
Redes neuronales: así de sencillo (Parte 48): Métodos para reducir la sobreestimación de los valores de la función Q

Introducción
En el artículo anterior, introdujimos el método Deep Deterministic Policy Gradient (DDPG) para el entrenamiento de modelos en un espacio de acción continuo. Esto nos permite llevar el entrenamiento de nuestros modelos al siguiente nivel. En consecuencia, nuestro último Agente no solo es capaz de predecir la próxima dirección de los precios, sino que también desempeña funciones de gestión del capital y del riesgo. Asimismo, indica el tamaño óptimo de la posición que debe abrirse, así como los niveles de stop loss y take profit.
No obstante, el DDPG no está exento de inconvenientes. Al igual que otros seguidores del aprendizaje Q, es vulnerable ante el problema de la sobreestimación de los valores de la función Q. Durante el proceso de entrenamiento, el error es capaz de acumularse, lo que finalmente lleva al agente a aprender una estrategia subóptima.
Me gustaría recordarle que en el DDPG, el modelo del Crítico enseña la función Q (predicción de la recompensa esperada) sobre los resultados de la interacción con el entorno, mientras que el modelo del Agente está entrenado para maximizar la recompensa esperada basándose únicamente en los resultados de la evaluación de las acciones del Crítico. Por consiguiente, la calidad del entrenamiento del Crítico influirá mucho en la estrategia de comportamiento del Agente y en su capacidad para tomar decisiones óptimas.
1. Enfoques para reducir la sobreestimación
El problema de la sobreestimación de los valores de la función Q aparece con bastante frecuencia al entrenar varios modelos usando el método DQN y sus derivados. Es característico tanto de los modelos con acciones discretas como de la resolución de problemas en un espacio continuo de acciones. Las causas de este fenómeno y los métodos para afrontar sus consecuencias pueden ser específicos en cada caso. Por lo tanto, resulta importante adoptar un enfoque global para resolver este problema. Uno de estos enfoques se presentó en el artículo "Addressing Function Approximation Error in Actor-Critic Methods", publicado en febrero de 2018. En este se propuso un algoritmo denominado Twin Delayed Deep Deterministic policy gradient (TD3). Este algoritmo es una extensión lógica del DDPG y le introduce algunas mejoras para mejorar la calidad del entrenamiento del modelo.
Al principio, los autores añaden un segundo Crítico. La idea no es nueva y ya se ha usado antes para modelos con un espacio de acción discreto. Sin embargo, los autores del método han aportado su comprensión, visión y enfoque al uso del segundo Crítico.
La idea es que ambos Críticos se inicialicen con parámetros aleatorios y se entrenen en paralelo con los mismos datos. Inicializados con diferentes parámetros iniciales, comienzan su aprendizaje partiendo de diferentes estados, pero ambos Críticos se entrenan con los mismos datos, por lo que deberían moverse hacia el mismo mínimo, idealmente global. Aunque es bastante natural que sus resultados de predicción converjan durante el proceso de aprendizaje, no resultarán idénticos debido a diversos factores, y sí, cada uno es susceptible al problema de la sobreestimación de la función Q. No obstante, en un momento dado, un modelo sobrestimará la función Q y el otro la subestimará, e incluso cuando ambos modelos sobrestimen la función Q, el error de un modelo será menor que el del otro. Basándose en estos supuestos, los autores del método proponen usar el mínimo de las predicciones para entrenar a ambos Críticos. De esta forma, minimizamos el impacto de la sobreestimación de la función Q y la acumulación de errores durante el proceso de aprendizaje.
Matemáticamente, esta técnica puede representarse de la forma que sigue:
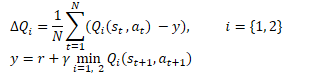
Al igual que el DDPG, los autores del TD3 recomiendan el uso de una actualización suave de los modelos objetivo. Mediante ejemplos prácticos, los autores demuestran que el uso de la actualización suave de los modelos objetivo conduce a un proceso de aprendizaje de la función Q más estable y con menos varianza en los resultados. Al mismo tiempo, el uso de objetivos más estables (menos actualizados) durante el entrenamiento redunda en una menor acumulación de error de sobreestimación de la función Q.
Los resultados de los experimentos llevan a los autores del método a sugerir una actualización menos frecuente de la política del Actor.
Recordemos que el entrenamiento de redes neuronales consiste en un proceso iterativo de reducción gradual del error. El ritmo del aprendizaje viene determinado por los coeficientes de entrenamiento y el algoritmo de actualización de parámetros. Este enfoque permite promediar el error en la muestra de entrenamiento y construir un modelo lo más semejante posible al proceso estudiado.
Los resultados del modelo del Actor forman parte de la muestra de entrenamiento del Crítico. Al actualizar la política del Actor con poca frecuencia, se reduce la estocasticidad de la muestra de entrenamiento del Crítico y, por consiguiente, aumenta la estabilidad de su aprendizaje.
A su vez, entrenar al Actor con los datos de evaluación de los resultados de un Crítico más preciso mejora la calidad de actuación del Actor y elimina operaciones de actualización innecesarias con resultados erróneos.
Además, los autores del algoritmo TD3 propusieron añadir el suavizado de la función objetivo al proceso de entrenamiento. El uso de este subproceso se basa en el supuesto de que acciones similares conducen a resultados semejantes. Suponemos que realizar dos acciones ligeramente diferentes conducirá al mismo resultado. En consecuencia, aunque añadir un poco de ruido a las acciones del Agente no cambiará la recompensa del entorno, esto sí que añadirá algo de estocasticidad al proceso de aprendizaje del Crítico y suavizará sus estimaciones en algún entorno de valores objetivo.
![]()
Esta técnica permite introducir una especie de regularización en el proceso de entrenamiento del Crítico y suavizar los picos que conducen a la sobreestimación de los valores de la función Q.
Así, el TD3 introduce 3 adiciones importantes al algoritmo del DDPG:
- El aprendizaje paralelo de dos Críticos
- El retraso en la actualización de los parámetros del Actor
- El suavizado de la función objetivo.
Como podemos ver, las 3 adiciones solo están relacionadas con la organización del proceso de aprendizaje y no afectan a la arquitectura de los modelos.
