
Нейросети — это просто (Часть 50): Soft Actor-Critic (оптимизация модели)

Введение
Продолжаем изучение алгоритма Soft Actor-Critic. В предыдущей статье мы реализовали данный алгоритм, но, к сожалению, не смогли обучить прибыльную модель. Сегодня мы поговорим о вариантах решения этой проблемы. Подобный вопрос уже поднимался в статье "Прокрастинация модели, причины и методы решения". Я предлагаю расширить наши знания в данной области и рассмотреть новые подходы на примере нашей модели Soft Actor-Critic.
1. Оптимизация модели
И прежде, чем перейти непосредственно к оптимизации построенной нами модели напомню, что Soft Actor-Critic является алгоритмом обучения с подкреплением стохастических моделей в непрерывном пространстве действий. Основной особенностью данного метода является введение энтропийной составляющей в функцию вознаграждения.
Использование стохастической политики Актера позволяет модели быть более гибкой и способной решать задачи в сложных средах, где некоторые действия могут быть неопределенными или невозможными к определению четких правил. Такая политика часто более устойчива в работе с данными, содержащими большое количество шума. Так как учитывает вероятностную составляющую, а не привязана к четким правилам.
Добавление энтропийной составляющей поощряет исследование окружающей среды, увеличивая вознаграждение действий с низкой вероятностью. Баланс между исследованием и эксплуатацией регулируется коэффициентом температуры.
В математическом виде метод Soft Actor-Critic можно представить следующей формулой.

1.1 Добавляем стохастичность политики Актера
В своей реализации мы отказались от использования стохастической политики Актера ввиду сложности её реализации средствами OpenCL. По аналогии с TD3, мы заменили её случайным смещение выбранного действия в некоторых его окрестностях. Такой подход проще в реализации и позволяет модели исследовать окружающую среду. Но он также имеет и минусы.,
Первое, что обращает внимание это отсутствие связи между семплированым действием и выученным моделью распределением. В одних случаях, когда выученное распределение шире области семплмрования, это сжимает область исследования. Значит политика модели с большой вероятностью не будет оптимальной, а зависит от случайно выбранной начальной точки обучения. Ведь при инициализации новой модели мы её заполняем случайными весами.
В других случаях, семплированное действие может выходить за рамки выученного распределения. Это расширяет область исследований, но входит в противоречие с энтропийной составляющей функции вознаграждения. Действие вне выученного распределения с точки зрения модели имеет нулевую вероятность. И получит максимальное вознаграждение вне зависимости от его ценности, благодаря энтропийной составляющей.
В процессе обучения модель стремится найти прибыльную стратегию и повышает вероятность действий с максимальным вознаграждением. В то же время, вероятность менее доходных и убыточных действий снижается. Простое семплирование, которое мы использовали ранее, не учитывает этот фактор. И с одинаковой долей вероятности выдаст нам любое действие из области семплирования. Низкая вероятность убыточных действий генерирует высокую энтропийную составляющую. Это искажает истинную ценность действий, нивелирует ранее накопленный опыт и ведет к построению некорректной политики Актера.
Решение здесь только одно — построение стохастической модели актера и семплироавние действий из выученного распределения.
Мы уже говорили об отсутствии генератора псевдослучайных чисел на стороне контекста OpenCL, поэтому воспользуемся генератором на стороне основной программы.
В то же время мы помним о наличии выученного распределения только на стороне OpenCL. Он содержится во внутренних объектах нашей модели. Следовательно, для организации процесса семплированиия нам предстоит организовать передачу данных между основной программой и контекстом OpenCL. И это не зависит от того, где будет организован процесс.
При организации процесса на стороне основной программы нам необходимо загрузить распределение. А это 2 буфера: вероятностей и соответствующих значений функции.
При организации процесса на стороне OpenCL контекста, нам предстоит передать буфер случайных значений. Который в последствии будет использован для выбора отдельного действия.
Здесь следует учесть ещё один момент — потребителя полученных значений. В процессе эксплуатации мы будем использовать сэмплированные значения для совершения действий. То есть на стороне основной программы. А вот в процессе обучения мы будем передавать их Критику на стороне OpenCL контекста. Как известно, наибольшие требования по сокращению времени на совершение операций именно в процессе обучения модели. И в этом свете вполне логично выглядит решение в передаче только одного буфера случайных значений в контекст OpenCL и организация там дальнейшего процесса сэмлирования.
Решение принято, приступаем к реализации. Вначале мы модифицируем кернел SAC_AlphaLogProbs OpenCL программы. Надо сказать, что наши изменения даже упростят алгоритм указанного кернела в какой-то мере.
Во внешних параметрах кернела мы добавляем один буфер случайных значений. Для организации процесса сэмплирования в данном буфере мы ожидаем получить набор случайных значений в диапазоне [0, 1].
__kernel void SAC_AlphaLogProbs(__global float *outputs, __global float *quantiles, __global float *probs, __global float *alphas, __global float *log_probs, __global float *random, const int count_quants, const int activation ) { const int i = get_global_id(0); int shift = i * count_quants; float prob = 0; float value = 0; float sum = 0; float rnd = random[i];
Для выбора действия мы организуем цикл перебора вероятностей всех квантилей анализируемого действия с подсчетам их накопительной суммы. В теле цикла одновременно с подсчетом накопительной суммы мы проверяем её текущее значение с полученным случайным значением. И как только она превысит это значение, мы используем текущий квантиль в качестве выбранного действия прерываем выполнение итераций цикла.
for(int r = 0; r < count_quants; r++) { prob = probs[shift + r]; sum += prob; if(sum >= rnd || r == (count_quants - 1)) { value = quantiles[shift + r]; break; } }
Теперь нам не нужно искать пару ближайших квантилей, как мы это делали ранее. У нас один выбранный квантиль с известной вероятность. Нам остается только активировать полученное значение и посчитать значение энтропийной составляющей.
