
Нейросети — это просто (Часть 61): Проблема оптимизма в офлайн обучении с подкреплением

Введение
В последнее время широкое распространение получили методы офлайн обучения с подкреплением, что обещает множество перспектив в решении задач различной сложности. Однако одной из основных проблем, с которой сталкиваются исследователи, является оптимизм, который может возникнуть в процессе обучения. Агент оптимизирует свою стратегию, основываясь на данных обучающей выборки, и приобретает уверенность в своих действиях. Но обучающая выборка довольно часто не способна покрыть все разнообразие возможных состояний и переходов окружающей среды. В условиях стохастичности окружающей среды подобная уверенность оказывается не совсем обоснованной. В таких случаях оптимистически настроенная стратегия агента может привести к повышению рисков и нежелательным последствиям.
В поисках решения данной проблемы стоит обратить внимание на исследования в области автономного вождения. Очевидно, что алгоритмы данной области исследований направлены на снижение рисков (повышение безопасности пользователей) и минимальное онлайн обучение. Одним из таких методов является SeParated Latent Trajectory Transformer (SPLT-Transformer), представленный в статье «Addressing Optimism Bias in Sequence Modeling for Reinforcement Learning» (Июль 2022г.)
1. Метод SPLT-Transformer
Модель SPLT-Transformer, аналогично Decision Transformer, относится к моделям генерации последовательностей с использованием архитектуры Трансформер. Но в отличии от упомянутого DT, использует два отдельных информационных потока для моделирования политика Актера и модели окружающей среды.
Авторы метода пытаются решить 2 основных задачи:
- Модели должны способствовать созданию разнообразных кандидатов для поведения Агента в любой ситуации;
- Модели должны охватывать большинство различных режимов потенциальных переходов в новое состояние окружающей среде.
Для достижения этой цели обучаются 2 отдельных VAE на основе трансформера для политики Актера и модели окружающей среды. Авторы метода генерируют стохастические латентные переменных для обоих потоков и используют их на всем горизонте планирования. Что позволяет осуществить перебор всех возможных траекторий-кандидатов без экспоненциального увеличения ветвления. И обеспечивает эффективный поиск вариантов поведения во время тестирования.
Идея заключается в том, что латентные переменные политики должны соответствовать различным высокоуровневым намерениям, аналогично навыкам иерархических алгоритмов. В то же время латентные переменные модели окружающей среды должны соответствовать различным возможным тенденциям и наиболее вероятному изменению её состояния.
В энкодерах политики и окружающей среды применяется одинаковая архитектура с использованием Трансформеров. Они получают одни и те же исходные данные в виде предшествующей траектории. Но в отличии от рассмотренных ранее алгоритмов, траектория включает только набор состояний и действий Актера. На выходе энкодеров получаем дискретные латентные переменные с ограниченным количеством значений в каждом измерении.
Авторы метода предлагают использовать среднее значение выходов трансформера для всех элементов, чтобы объединить всю траекторию в одно векторное представление.
Далее, каждый из этих выходов обрабатывается небольшим многослойным перцептроном, который выводит независимые категориальные распределения латентного представления.
Декодер политики получает на вход туже исходную траекторию, дополненную соответствующим латентным представлением. Целью декодера политики является оценка вероятностей и прогнозирование наиболее вероятного следующего действия в траектории. Авторы метода представляют декодер с использованием модели Трансформера.
Как уже было сказано выше, из последовательности исключается вознаграждение, но добавляем латентное представление. Однако латентное представление не заменяет вознаграждение в качестве элемента последовательности на каждом шаге. Авторы метода вводят латентное представление, которое преобразуется один вектор вставки, аналогично позиционному кодированию, применяемого в некоторых других работах с использованием архитектуры Трансформера.
Декодер модели окружающей среды имеет архитектуру схожую с декодером политики. Только на выходе декодер модели окружающей среды имеет "3 головы" для прогнозирования наиболее вероятных последующего состояния и его стоимости, а также вознаграждения за переход.
Обучение моделей, как и в DT, осуществляется на данных из обучающей выборки с использованием методов обучения с учителем. Модели обучаются сопоставлять траектории с последующими действиями (Актер), переходами в новые состояния и их стоимости (модель окружающей среды).
В процессе тестирования и эксплуатации выбор оптимального действия осуществляется на основании оценки прогнозных траекторий-кандидатов на заданном горизонте планирования. Для составления одной планируемой траектории-кандидата осуществляется последовательная генерация действий и состояний с вознаграждениями на горизонт планирования. Затем выбирается оптимальная траектория и осуществляется её первое действие. После перехода в новое состояние окружающей среды весь алгоритм повторяется.
Как можно заметить, алгоритмом предусматривается планирование нескольких траекторий-кандидатов, но выполняется только одно действие оптимальной траектории. Хотя такой подход может показаться не эффективным, он позволяет минимизировать риски за счет планирования на несколько шагов вперед. И в то же время существует возможность вовремя скорректировать траекторию в следствии переоценки каждого посещенного состояния.
Авторская визуализация метода представлена ниже.
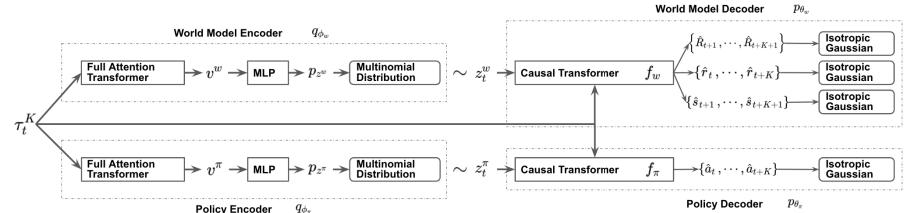
2. Реализация средствами MQL5
После рассмотрения теоретических аспектов метода SPLT-Transformer мы переходим к реализации предложенных подходов средствами MQL5. Сразу хочу сказать, что наша реализация будет как никогда далека от авторского алгоритма. И причина в моём субъективном восприятии. Весь опыт данной серии статей демонстрирует сложность создания модели окружающей среды для финансовых рынков. Все наши попытки давали довольно скромные результаты. Точность прогнозов довольно мала на 1-2 шага. А с ростом горизонта планирования стремится к 0. Поэтому я решил не строить траектроий-кандидатов, а ограничиться лишь генерацией нескольких вариантов действий-кандидатов из текущего состояния.
