トレーディングにおける機械学習:理論、モデル、実践、アルゴトレーディング - ページ 1258 1...125112521253125412551256125712581259126012611262126312641265...3399 新しいコメント Maxim Dmitrievsky 2019.01.16 14:41 #12571 エリブラリウス数式が多い((さて ) Rパッケージへのリンクがあります。私自身はRを使っていないので、数式は理解しています。 Rをお使いの方はお試しください ) Forester 2019.01.16 15:09 #12572 マキシム・ドミトリエフスキーさて ) Rパッケージへのリンクがあります。私自身はRを使っていないので、数式は理解しています。 Rをお使いの方はお試しください )今朝の記事はまだ開いています:https://towardsdatascience.com/bayesian-additive-regression-trees-paper-summary-9da19708fa71 最も残念な事実は、このアルゴリズムのPython実装が見つからなかったことです。著者らはRパッケージ(BayesTrees)を作成したが、いくつかの明らかな問題点-主に「予測」関数の欠如-があり、bartMachineという 別の、より広く使われている実装が作成された。このテクニックを実装した経験のある方、またはPythonのライブラリをご存知の方は、コメントにリンクを残してくださいだから、ファーストパッケージは予測できないから意味がない。 2つ目のリンク先には、再び数式が掲載されています。 ここでは、わかりやすい普通の木を紹介します。すべてがシンプルでロジカルです。しかも数式なしで。 Forester 2019.01.16 16:09 #12573 マキシム・ドミトリエフスキーおそらく、まだリブには手をつけていないのでしょう。木は巨大なベイズのトピックの特殊なケースに過ぎない。例えば、本やビデオの例はここにたくさんある Vladimirの論文に従って、NSのハイパーパラメータのベイズ最適化を行いました。よく効くんですよ。 でも、最適化する変数が多いと、ああも長くなってしまうんです。 マキシム・ドミトリエフスキー 何の木と同じように...ベイジアンニューラルネットワークがあります。 意外と知らない!? NSは、数学演算の+と*を使い、MAからデジタルフィルタまで、あらゆる指標を自身の内部で構築することができます。 しかし、木は単純なif(x<v){左の枝}else{右の枝}で右と左に分かれるのです。 それともif(x<v){左の枝}else{右の枝}でもいいのでしょうか? Maxim Dmitrievsky 2019.01.16 16:16 #12574 エリブラリウス でも、最適化する変数が多いと、ウンザリするんですよね。 意外と知らない!? NSは、数学演算の+と*を使用し、MAからデジタルフィルタまで、あらゆるインジケータを内部で構築することができます。 木は単純なif(x<v){左の枝}else{右の枝}で左右に分かれる。 それともベイジアンNSもif(x<v){left branch}else{right branch}なのでしょうか?そうですね、遅いので、今までの有用な知識から引っ張ってきて、いくつかのことを理解することができます。 いや、ベイジアンNSでは、分布から重みをサンプリングして最適化するだけで、出力も選択肢をたくさん含むが、平均や分散などを持つ分布になるのです。つまり、実際にはトレーニングデータセットに存在しないが、先験的に想定されている多くの変種を捕らえることができるのです。このようなNSは、サンプル数が多ければ多いほど、通常のNSに収束していく。つまり、ベイズアプローチは、あまり大きくないデータセットに対して最初に用いられる。これが今のところ分かっていることです。 つまり、このようなNSは、あまり大きなデータセットを必要とせず、結果は従来のものに収束する。しかし、学習後の出力は点推定ではなく、各サンプルの確率分布となる。 Кеша Рутов 2019.01.16 16:25 #12575 マキシム・ドミトリエフスキー遅いからこそ、今のところ役に立つ知識を引き出して、いくつかのことを理解することができます。 いや、ベイジアンNSでは、分布から重みをサンプリングして最適化するだけで、出力も選択肢をたくさん含むが、平均や分散などを持つ分布になるのです。つまり、実際にはトレーニングデータセットに存在しないが、先験的に想定されている多くの変種を捕らえることができるのです。