2. Implementación usando MQL5
En la parte práctica del artículo, analizaremos una variante de implementación del algoritmo TD3 utilizando herramientas MQL5. Permítanme decir de inmediato que en esta aplicación solo utilizaremos 2 de los 3 complementos. No hemos añadido suavizado a la función objetivo debido a la estocasticidad del propio mercado financiero, y en toda la muestra de entrenamiento es poco probable que encontremos 2 estados completamente idénticos.
También volveremos a la experiencia de utilizar 3 asesores:
- Research — recopilación de la base de datos de ejemplos
- Study — entrenamiento de los modelos
- Test — comprobación de los resultados obtenidos
Además, realizaremos cambios en la interpretación de los resultados del modelo, y con ello en el algoritmo comercial del asesor experto.
2.1. Cambio del algoritmo comercial
En primer lugar, hablaremos del cambio en el algoritmo comercial. Hemos decidido prescindir de la interminable apertura de nuevas posiciones según el principio de "abrir y olvidar" (las posiciones se abren según los resultados del análisis de la situación actual del mercado, y se cierran mediante stop-loss o take-profit). En su lugar, abriremos y mantendremos la posición. Al mismo tiempo, no excluiremos la recompra y el cierre parcial de la posición.
Este es el paradigma en el que modificaremos la interpretación de las señales del modelo. Como antes, el Agente retorna 6 valores: el tamaño de la posición, y el Stop Loss y el Take Profit en las 2 direcciones comerciales, pero ahora compararemos el volumen obtenido con la posición actual y, de ser necesario, añadiremos o cerraremos parcialmente la posición. Utilizaremos los medios estándar para recomprar posiciones, y para el cierre parcial de posiciones crearemos la función ClosePartial.
Aquí debemos decir que también podemos cerrar una parte de una posición usando los medios estándar, pero suponemos que existen varias posiciones abiertas como consecuencia de las recompras. Por lo tanto, la tarea de la función creada consistirá en cerrar posiciones utilizando el método FIFO (First In - First Out) para el volumen total.
La función obtendrá el tipo de posición y el volumen de cierre en los parámetros. En el cuerpo de la función comprobaremos directamente el volumen recibido del cierre de posiciones y finalizaremos la función si obtenemos un valor incorrecto.
A continuación, organizaremos un ciclo para enumerar todas las posiciones abiertas. En el cuerpo del ciclo, comprobaremos el instrumento y el tipo de posición abierta. Cuando encontremos el puesto necesario, comprobaremos el alcance del mismo. Aquí hay dos opciones:
- el volumen de la posición es inferior o igual al volumen de cierre: cerraremos la posición en su totalidad y reduciremos el volumen de cierre en la magnitud del volumen de la posición
- el volumen de la posición es mayor que el volumen de cierre: realizaremos un cierre parcial de la posición y pondremos a cero el volumen respecto al cierre.
El ciclo se repetirá hasta que se iteren todas las posiciones abiertas o hasta que el volumen a cerrar sea superior a "0".
bool ClosePartial(ENUM_POSITION_TYPE type, double value) { if(value <= 0) return true; //--- for(int i = 0; (i < PositionsTotal() && value > 0); i++) { if(PositionGetSymbol(i) != Symb.Name()) continue; if(PositionGetInteger(POSITION_TYPE) != type) continue; double pvalue = PositionGetDouble(POSITION_VOLUME); if(pvalue <= value) { if(Trade.PositionClose(PositionGetInteger(POSITION_TICKET))) { value -= pvalue; i--; } } else { if(Trade.PositionClosePartial(PositionGetInteger(POSITION_TICKET), value)) value = 0; } } //--- return (value <= 0); }
Con el alcance de la posición que hemos decidido. Ahora hablaremos de los niveles de stop loss y take profit. Partiendo de la experiencia comercial, sabemos que es una mala práctica mover el nivel de stop loss delante del precio cuando el precio se mueve en contra de la posición. Esto solo provocará mayores riesgos y una acumulación de las pérdidas. Por lo tanto, arrastraremos el stop loss solo en la dirección de la transacción. Permitiremos que el nivel de take profit se mueva en ambas direcciones. La lógica es simple. Podríamos haber fijado inicialmente el take profit de forma más conservadora, pero la evolución del mercado sugiere un movimiento más fuerte. En consecuencia, podemos arrastrar el stop loss detrás del precio y seguir subiendo el listón del beneficio esperado. O, por el contrario, si no hemos visto el movimiento esperado del mercado, bajaremos el listón de la rentabilidad. Solo aceptaremos lo que nos dé el mercado.
Para implementar la funcionalidad descrita, crearemos la función TrailPosition. En los parámetros de la función especificaremos el tipo de posición y los precios de stop loss y take profit. Tenga en cuenta que especificaremos exactamente los precios de los niveles comerciales, no la separación en pips respecto al precio actual.
En el cuerpo de la función no comprobaremos los niveles especificados, dejaremos esto al usuario y haremos una nota sobre la necesidad de dicho control en el lado del programa principal.
A continuación, organizaremos un ciclo para enumerar todas las posiciones abiertas. Y, de forma similar a la función de cierre parcial de posición, en el cuerpo del ciclo, comprobaremos el instrumento y el tipo de la posición abierta.
Al encontrar la posición deseada, guardaremos el stop loss y el take profit actual de la posición en las variables locales. Al mismo tiempo, estableceremos el indicador de modificación de posición en false.
Después comprobaremos la desviación de los niveles comerciales de la posición abierta respecto a los obtenidos en los parámetros. Aquí cabe señalar que la verificación sobre la necesidad de modificación dependerá del tipo de posición abierta. Por lo tanto, realizaremos este control en el cuerpo del operador switch comprobando además el tipo de posición. Si es necesario cambiar al menos uno de los niveles comerciales, sustituiremos el valor correspondiente en la variable local y cambiaremos el indicador de modificación de posición a true.
Al final de las operaciones del ciclo, comprobaremos el valor del indicador de modificación de posición y, de ser necesario, actualizaremos sus niveles comerciales. El resultado de la operación se guardará en una variable local.
