajetória em cada iteração, usaremos o método SampleTrajectory, cujos parâmetros passaremos o vetor de probabilidades acumuladas obtido anteriormente. O resultado das iterações será o índice da trajetória no buffer de reprodução de experiência.
int SampleTrajectory(vector<float> &probability) { //--- check ulong total = probability.Size(); if(total <= 0) return -1;
No corpo do método, verificamos o tamanho do vetor de probabilidades obtido e, se estiver vazio, imediatamente retornamos o índice incorreto "-1".
Em seguida, geramos um número aleatório no intervalo [0, 1] de uma distribuição uniforme e procuramos o elemento cuja faixa de probabilidade de escolha inclui o valor aleatório obtido.
Primeiro, verificamos os extremos (primeiro e último elemento do vetor de probabilidades).
//--- randomize float rnd = float(MathRand() / 32767.0); //--- search if(rnd <= probability[0] || total == 1) return 0; if(rnd > probability[total - 2]) return int(total - 1);
Se o valor amostrado não cair nos intervalos dos extremos, precisaremos percorrer os elementos do vetor em busca do valor necessário.
Intuitivamente, pode-se supor que a distribuição de probabilidades das trajetórias tende a ser uniforme. Além disso, começar a revisão dos elementos a partir do meio do vetor e mover na direção necessária será muito mais rápido do que revisar toda a matriz do começo. Por isso, multiplicamos o valor amostrado pelo tamanho do vetor e obtemos algum índice do elemento. Verificamos a probabilidade do elemento escolhido para corresponder ao valor amostrado. E se sua probabilidade for menor, então em um loop aumentamos o índice até encontrar o elemento necessário. Caso contrário, fazemos o mesmo, só que diminuímos o índice.
int result = int(rnd * total); if(probability[result] < rnd) while(probability[result] < rnd) result++; else while(probability[result - 1] >= rnd) result--; //--- return result return result; }
O resultado é retornado ao programa chamador.
Outra função auxiliar que precisaremos no processo de implementação do CWBC é a função de geração de ruído Noise. Nos parâmetros da função, passaremos o vetor de desvios padrão dos elementos do vetor de recompensas e um coeficiente escalar que define o nível máximo de ruído. A função retorna um vetor de ruído.
vector<float> Noise(vector<float> &std, float multiplyer) { //--- check ulong total = std.Size(); if(total <= 0) return vector<float>::Zeros(0);
No corpo da função, primeiro verificamos o tamanho do vetor de desvios padrão. E se estiver vazio, então retornamos um vetor de ruído vazio.
Após passar com sucesso pelo bloco de controles, criamos um vetor de valores zero. E então, em um ciclo, geramos um valor de ruído separado para cada elemento do vetor de recompensas.
vector<float> result = vector<float>::Zeros(total); for(ulong i = 0; i < total; i++) { float rnd = float(MathRand() / 32767.0); result[i] = std[i] * rnd * multiplyer; } //--- return result return result; }
Criamos blocos separados para implementar o CWBC e agora passamos para a implementação do algoritmo completo de treinamento do modelo do Agente, que é realizado no método Train.
No corpo do método, declaramos as variáveis locais necessárias e chamamos o método de ponderação de trajetórias GetProbTrajectories.
void Train(void) { float max_reward = 0, quantile = 0; vector<float> std; vector<float> probability = GetProbTrajectories(Buffer, max_reward, quantile, std, 0.95, 0.1f); uint ticks = GetTickCount();
Após isso, organizamos um sistema de ciclos de treinamento do modelo. No corpo do ciclo, primeiro chamamos o método SampleTrajectory para amostrar uma trajetória, e então escolhemos aleatoriamente um estado na trajetória selecionada para iniciar o processo de treinamento.
bool StopFlag = false; for(int iter = 0; (iter < Iterations && !IsStopped() && !StopFlag); iter ++) { int tr = SampleTrajectory(probability); int i = (int)((MathRand() * MathRand() / MathPow(32767, 2)) * MathMax(Buffer[tr].Total - 2 * HistoryBars - ValueBars, MathMin(Buffer[tr].Total, 20))); if(i < 0) { iter--; continue; }
Em seguida, organizamos um ciclo aninhado, no qual ocorre o treinamento direto do modelo nos estados sequenciais do ambiente. Lembro que para o treinamento e funcionamento correto do modelo Decision Transformer, é necessário usar os eventos em estrita conformidade com sua sequência histórica. O modelo coleta os dados recebidos conforme chegam no buffer interno e forma uma sequência histórica para análise.
