
ニューラルネットワークが簡単に(第65回):Distance Weighted Supervised Learning (DWSL)

はじめに
行動クローニング法は主に教師あり学習の原理に基づき、かなり良い結果を示していますが、その主な問題は、理想的なロールモデルを探すことです。これは、収集するのが非常に難しい場合もあります。その代わり、強化学習法は最適でない生データを扱うことができます。同時に、目標を達成するために最適でない方策を見つけることもできます。しかし、最適な方策を探す場合、高次元の確率的環境でより関連性の高い最適化問題に遭遇することがよくあります。
この2つのアプローチのギャップを埋めるために、科学者グループはDistance Weighted Supervised Learning (DWSL)法を提案し、「Distance Weighted Supervised Learning for Offline Interaction Data」稿で発表しました。これは、目標条件付き方策のためのオフライン教師あり学習アルゴリズムです。理論的には、DWSLは訓練セットからの軌跡のレベルで最小リターンの境界を持つ最適な方策に収束します。論文中の実例は、模倣学習や強化学習アルゴリズムに対する提案手法の優位性を示しています。このDWSLのアルゴリズムを詳しく見てみることをお勧めします。ここでは、現実的な問題を解決する上での長所と短所を評価します。
1.DWSLアルゴリズム
Distance Weighted Supervised Learning法の著者は、可能な限り最大のデータ集合を訓練に使用できるアルゴリズムを得るという目標を設定しました。このパラダイムでは、エージェントは決定論的マルコフ決定過程の中で行動すると仮定します。
- 状態空間S
- 行動空間A
- 決定論的力学St+1 = F(St,At)。ここで、St+1は、状態St;で行動Atをとった結果の新しい状態
- 目標空間G
- スパースな目標条件付き報酬関数R(S,A,G)
- 割引率γ
目標空間Gは、目標抽出関数G = φ(St)を持つ状態空間Sの部分空間です。これは、φ(St) = St+nと同一であることが多いです。アルゴリズムの目的は、目標条件付き方策π(A|S,G)を学習することです。これは、学習された環境を支配し、設定された目標を達成し、そこに留まり続けることができます。望ましい結果を得るために、目標分布p(G)から目標Gを達成することを条件として、報酬関数R(S,A,G)からの割引リターンを最大化します。
この問題設定は先に述べたものとは異なりますが、確率的最短経路問題とGCRLという2つの一般的な問題設定と強い関連性を持っています。
この手法の著者は、GCRLの分野では、ラベル付けされたサブ目標を持つ軌跡の存在を前提としていることに注目しています。これらのサブ目標は、方策の意図によって指定され、テスト中の目標p(G)の分布に関する情報をモデルに提供します。このため、オフラインのGCRLが学習できるデータは制限されます。その理由は、多くのオフラインデータソースには、各軌跡とともに目標ラベル(サブ目標)が含まれていないからです。しかも、目標を達成するのは難しいです。
最も広範なオフラインデータの集合から学習するために、この手法の著者はより一般的な状況を考慮しています。この状況では、真の環境ダイナミクス、報酬ラベル、テスト時間の目標分布にアクセスすることはできません。訓練段階では、任意の最適レベルの状態と行動から得られる軌道の集合のみが使用されます。分布p(G)は、データセットの全状態に目標抽出関数φ(St)を適用することで誘導される目標の分布とします。ほとんどの実用的なデータセットでは、データ分布にまつわる目標は、関心のあるタスク問題の目標に近い可能性が高いと想定されます。DWSL法は、既存の状態-動作シーケンスから純粋に計算できる任意のスパース報酬関数を使用することができます。しかし実際には、著者が発見した経験則に基づく推定もかなり有効でした。
直感的には、現在の状態Sから目標Gに到達するために指定された報酬関数を使用する場合、最良の目標達成戦略は、最小の時間ステップ数を持つ経路(最短経路)を使用することです。しかし、訓練データセットの軌跡が必ずしも最短経路をたどるとは限りません。その結果、行動クローニング技術は、最適とは言えない行動を示す可能性があります。
この問題に対処するため、DWSLは教師あり訓練を用いて距離を推定し、訓練データセットの分布内で訓練されたモデルを評価します。このモデルは、訓練データセットにおける状態間のペアワイズ距離の全分布を訓練します。そして、この分布を使用して、各州のデータセットに含まれる目標までの最短距離を推定します。その後、これらのパスをたどるための方策を学習します。以下は、著者が提供するDWSLメソッドの視覚化です。

任意の2つの状態SiとSjの間には、i < jの場合、少なくとも1つの「j-i」時間ステップのパスが存在します。この性質を利用して、訓練データセットに含まれる状態と目標間のすべてのペアワイズ距離を含むラベル付きデータセットを生成します。新しい分布から標本化された各状態と目標のペアについて、左の図1に示すように、現在の状態から目標までの時間ステップ数kに関する離散分布をモデル化します。これにより、ラベル付けされたデータセットのもとで、この分布のパラメータ化された推定値を最尤法で求めることができます。
![]()
実際には、この分布は可能な距離に対する離散的な分類器としてモデル化されます。ラベル付きデータセットに含まれるソース状態と目標状態の間の最短パスは、最小時間ステップ数kによって決定されます。ただし、分布は関数近似を用いて学習されるため、この方法で最小距離を推定すると、モデル化誤差を利用する可能性が高い。この誤差を最小化するために、この手法の著者は、最小距離のソフトな推定値を得るために、分布に対してLogSumExpを計算することを提案しています。
![]()
この式では、推定値の最大値ではなく最小値を得るために、距離に「-1」を掛けています。ここでαは温度のハイパーパラメータです。αが0に近づくと、関数d(s, g)の値は最小距離kに近づきます。
最小距離推定を学習した後、各状態を起点とする既知の経路をたどりたいのです。エージェントは状態Sにあり、目標Gを達成する必要があるとします。初期状態では、エージェントは2つの行動(A1またはA2)のいずれかを実行することができます。これらはそれぞれS1およびS2の状態になります。私たちは、最初の行動が、最小の歩数(目標までの推定距離が小さい)で目標に至る経路の始まりであれば、その行動を取ることを好みます。したがって、目標までの距離の推定値によって、異なる行動の可能性を重み付けしたいのです(上図右)。ただし、素朴にこの方法で行動に重み付けをすると、目標に近いすべてのデータ点に大きな重み付けをすることになります。目標から遠い状態は当然距離が大きくなるからです。その代わりに、目標までの推定距離の減少に応じて行動の可能性を重み付けします。この手法の著者はこれを「利点」と呼んでいます。これにより、モデルを訓練するための新たな目標を立てることができます。
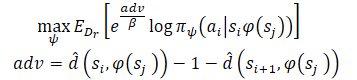
この手法の著者は、すべての重みが正であることを保証するために、指数化された「利点」を使用しています。
2.MQL5を使用した実装
距離重み付き教師あり学習法の理論的側面を理解した後、この記事の実践的な部分に移ることができます。MQL5でメソッド実装のバージョンを作成します。いつものように、提案されたアルゴリズムと、これまで蓄積してきた知識を組み合わせてみるつもりです。また、提案されたアプローチに対する認識についても再現を試みます。このアプローチが、ある程度、著者のアルゴリズムから距離を置くものであり、その忠実な再現ではないことには同意します。したがって、テスト中に特定できる弱点はすべて、この実装にのみ関係します。
元の論文では、ロボットアプリケーションの制御に関する実験が紹介されています。このような状況では、肯定的な結果を得るために目標設定が重要な役割を果たします。しかも、目標は個々のケースで明確です。私の実装では、訓練期間中のロボットの収益性を最大化することに重点を置いています。モデルを単純化するため、各ステップでサブ目標を設定しないことにしました。その結果、目標設定モデルを訓練しないことが可能になります。
ここでは、Actor-Criticアプローチを使用してモデルを訓練します。ドナーには、Stochastic Marginal Actor-Critic (SMAC)のモデルを使用します。他の開発でそれを補います。特に、CWBCから軌跡を計量するメカニズムを追加します。まず必要なことから始めていきます。まず、モデルのアーキテクチャを説明します。
2.1.モデルアーキテクチャ
いつものように、訓練済みモデルのアーキテクチャはCreateDescriptionsメソッドで表現されます。パラメータには、3つのモデルのアーキテクチャ記述の動的配列へのポインタを渡します。
- Actor
- Critic
- 無作為エンコーダ
ここで、SMACアルゴリズムが確率的潜在状態エンコーダの訓練を提供することを思い出してください。これは、Criticが使用できる機能とともに、以前にActorアーキテクチャに組み込まれていました。今回の実装では、このソリューションを使用します。
メソッド本体では、受け取ったポインタを確認し、必要であれば新しいオブジェクトインスタンスを生成します。
bool CreateDescriptions(CArrayObj *actor, CArrayObj *critic, CArrayObj *convolution) { //--- CLayerDescription *descr; //--- if(!actor) { actor = new CArrayObj(); if(!actor) return false; } if(!critic) { critic = new CArrayObj(); if(!critic) return false; } if(!convolution) { convolution = new CArrayObj(); if(!convolution) return false; }
Actorには、値動きと指標値の履歴データを入力しますが、これは生データ層のサイズに反映されます。
//--- Actor actor.Clear(); //--- Input layer if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBaseOCL; int prev_count = descr.count = (HistoryBars * BarDescr); descr.activation = None; descr.optimization = ADAM; if(!actor.Add(descr)) { delete descr; return false; }
