
MQL5 프로그래밍 기본: 목록

소개
MQL 언어의 새 버전은 자동화된 거래 시스템 개발자에게 복잡한 작업의 구현을 위한 효과적인 도구를 제공했습니다. 언어의 프로그래밍 기능이 상당히 확장되었다는 사실을 부정할 수 없습니다. MQL5 OOP 기능만으로도 충분히 가치가 있습니다. 또한 표준 라이브러리가 언급되지 않아야 합니다. 오류 코드 번호 359로 판단하면 클래스 템플릿이 곧 지원될 예정입니다.
이 글에서는 데이터 유형과 그 집합을 설명하는 주제의 확장 또는 연속이 어떤 식으로든 언급하고 싶습니다. 여기에서는 MQL5.community 웹사이트에 게시된 글을 참조하고자 합니다. Dmitry Fedoseev(Integer)는 그의 글 "MQL5 프로그래밍 기본: 배열"에서 배열 작업의 원리와 논리에 대한 매우 상세하고 포괄적인 설명을 제공했습니다.
그래서 오늘 저는 목록으로, 더 정확하게는 연결된 선형 목록으로 전환할 것을 제안합니다. 목록 구조, 의미 및 논리부터 시작하겠습니다. 그런 다음 표준 라이브러리에서 이미 사용 가능한 관련 도구를 고려할 것입니다. 결론적으로 MQL5로 작업할 때 목록을 사용하는 방법에 대한 예를 제공합니다.
- 목록과 노드의 개념: 이론
- 목록과 노드의 개념: 프로그래밍
- 2.1 단일 연결 목록의 노드
- 2.2 이중 연결 목록의 노드
- 2.3 언롤링된 이중 연결 목록의 노드
- 2.4 단일 연결 목록
- 2.5 이중 연결 목록
- 2.6 언롤링된 이중 연결 목록
- 2.7 순환 이중 연결 목록
- MQL5 표준 라이브러리의 목록
- MQL5에서 목록 사용의 예
1. 목록과 노드의 개념: 이론
그렇다면 개발자를 위한 목록은 무엇이며 어떻게 사용합니까? 이 용어의 일반적인 정의에 대해 공개 정보 출처인 Wikipedia를 참조하겠습니다.
컴퓨터 과학에서 목록은 동일한 값이 두 번 이상 나타날 수 있는 유한 순서 값 컬렉션을 구현하는 추상 데이터 유형입니다. 목록의 인스턴스는 튜플이라는 유한 시퀀스의 수학적 개념을 컴퓨터로 표현한 것입니다. 목록에 있는 값의 각 인스턴스는 일반적으로 목록의 항목, 엔트리 또는 요소라고 합니다. 동일한 값이 여러 번 발생하는 경우 각 발생은 고유한 항목으로 간주됩니다.
'목록'이라는 용어는 추상 목록, 특히 연결 목록을 구현하는 데 사용할 수 있는 몇 가지 구체적인 데이터 구조에도 사용됩니다
저는 당신이 이 정의가 다소 학문적이라는 데 동의할 것이라고 믿습니다.
이 글의 목적을 위해 우리는 이 정의의 마지막 문장에 더 관심이 있습니다. 그러니 이에 대해 생각해 봅시다.
컴퓨터 과학에서 연결 목록은 노드로 구성된 기본적인 동적 데이터 구조이며, 여기서 각 노드는 데이터와 하나 또는 두 개의 < 목록의 다음 및/또는 이전 노드에 대한 참조('링크').[1] 기존 배열배열에 비해 연결 목록의 주요 이점 a5>는 구조적 유연성입니다. 연결 목록 항목의 순서는 컴퓨터 메모리의 데이터 요소 순서와 일치할 필요가 없지만 목록 항목의 내부 링크는 목록 탐색을 위해 항상 유지됩니다.
차근차근 살펴보도록 하겠습니다.