switch(activation) { case 0: outputs[i] = tanh(value); break; case 1: outputs[i] = 1 / (1 + exp(-value)); break; case 2: if(value < 0) outputs[i] = value * 0.01f; else outputs[i] = value; break; default: outputs[i] = value; break; } log_probs[i] = -alphas[i] * log(prob); }
После внесения изменений в кернел, мы дополним код основной программы. И начнем мы с внесения изменений в класс CNeuronSoftActorCritic. Здесь мы добавляем буфер для случайных значений. Его инициализация происходит в методе Init аналогично буферу cLogProbs и мы не буем на этом останавливаться. Сохранять его нет необходимости, так как при каждом прямом проходе он заполняется заново. Следовательно, в методы работы с файлами мы не корректируем.
class CNeuronSoftActorCritic : public CNeuronFQF { protected: .......... .......... CBufferFloat cRandomize; .......... .......... };
Обратимся к методу прямого прохода CNeuronSoftActorCritic::feedForward. Здесь после прямого прохода родительского класса и внутреннего слоя cAlphas мы организовываем цикл по числу действий и заполним буфер cRandomize случайными значениями.
bool CNeuronSoftActorCritic::feedForward(CNeuronBaseOCL *NeuronOCL) { if(!CNeuronFQF::feedForward(NeuronOCL)) return false; if(!cAlphas.FeedForward(GetPointer(cQuantile0), cQuantile2.getOutput())) return false; //--- int actions = cRandomize.Total(); for(int i = 0; i < actions; i++) { float probability = (float)MathRand() / 32767.0f; cRandomize.Update(i, probability); } if(!cRandomize.BufferWrite()) return false;
Данные заполненного буфера мы переносим в память контекста OpenCL.
Далее у нас организован процесс постановки кернела в очередь выполнения. Здесь нам необходимо сделать передачу в добавленных в кернел параметров.
uint global_work_offset[1] = {0}; uint global_work_size[1] = {Neurons()}; if(!OpenCL.SetArgumentBuffer(def_k_SAC_AlphaLogProbs, def_k_sac_alp_alphas, cAlphas.getOutputIndex())) { printf("Error of set parameter kernel %s: %d; line %d", __FUNCTION__, GetLastError(), __LINE__); return false; } if(!OpenCL.SetArgumentBuffer(def_k_SAC_AlphaLogProbs, def_k_sac_alp_log_probs, cLogProbs.GetIndex())) { printf("Error of set parameter kernel %s: %d; line %d", __FUNCTION__, GetLastError(), __LINE__); return false; } if(!OpenCL.SetArgumentBuffer(def_k_SAC_AlphaLogProbs, def_k_sac_alp_outputs, getOutputIndex())) { printf("Error of set parameter kernel %s: %d; line %d", __FUNCTION__, GetLastError(), __LINE__); return false; } if(!OpenCL.SetArgumentBuffer(def_k_SAC_AlphaLogProbs, def_k_sac_alp_probs, cSoftMax.getOutputIndex())) { printf("Error of set parameter kernel %s: %d; line %d", __FUNCTION__, GetLastError(), __LINE__); return false; } if(!OpenCL.SetArgumentBuffer(def_k_SAC_AlphaLogProbs, def_k_sac_alp_quantiles, cQuantile2.getOutputIndex())) { printf("Error of set parameter kernel %s: %d; line %d", __FUNCTION__, GetLastError(), __LINE__); return false; } if(!OpenCL.SetArgumentBuffer(def_k_SAC_AlphaLogProbs, def_k_sac_alp_random, cRandomize.GetIndex())) { printf("Error of set parameter kernel %s: %d; line %d", __FUNCTION__, GetLastError(), __LINE__); return false; } if(!OpenCL.SetArgument(def_k_SAC_AlphaLogProbs, def_k_sac_alp_count_quants, (int)(cSoftMax.Neurons() / global_work_size[0]))) { printf("Error of set parameter kernel %s: %d; line %d", __FUNCTION__, GetLastError(), __LINE__); return false; } if(!OpenCL.SetArgument(def_k_SAC_AlphaLogProbs, def_k_sac_alp_activation, (int)activation)) { printf("Error of set parameter kernel %s: %d; line %d", __FUNCTION__, GetLastError(), __LINE__); return false; } if(!OpenCL.Execute(def_k_SAC_AlphaLogProbs, 1, global_work_offset, global_work_size)) { printf("Error of execution kernel %s: %d", __FUNCTION__, GetLastError()); return false; } //--- return true; }
Таким образом мы организовали стохастичность выбора действия при прямом проходе нашего Актера. Но есть нюанс с обратным проходом. Дело в том, что обратный проход должен распределить градиент ошибки до каждого элемента принятия решения в соответствии с его вкладом. Ранее мы использовали прямой проход родительского класса. И аналогично распределяли градиент ошибки. Сейчас мы внесли корректировки на конечном этапе выбора действия. Следовательно, это должно отразиться и на распределении градиента ошибки.
Генерация случайных значений выходит за рамки нашей модели, и мы не будем на них распределять градиент. Но мы должны организовать распределение градиента ошибки только на выбранное действие. Ведь ни одно из других значений не оказало влияние на совершенное действие Актера. Следовательно, их градиент ошибки равен "0".
В отличии от прямого прохода мы не можем дополнить функционал новым методом, ведь вызов метода родительского класса перепишет сохраненные нами градиенты. Поэтому нам предстоит полностью переопределить метод распределения градиентов ошибки через элементы нашего нейронного слоя.
Как всегда, мы начинаем с создания кернела SAC_OutputGradient. Структура параметров данного кернела напомнит Вам кернел FQF_OutputGradient родительского класса. Мы взяли его за основу и добавили 1 буфер и 2 константы:
- output — буфер результатов прямого прохода
- count_quants — количество квантилей по каждому действию
- activation — используемая функция активации.
__kernel void SAC_OutputGradient(__global float* quantiles, __global float* delta_taus, __global float* output_gr, __global float* quantiles_gr, __global float* taus_gr, __global float* output, const int count_quants, const int activation ) { size_t action = get_global_id(0); int shift = action * count_quants;
Запускать кернел мы будем в одномерном пространстве задач по числу действий.
В теле кернела мы сразу идентифицируем анализируемое действие Актера и определяем смещение в буферах данных.
