取引システムの開発における勾配ブースティング(CatBoost)素朴なアプローチ
Maxim Dmitrievsky | 11 12月, 2020
はじめに
勾配ブースティングは、強力な機械学習アルゴリズムです。このメソッドは、弱いモデル(たとえば、決定木)のアンサンブルを生成します。このアンサンブルでは、(バギングとは対照的に)モデルが独立して(並行して)ではなく、順次構築されます。これは、次の木が前の木の誤りから学習し、このプロセスが繰り返されて、弱いモデルの数が増えることを意味します。これにより、異種データを使用して一般化できる強力なモデルが構築されます。この実験では、Yandexが開発したCatBoostライブラリを使用しました。これは、XGboostやLightGBMと並んで、最も人気のあるライブラリの1つです。
この記事の目的は、機械学習に基づいたモデルの作成を示すことです。作成プロセスは、次の手順で構成されています。
- データを受信して前処理する
- 準備されたデータを使用してモデルを訓練する
- カスタムストラテジーテスターでモデルをテストする
- モデルをMetaTrader5に移植する
Python言語とMetaTrader5ライブラリは、データの準備とモデルの訓練に使用されます。
データの準備
必要なPythonモジュールをインポートします。
import MetaTrader5 as mt5 import pandas as pd import numpy as np from datetime import datetime import random import matplotlib.pyplot as plt from catboost import CatBoostClassifier from sklearn.model_selection import train_test_split mt5.initialize() # check for gpu devices is availible from catboost.utils import get_gpu_device_count print('%i GPU devices' % get_gpu_device_count())
次に、グローバル変数を初期化します。
LOOK_BACK = 250 MA_PERIOD = 15 SYMBOL = 'EURUSD' MARKUP = 0.0001 TIMEFRAME = mt5.TIMEFRAME_H1 START = datetime(2020, 5, 1) STOP = datetime(2021, 1, 1)
これらのパラメータの役割は以下の通りです。
- look_back — 分析された履歴の深さ
- ma_period — 価格増分を計算するための移動平均期間
- symbol — MetaTrader 5ターミナルから読み取る必要のある銘柄相場
- markup — マークアップ—カスタムテスターのスプレッドサイズ
- timeframe — 読み込まれる時間軸データ
- start, stop — データ範囲
生データを直接受け取り、訓練に必要な列を含むデータフレームを作成する関数を作成しましょう。
def get_prices(look_back = 15): prices = pd.DataFrame(mt5.copy_rates_range(SYMBOL, TIMEFRAME, START, STOP), columns=['time', 'close']).set_index('time') # set df index as datetime prices.index = pd.to_datetime(prices.index, unit='s') prices = prices.dropna() ratesM = prices.rolling(MA_PERIOD).mean() ratesD = prices - ratesM for i in range(look_back): prices[str(i)] = ratesD.shift(i) return prices.dropna()
この関数は、指定された時間軸の終値を受け取り、移動平均を計算し、その後、増分(価格と移動平均の差)を計算します。最後の手順では、look_backによって行が履歴に逆方向にシフトされた追加の列を計算します。これは、モデルに追加の(遅れている)機能を追加することを意味します。
たとえば、look_back = 10の場合、データフレームには、価格が増分する10個の追加の列が含まれます。