未処理のデータをモデルに投入します。したがって、生データ層の後に、バッチデータ正規化層を使用します。様々な情報源から得られた生のデータを比較可能な形にします。
//--- layer 1 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBatchNormOCL; descr.count = prev_count; descr.batch = 1000; descr.activation = None; descr.optimization = ADAM; if(!actor.Add(descr)) { delete descr; return false; }
その後、畳み込み層を使用して安定したデータパターンを識別しようとします。ソースデータの安定パターンへの割り当てを確率的に表現するために、SoftMax関数を使用します。
//--- layer 2 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronConvOCL; prev_count = descr.count = HistoryBars; descr.window = BarDescr; descr.step = BarDescr; int prev_wout = descr.window_out = BarDescr / 2; descr.activation = LReLU; descr.optimization = ADAM; if(!actor.Add(descr)) { delete descr; return false; } //--- layer 3 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronSoftMaxOCL; descr.count = prev_count; descr.step = prev_wout; descr.optimization = ADAM; descr.activation = None; if(!convolution.Add(descr)) { delete descr; return false; } //--- layer 4 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronConvOCL; prev_count = descr.count = prev_count; descr.window = prev_wout; descr.step = prev_wout; prev_wout = descr.window_out = 8; descr.activation = LReLU; descr.optimization = ADAM; if(!actor.Add(descr)) { delete descr; return false; } //--- layer 5 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronSoftMaxOCL; descr.count = prev_count; descr.step = prev_wout; descr.optimization = ADAM; descr.activation = None; if(!convolution.Add(descr)) { delete descr; return false; }
過去のデータの個々のローソク足のコンテキストで安定したパターンを検索します。
パターン検索の結果は、2つの全結合層によって分析されます。
//--- layer 6 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBaseOCL; descr.count = LatentCount; descr.optimization = ADAM; descr.activation = LReLU; if(!actor.Add(descr)) { delete descr; return false; } //--- layer 7 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBaseOCL; prev_count = descr.count = LatentCount; descr.activation = LReLU; descr.optimization = ADAM; if(!actor.Add(descr)) { delete descr; return false; }
得られたデータに、口座状況の説明を追加します。
//--- layer 8 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronConcatenate; descr.count = 2 * LatentCount; descr.window = prev_count; descr.step = AccountDescr; descr.optimization = ADAM; descr.activation = SIGMOID; if(!actor.Add(descr)) { delete descr; return false; }
次にSMAC法によって確率的潜在状態を生成します。
//--- layer 9 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronVAEOCL; descr.count = LatentCount; descr.optimization = ADAM; if(!actor.Add(descr)) { delete descr; return false; }
次に来るのは、2つの全結合層の意思決定ブロックです。
//--- layer 10 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBaseOCL; descr.count = LatentCount; descr.activation = LReLU; descr.optimization = ADAM; if(!actor.Add(descr)) { delete descr; return false; } //--- layer 11 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBaseOCL; descr.count = LatentCount; descr.activation = LReLU; descr.optimization = ADAM; if(!actor.Add(descr)) { delete descr; return false; }
Actor出力では、変分オートエンコーダブロックを設定し、方策を確率的にします。結果層のサイズは、エージェントの行動ベクトルの次元に対応します。
//--- layer 12 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBaseOCL; descr.count = 2 * NActions; descr.activation = SIGMOID; descr.optimization = ADAM; if(!actor.Add(descr)) { delete descr; return false; } //--- layer 13 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronVAEOCL; descr.count = NActions; descr.optimization = ADAM; if(!actor.Add(descr)) { delete descr; return false; }
Criticのアーキテクチャはそのまま使用されます。モデルの入力は、Actorの隠れ層からの環境状態の潜在的表現です。得られたデータを比較可能な形式に変換する必要はありません。したがって、このモデルではバッチ正規化層は使用しません。
//--- Critic critic.Clear(); //--- Input layer if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBaseOCL; prev_count = descr.count = LatentCount; descr.activation = None; descr.optimization = ADAM; if(!critic.Add(descr)) { delete descr; return false; }
潜在表現に、Actorの行動を追加します。
//--- layer 1 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronConcatenate; descr.count = LatentCount; descr.window = prev_count; descr.step = NActions; descr.optimization = ADAM; descr.activation = LReLU; if(!critic.Add(descr)) { delete descr; return false; }
連結されたデータは、3つの全結合層からなる意思決定ブロックによって分析されます。最後の層のサイズは、分解された報酬ベクトルのサイズに対応します。
//--- layer 2 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBaseOCL; descr.count = LatentCount; descr.activation = LReLU; descr.optimization = ADAM; if(!critic.Add(descr)) { delete descr; return false; } //--- layer 3 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBaseOCL; descr.count = LatentCount; descr.activation = LReLU; descr.optimization = ADAM; if(!critic.Add(descr)) { delete descr; return false; } //--- layer 4 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBaseOCL; descr.count = NRewards; descr.optimization = ADAM; descr.activation = None; if(!critic.Add(descr)) { delete descr; return false; }
