Redes neurais de maneira fácil (Parte 10): Atenção Multi-Cabeça

Índice
- Introdução
- 1. Atenção Multi-Cabeça
- 2. Um Pouco de Matemática
- 3. Codificação Posicional
- 4. Implementação
- 4.1. Eliminando as Chaves do Tensor
- 4.2. Classe Atenção Multi-Cabeça
- 4.3. Propagação direta
- 4.4. Retropropagação
- 4.5. Alterações nas Classes Base da Rede Neural
- 5. Teste
- Conclusão
- Referências
- Programas utilizados no artigo
Introdução
No artigo "Redes neurais de maneira fácil (Parte 8): Mecanismos de atenção", nós consideramos o mecanismo de self-attention (autoatenção) e uma variante de sua implementação. Na prática, as arquiteturas das redes neurais modernas usam a Atenção Multi-Cabeça (Multi-Head Attention). Esse mecanismo implica o lançamento de várias threads de autoatenção paralelas com pesos diferentes. Essa solução deve revelar melhor as conexões entre os vários elementos da sequência. Vamos tentar implementar uma arquitetura semelhante e comparar os resultados desses dois métodos.
1. Atenção Multi-Cabeça
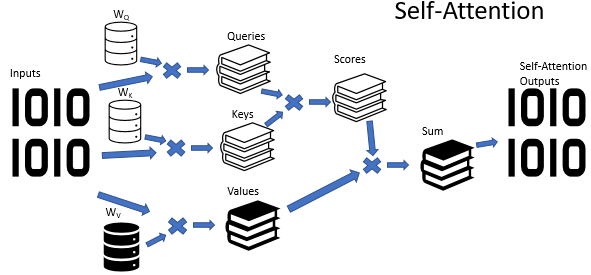
O algoritmo de Autoatenção usa três matrizes de peso treinadas (Wq, Wk e Wv). Os dados da matriz são usados para obter 3 entidades: Query, Key e Value. As duas primeiras entidades definem a relação dos pares entre os elementos da sequência e a última define o contexto do elemento analisado.
Não é segredo que as situações nem sempre são claras. Pelo contrário, parece que, na maioria dos casos, uma situação pode ser interpretada de diferentes pontos de vista. Portanto, as conclusões podem ser completamente opostas, dependendo do ponto de vista selecionado. É importante considerar todas as variantes possíveis em tais situações e tomar uma decisão somente após uma análise cuidadosa. O mecanismo Multi-Head Attention (Atenção Multi-Cabeça) foi proposto para resolver tais problemas. Cada "cabeça" tem sua opinião, enquanto a decisão é feita por um voto equilibrado.
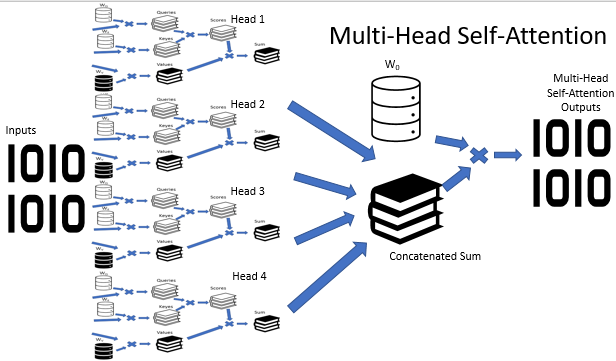
A arquitetura da Atenção Multi-Cabeça implica o uso paralelo de várias threads de autoatenção com pesos diferentes, o que imita uma análise versátil de uma situação. Os resultados da operação com as threads de autoatenção são concatenados em um único tensor. O resultado final do algoritmo é encontrado multiplicando o tensor pela matriz W0, cujos parâmetros são selecionados durante o processo de treinamento da rede neural. Toda a arquitetura substitui o bloco Self-Attention no codificador e no decodificador da arquitetura do transformador.
2. Um Pouco de Matemática
A fórmula a seguir pode fornecer uma descrição matemática do algoritmo de Self-Attention:
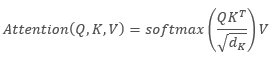 ,
,
onde 'Q' é o tensor Query, 'K' é o tensor Key, 'V' é o tensor Values, 'd' é a dimensão de um vetor chave.
Por sua vez
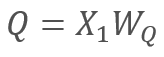 e
e 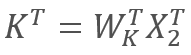 ,
,
onde X1 e X2 são os elementos da sequência; Wq e Wk são as matrizes de pesos de de Query e Key, respectivamente. Assim, nós temos o seguinte:
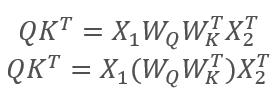
Pela propriedade de associatividade das matrizes, nós podemos primeiro multiplicar as matrizes de peso Wq e Wk. Como você pode ver, o produto das matrizes de peso não depende da sequência de entrada e é o mesmo para todas as iterações de um bloco de Self-Attention específico (é claro, isso é verdadeiro até a próxima atualização dos parâmetros da matriz). Portanto, para reduzir as operações computacionais, nós podemos calcular uma matriz intermediária uma vez para uma abordagem específica e, em seguida, usá-la para outros cálculos.
Nós podemos ir ainda mais longe e treinar uma matriz em vez de duas. Porém, curiosamente, nem sempre é possível reduzir o número de operações treinando apenas uma matriz. Por exemplo, para grandes dimensões do vetor de sequência de entrada, a dimensão pode ser reduzida pelas matrizes Wq e Wk. Nesse caso, se o comprimento dos vetores de entrada X1 e X2 for 100 elementos, a matriz única conterá 10K elementos (100*100). Se a dimensão for reduzida pelas matrizes Wq e Wk por um fator de 10, nós teremos duas matrizes, cada uma com 1K elementos (100*10). Portanto, você deve selecionar cuidadosamente uma solução, levando em consideração o desempenho da rede e a qualidade dos resultados de sua operação.
3. Codificação Posicional
Além disso, ao trabalhar com séries temporais, preste atenção à distância entre os elementos na sequência. O algoritmo de atenção realiza verificações par a par das dependências entre os elementos da sequência, usando as mesmas matrizes para todos os elementos da sequência. Ao mesmo tempo, a influência mútua dos elementos da série temporal depende fortemente do intervalo de tempo entre eles. Portanto, outra questão aguda é a adição de um algoritmo de codificação posicional.
Um algoritmo de codificação de posição ideal deve satisfazer vários critérios:
- Cada elemento da sequência deve receber um código único
- O passo entre quaisquer dois elementos consecutivos deve ser constante
- O modelo deve ser fácil de ajustar e generalizar para sequências de qualquer comprimento
- O modelo deve ser determinístico
Os autores da arquitetura do Transformer sugeriram o uso não de um elemento separado para codificar uma sequência, mas de um vetor inteiro com uma dimensão igual à dimensão de um elemento de sequência de entrada. Aqui, o seno é usado para descrever os elementos pares do vetor e o cosseno é usado para os elementos ímpares. Observe que o elemento de sequência não é um elemento de matriz específico, mas é um vetor que descreve o estado de uma posição separada. No nosso caso, ele é um vetor que descreve uma vela.
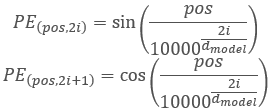 ,
,
onde 'pos' é a posição de um elemento de sequência, 'i' é a posição do elemento no vetor de um elemento de posição, 'd' é a dimensão do vetor de um elemento da sequência.
Esta solução permite definir as posições para cada elemento da sequência, bem como determinar a distância entre eles.
Diretamente na arquitetura do Transformer, a codificação posicional está fora do seu escopo. Ele é realizado adicionando o tensor de codificação posicional ao tensor de sequência de entrada antes de inserir os dados no primeiro encoder. Duas questões surgem:
- Por que a adição em vez de concatenação vetorial?
- Quanto a adição de tensores distorcerá os dados originais?
A concatenação aumentaria a dimensão dos dados e, portanto, o número de iterações. Isso reduziria o desempenho geral do sistema. O segundo aspecto dessa solução é que a adição de vetores permite posicionar não apenas o vetor de um elemento individual da sequência, mas também cada elemento do vetor. Hipoteticamente, isso permite a análise de dependências não apenas entre os elementos de uma sequência, mas também entre seus componentes individuais.
Quanto à distorção de dados, a rede neural não sabe nada sobre o significado de cada elemento e é treinada em dados com codificação adicionada, ou seja, não analisa cada elemento e sua posição separadamente. Por exemplo, se virmos o mesmo doji na 2ª e na 20ª posição, provavelmente nós daremos preferência ao mais próximo. Para uma rede neural com codificação posicional, esses sinais serão completamente diferentes e serão processados de acordo com os dados acumulados durante o treinamento.
4. Implementação
Vamos considerar a implementação das soluções acima. Na implementação anterior do algoritmo Self-Attention, a dimensão usada para os vetores Query e Key era semelhante à sequência de entrada. Portanto, eu reconstruí primeiro o algoritmo para treinar uma matriz.
