
Нейросети — это просто (Часть 90): Частотная интерполяция временных рядов (FITS)

Введение
Анализ временных рядов играет важную роль для принятия управленческих решений в области финансовых рынков. Данные временных рядов в финансовой сфере часто сложны и динамичны, а их обработка требует эффективных методов.
Недавние исследования в области анализа временных рядов привели к разработке сложных моделей и методов. Однако, эти модели часто требуют значительных вычислительных ресурсов, что делает их менее подходящими для использования в динамичных условиях финансовых рынков. То есть тогда, когда время принятия решения становится частью успешной стратегии.
Кроме того, в наше время все больше управляющих решений принимается с использованием мобильных устройств, которые также ограничены в ресурсах. Этот факт выдвигает дополнительные требования к моделям, используемым при принятии таких решений.
В данном контексте представление временных рядов в частотной области может обеспечить более эффективное и компактное представление наблюдаемых закономерностей. Например, использование спектральных данных и анализ частот с высокой амплитудой может помочь выявить важные признаки.
Ранее мы познакомились с методом FEDformer, который использует частотную область для поиска закономерностей во временном ряде. Однако используемый в нем Transformer не относится к легковесным моделям. Вместо сложных моделей, требующих больших вычислительных затрат, в статье "FITS: Modeling Time Series with 10k Parameters" был представлен метод частотной интерполяции временных рядов (Frequency Interpolation Time Series — FITS). Это компактное и эффективное решение для анализа и прогнозирования временных рядов. FITS использует интерполяцию в частотной области для расширения окна анализируемого временного сегмента, что позволяет эффективно извлекать временные признаки без значительных затрат вычислительных ресурсов.
Авторы FITS выделяют следующие преимущества своего метода:
- FITS является легкой моделью с небольшим количеством параметров, что делает его идеальным выбором для использования на устройствах с ограниченными ресурсами.
- В FITS используется комплексная нейронная сеть для сбора информации об амплитуде и фазе сигнала, что повышает эффективность анализа данных временных рядов.
1. Алгоритм FITS
Анализ временных рядов в частотной области позволяет разложить сигнал на линейную комбинацию синусоидальных компонент без потери данных. Каждая из этих компонент обладает уникальной частотой, начальной фазой и амплитудой. В то время как прогнозирование временного ряда может быть сложной задачей, прогнозирование отдельных синусоидальных компонент относительно проще, поскольку требуется только корректировка фазы синусоидальной волны на основе временного сдвига. Сдвинутые таким образом синусоидальные волны линейно объединяются для получения прогнозных значений анализируемого временного ряда.
Такой подход позволяет эффективно сохранять частотные характеристики анализируемого окна временного ряда. При этом сохраняется семантическая последовательность между временным окном и горизонтом прогнозирования.
Однако прогнозирование каждого синусоидального компонента во временной области может быть довольно трудоемким. Для решения этой проблемы авторы метода FITS предлагают использовать сложную частотную область, что обеспечивает более компактное и информативное представление данных.
Быстрое преобразование Фурье (FFT) эффективно преобразует сигналы дискретного временного ряда из временной области в комплексную частотную область. В анализе Фурье комплексная частотная область представляется последовательностью, в которой каждый частотный компонент характеризуется комплексным числом. Это комплексное число отражает амплитуду и фазу компонента, обеспечивая полное описание. Амплитуда частотного компонента представляет величину, или силу этого компонента в исходном сигнале во временной области. Напротив, фаза показывает временной сдвиг или задержку, вносимую этим компонентом. Математически комплексное число, связанное с частотной составляющей, можно представить как комплексный экспоненциальный элемент с заданной амплитудой и фазой:
![]()
где X(f) — комплексное число, связанное с частотной составляющей на частоте f,
|X(f)| — амплитуда компонента,
θ(f) — фаза компонента.
На комплексной плоскости экспоненциальный элемент можно представить в виде вектора с длиной, равной амплитуде, и углом, равным фазе:
![]()
Таким образом, комплексное число в частотной области обеспечивает краткий и элегантный способ представления амплитуды и фазы каждого частотного компонента в преобразовании Фурье.
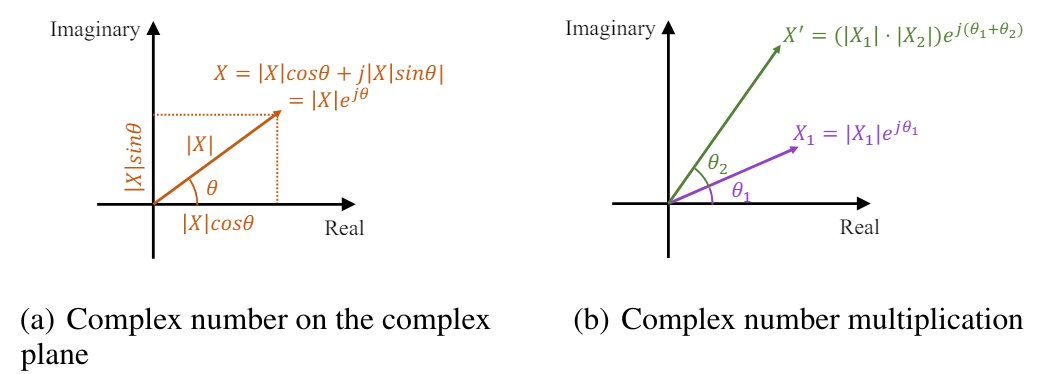
Временной сдвиг сигнала соответствует фазовому сдвигу в частотной области. В области комплексных частот такой сдвиг фазы можно выразить в виде умножения единичного элемента комплексной экспоненты на соответствующую фазу. Смещенный сигнал по-прежнему имеет амплитуду |X(f)|, а фаза показывает линейный сдвиг во времени.
Таким образом, масштабирование амплитуды и фазовый сдвиг могут быть одновременно выражены как умножение комплексных чисел.
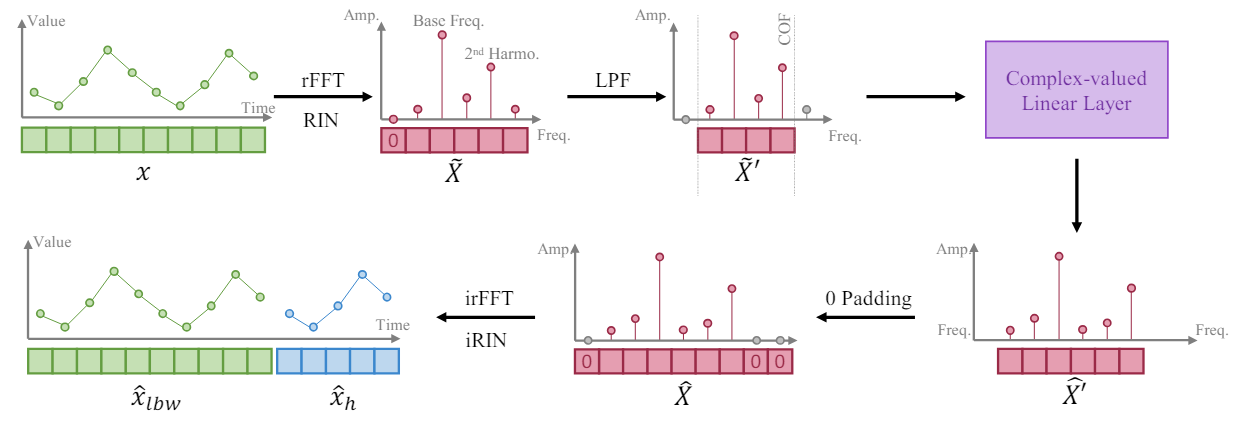
Руководствуясь тем фактом, что более длинный временной ряд обеспечивает более высокое частотное разрешение в своем частотном представлении, авторы метода FITS обучают модель расширять сегмент временного ряда путем интерполяции частотного представления анализируемого окна исходных данных. Они предлагают использовать один комплексный линейный слой для обучения такой интерполяции. В результате модель может изучать масштабирование амплитуды и фазовый сдвиг как умножение комплексных чисел во время процесса интерполяции. В алгоритме FITS используется быстрое преобразование Фурье для проецирования сегментов временных рядов в комплексную частотную область. А после интерполяции частотное представление проецируется обратно во временное представление с помощью обратного FFT.