컴퓨터 과학에서 목록 자체는 일부 데이터 유형입니다. 우리는 그것을 확립했습니다. 다른 데이터 유형을 포함하므로 오히려 합성 데이터 유형입니다. 목록은 배열과 다소 유사합니다. 단일 유형 데이터의 배열이 새로운 데이터 유형으로 분류된 적이 있다면 그것은 목록이 될 것입니다. 그러나 완전히 그렇지는 않습니다.
목록의 주요 이점은 필요에 따라 목록의 어느 지점에서나 노드를 삽입하거나 제거할 수 있다는 것입니다. 여기에서 목록은 목록의 경우 항상 ArrayResize() 함수를 사용할 필요가 없다는 점을 제외하면 동적 배열과 유사합니다.
메모리 요소의 순서와 관련하여 말하면 목록 노드는 저장되지 않으며 배열 요소가 인접한 메모리 영역에 저장되는 것과 같은 방식으로 저장할 필요가 없습니다.
그리고 그 정도입니다. 목록 아래로 더 이동합니다.
1.1 단일 연결 목록의 노드
목록을 사용하면 항목 대신 노드를 저장할 수 있습니다. 노드는 두 부분으로 구성된 데이터 유형입니다.
첫 번째 부분은 데이터 필드이고 두 번째 부분은 다른 노드와의 링크에 사용됩니다(그림 1). 목록의 첫 번째 노드를 '머리 (head)'라고 하고 목록의 마지막 노드를 '꼬리 (tail)'라고 합니다. 꼬리 링크 필드에 NULL 참조가 있습니다. 기본적으로 목록에 추가 노드가 없음을 나타내는 데 사용됩니다. 다른 전문 출처는 머리 뒤의 나머지 목록을 '꼬리'라고 합니다.

그림 1 단일 연결 목록의 노드
단일 연결 목록 노드 외에도 다른 유형의 노드가 있습니다. 이중 연결 목록의 노드는 아마도 가장 일반적인 노드일 것입니다.
1.2 이중 연결 목록의 노드
또한 이중 연결 목록의 요구 사항을 충족할 노드가 필요합니다. 이전 노드를 가리키는 다른 링크가 포함되어 있다는 점에서 이전 유형과 다릅니다. 그리고 자연스럽게 목록의 머리 노드에는 NULL 참조가 포함됩니다. 이러한 노드를 포함하는 목록의 구조를 보여주는 다이어그램(그림 2)에서 이전 노드를 가리키는 링크는 빨간색 화살표로 표시됩니다.

그림. 이중 연결 목록의 노드 2개
따라서 이중 연결 목록에서 노드의 기능은 단일 연결 목록 노드의 기능과 유사합니다. 이전 노드에 대한 링크를 하나 더 처리하면 됩니다.
1.3 순환 이중 연결 목록의 노드
위의 노드를 비선형 목록에서도 사용할 수 있는 경우가 있습니다. 이 글에서는 주로 선형 목록을 설명하지만 순환 목록의 예도 제공합니다.

그림. 원형 이중 연결 목록의 노드 3개
순환 이중 연결 목록의 다이어그램(그림 3)은 두 개의 연결 필드가 있는 노드가 단순히 순환 연결되어 있음을 보여줍니다. 이것은 주황색 및 녹색 화살표를 사용하여 수행됩니다. 따라서 머리 노드는 꼬리에 연결됩니다(이전 요소로). 그리고 꼬리 노드의 링크 필드는 머리를 가리키므로 비어 있지 않습니다.
1.4 주요 목록 작업
전문 문헌에 명시된 대로 모든 목록 작업은 3가지 기본 그룹으로 나눌 수 있습니다.
- 추가(목록에 새 노드 추가);
- 삭제(목록에서 노드);
- (노드의 데이터) 확인 중.
추가 방법은 다음과 같습니다.
- 목록의 시작 부분에 새 노드를 추가하는 단계;
- 목록의 끝에 새 노드를 추가하는 단계;
- 목록의 지정된 포지션에 노드를 추가하는 단계;
- 빈 목록에 노드를 추가하는 단계;
- 매개변수화된 생성자
삭제 작업에 관한 한 추가 그룹의 해당 작업을 가상으로 미러링합니다.
