
Algoritmos de optimización de la población: Optimización de malas hierbas invasoras (IWO)

Contenido:
1. Introducción
2. Descripción del algoritmo
3. Resultados de las pruebas
1. Introducción
El algoritmo metaheurístico de malas hierbas invasoras es un algoritmo de optimización basado en poblaciones que encuentra el óptimo global de la función optimizada simulando la compatibilidad y aleatoriedad de una colonia de malas hierbas.
El algoritmo de optimización de malas hierbas pertenece a los algoritmos basados en poblaciones inspirados en la naturaleza y refleja el comportamiento de las malas hierbas en un área limitada en la lucha por la supervivencia durante un tiempo limitado.
Las malas hierbas son poderosas gramíneas que suponen una grave amenaza para los cultivos debido a su crecimiento invasivo, y han demostrado ser muy resistentes y adaptables a los cambios ambientales. Por ello, analizando sus características, se puede crear un potente algoritmo de optimización. Este algoritmo intenta imitar la resistencia, adaptabilidad y aleatoriedad de una comunidad de malas hierbas en la naturaleza.
¿Qué tienen de especial las malas hierbas para lograr su ventaja? Las malas hierbas suelen ser pioneras en su expansión y se extienden por todas partes usando diversos mecanismos. Por ello, rara vez entran en la categoría de especies amenazadas.
Resumiendo un poco, las ocho formas básicas en que las malas hierbas se adaptan y sobreviven en la naturaleza son:
1. El genotipo universal. De los estudios realizados, podemos entender que las malas hierbas reaccionan a los cambios climatológicos, registrándose en la mayoría de ellos ciertos cambios evolutivos en las plantas.
2. Estrategias del ciclo vital, fecundidad. Las malas hierbas muestra una amplia gama de estrategias de ciclo vital, por lo que, a medida que se cambian los sistemas de labranza, las malas hierbas que antes no constituían un problema grave en un determinado sistema de cultivo se muestran más resistentes. Por ejemplo, los sistemas de labranza reducidos contribuyen especialmente al desarrollo de malas hierbas perennes con diferentes estrategias de ciclo vital. Además, el cambio climático está empezando a crear nuevos nichos para especies de malas hierbas o genotipos cuyas historias vitales se adaptan mejor a las condiciones cambiantes. Como resultado de la respuesta al aumento de las emisiones de dióxido de carbono, las malas hierbas se hacen más altas, más grandes y más fuertes, lo cual significa que podrán producir más semillas y esparcirlas más lejos desde las plantas más altas debido a sus propiedades aerodinámicas. Su fecundidad es excepcional: el cardo de los prados, por ejemplo, produce hasta 19.000 semillas.
3. Evolución rápida (germinación, crecimiento sin pretensiones, competitividad, sistema de reproducción, producción de semillas y peculiaridades de dispersión). El aumento de la capacidad de dispersión de las semillas y la consiguiente falta de pretensiones del cultivo le ofrecen una alta capacidad de supervivencia. Las malas hierbas son extremadamente indiferentes a las condiciones del suelo y toleran grandes fluctuaciones de temperatura y humedad.
4. Epigenética. Además de su rápida evolución, muchas plantas invasoras tienen la capacidad de responder rápidamente a los cambios de los factores ambientales cambiando la expresión de sus genes. En un entorno en constante cambio, las plantas deben saber adaptarse para soportar factores de estrés tales como variaciones de luz, temperatura, disponibilidad de agua y niveles de sal en el suelo. Para conseguir dicha adaptabilidad, las plantas son capaces de someterse por sí mismas a modificaciones epigenéticas.
5. Hibridación. Las especies de malas hierbas híbridas suelen mostrar un vigor híbrido, también conocido como heterosis, en el que la descendencia muestra una función biológica mejorada en comparación con ambas especies parentales. Por lo general, el híbrido mostrará un crecimiento más agresivo con una mayor capacidad para expandirse a nuevos territorios y para competir dentro de las zonas invadidas.
6. Resistencia y tolerancia a los herbicidas. En las últimas décadas se ha detectado un aumento espectacular de la resistencia a los herbicidas en la mayoría de las malas hierbas.
7. Evolución conjunta de las malas hierbas asociada a la actividad humana. Gracias a los métodos de control de las malas hierbas, como el uso de herbicidas y la escarda, estas han desarrollado mecanismos de resistencia, y sufren menos daños externos por la labranza que las plantas cultivadas. Por el contrario, estos daños resultan a menudo incluso útiles para la expansión de las malas hierbas de propagación vegetativa (por ejemplo, partes de la raíz, rizomas).
