
Нейросети — это просто (Часть 48): Методы снижения переоценки значений Q-функции

Введение
В предыдущей статье мы познакомились с методом Deep Deterministic Policy Gradient (DDPG), предназначенным для обучения моделей в непрерывном пространстве действий. Это позволяет нам перейти на новый уровень обучения наших моделей. Как следствие, наш последний Агент способен не только прогнозировать предстоящее направление движения цены, но также выполняет функции управления капиталом и рисками. Он указывает оптимальный размер открываемой позиции, а также уровни стоп-лосса и тейк-профита.
Тем не менее, DDPG не лишен недостатков. Как и другие последователи Q-обучения, он подвержен проблеме переоценки значений Q-функции. В процессе обучения ошибка способна накапливаться, что в итоге приводит к обучению агента неоптимальной стратегии.
Хочу напомнить, что в DDPG модель Критика учит Q-функцию (прогнозирование ожидаемого вознаграждения) на результатах взаимодействия со средой. В то время, как модель Агента обучается максимизировать ожидаемое вознаграждение, основываясь лишь на результатах оценки действий Критиком. Следовательно, качество обучения Критика сильно влияет на стратегию поведения Агента и его способность принимать оптимальные решения.
1. Подходы к снижению переоценки
Проблема переоценки значений Q-функции проявляется довольно часто при обучении различных моделей методом DQN и его производных. Она свойственна как моделям с дискретными действиями, так и при решении задач в непрерывном пространстве действий. Причины данного явления и методы борьбы с его последствиями могут быть специфичны в каждом отдельном случае. Поэтому важен комплексный подход к решению данной проблемы. Один из таких подходов был представлен в статье "Addressing Function Approximation Error in Actor-Critic Methods", которая была опубликована в феврале 2018 года. В ней был предложен алгоритм под названием Twin Delayed Deep Deterministic policy gradient (TD3). Данный алгоритм является логичным продолжением DDPG и вносит в него некоторые улучшения, которые позволяют повысить качество обучения моделей.
Вначале авторы добавляют второго Критика. Идея не нова и ранее использовалась для моделей с дискретным пространством действий. Однако, авторы метода внесли свое понимание, видение и подход к использованию второго Критика.
Идея заключается в том, что оба Критика инициализируются случайными параметрами и параллельно обучаются на одних и тех же данных. Инициализированные разными начальными параметрами они начинают свое обучение из разных состояний. Но обучаются оба Критика на одних и тех же данных, следовательно должны двигаться к одному, в идеале глобальному, минимуму. Вполне естественно, что в процессе обучения результаты их прогнозов будут сближаться. Однако, они не будут идентичными в силу воздействия различных факторов. И да, каждый из них подвержен проблеме переоценки Q-функции. Но в отдельно взятом моменте времени, одна модель переоценит Q-функцию, а вторая недооценит. И даже когда обе модели переоценят Q-функцию, то погрешность одной модели будет меньше второй. Основываясь на этих предположениях, авторы метода предлагают использовать минимальный из прогнозов для обучения обоих Критиков. Тем самым мы минимизируем влияние переоценки Q-функции и накопление ошибки в процессе обучения.
Математически данный прием можно представить в следующем виде:
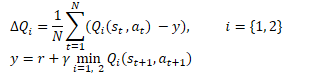
Аналогично DDPG, авторы TD3 рекомендуют использовать мягкое обновление целевых моделей. На практических примерах авторы демонстрируют, что использование мягкого обновления целевых моделей ведет к более стабильному процессу обучения Q-функции с меньшей дисперсией результатов. В то же время использование более стабильных (менее обновляемых) целей в процессе обучения ведет к снижению накопления ошибки переоценки Q-функции.
Результаты экспериментов приводят авторов метода к мысли о более редком обновлении политики Актера.
Напомню, обучение нейронных сетей итерационный процесс постепенного снижения ошибки. Скорость обучения определяется коэффициентов обучения и алгоритмом обновления параметров. Такой подход позволяет усреднить ошибку на обучающей выборке и построить модель максимально приближенную к изучаемому процессу.
Результаты работы модели Актера являются частью обучающей выборки критика. Редкое обновление политики Актера позволяет снизить стохастичность обучающей выборки Критика и, тем самым, повысить стабильность его обучения.
В свою очередь, обучение Актера на данных оценки результатов более точного Критика позволяет повысить качество работы Актера и исключить излишние операции обновления с ошибочными результатами.
Дополнительно, авторы алгоритма TD3 предложили добавить в процесс обучение сглаживание целевой функции. Использование данного подпроцесса основано на предположении, что похожие действия приводят к одинаковым результатам. Мы предполагаем, что совершение двух мало отличающихся действий приведет к одному результату. Следовательно, добавление незначительного шума к действиям Агента не приведет к изменению вознаграждения от окружающей среды. Но это позволит добавить некоторую стохастичность в процесс обучения Критика и сгладить его оценки в некотором окружении целевых значений.
![]()
Данный прием позволяет внести своеобразную регуляризацию в процесс обучения Критика и сгладить пики, ведущие к переоценки значений Q-функции.
Таким образом, Twin Delayed Deep Deterministic policy gradient (TD3) вводит 3 основных дополнения в алгоритм DDPG:
- Параллельное обучение 2 Критиков
- Задержка на обновление параметров Актера
- Сглаживание целевой функции.
Как можно заметить, все 3 дополнения относятся лишь к организации процесса обучения и не отражаются на архитектуре моделей.
