
Нейросети — это просто (Часть 82): Модели Обыкновенных Дифференциальных Уравнений (NeuralODE)

Введение
Предлагаю познакомиться с новым семейством моделей обыкновенных дифференциальных уравнений. Вместо указания дискретной последовательности скрытых слоев они параметризируют производную скрытого состояния с помощью нейронной сети. Результаты работы модели вычисляются с помощью "черного ящика" — решателя дифференциальных уравнений. Эти модели с непрерывной глубиной используют постоянный объем памяти и адаптируют свою стратегию оценки к каждому входному сигналу. Впервые подобные модели были предложены в статье "Neural Ordinary Differential Equations". В которой авторы метода демонстрируют возможности масштабирования обратного распространение ошибки с помощью любого решателя Обычных Дифференциальных Уравнений (ОДУ) без доступа к его внутренним операциям. Что позволяет осуществлять сквозное обучение ОДУ в рамках более крупных моделей.
1. Описание алгоритма
Основная техническая трудность при обучении моделей обыкновенных дифференциальных уравнений заключается в выполнении дифференцирования обратного режима распространение ошибки с помощью решателя ОДУ. Дифференциация с помощью операций прямого прохода проста, но требует больших затрат памяти и вносит дополнительную числовую ошибку.
Авторы метода предлагают рассматривать решатель ОДУ как черный ящик и вычислять градиенты, используя метод сопряженной чувствительности. Этот подход позволяет вычислять градиенты путем решения второго расширенного ОДУ назад во времени и применим ко всем решателям ОДУ. Он линейно масштабируется в зависимости от размера задачи и обладает низким потреблением памяти. При этом явно контролирует числовую ошибку.
Рассмотрим оптимизацию скалярной функции потерь L(), исходными данными которой являются результаты решателя ОДУ:
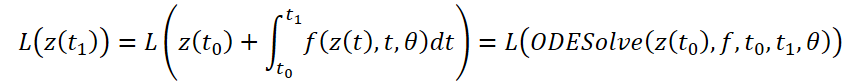
Для оптимизации ошибки L нам необходимы градиенты по θ. Первый шаг алгоритма, предложенного авторами метода, является определение, как градиент ошибки зависит от скрытого состояния z(t) в каждый момент a(t)=∂L/∂z(t). Его динамика задается другой ОДУ, которую можно рассматривать как аналог правила:
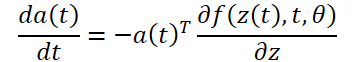
Мы можем вычислить ∂L/∂z(t) с помощью ещё одного вызовом решателя ОДУ. Этот решатель должен работать в обратном направлении, начиная с начального значения ∂L/∂z(t1). Одна из сложностей заключается в том, что для решение этого ОДУ необходимо знать значения z(t) по всей траектории. Однако мы можем просто перечислить z(t) назад во времени, начиная с его конечного значения z(t1).
Вычисление градиентов по параметрам θ требует определения третьего интеграла, который зависит от обоих z(t) и a(t):
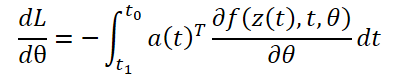
Все интегралы для решения 𝐳, 𝐚 и ∂L/∂θ могут быть вычислены за один вызов решателя ОДУ, который объединяет исходное состояние, сопряженное и другие частные производные в один вектор. Ниже представлен алгоритм построения необходимой динамики и вызова решателя ОДУ для вычисления всех градиентов одновременно.

Большинство решателей ОДУ имеют возможность вычисления состояния z(t) несколько раз. Когда потери зависят от этих промежуточных состояний, производную обратного режима необходимо разбить на последовательность отдельных решений, по одному между каждой последовательной парой выходных значений. При каждом наблюдении сопряженная должна быть скорректирована в направлении соответствующей частной производной ∂L/∂z(t).
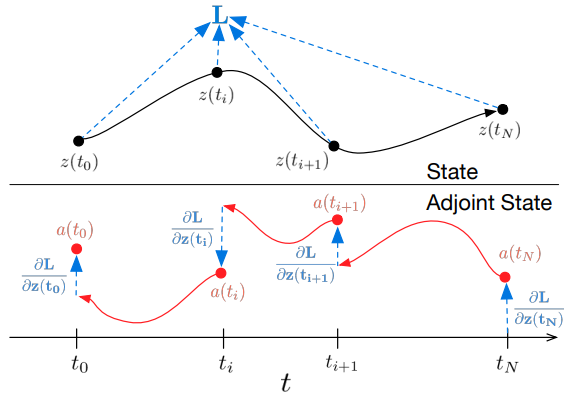
Решатели ОДУ могут приблизительно гарантировать, что полученные результаты находятся в пределах заданного допуска от истинного решения. Изменение допуска меняет поведение модели. Время, затраченное на прямой вызов, пропорционально количеству вычислений функции, поэтому настройка допуска дает нам компромисс между точностью и вычислительными затратами. Можно тренироваться с высокой точностью, но во время эксплуатации переключиться на более низкую точность.
2. Реализация средствами MQL5
Для реализации предложенных подходов мы создадим новый класс CNeuronNODEOCL, который унаследует базовый функционал от нашего полносвязного слоя CNeuronBaseOCL. Ниже приведена структура нового класса. В ней, помимо базового набора метода, добавляется и несколько специфических методов и объектов с функционалом которых мы познакомимся в процессе реализации.
class CNeuronNODEOCL : public CNeuronBaseOCL { protected: uint iDimension; uint iVariables; uint iLenth; int iBuffersK[]; int iInputsK[]; int iMeadl[]; CBufferFloat cAlpha; CBufferFloat cTemp; CCollection cBeta; CBufferFloat cSolution; CCollection cWeights; //--- virtual bool CalculateKBuffer(int k); virtual bool CalculateInputK(CBufferFloat* inputs, int k); virtual bool CalculateOutput(CBufferFloat* inputs); virtual bool feedForward(CNeuronBaseOCL *NeuronOCL); //--- virtual bool CalculateOutputGradient(CBufferFloat* inputs); virtual bool CalculateInputKGradient(CBufferFloat* inputs, int k); virtual bool CalculateKBufferGradient(int k); virtual bool updateInputWeights(CNeuronBaseOCL *NeuronOCL); public: CNeuronNODEOCL(void) {}; ~CNeuronNODEOCL(void) {}; //--- virtual bool Init(uint numOutputs, uint myIndex, COpenCLMy *open_cl, uint dimension, uint variables, uint lenth, ENUM_OPTIMIZATION optimization_type, uint batch); //--- virtual bool calcInputGradients(CNeuronBaseOCL *prevLayer); //--- virtual int Type(void) const { return defNeuronNODEOCL; } //--- methods for working with files virtual bool Save(int const file_handle); virtual bool Load(int const file_handle); virtual void SetOpenCL(COpenCLMy *obj); };
Прежде всего надо сказать, что для возможности работы с последовательностями нескольких состояний окружающей среды, описанных эмбедингами нескольких признаков, мы создаем объект, способный работать с исходными данными, предсталенными в 3 измерениях:
- iDimension — размер вектора эмбединга одного признака в отдельном состоянии окружающей среды;
- iVariables — количество признаков описания одного состояния окружающей среды;
- iLenth — количество анализируемых состояний системы.
Функция ОДУ в нашем случае будет представлена 2 полносвязными слоями с функцией активации ReLU между ними. Однако, мы допускаем, что динамика каждого отдельного признака может отличаться. Поэтому для каждого признака мы предусмотрим свои весовые матрицы. Такой подход на позволяет нам использовать сверточные слои в качестве внутренних, как это делалось ранее. Поэтому, в нашем новом классе мы декомпозируем внутренние слои функции ОДУ. Мы объявим буферы данных, составляющие внутренние слои данных. А затем создадим кернелы и методы реализации процессов.
2.1 Кернел прямого прохода функции
При построении кернела прямого прохода функции ОДУ мы исходим из следующих ограничений:
- Каждое состояние окружающей среды описано одинаковым фиксированным количеством признаков;
- Все признаки имеют одинаковый фиксированный размер эмбединга.
С учетом указанных ограничений мы создаем кернел FeedForwardNODEF на стороне OpenCL программы. В параметрах нашего кернела мы будем передавать указатели на 3 буфера данных и 3 переменные. Запуск кернела планируется в 3 мерном пространстве задач.
__kernel void FeedForwardNODEF(__global float *matrix_w, ///<[in] Weights matrix __global float *matrix_i, ///<[in] Inputs tensor __global float *matrix_o, ///<[out] Output tensor int dimension, ///< input dimension float step, ///< h int activation ///< Activation type (#ENUM_ACTIVATION) ) { int d = get_global_id(0); int dimension_out = get_global_size(0); int v = get_global_id(1); int variables = get_global_size(1); int i = get_global_id(2); int lenth = get_global_size(2);
В теле кернела мы сначала идентифицируем текущий поток по всем 3 измерения пространства задач. После чего определим смещения в буферах данных до анализируемых данных.
int shift = variables * i + v; int input_shift = shift * dimension; int output_shift = shift * dimension_out + d; int weight_shift = (v * dimension_out + d) * (dimension + 2);
После проведения подготовительной работы мы в цикле посчитаем значения текущего результата путем умножения вектора исходных данных на соответствующий вектор весовых коэффициентов.
float sum = matrix_w[dimension + 1 + weight_shift] + matrix_w[dimension + weight_shift] * step; for(int w = 0; w < dimension; w++) sum += matrix_w[w + weight_shift] * matrix_i[input_shift + w];
Здесь надо обратить внимание, что функция ОДУ зависит не только от состояния окружающей среды, но и от временной метки. В данном случае временная метка одна для всего состояния окружающей среды. И для исключения её дублирования по количеству признаков и длины последовательности, мы не стали добавлять временную метку в тензор исходных данных, а просто передали параметром step в кернел.
Далее нам остается лишь провести полученное значение через функцию активации и сохранить результат в соответствующий элемент буфера.
if(isnan(sum)) sum = 0; switch(activation) { case 0: sum = tanh(sum); break; case 1: sum = 1 / (1 + exp(-clamp(sum, -20.0f, 20.0f))); break; case 2: if(sum < 0) sum *= 0.01f; break; default: break; } matrix_o[output_shift] = sum; }
2.2 Кернел обратного прохода функции
После реализации кернела прямого прохода мы сразу создадим на стороне OpenCL программы обратный функционал — кернел распределения градиента ошибки HiddenGradientNODEF.