8. Las variaciones climáticas, cada vez más frecuentes, ofrecen a las malas hierbas la oportunidad de existir de forma más viable que las plantas cultivadas en "invernaderos". Las malas hierbas suponen un enorme perjuicio para la agricultura: menos exigentes en sus condiciones de crecimiento, superan a las plantas cultivadas en crecimiento y desarrollo. Absorbiendo la humedad, los nutrientes y la luz solar, las malas hierbas reducen drásticamente las cosechas, dificultan la recolección y trilla de los cultivos y empeoran la calidad del producto.
2. Descripción del algoritmo
El algoritmo de malas hierbas invasoras se inspira en el proceso de crecimiento de las malas hierbas en la naturaleza. Este método fue introducido por Mehrabian y Lucas en 2006. Naturalmente, las malas hierbas crecen con gran intensidad y este fuerte crecimiento supone una grave amenaza para las plantas útiles. Una característica importante de las malas hierbas es su resistencia y alta adaptabilidad en la naturaleza, lo cual conforma la base para optimizar el algoritmo IWO. Este algoritmo puede servir de base para planteamientos de optimización eficaces.
El IWO es un algoritmo numérico estocástico continuo que simula el comportamiento colonizador de las malas hierbas. En primer lugar, la población de semillas de origen se distribuye por todo el espacio de búsqueda de forma aleatoria. Estas malas hierbas finalmente crecerán y ejecutarán los siguientes pasos del algoritmo. El algoritmo consta de siete pasos, que pueden representarse en forma de pseudocódigo:
1. Sembrar semillas de forma aleatoria
2. Calcular FF
3. Sembrar semillas de malas hierbas
4. Calcular FF
5. Combinar malas hierbas hijas con malas hierbas parentales
6. Clasificar todas las malas hierbas
7. repetir el punto 3 hasta que se cumpla la condición de parada
El esquema de bloques representa el funcionamiento de un algoritmo en una sola iteración. El IWO comienza su trabajo con un proceso de inicialización de semillas que se dispersan de forma aleatoria y uniforme por el "campo" del espacio de búsqueda. A continuación, suponemos que las semillas han germinado y formado plantas adultas que deben valorarse usando una función de aptitud.
En el siguiente paso, conociendo la adaptabilidad de cada planta, podemos permitir que las malas hierbas se multipliquen a través de las semillas; el número de semillas será proporcional a la adaptabilidad. Después, combinamos las semillas germinadas con las plantas parentales y las clasificamos. En general, el algoritmo de malas hierbas invasoras puede considerarse sencillo de escribir en cuanto al código, la modificación y el uso conjunto con aplicaciones de terceros.

Figura 1. Esquema de bloques del algoritmo IWO.
Vamos a ver las características del algoritmo de las malas hierbas. El algoritmo ofrece muchas posibilidades de adaptación extrema para la supervivencia de las malas hierbas. Una característica distintiva de la colonia de malas hierbas, a diferencia de algoritmos como el genético, el de abejas y algunos otros, es que se garantiza la siembra de semillas por parte de todas las plantas de la colonia sin excepción. Esto garantiza que incluso las plantas con las peores adaptaciones puedan dejar descendencia, ya que siempre existe una probabilidad distinta de cero de que la peor se encuentre más cerca de un extremo global.
Cada una de las malas hierbas, como hemos dicho, dejará semillas en cantidades que van desde el mínimo posible al máximo posible (parámetros externos del algoritmo). Naturalmente, en tales condiciones, cuando cada planta deja al menos una o más semillas, habrá más plantas hijas que plantas parentales: esta característica se implementa de forma bastante interesante en el código y se discutirá más adelante. En general, el algoritmo se muestra de manera visual en la figura 2. Las plantas parentales esparcen semillas en un número proporcional a su adaptabilidad.
Así, la mejor planta, con el número 1, ha sembrado 6 semillas, mientras que la planta número 6 ha sembrado solo una semilla (una garantizada). Las semillas germinadas producen plantas que posteriormente se clasifican junto con sus progenitores: se trata de una simulación de la supervivencia. De todo el grupo clasificado, se seleccionarán nuevas plantas parentales y el ciclo de vida se repetirá en la siguiente iteración. Otra característica relacionada con la existencia de un número máximo y mínimo de semillas permitidas para cada planta, es que el algoritmo tiene un mecanismo para resolver el problema de la "sobrepoblación" o realización incompleta de la capacidad de siembra.
