
Teoría de categorías en MQL5 (Parte 14): Funtores con orden lineal
Introducción
Según la definición de Samuel Eilenberg y Saunders MacLane en la década de 1950, la teoría de categorías puede verse como un medio para estudiar sistemas con énfasis en la transformación en cada fase, y no las fases en sí. Se utiliza en muchas áreas del conocimiento humano, incluida la programación funcional en lenguajes como Haskell; el estudio de la estructura y la composición de las lenguas naturales en lingüística; la topología algebraica (que proporciona un enfoque unificado para comprender diversas construcciones topológicas e invariantes) y mucho más.
En esta serie de artículos, la teoría de categorías hasta ahora se ha ocupado de la información y la estructura a nivel de subcategorías; en nuestro caso, de conjuntos (de objetos). Hemos examinado sus relaciones y propiedades dentro de la categoría.
El objetivo del presente artículo, y de varios otros similares en el futuro, será alejarse de las categorías y comenzar a analizar las relaciones que las diferentes categorías pueden tener entre sí. Formalmente, se llaman funtores. Así que vamos a ver las diferentes categorías y sus posibles relaciones. Existen varias categorías candidatas en el conjunto de datos de un tráder que vale la pena explorar. No obstante, para resaltar las cualidades sobresalientes de la teoría de categorías, iremos más allá de los conceptos habituales y en este artículo veremos la relación de los datos de mareas oceánicas frente a la costa de California con la volatilidad del índice NASDAQ. ¿Acaso hay algo en las mareas oceánicas que presagie volatilidad en este índice? Nuestra intención es responder esta pregunta hasta cierto punto al final del artículo.
El presente artículo, y varios otros similares en el futuro, no introducirán nuevos conceptos per se, sino que explorarán lo que ya hemos analizado y tratarán de aplicar el conocimiento existente de una forma distinta, tal vez a mayor escala.
Las mareas oceánicas y el índice NASDAQ
Los datos de mareas oceánicas son publicados por la Administración Nacional Oceánica y Atmosférica (NOAA) en su sitio web. Los datos registran la altura de la marea del océano respecto a un punto de referencia cuatro veces al día. La hora y la altura de la marea en un momento dado es todo lo que se registra cada día durante todo el año. A continuación le ofrecemos un ejemplo:

Todos los océanos están divididos en cuatro regiones, con valores de marea recopilados de muchas estaciones de medición en cada región. Por ejemplo, en la costa oeste de América del Norte y del Sur, desde Alaska hasta Chile, existen 33 estaciones. En nuestro análisis, usaremos los datos recopilados en la estación de Monterrey en California para 2020.
NASDAQ es en esencia una bolsa de valores estadounidense, pero aquí lo consideramos principalmente como un índice que consta de un número bastante grande de empresas de alta tecnología como MSFT, AAPL, GOOG y AMZN, cuya sede se encuentra en California. Este índice puede ser negociado por la mayoría de los brókeres, por lo que su cotización informará a nuestra categoría al comprobar si el valor de mercado de estas empresas -que han revolucionado diversos sectores y ejemplifican el espíritu innovador de California- guarda alguna relación con los datos de las mareas oceánicas recogidos en sus costas.
Mapeo de datos utilizando los funtores de la teoría de categorías
Hasta ahora no hemos hablado explícitamente de los funtores en esta serie, pero los artículos en los que analizamos monoides, grupos de monoides, gráficos y órdenes implicaban que estábamos tratando con funtores, ya que cada uno de estos conceptos puede considerarse una categoría, y sus relaciones suponían a menudo la base de artículos. Por ejemplo, los morfismos entre monoides, de facto, eran funtores.
Formalmente, un funtor supone un mapeo de categorías que preserva su estructura y relaciones definidas por los objetos y sus morfismos dentro de cada categoría. Si C y D son categorías, entonces el funtor F de C a D
Consta de dos cosas, a saber: por cada objeto c en C hay un objeto asociado F(c) en D y por cada dos objetos en b, c en C con un morfismo f.