__kernel void HiddenGradientNODEF(__global float *matrix_w, ///<[in] Weights matrix __global float *matrix_g, ///<[in] Gradient tensor __global float *matrix_i, ///<[in] Inputs tensor __global float *matrix_ig, ///<[out] Inputs Gradient tensor int dimension_out, ///< output dimension int activation ///< Input Activation type (#ENUM_ACTIVATION) ) { int d = get_global_id(0); int dimension = get_global_size(0); int v = get_global_id(1); int variables = get_global_size(1); int i = get_global_id(2); int lenth = get_global_size(2);
Данный кернел мы так же планируем запускать в 3 мерном пространстве задач, идентификацию потока по которому мы осуществляем в теле кернела. Тут же мы определяем смещения в буферах данных до анализируемых элементов.
int shift = variables * i + v; int input_shift = shift * dimension + d; int output_shift = shift * dimension_out; int weight_step = (dimension + 2); int weight_shift = (v * dimension_out) * weight_step + d;
И суммируем градиент ошибки для анализируемого элемента исходных данных.
float sum = 0; for(int k = 0; k < dimension_out; k ++) sum += matrix_g[output_shift + k] * matrix_w[weight_shift + k * weight_step]; if(isnan(sum)) sum = 0;
Здесь стоит обратить внимание, что временная метка, по существу, у нас константа для отдельного состояния. Поэтому мы не распределяем до неё градиент ошибки.
Скорректируем полученную сумму на производную функции активации и сохраним полученное значение в соответствующий элемент буфера данных.
float out = matrix_i[input_shift]; switch(activation) { case 0: out = clamp(out, -1.0f, 1.0f); sum = clamp(sum + out, -1.0f, 1.0f) - out; sum = sum * max(1 - pow(out, 2), 1.0e-4f); break; case 1: out = clamp(out, 0.0f, 1.0f); sum = clamp(sum + out, 0.0f, 1.0f) - out; sum = sum * max(out * (1 - out), 1.0e-4f); break; case 2: if(out < 0) sum *= 0.01f; break; default: break; } //--- matrix_ig[input_shift] = sum; }
2.3 Решатель ОДУ
Первый этап работы мы выполнили. Теперь давайте посмотрим сторону решателя ОДУ. Для своей реализации я выбрал метод Дормана—Принса 5 порядка.
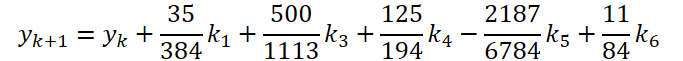
где
![]()
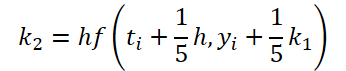
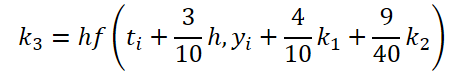
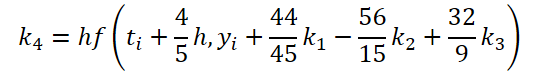
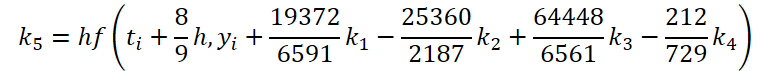
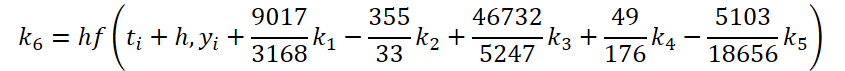
Легко заметить, что функция решения и корректировки исходных данных для вычисления коэффициентов k1..k6 отличаются только числовыми коэффициентами. Ведь отсутствующие коэффициенты ki мы можем добавить, умножив на 0, что не повлияет на результат. Поэтому для унификации процесса мы создадим один кернел FeedForwardNODEInpK на стороне OpenCL программы. В параметрах кернела мы передадим указатели буферы исходных данных и всех коэффициентов ki. Необходимые множители мы укажем в буфере matrix_beta.
__kernel void FeedForwardNODEInpK(__global float *matrix_i, ///<[in] Inputs tensor __global float *matrix_k1, ///<[in] K1 tensor __global float *matrix_k2, ///<[in] K2 tensor __global float *matrix_k3, ///<[in] K3 tensor __global float *matrix_k4, ///<[in] K4 tensor __global float *matrix_k5, ///<[in] K5 tensor __global float *matrix_k6, ///<[in] K6 tenтor __global float *matrix_beta, ///<[in] beta tensor __global float *matrix_o ///<[out] Output tensor ) { int i = get_global_id(0);
Кернел будем запускать в одномерном пространстве задач с параллельным вычислением значений для каждого отдельного значения буфера результатов.
После идентификации потока мы в цикле соберем сумму произведений.
float sum = matrix_i[i]; for(int b = 0; b < 6; b++) { float beta = matrix_beta[b]; if(beta == 0.0f || isnan(beta)) continue; //--- float val = 0.0f; switch(b) { case 0: val = matrix_k1[i]; break; case 1: val = matrix_k2[i]; break; case 2: val = matrix_k3[i]; break; case 3: val = matrix_k4[i]; break; case 4: val = matrix_k5[i]; break; case 5: val = matrix_k6[i]; break; } if(val == 0.0f || isnan(val)) continue; //--- sum += val * beta; }
Полученное значение сохраним в соответствующем элементе буфера результатов.
matrix_o[i] = sum; }
Для целей обратного прохода мы создадим кернел HiddenGradientNODEInpK, в котором распределим градиент ошибки в соответсвующие буфера данных с учетом тех же коэффициентов Beta.
__kernel void HiddenGradientNODEInpK(__global float *matrix_ig, ///<[in] Inputs tensor __global float *matrix_k1g, ///<[in] K1 tensor __global float *matrix_k2g, ///<[in] K2 tensor __global float *matrix_k3g, ///<[in] K3 tensor __global float *matrix_k4g, ///<[in] K4 tensor __global float *matrix_k5g, ///<[in] K5 tensor __global float *matrix_k6g, ///<[in] K6 tensor __global float *matrix_beta, ///<[in] beta tensor __global float *matrix_og ///<[out] Output tensor ) { int i = get_global_id(0); //--- float grad = matrix_og[i]; matrix_ig[i] = grad; for(int b = 0; b < 6; b++) { float beta = matrix_beta[b]; if(isnan(beta)) beta = 0.0f; //--- float val = beta * grad; if(isnan(val)) val = 0.0f; switch(b) { case 0: matrix_k1g[i] = val; break; case 1: matrix_k2g[i] = val; break; case 2: matrix_k3g[i] = val; break; case 3: matrix_k4g[i] = val; break; case 4: matrix_k5g[i] = val; break; case 5: matrix_k6g[i] = val; break; } } }
Обратите внимание, что в буфера данных мы записываем и нулевые значения. Это необходимо для исключения двойного учета ранее сохраненных значений.
2.4 Кернел обновления весов
Для завершения работы на стороне OpenCL программы мы сразу создадим кернел обновления весовых коэффициентов функции ОДУ. Как можно заметить из представленных выше формул, функция ОДУ будет использоваться для определения всех ki коэффициентов. Следовательно, при корректировке весовых коэффициентов мы должны собрать градиент ошибки со всех операций. Ни один из созданных нами ранее кернелов обновления весовых коэффициентов не работал с таким количеством буферов градиентов. Значит нам предстоит создать новый кернел. Для упрощения эксперимента мы создадим только кернел NODEF_UpdateWeightsAdam для обновления параметров методом Adam, который я использую наиболее часто.
__kernel void NODEF_UpdateWeightsAdam(__global float *matrix_w, ///<[in,out] Weights matrix __global const float *matrix_gk1, ///<[in] Tensor of gradients at k1 __global const float *matrix_gk2, ///<[in] Tensor of gradients at k2 __global const float *matrix_gk3, ///<[in] Tensor of gradients at k3 __global const float *matrix_gk4, ///<[in] Tensor of gradients at k4 __global const float *matrix_gk5, ///<[in] Tensor of gradients at k5 __global const float *matrix_gk6, ///<[in] Tensor of gradients at k6 __global const float *matrix_ik1, ///<[in] Inputs tensor __global const float *matrix_ik2, ///<[in] Inputs tensor __global const float *matrix_ik3, ///<[in] Inputs tensor __global const float *matrix_ik4, ///<[in] Inputs tensor __global const float *matrix_ik5, ///<[in] Inputs tensor __global const float *matrix_ik6, ///<[in] Inputs tensor __global float *matrix_m, ///<[in,out] Matrix of first momentum __global float *matrix_v, ///<[in,out] Matrix of seconfd momentum __global const float *alpha, ///< h const int lenth, ///< Number of inputs const float l, ///< Learning rates const float b1, ///< First momentum multiplier const float b2 ///< Second momentum multiplier ) { const int d_in = get_global_id(0); const int dimension_in = get_global_size(0); const int d_out = get_global_id(1); const int dimension_out = get_global_size(1); const int v = get_global_id(2); const int variables = get_global_id(2);
Как уже было отмечено выше, в параметрах кернела передаются указатели на довольно большое количество глобальных буферов данных. К ним добавляются стандартные параметры, используемого метода оптимизации.
Запускать кернел мы планируем в 3 мерном пространстве задач, которое учитывает размерность векторов эмбединга исходных данных и результатов, а так же количество анализируемых признаков. В теле кернела мы идентифицируем поток в пространстве задач по всем 3 измерениям. После чего определим смещения в буферах данных.
const int weight_shift = (v * dimension_out + d_out) * dimension_in; const int input_step = variables * (dimension_in - 2); const int input_shift = v * (dimension_in - 2) + d_in; const int output_step = variables * dimension_out; const int output_shift = v * dimension_out + d_out;
Далее мы в цикле собираем градиент ошибки по всем состояниям окружающей среды.
float weight = matrix_w[weight_shift]; float g = 0; for(int i = 0; i < lenth; i++) { int shift_g = i * output_step + output_shift; int shift_i = i * input_step + input_shift; switch(dimension_in - d_in) { case 1: g += matrix_gk1[shift_g] + matrix_gk2[shift_g] + matrix_gk3[shift_g] + matrix_gk4[shift_g] + matrix_gk5[shift_g] + matrix_gk6[shift_g]; break; case 2: g += matrix_gk1[shift_g] * alpha[0] + matrix_gk2[shift_g] * alpha[1] + matrix_gk3[shift_g] * alpha[2] + matrix_gk4[shift_g] * alpha[3] + matrix_gk5[shift_g] * alpha[4] + matrix_gk6[shift_g] * alpha[5]; break; default: g += matrix_gk1[shift_g] * matrix_ik1[shift_i] + matrix_gk2[shift_g] * matrix_ik2[shift_i] + matrix_gk3[shift_g] * matrix_ik3[shift_i] + matrix_gk4[shift_g] * matrix_ik4[shift_i] + matrix_gk5[shift_g] * matrix_ik5[shift_i] + matrix_gk6[shift_g] * matrix_ik6[shift_i]; break; } }
А затем скорректируем веса по уже отработанному алгоритму.
float mt = b1 * matrix_m[weight_shift] + (1 - b1) * g; float vt = b2 * matrix_v[weight_shift] + (1 - b2) * pow(g, 2); float delta = l * (mt / (sqrt(vt) + 1.0e-37f) - (l1 * sign(weight) + l2 * weight));
В завершении кернела сохраним результат и вспомогательные значения в соответствующие элементы буферов данных.
if(delta * g > 0) matrix_w[weight_shift] = clamp(matrix_w[weight_shift] + delta, -MAX_WEIGHT, MAX_WEIGHT); matrix_m[weight_shift] = mt; matrix_v[weight_shift] = vt; }
На этом мы завершаем работу на стороне OpenCL программы и возвращаемся к реализации нашего класса CNeuronNODEOCL.