Para el ejemplo, tomaremos un número de semillas (uno de los parámetros del algoritmo) igual a 50, y un número de plantas parentales igual a 5, con un número mínimo de semillas de 1 y un máximo de 6. Entonces, 5 * 6 = 30, que es menos de 50. Como podemos ver en este ejemplo, las posibilidades de la siembra no se aprovechan al 100%. En este caso, el derecho a dejar un descendiente pasa al siguiente de la lista hasta que se haya alcanzado el número máximo de descendientes permitido para todas las plantas parentales. Al alcanzar el final de la lista, el derecho pasará al primero de la lista y este podrá seguir teniendo descendientes por encima del límite.

Figura 2. Principio de funcionamiento del algoritmo IWO. El número de descendientes es proporcional a la adaptabilidad del progenitor.
El siguiente punto al que debemos prestar atención es la dispersión de las semillas. La varianza de la siembra en el algoritmo supone una función lineal decreciente proporcional al número de iteraciones. Los parámetros exteriores de la varianza son los límites inferior y superior de la dispersión de semillas. Así, aumentando las iteraciones, el radio de siembra disminuirá y se garantizará la mejora de los extremos encontrados. La distribución de siembra, como recomiendan los autores del algoritmo, debería ser normal, pero hemos simplificado los cálculos y hemos aplicado una función cúbica. La función de varianza del número de iteraciones puede verse en la figura 3.

Figura 3. Dependencia de la varianza respecto al número de iteraciones, donde 3 es el límite máximo y 2 el mínimo.
Ahora vamos a ver el código del algoritmo de optimización de las malas hierbas invasoras, el IWO. En el código destacan su sencillez y su rapidez de ejecución.
La unidad más simple (agente) del algoritmo es la "mala hierba", que también describirá las semillas de la mala hierba, lo cual nos permitirá utilizar el mismo tipo de datos para la clasificación posterior. La estructura consta de un array de coordenadas, una variable para almacenar el valor de la función de aptitud y un contador del número de semillas (descendientes). Este contador nos permitirá controlar el número mínimo y máximo de semillas permitido para cada planta.
//—————————————————————————————————————————————————————————————————————————————— struct S_Weed { double c []; //coordinates double f; //fitness int s; //number of seeds }; //——————————————————————————————————————————————————————————————————————————————
Ahora necesitaremos una estructura para implementar una función de probabilidad para elegir los progenitores de forma proporcional a su adaptabilidad. En este caso, aplicaremos el principio de la ruleta, que ya hemos visto en el algoritmo de la colonia de abejas. Las variables de inicio y fin son responsables del inicio y fin del campo de probabilidad.
//—————————————————————————————————————————————————————————————————————————————— struct S_WeedFitness { double start; double end; }; //——————————————————————————————————————————————————————————————————————————————
Vamos a declarar una clase de algoritmo de malas hierbas. Dentro de él, declararemos todas las variables necesarias que necesitaremos; como de costumbre, aquí tendremos los límites y el paso de los parámetros a optimizar, un array para describir las malas hierbas, así como un array de semillas, un array de las mejores coordenadas globales y el mejor valor de la función de aptitud alcanzado por el algoritmo. También necesitaremos la bandera de la primera iteración «sowing» y las variables constantes de los parámetros del algoritmo.
//—————————————————————————————————————————————————————————————————————————————— class C_AO_IWO { //============================================================================ public: double rangeMax []; //maximum search range public: double rangeMin []; //manimum search range public: double rangeStep []; //step search public: S_Weed weeds []; //weeds public: S_Weed weedsT []; //temp weeds public: S_Weed seeds []; //seeds public: double cB []; //best coordinates public: double fB; //fitness of the best coordinates public: void Init (const int coordinatesP, //Number of coordinates const int numberSeedsP, //Number of seeds const int numberWeedsP, //Number of weeds const int maxNumberSeedsP, //Maximum number of seeds per weed const int minNumberSeedsP, //Minimum number of seeds per weed const double maxDispersionP, //Maximum dispersion const double minDispersionP, //Minimum dispersion const int maxIterationP); //Maximum iterations public: void Sowing (int iter); public: void Germination (); //============================================================================ private: void Sorting (); private: double SeInDiSp (double In, double InMin, double InMax, double Step); private: double RNDfromCI (double Min, double Max); private: double Scale (double In, double InMIN, double InMAX, double OutMIN, double OutMAX, bool Revers); private: double vec []; //Vector private: int ind []; private: double val []; private: S_WeedFitness wf []; //Weed fitness private: bool sowing; //Sowing private: int coordinates; //Coordinates number private: int numberSeeds; //Number of seeds private: int numberWeeds; //Number of weeds private: int totalNumWeeds; //Total number of weeds private: int maxNumberSeeds; //Maximum number of seeds private: int minNumberSeeds; //Minimum number of seeds private: double maxDispersion; //Maximum dispersion private: double minDispersion; //Minimum dispersion private: int maxIteration; //Maximum iterations }; //——————————————————————————————————————————————————————————————————————————————
En el método abierto de la función de inicialización, asignaremos un valor a las variables constantes y comprobaremos que los parámetros de entrada del algoritmo tengan valores admisibles, de forma que el producto de las plantas parentales por el valor mínimo posible de semillas no pueda superar el número total de semillas. La suma de las plantas parentales y las semillas será necesaria para definir el array de clasificación.