Далее мы организовываем цикл, в котором будем сравнивать среднее значение каждого квантиля и совершенного действия из буфера результатов нашего слоя. Но здесь следует обратить внимание на один нюанс: средние значения квантилей хранятся в оригинальном значении, а выбранное действие в буфере результатов содержит значение после функции активации. Следовательно, перед сравнением значений нам необходимо применить функцию активации к среднему значению каждого квантиля.
for(int i = 0; i < count_quants; i++) { float quant = quantiles[shift + i]; switch(activation) { case 0: quant = tanh(quant); break; case 1: quant = 1 / (1 + exp(-quant)); break; case 2: if(quant < 0) quant = quant * 0.01f; break; } if(output[i] == quant) { float gradient = output_gr[action]; quantiles_gr[shift + i] = gradient * delta_taus[shift + i]; taus_gr[shift + i] = gradient * quant; } else { quantiles_gr[shift + i] = 0; taus_gr[shift + i] = 0; } } }
Надо сказать, что теоретически мы могли бы один раз выполнить обратную функцию и определить значение буфера результатов до функции активации. Однако, из-за погрешности в пределах точности вычислений мы с большой долей вероятности получим близкое, но отличное от исходного значение. И мы будем вынуждены проводить сравнение с неким толерансом. Что в свою очередь усложнит процесс сравнения и понизит точность.
При совпадении квантиля мы распределяем градиент ошибки на среднее значение квантиля и его вероятность. Для остальных квантилей и их вероятностей мы устанавливает градиент равный "0".
После завершения итераций цикла мы завершаем работу кернела.
На стороне основной программы, как уже было сказано выше, нам предстоит полностью переопределить метод распределения градиента ошибки calcInputGradients. Сразу скажу, что данный метод бы полностью скопирован с аналогичного метода родительского класса. Изменения коснулись лишь блока постановки в очередь, описанного выше кернела. Поэтому я не буду сейчас останавливаться на его описании и предлагаю вам самостоятельно с ним ознакомиться во вложенном файле "..\NeuroNet_DNG\NeuroNet.mqh".
1.2 Корректируем процесс обновления целевых моделей
Вы, наверное, заметили, что в своих моделях я предпочитаю использовать метод Adam для обновления весовых коэффициентов. И в этой связи возникла идея эксперимента с внедрением данного метода в процесс мягкого обновления целевых моделей критиков.
Напомню, что алгоритмом Soft Actor-Critic предусмотрено мягкое обновление целевых моделей с использованием постоянного коэффициента в диапазоне (0, 1}. При коэффициенте равном "1" происходит простое копирование параметров. Коэффициент равный "0" не применяется, так как в этом случае не осуществляется обновление целевой модели.
Использование метода Adam позволит модели самостоятельно корректировать коэффициенты для каждого отдельного обучаемого параметра. Это позволит быстрее приводить обновление параметров, смещаемых в одном направлении, а значит быстрее происходит смещение целевой модели от начальных значений к первому приближению. В то же время адаптивный метод позволяет снизить скорость копирования для разнонаправленных колебаний, что снизит шум значениях целевых моделей.
Однако, следует обратить внимание на риск разбалансировки моделей на начальном этапе обучения. Когда значительные различия в скорости копирования отдельных параметров могут привести к неожиданным и непредсказуемым результатам работы таких моделей.
Оценив все "За" и "Против" было принято решение проверить эффективность такого подхода на практике.
Процесс оптимизации моделей мы осуществляем на стороне контекста OpenCL. И актуальные значения всех обучаемых параметров модели хранятся в памяти контекста. Вполне логично, что и перенос данных параметров между обучаемой и целевой моделью для нас выгоднее осуществить на стороне OpenCL. В таком подходе есть только преимущества:
- мы исключаем процесс загрузки актуальных данных параметров обучаемой модели из контекста в основную память и последующее копирования новых параметров целевых моделей в память контекста;
- мы можем осуществлять перенос нескольких параметров одновременно в параллельных потоках данных.
Создадим кернел SoftUpdateAdam для выполнения операций переноса данных. В параметрах кернела мы будем передавать указатели на 4 буфера данных и 3 параметра, предусмотренных методом.
__kernel void SoftUpdateAdam(__global float *target, __global const float *source, __global float *matrix_m, __global float *matrix_v, const float tau, const float b1, const float b2 ) { const int i = get_global_id(0); float m, v, weight;
Запуск кернела мы планируем осуществлять последовательно для каждого нейронного слоя в одномерном пространстве задач по числу обновляемых параметров текущего слоя модели. В таком варианте идентификатор потока, который мы определяем в теле кернела, одновременно служит указателем на анализируемый параметром и смещением в буферах данных.
Тут же мы объявляем локальные переменные для хранения промежуточных данных и запишем в них исходные данные из глобальных буферов.
m = matrix_m[i]; v = matrix_v[i]; weight=target[i];
Метод Adam был разработан для обновления параметров модели в сторону антиградиента. В нашем случаем градиентом ошибки будет отклонение параметров целевой модели от обучаемой. И так как мы корректируем значение параметров в сторону антиградиента, то определяем отклонение как разницу параметра обучаемой модели от соответствующего параметра обучаемой модели.
float g = source[i] - weight; m = b1 * m + (1 - b1) * g; v = b2 * v + (1 - b2) * pow(g, 2);
И сразу определим экспоненциальные средние градиента ошибки его квадратичного значения.
Далее мы определяем необходимое смещения параметра и сохраняем его соответствующий элемент глобального буфера данных.
float delta = tau * m / (v != 0.0f ? sqrt(v) : 1.0f); if(delta * g > 0) target[i] = clamp(weight + delta, -MAX_WEIGHT, MAX_WEIGHT);
В завершении операций кернела мы сохраняем в глобальные буферы данных средние значения градиента ошибки и его квадрата. Они нам потребуются при последующих итерациях обновления параметров.
matrix_m[i] = m; matrix_v[i] = v; }
После создания кернела нам предстоит организовать процесс его вызова на стороне основной программы. Здесь у нас 2 варианта:
- создание нового метода
- дополнение ранее созданного метода.