CreateDescriptionsメソッドの最後に、無作為エンコーダアーキテクチャの説明を追加します。少し先の話になりますが、環境状態間の距離を決定するプロセスの一部として、エンコーダを使用します。環境の1つの状態を表現するために、2つのベクトルを使用します。
- 過去の価格と指標データ
- 口座状態と未決済ポジション
この2つのエンティティの連結ベクトルをエンコーダに入力します。
//--- Convolution convolution.Clear(); //--- Input layer if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBaseOCL; prev_count = descr.count = (HistoryBars * BarDescr) + AccountDescr; descr.activation = None; descr.optimization = ADAM; if(!convolution.Add(descr)) { delete descr; return false; }
エンコーダモデルは訓練されていません。したがって、バッチ正規化層を使用しても、必要な結果は得られません。そこで、データを比較可能な形にするために、全結合層を使用します。次に、SoftMax層を使用してデータを正規化します。
//--- layer 1 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBaseOCL; descr.count = HistoryBars * BarDescr; descr.optimization = ADAM; descr.activation = None; if(!convolution.Add(descr)) { delete descr; return false; } //--- layer 2 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronSoftMaxOCL; descr.count = HistoryBars; descr.step = BarDescr; descr.optimization = ADAM; descr.activation = None; if(!convolution.Add(descr)) { delete descr; return false; }
次に畳み込み層のブロックが来るが、これもSoftMax層で覆われています。
//--- layer 3 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronConvOCL; prev_count = descr.count = HistoryBars; descr.window = BarDescr; descr.step = BarDescr; prev_wout = descr.window_out = BarDescr / 2; descr.activation = LReLU; descr.optimization = ADAM; if(!convolution.Add(descr)) { delete descr; return false; } //--- layer 4 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronConvOCL; prev_count = descr.count = prev_count; descr.window = prev_wout; descr.step = prev_wout; prev_wout = descr.window_out = prev_wout / 2; descr.activation = LReLU; descr.optimization = ADAM; if(!convolution.Add(descr)) { delete descr; return false; } //--- layer 5 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronConvOCL; prev_count = descr.count = prev_count; descr.window = prev_wout; descr.step = prev_wout; prev_wout = descr.window_out = 2; descr.activation = LReLU; descr.optimization = ADAM; if(!convolution.Add(descr)) { delete descr; return false; } //--- layer 6 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronSoftMaxOCL; descr.count = prev_count * prev_wout; descr.optimization = ADAM; descr.activation = None; if(!convolution.Add(descr)) { delete descr; return false; }
エンコーダの出力では、全結合層を使用し、分析された環境の状態の埋め込みを返します。
//--- layer 7 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBaseOCL; descr.count = EmbeddingSize; descr.activation = LReLU; descr.optimization = ADAM; if(!convolution.Add(descr)) { delete descr; return false; } //--- return true; }
2.2ヘルパーメソッドの準備
使用するモデルのアーキテクチャを説明した後、モデル訓練アルゴリズムの実装に取り掛かります。ただし、学習プロセスを実装する前に、一般的なアルゴリズムの個々のブロックを実装するメソッドについて説明しましょう。
まず、CWBC法の枠組みの中で議論された、軌跡の重み付けと優先順位付けを用います。そのために、GetProbTrajectoriesメソッドとSampleTrajectoryメソッドを移行します。アルゴリズムについては前回の記事で詳述したので、今回は割愛します。
ActorとCriticを訓練するために、DWSL法のアプローチで重み付けされた報酬と行動を使用します。繰り返しの操作をなくすために、両方のモデルの目標ベクトルの計算を1つのGetTargetsメソッドにまとめます。1回の操作で2つのベクトルを転送できるようにするため、構造体を作成します。
struct STarget { vector<float> rewards; vector<float> actions; };
このように、GetTargetsメソッドはパラメータを受け取ります。
- パーセンタイルは、訓練セットから最も近い分析状態の数を決定する
- 分析された状態の埋め込み
- 訓練セットの状態埋め込み行列
- 訓練セットからの報酬の行列
- 訓練セットのエージェント行動の行列
最後の3つの行列は互いに対応しています。
その結果に基づいて、このメソッドは2つの目標ベクトルの構造を返します。
STarget GetTargets(int percentile, vector<float> &embedding, matrix<float> &state_embedding, matrix<float> &rewards, matrix<float> &actions ) { STarget result;
メソッド本体では、結果の構造を宣言し、分析された状態の埋め込みサイズと訓練セットからの状態の行列の対応関係を即座に確認します。
if(embedding.Size() != state_embedding.Cols()) { PrintFormat("%s -> %d Inconsistent embedding size", __FUNCTION__, __LINE__); return result; }
次に、分析された状態と訓練セットの状態との間の距離を決定します。ソフト距離を決定するために、DWSL法の著者によって提案されたLogSumExpを使用します。
ulong size = embedding.Size(); ulong states = state_embedding.Rows(); ulong k = ulong(states * percentile / 100); matrix<float> temp = matrix<float>::Zeros(states, size); for(ulong i = 0; i < size; i++) temp.Col(MathAbs(state_embedding.Col(i) - embedding[i]), i); float alpha=temp.Max(); vector<float> dist = MathLog(MathExp(temp/(-alpha)).Sum(1))*(-alpha);
その後、報酬、行動、埋め込みのローカル行列を作成します。最も近い状態に関するデータは、その行列に転送されます。
vector<float> min_dist = vector<float>::Zeros(k); matrix<float> k_rewards = matrix<float>::Zeros(k, NRewards); matrix<float> k_actions = matrix<float>::Zeros(k, NActions); matrix<float> k_embedding = matrix<float>::Zeros(k + 1, size); matrix<float> U, V; vector<float> S; float max = dist.Percentile(percentile); float min = dist.Min(); for(ulong i = 0, cur = 0; (i < states && cur < k); i++) { if(max < dist[i]) continue; min_dist[cur] = dist[i]; k_rewards.Row(rewards.Row(i), cur); k_actions.Row(actions.Row(i), cur); k_embedding.Row(state_embedding.Row(i), cur); cur++; } k_embedding.Row(embedding, k);