//—————————————————————————————————————————————————————————————————————————————— void C_AO_IWO::Init (const int coordinatesP, //Number of coordinates const int numberSeedsP, //Number of seeds const int numberWeedsP, //Number of weeds const int maxNumberSeedsP, //Maximum number of seeds per weed const int minNumberSeedsP, //Minimum number of seeds per weed const double maxDispersionP, //Maximum dispersion const double minDispersionP, //Minimum dispersion const int maxIterationP) //Maximum iterations { MathSrand (GetTickCount ()); sowing = false; fB = -DBL_MAX; coordinates = coordinatesP; numberSeeds = numberSeedsP; numberWeeds = numberWeedsP; maxNumberSeeds = maxNumberSeedsP; minNumberSeeds = minNumberSeedsP; maxDispersion = maxDispersionP; minDispersion = minDispersionP; maxIteration = maxIterationP; if (minNumberSeeds < 1) minNumberSeeds = 1; if (numberWeeds * minNumberSeeds > numberSeeds) numberWeeds = numberSeeds / minNumberSeeds; else numberWeeds = numberWeedsP; totalNumWeeds = numberWeeds + numberSeeds; ArrayResize (rangeMax, coordinates); ArrayResize (rangeMin, coordinates); ArrayResize (rangeStep, coordinates); ArrayResize (vec, coordinates); ArrayResize (cB, coordinates); ArrayResize (weeds, totalNumWeeds); ArrayResize (weedsT, totalNumWeeds); ArrayResize (seeds, numberSeeds); for (int i = 0; i < numberWeeds; i++) { ArrayResize (weeds [i].c, coordinates); ArrayResize (weedsT [i].c, coordinates); weeds [i].f = -DBL_MAX; weeds [i].s = 0; } for (int i = 0; i < numberSeeds; i++) { ArrayResize (seeds [i].c, coordinates); seeds [i].s = 0; } ArrayResize (ind, totalNumWeeds); ArrayResize (val, totalNumWeeds); ArrayResize (wf, numberWeeds); } //——————————————————————————————————————————————————————————————————————————————
El primer método público llamado en cada iteración es Sowing (). La lógica básica del algoritmo está implementada en él. Para facilitar la percepción del material, desglosaremos el método en varias partes que analizaremos por separado.
Cuando el algoritmo se encuentra en su primera iteración, deberemos sembrar las semillas en todo el espacio de búsqueda. Normalmente, esto se hace de forma aleatoria y uniforme. Después de generar números aleatorios en el rango de valores aceptables de los parámetros optimizados, comprobaremos si los valores obtenidos están fuera de rango y estableceremos la discreción fijada por los parámetros del algoritmo. Aquí también asignaremos un vector de distribución, que necesitaremos más adelante en el código al sembrar las semillas. Luego inicializaremos los valores de adaptabilidad de las semillas con un valor double mínimo y pondremos a cero el contador de semillas (las semillas se convertirán en las plantas en las que se utilizará el contador de semillas).
//the first sowing of seeds--------------------------------------------------- if (!sowing) { fB = -DBL_MAX; for (int s = 0; s < numberSeeds; s++) { for (int c = 0; c < coordinates; c++) { seeds [s].c [c] = RNDfromCI (rangeMin [c], rangeMax [c]); seeds [s].c [c] = SeInDiSp (seeds [s].c [c], rangeMin [c], rangeMax [c], rangeStep [c]); vec [c] = rangeMax [c] - rangeMin [c]; } seeds [s].f = -DBL_MAX; seeds [s].s = 0; } sowing = true; return; }
Esta sección de código calculará la varianza basándose en la iteración actual. Justo en este punto del código, se implementará el número mínimo garantizado de semillas para cada mala hierba parental de la que ya hemos hablado antes. El número mínimo de semillas se garantizará en dos ciclos, el primero de los cuales consistirá en iterar por las malas hierbas parentales, mientras que en el segundo se generarán realmente nuevas semillas, sin olvidar aumentar el contador de semillas. Como podemos ver, el objetivo de crear un nuevo descendiente consiste en agregar a la coordenada parental un número aleatorio con la distribución de función cúbica con una varianza previamente calculada. Vamos a comprobar si el nuevo valor de las coordenadas resultante es válido y a asignarle una discreción.