2.5 Метод инициализации класса CNeuronNODEOCL
Инициализация нашего объекта класса осуществляется в методе CNeuronNODEOCL::Init. В параметрах метода мы, как обычно, будем передавать основные параметры архитектуры объекта.
bool CNeuronNODEOCL::Init(uint numOutputs, uint myIndex, COpenCLMy *open_cl, uint dimension, uint variables, uint lenth, ENUM_OPTIMIZATION optimization_type, uint batch) { if(!CNeuronBaseOCL::Init(numOutputs, myIndex, open_cl, dimension * variables * lenth, optimization_type, batch)) return false;
А в теле метода мы первым делом осуществляем вызов аналогичного метода родительского класса, в котором организован контроль полученных параметров и инициализация унаследованных объектов. Обобщенный результат выполнения операций в теле родительского класса мы можем узнать по возвращаемому логическому значению.
Далее мы сохраним полученные параметры архитектуры объекта в локальные переменные класса.
iDimension = dimension; iVariables = variables; iLenth = lenth;
Объявим вспомогательные переменные и присвоим им необходимые значения.
uint mult = 2; uint weights = (iDimension + 2) * iDimension * iVariables;
Теперь давайте посмотрим на буферы коэффициентов ki и скорректированных исходных данных для их вычисления. Не сложно догадаться, что значения в данных буферах данных сохраняются от прямого прохода до обратного. При последующем прямом проходе значения перезаписываются. Следовательно, для экономии ресурсов мы не будем создавать указанные буферы в памяти основной программы. Создадим их только на стороне OpenCL контекста. А в классе мы создаем лишь массивы для хранения указателей на них. В каждом массиве мы создаем элементов в 3 раза больше, чем используется k коэффициентов. Это необходимо для сбора градиентов ошибки.
if(ArrayResize(iBuffersK, 18) < 18) return false; if(ArrayResize(iInputsK, 18) < 18) return false;
Аналогично мы поступаем с промежуточными значениями вычислений. Только размер массива будет меньше.
if(ArrayResize(iMeadl, 12) < 12) return false;
С целью повышения читабельности кода, буферы мы будем создавать в цикле.
for(uint i = 0; i < 18; i++) { iBuffersK[i] = OpenCL.AddBuffer(sizeof(float) * Output.Total(), CL_MEM_READ_WRITE); if(iBuffersK[i] < 0) return false; iInputsK[i] = OpenCL.AddBuffer(sizeof(float) * Output.Total(), CL_MEM_READ_WRITE); if(iInputsK[i] < 0) return false; if(i > 11) continue; //--- Initilize Meadl Output and Gradient buffers iMeadl[i] = OpenCL.AddBuffer(sizeof(float) * Output.Total(), CL_MEM_READ_WRITE); if(iMeadl[i] < 0) return false; }
Следующим этапом мы создаем матрицы весовых коэффициентов модели функции ОДУ и моментов к ним. Как уже было сказано выше, мы будем использовать 2 слоя.
//--- Initilize Weights for(int i = 0; i < 2; i++) { temp = new CBufferFloat(); if(CheckPointer(temp) == POINTER_INVALID) return false; if(!temp.Reserve(weights)) return false; float k = (float)(1 / sqrt(iDimension + 2)); for(uint w = 0; w < weights; w++) { if(!temp.Add((GenerateWeight() - 0.5f)* k)) return false; } if(!temp.BufferCreate(OpenCL)) return false; if(!cWeights.Add(temp)) return false;
for(uint d = 0; d < 2; d++) { temp = new CBufferFloat(); if(CheckPointer(temp) == POINTER_INVALID) return false; if(!temp.BufferInit(weights, 0)) return false; if(!temp.BufferCreate(OpenCL)) return false; if(!cWeights.Add(temp)) return false; } }
Затем мы создадим буферы константных множителей:
- Шаг времени Alpha
{
float temp_ar[] = {0, 0.2f, 0.3f, 0.8f, 8.0f / 9, 1, 1};
if(!cAlpha.AssignArray(temp_ar))
return false;
if(!cAlpha.BufferCreate(OpenCL))
return false;
}
- Корректировки исходных данных
//--- Beta K1 { float temp_ar[] = {0, 0, 0, 0, 0, 0}; temp = new CBufferFloat(); if(!temp || !temp.AssignArray(temp_ar)) { delete temp; return false; } if(!temp.BufferCreate(OpenCL)) { delete temp; return false; } if(!cBeta.Add(temp)) { delete temp; return false; } }
//--- Beta K2 { float temp_ar[] = {0.2f, 0, 0, 0, 0, 0}; temp = new CBufferFloat(); if(!temp || !temp.AssignArray(temp_ar)) { delete temp; return false; } if(!temp.BufferCreate(OpenCL)) { delete temp; return false; } if(!cBeta.Add(temp)) { delete temp; return false; } }
//--- Beta K3 { float temp_ar[] = {3.0f / 40, 9.0f / 40, 0, 0, 0, 0}; temp = new CBufferFloat(); if(!temp || !temp.AssignArray(temp_ar)) { delete temp; return false; } if(!temp.BufferCreate(OpenCL)) { delete temp; return false; } if(!cBeta.Add(temp)) { delete temp; return false; } }
//--- Beta K4 { float temp_ar[] = {44.0f / 44, -56.0f / 15, 32.0f / 9, 0, 0, 0}; temp = new CBufferFloat(); if(!temp || !temp.AssignArray(temp_ar)) { delete temp; return false; } if(!temp.BufferCreate(OpenCL)) { delete temp; return false; } if(!cBeta.Add(temp)) { delete temp; return false; } }
//--- Beta K5 { float temp_ar[] = {19372.0f / 6561, -25360 / 2187.0f, 64448 / 6561.0f, -212.0f / 729, 0, 0}; temp = new CBufferFloat(); if(!temp || !temp.AssignArray(temp_ar)) { delete temp; return false; } if(!temp.BufferCreate(OpenCL)) { delete temp; return false; } if(!cBeta.Add(temp)) { delete temp; return false; } }
//--- Beta K6 { float temp_ar[] = {9017 / 3168.0f, -355 / 33.0f, 46732 / 5247.0f, 49.0f / 176, -5103.0f / 18656, 0}; temp = new CBufferFloat(); if(!temp || !temp.AssignArray(temp_ar)) { delete temp; return false; } if(!temp.BufferCreate(OpenCL)) { delete temp; return false; } if(!cBeta.Add(temp)) { delete temp; return false; } }
- Решения ОДУ
{
float temp_ar[] = {35.0f / 384, 0, 500.0f / 1113, 125.0f / 192, -2187.0f / 6784, 11.0f / 84};
if(!cSolution.AssignArray(temp_ar))
return false;
if(!cSolution.BufferCreate(OpenCL))
return false;
}
В завершении метода инициализации добавим локальный буфер для записи промежуточных значений.
if(!cTemp.BufferInit(Output.Total(), 0) || !cTemp.BufferCreate(OpenCL)) return false; //--- return true; }
2.6 Организация прямого прохода
После инициализации объекта класса мы переходим к организации алгоритма прямого прохода. Здесь надо напомнить, что выше мы создали 2 кернела на стороне OpenCL программы для организации прямого прохода. Следовательно, нам предстоит создать методы для их вызова. Начнем мы с довольно простого метода CalculateInputK подготовки исходных данных для вычисления k коэффициентов.
bool CNeuronNODEOCL::CalculateInputK(CBufferFloat* inputs, int k) { if(k < 0) return false; if(iInputsK.Size()/3 <= uint(k)) return false;
В параметрах метода мы получаем указатель на буфер исходных данных, полученных от предыдущего слоя и индекс вычисляемого коэффициента. В теле метода мы проверяем соответствие указанного индекса коэффициента нашей архитектуре.
После успешного прохождения контрольного блока мы рассматриваем частный случай для k1.
![]()
В данном случае мы не вызываем выполнения кернела, а просто скопируем указатель на буфер исходных данных.
if(k == 0) { if(iInputsK[k] != inputs.GetIndex()) { OpenCL.BufferFree(iInputsK[k]); iInputsK[k] = inputs.GetIndex(); } return true; }
В общем же случае мы вызовем кернел FeedForwardNODEInpK и запишем скорректированные исходные данные в соответствующий буфер. Для этого мы сначала определим пространство задач. В данном случае одномерное.
uint global_work_offset[1] = {0}; uint global_work_size[1] = {Neurons()};
Передадим указатели на буферы в параметры кернела.
ResetLastError(); if(!OpenCL.SetArgumentBuffer(def_k_FeedForwardNODEInpK, def_k_ffdopriInp_matrix_i, inputs.GetIndex())) { printf("Error of set parameter kernel %s: %d; line %d", __FUNCTION__, GetLastError(), __LINE__); return false; }
if(!OpenCL.SetArgumentBuffer(def_k_FeedForwardNODEInpK, def_k_ffdopriInp_matrix_k1, iBuffersK[0])) { printf("Error of set parameter kernel %s: %d; line %d", __FUNCTION__, GetLastError(), __LINE__); return false; }
if(!OpenCL.SetArgumentBuffer(def_k_FeedForwardNODEInpK, def_k_ffdopriInp_matrix_k2, iBuffersK[1])) { printf("Error of set parameter kernel %s: %d; line %d", __FUNCTION__, GetLastError(), __LINE__); return false; }
if(!OpenCL.SetArgumentBuffer(def_k_FeedForwardNODEInpK, def_k_ffdopriInp_matrix_k3, iBuffersK[2])) { printf("Error of set parameter kernel %s: %d; line %d", __FUNCTION__, GetLastError(), __LINE__); return false; }
if(!OpenCL.SetArgumentBuffer(def_k_FeedForwardNODEInpK, def_k_ffdopriInp_matrix_k4, iBuffersK[3])) { printf("Error of set parameter kernel %s: %d; line %d", __FUNCTION__, GetLastError(), __LINE__); return false; }
if(!OpenCL.SetArgumentBuffer(def_k_FeedForwardNODEInpK, def_k_ffdopriInp_matrix_k5, iBuffersK[4])) { printf("Error of set parameter kernel %s: %d; line %d", __FUNCTION__, GetLastError(), __LINE__); return false; }
if(!OpenCL.SetArgumentBuffer(def_k_FeedForwardNODEInpK, def_k_ffdopriInp_matrix_k6, iBuffersK[5])) { printf("Error of set parameter kernel %s: %d; line %d", __FUNCTION__, GetLastError(), __LINE__); return false; }
if(!OpenCL.SetArgumentBuffer(def_k_FeedForwardNODEInpK, def_k_ffdopriInp_matrix_beta, ((CBufferFloat *)cBeta.At(k)).GetIndex())) { printf("Error of set parameter kernel %s: %d; line %d", __FUNCTION__, GetLastError(), __LINE__); return false; }
if(!OpenCL.SetArgumentBuffer(def_k_FeedForwardNODEInpK, def_k_ffdopriInp_matrix_o, iInputsK[k])) { printf("Error of set parameter kernel %s: %d; line %d", __FUNCTION__, GetLastError(), __LINE__); return false; }
И поставим кернел в очередь выполнения.