Однако среднее значение таких сегментов приведет к очень большому компоненту с нулевой частотой в его комплексном частотном представлении. Для решения этой проблемы полученный сигнал пропускают через обратимую нормализацию (RevIN), что позволяет получить экземпляр с нулевым средним.
Кроме того, авторы метода включают в FITS фильтр нижних частот (LPF) для уменьшения размера модели. Фильтр низких частот эффективно устраняет высокочастотные компоненты выше заданной частоты среза, уплотняя представление модели и сохраняя при этом важную информацию о временных рядах.
Несмотря на работу в частотной области, FITS обучается во временной области с использованием стандартных функций потерь, таких как среднеквадратическая ошибка (MSE) после обратного быстрого преобразования Фурье. Это обеспечивает универсальный подход, адаптированный к различным последующим задачам временных рядов.
В случае задач прогнозирования FITS генерирует окно ретроспективного анализа вместе с горизонтом планирования. Это позволяет обеспечить контроль над прогнозированием и ретроспективным анализом, при этом модели рекомендуется точно реконструировать окно ретроспективного анализа. Проведенный в авторской статье анализ показывает, что сочетание ретроспективного анализа и надзора за прогнозами может привести к повышению производительности в определенных сценариях.
Для задач реконструкции FITS субдискретизирует исходный сегмент временного ряда на основе определенной скорости субдискретизации. Затем выполняется частотная интерполяция, которая позволяет восстановить сегмент с пониженной дискретизацией обратно в его исходную форму. Таким образом, применяется прямой контроль с использованием потерь для обеспечения точной реконструкции сигнала.
Чтобы контролировать длину тензора результатов модели, авторы метода вводят скорость интерполяции, обозначаемую как 𝜂, которая представляет собой отношение требуемого размера тензора результатов модели на соответствующий размер тензора исходных данных.
Примечательно, что при применении фильтра нижних частот (LPF) размер тензора исходных данных нашего комплексного слоя соответствует частоте среза (COF) LPF. После выполнения частотной интерполяции представление комплексной частоты дополняется нулями до требуемого размера тензора результатов. Перед применением обратного FFT вводится дополнительный нуль как компонент нулевой частоты представления.
Основная цель включения LPF в FITS — сжатие объема модели при сохранении важной информации. LPF достигает этого путем отбрасывания частотных составляющих выше заданной частоты среза (COF), что приводит к более краткому представлению в частотной области. LPF сохраняет соответствующую информацию во временных рядах, отбрасывая при этом компоненты, выходящие за рамки возможностей обучения модели. Это гарантирует сохранение значительной части значимого содержания исходного временного ряда. Проведенные авторами метода эксперименты показывают, что отфильтрованный сигнал демонстрирует минимальные искажения даже при сохранении только четверти исходного представления в частотной области. Более того, высокочастотные компоненты, отфильтрованные LPF, обычно содержат шум, который по своей сути не имеет значения для эффективного моделирования временных рядов.
Выбор подходящей частоты среза (COF) остается нетривиальной задачей. Чтобы решить эту проблему, авторы FITS предлагают метод, основанный на гармоническом содержании доминирующей частоты. Гармоники, которые являются целыми числами, кратными доминирующей частоте, играют важную роль в формировании формы сигнала временного ряда. Сравнивая частоту среза с этими гармониками, мы сохраняем соответствующие частотные компоненты, связанные со структурой и периодичностью сигнала. Этот подход использует внутреннюю связь между частотами для извлечения значимой информации, одновременно подавляя шум и ненужные высокочастотные компоненты.
Авторская визуализация FITS представлена ниже.
2. Реализация средствами MQL5
После ознакомления с теоретическими аспектами метода FITS, мы переходим к практической реализации предложенных подходов средствами MQL5.
Как обычно, мы воспользуемся предложенными подходами, но наша реализация будет несколько отличаться от авторского видения алгоритма ввиду специфики решаемой задачи.
2.1 Реализация FFT
Из представленного выше теоретического описания метода можно заметить, что в его основе лежит прямое и обратное быстрое разложение Фурье. С его помощью мы сначала переводим анализируемый сигнал в область частотных характеристик, а затем прогнозную последовательность возвращаем в представление временного ряда. В данном случае можно выделить два преимущества быстрого преобразования Фурье:
- скорость выполнения операций по сравнению с другими аналогичными преобразованиями;
- возможность выразить обратное преобразование через прямое.
Здесь стоит отметить, что в рамках нашей задачи нам необходима реализация FFT многомерного временного ряда. Которое на практике является тем же FFT, примененным к каждому унитарному временному ряду в нашей многомерной последовательности.
Напомню, что основной объем математических операций в наших реализациях перенесен в OpenCL. Это позволяет нам распределить выполнение большого количества однотипных операций с независимыми данными по нескольким параллельным потокам. И тем самым сократить время выполнения операций. Операции быстрого разложения Фурье мы также будем выполнять на стороне OpenCL. В каждом из параллельных потоков мы выполним разложение отдельного унитарного временного ряда.
Алгоритм выполнения операций мы оформим в виде кернела FFT. В параметрах кернела мы будем передавать указатели на 4 массива данных. Здесь мы используем по два массива для исходных данных и результатов операций. Один массив содержит действительную часть комплексного значения (амплитуду сигнала), а второй — мнимую (его фазу).
Однако стоит обратить внимание, что не всегда мы на вход кернела будем подавать мнимую часть сигнала. Например, при разложении исходного временного ряда у нас её просто нет. В этой ситуации выход довольно прост – мы заменяем недостающие данные нулевыми значениями. А чтобы не передавать отдельный буфер, заполненный нулевыми значениями, мы просто создадим флаг input_complex в параметрах кернела.