![]()
existe un morfismo asociado F(f)
en D. Los funtores también tienen axiomas adicionales para preservar el significado de la composición, si tenemos morfismos
![]()
y
en C, entonces F conserva una composición en C tal que
y los morfismos de identidad en C se conservan para cada objeto mapeable en D, de forma que si
entonces
La importancia de relacionar las distintas categorías radica en el descubrimiento. Para cada sistema clasificado como una categoría, con frecuencia no existe manera predeterminada no solo de traducir una categoría a otra, sino también de establecer la "posición relativa" y tal vez la importancia de cada categoría en un contexto más amplio. Esta es la razón por la que los funtores pueden, por ejemplo, hacer coincidir una categoría de valores negociables con su propio portafolio de morfismos ponderados con otra categoría de estrategias comerciales. El beneficio de un funtor de este tipo para los tráders puede estar relacionado con la perspectiva, pero si el funtor mapea con un cierto retraso temporal, podremos establecer qué estrategias utilizar según nuestros valores en la cartera o qué valores mantener como siguientes en función de nuestra estrategia actual, por ejemplo.
Recordemos que el orden lineal u orden completo, además de cumplir con los axiomas de transitividad y reflexividad, también cumple con los requisitos de antisimetría y comparabilidad. Normalmente, esto significa que todos los datos en orden lineal deben ser numéricos o, si son de texto, discretos, de forma que la operación binaria "<=" pueda aplicarse sin ambigüedad ni producir un resultado indefinido. Los datos de las mareas oceánicas presentados en el sitio web de la NOAA son multidimensionales cuando tomamos un día como un único punto de datos. Tienen 4 entradas de fecha y hora para cada altitud, 4 valores de altitud de punto flotante y una entrada de fecha y hora para el día. Si usamos nuestro orden lineal para comparar el valor de fecha y hora del día para cada punto de datos, entonces los datos de las mareas se convertirán en una serie temporal simple con dos datos en cada punto: la fecha como fecha y la hora y la altura de la marea como datos de punto flotante.
Representar este orden lineal como una categoría significaría que la operación binaria entre dos puntos de datos consecutivos se convierte en un morfismo, y cada punto de datos se convierte en un objeto que contiene 4 datos, 4 fechas y horas de registro de la altura y 4 valores de altura, si tuviéramos que agrupar estos datos por día, ya que los valores de marea se han registrado diariamente. No obstante, necesitaremos normalizar un poco más estos datos ya que no todos los días tienen 4 puntos de datos. Algunos tienen solo 3. Como nuestra categoría tendrá relaciones isomórficas, resulta importante que seamos consistentes en el número de elementos en cada dominio (día).
La categoría de volatilidad del NASDAQ seguirá el mismo principio que las mareas oceánicas en el sentido de que estaremos asociando puntos de datos de precio según la secuencia en el tiempo como morfismos.
Evaluación comparativa e ideas
Si mapeamos nuestra categoría de marea con la categoría del índice NASDAQ, tendríamos que hacerlo con un desfase temporal para obtener algún beneficio predictivo de ella. Pero primero necesitaremos crear un ejemplar de la categoría de clase de mareas oceánicas, y esto se puede representar de la siguiente manera:
protected:
...
CCategory _category_ocean,_category_nasdaq;
CDomain<string> _domain_ocean,_domain_nasdaq;
CHomomorphism<string,string> _hmorph_ocean,_hmorph_nasdaq; Como estamos interesados en utilizar este funtor para realizar pronósticos, nuestra categoría será dinámica ya que se redefinirá en cada nueva barra, pero el funtor desde ella hasta la categoría NASDAQ será constante. Por lo tanto, dado que nuestro retraso es de un día, los tres morfismos anteriores que relacionan las alturas del océano registradas se podrán determinar leyendo los datos de las mareas del océano desde un archivo csv de la forma que sigue:
void CTrailingCT::SetOcean(int Index)
{
...
if(_handle!=INVALID_HANDLE)
{
...
while(!FileIsLineEnding(_handle))
{
...