>>> pr = get_prices(look_back=LOOK_BACK) >>> pr close 0 1 2 3 4 5 6 7 8 9 time 2020-05-01 16:00:00 1.09750 0.001405 0.002169 0.001600 0.002595 0.002794 0.002442 0.001477 0.001190 0.000566 0.000285 2020-05-01 17:00:00 1.10074 0.004227 0.001405 0.002169 0.001600 0.002595 0.002794 0.002442 0.001477 0.001190 0.000566 2020-05-01 18:00:00 1.09976 0.002900 0.004227 0.001405 0.002169 0.001600 0.002595 0.002794 0.002442 0.001477 0.001190 2020-05-01 19:00:00 1.09874 0.001577 0.002900 0.004227 0.001405 0.002169 0.001600 0.002595 0.002794 0.002442 0.001477 2020-05-01 20:00:00 1.09817 0.000759 0.001577 0.002900 0.004227 0.001405 0.002169 0.001600 0.002595 0.002794 0.002442 ... ... ... ... ... ... ... ... ... ... ... ... 2020-11-02 23:00:00 1.16404 0.000400 0.000105 -0.000581 -0.001212 -0.000999 -0.000547 -0.000344 -0.000773 -0.000326 0.000501 2020-11-03 00:00:00 1.16392 0.000217 0.000400 0.000105 -0.000581 -0.001212 -0.000999 -0.000547 -0.000344 -0.000773 -0.000326 2020-11-03 01:00:00 1.16402 0.000270 0.000217 0.000400 0.000105 -0.000581 -0.001212 -0.000999 -0.000547 -0.000344 -0.000773 2020-11-03 02:00:00 1.16423 0.000465 0.000270 0.000217 0.000400 0.000105 -0.000581 -0.001212 -0.000999 -0.000547 -0.000344 2020-11-03 03:00:00 1.16464 0.000885 0.000465 0.000270 0.000217 0.000400 0.000105 -0.000581 -0.001212 -0.000999 -0.000547 [3155 rows x 11 columns]
黄色の強調表示は、各列のデータセットが同じであるが、オフセットがあることを示しています。したがって、各行は個別の訓練の例です。
訓練ラベルの作成(無作為抽出)
訓練の例は、機能のコレクションとそれに対応するラベルです。モデルは特定の情報を出力する必要があり、それを予測するために学習する必要があります。モデルが訓練の例をクラス0または1として決定する確率を予測する二項分類について考えてみましょう。0と1は、取引の方向性(購入または販売)に使用できます。言い換えると、モデルは、特定の環境パラメータ(機能のセット)の取引の方向を予測することを学習する必要があります。
def add_labels(dataset, min, max): labels = [] for i in range(dataset.shape[0]-max): rand = random.randint(min, max) if dataset['close'][i] >= (dataset['close'][i + rand]): labels.append(1.0) elif dataset['close'][i] <= (dataset['close'][i + rand]): labels.append(0.0) else: labels.append(0.0) dataset = dataset.iloc[:len(labels)].copy() dataset['labels'] = labels dataset = dataset.dropna() return dataset