Второй момент, о котором следует помнить — используемый нами алгоритм Кули-Тьюки для FFT работает только для последовательностей, длина которых является степенью 2. И это условие накладывает серьезные ограничения. Но сразу скажу, что это ограничение на подготовку анализируемого сигнала. Метод отлично работает, если мы заполним недостающие элементы последовательности нулевыми значениями. И опять, чтобы не осуществлять излишнее копирование данных с целью переформатирования временного ряда, мы добавим в параметрах кернала две переменные: input_window и output_window. В первой мы укажем реальную длину анализируемой последовательности, а во второй — размер вектора результатов разложения, который является степенью 2. Уточню, что в данном случае мы говорим о размерах унитарной последовательности.
Ещё один параметр reverse указывает на направление операции: прямое или обратное преобразование.
__kernel void FFT(__global float *inputs_re, __global float *inputs_im, __global float *outputs_re, __global float *outputs_im, const int input_window, const int input_complex, const int output_window, const int reverse ) { size_t variable = get_global_id(0);
В теле кернела мы сначала определяем идентификатор потока, который нам укажет на анализируемую унитарную последовательность. Тут же мы определим смещения в буферах данных и другие необходимые константы.
const ulong N = output_window; const ulong N2 = N / 2; const ulong inp_shift = input_window * variable; const ulong out_shift = output_window * variable;
Следующим этапом мы пересортируем исходные данные в специфическом порядке, который позволит немного оптимизировать алгоритм FFT.
uint target = 0; for(uint position = 0; position < N; position++) { if(target > position) { outputs_re[out_shift + position] = (target < input_window ? inputs_re[inp_shift + target] : 0); outputs_im[out_shift + position] = ((target < input_window && input_complex) ? inputs_im[inp_shift + target] : 0); outputs_re[out_shift + target] = inputs_re[inp_shift + position]; outputs_im[out_shift + target] = (input_complex ? inputs_im[inp_shift + position] : 0); } else { outputs_re[out_shift + position] = inputs_re[inp_shift + position]; outputs_im[out_shift + position] = (input_complex ? inputs_im[inp_shift + position] : 0); } unsigned int mask = N; while(target & (mask >>= 1)) target &= ~mask; target |= mask; }
Далее идет непосредственное преобразование данных, которое осуществляется в системе вложенных циклов. Во внешнем цикле мы строим итерации FFT для отрезков длиной 2, 4, 8, ... n.
float real = 0, imag = 0; for(int len = 2; len <= (int)N; len <<= 1) { float w_real = (float)cos(2 * M_PI_F / len); float w_imag = (float)sin(2 * M_PI_F / len);
В теле цикла мы определим множитель поворота аргумента на 1 пункт длины цикла и организуем вложенный цикл перебора блоков в анализируемой последовательности.
for(int i = 0; i < (int)N; i += len) { float cur_w_real = 1; float cur_w_imag = 0;
Здесь мы объявляем переменные текущего поворота фазы и организуем ещё один вложенный цикл перебора элементов в блоке.
for(int j = 0; j < len / 2; j++) { real = cur_w_real * outputs_re[out_shift + i + j + len / 2] - cur_w_imag * outputs_im[out_shift + i + j + len / 2]; imag = cur_w_imag * outputs_re[out_shift + i + j + len / 2] + cur_w_real * outputs_im[out_shift + i + j + len / 2]; outputs_re[out_shift + i + j + len / 2] = outputs_re[out_shift + i + j] - real; outputs_im[out_shift + i + j + len / 2] = outputs_im[out_shift + i + j] - imag; outputs_re[out_shift + i + j] += real; outputs_im[out_shift + i + j] += imag; real = cur_w_real * w_real - cur_w_imag * w_imag; cur_w_imag = cur_w_imag * w_real + cur_w_real * w_imag; cur_w_real = real; } } }
В теле цикла мы сначала модифицируем анализируемые элементы, а затем изменяем значение переменных текущей фазы для следующей итерации.
Обратите внимание, что модификация элементов буферов осуществляется "по месту" без выделения дополнительной памяти.
После завершения итераций системы циклов мы проверяем значение флага reverse. И в случае выполнения обратного преобразования, мы пересортируем данные в буфере результатов. При этом полученные значения разделим на количество элементов в последовательности.
if(reverse) { outputs_re[0] /= N; outputs_im[0] /= N; outputs_re[N2] /= N; outputs_im[N2] /= N; for(int i = 1; i < N2; i++) { real = outputs_re[i] / N; imag = outputs_im[i] / N; outputs_re[i] = outputs_re[N - i] / N; outputs_im[i] = outputs_im[N - i] / N; outputs_re[N - i] = real; outputs_im[N - i] = imag; } } }
2.2 Объединение вещественной и мнимой частей прогнозного распределения
Представленный выше кернел позволяет выполнять прямое и обратное быстрое разложение Фурье, что в принципе покрывает наши потребности в данном вопросе. Но есть ещё один момент в методе FITS, на который следует обратить внимание. Авторы метода используют комплексную нейронную сесть для интерполяции данных. Для детального ознакомления с комплексными нейронными сетями я предлагаю познакомиться со статьей "A Survey of Complex-Valued Neural Networks". В рамках данной реализации мы воспользуемся существующими классами нейронных слоев, которые будут отдельно интерполировать вещественную и мнимую части с последующим их объединением по формуле:
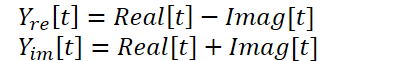
Для выполнения данных операций создадим кернел ComplexLayer. Алгоритм кернела довольно прост. Мы лишь идентифицируем поток в двух измерениях, который указывает нам на строку и столбец матриц. Определяем смещения в буферах данных и выполняем несложные математические операции.
__kernel void ComplexLayer(__global float *inputs_re, __global float *inputs_im, __global float *outputs_re, __global float *outputs_im ) { size_t i = get_global_id(0); size_t j = get_global_id(1); size_t total_i = get_global_size(0); size_t total_j = get_global_size(1); uint shift = i * total_j + j; //--- outputs_re[shift] = inputs_re[shift] - inputs_im[shift]; outputs_im[shift] = inputs_im[shift] + inputs_re[shift]; }
Аналогичным образом построен кернел обратного распространения ошибки ComplexLayerGradient, с кодом которого я предлагаю вам самостоятельно познакомиться во вложении.
На этом мы завершаем работу на стороне OpenCL программы.
