神经网络变得轻松(第十二部分):舍弃
Dmitriy Gizlyk | 11 五月, 2021
内容
概述
自从本系列文章开始以来,我们已在研究各种神经网络模型方面取得了长足的进步。 但学习过程总是在没有我们参与的情况下进行的。 与此同时,总是希望以某种方式帮助神经网络改进训练效果,这也可能会设计神经网络收敛。 在本文中,我们将研究一种名为舍弃的方法。
1. 舍弃:提升神经网络收敛性的一种方法
在训练神经网络时,会将大量特征馈入每个神经元,且很难评估每个独立特征的影响。 结果就是,某些神经元的误差会被其他神经元的调整值抹平,这些误差从而会在神经网络输出处累积。 这会导致训练在某个局部最小值处停止,且误差较大。 这种效应涉及特征检测器的协同适应,其中每个特征的影响会随环境而变化。 当环境分解成单独的特征,且可以分别评估每个特征的影响时,很可能会有相反的效果。
2012年,多伦多大学的一组科学家提议从学习过程中随机排除一些神经元,作为复杂协同适应问题的解决方案 [12]。 训练中减少特征的数量,会增加每个特征的重要性,且特征的数量和质量构成的持续变化降低了它们协同适应的风险。 此方法称为舍弃。 有时拿这种方法的应用与决策树进行比较:通过舍弃一些神经元,我们在每次训练迭代中获得一个含有其自身权重的新神经网络。 根据组合规则,这样的网络具有很大的可变性。
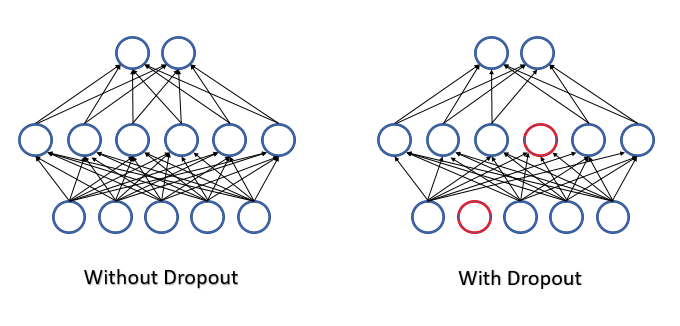
在神经网络操作期间评估所有特征和神经元,从而我们能得到所分析环境当前状态的最准确和独立的评估。
作者在他们的文章(12)中谈及使用该方法来提高预训练模型品质的可能性。
从数学的角度来看,我们可以这样描述这个过程:以给定的概率 p 从过程中舍弃每个独立的神经元。 换句话说,神经元能够参与神经网络学习过程的概率为 q = 1-p 。
由含有正态分布的伪随机数生成器来判定将被排除的神经元列表。 这种方式可以实现最大程度地统一排除神经元。 我们将生成一个练习向量,其大小与输入序列相等。 向量中的 "1" 将会参与训练,且 "0" 则为排除元素。
然而,排除已分析特征无疑会导致神经元激活函数输入量的减少。 为了补偿这种影响,我们将每个特征的值乘以系数 1/q 。 该系数将提升该数值,因为概率 q 始终在 0 到 1 之间。
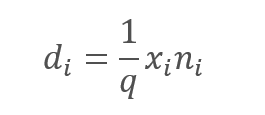 ,
,
其中:
d — 舍弃结果向量的元素,
q — 在训练过程中用到的神经元概率,
x — 掩码向量的元素,
n — 输入序列的元素.
在学习过程中的前馈验算过程中,误差梯度乘以上述函数的导数。 如您所见,在舍弃的情况下,反馈验算与前馈验算类似,均采用前馈验算的掩码向量。
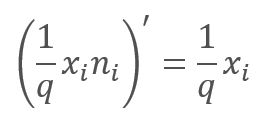
在神经网络的操作过程中,掩码向量用 “1” 填充,这允许数值在两个方向上平滑传递。
实际上,系数 1/q 在整个训练期间都是恒定的,因此我们可以轻松地一次性计算该系数,然后将其代替 “1” 写入掩码张量当中。 因此,在每次训练迭代中,我们可以排除系数的重新计算操作,并将其乘以掩码 “1”。
2. 实现
如今,我们已研究过理论方面,我们来继续研究如何在函数库中实现此方法的变体。 我们遇到的第一件事是实现两种不同算法。 其一在训练过程需要,而第二个则用于生产。 相应地,我们需要根据每种独立情况,为神经元明确指出应采用的算法。 为此目的,我们将在基准神经元级别引入 bTrain 标志。 该标志值对于训练 应设为 true,而对于测试 则设为 false。
class CNeuronBaseOCL : public CObject { protected: bool bTrain; ///< Training Mode Flag
以下辅助方法将控制该标志值。
virtual void TrainMode(bool flag) { bTrain=flag; }///< Set Training Mode Flag virtual bool TrainMode(void) { return bTrain; }///< Get Training Mode Flag
该标志特意在基准神经元级别实现。 如此在以后开发时能够启用舍弃相关的代码。
2.1. 为我们的模型创建一个新类
为了实现舍弃算法,我们来创建新的 CNeuronDropoutOCL 类,它将包含在我们的模型当中作为单独的层。 新类将直接继承自 CNeuronBaseOCL 基准神经元类。 在受保护模块中声明变量:
- OutProbability — 指定神经元的舍弃概率。
- OutNumber — 神经元的舍弃数量。
- dInitValue — 掩码向量初始化值;在本文的理论部分,该系数被指定为 1/q。
另外,声明两个指向类的指针:
- DropOutMultiplier — 舍弃向量。
- PrevLayer — 指向上一层对象的指针;它在测试和实际应用时会用到。
class CNeuronDropoutOCL : public CNeuronBaseOCL { protected: CNeuronBaseOCL *PrevLayer; double OutProbability; double OutNumber; CBufferDouble *DropOutMultiplier; double dInitValue; //--- virtual bool feedForward(CNeuronBaseOCL *NeuronOCL); ///<\brief Feed Forward method of calling kernel ::FeedForward().@param NeuronOCL Pointer to previous layer. virtual bool updateInputWeights(CNeuronBaseOCL *NeuronOCL) {return true;} ///< Method for updating weights.@param NeuronOCL Pointer to previous layer. //--- int RND(void) { xor128; return (int)((double)(Neurons()-1)/UINT_MAX*rnd_w); } ///< Generates a random neuron position to turn off public: CNeuronDropoutOCL(void); ~CNeuronDropoutOCL(void); //--- virtual bool Init(uint numOutputs, uint myIndex, COpenCLMy *open_cl, uint numNeurons,double out_prob, ENUM_OPTIMIZATION optimization_type); ///< Method of initialization class.@param[in] numOutputs Number of connections to next layer.@param[in] myIndex Index of neuron in layer.