- 머리 노드를 삭제하는 단계;
- 꼬리 노드 삭제;
- 목록의 지정된 포지션에서 노드를 삭제하는 단계;
- 소멸자 (destructor).
여기서 소멸자는 목록 작업을 올바르게 완료하고 종료할 뿐만 아니라 모든 요소를 적절하게 삭제하는 역할도 한다는 점에 주목하고 싶습니다.
다양한 검사 작업의 세 번째 그룹은 실제로 목록의 노드 또는 노드 값에 대한 액세스를 제공합니다.
- 주어진 값 검색;
- 목록이 비어 있는지 확인하는 단계;
- 목록에서 i번째 노드의 값을 가져옵니다.
- 목록에서 i번째 노드에 대한 포인터를 가져옵니다.
- 목록 크기 가져오기;
- 목록 요소의 값을 인쇄합니다.
기본 그룹 외에도 네 번째 서비스 그룹도 분리합니다. 이전 그룹에 서비스를 제공합니다.
- 할당 연산자;
- 복사 생성자;
- 동적 포인터로 작업하기;
- 값으로 목록을 복사합니다;
- 정렬.
그게 다야. 물론 개발자는 필요에 따라 언제든지 목록 클래스의 기능과 기능을 확장할 수 있습니다.
2. 목록과 노드의 개념: 프로그래밍
이 부분에서는 노드 및 목록 프로그래밍으로 직접 진행해야 한다고 제안합니다. 필요한 경우 코드에 대한 그림이 제공됩니다.
2.1 단일 연결 목록의 노드
단일 연결 목록의 요구 사항을 충족하는 노드 클래스(그림 4)에 대한 토대를 마련해 보겠습니다. "UML 도구를 사용하여 Expert Advisor를 개발하는 방법"이라는 제목의 글에서 클래스 다이어그램 표기법(모델)에 익숙해질 수 있습니다(그림 5 참조). CTradeExpert 클래스의 UML 모델).

그림 4 CiSingleNode 클래스 모델
이제 코드로 작업해 보겠습니다. Art Friedman과 다른 저자들이 책에서 제공한 예를 기반으로 합니다. "C/C++ 주석이 달린 아카이브".
//+------------------------------------------------------------------+ //| CiSingleNode class | //+------------------------------------------------------------------+ class CiSingleNode { protected: int m_val; // data CiSingleNode *m_next; // pointer to the next node public: void CiSingleNode(void); // default constructor void CiSingleNode(int _node_val); // parameterized constructor void ~CiSingleNode(void); // destructor void SetVal(int _node_val); // set-method for data void SetNextNode(CiSingleNode *_ptr_next); // set-method for the next node virtual void SetPrevNode(CiSingleNode *_ptr_prev){}; // set-method for the previous node virtual CiSingleNode *GetPrevNode(void) const {return NULL;}; // get-method for the previous node CiSingleNode *GetNextNode(void) const; // get-method for the next node int GetVal(void){TRACE_CALL(_t_flag) return m_val;} // get-method for data };-->
CiSingleNode 클래스의 각 메소드는 설명하지 않겠습니다. 첨부된 CiSingleNode.mqh 파일에서 자세히 살펴보실 수 있습니다. 그러나 흥미로운 뉘앙스에주의를 기울이고 싶습니다. 클래스에는 이전 노드에서 작동하는 가상 메소드가 포함되어 있습니다. 그들은 실제로 더미이며 그들의 존재는 오히려 미래의 후손을 위한 다형성의 목적을 위한 것입니다.
이 코드는 사용된 각 메소드의 호출을 추적하는 데 필요한 TRACE_CALL(f) 전처리기 지시문을 사용합니다.
#define TRACE_CALL(f) if(f) Print("Calling: "+__FUNCSIG__);-->
CiSingleNode 클래스만 사용할 수 있으므로 단일 연결 목록을 만들 수 있습니다. 코드의 예를 보여드리겠습니다.