add_labels関数は無作為に(最小~最大の範囲で)各取引の期間をバーで設定します。最大期間と最小期間を変更することで、取引の抽出頻度を変更します。したがって、現在の価格が次の「rand」バーよりも大きい場合、これは売りラベルです(1)。逆の場合、ラベルは0です。上記の関数を適用した後のデータセットの外観を見てみましょう。
>>> pr = add_labels(pr, 10, 25) >>> pr close 0 1 2 3 4 5 6 7 8 9 labels time 2020-05-01 16:00:00 1.09750 0.001405 0.002169 0.001600 0.002595 0.002794 0.002442 0.001477 0.001190 0.000566 0.000285 1.0 2020-05-01 17:00:00 1.10074 0.004227 0.001405 0.002169 0.001600 0.002595 0.002794 0.002442 0.001477 0.001190 0.000566 1.0 2020-05-01 18:00:00 1.09976 0.002900 0.004227 0.001405 0.002169 0.001600 0.002595 0.002794 0.002442 0.001477 0.001190 1.0 2020-05-01 19:00:00 1.09874 0.001577 0.002900 0.004227 0.001405 0.002169 0.001600 0.002595 0.002794 0.002442 0.001477 1.0 2020-05-01 20:00:00 1.09817 0.000759 0.001577 0.002900 0.004227 0.001405 0.002169 0.001600 0.002595 0.002794 0.002442 1.0 ... ... ... ... ... ... ... ... ... ... ... ... ... 2020-10-29 20:00:00 1.16700 -0.003651 -0.005429 -0.005767 -0.006750 -0.004699 -0.004328 -0.003475 -0.003769 -0.002719 -0.002075 1.0 2020-10-29 21:00:00 1.16743 -0.002699 -0.003651 -0.005429 -0.005767 -0.006750 -0.004699 -0.004328 -0.003475 -0.003769 -0.002719 0.0 2020-10-29 22:00:00 1.16731 -0.002276 -0.002699 -0.003651 -0.005429 -0.005767 -0.006750 -0.004699 -0.004328 -0.003475 -0.003769 0.0 2020-10-29 23:00:00 1.16740 -0.001648 -0.002276 -0.002699 -0.003651 -0.005429 -0.005767 -0.006750 -0.004699 -0.004328 -0.003475 0.0 2020-10-30 00:00:00 1.16695 -0.001655 -0.001648 -0.002276 -0.002699 -0.003651 -0.005429 -0.005767 -0.006750 -0.004699 -0.004328 1.0
「labels」列が追加されました。この列には、それぞれ売りと買いのクラス番号(0または1)が含まれています。現在、各訓練例または機能のセット(ここでは10)には独自のラベルがあり、買いの条件と売りの条件(つまり、どのクラスに属するか)を示しています。モデルは、これらの例を記憶して一般化できる必要があります。この機能については、後で説明します。
カスタムテスターの開発
取引システムを作成しているので、タイムリーなモデルテストのためのストラテジーテスターが望ましくなります。以下は、そのようなテスターの例です。
def tester(dataset, markup = 0.0): last_deal = int(2) last_price = 0.0 report = [0.0] for i in range(dataset.shape[0]): pred = dataset['labels'][i] if last_deal == 2: last_price = dataset['close'][i] last_deal = 0 if pred <=0.5 else 1 continue if last_deal == 0 and pred > 0.5: last_deal = 1 report.append(report[-1] - markup + (dataset['close'][i] - last_price)) last_price = dataset['close'][i] continue if last_deal == 1 and pred <=0.5: last_deal = 0 report.append(report[-1] - markup + (last_price - dataset['close'][i])) last_price = dataset['close'][i] return report