Actions = vector<float>::Zeros(NActions); Agent.Clear(); for(int state = i; state < MathMin(Buffer[tr].Total - 1 - ValueBars, i + HistoryBars * 3); state++) { //--- History data State.AssignArray(Buffer[tr].States[state].state);
No corpo do ciclo, coletamos dados no buffer de dados de entrada. Primeiro carregamos os dados históricos de movimento de preços e indicadores analisados.
Em seguida, vem a informação sobre o estado da conta e posições abertas.
//--- Account description float PrevBalance = (state == 0 ? Buffer[tr].States[state].account[0] : Buffer[tr].States[state - 1].account[0]); float PrevEquity = (state == 0 ? Buffer[tr].States[state].account[1] : Buffer[tr].States[state - 1].account[1]); State.Add((Buffer[tr].States[state].account[0] - PrevBalance) / PrevBalance); State.Add(Buffer[tr].States[state].account[1] / PrevBalance); State.Add((Buffer[tr].States[state].account[1] - PrevEquity) / PrevEquity); State.Add(Buffer[tr].States[state].account[2]); State.Add(Buffer[tr].States[state].account[3]); State.Add(Buffer[tr].States[state].account[4] / PrevBalance); State.Add(Buffer[tr].States[state].account[5] / PrevBalance); State.Add(Buffer[tr].States[state].account[6] / PrevBalance);
Depois, formamos a rótulo temporal.
//--- Time label double x = (double)Buffer[tr].States[state].account[7] / (double)(D'2024.01.01' - D'2023.01.01'); State.Add((float)MathSin(2.0 * M_PI * x)); x = (double)Buffer[tr].States[state].account[7] / (double)PeriodSeconds(PERIOD_MN1); State.Add((float)MathCos(2.0 * M_PI * x)); x = (double)Buffer[tr].States[state].account[7] / (double)PeriodSeconds(PERIOD_W1); State.Add((float)MathSin(2.0 * M_PI * x)); x = (double)Buffer[tr].States[state].account[7] / (double)PeriodSeconds(PERIOD_D1); State.Add((float)MathSin(2.0 * M_PI * x));
E adicionamos ao buffer o vetor das últimas ações do Agente.
//--- Prev action if(state > 0) State.AddArray(Buffer[tr].States[state - 1].action); else State.AddArray(vector<float>::Zeros(NActions));
Em seguida, só nos resta adicionar ao buffer a diretriz na forma de RTG. Neste bloco, usaremos a diretriz não até o final da passagem, mas apenas em um pequeno segmento local. E aqui também adicionamos o processo de regulação conservadora. Para isso, primeiro verificamos a rentabilidade da trajetória usada e, se necessário, formamos um vetor de ruído. Lembro que, segundo o CWBC, o ruído é adicionado apenas ás passagens mais lucrativas.
//--- Return to go vector<float> target, result; vector<float> noise = vector<float>::Zeros(NRewards); target.Assign(Buffer[tr].States[0].rewards); if(target.Sum() >= quantile) noise = Noise(std, 100);
Em seguida, calculamos a rentabilidade real no segmento histórico local. Adicionamos o vetor de ruído obtido. E adicionamos os valores obtidos ao buffer de dados de entrada.
target.Assign(Buffer[tr].States[state + 1].rewards); result.Assign(Buffer[tr].States[state + ValueBars].rewards); target = target - result * MathPow(DiscFactor, ValueBars) + noise; State.AddArray(target);
Agora, quando formamos o conjunto completo de dados necessários, realizamos a propagação do Agente para formar o vetor de ações.
//--- Feed Forward if(!Agent.feedForward(GetPointer(State), 1, false, (CBufferFloat*)NULL)) { PrintFormat("%s -> %d", __FUNCTION__, __LINE__); StopFlag = true; break; }
Após a propagação bem-sucedida, chamamos o método de retropropagação do Agente com o objetivo de minimizar as discrepâncias entre as ações previstas e as reais do Agente. Esse processo é semelhante ao treinamento do DT original.
//--- Policy study Result.AssignArray(Buffer[tr].States[state].action); if(!Agent.backProp(Result, (CBufferFloat*)NULL)) { PrintFormat("%s -> %d", __FUNCTION__, __LINE__); StopFlag = true; break; }
Resta-nos apenas informar o usuário sobre o progresso do processo de treinamento do modelo e passar para a próxima iteração do nosso sistema de ciclos de treinamento do modelo.