//=========== Example 1 (processing the CiSingleNode type ) CiSingleNode *p_sNodes[3]; // #1 p_sNodes[0]=NULL; srand(GetTickCount()); // initialize a random number generator //--- create nodes for(int i=0;i<ArraySize(p_sNodes);i++) p_sNodes[i]=new CiSingleNode(rand()); // #2 //--- links for(int j=0;j<(ArraySize(p_sNodes)-1);j++) p_sNodes[j].SetNextNode(p_sNodes[j+1]); // #3 //--- check values for(int i=0;i<ArraySize(p_sNodes);i++) { int val=p_sNodes[i].GetVal(); // #4 Print("Node #"+IntegerToString(i+1)+ // #5 " value = "+IntegerToString(val)); } //--- check next-nodes for(int j=0;j<(ArraySize(p_sNodes)-1);j++) { CiSingleNode *p_sNode_next=p_sNodes[j].GetNextNode(); // #9 int snode_next_val=p_sNode_next.GetVal(); // #10 Print("Next-Node #"+IntegerToString(j+1)+ // #11 " value = "+IntegerToString(snode_next_val)); } //--- delete nodes for(int i=0;i<ArraySize(p_sNodes);i++) delete p_sNodes[i]; // #12-->
문자열 #1에서 CiSingleNode 유형의 개체에 대한 포인터 배열을 선언합니다. 문자열 #2에서 배열은 생성된 포인터로 채워집니다. 각 노드의 데이터에 대해 rand() 함수를 사용하여 0에서 32767 사이의 의사 난수 정수를 취합니다. >. 노드는 문자열 #3의 다음 포인터와 연결됩니다. 문자열 #4-5에서 노드의 값을 확인하고 문자열 #9-11에서 링크의 성능을 확인합니다. 포인터는 문자열 #12에서 삭제됩니다.
이것은 로그에 인쇄된 내용입니다.
DH 0 23:23:10 test_nodes (EURUSD,H4) Node #1 value = 3335 KP 0 23:23:10 test_nodes (EURUSD,H4) Node #2 value = 21584 GI 0 23:23:10 test_nodes (EURUSD,H4) Node #3 value = 917 HQ 0 23:23:10 test_nodes (EURUSD,H4) Next-Node #1 value = 21584 HI 0 23:23:10 test_nodes (EURUSD,H4) Next-Node #2 value = 917-->
결과 노드 구조는 다음과 같이 개략적으로 표시될 수 있습니다(그림 5).
![그림 5 CiSingleNode *p_sNodes[3] 배열의 노드 간 링크](https://c.mql5.com/2/6/5__1.png "그림 5 CiSingleNode *p_sNodes[3] 배열의 노드 간 링크")
그림 5 CiSingleNode *p_sNodes[3] 배열의 노드 간 링크
이제 이중 연결 목록의 노드로 진행해 보겠습니다
2.2 이중 연결 목록의 노드
먼저 이중 연결 목록의 노드가 두 개의 포인터, 즉 다음 노드 포인터와 이전 노드 포인터가 있다는 점에서 구별된다는 사실을 정리해야 합니다. 즉. 다음 노드 링크 외에 단일 연결 목록 노드에 이전 노드에 대한 포인터를 추가해야 합니다.
이를 위해 상속을 클래스 관계로 사용할 것을 제안합니다. 그러면 이중 연결 목록의 노드에 대한 클래스 모델은 다음과 같이 보일 수 있습니다(그림 6).

그림 6 CDoubleNode 클래스 모델
이제 코드를 살펴볼 차례입니다.
//+------------------------------------------------------------------+ //| CDoubleNode class | //+------------------------------------------------------------------+ class CDoubleNode : public CiSingleNode { protected: CiSingleNode *m_prev; // pointer to the previous node public: void CDoubleNode(void); // default constructor void CDoubleNode(int node_val); // parameterized constructor void ~CDoubleNode(void){TRACE_CALL(_t_flag)};// destructor virtual void SetPrevNode(CiSingleNode *_ptr_prev); // set-method for the previous node virtual CiSingleNode *GetPrevNode(void) const; // get-method for the previous node CDoubleNode };-->
추가 방법은 거의 없습니다. 가상이며 이전 노드 작업과 관련이 있습니다. 전체 클래스 설명은 CDoubleNode.mqh에 제공됩니다.