テスター関数は、データセットと「マークアップ」(オプション)を受け入れ、MetaTrader 5テスターで行われるのと同様に、データセット全体を確認します。シグナル(ラベル)は新しいバーごとに確認され、ラベルが変更されると取引が取り消されます。したがって、売りシグナルは買いポジションを決済して売りポジションを開くためのシグナルとして機能します。それでは、上記のデータセットをテストしてみましょう。
pr = get_prices(look_back=LOOK_BACK) pr = add_labels(pr, 10, 25) rep = tester(pr, MARKUP) plt.plot(rep) plt.show()
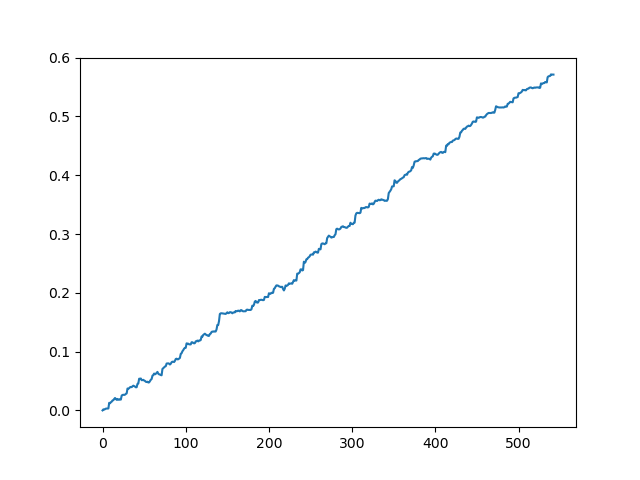
スプレッドなしでの元のデータセットのテスト
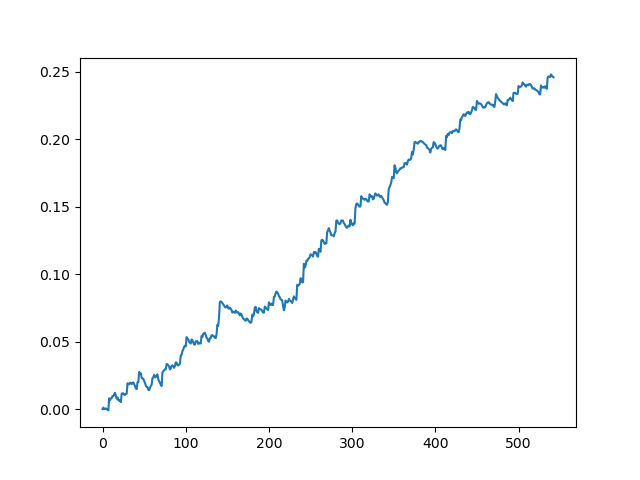
70個の5桁のポイントのスプレッドでの元のデータセットのテスト
これは一種の理想的な画像です(これがモデルの動作方法です)。ラベルは無作為に抽出されるため、取引の最小および最大の存続期間に関与するパラメータの範囲に応じて、曲線は常に異なります。それにもかかわらず、それらはすべて(Y軸に沿って)良いポイントの増加と(X軸に沿って)異なる取引数を示します。
CatBoostモデルの訓練
それでは、モデルの訓練に直接移りましょう。まず、データセットを訓練と検証の2つのサンプルに分割しましょう。これは、モデルの過剰適合を減らすために使用されます。モデルは取引サブサンプルで訓練を続け、分類エラーを最小限に抑えようとしますが、同じエラーが検証サブサンプルでも測定されます。これらのエラーの差が大きい場合、モデルは過剰適合であると言われます。逆に、近い値はモデルの訓練の適切さを示します。
#splitting on train and validation subsets X = pr[pr.columns[1:-1]] y = pr[pr.columns[-1]] train_X, test_X, train_y, test_y = train_test_split(X, y, train_size = 0.5, test_size = 0.5, shuffle=True)
訓練例を無作為に混合した後、データを同じ長さの2つのデータセットに分割しましょう。次に、モデルを作成して訓練します。
#learning with train and validation subsets model = CatBoostClassifier(iterations=1000, depth=6, learning_rate=0.01, custom_loss=['Accuracy'], eval_metric='Accuracy', verbose=True, use_best_model=True, task_type='CPU') model.fit(train_X, train_y, eval_set = (test_X, test_y), early_stopping_rounds=50, plot=False)
モデルはいくつかのパラメータを取りますが、この例ではすべてのパラメータが示されているわけではありません原則として必須ではないモデルを微調整したい場合は、ドキュメントを参照してください。CatBoostは、最小限に調整してすぐに機能します。
モデルパラメータの簡単な説明は次のとおりです。
- iterations — モデル内の木の最大数。モデルでは、反復ごとに弱いモデル(木)の数が増えるため、十分に大きい値を設定してください。私の実践から、この特定の例では通常、1000回の反復で十分です。
- depth - 各木の深さ。値が小さいほどモデルは粗くなり、出力される取引は少なくなります。6~10が最適のようです。
- learning_rate — 勾配ステップ値。これは、ニューラルネットワークで使用されるのと同じ原理です。妥当な範囲は0.01〜0.1です。値が小さいほど、モデルの訓練に時間がかかりますが、より良いバリアントを見つけることができます。