4.1. Eliminando as Chaves do Tensor
A solução prática é bem simples. No método CNeuronAttentionOCL::feedForward, eu comentei a chamada do método semelhante ao da camada convolucional Key. Eu também substituí a camada convolucional Key pela camada neural anterior na chamada do kernel de cálculo Score. As alterações no código do método são destacadas abaixo.
bool CNeuronAttentionOCL::feedForward(CNeuronBaseOCL *prevLayer) { if(CheckPointer(prevLayer)==POINTER_INVALID) return false; //--- { uint global_work_offset[1]={0}; uint global_work_size[1]; global_work_size[0]=1; OpenCL.SetArgumentBuffer(def_k_Normilize,def_k_norm_buffer,prevLayer.getOutputIndex()); OpenCL.SetArgument(def_k_Normilize,def_k_norm_dimension,prevLayer.Neurons()); if(!OpenCL.Execute(def_k_Normilize,1,global_work_offset,global_work_size)) { printf("Error of execution kernel Normalize: %d",GetLastError()); return false; } if(!prevLayer.Output.BufferRead()) return false; } //--- if(CheckPointer(Querys)==POINTER_INVALID || !Querys.FeedForward(prevLayer)) return false; //if(CheckPointer(Keys)==POINTER_INVALID || !Keys.FeedForward(prevLayer)) // return false; if(CheckPointer(Values)==POINTER_INVALID || !Values.FeedForward(prevLayer)) return false; //--- { uint global_work_offset[1]={0}; uint global_work_size[1]; global_work_size[0]=iUnits; OpenCL.SetArgumentBuffer(def_k_AttentionScore,def_k_as_querys,Querys.getOutputIndex()); OpenCL.SetArgumentBuffer(def_k_AttentionScore,def_k_as_keys,prevLayer.getOutputIndex()); OpenCL.SetArgumentBuffer(def_k_AttentionScore,def_k_as_score,Scores.GetIndex()); OpenCL.SetArgument(def_k_AttentionScore,def_k_as_dimension,iWindow); if(!OpenCL.Execute(def_k_AttentionScore,1,global_work_offset,global_work_size)) { printf("Error of execution kernel AttentionScore: %d",GetLastError()); return false; } if(!Scores.BufferRead()) return false; } //--- Further code has no changes
Alterações semelhantes foram implementadas no método de retropropagação CNeuronAttentionOCL::calcInputGradients. Observe que, como a primeira parte dos gradientes de erro é gravada no buffer da camada anterior, o processo de acumulação do gradiente começa mais cedo. As alterações são destacadas no código abaixo.
bool CNeuronAttentionOCL::calcInputGradients(CNeuronBaseOCL *prevLayer) { if(CheckPointer(prevLayer)==POINTER_INVALID) return false; //--- if(!FF2.calcInputGradients(FF1)) return false; if(!FF1.calcInputGradients(AttentionOut)) return false; //--- { uint global_work_offset[1]={0}; uint global_work_size[1]; global_work_size[0]=iUnits; OpenCL.SetArgumentBuffer(def_k_MatrixSum,def_k_sum_matrix1,AttentionOut.getGradientIndex()); OpenCL.SetArgumentBuffer(def_k_MatrixSum,def_k_sum_matrix2,Gradient.GetIndex()); OpenCL.SetArgumentBuffer(def_k_MatrixSum,def_k_sum_matrix_out,AttentionOut.getGradientIndex()); OpenCL.SetArgument(def_k_MatrixSum,def_k_sum_dimension,iWindow); OpenCL.SetArgument(def_k_MatrixSum,def_k_sum_multiplyer,0.5); if(!OpenCL.Execute(def_k_MatrixSum,1,global_work_offset,global_work_size)) { printf("Error of execution kernel MatrixSum: %d",GetLastError()); return false; } double temp[]; if(AttentionOut.getGradient(temp)<=0) return false; } //--- { uint global_work_offset[2]={0,0}; uint global_work_size[2]; global_work_size[0]=iUnits; global_work_size[1]=iWindow; OpenCL.SetArgumentBuffer(def_k_AttentionGradients,def_k_ag_gradient,AttentionOut.getGradientIndex()); OpenCL.SetArgumentBuffer(def_k_AttentionGradients,def_k_ag_keys,prevLayer.getOutputIndex()); OpenCL.SetArgumentBuffer(def_k_AttentionGradients,def_k_ag_keys_g,prevLayer.getGradientIndex()); OpenCL.SetArgumentBuffer(def_k_AttentionGradients,def_k_ag_querys,Querys.getOutputIndex()); OpenCL.SetArgumentBuffer(def_k_AttentionGradients,def_k_ag_querys_g,Querys.getGradientIndex()); OpenCL.SetArgumentBuffer(def_k_AttentionGradients,def_k_ag_values,Values.getOutputIndex()); OpenCL.SetArgumentBuffer(def_k_AttentionGradients,def_k_ag_values_g,Values.getGradientIndex()); OpenCL.SetArgumentBuffer(def_k_AttentionGradients,def_k_ag_scores,Scores.GetIndex()); if(!OpenCL.Execute(def_k_AttentionGradients,2,global_work_offset,global_work_size)) { printf("Error of execution kernel AttentionGradients: %d",GetLastError()); return false; } double temp[]; if(Querys.getGradient(temp)<=0) return false; } //--- { uint global_work_offset[1]={0}; uint global_work_size[1]; global_work_size[0]=iUnits; OpenCL.SetArgumentBuffer(def_k_MatrixSum,def_k_sum_matrix1,AttentionOut.getGradientIndex()); OpenCL.SetArgumentBuffer(def_k_MatrixSum,def_k_sum_matrix2,prevLayer.getGradientIndex()); OpenCL.SetArgumentBuffer(def_k_MatrixSum,def_k_sum_matrix_out,AttentionOut.getGradientIndex()); OpenCL.SetArgument(def_k_MatrixSum,def_k_sum_dimension,iWindow); OpenCL.SetArgument(def_k_MatrixSum,def_k_sum_multiplyer,1.0); if(!OpenCL.Execute(def_k_MatrixSum,1,global_work_offset,global_work_size)) { printf("Error of execution kernel MatrixSum: %d",GetLastError()); return false; } double temp[]; if(AttentionOut.getGradient(temp)<=0) return false; } //--- if(!Querys.calcInputGradients(prevLayer)) return false; //--- { uint global_work_offset[1]={0}; uint global_work_size[1]; global_work_size[0]=iUnits; OpenCL.SetArgumentBuffer(def_k_MatrixSum,def_k_sum_matrix1,AttentionOut.getGradientIndex()); OpenCL.SetArgumentBuffer(def_k_MatrixSum,def_k_sum_matrix2,prevLayer.getGradientIndex()); OpenCL.SetArgumentBuffer(def_k_MatrixSum,def_k_sum_matrix_out,AttentionOut.getGradientIndex()); OpenCL.SetArgument(def_k_MatrixSum,def_k_sum_dimension,iWindow); OpenCL.SetArgument(def_k_MatrixSum,def_k_sum_multiplyer,1.0); if(!OpenCL.Execute(def_k_MatrixSum,1,global_work_offset,global_work_size)) { printf("Error of execution kernel MatrixSum: %d",GetLastError()); return false; } double temp[]; if(AttentionOut.getGradient(temp)<=0) return false; } ////--- // if(!Keys.calcInputGradients(prevLayer)) // return false; ////--- // { // uint global_work_offset[1]={0}; // uint global_work_size[1]; // global_work_size[0]=iUnits; // OpenCL.SetArgumentBuffer(def_k_MatrixSum,def_k_sum_matrix1,AttentionOut.getGradientIndex()); // OpenCL.SetArgumentBuffer(def_k_MatrixSum,def_k_sum_matrix2,prevLayer.getGradientIndex()); // OpenCL.SetArgumentBuffer(def_k_MatrixSum,def_k_sum_matrix_out,AttentionOut.getGradientIndex()); // OpenCL.SetArgument(def_k_MatrixSum,def_k_sum_dimension,iWindow); // OpenCL.SetArgument(def_k_MatrixSum,def_k_sum_multiplyer,1.0); // if(!OpenCL.Execute(def_k_MatrixSum,1,global_work_offset,global_work_size)) // { // printf("Error of execution kernel MatrixSum: %d",GetLastError()); // return false; // } // double temp[]; // if(AttentionOut.getGradient(temp)<=0) // return false; // } //--- Further code has no changes
Eu também comentei a atualização dos pesos da camada convolucional Key no método CNeuronAttentionOCL::updateInputWeights, bem como a declaração desse objeto no geral.
O código completo de todos os métodos e funções está disponível em anexo.