В данной статье я предлагаю рассмотреть вариант с созданием нового метода, который мы создадим на уровне базового класса нейронного слоя CNeuronBaseOCL::WeightsUpdateAdam. В параметрах метода мы передадим указатель на слой нейронного слоя обучаемой модели и коэффициент обновления, аналогично ранее созданному методу мягкого обновления целевой модели. Гиперпараметры метода Adam мы будем использовать заданные для обновления моделей по умолчанию.
bool CNeuronBaseOCL::WeightsUpdateAdam(CNeuronBaseOCL *source, float tau) { if(!OpenCL || !source) return false; if(Type() != source.Type()) return false; if(!Weights || Weights.Total() == 0) return true; if(!source.Weights || Weights.Total() != source.Weights.Total()) return false;
В теле метода мы организуем блок контролей. Здесь мы проверяем актуальность указателей на используемые объекты. А так же проверяем соответствие типа текущего нейронного слоя и полученного указателя.
После успешного прохождения блока контролей мы осуществляем передачу параметров кернелу и постановку его в очередь выполнения.
Здесь следует обратить внимание, что метод Adam требует создание двух дополнительных буферов данных. Но давайте вспомним, что мы создаем аналогичные буфера в каждой модели для обновления обучаемых параметров модели. В данном случае мы имеем дело с целевой моделью, в которой по определению процесс обновления параметров. Её оптимизация осуществляется путем периодического переноса данных из обучаемой модели. Иными словами, у нас модель с ограниченным функционалом. В то же время мы не создавали отдельных типов объектов для целевых моделей, а использовали ранее созданные для полностью функциональных моделей с созданием всех необходимых объектов и буферов. В этом можно заметить не эффективности использование ресурсов памяти. Но мы осознанно пошли на этот шаг с целью унификации моделей. И теперь у нас есть созданные и неиспользуемые буфера целевых моделей. Их мы и задействуем в процессе обновления параметров.
uint global_work_offset[1] = {0}; uint global_work_size[1] = {Weights.Total()}; ResetLastError(); if(!OpenCL.SetArgumentBuffer(def_k_SoftUpdateAdam, def_k_sua_target, getWeightsIndex())) { printf("Error of set parameter kernel %s: %d; line %d", __FUNCTION__, GetLastError(), __LINE__); return false; } if(!OpenCL.SetArgumentBuffer(def_k_SoftUpdateAdam, def_k_sua_source, source.getWeightsIndex())) { printf("Error of set parameter kernel %s: %d; line %d", __FUNCTION__, GetLastError(), __LINE__); return false; } if(!OpenCL.SetArgumentBuffer(def_k_SoftUpdateAdam, def_k_sua_matrix_m, getFirstMomentumIndex())) { printf("Error of set parameter kernel %s: %d; line %d", __FUNCTION__, GetLastError(), __LINE__); return false; } if(!OpenCL.SetArgumentBuffer(def_k_SoftUpdateAdam, def_k_sua_matrix_v, getSecondMomentumIndex())) { printf("Error of set parameter kernel %s: %d; line %d", __FUNCTION__, GetLastError(), __LINE__); return false; } if(!OpenCL.SetArgument(def_k_SoftUpdateAdam, def_k_sua_tau, (float)tau)) { printf("Error of set parameter kernel %s: %d; line %d", __FUNCTION__, GetLastError(), __LINE__); return false; } if(!OpenCL.SetArgument(def_k_SoftUpdateAdam, def_k_sua_b1, (float)b1)) { printf("Error of set parameter kernel %s: %d; line %d", __FUNCTION__, GetLastError(), __LINE__); return false; } if(!OpenCL.SetArgument(def_k_SoftUpdateAdam, def_k_sua_b2, (float)b2)) { printf("Error of set parameter kernel %s: %d; line %d", __FUNCTION__, GetLastError(), __LINE__); return false; } if(!OpenCL.Execute(def_k_SoftUpdateAdam, 1, global_work_offset, global_work_size)) { printf("Error of execution kernel %s: %d", __FUNCTION__, GetLastError()); return false; } //--- return true; }
Не забываем контролировать корректность выполнения операций на каждом этапе. И после успешного выполнения всех итераций завершаем работу метода.
После создания метода нам необходимо продумать и организовать процесс его вызова. Мне хотелось найти такой подход, который бы позволил сделать его вызов максимально простым с минимальным количество изменений в общей структуре моделей. И мне кажется я нашел компромиссное решение. Я не стал создавать отдельную ветку вызова метода со стороны внешней программы через диспетчерский класс модели и динамического массива нейронных слоев. Вместо этого я перешел в ранее созданный метод мягкого обновления CNeuronBaseOCL::WeightsUpdate и установил проверку метода обновления параметров обучаемой модели, который задается пользователем для каждого нейронного слоя при описании архитектуры модели. И если пользователем был указан метод Adam для обновления параметров модели мы просто перенаправляем поток операций на выполнение нашего нового метода. Для других методов обновления параметров мы используем классическое мягкое обновление.
bool CNeuronBaseOCL::WeightsUpdate(CNeuronBaseOCL *source, float tau) { if(optimization == ADAM) return WeightsUpdateAdam(source, tau); //--- ........ ........ }
Такой подход, кроме всего прочего, гарантирует нам наличие необходимых буферов данных.
1.3 Внесение изменений в структуре исходных данных
Ещё я обратил внимание на структуру исходных данных. Как вы знаете описание каждого бара исторических данных состоит из 12 элементов:
- разница между ценами открытия и закрытия
- разница между ценами открытия и максимальной
- разница между ценами открытия и минимальной
- час свечи
- день недели
- месяц
- 5 показателей индикаторов.
State.Add((float)Rates[b].close - open); State.Add((float)Rates[b].high - open); State.Add((float)Rates[b].low - open); State.Add((float)Rates[b].tick_volume / 1000.0f); State.Add((float)sTime.hour); State.Add((float)sTime.day_of_week); State.Add((float)sTime.mon); State.Add(rsi); State.Add(cci); State.Add(atr); State.Add(macd); State.Add(sign);
В этом наборе данных мое внимание было обращено на временные метки. Я согласен, что оценка временной составляющей имеет огромную ценность для понимания сезонности, различного поведения валют в различные сессии. Но насколько важно их наличие для каждой свечи? Лично мое мнение, что достаточно одного набора временных меток для общего набора "снимка" текущего состояния рынка. Ранее, при использовании одного буфера исходных данных, для сохранения структуры описания каждой свечи мы были вынуждены повторять эти данные. Сейчас же, когда наши модели имею по 2 источника исходных данных, мы можем вынести временные метки в буфер описания состояния счета. А здесь оставить только исторические данные снимка рыночной ситуации. Таким образом мы сокращаем общий объем анализируемых данных без потери информативности. Следовательно, снижаем количество выполняемых операций, а вместе с тем и повышаем производительность нашей модели.