訓練の目標報酬ベクトルを得るためには、分析された状態からの距離に基づいて、選択された報酬の行列を重み付けする必要があります。最小距離は、対応する報酬の最小の重みをを与えます。しかし、これは一般的な論理と矛盾します。最も関連性の高い値は、最終的な結果には最小限の影響しか与えません。これは簡単に修正できます。単純に距離ベクトルに「-1」を掛けます。SoftMax関数は、得られた値を確率平面に変換します。後は、得られた確率ベクトルに、最も近い状態の報酬行列を掛け合わせるだけです。
vector<float> sf; (min_dist*(-1)).Activation(sf, AF_SOFTMAX); result.rewards = sf.MatMul(k_rewards);
ここでは、Actorの学習を促すために核規範も追加します。
k_embedding.SVD(U, V, S); result.rewards[NRewards - 2] = S.Sum() / (MathSqrt(MathPow(k_embedding, 2.0f).Sum() * MathMax(k + 1, size))); result.rewards[NRewards - 1] = EntropyLatentState(Actor);
次に、行動の目標ベクトルを形成します。今回は、優遇される報酬によって行動を量ることにします。距離ベクトルと同様に、LogSumExp関数を使用して報酬ベクトルを計算します。
vector<float> act_sf; alpha=MathAbs(k_rewards).Max(); dist = MathLog(MathExp(k_rewards/(-alpha)).Sum(1))*(-alpha);
今回は最大の報酬が最大の影響を与えるはずなので、値を逆にする必要はありません。SoftMax関数を使用して、報酬を確率的な値の領域に移すだけです。その後、得られたベクトルに行動行列を掛けます。結果は構造体に書き込まれます。そして、目標値の両方のベクトルを呼び出し元に返します。
これで準備作業は完了なので、メインアルゴリズムの実装に移ります。
2.3訓練データ収集EA
次に、オフラインでのモデル訓練のためのデータ収集プログラムに移ります。前回同様、このタスクはEA「...\DWSL\Research.mq5」に実装します。このEAのメソッドのほとんどは、以前の記事で使用され、詳細に検討されているため、コード全体を完全にレビューすることはしません。主な特徴を見てみましょう。OnTickティック処理メソッドから始めます。その本体はメインのアルゴリズムを実装します。
メソッドの最初に、新しいバーが開いたかどうかを確認し、必要であれば、過去の価格と指標のデータを読み込みます。
void OnTick() { //--- if(!IsNewBar()) return; //--- int bars = CopyRates(Symb.Name(), TimeFrame, iTime(Symb.Name(), TimeFrame, 1), HistoryBars, Rates); if(!ArraySetAsSeries(Rates, true)) return; //--- RSI.Refresh(); CCI.Refresh(); ATR.Refresh(); MACD.Refresh(); Symb.Refresh(); Symb.RefreshRates();
得られたデータを使用して、初期データのバッファを形成します。
float atr = 0; for(int b = 0; b < (int)HistoryBars; b++) { float open = (float)Rates[b].open; float rsi = (float)RSI.Main(b); float cci = (float)CCI.Main(b); atr = (float)ATR.Main(b); float macd = (float)MACD.Main(b); float sign = (float)MACD.Signal(b); if(rsi == EMPTY_VALUE || cci == EMPTY_VALUE || atr == EMPTY_VALUE || macd == EMPTY_VALUE || sign == EMPTY_VALUE) continue; //--- int shift = b * BarDescr; sState.state[shift] = (float)(Rates[b].close - open); sState.state[shift + 1] = (float)(Rates[b].high - open); sState.state[shift + 2] = (float)(Rates[b].low - open); sState.state[shift + 3] = (float)(Rates[b].tick_volume / 1000.0f); sState.state[shift + 4] = rsi; sState.state[shift + 5] = cci; sState.state[shift + 6] = atr; sState.state[shift + 7] = macd; sState.state[shift + 8] = sign; } bState.AssignArray(sState.state);
そして口座ステータスバッファです。
sState.account[0] = (float)AccountInfoDouble(ACCOUNT_BALANCE); sState.account[1] = (float)AccountInfoDouble(ACCOUNT_EQUITY); //--- double buy_value = 0, sell_value = 0, buy_profit = 0, sell_profit = 0; double position_discount = 0; double multiplyer = 1.0 / (60.0 * 60.0 * 10.0); int total = PositionsTotal(); datetime current = TimeCurrent(); for(int i = 0; i < total; i++) { if(PositionGetSymbol(i) != Symb.Name()) continue; double profit = PositionGetDouble(POSITION_PROFIT); switch((int)PositionGetInteger(POSITION_TYPE)) { case POSITION_TYPE_BUY: buy_value += PositionGetDouble(POSITION_VOLUME); buy_profit += profit; break; case POSITION_TYPE_SELL: sell_value += PositionGetDouble(POSITION_VOLUME); sell_profit += profit; break; } position_discount += profit - (current - PositionGetInteger(POSITION_TIME)) * multiplyer * MathAbs(profit); } sState.account[2] = (float)buy_value; sState.account[3] = (float)sell_value; sState.account[4] = (float)buy_profit; sState.account[5] = (float)sell_profit; sState.account[6] = (float)position_discount; sState.account[7] = (float)Rates[0].time; //--- bAccount.Clear(); bAccount.Add((float)((sState.account[0] - PrevBalance) / PrevBalance)); bAccount.Add((float)(sState.account[1] / PrevBalance)); bAccount.Add((float)((sState.account[1] - PrevEquity) / PrevEquity)); bAccount.Add(sState.account[2]); bAccount.Add(sState.account[3]); bAccount.Add((float)(sState.account[4] / PrevBalance)); bAccount.Add((float)(sState.account[5] / PrevBalance)); bAccount.Add((float)(sState.account[6] / PrevBalance)); double x = (double)Rates[0].time / (double)(D'2024.01.01' - D'2023.01.01'); bAccount.Add((float)MathSin(2.0 * M_PI * x)); x = (double)Rates[0].time / (double)PeriodSeconds(PERIOD_MN1); bAccount.Add((float)MathCos(2.0 * M_PI * x)); x = (double)Rates[0].time / (double)PeriodSeconds(PERIOD_W1); bAccount.Add((float)MathSin(2.0 * M_PI * x)); x = (double)Rates[0].time / (double)PeriodSeconds(PERIOD_D1); bAccount.Add((float)MathSin(2.0 * M_PI * x));
収集したデータをActorモデルに転送し、フィードフォワードメソッドを呼び出します。操作の実行を制御することを忘れないでください。
if(bAccount.GetIndex() >= 0) if(!bAccount.BufferWrite()) return; //--- if(!Actor.feedForward(GetPointer(bState), 1, false, GetPointer(bAccount))) return;
フィードフォワードパスの結果、Actorモデルは行動ベクトルを生成します。ここでは、利益を生まないカウンタ操作の量だけを取り除きます。これまでみてきた他の作業とは異なり、環境を探索するために結果のベクトルにノイズを追加することはしません。Actorの確率的な方策は、潜在的な状態の確率性とともに、行動空間の直接的な環境を探索するのに十分な行動の広がりをすでに生み出しています。
