계량경제학: 한 발 앞서 예측
2호에 부속된 KotirOut 인디케이터를 이용하여 D1에서 선택
날짜,코티르
2011.08.01 00:00,1.4361
2011.08.02 00:00,1.4254
2011.08.03 00:00,1.4188
2011.08.04 00:00,1.4361
2011.08.05 00:00,1.4092
2011.08.08 00:00,1.4368
2011.08.09 00:00,1.4164
2011.08.10 00:00,1.4392
2011.08.11 00:00,1.4161
2011.08.12 00:00,1.4238
.
.
.
11.11.01 00:00,1.3842
2011.11.02 00:00,1.3662
2011.11.03 00:00,1.3725
2011.11.04 00:00,1.3824
2011.11.06 00:00,1.3828
2011.11.07 00:00,1.3816
2011.11.08 00:00,1.3766
2011.11.09 00:00,1.383
총 76개의 글이 있습니다. 마지막 날짜는 현재 날짜입니다. 내일 11월 10일 일기예보를 받습니다.
회귀 방정식:
추정 방정식:
===========================
KOTIR = C(1)*HP1(-1) + C(2)*HP1_D(-1) + C(3)*HP1_D(-2)
대체 계수:
===========================
KOTIR = 0.999499248852*HP1(-1) - 0.0151635132798*HP1_D(-1) - 0.176713388909*HP1_D(-2)
EViews에서 MOD2_T 프로그램을 실행하고 결과를 얻습니다.

So: 00:00시부터 내일에 대한 예측 1.3798
그러나 몇 가지 중요한 단점이 있습니다. 예측 오류는 97핍입니다. 샘플 실행은 좋지 않은 결과를 제공했습니다: 이익 계수 = 0.89
결과는 역겹고 이유를 찾아야합니다.
회귀 평가 결과를 보자.
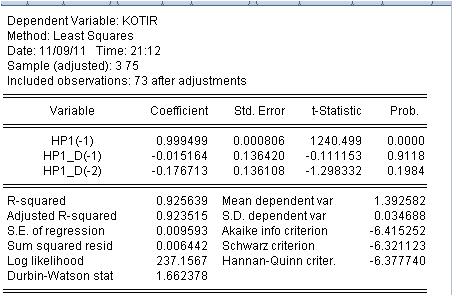
잘. 깊이 파고들 필요가 없었다. 마지막 두 계수가 0일 확률은 매우 높습니다. 마지막 두 계수가 0이라는 가설을 기각할 수 없습니다.
이 회귀 방정식은 좋지 않으며 변경해야 합니다. 그건 그렇고, Hedrick-Prescott 지표에 세워졌습니다. 이 모델의 수익성을 논하는 것은 무의미합니다.
제안을 기다리는 중
IMHO, 먼저 필요한 최소 인수 f (x) 를 찾아야 합니다. 현재 기간의 가격만으로는 충분하지 않다는 것이 쉽게 드러날 수 있습니다. 다른 쪽에서 접근할 수 있고, 테스터에 모든 상상력을 투입하고, 방정식 f(x)=a*X1+b*X2+c*X3....를 다시 작성할 수 있습니다. 이제 유전학의 도움으로 우리는 계수 a,b,c 를 최적화하여 최대값을 찾습니다.
귀하의 접근 방식은 그다지 성공적이지 않은 것 같습니다. 명시적 플랫이 있는 차트의 섹션을 가져오십시오. 이 영역의 가격은 정규분포 확률변수에 가까운 것 같고, 다음 머리나 꼬리의 손실에 대한 방정식을 쓰는 것이 가능하다는 것이 믿기 어렵습니다.
faa1947 :
Итак первый прогноз .
그건 그렇고, Hedrick-Prescott 지표에 세워졌습니다. 이 모델의 수익성을 논하는 것은 무의미합니다.
제안을 기다리는 중
이상하게도 그 XP를 놓지 못하는구나... 무의미하더라도....최면에 걸린 것처럼 이 XP를 붙잡고....그리고 꽤 오랫동안 계속되고 있어...
제안은 다음과 같습니다. 다음 모델이 작동하지 않으면 동정과 후회 없이 휴지통에 버리십시오. 다른 옵션을 고려하십시오. 이렇게 하면 유사점과 차이점, 미묘한 뉘앙스를 볼 수 있습니다.
나는 경험을 통해 알고 있으며 미래에는 이전에 폐기된 일부 모델로 돌아갈 수 있지만 새로운 위치에서 다시 말할 수 있다고 말할 수 있습니다.
2조 TS의 핵심은? 가격이 평활 값으로 돌아갈 것으로 예상됩니까?