if(_date>_data_time)
{
_category_ocean.SetDomain(_category_ocean.Domains(),_domain_ocean);
break;
}
else if(__DATETIME.day_of_week!=6 && __DATETIME.day_of_week!=0 && datetime(int(_data_time)-int(_date))<=PeriodSeconds(PERIOD_D1))//_date<=_data_time && datetime(int(_data_time)-(1*PeriodSeconds(PERIOD_D1)))<=_date)
{
_element_value.Let();_element_value.Cardinality(1);_element_value.Set(0,DoubleToString(_value));
_domain_ocean.Cardinality(_elements);_domain_ocean.Set(_elements-1,_element_value);
_elements++;
}
}
FileClose(_handle);
}
else
{
printf(__FUNCSIG__+" failed to load file. Err: "+IntegerToString(GetLastError()));
}
} De manera similar, construiremos nuestro conjunto de volatilidad del NASDAQ usando la siguiente lista:
void CTrailingCT::SetNasdaq(int Index)
{
m_high.Refresh(-1);
m_low.Refresh(-1);
_value=0.0;
_value=(m_high.GetData(Index+StartIndex()+m_high.MaxIndex(Index,_category_ocean.Homomorphisms()))-m_low.GetData(Index+StartIndex()+m_low.MinIndex(Index,_category_ocean.Homomorphisms())))/m_symbol.Point();
_element_value.Let();_element_value.Cardinality(1);_element_value.Set(0,DoubleToString(_value));
_domain_nasdaq.Cardinality(1);_domain_nasdaq.Set(0,_element_value);
_category_nasdaq.SetDomain(_category_nasdaq.Domains(),_domain_nasdaq);
} Sus morfismos también se compilan de forma muy similar. Ahora el funtor, como ya hemos señalado en la definición, reflejará no solo objetos de dos categorías, sino también morfismos. Y esto implica que uno controlará al otro. Si comenzamos mostrando un objeto, parte de nuestro funtor para los datos de las mareas oceánicas NASDAQ, se inicializará así:
double CTrailingCT::GetOutput()
{
...
...
_domain.Init(3+1,3);
for(int r=0;r<4;r++)
{
CDomain<string> _d;_d.Let();
_category_ocean.GetDomain(_category_ocean.Domains()-r-1,_d);
for(int c=0;c<_d.Cardinality();c++)
{
CElement<string> _e; _d.Get(c,_e);
string _s; _e.Get(0,_s);
_domain[r][c]=StringToDouble(_s);
}
}
_codomain.Init(3);
for(int r=0;r<3;r++)
{
CDomain<string> _d;
_category_nasdaq.GetDomain(_category_nasdaq.Domains()-r-1,_d);
CElement<string> _e; _d.Get(0,_e);
string _s; _e.Get(0,_s);
_codomain[r]=StringToDouble(_s);
}
_inputs.Init(3);_inputs.Fill(m_consant_morph);
M(_domain,_codomain,_inputs,_output,1);
return(_output);
} De manera similar, la construcción del funtor de morfismo tomará la forma siguiente:
double CTrailingCT::GetOutput()
{
...
...
_domain.Init(3+1,3);
for(int r=0;r<4;r++)
{
...
if(_category_ocean.Domains()-r-1-1>=0){ _category_ocean.GetDomain(_category_ocean.Domains()-r-1-1,_d_old); }
for(int c=0;c<_d_new.Cardinality();c++)
{
...
CElement<string> _e_old; _d_old.Get(c,_e_old);
string _s_old; _e_old.Get(0,_s_old);
_domain[r][c]=StringToDouble(_s_new)-StringToDouble(_s_old);
}
}
_codomain.Init(3);
for(int r=0;r<3;r++)
{
...
if(_category_nasdaq.Domains()-r-1-1>=0){ _category_nasdaq.GetDomain(_category_nasdaq.Domains()-r-1-1,_d_old); }
...