Но такой подход влечет за собой разрыв между действием и его оценкой. Как можно заметить на представленной выше визуализации, политика Актера и модель окружающей среды получают одинаковые исходные данные. Но далее информация идет параллельными потоками. Следовательно, при прогнозе последующего состояния и ожидаемого вознаграждения модель окружающей среды ничего не знает о действии, которое выберет Агент. Здесь можно лишь говорить о некотором предположении с определенной долей вероятности на основании предыдущего опыта из обучающей выборки. И надо обратить внимание, что обучающая выборка была создана на основании политик Актера отличных от используемой в данный момент.
В авторском варианте это нивелируется за счет добавления действия Агента и прогнозного состояния в траекторию на следующем шаге. Однако в нашем случае с учетом опыта низкого качества планирования последующего состояния окружающей среды мы рискуем добавить в траекторию абсолютно не согласованные состояния и действия. Что приведет к ещё большему снижению качества планирования последующих шагов в прогнозной траектории. На мой взгляд, эффективность подобного планирования и оценки подобных траекторий очень сомнительна. Поэтому мы не будем тратить ресурсы на прогнозирование траэткорий-кандидатов.
В то же время нам необходим механизм способный сопоставить действия Агента и ожидаемое вознаграждение. С одной стороны мы можем воспользоваться моделью Критика, но это в корне ломает алгоритм и полностью исключает модель окружающей среды. Если, конечно, не использовать её в качестве Критика.
Однако, я решил поэкспериментировать с другим подходом, более близким к исходному алгоритму. Для начала я решил использовать один энкодер для обоих потоков. Полученное латентное состояние добавляется к траектории и подается на вход 2 декодеров. Актер на основании исходных данных генерирует прогнозное действие, а модель окружающей среды возвращает сумму будущего дисконтированного вознаграждения.
Идея заключается в том, что получая на вход одни и те же данные модели возвращают согласованные результаты. Для этого в моделях Актера и модели окружающей среды мы исключаем стохастичность. При этом мы создаем стохастичность латентного представления, что позволяет нам создавать несколько действий-кандидатов и связанных оценок прогнозного состояния. На основании этих оценок мы и будем ранжировать действия-кандидаты для выбора оптимального взвешенного шага.
Для оптимизации количества выполняемых операций следует обратить внимание еще на один момент. Подавая на вход Энкодера одну и ту же траекторию мы с математической точностью повторим результаты всех его внутренних слоёв. Отличия формируются лишь в слое вариационного автоэнкодера при семплировании из заданного распределения. Следовательно, для формирования действий-кандидатов нам целесообразно вынести указанный слой за пределы Энкодера. Это позволит нам на каждой итерации осуществлять только один проход Энкодера. После недолгих размышлений, я перенес слой вариационного автоэнкодера в модель окружающей среды.
Должен сказать, что я пошел дальше по путти оптимизации потока операций. Все 3 наши модели используют в качестве исходных данных одну траекторию. Как вы знаете, элементы траектории неоднородны. И перед обработкой проходят через слой Эмбединга. Это натолкнуло меня на мысль об эмбединге данных только в одной моделе, с последующим использование полученных данных в 2 оставшихся. Таким образо слой эмбединга я оставил только в Энкодере.
И ещё один момент. Модель окружающей среды и Актер в качестве исходных данных используют конкатенированный вектор траектории и латентного представления. Выше мы уже определились, что слой вариационного автоэнкодера для формирования стохастического латентного представления перенесен в модель окружающей среды. Здесь же мы и осуществим объединение векторов. А вот уже полученный результат мы передадим на вход Актера.
А теперь перенесем изложенные идеи в код. Создадим описание наших моделей. Которое, как всегда, формируется в методе CreateDescriptions. В параметрах метод получает указатели на 3 объекта описания наших моделей.
bool CreateDescriptions(CArrayObj *agent, CArrayObj *latent, CArrayObj *world) { //--- CLayerDescription *descr;
Описание архитектуры, наверное, стоит начать с модели энкодера, на вход которого подаются не обработанные данные последовательности.
//--- latent.Clear(); //--- Input layer if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBaseOCL; prev_count = descr.count = (BarDescr * NBarInPattern + AccountDescr + TimeDescription + NActions); descr.activation = None; descr.optimization = ADAM; if(!latent.Add(descr)) { delete descr; return false; }
Полученные данные мы пропускаем через слой пакетной нормализации для приведения их в сопоставимый вид.
//--- layer 1 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBatchNormOCL; descr.count = prev_count; descr.batch = 1000; descr.activation = None; descr.optimization = ADAM; if(!latent.Add(descr)) { delete descr; return false; }
И уже нормализованные данные мы пропускаем через слой эмбединга. Запомните этот слой. С него мы потом будем забирать данные в модель окружающей среды.
//--- layer 2 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronEmbeddingOCL; prev_count = descr.count = HistoryBars; { int temp[] = {BarDescr * NBarInPattern, AccountDescr, TimeDescription, NActions}; ArrayCopy(descr.windows, temp); } int prev_wout = descr.window_out = EmbeddingSize; if(!latent.Add(descr)) { delete descr; return false; }
Далее мы полученную траекторию проводим через блок Трансформера. Я использовал блок разреженного внимания с 8 головами Self-Attention и 4 слоями в блоке.
//--- layer 3 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronMLMHSparseAttentionOCL; prev_count = descr.count = prev_count * 4; descr.window = prev_wout; descr.step = 8; descr.window_out = 32; descr.layers = 4; descr.probability = Sparse; descr.optimization = ADAM; if(!latent.Add(descr)) { delete descr; return false; }
После блока внимания мы немного понизим размерность сверточным слоем и пропустим данные через блок принятия решения из полносвязных слоев.