외삽 스무드 + 노이즈
IMHO, 먼저 필요한 최소 인수 f (x) 를 찾아야 합니다. 현재 기간의 가격만으로는 충분하지 않다는 것이 쉽게 드러날 수 있습니다. 다른 쪽에서 접근할 수 있고, 테스터에 모든 상상력을 투입하고, 방정식 f(x)=a*X1+b*X2+c*X3....를 다시 작성할 수 있습니다. 이제 유전학의 도움으로 우리는 계수 a,b,c 를 최적화하여 최대값을 찾습니다.
귀하의 접근 방식은 그다지 성공적이지 않은 것 같습니다. 깨끗한 평면으로 차트의 일부를 가져오십시오. 이 영역의 가격은 정규분포 확률변수에 가까운 것 같고, 다음 헤드 또는 테일 손실에 대한 방정식을 쓰는 것이 가능하다는 것이 믿기 어렵습니다.
IMHO, 먼저 필요한 최소 인수 f (x) 를 찾아야 합니다. 현재 기간의 가격만으로는 충분하지 않다는 것을 쉽게 알 수 있습니다.
내 용어로 : 변수가 누락되었습니다. 누락된 변수가 있는지 조사 대상입니다. 아래에서 하겠습니다.
귀하의 접근 방식은 그다지 성공적이지 않은 것 같습니다. 명시적 플랫이 있는 차트 섹션을 가져오십시오.
아이디어는 다릅니다. 모든 사이트. 회귀를 조정하고 다음 캔들에 대한 예측을 조정합니다. 새 양초가 도착 하고 다시 조정(창 이동)하고 다음 양초에 대한 예측 등을 다시 수행합니다.
C는 오크에서 쓰러졌다? 뉴스 읽었어? (사람만 비웃습니다). 구입하다! (최대 3650)
이상하게도 그 XP를 놓지 못하는구나... 무의미하더라도....최면에 걸린 것처럼 이 XP를 붙잡고....그리고 꽤 오랫동안 계속되고 있어...
Hodrikt는 그것과 전혀 관련이 없습니다.
사용된 모델에는 다음과 같은 아이디어가 있습니다. 결정적 구성 요소를 선택하고 여기에 노이즈를 추가합니다.
다른 생각이 있습니다. 당신은 어떻습니까? 아파트에 가스가 있습니까? 또는 아이디어가 있으면 계산 결과를 보여 드리겠습니다.
이전 예측의 결과입니다.
예측은 반바지에 대한 것이었습니다 - 우리는 반바지가 있습니다 - 예측은 성공적입니다!
같은 제목으로 기사 번호 2를 게시했습니다. 이 기사는 다른 기사 #1의 연속입니다. 이 기사는 계량 경제학에 대한 간략한 개요를 제공합니다.
이 기사를 사용하여 포럼 사용자에게 다음과 같이 제안합니다. 통화 쌍 시세 예측을 위한 계량 경제학 모델 생성에 대해 공동으로 작업하기 위해 한 단계 앞서 있습니다. 한 단계의 크기는 기사 #2에 설명된 Expert Advisor가 첨부된 시간 프레임에 해당합니다.
제안된 순서는 다음과 같습니다. 나는 기사 #2에 제시된 모델을 사용하여 H1과 D1에 대해 두 가지 예측을 할 것입니다. 결과를 봅시다. 그런 다음 팀에서 이 모델 또는 자체 모델에 대한 개선 사항을 제공하기를 바랍니다. 나는 다른 사람들의 모델을 취하여 예측하고 결과를 게시할 것을 약속합니다. 그 과정에서 질문에 답하고 게시물에 댓글을 달 준비가 되어 있습니다.
모델은 y = f(x1, x2, .... xn) 형식의 임의 함수(회귀)입니다. y 함수는 예를 들어 EURUSD 쌍 또는 기타 통화 쌍입니다. хi - 함수 인수(독립 변수, 회귀자) - 터미널에서 사용할 수 있는 다른 따옴표입니다. 예를 들어 항목:
EURUSD EURUSD(-1) GBRUSD(-1)
즉, 다른 두 통화 쌍에 대한 유로달러 값을 계산하고 함수(EURUSD의 종속 변수)와 관련하여 이러한 쌍의 이전 값을 취합니다. 분명히, 지연된 값에 대해 하나의 통화 쌍에 대한 모델을 구축할 수 있습니다. 이것은 고전적인 TA 접근 방식이거나 다중 통화 모델을 구축할 수 있습니다. TA와 달리 복잡성 측면에서는 차이가 없습니다. 그러나 모든 영광 속에서 우리는 상관 관계가 무엇인지와 거래에서 그 가치를 보게 될 것입니다.
MQL4 및 EViews의 파일은 기사에 첨부됩니다. 누구든지 나와 같은 일을 할 수 있도록 하는 것입니다.