Дополнительно мы изменили представление временных меток для нашей модели. Напомню, что для описания состояния счета мы используем относительные показатели. Это позволяет привести их в сопоставимый и, отчасти, нормализованный вид. И мы бы хотели иметь нормализованный вид временных меток. При этом важно сохранить информацию о сезонности процессов. В подобных случаях часто приходят к использованию функций синуса и косинуса. Графики этих функций непрерывны и цикличны. Длина цикла функций известна и равна 2π.
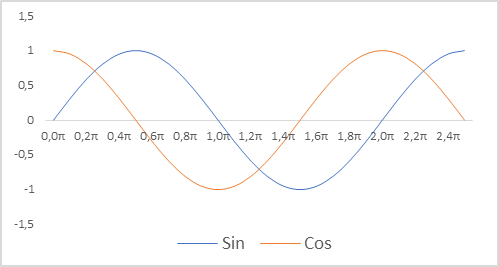
Для нормализации временной метки и с учетом цикличности нам необходимо:
- Разделить текущее время на размер периода
- Полученное значение умножить на константу "2π"
- Вычислить значение функции (sin или cos)
- Полученное значение добавляем в буфер
В своей реализации я использовал периоды года, месяца, недели, дня.
double x = (double)Rates[0].time / (double)(D'2024.01.01' - D'2023.01.01'); Account.Add((float)MathSin(x != 0 ? 2.0 * M_PI * x : 0)); x = (double)Rates[0].time / (double)PeriodSeconds(PERIOD_MN1); Account.Add((float)MathCos(x != 0 ? 2.0 * M_PI * x : 0)); x = (double)Rates[0].time / (double)PeriodSeconds(PERIOD_W1); Account.Add((float)MathSin(x != 0 ? 2.0 * M_PI * x : 0)); x = (double)Rates[0].time / (double)PeriodSeconds(PERIOD_D1); Account.Add((float)MathSin(x != 0 ? 2.0 * M_PI * x : 0));
И не забываем изменить константы размера описания одной свечи и состояния счета. Их значения отразятся на архитектуре нашей модели и размерах массивов буфером описания траекторий накопленного опыта.
#define BarDescr 9 //Elements for 1 bar description #define AccountDescr 12 //Account description
Стоит отметить, что подготовка исходных данных и нормализация временных меток, в частности, не имеет отношения к построению самой модели и её архитектуры. Осуществляется на стороне внешней программы. Но качество подготовки исходных данных оказывает большое влияние на процесс обучения модели и результат этого обучения.
2. Обучение модели
После внесения конструктивных изменений в организацию работы модели мы переходим процессу её обучения. На первом этапе мы используем советник "..\SoftActorCritic\Research.mq5" для взаимодействия с окружающей средой и сбора данных в обучающую выборку.
В указанном советнике мы вносим описанные выше изменения по переносу временных меток из буфера описания состояния окружающей среды в буфер описания состояния счета.
//+------------------------------------------------------------------+ //| Expert tick function | //+------------------------------------------------------------------+ void OnTick() { //--- ......... ......... //--- float atr = 0; for(int b = 0; b < (int)HistoryBars; b++) { float open = (float)Rates[b].open; float rsi = (float)RSI.Main(b); float cci = (float)CCI.Main(b); atr = (float)ATR.Main(b); float macd = (float)MACD.Main(b); float sign = (float)MACD.Signal(b); if(rsi == EMPTY_VALUE || cci == EMPTY_VALUE || atr == EMPTY_VALUE || macd == EMPTY_VALUE || sign == EMPTY_VALUE) continue; //--- int shift = b * BarDescr; sState.state[shift] = (float)(Rates[b].close - open); sState.state[shift + 1] = (float)(Rates[b].high - open); sState.state[shift + 2] = (float)(Rates[b].low - open); sState.state[shift + 3] = (float)(Rates[b].tick_volume / 1000.0f); sState.state[shift + 4] = rsi; sState.state[shift + 5] = cci; sState.state[shift + 6] = atr; sState.state[shift + 7] = macd; sState.state[shift + 8] = sign; } State.AssignArray(sState.state); //--- ........ ........ //--- Account.Clear(); Account.Add((float)((sState.account[0] - PrevBalance) / PrevBalance)); Account.Add((float)(sState.account[1] / PrevBalance)); Account.Add((float)((sState.account[1] - PrevEquity) / PrevEquity)); Account.Add(sState.account[2]); Account.Add(sState.account[3]); Account.Add((float)(sState.account[4] / PrevBalance)); Account.Add((float)(sState.account[5] / PrevBalance)); Account.Add((float)(sState.account[6] / PrevBalance)); double x = (double)Rates[0].time / (double)(D'2024.01.01' - D'2023.01.01'); Account.Add((float)MathSin(x != 0 ? 2.0 * M_PI * x : 0)); x = (double)Rates[0].time / (double)PeriodSeconds(PERIOD_MN1); Account.Add((float)MathCos(x != 0 ? 2.0 * M_PI * x : 0)); x = (double)Rates[0].time / (double)PeriodSeconds(PERIOD_W1); Account.Add((float)MathSin(x != 0 ? 2.0 * M_PI * x : 0)); x = (double)Rates[0].time / (double)PeriodSeconds(PERIOD_D1); Account.Add((float)MathSin(x != 0 ? 2.0 * M_PI * x : 0)); //--- if(Account.GetIndex() >= 0) if(!Account.BufferWrite()) return;
Кроме того, было принято решение об отказе от хеджирующих операций. Сделка открывается только на разницу объемов в направлении большего из них. Для этого мы проверяем прогнозные объемы совершаемых операций и уменьшаем их на меньший объем.