2. Реализация средствами MQL5
В практической части статьи мы рассмотрим вариант реализации алгоритма TD3 средствами MQL5. Сразу скажу, что в данной реализации мы используем только 2 дополнения из 3. Я не стал добавлять сглаживание целевой функции ввиду стохастичности самого финансового рынка. И во всей обучающей выборке мы вряд ли найдем 2 полностью идентичных состояния.
Мы также возвращаемся к опыту использования 3 советников:
- Research — сбор базы примеров
- Study — обучение моделей
- Test — проверка полученных результатов.
Кроме того, мы вносим изменения в трактовку результатов модели, а вместе с тем и алгоритм торговли советника.
2.1. Изменение в алгоритме торговли
Вначале поговорим об изменении алгоритма торговли. Было решено уйти от бесконечного открытия новых позиций по принципу "открыл и забыл" (позиция открывается по результатам анализа текущей рыночной ситуации, а закрывается по стоп-лоссу или тейк-профиту). Вместо этого мы будем открывать и сопровождать позицию. При этом мы не исключаем доливок и частичного закрытия позиции.
В этой парадигме мы и изменяем трактовку сигналов модели. Как и ранее, Агент возвращает 6 значений: размер позиции, стоп-лосс и тейк-профит в 2 направлениях торговли. Но теперь мы будем сравнивать полученный объем с текущей позицией и, при необходимости доливать или частично закрывать позицию. Доливаться мы будем стандартными средствами, а для частичного закрытия позиций мы создадим функцию ClosePartial.
Здесь надо сказать, что закрыть часть одной позиции мы можем и стандартными средствами. Но мы предполагаем наличие нескольких позиций, открытых в результате доливок. Поэтому задача создаваемой функции закрывать позиции по методу FIFO (First In - First Out) на суммарный объем.
В параметрах функция получает тип позиции и объем закрытия. В теле функции мы сразу проверяем полученный объем закрытия позиций и при получении не корректного значения завершаем работу функции.
Далее мы организовываем цикл перебора всех открытых позиций. В теле цикла мы проверяем инструмент и тип открытой позиции. При нахождении необходимой позиции мы проверяем её объем. И здесь есть 2 варианта:
- объем позиции меньше или равен объему к закрытию — мы закрываем позицию полностью, а объем к закрытию уменьшаем на объем позиции
- объем позиции больше объема к закрытию — проводим частичное закрытие позиции, а объем к закрытию обнуляем.
Итерации цикла осуществляем до перебора всех открытых позиций или пока объем к закрытию больше «0».
bool ClosePartial(ENUM_POSITION_TYPE type, double value) { if(value <= 0) return true; //--- for(int i = 0; (i < PositionsTotal() && value > 0); i++) { if(PositionGetSymbol(i) != Symb.Name()) continue; if(PositionGetInteger(POSITION_TYPE) != type) continue; double pvalue = PositionGetDouble(POSITION_VOLUME); if(pvalue <= value) { if(Trade.PositionClose(PositionGetInteger(POSITION_TICKET))) { value -= pvalue; i--; } } else { if(Trade.PositionClosePartial(PositionGetInteger(POSITION_TICKET), value)) value = 0; } } //--- return (value <= 0); }
С объемом позиции мы определились. Теперь поговорим об уровнях стоп-лосса и тейк-профита. Из опыта торговли мы знаем, что при движении цены против позиции сдвигать уровень стоп-лосса перед ценой — плохая практика. Это ведет лишь к повышению рисков и накоплению убытков. Поэтому стоп-лосс мы будем тралить только в направлении сделки. Передвижение же уровня тейк-профита мы допускаем в обоих направлениях. Здесь логика проста. Мы могли изначально установить тейк-профит более консервативно, но развитие рынка предполагает более сильное движение. Следовательно, мы можем тралить стоп-лосс за ценой и при этом поднять планку ожидаемой прибыли. Или же наоборот мы не увидели ожидаемого движения рынка. Понижаем планку доходности. Забираем лишь то, что дает рынок.
Для реализации описанного функционала создаем функцию TrailPosition. В параметрах функции мы указываем тип позиции, цены стоп-лосса и тейк-профита. Обратите внимание, мы указываем именно цены торговых уровней, а не отступы в пунктах от текущей цены.
В теле функции мы не осуществляем проверку указанных уровней, оставим это за пользователем и сделаем пометку о необходимости такого контроля на стороне основной программы.
Далее мы организовываем цикл перебора всех открытых позиций. И, аналогично функции частичного закрытия позиции, в теле цикла проверяем инструмент и тип открытой позиции.
При нахождении нужной позиции мы сохраняем в локальные переменные текущий стоп-лосс и тейк-профит позиции. При этом устанавливаем флаг модификации позиции в положение false.
После этого мы проверяем отклонение торговых уровней открытой позиции от полученных в параметрах. Здесь надо отметить, что проверка необходимости модификации зависит от типа открытой позиции. Поэтому данный контроль мы осуществляем в теле оператора switch с проверкой типа позиции. При необходимости изменения хотя бы одного из торговых уровней мы заменяем соответствующее значение в локальной переменной и изменяем флаг модификации позиции в положение true.
В завершение операций цикла мы проверяем значение флага модификации позиции и, при необходимости, осуществляем обновление её торговых уровней. Результат операции сохраняем в локальную переменную.