if(!OpenCL.Execute(def_k_FeedForwardNODEInpK, 1, global_work_offset, global_work_size)) { printf("Error of execution kernel %s: %d", __FUNCTION__, GetLastError()); return false; } //--- return true; }
После корректировки исходных данных нам предстоит вычислить значение коэффициентов. Этот процесс организован в методе CalculateKBuffer. Так как метод работает только с внутренними объектами, то для выполнения операций в параметрах метода достаточно только указать индекс требуемого коэффициента.
bool CNeuronNODEOCL::CalculateKBuffer(int k) { if(k < 0) return false; if(iInputsK.Size()/3 <= uint(k)) return false;
В теле метода мы проверяем полученный индекс на соответствие архитектуре класса.
Далее мы определяем 3 мерное пространство задач.
uint global_work_offset[3] = {0, 0, 0}; uint global_work_size[3] = {iDimension, iVariables, iLenth};
Затем мы передаем параметры в кернел для прохождения первого слоя. Здесь мы используем LReLU для создания нелинейности.
if(!OpenCL.SetArgumentBuffer(def_k_FeedForwardNODEF, def_k_ffdoprif_matrix_i, iInputsK[k])) { printf("Error of set parameter kernel %s: %d; line %d", __FUNCTION__, GetLastError(), __LINE__); return false; } if(!OpenCL.SetArgumentBuffer(def_k_FeedForwardNODEF, def_k_ffdoprif_matrix_w, ((CBufferFloat*)cWeights.At(0)).GetIndex())) { printf("Error of set parameter kernel %s: %d; line %d", __FUNCTION__, GetLastError(), __LINE__); return false; } if(!OpenCL.SetArgumentBuffer(def_k_FeedForwardNODEF, def_k_ffdoprif_matrix_o, iMeadl[k * 2])) { printf("Error of set parameter kernel %s: %d; line %d", __FUNCTION__, GetLastError(), __LINE__); return false; } if(!OpenCL.SetArgument(def_k_FeedForwardNODEF, def_k_ffdoprif_dimension, int(iDimension))) { printf("Error of set parameter kernel %s: %d; line %d", __FUNCTION__, GetLastError(), __LINE__); return false; } if(!OpenCL.SetArgument(def_k_FeedForwardNODEF, def_k_ffdoprif_step, float(cAlpha.At(k)))) { printf("Error of set parameter kernel %s: %d; line %d", __FUNCTION__, GetLastError(), __LINE__); return false; } if(!OpenCL.SetArgument(def_k_FeedForwardNODEF, def_k_ffdoprif_activation, int(LReLU))) { printf("Error of set parameter kernel %s: %d; line %d", __FUNCTION__, GetLastError(), __LINE__); return false; }
И осуществляем постановку кернела в очередь выполнения.
if(!OpenCL.Execute(def_k_FeedForwardNODEF, 3, global_work_offset, global_work_size)) { printf("Error of execution kernel %s: %d", __FUNCTION__, GetLastError()); return false; }
Следующим шагом мы осуществляем прямой проход второго слоя. Пространство задач остается прежним. Поэтому мы не изменяем соответствующие массивы. Нам необходимо заново передать параметры кернелу. Здесь мы изменяем буфера исходных данных, весовых коэффициентов и результатов.
if(!OpenCL.SetArgumentBuffer(def_k_FeedForwardNODEF, def_k_ffdoprif_matrix_i, iMeadl[k * 2])) { printf("Error of set parameter kernel %s: %d; line %d", __FUNCTION__, GetLastError(), __LINE__); return false; } if(!OpenCL.SetArgumentBuffer(def_k_FeedForwardNODEF, def_k_ffdoprif_matrix_w, ((CBufferFloat*)cWeights.At(3)).GetIndex())) { printf("Error of set parameter kernel %s: %d; line %d", __FUNCTION__, GetLastError(), __LINE__); return false; } if(!OpenCL.SetArgumentBuffer(def_k_FeedForwardNODEF, def_k_ffdoprif_matrix_o, iBuffersK[k])) { printf("Error of set parameter kernel %s: %d; line %d", __FUNCTION__, GetLastError(), __LINE__); return false; }
А также не используем функцию активации.
if(!OpenCL.SetArgument(def_k_FeedForwardNODEF, def_k_ffdoprif_activation, int(None))) { printf("Error of set parameter kernel %s: %d; line %d", __FUNCTION__, GetLastError(), __LINE__); return false; }
Прочие параметры повторяем без изменений.
if(!OpenCL.SetArgument(def_k_FeedForwardNODEF, def_k_ffdoprif_dimension, int(iDimension))) { printf("Error of set parameter kernel %s: %d; line %d", __FUNCTION__, GetLastError(), __LINE__); return false; } if(!OpenCL.SetArgument(def_k_FeedForwardNODEF, def_k_ffdoprif_step, cAlpha.At(k))) { printf("Error of set parameter kernel %s: %d; line %d", __FUNCTION__, GetLastError(), __LINE__); return false; }
И отправляем кернел в очередь выполнения.
if(!OpenCL.Execute(def_k_FeedForwardNODEF, 3, global_work_offset, global_work_size)) { printf("Error of execution kernel %s: %d", __FUNCTION__, GetLastError()); return false; } //-- return true; }
После вычисления всех k коэффициентов мы можем определить результат решения ОДУ. Практически, для этих целей мы будем использовать кернел FeedForwardNODEInpK, вызов которого мы уже реализовали в методе CalculateInputK. Но в данном случае нам предстоит изменить используемые буферы данных. Поэтому мы перепишем алгоритм в методе CalculateOutput.
bool CNeuronNODEOCL::CalculateOutput(CBufferFloat* inputs) { //--- uint global_work_offset[1] = {0}; uint global_work_size[1] = {Neurons()};
В параметрах данного метода мы получаем только указатель на буфер исходных данных. И в теле метода мы сразу определяем одномерное пространство задач. После чего передадим в параметры кернела указатели на буферы исходных данных.
ResetLastError(); if(!OpenCL.SetArgumentBuffer(def_k_FeedForwardNODEInpK, def_k_ffdopriInp_matrix_i, inputs.GetIndex())) { printf("Error of set parameter kernel %s: %d; line %d", __FUNCTION__, GetLastError(), __LINE__); return false; }
if(!OpenCL.SetArgumentBuffer(def_k_FeedForwardNODEInpK, def_k_ffdopriInp_matrix_k1, iBuffersK[0])) { printf("Error of set parameter kernel %s: %d; line %d", __FUNCTION__, GetLastError(), __LINE__); return false; }
if(!OpenCL.SetArgumentBuffer(def_k_FeedForwardNODEInpK, def_k_ffdopriInp_matrix_k2, iBuffersK[1])) { printf("Error of set parameter kernel %s: %d; line %d", __FUNCTION__, GetLastError(), __LINE__); return false; }
if(!OpenCL.SetArgumentBuffer(def_k_FeedForwardNODEInpK, def_k_ffdopriInp_matrix_k3, iBuffersK[2])) { printf("Error of set parameter kernel %s: %d; line %d", __FUNCTION__, GetLastError(), __LINE__); return false; }
if(!OpenCL.SetArgumentBuffer(def_k_FeedForwardNODEInpK, def_k_ffdopriInp_matrix_k4, iBuffersK[3])) { printf("Error of set parameter kernel %s: %d; line %d", __FUNCTION__, GetLastError(), __LINE__); return false; }
if(!OpenCL.SetArgumentBuffer(def_k_FeedForwardNODEInpK, def_k_ffdopriInp_matrix_k5, iBuffersK[4])) { printf("Error of set parameter kernel %s: %d; line %d", __FUNCTION__, GetLastError(), __LINE__); return false; }
if(!OpenCL.SetArgumentBuffer(def_k_FeedForwardNODEInpK, def_k_ffdopriInp_matrix_k6, iBuffersK[5])) { printf("Error of set parameter kernel %s: %d; line %d", __FUNCTION__, GetLastError(), __LINE__); return false; }
В качестве множителей укажем буфер коэффициентов решения ОДУ.
if(!OpenCL.SetArgumentBuffer(def_k_FeedForwardNODEInpK, def_k_ffdopriInp_matrix_beta, cSolution.GetIndex())) { printf("Error of set parameter kernel %s: %d; line %d", __FUNCTION__, GetLastError(), __LINE__); return false; }
А результаты запишем в буфер результатов нашего класса.
if(!OpenCL.SetArgumentBuffer(def_k_FeedForwardNODEInpK, def_k_ffdopriInp_matrix_o, Output.GetIndex())) { printf("Error of set parameter kernel %s: %d; line %d", __FUNCTION__, GetLastError(), __LINE__); return false; }
И поставим кернел в очередь выполнения.
if(!OpenCL.Execute(def_k_FeedForwardNODEInpK, 1, global_work_offset, global_work_size)) { printf("Error of execution kernel %s: %d", __FUNCTION__, GetLastError()); return false; }
Полученные знаяения сложим с исходными данными и нормализуем.
if(!SumAndNormilize(Output, inputs, Output, iDimension, true, 0, 0, 0, 1)) return false; //--- return true; }
Выше мы подготовили методы вызова кернелов организации процесса прямого прохода. Теперь нам остается лишь формализовать алгоритм в верхнеуровневом методе CNeuronNODEOCL::feedForward.
bool CNeuronNODEOCL::feedForward(CNeuronBaseOCL *NeuronOCL) { for(int k = 0; k < 6; k++) { if(!CalculateInputK(NeuronOCL.getOutput(), k)) return false; if(!CalculateKBuffer(k)) return false; } //--- return CalculateOutput(NeuronOCL.getOutput()); }
В параметрах метод получает указатель на объект предыдущего слоя. В теле метода мы организовываем цикл, в котором последовательно корректируем исходные данные и вычисляем все k коэффициенты. При этом на каждой итерации контролируем процесс выполнения операций. И после успешного вычисления необходимых коэффициентов мы вызываем метод решения ОДУ. Благодаря большой подготовительной работе алгоритм верхнеуровнево метода получился довольно лаконичен.