- custom_loss、eval_metric - モデルの評価に使用される指標。分類の古典的な指標は「精度」です。
- use_best_model — 各手順で、モデルは「精度」を評価します。これは時間の経過とともに変化する可能性があります。このフラグを使用すると、エラーを最小限に抑えてモデルを保存できます。それ以外の場合は、最後の反復で取得されたモデルが保存されます。
- task_type — GPUでモデルを訓練できます(デフォルトではCPUが使用されます)。これは、データが非常に大きな場合にのみ当てはまります。その他の場合、訓練はプロセッサよりもGPUコアでより低速に実行されます。
- early_stopping_rounds — モデルには、単純な原理に従って動作する過剰適合検出器が組み込まれています。指定された反復回数中に指標の減少/増加が停止すると(「精度」の場合は増加が停止)訓練が停止します。
訓練が開始されると、各反復でのモデルの現在の状態がコンソールに表示されます。
170: learn: 1.0000000 test: 0.7712509 best: 0.7767795 (165) total: 11.2s remaining: 21.5s 171: learn: 1.0000000 test: 0.7726330 best: 0.7767795 (165) total: 11.2s remaining: 21.4s 172: learn: 1.0000000 test: 0.7733241 best: 0.7767795 (165) total: 11.3s remaining: 21.3s 173: learn: 1.0000000 test: 0.7740152 best: 0.7767795 (165) total: 11.3s remaining: 21.3s 174: learn: 1.0000000 test: 0.7712509 best: 0.7767795 (165) total: 11.4s remaining: 21.2s 175: learn: 1.0000000 test: 0.7726330 best: 0.7767795 (165) total: 11.5s remaining: 21.1s 176: learn: 1.0000000 test: 0.7712509 best: 0.7767795 (165) total: 11.5s remaining: 21s 177: learn: 1.0000000 test: 0.7740152 best: 0.7767795 (165) total: 11.6s remaining: 21s 178: learn: 1.0000000 test: 0.7719419 best: 0.7767795 (165) total: 11.7s remaining: 20.9s 179: learn: 1.0000000 test: 0.7747063 best: 0.7767795 (165) total: 11.7s remaining: 20.8s 180: learn: 1.0000000 test: 0.7705598 best: 0.7767795 (165) total: 11.8s remaining: 20.7s Stopped by overfitting detector (15 iterations wait) bestTest = 0.7767795439 bestIteration = 165
上記の例では、過剰適合検出器がトリガーし、反復180で訓練を停止しました。また、コンソールには、訓練サブサンプル(学習)と検証サブサンプル(テスト)の統計、およびモデルの合計訓練時間(わずか20秒)が表示されます。出力では、訓練サブサンプル1.0(理想的な結果に対応)で最高の精度が得られ、検証サブサンプルで0.78の精度が得られました。これは劣りますが、0.5は超えています(無作為と見なされます)。最適な反復は165で、このモデルは保存されます。これで、テスターでテストできます。
#test the learned model p = model.predict_proba(X) p2 = [x[0]<0.5 for x in p] pr2 = pr.iloc[:len(p2)].copy() pr2['labels'] = p2 rep = tester(pr2, MARKUP) plt.plot(rep) plt.show()