//--- if(GetTickCount() - ticks > 500) { string str = StringFormat("%-15s %5.2f%% -> Error %15.8f\n", "Agent", iter * 100.0 / (double)(Iterations), Agent.getRecentAverageError()); Comment(str); ticks = GetTickCount(); } } }
Após a conclusão do ciclo completo de iterações de treinamento do modelo, limpamos o campo de comentários no gráfico. Exibimos os resultados do treinamento no log e iniciamos a conclusão do trabalho do EA.
Comment(""); //--- PrintFormat("%s -> %d -> %-15s %10.7f", __FUNCTION__, __LINE__, "Agent", Agent.getRecentAverageError()); ExpertRemove(); //--- }
Com isso, concluímos a introdução ao algoritmo de treinamento do Agente. O treinamento do modelo de avaliação de custo do estado do ambiente é construído sobre um princípio semelhante no EA "...\CWBC\StudyRTG.mq5" e sugiro que você se familiarize com ele no anexo. Lá você também encontrará todos os programas usados neste artigo.
E eu gostaria de destacar mais um ponto. Formamos a amostra de treinamento inicial selecionando as melhores das trajetórias amostradas. Elas podem ser consideradas subótimas, pois atendem a alguns dos nossos requisitos. E gostaríamos de otimizar a política do Agente treinado com esses dados. Para isso, precisamos verificar o funcionamento do modelo treinado em dados históricos e, paralelamente, coletar informações sobre a possibilidade de otimização da política. Com esse objetivo, na próxima passagem no testador de estratégias no segmento histórico da amostra de treinamento, realizaremos ações dentro de um certo intervalo de confiança das previstas pelo Agente e adicionaremos os resultados dessas passagens ao nosso buffer de reprodução de experiência. Após isso, realizaremos uma iteração de re-treinamento dos modelos.
A funcionalidade de coleta de passagens adicionais implementaremos no EA "...\CWBC\Research.mq5". Neste artigo, não detalharemos todos os métodos do EA. Consideraremos apenas o método de processamento de ticks OnTick, no qual é implementada a interação com o ambiente.
No corpo do método, como de costume, verificamos a ocorrência do evento de abertura de um novo bar e, se necessário, carregamos os dados históricos.
void OnTick() { //--- if(!IsNewBar()) return; //--- int bars = CopyRates(Symb.Name(), TimeFrame, iTime(Symb.Name(), TimeFrame, 1), History, Rates); if(!ArraySetAsSeries(Rates, true)) return; //--- RSI.Refresh(); CCI.Refresh(); ATR.Refresh(); MACD.Refresh(); Symb.Refresh(); Symb.RefreshRates();
Dos dados obtidos, primeiro formamos o vetor de dados de entrada para avaliação do custo do estado e chamamos a propagação do modelo correspondente.
//--- History data float atr = 0; bState.Clear(); for(int b = ValueBars - 1; b >= 0; b--) { float open = (float)Rates[b].open; float rsi = (float)RSI.Main(b); float cci = (float)CCI.Main(b); atr = (float)ATR.Main(b); float macd = (float)MACD.Main(b); float sign = (float)MACD.Signal(b); if(rsi == EMPTY_VALUE || cci == EMPTY_VALUE || atr == EMPTY_VALUE || macd == EMPTY_VALUE || sign == EMPTY_VALUE) continue; //--- bState.Add((float)(Rates[b].close - open)); bState.Add((float)(Rates[b].high - open)); bState.Add((float)(Rates[b].low - open)); bState.Add((float)(Rates[b].tick_volume / 1000.0f)); bState.Add(rsi); bState.Add(cci); bState.Add(atr); bState.Add(macd); bState.Add(sign); } if(!RTG.feedForward(GetPointer(bState), 1, false)) return;
Depois, formamos o tensor de dados de entrada do nosso Agente. Neste caso, mantemos a sequência de dados usada durante o treinamento do modelo. Só que em vez do buffer de reprodução de experiência, usamos dados do ambiente circundante.