//--- layer 4 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronConvOCL; descr.count = prev_count; descr.window = prev_wout; descr.step = prev_wout; descr.window_out = 4; descr.optimization = ADAM; descr.activation = LReLU; if(!latent.Add(descr)) { delete descr; return false; } //--- layer 5 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBaseOCL; descr.count = LatentCount; descr.optimization = ADAM; descr.activation = LReLU; if(!latent.Add(descr)) { delete descr; return false; } //--- layer 6 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBaseOCL; prev_count = descr.count = LatentCount; descr.activation = TANH; descr.optimization = ADAM; if(!latent.Add(descr)) { delete descr; return false; } //--- layer 7 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBaseOCL; descr.count = LatentCount; descr.activation = LReLU; descr.optimization = ADAM; if(!latent.Add(descr)) { delete descr; return false; } //--- layer 8 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBaseOCL; descr.count = 2 * EmbeddingSize; descr.activation = None; descr.optimization = ADAM; if(!latent.Add(descr)) { delete descr; return false; }
На выходе модели Энкодера мы используем полносвязный нейронный слой без функции активации и размером в 2 раза превышающий размер эмбединга одного элемента траектории. Что представляет собой средние значения и дисперсии для распределения латентного представления. Это позволит нам семплировать латентное представление из заданного распределения на следующем этапе.
Далее мы переходим к описанию модели окружающей среды. Её слой исходных данных равен слою результатов модели Энкодера. А за ним следует слой вариационного автоэнкодера, что позволяет нам сразу семплировать латентное представление.
//--- World if(!world) { world = new CArrayObj(); if(!world) return false; } //--- world.Clear(); //--- Input layer if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBaseOCL; prev_count = descr.count = 2 * EmbeddingSize; descr.activation = None; descr.optimization = ADAM; if(!world.Add(descr)) { delete descr; return false; } //--- layer 1 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronVAEOCL; prev_count = descr.count = prev_count / 2; descr.activation = None; descr.optimization = ADAM; if(!world.Add(descr)) { delete descr; return false; }
Затем нам предстоит добавить тензор эмбедингов траектории. Для этого мы воспользуемся слоем конкатенации. На выходе данного слоя мы получаем обработанные исходные данные для нашей модели окружающей среды и Актера.
//--- layer 2 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronConcatenate; descr.step = 4 * EmbeddingSize * HistoryBars; prev_count = descr.count = descr.step + prev_count; descr.activation = LReLU; descr.optimization = ADAM; if(!world.Add(descr)) { delete descr; return false; }
Проведем данные через блок разряженного Self-Attemtion. Как и в энкодере используем 8 голов и 4 слоя.
//--- layer 3 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronMLMHSparseAttentionOCL; prev_count = descr.count = prev_count / EmbeddingSize; descr.window = EmbeddingSize; descr.step = 8; descr.window_out = 32; descr.layers = 4; descr.probability = Sparse; descr.optimization = ADAM; if(!world.Add(descr)) { delete descr; return false; }
Понижаем размерность данных с помощью сверточного слоя.
//--- layer 4 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronConvOCL; descr.count = prev_count; descr.window = prev_wout; descr.step = prev_wout; descr.window_out = 4; descr.optimization = ADAM; descr.activation = LReLU; if(!world.Add(descr)) { delete descr; return false; }
И обработаем полученные данные полносвязным перцептроном блока принятия решения.
//--- layer 5 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBaseOCL; descr.count = LatentCount; descr.optimization = ADAM; descr.activation = LReLU; if(!world.Add(descr)) { delete descr; return false; } //--- layer 6 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBaseOCL; prev_count = descr.count = LatentCount; descr.activation = TANH; descr.optimization = ADAM; if(!world.Add(descr)) { delete descr; return false; } //--- layer 7 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBaseOCL; descr.count = LatentCount; descr.activation = LReLU; descr.optimization = ADAM; if(!world.Add(descr)) { delete descr; return false; } //--- layer 8 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBaseOCL; descr.count = NRewards; descr.activation = None; descr.optimization = ADAM; if(!world.Add(descr)) { delete descr; return false; }
На выходе модели мы получаем вектор декомпозированного вознаграждения.
И в завершении данного блока мы рассмотрим структуру модели нашего Актера. Как уже было сказано выше, исходные данные модель получает из скрытого состояния модели окружающей среды. Соответственно и слой исходных данных должен быть достаточного размера.
//--- if(!agent) { agent = new CArrayObj(); if(!agent) return false; } //--- Agent agent.Clear(); //--- Input layer if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBaseOCL; int prev_count = descr.count = EmbeddingSize * (4 * HistoryBars + 1); descr.activation = None; descr.optimization = ADAM; if(!agent.Add(descr)) { delete descr; return false; }
Полученные данные являются результатом работы модели и не требуют дополнительной обработки. Поэтому мы сразу используем блок разреженного внимания. Параметры блока аналогичны, используемым в рассмотренных выше моделях. Таким образом все 3 модели используют одинаковую архитектуру трансформера.
//--- layer 1 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronMLMHSparseAttentionOCL; prev_count = descr.count = prev_count / EmbeddingSize; descr.window = EmbeddingSize; descr.step = 8; descr.window_out = 32; descr.layers = 4; descr.probability = Sparse; descr.optimization = ADAM; if(!agent.Add(descr)) { delete descr; return false; }
Аналогично модели окружающей среды, мы понижаем размерность и обрабатываем данные в полносвязном перцептроне принятия решений.
//--- layer 2 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronConvOCL; descr.count = prev_count; descr.window = EmbeddingSize; descr.step = EmbeddingSize; descr.window_out = 4; descr.optimization = ADAM; descr.activation = LReLU; if(!agent.Add(descr)) { delete descr; return false; } //--- layer 3 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBaseOCL; descr.count = LatentCount; descr.optimization = ADAM; descr.activation = LReLU; if(!agent.Add(descr)) { delete descr; return false; } //--- layer 4 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBaseOCL; prev_count = descr.count = LatentCount; descr.activation = TANH; descr.optimization = ADAM; if(!agent.Add(descr)) { delete descr; return false; } //--- layer 5 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBaseOCL; descr.count = LatentCount; descr.activation = LReLU; descr.optimization = ADAM; if(!agent.Add(descr)) { delete descr; return false; } //--- layer 6 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBaseOCL; descr.count = NActions; descr.activation = SIGMOID; descr.optimization = ADAM; if(!agent.Add(descr)) { delete descr; return false; } //--- return true; }
На выходе модели формируется вектор действий Агента.
Тут же нужно обратить внимание, что для реализации данного метода нам потребуется добавление в буфер воспроизведения опыта дополнительной сущности в виде распределения латентного представления, которое формируется на выходе Энкодера. Для этого мы создадим дополнительный массив в структуре описания состояния окружающей среды.
struct SState { ....... ....... float latent[2 * EmbeddingSize]; ....... ....... }
Размер нового массива равен 2 эмбедингам, так как включает средние значения и дисперсии распределения.