@param[in] open_cl Pointer to #COpenCLMy object. #param[in] numNeurons Number of neurons in layer #param[in] out_prob Probability of neurons shutdown @param optimization_type Optimization type (#ENUM_OPTIMIZATION)@return Boolen result of operations. //--- virtual int getOutputIndex(void) { return (bTrain ? Output.GetIndex() : PrevLayer.getOutputIndex()); } ///< Get index of output buffer @return Index virtual int getGradientIndex(void) { return (bTrain ? Gradient.GetIndex() : PrevLayer.getGradientIndex()); } ///< Get index of gradient buffer @return Index //--- virtual int getOutputVal(double &values[]) { return (bTrain ? Output.GetData(values) : PrevLayer.getOutputVal(values)); } ///< Get values of output buffer @param[out] values Array of data @return number of items virtual int getOutputVal(CArrayDouble *values) { return (bTrain ? Output.GetData(values) : PrevLayer.getOutputVal(values)); } ///< Get values of output buffer @param[out] values Array of data @return number of items virtual int getGradient(double &values[]) { return (bTrain ? Gradient.GetData(values) : PrevLayer.getGradient(values)); } ///< Get values of gradient buffer @param[out] values Array of data @return number of items virtual CBufferDouble *getOutput(void) { return (bTrain ? Output : PrevLayer.getOutput()); } ///< Get pointer of output buffer @return Pointer to object virtual CBufferDouble *getGradient(void) { return (bTrain ? Gradient : PrevLayer.getGradient()); } ///< Get pointer of gradient buffer @return Pointer to object //--- virtual bool calcInputGradients(CNeuronBaseOCL *NeuronOCL); ///< Method to transfer gradient to previous layer by calling kernel ::CalcHiddenGradient(). @param NeuronOCL Pointer to next layer. //--- virtual bool Save(int const file_handle);///< Save method @param[in] file_handle handle of file @return logical result of operation virtual bool Load(int const file_handle);///< Load method @param[in] file_handle handle of file @return logical result of operation //--- virtual int Type(void) const { return defNeuronDropoutOCL; }///< Identificator of class.@return Type of class };
您必须熟悉类方法的清单,因为它们都会覆盖父类的方法。 唯一排除在外的是 RND 方法,它用来生成均匀分布的伪随机数。 在文章的第十三部分中已讲述过该方法的算法。 在我们的神经网络里,为了确保所有对象中数值的最大可能随机性,伪随机序列生成器在实现时以宏替换来定义全局变量。
#define xor128 rnd_t=(rnd_x^(rnd_x<<11)); \ rnd_x=rnd_y; \ rnd_y=rnd_z; \ rnd_z=rnd_w; \ rnd_w=(rnd_w^(rnd_w>>19))^(rnd_t^(rnd_t>>8)) uint rnd_x=MathRand(), rnd_y=MathRand(), rnd_z=MathRand(), rnd_w=MathRand(), rnd_t=0;
所提议算法将生成一个范围在 [0,UINT_MAX=4294967295] 内的整数序列。 因此,在伪随机序列生成器方法中,宏替换执行之后,将结果值常规化为序列的大小。
int RND(void) { xor128; return (int)((double)(Neurons()-1)/UINT_MAX*rnd_w); }
如果您阅读过本系列中的早前文章,您可能已经注意到,在以前的版本中,我们没有覆盖来自其他对象的操控类数据缓冲区的方法。 当神经元访问上一层或下一层的数据时,这些方法可在神经网络的各层之间交换数据。
选择该解决方案是为了在实际应用中优化神经网络的运行。 不要忘记仅在神经网络训练时才会用到舍弃层。 在测试和以后的应用期间,会禁用此算法。 通过覆盖数据缓冲区的访问方法,我们启用略过舍弃层。 所有被覆盖的方法都应遵循相同的原理。 取代复制数据,我们实现了用上一层缓冲区替换舍弃层缓冲区。 因此,在以后的操作期间,含有舍弃层的神经网络在速度上可比没有舍弃层的类似网络,而我们在训练阶段已获得了神经元舍弃的所有优势。
virtual int getOutputIndex(void) { return (bTrain ? Output.GetIndex() : PrevLayer.getOutputIndex()); }
在附件中可找到所有类方法的完整代码。
2.2. 前馈