//guaranteed sowing of seeds by each weed------------------------------------- int pos = 0; double r = 0.0; double dispersion = ((maxIteration - iter) / (double)maxIteration) * (maxDispersion - minDispersion) + minDispersion; for (int w = 0; w < numberWeeds; w++) { weeds [w].s = 0; for (int s = 0; s < minNumberSeeds; s++) { for (int c = 0; c < coordinates; c++) { r = RNDfromCI (-1.0, 1.0); r = r * r * r; seeds [pos].c [c] = weeds [w].c [c] + r * vec [c] * dispersion; seeds [pos].c [c] = SeInDiSp (seeds [pos].c [c], rangeMin [c], rangeMax [c], rangeStep [c]); } pos++; weeds [w].s++; } }
Con este código, ofreceremos campos de probabilidad para cada una de las plantas parentales de forma proporcional a la adaptación según el principio de la ruleta. El código anterior ofrecía un número garantizado de semillas para cada una de las plantas en un momento, mientras que aquí el número de semillas está sujeto a una ley aleatoria, de forma que cuanto más adaptada esté la mala hierba, más semillas podrá dejar y, a la inversa, cuanto menos adaptada esté la planta, menos semillas producirá.
//============================================================================ //sowing seeds in proportion to the fitness of weeds-------------------------- //the distribution of the probability field is proportional to the fitness of weeds wf [0].start = weeds [0].f; wf [0].end = wf [0].start + (weeds [0].f - weeds [numberWeeds - 1].f); for (int f = 1; f < numberWeeds; f++) { if (f != numberWeeds - 1) { wf [f].start = wf [f - 1].end; wf [f].end = wf [f].start + (weeds [f].f - weeds [numberWeeds - 1].f); } else { wf [f].start = wf [f - 1].end; wf [f].end = wf [f].start + (weeds [f - 1].f - weeds [f].f) * 0.1; } }
Usando los campos de probabilidad resultantes, seleccionaremos una planta parental que tenga derecho a dejar descendencia. Si el contador de semillas ha alcanzado el valor máximo permitido, el derecho pasará a la siguiente planta de la lista clasificada. Si llegamos al final de la lista, el derecho no pasará a la siguiente planta de la lista, sino a la primera, y luego se formará la planta descendiente según la regla descrita antes con la varianza calculada.
bool seedingLimit = false; int weedsPos = 0; for (int s = pos; s < numberSeeds; s++) { r = RNDfromCI (wf [0].start, wf [numberWeeds - 1].end); for (int f = 0; f < numberWeeds; f++) { if (wf [f].start <= r && r < wf [f].end) { weedsPos = f; break; } } if (weeds [weedsPos].s >= maxNumberSeeds) { seedingLimit = false; while (!seedingLimit) { weedsPos++; if (weedsPos >= numberWeeds) { weedsPos = 0; seedingLimit = true; } else { if (weeds [weedsPos].s < maxNumberSeeds) { seedingLimit = true; } } } } for (int c = 0; c < coordinates; c++) { r = RNDfromCI (-1.0, 1.0); r = r * r * r; seeds [s].c [c] = weeds [weedsPos].c [c] + r * vec [c] * dispersion; seeds [s].c [c] = SeInDiSp (seeds [s].c [c], rangeMin [c], rangeMax [c], rangeStep [c]); } seeds [s].s = 0; weeds [weedsPos].s++; }
El segundo método abierto será obligatorio en cada iteración requerida después de que se calcule la función de aptitud para cada mala hierba descendiente. Antes de aplicar la clasificación, colocaremos las semillas germinadas en el array común con las plantas parentales al final de la lista, sustituyendo así a la generación anterior, que podría incluir tanto descendientes como progenitores de la iteración anterior. De este modo, se descartarán las malas hierbas poco adaptadas, como ocurre en la naturaleza. Después, aplicaremos la clasificación, mientras que la primera mala hierba de la lista resultante será merecedora de actualizar la mejor solución alcanzada globalmente, si efectivamente es mejor.