Помимо объявления массива нам нужно добавить и его обслуживание во все методы структуры:
- Инициализация начальными значениями
SState::SState(void) { ....... ....... ArrayInitialize(latent, 0); }
- Очистка структуры
void Clear(void) { ....... ....... ArrayInitialize(latent, 0); }
- Копирование структуры
void operator=(const SState &obj) { ....... ....... ArrayCopy(latent, obj.latent); }
- Сохранение структуры
bool SState::Save(int file_handle) { ....... ....... //--- total = ArraySize(latent); if(FileWriteInteger(file_handle, total) < sizeof(int)) return false; for(int i = 0; i < total; i++) if(FileWriteFloat(file_handle, latent[i]) < sizeof(float)) return false; //--- return true; }
- Загрузка структуры из файла
bool SState::Load(int file_handle) { ....... ....... //--- total = FileReadInteger(file_handle); if(total != ArraySize(latent)) return false; //--- for(int i = 0; i < total; i++) { if(FileIsEnding(file_handle)) return false; latent[i] = FileReadFloat(file_handle); } //--- return true; }
Мы познакомились с архитектурой обучаемых моделей и актуализировали структуру данных. Следующим этапом нам предстоит собрать данные для их обучения. Данный функционал выполняется в советнике "...\SPLT\Research.mq5". И сразу надо обратить внимание, что методом SPLT-Transformer предусмотрена генерация траекторий-кандидатов (в нашей реализации действий-кандидатов). Количество таких кандидатов является одним из гиперпараметров модели, который мы выносим во внешние параметры советника.
input int Agents = 5;
Но напомню, что раньше мы использовали внешний параметр "Agents" в качестве вспомогательного для указания количества параллельных агентов исследования окружающей среды в режиме оптимизации тестера стратегий. Сейчас мы переименуем служебный параметр советника.
input int OptimizationAgents = 1;
Далее мы не будем подробно останавливаться на всех методах советника сбора обучающей выборки. Их алгоритм уже много раз описан в рамках данной серии статей. А с полным кодом всех используемых в статье программ вы можете самостоятельно ознакомиться во вложении. Рассмотрим лишь метод непосредственного взаимодействия с окружающей средой OnTick, в котором реализованы ключевые особенности, реализуемого алгоритма.
В начале метода мы, как обычно, проверяем наступление события открытия нового бара и, при необходимости, обновляем исторические данные ценового движения и значений анализируемых индикаторов.
//+------------------------------------------------------------------+ //| Expert tick function | //+------------------------------------------------------------------+ void OnTick() { //--- if(!IsNewBar()) return; //--- int bars = CopyRates(Symb.Name(), TimeFrame, iTime(Symb.Name(), TimeFrame, 1), NBarInPattern, Rates); if(!ArraySetAsSeries(Rates, true)) return; //--- RSI.Refresh(); CCI.Refresh(); ATR.Refresh(); MACD.Refresh(); Symb.Refresh(); Symb.RefreshRates();
После чего мы формируем буфер исходных данных для моделей. Первыми мы вносим исторические данные о ценовом движении и значения анализируемых индикаторов.
//+------------------------------------------------------------------+ //| Expert tick function | //+------------------------------------------------------------------+ void OnTick() { //--- if(!IsNewBar()) return; //--- int bars = CopyRates(Symb.Name(), TimeFrame, iTime(Symb.Name(), TimeFrame, 1), NBarInPattern, Rates); if(!ArraySetAsSeries(Rates, true)) return; //--- RSI.Refresh(); CCI.Refresh(); ATR.Refresh(); MACD.Refresh(); Symb.Refresh(); Symb.RefreshRates(); //--- History data float atr = 0; for(int b = 0; b < (int)NBarInPattern; b++) { float open = (float)Rates[b].open; float rsi = (float)RSI.Main(b); float cci = (float)CCI.Main(b); atr = (float)ATR.Main(b); float macd = (float)MACD.Main(b); float sign = (float)MACD.Signal(b); if(rsi == EMPTY_VALUE || cci == EMPTY_VALUE || atr == EMPTY_VALUE || macd == EMPTY_VALUE || sign == EMPTY_VALUE) continue; //--- int shift = b * BarDescr; sState.state[shift] = (float)(Rates[b].close - open); sState.state[shift + 1] = (float)(Rates[b].high - open); sState.state[shift + 2] = (float)(Rates[b].low - open); sState.state[shift + 3] = (float)(Rates[b].tick_volume / 1000.0f); sState.state[shift + 4] = rsi; sState.state[shift + 5] = cci; sState.state[shift + 6] = atr; sState.state[shift + 7] = macd; sState.state[shift + 8] = sign; } bState.AssignArray(sState.state);
Затем добавим текущее состояние счета и информацию об открытых позициях.
//--- Account description sState.account[0] = (float)AccountInfoDouble(ACCOUNT_BALANCE); sState.account[1] = (float)AccountInfoDouble(ACCOUNT_EQUITY); //--- double buy_value = 0, sell_value = 0, buy_profit = 0, sell_profit = 0; double position_discount = 0; double multiplyer = 1.0 / (60.0 * 60.0 * 10.0); int total = PositionsTotal(); datetime current = TimeCurrent(); for(int i = 0; i < total; i++) { if(PositionGetSymbol(i) != Symb.Name()) continue; double profit = PositionGetDouble(POSITION_PROFIT); switch((int)PositionGetInteger(POSITION_TYPE)) { case POSITION_TYPE_BUY: buy_value += PositionGetDouble(POSITION_VOLUME); buy_profit += profit; break; case POSITION_TYPE_SELL: sell_value += PositionGetDouble(POSITION_VOLUME); sell_profit += profit; break; } position_discount += profit - (current - PositionGetInteger(POSITION_TIME)) * multiplyer * MathAbs(profit); } sState.account[2] = (float)buy_value; sState.account[3] = (float)sell_value; sState.account[4] = (float)buy_profit; sState.account[5] = (float)sell_profit; sState.account[6] = (float)position_discount; sState.account[7] = (float)Rates[0].time; //--- bState.Add((float)((sState.account[0] - PrevBalance) / PrevBalance)); bState.Add((float)(sState.account[1] / PrevBalance)); bState.Add((float)((sState.account[1] - PrevEquity) / PrevEquity)); bState.Add(sState.account[2]); bState.Add(sState.account[3]); bState.Add((float)(sState.account[4] / PrevBalance)); bState.Add((float)(sState.account[5] / PrevBalance)); bState.Add((float)(sState.account[6] / PrevBalance));
Далее мы осуществляем временную идентификацию данных, добавляя метку времени в наш буфер данных.