4.2. Classe Atenção Multi-Cabeça
A construção da Atenção Multi-Cabeça é implementada em uma classe separada CNeuronMHAttentionOCL, com base na classe pai CNeuronAttentionOCL. No bloco protegido, declaramos instâncias adicionais de camadas convolucionais Querys eValues, de acordo com o número de cabeças de atenção. Quatro cabeças são usadas no exemplo. Além disso, adicionamos o buffer Scores e a camada totalmente conectada AttentionOut para cada cabeça de atenção. Além disso, nós precisamos de uma camada totalmente conectada para concatenar os dados das cabeças de atenção - AttentionConcatenate - e uma camada convolucional Weights0, que permitiria imitar a votação ponderada e reduzir a dimensão do tensor de resultados.
class CNeuronMHAttentionOCL : public CNeuronAttentionOCL { protected: CNeuronConvOCL *Querys2; ///< Convolution layer for Querys Head 2 CNeuronConvOCL *Querys3; ///< Convolution layer for Querys Head 3 CNeuronConvOCL *Querys4; ///< Convolution layer for Querys Head 4 CNeuronConvOCL *Values2; ///< Convolution layer for Values Head 2 CNeuronConvOCL *Values3; ///< Convolution layer for Values Head 3 CNeuronConvOCL *Values4; ///< Convolution layer for Values Head 4 CBufferDouble *Scores2; ///< Buffer for Scores matrix Head 2 CBufferDouble *Scores3; ///< Buffer for Scores matrix Head 3 CBufferDouble *Scores4; ///< Buffer for Scores matrix Head 4 CNeuronBaseOCL *AttentionOut2; ///< Layer of Self-Attention Out CNeuronBaseOCL *AttentionOut3; ///< Layer of Self-Attention Out CNeuronBaseOCL *AttentionOut4; ///< Layer of Self-Attention Out CNeuronBaseOCL *AttentionConcatenate;///< Layer of Concatenate Self-Attention Out CNeuronConvOCL *Weights0; ///< Convolution layer for Weights0 //--- virtual bool feedForward(CNeuronBaseOCL *prevLayer); ///< Feed Forward method.@param prevLayer Pointer to previous layer. virtual bool updateInputWeights(CNeuronBaseOCL *prevLayer); ///< Method for updating weights.@param prevLayer Pointer to previous layer. /// Method to transfer gradients inside Head Self-Attention virtual bool calcHeadGradient(CNeuronConvOCL *query, CNeuronConvOCL *value, CBufferDouble *score, CNeuronBaseOCL *attention, CNeuronBaseOCL *prevLayer); public: /** Constructor */CNeuronMHAttentionOCL(void){}; /** Destructor */~CNeuronMHAttentionOCL(void); virtual bool Init(uint numOutputs,uint myIndex,COpenCLMy *open_cl, uint window, uint units_count, ENUM_OPTIMIZATION optimization_type); ///< Method of initialization class.@param[in] numOutputs Number of connections to next layer.@param[in] myIndex Index of neuron in layer.@param[in] open_cl Pointer to #COpenCLMy object.@param[in] window Size of in/out window and step.@param[in] units_countNumber of neurons.@param[in] optimization_type Optimization type (#ENUM_OPTIMIZATION)@return Boolean result of operations. virtual bool calcInputGradients(CNeuronBaseOCL *prevLayer); ///< Method to transfer gradients to previous layer @param[in] prevLayer Pointer to previous layer. //--- virtual int Type(void) const { return defNeuronMHAttentionOCL; }///< Identificator of class.@return Type of class //--- methods for working with files virtual bool Save(int const file_handle); ///< Save method @param[in] file_handle handle of file @return logical result of operation virtual bool Load(int const file_handle); ///< Load method @param[in] file_handle handle of file @return logical result of operation };
O conjunto de métodos de classe reescreve os métodos virtuais da classe pai. Provavelmente, ele já pode ser chamado de padrão. A única exceção é o método calcHeadGradient que descreve as iterações de propagação do gradiente de erro, que são repetidas para cada cabeça.
Deixamos o construtor da classe vazio e movemos a inicialização de novos objetos para o método de inicialização Init. No destrutor de classe, implementamos a exclusão de instâncias de objeto que foram criadas por esta classe e declaradas no bloco "protected".
CNeuronMHAttentionOCL::~CNeuronMHAttentionOCL(void) { if(CheckPointer(Querys2)!=POINTER_INVALID) delete Querys2; if(CheckPointer(Querys3)!=POINTER_INVALID) delete Querys3; if(CheckPointer(Querys4)!=POINTER_INVALID) delete Querys4; if(CheckPointer(Values2)!=POINTER_INVALID) delete Values2; if(CheckPointer(Values3)!=POINTER_INVALID) delete Values3; if(CheckPointer(Values4)!=POINTER_INVALID) delete Values4; if(CheckPointer(Scores2)!=POINTER_INVALID) delete Scores2; if(CheckPointer(Scores3)!=POINTER_INVALID) delete Scores3; if(CheckPointer(Scores4)!=POINTER_INVALID) delete Scores4; if(CheckPointer(Weights0)!=POINTER_INVALID) delete Weights0; if(CheckPointer(AttentionOut2)!=POINTER_INVALID) delete AttentionOut2; if(CheckPointer(AttentionOut3)!=POINTER_INVALID) delete AttentionOut3; if(CheckPointer(AttentionOut4)!=POINTER_INVALID) delete AttentionOut4; if(CheckPointer(AttentionConcatenate)!=POINTER_INVALID) delete AttentionConcatenate; }
O método Init é construído por analogia com o método da classe pai. No início do método, chamamos o método relevante da classe pai.
bool CNeuronMHAttentionOCL::Init(uint numOutputs,uint myIndex,COpenCLMy *open_cl,uint window,uint units_count,ENUM_OPTIMIZATION optimization_type) { if(!CNeuronAttentionOCL::Init(numOutputs,myIndex,open_cl,window,units_count,optimization_type)) return false;
Em seguida, inicializamos as instâncias das instâncias da camada de convolução Querys. Observe que nós inicializamos objetos a partir da segunda cabeça, uma vez que as instâncias de todos os objetos da primeira cabeça são inicializadas na classe pai.
if(CheckPointer(Querys2)==POINTER_INVALID) { Querys2=new CNeuronConvOCL(); if(CheckPointer(Querys2)==POINTER_INVALID) return false; if(!Querys2.Init(0,6,open_cl,window,window,window,units_count,optimization_type)) return false; Querys2.SetActivationFunction(None); } //--- if(CheckPointer(Querys3)==POINTER_INVALID) { Querys3=new CNeuronConvOCL(); if(CheckPointer(Querys3)==POINTER_INVALID) return false; if(!Querys3.Init(0,7,open_cl,window,window,window,units_count,optimization_type)) return false; Querys3.SetActivationFunction(None); } //--- if(CheckPointer(Querys4)==POINTER_INVALID) { Querys4=new CNeuronConvOCL(); if(CheckPointer(Querys4)==POINTER_INVALID) return false; if(!Querys4.Init(0,8,open_cl,window,window,window,units_count,optimization_type)) return false; Querys4.SetActivationFunction(None); }
De forma semelhante, inicializamos as instâncias de classe para Values, Scores para AttentionOut.
if(CheckPointer(Values2)==POINTER_INVALID) { Values2=new CNeuronConvOCL(); if(CheckPointer(Values2)==POINTER_INVALID) return false; if(!Values2.Init(0,9,open_cl,window,window,window,units_count,optimization_type)) return false; Values2.SetActivationFunction(None); } //--- if(CheckPointer(Values3)==POINTER_INVALID) { Values3=new CNeuronConvOCL(); if(CheckPointer(Values3)==POINTER_INVALID) return false; if(!Values3.Init(0,10,open_cl,window,window,window,units_count,optimization_type)) return false; Values3.SetActivationFunction(None); } //--- if(CheckPointer(Values4)==POINTER_INVALID) { Values4=new CNeuronConvOCL(); if(CheckPointer(Values4)==POINTER_INVALID) return false; if(!Values4.Init(0,11,open_cl,window,window,window,units_count,optimization_type)) return false; Values4.SetActivationFunction(None); } //--- if(CheckPointer(Scores2)==POINTER_INVALID) { Scores2=new CBufferDouble(); if(CheckPointer(Scores2)==POINTER_INVALID) return false; } if(!Scores2.BufferInit(units_count*units_count,0.0)) return false; if(!Scores2.BufferCreate(OpenCL)) return false; //--- if(CheckPointer(Scores3)==POINTER_INVALID) { Scores3=new CBufferDouble(); if(CheckPointer(Scores3)==POINTER_INVALID) return false; } if(!Scores3.BufferInit(units_count*units_count,0.0)) return false; if(!Scores3.BufferCreate(OpenCL)) return false; //--- if(CheckPointer(Scores4)==POINTER_INVALID) { Scores4=new CBufferDouble(); if(CheckPointer(Scores4)==POINTER_INVALID) return false; } if(!Scores4.BufferInit(units_count*units_count,0.0)) return false; if(!Scores4.BufferCreate(OpenCL)) return false; //--- if(CheckPointer(AttentionOut2)==POINTER_INVALID) { AttentionOut2=new CNeuronBaseOCL(); if(CheckPointer(AttentionOut2)==POINTER_INVALID) return false; if(!AttentionOut2.Init(0,12,open_cl,window*units_count,optimization_type)) return false; AttentionOut2.SetActivationFunction(None); } //--- if(CheckPointer(AttentionOut3)==POINTER_INVALID) { AttentionOut3=new CNeuronBaseOCL(); if(CheckPointer(AttentionOut3)==POINTER_INVALID) return false; if(!AttentionOut3.Init(0,13,open_cl,window*units_count,optimization_type)) return false; AttentionOut3.SetActivationFunction(None); } //--- if(CheckPointer(AttentionOut4)==POINTER_INVALID) { AttentionOut4=new CNeuronBaseOCL(); if(CheckPointer(AttentionOut4)==POINTER_INVALID) return false; if(!AttentionOut4.Init(0,14,open_cl,window*units_count,optimization_type)) return false; AttentionOut4.SetActivationFunction(None); }
Inicializamos a camada para concatenação dos dados AttentionConcatenate. Esta é uma camada totalmente conectada que só será usada para a transmissão de dados. Portanto, o número de conexões de saída é igual a "0". O tamanho da camada deve ser suficiente para armazenar os dados de saída de todas as quatro cabeças de atenção. Indicamos o número de neurônios na camada igual ao produto de quatro janelas da camada de saída de uma cabeça pelo número de elementos na sequência.