Una vez iteradas todas las posiciones abiertas, finalizaremos la función. En este caso, retornaremos al programa de llamada el resultado lógico de las operaciones realizadas.
bool TrailPosition(ENUM_POSITION_TYPE type, double sl, double tp) { int total = PositionsTotal(); bool result = true; //--- for(int i = 0; i <total; i++) { if(PositionGetSymbol(i) != Symb.Name()) continue; if(PositionGetInteger(POSITION_TYPE) != type) continue; bool modify = false; double psl = PositionGetDouble(POSITION_SL); double ptp = PositionGetDouble(POSITION_TP); switch(type) { case POSITION_TYPE_BUY: if((sl - psl) >= Symb.Point()) { psl = sl; modify = true; } if(MathAbs(tp - ptp) >= Symb.Point()) { ptp = tp; modify = true; } break; case POSITION_TYPE_SELL: if((psl - sl) >= Symb.Point()) { psl = sl; modify = true; } if(MathAbs(tp - ptp) >= Symb.Point()) { ptp = tp; modify = true; } break; } if(modify) result = (Trade.PositionModify(PositionGetInteger(POSITION_TICKET), psl, ptp) && result); } //--- return result; }
Hablando de cambios en la interpretación de las señales del Actor, merece la pena prestar atención a otro punto más. Antes, utilizábamos LReLU como función de activación en la salida del Actor. Esto permite obtener resultados sin restricciones en los valores superiores, pero también nos permite obtener un resultado negativo, que considerábamos una señal de ausencia de transacción. En el paradigma de la interpretación actual de las señales del Actor, hemos decidido cambiar la función de activación por una sigmoidea, cuyo rango de valores irá de 0 a 1. Como volumen de transacciones, estos valores resultan bastante satisfactorios, pero como niveles comerciales, no tanto. Y para descifrar los valores de los niveles comerciales, introduciremos 2 constantes que definirán el tamaño máximo del stop loss y el take profit del precio. Multiplicando estas constantes por los datos correspondientes del Actor, obtendremos los niveles comerciales en pips partiendo del precio actual.
#define MaxSL 1000 #define MaxTP 1000
Por lo demás, no hemos cambiado la arquitectura de nuestros modelos, así que no la describiremos aquí, pero puede familiarizarse con ella en el archivo adjunto. Como siempre, podrá encontrar la descripción de la arquitectura de los modelos en el archivo "TD3\Trajectory.mqh", función CreateDescriptions.
2.2. Creamos un asesor para recopilar una base de datos de ejemplos
Ahora que ya hemos tomado las decisiones oportunas sobre los principios de decodificación de las señales del Actor y los fundamentos del algoritmo comercial, podemos empezar a trabajar directamente en nuestro modelo de entrenamiento de asesores.
En primer lugar, crearemos un asesor experto para recoger la muestra de entrenamiento de ejemplos "TD3\Research.mq5". El asesor experto está construido sobre la base de asesores expertos similares anteriormente analizados. En el marco de este artículo, solo consideraremos el método OnTick, que implementa el algoritmo comercial descrito anteriormente. Por lo demás, la nueva versión del asesor experto no difiere mucho de las anteriores.
Al principio del método, como antes, comprobaremos la aparición de un nuevo evento de apertura de vela. Después de ello, cargaremos los datos históricos de los movimientos de precio del instrumento y las métricas de los indicadores analizados.
void OnTick() { //--- if(!IsNewBar()) return; //--- int bars = CopyRates(Symb.Name(), TimeFrame, iTime(Symb.Name(), TimeFrame, 1), HistoryBars, Rates); if(!ArraySetAsSeries(Rates, true)) return; //--- RSI.Refresh(); CCI.Refresh(); ATR.Refresh(); MACD.Refresh(); Symb.Refresh(); Symb.RefreshRates();
Luego transferiremos los datos descargados al búfer que describe el estado actual del entorno.
MqlDateTime sTime; float atr = 0; State.Clear(); for(int b = 0; b < (int)HistoryBars; b++) { float open = (float)Rates[b].open; TimeToStruct(Rates[b].time, sTime); float rsi = (float)RSI.Main(b); float cci = (float)CCI.Main(b); atr = (float)ATR.Main(b); float macd = (float)MACD.Main(b); float sign = (float)MACD.Signal(b); if(rsi == EMPTY_VALUE || cci == EMPTY_VALUE || atr == EMPTY_VALUE || macd == EMPTY_VALUE || sign == EMPTY_VALUE) continue; //--- State.Add((float)Rates[b].close - open); State.Add((float)Rates[b].high - open); State.Add((float)Rates[b].low - open); State.Add((float)Rates[b].tick_volume / 1000.0f); State.Add((float)sTime.hour); State.Add((float)sTime.day_of_week); State.Add((float)sTime.mon); State.Add(rsi); State.Add(cci); State.Add(atr); State.Add(macd); State.Add(sign); }
El siguiente paso consistirá en preparar un vector para describir el estado de la cuenta.
sState.account[0] = (float)AccountInfoDouble(ACCOUNT_BALANCE); sState.account[1] = (float)AccountInfoDouble(ACCOUNT_EQUITY); //--- double buy_value = 0, sell_value = 0, buy_profit = 0, sell_profit = 0; double position_discount = 0; double multiplyer = 1.0 / (60.0 * 60.0 * 10.0); int total = PositionsTotal(); datetime current = TimeCurrent(); for(int i = 0; i < total; i++) { if(PositionGetSymbol(i) != Symb.Name()) continue; double profit = PositionGetDouble(POSITION_PROFIT); switch((int)PositionGetInteger(POSITION_TYPE)) { case POSITION_TYPE_BUY: buy_value += PositionGetDouble(POSITION_VOLUME); buy_profit += profit; break; case POSITION_TYPE_SELL: sell_value += PositionGetDouble(POSITION_VOLUME); sell_profit += profit; break; } position_discount += profit - (current - PositionGetInteger(POSITION_TIME)) * multiplyer * MathAbs(profit); } sState.account[2] = (float)buy_value; sState.account[3] = (float)sell_value; sState.account[4] = (float)buy_profit; sState.account[5] = (float)sell_profit; sState.account[6] = (float)position_discount; //--- Account.Clear(); Account.Add((float)((sState.account[0] - PrevBalance) / PrevBalance)); Account.Add((float)(sState.account[1] / PrevBalance)); Account.Add((float)((sState.account[1] - PrevEquity) / PrevEquity)); Account.Add(sState.account[2]); Account.Add(sState.account[3]); Account.Add((float)(sState.account[4] / PrevBalance)); Account.Add((float)(sState.account[5] / PrevBalance)); Account.Add((float)(sState.account[6] / PrevBalance));
Como puede ver, la preparación de los datos iniciales resulta similar a la organización de este proceso en los asesores anteriormente comentados.