X - 機能はあるがラベルがないソースデータセットです。ラベルを取得するには、訓練済みモデルからラベルを取得し、クラス0または1への割り当ての「p」確率を予測する必要があります。モデルは2つのクラスの確率を生成しますが、必要なのは0または1のみです。「p2」変数は最初の次元(0)でのみ確率を受け取ります。さらに、元のデータセットのラベルは、モデルによって予測されたラベルに置き換えられます。テスターでの結果は次のとおりです。
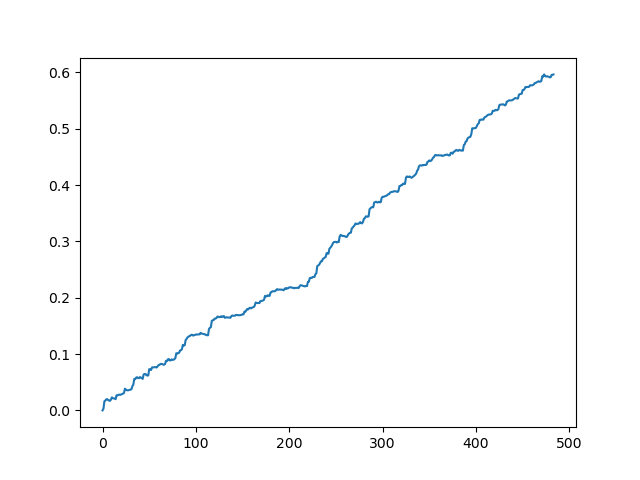
取引を抽出した後の理想的な結果
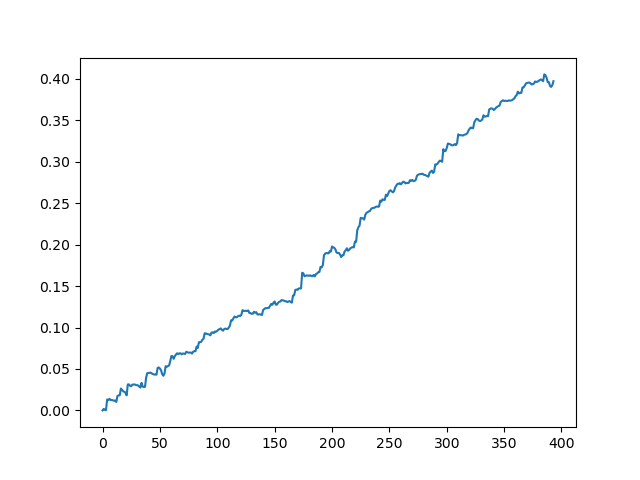
モデル出力で得られた結果
ご覧のとおり、モデルは十分に学習しています。つまり、訓練例を記憶しており、検証セットで無作為よりも優れた結果を示しています。モデルのエクスポートと自動売買ロボットの作成という最終段階に進みましょう。
モデルのMetaTrader5への移植
MetaTrader 5 Python APIでは、Pythonプログラムから直接取引できるため、モデルを移植する必要はありません。ただし、カスタムテスターを確認して、標準のストラテジーテスターと比較したいと思いました。さらに、コンパイルされたボットの可用性は、VPSでの使用を含む多くの状況で便利です(この場合、Pythonをインストールする必要はありません)。そこで、準備ができたモデルをMQHファイルに保存するヘルパー関数を作成しました。次のとおりです。
def export_model_to_MQL_code(model):
model.save_model('catmodel.h',
format="cpp",
export_parameters=None,
pool=None)
code = 'double catboost_model' + '(const double &features[]) { \n'
code += ' '
with open('catmodel.h', 'r') as file:
data = file.read()
code += data[data.find("unsigned int TreeDepth"):data.find("double Scale = 1;")]
code +='\n\n'
code+= 'return ' + 'ApplyCatboostModel(features, TreeDepth, TreeSplits , BorderCounts, Borders, LeafValues); } \n\n'
code += 'double ApplyCatboostModel(const double &features[],uint &TreeDepth_[],uint &TreeSplits_[],uint &BorderCounts_[],float &Borders_[],double &LeafValues_[]) {\n\
uint FloatFeatureCount=ArrayRange(BorderCounts_,0);\n\
uint BinaryFeatureCount=ArrayRange(Borders_,0);\n\
uint TreeCount=ArrayRange(TreeDepth_,0);\n\
bool binaryFeatures[];\n\
ArrayResize(binaryFeatures,BinaryFeatureCount);\n\
uint binFeatureIndex=0;\n\
for(uint i=0; i<FloatFeatureCount; i++) {\n\
for(uint j=0; j<BorderCounts_[i]; j++) {\n\
binaryFeatures[binFeatureIndex]=features[i]>Borders_[binFeatureIndex];\n\
binFeatureIndex++;\n\
}\n\
}\n\
double result=0.0;\n\
uint treeSplitsPtr=0;\n\
uint leafValuesForCurrentTreePtr=0;\n\
for(uint treeId=0; treeId<TreeCount; treeId++) {\n\
uint currentTreeDepth=TreeDepth_[treeId];\n\
uint index=0;\n\
for(uint depth=0; depth<currentTreeDepth; depth++) {\n\
index|=(binaryFeatures[TreeSplits_[treeSplitsPtr+depth]]<<depth);\n\
}\n\
