어쩌면 나는 아직 그것에 익숙해지지 않았습니다. 나무는 거대한 베이지안 테마의 특별한 경우일 뿐입니다. 예를 들어 여기에 많은 책과 비디오 예제가 있습니다.
Vladimir의 기사에 따른 NN 하이퍼파라미터의 베이지안 최적화가 사용되었습니다. 잘 작동합니다.
그러나 많은 변수를 최적화하면 너무 깁니다.
막심 드미트리예프스키 :
예를 들어, 그 나무 .. 베이지안 신경망이 있습니다
갑자기! NS는 매트 연산 + 및 *와 함께 작동하며 MA에서 디지털 필터 에 이르기까지 자체 내에서 모든 표시기를 만들 수 있습니다. 간단한 if(x<v){left branch}else{right branch}를 사용하여 오른쪽과 왼쪽 부분으로 나눕니다. 또는 Baysian NN은 if(x<v){left branch}else{right branch}이기도 합니까?
갑자기! NS는 매트 연산 + 및 *와 함께 작동하며 MA에서 디지털 필터 에 이르기까지 자체 내에서 모든 표시기를 만들 수 있습니다. 간단한 if(x<v){left branch}else{right branch}를 사용하여 오른쪽과 왼쪽 부분으로 나눕니다. 또는 Baysian NN은 if(x<v){left branch}else{right branch}이기도 합니까?
예, 느려서 지금은 유용한 지식을 찢고 있습니다. 몇 가지 이해를 제공합니다.
아니요, 베이지안 NN에서 가중치는 단순히 분포에서 가중치를 샘플링하여 최적화되며 출력은 또한 많은 옵션을 포함하지만 평균, 분산 등이 있는 분포입니다. 즉, 실제로 훈련 데이터 세트에는 없지만 선험적으로 가정된 많은 옵션을 캡처하는 것 같습니다. 이러한 NN에 더 많은 샘플이 공급될수록 일반적인 NN에 더 가깝게 수렴됩니다. 베이지안 접근 방식은 처음에는 och가 아닙니다. 큰 데이터 세트. 이것은 내가 지금까지 알고 있는 것입니다.
저것들. 이러한 NN에는 매우 큰 데이터 세트가 필요하지 않으며 결과는 일반적인 데이터 세트로 수렴됩니다. 그러나 훈련 후 출력은 각 샘플에 대한 점 추정치가 아니라 확률 분포입니다.
아니요, 베이지안 NN에서 가중치는 단순히 분포에서 가중치를 샘플링하여 최적화되며 출력은 또한 많은 옵션을 포함하지만 평균, 분산 등이 있는 분포입니다. 즉, 훈련 데이터 세트에 실제로는 없지만 선험적으로 가정된 많은 옵션을 캡처하는 것 같습니다. 이러한 NN에 더 많은 샘플이 공급될수록 일반적인 NN에 더 가깝게 수렴됩니다. 베이지안 접근 방식은 처음에는 och가 아닙니다. 큰 데이터 세트. 이것은 내가 지금까지 알고 있는 것입니다.
저것들. 이러한 NN은 매우 큰 데이터 세트가 필요하지 않으며 결과는 일반적인 데이터 세트로 수렴됩니다. 그러나 훈련 후 출력은 각 샘플에 대한 점 추정치가 아니라 확률 분포입니다.
당신은 속도를 내고 있는 것처럼 서두르며, 그 다음에는 다른 것, 다음에는 세 번째 ... 그러나 소용이 없습니다.
시간이 지남에 따라 어떤 신사처럼 지붕 위에서 자유 시간이 있습니다. 일하고 열심히 일하고 경력 성장을 달성해야하며 신경망에서 베이로 서두르지 않아야합니다.
저를 믿으세요. 정상적인 가창자라면 누구도 과학적 말과 기사에 돈을 주지 않을 것이며 오직 세계 프라임 브로커가 확인하는 형평성만 있을 뿐입니다.
