Teoría de categorías en MQL5 (Parte 12): Orden
Introducción
En el artículo anterior, analizamos los gráficos, vértices y flechas de un sistema interconectado en el marco de la teoría de categorías y exploramos cómo se pueden usar diferentes caminos con sus atributos para definir distintos métodos de trailing stop en un sistema comercial típico.
En este artículo veremos el orden dentro de la teoría de categorías y cómo puede complementar las configuraciones comerciales utilizando trailing stops. En pocas palabras, el orden tiene que ver con la clasificación de la "magnitud" de los diferentes elementos que normalmente se hallan en un conjunto, e implementa la idea de que los elementos de un conjunto determinado se pueden clasificar según varios criterios. La teoría de categorías añade una nueva dimensión a esta idea introduciendo el concepto de conjunto de conjuntos e incluso de conjunto de conjuntos de conjuntos, etc. Por lo tanto, en este artículo nos centraremos en los rangos de conjuntos (set ranks).
En particular, nos focalizaremos en los patrones en conjuntos ordenados como medio para generar salidas de transacciones. Existen bastantes conjuntos a considerar para nuestros objetivos, ya que la lista puede variar desde patrones de acción del precio hasta patrones de indicadores o incluso patrones comunes de índices de múltiples activos. Sin embargo, siguiendo los pasos del sistema de comercio básico que abarcamos en artículos anteriores, dividiremos los tres pasos internos entre el primer y el último paso de nuestro proceso de cinco pasos en subconjuntos para obtener nuestros conjuntos de patrones ordenados.
Comprendiendo el orden en la teoría de categorías
Según la relación de orden, existen tres tipos principales de orden: los pre-órdenes (pre-orders), los órdenes parciales (partial orders) y los órdenes lineales o totales (linear or total orders). El pre-orden es una clasificación de los elementos de un conjunto en la que cada elemento del conjunto se compara con todos los demás elementos (reflexividad), y los resultados de cada comparación tienen un significado lógico para la comparación de otros elementos (transitividad). El pre-orden tiene en cuenta la ambigüedad: si dos elementos cualesquiera tienen la misma magnitud según una operación binaria, ambos podrán incluirse en el conjunto de salida. Además, los conjuntos de órdenes anticipados consideran los resultados inciertos que surgen cuando dos elementos no se pueden comparar debido, por ejemplo, a una diferencia fundamental. El orden parcial es un tipo de pre-orden que introduce el concepto adicional de antisimetría. Esto significa que si la operación de comparación binaria encuentra que dos elementos cualesquiera tienen el mismo valor, entonces solo uno de ellos se incluirá en el conjunto de salida. Por lo tanto, se utiliza la definición de "parcial" porque solo se muestra uno de los elementos iguales. Finalmente, el orden lineal es una forma especializada de orden parcial en el que no hay resultados inciertos. Esto significa que todos los elementos son comparables. Al igual que con el pre-orden, algunos elementos pueden ser incomparables, lo que significa que la operación binaria producirá un resultado indefinido. Esto no se tiene en cuenta en el orden lineal.
Por tanto, formalmente para un conjunto S con una relación binaria R
R ⊆ S x S
R se considerará un pre-orden si para todos:
s, s', s” ∈ S
tenemos la reflexividad, que se representa formalmente como:
s ≦ s
así como la transitividad, que se implica de la forma siguiente:
s ≦ s' y s' ≦ s”, lo que significa s ≦ s”
El orden parcial, como hemos mencionado anteriormente, añade antisimetría al pre-orden, por lo que si:
s ≦ s' y s' ≦ s, entonces s = s',
lo cual implica que solo uno de s o s' está representado en la salida.
El orden lineal añadirá comparabilidad al orden parcial, de modo que para dos elementos cualesquiera exista una cierta relación:
s ≦ s' o s' ≦ s,
lo cual significa que los resultados no definidos no se tendrán en cuenta.