После перебора всех открытых позиций мы завершаем работу функции. При этом возвращаем логический результат выполненных операций вызывающей программе.
bool TrailPosition(ENUM_POSITION_TYPE type, double sl, double tp) { int total = PositionsTotal(); bool result = true; //--- for(int i = 0; i <total; i++) { if(PositionGetSymbol(i) != Symb.Name()) continue; if(PositionGetInteger(POSITION_TYPE) != type) continue; bool modify = false; double psl = PositionGetDouble(POSITION_SL); double ptp = PositionGetDouble(POSITION_TP); switch(type) { case POSITION_TYPE_BUY: if((sl - psl) >= Symb.Point()) { psl = sl; modify = true; } if(MathAbs(tp - ptp) >= Symb.Point()) { ptp = tp; modify = true; } break; case POSITION_TYPE_SELL: if((psl - sl) >= Symb.Point()) { psl = sl; modify = true; } if(MathAbs(tp - ptp) >= Symb.Point()) { ptp = tp; modify = true; } break; } if(modify) result = (Trade.PositionModify(PositionGetInteger(POSITION_TICKET), psl, ptp) && result); } //--- return result; }
Говоря об изменениях в трактовке сигналов Актера, стоит обратить внимание ещё на один момент. Ранее, на выходе актера мы использовали LReLU в качестве функции активации. Это позволяет получать неограниченный результат в верхних значения. Но также позволяет выводить отрицательный результат, что мы расценивали в качестве сигнала отсутствия сделки. В парадигме текущей трактовки сигналов Актера мы решили изменить функцию активации на сигмоиду, область значений которой от 0 до 1. В качестве объема сделки нас вполне устраивают данные значения. А вот в качестве торговых уровней не совсем. И для дешифровки значений торговых уровней мы вводим 2 константы, которые определяют максимальный размер отступа стоп-лосса и тейк-профита от цены. Умножив данные константы на соответствующие данные Актера, мы получим торговые уровни в пунктах от текущей цены.
#define MaxSL 1000 #define MaxTP 1000
В остальном мы не стали изменять архитектуру наших моделей. Поэтому я не буду здесь приводить её описание, но вы можете ознакомиться с ней во вложении. Как всегда, описание архитектуры моделей находится в файле "TD3\Trajectory.mqh" функция CreateDescriptions.
2.2. Построение советника сбора базы примеров
Теперь, когда мы определились с принципами дешифровки сигналов Актера и основами алгоритма торговли, мы можем начинать работу непосредственно над нашими советниками обучения модели.
Первым мы создадим советник для сбора обучающей выборки примеров "TD3\Research.mq5". Советник построен на базе рассмотренных ранее аналогичных экспертов. В рамках данной статьи мы лишь рассмотрим метод OnTick, в котором реализован описанный выше алгоритм торговли. В остальном новая версия советника мало чем отличается от предыдущих.
В начале метода, как и ранее, мы проверяем наступление события открытия новой свечи. После чего загружаем исторические данные движения цены инструмента и показатели анализируемых индикаторов.
void OnTick() { //--- if(!IsNewBar()) return; //--- int bars = CopyRates(Symb.Name(), TimeFrame, iTime(Symb.Name(), TimeFrame, 1), HistoryBars, Rates); if(!ArraySetAsSeries(Rates, true)) return; //--- RSI.Refresh(); CCI.Refresh(); ATR.Refresh(); MACD.Refresh(); Symb.Refresh(); Symb.RefreshRates();
Загруженные данные мы переносим в буфер описания текущего состояния окружающей среды.
MqlDateTime sTime; float atr = 0; State.Clear(); for(int b = 0; b < (int)HistoryBars; b++) { float open = (float)Rates[b].open; TimeToStruct(Rates[b].time, sTime); float rsi = (float)RSI.Main(b); float cci = (float)CCI.Main(b); atr = (float)ATR.Main(b); float macd = (float)MACD.Main(b); float sign = (float)MACD.Signal(b); if(rsi == EMPTY_VALUE || cci == EMPTY_VALUE || atr == EMPTY_VALUE || macd == EMPTY_VALUE || sign == EMPTY_VALUE) continue; //--- State.Add((float)Rates[b].close - open); State.Add((float)Rates[b].high - open); State.Add((float)Rates[b].low - open); State.Add((float)Rates[b].tick_volume / 1000.0f); State.Add((float)sTime.hour); State.Add((float)sTime.day_of_week); State.Add((float)sTime.mon); State.Add(rsi); State.Add(cci); State.Add(atr); State.Add(macd); State.Add(sign); }
Следующим этапом мы подготовим вектор описания состояния счета.
sState.account[0] = (float)AccountInfoDouble(ACCOUNT_BALANCE); sState.account[1] = (float)AccountInfoDouble(ACCOUNT_EQUITY); //--- double buy_value = 0, sell_value = 0, buy_profit = 0, sell_profit = 0; double position_discount = 0; double multiplyer = 1.0 / (60.0 * 60.0 * 10.0); int total = PositionsTotal(); datetime current = TimeCurrent(); for(int i = 0; i < total; i++) { if(PositionGetSymbol(i) != Symb.Name()) continue; double profit = PositionGetDouble(POSITION_PROFIT); switch((int)PositionGetInteger(POSITION_TYPE)) { case POSITION_TYPE_BUY: buy_value += PositionGetDouble(POSITION_VOLUME); buy_profit += profit; break; case POSITION_TYPE_SELL: sell_value += PositionGetDouble(POSITION_VOLUME); sell_profit += profit; break; } position_discount += profit - (current - PositionGetInteger(POSITION_TIME)) * multiplyer * MathAbs(profit); } sState.account[2] = (float)buy_value; sState.account[3] = (float)sell_value; sState.account[4] = (float)buy_profit; sState.account[5] = (float)sell_profit; sState.account[6] = (float)position_discount; //--- Account.Clear(); Account.Add((float)((sState.account[0] - PrevBalance) / PrevBalance)); Account.Add((float)(sState.account[1] / PrevBalance)); Account.Add((float)((sState.account[1] - PrevEquity) / PrevEquity)); Account.Add(sState.account[2]); Account.Add(sState.account[3]); Account.Add((float)(sState.account[4] / PrevBalance)); Account.Add((float)(sState.account[5] / PrevBalance)); Account.Add((float)(sState.account[6] / PrevBalance));
Как можно заметить, подготовка исходных данных аналогична организации данного процесса в ранее рассмотренных советниках.