//—————————————————————————————————————————————————————————————————————————————— void C_AO_IWO::Germination () { for (int s = 0; s < numberSeeds; s++) { weeds [numberWeeds + s] = seeds [s]; } Sorting (); if (weeds [0].f > fB) fB = weeds [0].f; } //——————————————————————————————————————————————————————————————————————————————
3. Resultados de las pruebas
Impresión del funcionamiento del banco de pruebas:
2023.01.13 18:12:29.880 Test_AO_IWO (EURUSD,M1) C_AO_IWO:50;12;5;2;0.2;0.01
2023.01.13 18:12:29.880 Test_AO_IWO (EURUSD,M1) =============================
2023.01.13 18:12:32.251 Test_AO_IWO (EURUSD,M1) 5 Rastrigin's; Func runs 10000 result: 79.71791976868334
2023.01.13 18:12:32.251 Test_AO_IWO (EURUSD,M1) Score: 0.98775
2023.01.13 18:12:36.564 Test_AO_IWO (EURUSD,M1) 25 Rastrigin's; Func runs 10000 result: 66.60305588198622
2023.01.13 18:12:36.564 Test_AO_IWO (EURUSD,M1) Score: 0.82525
2023.01.13 18:13:14.024 Test_AO_IWO (EURUSD,M1) 500 Rastrigin's; Func runs 10000 result: 45.4191288396659
2023.01.13 18:13:14.024 Test_AO_IWO (EURUSD,M1) Score: 0.56277
2023.01.13 18:13:14.024 Test_AO_IWO (EURUSD,M1) =============================
2023.01.13 18:13:16.678 Test_AO_IWO (EURUSD,M1) 5 Forest's; Func runs 10000 result: 1.302934874807614
2023.01.13 18:13:16.678 Test_AO_IWO (EURUSD,M1) Score: 0.73701
2023.01.13 18:13:22.113 Test_AO_IWO (EURUSD,M1) 25 Forest's; Func runs 10000 result: 0.5630336066477166
2023.01.13 18:13:22.113 Test_AO_IWO (EURUSD,M1) Score: 0.31848
2023.01.13 18:14:05.092 Test_AO_IWO (EURUSD,M1) 500 Forest's; Func runs 10000 result: 0.11082098547471195
2023.01.13 18:14:05.092 Test_AO_IWO (EURUSD,M1) Score: 0.06269
2023.01.13 18:14:05.092 Test_AO_IWO (EURUSD,M1) =============================
2023.01.13 18:14:09.102 Test_AO_IWO (EURUSD,M1) 5 Megacity's; Func runs 10000 result: 6.640000000000001
2023.01.13 18:14:09.102 Test_AO_IWO (EURUSD,M1) Score: 0.55333
2023.01.13 18:14:15.191 Test_AO_IWO (EURUSD,M1) 25 Megacity's; Func runs 10000 result: 2.6
2023.01.13 18:14:15.191 Test_AO_IWO (EURUSD,M1) Score: 0.21667
2023.01.13 18:14:55.886 Test_AO_IWO (EURUSD,M1) 500 Megacity's; Func runs 10000 result: 0.5668
2023.01.13 18:14:55.886 Test_AO_IWO (EURUSD,M1) Score: 0.04723
Basta un rápido vistazo para darse cuenta de los elevados resultados del algoritmo en las funciones de prueba. Existe una marcada preferencia por el rendimiento en funciones suaves, aunque hasta ahora ninguno de los algoritmos analizados ha mostrado mejor convergencia en funciones discretas que en funciones suaves, lo cual se debe a la complejidad de las funciones Forest y Megacity para todos los algoritmos sin excepción. Es posible, aunque no en absoluto probable, que en el futuro consigamos algún algoritmo que resuelva mejor las funciones discretas que las suaves.

IWO en la función de prueba Rastrigin.

IWO en la función de prueba Forest.

IWO en la función de prueba Megacity.
El algoritmo de malas hierbas invasoras ha mostrado un rendimiento impresionante en la mayoría de las pruebas, especialmente en la función Rastrigin suave con 10 y 50 parámetros: en esta, el rendimiento ha descendido ligeramente solo en la prueba con 1000 parámetros, lo que en general indica un buen rendimiento en funciones suaves, cosa que en principio permite recomendar el algoritmo de malas hierbas invasoras para trabajar con funciones suaves complejas a la hora de trabajar con redes neuronales. En cuanto a las funciones Forest, el algoritmo se ha comportado de forma ligeramente distinta en la primera prueba con 10 parámetros, pero sigue mostrando resultados medios. En la función discreta Megacity, el algoritmo de malas hierbas invasoras ha obtenido resultados por encima de la media, mostrando especialmente una excelente escalabilidad en la prueba con 1000 variables, y cediendo el primer puesto en la prueba solo ante el algoritmo de luciérnagas, pero muy por delante de él en las pruebas con 10 y 50 parámetros.
