
Нейросети — это просто (Часть 51): Актор-критик, управляемый поведением (BAC)

Введение
Последние 2 статьи были посвящены алгоритму Soft Actor-Critic. Напомню, что данный алгоритм применяется для обучения стохастических моделей в непрерывном пространстве действий. Основной особенностью данного метода является введение энтропийной составляющей в функцию вознаграждения, что позволяет регулировать баланс между исследованием окружающей среды и эксплуатацией модели. Но, в то же время, данный подход накладывает и некоторые ограничения на обучаемые модели. Использование энтропии требует некого представления о вероятности совершения действий, что довольно сложно напрямую посчитать для непрерывного пространства действий.
Мы использовали подход квантильного распределения. И здесь добавляется настройка гиперпараметров квантильного распределения. Сам подход использования квантильного распределения немного отодвигает нас от непрерывного пространства действий. Ведь каждый раз при выборе действия мы выбирали квантиль из выученного вероятностного распределения и в качестве действия использовали его среднее значение. Да, при достаточно большом количестве квантилей и достаточно малом диапазоне возможных значений мы приближаемся к непрерывному пространству действий. Но это ведет к увеличению сложности модели и росту затрат на её обучение и эксплуатацию. И конечно это накладывает ограничение на архитектуру обучаемых моделей.
В данной статье мы поговорим об альтернативном подходе Behavior-Guided Actor-Critic (BAC), который был представлен в апреле 2021 года.
1. Особенности построения алгоритма
Вначале давайте порассуждаем о необходимости исследования окружающей среды в целом. Думаю, все согласны с необходимостью данного процесса. Но для чего конкретно и на какой стадии?
Начнем с простого примера. Мы впервые попадаем в некую комнату с 3 одинаковыми дверями и нам нужен выход на улицу. Что мы делаем? Поочередно открываем двери, пока не найдем нужную. Попадая повторно в эту же комнату для выхода на улицу, мы уже не будем открывать все двери, а сразу направимся к уже известному выходу. Если же в этой ситуации у нас будет другая задача, то тут возможны варианты. Мы можем снова открывать все двери, кроме уже известного нам выхода, и искать нужную. А можем сначала вспомнить какие мы двери открывали ранее при поиске выхода и была ли среди них нужная нам. Если мы помним нужную дверь, то направляемся к ней. В противном случае проверяем двери, которые не открывали ранее.
Вывод: исследование окружающей среды нам необходимо в незнаком состоянии для выбора правильного действия. После нахождения необходимого маршрута дополнительное исследование окружающей среды может только мешать.
Однако, при изменении задачи в известном состоянии нам может потребоваться дополнительное исследование окружающей среды. Сюда можно отнести и поиск более оптимального маршрута. В приведенном выше примере, если для выхода нам потребовалось пройти ещё несколько помещений или вышли не с той стороны здания.
Следовательно, нам нужен такой алгоритм, который позволяет усиливать исследование окружающей среды в неизученных состояниях и минимизировать в ранее исследованных.
Применяемая в Soft Actor-Critic энтропийная регуляризация может соответствовать этому требованию, но только с рядом условностей. Энтропия действия велика тогда, когда мала его вероятность. Да, состояние, в которое мы переходим после действия с малой вероятностью, скорее всего плохо изучено. И энтропийная регуляризация толкает нас совершать его повторно, чтобы лучше изучить последующие состояния. Но что происходит после изучения этого вектора движения? Если мы нашли более оптимальный путь, то в процессе обучения модели вероятность действия увеличивается и снижается энтропия. Это соответствует нашим требованиям. Однако снижается вероятность других действий и растет их энтропия. Что толкает нас к дополнительному исследованию других направлений. И только значительный уровень положительного вознаграждения может удержать наш акцент на этом пути.
С другой стороны, если новый маршрут не удовлетворяет нашим требования, то в процессе обучения модели мы снижаем вероятность такого действия. При этом ещё больше растет его энтропия, которая толкает нас совершать его повторно. И только значительное отрицательное вознаграждение (штраф) способно нас оттолкнуть от повторного совершения опрометчивого шага.
Именно поэтому очень важен правильный взвешенный выбор коэффициента температуры, чтобы обеспечить нужный баланс между исследованием и эксплуатацией модели.
Немного странно. Мы начинали с ε-жадной стратегии, в которой баланс между исследованием и эксплуатацией регулировался константой вероятности. Усложняем модель и опять говорим о важности выбора коэффициента. Дежавю.
В поисках иного решения мы обращаем свое внимание на алгоритм Behavior-Guided Actor-Critic (BAC), который был представлен в статье "Behavior-Guided Actor-Critic: Improving Exploration via Learning Policy Behavior Representation for Deep Reinforcement Learning". Авторы метода предлагают заменить энтропийную составляющую в функции вознаграждения на некую величину оценки изученности моделью пары состояние—действие.
Выбор пары "Состояние—Действие" вполне очевиден — это то, что мы знаем в конкретный момент времени. Оказавшись в некоем состоянии, мы выбираем действие. И от него, в какой-то мере, зависит наш переход в следующее состояние и вознаграждение за этот переход. При этом, за одним и тем же действием может быть переход в ожидаемое новое состояние, а может быть и иное состояние (с определенной долей вероятности). К примеру, чтобы открыть дверь нам нужно подойти к ней. Здесь вполне ожидаемо, что после каждого шага мы будем ближе к двери. Затем, повернув ручку двери мы её открываем. Но она может оказаться закрытой на замок и не открыться (не зависящий от нас фактор). Вознаграждение или штраф нас ждет за дверью. Но мы не узнаем этого, пока не попадем туда. Таким образом, только рассмотрев все возможные действия из отдельного состояния мы можем говорить о полном его исследовании.
В качестве меры изучения пары "Состояние—Действие" авторы метода предлагают использовать автоэнкодер. Надо сказать, что мы уже несколько раз сталкивались с использованием автоэнкодеров в разных алгоритмах. Но всегда это было связано со сжатием данных или построением неких моделей взаимозависимостей. Опыт показывает, что построение моделей финансовых рынков довольно сложная задача ввиду большого числа не всегда очевидных влияющих факторов. В данном же случае используется другое свойство автоэнкодера.