Далее мы передаем подготовленные данные на вход модели Актера и осуществляем прямой проход.
if(Account.GetIndex() >= 0) if(!Account.BufferWrite()) return; //--- if(!Actor.feedForward(GetPointer(State), 1, false, GetPointer(Account))) return;
Сохраняем данные, необходимые нам на следующем баре, и получаем результат работы Актера.
PrevBalance = sState.account[0]; PrevEquity = sState.account[1]; //--- vector<float> temp; Actor.getResults(temp); float delta = MathAbs(ActorResult - temp).Sum(); ActorResult = temp;
Обратите внимание, что в данном советнике мы используем только модель Актера. Ведь именно Актер генерирует действие в соответствии с выученной политикой (стратегией). Модели Критиков мы будем использовать в процессе обучения модели.
Далее, с целью максимального изучения окружающей среды мы добавим небольшой шум к результатам работы Актера.
Здесь надо вспомнить, что у нас есть 2 режима запуска советника. На начальном этапе мы запускаем советник без предварительно обученной модели и инициализируем нашего Актера случайными параметрами. В таком режиме нам нет необходимости добавлять шум для исследования окружающей среды. Ведь необученная модель будет давать и без того хаотичные значения. А вот при загрузке предварительно обученной модели добавление шума позволит нам исследовать окружающую среду в окрестностях решений Актера.
Полученные значения мы ограничиваем областью допустимых значений сигмоиды, которую мы используем в качестве функции активации на выходе модели Актера.
if(AddSmooth) { int err = 0; for(ulong i = 0; i < temp.Size(); i++) temp[i] += (float)(temp[i] * Math::MathRandomNormal(0, 0.3, err)); temp.Clip(0.0f, 1.0f); }
И переходим к стадии дешифровки вектора результатов Актера. Сначала мы сохраним в локальные переменные основные константы: минимальный объем позиции, шаг изменения объема позиции и минимальные отступы торговых уровней.
double min_lot = Symb.LotsMin(); double step_lot = Symb.LotsStep(); double stops = MathMax(Symb.StopsLevel(), 1) * Symb.Point();
Первыми мы дешифруем показатели длинных позиций. Первый элемент вектора отождествляется с объемом позиции. Он должен быть больше или равен минимальному объему позиции. Второй и третий элемент указывают значения тейк-профита и стоп-лосса, соответственно. Скорректируем данные элементы на константы максимальных тейк-профита и стоп-лосса, а также умножим на величину одного пункта инструмента. В результате мы должны получить значение боле минимального отступа торговых уровней. Если хотя бы один показатель не удовлетворяет условиям, мы закрываем все открытые позиции в данном направлении.
//--- buy control if(temp[0] < min_lot || (temp[1] * MaxTP * Symb.Point()) <= stops || (temp[2] * MaxSL * Symb.Point()) <= stops) { if(buy_value > 0) CloseByDirection(POSITION_TYPE_BUY); }
Когда же результаты работы Актера рекомендуют нам открыть или удерживать длинную позицию, мы нормализуем размер позиции в соответствии с требованиями брокера по анализируемому инструмента. Переведем торговые уровни в конкретные ценовые значения. После чего вызовем выше описанную функцию модификации открытых позиций, указав тип позиции POSITION_TYPE_BUY и полученные ценовые значения торговых уровней.
else { double buy_lot = min_lot+MathRound((double)(temp[0]-min_lot) / step_lot) * step_lot; double buy_tp = NormalizeDouble(Symb.Ask() + temp[1] * MaxTP * Symb.Point(), Symb.Digits()); double buy_sl = NormalizeDouble(Symb.Ask() - temp[2] * MaxSL * Symb.Point(), Symb.Digits()); if(buy_value > 0) TrailPosition(POSITION_TYPE_BUY, buy_sl, buy_tp);
Далее мы выравниваем размер открытых позиций с рекомендациями Актера. Если объем открытых позиций больше рекомендуемого, то мы вызываем функцию частичного закрытия позиций. В параметрах данной функции мы указываем тип позиции POSITION_TYPE_BUY и разницу между открытым и рекомендуемым объемами в качестве размера закрываемых позиций.
Если же рекомендуется доливка, то открываем дополнительную позицию на недостающий объем. При этом указываем рекомендуемые уровни стоп-лосса и тейк-профита.
if(buy_value != buy_lot) { if(buy_value > buy_lot) ClosePartial(POSITION_TYPE_BUY, buy_value - buy_lot); else Trade.Buy(buy_lot - buy_value, Symb.Name(), Symb.Ask(), buy_sl, buy_tp); } }
Аналогичным образом дешифруем показатели короткой позиции.