传统上,我们在 feedForward 方法中实现前馈验算。 在方法伊始,检查接收到的指向神经网络上一层的指针,和指向 OpenCL 对象的指针的有效性。 此后,保存上一层所用的激活函数,和指向上一层对象的指针。 对于神经网络实际操作模式,舍弃层的前馈验算到此结束。 以后尝试从下一层访问该层将激活上述替换数据缓冲区的机制。
bool CNeuronDropoutOCL::feedForward(CNeuronBaseOCL *NeuronOCL) { if(CheckPointer(OpenCL)==POINTER_INVALID || CheckPointer(NeuronOCL)==POINTER_INVALID) return false; //--- activation=(ENUM_ACTIVATION)NeuronOCL.Activation(); PrevLayer=NeuronOCL; if(!bTrain) return true;
后续迭代仅与神经网络训练模式相关。 首先,生成一个掩码向量,在其中,我们需定义在此步骤中舍弃的神经元。 将掩码写入 DropOutMultiplier 缓冲区中,检查之前创建对象的可用性,并在必要时创建一个新对象。 用初始值初始化缓冲区。 为了降低计算量,我们以递增的因子 1/q 来初始化缓冲区。
if(CheckPointer(DropOutMultiplier)==POINTER_INVALID) DropOutMultiplier=new CBufferDouble(); if(!DropOutMultiplier.BufferInit(NeuronOCL.Neurons(),dInitValue)) return false; for(int i=0;i<OutNumber;i++) { uint p=RND(); double val=DropOutMultiplier.At(p); if(val==0 || val==DBL_MAX) { i--; continue; } if(!DropOutMultiplier.Update(RND(),0)) return false; }
缓冲区初始化后,规划一个循环,而其重复次数等于要舍弃的神经元数量。 缓冲区中随机选择的元素将以零值替换。 为避免在一个单元内两次写入 “0” 的风险,在循环内部实现额外检查。
生成掩码后,直接在 GPU 内存中创建一个缓冲区,并传输数据。
if(!DropOutMultiplier.BufferCreate(OpenCL)) return false;
现在,我们需要将两个向量的元素逐个相乘。 此操作的结果将成为舍弃层的输出。 向量乘法运算将在 GPU 上利用 OpenCL 实现。 元素相乘的最有效方法是采用向量运算。 我在 OpenCL 内核里采用 double4 类型的变量, 即 四个元素的向量。 因此,启动线的程数量将比向量中元素的数量少 4 倍。
uint global_work_offset[1]= {0}; uint global_work_size[1]; int i=Neurons()%4; global_work_size[0]=(Neurons()-i)/4+(i>0 ? 1 : 0);
接下来,指示初始数据缓冲区和变量,并启动内核加以执行。
if(!OpenCL.SetArgumentBuffer(def_k_Dropout,def_k_dout_input,NeuronOCL.getOutputIndex())) return false; if(!OpenCL.SetArgumentBuffer(def_k_Dropout,def_k_dout_map,DropOutMultiplier.GetIndex())) return false; if(!OpenCL.SetArgumentBuffer(def_k_Dropout,def_k_dout_out,Output.GetIndex())) return false; if(!OpenCL.SetArgument(def_k_Dropout,def_k_dout_dimension,Neurons())) return false; ResetLastError(); if(!OpenCL.Execute(def_k_Dropout,1,global_work_offset,global_work_size)) { printf("Error of execution kernel Dropout: %d",GetLastError()); return false; }
在方法的最后得到内核执行操作的结果。 在此,掩码缓冲区已从 GPU 内存中删除。
if(!Output.BufferRead()) return false; DropOutMultiplier.BufferFree(); //--- return true; }
完成操作后,以 true 退出方法。
如果不考虑 GPU 端的操作,前馈方法的描述将是不完整的。 这是内核代码。
__kernel void Dropout (__global double *inputs, ///<[in] Input matrix __global double *map, ///<[in] Dropout map matrix __global double *out, ///<[out] Output matrix int dimension ///< Dimension of matrix )
内核从参数里接收指向两个含有初始数据的输入张量的指针,和结果张量,以及向量的大小。
在内核代码中,根据线程编号判定需要相乘的元素。 之后,代码被分为两条分支。 第一条分支是主要分支:运用向量运算将四个连续的元素相乘,并将得到的数据写入结果缓冲区的相应元素。
{
const int i=get_global_id(0)*4;
if(i+3<dimension)
{
double4 k=(double4)(inputs[i],inputs[i+1],inputs[i+2],inputs[i+3])*(double4)(map[i],map[i+1],map[i+2],map[i+3]);
out[i]=k.s0;
out[i+1]=k.s1;
out[i+2]=k.s2;
out[i+3]=k.s3;
}
else
for(int k=i;k<min(dimension,i+4);k++)
out[i+k]=(inputs[i+k]*map[i+k]);
}
仅当张量中的元素数量并非 4 的倍数,且在循环中剩余元素相乘时,第二条分支才被激活。 这样的循环不会超过 3 次迭代,故此它不是时间紧迫的。
附件中提供了所有类及其方法的完整代码。
2.3. 反馈
在之前研究过的所有神经元反馈验算分为两种方法:
- calcInputGradients — 将误差梯度传播到上一层。
- updateInputWeights — 更新神经层的权重。
在舍弃的情况下,我们没有权重张量。 然而,为了保持对象的一般结构,我们将覆盖 updateInputWeights 方法 - 但在这种情况下,它将始终返回 true。
virtual bool updateInputWeights(CNeuronBaseOCL *NeuronOCL) {return true;} ///< Method for updating weights.