Автоэнкодер в чистом виде довольно хорошо копирует исходные данные. Но автоэнкодер — это нейронная сеть. И мы с самого начала говорили, что нейронные сети хорошо работают только на изученных данных. Иначе их результат может быть непредсказуем. Именно поэтому мы всегда акцентируем внимание на репрезентативности обучающей выборки. И неизменности гиперпараметров модели при обучении и эксплуатации.
Авторы метода воспользовались этим свойством нейронных сетей. После обучения на некоем наборе состояний и соответствующих действий мы получаем их хорошую копию на выходе автоэнкодера. Но стоит нам на вход модели только подать неизвестную пару "Состояние—Действие", как ошибка копирования данных сильно возрастет. Именно ошибку копирования данных мы и будем использовать в качестве меры изученности отдельной пары "Состояние—Действие".
Такой подход имеет ряд преимуществ перед энтропийной регуляризацией. Во-первых, такой подход применим как для стохастических, так и для детерминированных моделей. Использование автоэнкодера не влияет на выбор архитектуры Актера.
Во-вторых, стимулирующее вознаграждение пары "Состояние—Действие" снижается по мере изучения не зависимо от получаемого вознаграждения и вероятности совершения действия в будущем. И по мере обучения автоэнкодера стремится к "0", что ведет к полной эксплуатации модели.
Однако, при появлении нового состояния (а с учетом обобщающей способности нейронных сетей можно сказать не похожего на ранее изученные) сразу включается режим исследования окружающей среды.
И стимулирующее вознаграждение одной пары "Состояние—Действие" абсолютно не зависит от степени изучения, вероятности совершения или иных факторов другого действия в том же состоянии.
Разумеется, мы имеем дело с непрерывным пространством действий, а модель способно обобщать полученный опыт. И при изучении одной пары "Состояние-Действие" она может применять ранее полученный опыт на похожих состояниях и близких действиях. Но при этом ошибка переноса данных будет так же непрерывно изменяться и зависеть от близости (сходства) состояний и действий.
Математически обучение политики можно представить в следующем виде:
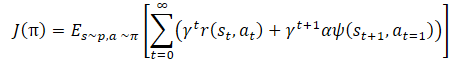
где γ — коэффициент дисконтирования,
α — коэффициент температуры,
ψ(St+1,At=1) — функция поведения последующего состояния (ошибка копирования автоэнкодером).
И мы опять видим коэффициент температуры для регулирования баланса между исследованием и эксплуатацией модели. Что опять ведет к вышеописанным сложностям настройки гиперпараметра и обучения модели. Авторы метода предложили немного изменить функцию обучения политики.
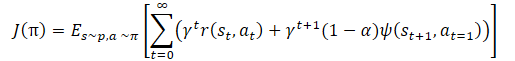
А сам коэффициент температуры α определять по формуле
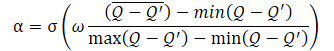
где σ — функция сигмоиды,
ω — равна 10,
Q — нейронная сеть оценки качества действия.
Используемая здесь нейронная сеть Q является аналогом критика и оценивает качество действия в определенном состоянии с учетом текущей политики.
Как можно заметить из представленной формулы, коэффициент температуры (1−α) колеблется в диапазоне от 0 до 0.5. Возрастает при повышении оценки качества действия. Очевидно, что в этот момент ошибка копирования данных автоэнкодером стремится к "0". С большой долей вероятности модель в данный момент находится в некоем локальном минимуме и исследование окружающей среды может помочь выбраться из данного состояния.
Когда же точность копирования данных мала, одновременно снижается и качество оценки действия в данном состоянии. Что приводит к росту знаменателя выражения внутри функции сигмоиды. И, соответственно, все значение аргумента сигмоиды снижается, а её результат стремится к 0.5.
Здесь надо обратить внимание, что мы всегда вычитаем меньшую ошибку из большей. Поэтому аргумент сигмоиды всегда больше "0". И практически никогда не равен "0", так как мы не можем делить на "0".
Так же надо сказать, что представленный алгоритм все же является членом большого семейства алгоритмов Актер-Критик и использует общие подходы данного семейства алгоритмов. Как и Soft Actor-Critic, алгоритм используется для обучения политик Актера в непрерывном пространстве действий. Мы будем использовать 2 модели Критиков для оценки качества действия и распределения градиента ошибки от вознаграждения к действию. Мы так же будем использовать мягкое обновление целевых моделей, буфер накопления опыта и другие общие подходы к обучению моделей Актер-Критик.
2. Реализация средствами MQL5
После рассмотрения теоретических аспектов предложенного подхода мы переходим к его реализации средствами MQL5. И первое с чего мы начинаем — это архитектура моделей. Для сопоставимости работы методов я не стал сильно менять архитектуру моделей из предыдущей статьи. Однако, я немного упростил архитектуру Актера и убрал сложный последний нейронный слой, созданный нами для реализации алгоритма стохастического Актера из метода Soft Actor-Critic. Однако, я оставил использование стохастической политики Актера. Но в этот раз она достигается за счет использования слоя латентного состояния вариационного автоэнкодера. Как вы помните, на вход данного нейронного слоя подается тензор данных ровно в 2 раза превышающий размер буфера его результатов. Указанный тензор исходных данных содержит средние значения и дисперсию распределения для каждого элемента результатов. Таким образом мы снижаем сложность вычислений, но оставляем стохастическую модель Актера в непрерывном пространстве действий.