2.3 Создание класса метода FITS
После завершения работы с кернелами программы OpenCL, мы переходим к основной программе, где создадим класс CNeuronFITSOCL для имплементации подходов, предложенных авторами метода FITS. Новый класс мы создаем наследником базового класса нейронных слоев CNeuronBaseOCL. Структура нового класса представлена ниже.
class CNeuronFITSOCL : public CNeuronBaseOCL { protected: //--- uint iWindow; uint iWindowOut; uint iCount; uint iFFTin; uint iIFFTin; //--- CNeuronBaseOCL cInputsRe; CNeuronBaseOCL cInputsIm; CNeuronBaseOCL cFFTRe; CNeuronBaseOCL cFFTIm; CNeuronDropoutOCL cDropRe; CNeuronDropoutOCL cDropIm; CNeuronConvOCL cInsideRe1; CNeuronConvOCL cInsideIm1; CNeuronConvOCL cInsideRe2; CNeuronConvOCL cInsideIm2; CNeuronBaseOCL cComplexRe; CNeuronBaseOCL cComplexIm; CNeuronBaseOCL cIFFTRe; CNeuronBaseOCL cIFFTIm; CBufferFloat cClear; //--- virtual bool FFT(CBufferFloat *inp_re, CBufferFloat *inp_im, CBufferFloat *out_re, CBufferFloat *out_im, bool reverse = false); virtual bool ComplexLayerOut(CBufferFloat *inp_re, CBufferFloat *inp_im, CBufferFloat *out_re, CBufferFloat *out_im); virtual bool ComplexLayerGradient(CBufferFloat *inp_re, CBufferFloat *inp_im, CBufferFloat *out_re, CBufferFloat *out_im); //--- virtual bool feedForward(CNeuronBaseOCL *NeuronOCL); virtual bool updateInputWeights(CNeuronBaseOCL *NeuronOCL); virtual bool calcInputGradients(CNeuronBaseOCL *NeuronOCL); public: CNeuronFITSOCL(void) {}; ~CNeuronFITSOCL(void) {}; //--- virtual bool Init(uint numOutputs, uint myIndex, COpenCLMy *open_cl, uint window, uint window_out, uint count, float dropout, ENUM_OPTIMIZATION optimization_type, uint batch); //--- virtual bool Save(int const file_handle); virtual bool Load(int const file_handle); //--- virtual int Type(void) const { return defNeuronFITSOCL; } virtual void SetOpenCL(COpenCLMy *obj); virtual void TrainMode(bool flag); //--- virtual bool WeightsUpdate(CNeuronBaseOCL *source, float tau); };
Не сложно заметить, что в структуре нового класса объявляется довольно большое количество объектов внутренних нейронных слоев. И это вызывает некий диссонанс на фоне заявленной простоты модели. Но тут сразу стоит сказать, что обучать мы будем лишь параметры 4 вложенных нейронных слоев, отвечающих за интерполяцию данных (cInsideRe* и cInsideIm*). Остальные выполняют роль промежуточных буферов данных, с назначением которых мы познакомимся в процессе реализации методов.
Тут же надо обратить внимание на наличие 2 слоев CNeuronDropoutOCL. В данной реализации я решил отказаться от использования LFP, который предусматривает определения некой частоты среза. Здесь я вспомнил об экспериментах авторов метода FEDformer, которые говорят об эффективности сэмплирования набора частотных характеристик. Поэтому я решил воспользоваться слоем Dropout для обнуления некоторого числа случайных частотных характеристик.
Все внутренние объекты мы объявляем статическими, что позволяет нам оставить "пустыми" конструктор и деструктор класса. Непосредственно инициализация объектов и всех локальных переменных осуществляется в методе Init. Как обычно, в параметрах метода указываются переменные, позволяющие однозначно определить требуемую структуру объекта. Здесь мы видим размеры окна унитарной последовательности исходных данных и результатов (window и window_out), количество унитарных временных рядов (count) и долю обнуляемых частотных характеристик (dropout). Стоит обратить внимание, что мы строим унифицированный слой, и размер окон как исходных данных, так и результатов может быть любым положительным числом без привязки к требованиям алгоритма FFT. Напомню, что указанный алгоритм требует размер исходных данных, равный одной из степеней 2.
bool CNeuronFITSOCL::Init(uint numOutputs, uint myIndex, COpenCLMy *open_cl, uint window, uint window_out, uint count, float dropout, ENUM_OPTIMIZATION optimization_type, uint batch) { if(window <= 0) return false; if(!CNeuronBaseOCL::Init(numOutputs, myIndex, open_cl, window_out * count, optimization_type, batch)) return false;
В теле метода мы сначала организовываем небольшой контрольный блок, в котором проверяем размер окна исходных данных (должен быть положительным числом) и вызываем одноименный метод родительского класса. Как вы знаете, в методе родительского класса реализованы дополнительные контроли и инициализация унаследованных объектов.
После успешного прохождения блока контролей мы сохраняем полученные параметры в локальные переменные.
//--- Save constants
iWindow = window;
iWindowOut = window_out;
iCount = count;
activation=None;
Определяем размеры тензоров для прямого и обратного FFT в виде ближайших больших степеней 2 к соответствующим полученным параметрам.
//--- Calculate FFT and iFFT size int power = int(MathLog(iWindow) / M_LN2); if(MathPow(2, power) != iWindow) power++; iFFTin = uint(MathPow(2, power)); power = int(MathLog(iWindowOut) / M_LN2); if(MathPow(2, power) != iWindowOut) power++; iIFFTin = uint(MathPow(2, power));
После чего идет блок инициализации вложенных объектов. Объекты cInputs* используются в качестве буферов исходных данных для прямого FFT. Их размер равен произведению размера унитарной последовательности на входе данного блока и количества анализируемых последовательностей.
if(!cInputsRe.Init(0, 0, OpenCL, iFFTin * iCount, optimization, iBatch)) return false; if(!cInputsIm.Init(0, 1, OpenCL, iFFTin * iCount, optimization, iBatch)) return false;
Аналогичный размер имеют и объекты для записи результатов прямого разложения Фурье cFFT*.
if(!cFFTRe.Init(0, 2, OpenCL, iFFTin * iCount, optimization, iBatch)) return false; if(!cFFTIm.Init(0, 3, OpenCL, iFFTin * iCount, optimization, iBatch)) return false;
Далее мы объявим объекты Dropout. Не сложно догадаться, что их размер будет равен предыдущим.
if(!cDropRe.Init(0, 4, OpenCL, iFFTin * iCount, dropout, optimization, iBatch)) return false; if(!cDropIm.Init(0, 5, OpenCL, iFFTin * iCount, dropout, optimization, iBatch)) return false;
Для интерполяции последовательности мы будем использовать MLP с одним скрытым слоем и активацией tanh между слоями. На выходе блока мы получаем данные в соответствии с требованиями блока обратного FFT.
if(!cInsideRe1.Init(0, 6, OpenCL, iFFTin, iFFTin, 4*iIFFTin, iCount, optimization, iBatch)) return false; cInsideRe1.SetActivationFunction(TANH); if(!cInsideIm1.Init(0, 7, OpenCL, iFFTin, iFFTin, 4*iIFFTin, iCount, optimization, iBatch)) return false; cInsideIm1.SetActivationFunction(TANH); if(!cInsideRe2.Init(0, 8, OpenCL, 4*iIFFTin, 4*iIFFTin, iIFFTin, iCount, optimization, iBatch)) return false; cInsideRe2.SetActivationFunction(None); if(!cInsideIm2.Init(0, 9, OpenCL, 4*iIFFTin, 4*iIFFTin, iIFFTin, iCount, optimization, iBatch)) return false; cInsideIm2.SetActivationFunction(None);
Результаты интерполяции мы объединим в объектах cComplex*.
if(!cComplexRe.Init(0, 10, OpenCL, iIFFTin * iCount, optimization, iBatch)) return false; if(!cComplexIm.Init(0, 11, OpenCL, iIFFTin * iCount, optimization, iBatch)) return false;
Согласно методу FITS, интерполированные последовательности проходят обратное разложение Фурье, в ходе которого частотные характеристики преобразуются во временной ряд. Результаты данной операции мы будем записывать в объекты cIFFT.
if(!cIFFTRe.Init(0, 12, OpenCL, iIFFTin * iCount, optimization, iBatch)) return false; if(!cIFFTIm.Init(0, 13, OpenCL, iIFFTin * iCount, optimization, iBatch)) return false;
Дополнительно мы объявим вспомогательный буфер нулевых значений, которыми будем дополнять недостающие значения.
if(!cClear.BufferInit(MathMax(iFFTin, iIFFTin)*iCount, 0)) return false; cClear.BufferCreate(OpenCL); //--- return true; }
После успешной инициализации всех вложенных объектов мы завершаем работу метода.