研究 calcInputGradients方法的实现。 该方法从参数中接收指向上一层的指针。 在方法开始时,检查接收到的指针和指向 OpenCL 对象的指针的有效性。 然后,与前馈验算一样,将算法划分为训练和操作过程。 在测试或操作模式下,我们退出该方法,因为由于数据缓冲区替换,下一个神经层已将梯度直接写入了前一层的缓冲区,从而避免了舍弃层中不必要的迭代。
bool CNeuronDropoutOCL::calcInputGradients(CNeuronBaseOCL *NeuronOCL) { if(CheckPointer(OpenCL)==POINTER_INVALID || CheckPointer(NeuronOCL)==POINTER_INVALID) return false; //--- if(!bTrain) return true;
在训练模式下,梯度将以不同的方式传播。 以下算法仅与神经网络训练过程有关。 如同前馈方法一样,检查指向掩码缓冲区 DropOutMultiplier 指针的有效性。 不过,与前馈验算不同,验证错误不会导致创建新的缓冲区 - 在这种情况下,我们将以 false 退出该方法。 这是因为反馈验算使用前馈通道生成的掩码。 这种方法可确保数据的可比性,以及神经元之间误差梯度的正确分布。
if(CheckPointer(DropOutMultiplier)==POINTER_INVALID) return false; //--- if(!DropOutMultiplier.BufferCreate(OpenCL)) return false;
在成功验证 DropOutMultiplier 对象之后,在 GPU 内存中创建一个缓冲区,并向其中填充数据。
现在我们需要将两个向量元素逐个相乘。 您对此是否似曾相识? 在上面前馈传递的讲述中,曾给出完全相同的句子。 确实是的。 在理论部分,我们已经看到数学函数 Dropout 的导数等于递增系数。 因此,在反馈验算中,我们还将下一层的梯度乘以 DropOutMultiplier 掩码缓冲区中写入的递增系数。 因此,若前馈和反馈采用相同的内核,则 CNeuronDropoutOCL 类是一种独有的情况,但在这些情况下将馈送不同的输入数据:对于前馈验算,它是神经元的输出数据;对于反馈验算是误差梯度。
因此,我们需指定数据缓冲区,并调用内核执行。 该代码与前馈代码相似,因此务须赘述。
uint global_work_offset[1]= {0}; uint global_work_size[1]; int i=Neurons()%4; global_work_size[0]=(Neurons()-i)/4+(i>0 ? 1 : 0); if(!OpenCL.SetArgumentBuffer(def_k_Dropout,def_k_dout_input,Gradient.GetIndex())) return false; if(!OpenCL.SetArgumentBuffer(def_k_Dropout,def_k_dout_map,DropOutMultiplier.GetIndex())) return false; if(!OpenCL.SetArgumentBuffer(def_k_Dropout,def_k_dout_out,NeuronOCL.getGradientIndex())) return false; if(!OpenCL.SetArgument(def_k_Dropout,def_k_dout_dimension,Neurons())) return false; ResetLastError(); if(!OpenCL.Execute(def_k_Dropout,1,global_work_offset,global_work_size)) { printf("Error of execution kernel Dropout: %d",GetLastError()); return false; } if(!NeuronOCL.getGradient().BufferRead()) return false; DropOutMultiplier.BufferFree(); //--- return true; }
附件中提供了所有类及其方法的完整代码。
2.4. 数据保存和加载方法
我们来看一下保存和加载舍弃神经层对象的方法。 无需保存掩码缓冲区对象,因为在每个训练周期都会生成新的掩码。 仅在 CNeuronDropoutOCL 类的初始化方法中添加了一个变量:应加以保存的排除神经元的概率。
在 Save 方法中,我们将调用父类的相关方法。 成功完成后,我们将保存给定的神经元舍弃概率。
bool CNeuronDropoutOCL::Save(const int file_handle) { if(!CNeuronBaseOCL::Save(file_handle)) return false; //--- if(FileWriteDouble(file_handle,OutProbability)<=0) return false; //--- return true; }
在 Load 方法中,我们将从硬盘读取数据,并还原该类的所有元素。 因此,该方法算法比 Save 算法复杂一些。
与类的保存方法相似,我们调用父类当中的同名方法。 完成后,计算神经元舍弃的概率。 如此即完成了保存方法,但是我们需要复原缺失的元素。 根据神经元舍弃的概率,我们计算需要排除的神经元数量,和递增系数值,该值也用作初始化掩蔽向量的值。
bool CNeuronDropoutOCL::Load(const int file_handle) { if(!CNeuronBaseOCL::Load(file_handle)) return false; //--- OutProbability=FileReadDouble(file_handle); OutNumber=(int)(Neurons()*OutProbability); dInitValue=1/(1-OutProbability); if(CheckPointer(DropOutMultiplier)==POINTER_INVALID) DropOutMultiplier=new CBufferDouble(); if(!DropOutMultiplier.BufferInit(Neurons()+1,dInitValue)) return false; //--- return true; }
现在,计算完毕之后,我们可以复原掩码向量。 检查指向 DropOutMultiplier 中数据缓冲区对象的指针的有效性,并在必要时创建一个新对象。 然后采用初始值来初始化掩码缓冲区。
2.5. 神经网络基类的变化
同样,应将新类正确添加到函数库操作中。 我们从声明操控新内核的宏替换开始。 另外,我们需要为新类设置标识常量。
#define def_k_Dropout 23 ///< Index of the kernel for Dropout process (#Dropout) #define def_k_dout_input 0 ///< Inputs Tensor #define def_k_dout_map 1 ///< Map Tensor #define def_k_dout_out 2 ///< Out Tensor #define def_k_dout_dimension 3 ///< Dimension of Inputs #define defNeuronDropoutOCL 0x7890 ///<Dropout neuron OpenCL \details Identified class #CNeuronDropoutOCL
然后,在神经层描述方法中,我们添加一个新变量来记录神经元舍弃的概率。