//--- Time label double x = (double)Rates[0].time / (double)(D'2024.01.01' - D'2023.01.01'); bState.Add((float)MathSin(2.0 * M_PI * x)); x = (double)Rates[0].time / (double)PeriodSeconds(PERIOD_MN1); bState.Add((float)MathCos(2.0 * M_PI * x)); x = (double)Rates[0].time / (double)PeriodSeconds(PERIOD_W1); bState.Add((float)MathSin(2.0 * M_PI * x)); x = (double)Rates[0].time / (double)PeriodSeconds(PERIOD_D1); bState.Add((float)MathSin(2.0 * M_PI * x));
И укажем последние действия Агента, которые привили нас в это состояние окружающей среды.
//--- Prev action
bState.AddArray(AgentResult);
Собранных данных о текущем шаге достаточно для генерации латентного представления и мы вызываем метод прямого прохода Энкодера. При этом обязательно контролируем процесс выполнения операций. И, при необходимости, информируем пользователя.
//--- Latent representation ResetLastError(); if(!Latent.feedForward(GetPointer(bState), 1, false)) { PrintFormat("Error of Latent model feed forward: %d",GetLastError()); return; }
После успешного создания латентного представления мы переходим к нашим декодерам.
Напомню, что на данном этапе нам предстоит сгенерировать действия-кандидаты. Формировать их мы будем в цикле, число итераций которого равно количеству необходимых кандидатов и указано во внешних параметрах советника.
Для записи информации о сгенерированных действиях-кандидатах мы создадим 2 матрицы actions и values. В первую будем записывать векторы действий. А во вторую — ожидаемых вознаграждений в следствии применения политики.
Как уже было сказано выше, в модели Энкодера мы лишь формируем данные о распределении латентного представления. Семплирование вектора латентного представления осуществляется в модели окружающей среды. Следовательно, в теле цикла мы сначала выполняем прямой проход модели окружающей среды. А затем вызываем метод прямого прохода Агента, который используем скрытые состояния модели окружающей среды в качестве исходных данных.
Результаты прямых проходов моделей мы сохраняем в ранее подготовленные матрицы.
matrix<float> actions = matrix<float>::Zeros(Agents, NActions); matrix<float> values = matrix<float>::Zeros(Agents, NRewards); for(ulong i = 0; i < (ulong)Agents; i++) { if(!World.feedForward(GetPointer(Latent), -1, GetPointer(Latent), LatentLayer) || !Agent.feedForward(GetPointer(World), 2,(CBufferFloat *)NULL)) return; vector<float> result; Agent.getResults(result); actions.Row(result, i); World.getResults(result); values.Row(result, i); }
Использование стохастических политик основано на предположении о равной вероятности появления одного из событий в пределах выученного распределения. Следовательно, каждое семплированное действие-кандидат имеет равную вероятность на получение ожидаемого вознаграждения в окружающей среде. Наша цель получения максимальной доходности. Значит в условиях равной вероятности мы выбираем действие с максимальной ожидаемой доходностью.
Как вы понимаете, наши матрицы построчно скоррелированы. Мы ищем строку с максимальным ожидаемым вознаграждением в матрице values и выбираем действие из соответствующей строки матрицы actions.
vector<float> temp = values.Sum(1); temp = actions.Row(temp.ArgMax());
Выбранное действие осуществляется в окружающей среде.
//--- PrevBalance = sState.account[0]; PrevEquity = sState.account[1]; //--- double min_lot = Symb.LotsMin(); double step_lot = Symb.LotsStep(); double stops = MathMax(Symb.StopsLevel(), 1) * Symb.Point(); if(temp[0] >= temp[3]) { temp[0] -= temp[3]; temp[3] = 0; } else { temp[3] -= temp[0]; temp[0] = 0; } float delta = MathAbs(AgentResult - temp).Sum(); AgentResult = temp; //--- buy control if(temp[0] < min_lot || (temp[1] * MaxTP * Symb.Point()) <= stops || (temp[2] * MaxSL * Symb.Point()) <= stops) { if(buy_value > 0) CloseByDirection(POSITION_TYPE_BUY); } else { double buy_lot = min_lot + MathRound((double)(temp[0] - min_lot) / step_lot) * step_lot; double buy_tp = Symb.NormalizePrice(Symb.Ask() + temp[1] * MaxTP * Symb.Point()); double buy_sl = Symb.NormalizePrice(Symb.Ask() - temp[2] * MaxSL * Symb.Point()); if(buy_value > 0) TrailPosition(POSITION_TYPE_BUY, buy_sl, buy_tp); if(buy_value != buy_lot) { if(buy_value > buy_lot) ClosePartial(POSITION_TYPE_BUY, buy_value - buy_lot); else Trade.Buy(buy_lot - buy_value, Symb.Name(), Symb.Ask(), buy_sl, buy_tp); } } //--- sell control if(temp[3] < min_lot || (temp[4] * MaxTP * Symb.Point()) <= stops || (temp[5] * MaxSL * Symb.Point()) <= stops) { if(sell_value > 0) CloseByDirection(POSITION_TYPE_SELL); } else { double sell_lot = min_lot + MathRound((double)(temp[3] - min_lot) / step_lot) * step_lot;; double sell_tp = Symb.NormalizePrice(Symb.Bid() - temp[4] * MaxTP * Symb.Point()); double sell_sl = Symb.NormalizePrice(Symb.Bid() + temp[5] * MaxSL * Symb.Point()); if(sell_value > 0) TrailPosition(POSITION_TYPE_SELL, sell_sl, sell_tp); if(sell_value != sell_lot) { if(sell_value > sell_lot) ClosePartial(POSITION_TYPE_SELL, sell_value - sell_lot); else Trade.Sell(sell_lot - sell_value, Symb.Name(), Symb.Bid(), sell_sl, sell_tp); } }
А результаты взаимодействия с окружающей средой собираются в ранее подготовленную структуру и сохраняются в буфер воспроизведения опыта.
