알고리즘을 처음 실행했을 때 적은 양의 초기 데이터에서 긍정적인 결과가 없었고 y-aware pca와 단순 pca 모두에서 약 50%의 오류가 발생했습니다. 이제 mt5에서 보다 완전한 데이터 세트를 얻었습니다. 모든 버퍼가 있는 거의 모든 표준 표시기, 일부 표시기는 다른 매개변수로 여러 번 반복됩니다. 또한 일부 지표에 대한 전문 고문을 만들고 도움을 받아 지표의 매개변수를 최적화하여 보다 수익성 있는 거래를 했습니다. 이러한 데이터에서 단순 pca는 여전히 50% 잘못되었으며 y-aware로 전면 테스트의 오류는 40%로 눈에 띄게 떨어집니다. y-aware 알고리즘이 원시 데이터를 가져와 10번 중 6번 올바르게 작동하는 분류기로 만드는 것이 매우 흥미롭습니다. 결론은 더 많은 원시 데이터가 필요하다는 것입니다.
그러나 그것이 모든 긍정적 인 것이 끝나는 곳입니다. 95%의 정확도를 위해서는 73개의 표준 구성 요소가 필요합니다.구성 요소의 예측 변수 로딩은 명백한 리더 없이 큰 것에서 작은 것으로 변동합니다. 즉, 특정 예측 변수를 선택할 수 있는 징후가 전혀 없습니다. 모델은 어떻게든 작동하지만 결과를 개선하기 위해 모델로 무엇을 해야 하는지 또는 모델에서 예측자의 유용성을 추출하는 방법이 명확하지 않습니다.
알고리즘을 처음 실행했을 때 적은 양의 초기 데이터에서 긍정적인 결과가 없었고 y-aware pca와 단순 pca 모두에서 약 50%의 오류가 발생했습니다. 이제 mt5에서 보다 완전한 데이터 세트를 얻었습니다. 모든 버퍼가 있는 거의 모든 표준 표시기, 일부 표시기는 다른 매개변수로 여러 번 반복됩니다. 또한 일부 지표에 대한 전문 고문을 만들고 도움을 받아 지표의 매개변수를 최적화하여 보다 수익성 있는 거래를 했습니다. 이러한 데이터에서 단순 pca는 여전히 50% 잘못되었으며 y-aware로 전면 테스트의 오류는 40%로 눈에 띄게 떨어집니다. y-aware 알고리즘이 원시 데이터를 가져와 10번 중 6번 올바르게 작동하는 분류기로 만드는 것이 매우 흥미롭습니다. 결론은 더 많은 원시 데이터가 필요하다는 것입니다.
그러나 그것이 모든 긍정적 인 것이 끝나는 곳입니다. 95%의 정확도를 위해서는 73개의 표준 구성 요소가 필요합니다.구성 요소의 예측 변수 로딩은 명백한 리더 없이 큰 것에서 작은 것으로 변동합니다. 즉, 특정 예측 변수를 선택할 수 있는 징후가 전혀 없습니다. 모델은 어떻게든 작동하지만 결과를 개선하기 위해 모델로 무엇을 해야 하는지 또는 모델에서 예측자의 유용성을 추출하는 방법이 명확하지 않습니다.
안녕하세요!
한 가지 아이디어가 있습니다. 확인하고 싶지만 구현 도구를 모릅니다... 내 데이터에 따르면 3 또는 5와 같이 앞으로 여러 지점을 예측할 수 있는 알고리즘이 필요합니다(다음을 수행하는 것이 바람직합니다. 신경망)
안녕하세요!
한 가지 아이디어가 있습니다. 확인하고 싶지만 구현 도구를 모릅니다... 내 데이터에 따라 3 또는 5와 같이 앞으로 여러 지점을 예측할 수 있는 알고리즘이 필요합니다. 신경망)
그 전에는 분류 작업만 했습니다. 어떻게 생겼는지 도무지 이해가 안 가거든요. 어떻게 했는지 알려주거나 R에서 패키지를 추천해 주세요.
추신 좋은 기사 알렉스
이들은 예측과 같은 기존 추세를 외삽하는 패키지입니다. 다양한 스플라인이 매우 흥미롭습니다.
꽤 견고해 보입니다.
그리고 유용한 결과가 없습니까?