//--- sell control if(temp[3] < min_lot || (temp[4] * MaxTP * Symb.Point()) <= stops || (temp[5] * MaxSL * Symb.Point()) <= stops) { if(sell_value > 0) CloseByDirection(POSITION_TYPE_SELL); } else { double sell_lot = min_lot+MathRound((double)(temp[3]-min_lot) / step_lot) * step_lot;; double sell_tp = NormalizeDouble(Symb.Bid() - temp[4] * MaxTP * Symb.Point(), Symb.Digits()); double sell_sl = NormalizeDouble(Symb.Bid() + temp[5] * MaxSL * Symb.Point(), Symb.Digits()); if(sell_value > 0) TrailPosition(POSITION_TYPE_SELL, sell_sl, sell_tp); if(sell_value != sell_lot) { if(sell_value > sell_lot) ClosePartial(POSITION_TYPE_SELL, sell_value - sell_lot); else Trade.Sell(sell_lot - sell_value, Symb.Name(), Symb.Bid(), sell_sl, sell_tp); } }
В завершении метода мы добавим данные в массив траектории для последующего сохранения в базу примеров. Здесь мы сначала формируем вознаграждение от окружающей среды. В качестве вознаграждения мы используем относительное изменение баланса, которое мы ранее записали в первый элемент вектора описания состояния счета. К данному вознаграждению мы, при необходимости, добавляем штраф за отсутствие открытых позиций.
В структуру описания состояния мы добавляем векторы текущего состояния окружающей среды и результатов Актера. Данные описания состояния счета мы внесли ранее. И вызываем метод добавления текущего состояния в массив траектории.
//--- float reward = Account[0]; if((buy_value + sell_value) == 0) reward -= (float)(atr / PrevBalance); for(ulong i = 0; i < temp.Size(); i++) sState.action[i] = temp[i]; State.GetData(sState.state); if(!Base.Add(sState, reward)) ExpertRemove(); }
Прочие функции советника были перенесены практически без изменений. И вы можете самостоятельно ознакомиться с ними во вложении. А мы переходим к следующему этапу нашей работы.
2.3. Создание советника обучения моделей
Обучение модели осуществляется в советнике "TD3\Study.mq5". В данном советнике мы организуем весь алгоритм TD3 с обучением Актера и 2 Критиков.
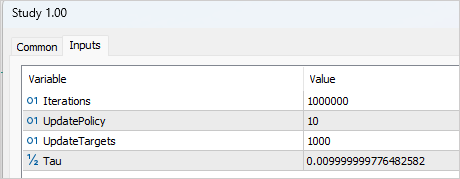
Организация процесса обучения требует добавления нескольких внешних переменных, которые помогут нам управлять процессом обучения. Как обычно, здесь мы указываем количество итераций обновления параметров моделей. В контексте метода TD3 это относится к обучению моделей Критиков.
input int Iterations = 1000000;
Для указания периодичности обновления Актера мы создадим переменную UpdatePolicy, в которой укажем на сколько обновлений Критика приходится 1 обновление Актера.
input int UpdatePolicy = 3;
Кроме того, мы укажем периодичность обновления целевых моделей и коэффициент обновления.
input int UpdateTargets = 100; input float Tau = 0.01f;
В области глобальных переменных мы объявим 6 экземпляров класса нейронной сети: Актер, 2 Критика и целевые модели.
CNet Actor; CNet Critic1; CNet Critic2; CNet TargetActor; CNet TargetCritic1; CNet TargetCritic2;
Надо сказать, что метод инициализации советника практически идентичен аналогичным советника из предыдущих статей. Конечно, с учетом различного количества обучаемых моделей. И вы можете ознакомиться с ним во вложении.
А вот в методе деинициализации мы осуществляем обновление и сохранение целевых моделей, а не обучаемых (как это делалось ранее). Целевые модели более статичны и менее накапливают ошибки.
void OnDeinit(const int reason) { //--- TargetActor.WeightsUpdate(GetPointer(Actor), Tau); TargetCritic1.WeightsUpdate(GetPointer(Critic1), Tau); TargetCritic2.WeightsUpdate(GetPointer(Critic2), Tau); TargetActor.Save(FileName + "Act.nnw", 0, 0, 0, TimeCurrent(), true); TargetCritic1.Save(FileName + "Crt1.nnw", TargetCritic1.getRecentAverageError(), 0, 0, TimeCurrent(), true); TargetCritic1.Save(FileName + "Crt2.nnw", TargetCritic2.getRecentAverageError(), 0, 0, TimeCurrent(), true); delete Result; }
Непосредственно процесс обучения моделей организован в функции Train. В теле функции мы сохраняем в локальную переменную количество загруженных траекторий обучающей выборки и организовываем цикл обучения по количеству итераций, указанных во внешнем параметре.
void Train(void) { int total_tr = ArraySize(Buffer); uint ticks = GetTickCount();
В теле цикла мы случайным образом выбираем траекторию и состояние из выбранной траектории.
for(int iter = 0; (iter < Iterations && !IsStopped()); iter ++) { int tr = (int)((MathRand() / 32767.0) * (total_tr - 1)); int i = (int)((MathRand() * MathRand() / MathPow(32767, 2)) * (Buffer[tr].Total - 2));
Сначала мы осуществляем прямой проход целевых моделей, что позволит нам получить прогнозную ценность последующего состояния.
Надо сказать, что теоретически мы могли бы обучить модели и без целевой функции. Ведь мы могли бы определить стоимость последующего состояния из накопленного фактического последующего вознаграждения. Такой подход мог быть уместным, если бы мы имели дело с конечным состоянием среды. Но мы тренируем модель для финансовых рынков, которые бесконечны на обозримом горизонте времени. И похожие состояния 1 или 3 месяца назад для нас имеют одинаковую ценность. Ведь мы хотим воспользоваться этим опытом в будущем. Поэтому хорошо обученная модель Критика сделает сопоставимыми результаты независимо от глубины истории.