A continuación, transmitiremos los datos preparados a la entrada del modelo del Actor y realizaremos una pasada directa.
if(Account.GetIndex() >= 0) if(!Account.BufferWrite()) return; //--- if(!Actor.feedForward(GetPointer(State), 1, false, GetPointer(Account))) return;
Luego guardaremos los datos que necesitamos en la siguiente barra y obtendremos el resultado del Actor.
PrevBalance = sState.account[0]; PrevEquity = sState.account[1]; //--- vector<float> temp; Actor.getResults(temp); float delta = MathAbs(ActorResult - temp).Sum(); ActorResult = temp;
Tenga en cuenta que en este asesor solo utilizaremos el modelo del Actor. Al fin y al cabo, es el Actor quien genera la acción según la política (estrategia) aprendida. Los modelos de los Críticos los utilizaremos en el proceso de entrenamiento del modelo.
A continuación, para maximizar la exploración del entorno, añadiremos un poco de ruido a los resultados del Actor.
Aquí deberemos recordar que tenemos 2 modos de ejecución del asesor experto. En la fase inicial, ejecutaremos el asesor sin un modelo preentrenado e inicializaremos nuestro Actor con parámetros aleatorios. En este modo, no será necesario añadir ruido para explorar el entorno. Al fin y al cabo, un modelo no entrenado producirá valores ya de por sí caóticos, pero al cargar un modelo preentrenado, la adición de ruido nos permitirá explorar el entorno en las proximidades de las soluciones del Actor.
Los valores obtenidos los restringiremos a la región de valores aceptables de la sigmoide que utilizamos como función de activación en la salida del modelo Actor.
if(AddSmooth) { int err = 0; for(ulong i = 0; i < temp.Size(); i++) temp[i] += (float)(temp[i] * Math::MathRandomNormal(0, 0.3, err)); temp.Clip(0.0f, 1.0f); }
Y luego pasaremos a la etapa de descodificación del vector de resultados del Actor. En primer lugar, guardaremos en las variables locales las constantes principales: el volumen mínimo de posición, el paso de cambio de volumen de la posición y la separación mínima de los niveles comerciales.
double min_lot = Symb.LotsMin(); double step_lot = Symb.LotsStep(); double stops = MathMax(Symb.StopsLevel(), 1) * Symb.Point();
Primero descifraremos el rendimiento de las posiciones largas. El primer elemento del vector se identificará con el volumen de la posición. Deberá ser superior o igual al volumen mínimo de la posición. El segundo y tercer elemento indicarán los valores de take profit y stop loss, respectivamente. Ajustaremos estos elementos según las constantes de take profit y stop loss máximos y los multiplicaremos por el valor de un punto del instrumento. Como resultado, deberíamos obtener un valor superior a la separación mínima de los niveles comerciales. Si al menos un indicador no cumple las condiciones, cerraremos todas las posiciones abiertas en esta dirección.
//--- buy control if(temp[0] < min_lot || (temp[1] * MaxTP * Symb.Point()) <= stops || (temp[2] * MaxSL * Symb.Point()) <= stops) { if(buy_value > 0) CloseByDirection(POSITION_TYPE_BUY); }
Cuando los resultados del Actor nos recomiendan abrir o mantener una posición larga, normalizaremos el tamaño de la posición según los requisitos del bróker para el instrumento analizado. Luego convertiremos los niveles comerciales en valores de precios concretos. A continuación, llamaremos a la función de modificación de posiciones abiertas descrita anteriormente, especificando el tipo de posición POSITION_TYPE_BUY y los valores obtenidos del precio de los niveles comerciales.
else { double buy_lot = min_lot+MathRound((double)(temp[0]-min_lot) / step_lot) * step_lot; double buy_tp = NormalizeDouble(Symb.Ask() + temp[1] * MaxTP * Symb.Point(), Symb.Digits()); double buy_sl = NormalizeDouble(Symb.Ask() - temp[2] * MaxSL * Symb.Point(), Symb.Digits()); if(buy_value > 0) TrailPosition(POSITION_TYPE_BUY, buy_sl, buy_tp);
A continuación, ajustaremos el tamaño de las posiciones abiertas a las recomendaciones del Actor. Si el volumen de posiciones abiertas es superior al volumen recomendado, llamaremos a la función de cierre parcial de posiciones. En los parámetros de esta función, indicaremos el tipo de posición POSITION_TYPE_BUY y la diferencia entre los volúmenes abierto y recomendado como tamaño de las posiciones a cerrar.
Si se recomienda recomprar, abriremos una posición adicional para el volumen restante. Al mismo tiempo, especificaremos los niveles recomendados de stop loss y take profit.
if(buy_value != buy_lot) { if(buy_value > buy_lot) ClosePartial(POSITION_TYPE_BUY, buy_value - buy_lot); else Trade.Buy(buy_lot - buy_value, Symb.Name(), Symb.Ask(), buy_sl, buy_tp); } }
Del mismo modo, descodificaremos las lecturas de la posición corta.