if(CheckPointer(AttentionConcatenate)==POINTER_INVALID) { AttentionConcatenate=new CNeuronBaseOCL(); if(CheckPointer(AttentionConcatenate)==POINTER_INVALID) return false; if(!AttentionConcatenate.Init(0,15,open_cl,4*window*units_count,optimization_type)) return false; AttentionConcatenate.SetActivationFunction(None); }
No final do método, inicializamos a camada convolucional Weights0. O objetivo da camada é selecionar uma estratégia ótima com base nos dados recebidos de todas as cabeças de atenção. A dimensão dos dados de saída será reduzida à dimensão dos dados originais que são inseridos no bloco Multi-Head Attention. Ao inicializar uma camada, indicamos o tamanho da janela de entrada e passo igual a quatro janelas de dados da camada anterior, e o tamanho da janela de saída igual à janela de dados da camada anterior.
if(CheckPointer(Weights0)==POINTER_INVALID) { Weights0=new CNeuronConvOCL(); if(CheckPointer(Weights0)==POINTER_INVALID) return false; if(!Weights0.Init(0,16,open_cl,4*window,4*window,window,units_count,optimization_type)) return false; Weights0.SetActivationFunction(None); } //--- return true; }
O código completo de todos os métodos e funções está disponível em anexo.
4.3. Propagação direta
O algoritmo de propagação direta (feed-forward) foi construído principalmente usando o programa OpenCL, que foi criado anteriormente. A única exceção é a criação de um kernel concatenando os dados de 4 tensores de cada cabeça de atenção em um único tensor. O kernel recebe nos parâmetros o seguinte: ponteiros para os buffers de dados e cada tamanho de janela de buffer, bem como um ponteiro para o tensor de resultados. Os tamanhos da janela detalhados por buffers de dados de entrada foram adicionados para permitir a concatenação dos tensores de tamanhos diferentes com tamanhos de janela diferentes.
__kernel void ConcatenateBuffers(__global double *input1, int window1, __global double *input2, int window2, __global double *input3, int window3, __global double *input4, int window4, __global double *output)
No corpo do kernel, os dados são copiados das matrizes de entrada para a matriz de saída, elemento por elemento. O algoritmo é bastante simples, então eu acho que o código anexado é fácil de entender.
Na classe CNeuronMHAttentionOCL, a propagação direta é implementada no método feedForward. No início do método, verificamos a validade do link recebido para a camada anterior e normalizamos os dados de entrada.
bool CNeuronMHAttentionOCL::feedForward(CNeuronBaseOCL *prevLayer) { if(CheckPointer(prevLayer)==POINTER_INVALID) return false; //--- { uint global_work_offset[1]={0}; uint global_work_size[1]; global_work_size[0]=1; OpenCL.SetArgumentBuffer(def_k_Normilize,def_k_norm_buffer,prevLayer.getOutputIndex()); OpenCL.SetArgument(def_k_Normilize,def_k_norm_dimension,prevLayer.Neurons()); if(!OpenCL.Execute(def_k_Normilize,1,global_work_offset,global_work_size)) { printf("Error of execution kernel Normalize: %d",GetLastError()); return false; } if(!prevLayer.Output.BufferRead()) return false; }
Em seguida, chamamos os métodos da camada convolucional apropriados e recalculamos os valores dos tensores Querys e Values para todas as cabeças de atenção.
if(CheckPointer(Querys)==POINTER_INVALID || !Querys.FeedForward(prevLayer)) return false; if(CheckPointer(Querys2)==POINTER_INVALID || !Querys2.FeedForward(prevLayer)) return false; if(CheckPointer(Querys3)==POINTER_INVALID || !Querys3.FeedForward(prevLayer)) return false; if(CheckPointer(Querys4)==POINTER_INVALID || !Querys4.FeedForward(prevLayer)) return false; if(CheckPointer(Values)==POINTER_INVALID || !Values.FeedForward(prevLayer)) return false; if(CheckPointer(Values2)==POINTER_INVALID || !Values2.FeedForward(prevLayer)) return false; if(CheckPointer(Values3)==POINTER_INVALID || !Values3.FeedForward(prevLayer)) return false; if(CheckPointer(Values4)==POINTER_INVALID || !Values4.FeedForward(prevLayer)) return false;
Em seguida, recalculamos a atenção para cada cabeça. O algoritmo é semelhante à classe pai descrita no artigo 8. Abaixo está o código para uma cabeça de atenção. O código para outras cabeças é semelhante, apenas os ponteiros para os objetos da cabeça de atenção apropriada são semelhantes.
//--- Scores Head 1 { uint global_work_offset[1]={0}; uint global_work_size[1]; global_work_size[0]=iUnits; OpenCL.SetArgumentBuffer(def_k_AttentionScore,def_k_as_querys,Querys.getOutputIndex()); OpenCL.SetArgumentBuffer(def_k_AttentionScore,def_k_as_keys,prevLayer.getOutputIndex()); OpenCL.SetArgumentBuffer(def_k_AttentionScore,def_k_as_score,Scores.GetIndex()); OpenCL.SetArgument(def_k_AttentionScore,def_k_as_dimension,iWindow); if(!OpenCL.Execute(def_k_AttentionScore,1,global_work_offset,global_work_size)) { printf("Error of execution kernel AttentionScore: %d",GetLastError()); return false; } if(!Scores.BufferRead()) return false; } //--- { uint global_work_offset[2]={0,0}; uint global_work_size[2]; global_work_size[0]=iUnits; global_work_size[1]=iWindow; OpenCL.SetArgumentBuffer(def_k_AttentionOut,def_k_aout_scores,Scores.GetIndex()); OpenCL.SetArgumentBuffer(def_k_AttentionOut,def_k_aout_inputs,prevLayer.getOutputIndex()); OpenCL.SetArgumentBuffer(def_k_AttentionOut,def_k_aout_values,Values.getOutputIndex()); OpenCL.SetArgumentBuffer(def_k_AttentionOut,def_k_aout_out,AttentionOut.getOutputIndex()); if(!OpenCL.Execute(def_k_AttentionOut,2,global_work_offset,global_work_size)) { printf("Error of execution kernel Attention Out: %d",GetLastError()); return false; } double temp[]; if(!AttentionOut.getOutputVal(temp)) return false; }
Depois de calcular a atenção para cada cabeça, concatenamos os resultados em um único tensor usando o kernel previamente escrito.
{
uint global_work_offset[1]={0};
uint global_work_size[1];
global_work_size[0]=iUnits;
OpenCL.SetArgumentBuffer(def_k_ConcatenateMatrix,def_k_conc_input1,AttentionOut.getOutputIndex());
OpenCL.SetArgument(def_k_ConcatenateMatrix,def_k_conc_window1,iWindow);
OpenCL.SetArgumentBuffer(def_k_ConcatenateMatrix,def_k_conc_input2,AttentionOut2.getOutputIndex());
OpenCL.SetArgument(def_k_ConcatenateMatrix,def_k_conc_window2,iWindow);
OpenCL.SetArgumentBuffer(def_k_ConcatenateMatrix,def_k_conc_input3,AttentionOut3.getOutputIndex());
OpenCL.SetArgument(def_k_ConcatenateMatrix,def_k_conc_window3,iWindow);
OpenCL.SetArgumentBuffer(def_k_ConcatenateMatrix,def_k_conc_input4,AttentionOut4.getOutputIndex());
OpenCL.SetArgument(def_k_ConcatenateMatrix,def_k_conc_window4,iWindow);
OpenCL.SetArgumentBuffer(def_k_ConcatenateMatrix,def_k_conc_out,AttentionConcatenate.getOutputIndex());
if(!OpenCL.Execute(def_k_ConcatenateMatrix,1,global_work_offset,global_work_size))
{
printf("Error of execution kernel Concatenate Matrix: %d",GetLastError());
return false;
}
double temp[];
if(!AttentionConcatenate.getOutputVal(temp))
return false;
}
Passamos o resultado da concatenação do tensor através da camada convolucional Weights0 para reduzir o tamanho do resultado do trabalho da Atenção Multi-Cabeça.
if(CheckPointer(Weights0)==POINTER_INVALID || !Weights0.FeedForward(AttentionConcatenate)) return false;
Em seguida, calculamos a média do resultado obtido com os dados da camada anterior e normalizamos o resultado.