bool CreateDescriptions(CArrayObj *actor, CArrayObj *critic, CArrayObj *autoencoder) { //--- CLayerDescription *descr; //--- if(!actor) { actor = new CArrayObj(); if(!actor) return false; } if(!critic) { critic = new CArrayObj(); if(!critic) return false; } if(!autoencoder) { autoencoder = new CArrayObj(); if(!autoencoder) return false; } //--- Actor actor.Clear(); //--- Input layer if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBaseOCL; int prev_count = descr.count = (HistoryBars * BarDescr); descr.activation = None; descr.optimization = ADAM; if(!actor.Add(descr)) { delete descr; return false; } //--- layer 1 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBatchNormOCL; descr.count = prev_count; descr.batch = 1000; descr.activation = None; descr.optimization = ADAM; if(!actor.Add(descr)) { delete descr; return false; } //--- layer 2 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronConvOCL; prev_count = descr.count = prev_count - 1; descr.window = 2; descr.step = 1; descr.window_out = 8; descr.activation = LReLU; descr.optimization = ADAM; if(!actor.Add(descr)) { delete descr; return false; } //--- layer 3 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronConvOCL; prev_count = descr.count = prev_count; descr.window = 8; descr.step = 8; descr.window_out = 8; descr.activation = LReLU; descr.optimization = ADAM; if(!actor.Add(descr)) { delete descr; return false; } //--- layer 4 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBaseOCL; descr.count = 256; descr.optimization = ADAM; descr.activation = LReLU; if(!actor.Add(descr)) { delete descr; return false; } //--- layer 5 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBaseOCL; prev_count = descr.count = 128; descr.activation = LReLU; descr.optimization = ADAM; if(!actor.Add(descr)) { delete descr; return false; } //--- layer 6 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronConcatenate; descr.count = LatentCount; descr.window = prev_count; descr.step = AccountDescr; descr.optimization = ADAM; descr.activation = SIGMOID; if(!actor.Add(descr)) { delete descr; return false; } //--- layer 7 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBaseOCL; descr.count = 256; descr.activation = LReLU; descr.optimization = ADAM; if(!actor.Add(descr)) { delete descr; return false; } //--- layer 8 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBaseOCL; descr.count = 256; descr.activation = LReLU; descr.optimization = ADAM; if(!actor.Add(descr)) { delete descr; return false; } //--- layer 9 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBaseOCL; descr.count = 2*NActions; descr.activation = LReLU; descr.optimization = ADAM; if(!actor.Add(descr)) { delete descr; return false; } //--- layer 10 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronVAEOCL; descr.count = NActions; descr.optimization = ADAM; if(!actor.Add(descr)) { delete descr; return false; }
Модель критика перенесена без изменений, и мы не будем на ней останавливаться.
Немного поговорим о модели автоэнкодера. Как было сказано в теоретическом блоке, автоэнкодер используется в качестве элемента памяти ранее рассмотренных пар "Состояние—Действие". Можно сказать своеобразный счетчик количества посещений данных пар. Но давайте вспомним, что именно пары "Состояние—Действие" оценивают и наши Критики. Точнее Критик оценивает отдельное действие в конкретном состоянии. Игра слов и понятий, но один набор исходных данных.
Ранее, для экономии ресурсов и времени обучения моделей мы исключили блок предварительной обработки исходных данных из архитектуры Критиков. Вместо этого мы используем уже обработанные данные из скрытого состояния модели Актера. И на входе Критика мы конкатенируем скрытое состояние и буфер результатов Актера, тем самым объединяем в один тензор состояние и действие.
Сейчас мы пойдем ещё дальше. На вход нашего автоэнкодера мы подадим скрытое состояние одного из Критиков. Да, мы могли по аналогии с Критиком использовать слой конкатенации 2 тензоров исходных данных. Но тогда нам бы пришлось решать вопрос сравнения 1 буфера результатов работы автоэнкодера с 2 буферами исходных данных. А использование одного буфера исходных данных из латентного представления Критика нам позволяет использовать более простую модель автоэнкодера и сравнивать исходные данные с результатами его работы "1:1". Таким образом, в архитектуре автоэнкодера мы будем использовать только полносвязные слои.
//--- Autoencoder autoencoder.Clear(); //--- Input layer if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBaseOCL; prev_count = descr.count = LatentCount; descr.activation = None; descr.optimization = ADAM; if(!autoencoder.Add(descr)) { delete descr; return false; } //--- layer 1 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBaseOCL; prev_count = descr.count = prev_count / 2; descr.optimization = ADAM; descr.activation = LReLU; if(!autoencoder.Add(descr)) { delete descr; return false; } //--- layer 2 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBaseOCL; prev_count = descr.count = prev_count / 2; descr.activation = LReLU; descr.optimization = ADAM; if(!autoencoder.Add(descr)) { delete descr; return false; } //--- layer 3 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBaseOCL; prev_count = descr.count = 20; descr.count = LatentCount; descr.activation = LReLU; descr.optimization = ADAM; if(!autoencoder.Add(descr)) { delete descr; return false; } //--- layer 4 if(!(descr = new CLayerDescription())) return false; if(!(descr.Copy(autoencoder.At(2)))) { delete descr; return false; } if(!autoencoder.Add(descr)) { delete descr; return false; } //--- layer 5 if(!(descr = new CLayerDescription())) return false; if(!(descr.Copy(autoencoder.At(1)))) { delete descr; return false; } if(!autoencoder.Add(descr)) { delete descr; return false; } //--- layer 6 if(!(descr = new CLayerDescription())) return false; if(!(descr.Copy(autoencoder.At(0)))) { delete descr; return false; } if(!autoencoder.Add(descr)) { delete descr; return false; } //--- return true; }
Обратите внимание, что начиная с 4 слоя автоэнкодера мы не стали полностью создавать описание новых нейронных слоёв. Вместо этого, мы просто скопировали ранее созданные описания в обратном порядке. Что позволило нам создать в Декодере зеркальную копию Энкодера. И любые изменения в архитектуре Энкодера (за исключением добавления новых слоёв) сразу отразятся в соответствующих слоях Декодера. Довольно удобный способ синхронизации описания архитектур нейронных слоев и может быть применен в различных случаях.
После создания описания архитектуры моделей мы переходим к организации процесса сбора базы примеров для обучения модели. Как и ранее, этот процесс организован в советнике "..\BAC\Research.mq5". Надо сказать, что метод BAC не вносит каких-либо изменений в алгоритм сбора первичных данных. Поэтому и изменения в данном советнике были минимальны.
Выше мы изменили функцию описания архитектуры моделей, добавив в нее описание Автоэнкодера. Следовательно, и при вызове данной функции в методе OnInit советника Research.mq5 нам необходимо передать 3 указателя на динамические массивы описания архитектуры моделей. Но так как в данном советнике мы будем использовать только Актера и нам не нужно описание других моделей. То мы и не будем создавать дополнительный массив объектов, а дважды укажем указатель на массив описания архитектуры Критика. При таком вызове в функции будет сначала создано описание архитектуры критика, затем оно будет удалено и в массив запишется архитектура автоэнкодера. В данном случае для нас это не критично, так как не используется ни модель критика, ни модель автоэнкодера.