for(int b = 0; b < (int)NBarInPattern; b++) { float open = (float)Rates[b].open; float rsi = (float)RSI.Main(b); float cci = (float)CCI.Main(b); atr = (float)ATR.Main(b); float macd = (float)MACD.Main(b); float sign = (float)MACD.Signal(b); if(rsi == EMPTY_VALUE || cci == EMPTY_VALUE || atr == EMPTY_VALUE || macd == EMPTY_VALUE || sign == EMPTY_VALUE) continue; //--- int shift = b * BarDescr; sState.state[shift] = (float)(Rates[b].close - open); sState.state[shift + 1] = (float)(Rates[b].high - open); sState.state[shift + 2] = (float)(Rates[b].low - open); sState.state[shift + 3] = (float)(Rates[b].tick_volume / 1000.0f); sState.state[shift + 4] = rsi; sState.state[shift + 5] = cci; sState.state[shift + 6] = atr; sState.state[shift + 7] = macd; sState.state[shift + 8] = sign; } bState.AssignArray(sState.state);
Paralelamente, coletamos os dados usados em uma estrutura para salvar no buffer de reprodução de experiência.
Também realizamos uma pesquisa do ambiente (solicitações ao terminal) para coletar informações sobre o estado da conta e posições abertas.
//--- Account description sState.account[0] = (float)AccountInfoDouble(ACCOUNT_BALANCE); sState.account[1] = (float)AccountInfoDouble(ACCOUNT_EQUITY); //--- double buy_value = 0, sell_value = 0, buy_profit = 0, sell_profit = 0; double position_discount = 0; double multiplyer = 1.0 / (60.0 * 60.0 * 10.0); int total = PositionsTotal(); datetime current = TimeCurrent(); for(int i = 0; i < total; i++) { if(PositionGetSymbol(i) != Symb.Name()) continue; double profit = PositionGetDouble(POSITION_PROFIT); switch((int)PositionGetInteger(POSITION_TYPE)) { case POSITION_TYPE_BUY: buy_value += PositionGetDouble(POSITION_VOLUME); buy_profit += profit; break; case POSITION_TYPE_SELL: sell_value += PositionGetDouble(POSITION_VOLUME); sell_profit += profit; break; } position_discount += profit - (current - PositionGetInteger(POSITION_TIME)) * multiplyer * MathAbs(profit); } sState.account[2] = (float)buy_value; sState.account[3] = (float)sell_value; sState.account[4] = (float)buy_profit; sState.account[5] = (float)sell_profit; sState.account[6] = (float)position_discount; sState.account[7] = (float)Rates[0].time; //--- bState.Add((float)((sState.account[0] - PrevBalance) / PrevBalance)); bState.Add((float)(sState.account[1] / PrevBalance)); bState.Add((float)((sState.account[1] - PrevEquity) / PrevEquity)); bState.Add(sState.account[2]); bState.Add(sState.account[3]); bState.Add((float)(sState.account[4] / PrevBalance)); bState.Add((float)(sState.account[5] / PrevBalance)); bState.Add((float)(sState.account[6] / PrevBalance));
A rótulo temporal é formada com total conformidade com o algoritmo do processo de treinamento.
//--- Time label double x = (double)Rates[0].time / (double)(D'2024.01.01' - D'2023.01.01'); bState.Add((float)MathSin(2.0 * M_PI * x)); x = (double)Rates[0].time / (double)PeriodSeconds(PERIOD_MN1); bState.Add((float)MathCos(2.0 * M_PI * x)); x = (double)Rates[0].time / (double)PeriodSeconds(PERIOD_W1); bState.Add((float)MathSin(2.0 * M_PI * x)); x = (double)Rates[0].time / (double)PeriodSeconds(PERIOD_D1); bState.Add((float)MathSin(2.0 * M_PI * x));
Ao finalizar o processo de coleta do vetor de dados de entrada, adicionamos as últimas ações do Agente e as diretrizes formadas pelo nosso modelo.
//--- Prev action bState.AddArray(AgentResult); //--- Latent representation RTG.getResults(Result); bState.AddArray(Result);
Os dados coletados são transmitidos para o método de propagação do nosso Agente para formar o vetor de ações subsequentes.
//--- if(!Agent.feedForward(GetPointer(bState), 1, false, (CBufferFloat *)NULL)) return;
O vetor de ações previstas do Agente distorcemos um pouco adicionando ruído aleatório. Assim, incentivamos a exploração do ambiente em um contexto das ações previstas.