Следующим этапом мы приступаем к реализации функционала класса. Но прежде, чем перейти непосредственно к методам прямого и обратного проходов, нам необходимо выполнить подготовительную работу по реализации функционала постановки построенных выше кернелов в очередь выполнения. Алгоритм подобных кернелов однотипен. И в рамках данной статьи мы рассмотрим лишь метод вызова кернела быстрого преобразования Фурье CNeuronFITSOCL::FFT.
bool CNeuronFITSOCL::FFT(CBufferFloat *inp_re, CBufferFloat *inp_im, CBufferFloat *out_re, CBufferFloat *out_im, bool reverse = false) { uint global_work_offset[1] = {0}; uint global_work_size[1] = {iCount};
В параметрах метода мы передаем указатели на 4 буфера данных, с которыми будем работать (2 исходных данных и 2 результатов), и флаг направления операций.
В теле метода мы определяем пространство задач. Здесь мы используем одномерное пространство задач по числу анализируемых последовательностей.
И затем передаем параметры кернелу. Сначала указатели на буферы исходных данных.
if(!OpenCL.SetArgumentBuffer(def_k_FFT, def_k_fft_inputs_re, inp_re.GetIndex())) { printf("Error of set parameter kernel %s: %d; line %d", __FUNCTION__, GetLastError(), __LINE__); return false; } if(!OpenCL.SetArgumentBuffer(def_k_FFT, def_k_fft_inputs_im, (!!inp_im ? inp_im.GetIndex() : inp_re.GetIndex()))) { printf("Error of set parameter kernel %s: %d; line %d", __FUNCTION__, GetLastError(), __LINE__); return false; }
Здесь стоит обратить внимание, что допускаем возможность запуска кернела без наличия буфера мнимой части сигнала. Как вы помните, для этого в кернеле мы использовали флаг input_complex. Однако без передачи всех необходимых параметров кернелу, мы получим ошибку выполнения. Поэтому при отсутствии буфера мнимой части мы указываем указатель на буфер вещественной части сигнала и указываем false для соответствующего флага.
if(!OpenCL.SetArgument(def_k_FFT, def_k_fft_input_complex, int(!!inp_im))) { printf("Error of set parameter kernel %s: %d; line %d", __FUNCTION__, GetLastError(), __LINE__); return false; }
Затем передаем указатели на буферы результатов.
if(!OpenCL.SetArgumentBuffer(def_k_FFT, def_k_fft_outputs_re, out_re.GetIndex())) { printf("Error of set parameter kernel %s: %d; line %d", __FUNCTION__, GetLastError(), __LINE__); return false; } if(!OpenCL.SetArgumentBuffer(def_k_FFT, def_k_fft_outputs_im, out_im.GetIndex())) { printf("Error of set parameter kernel %s: %d; line %d", __FUNCTION__, GetLastError(), __LINE__); return false; }
Размеры окон исходных данных и результатов. Последнее является степенью 2. При этом обратите внимание, что мы вычисляем размеры окон, а не берем из констант. Это связано с тем, что данный метод мы будем использовать как для прямого, так и для обратного преобразования Фурье, которое будет осуществляться с разными буферами и, соответственно, с разными окнами исходных данных и результатов.
if(!OpenCL.SetArgument(def_k_FFT, def_k_fft_input_window, (int)(inp_re.Total() / iCount))) { printf("Error of set parameter kernel %s: %d; line %d", __FUNCTION__, GetLastError(), __LINE__); return false; } if(!OpenCL.SetArgument(def_k_FFT, def_k_fft_output_window, (int)(out_re.Total() / iCount))) { printf("Error of set parameter kernel %s: %d; line %d", __FUNCTION__, GetLastError(), __LINE__); return false; }
Последним мы передаем флаг указания использования алгоритма обратного преобразования.
if(!OpenCL.SetArgument(def_k_FFT, def_k_fft_reverse, int(reverse))) { printf("Error of set parameter kernel %s: %d; line %d", __FUNCTION__, GetLastError(), __LINE__); return false; }
И ставим кернел в очередь выполнения.
if(!OpenCL.Execute(def_k_FFT, 1, global_work_offset, global_work_size)) { printf("Error of execution kernel %s: %d", __FUNCTION__, GetLastError()); return false; } //--- return true; }
На каждом этапе мы контролируем процесс выполнения операций и возвращаем вызывающей программе логическое значение выполненных операций.
Методы CNeuronFITSOCL::ComplexLayerOut и CNeuronFITSOCL::ComplexLayerGradient, в которых осуществляется вызов одноименных кернелов, построены по аналогичному принципу. И я предлагаю Вам самостоятельно ознакомиться с ними во вложении.
После завершения подготовительной работы мы переходим к построению алгоритма прямого прохода, который описан в методе CNeuronFITSOCL::feedForward.
В параметрах метод получает указатель на объект предшествующего нейронного слоя, который передает нам исходные данные. И в теле метода мы сразу проверяем полученный указатель.
bool CNeuronFITSOCL::feedForward(CNeuronBaseOCL *NeuronOCL) { if(!NeuronOCL) return false;
Здесь надо сказать, что метод FITS предусматривает предварительную нормализацию данных. Мы предполагаем осуществление нормализации данных на предшествующих нейронных слоях и опускаем этот шаг в рамках данного класса.
Полученные данные мы переводим в область частотных характеристик с помощью прямого быстрого преобразования Фурье. Для этого мы вызываем соответствующий метод, алгоритм которого представлен выше.
//--- FFT if(!FFT(NeuronOCL.getOutput(), NULL, cFFTRe.getOutput(), cFFTIm.getOutput(), false)) return false;
Полученные частотные характеристики мы прореживаем с помощью слоев Dropout.
//--- DropOut if(!cDropRe.FeedForward(cFFTRe.AsObject())) return false; if(!cDropIm.FeedForward(cFFTIm.AsObject())) return false;
После чего интерполируем частотные характеристики на размер прогнозных значений.
//--- Complex Layer if(!cInsideRe1.FeedForward(cDropRe.AsObject())) return false; if(!cInsideRe2.FeedForward(cInsideRe1.AsObject())) return false; if(!cInsideIm1.FeedForward(cDropIm.AsObject())) return false; if(!cInsideIm2.FeedForward(cInsideIm1.AsObject())) return false;
Объединим отдельные интерполяции вещественной и мнимой частей сигнала.
if(!ComplexLayerOut(cInsideRe2.getOutput(), cInsideIm2.getOutput(), cComplexRe.getOutput(), cComplexIm.getOutput())) return false;
Полученный сингал вернем во временную область путем обратного разложения.