//+------------------------------------------------------------------+ //| Expert initialization function | //+------------------------------------------------------------------+ int OnInit() { //--- ........ ........ //--- load models float temp; if(!Actor.Load(FileName + "Act.nnw", temp, temp, temp, dtStudied, true)) { CArrayObj *actor = new CArrayObj(); CArrayObj *critic = new CArrayObj(); if(!CreateDescriptions(actor, critic, critic)) { delete actor; delete critic; return INIT_FAILED; } if(!Actor.Create(actor)) { delete actor; delete critic; return INIT_FAILED; } delete actor; delete critic; //--- } //--- ........ ........ //--- return(INIT_SUCCEEDED); }
Кроме того, мы исключаем энтропийную составляющую из функции вознаграждения. В остальном код советника остался без изменений. А с полным кодом советника и всех его функций можно ознакомиться во вложении.
А вот с кодом советника обучения моделей "..\BAC\Study.mq5" пришлось поработать. Здесь мы используем и инициализируем все модели. Поэтому перед вызовом метода создания описания архитектуры моделей создаем дополнительный динамический массив для Автоэнкодера.
int OnInit() { //--- ResetLastError(); if(!LoadTotalBase()) { PrintFormat("Error of load study data: %d", GetLastError()); return INIT_FAILED; } //--- load models float temp; if(!Actor.Load(FileName + "Act.nnw", temp, temp, temp, dtStudied, true) || !Critic1.Load(FileName + "Crt1.nnw", temp, temp, temp, dtStudied, true) || !Critic2.Load(FileName + "Crt2.nnw", temp, temp, temp, dtStudied, true) || !Autoencoder.Load(FileName + "AEnc.nnw", temp, temp, temp, dtStudied, true) || !TargetCritic1.Load(FileName + "Crt1.nnw", temp, temp, temp, dtStudied, true) || !TargetCritic2.Load(FileName + "Crt2.nnw", temp, temp, temp, dtStudied, true)) { CArrayObj *actor = new CArrayObj(); CArrayObj *critic = new CArrayObj(); CArrayObj *autoencoder = new CArrayObj(); if(!CreateDescriptions(actor, critic, autoencoder)) { delete actor; delete critic; delete autoencoder; return INIT_FAILED; }
После получения архитектуры моделей инициализируем все модели и контролируем процесс выполнения операций.
if(!Actor.Create(actor) || !Critic1.Create(critic) || !Critic2.Create(critic) || !Autoencoder.Create(autoencoder)) { delete actor; delete critic; delete autoencoder; return INIT_FAILED; }
И не забываем о целевых моделях критиков.
if(!TargetCritic1.Create(critic) || !TargetCritic2.Create(critic)) { delete actor; delete critic; delete autoencoder; return INIT_FAILED; } delete actor; delete critic; delete autoencoder; //--- TargetCritic1.WeightsUpdate(GetPointer(Critic1), 1.0f); TargetCritic2.WeightsUpdate(GetPointer(Critic2), 1.0f); }
После чего обязательно переносим все модели в один контекст OpenCL. Автоэнкодер не является исключением.
OpenCL = Actor.GetOpenCL(); Critic1.SetOpenCL(OpenCL); Critic2.SetOpenCL(OpenCL); TargetCritic1.SetOpenCL(OpenCL); TargetCritic2.SetOpenCL(OpenCL); Autoencoder.SetOpenCL(OpenCL);
Далее идет блок проверки соответствия моделей.
Actor.getResults(Result); if(Result.Total() != NActions) { PrintFormat("The scope of the actor does not match the actions count (%d <> %d)", NActions, Result.Total()); return INIT_FAILED; } //--- Actor.GetLayerOutput(0, Result); if(Result.Total() != (HistoryBars * BarDescr)) { PrintFormat("Input size of Actor doesn't match state description (%d <> %d)", Result.Total(), (HistoryBars * BarDescr)); return INIT_FAILED; } //--- Actor.GetLayerOutput(LatentLayer, Result); int latent_state = Result.Total(); Critic1.GetLayerOutput(0, Result); if(Result.Total() != latent_state) { PrintFormat("Input size of Critic doesn't match latent state Actor (%d <> %d)", Result.Total(), latent_state); return INIT_FAILED; }
И здесь мы добавляем проверку соответствия архитектур Автоэнкодера и Критика.
Critic1.GetLayerOutput(1, Result); latent_state = Result.Total(); Autoencoder.GetLayerOutput(0, Result); if(Result.Total() != latent_state) { PrintFormat("Input size of Autoencoder doesn't match latent state Critic (%d <> %d)", Result.Total(), latent_state); return INIT_FAILED; }
В завершении метода мы, как и ранее, инициализируем вспомогательный буфер и вызываем событие обучение модели.
Gradient.BufferInit(AccountDescr, 0); //--- if(!EventChartCustom(ChartID(), 1, 0, 0, "Init")) { PrintFormat("Error of create study event: %d", GetLastError()); return INIT_FAILED; } //--- return(INIT_SUCCEEDED); }
Думаю, Вы заметили, что мы не создали дополнительную модель оценки качества действия для функции динамического расчета коэффициента температуры. Мы не зря акцентировали внимание, что функционал этой модели похож на работу Критика. И для упрощения общего процесса обучения мы будем использовать модели наших критиков в реализации динамического расчета коэффициента температуры.
После создания моделей мы незабываем осуществить сохранение обученных моделей в методе деинициализации советника OnDeinit. Здесь мы обращаем внимание на сохранение всех моделей. А так же на суффиксы названий файлов при сохранении и указанных при загрузке соответствующих моделей.
void OnDeinit(const int reason) { //--- TargetCritic1.WeightsUpdate(GetPointer(Critic1), Tau); TargetCritic2.WeightsUpdate(GetPointer(Critic2), Tau); Actor.Save(FileName + "Act.nnw", 0, 0, 0, TimeCurrent(), true); TargetCritic1.Save(FileName + "Crt1.nnw", Critic1.getRecentAverageError(), 0, 0, TimeCurrent(), true); TargetCritic1.Save(FileName + "Crt2.nnw", Critic2.getRecentAverageError(), 0, 0, TimeCurrent(), true); Autoencoder.Save(FileName + "AEnc.nnw", Autoencoder.getRecentAverageError(), 0, 0, TimeCurrent(), true); delete Result; }
На этом подготовительная работа закончена, и мы можем перейти к реализации непосредственного алгоритма обучения моделей в методе Train нашего советника.