//--- sell control if(temp[3] < min_lot || (temp[4] * MaxTP * Symb.Point()) <= stops || (temp[5] * MaxSL * Symb.Point()) <= stops) { if(sell_value > 0) CloseByDirection(POSITION_TYPE_SELL); } else { double sell_lot = min_lot+MathRound((double)(temp[3]-min_lot) / step_lot) * step_lot;; double sell_tp = NormalizeDouble(Symb.Bid() - temp[4] * MaxTP * Symb.Point(), Symb.Digits()); double sell_sl = NormalizeDouble(Symb.Bid() + temp[5] * MaxSL * Symb.Point(), Symb.Digits()); if(sell_value > 0) TrailPosition(POSITION_TYPE_SELL, sell_sl, sell_tp); if(sell_value != sell_lot) { if(sell_value > sell_lot) ClosePartial(POSITION_TYPE_SELL, sell_value - sell_lot); else Trade.Sell(sell_lot - sell_value, Symb.Name(), Symb.Bid(), sell_sl, sell_tp); } }
Al final del método, añadiremos los datos al array de trayectorias para guardarlos posteriormente en la base de datos de ejemplos. Aquí, primero generaremos las recompensas del entorno. Como recompensa, utilizaremos el cambio relativo en el balance que registramos previamente en el primer elemento del vector de descripción del estado de la cuenta. A esta recompensa le añadiremos, en su caso, una penalización por no tener posiciones abiertas.
Luego añadiremos a la estructura de descripción del estado los vectores con el estado actual del entorno y los resultados del Actor. Ya hemos introducido anteriormente estas descripciones del estado de la cuenta. Y después llamaremos al método para añadir el estado actual al array de trayectorias.
//--- float reward = Account[0]; if((buy_value + sell_value) == 0) reward -= (float)(atr / PrevBalance); for(ulong i = 0; i < temp.Size(); i++) sState.action[i] = temp[i]; State.GetData(sState.state); if(!Base.Add(sState, reward)) ExpertRemove(); }
Las otras características del asesor se han mantenido sin apenas cambios. El lector podrá comprobarlas por sí mismo en el archivo adjunto. Ahora vamos a pasar a la siguiente fase de nuestro trabajo.
2.3. Creamos un modelo de asesor de entrenamiento
El modelo se entrenará con el asesor experto "TD3\Study.mq5". En este asesor, organizaremos todo el algoritmo de TD3 con el entrenamiento de un Actor y 2 Críticos.
Para organizar el proceso de entrenamiento, deberemos añadir varias variables externas que nos ayuden a gestionarlo. Como es habitual, aquí especificaremos el número de iteraciones para actualizar los parámetros de los modelos. En el contexto del método de TD3, a esto se refiere el entrenamiento de los modelos de los Críticos.
input int Iterations = 1000000;
Para especificar la frecuencia de las actualizaciones del Actor, crearemos la variable UpdatePolicy, en la que especificaremos cuántas actualizaciones del Crítico suponen 1 actualización del Actor.
input int UpdatePolicy = 3;
Además, indicaremos la frecuencia de actualización de los modelos objetivo y la tasa de actualización.
input int UpdateTargets = 100; input float Tau = 0.01f;
En el área de variables globales, declararemos 6 ejemplares de la clase de red neuronal: El Actor, 2 Críticos y los modelos objetivo.
CNet Actor; CNet Critic1; CNet Critic2; CNet TargetActor; CNet TargetCritic1; CNet TargetCritic2;
Debemos decir que el método de inicialización del asesor es casi idéntico a los métodos similares de los artículos anteriores. Obviamente, teniendo en cuenta el número variable de modelos que hay que entrenar. Podrá familiarizarse con ello en el archivo adjunto.
Entre tanto, en el método de desinicialización actualizaremos y guardaremos los modelos objetivo, no los modelos entrenados (como se hacía antes). Los modelos objetivo son más estáticos y menos propensos a acumular errores.
void OnDeinit(const int reason) { //--- TargetActor.WeightsUpdate(GetPointer(Actor), Tau); TargetCritic1.WeightsUpdate(GetPointer(Critic1), Tau); TargetCritic2.WeightsUpdate(GetPointer(Critic2), Tau); TargetActor.Save(FileName + "Act.nnw", 0, 0, 0, TimeCurrent(), true); TargetCritic1.Save(FileName + "Crt1.nnw", TargetCritic1.getRecentAverageError(), 0, 0, TimeCurrent(), true); TargetCritic1.Save(FileName + "Crt2.nnw", TargetCritic2.getRecentAverageError(), 0, 0, TimeCurrent(), true); delete Result; }
El propio proceso de entrenamiento del modelo se organiza en la función Train. En el cuerpo de la función, almacenaremos en una variable local el número de trayectorias cargadas de la muestra de entrenamiento y organizaremos el ciclo de entrenamiento por el número de iteraciones especificado en el parámetro externo.
void Train(void) { int total_tr = ArraySize(Buffer); uint ticks = GetTickCount();
En el cuerpo del ciclo, seleccionaremos aleatoriamente una trayectoria y un estado de la trayectoria seleccionada.
for(int iter = 0; (iter < Iterations && !IsStopped()); iter ++) { int tr = (int)((MathRand() / 32767.0) * (total_tr - 1)); int i = (int)((MathRand() * MathRand() / MathPow(32767, 2)) * (Buffer[tr].Total - 2));
Primero realizaremos una pasada directa de los modelos objetivo, lo cual nos permitirá obtener el valor predictivo del estado posterior.
Debemos decir que teóricamente también podríamos entrenar los modelos sin una función objetivo. Al fin y al cabo, podríamos determinar el valor del estado posterior partiendo de la recompensa posterior real acumulada. Este enfoque podría resultar adecuado si se tratara de un estado finito del entorno. Sin embargo, estamos entrenando un modelo para los mercados financieros, que son infinitos en el horizonte temporal previsible, y los estados similares hace 1 o 3 meses tienen el mismo valor para nosotros. Al fin y al cabo, queremos beneficiarnos de esta experiencia en el futuro. Por consiguiente, un modelo del Crítico bien entrenado obtendrá resultados comparables independientemente de la profundidad de la historia.
Volvamos a nuestro asesor. Ahora trasladaremos los datos de la base de datos de ejemplos a los búferes de descripción del estado del entorno y generaremos el vector de descripción del estado de la cuenta. Tenga en cuenta que no tomamos los datos del estado seleccionado, sino los del siguiente.