//--- iFFT if(!FFT(cComplexRe.getOutput(), cComplexIm.getOutput(), cIFFTRe.getOutput(), cIFFTIm.getOutput(), true)) return false;
Здесь стоит обратить внимание, что полученный прогнозный ряд может превышать размер последовательности, который мы должны передать последующему нейронному слою. Поэтому мы выделим из вещественной части сигнала только необходимый нам блок.
//--- To Output if(!DeConcat(Output, cIFFTRe.getGradient(), cIFFTRe.getOutput(), iWindowOut, iIFFTin - iWindowOut, iCount)) return false; //--- return true; }
Не забываем контролировать процесс выполнения операций на каждом шаге. И по завершении всех итераций вернем логический результат выполненных операций вызывающей программе.
После реализации прямого прохода, мы переходим к построению методов обратного прохода. И здесь мы начинаем работу с метода распределения градиента ошибки до всех внутренних объектов и предыдущего слоя в соответствии с их влиянием на конечный результат CNeuronFITSOCL::calcInputGradients.
bool CNeuronFITSOCL::calcInputGradients(CNeuronBaseOCL *NeuronOCL) { if(!NeuronOCL) return false;
В параметрах метод получает указатель на объект предыдущего слоя, которому нам предстоит передать градиент ошибки. И в теле метода мы сразу проверяем актуальность полученного указателя.
Градиент ошибки, который мы получили от последующего слоя, уже хранится в буфере Gradient. Однако там содержится только вещественная часть сигнала. И только на заданную глубину прогноза. Нам же необходим градиент ошибки как для вещественной, так и для мнимой части в горизонте полного сигнала от обратного преобразования. Для формирования подобных данных мы исходим из 2 предположений:
- На выходе блока обратного преобразования Фурье при прямом проходе мы ожидаем получить значения дискретного временного ряда. В этом случае вещественная часть сигнала соответствует требуемому временному ряду, а мнимая часть равна (или близка) к "0". Следовательно, ошибка мнимой части равна её значению, взятому с противоположным знаком.
- Так как у нас нет информации о корректности прогнозных значений за пределами заданного горизонта планирования, то мы просто пренебрегаем возможными отклонениями и считаем для них ошибку раной "0".
//--- Copy Gradients if(!SumAndNormilize(cIFFTIm.getOutput(), GetPointer(cClear), cIFFTIm.getGradient(), 1, false, 0, 0, 0, -1)) return false;
if(!Concat(Gradient, GetPointer(cClear), cIFFTRe.getGradient(), iWindowOut, iIFFTin - iWindowOut, iCount)) return false;
Далее следует обратить внимание, что градиент ошибку у нас представлен в виде временного ряда. Прогнозирование же мы осуществляли в частотной области. Следовательно, градиент ошибки нам также нужно перевести в частотную область. А эта операция подразумевает применение быстрого преобразования Фурье.
//--- FFT if(!FFT(cIFFTRe.getGradient(), cIFFTIm.getGradient(), cComplexRe.getGradient(), cComplexIm.getGradient(), false)) return false;
Частотные характеристики распределим между 2 MLP вещественной и мнимой части.
//--- Complex Layer if(!ComplexLayerGradient(cInsideRe2.getGradient(), cInsideIm2.getGradient(), cComplexRe.getGradient(), cComplexIm.getGradient())) return false;
После чего распределим градиент ошибки через MLP.
if(!cInsideRe1.calcHiddenGradients(cInsideRe2.AsObject())) return false; if(!cInsideIm1.calcHiddenGradients(cInsideIm2.AsObject())) return false; if(!cDropRe.calcHiddenGradients(cInsideRe1.AsObject())) return false; if(!cDropIm.calcHiddenGradients(cInsideIm1.AsObject())) return false;
Через слой Dropout доведем градиент ошибки до выхода блока прямого преобразования Фурье.
//--- Dropout if(!cFFTRe.calcHiddenGradients(cDropRe.AsObject())) return false; if(!cFFTIm.calcHiddenGradients(cDropIm.AsObject())) return false;
И теперь нам предстоит преобразовать градиент ошибки из частотной области во временной ряд. Эту операцию мы выполняем с помощью обратного преобразования.
//--- IFFT if(!FFT(cFFTRe.getGradient(), cFFTIm.getGradient(), cInputsRe.getGradient(), cInputsIm.getGradient(), true)) return false;
И в завершении, на предыдущий слой мы передаем только необходимую часть вещественного градиента ошибки.
//--- To Input Layer if(!DeConcat(NeuronOCL.getGradient(), cFFTIm.getGradient(), cFFTRe.getGradient(), iWindow, iFFTin - iWindow, iCount)) return false; //--- return true; }
Как всегда, мы контролируем процесс выполнения всех операций в теле метода, а в завершении возвращаем вызывающей программе логическое значение корректности выполненных операций.
За распределением градиента ошибки следует процесс обновления параметров модели, который реализован в методе CNeuronFITSOCL::updateInputWeights. Как уже было сказано, среди множества объявленных в классе объектов, обучаемые параметры содержат только слои MLP. Их параметры мы и скорректируем в указанном методе.
bool CNeuronFITSOCL::updateInputWeights(CNeuronBaseOCL *NeuronOCL) { if(!cInsideRe1.UpdateInputWeights(cDropRe.AsObject())) return false; if(!cInsideIm1.UpdateInputWeights(cDropIm.AsObject())) return false; if(!cInsideRe2.UpdateInputWeights(cInsideRe1.AsObject())) return false; if(!cInsideIm2.UpdateInputWeights(cInsideIm1.AsObject())) return false; //--- return true; }
Наличие большого количества внутренних объектов, которые не содержат обучаемых параметров, накладывает отпечаток и на методы работы с файлами. Согласитесь, нам нет смысла сохранять довольно существенные объемы информации, которая не имеет никакой ценности. Поэтому в методе сохранения данных CNeuronFITSOCL::Save мы сначала вызываем одноименный метод родительского класса.
bool CNeuronFITSOCL::Save(const int file_handle) { if(!CNeuronBaseOCL::Save(file_handle)) return false;
После чего сохраняем константы архитектуры.
//--- Save constants if(FileWriteInteger(file_handle, int(iWindow)) < INT_VALUE) return false; if(FileWriteInteger(file_handle, int(iWindowOut)) < INT_VALUE) return false; if(FileWriteInteger(file_handle, int(iCount)) < INT_VALUE) return false; if(FileWriteInteger(file_handle, int(iFFTin)) < INT_VALUE) return false; if(FileWriteInteger(file_handle, int(iIFFTin)) < INT_VALUE) return false;
И сохраняем объекты MLP.