2.7 Организация обратного прохода
Алгоритм прямого прохода обеспечивает нам процесс эксплуатации модели. Однако, обучение модели не отделимо от процесса обратного прохода. Именно здесь осуществляется корректировка обучаемых параметров с целью минимизации ошибки работы модели.
По аналогии с кернелами прямого прохода, на стороне OpenCL программы мы создали 2 кернела обратного прохода. И теперь, на стороне основной программы нам предстоит создать методы, для вызова кернелов обратного прохода. И так как мы организовываем обратный проход, то и работу с методами мы осуществим в последовательности обратного прохода.
При получении градиента ошибки от последующего мы распределяем полученный градиент между слоем исходных данных и k коэффициентами. Этот процесс организован в методе CalculateOutputGradient, который вызывает кернел HiddenGradientNODEInpK.
bool CNeuronNODEOCL::CalculateOutputGradient(CBufferFloat *inputs) { //--- uint global_work_offset[1] = {0}; uint global_work_size[1] = {Neurons()};
В параметрах метода мы получаем указатель на буфер градиентов ошибки предыдущего слоя. А в теле метода мы организовываем процесс вызова кернела программы OpenCL. Вначале определим одномерное пространство задач. После чего передадим указатели на буферы данных параметры кернела.
Обратите внимание, что параметры кернела HiddenGradientNODEInpK полностью повторяют параметры кернела FeedForwardNODEInpK. С той лишь разницей, что при прямом проходе использовались буферы исходных данных и k коэффициентов. А при обратном проходе используются буферы соответсвующих градиентов. По этой причине я не стал переопределять константы буферов кернела, а воспользовался константами прямого прохода.
if(!OpenCL.SetArgumentBuffer(def_k_HiddenGradientNODEInpK, def_k_ffdopriInp_matrix_i, inputs.GetIndex())) { printf("Error of set parameter kernel %s: %d; line %d", __FUNCTION__, GetLastError(), __LINE__); return false; } if(!OpenCL.SetArgumentBuffer(def_k_HiddenGradientNODEInpK, def_k_ffdopriInp_matrix_k1, iBuffersK[6])) { printf("Error of set parameter kernel %s: %d; line %d", __FUNCTION__, GetLastError(), __LINE__); return false; } if(!OpenCL.SetArgumentBuffer(def_k_HiddenGradientNODEInpK, def_k_ffdopriInp_matrix_k2, iBuffersK[7])) { printf("Error of set parameter kernel %s: %d; line %d", __FUNCTION__, GetLastError(), __LINE__); return false; } if(!OpenCL.SetArgumentBuffer(def_k_HiddenGradientNODEInpK, def_k_ffdopriInp_matrix_k3, iBuffersK[8])) { printf("Error of set parameter kernel %s: %d; line %d", __FUNCTION__, GetLastError(), __LINE__); return false; } if(!OpenCL.SetArgumentBuffer(def_k_HiddenGradientNODEInpK, def_k_ffdopriInp_matrix_k4, iBuffersK[9])) { printf("Error of set parameter kernel %s: %d; line %d", __FUNCTION__, GetLastError(), __LINE__); return false; } if(!OpenCL.SetArgumentBuffer(def_k_HiddenGradientNODEInpK, def_k_ffdopriInp_matrix_k5, iBuffersK[10])) { printf("Error of set parameter kernel %s: %d; line %d", __FUNCTION__, GetLastError(), __LINE__); return false; } if(!OpenCL.SetArgumentBuffer(def_k_HiddenGradientNODEInpK, def_k_ffdopriInp_matrix_k6, iBuffersK[11])) { printf("Error of set parameter kernel %s: %d; line %d", __FUNCTION__, GetLastError(), __LINE__); return false; } if(!OpenCL.SetArgumentBuffer(def_k_HiddenGradientNODEInpK, def_k_ffdopriInp_matrix_beta, cSolution.GetIndex())) { printf("Error of set parameter kernel %s: %d; line %d", __FUNCTION__, GetLastError(), __LINE__); return false; } if(!OpenCL.SetArgumentBuffer(def_k_HiddenGradientNODEInpK, def_k_ffdopriInp_matrix_o, Gradient.GetIndex())) { printf("Error of set parameter kernel %s: %d; line %d", __FUNCTION__, GetLastError(), __LINE__); return false; }
И еще один момент, для записи k коэффициентов мы использовали буферы с соответствующим индексом в диапазоне [0, 5]. В данном случае для записи градиентов ошибки мы используем буферы с индексом в диапазоне [6, 11].
После успешной передаче всех параметров кернелу мы осуществляем его постановку в очередь выполнения.
if(!OpenCL.Execute(def_k_HiddenGradientNODEInpK, 1, global_work_offset, global_work_size)) { printf("Error of execution kernel %s: %d", __FUNCTION__, GetLastError()); return false; } //--- return true; }
Далее предлагаю рассмотреть метод CalculateInputKGradient, который вызывает тот же кернел. Но есть нюансы в построении алгоритма, на которые я хотел бы обратить внимание.
Первое, это конечно параметры метода. Здесь добавляется индекс k коэффициента.
bool CNeuronNODEOCL::CalculateInputKGradient(CBufferFloat *inputs, int k) { //--- uint global_work_offset[1] = {0}; uint global_work_size[1] = {Neurons()};
В теле метода мы определяем все то же одномерное пространство задач. После чего передаем параметры кернелу.
ResetLastError(); if(!OpenCL.SetArgumentBuffer(def_k_HiddenGradientNODEInpK, def_k_ffdopriInp_matrix_i, inputs.GetIndex())) { printf("Error of set parameter kernel %s: %d; line %d", __FUNCTION__, GetLastError(), __LINE__); return false; }
Только на этот раз для записи градиентов ошибки k коэффициентов мы используем буферы с индексом в диапазоне [12, 17]. Это связано с необходимостью накопления градиентов ошибки по каждому коэффициенту.
if(!OpenCL.SetArgumentBuffer(def_k_HiddenGradientNODEInpK, def_k_ffdopriInp_matrix_k1, iBuffersK[12])) { printf("Error of set parameter kernel %s: %d; line %d", __FUNCTION__, GetLastError(), __LINE__); return false; } if(!OpenCL.SetArgumentBuffer(def_k_HiddenGradientNODEInpK, def_k_ffdopriInp_matrix_k2, iBuffersK[13])) { printf("Error of set parameter kernel %s: %d; line %d", __FUNCTION__, GetLastError(), __LINE__); return false; } if(!OpenCL.SetArgumentBuffer(def_k_HiddenGradientNODEInpK, def_k_ffdopriInp_matrix_k3, iBuffersK[14])) { printf("Error of set parameter kernel %s: %d; line %d", __FUNCTION__, GetLastError(), __LINE__); return false; } if(!OpenCL.SetArgumentBuffer(def_k_HiddenGradientNODEInpK, def_k_ffdopriInp_matrix_k4, iBuffersK[15])) { printf("Error of set parameter kernel %s: %d; line %d", __FUNCTION__, GetLastError(), __LINE__); return false; } if(!OpenCL.SetArgumentBuffer(def_k_HiddenGradientNODEInpK, def_k_ffdopriInp_matrix_k5, iBuffersK[16])) { printf("Error of set parameter kernel %s: %d; line %d", __FUNCTION__, GetLastError(), __LINE__); return false; } if(!OpenCL.SetArgumentBuffer(def_k_HiddenGradientNODEInpK, def_k_ffdopriInp_matrix_k6, iBuffersK[17])) { printf("Error of set parameter kernel %s: %d; line %d", __FUNCTION__, GetLastError(), __LINE__); return false; }
Кроме того мы используем множители из массива cBeta.
if(!OpenCL.SetArgumentBuffer(def_k_HiddenGradientNODEInpK, def_k_ffdopriInp_matrix_beta, ((CBufferFloat *)cBeta.At(k)).GetIndex())) { printf("Error of set parameter kernel %s: %d; line %d", __FUNCTION__, GetLastError(), __LINE__); return false; } if(!OpenCL.SetArgumentBuffer(def_k_HiddenGradientNODEInpK, def_k_ffdopriInp_matrix_o, iInputsK[k + 6])) { printf("Error of set parameter kernel %s: %d; line %d", __FUNCTION__, GetLastError(), __LINE__); return false; }
После успешной передачи всех необходимых кернелу параметров мы осуществляем его постановку в очередь выполнения.
if(!OpenCL.Execute(def_k_HiddenGradientNODEInpK, 1, global_work_offset, global_work_size)) { printf("Error of execution kernel %s: %d", __FUNCTION__, GetLastError()); return false; }
Далее нам предстоит суммировать текущий градиент ошибки с накопленным ранее по соответствующего k коэффициенту. Для этого мы организуем обратный цикл, в котором будем последовательно складывать градиенты ошибок начиная анализируемого k коэффициента до минимального.
for(int i = k - 1; i >= 0; i--) { float mult = 1.0f / (i == (k - 1) ? 6 - k : 1); uint global_work_offset[1] = {0}; uint global_work_size[1] = {iLenth * iVariables}; if(!OpenCL.SetArgumentBuffer(def_k_MatrixSum, def_k_sum_matrix1, iBuffersK[k + 6])) { printf("Error of set parameter kernel %s: %d; line %d", __FUNCTION__, GetLastError(), __LINE__); return false; } if(!OpenCL.SetArgumentBuffer(def_k_MatrixSum, def_k_sum_matrix2, iBuffersK[k + 12])) { printf("Error of set parameter kernel %s: %d; line %d", __FUNCTION__, GetLastError(), __LINE__); return false; } if(!OpenCL.SetArgumentBuffer(def_k_MatrixSum, def_k_sum_matrix_out, iBuffersK[k + 6])) { printf("Error of set parameter kernel %s: %d; line %d", __FUNCTION__, GetLastError(), __LINE__); return false; } if(!OpenCL.SetArgument(def_k_MatrixSum, def_k_sum_dimension, iDimension)) { printf("Error of set parameter kernel %s: %d; line %d", __FUNCTION__, GetLastError(), __LINE__); return false; } if(!OpenCL.SetArgument(def_k_MatrixSum, def_k_sum_shift_in1, 0)) { printf("Error of set parameter kernel %s: %d; line %d", __FUNCTION__, GetLastError(), __LINE__); return false; } if(!OpenCL.SetArgument(def_k_MatrixSum, def_k_sum_shift_in2, 0)) { printf("Error of set parameter kernel %s: %d; line %d", __FUNCTION__, GetLastError(), __LINE__); return false; } if(!OpenCL.SetArgument(def_k_MatrixSum, def_k_sum_shift_out, 0)) { printf("Error of set parameter kernel %s: %d; line %d", __FUNCTION__, GetLastError(), __LINE__); return false; } if(!OpenCL.SetArgument(def_k_MatrixSum, def_k_sum_multiplyer, mult)) { printf("Error of set parameter kernel %s: %d; line %d", __FUNCTION__, GetLastError(), __LINE__); return false; } if(!OpenCL.Execute(def_k_MatrixSum, 1, global_work_offset, global_work_size)) { string error; CLGetInfoString(OpenCL.GetContext(), CL_ERROR_DESCRIPTION, error); printf("Error of execution kernel %s: %d", __FUNCTION__, GetLastError()); return false; } } //--- return true; }
Обратите внимание, что мы суммируем только градиенты ошибки для k коэффициентов с индексом меньше текущего. Это связано с тем, что ß множитель при коэффициентах с большем индексом очевидно равен "0". Так как такие коэффициенты рассчитываются после текущего и не участвуют в его определении. Соответственно, их градиент ошибки будет нулевым. Кроме того, для более стабильного обучения мы усредняем накопленные градиенты ошибок.