Aunque el algoritmo de malas hierbas invasoras tiene un número bastante grande de parámetros, esto no supondría una desventaja para el algoritmo, ya que los parámetros son muy intuitivos y no resultan en absoluto difíciles de establecer. Además, en su mayor parte, el ajuste de la precisión del algoritmo solo influye en los resultados de las pruebas de las funciones discretas, mientras que los resultados en la función suave siguen siendo buenos.
La visualización de las funciones de prueba muestra claramente la capacidad del algoritmo para destacar y explorar áreas específicas del espacio de búsqueda, como lo hace en el algoritmo de colonia de abejas y algún otro más, aunque hemos encontrado en varias publicaciones la opinión de que el algoritmo es propenso a atascarse y posee una débil capacidad de búsqueda. Como el algoritmo no se centra en el extremo global y carece de mecanismos para "saltar" fuera de las trampas locales, el IWO se las arregla de alguna manera para trabajar decentemente en funciones tan complejas como Forest y Megacity. Y al trabajar con una función discreta, cuantos más parámetros haya que optimizar, más estables serán los resultados.
Como la varianza de la dispersión de las semillas disminuye linealmente con cada iteración, el afinamiento de los extremos aumentará cada vez más hacia el final de la optimización. A nuestro juicio, esto no resulta del todo óptimo, porque la capacidad exploratoria del algoritmo no se distribuye uniformemente en el tiempo, lo cual podemos notar en la visualización de las funciones de prueba como ruido blanco la mayor parte del tiempo. La irregularidad de la búsqueda también puede juzgarse partiendo de los gráficos de convergencia de la parte derecha de la ventana del banco de pruebas. Podemos observar cierta aceleración de la convergencia al principio de la optimización, lo cual es característico de casi todos los algoritmos; después de un comienzo brusco, se da una notable ralentización de la convergencia en la mayor parte de la optimización. Solo hacia el final se observa nuevamente una aceleración significativa de la convergencia. De lo anterior, podemos concluir que la variación dinámica de la dispersión es motivo para una investigación y experimentación más detalladas. Como podemos ver, la convergencia podría haber continuado si el número de iteraciones hubiera sido mayor. No obstante, las pruebas comparativas tienen limitaciones que deben cumplirse para mantener la objetividad y la validez práctica.
Bien, vamos a analizar de la tabla de calificación final. La tabla muestra que el líder absoluto al momento de escribir este artículo es el IWO: el algoritmo ha obtenido los mejores resultados en dos de las nueve pruebas, mientras que en las demás se ha situado muy por encima de la media, por lo que su puntuación final es de 100. En el segundo puesto se encuentra ACOm, una versión modificada del algoritmo de colonia de hormigas, que sigue siendo el mejor en 5 de las 9 pruebas.