//--- Save objects if(!cInsideRe1.Save(file_handle)) return false; if(!cInsideIm1.Save(file_handle)) return false; if(!cInsideRe2.Save(file_handle)) return false; if(!cInsideIm2.Save(file_handle)) return false;
Добавим ещё объекты блока Dropout.
if(!cDropRe.Save(file_handle)) return false; if(!cDropIm.Save(file_handle)) return false; //--- return true; }
И все. Остальные объекты содержат только буфера данных, информация в которых актуальна только в рамках одного цикла прямого-обратного проходов. Поэтому не сохраняем их и тем самым экономим дисковое пространство. Но за эту экономию мы заплатим усложнением алгоритма метода загрузки данных CNeuronFITSOCL::Load.
bool CNeuronFITSOCL::Load(const int file_handle) { if(!CNeuronBaseOCL::Load(file_handle)) return false;
В нем мы сначала зеркально повторяем метод сохранения данных:
- Вызываем одноименный метод родительского класса.
- Загружаем константы. При этом контролируем достижение конца файла данных.
//--- Load constants if(FileIsEnding(file_handle)) return false; iWindow = uint(FileReadInteger(file_handle)); if(FileIsEnding(file_handle)) return false; iWindowOut = uint(FileReadInteger(file_handle)); if(FileIsEnding(file_handle)) return false; iCount = uint(FileReadInteger(file_handle)); if(FileIsEnding(file_handle)) return false; iFFTin = uint(FileReadInteger(file_handle)); if(FileIsEnding(file_handle)) return false; iIFFTin = uint(FileReadInteger(file_handle)); activation=None;
- Считываем параметры MLP и Dropout.
//--- Load objects if(!LoadInsideLayer(file_handle, cInsideRe1.AsObject())) return false; if(!LoadInsideLayer(file_handle, cInsideIm1.AsObject())) return false; if(!LoadInsideLayer(file_handle, cInsideRe2.AsObject())) return false; if(!LoadInsideLayer(file_handle, cInsideIm2.AsObject())) return false; if(!LoadInsideLayer(file_handle, cDropRe.AsObject())) return false; if(!LoadInsideLayer(file_handle, cDropIm.AsObject())) return false;
А вот дальше нам предстоит инициализировать недостающие объекты. И здесь мы повторяем часть кода из метода инициализации класса.
//--- Init objects if(!cInputsRe.Init(0, 0, OpenCL, iFFTin * iCount, optimization, iBatch)) return false; if(!cInputsIm.Init(0, 1, OpenCL, iFFTin * iCount, optimization, iBatch)) return false; if(!cFFTRe.Init(0, 2, OpenCL, iFFTin * iCount, optimization, iBatch)) return false; if(!cFFTIm.Init(0, 3, OpenCL, iFFTin * iCount, optimization, iBatch)) return false; if(!cComplexRe.Init(0, 8, OpenCL, iIFFTin * iCount, optimization, iBatch)) return false; if(!cComplexIm.Init(0, 9, OpenCL, iIFFTin * iCount, optimization, iBatch)) return false; if(!cIFFTRe.Init(0, 10, OpenCL, iIFFTin * iCount, optimization, iBatch)) return false; if(!cIFFTIm.Init(0, 11, OpenCL, iIFFTin * iCount, optimization, iBatch)) return false; if(!cClear.BufferInit(MathMax(iFFTin, iIFFTin)*iCount, 0)) return false; cClear.BufferCreate(OpenCL); //--- return true; }
На этом мы завершаем работу по описанию методов нашего нового класса CNeuronFITSOCL и их алгоритмов. Полный код данного класса и всех его методов Вы можете найти во вложении. Там же находятся все программы, используемые при подготовке данной статьи. А мы переходим к описанию архитектуры обучаемых моделей.
2.4 Архитектура моделей
Метод FITS был предложен для анализа и прогнозирования временных рядов. И, думаю, Вы уже догадались, что предложенные подходы мы будем использовать в Энкодере состояния окружающей среды. Его архитектура описана в методе CreateEncoderDescriptions.
bool CreateEncoderDescriptions(CArrayObj *encoder) { //--- CLayerDescription *descr; //--- if(!encoder) { encoder = new CArrayObj(); if(!encoder) return false; }
В параметрах метода получаем указатель на объект динамического массива для сохранения архитектуры создаваемой модели. И в теле метода мы сразу проверяем актуальность полученного указателя. При необходимости мы создаем новый экземпляр объекта динамического массива.
На вход модели мы, как всегда, будем подавать "сырые" данные описания текущего состояния окружающей среды.
//--- Encoder encoder.Clear(); //--- Input layer if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBaseOCL; int prev_count = descr.count = (HistoryBars * BarDescr); descr.activation = None; descr.optimization = ADAM; if(!encoder.Add(descr)) { delete descr; return false; }
Первичную обработку полученные данные проходят в слое пакетной нормализации, что позволяет привести данные в сопоставимый вид и повысить устойчивость процесса обучения модели.
//--- layer 1 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBatchNormOCL; descr.count = prev_count; descr.batch = 1000; descr.activation = None; descr.optimization = ADAM; if(!encoder.Add(descr)) { delete descr; return false; }
Наши исходные данные представляют собой многомерный временной ряд. Каждый блок последовательных данных содержит различные параметры описания одной свечи исторических данных. Однако для анализа унитарных последовательностей в нашем наборе данных, нам необходимо транспонировать полученный тензор.
//--- layer 2 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronTransposeOCL; descr.count = HistoryBars; descr.window = BarDescr; if(!encoder.Add(descr)) { delete descr; return false; }
На этом этапе можно считать завершенной подготовительную работу и переходить к непосредственному анализу и прогнозированию унитарных временных рядов. Этот процесс мы осуществляем в объекте нашего нового класса.
//--- layer 3 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronFITSOCL; descr.count = BarDescr; descr.window = HistoryBars; descr.activation = None; descr.window_out = NForecast; if(!encoder.Add(descr)) { delete descr; return false; }
Здесь стоит отметить, что в теле нашего класса мы реализовали практически весь предложенный метод FITS. И на выходе нейронного слоя мы уже имеем прогнозные значения. Нам остается лишь транспонировать тензор прогнозных значений в размерность ожидаемых результатов.
//--- layer 4 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronTransposeOCL; descr.count = BarDescr; descr.window = NForecast; if(!encoder.Add(descr)) { delete descr; return false; }
И добавить изъятые ранее параметры статистического распределения исходных данных.
//--- layer 5 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronRevInDenormOCL; descr.count = BarDescr * NForecast; descr.activation = None; descr.optimization = ADAM; descr.layers = 1; if(!encoder.Add(descr)) { delete descr; return false; } //--- return true; }
Как можно заметить, модель анализа и прогнозирования последующих состояний окружающей среды получилась довольно короткой, как и обещали авторы метода FITS. При этом внесенные нами изменения архитектуры модели абсолютно не повлияли ни на объем, ни на формат исходных данных. Мы также не изменили формат результатов работы модели. Это позволяет нам использовать без изменений созданные ранее архитектуры моделей Актера и Критика. Кроме того, мы можем использовать построенные ранее советники взаимодействия с окружающей средой и обучения моделей, а так же уже собранные обучающие выборки. Единственное, что мы должны изменить, так это указатель на слой латентного представления состояния окружающей среды.
#define LatentLayer 3
С полным кодом всех программ, используемых при подготовке статьи, вы можете самостоятельно ознакомиться во вложении. А мы переходим к этапу тестирования результатов проделанной работы.