Последний кернел, который участвует в распределении градиента ошибки, является кернел распределения градиента ошибки через внутренний слой функции ОДУ HiddenGradientNODEF. Его вызов осуществляется в методе CalculateKBufferGradient. В параметрах метод получает только индекс k коэффициента, по которому осуществляется распределение градиента.
bool CNeuronNODEOCL::CalculateKBufferGradient(int k) { if(k < 0) return false; if(iInputsK.Size()/3 <= uint(k)) return false;
В теле метода мы проверяем полученный индекс на соответствие архитектуре объекта. После чего определяем 3 мерное пространство задач.
uint global_work_offset[3] = {0, 0, 0}; uint global_work_size[3] = {iDimension, iVariables, iLenth};
И организовываем передачу параметров кернелу. Так как мы осуществляем распределение градиента ошибки в рамках обратного прохода, то сначала мы указываем буферы 2 слоя функции.
ResetLastError(); if(!OpenCL.SetArgumentBuffer(def_k_HiddenGradientNODEF, def_k_hddoprif_matrix_i, iMeadl[k * 2])) { printf("Error of set parameter kernel %s: %d; line %d", __FUNCTION__, GetLastError(), __LINE__); return false; } if(!OpenCL.SetArgumentBuffer(def_k_HiddenGradientNODEF, def_k_hddoprif_matrix_ig, iMeadl[k * 2 + 1])) { printf("Error of set parameter kernel %s: %d; line %d", __FUNCTION__, GetLastError(), __LINE__); return false; } if(!OpenCL.SetArgumentBuffer(def_k_HiddenGradientNODEF, def_k_hddoprif_matrix_w, ((CBufferFloat*)cWeights.At(3)).GetIndex())) { printf("Error of set parameter kernel %s: %d; line %d", __FUNCTION__, GetLastError(), __LINE__); return false; } if(!OpenCL.SetArgumentBuffer(def_k_HiddenGradientNODEF, def_k_hddoprif_matrix_g, iBuffersK[k + 6])) { printf("Error of set parameter kernel %s: %d; line %d", __FUNCTION__, GetLastError(), __LINE__); return false; } if(!OpenCL.SetArgument(def_k_HiddenGradientNODEF, def_k_hddoprif_dimension_out, int(iDimension))) { printf("Error of set parameter kernel %s: %d; line %d", __FUNCTION__, GetLastError(), __LINE__); return false; } if(!OpenCL.SetArgument(def_k_HiddenGradientNODEF, def_k_hddoprif_activation, int(LReLU))) { printf("Error of set parameter kernel %s: %d; line %d", __FUNCTION__, GetLastError(), __LINE__); return false; }
И осуществляем постановку кернела в очередь выполнения.
if(!OpenCL.Execute(def_k_HiddenGradientNODEF, 3, global_work_offset, global_work_size)) { printf("Error of execution kernel %s: %d", __FUNCTION__, GetLastError()); return false; }
Следующим шагом, при неизменности массивов определения пространства задач, мы передаем в параметры кернела данные 1 слоя функции.
if(!OpenCL.SetArgumentBuffer(def_k_HiddenGradientNODEF, def_k_hddoprif_matrix_i, iInputsK[k])) { printf("Error of set parameter kernel %s: %d; line %d", __FUNCTION__, GetLastError(), __LINE__); return false; } if(!OpenCL.SetArgumentBuffer(def_k_HiddenGradientNODEF, def_k_hddoprif_matrix_ig, iInputsK[k + 12])) { printf("Error of set parameter kernel %s: %d; line %d", __FUNCTION__, GetLastError(), __LINE__); return false; } if(!OpenCL.SetArgumentBuffer(def_k_HiddenGradientNODEF, def_k_hddoprif_matrix_w, ((CBufferFloat*)cWeights.At(0)).GetIndex())) { printf("Error of set parameter kernel %s: %d; line %d", __FUNCTION__, GetLastError(), __LINE__); return false; } if(!OpenCL.SetArgumentBuffer(def_k_HiddenGradientNODEF, def_k_hddoprif_matrix_g, iMeadl[k * 2 + 1])) { printf("Error of set parameter kernel %s: %d; line %d", __FUNCTION__, GetLastError(), __LINE__); return false; } if(!OpenCL.SetArgument(def_k_HiddenGradientNODEF, def_k_hddoprif_dimension_out, int(iDimension))) { printf("Error of set parameter kernel %s: %d; line %d", __FUNCTION__, GetLastError(), __LINE__); return false; } if(!OpenCL.SetArgument(def_k_HiddenGradientNODEF, def_k_hddoprif_activation, int(None))) { printf("Error of set parameter kernel %s: %d; line %d", __FUNCTION__, GetLastError(), __LINE__); return false; }
И вызываем выполнение кернела.
if(!OpenCL.Execute(def_k_HiddenGradientNODEF, 3, global_work_offset, global_work_size)) { printf("Error of execution kernel %s: %d", __FUNCTION__, GetLastError()); return false; } //-- return true; }
Выше мы создали методы вызова кернелов распределения градиента ошибки между объектами слоя. Но в таком состоянии это лишь разрозненные куски программы, не составляющие единый алгоритм. И нам предстоит собрать их в единое целое. Общей алгоритм распределения градиента ошибки внутри нашего класса мы организуем с помощью метода calcInputGradients.
bool CNeuronNODEOCL::calcInputGradients(CNeuronBaseOCL *prevLayer) { if(!CalculateOutputGradient(prevLayer.getGradient())) return false; for(int k = 5; k >= 0; k--) { if(!CalculateKBufferGradient(k)) return false; if(!CalculateInputKGradient(GetPointer(cTemp), k)) return false; if(!SumAndNormilize(prevLayer.getGradient(), GetPointer(cTemp), prevLayer.getOutput(), iDimension, false, 0, 0, 0, 1.0f / (k == 0 ? 6 : 1))) return false; } //--- return true; }
В параметрах метод получает указатель на объект предыдущего слоя, в который нам предстоит передать градиент ошибки. На первом этапе мы распределяем полученный от последующего слоя градиент ошибки между предыдущим слоем и k коэффициентами согласно множителям решения ОДУ. Как Вы помните, этот процесс мы организовали в методе CalculateOutputGradient.
Затем мы организовываем обратный цикл распределения градиентов через функцию ОДУ при вычислении соответствующих коэффициентов. Тут мы сначала проводим градиент ошибки через наши 2 слоя в методе CalculateKBufferGradient. Затем распределяем полученный градиент ошибки между соответствующими k коэффициентами и исходными данными в методе CalculateInputKGradient. Только вместо буфера градиентов ошибки предыдущего слоя мы получаем данные во временный буфер. А затем прибавляем полученный градиент к ранее накопленному в буфере градиентов предыдущего слоя с помощью метода SumAndNormilize. При этом на последней итерации усредняем накопленный градиент ошибки.
На данном этапе мы полностью распределили градиент ошибки между всеми объектами, влияющими на получения результата в соответствии с их вкладом. И нам остается лишь обновить параметры модели. Ранее, для выполнения этого функционала мы создали кернел NODEF_UpdateWeightsAdam. И теперь нам предстоит организовать вызов указанного кернела на стороне основной программы. Данный функционал выполняется в методе updateInputWeights.
bool CNeuronNODEOCL::updateInputWeights(CNeuronBaseOCL *NeuronOCL) { uint global_work_offset[3] = {0, 0, 0}; uint global_work_size[3] = {iDimension + 2, iDimension, iVariables};
В параметрах метод получает указатель на объект предыдущего нейронного слоя, который в данном случае является номинальным и необходим только для процедуры виртуализации методов.
Действительно, в процессе прямого и обратного проходов мы использовали данные предыдущего слоя. И для обновления параметров первого слоя функции ОДУ они будут нужны. Но ситуация такова, что указатель на буфер результатов предыдущего слоя при прямом проходе мы сохранили в массиве iInputsK с индексом "0". Им мы и воспользуемся в нашей реализации.
В теле метода мы сначала определяем 3 мерное пространство задач. А затем передаем необходимые кернелу параметры. Сначала мы осуществим обновления параметров 1 слоя.