//--- int shift = BarDescr * (NBarInPattern - 1); sState.rewards[0] = bState[shift]; sState.rewards[1] = bState[shift + 1] - 1.0f; if((buy_value + sell_value) == 0) sState.rewards[2] -= (float)(atr / PrevBalance); else sState.rewards[2] = 0; for(ulong i = 0; i < NActions; i++) sState.action[i] = AgentResult[i]; Latent.getResults(sState.latent); if(!Base.Add(sState)) ExpertRemove(); }
На этом мы завершаем наше знакомство с советником взаимодействия с окружающей средой и сбора данных для обучающей выборки. А с полным его кодом Вы можете ознакомиться во вложении. Там же можно найти полный код всех программ, используемых в статье. А мы переходим к работе над советником офлайн обучения моделей "...\SPLT\Study.mq5".
В методе инициализации советника мы сначала загружаем обучающую выборку. И обязательно контролируем процесс выполнения операций. Для офлайн обучения моделей это единственный источник данных и его отсутствие делает невозможным весь остальной процесс.
//+------------------------------------------------------------------+ //| Expert initialization function | //+------------------------------------------------------------------+ int OnInit() { //--- ResetLastError(); if(!LoadTotalBase()) { PrintFormat("Error of load study data: %d", GetLastError()); return INIT_FAILED; }
Далее мы пробуем загрузить предварительно обученные модели. И, при необходимости, создаем новые.
//--- load models float temp; if(!Agent.Load(FileName + "Act.nnw", temp, temp, temp, dtStudied, true) || !World.Load(FileName + "Wld.nnw", temp, temp, temp, dtStudied, true) || !Latent.Load(FileName + "Lat.nnw", temp, temp, temp, dtStudied, true)) { CArrayObj *agent = new CArrayObj(); CArrayObj *latent = new CArrayObj(); CArrayObj *world = new CArrayObj(); if(!CreateDescriptions(agent, latent, world)) { delete agent; delete latent; delete world; return INIT_FAILED; } if(!Agent.Create(agent) || !World.Create(world) || !Latent.Create(latent)) { delete agent; delete latent; delete world; return INIT_FAILED; } delete agent; delete latent; delete world; //--- }
Как Вы могли заметить в алгоритме советника сбора обучающей выборки часто используется передача данных между обучаемыми моделями. В процессе обучения объем передаваемых данных увеличивается, ведь поток данных осуществляется в двух направлениях: прямой и обратный проходы. С целью исключения излишних операций копирования данных между контекстом OpenCL и основной памятью мы перенесем все модели в единый контекст OpenCL.
COpenCL *opcl = Agent.GetOpenCL(); Latent.SetOpenCL(opcl); World.SetOpenCL(opcl);
Далее мы проверяем соответствие архитектуры обучаемых моделей.
Agent.getResults(Result); if(Result.Total() != NActions) { PrintFormat("The scope of the Agent does not match the actions count (%d <> %d)", 6, Result.Total()); return INIT_FAILED; } //--- Latent.GetLayerOutput(0, Result); if(Result.Total() != (BarDescr * NBarInPattern + AccountDescr + TimeDescription + NActions)) { PrintFormat("Input size of Latent model doesn't match state description (%d <> %d)", Result.Total(), (BarDescr * NBarInPattern + AccountDescr + TimeDescription + NActions)); return INIT_FAILED; } Latent.Clear();
После успешного прохождения всех контролей генерируем событие начала обучения моделей и завершаем работу метода инициализации советника.
//--- if(!EventChartCustom(ChartID(), 1, 0, 0, "Init")) { PrintFormat("Error of create study event: %d", GetLastError()); return INIT_FAILED; } //--- return(INIT_SUCCEEDED); }
Непосредственно процесс обучения моделей организован в методе Train. В теле метода мы определяем количество траекторий в буфере воспроизведения опыта и фиксируем в локальной переменной время начала процесса обучения. Оно нам послужит ориентиром для периодического информирования пользователя о ходе процесса обучения моделей.
//+------------------------------------------------------------------+ //| Train function | //+------------------------------------------------------------------+ void Train(void) { int total_tr = ArraySize(Buffer); uint ticks = GetTickCount();
Напомню, что в наших моделях используется архитектура GPT, которая чувствительна к последовательности исходных данных. Как и ранее в подобных случаях, для обучения моделей мы будем использовать систему вложенных циклов. Во внешнем цикле мы семплируем траекторию из буфера воспроизведения опыта и начальное состояние окружающей среды.
bool StopFlag = false; for(int iter = 0; (iter < Iterations && !IsStopped() && !StopFlag); iter ++) { int tr = (int)((MathRand() / 32767.0) * (total_tr - 1)); int i = (int)((MathRand() * MathRand() / MathPow(32767, 2)) * MathMax(Buffer[tr].Total - 2 * HistoryBars,MathMin(Buffer[tr].Total,20))); if(i < 0) { iter--; continue; }
Затем инициализируем буферы моделей и создаем вложенный цикл, в котором последовательно подаем на вход модели отдельный фрагмент исторических данных.
Actions = vector<float>::Zeros(NActions); Latent.Clear(); for(int state = i; state < MathMin(Buffer[tr].Total - 2,i + HistoryBars * 3); state++) {
В теле вложенного цикла операции могут отчасти напомнить сбор обучающих данных. Мы так же заполняем буфер исходных данных. Только теперь мы данные не запрашиваем из окружающей среды, а извлекаем из буфера воспроизведения опыта. При этом строго соблюдаем последовательность записи данных. Первыми в буфер исходных данных мы вносим информацию о ценовом движении и показателях анализируемых индикаторов.
//--- History data
State.AssignArray(Buffer[tr].States[state].state);
Затем идут данные о состоянии счета и открытых позициях.