{
uint global_work_offset[1]={0};
uint global_work_size[1];
global_work_size[0]=iUnits;
OpenCL.SetArgumentBuffer(def_k_MatrixSum,def_k_sum_matrix1,Weights0.getOutputIndex());
OpenCL.SetArgumentBuffer(def_k_MatrixSum,def_k_sum_matrix2,prevLayer.getOutputIndex());
OpenCL.SetArgumentBuffer(def_k_MatrixSum,def_k_sum_matrix_out,Weights0.getOutputIndex());
OpenCL.SetArgument(def_k_MatrixSum,def_k_sum_dimension,iWindow);
OpenCL.SetArgument(def_k_MatrixSum,def_k_sum_multiplyer,0.5);
if(!OpenCL.Execute(def_k_MatrixSum,1,global_work_offset,global_work_size))
{
printf("Error of execution kernel MatrixSum: %d",GetLastError());
return false;
}
if(!Output.BufferRead())
return false;
}
//---
{
uint global_work_offset[1]={0};
uint global_work_size[1];
global_work_size[0]=1;
OpenCL.SetArgumentBuffer(def_k_Normilize,def_k_norm_buffer,Weights0.getOutputIndex());
OpenCL.SetArgument(def_k_Normilize,def_k_norm_dimension,Weights0.Neurons());
if(!OpenCL.Execute(def_k_Normilize,1,global_work_offset,global_work_size))
{
printf("Error of execution kernel Normalize: %d",GetLastError());
return false;
}
double temp[];
if(!Weights0.getOutputVal(temp))
return false;
}
Em seguida, de forma semelhante à classe pai, passamos o resultado por meio do bloco FeedForward.
if(!FF1.FeedForward(Weights0)) return false; if(!FF2.FeedForward(FF1)) return false; //--- { uint global_work_offset[1]={0}; uint global_work_size[1]; global_work_size[0]=iUnits; OpenCL.SetArgumentBuffer(def_k_MatrixSum,def_k_sum_matrix1,Weights0.getOutputIndex()); OpenCL.SetArgumentBuffer(def_k_MatrixSum,def_k_sum_matrix2,FF2.getOutputIndex()); OpenCL.SetArgumentBuffer(def_k_MatrixSum,def_k_sum_matrix_out,Output.GetIndex()); OpenCL.SetArgument(def_k_MatrixSum,def_k_sum_dimension,iWindow); OpenCL.SetArgument(def_k_MatrixSum,def_k_sum_multiplyer,0.5); if(!OpenCL.Execute(def_k_MatrixSum,1,global_work_offset,global_work_size)) { printf("Error of execution kernel MatrixSum: %d",GetLastError()); return false; } if(!Output.BufferRead()) return false; } //--- return true; }
O código completo de todos os métodos e funções está disponível em anexo.
4.4. Retropropagação
O processo de retropropagação contém dois subprocessos: passar o gradiente de erro um nível abaixo e atualizar as matrizes de peso. Os pesos são atualizados usando os kernels OpenCL criados anteriormente, enquanto para o processo de retropropagação do erro, nós precisamos fazer algumas alterações.
Em primeiro lugar, nós precisamos propagar o gradiente de erro por cabeças de atenção. Para executar esta função, criamos o kernel DeconcatenateBuffers. A entrada para o kernel aponta para os buffers de propagação do gradiente, tamanhos da janela para cada buffer e um ponteiro para o buffer de gradientes recebidos da iteração anterior.
__kernel void DeconcatenateBuffers(__global double *output1, int window1, __global double *output2, int window2, __global double *output3, int window3, __global double *output4, int window4, __global double *inputs)
No início do kernel, definimos o número ordinal do elemento de sequência e a primeira mudança de posição para o tensor original e o primeiro tensor da cabeça de atenção.
{
int n=get_global_id(0);
int shift=n*(window1+window2+window3+window4);
int shift_out=n*window1;
Em seguida, em um loop, movemos o vetor de gradientes de erro para a primeira cabeça de atenção.
for(int i=0;i<window1;i++) output1[shift_out+i]=inputs[shift+i];
Assim que o ciclo terminar, ajustamos a posição do ponteiro no tensor original e determinamos a primeira mudança de posição no buffer da segunda cabeça de atenção. Em seguida, executamos um ciclo de cópia de dados para a segunda cabeça de atenção. As operações são repetidas para cada cabeça de atenção.
//--- Head 2 shift+=window1; shift_out=n*window2; for(int i=0;i<window2;i++) output2[shift_out+i]=inputs[shift+i]; //--- Head 3 shift+=window2; shift_out=n*window3; for(int i=0;i<window3;i++) output3[shift_out+i]=inputs[shift+i]; //--- Head 4 shift+=window3; shift_out=n*window4; for(int i=0;i<window4;i++) output4[shift_out+i]=inputs[shift+i]; }
Posteriormente, após calcular os gradientes de erro para cada cabeça de atenção, é necessário combinar os gradientes em um único buffer de dados na camada anterior da rede neural. Tecnicamente, nós poderíamos usar o kernel SumMatrix adicionando os gradientes de todas as cabeças de atenção aos pares. Mas esta solução não é ideal em termos de desempenho. Então, vamos criar outro kernel - Sum5Matrix. Nos parâmetros do kernel, nós passamos os ponteiros para os buffers de dados (5 entradas e 1 saída), o tamanho da janela de dados e um multiplicador (o fator de correção de soma). Talvez eu precise explicar por que existem 5 buffers de entrada com 4 cabeças de atenção. O quinto buffer é usado para a passar do gradiente de erro para minimizar o risco de desvanecimento do gradiente.
__kernel void Sum5Matrix(__global double *matrix1, ///<[in] First matrix __global double *matrix2, ///<[in] Second matrix __global double *matrix3, ///<[in] Third matrix __global double *matrix4, ///<[in] Fourth matrix __global double *matrix5, ///<[in] Fifth matrix __global double *matrix_out, ///<[out] Output matrix int dimension, ///< Dimension of matrix double multiplyer ///< Multiplyer for output )
No corpo do kernel, definimos o deslocamento do primeiro elemento dos vetores processados nas sequências e iniciamos o ciclo de soma dos gradientes. A multiplicação da soma dos gradientes de erro por 0.2 permite que os valores do erro transmitido sejam suavizados sobre a camada anterior da rede neural. Por sua vez, o multiplicador é implementado nos parâmetros de maneira intencional, para permitir a seleção de seu valor durante o ajuste do algoritmo.
{
const int i=get_global_id(0)*dimension;
for(int k=0;k<dimension;k++)
matrix_out[i+k]=(matrix1[i+k]+matrix2[i+k]+matrix3[i+k]+matrix4[i+k]+matrix5[i+k])*multiplyer;
}
Na classe CNeuronMHAttentionOCL, cada subprocesso recebe seu método. A propagação do gradiente de erro é realizada pelo método calcInputGradients. O método recebe nos parâmetros um ponteiro para o objeto da camada da rede neural anterior. Verificamos a validade do ponteiro no início do método.
bool CNeuronMHAttentionOCL::calcInputGradients(CNeuronBaseOCL *prevLayer) { if(CheckPointer(prevLayer)==POINTER_INVALID) return false;
Em seguida, calculamos os gradientes de erro por meio do bloco FeedForward, usando os métodos apropriados das camadas convolucionais FF1 e FF2.
if(!FF2.calcInputGradients(FF1)) return false; if(!FF1.calcInputGradients(Weights0)) return false;
Passamos o gradiente de erro ao redor do bloco FeedForward. Salvamos o valor de erro médio no buffer do gradiente da camada Weights0.
{
uint global_work_offset[1]={0};
uint global_work_size[1];
global_work_size[0]=iUnits;
OpenCL.SetArgumentBuffer(def_k_MatrixSum,def_k_sum_matrix1,Weights0.getGradientIndex());
OpenCL.SetArgumentBuffer(def_k_MatrixSum,def_k_sum_matrix2,Gradient.GetIndex());
OpenCL.SetArgumentBuffer(def_k_MatrixSum,def_k_sum_matrix_out,Weights0.getGradientIndex());
OpenCL.SetArgument(def_k_MatrixSum,def_k_sum_dimension,iWindow);
OpenCL.SetArgument(def_k_MatrixSum,def_k_sum_multiplyer,0.5);
if(!OpenCL.Execute(def_k_MatrixSum,1,global_work_offset,global_work_size))
{
printf("Error of execution kernel MatrixSum: %d",GetLastError());
return false;
}
double temp[];
if(Weights0.getGradient(temp)<=0)
return false;
}
Agora, é hora da propagação de erros pelas cabeças de atenção. Nós precisamos aumentar o tamanho do tensor do gradiente para o tamanho do buffer de atenção concatenado. Para fazer isso, passamos o gradiente de erro pela camada convolucional Weights0, chamando o método apropriado da camada convolucional.
if(!Weights0.calcInputGradients(AttentionConcatenate)) return false;
Depois de receber um tensor de gradientes de erro grande o suficiente, nós podemos distribuir o erro pelos buffers das cabeças de atenção. Usamos o kernel de desconcatenação criado acima.
