A probabilistic neural network
1)Вероятностная нейронная сеть. Как функционирует(не пойму).
2)Как настроить веса и т.д. Везде поверхостное описание. Можете рассказать мат. аппорат.
1) Probabilistic Neural Networks (PNN) are the same as Multilayer Perspectron (MLP).
3) In general, this multiplicity of networks is only confusing. In fact, networks are divided into:
a) by the number of hidden layers
b) according to the topology of links, star, lattice (and others that come to mind)
c) by type of activation function in neurons
d) With or without feedbacks, with or without hybrid links
e) a), b), c) and d) can be in one network.
1) Вероятностные нейронные сети (PNN) есть тоже самое, что и многослойный персептрон (MLP).
3) Вообще, это многообразие сетей лишь запутывает. На самом деле, сети делятся:
а) по количеству скрытых слоев
б) по топологии связей, звездообразные, решетка (и др. какие взбредут в голову)
в) по типу активационной функции в нейронах
г) С обратными связями или без, с гибридными связями.
Вот у нас есть образцы n из A и k из B. каждый обр. обладает z кол-вом параметров. Появляется неизвестный элемент и нам надо его отнести к А или B. Ну и как? Евклидово расстояние брать?
in 2 words:
at a given point(recognizable vector) the activity of radial functions(potential) is summed, first summed over class A, then over class B, the conclusion about which class the recognizable vector belongs to is made by comparing the sums(whoever is the bigger one wins).
2 joo:
The Probabilistic Network and MLP are very different. Anyway, the principle behind them is different.
Another thing is that I also do not recommend getting bogged down with different grids, all that is needed is squeezed out of a regular MLP.
You have a classification task.
To train the network we use examples, the answer to which is either 1 or -1 (belonging to A or B)
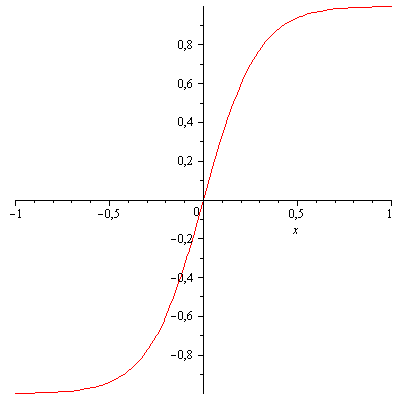
We will use the sigmoid as an activation function of neurons
![]()
It has the form:
Let's say that space A contains all responses 1, and space B contains all responses -1. Note that these spaces are not necessarily separated by a straight line (a curve could be).
All answers that do not fit exactly into either A or B based on the attributes available (read - input data) will be arranged in a grid in space -1...1
with this probability:
PS You knew that, didn't you?
У Вас задача классификации.
Для обучения сети используются примеры, ответ на который либо 1, либо -1 (принадлежность к А или В)
В качестве активационной функции нейронов используем сигмоиду
Имеет вид:
Скажем, к пространству А относятся все ответы 1, а к пространству В все ответы -1. Причем, эти пространства необязательно разделены четкой прямой линией (может быть и кривая)
Все ответы точно не попадающие ни в А ни в Б по имеющимся признакам (читаем - входные данные) будут расположены сеткой в пространстве -1...1
с вероятностью такой:
PS Вы же это знали, не так ли?
2 joo:
Вероятностная сеть и МЛП очень сильно различаются. Во всяком случае принцип у них заложен разный.
Другое дело что я тоже не рекомендую заморачивать на разных сетках, всё что нужно выжимается из обычного МЛП.
The question was about the mate. The differences are by teacher. PNN has -1 and 1 answers, everything in between is probability of class membership, while MLP (MNN) has -1 and 1 answers over the whole interval. The difference is only in the teacher (control data for learning), and the nets are the same.
Вопрос был про мат аппарат. Различия у них по учителю. У PNN ответы -1 и 1, все что между ними - вероятность принадлежности к классу, а у MLP (MNN) ответы на всем промежутке -1 и 1. Разница только в учителе (контрольные данные для обучения), а сети одни и те же.
It's not just the teacher. The principle is different. MLP draws lines (hyperplanes) and probabilistic draws circles (hyperballs).
Take a simple example:
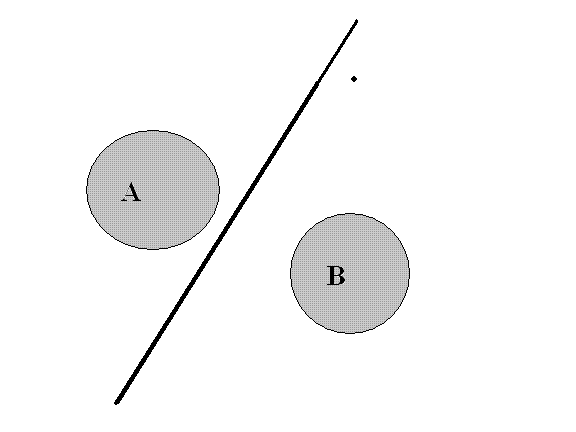
A linear perceptron just draws a line and that's it, its line is infinite.
And the value of potentials of both classes will be practically zero. Is there a difference?
Example.
A classification, male or female, needs to be organised.
There are such signs, the number of signs corresponds to the number of neurons in the input layer
1. Presence/absence of primary sex characteristics.
2. Presence/absence of secondary sex characteristics
3. Length of hair
4. hip width
5. Width of shoulders.
6. Presence of hair on the extremities.
7. Presence of makeup.
Coding the features in the range -1...1.
Present the nets when training 100% of the features belonging to the sex. Answers -1 and 1.
Combinations of traits will give non "fuzzy answers", e.g. (-0,8) will correspond to 80% probability of being female.
- Free trading apps
- Over 8,000 signals for copying
- Economic news for exploring financial markets
You agree to website policy and terms of use
A probabilistic neural network. How does it function(don't understand). How to adjust weights etc. Everywhere is a spatial description. Can you tell the mathematical apparatus.