class CLayerDescription : public CObject { public: /** Constructor */ CLayerDescription(void); /** Destructor */~CLayerDescription(void) {}; //--- int type; ///< Type of neurons in layer (\ref ObjectTypes) int count; ///< Number of neurons int window; ///< Size of input window int window_out; ///< Size of output window int step; ///< Step size int layers; ///< Layers count ENUM_ACTIVATION activation; ///< Type of activation function (#ENUM_ACTIVATION) ENUM_OPTIMIZATION optimization; ///< Type of optimization method (#ENUM_OPTIMIZATION) double probability; ///< Probability of neurons shutdown, only Dropout used };
在神经网络方法创建方法 CNe ::CNet 里,在层创建和初始化模块中,我们添加初始化新层的代码(在下面的代码中高亮显示)。
for(int i=0; i<total; i++) { prev=desc; desc=Description.At(i); if((i+1)<total) { next=Description.At(i+1); if(CheckPointer(next)==POINTER_INVALID) return; } else next=NULL; int outputs=(next==NULL || (next.type!=defNeuron && next.type!=defNeuronBaseOCL) ? 0 : next.count); temp=new CLayer(outputs); int neurons=(desc.count+(desc.type==defNeuron || desc.type==defNeuronBaseOCL ? 1 : 0)); if(CheckPointer(opencl)!=POINTER_INVALID) { CNeuronBaseOCL *neuron_ocl=NULL; CNeuronConvOCL *neuron_conv_ocl=NULL; CNeuronAttentionOCL *neuron_attention_ocl=NULL; CNeuronMLMHAttentionOCL *neuron_mlattention_ocl=NULL; CNeuronDropoutOCL *dropout=NULL; switch(desc.type) { case defNeuron: case defNeuronBaseOCL: neuron_ocl=new CNeuronBaseOCL(); if(CheckPointer(neuron_ocl)==POINTER_INVALID) { delete temp; return; } if(!neuron_ocl.Init(outputs,0,opencl,desc.count,desc.optimization)) { delete neuron_ocl; delete temp; return; } neuron_ocl.SetActivationFunction(desc.activation); if(!temp.Add(neuron_ocl)) { delete neuron_ocl; delete temp; return; } neuron_ocl=NULL; break; //--- case defNeuronConvOCL: neuron_conv_ocl=new CNeuronConvOCL(); if(CheckPointer(neuron_conv_ocl)==POINTER_INVALID) { delete temp; return; } if(!neuron_conv_ocl.Init(outputs,0,opencl,desc.window,desc.step,desc.window_out,desc.count,desc.optimization)) { delete neuron_conv_ocl; delete temp; return; } neuron_conv_ocl.SetActivationFunction(desc.activation); if(!temp.Add(neuron_conv_ocl)) { delete neuron_conv_ocl; delete temp; return; } neuron_conv_ocl=NULL; break; //--- case defNeuronAttentionOCL: neuron_attention_ocl=new CNeuronAttentionOCL(); if(CheckPointer(neuron_attention_ocl)==POINTER_INVALID) { delete temp; return; } if(!neuron_attention_ocl.Init(outputs,0,opencl,desc.window,desc.count,desc.optimization)) { delete neuron_attention_ocl; delete temp; return; } neuron_attention_ocl.SetActivationFunction(desc.activation); if(!temp.Add(neuron_attention_ocl)) { delete neuron_attention_ocl; delete temp; return; } neuron_attention_ocl=NULL; break; //--- case defNeuronMHAttentionOCL: neuron_attention_ocl=new CNeuronMHAttentionOCL(); if(CheckPointer(neuron_attention_ocl)==POINTER_INVALID) { delete temp; return; } if(!neuron_attention_ocl.Init(outputs,0,opencl,desc.window,desc.count,desc.optimization)) { delete neuron_attention_ocl; delete temp; return; } neuron_attention_ocl.SetActivationFunction(desc.activation); if(!temp.Add(neuron_attention_ocl)) { delete neuron_attention_ocl; delete temp; return; } neuron_attention_ocl=NULL; break; //--- case defNeuronMLMHAttentionOCL: neuron_mlattention_ocl=new CNeuronMLMHAttentionOCL(); if(CheckPointer(neuron_mlattention_ocl)==POINTER_INVALID) { delete temp; return; } if(!neuron_mlattention_ocl.Init(outputs,0,opencl,desc.window,desc.window_out,desc.step,desc.count,desc.layers,desc.optimization)) { delete neuron_mlattention_ocl; delete temp; return; } neuron_mlattention_ocl.SetActivationFunction(desc.activation); if(!temp.Add(neuron_mlattention_ocl)) { delete neuron_mlattention_ocl; delete temp; return; } neuron_mlattention_ocl=NULL; break; //--- case defNeuronDropoutOCL: dropout=new CNeuronDropoutOCL(); if(CheckPointer(dropout)==POINTER_INVALID) { delete temp; return; } if(!dropout.Init(outputs,0,opencl,desc.count,desc.probability,desc.optimization)) { delete dropout; delete temp; return; } if(!temp.Add(dropout)) { delete dropout; delete temp; return; } dropout=NULL; break; //--- default: return; break; } }