//--- Target State.AssignArray(Buffer[tr].States[i + 1].state); float PrevBalance = Buffer[tr].States[i].account[0]; float PrevEquity = Buffer[tr].States[i].account[1]; Account.Clear(); Account.Add((Buffer[tr].States[i + 1].account[0] - PrevBalance) / PrevBalance); Account.Add(Buffer[tr].States[i + 1].account[1] / PrevBalance); Account.Add((Buffer[tr].States[i + 1].account[1] - PrevEquity) / PrevEquity); Account.Add(Buffer[tr].States[i + 1].account[2]); Account.Add(Buffer[tr].States[i + 1].account[3]); Account.Add(Buffer[tr].States[i + 1].account[4] / PrevBalance); Account.Add(Buffer[tr].States[i + 1].account[5] / PrevBalance); Account.Add(Buffer[tr].States[i + 1].account[6] / PrevBalance);
Después organizaremos una pasada directa del modelo del Actor objetivo.
if(Account.GetIndex() >= 0) Account.BufferWrite(); if(!TargetActor.feedForward(GetPointer(State), 1, false, GetPointer(Account))) { PrintFormat("%s -> %d", __FUNCTION__, __LINE__); ExpertRemove(); break; }
A continuación, haremos una pasada directa de los 2 modelos objetivo del Crítico. Los datos de entrada para ambos modelos serán el modelo objetivo del Actor.
if(!TargetCritic1.feedForward(GetPointer(TargetActor), LatentLayer, GetPointer(TargetActor)) || !TargetCritic2.feedForward(GetPointer(TargetActor), LatentLayer, GetPointer(TargetActor))) { PrintFormat("%s -> %d", __FUNCTION__, __LINE__); ExpertRemove(); break; }
Los resultados nos permitirán generar valores objetivo para entrenar los modelos del Crítico.
Recordemos que cada Crítico retornará solo un valor del coste previsto de la acción en las condiciones actuales, así que tendremos el mismo número que el valor objetivo.
Según el algoritmo TD3, tomaremos el valor mínimo de los 2 resultados Target de los modelos de los Críticos. Luego multiplicaremos el valor resultante por el factor de descuento y añadiremos la recompensa real de la base de datos de ejemplos.
TargetCritic1.getResults(Result); float reward = Result[0]; TargetCritic2.getResults(Result); reward = DiscFactor * MathMin(reward, Result[0]) + (Buffer[tr].Revards[i] - Buffer[tr].Revards[i + 1]);
En este punto, tendremos un valor objetivo para el Crítico. El algoritmo TD3 solo ofrece un valor objetivo para los 2 modelos del Crítico, pero antes de la pasada inversa, tendremos que hacer una pasada directa del Crítico. Y aquí debemos prestar atención a cierto momento. Como ya sabe, la arquitectura del Crítico no ofrece un bloque de procesamiento primario de datos. Esta funcionalidad la realiza el Actor, mientras que el Crítico recibirá el estado latente del Actor como datos de entrada para describir el estado del entorno. Por lo tanto, primero tomamos los datos de origen de la base de datos de ejemplos y realizaremos una pasada directa del modelo del Actor.
//--- Q-function study State.AssignArray(Buffer[tr].States[i].state); PrevBalance = Buffer[tr].States[MathMax(i - 1, 0)].account[0]; PrevEquity = Buffer[tr].States[MathMax(i - 1, 0)].account[1]; Account.Clear(); Account.Add((Buffer[tr].States[i].account[0] - PrevBalance) / PrevBalance); Account.Add(Buffer[tr].States[i].account[1] / PrevBalance); Account.Add((Buffer[tr].States[i].account[1] - PrevEquity) / PrevEquity); Account.Add(Buffer[tr].States[i].account[2]); Account.Add(Buffer[tr].States[i].account[3]); Account.Add(Buffer[tr].States[i].account[4] / PrevBalance); Account.Add(Buffer[tr].States[i].account[5] / PrevBalance); Account.Add(Buffer[tr].States[i].account[6] / PrevBalance); //--- if(Account.GetIndex() >= 0) Account.BufferWrite(); //--- if(!Actor.feedForward(GetPointer(State), 1, false, GetPointer(Account))) { PrintFormat("%s -> %d", __FUNCTION__, __LINE__); ExpertRemove(); break; }
Y aquí debemos recordar que durante el entrenamiento del Actor, con una alta probabilidad, este retornará acciones diferentes a las almacenadas en la base de datos de ejemplos. Sin embargo, la recompensa no se corresponderá con la acción guardada. Por ello, descargaremos el estado latente del Actor. Luego cargaremos la acción completada desde la base de datos de ejemplos, y sobre estos datos haremos una pasada directa de ambos Críticos.
if(!Critic1.feedForward(Result,1,false, GetPointer(Actions)) || !Critic2.feedForward(Result,1,false, GetPointer(Actions))) { PrintFormat("%s -> %d", __FUNCTION__, __LINE__); ExpertRemove(); break; }
Llamaremos la atención sobre un punto más. En teoría, podríamos haber guardado el estado latente del Actor durante la fase de recopilación de la base de datos de ejemplos, y ahora simplemente utilizaríamos los datos guardados, pero recordemos que durante el entrenamiento del modelo se modifican los parámetros de todas las capas neuronales. Como consecuencia, la unidad de preprocesamiento de datos también cambiará durante el proceso de aprendizaje del Actor, y debido a ello, cambiará la representación latente del mismo estado del entorno. Y si entrenamos al Crítico con datos de entrada incorrectos, obtendremos un resultado impredecible al entrenar al Actor, y no querríamos eso. Por lo tanto, para entrenar a los Críticos, utilizaremos la representación latente correcta del estado del entorno junto con las acciones realizadas de la base de datos de ejemplos y la recompensa correspondiente.
Después rellenaremos el búfer de valores objetivo y realizaremos una pasada inversa de ambos Críticos.
Result.Clear(); Result.Add(reward); if(!Critic1.backProp(Result, GetPointer(Actions), GetPointer(Gradient)) || !Critic2.backProp(Result, GetPointer(Actions), GetPointer(Gradient))) { PrintFormat("%s -> %d", __FUNCTION__, __LINE__); ExpertRemove(); break; }
Bien, ya hemos tratado los entresijos del entrenamiento de los críticos. Pasemos ahora al entrenamiento del actor. Como hemos mencionado en la parte teórica de este artículo, los parámetros del Actor se actualizan con menos frecuencia. Por ello, primero verificaremos la necesidad de este procedimiento en la iteración actual.