Вернемся к нашему советнику. Мы переносим данные из базы примеров в буферы описания состояния окружающей среды и формируем вектор описания состояния счета. Обратите внимание, данные мы берем не для выбранного, а для последующего состояния.
//--- Target State.AssignArray(Buffer[tr].States[i + 1].state); float PrevBalance = Buffer[tr].States[i].account[0]; float PrevEquity = Buffer[tr].States[i].account[1]; Account.Clear(); Account.Add((Buffer[tr].States[i + 1].account[0] - PrevBalance) / PrevBalance); Account.Add(Buffer[tr].States[i + 1].account[1] / PrevBalance); Account.Add((Buffer[tr].States[i + 1].account[1] - PrevEquity) / PrevEquity); Account.Add(Buffer[tr].States[i + 1].account[2]); Account.Add(Buffer[tr].States[i + 1].account[3]); Account.Add(Buffer[tr].States[i + 1].account[4] / PrevBalance); Account.Add(Buffer[tr].States[i + 1].account[5] / PrevBalance); Account.Add(Buffer[tr].States[i + 1].account[6] / PrevBalance);
После чего организовываем прямой проход целевой модели Актера.
if(Account.GetIndex() >= 0) Account.BufferWrite(); if(!TargetActor.feedForward(GetPointer(State), 1, false, GetPointer(Account))) { PrintFormat("%s -> %d", __FUNCTION__, __LINE__); ExpertRemove(); break; }
Далее мы осуществляем прямой проход 2 целевых моделей Критиков. Исходными данными для обоих моделей служит целевая модель Актера.
if(!TargetCritic1.feedForward(GetPointer(TargetActor), LatentLayer, GetPointer(TargetActor)) || !TargetCritic2.feedForward(GetPointer(TargetActor), LatentLayer, GetPointer(TargetActor))) { PrintFormat("%s -> %d", __FUNCTION__, __LINE__); ExpertRemove(); break; }
Полученные данные позволяют нам сформировать целевые значения для обучения моделей Критика.
Напомню, что каждый Критик возвращает только одно значения прогнозной стоимости действия в текущих условиях. Следовательно, и целевое значение у нас будет одно число.
В соответствии с алгоритмом TD3 мы берем минимальное значение из 2 результатов Target моделей Критиков. Умножаем полученное значение на коэффициент дисконтирования и прибавляем фактическое вознаграждение за совершенное действие из базы примеров.
TargetCritic1.getResults(Result); float reward = Result[0]; TargetCritic2.getResults(Result); reward = DiscFactor * MathMin(reward, Result[0]) + (Buffer[tr].Revards[i] - Buffer[tr].Revards[i + 1]);
На данном этапе у нас есть целевое значение для Критика. Алгоритмом TD3 предусмотрено только одно целевое значение для 2 моделей Критиков. Но перед обратным проходом нам необходимо совершить прямой проход Критиков. И здесь есть один момент. Как вы знаете, архитектурой Критика не предусмотрен блок первичной обработки данных. Этот функционал выполняется Актером, а Критику мы передаем латентное состояния Актера в качестве исходных данных описания состояния среды. Следовательно, сначала мы берем исходные данные из базы примеров и осуществляем прямой проход модели Актера.
//--- Q-function study State.AssignArray(Buffer[tr].States[i].state); PrevBalance = Buffer[tr].States[MathMax(i - 1, 0)].account[0]; PrevEquity = Buffer[tr].States[MathMax(i - 1, 0)].account[1]; Account.Clear(); Account.Add((Buffer[tr].States[i].account[0] - PrevBalance) / PrevBalance); Account.Add(Buffer[tr].States[i].account[1] / PrevBalance); Account.Add((Buffer[tr].States[i].account[1] - PrevEquity) / PrevEquity); Account.Add(Buffer[tr].States[i].account[2]); Account.Add(Buffer[tr].States[i].account[3]); Account.Add(Buffer[tr].States[i].account[4] / PrevBalance); Account.Add(Buffer[tr].States[i].account[5] / PrevBalance); Account.Add(Buffer[tr].States[i].account[6] / PrevBalance); //--- if(Account.GetIndex() >= 0) Account.BufferWrite(); //--- if(!Actor.feedForward(GetPointer(State), 1, false, GetPointer(Account))) { PrintFormat("%s -> %d", __FUNCTION__, __LINE__); ExpertRemove(); break; }
И тут мы должны вспомнить, что в процессе обучения Актера с большой долей вероятности он вернет действия отличные от сохраненных в базе примеров. Однако, вознаграждение не соответствует сохраненному действию. Поэтому мы выгружаем латентное состояние Актера. Загружаем из базы примеров совершенное действие. И на этих данных осуществляем прямой проход обоих Критиков.
if(!Critic1.feedForward(Result,1,false, GetPointer(Actions)) || !Critic2.feedForward(Result,1,false, GetPointer(Actions))) { PrintFormat("%s -> %d", __FUNCTION__, __LINE__); ExpertRemove(); break; }
Обратим внимание еще на один момент. Теоретически, мы могли сохранить латентное состояние Актера на стадии сбора базы примеров и сейчас просто воспользоваться сохраненными данными. Но давайте вспомним, что в процессе обучения модели изменяются параметры всех нейронных слоев. Следовательно, в процессе обучения Актера изменяется и блок предварительной обработки данных. Как следствие, изменяется латентное представление того же состояния окружающей среды. И если мы обучим Критика на некорректных исходных данных, то в результате получим непредсказуемый результат при обучении Актера. А нам бы этого не хотелось. Поэтому для обучения Критиков мы используем корректное латентное представление состояния окружающей среды вместе с совершенными действиями из базы примеров и соответствующим вознаграждением.