Como ya hemos mencionado, estos formatos de órdenes resultan útiles para indicar patrones que pueden ayudar a la toma de decisiones en cualquier sistema comercial. En este artículo, recrearemos los conjuntos de monoides intra-paso usados en artículos anteriores para el periodo de análisis retrospectivo, el precio aplicado y el indicador, manteniendo al mismo tiempo (para una mayor simpleza) los conjuntos finales del marco temporal y la acción comercial. Al igual que en el artículo anterior, el principal parámetro probado será el orden de toma de decisiones; sin embargo, como consideraremos un orden parcial, existe la posibilidad de resultados inciertos, y esto significará que nuestro orden de salida de los conjuntos de monoides que representan puntos de decisión puede ser inferior al orden de entrada 3, llegando incluso a 2 o 1. Esto significa que en determinadas situaciones es posible que solo tengamos que tomar 3 o 4 decisiones en lugar de las 5 predeterminadas al evaluar si debemos cambiar nuestro stop loss.
Aplicando la relación de orden en MQL5
En este artículo no consideraremos el pre-orden, ya que en este caso nos extenderíamos demasiado. En lugar de ello, nos centraremos en los órdenes parcial y lineal. Como ya tenemos las estructuras de datos que definen nuestros cinco pasos comerciales según el artículo anterior, lo principal que esperaremos de la implementación de la relación de orden serán funciones binarias que procesen nuestras estructuras de datos y generen un conjunto (generalmente un subconjunto de los datos de entrada). Dado que estamos considerando un orden lineal y parcial, cada uno de ellos tendrá su propia función.
Podría resultar útil resaltar las diferencias y ventajas relativas de las dos formas de orden que estamos considerando en este artículo. Como hemos mencionado antes, a diferencia del orden lineal, el orden parcial permite realizar una clasificación vaga de los resultados. Esto podría resultar útil en varios casos. Veamos un caso sencillo de clasificación de barras de precios en un gráfico como barras alcistas o bajistas. En este proceso, seguramente encontrará una vela Doji de pie largo que, estrictamente hablando, no es ni alcista ni bajista. Al clasificar un orden lineal, este dato debería omitirse porque no respetaría el axioma de comparabilidad.
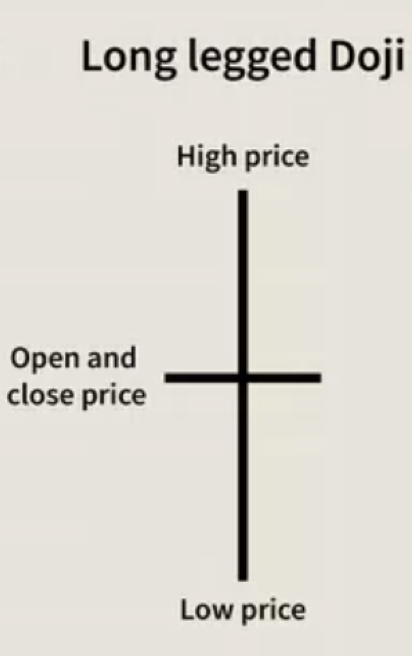
No obstante, en un orden parcial, incluir este punto de datos y, por lo tanto, su resultado hará que el conjunto de resultados sea el más completo y representativo del conjunto de datos. Para mostrar por qué esto es importante, las velas Doji de pie largo y otras velas similares, incluidas Gravestone Doji y Dragonfly Doji, tienden a aparecer en áreas importantes de apoyo y resistencia de precios. Por lo tanto, si a nuestra clasificación le falta alguno de estos patrones, su análisis y, por lo tanto, sus pronósticos resultarán menos precisos, ya que para la mayoría de los sistemas comerciales, a largo plazo, las áreas de apoyo y resistencia de precios desempeñan un papel fundamental en la determinación de las configuraciones comerciales. Por lo tanto, la adición de la propiedad de antisimetría con un orden parcial puede usarse para filtrar mejor las señales comerciales.