| AO | Description | Rastrigin | Rastrigin final | Forest | Forest final | Megacity (discrete) | Megacity final | Final result | ||||||
| 10 params (5 F) | 50 params (25 F) | 1000 params (500 F) | 10 params (5 F) | 50 params (25 F) | 1000 params (500 F) | 10 params (5 F) | 50 params (25 F) | 1000 params (500 F) | ||||||
| IWO | invasive weed optimization | 1,00000 | 1,00000 | 0,33519 | 2,33519 | 0,79937 | 0,46349 | 0,41071 | 1,67357 | 0,75912 | 0,44903 | 0,94088 | 2,14903 | 100,000 |
| ACOm | ant colony optimization M | 0,36118 | 0,26810 | 0,17991 | 0,80919 | 1,00000 | 1,00000 | 1,00000 | 3,00000 | 1,00000 | 1,00000 | 0,10959 | 2,10959 | 95,996 |
| COAm | cuckoo optimization algorithm M | 0,96423 | 0,69756 | 0,28892 | 1,95071 | 0,64504 | 0,34034 | 0,21362 | 1,19900 | 0,67153 | 0,34273 | 0,45422 | 1,46848 | 74,204 |
| FAm | firefly algorithm M | 0,62430 | 0,50653 | 0,18102 | 1,31185 | 0,55408 | 0,42299 | 0,64360 | 1,62067 | 0,21167 | 0,28416 | 1,00000 | 1,49583 | 71,024 |
| BA | bat algorithm | 0,42290 | 0,95047 | 1,00000 | 2,37337 | 0,17768 | 0,17477 | 0,33595 | 0,68840 | 0,15329 | 0,07158 | 0,46287 | 0,68774 | 59,650 |
| ABC | artificial bee colony | 0,81573 | 0,48767 | 0,22588 | 1,52928 | 0,58850 | 0,21455 | 0,17249 | 0,97554 | 0,47444 | 0,26681 | 0,35941 | 1,10066 | 57,237 |
| FSS | fish school search | 0,48850 | 0,37769 | 0,11006 | 0,97625 | 0,07806 | 0,05013 | 0,08423 | 0,21242 | 0,00000 | 0,01084 | 0,18998 | 0,20082 | 20,109 |
| PSO | particle swarm optimisation | 0,21339 | 0,12224 | 0,05966 | 0,39529 | 0,15345 | 0,10486 | 0,28099 | 0,53930 | 0,08028 | 0,02385 | 0,00000 | 0,10413 | 14,232 |
| RND | random | 0,17559 | 0,14524 | 0,07011 | 0,39094 | 0,08623 | 0,04810 | 0,06094 | 0,19527 | 0,00000 | 0,00000 | 0,08904 | 0,08904 | 8,142 |
| GWO | grey wolf optimizer | 0,00000 | 0,00000 | 0,00000 | 0,00000 | 0,00000 | 0,00000 | 0,00000 | 0,00000 | 0,18977 | 0,04119 | 0,01802 | 0,24898 | 1,000 |
El algoritmo de malas hierbas invasoras resulta muy efectivo para la búsqueda global. Este algoritmo tiene una buena usabilidad, aunque no se utilice el mejor miembro de la población y no haya mecanismos de protección contra posibles atascos en los extremos locales. No existe equilibrio entre la exploración y el funcionamiento del algoritmo, pero esto no ha influido negativamente en su precisión y velocidad. Este algoritmo presenta otras desventajas. El rendimiento desigual de la búsqueda durante la optimización sugiere que la productividad de IWO podría ser potencialmente mayor si se resuelven los problemas señalados.
El histograma con los resultados de las pruebas de los algoritmos se encuentra en la figura 4.
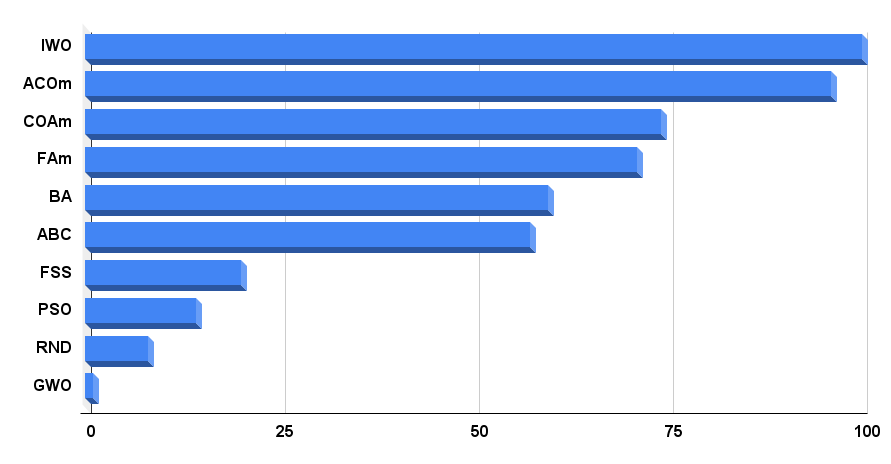
Figura 4. Histograma con los resultados finales de los algoritmos de prueba.
Conclusiones sobre las propiedades del algoritmo de optimización de malas hierbas invasoras (IWO):
Ventajas:
1. Es rápido.
2. Funciona bien con varios tipos de funciones, tanto suaves como discretas.
3. Buena escalabilidad.
Desventajas:
1. Requiere muchos ajustes (aunque los parámetros son intuitivos, el gran número de parámetros sigue suponiendo una desventaja).
Traducción del ruso hecha por MetaQuotes Ltd.
Artículo original: https://www.mql5.com/ru/articles/11990
- Aplicaciones de trading gratuitas
- 8 000+ señales para copiar
- Noticias económicas para analizar los mercados financieros
Usted acepta la política del sitio web y las condiciones de uso