不要忘记在同一方法里声明一个新内核。
opencl.SetKernelsCount(24); opencl.KernelCreate(def_k_FeedForward,"FeedForward"); opencl.KernelCreate(def_k_CalcOutputGradient,"CalcOutputGradient"); opencl.KernelCreate(def_k_CalcHiddenGradient,"CalcHiddenGradient"); opencl.KernelCreate(def_k_UpdateWeightsMomentum,"UpdateWeightsMomentum"); opencl.KernelCreate(def_k_UpdateWeightsAdam,"UpdateWeightsAdam"); opencl.KernelCreate(def_k_AttentionGradients,"AttentionInsideGradients"); opencl.KernelCreate(def_k_AttentionOut,"AttentionOut"); opencl.KernelCreate(def_k_AttentionScore,"AttentionScore"); opencl.KernelCreate(def_k_CalcHiddenGradientConv,"CalcHiddenGradientConv"); opencl.KernelCreate(def_k_CalcInputGradientProof,"CalcInputGradientProof"); opencl.KernelCreate(def_k_FeedForwardConv,"FeedForwardConv"); opencl.KernelCreate(def_k_FeedForwardProof,"FeedForwardProof"); opencl.KernelCreate(def_k_MatrixSum,"SumMatrix"); opencl.KernelCreate(def_k_Matrix5Sum,"Sum5Matrix"); opencl.KernelCreate(def_k_UpdateWeightsConvAdam,"UpdateWeightsConvAdam"); opencl.KernelCreate(def_k_UpdateWeightsConvMomentum,"UpdateWeightsConvMomentum"); opencl.KernelCreate(def_k_Normilize,"Normalize"); opencl.KernelCreate(def_k_NormilizeWeights,"NormalizeWeights"); opencl.KernelCreate(def_k_ConcatenateMatrix,"ConcatenateBuffers"); opencl.KernelCreate(def_k_DeconcatenateMatrix,"DeconcatenateBuffers"); opencl.KernelCreate(def_k_MHAttentionGradients,"MHAttentionInsideGradients"); opencl.KernelCreate(def_k_MHAttentionScore,"MHAttentionScore"); opencl.KernelCreate(def_k_MHAttentionOut,"MHAttentionOut"); opencl.KernelCreate(def_k_Dropout,"Dropout");
必须添加相同的新内核声明,以便从硬盘读取预训练神经网络的方法 - CNet::Load。
关注加载预训练的神经网络的过程,我们还需要添加相关代码来调整 CLayer::CreateElement 方法,以便创建神经网络层,从而创建舍弃元素。 修改高亮在下面。
bool CLayer::CreateElement(int index) { if(index>=m_data_max) return false; //--- bool result=false; CNeuronBase *temp=NULL; CNeuronProof *temp_p=NULL; CNeuronBaseOCL *temp_ocl=NULL; CNeuronConvOCL *temp_con_ocl=NULL; CNeuronAttentionOCL *temp_at_ocl=NULL; CNeuronMLMHAttentionOCL *temp_mlat_ocl=NULL; CNeuronDropoutOCL *temp_drop_ocl=NULL; if(iFileHandle<=0) { temp=new CNeuron(); if(CheckPointer(temp)==POINTER_INVALID || !temp.Init(iOutputs,index,SGD)) return false; result=true; } else { int type=FileReadInteger(iFileHandle); switch(type) { case defNeuron: temp=new CNeuron(); if(CheckPointer(temp)==POINTER_INVALID) result=false; result=temp.Init(iOutputs,index,ADAM); break; case defNeuronProof: temp_p=new CNeuronProof(); if(CheckPointer(temp_p)==POINTER_INVALID) result=false; if(temp_p.Init(iOutputs,index,1,1,1,ADAM)) { temp=temp_p; result=true; } break; case defNeuronConv: temp_p=new CNeuronConv(); if(CheckPointer(temp_p)==POINTER_INVALID) result=false; if(temp_p.Init(iOutputs,index,1,1,1,ADAM)) { temp=temp_p; result=true; } break; case defNeuronLSTM: temp_p=new CNeuronLSTM(); if(CheckPointer(temp_p)==POINTER_INVALID) result=false; if(temp_p.Init(iOutputs,index,1,1,1,ADAM)) { temp=temp_p; result=true; } break; case defNeuronBaseOCL: if(CheckPointer(OpenCL)==POINTER_INVALID) return false; temp_ocl=new CNeuronBaseOCL(); if(CheckPointer(temp_ocl)==POINTER_INVALID) result=false; if(temp_ocl.Init(iOutputs,index,OpenCL,1,ADAM)) { m_data[index]=temp_ocl; return true; } break; case defNeuronConvOCL: if(CheckPointer(OpenCL)==POINTER_INVALID) return false; temp_con_ocl=new CNeuronConvOCL(); if(CheckPointer(temp_con_ocl)==POINTER_INVALID) result=false; if(temp_con_ocl.Init(iOutputs,index,OpenCL,1,1,1,1,ADAM)) { m_data[index]=temp_con_ocl; return true; } break; case