Далее мы заполняем буфер целевых значений и осуществляем обратный проход обоих Критиков.
Result.Clear(); Result.Add(reward); if(!Critic1.backProp(Result, GetPointer(Actions), GetPointer(Gradient)) || !Critic2.backProp(Result, GetPointer(Actions), GetPointer(Gradient))) { PrintFormat("%s -> %d", __FUNCTION__, __LINE__); ExpertRemove(); break; }
С тонкостями обучения Критиков разобрались. Переходим к обучению Актера. Как было сказано в теоретической части данной статьи, обновление параметров Актера осуществляется реже. Поэтому мы сначала проверяем необходимость проведения данной процедуры на текущей итерации.
//--- Policy study if(iter > 0 && (iter % UpdatePolicy) == 0) {
В случае наступления момента обновления параметров Актера, то с целью сохранения объективности мы случайным образом выбираем новые исходные данные.
tr = (int)((MathRand() / 32767.0) * (total_tr - 1)); i = (int)((MathRand() * MathRand() / MathPow(32767, 2)) * (Buffer[tr].Total - 2)); State.AssignArray(Buffer[tr].States[i].state); PrevBalance = Buffer[tr].States[MathMax(i - 1, 0)].account[0]; PrevEquity = Buffer[tr].States[MathMax(i - 1, 0)].account[1]; Account.Clear(); Account.Add((Buffer[tr].States[i].account[0] - PrevBalance) / PrevBalance); Account.Add(Buffer[tr].States[i].account[1] / PrevBalance); Account.Add((Buffer[tr].States[i].account[1] - PrevEquity) / PrevEquity); Account.Add(Buffer[tr].States[i].account[2]); Account.Add(Buffer[tr].States[i].account[3]); Account.Add(Buffer[tr].States[i].account[4] / PrevBalance); Account.Add(Buffer[tr].States[i].account[5] / PrevBalance); Account.Add(Buffer[tr].States[i].account[6] / PrevBalance);
И осуществляем прямой проход Актера.
if(Account.GetIndex() >= 0) Account.BufferWrite(); //--- if(!Actor.feedForward(GetPointer(State), 1, false, GetPointer(Account))) { PrintFormat("%s -> %d", __FUNCTION__, __LINE__); ExpertRemove(); break; }
Следом мы осуществляем прямой проход одного Критика. Обратите внимание, в данном случае мы не используем данные из базы примеров. Прямой проход Критика осуществляется полностью на новых результатах Актера. Ведь нам важно оценить текущую политику модели.
if(!Critic1.feedForward(GetPointer(Actor), LatentLayer, GetPointer(Actor))) { PrintFormat("%s -> %d", __FUNCTION__, __LINE__); ExpertRemove(); break; }
Для обновления параметров Актера я использовал Критика1. По моим наблюдениям, выбор модели Критика в данном случае не критичен. Несмотря на разницу в оценках, во время тестирования оба Критика возвращали идентичные значения градиента ошибки Актеру.
Обучение Актера направлено на максимизацию ожидаемого вознаграждения. Мы берем текущий результат оценки действий Критиком и прибавляем к нему небольшую положительную константу. Надо отметить, что в случае получения отрицательной оценки действий, в качестве целевого значения я использовал свою положительную константу. Таким образом я стремился ускорить выход из зоны отрицательных оценок.
Critic1.getResults(Result); float forecast = Result[0]; Result.Update(0, (forecast > 0 ? forecast + PoliticAdjust : PoliticAdjust));
Немаловажен и тот факт, что в процессе обновления параметров Актера модель Критика используется только в качестве своеобразной функции потерь. Она лишь генерирует градиент ошибки на выходе Актера. При этом не изменяются параметры самого критика. С этой целью перед обратным проходом мы отключаем у Критика режим обучения. А после передачи градиента ошибки Актеру, возвращаем Критика в режим обучения.
Critic1.TrainMode(false); if(!Critic1.backProp(Result, GetPointer(Actor)) || !Actor.backPropGradient(GetPointer(Account), GetPointer(Gradient))) { Critic1.TrainMode(true); PrintFormat("%s -> %d", __FUNCTION__, __LINE__); ExpertRemove(); break; } Critic1.TrainMode(true); }
После получения градиента ошибки от Критика мы осуществляем обратный проход Актера.
На этом этапе мы организовали процесс изучения Q-функции Критиками и обучение политики Актерам. Нам остается реализовать мягкое обновление целевых моделей. Организация данного процесса была подробно описана в предыдущей статье. Здесь мы лишь проверяем наступление момента обновления моделей и вызываем соответствующие методы для каждой целевой модели.
//--- Update Target Nets if(iter > 0 && (iter % UpdateTargets) == 0) { TargetActor.WeightsUpdate(GetPointer(Actor), Tau); TargetCritic1.WeightsUpdate(GetPointer(Critic1), Tau); TargetCritic2.WeightsUpdate(GetPointer(Critic2), Tau); }
В завершении итерации цикла мы информируем пользователе о состоянии процесса обучения и выводим текущие ошибки обоих критиков. Мы не выводим показатели качества обучения Актера, так как для данной модели не рассчитывается ошибка.
if(GetTickCount() - ticks > 500) { string str = StringFormat("%-15s %5.2f%% -> Error %15.8f\n", "Critic1", iter * 100.0 / (double)(Iterations), Critic1.getRecentAverageError()); str += StringFormat("%-15s %5.2f%% -> Error %15.8f\n", "Critic2", iter * 100.0 / (double)(Iterations), Critic2.getRecentAverageError()); Comment(str); ticks = GetTickCount(); } }
После завершения итераций цикла мы очищаем область комментариев и инициализируем процесс завершения работы советника.