//--- Policy study if(iter > 0 && (iter % UpdatePolicy) == 0) {
Si ha llegado el momento de actualizar los parámetros del Actor, para preservar la objetividad, seleccionaremos aleatoriamente nuevos datos de entrada,
tr = (int)((MathRand() / 32767.0) * (total_tr - 1)); i = (int)((MathRand() * MathRand() / MathPow(32767, 2)) * (Buffer[tr].Total - 2)); State.AssignArray(Buffer[tr].States[i].state); PrevBalance = Buffer[tr].States[MathMax(i - 1, 0)].account[0]; PrevEquity = Buffer[tr].States[MathMax(i - 1, 0)].account[1]; Account.Clear(); Account.Add((Buffer[tr].States[i].account[0] - PrevBalance) / PrevBalance); Account.Add(Buffer[tr].States[i].account[1] / PrevBalance); Account.Add((Buffer[tr].States[i].account[1] - PrevEquity) / PrevEquity); Account.Add(Buffer[tr].States[i].account[2]); Account.Add(Buffer[tr].States[i].account[3]); Account.Add(Buffer[tr].States[i].account[4] / PrevBalance); Account.Add(Buffer[tr].States[i].account[5] / PrevBalance); Account.Add(Buffer[tr].States[i].account[6] / PrevBalance);
y realizaremos una pasada directa del Actor.
if(Account.GetIndex() >= 0) Account.BufferWrite(); //--- if(!Actor.feedForward(GetPointer(State), 1, false, GetPointer(Account))) { PrintFormat("%s -> %d", __FUNCTION__, __LINE__); ExpertRemove(); break; }
A continuación, haremos una pasada directa del Crítico. Tenga en cuenta que en este caso no usaremos los datos de la base de datos de ejemplos. La pasada directa del Crítico se realizará íntegramente con los nuevos resultados del Actor. Después de todo, es importante que evaluemos la política actual del modelo.
if(!Critic1.feedForward(GetPointer(Actor), LatentLayer, GetPointer(Actor))) { PrintFormat("%s -> %d", __FUNCTION__, __LINE__); ExpertRemove(); break; }
Para actualizar los parámetros del Actor, hemos utilizado el Crítico 1. Según mis observaciones, la selección del modelo por parte del Crítico no resulta esencial en este caso. A pesar de la diferencia de puntuaciones, durante las pruebas, ambos Críticos ha retornado idénticos valores de gradiente de error al Actor.
El objetivo del entrenamiento del Actor consiste en maximizar la recompensa esperada. Tomaremos el resultado actual de la valoración de las acciones del Crítico y le añadiremos una pequeña constante positiva. Cabe señalar que, en el caso de obtener una valoración de acción negativa, hemos utilizado una constante propia positiva como valor objetivo. De esta forma pretendíamos acelerar la salida de la zona negativa.
Critic1.getResults(Result); float forecast = Result[0]; Result.Update(0, (forecast > 0 ? forecast + PoliticAdjust : PoliticAdjust));
También resulta significativo que durante la actualización de los parámetros del Actor, el modelo del Crítico solo se ha utilizado como una especie de función de pérdida. Solo genera un gradiente de error en la salida del Actor. Esto no cambiará los parámetros del propio Crítico. Para ello, desactivaremos el modo de entrenamiento del Crítico antes de la pasada inversa, y después de transmitir el gradiente de error al Actor, devolveremos el Crítico al modo de entrenamiento.
Critic1.TrainMode(false); if(!Critic1.backProp(Result, GetPointer(Actor)) || !Actor.backPropGradient(GetPointer(Account), GetPointer(Gradient))) { Critic1.TrainMode(true); PrintFormat("%s -> %d", __FUNCTION__, __LINE__); ExpertRemove(); break; } Critic1.TrainMode(true); }
Tras obtener el gradiente de error del Crítico, realizaremos una pasada inversa del Actor.
En esta fase, organizaremos el proceso de entrenamiento de la función Q por parte de los Críticos y la entrenamiento de la política por parte de los Actores. Nos queda aplicar una actualización suave de los modelos objetivo. Ya describimos con detalle la organización de este proceso en el artículo anterior. Aquí, solo comprobamos la aparición de las actualizaciones del modelo y llamaremos a los métodos correspondientes para cada modelo objetivo.
//--- Update Target Nets if(iter > 0 && (iter % UpdateTargets) == 0) { TargetActor.WeightsUpdate(GetPointer(Actor), Tau); TargetCritic1.WeightsUpdate(GetPointer(Critic1), Tau); TargetCritic2.WeightsUpdate(GetPointer(Critic2), Tau); }
Al final de la iteración del ciclo, informaremos al usuario del estado del proceso de entrenamiento y mostraremos los errores actuales de ambos críticos. No obtendremos lecturas sobre la calidad del aprendizaje del Actor, ya que no calcularemos ningún error para este modelo.
if(GetTickCount() - ticks > 500) { string str = StringFormat("%-15s %5.2f%% -> Error %15.8f\n", "Critic1", iter * 100.0 / (double)(Iterations), Critic1.getRecentAverageError()); str += StringFormat("%-15s %5.2f%% -> Error %15.8f\n", "Critic2", iter * 100.0 / (double)(Iterations), Critic2.getRecentAverageError()); Comment(str); ticks = GetTickCount(); } }
Una vez completadas las iteraciones del ciclo, eliminaremos el área de comentarios e inicializaremos el proceso de finalización del asesor.
Comment(""); //--- PrintFormat("%s -> %d -> %-15s %10.7f", __FUNCTION__, __LINE__, "Critic1", Critic1.getRecentAverageError()); PrintFormat("%s -> %d -> %-15s %10.7f", __FUNCTION__, __LINE__, "Critic2", Critic2.getRecentAverageError()); ExpertRemove(); //--- }
No nos detendremos en la descripción del algoritmo del asesor experto para probar el modelo entrenado "TD3\Test.mq5". Su código es casi idéntico al del asesor encargado de recopilar bases de datos de ejemplos. Solo hemos excluido la adición de ruido a los resultados del Actor. Al fin y al cabo, en las pruebas queremos evaluar la calidad del entrenamiento del modelo, lo cual excluye la exploración del entorno. Al mismo tiempo, hemos dejado el bloque de recopilación de la trayectoria y su escritura en la base de datos de ejemplos. Esto nos permitirá conservar las pasadas exitosas y las no tan exitosas, y luego, al poner en marcha el proceso de entrenamiento, "trabajar sobre los errores".