........ ........ //--- vector<float> temp; Actor.getResults(temp); float delta = MathAbs(ActorResult - temp).Sum(); ActorResult = temp; //--- if(temp[0] >= temp[3]) { temp[0] -= temp[3]; temp[3] = 0; } else { temp[3] -= temp[0]; temp[0] = 0; }
Кроме того, я обратил внимание на формируемое вознаграждение. И здесь надо сказать, что при формировании основного тела вознаграждения мы использовали относительное изменение баланса счета. Его величина разрежена и значительно ниже 1. В то же время величина энтропийной составляющей вознаграждения на начальном этапе обучения колебалась в диапазоне 8-12. Очевидно, что размер энтропийной составляющей несопоставимо велик. Для компенсации данного разрыва значений я раздели её на сумму баланса, как это делается с его изменением при формировании целевой части вознаграждения. И дополнительно ввел понижающий коэффициент LogProbMultiplier.
........ ........ //--- float reward = Account[0]; if((buy_value + sell_value) == 0) reward -= (float)(atr / PrevBalance); for(ulong i = 0; i < temp.Size(); i++) sState.action[i] = temp[i]; if(Actor.GetLogProbs(temp)) reward += LogProbMultiplier * temp.Sum() / (float)PrevBalance; if(!Base.Add(sState, reward)) ExpertRemove(); }
После внесения указанных изменений я запустил первый этап сбора обучающих данных. Для этого я использовал исторические данные инструмента EURUSD тайм-фрейм H1. Сбор данных осуществлялся в тестере стратегий на временном отрезке за первые 5 месяцев 2023 года в режиме полного перебора параметров. Стартовый капитал 10000USD. На этом этапе я собрал базу примеров из 200 проходов, что на указанном временном интервале дает нам более 0.5 млн. наборов данных "Состояние"→"Действие"→"Новое состояние"→"Вознаграждение".
Напомню, что на данном этапе у нас нет предварительно обученной модели. И при каждом проходе советник генерирует новую модель и заполняет её случайными параметрами. В процессе прохода по истории процесс обучения моделей не осуществляется. Поэтому мы получаем 200 абсолютно случайных и независимых проходом. И ни один из них не показал прибыль.

Непосредственно процесс обучения модели организован в советнике "..\SoftActorCritic\Study.mq5". Здесь мы также внесли некоторые точечные правки.
Вначале мы внесли изменения в процесс формирования вектора описания состояния счета в части добавления временных меток, аналогично описанному выше подходу в советнике исследования окружающей среды.
Кроме того, мы скорректировали формирование целевого вознаграждения в части энтропийной составляющей. Подход должен быть единый во всех 3 советниках.
void Train(void) { ......... ......... //--- for(int iter = 0; (iter < Iterations && !IsStopped()); iter ++) { ......... ......... Account.Clear(); Account.Add((Buffer[tr].States[i + 1].account[0] - PrevBalance) / PrevBalance); Account.Add(Buffer[tr].States[i + 1].account[1] / PrevBalance); Account.Add((Buffer[tr].States[i + 1].account[1] - PrevEquity) / PrevEquity); Account.Add(Buffer[tr].States[i + 1].account[2]); Account.Add(Buffer[tr].States[i + 1].account[3]); Account.Add(Buffer[tr].States[i + 1].account[4] / PrevBalance); Account.Add(Buffer[tr].States[i + 1].account[5] / PrevBalance); Account.Add(Buffer[tr].States[i + 1].account[6] / PrevBalance); double x = (double)Buffer[tr].States[i + 1].account[7] / (double)(D'2024.01.01' - D'2023.01.01'); Account.Add((float)MathSin(x != 0 ? 2.0 * M_PI * x : 0)); x = (double)Buffer[tr].States[i + 1].account[7] / (double)PeriodSeconds(PERIOD_MN1); Account.Add((float)MathCos(x != 0 ? 2.0 * M_PI * x : 0)); x = (double)Buffer[tr].States[i + 1].account[7] / (double)PeriodSeconds(PERIOD_W1); Account.Add((float)MathSin(x != 0 ? 2.0 * M_PI * x : 0)); x = (double)Buffer[tr].States[i + 1].account[7] / (double)PeriodSeconds(PERIOD_D1); Account.Add((float)MathSin(x != 0 ? 2.0 * M_PI * x : 0)); //--- ......... ......... //--- TargetCritic1.getResults(Result); float reward = Result[0]; TargetCritic2.getResults(Result); reward = Buffer[tr].Revards[i] + DiscFactor * (MathMin(reward, Result[0]) - Buffer[tr].Revards[i + 1] + LogProbMultiplier * log_prob.Sum() / (float)PrevBalance);
Затем мы разделили процессы обучения Актера и Критика. Как и ранее, мы чередуем Критик1 и Критик2 на четной и нечетной итерации обучения. Но теперь при обучении Актера мы отключаем функционал обучения используемого Критика. Он только передает градиент ошибки Актеру. При этом не осуществляется обновление параметров Критика. Таким образом мы стремимся обучить объективного Критика на реальных вознаграждениях от окружающей среды.
........ ........ //--- if((iter % 2) == 0) { if(!Critic1.feedForward(GetPointer(Actor), LatentLayer, GetPointer(Actor)) || !Critic2.feedForward(GetPointer(Actor), LatentLayer, GetPointer(Actions))) { PrintFormat("%s -> %d", __FUNCTION__, __LINE__); break; } Critic1.getResults(Result); Actor.GetLogProbs(log_prob); Result.Update(0, reward); Critic1.TrainMode(false); if(!Critic1.backProp(Result, GetPointer(Actor)) || !Critic1.AlphasGradient(GetPointer(Actor)) || !Actor.backPropGradient(GetPointer(Account), GetPointer(Gradient), LatentLayer) || !Actor.backPropGradient(GetPointer(Account), GetPointer(Gradient))) { PrintFormat("%s -> %d", __FUNCTION__, __LINE__); Critic1.TrainMode(true); break; } Critic1.TrainMode(true);
Кроме того, при обучении критика мы исключаем из целевого вознаграждения энтропийную составляющую. Ведь нам нужен объективный Критик. А функция энтропийной составляющей — стимулирование Актера к исследованию окружающей среды.