result+=LeafValues_[leafValuesForCurrentTreePtr+index];\n\
treeSplitsPtr+=currentTreeDepth;\n\
leafValuesForCurrentTreePtr+=(1<<currentTreeDepth);\n\
}\n\
return 1.0/(1.0+MathPow(M_E,-result));\n\
}'
file = open('C:/Users/dmitrievsky/AppData/Roaming/MetaQuotes/Terminal/D0E8209F77C8CF37AD8BF550E51FF075/MQL5/Include/' + 'cat_model' + '.mqh', "w")
file.write(code)
file.close()
print('The file ' + 'cat_model' + '.mqh ' + 'has been written to disc')
関数コードは奇妙で扱いにくいように見えます。関数には訓練されたモデルオブジェクトが入力され、オブジェクトがC++形式で保存されます。
model.save_model('catmodel.h',
format="cpp",
export_parameters=None,
pool=None)
次に、文字列が作成され、標準のPython関数を使用してC++コードがMQL5に解析されます。
code = 'double catboost_model' + '(const double &features[]) { \n' code += ' ' with open('catmodel.h', 'r') as file: data = file.read() code += data[data.find("unsigned int TreeDepth"):data.find("double Scale = 1;")] code +='\n\n' code+= 'return ' + 'ApplyCatboostModel(features, TreeDepth, TreeSplits , BorderCounts, Borders, LeafValues); } \n\n'
このライブラリの「ApplyCatboostModel」関数は、上記の操作の後に挿入され、保存されたモデルと渡された特徴のベクトルに基づいて、(0; 1)の範囲の計算結果を返します。
その後、モデルが保存されるMetaTrader5ターミナルの\\Includeフォルダーへのパスを指定する必要があるため、すべてのパラメータを設定した後で、モデルはワンクリックで取引され、MQHファイルとしてすぐに保存されます。これは非常に便利です。このオプションは、Pythonでモデルを教えるための一般的で人気のある方法であり、これも適しています。
MetaTrader5でボット取引を書く
CatBoostモデルを訓練して保存した後は、テスト用の簡単なボットを作成します。
#include <MT4Orders.mqh> #include <Trade\AccountInfo.mqh> #include <cat_model.mqh> sinput int look_back = 50; sinput int MA_period = 15; sinput int OrderMagic = 666; //Orders magic sinput double MaximumRisk=0.01; //Maximum risk sinput double CustomLot=0; //Custom lot input int stoploss = 500; static datetime last_time=0; #define Ask SymbolInfoDouble(_Symbol, SYMBOL_ASK) #define Bid SymbolInfoDouble(_Symbol, SYMBOL_BID) int hnd;
次に、保存したcat_model.mqhとMT4Orders.mqhをfxsaberで接続します。
look_backパラメータとMA_periodパラメータは、Pythonプログラムでの訓練中に指定されたとおりに正確に設定する必要があります。そうしないと、エラーがスローされます。
さらに、各バーで、増分のベクトル(価格と移動平均の差)の入力先となる、モデルのシグナルを確認します。