알고리즘을 처음 실행했을 때 적은 양의 초기 데이터에서 긍정적인 결과가 없었고 y-aware pca와 단순 pca 모두에서 약 50%의 오류가 발생했습니다. 이제 mt5에서 보다 완전한 데이터 세트를 얻었습니다. 모든 버퍼가 있는 거의 모든 표준 표시기, 일부 표시기는 다른 매개변수로 여러 번 반복됩니다. 또한 일부 지표에 대한 전문 고문을 만들고 도움을 받아 지표의 매개변수를 최적화하여 보다 수익성 있는 거래를 했습니다. 이러한 데이터에서 단순 pca는 여전히 50% 잘못되었으며 y-aware로 전면 테스트의 오류는 40%로 눈에 띄게 떨어집니다. y-aware 알고리즘이 원시 데이터를 가져와 10번 중 6번 올바르게 작동하는 분류기로 만드는 것이 매우 흥미롭습니다. 결론은 더 많은 원시 데이터가 필요하다는 것입니다.
그러나 그것이 모든 긍정적 인 것이 끝나는 곳입니다. 95%의 정확도를 위해서는 73개의 표준 구성 요소가 필요합니다.구성 요소의 예측 변수 로딩은 명백한 리더 없이 큰 것에서 작은 것으로 변동합니다. 즉, 특정 예측 변수를 선택할 수 있는 징후가 전혀 없습니다. 모델은 어떻게든 작동하지만 결과를 개선하기 위해 모델로 무엇을 해야 하는지 또는 모델에서 예측자의 유용성을 추출하는 방법이 명확하지 않습니다.
구성 요소 중요도:
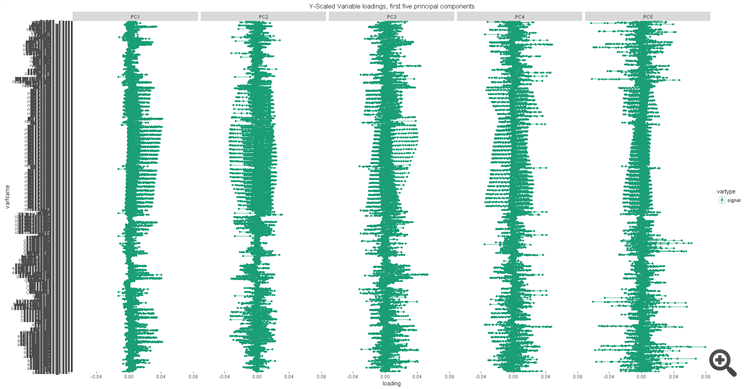
처음 5개 구성요소에 대한 예측자 로드:
아리마
그러나 Arima는 시계열에 대해 결정을 내립니다. 그리고 내 데이터 세트에서 결정을 내리기 위한 모델이 필요합니다.
그 누구도 여러 출력 뉴런이 있는 신경망 훈련을 막지 못할 것입니다. 동시에 결과를 관찰하는 것도 흥미로울 것입니다.
알고리즘을 처음 실행했을 때 적은 양의 초기 데이터에서 긍정적인 결과가 없었고 y-aware pca와 단순 pca 모두에서 약 50%의 오류가 발생했습니다. 이제 mt5에서 보다 완전한 데이터 세트를 얻었습니다. 모든 버퍼가 있는 거의 모든 표준 표시기, 일부 표시기는 다른 매개변수로 여러 번 반복됩니다. 또한 일부 지표에 대한 전문 고문을 만들고 도움을 받아 지표의 매개변수를 최적화하여 보다 수익성 있는 거래를 했습니다. 이러한 데이터에서 단순 pca는 여전히 50% 잘못되었으며 y-aware로 전면 테스트의 오류는 40%로 눈에 띄게 떨어집니다. y-aware 알고리즘이 원시 데이터를 가져와 10번 중 6번 올바르게 작동하는 분류기로 만드는 것이 매우 흥미롭습니다. 결론은 더 많은 원시 데이터가 필요하다는 것입니다.
그러나 그것이 모든 긍정적 인 것이 끝나는 곳입니다. 95%의 정확도를 위해서는 73개의 표준 구성 요소가 필요합니다.구성 요소의 예측 변수 로딩은 명백한 리더 없이 큰 것에서 작은 것으로 변동합니다. 즉, 특정 예측 변수를 선택할 수 있는 징후가 전혀 없습니다. 모델은 어떻게든 작동하지만 결과를 개선하기 위해 모델로 무엇을 해야 하는지 또는 모델에서 예측자의 유용성을 추출하는 방법이 명확하지 않습니다.
구성 요소 중요도:
처음 5개 구성요소에 대한 예측자 로드:
이미 이 작업을 수행했지만 신경망은 내가 요청한 대상에 대해 더 넓은 범위에서 학습하지 않습니다.
소음에서 배우기 때문에 배우지 않은 것이 좋습니다. 하지만 만약 내가 배웠다면, 그래, 성배 , 하지만 실제로는 ....
소음을 제거하기 위해 여기에서 바쁘다. 그렇기 때문에 우리는 적어도 무언가가 남을 것이라는 희망으로 많은 예측 변수를 사용합니다.