{
uint global_work_offset[1]={0};
uint global_work_size[1];
global_work_size[0]=iUnits;
OpenCL.SetArgumentBuffer(def_k_DeconcatenateMatrix,def_k_dconc_output1,AttentionOut.getGradientIndex());
OpenCL.SetArgument(def_k_DeconcatenateMatrix,def_k_dconc_window1,iWindow);
OpenCL.SetArgumentBuffer(def_k_DeconcatenateMatrix,def_k_dconc_output2,AttentionOut2.getGradientIndex());
OpenCL.SetArgument(def_k_DeconcatenateMatrix,def_k_dconc_window2,iWindow);
OpenCL.SetArgumentBuffer(def_k_DeconcatenateMatrix,def_k_dconc_output3,AttentionOut3.getGradientIndex());
OpenCL.SetArgument(def_k_DeconcatenateMatrix,def_k_dconc_window3,iWindow);
OpenCL.SetArgumentBuffer(def_k_DeconcatenateMatrix,def_k_dconc_output4,AttentionOut4.getGradientIndex());
OpenCL.SetArgument(def_k_DeconcatenateMatrix,def_k_dconc_window4,iWindow);
OpenCL.SetArgumentBuffer(def_k_DeconcatenateMatrix,def_k_dconc_inputs,AttentionConcatenate.getGradientIndex());
if(!OpenCL.Execute(def_k_DeconcatenateMatrix,1,global_work_offset,global_work_size))
{
printf("Error of execution kernel Deconcatenate Matrix: %d",GetLastError());
return false;
}
double temp[];
if(AttentionConcatenate.getGradient(temp)<=0)
return false;
}
O cálculo do gradiente de erro dentro de uma cabeça de atenção é implementado em um método separado - calcHeadGradient. Aqui nós chamamos esse método para cada segmento de atenção.
if(!calcHeadGradient(Querys,Values,Scores,AttentionOut,prevLayer)) return false; if(!calcHeadGradient(Querys2,Values2,Scores2,AttentionOut2,prevLayer)) return false; if(!calcHeadGradient(Querys3,Values3,Scores3,AttentionOut3,prevLayer)) return false; if(!calcHeadGradient(Querys4,Values4,Scores4,AttentionOut4,prevLayer)) return false;
No final do método, somamos os gradientes de erro de todas as cabeças de atenção e passamos o resultado para a camada anterior da rede neural.
{
uint global_work_offset[1]={0};
uint global_work_size[1];
global_work_size[0]=iUnits;
OpenCL.SetArgumentBuffer(def_k_Matrix5Sum,def_k_sum5_matrix1,AttentionOut.getGradientIndex());
OpenCL.SetArgumentBuffer(def_k_Matrix5Sum,def_k_sum5_matrix2,AttentionOut2.getGradientIndex());
OpenCL.SetArgumentBuffer(def_k_Matrix5Sum,def_k_sum5_matrix3,AttentionOut3.getGradientIndex());
OpenCL.SetArgumentBuffer(def_k_Matrix5Sum,def_k_sum5_matrix4,AttentionOut4.getGradientIndex());
OpenCL.SetArgumentBuffer(def_k_Matrix5Sum,def_k_sum5_matrix5,Weights0.getGradientIndex());
OpenCL.SetArgumentBuffer(def_k_Matrix5Sum,def_k_sum5_matrix_out,prevLayer.getGradientIndex());
OpenCL.SetArgument(def_k_Matrix5Sum,def_k_sum5_dimension,iWindow);
OpenCL.SetArgument(def_k_Matrix5Sum,def_k_sum5_multiplyer,0.2);
if(!OpenCL.Execute(def_k_Matrix5Sum,1,global_work_offset,global_work_size))
{
printf("Error of execution kernel Matrix5Sum: %d",GetLastError());
return false;
}
double temp[];
if(prevLayer.getGradient(temp)<=0)
return false;
}
//---
return true;
}
Vamos dar uma olhada no método calcHeadGradient. O método recebe nos parâmetros os ponteiros para as camadas neurais internas 'query', 'value', 'score', 'attention', relacionados à cabeça de atenção em consideração, e um ponteiro para a camada neural anterior.
bool CNeuronMHAttentionOCL::calcHeadGradient(CNeuronConvOCL *query,CNeuronConvOCL *value,CBufferDouble *score,CNeuronBaseOCL *attention,CNeuronBaseOCL *prevLayer) { if(CheckPointer(prevLayer)==POINTER_INVALID) return false;
O corpo do método começa verificando a validade do ponteiro para a camada neural anterior. Para distribuir o gradiente de erro nas camadas internas, chamamos o kernel AttentionInsideGradients, que foi discutido no artigo 8.
{
uint global_work_offset[2]={0,0};
uint global_work_size[2];
global_work_size[0]=iUnits;
global_work_size[1]=iWindow;
OpenCL.SetArgumentBuffer(def_k_AttentionGradients,def_k_ag_gradient,attention.getGradientIndex());
OpenCL.SetArgumentBuffer(def_k_AttentionGradients,def_k_ag_keys,prevLayer.getOutputIndex());
OpenCL.SetArgumentBuffer(def_k_AttentionGradients,def_k_ag_keys_g,prevLayer.getGradientIndex());
OpenCL.SetArgumentBuffer(def_k_AttentionGradients,def_k_ag_querys,query.getOutputIndex());
OpenCL.SetArgumentBuffer(def_k_AttentionGradients,def_k_ag_querys_g,query.getGradientIndex());
OpenCL.SetArgumentBuffer(def_k_AttentionGradients,def_k_ag_values,value.getOutputIndex());
OpenCL.SetArgumentBuffer(def_k_AttentionGradients,def_k_ag_values_g,value.getGradientIndex());
OpenCL.SetArgumentBuffer(def_k_AttentionGradients,def_k_ag_scores,score.GetIndex());
if(!OpenCL.Execute(def_k_AttentionGradients,2,global_work_offset,global_work_size))
{
printf("Error of execution kernel AttentionGradients: %d",GetLastError());
return false;
}
double temp[];
if(query.getGradient(temp)<=0)
return false;
}
Este exemplo mostra o treinamento de uma matriz, sem dividir em 'query' e 'key'. Portanto, os buffers da camada anterior são especificados em vez dos buffers da camada key. Para não sobrescrever o gradiente de erro, obtido na camada anterior, ao calcular nas outras camadas internas, transferimos os dados para o tensor AttentionOut da cabeça de atenção atual. Eu não forneci um tensor separado para copiar os dados entre os buffers. Esta operação foi realizada usando o kernel de adição de duas matrizes SumMatrix. Como nós temos apenas uma matriz, indicamos a camada anterior nos ponteiros de ambos os tensores. Para evitar a duplicação de valores, usamos um multiplicador de 0.5.
{
uint global_work_offset[1]={0};
uint global_work_size[1];
global_work_size[0]=iUnits;
OpenCL.SetArgumentBuffer(def_k_MatrixSum,def_k_sum_matrix1,prevLayer.getGradientIndex());
OpenCL.SetArgumentBuffer(def_k_MatrixSum,def_k_sum_matrix2,prevLayer.getGradientIndex());
OpenCL.SetArgumentBuffer(def_k_MatrixSum,def_k_sum_matrix_out,attention.getGradientIndex());
OpenCL.SetArgument(def_k_MatrixSum,def_k_sum_dimension,iWindow);
OpenCL.SetArgument(def_k_MatrixSum,def_k_sum_multiplyer,0.5);
if(!OpenCL.Execute(def_k_MatrixSum,1,global_work_offset,global_work_size))
{
printf("Error of execution kernel MatrixSum: %d",GetLastError());
return false;
}
double temp[];
if(attention.getGradient(temp)<=0)
return false;
}
Em seguida, calculamos o gradiente de erro passando pela camada query chamando o método da camada 'query' correspondente. O resultado é somado ao gradiente obtido na iteração anterior. O multiplicador igual a 1 é usado nesta etapa. O gradiente aumentado será calculado na próxima etapa.
if(!query.calcInputGradients(prevLayer)) return false; //--- { uint global_work_offset[1]={0}; uint global_work_size[1]; global_work_size[0]=iUnits; OpenCL.SetArgumentBuffer(def_k_MatrixSum,def_k_sum_matrix1,attention.getGradientIndex()); OpenCL.SetArgumentBuffer(def_k_MatrixSum,def_k_sum_matrix2,prevLayer.getGradientIndex()); OpenCL.SetArgumentBuffer(def_k_MatrixSum,def_k_sum_matrix_out,attention.getGradientIndex()); OpenCL.SetArgument(def_k_MatrixSum,def_k_sum_dimension,iWindow); OpenCL.SetArgument(def_k_MatrixSum,def_k_sum_multiplyer,1.0); if(!OpenCL.Execute(def_k_MatrixSum,1,global_work_offset,global_work_size)) { printf("Error of execution kernel MatrixSum: %d",GetLastError()); return false; } double temp[]; if(attention.getGradient(temp)<=0) return false; }
Novamente, no final do método, calculamos o gradiente através da camada 'value' e somamos com os gradientes obtidos anteriormente. O gradiente sobre a cabeça de atenção como um todo pode ser calculado usando o multiplicador de 0.33.