아니요, 베이지안 NN에서 가중치는 단순히 분포에서 가중치를 샘플링하여 최적화되며 출력은 또한 많은 옵션을 포함하지만 평균, 분산 등이 있는 분포입니다. 즉, 훈련 데이터 세트에 실제로는 없지만 선험적으로 가정된 많은 옵션을 캡처하는 것 같습니다. 이러한 NN에 더 많은 샘플이 공급될수록 일반적인 NN에 더 가깝게 수렴됩니다. 베이지안 접근 방식은 처음에는 och가 아닙니다. 큰 데이터 세트. 이것은 내가 지금까지 알고 있는 것입니다.
저것들. 이러한 NN은 매우 큰 데이터 세트가 필요하지 않으며 결과는 일반적인 데이터 세트로 수렴됩니다.
10개의 점에 대한 예에서와 같이 베이지안 곡선을 투영한 다음 이 곡선에서 100 또는 1000개의 점을 가져와서 NS/숲을 배우는 것과 같습니까? 다음은 의견 https://www.mql5.com/ru/forum/226219에서베이지안 최적화 에 대한 Vladimir의 기사 에서 여러 점에 걸쳐 곡선을 작성하는 방법입니다. 하지만 그는 숲/ns도 필요하지 않습니다. 이 곡선에서 바로 답을 찾을 수 있습니다.
또 다른 문제는 옵티마이저가 제대로 훈련되지 않은 경우 NN이 이해할 수 없는 쓰레기를 가르칠 것이라는 점입니다. 다음은 3가지 징후에 대한 Bayes의 작업입니다. 배운 패턴
무슨 말을 하는 겁니까? 당신은 링크를 수집하고 다양한 과학적 이미지를 수집하여 신규 이민자에게 깊은 인상을 남깁니다. SanSanych는 이미 그의 기사에 모든 것을 작성했으며 추가할 내용이 거의 없습니다. 이제 모든 종류의 판매자와 기사가 스스로를 끌어올려 모든 것을 갈퀴로 부끄럽고 부끄럽게 칠했습니다. 역겨운. 그들은 "수학자"를 "양자"로 만듭니다 ....
공식의 무리
음) R 패키지에 대한 링크가 있습니다. 나는 R을 직접 사용하지 않고 공식을 복제합니다
R을 사용하는 경우 시도하십시오)
음) R 패키지에 대한 링크가 있습니다. 나는 R을 직접 사용하지 않고 공식을 복제합니다
R을 사용하는 경우 시도하십시오)
조간 신문 공개: https://towardsdatascience.com/bayesian-additive-regression-trees-paper-summary-9da19708fa71
가장 실망스러운 사실은 이 알고리즘의 Python 구현을 찾을 수 없다는 것입니다. 작성자는 대부분 "예측" 기능이 없는 몇 가지 명백한 문제가 있는 R 패키지( BayesTrees )를 만들었 으며 bartMachine 이라는 더 널리 사용되는 구현이 만들어졌습니다.
이 기술을 구현한 경험이 있거나 Python 라이브러리를 알고 있다면 댓글에 링크를 남겨주세요!
따라서 첫 번째 패키지는 쓸모가 없습니다. 예측할 수 없습니다.
두 번째 링크에서 다시 수식.
여기 이해하기 쉬운 평범한 나무가 있습니다. 모든 다운타임은 논리적입니다. 그리고 공식 없이
어쩌면 나는 아직 그것에 익숙해지지 않았습니다. 나무는 거대한 베이지안 테마의 특별한 경우일 뿐입니다. 예를 들어 여기에 많은 책과 비디오 예제가 있습니다.
Vladimir의 기사에 따른 NN 하이퍼파라미터의 베이지안 최적화가 사용되었습니다. 잘 작동합니다.예를 들어, 그 나무 .. 베이지안 신경망이 있습니다
갑자기!
NS는 매트 연산 + 및 *와 함께 작동하며 MA에서 디지털 필터 에 이르기까지 자체 내에서 모든 표시기를 만들 수 있습니다.
간단한 if(x<v){left branch}else{right branch}를 사용하여 오른쪽과 왼쪽 부분으로 나눕니다.