//--- Account description float PrevBalance = (state == 0 ? Buffer[tr].States[state].account[0] : Buffer[tr].States[state - 1].account[0]); float PrevEquity = (state == 0 ? Buffer[tr].States[state].account[1] : Buffer[tr].States[state - 1].account[1]); State.Add((Buffer[tr].States[state].account[0] - PrevBalance) / PrevBalance); State.Add(Buffer[tr].States[state].account[1] / PrevBalance); State.Add((Buffer[tr].States[state].account[1] - PrevEquity) / PrevEquity); State.Add(Buffer[tr].States[state].account[2]); State.Add(Buffer[tr].States[state].account[3]); State.Add(Buffer[tr].States[state].account[4] / PrevBalance); State.Add(Buffer[tr].States[state].account[5] / PrevBalance); State.Add(Buffer[tr].States[state].account[6] / PrevBalance);
Которые идентифицируются временной меткой.
//--- Time label double x = (double)Buffer[tr].States[state].account[7] / (double)(D'2024.01.01' - D'2023.01.01'); State.Add((float)MathSin(2.0 * M_PI * x)); x = (double)Buffer[tr].States[state].account[7] / (double)PeriodSeconds(PERIOD_MN1); State.Add((float)MathCos(2.0 * M_PI * x)); x = (double)Buffer[tr].States[state].account[7] / (double)PeriodSeconds(PERIOD_W1); State.Add((float)MathSin(2.0 * M_PI * x)); x = (double)Buffer[tr].States[state].account[7] / (double)PeriodSeconds(PERIOD_D1); State.Add((float)MathSin(2.0 * M_PI * x));
И конечно указываем действия Агента, которые привели нас в это состояние.
//--- Prev action
State.AddArray(Actions);
Ещё раз хочу акцентировать внимание на строгом соблюдении последовательности. Дело в том, что данные в буфере не именованные. Модель оценивает данные в соответствии с их положением в буфере. Изменение последовательности воспринимается моделью как абсолютно другое состояние. Результат принятия решения будет абсолютно другим и не предсказуемым. Поэтому, чтобы не путать модель и всегда получать адекватные решения нам необходимо четко соблюдать последовательность данных на всех этапах обучения и эксплуатации модели.
После сбора буфера исходных данных мы сначала осуществляем прямой проход Энкодера и модели окружающей среды.
//--- Latent and Wordl if(!Latent.feedForward(GetPointer(State)) || !World.feedForward(GetPointer(Latent), -1, GetPointer(Latent), LatentLayer)) { PrintFormat("%s -> %d", __FUNCTION__, __LINE__); StopFlag = true; break; }
Обратите внимание, что в процессе обучения мы не генерируем действия-кандидаты. Более того, обучение модели окружающей среды и политики Актера осуществляется отдельно. Это связано со спецификой обучения моделей.
Модель окружающей среды обучается оценивать политику Агента по предыдущей траектории и спрогнозировать получение вознаграждения в будущем с учетом текущего состояния окружающей среды и используемой политики. Одновременно мы корректируем распределение латентного представления. Для этого после успешного прямого прохода мы осуществляем обратный проход модели окружающей среды и энкодера, направленный на минимизацию ошибки прогнозов модели окружающей среды и фактическим вознаграждением из буфера воспроизведения опыта.
Actions.Assign(Buffer[tr].States[state].rewards); vector<float> result; World.getResults(result); Result.AssignArray(CAGrad(Actions - result) + result); if(!World.backProp(Result,GetPointer(Latent),LatentLayer) || !Latent.backPropGradient((CBufferFloat *)NULL,(CBufferFloat *)NULL,LatentLayer) || !Latent.backPropGradient((CBufferFloat *)NULL,(CBufferFloat *)NULL)) { PrintFormat("%s -> %d", __FUNCTION__, __LINE__); StopFlag = true; break; }
Обратите внимание, что после обратного прохода модели окружающей среды мы сначала осуществляем частичный обратный проход Энкодера для оптимизации параметров Эмбединга под требования модели окружающей среды. А затем осуществляем полный обратный проход Энкодера, в ходе которого оптимизируется распределение латентного представления.
Политику Актера мы оптимизируем для сопоставления латентного состояния и выполняемого действия. Поэтому мы извлекаем из буфера воспроизведения опыта распределение латентного представления и подаем его на вход модели окружающей среды для повторного семплирования латентного представления. И осуществляем прямой проход моделей окружающей среды и Актера.
//--- Policy Feed Forward Result.AssignArray(Buffer[tr].States[state+1].latent); Latent.GetLayerOutput(LatentLayer,Result2); if(Result2.GetIndex()>=0) Result2.BufferWrite(); if(!World.feedForward(Result, 1, false, Result2) || !Agent.feedForward(GetPointer(World),2,(CBufferFloat *)NULL)) { PrintFormat("%s -> %d", __FUNCTION__, __LINE__); StopFlag = true; break; }
После чего осуществляем обратный проход Актера для минимизации ошибки между прогнозным действием и фактически выполненным из буфера воспроизведения опыта.
//--- Policy study Actions.Assign(Buffer[tr].States[state].action); Agent.getResults(result); Result.AssignArray(CAGrad(Actions - result) + result); if(!Agent.backProp(Result,NULL,NULL)) { PrintFormat("%s -> %d", __FUNCTION__, __LINE__); StopFlag = true; break; }
Таким образом, мы обучаем политику Актера и делаем её более предсказуемой. Одновременно мы обучаем модель окружающей среды оценивать предшествующие траектории для понимания возможности извлечения прибыли. Обучаем Энкодер дистиллировать входящие траектории для извлечения основной информации о трендах окружающей среды и текущей политики Актера.
Все это вместе позволяет создавать довольно интересные политики Актера с учетом стохастичности окружающей среды и вероятностей получения прибыли.
После успешного завершения операций обновления моделей мы информируем пользователя о ходе процесса обучения и переходим к следующей итерации нашей системы вложенных циклов.
if(GetTickCount() - ticks > 500) { string str = StringFormat("%-15s %5.2f%% -> Error %15.8f\n", "Agent", iter * 100.0 / (double)(Iterations), Agent.getRecentAverageError()); str += StringFormat("%-15s %5.2f%% -> Error %15.8f\n", "World", iter * 100.0 / (double)(Iterations), World.getRecentAverageError()); Comment(str); ticks = GetTickCount(); } } }
По завершении всех итераций системы циклов мы очищаем поле комментариев. Результаты обучения моделей выводим в журнал. И инициализируем процесс завершения работы советника.