if(!value.calcInputGradients(prevLayer)) return false; //--- { uint global_work_offset[1]={0}; uint global_work_size[1]; global_work_size[0]=iUnits; OpenCL.SetArgumentBuffer(def_k_MatrixSum,def_k_sum_matrix1,attention.getGradientIndex()); OpenCL.SetArgumentBuffer(def_k_MatrixSum,def_k_sum_matrix2,prevLayer.getGradientIndex()); OpenCL.SetArgumentBuffer(def_k_MatrixSum,def_k_sum_matrix_out,attention.getGradientIndex()); OpenCL.SetArgument(def_k_MatrixSum,def_k_sum_dimension,iWindow+1); OpenCL.SetArgument(def_k_MatrixSum,def_k_sum_multiplyer,0.33); if(!OpenCL.Execute(def_k_MatrixSum,1,global_work_offset,global_work_size)) { printf("Error of execution kernel MatrixSum: %d",GetLastError()); return false; } double temp[]; if(prevLayer.getGradient(temp)<=0) return false; } //--- return true; }
Depois de recalcular os gradientes de erro, atualizamos os pesos de todas as camadas internas. No método updateInputWeights, escrevemos uma chamada sequencial dos métodos relevantes de todas as camadas neurais internas.
bool CNeuronMHAttentionOCL::updateInputWeights(CNeuronBaseOCL *prevLayer) { if(!Querys.UpdateInputWeights(prevLayer) || !Querys2.UpdateInputWeights(prevLayer) || !Querys3.UpdateInputWeights(prevLayer) || !Querys4.UpdateInputWeights(prevLayer)) return false; //--- if(!Values.UpdateInputWeights(prevLayer) || !Values2.UpdateInputWeights(prevLayer) || !Values3.UpdateInputWeights(prevLayer) || !Values4.UpdateInputWeights(prevLayer)) return false; if(!Weights0.UpdateInputWeights(AttentionConcatenate)) return false; if(!FF1.UpdateInputWeights(Weights0)) return false; if(!FF2.UpdateInputWeights(FF1)) return false; //--- return true; }
O código completo de todos os métodos e funções está disponível em anexo.
4.5. Alterações nas Classes Base da Rede Neural
Depois de implementar o algoritmo Atenção Multi-Cabeça (Multi-Head Attention), nós precisamos implementar o Codificador Posicional. Este processo está incluído no método CNet::feedForward da classe de rede neural. Dois parâmetros foram adicionados ao método para sua implementação: window e tem. O primeiro especifica o tamanho da janela de dados e o segundo é responsável pela necessidade de habilitar/desabilitar a função.
bool CNet::feedForward(CArrayDouble *inputVals,int window=1,bool tem=true)
O próprio processo é implementado no bloco para alimentar os dados de entrada na rede. Primeiro, declaramos 2 variáveis internas, pos (posição na sequência) e dim (o número ordinal do elemento dentro da janela de dados). Determinamos o número ordinal do elemento dentro da janela de dados. Para fazer isso, usamos o restante da divisão do número ordinal do elemento no tensor de dados de origem pelo tamanho da janela. A posição na sequência é determinada pelo resultado inteiro da divisão do número ordinal do elemento no tensor de dados de origem pelo tamanho da janela. Então, ao salvar os dados iniciais no tensor de entrada da rede neural pronta, adicionamos o resultado do cálculo usando as fórmulas indicadas na seção 3 deste artigo.
CNeuronBaseOCL *neuron_ocl=current.At(0); double array[]; int total_data=inputVals.Total(); if(ArrayResize(array,total_data)<0) return false; for(int d=0;d<total_data;d++) { int pos=d; int dim=0; if(window>1) { dim=d%window; pos=(d-dim)/window; } array[d]=inputVals.At(d)+(tem ? (dim%2==0 ? sin(pos/pow(10000,(2*dim+1)/(window+1))) : cos(pos/pow(10000,(2*dim+1)/(window+1)))) : 0); } if(!opencl.BufferWrite(neuron_ocl.getOutputIndex(),array,0,0,total_data)) return false;
Agora, é necessário fazer algumas mudanças adicionais para o funcionamento normal da rede neural. Adicionamos as constantes para trabalhar com os novos kernels ao bloco define.
#define def_k_ConcatenateMatrix 17 ///< Index of the Multi Head Attention Neuron Concatenate Output kernel (#ConcatenateBuffers) #define def_k_conc_input1 0 ///< Matrix of Buffer 1 #define def_k_conc_window1 1 ///< Window of Buffer 1 #define def_k_conc_input2 2 ///< Matrix of Buffer 2 #define def_k_conc_window2 3 ///< Window of Buffer 2 #define def_k_conc_input3 4 ///< Matrix of Buffer 3 #define def_k_conc_window3 5 ///< Window of Buffer 3 #define def_k_conc_input4 6 ///< Matrix of Buffer 4 #define def_k_conc_window4 7 ///< Window of Buffer 4 #define def_k_conc_out 8 ///< Output tensor //--- #define def_k_DeconcatenateMatrix 18 ///< Index of the Multi Head Attention Neuron Deconcatenate Output kernel (#DeconcatenateBuffers) #define def_k_dconc_output1 0 ///< Matrix of Buffer 1 #define def_k_dconc_window1 1 ///< Window of Buffer 1 #define def_k_dconc_output2 2 ///< Matrix of Buffer 2 #define def_k_dconc_window2 3 ///< Window of Buffer 2 #define def_k_dconc_output3 4 ///< Matrix of Buffer 3 #define def_k_dconc_window3 5 ///< Window of Buffer 3 #define def_k_dconc_output4 6 ///< Matrix of Buffer 4 #define def_k_dconc_window4 7 ///< Window of Buffer 4 #define def_k_dconc_inputs 8 ///< Input tensor //--- #define def_k_Matrix5Sum 19 ///< Index of the kernel for calculation Sum of 2 matrix with multiplyer (#SumMatrix) #define def_k_sum5_matrix1 0 ///< First matrix #define def_k_sum5_matrix2 1 ///< Second matrix #define def_k_sum5_matrix3 2 ///< Third matrix #define def_k_sum5_matrix4 3 ///< Fourth matrix #define def_k_sum5_matrix5 4 ///< Fifth matrix #define def_k_sum5_matrix_out 5 ///< Output matrix #define def_k_sum5_dimension 6 ///< Dimension of matrix #define def_k_sum5_multiplyer 7 ///< Multiplyer for output
Adicionamos uma constante para identificar a nova classe.
#define defNeuronMHAttentionOCL 0x7888 ///<Multi-Head Attention neuron OpenCL \details Identified class #CNeuronAttentionOCL
No construtor de classe da rede neural, adicionamos uma nova classe ao bloco de inicialização da classe OpenCL.
next=Description.At(1); if(next.type==defNeuron || next.type==defNeuronBaseOCL || next.type==defNeuronConvOCL || next.type==defNeuronAttentionOCL || next.type==defNeuronMHAttentionOCL) { opencl=new COpenCLMy(); if(CheckPointer(opencl)!=POINTER_INVALID && !opencl.Initialize(cl_program,true)) delete opencl; }
Adicionamos um novo tipo de neurônio no bloco de inicialização de neurônios na rede.
case defNeuronMHAttentionOCL: neuron_attention_ocl=new CNeuronMHAttentionOCL(); if(CheckPointer(neuron_attention_ocl)==POINTER_INVALID) { delete temp; return; } if(!neuron_attention_ocl.Init(outputs,0,opencl,desc.window,desc.count,desc.optimization)) { delete neuron_attention_ocl; delete temp; return; } neuron_attention_ocl.SetActivationFunction(desc.activation); if(!temp.Add(neuron_attention_ocl)) { delete neuron_attention_ocl; delete temp; return; } neuron_attention_ocl=NULL; break;
Adicionamos a declaração de novos kernels.
if(CheckPointer(opencl)==POINTER_INVALID) return; //--- create kernels opencl.SetKernelsCount(20); opencl.KernelCreate(def_k_FeedForward,"FeedForward"); opencl.KernelCreate(def_k_CalcOutputGradient,"CalcOutputGradient"); opencl.KernelCreate(def_k_CalcHiddenGradient,"CalcHiddenGradient"); opencl.KernelCreate(def_k_UpdateWeightsMomentum,"UpdateWeightsMomentum"); opencl.KernelCreate(def_k_UpdateWeightsAdam,"UpdateWeightsAdam"); opencl.KernelCreate(def_k_AttentionGradients,"AttentionInsideGradients"); opencl.KernelCreate(def_k_AttentionOut,"AttentionOut"); opencl.KernelCreate(def_k_AttentionScore,"AttentionScore"); opencl.KernelCreate(def_k_CalcHiddenGradientConv,"CalcHiddenGradientConv"); opencl.KernelCreate(def_k_CalcInputGradientProof,"CalcInputGradientProof"); opencl.KernelCreate(def_k_FeedForwardConv,"FeedForwardConv"); opencl.KernelCreate(def_k_FeedForwardProof,"FeedForwardProof"); opencl.KernelCreate(def_k_MatrixSum,"SumMatrix"); opencl.KernelCreate(def_k_Matrix5Sum,"Sum5Matrix"); opencl.KernelCreate(def_k_UpdateWeightsConvAdam,"UpdateWeightsConvAdam"); opencl.KernelCreate(def_k_UpdateWeightsConvMomentum,"UpdateWeightsConvMomentum"); opencl.KernelCreate(def_k_Normilize,"Normalize"); opencl.KernelCreate(def_k_NormilizeWeights,"NormalizeWeights"); opencl.KernelCreate(def_k_ConcatenateMatrix,"ConcatenateBuffers"); opencl.KernelCreate(def_k_DeconcatenateMatrix,"DeconcatenateBuffers");
Adicionamos uma nova classe aos métodos do dispatcher da classe CNeuronBaseOCL. As alterações são destacadas no código abaixo.