CElement<string> _e_old; _d_old.Get(0,_e_old);
string _s_old; _e_old.Get(0,_s_old);
_codomain[r]=StringToDouble(_s_new)-StringToDouble(_s_old);
}
_inputs.Init(3);_inputs.Fill(m_consant_morph);
M(_domain,_codomain,_inputs,_output,1);
return(_output);
} La parte principal del trabajo aquí consiste en poner los datos de las mareas oceánicas a disposición de MQL5. Para lograr esto, accederemos a los datos desde un archivo csv en una carpeta de datos compartida en formato tabular, que será similar a nuestro elemento en la categoría de mareas oceánicas. El formato de datos incluye un campo de fecha y hora para realizar la sincronización con la hora de nuestro servidor comercial al seleccionarse los valores correctos. En MQL5 IDE existen otras alternativas para acceder a estos datos secundarios, y una de ellas es a través de la base de datos, pues podemos crear nuestra propia conexión en IDE. Si tenemos una base de datos en nuestra computadora local o una conexión a la nube, podemos organizar el acceso. No obstante, para nuestro cometido, como queremos que los lectores reproduzcan fácilmente los resultados de las pruebas que publicamos aquí, utilizaremos un archivo csv en la carpeta pública.
Nuestro funtor coincide con dos elementos, lo cual significa que una conexión verificará la otra para evitar duplicaciones. Como al principio no sabemos cuál de estas configuraciones resultará ideal para nuestro sistema comercial, probaremos ambas.