if(!OpenCL.SetArgumentBuffer(def_k_NODEF_UpdateWeightsAdam, def_k_uwdoprif_matrix_ik1, iInputsK[0])) { printf("Error of set parameter kernel %s: %d; line %d", __FUNCTION__, GetLastError(), __LINE__); return false; } if(!OpenCL.SetArgumentBuffer(def_k_NODEF_UpdateWeightsAdam, def_k_uwdoprif_matrix_gk1, iMeadl[1])) { printf("Error of set parameter kernel %s: %d; line %d", __FUNCTION__, GetLastError(), __LINE__); return false; }
if(!OpenCL.SetArgumentBuffer(def_k_NODEF_UpdateWeightsAdam, def_k_uwdoprif_matrix_ik2, iInputsK[1])) { printf("Error of set parameter kernel %s: %d; line %d", __FUNCTION__, GetLastError(), __LINE__); return false; } if(!OpenCL.SetArgumentBuffer(def_k_NODEF_UpdateWeightsAdam, def_k_uwdoprif_matrix_gk2, iMeadl[3])) { printf("Error of set parameter kernel %s: %d; line %d", __FUNCTION__, GetLastError(), __LINE__); return false; }
if(!OpenCL.SetArgumentBuffer(def_k_NODEF_UpdateWeightsAdam, def_k_uwdoprif_matrix_ik3, iInputsK[2])) { printf("Error of set parameter kernel %s: %d; line %d", __FUNCTION__, GetLastError(), __LINE__); return false; } if(!OpenCL.SetArgumentBuffer(def_k_NODEF_UpdateWeightsAdam, def_k_uwdoprif_matrix_gk3, iMeadl[5])) { printf("Error of set parameter kernel %s: %d; line %d", __FUNCTION__, GetLastError(), __LINE__); return false; }
if(!OpenCL.SetArgumentBuffer(def_k_NODEF_UpdateWeightsAdam, def_k_uwdoprif_matrix_ik4, iInputsK[3])) { printf("Error of set parameter kernel %s: %d; line %d", __FUNCTION__, GetLastError(), __LINE__); return false; } if(!OpenCL.SetArgumentBuffer(def_k_NODEF_UpdateWeightsAdam, def_k_uwdoprif_matrix_gk4, iMeadl[7])) { printf("Error of set parameter kernel %s: %d; line %d", __FUNCTION__, GetLastError(), __LINE__); return false; }
if(!OpenCL.SetArgumentBuffer(def_k_NODEF_UpdateWeightsAdam, def_k_uwdoprif_matrix_ik5, iInputsK[4])) { printf("Error of set parameter kernel %s: %d; line %d", __FUNCTION__, GetLastError(), __LINE__); return false; } if(!OpenCL.SetArgumentBuffer(def_k_NODEF_UpdateWeightsAdam, def_k_uwdoprif_matrix_gk5, iMeadl[9])) { printf("Error of set parameter kernel %s: %d; line %d", __FUNCTION__, GetLastError(), __LINE__); return false; }
if(!OpenCL.SetArgumentBuffer(def_k_NODEF_UpdateWeightsAdam, def_k_uwdoprif_matrix_ik6, iInputsK[5])) { printf("Error of set parameter kernel %s: %d; line %d", __FUNCTION__, GetLastError(), __LINE__); return false; } if(!OpenCL.SetArgumentBuffer(def_k_NODEF_UpdateWeightsAdam, def_k_uwdoprif_matrix_gk6, iMeadl[11])) { printf("Error of set parameter kernel %s: %d; line %d", __FUNCTION__, GetLastError(), __LINE__); return false; }
if(!OpenCL.SetArgumentBuffer(def_k_NODEF_UpdateWeightsAdam, def_k_uwdoprif_matrix_w, ((CBufferFloat*)cWeights.At(0)).GetIndex())) { printf("Error of set parameter kernel %s: %d; line %d", __FUNCTION__, GetLastError(), __LINE__); return false; } if(!OpenCL.SetArgumentBuffer(def_k_NODEF_UpdateWeightsAdam, def_k_uwdoprif_matrix_m, ((CBufferFloat*)cWeights.At(1)).GetIndex())) { printf("Error of set parameter kernel %s: %d; line %d", __FUNCTION__, GetLastError(), __LINE__); return false; } if(!OpenCL.SetArgumentBuffer(def_k_NODEF_UpdateWeightsAdam, def_k_uwdoprif_matrix_v, ((CBufferFloat*)cWeights.At(2)).GetIndex())) { printf("Error of set parameter kernel %s: %d; line %d", __FUNCTION__, GetLastError(), __LINE__); return false; }
if(!OpenCL.SetArgumentBuffer(def_k_NODEF_UpdateWeightsAdam, def_k_uwdoprif_alpha, cAlpha.GetIndex())) { printf("Error of set parameter kernel %s: %d; line %d", __FUNCTION__, GetLastError(), __LINE__); return false; } if(!OpenCL.SetArgument(def_k_NODEF_UpdateWeightsAdam, def_k_uwdoprif_lenth, int(iLenth))) { printf("Error of set parameter kernel %s: %d; line %d", __FUNCTION__, GetLastError(), __LINE__); return false; }
if(!OpenCL.SetArgument(def_k_NODEF_UpdateWeightsAdam, def_k_uwdoprif_l, lr)) { printf("Error of set parameter kernel %s: %d; line %d", __FUNCTION__, GetLastError(), __LINE__); return false; } if(!OpenCL.SetArgument(def_k_NODEF_UpdateWeightsAdam, def_k_uwdoprif_b1, b1)) { printf("Error of set parameter kernel %s: %d; line %d", __FUNCTION__, GetLastError(), __LINE__); return false; } if(!OpenCL.SetArgument(def_k_NODEF_UpdateWeightsAdam, def_k_uwdoprif_b2, b2)) { printf("Error of set parameter kernel %s: %d; line %d", __FUNCTION__, GetLastError(), __LINE__); return false; }
И поставим кернел в очередь выполнения.
if(!OpenCL.Execute(def_k_NODEF_UpdateWeightsAdam, 3, global_work_offset, global_work_size)) { printf("Error of execution kernel %s: %d", __FUNCTION__, GetLastError()); return false; }
Затем повторим операции для организации процесса обновления параметров 2 слоя.
if(!OpenCL.SetArgumentBuffer(def_k_NODEF_UpdateWeightsAdam, def_k_uwdoprif_matrix_ik1, iMeadl[0])) { printf("Error of set parameter kernel %s: %d; line %d", __FUNCTION__, GetLastError(), __LINE__); return false; } if(!OpenCL.SetArgumentBuffer(def_k_NODEF_UpdateWeightsAdam, def_k_uwdoprif_matrix_gk1, iBuffersK[6])) { printf("Error of set parameter kernel %s: %d; line %d", __FUNCTION__, GetLastError(), __LINE__); return false; } if(!OpenCL.SetArgumentBuffer(def_k_NODEF_UpdateWeightsAdam, def_k_uwdoprif_matrix_ik2, iMeadl[2])) { printf("Error of set parameter kernel %s: %d; line %d", __FUNCTION__, GetLastError(), __LINE__); return false; } if(!OpenCL.SetArgumentBuffer(def_k_NODEF_UpdateWeightsAdam, def_k_uwdoprif_matrix_gk2, iBuffersK[7])) { printf("Error of set parameter kernel %s: %d; line %d", __FUNCTION__, GetLastError(), __LINE__); return false; } if(!OpenCL.SetArgumentBuffer(def_k_NODEF_UpdateWeightsAdam, def_k_uwdoprif_matrix_ik3, iMeadl[4])) { printf("Error of set parameter kernel %s: %d; line %d", __FUNCTION__, GetLastError(), __LINE__); return false; } if(!OpenCL.SetArgumentBuffer(def_k_NODEF_UpdateWeightsAdam, def_k_uwdoprif_matrix_gk3, iBuffersK[8])) { printf("Error of set parameter kernel %s: %d; line %d", __FUNCTION__, GetLastError(), __LINE__); return false; } if(!OpenCL.SetArgumentBuffer(def_k_NODEF_UpdateWeightsAdam, def_k_uwdoprif_matrix_ik4, iMeadl[6])) { printf("Error of set parameter kernel %s: %d; line %d", __FUNCTION__, GetLastError(), __LINE__); return false; } if(!OpenCL.SetArgumentBuffer(def_k_NODEF_UpdateWeightsAdam, def_k_uwdoprif_matrix_gk4, iBuffersK[9])) { printf("Error of set parameter kernel %s: %d; line %d", __FUNCTION__, GetLastError(), __LINE__); return false; } if(!OpenCL.SetArgumentBuffer(def_k_NODEF_UpdateWeightsAdam, def_k_uwdoprif_matrix_ik5, iMeadl[8])) { printf("Error of set parameter kernel %s: %d; line %d", __FUNCTION__, GetLastError(), __LINE__); return false; } if(!OpenCL.SetArgumentBuffer(def_k_NODEF_UpdateWeightsAdam, def_k_uwdoprif_matrix_gk5, iBuffersK[10])) { printf("Error of set parameter kernel %s: %d; line %d", __FUNCTION__, GetLastError(), __LINE__); return false; } if(!OpenCL.SetArgumentBuffer(def_k_NODEF_UpdateWeightsAdam, def_k_uwdoprif_matrix_ik6, iMeadl[10])) { printf("Error of set parameter kernel %s: %d; line %d", __FUNCTION__, GetLastError(), __LINE__); return false; } if(!OpenCL.SetArgumentBuffer(def_k_NODEF_UpdateWeightsAdam, def_k_uwdoprif_matrix_gk6, iBuffersK[11])) { printf("Error of set parameter kernel %s: %d; line %d", __FUNCTION__, GetLastError(), __LINE__); return false; } if(!OpenCL.SetArgumentBuffer(def_k_NODEF_UpdateWeightsAdam, def_k_uwdoprif_matrix_w, ((CBufferFloat*)cWeights.At(3)).GetIndex())) { printf("Error of set parameter kernel %s: %d; line %d", __FUNCTION__, GetLastError(), __LINE__); return false; } if(!OpenCL.SetArgumentBuffer(def_k_NODEF_UpdateWeightsAdam, def_k_uwdoprif_matrix_m, ((CBufferFloat*)cWeights.At(4)).GetIndex())) { printf("Error of set parameter kernel %s: %d; line %d", __FUNCTION__, GetLastError(), __LINE__); return false; } if(!OpenCL.SetArgumentBuffer(def_k_NODEF_UpdateWeightsAdam, def_k_uwdoprif_matrix_v, ((CBufferFloat*)cWeights.At(5)).GetIndex())) { printf("Error of set parameter kernel %s: %d; line %d", __FUNCTION__, GetLastError(), __LINE__); return false; } if(!OpenCL.SetArgumentBuffer(def_k_NODEF_UpdateWeightsAdam, def_k_uwdoprif_alpha, cAlpha.GetIndex())) { printf("Error of set parameter kernel %s: %d; line %d", __FUNCTION__, GetLastError(), __LINE__); return false; } if(!OpenCL.SetArgument(def_k_NODEF_UpdateWeightsAdam, def_k_uwdoprif_lenth, int(iLenth))) { printf("Error of set parameter kernel %s: %d; line %d", __FUNCTION__, GetLastError(), __LINE__); return false; } if(!OpenCL.SetArgument(def_k_NODEF_UpdateWeightsAdam, def_k_uwdoprif_l, lr)) { printf("Error of set parameter kernel %s: %d; line %d", __FUNCTION__, GetLastError(), __LINE__); return false; } if(!OpenCL.SetArgument(def_k_NODEF_UpdateWeightsAdam, def_k_uwdoprif_b1, b1)) { printf("Error of set parameter kernel %s: %d; line %d", __FUNCTION__, GetLastError(), __LINE__); return false; } if(!OpenCL.SetArgument(def_k_NODEF_UpdateWeightsAdam, def_k_uwdoprif_b2, b2)) { printf("Error of set parameter kernel %s: %d; line %d", __FUNCTION__, GetLastError(), __LINE__); return false; } if(!OpenCL.Execute(def_k_NODEF_UpdateWeightsAdam, 3, global_work_offset, global_work_size)) { printf("Error of execution kernel %s: %d", __FUNCTION__, GetLastError()); return false; } //-- return true; }
2.8 Методы работы с файлами
Выше мы рассмотрели методы организации основного процесса в классе. Однако, хотелось пару слов сказать о методах работы с файлами. Если внимательно посмотреть на структуру внутренних объектов класса, то можно выделить для сохранения только коллекцию cWeights, содержащую весовые коэффициенты моменты их корректировки. А также 3 параметра, определяющие архитектуру класса. Их мы и сохраним в методе Save.
bool CNeuronNODEOCL::Save(const int file_handle) { if(!CNeuronBaseOCL::Save(file_handle)) return false; if(!cWeights.Save(file_handle)) return false; if(FileWriteInteger(file_handle, int(iDimension), INT_VALUE) < INT_VALUE || FileWriteInteger(file_handle, int(iVariables), INT_VALUE) < INT_VALUE || FileWriteInteger(file_handle, int(iLenth), INT_VALUE) < INT_VALUE) return false; //--- return true; }
В параметрах метод получает хендл файла для сохранения данных. И сразу в теле метода мы вызываем одноименный метод родительского класса. Затем мы сохраним коллекцию и константы.