В начале метода нас не ждет никаких сюрпризов. Мы, как и ранее, организовываем цикл обучения с указанным во внешних параметрах советника числом итераций.
void Train(void) { int total_tr = ArraySize(Buffer); uint ticks = GetTickCount(); //--- for(int iter = 0; (iter < Iterations && !IsStopped()); iter ++) { int tr = (int)((MathRand() / 32767.0) * (total_tr - 1)); int i = (int)((MathRand() * MathRand() / MathPow(32767, 2)) * (Buffer[tr].Total - 2));
В теле цикла случайным образом определяем траекторию из базы примеров и конкретный шаг траектории. После чего загружаем информацию о последующем состоянии в буфера данных.
//--- Target State.AssignArray(Buffer[tr].States[i + 1].state); float PrevBalance = Buffer[tr].States[i].account[0]; float PrevEquity = Buffer[tr].States[i].account[1]; Account.Clear(); Account.Add((Buffer[tr].States[i + 1].account[0] - PrevBalance) / PrevBalance); Account.Add(Buffer[tr].States[i + 1].account[1] / PrevBalance); Account.Add((Buffer[tr].States[i + 1].account[1] - PrevEquity) / PrevEquity); Account.Add(Buffer[tr].States[i + 1].account[2]); Account.Add(Buffer[tr].States[i + 1].account[3]); Account.Add(Buffer[tr].States[i + 1].account[4] / PrevBalance); Account.Add(Buffer[tr].States[i + 1].account[5] / PrevBalance); Account.Add(Buffer[tr].States[i + 1].account[6] / PrevBalance); double x = (double)Buffer[tr].States[i + 1].account[7] / (double)(D'2024.01.01' - D'2023.01.01'); Account.Add((float)MathSin(x != 0 ? 2.0 * M_PI * x : 0)); x = (double)Buffer[tr].States[i + 1].account[7] / (double)PeriodSeconds(PERIOD_MN1); Account.Add((float)MathCos(x != 0 ? 2.0 * M_PI * x : 0)); x = (double)Buffer[tr].States[i + 1].account[7] / (double)PeriodSeconds(PERIOD_W1); Account.Add((float)MathSin(x != 0 ? 2.0 * M_PI * x : 0)); x = (double)Buffer[tr].States[i + 1].account[7] / (double)PeriodSeconds(PERIOD_D1); Account.Add((float)MathSin(x != 0 ? 2.0 * M_PI * x : 0)); //--- if(Account.GetIndex() >= 0) Account.BufferWrite();
Дале мы осуществляем прямой проход Актера и 2 целевых моделей Критиков для определения ценности будущего состояния с учетом обновленной стратегии Актера.
if(!Actor.feedForward(GetPointer(State), 1, false, GetPointer(Account))) { PrintFormat("%s -> %d", __FUNCTION__, __LINE__); ExpertRemove(); break; } //--- if(!TargetCritic1.feedForward(GetPointer(Actor), LatentLayer, GetPointer(Actor)) || !TargetCritic2.feedForward(GetPointer(Actor), LatentLayer, GetPointer(Actor))) { PrintFormat("%s -> %d", __FUNCTION__, __LINE__); break; } TargetCritic1.getResults(Result); float reward = Result[0]; TargetCritic2.getResults(Result); reward = Buffer[tr].Revards[i] + DiscFactor * (MathMin(reward, Result[0]) - Buffer[tr].Revards[i + 1]);
На первый взгляд все, как и при использовании алгоритма Soft Actor-Critic. Мы так же используем минимальную оценку состояния из полученных от 2 Критиков. Но обратите внимание, мы исключили энтропийную составляющую. Это вполне логично в свете использования метода BAC. Однако мы не добавили поведенческую составляющую. Это намеренное отступление от оригинального алгоритма. Дело в том, что мы используем базу примеров, полученную в результате проходов Актеров с различными политиками. И введение сейчас поведенческой составляющей исказит оценку Критика, но не стимулирует Актера на прямую. Да, в последующем мы получим опосредованное стимулирование Актера при его обучении на оценках Критиков. Но есть и другая сторона медали. Каково соответствие количества раз использования пары "Состояние-Действие" при обучении Критика и той же или похожей (близкой) пары "Состояние-Действие" при обучении Актера. Перекос возможен как в одну, так и в другую сторону. Поэтому я решил использовать Автоэнкодер для оценки состояний и действий при обучении Актера. По моему убеждению, это позволит точнее оценивать частоту посещения состояний и используемых действий Актером с учетом обновления его политики поведения.
Следующим этапом идет процесс обучения Критиков. И мы загружаем данные выбранного состояния из базы примеров в буфера данных.
//--- Q-function study State.AssignArray(Buffer[tr].States[i].state); PrevBalance = Buffer[tr].States[MathMax(i - 1, 0)].account[0]; PrevEquity = Buffer[tr].States[MathMax(i - 1, 0)].account[1]; Account.Update(0, (Buffer[tr].States[i].account[0] - PrevBalance) / PrevBalance); Account.Update(1, Buffer[tr].States[i].account[1] / PrevBalance); Account.Update(2, (Buffer[tr].States[i].account[1] - PrevEquity) / PrevEquity); Account.Update(3, Buffer[tr].States[i].account[2]); Account.Update(4, Buffer[tr].States[i].account[3]); Account.Update(5, Buffer[tr].States[i].account[4] / PrevBalance); Account.Update(6, Buffer[tr].States[i].account[5] / PrevBalance); Account.Update(7, Buffer[tr].States[i].account[6] / PrevBalance); x = (double)Buffer[tr].States[i].account[7] / (double)(D'2024.01.01' - D'2023.01.01'); Account.Add((float)MathSin(x != 0 ? 2.0 * M_PI * x : 0)); x = (double)Buffer[tr].States[i].account[7] / (double)PeriodSeconds(PERIOD_MN1); Account.Add((float)MathCos(x != 0 ? 2.0 * M_PI * x : 0)); x = (double)Buffer[tr].States[i].account[7] / (double)PeriodSeconds(PERIOD_W1); Account.Add((float)MathSin(x != 0 ? 2.0 * M_PI * x : 0)); x = (double)Buffer[tr].States[i].account[7] / (double)PeriodSeconds(PERIOD_D1); Account.Add((float)MathSin(x != 0 ? 2.0 * M_PI * x : 0)); Account.BufferWrite();
После чего осуществляем прямой проход Актера. Напомню, что в данном случае мы используем его для предварительной обработки исходных данных состояния окружающей среды.
if(!Actor.feedForward(GetPointer(State), 1, false, GetPointer(Account))) { PrintFormat("%s -> %d", __FUNCTION__, __LINE__); break; }
Затем нам необходимо осуществить прямой и обратный проход Критиков для корректировки их параметров. При обучении моделей методом Soft Actor-Critic мы использовали чередование моделей. В данном случаем будем параллельно осуществлять обучение обоих Критиков на одних примерах. Мы вызываем методы прямого прохода Критиков для действий из базы примеров.