Entonces, en la primera configuración, tendremos un funtor de objetos que confirmará o comprobará los morfismos entre objetos en el codominio (el conjunto NASDAQ). Esquemáticamente, lo podemos representar de la siguiente manera:
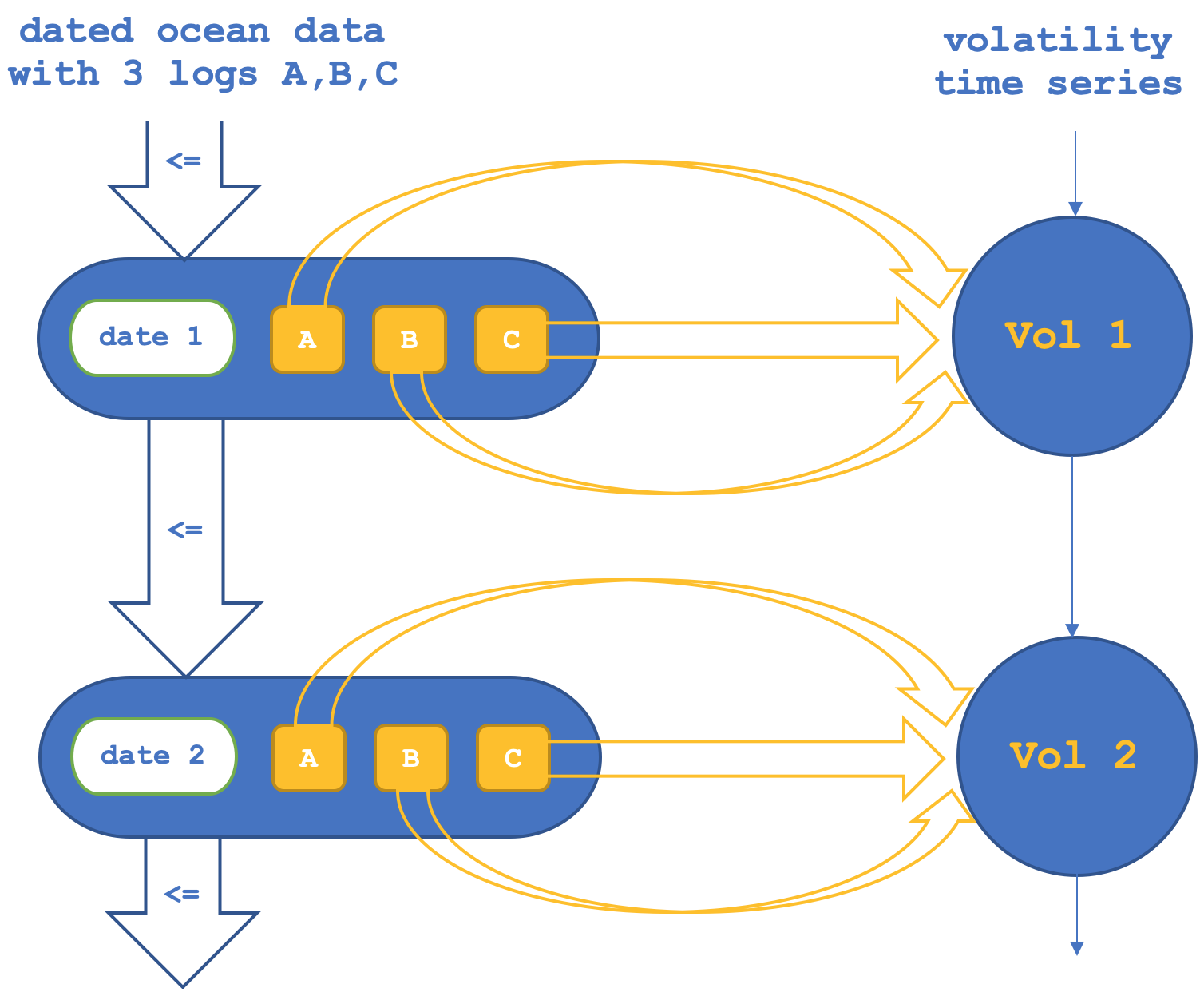
Si ejecutamos pruebas para intentar predecir la volatilidad del NASDAQ basándonos únicamente en funtores de objetos, obtendremos informes como el que sigue (el código necesario se adjunta como archivo TraillingCT_14_1a):

Si, como hemos mencionado, trabajamos hacia atrás y nos enfocamos en los funtores de morfismo; luego validaremos los objetos, cosa que se puede representar de la siguiente manera:
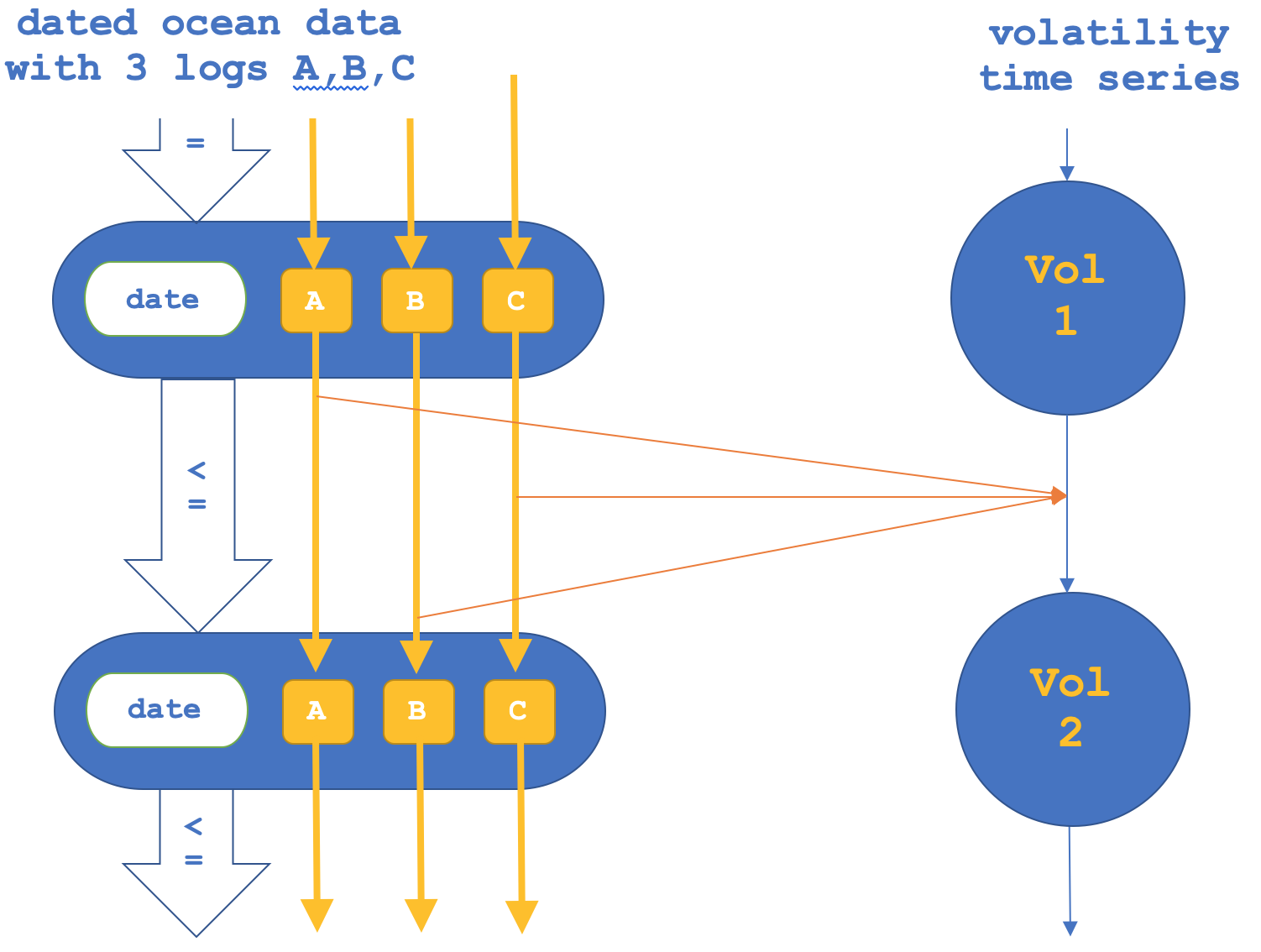
El informe del simulador solo para funtores de morfismo se muestra a continuación:

Nuestras dos opciones de prueba descritas anteriormente, el mapeo de objetos y el mapeo de morfismos, han producido resultados diferentes incluso en una ventana de prueba muy corta que va desde el 1 de enero 2020 hasta el 15 de marzo del mismo año en el gráfico diario. ¿Cuál de las dos opciones resulta más útil para los tráders a la hora de hacer pronósticos de cualquier tipo, no solo pronósticos de volatilidad? Para responder a esta pregunta, deberemos realizar pruebas durante periodos de tiempo más largos sobre un aspecto específico del sistema comercial testado, ya sea una señal de entrada, la gestión de dinero o un trailing stop.