defNeuronAttentionOCL: if(CheckPointer(OpenCL)==POINTER_INVALID) return false; temp_at_ocl=new CNeuronAttentionOCL(); if(CheckPointer(temp_at_ocl)==POINTER_INVALID) result=false; if(temp_at_ocl.Init(iOutputs,index,OpenCL,1,1,ADAM)) { m_data[index]=temp_at_ocl; return true; } break; case defNeuronMHAttentionOCL: if(CheckPointer(OpenCL)==POINTER_INVALID) return false; temp_at_ocl=new CNeuronMHAttentionOCL(); if(CheckPointer(temp_at_ocl)==POINTER_INVALID) result=false; if(temp_at_ocl.Init(iOutputs,index,OpenCL,1,1,ADAM)) { m_data[index]=temp_at_ocl; return true; } break; case defNeuronMLMHAttentionOCL: if(CheckPointer(OpenCL)==POINTER_INVALID) return false; temp_mlat_ocl=new CNeuronMLMHAttentionOCL(); if(CheckPointer(temp_mlat_ocl)==POINTER_INVALID) result=false; if(temp_mlat_ocl.Init(iOutputs,index,OpenCL,1,1,1,1,0,ADAM)) { m_data[index]=temp_mlat_ocl; return true; } break; case defNeuronDropoutOCL: if(CheckPointer(OpenCL)==POINTER_INVALID) return false; temp_drop_ocl=new CNeuronDropoutOCL(); if(CheckPointer(temp_drop_ocl)==POINTER_INVALID) result=false; if(temp_drop_ocl.Init(iOutputs,index,OpenCL,1,0.1,ADAM)) { m_data[index]=temp_drop_ocl; return true; } break; default: result=false; break; } } if(result) m_data[index]=temp; //--- return (result); }
新类应添加到 CNeuronBaseOCL 基类的调度程序方法当中。
前馈验算 CNeuronBaseOCL::FeedForward。
bool CNeuronBaseOCL::FeedForward(CObject *SourceObject) { if(CheckPointer(SourceObject)==POINTER_INVALID) return false; //--- CNeuronBaseOCL *temp=NULL; switch(SourceObject.Type()) { case defNeuronBaseOCL: case defNeuronConvOCL: case defNeuronAttentionOCL: case defNeuronMHAttentionOCL: case defNeuronMLMHAttentionOCL: case defNeuronDropoutOCL: temp=SourceObject; return feedForward(temp); break; } //--- return false; }
误差梯度传播方法 CNeuronBaseOCL::calcHiddenGradients。
bool CNeuronBaseOCL::calcHiddenGradients(CObject *TargetObject) { if(CheckPointer(TargetObject)==POINTER_INVALID) return false; //--- CNeuronBaseOCL *temp=NULL; CNeuronAttentionOCL *at=NULL; CNeuronMLMHAttentionOCL *mlat=NULL; CNeuronConvOCL *conv=NULL; CNeuronDropoutOCL *dropout=NULL; switch(TargetObject.Type()) { case defNeuronBaseOCL: temp=TargetObject; return calcHiddenGradients(temp); break; case defNeuronConvOCL: conv=TargetObject; temp=GetPointer(this); return conv.calcInputGradients(temp); break; case defNeuronAttentionOCL: case defNeuronMHAttentionOCL: at=TargetObject; temp=GetPointer(this); return at.calcInputGradients(temp); break; case defNeuronMLMHAttentionOCL: mlat=TargetObject; temp=GetPointer(this); return mlat.calcInputGradients(temp); break; case defNeuronDropoutOCL: dropout=TargetObject; temp=GetPointer(this); return dropout.calcInputGradients(temp); break; } //--- return false; }
而且,令人惊讶的是,此处是权重更新方法 CNeuronBaseOCL::UpdateInputWeights。
bool CNeuronBaseOCL::UpdateInputWeights(CObject *SourceObject) { if(CheckPointer(SourceObject)==POINTER_INVALID) return false; //--- CNeuronBaseOCL *temp=NULL; switch(SourceObject.Type()) { case defNeuronBaseOCL: case defNeuronConvOCL: case defNeuronAttentionOCL: case defNeuronMHAttentionOCL: case defNeuronMLMHAttentionOCL: case defNeuronDropoutOCL: temp=SourceObject; return updateInputWeights(temp); break; } //--- return false; }
即使上述修改看起来很小或微不足道,但即使缺少了其中之一,也会导致整个神经网络的错误操作。
附件中提供了所有类及其方法的完整代码。
3. 测试
为了保持一致,我们将借用文章第十一部分中的智能交易系统,并在其中添加了 4 个舍弃层:
- 1 个位于初始数据之后,
- 1 个位于嵌入代码之后,
- 1 个位于关注模块之后,
- 1 个位于完全连接层之后。
下面的代码描述了神经网络的结构。