PrevBalance = sState.account[0]; PrevEquity = sState.account[1]; //--- vector<float> temp; Actor.getResults(temp); //--- double min_lot = Symb.LotsMin(); double step_lot = Symb.LotsStep(); double stops = MathMax(Symb.StopsLevel(), 1) * Symb.Point(); if(temp[0] >= temp[3]) { temp[0] -= temp[3]; temp[3] = 0; } else { temp[3] -= temp[0]; temp[0] = 0; }
次に、既存のポジションとActorの予測を比較し、必要であれば取引操作をおこないます。まずはロングポジションです。
//--- buy control if(temp[0] < min_lot || (temp[1] * MaxTP * Symb.Point()) <= stops || (temp[2] * MaxSL * Symb.Point()) <= stops) { if(buy_value > 0) CloseByDirection(POSITION_TYPE_BUY); } else { double buy_lot = min_lot + MathRound((double)(temp[0] - min_lot) / step_lot) * step_lot; double buy_tp = NormalizeDouble(Symb.Ask() + temp[1] * MaxTP * Symb.Point(), Symb.Digits()); double buy_sl = NormalizeDouble(Symb.Ask() - temp[2] * MaxSL * Symb.Point(), Symb.Digits()); if(buy_value > 0) TrailPosition(POSITION_TYPE_BUY, buy_sl, buy_tp); if(buy_value != buy_lot) { if(buy_value > buy_lot) ClosePartial(POSITION_TYPE_BUY, buy_value - buy_lot); else Trade.Buy(buy_lot - buy_value, Symb.Name(), Symb.Ask(), buy_sl, buy_tp); } }
その後、ショートポジションで繰り返します。
//--- sell control if(temp[3] < min_lot || (temp[4] * MaxTP * Symb.Point()) <= stops || (temp[5] * MaxSL * Symb.Point()) <= stops) { if(sell_value > 0) CloseByDirection(POSITION_TYPE_SELL); } else { double sell_lot = min_lot + MathRound((double)(temp[3] - min_lot) / step_lot) * step_lot;; double sell_tp = NormalizeDouble(Symb.Bid() - temp[4] * MaxTP * Symb.Point(), Symb.Digits()); double sell_sl = NormalizeDouble(Symb.Bid() + temp[5] * MaxSL * Symb.Point(), Symb.Digits()); if(sell_value > 0) TrailPosition(POSITION_TYPE_SELL, sell_sl, sell_tp); if(sell_value != sell_lot) { if(sell_value > sell_lot) ClosePartial(POSITION_TYPE_SELL, sell_value - sell_lot); else Trade.Sell(sell_lot - sell_value, Symb.Name(), Symb.Bid(), sell_sl, sell_tp); } }
メソッド操作の最後には、環境からのフィードバックを収集し、そのデータを経験再生バッファに転送する必要があります。
sState.rewards[0] = bAccount[0]; sState.rewards[1] = 1.0f - bAccount[1]; if((buy_value + sell_value) == 0) sState.rewards[2] -= (float)(atr / PrevBalance); else sState.rewards[2] = 0; for(ulong i = 0; i < NActions; i++) sState.action[i] = temp[i]; sState.rewards[3] = 0; sState.rewards[4] = 0; if(!Base.Add(sState)) ExpertRemove(); }
この時点で、データ収集プロセスは完了したとみなすことができますが、このEAに関する作業はまだ完了していません。DWSLメソッドの実装の一環として、1つの細かい点に注目してください。この記事の理論部分では、DWSL法が訓練セットからの軌道レベルで最小リターン境界を持つ最適なポリシーに収束すると述べました。当然ながら、最適な軌道を探すにあたっては、収益性の下限をできるだけ高くしたいです。そのために、新しい軌跡を経験再生バッファに追加するプロセスに変更を追加します。最初にバッファを満たした後、収益性の低いパスをより収益性の高いパスに徐々に置き換えていきます。この処理はOnTesterPassメソッドに実装され、ストラテジーテスターのパス完了イベントを処理します。
メソッド本体では、まずローカル変数を初期化します。すぐにループを作り、パスフレームをポーリングします。
void OnTesterPass() { //--- ulong pass; string name; long id; double value; STrajectory array[]; while(FrameNext(pass, name, id, value, array)) {
ループの本体では、フレームが現在のプログラムにマッチするかどうかを確認します。
int total = ArraySize(Buffer); if(name != MQLInfoString(MQL_PROGRAM_NAME)) continue; if(id <= 0) continue;
その後、経験再生バッファの埋まり具合によって処理が分岐します。バッファがすでに指定された最大サイズまで埋まっている場合は、バッファから最もリターンの小さいパスを探します。これは最高の損失であったり、最低の利益であったりします。
if(total >= MaxReplayBuffer) { for(int a = 0; a < id; a++) { float min = FLT_MAX; int min_tr = 0; for(int i = 0; i < total; i++) { float prof = Buffer[i].States[Buffer[i].Total - 1].account[1]; if(prof < min) { min = MathMin(prof, min); min_tr = i; } }
次に、結果の値を前回のパスの戻り値と比較します。それ以上の場合は、最も低い値を返す代わりに、新しいパスのデータを書き込みます。そうでなければ、次のパスに進みます。
float prof = array[a].States[array[a].Total - 1].account[1]; if(min <= prof) { Buffer[min_tr] = array[a]; PrintFormat("Replace %.2f to %.2f -> bars %d", min, prof, array[a].Total); } } }
バッファがまだ一杯でない場合は、不必要な制御操作をせずに新しいパスを追加するだけでよくなります。
else { if(ArrayResize(Buffer, total + (int)id, 10) < 0) return; ArrayCopy(Buffer, array, total, 0, (int)id); } } }
以下の優先順位を守っています。
- 訓練されたモデルに環境に関する最も完全な情報を提供するために、経験再生バッファを最大限に埋めます。
- 経験再生バッファを満たした後、最も収益性の高いパスを選択し、最適な戦略を構築します。
EAの完全なコードとそのすべてのメソッドは、添付ファイルに記載されています。添付ファイルには、テスト用EAのモデルコード「...\DWSLTest.mq5」も含まれています。これはティック処理手法と同様のアルゴリズムを持ちますが、ストラテジーテスターで1回実行するためのものです。本稿の範囲内では考慮しません。
2.4モデル訓練EA
モデルの訓練処理は、EA「...\DWSLStudy.mq5」に実装されています。すべてのメソッドについて詳しく説明することはしません。ここでは、モデルを訓練するための主なアルゴリズムを整理したTrainメソッドだけを見てみましょう。
メソッド本体では、操作に費やされた時間を追跡するために、経験再生バッファのサイズを定義し、それをローカルのティックカウンタ状態変数に保存します。
void Train(void) { int total_tr = ArraySize(Buffer); uint ticks = GetTickCount();
次に、すべての軌跡をループして、経験再生バッファ内の状態の総数を数えます。これによって、状態の埋め込みと、それに対応するエージェントの報酬と行動を記録するのに十分なサイズの行列を用意することができます。GetTargetsメソッドでこれらの行列を使用することはすでに見ました。
int total_states = Buffer[0].Total; for(int i = 1; i < total_tr; i++) total_states += Buffer[i].Total; vector<float> temp, next; Convolution.getResults(temp); matrix<float> state_embedding = matrix<float>::Zeros(total_states, temp.Size()); matrix<float> rewards = matrix<float>::Zeros(total_states, NRewards); matrix<float> actions = matrix<float>::Zeros(total_states, NActions);