Agent.getResults(AgentResult); for(ulong i = 0; i < AgentResult.Size(); i++) { float rnd = ((float)MathRand() / 32767.0f - 0.5f) * 0.03f; float t = AgentResult[i] + rnd; if(t > 1 || t < 0) t = AgentResult[i] - rnd; AgentResult[i] = t; } AgentResult.Clip(0.0f, 1.0f);
Depois, salvamos em variáveis locais os dados necessários para as próximas velas.
PrevBalance = sState.account[0]; PrevEquity = sState.account[1];
Ajustamos os volumes sobrepostos de posições em direções opostas.
double min_lot = Symb.LotsMin(); double step_lot = Symb.LotsStep(); double stops = MathMax(Symb.StopsLevel(), 1) * Symb.Point(); if(AgentResult[0] >= AgentResult[3]) { AgentResult[0] -= AgentResult[3]; AgentResult[3] = 0; } else { AgentResult[3] -= AgentResult[0]; AgentResult[0] = 0; }
E deciframos o vetor de ações do Agente resultante. Depois disso, realizamos essas ações no ambiente.
//--- buy control if(AgentResult[0] < 0.9*min_lot || (AgentResult[1] * MaxTP * Symb.Point()) <= stops || (AgentResult[2] * MaxSL * Symb.Point()) <= stops) { if(buy_value > 0) CloseByDirection(POSITION_TYPE_BUY); } else { double buy_lot = min_lot + MathRound((double)(AgentResult[0] - min_lot) / step_lot) * step_lot; double buy_tp = Symb.NormalizePrice(Symb.Ask() + AgentResult[1] * MaxTP * Symb.Point()); double buy_sl = Symb.NormalizePrice(Symb.Ask() - AgentResult[2] * MaxSL * Symb.Point()); if(buy_value > 0) TrailPosition(POSITION_TYPE_BUY, buy_sl, buy_tp); if(buy_value != buy_lot) { if(buy_value > buy_lot) ClosePartial(POSITION_TYPE_BUY, buy_value - buy_lot); else Trade.Buy(buy_lot - buy_value, Symb.Name(), Symb.Ask(), buy_sl, buy_tp); } }
//--- sell control if(AgentResult[3] < 0.9*min_lot || (AgentResult[4] * MaxTP * Symb.Point()) <= stops || (AgentResult[5] * MaxSL * Symb.Point()) <= stops) { if(sell_value > 0) CloseByDirection(POSITION_TYPE_SELL); } else { double sell_lot = min_lot + MathRound((double)(AgentResult[3] - min_lot) / step_lot) * step_lot;; double sell_tp = Symb.NormalizePrice(Symb.Bid() - AgentResult[4] * MaxTP * Symb.Point()); double sell_sl = Symb.NormalizePrice(Symb.Bid() + AgentResult[5] * MaxSL * Symb.Point()); if(sell_value > 0) TrailPosition(POSITION_TYPE_SELL, sell_sl, sell_tp); if(sell_value != sell_lot) { if(sell_value > sell_lot) ClosePartial(POSITION_TYPE_SELL, sell_value - sell_lot); else Trade.Sell(sell_lot - sell_value, Symb.Name(), Symb.Bid(), sell_sl, sell_tp); } }
Depois, só nos resta obter a recompensa do ambiente pela transição para o estado atual (ações anteriores do Agente) e transmitir os dados coletados para o buffer de reprodução de experiência.
int shift = BarDescr * (NBarInPattern - 1); sState.rewards[0] = bState[shift]; sState.rewards[1] = bState[shift + 1] - 1.0f; if((buy_value + sell_value) == 0) sState.rewards[2] -= (float)(atr / PrevBalance); else sState.rewards[2] = 0; for(ulong i = 0; i < NActions; i++) sState.action[i] = AgentResult[i]; if(!Base.Add(sState)) ExpertRemove(); }
Com o código completo do EA e todos os seus métodos, você pode se familiarizar no anexo.
O EA de teste do modelo treinado "...\CWBC\Test.mq5" é criado com um algoritmo semelhante, exceto pela distorção do vetor de ações previstas pelo Agente. Seu código também está incluído no anexo do artigo.
E após a criação de todos os programas necessários, passamos para o teste do trabalho realizado.
3. Teste
Na parte prática do nosso artigo, realizamos um trabalho considerável para implementar nossa visão do método ConserWeightive Behavioral Cloning com as ferramentas MQL5. E agora é hora de avaliar na prática o resultado de nossos esforços. Como sempre, treinaremos e testaremos nossos modelos em dados históricos do par EURUSD no timeframe H1. Como dados de treinamento, utilizaremos o período histórico dos primeiros 7 meses de 2023. E realizaremos os testes com dados de agosto de 2023.