또는 Baysian NN은 if(x<v){left branch}else{right branch}이기도 합니까?
그러나 많은 변수를 최적화하면 너무 깁니다.
갑자기!
NS는 매트 연산 + 및 *와 함께 작동하며 MA에서 디지털 필터 에 이르기까지 자체 내에서 모든 표시기를 만들 수 있습니다.
간단한 if(x<v){left branch}else{right branch}를 사용하여 오른쪽과 왼쪽 부분으로 나눕니다.
또는 Baysian NN은 if(x<v){left branch}else{right branch}이기도 합니까?
예, 느려서 지금은 유용한 지식을 찢고 있습니다. 몇 가지 이해를 제공합니다.
아니요, 베이지안 NN에서 가중치는 단순히 분포에서 가중치를 샘플링하여 최적화되며 출력은 또한 많은 옵션을 포함하지만 평균, 분산 등이 있는 분포입니다. 즉, 실제로 훈련 데이터 세트에는 없지만 선험적으로 가정된 많은 옵션을 캡처하는 것 같습니다. 이러한 NN에 더 많은 샘플이 공급될수록 일반적인 NN에 더 가깝게 수렴됩니다. 베이지안 접근 방식은 처음에는 och가 아닙니다. 큰 데이터 세트. 이것은 내가 지금까지 알고 있는 것입니다.
저것들. 이러한 NN에는 매우 큰 데이터 세트가 필요하지 않으며 결과는 일반적인 데이터 세트로 수렴됩니다. 그러나 훈련 후 출력은 각 샘플에 대한 점 추정치가 아니라 확률 분포입니다.
예, 느려서 지금은 유용한 지식을 찢고 있습니다. 몇 가지 이해를 제공합니다.
아니요, 베이지안 NN에서 가중치는 단순히 분포에서 가중치를 샘플링하여 최적화되며 출력은 또한 많은 옵션을 포함하지만 평균, 분산 등이 있는 분포입니다. 즉, 훈련 데이터 세트에 실제로는 없지만 선험적으로 가정된 많은 옵션을 캡처하는 것 같습니다. 이러한 NN에 더 많은 샘플이 공급될수록 일반적인 NN에 더 가깝게 수렴됩니다. 베이지안 접근 방식은 처음에는 och가 아닙니다. 큰 데이터 세트. 이것은 내가 지금까지 알고 있는 것입니다.
저것들. 이러한 NN은 매우 큰 데이터 세트가 필요하지 않으며 결과는 일반적인 데이터 세트로 수렴됩니다. 그러나 훈련 후 출력은 각 샘플에 대한 점 추정치가 아니라 확률 분포입니다.
당신은 속도를 내고 있는 것처럼 서두르며, 그 다음에는 다른 것, 다음에는 세 번째 ... 그러나 소용이 없습니다.
시간이 지남에 따라 어떤 신사처럼 지붕 위에서 자유 시간이 있습니다. 일하고 열심히 일하고 경력 성장을 달성해야하며 신경망에서 베이로 서두르지 않아야합니다.
저를 믿으세요. 정상적인 가창자라면 누구도 과학적 말과 기사에 돈을 주지 않을 것이며 오직 세계 프라임 브로커가 확인하는 형평성만 있을 뿐입니다.서두르지 않고 단순한 것부터 복잡한 것까지 꾸준히 공부한다
주인을 위해 직접 일하십시오. 일이 없으면 예를 들어 mql에서 무언가를 다시 작성할 수 있습니다.
나는 주인을 위해 일하고 다른 사람들처럼 일합니다. 일하지 않는 것이 이상합니다. 거리에서 3 개월 만에 직장을 잃으면 주인, 상속인, 황금 소년, 평범한 남자를 직접 볼 수 있습니다. 반년의 시체.