次のステップは、これらの行列を埋めることです。そのために、経験再生バッファからすべての状態を完全に検索するループのシステムを作成します。このループシステムの本体では、個々の状態の記述を1つのデータバッファに集めています。
int state = 0; for(int tr = 0; tr < total_tr; tr++) { for(int st = 0; st < Buffer[tr].Total; st++) { State.AssignArray(Buffer[tr].States[st].state); float PrevBalance = Buffer[tr].States[MathMax(st - 1, 0)].account[0]; float PrevEquity = Buffer[tr].States[MathMax(st - 1, 0)].account[1]; State.Add((Buffer[tr].States[st].account[0] - PrevBalance) / PrevBalance); State.Add(Buffer[tr].States[st].account[1] / PrevBalance); State.Add((Buffer[tr].States[st].account[1] - PrevEquity) / PrevEquity); State.Add(Buffer[tr].States[st].account[2]); State.Add(Buffer[tr].States[st].account[3]); State.Add(Buffer[tr].States[st].account[4] / PrevBalance); State.Add(Buffer[tr].States[st].account[5] / PrevBalance); State.Add(Buffer[tr].States[st].account[6] / PrevBalance); double x = (double)Buffer[tr].States[st].account[7] / (double)(D'2024.01.01' - D'2023.01.01'); State.Add((float)MathSin(x != 0 ? 2.0 * M_PI * x : 0)); x = (double)Buffer[tr].States[st].account[7] / (double)PeriodSeconds(PERIOD_MN1); State.Add((float)MathCos(x != 0 ? 2.0 * M_PI * x : 0)); x = (double)Buffer[tr].States[st].account[7] / (double)PeriodSeconds(PERIOD_W1); State.Add((float)MathSin(x != 0 ? 2.0 * M_PI * x : 0)); x = (double)Buffer[tr].States[st].account[7] / (double)PeriodSeconds(PERIOD_D1); State.Add((float)MathSin(x != 0 ? 2.0 * M_PI * x : 0));
次に、エンコーダのフィードフォワードパスで、埋め込みを生成します。
if(!Convolution.feedForward(GetPointer(State), 1, false, NULL)) { PrintFormat("%s -> %d", __FUNCTION__, __LINE__); ExpertRemove(); return; } Convolution.getResults(temp);
出力ベクトルはstate_embedding行列に保存されます。
if(!state_embedding.Row(temp, state)) continue;
経験再生バッファからの関連データは、rewards行列とエージェントのactions行列に保存されます。
if(!temp.Assign(Buffer[tr].States[st].rewards) || !next.Assign(Buffer[tr].States[st + 1].rewards) || !rewards.Row(temp - next * DiscFactor, state)) continue; if(!temp.Assign(Buffer[tr].States[st].action) || !actions.Row(temp, state)) continue;
報酬行列には、次の状態に移行するための利点のみを追加します。また、何らかのエラーが発生しても、プログラムを完全に終了させるのではなく、次の状態に移行するだけです。したがって、学習プロセスをすべて完了させるのではなく、比較のためのベースをわずかに減らすだけです。
そして、保存された埋め込みのカウンタをインクリメントします。ループシステムの次の反復に移る前に、状態エンコード処理の進捗状況をユーザーに知らせます。
state++; if(GetTickCount() - ticks > 500) { string str = StringFormat("%-15s %6.2f%%", "Embedding ", state * 100.0 / (double)(total_states)); Comment(str); ticks = GetTickCount(); } } }
エンコード処理が完了したら、行列を実際のデータ量に縮小します。
if(state != total_states)
{
rewards.Resize(state, NRewards);
actions.Resize(state, NActions);
state_embedding.Reshape(state, state_embedding.Cols());
total_states = state;
}
次のステップは、ローカル変数を準備し、軌道の優先順位を整理することです。軌道を選択する確率を計算するプロセスは、別のGetProbTrajectoriesメソッドに実装されており、そのアルゴリズムは前回の記事で紹介しました。
vector<float> rewards1, rewards2, target_reward; STarget target; //--- vector<float> probability = GetProbTrajectories(Buffer, 0.9);
これでデータの準備段階は完了です。次に、モデル訓練アルゴリズムに移りますが、これもループで構成されています。モデル訓練ループの反復回数は、EAの外部パラメータに表示されます。
ループ本体では、まず、上で計算した確率を考慮して軌道を標本化します。このプロセスはSampleTrajectoryメソッドで実装されており、そのアルゴリズムは前回の記事でも紹介しました。次に、選択された軌道上の状態を標本化します。
vector<float> probability = GetProbTrajectories(Buffer, 0.9); int bar = (HistoryBars - 1) * BarDescr; for(int iter = 0; (iter < Iterations && !IsStopped()); iter ++) { int tr = SampleTrajectory(probability); int i = (int)((MathRand() * MathRand() / MathPow(32767, 2)) * (Buffer[tr].Total - 2)); if(i < 0) { iter--; continue; }
次に、完了した訓練の反復によって分岐プロセスを整理しました。訓練されていないモデルによる状態の推定は完全にランダムであり、学習プロセスを間違った方向に導く可能性があるため、初期段階では目標モデルによるその後の状態の推定を除外します。そして、十分な精度を持つモデルによってその後の状態を評価することで、このステップで使用された方策から未来期待されるリターンを推定することができます。そうすることで、その後のリターンを考慮した上で、行動の優先順位をつけることができます。
このブロックでは、初期データバッファに、その後の環境の状態を記述します。
State.AssignArray(Buffer[tr].States[i + 1].state); float PrevBalance = Buffer[tr].States[i].account[0]; float PrevEquity = Buffer[tr].States[i].account[1]; Account.Clear(); Account.Add((Buffer[tr].States[i + 1].account[0] - PrevBalance) / PrevBalance); Account.Add(Buffer[tr].States[i + 1].account[1] / PrevBalance); Account.Add((Buffer[tr].States[i + 1].account[1] - PrevEquity) / PrevEquity); Account.Add(Buffer[tr].States[i + 1].account[2]); Account.Add(Buffer[tr].States[i + 1].account[3]); Account.Add(Buffer[tr].States[i + 1].account[4] / PrevBalance); Account.Add(Buffer[tr].States[i + 1].account[5] / PrevBalance); Account.Add(Buffer[tr].States[i + 1].account[6] / PrevBalance); double x = (double)Buffer[tr].States[i + 1].account[7] / (double)(D'2024.01.01' - D'2023.01.01'); Account.Add((float)MathSin(x != 0 ? 2.0 * M_PI * x : 0)); x = (double)Buffer[tr].States[i + 1].account[7] / (double)PeriodSeconds(PERIOD_MN1); Account.Add((float)MathCos(x != 0 ? 2.0 * M_PI * x : 0)); x = (double)Buffer[tr].States[i + 1].account[7] / (double)PeriodSeconds(PERIOD_W1); Account.Add((float)MathSin(x != 0 ? 2.0 * M_PI * x : 0)); x = (double)Buffer[tr].States[i + 1].account[7] / (double)PeriodSeconds(PERIOD_D1); Account.Add((float)MathSin(x != 0 ? 2.0 * M_PI * x : 0));