3. Тестирование
Мы познакомились с методом FITS и провели серьёзную работу по имплементации предложенных подходов средствами MQL5. И теперь пришло время проверить эффективность данного решения на реальных исторических данных. Как и ранее, обучать и тестировать модели мы будем на исторических данных инструмента EURUSD тайм-фрейм H1. Обучение осуществляется на исторических данных за весь 2023 год. А тестирование обученной модели мы проведем на данных Января 2024 года.
Обучение моделей мы осуществляем аналогично процессу, описанному в предыдущей статье. Сначала мы обучаем Энкодер состояния окружающей среды прогнозированию последующих состояний. А затем итерационно обучаем политику поведения Актера для достижения максимальной доходности.
Как и ожидалось, модель Энкодера получилась довольно легкой. Процесс обучения сравнительно быстрый и ровный. Несмотря на малый размер модель демонстрирует показатели, сопоставимые с рассмотренной в прошлой статье моделью FEDformer. Здесь стоит отметить, что размер модели почти в 84 раза меньше.

А вот на стадии обучения политики Актера нас ждало разочарование. Модель способна демонстрировать доходность только на отдельных исторических участках. На представленном ниже графике баланса не тестовом участке мы видим довольно стремительный рост в первой декаде месяца. А вот вторая декада характеризуется тенденцией к потере депозита с редкими прибыльными сделками. Третья декада приближается к паритету прибыльных и убыточных сделок.

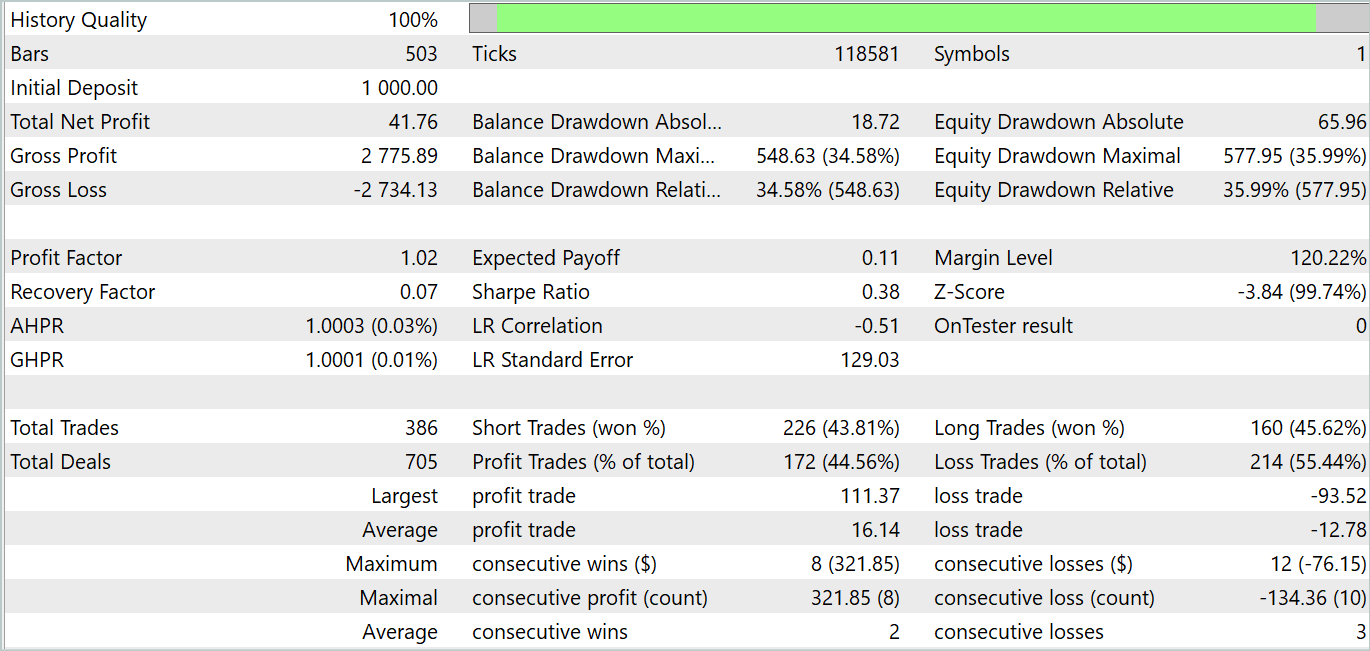
В целом по месяцу мы получили небольшой доход. Здесь можно отметить, что размер максимальной и средней прибыльной сделки превышает соответствующие убыточные показатели. Однако, количество прибыльных сделок меньше половины, что нивелирует превосходство средней прибыльной сделки.
Здесь можно отметить, что результаты тестирования отчасти подтверждают выводы, сделанные авторами метода FEDformer: из-за отсутствия ярко выраженной периодичности в исходных данных, DFT не способен определить момент изменения тенденций.
Заключение
В данной статье мы познакомились с новым методом анализа и прогнозирования временных рядов FITS. Ключевой особенностью данного метода является анализ и прогнозирования временных рядов в области частотных характеристик. При этом, благодаря использованию алгоритмом прямого и обратного быстрого преобразования Фурье, на входе и выходе модели мы оперируем привычными дискретными временными рядами. Эта особенность позволяет предложенной легковесной архитектуре быть имплементированной во многие сферы, где используется анализ и прогнозирование временных рядов.
В практической части данной статьи мы реализовали свое видение предложенных подходов средствами MQL5. Обучили и провели тестирование моделей на реальных исторических данных. К сожалению, результаты тестирования не дали желаемого результата. Однако хочу обратить внимание, что представленные результаты актуальны только для представленной реализации предложенных подходов. Использование авторского алгоритма может продемонстрировать другие результаты.
Ссылки
- FITS: Modeling Time Series with 10k Parameters
- A Survey of Complex-Valued Neural Networks
- Другие статьи серии
Программы, используемые в статье
| # | Имя | Тип | Описание |
|---|---|---|---|
| 1 | Research.mq5 | Советник | Советник сбора примеров |
| 2 | ResearchRealORL.mq5 | Советник | Советник сбора примеров методом Real-ORL |
| 3 | Study.mq5 | Советник | Советник обучения Моделей |
| 4 | StudyEncoder.mq5 | Советник | Советник обучения Энкодера |
| 5 | Test.mq5 | Советник | Советник для тестирования модели |
| 6 | Trajectory.mqh | Библиотека класса | Структура описания состояния системы |
| 7 | NeuroNet.mqh | Библиотека класса | Библиотека классов для создания нейронной сети |
| 8 | NeuroNet.cl | Библиотека | Библиотека кода программы OpenCL |
 Прогнозирование на основе глубокого обучения и открытие ордеров с помощью пакета MetaTrader 5 python и файла модели ONNX
Прогнозирование на основе глубокого обучения и открытие ордеров с помощью пакета MetaTrader 5 python и файла модели ONNX
- Бесплатные приложения для трейдинга
- 8 000+ сигналов для копирования
- Экономические новости для анализа финансовых рынков
Вы принимаете политику сайта и условия использования