거래에서 MO에 대한 주제가 전혀 없다면 산책을 가십시오. 그렇지 않으면 가난한 사람들이 거지 만 모았다고 생각할 수 있습니다)
예, MO에 따라 모든 것을 보여주었습니다. 솔직히 어린이 비밀이 없었고 찢어진 것이 여기에서 어떻게 암호화되었는지 테스트 오류는 10-15 %이지만 시장은 끊임없이 변화하고 거래가 없으며 잡담은 거의 0에 가깝습니다.
산책해, Vasya, 난 징징거리는 거 관심 없어
징징대는 소리만 하고 결과는 없고 갈퀴로 물을 파기만 하면 시간낭비를 인정할 용기가 없다
군대에 보내거나 최소한 건설 현장에서 남자들과 육체적으로 일하고 성격을 교정하십시오.예, 느려서 지금은 유용한 지식을 찢고 있습니다. 몇 가지 이해를 제공합니다.
아니요, 베이지안 NN에서 가중치는 단순히 분포에서 가중치를 샘플링하여 최적화되며 출력은 또한 많은 옵션을 포함하지만 평균, 분산 등이 있는 분포입니다. 즉, 훈련 데이터 세트에 실제로는 없지만 선험적으로 가정된 많은 옵션을 캡처하는 것 같습니다. 이러한 NN에 더 많은 샘플이 공급될수록 일반적인 NN에 더 가깝게 수렴됩니다. 베이지안 접근 방식은 처음에는 och가 아닙니다. 큰 데이터 세트. 이것은 내가 지금까지 알고 있는 것입니다.
저것들. 이러한 NN은 매우 큰 데이터 세트가 필요하지 않으며 결과는 일반적인 데이터 세트로 수렴됩니다.
다음은 의견 https://www.mql5.com/ru/forum/226219에서 베이지안 최적화 에 대한 Vladimir의 기사 에서 여러 점에 걸쳐 곡선을 작성하는 방법입니다. 하지만 그는 숲/ns도 필요하지 않습니다. 이 곡선에서 바로 답을 찾을 수 있습니다.
또 다른 문제는 옵티마이저가 제대로 훈련되지 않은 경우 NN이 이해할 수 없는 쓰레기를 가르칠 것이라는 점입니다.
 배운 패턴
배운 패턴 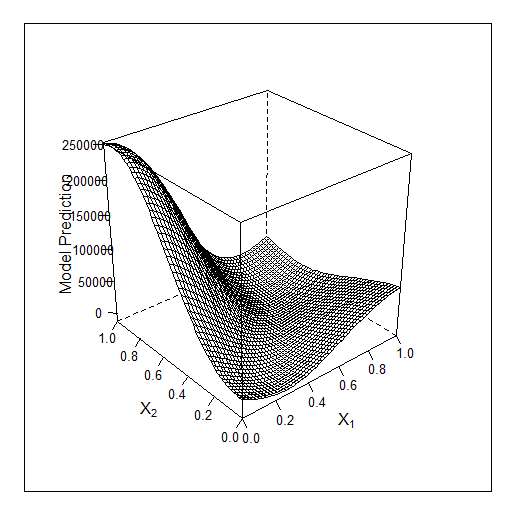
다음은 3가지 징후에 대한 Bayes의 작업입니다.
대화가 전혀 흥미롭지 않은 주제의 바보들 때문에
숨이 막히는 소리를 내다
무슨 말을 하는 겁니까? 당신은 링크를 수집하고 다양한 과학적 이미지를 수집하여 신규 이민자에게 깊은 인상을 남깁니다. SanSanych는 이미 그의 기사에 모든 것을 작성했으며 추가할 내용이 거의 없습니다. 이제 모든 종류의 판매자와 기사가 스스로를 끌어올려 모든 것을 갈퀴로 부끄럽고 부끄럽게 칠했습니다. 역겨운. 그들은 "수학자"를 "양자"로 만듭니다 ....
수학을 원한다면 http://www.kurims.kyoto-u.ac.jp/~motizuki/Inter-universal%20Teichmuller%20Theory%20I.pdf 를 읽어보십시오.
그리고 당신은 수학자가 아니라 zilch라는 것을 이해하지 못할 것입니다.