このようなNSは、サンプル数が多ければ多いほど、通常のNSに収束していく。つまり、ベイズアプローチは、あまり大きくないデータセットに対して最初に用いられる。これが今のところ分かっていることです。 つまり、このようなNSは、あまり大きなデータセットを必要とせず、結果は従来のものに収束する。しかし、学習後の出力は点推定ではなく、各サンプルの確率分布となる。まるでスピードのように走り回り、一つずつ、また一つ......と、無駄なことを繰り返している。 自由な時間がたっぷりあるようですが、どこかの紳士のように、ニューラルネットワークから基本を急がず、仕事、キャリアアップに励んでください。 信じてください、普通の証券会社では、科学的な言葉や記事には誰もお金をくれません、世界のプライムブローカーによって確認された株式だけです。 Кеша Рутов 2019.01.16 16:31 #12576 マキシム・ドミトリエフスキー焦らず、シンプルなものから複雑なものまで一貫して勉強している 仕事がなければ、例えばmqlで何かを書き換えるというようなことを提案することもできます。私も皆と同じように大家のために働いている、働かないのはおかしい、自分も大家、跡取り、金づる、普通の男なら路上で3ヶ月で職を失えば半年で死んでしまうのだ。 Кеша Рутов 2019.01.16 16:34 #12577 マキシム・ドミトリエフスキートレーディングのMOについて全く何もないなら、散歩でもしてろ、ここにいるのは乞食だけだと思うだろうが)私はIRでそれらをすべて示した、正直に、子供じみた秘密、でたらめ、テストの誤差は10〜15%ですが、市場は常に変化している、貿易は行っていない、ゼロに近いチャタリングを行います。 Кеша Рутов 2019.01.16 16:36 #12578 マキシム・ドミトリエフスキー要するに、消えろ、ヴァシャ、泣き言には興味ないんだよ泣き言ばかりで結果が出ない、水面にフォークを掘って終わり、でも時間の無駄を認める勇気はない 軍隊に入るか、せめて建設現場で男と肉体労働すれば、人格が向上するはずだ。 Forester 2019.01.16 16:39 #12579 マキシム・ドミトリエフスキー: そうですね、遅いので、今までの有用な知識から引っ張ってきて、いくつかのことを理解することができます。いや、ベイジアンNSでは、分布から重みをサンプリングして最適化するだけで、出力も選択肢をたくさん含むが、平均や分散などを持つ分布になるのです。つまり、実際にはトレーニングデータセットに存在しないが、先験的に想定されている多くの変種を捕らえることができるのです。このようなNSは、サンプル数が多ければ多いほど、通常のNSに収束していく。つまり、ベイズアプローチは、あまり大きくないデータセットに対して最初に用いられる。これが今のところ分かっていることです。つまり、このようなNSでは、あまり大きなデータセットを必要とせず、結果は従来のものに収束するのである。 例のようなベイズ曲線を10ポイントずつ投影して、この曲線から100ポイントとか1000ポイントとか取って、それを使ってNS/フォレストを教えるようなことでしょうか。 ウラジミールのベイズ最適 化の記事へのコメント(https://www.mql5.com/ru/forum/226219)から、複数のポイントに渡ってカーブをプロットする方法を紹介します。でも、それならNSや森林も必要ない。この曲線の右にある答えを探せばいいんです。もう一つの問題は、オプティマイザーが学習を怠ると、NSに訳の分からないゴミを教えてしまうことだ。 ここでは3つの特徴量についてベイズの仕事 サンプルが教えられる Обсуждение статьи "Глубокие нейросети (Часть V). Байесовская оптимизация гиперпараметров DNN" 2018.01.31www.mql5.com Опубликована статья Глубокие нейросети (Часть V). Байесовская оптимизация гиперпараметров DNN: Автор: Vladimir Perervenko... Кеша Рутов 2019.01.16 16:42 #12580 マキシム・ドミトリエフスキースレにいるクズ共のせいで全く面白くない。 独り言のような愚痴をこぼしながら何を話すんだ?