Una consideración del sistema comercial que difiere de nuestro proceso de cinco pasos discutido en artículos anteriores puede implicar la vectorización de las barras de precios. Mostrando cada barra de precios como un vector (que simplemente supone un array de pesos) podremos comparar cómo de similares son los diferentes patrones. Si entrenamos durante un periodo de tiempo suficiente e identificamos posibles formaciones de precios para un número significativo de modelos vectorizados, podremos comparar cualquier modelo nuevo con el que hemos entrenado y, según la distancia euclidiana respecto a esos modelos entrenados, el modelo que se encuentre más próximo a nuestro nuevo modelo, podrá considerar su formación “post-precio” como el resultado más probable del nuevo modelo.
Un orden lineal puede resultar preferible a un orden parcial al analizar el portafolio. Si nos enfrentamos a una amplia gama de activos que deben valorarse o incluirse en un portafolio, entonces deberemos utilizar obligatoriamente un orden lineal con requisitos estrictos de igual ponderación (comparabilidad). Esto sucede por varios motivos, algunos de las cuales se dan por sentado. El orden lineal permite valorar los activos de forma consistente, lo que da como resultado un proceso ágil. Independientemente de la cantidad de activos, las prioridades ya se han determinado mediante la ponderación de activos, que puede ser un valor que cuantifica todo, desde un valor realizado en el pasado hasta el riesgo potencial futuro. Esto no solo ayuda a lograr una mayor eficiencia, sino que también permite al tráder no dispersar su atención en todos los activos posibles.
Esta priorización implica que las decisiones de inversión en los activos más importantes se considerarán primero, lo cual nos lleva a la cuestión esencial de la asignación de activos. ¿Cómo se determinará el tamaño de cada activo del portafolio? Con un orden lineal, el peso de cada activo a menudo puede actuar como un indicador justo sobre cuánto capital debemos utilizar para comprar un activo, lo cual resultaría más difícil de hacer de forma consistente con un orden parcial.
Ejemplo: Desarrollando un sistema comercial con diferentes formatos de orden.
La estrategia comercial elegida se basará en el sistema que hemos discutido en artículos anteriores e implicará la selección de los pasos intermedios del 2 al 4 de nuestro método de 5 pasos. Los seleccionaremos usando el método de orden parcial en un sistema comercial, así como el método de orden lineal en otro sistema.
Para seleccionar directamente un orden parcial, todos nuestros conjuntos de monoides resultarán incomparables porque tendremos un periodo de búsqueda que es de tipo entero. Aplicaremos un precio que será una enumeración de tipo string. Asimismo, usaremos un tipo de indicador, que también será, estrictamente hablando, una selección de líneas. Entonces, para presentar la posibilidad de usar un operador binario:
≦
Normalizaremos solo un par de conjuntos, dejando el tercero en el formato por defecto. Los datos de entrada de la función que impondrá un orden parcial serán inherentemente una acción del precio. Los parámetros de precio que consideraremos como datos de entrada para nuestra función de orden parcial se indexarán mediante autocorrelación. Simplemente asignaremos índices a los diversos patrones de autocorrelación, y para cada índice tendremos un par de conjuntos normalizados específicos, que luego informarán el orden seleccionado para nuestro sistema comercial. Con un orden parcial como el anterior, tener conjuntos indefinidos implicará que solo se elegirán dos conjuntos, lo cual significará que casi con seguridad siempre tendremos un proceso de 4 pasos en lugar del proceso de 5 pasos que utilizábamos.
No obstante, para el orden lineal, todos los conjuntos de monoides estarán normalizados. Esto debería proporcionarnos los 5 pasos completos que hemos analizado y, al igual que sucede con el orden parcial, los datos de entrada para la función de orden lineal serán nuestro índice de autocorrelación. El propósito del índice de autocorrelación será muy simple, como podemos ver en el listado a continuación.