更新された方策を考慮してエージェントの行動を生成します。
if(Account.GetIndex() >= 0) Account.BufferWrite(); if(!Actor.feedForward(GetPointer(State), 1, false, GetPointer(Account))) { PrintFormat("%s -> %d", __FUNCTION__, __LINE__); break; }
次に、目標となるCriticの2つのモデルを使用して、結果の行動を評価します。
if(!TargetCritic1.feedForward(GetPointer(Actor), LatentLayer, GetPointer(Actor)) || !TargetCritic2.feedForward(GetPointer(Actor), LatentLayer, GetPointer(Actor))) { PrintFormat("%s -> %d", __FUNCTION__, __LINE__); break; }
期待報酬の計算には、最小の推定値を使用します。
TargetCritic1.getResults(rewards1); TargetCritic2.getResults(rewards2); target_reward.Assign(Buffer[tr].States[i + 1].rewards); if(rewards1.Sum() <= rewards2.Sum()) target_reward = rewards1 - target_reward; else target_reward = rewards2 - target_reward; target_reward[NRewards - 1] = EntropyLatentState(Actor); target_reward *= DiscFactor; }
次の段階では、Criticモデルを訓練するプロセスに移ります。これらのモデルは、経験再生バッファの状態と行動を使用して訓練されます。
まず、環境の現在の状態の記述をソースデータバッファにコピーします。
//--- Q-function study
State.AssignArray(Buffer[tr].States[i].state);
次に、口座の状態を記述するためのバッファを作成します。
float PrevBalance = Buffer[tr].States[MathMax(i - 1, 0)].account[0]; float PrevEquity = Buffer[tr].States[MathMax(i - 1, 0)].account[1]; Account.Clear(); Account.Add((Buffer[tr].States[i].account[0] - PrevBalance) / PrevBalance); Account.Add(Buffer[tr].States[i].account[1] / PrevBalance); Account.Add((Buffer[tr].States[i].account[1] - PrevEquity) / PrevEquity); Account.Add(Buffer[tr].States[i].account[2]); Account.Add(Buffer[tr].States[i].account[3]); Account.Add(Buffer[tr].States[i].account[4] / PrevBalance); Account.Add(Buffer[tr].States[i].account[5] / PrevBalance); Account.Add(Buffer[tr].States[i].account[6] / PrevBalance); double x = (double)Buffer[tr].States[i].account[7] / (double)(D'2024.01.01' - D'2023.01.01'); Account.Add((float)MathSin(x != 0 ? 2.0 * M_PI * x : 0)); x = (double)Buffer[tr].States[i].account[7] / (double)PeriodSeconds(PERIOD_MN1); Account.Add((float)MathCos(x != 0 ? 2.0 * M_PI * x : 0)); x = (double)Buffer[tr].States[i].account[7] / (double)PeriodSeconds(PERIOD_W1); Account.Add((float)MathSin(x != 0 ? 2.0 * M_PI * x : 0)); x = (double)Buffer[tr].States[i].account[7] / (double)PeriodSeconds(PERIOD_D1); Account.Add((float)MathSin(x != 0 ? 2.0 * M_PI * x : 0)); if(Account.GetIndex() >= 0) Account.BufferWrite();
収集したデータによって、Actorのフィードフォワードパスを実行することができます。
if(!Actor.feedForward(GetPointer(State), 1, false, GetPointer(Account))) { PrintFormat("%s -> %d", __FUNCTION__, __LINE__); break; }
Criticの訓練の前に、フィードフォワードのActorパスを実行します。ただし、訓練の過程では、経験再生バッファからの行動を使用します。これは、Actorの潜在的な状態をCriticの入力として使用するためです。
次に、訓練データベースから行動バッファを満たし、Criticsのフィードフォワードパスメソッドを呼び出します。
Actions.AssignArray(Buffer[tr].States[i].action); if(Actions.GetIndex() >= 0) Actions.BufferWrite(); //--- if(!Critic1.feedForward(GetPointer(Actor), LatentLayer, GetPointer(Actions)) || !Critic2.feedForward(GetPointer(Actor), LatentLayer, GetPointer(Actions))) { PrintFormat("%s -> %d", __FUNCTION__, __LINE__); break; }
モデルを訓練する際の目標値として、重み付けされた報酬を使用します。それを得るには、まず、環境の現在の状態のバッファに口座の状態の記述を追加し、分析された状態の埋め込みを生成します。
if(!State.AddArray(GetPointer(Account)) || !Convolution.feedForward(GetPointer(State), 1, false, NULL)) { PrintFormat("%s -> %d", __FUNCTION__, __LINE__); break; } Convolution.getResults(temp);
この段階で利用可能なデータセットは、先に説明したGetTargetsメソッドを呼び出すのに十分です。このメソッドは重み付けされた報酬と行動のベクトルを返します。
target = GetTargets(Percent, temp, state_embedding, rewards, actions);
目標データが手元にあれば、Criticモデルのバックプロパゲーションパスを実行できます。しかし、まずはCAGrad法を用いて誤差勾配を修正します。
Critic1.getResults(rewards1); Result.AssignArray(CAGrad(target.rewards + target_reward - rewards1) + rewards1); if(!Critic1.backProp(Result, GetPointer(Actions), GetPointer(Gradient)) || !Actor.backPropGradient(GetPointer(Account), GetPointer(Gradient), LatentLayer)) { PrintFormat("%s -> %d", __FUNCTION__, __LINE__); break; } Critic2.getResults(rewards2); Result.AssignArray(CAGrad(target.rewards + target_reward - rewards2) + rewards2); if(!Critic2.backProp(Result, GetPointer(Actions), GetPointer(Gradient)) || !Actor.backPropGradient(GetPointer(Account), GetPointer(Gradient), LatentLayer)) { PrintFormat("%s -> %d", __FUNCTION__, __LINE__); break; }
次のステップでは、Actorの方策を更新します。このモデルのフィードフォワードパスはすでに実行しました。また、目標行動の重み付きベクトルも得られました。したがって、教師あり学習モードでバックプロパゲーションパスを実行するのに必要なデータはすべて揃っています。
//--- Policy study Actor.getResults(rewards1); Result.AssignArray(CAGrad(target.actions - rewards1) + rewards1); if(!Actor.backProp(Result, GetPointer(Account), GetPointer(Gradient))) { PrintFormat("%s -> %d", __FUNCTION__, __LINE__); break; }