あなたは、新参者を感動させるために、リンクやさまざまな科学の抽象的なものを集めているだけです、SanSanychは彼の記事ですべてを書いており、追加することはあまりありません、今、別の売り手と記事ライターが恥ずかしさと嫌悪感で彼らの投石器ですべてを塗りつぶしました。彼らは自らを「数学者」と呼び、「量子」と呼ぶ・・・・・。 このhttp://www.kurims.kyoto-u.ac.jp/~motizuki/Inter-universal%20Teichmuller%20Theory%20I.pdf を読んでみる数学が欲しい。 そして、あなたは数学者ではなく、はみ出し者であることが理解できないでしょう。 1...125112521253125412551256125712581259126012611262126312641265...3399 新しいコメント 理由: キャンセル 取引の機会を逃しています。 無料取引アプリ 8千を超えるシグナルをコピー 金融ニュースで金融マーケットを探索 新規登録 ログイン スペースを含まないラテン文字 このメールにパスワードが送信されます エラーが発生しました Googleでログイン WebサイトポリシーおよびMQL5.COM利用規約に同意します。 新規登録 MQL5.com WebサイトへのログインにCookieの使用を許可します。 ログインするには、ブラウザで必要な設定を有効にしてください。 ログイン/パスワードをお忘れですか? Googleでログイン
数式が多い((
さて ) Rパッケージへのリンクがあります。私自身はRを使っていないので、数式は理解しています。
Rをお使いの方はお試しください )
さて ) Rパッケージへのリンクがあります。私自身はRを使っていないので、数式は理解しています。
Rをお使いの方はお試しください )
今朝の記事はまだ開いています:https://towardsdatascience.com/bayesian-additive-regression-trees-paper-summary-9da19708fa71
最も残念な事実は、このアルゴリズムのPython実装が見つからなかったことです。著者らはRパッケージ(BayesTrees)を作成したが、いくつかの明らかな問題点-主に「予測」関数の欠如-があり、bartMachineという 別の、より広く使われている実装が作成された。
このテクニックを実装した経験のある方、またはPythonのライブラリをご存知の方は、コメントにリンクを残してください
だから、ファーストパッケージは予測できないから意味がない。
2つ目のリンク先には、再び数式が掲載されています。
ここでは、わかりやすい普通の木を紹介します。すべてがシンプルでロジカルです。しかも数式なしで。
おそらく、まだリブには手をつけていないのでしょう。木は巨大なベイズのトピックの特殊なケースに過ぎない。例えば、本やビデオの例はここにたくさんある
Vladimirの論文に従って、NSのハイパーパラメータのベイズ最適化を行いました。よく効くんですよ。何の木と同じように...ベイジアンニューラルネットワークがあります。
意外と知らない!?
NSは、数学演算の+と*を使い、MAからデジタルフィルタまで、あらゆる指標を自身の内部で構築することができます。
しかし、木は単純なif(x<v){左の枝}else{右の枝}で右と左に分かれるのです。
それともif(x<v){左の枝}else{右の枝}でもいいのでしょうか?
でも、最適化する変数が多いと、ウンザリするんですよね。
意外と知らない!?
NSは、数学演算の+と*を使用し、MAからデジタルフィルタまで、あらゆるインジケータを内部で構築することができます。
木は単純なif(x<v){左の枝}else{右の枝}で左右に分かれる。
それともベイジアンNSもif(x<v){left branch}else{right branch}なのでしょうか?
そうですね、遅いので、今までの有用な知識から引っ張ってきて、いくつかのことを理解することができます。
いや、ベイジアンNSでは、分布から重みをサンプリングして最適化するだけで、出力も選択肢をたくさん含むが、平均や分散などを持つ分布になるのです。つまり、実際にはトレーニングデータセットに存在しないが、先験的に想定されている多くの変種を捕らえることができるのです。このようなNSは、サンプル数が多ければ多いほど、通常のNSに収束していく。つまり、ベイズアプローチは、あまり大きくないデータセットに対して最初に用いられる。これが今のところ分かっていることです。