El periodo elegido para las pruebas, aunque muy corto, era realmente importante para el Nasdaq, ya que entonces el índice alcanzó su máximo histórico y luego, en el punto álgido de la pandemia, cayó de manera bastante pronunciada. Entonces, si bien esta prueba sugiere una posible correlación con los datos de las mareas oceánicas, ciertamente no implica ninguna causalidad.
Como ocurre con estas series, la señal de entrada que usamos es muy sencilla. En este caso, se trata del Awesome Oscillator incorporado con los ajustes por defecto del archivo de señal correspondiente. El tamaño de la posición también es fijo, como de costumbre. Hemos probado el NASDAQ en un intervalo diario porque los datos de nuestras categorías de dominio se han recopilado diariamente en tres intervalos. Así, en un formato de orden lineal equivalente a la categoría, cada día ha representado un dominio (objeto) con tres elementos. Como ya hemos mencionado, estos representan tres puntos de datos para cada día.
La conclusión principal aquí es que podemos examinar y probar conjuntos de datos dispares y aparentemente no relacionados para detectar relaciones retrasadas útiles que puedan ayudarnos a la hora de tomar decisiones comerciales. En nuestras pruebas el retraso ha sido de un día; en el caso del lector, puede ser más larga. En lugar de las mareas oceánicas, podríamos seleccionar posibles conjuntos de datos alternativos. Existen muchas opciones, pero podría ser útil compartir algunos ejemplos de conjuntos de datos que podrían reemplazar los datos de las mareas oceánicas utilizados anteriormente, lo que también proporcionaría una mejor comprensión del grado de interrelación de nuestros mercados y los sistemas exógenos.