Result.Update(0, reward - LogProbMultiplier * log_prob.Sum() / (float)PrevBalance); if(!Critic2.backProp(Result, GetPointer(Actions), GetPointer(Gradient))) { PrintFormat("%s -> %d", __FUNCTION__, __LINE__); break; } //--- Update Target Nets TargetCritic2.WeightsUpdate(GetPointer(Critic2), Tau); }
И после обновления параметров Критика мы обновляем целевую модель только одного Критика. В остальном код советника остался без изменений, и вы можете ознакомиться с ним во вложении.
После внесения изменений мы запускам процесс обучения модели с циклом в 100000 итераций (параметры по умолчанию). На этом этапе форсируются модели Актера и 2 Критиков. А также осуществляется их первичное обучение.
Не следует ожидать значительных успехов от первого цикла обучения модели. И тому есть целый ряд причин. Выполненное количество итераций покрывает лишь 1/5 нашей базы примеров. Да и её нельзя назвать полной. В ней нет ни одного прибыльного прохода, чтобы модель могла её выучить.
После завершения первого этапа процесса обучения модели я удалил ранее собранную базу примеров. Моя логика здесь довольно проста. В этой базе примеров собраны случайные независимы проходы. В вознаграждениях указана неизвестная энтропийная составляющая. Я предполагаю, что в необученной модели все действия равновероятны. Но в любом случае, они будут несопоставимы с вероятностным распределением нашей модели. Поэтому мы удаляем ранее собранную базу примеров и формируем новую.
При этом повторяем процесс сбора обучающей выборки и повторно запускаем оптимизацию советника исследования окружающей среды с полным перебором параметров. Только на этот раз мы смещаем значение перебираемых Агентов. Это простой трюк необходим, чтобы исключить загрузку данных из кеша предыдущей оптимизации.
Главное отличие новой базы примеров состоит в том, что в процессе исследования окружающей среды использовалась наша предварительно обученная модель. Разнообразие действий Агента обусловлено стохастичностью политики Актера. И все совершенные действия лежат в пределах выученного вероятностного распределения нашей модели. На этом этапе мы последний раз собираем все проходы нашего Агента.
После сбора новой базы примеров мы повторно запускаем советник обучения модели "..\SoftActorCritic\Study.mq5". На это раз мы увеличиваем число итераций обучения до 500000.
После завершения второго цикла процесса обучения мы обращаемся к советнику тестирования обученной модели "..\SoftActorCritic\Test.mq5". В него мы вносим правки аналогичные советнику исследования окружающей среды. Вы можете самостоятельно ознакомиться с ними во вложении.
Переход к советнику тестирования вовсе не означает завершения процесса обучения. Мы несколько раз запускаем советник на исторических данных обучающего периода. В моем случае это первые 5 месяцем 2023 года. Я осуществил 10 проходов и по полученным результатам определяем примерно верхнюю 1/4 или 1/5 диапазона полученных доходов. Возвращаемся к коду советника исследования окружающей среды и вводим ограничение по минимальной доходности проходов, сохраняемых в базу примеров.
input double MinProfit = 10;
double OnTester() { //--- double ret = 0.0; //--- double profit = TesterStatistics(STAT_PROFIT); Frame[0] = Base; if(profit >= MinProfit && profit != 0) FrameAdd(MQLInfoString(MQL_PROGRAM_NAME), 1, profit, Frame); //--- return(ret); }
Таким образом мы стремимся отобрать только лучшие проходы и обучить на них нашего Актера оптимальной стратегии.
Мы намеренно вынесли показатель минимальной доходности во внешние параметры, так как в процессе обучения модели мы будем постепенно поднимать планку.
После внесения изменений мы устанавливаем определенный ранее уровень минимальной доходности и осуществляем ещё 100 проходом в режиме оптимизации тестера стратегий на обучающих данных.
Мы повторяем итерации процесса обучения модели до получения желаемых результатов или достижения верхнего предела возможностей модели, когда очередной цикл обучений не даст изменения доходности. Это можно заметить и при осуществлении одиночных проходов советника тестирования. Когда, несмотря на стохастичность политики Актера, несколько совершенных проходов будут иметь практически идентичный результат. Это является свидетельством того, что модель максимально увеличила вероятность отдельных действий в соответствующих состояниях. И получаем эффект детерминированной стратегии. Такой результат не всегда является недостатком. Ведь стабильная и детерминированная стратегия может быть предпочтительной в некоторых задачах, особенно если детерминированные действия приводят к хорошим результатам.
3. Тестирование
Примерно после 15 итераций обновления базы примеров, обучения модели, тестирования на обучающей выборке, повышения планки минимальной доходности и очередного пополнения базы примеров мне удалость получить модель стабильно генерирующую прибыль на обучающем диапазоне исторических данных.
Следующим этапом идет проверка возможностей обученной модели вне обучающей выборки, на новых данных. Я проверял работу обученной модели на исторических данных за июнь 2023 года. Как можно заметить, это месяц, следующий за обучающем периодом.
Надо сказать, что за период тестирования модель совершила всего 4 длинные сделки. И только одна из них была прибыльной. Наверное, это не тот результат, который мы ожидали. Но посмотрите на график баланса. 3 убыточные сделки дали всего 300USD убытка при стартовом балансе в 10000USD. В то же время одна прибыльная сделка дала доход более 2000USD. В итоге по месяцу мы имеем доход 17.5%. Профит фактор составил 6.77, фактор восстановления — 1.32, просадка по балансу — 1.65%.


Да, смущает малое количество сделок и их однонаправленность. Но что важнее? Количество сделок и их разнообразие или итоговое изменение баланса?
Заключение
В данной статье мы продолжили работу над построением алгоритма Soft Actor-Critic. Внесенные дополнения помогли на обучить прибыльную стратегию Актера. Не могу судить, насколько полученная модель оптимальна. Все познается в сравнении.