ご覧のように、Actorの目標行動のベクトルを形成する際には、経験再生バッファから直接抽出した行動のアドバンテージを使用しました。したがって、訓練されたCriticモデルは使用されませんでした。Actorの方策にかかわらず、市場の動きへの影響はごくわずかです。したがって、近似的なCriticを用いて「利点」を過大評価すると、モデリングエラーによってデータが歪む可能性があります。このようなパラダイムでは、Criticモデルの訓練は不要に思えるかもしれません。しかし、調査した方策が未来の期待リターンに与える影響も考慮したいです。このため、訓練の結果、最も誤差の少ないCriticを選択します。また、新しい方策によって発生するActorの行動も評価します。得られた推定値と重み付けされた推定値との偏差の勾配は、パラメータを最適化するためにActorに渡されます。
CNet *critic = NULL; if(Critic1.getRecentAverageError() <= Critic2.getRecentAverageError()) critic = GetPointer(Critic1); else critic = GetPointer(Critic2); if(MathAbs(critic.getRecentAverageError()) <= MaxErrorActorStudy) { if(!critic.feedForward(GetPointer(Actor), LatentLayer, GetPointer(Actor))) { PrintFormat("%s -> %d", __FUNCTION__, __LINE__); break; } critic.getResults(rewards1); Result.AssignArray(CAGrad(target.rewards + target_reward - rewards1) + rewards1); critic.TrainMode(false); if(!critic.backProp(Result, GetPointer(Actor)) || !Actor.backPropGradient(GetPointer(Account), GetPointer(Gradient))) { PrintFormat("%s -> %d", __FUNCTION__, __LINE__); critic.TrainMode(true); break; } critic.TrainMode(true); }
これらの操作は、Criticが適切な評価を与えてくれると確信が持てる場合にのみ実行されます。このプロセスを調整するために、追加の外部パラメータMaxErrorActorStudyを導入しました。これは、指定されたプロセスを有効にするためのCriticの評価の最大誤差を決定します。
モデルの訓練プロセスが完了したら、訓練したCriticモデルのパラメータを目標モデルにコピーします。また、最初の段階では、その後の状態を評価するプロセスを可能にする前に、訓練されたモデルのパラメータを目標のモデルに完全に移し替えることにも留意すべきです。後続の状態を推定するメカニズムを使用することで、パラメータのソフトコピーが可能になります。
//--- Update Target Nets if(iter >= StartTargetIter) { TargetCritic1.WeightsUpdate(GetPointer(Critic1), Tau); TargetCritic2.WeightsUpdate(GetPointer(Critic2), Tau); } else { TargetCritic1.WeightsUpdate(GetPointer(Critic1), 1); TargetCritic2.WeightsUpdate(GetPointer(Critic2), 1); }
これで1回のモデル訓練反復の操作は完了です。あとは、モデルの訓練プロセスの進捗状況をユーザーに知らせ、次の反復に進むだけです。
if(GetTickCount() - ticks > 500) { string str = StringFormat("%-15s %5.2f%% -> Error %15.8f\n", "Critic1", iter * 100.0 / (double)(Iterations), Critic1.getRecentAverageError()); str += StringFormat("%-15s %5.2f%% -> Error %15.8f\n", "Critic2", iter * 100.0 / (double)(Iterations), Critic2.getRecentAverageError()); str += StringFormat("%-14s %5.2f%% -> Error %15.8f\n", "Actor", iter * 100.0 / (double)(Iterations), Actor.getRecentAverageError()); Comment(str); ticks = GetTickCount(); } }
モデル訓練サイクルのすべての反復が成功したら、チャートのコメントフィールドを消去します。学習結果をユーザーに通知し、EAの終了を開始します。
Comment(""); //--- PrintFormat("%s -> %d -> %-15s %10.7f", __FUNCTION__, __LINE__, "Critic1", Critic1.getRecentAverageError()); PrintFormat("%s -> %d -> %-15s %10.7f", __FUNCTION__, __LINE__, "Critic2", Critic2.getRecentAverageError()); PrintFormat("%s -> %d -> %-15s %10.7f", __FUNCTION__, __LINE__, "Actor", Actor.getRecentAverageError()); ExpertRemove(); //--- }
これで、この記事の実践編は終わりです。この記事で使用されているすべてのプログラムの完全なコードを添付ファイルでご覧ください。テスト段階に移ります。
3.テスト
MQL5を使用してDWSLメソッドのビジョンを実装するために広範な作業をおこないました。以前議論した手法の数々から、一種の集大成に行き着いたことを認めなければなりません。これはかなり大きな実験です。ソリューションの有効性は、過去のデータで確認することができます。これがこれからやることです。
これまでのすべてのケースと同様に、モデルの訓練は2023年の最初の7ヶ月間のEURUSDH1データを使用しておこなわれます。訓練モデル用のデータは、フルパラメータ最適化モードのMetaTrader5ストラテジーテスターで収集されました。第1段階では、500個の無作為な軌跡を収集します。OnTesterPassメソッドのアルゴリズムを最適化したので、もう少し多くのパスを実行できます。最も良いリターンを示したものは、経験再生バッファ選択されます。
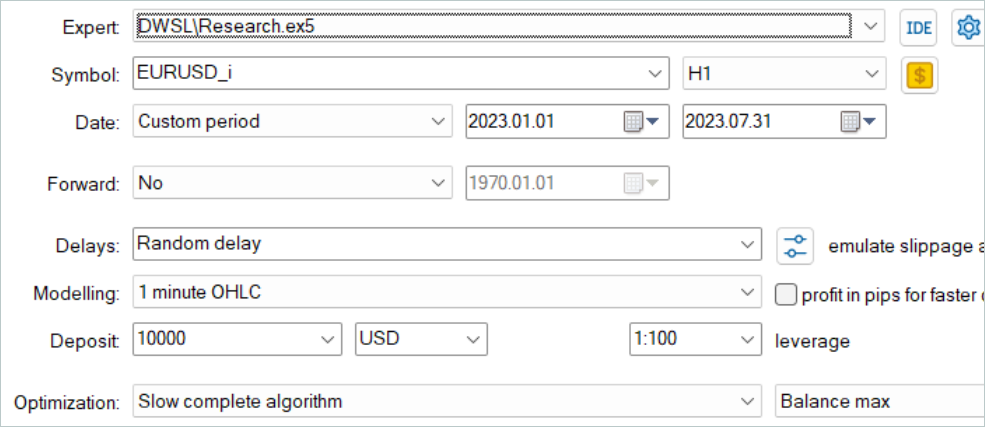
ここで注意してほしいのは、無作為な方策で利益の出るパスを得ようとしてはいけないということです。現段階では、かなり無作為なプロセスです。先に見たように、全区間にわたって無作為な方策で完全に有益なパスを得る確率は0に近いです。幸いなことに、DWSL法はどのような品質の生データでも扱うことができます。
訓練データセットを収集した後、モデルの訓練EAを初めて実行します。
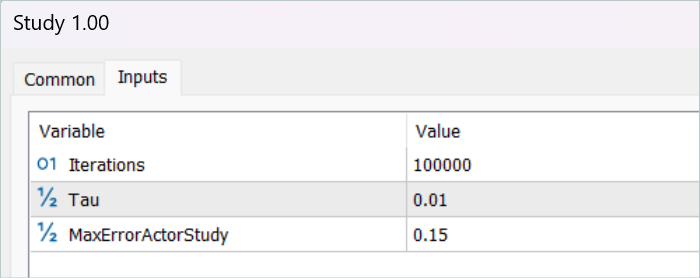
現段階では、完全に利益を上げる戦略には至っていません。これは、訓練データセットからのパスのリターンが少ないことが主な原因です。しかし、最初の訓練サイクルの後、環境と相互作用するEAを再実行すると、明らかに高いリターンの軌道が得られたことに注目すべきです。全訓練期間中、1度だけ、おそらく無作為に、利益を上げるランがありました。これは一般的に、この手法の有効性を示し、より良い結果を得る可能性を約束するものです。
軌跡の収集と訓練を何度か繰り返した結果、一貫して利益を生み出せるモデルを手に入れることができました。出来上がったモデルは、訓練セットに含まれていない2023年8月の過去のデータを使用してテストされましたが、これらのデータセットは訓練期間と同じであるため、比較可能であると考えられます。


テスト結果によると、このモデルは利益を上げることができ、利益率は1.3に達しました。残高のグラフを見ると、月の前半にかなり急激な伸びを示しています。その後、かなり狭い範囲で変動しました。以下のテスト結果は肯定的とみなすことができます。
- ポジションの50%以上が利益を上げている
- 最大利益の取引は最大損失の取引のほぼ4倍であり、平均利益の取引は平均損失の取引のほぼ4分の1である
- 双方向の取引がある(ショート60%、ロング40%)。ショートポジションのほぼ55%、ロングポジションの46%が利益をもって決済された
- 利益を上げた最長のシリーズは、取引回数においても金額において損失を出した最長のシリーズを上回っている
得られた結果は一般的にポジティブな印象を与えます。
結論
この記事では、モデルを訓練するためのもう1つの興味深い手法、Distance Weighted Supervised Learningを紹介しました。利用可能なデータの重み付け評価を使用することで、収集された非最適軌道のオフライン最適化と、非常に興味深い方策の訓練を可能にし、その後、良い結果が出ました。
検討した手法の有効性は、実用的な結果によって確認されました。訓練の過程で、訓練した内容を新しいデータに汎化できる方策を得ました。その結果、テスト中に黒字の残高グラフが得られました。
ただし、もう一度言っておきますが、この記事で紹介するプログラムはすべて、技術のデモンストレーションを目的としたものであり、実際の取引に使用することはできません。
参照文献
記事で使用されているプログラム
| # | 名前 | 種類 | 詳細 |
|---|---|---|---|
| 1 | Research.mq5 | EA | コレクションEAの例 |
| 2 | Study.mq5 | EA | エージェント訓練EA |
| 3 | Test.mq5 | EA | モデルをテストするEA |
| 4 | Trajectory.mqh | クラスライブラリ | システム状態記述の構造 |
| 5 | NeuroNet.mqh | クラスライブラリ | ニューラルネットワークを作成するためのクラスのライブラリ |
| 6 | NeuroNet.cl | コードベース | OpenCLプログラムコードライブラリ |
MetaQuotes Ltdによってロシア語から翻訳されました。
元の記事: https://www.mql5.com/ru/articles/13779
- 無料取引アプリ
- 8千を超えるシグナルをコピー
- 金融ニュースで金融マーケットを探索