Comment(""); //--- PrintFormat("%s -> %d -> %-15s %10.7f", __FUNCTION__, __LINE__, "Agent", Agent.getRecentAverageError()); PrintFormat("%s -> %d -> %-15s %10.7f", __FUNCTION__, __LINE__, "World", World.getRecentAverageError()); ExpertRemove(); //--- }
На этом мы завершаем рассмотрение советника обучения моделей нашей интерпретации метода SPLT-Transformer. А с полным кодом советника, как и всех программ, используемых в статье, Вы можете ознакомиться во вложении. Там же есть код советника тестирования моделей "...\SPLT\Test.mq5". Мы не будем останавливаться на рассмотрении его методов в данной статье. Структура советника повторяет рассмотренным ранее аналогичные советники из предыдущих статей. А особенности реализации представленного алгоритма в функции OnTick полностью повторяют реализацию аналогичного метода в советнике сбора данных для обучающей выборки. Предлагаю Вам самостоятельно ознакомиться с данным советником в прилагаемых файлах.
Мы переходим к следующему этапу — тестирования моделей на исторических данных в тестере стратегий MetaTrader 5.
3.Тестирование
Обучение моделей, как и ранее, осуществлялось на исторических данных за первые 7 месяцев инструмента EURUSD таймфрейм H1. Параметры всех индикаторов используются установленные по умолчанию без дополнительной их оптимизации.
Вначале мы запускаем советник сбора обучающей выборки в режиме медленной оптимизации тестера стратегий. Это позволяет нам параллельно собирать данные несколькими агентами тестирования. Тем самым мы увеличиваем количество траекторий в буфере воспроизведения опыта при минимизации затрат времени на сбор данных.
Рассмотренный алгоритм предполагает обучение моделей только офлайн. Поэтому для теста его производительности я предлагаю максимально увеличить буфер воспроизведения опыта и заполнить его разнообразными траекториями. Но стоит обратить внимание, что генерации действий-кандидатов довольно затратный процесс. И с ростом числа кандидатов растут и затраты на сбор данных.
После сбора данных я обучал модели без дополнительного сбора траекторий, как это делалось ранее. Обучение модели, как всегда, длительный процесс. Так как я не планировал дополнительный сбор траекторий, то увеличил количество траекторий и оставил компьютер на длительное обучение.
Далее обученная модель была протестирована на исторических данных за Август 2023, которые не входили в обучающую выборку.
Должен сказать, что по результатам тестирования модель показала небольшую прибыль и довольно аккуратную торговлю. Напомню, что метод SPLT-Transformer был разработан для автономного вождения и предусматривает максимальное снижение рисков.
На графике тестирования мы видим тенденцию к росту баланса практически на протяжении всего месяца. Серия убыточных сделок наблюдается лишь на последней неделе месяца. Однако, накопленной ранее прибыли хватило на покрытие убытков. И в целом по итогам месяца была зафиксирована небольшая прибыль.


За весь период тестирования моделью было открыто всего 16 позиций с минимальным объемом. Доля прибыльных сделок составляет всего 37.5%. Однако средняя прибыльная сделка почти на 70% превышает средний убыток. Как следствие, по результатам теста зафиксирован профит-фактор на уровне 1.02.
Заключение
В данной статье мы представили SPLT-Transformer — инновационный метод, который был разработан для решения проблем в офлайн обучении с подкреплением, связанных с оптимистичным поведением Агента. С помощью двух отдельных моделей, представляющих политику и модель мира достигается построение надежных и эффективных политик Агента.
Основные компоненты SPLT-Transformer, включая алгоритм генерации траекторий-канддидатов, позволяют моделировать разнообразные сценарии и принимать решения с учетом множества возможных будущих исходов. Это делает представленный метод высоко адаптивным и безопасным в различных стохастических средах. Авторы метода предоставили результаты экспериментов в области автономного вождения, подтверждают превосходную производительность SPLT-Transformer в сравнении с существующими методами.
В практической части статьи мы создали свою, немного упрощенную интерпретацию рассмотренного метода. Мы обучили и протестировали полученные модели. Результаты тестов продемонстрировали, что модель способна демонстрировать как осторожное, так и оптимистичное поведение в зависимости от ситуации. Это делает ее идеальным выбором для критически важных систем.
В целом, метод заслуживает на его дальнейшую проработку. Более тщательное обучение моделей по моему мнению способно дать более высокие результаты.
И ещё раз напоминаю, что все программы, представленные в данной серии статей, создавались только для демонстрации и тестирования рассматриваемых алгоритмов. И не пригодны для использования в торговле на реальных счетах. Перед использованием той или иной модели в реальной торговли рекомендуется провести её тщательное обучение с последующим всесторонним тестирование.
Ссылки
- Addressing Optimism Bias in Sequence Modeling for Reinforcement Learning
- Нейросети — это просто (Часть 58): Трансформер решений (Decision Transformer—DT)
- Нейросети — это просто (Часть 59): Дихотомия контроля (Dichotomy of Control — DoC)
- Нейросети — это просто (Часть 60): Онлайн Трансформер решений (Online Decision Transformer—ODT)
Программы, используемые в статье
| # | Имя | Тип | Описание |
|---|---|---|---|
| 1 | Research.mq5 | Советник | Советник сбора примеров |
| 2 | Study.mq5 | Советник | Советник обучения агента |
| 3 | Test.mq5 | Советник | Советник для тестирования модели |
| 4 | Trajectory.mqh | Библиотека класса | Структура описания состояния системы |
| 5 | NeuroNet.mqh | Библиотека класса | Библиотека классов для создания нейронной сети |
| 6 | NeuroNet.cl | Библиотека | Библиотека кода программы OpenCL |
 Эксперименты с нейросетями (Часть 7): Передаем индикаторы
Эксперименты с нейросетями (Часть 7): Передаем индикаторы
- Бесплатные приложения для трейдинга
- 8 000+ сигналов для копирования
- Экономические новости для анализа финансовых рынков
Вы принимаете политику сайта и условия использования
Нейросети — это просто (Часть 61)
61 часть, результат можно увидеть в денежном эквиваленте?
Нейросети — это просто (Часть 61)
61 часть, результат можно увидеть в денежном эквиваленте?
Нужно сказать большое спасибо автору, который берет сугубо теоретическую статью и популярным языком объясняет, как это можно:
Посмотрите на оригинал статьи и оцените сами, какой труд проделал Дмитрий - https://arxiv.org/abs/2207.10295