bool CNeuronBaseOCL::FeedForward(CObject *SourceObject) { if(CheckPointer(SourceObject)==POINTER_INVALID) return false; //--- CNeuronBaseOCL *temp=NULL; switch(SourceObject.Type()) { case defNeuronBaseOCL: case defNeuronConvOCL: case defNeuronAttentionOCL: case defNeuronMHAttentionOCL: temp=SourceObject; return feedForward(temp); break; } //--- return false; } bool CNeuronBaseOCL::calcHiddenGradients(CObject *TargetObject) { if(CheckPointer(TargetObject)==POINTER_INVALID) return false; //--- CNeuronBaseOCL *temp=NULL; CNeuronAttentionOCL *at=NULL; CNeuronConvOCL *conv=NULL; switch(TargetObject.Type()) { case defNeuronBaseOCL: temp=TargetObject; return calcHiddenGradients(temp); break; case defNeuronConvOCL: conv=TargetObject; temp=GetPointer(this); return conv.calcInputGradients(temp); break; case defNeuronAttentionOCL: case defNeuronMHAttentionOCL: at=TargetObject; temp=GetPointer(this); return at.calcInputGradients(temp); break; } //--- return false; } bool CNeuronBaseOCL::UpdateInputWeights(CObject *SourceObject) { if(CheckPointer(SourceObject)==POINTER_INVALID) return false; //--- CNeuronBaseOCL *temp=NULL; switch(SourceObject.Type()) { case defNeuronBaseOCL: case defNeuronConvOCL: case defNeuronAttentionOCL: case defNeuronMHAttentionOCL: temp=SourceObject; return updateInputWeights(temp); break; } //--- return false; }
O código completo de todos os métodos e funções está disponível em anexo.
5. Teste
O Expert Advisor Fractal_OCL_AttentionMHTE foi criado para testar a nova arquitetura. Este Expert Advisor foi criado com base no Expert Advisor Fractal_OCL_Attention do artigo 8. Ele difere do EA pai apenas no tipo de classe de neurônios de atenção e no uso do mecanismo para codificar a posição dos elementos de dados de entrada.
CArrayObj *Topology=new CArrayObj(); if(CheckPointer(Topology)==POINTER_INVALID) return INIT_FAILED; //--- CLayerDescription *desc=new CLayerDescription(); if(CheckPointer(desc)==POINTER_INVALID) return INIT_FAILED; desc.count=(int)HistoryBars*12; desc.type=defNeuronBaseOCL; desc.optimization=ADAM; desc.activation=TANH; if(!Topology.Add(desc)) return INIT_FAILED; //--- desc=new CLayerDescription(); if(CheckPointer(desc)==POINTER_INVALID) return INIT_FAILED; desc.count=(int)HistoryBars; desc.type=defNeuronConvOCL; desc.window=12; desc.step=12; desc.window_out=36; desc.optimization=ADAM; desc.activation=SIGMOID; if(!Topology.Add(desc)) return INIT_FAILED; //--- bool result=true; for(int i=0; (i<2 && result); i++) { desc=new CLayerDescription(); if(CheckPointer(desc)==POINTER_INVALID) return INIT_FAILED; desc.count=(int)HistoryBars; desc.type=defNeuronMHAttentionOCL; desc.window=36; desc.optimization=ADAM; desc.activation=None; result=Topology.Add(desc); } if(!result) { delete Topology; return INIT_FAILED; } //--- desc=new CLayerDescription(); if(CheckPointer(desc)==POINTER_INVALID) return INIT_FAILED; desc.count=200; desc.type=defNeuron; desc.activation=TANH; desc.optimization=ADAM; if(!Topology.Add(desc)) return INIT_FAILED; //--- desc=new CLayerDescription(); if(CheckPointer(desc)==POINTER_INVALID) return INIT_FAILED; desc.count=200; desc.type=defNeuron; desc.activation=TANH; desc.optimization=ADAM; if(!Topology.Add(desc)) return INIT_FAILED; //--- desc=new CLayerDescription(); if(CheckPointer(desc)==POINTER_INVALID) return INIT_FAILED; desc.count=3; desc.type=defNeuron; desc.activation=SIGMOID; desc.optimization=ADAM; if(!Topology.Add(desc)) return INIT_FAILED; delete Net; Net=new CNet(Topology); delete Topology;
Para a pureza do experimento, eu testei em paralelo dois Expert Advisors (Autoatenção e Atenção Multi-Cabeça). O teste do EA foi realizado nas mesmas condições: símbolo EURUSD, tempo gráfico H1, alimentando a rede com os dados das 20 velas consecutivas e o treinamento é executado usando o histórico dos últimos dois anos, com os parâmetros sendo atualizados pelo método de Adam.
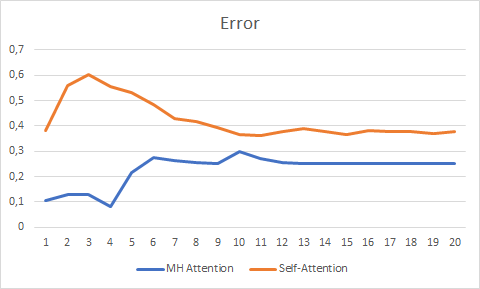
Testes em mais de 20 épocas mostraram a vantagem do Atenção Multi-Cabeça, que teve um gráfico de mudança de erro mais suave e estabilizou com o erro de 0.25 contra 0.37 para a Autoatenção.
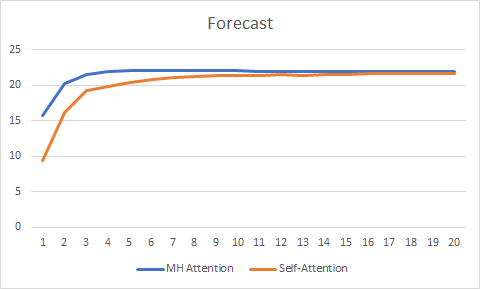
O gráfico de previsão também mostrou um melhor desempenho da tecnologia Atenção Multi-Cabeça, embora não tão significativo.
O código completo de todas as classes e Expert Advisors está disponível no anexo.
Conclusão
Neste artigo, nós consideramos a implementação do algoritmo Multi-Head Attention e conduzimos testes comparativos com a arquitetura Single-Head Self-Attention. Com condições de teste iguais, o Multi-Head Attention gerou melhores resultados. Deve-se notar, entretanto, que a melhoria da qualidade da rede requer custos computacionais extras.
Referências
- Redes neurais de maneira fácil
- Redes neurais de maneira fácil (Parte 2): Treinamento e teste da rede
- Redes Neurais de Maneira Fácil (Parte 3): Redes Convolucionais
- Redes Neurais de Maneira Fácil (Parte 4): Redes Recorrentes
- Redes Neurais de Maneira Fácil (Parte 5): Cálculos em Paralelo com o OpenCL
- Redes neurais de Maneira Fácil (Parte 6): Experimentos com a taxa de aprendizado da rede neural
- Redes Neurais de Maneira Fácil(Parte 7): Métodos de otimização adaptativos
- Redes Neurais de Maneira Fácil (Parte 8): Mecanismos de Atenção
- Redes Neurais de Maneira Fácil (Parte 9): Documentação do trabalho
- Attention Is All You Need
- Multi-Head Attention: Collaborate Instead of Concatenate
Programas utilizados no artigo
| # | Nome | Tipo | Descrição |
|---|---|---|---|
| 1 | Fractal_OCL_Attention.mq5 | Expert Advisor | Um Expert Advisor com a rede neural de classificação (3 neurônios na camada de saída) usando o mecanismo de Self-Attention |
| 2 | Fractal_OCL_AttentionMHTE.mq5 | Expert Advisor | Um Expert Advisor com a rede neural de classificação (3 neurônios na camada de saída) usando o mecanismo de Atenção Multi-Cabeça |
| 3 | NeuroNet.mqh | Biblioteca de classe | Uma biblioteca de classes para a criação de uma rede neural |
| 4 | NeuroNet.cl | Código Base | Biblioteca do código do programa OpenCL |
| 5 | NN.chm | Ajuda HTML | O arquivo de ajuda HTML convertido. |
Traduzido do russo pela MetaQuotes Ltd.
Artigo original: https://www.mql5.com/ru/articles/8909
 Força bruta para encontrar padrões (Parte III): novos horizontes
Força bruta para encontrar padrões (Parte III): novos horizontes
 Algoritmo auto-adaptável (Parte III): evitando a otimização
Algoritmo auto-adaptável (Parte III): evitando a otimização
- Aplicativos de negociação gratuitos
- 8 000+ sinais para cópia
- Notícias econômicas para análise dos mercados financeiros
Você concorda com a política do site e com os termos de uso