CDoubleNode 클래스를 기반으로 이중 연결 목록을 만들어 봅시다. 코드의 예를 보여드리겠습니다.
//=========== Example 2 (processing the CDoubleNode type) CiSingleNode *p_dNodes[3]; // #1 p_dNodes[0]=NULL; srand(GetTickCount()); // initialize a random number generator //--- create nodes for(int i=0;i<ArraySize(p_dNodes);i++) p_dNodes[i]=new CDoubleNode(rand()); // #2 //--- links for(int j=0;j<(ArraySize(p_dNodes)-1);j++) { p_dNodes[j].SetNextNode(p_dNodes[j+1]); // #3 p_dNodes[j+1].SetPrevNode(p_dNodes[j]); // #4 } //--- check values for(int i=0;i<ArraySize(p_dNodes);i++) { int val=p_dNodes[i].GetVal(); // #4 Print("Node #"+IntegerToString(i+1)+ // #5 " value = "+IntegerToString(val)); } //--- check next-nodes for(int j=0;j<(ArraySize(p_dNodes)-1);j++) { CiSingleNode *p_sNode_next=p_dNodes[j].GetNextNode(); // #9 int snode_next_val=p_sNode_next.GetVal(); // #10 Print("Next-Node #"+IntegerToString(j+1)+ // #11 " value = "+IntegerToString(snode_next_val)); } //--- check prev-nodes for(int j=0;j<(ArraySize(p_dNodes)-1);j++) { CiSingleNode *p_sNode_prev=p_dNodes[j+1].GetPrevNode(); // #12 int snode_prev_val=p_sNode_prev.GetVal(); // #13 Print("Prev-Node #"+IntegerToString(j+2)+ // #14 " value = "+IntegerToString(snode_prev_val)); } //--- delete nodes for(int i=0;i<ArraySize(p_dNodes);i++) delete p_dNodes[i]; // #15-->
원칙적으로 이것은 단일 연결 목록을 만드는 것과 유사하지만 몇 가지 특징이 있습니다. 포인터 배열 p_dNodes[]가 문자열 #1에서 어떻게 선언되는지 주목하십시오. 포인터의 유형은 기본 클래스와 동일하게 설정할 수 있습니다. string #2의 다형성 원리는 미래에 그것들을 인식하는 데 도움이 될 것입니다. 이전 노드는 문자열 #12-14에서 확인됩니다.
다음 정보가 로그에 추가되었습니다.
GJ 0 16:28:12 test_nodes (EURUSD,H4) Node #1 value = 17543 IQ 0 16:28:12 test_nodes (EURUSD,H4) Node #2 value = 1185 KK 0 16:28:12 test_nodes (EURUSD,H4) Node #3 value = 23216 DS 0 16:28:12 test_nodes (EURUSD,H4) Next-Node #1 value = 1185 NH 0 16:28:12 test_nodes (EURUSD,H4) Next-Node #2 value = 23216 FR 0 16:28:12 test_nodes (EURUSD,H4) Prev-Node #2 value = 17543 LI 0 16:28:12 test_nodes (EURUSD,H4) Prev-Node #3 value = 1185-->
결과 노드 구조는 다음과 같이 개략적으로 표시될 수 있습니다(그림 7).
![그림 7 CDoubleNode *p_sNodes[3] 배열의 노드 간 링크](https://c.mql5.com/2/6/7.png "그림 7 CDoubleNode *p_sNodes[3] 배열의 노드 간 링크")
그림 7 CDoubleNode *p_sNodes[3] 배열의 노드 간 링크
이제 언롤링된 이중 연결 목록을 만드는 데 필요한 노드를 고려하는 것이 좋습니다.