Los conjuntos de datos alternativos podrían incluir los precios de los productos básicos; las noticias sobre tecnología, donde podemos rastrear el número de artículos sobre las nuevas tendencias tecnológicas, como la inteligencia artificial, en comparación con los artículos de noticias alternativas, como el entretenimiento, para detectar una posible correlación; los datos del sentimiento en las redes sociales sobre el tono de las publicaciones en las mismas, cuantificados desde un punto de vista lexicológico para determinar su relación con la volatilidad del NASDAQ (o cualquier valor comerciado), especialmente si está relacionado con acciones tecnológicas. Los ejemplos son bastante esotéricos, pero podemos considerar una variedad de datos más cercana a nuestro tema, como los precios de otros valores o los valores de sus indicadores.
Conclusión
Hoy hemos examinado cómo los datos en la categoría de formato de orden lineal se pueden relacionar usando un funtor con los precios de los valores. En este caso, nuestros datos de dominio han supuesto un conjunto improbable de datos sobre la altura de las mareas oceánicas tomados frente a la costa de California. Asimismo, hemos intentado relacionarlos con la volatilidad del NASDAQ con un retraso diario usando un funtor. Esta relación puede admitir dos formatos: de objetos a objetos o de morfismos a morfismos. En nuestras pruebas, que han incluido el uso de las mismas señales de entrada y métodos de dimensionamiento de posiciones, ambos formatos han producido resultados significativamente distintos dada la breve ventana de prueba.
Los funtores de la teoría de categorías pueden desempeñar un papel importante al hacer coincidir diferentes tipos de datos. Para este artículo, hemos usado un conjunto de datos bastante complejo para la clasificación y el mapeo, pero el lector puede encontrar mejores opciones: aunque estas no le ofrecerán necesariamente una ventaja, podrían ser útiles para realizar pruebas.
Las oportunidades futuras en la vinculación de órdenes lineales con conjuntos desde la perspectiva de los tráders podrían desarrollarse en varias direcciones: estas pueden incluir el pronóstico del tiempo, la integración de datos y gráficos en áreas como la inteligencia artificial, el aprendizaje automático y el aprendizaje por transferencia, en los que las órdenes lineales, que son funtores asociados con datos financieros, se pueden desarrollar aún más, como los pesos de los funtores, obtenidos entre las dos categorías. Dichas categorías podrían probarse o incluso aplicarse en diferentes campos, mejorando potencialmente los modelos de aprendizaje automático y su eficacia.
Existen muchas otras posibilidades, como el análisis estadístico y la fusión de datos, los estudios de correlación y inferencia aleatoria, la financiación cuantitativa con financiación algorítmica, la toma de decisiones basada en datos y mucho más. La aplicación que elijamos dependerá de nuestro punto de vista o enfoque comercial.
Animamos al lector a explorar esta área en función de su propia área de especialización y el enfoque de los mercados. Esta área temática tiene un gran potencial, incluido el análisis de datos interdisciplinarios.
Coloque los archivos TrailingCT_14_1a.mqh y TrailingCT_14_1b.mqh en la carpeta MQL5\include\Expert\Trailing\, el archivo ct_14_1s.mqh se puede colocar en la carpeta Include.
Quizá le resulten útiles las recomendaciones mostradas aquí sobre cómo crear un asesor utilizando el Wizard. Como indicamos en el artículo, hemos usado el Awesome Oscillator como señal de entrada y el margen fijo para la gestión del dinero. Ambos componentes forman parte de la biblioteca MQL5. Como siempre, en este artículo no pretendemos presentarle el Grial, sino ofrecerle una idea que pueda adaptar a su propia estrategia. Los archivos adjuntos se han compilado en el Wizard. Podrá compilarlos o crearlos por sí mismo.
Traducción del inglés realizada por MetaQuotes Ltd.
Artículo original: https://www.mql5.com/en/articles/13018
- Aplicaciones de trading gratuitas
- 8 000+ señales para copiar
- Noticias económicas para analizar los mercados financieros
Usted acepta la política del sitio web y las condiciones de uso