Actions.AssignArray(Buffer[tr].States[i].action); if(Actions.GetIndex() >= 0) Actions.BufferWrite(); //--- if(!Critic1.feedForward(GetPointer(Actor), LatentLayer, GetPointer(Actions)) || !Critic2.feedForward(GetPointer(Actor), LatentLayer, GetPointer(Actions))) { PrintFormat("%s -> %d", __FUNCTION__, __LINE__); break; }
Но прежде, чем осуществить обратный проход мы подготовим данные для расчета коэффициента температуры поведенческой составляющей нашей функции вознаграждения. Сначала мы сравним результаты оценки первым Критиком с рассчитанной выше оценкой будущего состояния и обновим значения минимальной, максимальной и средней ошибки.
Обратите внимание, что для первой итерации мы просто переносим текущую ошибку во все 3 переменные. А далее мы максимум и минимум обновляем по результатам сравнения. Затем считаем экспоненциальное среднее значение.
Critic1.getResults(Result); float error = reward - Result[0]; if(iter == 0) { MaxCriticError = error; MinCriticError = error; AvgCriticError = error; } else { MaxCriticError = MathMax(error, MaxCriticError); MinCriticError = MathMin(error, MinCriticError); AvgCriticError = 0.99f * AvgCriticError + 0.01f * error; }
Для второго Критика у нас уже есть начальные значения переменных. И мы обновляем их значения вне зависимости от итерации обучения моделей.
Critic2.getResults(Result); error = reward - Result[0]; MaxCriticError = MathMax(error, MaxCriticError); MinCriticError = MathMin(error, MinCriticError); AvgCriticError = 0.99f * AvgCriticError + 0.01f * error;
В завершении процесса обновления параметров Критиков нам остается осуществить обратны проход обоих моделей с указанием в качестве эталонного значения минимальной оценки будущего состояния от целевых моделей.
Result.Update(0, reward); if(!Critic1.backProp(Result, GetPointer(Actions), GetPointer(Gradient)) || !Critic2.backProp(Result, GetPointer(Actions), GetPointer(Gradient))) { PrintFormat("%s -> %d", __FUNCTION__, __LINE__); break; }
На этом завершается процесс обновления параметров критиков, и мы перехожим к обучению Актера. Авторами метода BAC для обучения Актера рекомендуется использовать Критика с минимальной оценкой выбранного действия. Чтобы не осуществлять прямой проход 2 Критиками и последующего сравнения их результатов, мы поступим немного иначе. Возьмем Критика с минимальной средней ошибкой предсказания оценки состояния и действия. Переоценка данной величины осуществляется при каждом обратном проходе модели Критика. И её извлечение потребует минимальных затрат, которые ничтожны по сравнению с осуществлением прямого прохода модели.
А чтобы не создавать сложные разветвленные структуры с повтором действий для одной и второй модели Критика мы проста сохраним указатель на нужную модель в локальную переменную. И далее будем работать с этой локальной переменной.
//--- Policy study CNet *critic = NULL; if(Critic1.getRecentAverageError() <= Critic2.getRecentAverageError()) critic = GetPointer(Critic1); else critic = GetPointer(Critic2);
В отличии от TD3, методы Актер-Критик обновляют политику Актера на каждой итерации. И мы будем использовать тот же набор исходных данных, который выбрали для обучения Критиков. Напомню, что в процессе обучения Критиков мы уже осуществили прямой проход Актера с текущим набором исходных данных. Поэтому сейчас нам достаточно осуществить прямой проход выбранного Критика для оценки действий Актера в текущем состоянии с учетом обновления его политики.
if(!critic.feedForward(GetPointer(Actor), LatentLayer, GetPointer(Actor)) || !Autoencoder.feedForward(critic, 1, NULL, -1)) { PrintFormat("%s -> %d", __FUNCTION__, __LINE__); break; }
После прямого прохода Критика мы осуществляем прямой проход Автоэнкодера. И здесь есть одни тонкий момент. Дело в том, что ранее, увязывая 2 модели в единое целое, мы добавили в метод прямого прохода замену слоя исходных данных последующей модели на указатель латентного слоя модели, предоставляющей эти исходные данные. И это работает замечательно, когда мы используем одного Актера в качестве донора для 2 Критиков. При первой итерации Критики удаляют ненужный слой исходных данных и сохраняют указатель на слой латентного состояния Актера. А вот в случае Автоэнкодера у нас обратная ситуация. Мы используем 2 модели Критика в качестве донора для одного Автоэнкодера. И при первой итерации Автоэнкодер удаляет ненужный слой исходных данных и сохраняет указатель на латентный слой используемого Критика. Но при смене Критика произойдет удаление слоя одного Критика и сохранение указателя на слой другого Критика. Такой процесс нам крайне не желателен. Более того, он губительный для всего нашего процесса обучения. Поэтому после первого удаления слоя исходных данных нам необходимо отключить флаг удаления объектов при обновлении массива нейронного слоя.
bool CNet::feedForward(CNet *inputNet, int inputLayer = -1, CNet *secondNet = NULL, int secondLayer = -1) { ........ ........ //--- if(layer.At(0) != neuron) if(!layer.Update(0, neuron)) { if(del_second) delete second; return false; } else layer.FreeMode(false); //--- ........ ........ //--- return true; }
Это небольшое отступление от процесса обучения и алгоритма BAC, но критично для нашей реализации построения процесса.