//--- 0 CLayerDescription *desc=new CLayerDescription(); if(CheckPointer(desc)==POINTER_INVALID) return INIT_FAILED; desc.count=(int)HistoryBars*12; desc.type=defNeuronBaseOCL; desc.optimization=ADAM; desc.activation=TANH; if(!Topology.Add(desc)) return INIT_FAILED; //--- 1 desc=new CLayerDescription(); if(CheckPointer(desc)==POINTER_INVALID) return INIT_FAILED; desc.count=(int)HistoryBars*12; desc.type=defNeuronDropoutOCL; desc.probability=0.2; desc.optimization=ADAM; desc.activation=TANH; if(!Topology.Add(desc)) return INIT_FAILED; //--- 2 desc=new CLayerDescription(); if(CheckPointer(desc)==POINTER_INVALID) return INIT_FAILED; desc.count=(int)HistoryBars; desc.type=defNeuronConvOCL; desc.window=12; desc.step=12; desc.window_out=24; desc.optimization=ADAM; desc.activation=SIGMOID; if(!Topology.Add(desc)) return INIT_FAILED; //--- 3 desc=new CLayerDescription(); if(CheckPointer(desc)==POINTER_INVALID) return INIT_FAILED; desc.count=(int)HistoryBars; desc.type=defNeuronDropoutOCL; desc.probability=0.2; desc.optimization=ADAM; desc.activation=SIGMOID; if(!Topology.Add(desc)) return INIT_FAILED; //--- 4 desc=new CLayerDescription(); if(CheckPointer(desc)==POINTER_INVALID) return INIT_FAILED; desc.count=(int)HistoryBars; desc.type=defNeuronMLMHAttentionOCL; desc.window=24; desc.window_out=4; desc.step=8; //heads desc.layers=5; desc.optimization=ADAM; desc.activation=SIGMOID; if(!Topology.Add(desc)) return INIT_FAILED; //--- 5 desc=new CLayerDescription(); if(CheckPointer(desc)==POINTER_INVALID) return INIT_FAILED; desc.count=(int)HistoryBars; desc.type=defNeuronDropoutOCL; desc.probability=0.2; desc.optimization=ADAM; desc.activation=SIGMOID; if(!Topology.Add(desc)) return INIT_FAILED; //--- 6 desc=new CLayerDescription(); if(CheckPointer(desc)==POINTER_INVALID) return INIT_FAILED; desc.count=200; desc.type=defNeuron; desc.activation=TANH; desc.optimization=ADAM; if(!Topology.Add(desc)) return INIT_FAILED; //--- 7 desc=new CLayerDescription(); if(CheckPointer(desc)==POINTER_INVALID) return INIT_FAILED; desc.count=200; desc.type=defNeuronDropoutOCL; desc.probability=0.2; desc.optimization=ADAM; desc.activation=TANH; if(!Topology.Add(desc)) return INIT_FAILED; //--- 8 desc=new CLayerDescription(); if(CheckPointer(desc)==POINTER_INVALID) return INIT_FAILED; desc.count=200; desc.type=defNeuron; desc.activation=TANH; desc.optimization=ADAM; if(!Topology.Add(desc)) return INIT_FAILED; //--- 9 desc=new CLayerDescription(); if(CheckPointer(desc)==POINTER_INVALID) return INIT_FAILED; desc.count=3; desc.type=defNeuron; desc.activation=SIGMOID; desc.optimization=ADAM;
智能交易系统已基于 EURUSD,H1 时间帧进行了测试,最后 20 根烛条的历史数据被输入到神经网络中。 基于相似数据集测试所有体系结构,可以最大程度地减少外部因素的影响,并可评估相似条件下各种体系结构的性能。
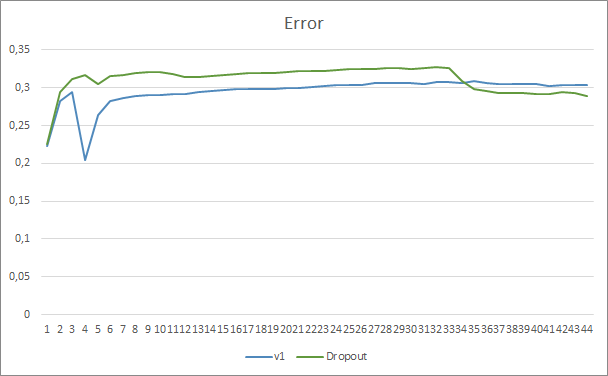
通过比较含有舍弃和不含有舍弃的两个神经网络学习图表,我们可看到神经网络误差曲线的前 30 个迭代几乎是平行的,而没有舍弃的神经网络则展示出更好的结果。 但是在第 33 个迭代之后,采用舍弃的智能交易系统有所降低。 在第 35 迭代之后,舍弃表现出最好的结果,其有误差降低的趋势。 没有舍弃的智能交易系统会把误差持续保持在同一水平。
错失的形态图表还表明,采用舍弃技术的智能交易系统的效果更好。 该图表提供了更多详细信息。 采用舍弃的智能交易系统立即展示出差距缩小的趋势。 与之对比,没有舍弃的智能交易系统会逐渐增加错失形态区域。
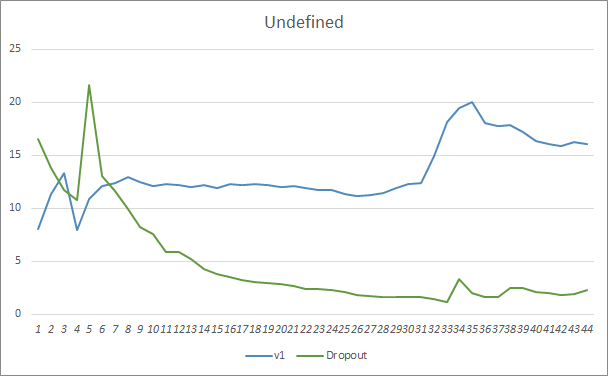
两款智能交易系统的预测命中图表非常接近。 经过 44 个迭代的训练,带有舍弃的 EA 仅提升了 0.5%。
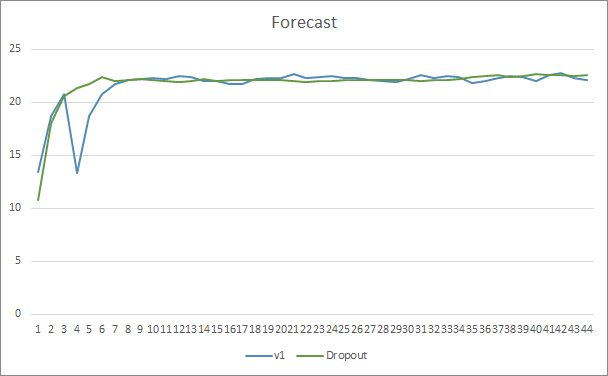
结束语
在本文中,我们开始研究提升神经网络收敛性的方法,并体验其中一种方法,即舍弃。 该方法已被加入我们以前的智能交易系统之一。 此方法的效率已展示在 EA 测试当中。 当然,利用这种方法会增加神经网络的训练成本。 但这些成本会被最终结果的效率提高所掩盖。
我邀请所有人尝试这种方法,并评估其有效性。
参考
- 神经网络变得轻松
- 神经网络变得轻松(第二部分):网络训练和测试
- 神经网络变得轻松(第三部分):卷积网络
- 神经网络变得轻松(第四部分):循环网络
- 神经网络变得轻松(第五部分):OpenCL 中的多线程计算
- 神经网络变得轻松(第六部分):神经网络学习率实验
- 神经网络变得轻松(第七部分):自适应优化方法
- 神经网络变得轻松(第八部分):关注机制
- 神经网络变得轻松(第九部分):操作归档
- 神经网络变得轻松(第十部分):多目击者关注
- 神经网络变得轻松(第十一部分):自 GPT 获取
- 通过防止特征检测器的协同适应来改善神经网络
- 统计评估
…
本文中用到的程序
| # | 发行 | 类型 | 说明 |
|---|---|---|---|
| 1 | Fractal_OCL_AttentionMLMH.mq5 | 智能交易系统 | 采用 GTP 架构的分类神经网络(输出层中有 3 个神经元)和 5 个关注层的智能交易系统 |
| 2 | Fractal_OCL_AttentionMLMH_d.mq5 | 智能交易系统 | 采用 GTP 架构的分类神经网络(输出层中有 3 个神经元)和 5 个关注层的智能交易系统 + 舍弃 |
| 3 | NeuroNet.mqh | 类库 | 用于创建神经网络的类库 |
| 4 | NeuroNet.cl | 代码库 | OpenCL 程序代码库 |
| 5 | NN.chm | HTML 帮助 | 一个编译后的函数库帮助 CHM 文件。 |