Метод сохранения класса довольно краток и позволяет сохранить максимум дискового пространства. Однако, за экономию приходится платить в методе загрузки данных.
bool CNeuronNODEOCL::Load(const int file_handle) { if(!CNeuronBaseOCL::Load(file_handle)) return false; if(!cWeights.Load(file_handle)) return false; cWeights.SetOpenCL(OpenCL); //--- iDimension = (int)FileReadInteger(file_handle); iVariables = (int)FileReadInteger(file_handle); iLenth = (int)FileReadInteger(file_handle);
Здесь мы сначала загружаем сохраненные данные. А затем организовываем процесс создания недостающих объектов в соответствии с загруженными параметрами архитектуры объекта.
//--- CBufferFloat *temp = NULL; for(uint i = 0; i < 18; i++) { OpenCL.BufferFree(iBuffersK[i]); OpenCL.BufferFree(iInputsK[i]); //--- iBuffersK[i] = OpenCL.AddBuffer(sizeof(float) * Output.Total(), CL_MEM_READ_WRITE); if(iBuffersK[i] < 0) return false; iInputsK[i] = OpenCL.AddBuffer(sizeof(float) * Output.Total(), CL_MEM_READ_WRITE); if(iBuffersK[i] < 0) return false; if(i > 11) continue; //--- Initilize Output and Gradient buffers OpenCL.BufferFree(iMeadl[i]); iMeadl[i] = OpenCL.AddBuffer(sizeof(float) * Output.Total(), CL_MEM_READ_WRITE); if(iMeadl[i] < 0) return false; } //--- cTemp.BufferFree(); if(!cTemp.BufferInit(Output.Total(), 0) || !cTemp.BufferCreate(OpenCL)) return false; //--- return true; }
На этом мы завершаем рассмотрение методов нашего нового класса CNeuronNODEOCL. А с полным кодом созданного класса и его методов, как и со всеми программами, используемыми при подготовке статьи, Вы можете самостоятельно ознакомиться во вложении.
2.9 Архитектура обучаемых моделей
Выше мы создали новый класс нейронного слоя на основе решения ОДУ CNeuronNODEOCL. Объект данного класса мы добавим в архитектуру Энкодера, созданного в предыдущей статье.
Как всегда, архитектура моделей указана в методе CreateDescriptions, в параметрах которого передаются указатели на 3 динамических массива для указания архитектуры создаваемых моделей.
bool CreateDescriptions(CArrayObj *encoder, CArrayObj *actor, CArrayObj *critic) { //--- CLayerDescription *descr; //--- if(!encoder) { encoder = new CArrayObj(); if(!encoder) return false; } if(!actor) { actor = new CArrayObj(); if(!actor) return false; } if(!critic) { critic = new CArrayObj(); if(!critic) return false; }
В теле метода мы проверяем полученные указатели и, при необходимости, создаем новые объекты массивов.
На вход модели Энкодера мы подаем "сырые" данные описания состояния окружающей среды.
//--- Encoder encoder.Clear(); //--- Input layer if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBaseOCL; int prev_count = descr.count = (HistoryBars * BarDescr); descr.activation = None; descr.optimization = ADAM; if(!encoder.Add(descr)) { delete descr; return false; }
Полученные данные проходят первичную обработку в слое пакетной нормализации.
//--- layer 1 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBatchNormOCL; descr.count = prev_count; descr.batch = MathMax(1000, GPTBars); descr.activation = None; descr.optimization = ADAM; if(!encoder.Add(descr)) { delete descr; return false; }
Далее мы генерируем эмбединги полученных состояний с помощью слоя Эмбединга и последующего сверточного слоя.
//--- layer 2 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronEmbeddingOCL; { int temp[] = {prev_count}; ArrayCopy(descr.windows, temp); } prev_count = descr.count = GPTBars; int prev_wout = descr.window_out = EmbeddingSize / 2; if(!encoder.Add(descr)) { delete descr; return false; } //--- layer 3 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronConvOCL; descr.count = prev_count; descr.step = descr.window = prev_wout; prev_wout = descr.window_out = EmbeddingSize; if(!encoder.Add(descr)) { delete descr; return false; }
Сгенерированные эмбединги дополняются позиционным кодированием.
//--- layer 4 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronPEOCL; descr.count = prev_count; descr.window = prev_wout; if(!encoder.Add(descr)) { delete descr; return false; }
А затем мы используем комплексный слой анализа данных с учетом контекста.
//--- layer 5 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronCCMROCL; descr.count = prev_count; descr.window = prev_wout; descr.window_out = EmbeddingSize; if(!encoder.Add(descr)) { delete descr; return false; }
До этого момента мы полностью повторили модель из предыдущей статьи. Но далее мы добавим 2 слоя нового класса.
//--- layer 6 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronNODEOCL; descr.count = prev_count; descr.window = EmbeddingSize/4; descr.step = 4; if(!encoder.Add(descr)) { delete descr; return false; } //--- layer 7 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronNODEOCL; descr.count = prev_count; descr.window = EmbeddingSize/4; descr.step = 4; if(!encoder.Add(descr)) { delete descr; return false; }
Модели Актера и Критика полностью перенесены из предыдущей статьи без изменений. Поэтому мы не будем сейчас останавливаться на их рассмотрении.
Добавление новых слоев не отражается на процессах взаимодействия с окружающей средой и обучением моделей. Следовательно, все советники перенесены без изменений. С полным кодом всех программ, используемых при подготовке статьи Вы можете ознакомиться во вложении. А мы переходим к следующему этапу — тестированию проделанной работы.
3. Тестирование
Выше мы познакомились с новым семейством моделей обыкновенных дифференциальных уравнений. И с учетом предложенных подходов мы реализовали средствами MQL5 новый класс CNeuronNODEOCL для организации нейронного слоя в наших моделях. И сейчас мы переходим к 3 этапу нашей работы: обучение и тестирование моделей на реальных данных в тестере стратегий MetaTrader 5.
Как и все ранее созданные модели, обучение и тестирование осуществляется на исторических данных инструмента EURUSD тайм-фрейм H1. Мы осуществляли офлайн обучение моделей. Для этого была собрана обучающая выборка из различных 500 траекторий на исторических данных за первые 7 месяцев 2023 года. Надо сказать, что большая часть траекторий была собрана случайными проходами. При этом доля прибыльных проходов довольно мала. С целью выравнивания средней доходности проходов в процессе обучения мы используем сэмплированиие траекторий с приоритезацией на их результат. Это позволяет прибыльным проходом присвоить больший вес. А вместе с тем и вероятность их выбора.
Тестирование обученных моделей осуществлялось в тестере стратегий на исторических данных Августа 2023 года с сохранением инструмента и тайм-фрейма.Такой подход дает возможность оценить работу обученной модели на новых данных (не входящих в обучающую выборку) с максимальным сохранением статистических показателей обучающей и тестовой выборок.
Результаты тестирования продемонстрировали возможность подхода к обучению стратегий, генерирующих прибыль как на обучающем, так и на тестовом временном отрезке. Скриншоты тестов представлены ниже.


По результатам тестов за Август 2023 года обученная модель совершила 160 сделок, 84 из которых закрылись с прибылью. Что составляет 52.5%. Можно сказать, что паритет сделок немного склонился в сторону прибыли. Средняя прибыльная сделка чуть более 4% превышает среднюю убыточную. Средняя серия прибыльных сделок равна средней серии убыточных. Максимальная прибыльная серия по количеству сделок равна максимальной убыточной серии по данному параметру. Однако, максимальная прибыльная сделка и максимальная прибыльная серия по сумме превышают аналогичные показатели убыточных сделок. В результате, за период тестирования модель показала профит-фактор на уровне 1.15 с коэффициентом Шарпа 2.14.
Заключение
В данной статье мы познакомились с новым классом моделей обыкновенных дифференциальных уравнений (ОДУ — ODE). Использование ODE как компонентов моделей машинного обучения обладает рядом преимуществ и потенциалов. Они позволяют моделировать динамические процессы и изменения в данных, что особенно важно для задач, связанных с временными рядами, динамикой систем и прогнозированием. Нейронные ОДУ могут быть успешно интегрированы в различные архитектуры нейронных сетей, включая глубокие и рекуррентные модели, что расширяет область применения этих методов.
В практической части нашей статьи мы реализовали предложенные подходы средствами MQL5. Обучили и протестировали модель на реальных данных в тестере стратегий MetaTrader 5. Результаты тестирования представлены выше. Они позволяют судить об эффективности предложенных подходов для решения наших задач.
Тем не менее, напоминаю, что все программы, представленный в данной статье носят информативный характер и предназначены только для демонстрации и проверки предложенных подходов.
Ссылки
Программы, используемые в статье
| # | Имя | Тип | Описание |
|---|---|---|---|
| 1 | Research.mq5 | Советник | Советник сбора примеров |
| 2 | ResearchRealORL.mq5 | Советник | Советник сбора примеров методом Real-ORL |
| 3 | Study.mq5 | Советник | Советник обучения Моделей |
| 4 | Test.mq5 | Советник | Советник для тестирования модели |
| 5 | Trajectory.mqh | Библиотека класса | Структура описания состояния системы |
| 6 | NeuroNet.mqh | Библиотека класса | Библиотека классов для создания нейронной сети |
| 7 | NeuroNet.cl | Библиотека | Библиотека кода программы OpenCL |
 Создаем простой мультивалютный советник с использованием MQL5 (Часть 4): Треугольная скользящая средняя — Сигналы индикатора
Создаем простой мультивалютный советник с использованием MQL5 (Часть 4): Треугольная скользящая средняя — Сигналы индикатора
- Бесплатные приложения для трейдинга
- 8 000+ сигналов для копирования
- Экономические новости для анализа финансовых рынков
Вы принимаете политику сайта и условия использования