2.3 언롤링된 이중 연결 목록의 노드
단일 값 대신 전체 배열에 기인하는 데이터 멤버를 포함하는 노드를 생각해 보십시오. 즉, 전체 배열을 포함하고 설명합니다. 그런 다음 이러한 노드를 사용하여 펼쳐진 목록을 만들 수 있습니다. 이 노드는 이중 연결 목록의 표준 노드와 정확히 동일하기 때문에 여기에 어떤 설명도 제공하지 않기로 결정했습니다. 유일한 차이점은 '데이터 (data)' 속성이 전체 배열을 캡슐화한다는 것입니다.
상속을 다시 사용하겠습니다. CDoubleNode 클래스는 언롤링된 이중 연결 목록에서 노드의 기본 클래스 역할을 합니다. 그리고 언롤링된 이중 연결 목록의 노드에 대한 클래스 모델은 다음과 같습니다(그림 8).

그림 8 CiUnrollDoubleNode 클래스 모델
CiUnrollDoubleNode 클래스는 다음 코드를 사용하여 정의할 수 있습니다.
//+------------------------------------------------------------------+ //| CiUnrollDoubleNode class | //+------------------------------------------------------------------+ class CiUnrollDoubleNode : public CDoubleNode { private: int m_arr_val[]; // data array public: void CiUnrollDoubleNode(void); // default constructor void CiUnrollDoubleNode(int &_node_arr[]); // parameterized constructor void ~CiUnrollDoubleNode(void); // destructor bool GetArrVal(int &_dest_arr_val[])const; // get-method for data array bool SetArrVal(const int &_node_arr_val[]); // set-method for data array };-->
CiUnrollDoubleNode.mqh에서 각 방법에 대해 자세히 알아볼 수 있습니다.
매개변수화된 생성자를 예로 들어 보겠습니다.
//+------------------------------------------------------------------+ //| Parameterized constructor | //+------------------------------------------------------------------+ void CiUnrollDoubleNode::CiUnrollDoubleNode(int &_node_arr[]) : CDoubleNode(ArraySize(_node_arr)) { ArrayCopy(this.m_arr_val,_node_arr); TRACE_CALL(_t_flag) }-->
여기서 초기화 목록을 사용하여 this.m_val 데이터 멤버에 1차원 배열의 크기를 입력합니다.
그 후 언롤링된 이중 연결 목록을 '수동으로' 만들고 그 안의 링크를 확인합니다.
//=========== Example 3 (processing the CiUnrollDoubleNode type) //--- data arrays int arr1[],arr2[],arr3[]; // #1 int arr_size=15; ArrayResize(arr1,arr_size); ArrayResize(arr2,arr_size); ArrayResize(arr3,arr_size); srand(GetTickCount()); // initialize a random number generator //--- fill the arrays with pseudorandom integers for(int i=0;i<arr_size;i++) { arr1[i]=rand(); // #2 arr2[i]=rand(); arr3[i]=rand(); } //--- create nodes CiUnrollDoubleNode *p_udNodes[3]; // #3 p_udNodes[0]=new CiUnrollDoubleNode(arr1); p_udNodes[1]=new CiUnrollDoubleNode(arr2); p_udNodes[2]=new CiUnrollDoubleNode(arr3); //--- links for(int j=0;j<(ArraySize(p_udNodes)-1);j++) { p_udNodes[j].SetNextNode(p_udNodes[j+1]); // #4 p_udNodes[j+1].SetPrevNode(p_udNodes[j]); // #5 } //--- check values for(int i=0;i<ArraySize(p_udNodes);i++) { int val=p_udNodes[i].GetVal(); // #6 Print("Node #"+IntegerToString(i+1)+ // #7 " value = "+IntegerToString(val)); } //--- check array values for(int i=0;i<ArraySize(p_udNodes);i++) { int t_arr[]; // destination array bool isCopied=p_udNodes[i].GetArrVal(t_arr); // #8 if(isCopied) { string arr_str=NULL; for(int n=0;n<ArraySize(t_arr);n++) arr_str+=IntegerToString(t_arr[n])+", "; int