Como já mencionado anteriormente, o treinamento inicial será realizado com dados amostrados no artigo Control Transformer. Assim, omitimos este processo e passamos diretamente para o treinamento dos modelos.
Anteriormente, criamos 2 EAs para treinar dois modelos. Isso nos permite realizar o treinamento paralelo de 2 modelos. Este processo pode ser realizado em diferentes dispositivos independentemente.
Após o treinamento inicial dos modelos, verificamos a eficácia do modelo treinado na amostra de treinamento e realizamos a coleta de trajetórias adicionais, por meio do lançamento dos EAs "...\CWBC\Research.mq5" e "...\CWBC\Test.mq5" no testador de estratégias no período histórico da amostra de treinamento. A sequência de lançamento dos EAs neste caso não influencia o processo de treinamento dos modelos.
Em seguida, realizamos o re-treinamento dos modelos com dados do buffer de reprodução de experiência atualizado.
Observe que, no meu caso, um aumento no desempenho do modelo foi observado apenas após a primeira iteração de re-treinamento. Iterações subsequentes de coleta de trajetórias adicionais e re-treinamento do modelo não resultaram em melhorias. Mas isso pode ser um caso específico.
No processo de treinamento, consegui obter um modelo que gera lucro no segmento histórico da amostra de treinamento.


Durante o período de treinamento, o modelo realizou 141 transações. Cerca de 40% foram fechadas com lucro. A transação mais lucrativa foi mais de 4 vezes maior que a maior perda. E a transação lucrativa média foi quase 2 vezes maior que a perda média. Além disso, a transação lucrativa média foi 13% maior que a maior perda. Tudo isso resultou em um fator de lucro de 1.11. Resultados semelhantes foram observados também nos novos dados.
Mas nos resultados obtidos há uma "mosca na sopa". O modelo realizou apenas posições longas, o que em geral corresponde à tendência global no intervalo histórico dado. Como consequência, a linha de saldo se assemelha muito ao gráfico do instrumento.


A análise detalhada do teste mostra perdas em fevereiro e maio de 2023, que são compensadas nos meses seguintes. Março foi o mês mais lucrativo. E, em termos semanais, quarta-feira demonstrou a maior rentabilidade.
Considerações finais
Neste artigo, exploramos o método ConserWeightive Behavioral Cloning (CWBC), que combina ponderação de trajetórias e regulação conservadora para aumentar a confiabilidade das estratégias de treinamento. Implementamos o método proposto com ferramentas MQL5 e realizamos testes com dados históricos reais.
Nossos resultados mostram que o CWBC demonstra um grau bastante elevado de estabilidade durante o treinamento off-line de modelos. Em particular, o método lida com sucesso com condições em que as trajetórias com altos retornos constituem uma pequena parte do conjunto de dados de treinamento. É importante ressaltar a importância de ajustar cuidadosamente os hiperparâmetros necessários, o que desempenha um papel crucial na eficácia do CWBC.
Links
Programas utilizados no artigo
| # | Nome | Tipo | Descrição |
|---|---|---|---|
| 1 | Faza1.mq5 | Expert Advisor | EA para coleta de exemplos |
| 2 | Research.mq5 | Expert Advisor | EA para coleta de trajetórias adicionais |
| 3 | StudyAgentmq5 | Expert Advisor | EA para treinamento do modelo de política local |
| 4 | StudyRTG.mq5 | Expert Advisor | EA para treinamento da Função de Custo |
| 5 | Test.mq5 | Expert Advisor | EA para teste do modelo |
| 6 | Trajectory.mqh | Biblioteca de classe | Estrutura de descrição do estado do sistema |
| 7 | NeuroNet.mqh | Biblioteca de classe | Biblioteca de classes para criação de rede neural |
| 8 | NeuroNet.cl | Biblioteca | Biblioteca de código do programa OpenCL |
Traduzido do russo pela MetaQuotes Ltd.
Artigo original: https://www.mql5.com/ru/articles/13742
- Aplicativos de negociação gratuitos
- 8 000+ sinais para cópia
- Notícias econômicas para análise dos mercados financeiros
Você concorda com a política do site e com os termos de uso