つまり、このようなNSは、あまり大きなデータセットを必要とせず、結果は従来のものに収束する。しかし、学習後の出力は点推定ではなく、各サンプルの確率分布となる。
遅いからこそ、今のところ役に立つ知識を引き出して、いくつかのことを理解することができます。
いや、ベイジアンNSでは、分布から重みをサンプリングして最適化するだけで、出力も選択肢をたくさん含むが、平均や分散などを持つ分布になるのです。つまり、実際にはトレーニングデータセットに存在しないが、先験的に想定されている多くの変種を捕らえることができるのです。このようなNSは、サンプル数が多ければ多いほど、通常のNSに収束していく。つまり、ベイズアプローチは、あまり大きくないデータセットに対して最初に用いられる。これが今のところ分かっていることです。
つまり、このようなNSは、あまり大きなデータセットを必要とせず、結果は従来のものに収束する。しかし、学習後の出力は点推定ではなく、各サンプルの確率分布となる。
まるでスピードのように走り回り、一つずつ、また一つ......と、無駄なことを繰り返している。
自由な時間がたっぷりあるようですが、どこかの紳士のように、ニューラルネットワークから基本を急がず、仕事、キャリアアップに励んでください。
信じてください、普通の証券会社では、科学的な言葉や記事には誰もお金をくれません、世界のプライムブローカーによって確認された株式だけです。焦らず、シンプルなものから複雑なものまで一貫して勉強している
仕事がなければ、例えばmqlで何かを書き換えるというようなことを提案することもできます。
私も皆と同じように大家のために働いている、働かないのはおかしい、自分も大家、跡取り、金づる、普通の男なら路上で3ヶ月で職を失えば半年で死んでしまうのだ。
トレーディングのMOについて全く何もないなら、散歩でもしてろ、ここにいるのは乞食だけだと思うだろうが)
私はIRでそれらをすべて示した、正直に、子供じみた秘密、でたらめ、テストの誤差は10〜15%ですが、市場は常に変化している、貿易は行っていない、ゼロに近いチャタリングを行います。
要するに、消えろ、ヴァシャ、泣き言には興味ないんだよ
泣き言ばかりで結果が出ない、水面にフォークを掘って終わり、でも時間の無駄を認める勇気はない
軍隊に入るか、せめて建設現場で男と肉体労働すれば、人格が向上するはずだ。そうですね、遅いので、今までの有用な知識から引っ張ってきて、いくつかのことを理解することができます。
いや、ベイジアンNSでは、分布から重みをサンプリングして最適化するだけで、出力も選択肢をたくさん含むが、平均や分散などを持つ分布になるのです。つまり、実際にはトレーニングデータセットに存在しないが、先験的に想定されている多くの変種を捕らえることができるのです。このようなNSは、サンプル数が多ければ多いほど、通常のNSに収束していく。つまり、ベイズアプローチは、あまり大きくないデータセットに対して最初に用いられる。これが今のところ分かっていることです。
つまり、このようなNSでは、あまり大きなデータセットを必要とせず、結果は従来のものに収束するのである。
ウラジミールのベイズ最適 化の記事へのコメント(https://www.mql5.com/ru/forum/226219)から、複数のポイントに渡ってカーブをプロットする方法を紹介します。でも、それならNSや森林も必要ない。この曲線の右にある答えを探せばいいんです。
もう一つの問題は、オプティマイザーが学習を怠ると、NSに訳の分からないゴミを教えてしまうことだ。
 サンプルが教えられる
サンプルが教えられる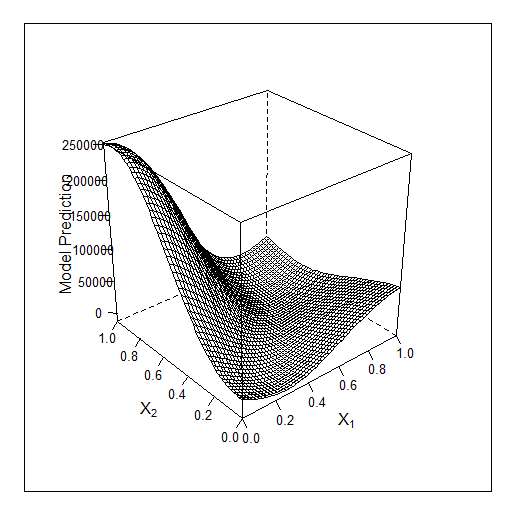
ここでは3つの特徴量についてベイズの仕事
スレにいるクズ共のせいで全く面白くない。
独り言のような愚痴をこぼしながら
何を話すんだ?あなたは、新参者を感動させるために、リンクやさまざまな科学の抽象的なものを集めているだけです、SanSanychは彼の記事ですべてを書いており、追加することはあまりありません、今、別の売り手と記事ライターが恥ずかしさと嫌悪感で彼らの投石器ですべてを塗りつぶしました。彼らは自らを「数学者」と呼び、「量子」と呼ぶ・・・・・。
このhttp://www.kurims.kyoto-u.ac.jp/~motizuki/Inter-universal%20Teichmuller%20Theory%20I.pdf を読んでみる数学が欲しい。
そして、あなたは数学者ではなく、はみ出し者であることが理解できないでしょう。