Вернемся к алгоритму нашего метода обучения моделей Train. После прямого прохода Автоэнкодера нам предстоит оценить погрешность копирования данных. Для этого мы загружаем результат работы Автоэнкодера и исходные данные из латентного состояния Критика. Для повышения эффективности нашего кода воспользуемся векторными переменными, в которые и загрузим оба буфера данных.
Autoencoder.getResults(AutoencoderResult);
critic.GetLayerOutput(1, Result);
Result.GetData(CriticResult);
И тут же мы загрузим результаты оценки действий Критиком.
critic.getResults(Result);
Оба потока информации нам необходимы для определения целевого значения при обучении политики Актера. Поэтому мы совместим весь расчет в одном блоке.
Ранее мы подготовили данные для вычисления коэффициента температуры. И сейчас мы сначала вычислим аргумент сигмоиды. Затем определим значение функции и вычтем его из "1".
float alpha = (MaxCriticError == MinCriticError ? 0 : 10.0f * (AvgCriticError - MinCriticError) / (MaxCriticError - MinCriticError)); alpha = 1.0f / (1.0f + MathExp(-alpha)); alpha = 1 - alpha; reward = Result[0]; reward = (reward > 0 ? reward + PoliticAdjust : PoliticAdjust); reward += AutoencoderResult.Loss(CriticResult, LOSS_MSE) * alpha;
Далее, по аналогии с подходов в TD3, мы смещаем параметры Актера в сторону увеличения доходности операций. Поэтому к текущей оценке действия мы прибавляем небольшую константу, стимулирующую смещение градиентов в сторону увеличения доходности.
И в завершении формирования целевого значения прибавляем поведенческую составляющую с учетом функции потерь Автоэнкодера. Обратите внимание, что благодаря векторным операциям размер функции потерь независимо от размера буферов данных определяется буквально в одну строчку.
Теперь, после формирования целевого значения мы можем осуществить обратный проход Критика и Актера для распределения градиента ошибки до действия и последующей корректировки параметров Актера.
Как и ранее, для исключения взаимной подстройки параметров Критика и Актера, перед осуществлением обратного прохода мы отключаем режим обучения Критика и не забываем его включить обратно после осуществления операций.
Result.Update(0, reward); critic.TrainMode(false); if(!critic.backProp(Result, GetPointer(Actor)) || !Actor.backPropGradient(GetPointer(Account), GetPointer(Gradient), LatentLayer) || !Actor.backPropGradient(GetPointer(Account), GetPointer(Gradient))) { PrintFormat("%s -> %d", __FUNCTION__, __LINE__); critic.TrainMode(true); break; } critic.TrainMode(true);
И здесь обратите внимание, что мы осуществляем 2 типа обратного прохода для Актера. Сначала мы распределяем градиент ошибки по блоку предварительной обработки данных, что позволит нам более точно настроить фильтры сверточных слоев с учетом требований Критиков. А затем осуществляем обратный проход для корректировки блока принятия решений о выборе конкретного действия. Очень важно осуществлять операции именно в этой последовательности. Так как после полного прямого прохода с корректировкой параметров блока принятия решения будут переписаны и градиенты ошибки для блока предварительной обработки данных. И в таком случае вызов дополнительного обратного прохода не только не будет иметь положительного эффекта, но и возможно его отрицательное влияния.
На данном этапе у нас обновлены параметры Критиков и Актера. Остается нам обновить параметры Автоэнкодера. Здесь все довольно просто. Мы передаем данные латентного состояния Критика в качестве эталонных значений и осуществляем обратный проход модели.
//--- Autoencoder study Result.AssignArray(CriticResult); if(!Autoencoder.backProp(Result, critic, 1)) { PrintFormat("%s -> %d", __FUNCTION__, __LINE__); break; }
В завершении итераций цикла обучения мы обновляем целевые модели обоих Критиков и информируем пользователя о ходе обучения.
//--- Update Target Nets TargetCritic1.WeightsUpdate(GetPointer(Critic1), Tau); TargetCritic2.WeightsUpdate(GetPointer(Critic2), Tau); //--- if(GetTickCount() - ticks > 500) { string str = StringFormat("%-15s %5.2f%% -> Error %15.8f\n", "Critic1", iter * 100.0 / (double)(Iterations), Critic1.getRecentAverageError()); str += StringFormat("%-15s %5.2f%% -> Error %15.8f\n", "Critic2", iter * 100.0 / (double)(Iterations), Critic2.getRecentAverageError()); Comment(str); ticks = GetTickCount(); } }
Финал метода обучения уже классический:
- очищаем поле комментариев,
- выводим результаты обучения,
- инициализируем завершение работы советника.
Comment(""); //--- PrintFormat("%s -> %d -> %-15s %10.7f", __FUNCTION__, __LINE__, "Critic1", Critic1.getRecentAverageError()); PrintFormat("%s -> %d -> %-15s %10.7f", __FUNCTION__, __LINE__, "Critic2", Critic2.getRecentAverageError()); ExpertRemove(); //--- }
С полным кодом советника обучения и всех используемых программ можно ознакомиться во вложении. Там же вы найдете и код советника тестирования, который практически без изменений перекочевал из прошлой статьи. В коде советника удалена лишь энтропийная составляющая при сохранении пройденной траектории.
На этом мы завершаем работу над построением советников и переходим к тестированию проделанной работы и обучению моделей.
Должен сказать, что, на мой взгляд, в данной работе получилось довольно большое количество итераций обмена данными между основной памятью и контекстом OpenCL. Это заметно в блоке определения поведенческой составляющей функции вознаграждения. И здесь есть над чем подумать. Но посмотрим, как это отразится на общей производительность процесса обучения модели.
3. Тестирование
Выше была проделана довольно большая работа по реализации алгоритма Behavior-Guided Actor-Critic и теперь настало время посмотреть на результат нашей работы. Как и ранее обучение моделей осуществлялось на исторических данных инструмента EURUSD тайм-фрейм H1 временной интервал в первые 5 месяцев 2023 года. Все параметры индикаторов используются по умолчанию. Начальный баланс 10000 USD.