//+------------------------------------------------------------------+ //| | //+------------------------------------------------------------------+ bool CTrailingCT::Ordering(int Lookback) { m_low.Refresh(-1); m_high.Refresh(-1); m_close.Refresh(-1); double _c[],_l[],_h[]; ArrayResize(_c,Lookback);ArrayInitialize(_c,0.0); ArrayResize(_l,Lookback);ArrayInitialize(_l,0.0); ArrayResize(_h,Lookback);ArrayInitialize(_h,0.0); for(int i=0;i<Lookback;i++) { _c[i]=m_close.GetData(i); _l[i]=m_low.GetData(Lookback+i); _h[i]=m_high.GetData(Lookback+i); } double _r_h=0.0,_r_l=0.0; if(MathCorrelationSpearman(_c,_l,_r_l) && MathCorrelationSpearman(_c,_h,_r_h)) { if(_r_l>=__PHI){ LongIndex(5); } else if(_r_l>=1.0-__PHI){ LongIndex(4); } else if(_r_l>=0.0){ LongIndex(3); } else if(_r_l>=(-1.0+__PHI)){ LongIndex(2); } else if(_r_l>=(-__PHI)){ LongIndex(1); } else{ LongIndex(0);} if(_r_h>=__PHI){ ShortIndex(5); } else if(_r_h>=1.0-__PHI){ ShortIndex(4); } else if(_r_h>=0.0){ ShortIndex(3); } else if(_r_h>=(-1.0+__PHI)){ ShortIndex(2); } else if(_r_h>=(-__PHI)){ ShortIndex(1); } else{ ShortIndex(0);} return(true); } return(false); }
Para procesar el orden parcial, el código se integrará en las funciones de procesamiento de trailing stop largo y corto, como se describe en el apéndice del artículo a continuación. Aquí resulta notable que, en efecto, cada índice asignado representa solo dos conjuntos, ya que el tercero no está definido. El orden definido por cada posible índice implicará que el primer conjunto asignado tenga un peso mayor que el último. Así, eliminaremos la necesidad de crear una función normalizadora que ofrezca peso físico a cada uno de ellos, ya que no tendrá un impacto significativo en el resultado final.
De forma análoga, una función de orden lineal se vería así:
ENUM_TIMEFRAMES _timeframe=GetTimeframe(m_timeframe,__TIMEFRAMES); int _lookback=m_default_lookback; ENUM_APPLIED_PRICE _appliedprice=__APPLIEDPRICES[m_default_appliedprice]; double _indicator=m_default_indicator; if(m_long_index==0) { _lookback=GetLookback(m_lookback,__LOOKBACKS,_timeframe); _appliedprice=GetAppliedprice(m_appliedprice,__APPLIEDPRICES,_lookback,_timeframe); _indicator=GetIndicator(_lookback,_timeframe,_appliedprice); } else if(m_long_index==1) { _appliedprice=GetAppliedprice(m_appliedprice,__APPLIEDPRICES,__LOOKBACKS[m_default_lookback],_timeframe); _lookback=GetLookback(m_lookback,__LOOKBACKS,_timeframe); _indicator=GetIndicator(_lookback,_timeframe,_appliedprice); } else if(m_long_index==2) { _appliedprice=GetAppliedprice(m_appliedprice,__APPLIEDPRICES,__LOOKBACKS[m_default_lookback],_timeframe); _indicator=GetIndicator(m_default_lookback,_timeframe,_appliedprice); _lookback=GetLookback(m_lookback,__LOOKBACKS,_timeframe); } else if(m_long_index==3) { _indicator=GetIndicator(__LOOKBACKS[m_default_lookback],_timeframe,__APPLIEDPRICES[m_default_appliedprice]); _appliedprice=GetAppliedprice(m_appliedprice,__APPLIEDPRICES,m_default_lookback,_timeframe); _lookback=GetLookback(m_lookback,__LOOKBACKS,_timeframe); } else if(m_long_index==4) { _indicator=GetIndicator(__LOOKBACKS[m_default_lookback],_timeframe,__APPLIEDPRICES[m_default_appliedprice]); _lookback=GetLookback(m_lookback,__LOOKBACKS,_timeframe); _appliedprice=GetAppliedprice(m_appliedprice,__APPLIEDPRICES,_lookback,_timeframe); } else if(m_long_index==5) { _lookback=GetLookback(m_lookback,__LOOKBACKS,_timeframe); _indicator=GetIndicator(_lookback,_timeframe,__APPLIEDPRICES[m_default_appliedprice]); _appliedprice=GetAppliedprice(m_appliedprice,__APPLIEDPRICES,_lookback,_timeframe); } // int _trade_decision=GetTradeDecision(_timeframe,_lookback,_appliedprice,_indicator);
Aquí lo notable sería que cada índice ofrece una lista exhaustiva de todos los conjuntos, ya que la comparabilidad es un requisito para todos ellos, y, como hemos mencionado anteriormente, evitaremos el proceso de asignación de números de peso a cada conjunto, que luego se utilizarán en la clasificación, puesto que la indexación utilizada implica un orden de ponderación que se implementa como mostramos arriba.