Предложенные в статье подходы позволили повысить доходность нашей модели, но они не являются единственными и исчерпывающими. К примеру, в ветке форума к предыдущей статье пользователь под ником JimReaper предложил свою архитектуру модели. Это то же вполне возможный вариант. Лично я его ещё не тестировал, но вполне допускаю возможность получения прибыли при использовании предложенной или какой-то другой архитектуры. С большой долей вероятности добавление новых данных для анализа моделью поможет повысить её эффективность. Я всегда призываю к поиску и новым исследования. При разработке и оптимизации моделей в области обучения с подкреплением (как и в других областях машинного обучения) исследование и экспериментирование с различными архитектурами, гиперпараметрами и новыми данными — это ключевые элементы, которые могут привести к оптимизации и улучшению модели.
Ссылки
- Soft Actor-Critic: Off-Policy Maximum Entropy Deep Reinforcement Learning with a Stochastic Actor
- Soft Actor-Critic Algorithms and Applications
- Нейросети — это просто (Часть 49): Мягкий Актер-Критик (Soft Actor-Critic)
Программы, используемые в статье
| # | Имя | Тип | Описание |
|---|---|---|---|
| 1 | Research.mq5 | Советник | Советник сбора примеров |
| 2 | Study.mq5 | Советник | Советник обучения агента |
| 3 | Test.mq5 | Советник | Советник для тестирования модели |
| 4 | Trajectory.mqh | Библиотека класса | Структура описания состояния системы |
| 5 | NeuroNet.mqh | Библиотека класса | Библиотека классов для создания нейронной сети |
| 6 | NeuroNet.cl | Библиотека | Библиотека кода программы OpenCL |
- Бесплатные приложения для трейдинга
- 8 000+ сигналов для копирования
- Экономические новости для анализа финансовых рынков
Вы принимаете политику сайта и условия использования
Теоретически можно, но все упирается в ресурсы. К примеру мы говорим о размере ТП в 1000 пунктов. В концепции непрерывного пространства действий это 1000 вариантов. Даже если мы возьмем с шагом 10, то 100 вариантов. Пусть столько же СЛ или даже половина (50 вариантов). Накиньте хотя бы 5 вариантов объема сделки и получаем 100 * 50 * 5 = 25000 вариантов. Умножаем на 2 (buy / sell) - 50 000 вариантов для одной свечи. Умножьте на длину траектории и получите число траекторий для полного покрытия всего возможного пространства.
При пошаговом обучении мы семплируем траектории в ближайшем окружении текущих действий Актера. Тем самым сильно сужаем область изучения. И изучаем не все возможные варианты, а только малую область с поиском вариантов улучшить текущую стратегию. После небольшого "тюнинга" текущей стратегии мы собираем новые данные в той области, куда нас привели эти улучшения и определяем дальнейший вектор движения.
Это может может напомнить поиск пути выхода в неизвестном лабиринте. Или путь туриста, который идет по улице и спрашивает у прохожих как пройти.
Понятно. Спасибо.
Я вот сейчас заметил что когда делаешь сбор Research.mqh то результаты формируются как-то группами с очень близким балансом конечным в группе. И вроде бы в Research.mqh как будто есть какой-то прогресс (положительные группы исходов стали появляться чаще что-ли). А вот с Test.mqh прогресса как будто нет совсем. Он даёт какой-то рандом и вообще чаще завершает проход минусом. Когда-то сначала идёт вверх а потом вниз, а когда-то сразу вниз и потом топчется на месте. Еще в конце походу объём входа наращивает. Иногда бывает торгует не в минус а просто в районе нуля. Ещё я заметил что он меняет количество сделок - за 5 месяцев он открывает когда-то 150 сделок, а ког-то 500 (примерно). Это всё нормально, что я наблюдаю?
Понятно. Спасибо.
Я вот сейчас заметил что когда делаешь сбор Research.mqh то результаты формируются как-то группами с очень близким балансом конечным в группе. И вроде бы в Research.mqh как будто есть какой-то прогресс (положительные группы исходов стали появляться чаще что-ли). А вот с Test.mqh прогресса как будто нет совсем. Он даёт какой-то рандом и вообще чаще завершает проход минусом. Когда-то сначала идёт вверх а потом вниз, а когда-то сразу вниз и потом топчется на месте. Еще в конце походу объём входа наращивает. Иногда бывает торгует не в минус а просто в районе нуля. Ещё я заметил что он меняет количество сделок - за 5 месяцев он открывает когда-то 150 сделок, а ког-то 500 (примерно). Это всё нормально, что я наблюдаю?
Рандомность - это результат стохастичности Актера. По мере обучения она будет становиться меньше. Может не исчезнуть полностью, но результаты будут близкие.
Дмитрий у меня теперь что-то изменилось с нейронкой - Она стала как-то странно открывать сделки (на одной свече откроет а на следующей закрывает) и почему-то не меняется баланс и эквити. На графике просто прямая линия рисуется. И изменение баланса по итогу проходов 0. Притом такое происходит и на советнике Test.mqh и на Research.mqh. И вся база теперь заполнилась такими проходами. Это нормально? Что делать - дальше учить или у меня появилась мысль снести базу и модели обученные перенести из папки в другую временно и создать новую базу со случайными моделями, а потом вернуть назад модели и продолжить их учить. Чтобы как то их избавить от прямой линии.
База примеров не "забьётся" проходами без сделок. В Research.mq5 стоит проверка и не сохраняет такие проходы. Но хорошо, что такой проход сохранится из Test.mq5. При формировании вознаграждения есть штраф за отсутствие сделок. И это должно помочь модели выйти из такой ситуации.
Дмитрий я сделал уэе 90 циклов (обучение- тест-сбор БД) и у меня до сих пор модель даёт рандом. Могу сказать так из 10 проходов Test.mqh 7 сливает 2-3 в 0 и 1-2 раза за примерно 4-5 циклов есть прогон в плюс. Вы в статье указали что у Вас положительный результат получился за 15 циклов. Я понимаю что тут много рандома в системе, но мне не понятно почему такая разница? Ну я понимаю если бы у меня модель дала положительный исход к примеру через 30 циклов, ну пусть 50, ну уже 90 и особо не видно почти прогресса....
А Вы точно выложили тот-же код, что и сами обучали? Может что исправили для тестов и случайно забыли и не тот вариант выложили.....?
А если допустим коэффициент обучения повысить на один разряд, она не быстрей будет учиться?
Я чё-то не понимаю......