На первом этапе была создана обучающая выборка из 300 случайных проходов, что дало более 750 тыс. отдельных наборов данных "Состояние → Действие → Новое состояние → Вознаграждение". Я акцентирую внимание на словах "случайных проходов". На данном этапе у нас нет предварительно обученной модели. И при каждом проходе в тестере стратегий советник "..\BAC\Research.mq5" генерирует новую модель и заполняет ее случайными параметрами. Соответственно, работа таких моделей будет также случайна, как и их параметры. На данном этапе я не ограничивал уровень минимальной доходности прохода для сохранения в базу примеров.
После сбора примеров мы осуществляем первичное обучение нашей модели. Для этого мы запускаем советник "..\BAC\Study.mq5" на 500000 итераций обучения моделей.
Должен сказать, что после первичного обучения модели довольно сильно ощущается стохастичность политики Актера. Это выражается в большом разбросе результатов отдельных проходов.
На втором этапе мы повторно запускаем советник сбора обучающих данных в режиме оптимизации тестера стратегий на 300 итераций с полным перебором параметров. На этот раз мы ограничиваем минимальный уровень доходности на уровне положительных результатов (0 или немного выше). В результате было добавлено относительно небольшое количество результатов. Буквально 15-20 проходов.
Обратите внимание, что при запуске советника сбора данных после первичного обучения при всех проходах используется одна предварительно обученная модель. И весь разброс результатов обусловлен стохастичностью политики Актера.
Далее мы повторно запускаем процесс обучения модели на тех же 500000 итераций.
Процесс сбора примеров и обучения модели повторяем несколько раз до получения желаемого результата или достижения локального минимума, когда очередная итераций сбора примеров и обучения модели не дает прогресса результатов.
Стоит отметить, что при очередном запуске советника сбора базы примеров, собранные ранее проходы не удаляются. А новые добавляются в конец файла. Но для предотвращения накопления слишком большой базы примеров была добавлена константа MaxReplayBuffer в файле "..\BAC\Trajectory.mqh". Данная константа определяет максимальное количество проходов (не размер файла). И по мере заполнения буфера более стары проходы будут удаляться. Я рекомендую Вам воспользоваться данной константой для регулирования размера базы примеров в соответствии с техническими возможностями вашего оборудования.
#define MaxReplayBuffer 500
Примерно после 7 итераций обновления базы примеров и обучения модели мне удалось получить модель, способную генерировать прибыль на обучающем временном интервале. На представленном графике явно прослеживается тенденция к росту капитала. Однако, есть и некоторые убыточные зоны.


За 5 месяцев периода обучения советник заработал 16% прибыли при максимальной просадке 8.41% по Эквити. А по балансу просадка была немного ниже и составила 6.68%. В целом было совершено 99 сделок, 51.5% из них было закрыто с прибылью. Количество прибыльных сделок практически равно количеству убыточных. Но средняя прибыльная сделка почти на 50% превышает среднюю убыточную сделку. Профит-фактор составил 1.53 и почти на таком же уровне показатель фактора восстановления.
Но мы обучаем модель для возможности использования в будущем, а не только в тестере стратегий. Поэтому для нас более важен тест модели на данных за пределами обучающей выборки. И мы провели тест той же модели на исторических данных июня 2023 года. Все прочие параметры тестирования остались без изменений.


Надо сказать, что результаты тестирования модели на новых данных сопоставимы с результатами на обучающей выборке. За 1 месяц советник заработал немного более 3% прибыли, что вполне сопоставимо с 16% за 5 месяцев обучающей выборки. Было совершено 11 сделок, что ниже соответствующего показателя на обучающей выборке. К сожалению, доля прибыльных сделок тоже ниже показателя обучающей выборке и составила только 36.4%. Однако средняя прибыльная сделка почти в 6 раз превышает среднюю убыточную. Благодаря этому профит-фактор увеличился до 3.12.
Заключение
В данной статье мы познакомились с ещё одним алгоритмом обучения моделей Behavior-Guided Actor-Critic. Он так же, как и метод Soft Actor-Critic, относится к большому семейству алгоритмов Актер-Критик и является альтернативой использованию метода Мягкого Актер-Критик. К преимуществам рассмотренного алгоритма можно отнести возможность обучения как стохастических, так и детерминированных моделей в непрерывном пространстве действий. Использование данного метода не несет каких-либо ограничений в построении обучаемых моделей.
В практической части данной статьи был реализован предложенный алгоритм средствами MQL5. И эффективность нашей реализации подтверждается результатами тестирования.
Но ещё раз повторюсь, что все представленные программы лишь демонстрируют возможность использования технологии. И не готовы для использования на реальных финансовых рынках. Перед их использование требуется доработка советников и дополнительное всестороннее тестирование.
Ссылки
Программы, используемые в статье
| # | Имя | Тип | Описание |
|---|---|---|---|
| 1 | Research.mq5 | Советник | Советник сбора примеров |
| 2 | Study.mq5 | Советник | Советник обучения агента |
| 3 | Test.mq5 | Советник | Советник для тестирования модели |
| 4 | Trajectory.mqh | Библиотека класса | Структура описания состояния системы |
| 5 | NeuroNet.mqh | Библиотека класса | Библиотека классов для создания нейронной сети |
| 6 | NeuroNet.cl | Библиотека | Библиотека кода программы OpenCL |
- Бесплатные приложения для трейдинга
- 8 000+ сигналов для копирования
- Экономические новости для анализа финансовых рынков
Вы принимаете политику сайта и условия использования
Thanks Sir @Dmitriy
//+------------------------------------------------------------------+
Всем здравствуйте. У меня данная версия примерно после 3-4 цикла (сбор БД - обучение - тест) стала давать просто прямую линию на тестах. Сделки не открывает. Обучение делал все разы по 500 000 итераций. Ещё интересный момент - в определённый момент ошибка одного из критиков стала сначала очень большой, а потом постепенно снизились ошибки обоих критиков до 0. И уже 2-3 цикла ошибки обоих критиков стоят на 0. И на тестах Test.mqh выдаётся прямая линия и отсутствие сделок. В проходах Research.mqh бывают проходы с отрицательной прибылью и сделками. Так же есть проходы с отсутствием сделок и нулевым исходом. С положительным исходом било только 5 проходов в одном из циклов.
Вообще как-то странно. Я выполнял обучение строго по инструкции Дмитрия во всех статьях, и ни с одной статьи не получилось получить результат. Я не понимаю что я делаю не так...