if(!isNewBar()) return; double ma[]; double pr[]; double ret[]; ArrayResize(ret, look_back); CopyBuffer(hnd, 0, 1, look_back, ma); CopyClose(NULL,PERIOD_CURRENT,1,look_back,pr); for(int i=0; i<look_back; i++) ret[i] = pr[i] - ma[i]; ArraySetAsSeries(ret, true); double sig = catboost_model(ret);
取引オープニングロジックはカスタムテスターロジックに似ていますが、mql5 + MT4Ordersスタイルで実行されます。
for(int b = OrdersTotal() - 1; b >= 0; b--) if(OrderSelect(b, SELECT_BY_POS) == true) { if(OrderType() == 0 && OrderSymbol() == _Symbol && OrderMagicNumber() == OrderMagic && sig > 0.5) if(OrderClose(OrderTicket(), OrderLots(), OrderClosePrice(), 0, Red)) { } if(OrderType() == 1 && OrderSymbol() == _Symbol && OrderMagicNumber() == OrderMagic && sig < 0.5) if(OrderClose(OrderTicket(), OrderLots(), OrderClosePrice(), 0, Red)) { } } if(countOrders(0) == 0 && countOrders(1) == 0) { if(sig < 0.5) OrderSend(Symbol(),OP_BUY,LotsOptimized(), Ask, 0, Bid-stoploss*_Point, 0, NULL, OrderMagic); else if(sig > 0.5) OrderSend(Symbol(),OP_SELL,LotsOptimized(), Bid, 0, Ask+stoploss*_Point, 0, NULL, OrderMagic); return; }
機械学習を使用したボットのテスト
コンパイルされたボットは、標準のMetaTrader 5ストラテジーテスターでテストできます。適切な時間軸(モデルの訓練で使用された時間軸と一致する必要があります)を選択し、look_backとMA_periodを入力します。これらは、Pythonプログラムのパラメータと一致する必要があります。訓練期間中のモデルを確認しましょう(訓練+検証サブサンプル)。
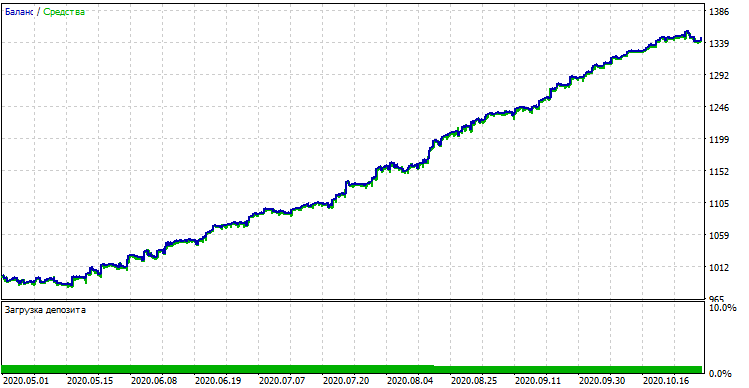
モデルのパフォーマンス(訓練+検証サブサンプル)
カスタムテスターで得られた結果と比較すると、これらの結果は、スプレッドの偏差を除いて同じです。それでは、今年の初めから、完全に新しいデータを使用してモデルをテストしてみましょう。
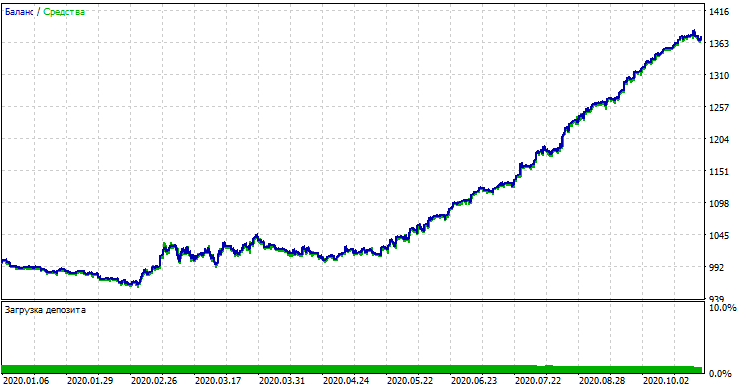
新しいデータでのモデルのパフォーマンス
新しいデータでは、モデルのパフォーマンスが大幅に低下しました。このような悪い結果は、客観的な理由に関連しています。これについては、さらに詳しく説明します。
素朴なモデルから意味のあるモデルへ(さらなる研究)
本稿のタイトルには「ナイーブアプローチ」を使用していると書いてあります。ナイーブなのは次の理由からです。
- モデルには、パターンに関する以前のデータは含まれていません。パターンの識別は、勾配ブースティングによって完全に実行されますが、その可能性は限られています。
- モデルは取引の無作為抽出を使用するため、異なる訓練サイクルでの結果は異なる可能性があります。これは欠点であるだけでなく、この機能が力ずくのアプローチを可能にするため、利点と見なすこともできます。
- 一般集団の特徴は訓練では知られていません。モデルが新しいデータでどのように動作するかはわかりませんでした。
モデルのパフォーマンスを改善するための可能な方法(別の記事で説明します)は以下の通りです。
- いくつかの外部基準(たとえば、新しいデータのパフォーマンス)によるモデルの選択
- データ抽出とモデルの訓練、分類器スタッキングへの新しいアプローチ
- 先験的な知識や仮定に基づいた、異なる性質の機能の選択
終わりに
この記事では、CatBoostというタイトルの優れた機械学習モデルについて考察します。時系列予測の問題におけるモデルの設定と二項分類の訓練に関連する主な側面について説明しました。モデルを準備してテストし、既製のロボットとしてMQL言語に移植しました。PythonおよびMQLアプリケーションを以下に添付します。