Si realizamos pruebas usando nuestras nuevas clases finales en la clase de señal de la biblioteca Awesome Oscillator utilizando un margen fijo para el símbolo USDJPY durante los últimos 12 meses, obtendremos los siguientes informes para cada uno de los métodos de orden. Método de orden parcial:

Nuestro asesor ha ganado más de 100 000, como siempre ocurre en esta serie de artículos, si no usamos precios objetivo para el take profit o el stop loss y mantenemos las posiciones solo hasta que el indicador de señal no considere que hay que cerrarlas. Además, como estamos mejorando nuestro trailing stop, la mayoría de las posiciones cerradas rentables en realidad han estado vinculadas al mismo, lo cual habla de las ventajas del orden parcial a la hora de crear indicadores fiables para configurar el trailing stop. También hemos probado trailing stops basados en el orden lineal. Los resultados se muestran a continuación.

El beneficio aquí es sorprendentemente inferior al obtenido con el orden parcial (“ambiguo”, adaptativo). Por extraño que parezca, la reducción de capital se vuelve aún mayor cuando se ejecutan menos transacciones. Para sacar conclusiones definitivas, necesitaremos realizar pruebas durante periodos más largos y con múltiples símbolos, pero podemos afirmar con seguridad que el orden parcial resulta más prometedor que el orden lineal.
Conclusión
Hoy hemos analizado la efectividad del orden parcial en comparación con el orden lineal al establecer y cambiar trailing stops para un asesor experto típico. Antes hemos analizado los méritos relativos de estos dos principios de orden sin tener en cuenta el principio de vinculación de ambos, es decir, el pre-orden, ya que esto haría que el artículo resultara demasiado largo. Recuerde que el orden parcial es una forma especializada de pre-orden, mientras que el orden lineal también es una forma especializada de orden parcial. Como las definiciones básicas de estos tipos de orden son en gran medida las mismas, nos hemos centrado en los dos últimos órdenes.
Así, hemos utilizado los métodos de relación del orden lineal y parcial según sus ventajas específicas. El orden parcial permite una mayor flexibilidad en la clasificación de conjuntos de datos sin procesar, lo cual puede ayudarnos a lograr un análisis más completo y preciso. Por el contrario, el orden lineal, más estricto, normalmente requiere la normalización de los datos sin procesar para garantizar la comparabilidad, lo cual da como resultado una priorización común, así como una buena eficiencia en la toma de decisiones.
Estas técnicas de secuenciación tienen potencial para una mayor investigación y mejora a medida que vayamos integrando conceptos pasados en otros nuevos.
Traducción del inglés realizada por MetaQuotes Ltd.
Artículo original: https://www.mql5.com/en/articles/12873
- Aplicaciones de trading gratuitas
- 8 000+ señales para copiar
- Noticias económicas para analizar los mercados financieros
Usted acepta la política del sitio web y las condiciones de uso