Le recuerdo que en el archivo adjunto encontrará el código completo de todos los programas utilizados en este artículo.
3. Simulación
Una vez finalizado el trabajo de creación de los programas, procederemos a entrenar y validar los resultados. Como es habitual, los modelos se han entrenado con los datos históricos del marco temporal H1 de EURUSD para el periodo comprendido entre enero y mayo de 2023. En cuanto a los parámetros de los indicadores y todos los hiperparámetros, hemos utilizado los parámetros establecidos por defecto.
Diremos de entrada que el proceso de entrenamiento ha sido bastante largo e iterativo. En la primera fase hemos creado una base de datos con 200 trayectorias. El primer proceso de entrenamiento se ha ejecutado durante 1 000 000 de iteraciones. La política del Actor se ha actualizado 1 vez después de cada 10 iteraciones de actualización de los parámetros del Crítico. Asimismo, hemos realizado actualizaciones suaves de los modelos objetivo después de cada 1 000 iteraciones de actualización del Crítico.
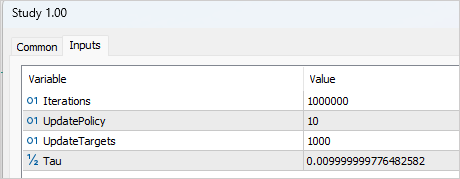
Tras la primera fase de entrenamiento, hemos añadido otras 50 trayectorias a la base de datos de ejemplos y hemos iniciado la segunda fase de entrenamiento del modelo. Al mismo tiempo, el número de iteraciones antes de actualizar los modelos del Actor y objetivo se ha reducido a 3 y 100, respectivamente.
Tras unos 5 ciclos de entrenamiento (hemos añadido 50 trayectorias en cada ciclo), hemos obtenido un modelo capaz de generar beneficios con la muestra de entrenamiento. En la muestra de entrenamiento de 5 meses, el modelo ha sido capaz de generar casi un 10% de rentabilidad. Esta lectura no es grande. Se han realizado 58 transacciones. La proporción de transacciones rentables se ha acercado solo al 40%. El factor de beneficio es 1,05, y el factor de recuperación es 1,50. Hemos obtenido beneficios gracias al tamaño de las posiciones rentables. El beneficio medio de por transacción es 1,6 veces superior a la pérdida media, mientras que el beneficio máximo es 3,5 veces superior a la pérdida máxima de una operación.
En particular, la reducción del balance es de casi el 32%, mientras que según la Equidad, apenas supera el 6%. Como podemos observar en el gráfico, cuando la línea de la Equidad es plana o incluso ascendente, vemos reducciones del balance. Este efecto se explica por la apertura simultánea de posiciones multidireccionales. Cuando se activa el stop loss de una posición perdedora, vemos una reducción en el saldo, pero al mismo tiempo, una posición abierta en sentido contrario acumula beneficios que se reflejan en la línea de Equidad.


Como recordará, en el artículo anterior el modelo mostró un resultado más significativo en la muestra de entrenamiento, pero fue incapaz de replicarlo en los nuevos datos. Ahora la situación es la opuesta. No hemos obtenido una superganancia en la muestra de entrenamiento, pero el modelo ha mostrado un resultado estable también fuera de la muestra de entrenamiento. Al probar el rendimiento del modelo con datos posteriores fuera de la muestra de entrenamiento, vemos una "copia reducida" de la prueba anterior. El modelo ha generado un rendimiento del 2,5% en 1 mes. El factor de beneficio es 1,07 y el factor de recuperación 1,16. Solo hay un 27% de transacciones rentables, pero al mismo tiempo la media de transacciones rentables es casi 3 veces superior a la media de transacciones perdedoras. La reducción es del 32% en el Balance, y solo del 2% en la Equidad.


Conclusión
En este artículo, hemos introducido el Twin Delayed Deep Deterministic policy gradient (TD3). Los autores de este método proponen varias mejoras importantes al algoritmo de DDPG que mejoran la eficacia del método y la estabilidad del entrenamiento del modelo.
En el marco de este artículo, hemos aplicado dicho método utilizando las herramientas MQL5 y lo hemos probado con datos históricos. El proceso de entrenamiento ha producido un modelo capaz de generar beneficios con los datos de entrenamiento, además de utilizar la experiencia obtenida con los nuevos datos. Cabe señalar que, con los nuevos datos, el modelo ha obtenido resultados comparables a los de la muestra de entrenamiento. Sí, los resultados no son exactamente los que nos gustaría ver, y hay puntos sobre los que todavía hay que trabajar. Pero una cosa es cierta: el algoritmo TD3 nos permite entrenar un modelo estable con datos nuevos.
En general, podemos utilizar el algoritmo para seguir investigando la construcción de un modelo para el comercio real.
Enlaces
Programas usados en el artículo
| # | Nombre | Tipo | Descripción |
|---|---|---|---|
| 1 | Research.mq5 | Asesor | Asesor de recopilación de datos |
| 2 | Study.mq5 | Asesor | Asesor de entrenamiento del agente |
| 3 | Test.mq5 | Asesor | Asesor para la prueba de modelos |
| 4 | Trajectory.mqh | Biblioteca de clases | Estructura de descripción del estado del sistema. |
| 5 | NeuroNet.mqh | Biblioteca de clases | Biblioteca de clases para crear una red neuronal |
| 6 | NeuroNet.cl | Biblioteca | Biblioteca de código de programa OpenCL |
Traducción del ruso hecha por MetaQuotes Ltd.
Artículo original: https://www.mql5.com/ru/articles/12892
- Aplicaciones de trading gratuitas
- 8 000+ señales para copiar
- Noticias económicas para analizar los mercados financieros
Usted acepta la política del sitio web y las condiciones de uso