Comment(""); //--- PrintFormat("%s -> %d -> %-15s %10.7f", __FUNCTION__, __LINE__, "Critic1", Critic1.getRecentAverageError()); PrintFormat("%s -> %d -> %-15s %10.7f", __FUNCTION__, __LINE__, "Critic2", Critic2.getRecentAverageError()); ExpertRemove(); //--- }
Мы не будем останавливаться на описании алгоритма работы советника тестирования обученной модели "TD3\Test.mq5". Его код практически полностью повторяет советник сбора базы примеров. Мы исключили лишь добавление шума к результатам работы Актера. Ведь в процессе тестирования мы хотим оценить качество обучения модели, что исключает исследование окружающей среды. В то же время мы оставили блок сбора траектории и записи её в базу примеров. Это позволит нам сохранить удачные и не очень проходы. А при последующем запуске процесса обучения "сделать работу над ошибками".
Напомню, что с полным кодом всех используемых в статье программы вы можете ознакомиться во вложении.
3. Тестирование
После завершения работы по созданию программ мы переходим к процессу обучения и проверки полученных результатов. Как обычно, обучение моделей осуществлялось на исторических данных инструмента EURUSD таймфрейм H1 за период январь—май 2023 года. Параметры индикаторов и все гиперпараметры использовались установленные по умолчанию.
Сразу скажем, что процесс обучения был довольно длительный и итерационный. На первом этапе была создана база из 200 траекторий. Первый процесс обучения был запущен на 1 000 000 итераций. Обновление политики Актера осуществлялось 1 раз после каждых 10 итераций обновления параметров Критиков. А мягкое обновление целевых моделей осуществлялось после каждых 1 000 итераций обновления Критиков.
После первого этапа обучения было добавлено еще 50 траекторий в базу примеров и запущен второй этап обучения моделей. При этом количество итераций до обновления Актера и целевых моделей было снижено до 3 и 100, соответственно.
Примерно после 5 циклов обучения (на каждом цикле добавлялось 50 траекторий) была получена модель, способная генерировать прибыль на обучающей выборке. За 5 месяцем обучающей выборки модель смогла получить почти 10% дохода. Показатель не самый большой. Было совершено 58 сделок. Доля прибыльных приблизилась всего лишь к 40%. Профит фактор — 1.05, фактор восстановления — 1.50. Прибыль была достигнута благодаря размеру прибыльных позиций. Средняя прибыль от одной сделки в 1.6 раза больше среднего убытка. А максимальная прибыль в 3.5 раза превышает максимальный убыток от одной торговой операции.
Примечательно, что просадка по балансу составляет почти 32%. В то время как по Эквити едва превышает 6%. Как можно заметить на графике, при ровной или даже растущей линии Эквити мы наблюдаем просадки по балансу. Этот эффект объясняется одновременным открытием разнонаправленных позиций. При срабатывании стоп-лосса убыточной позиции мы наблюдаем просадку по балансу. Но одновременно открытая противоположно направленная позиция накапливает прибыль, что отражается на линии Эквити.


Как мы помним, в предыдущей статье модель показала более существенный результат на обучающей выборке, но не смогла его повторить на новых данных. Сейчас же ситуация обратная. Мы не получили сверхприбыль на обучающей выборке, но модель показала стабильный результат и вне обучающей выборки. При тестировании работы модели на последующих данных, не входящих в обучающую выборку, мы видим "уменьшенную копию" предыдущего теста. Модель получила 2,5% прибыли за 1 месяц. Профит фактор — 1.07, фактор восстановления — 1.16. Всего 27% прибыльных сделок, но при этом средняя прибыльная сделка почти в 3 раза превышает среднюю убыточную сделку. 32% просадка по балансу и только 2% по Эквити.


Заключение
В данной статье мы познакомились с алгоритмом Twin Delayed Deep Deterministic policy gradient (TD3). Авторы данного метода предлагаю несколько важных улучшений в алгоритм DDPG, которые позволяют повысить эффективность метода и стабильность обучения моделей.
В рамках статьи мы реализовали данный метод средствами MQL5 и провели его тестирование на исторических данных. В процессе обучения была получена модель, способная генерировать прибыль не только на обучающих данных, но и использовать полученный опыт на новых данных. Стоит отметить, что на новых данных модель получила результаты, сопоставимые с результатами обучающей выборки. Да, результаты не совсем такие, которые мы бы хотели получить. И есть моменты, над которыми еще стоит поработать. Но одно не вызывает сомнений — алгоритм TD3 позволяет обучать модель стабильно работающие на новых данных.
В целом мы можем приять алгоритм в копилку для последующих исследований в построении модели для реальной торговли.
Ссылки
Программы, используемые в статье
| # | Имя | Тип | Описание |
|---|---|---|---|
| 1 | Research.mq5 | Советник | Советник сбора примеров |
| 2 | Study.mq5 | Советник | Советник обучения агента |
| 3 | Test.mq5 | Советник | Советник для тестирования модели |
| 4 | Trajectory.mqh | Библиотека класса | Структура описания состояния системы |
| 5 | NeuroNet.mqh | Библиотека класса | Библиотека классов для создания нейронной сети |
| 6 | NeuroNet.cl | Библиотека | Библиотека кода программы OpenCL |
- Бесплатные приложения для трейдинга
- 8 000+ сигналов для копирования
- Экономические новости для анализа финансовых рынков
Вы принимаете политику сайта и условия использования