end_of_string=StringLen(arr_str); arr_str=StringSubstr(arr_str,0,end_of_string-2); Print("Node #"+IntegerToString(i+1)+ // #9 " array values = "+arr_str); } } //--- check next-nodes for(int j=0;j<(ArraySize(p_udNodes)-1);j++) { int t_arr[]; // destination array CiUnrollDoubleNode *p_udNode_next=p_udNodes[j].GetNextNode(); // #10 bool isCopied=p_udNode_next.GetArrVal(t_arr); if(isCopied) { string arr_str=NULL; for(int n=0;n<ArraySize(t_arr);n++) arr_str+=IntegerToString(t_arr[n])+", "; int end_of_string=StringLen(arr_str); arr_str=StringSubstr(arr_str,0,end_of_string-2); Print("Next-Node #"+IntegerToString(j+1)+ " array values = "+arr_str); } } //--- check prev-nodes for(int j=0;j<(ArraySize(p_udNodes)-1);j++) { int t_arr[]; // destination array CiUnrollDoubleNode *p_udNode_prev=p_udNodes[j+1].GetPrevNode(); // #11 bool isCopied=p_udNode_prev.GetArrVal(t_arr); if(isCopied) { string arr_str=NULL; for(int n=0;n<ArraySize(t_arr);n++) arr_str+=IntegerToString(t_arr[n])+", "; int end_of_string=StringLen(arr_str); arr_str=StringSubstr(arr_str,0,end_of_string-2); Print("Prev-Node #"+IntegerToString(j+2)+ " array values = "+arr_str); } } //--- delete nodes for(int i=0;i<ArraySize(p_udNodes);i++) delete p_udNodes[i]; // #12 }-->
코드의 양이 약간 커졌습니다. 이것은 각 노드에 대한 배열을 만들고 채워야 한다는 사실과 관련이 있습니다.
데이터 배열 작업은 문자열 #1에서 시작합니다. 기본적으로 이전 노드에서 고려했던 것과 유사합니다. 전체 배열(예: 문자열 #9)에 대한 각 노드의 데이터 값을 인쇄해야 하는 것뿐입니다.
이것은 제가 가진 것입니다:
IN 0 00:09:13 test_nodes (EURUSD.m,H4) Node #1 value = 15 NF 0 00:09:13 test_nodes (EURUSD.m,H4) Node #2 value = 15 CI 0 00:09:13 test_nodes (EURUSD.m,H4) Node #3 value = 15 FQ 0 00:09:13 test_nodes (EURUSD.m,H4) Node #1 array values = 31784, 4837, 25797, 29079, 4223, 27234, 2155, 32351, 12010, 10353, 10391, 22245, 27895, 3918, 12069 EG 0 00:09:13 test_nodes (EURUSD.m,H4) Node #2 array values = 1809, 18553, 23224, 20208, 10191, 4833, 25959, 2761, 7291, 23254, 29865, 23938, 7585, 20880, 25756 MK 0 00:09:13 test_nodes (EURUSD.m,H4) Node #3 array values = 18100, 26358, 31020, 23881, 11256, 24798, 31481, 14567, 13032, 4701, 21665, 1434, 1622, 16377, 25778 RP 0 00:09:13 test_nodes (EURUSD.m,H4) Next-Node #1 array values = 1809, 18553, 23224, 20208, 10191, 4833, 25959, 2761, 7291, 23254, 29865, 23938, 7585, 20880, 25756 JD 0 00:09:13 test_nodes (EURUSD.m,H4) Next-Node #2 array values = 18100, 26358, 31020, 23881, 11256, 24798, 31481, 14567, 13032, 4701, 21665, 1434, 1622, 16377, 25778 EH 0 00:09:13 test_nodes (EURUSD.m,H4) Prev-Node #2 array values = 31784, 4837, 25797, 29079, 4223, 27234, 2155, 32351, 12010, 10353, 10391, 22245, 27895, 3918, 12069 NN 0 00:09:13 test_nodes (EURUSD.m,H4) Prev-Node #3 array values = 1809, 18553, 23224, 20208, 10191, 4833, 25959, 2761, 7291, 23254, 29865, 23938, 7585, 20880, 25756-->
노드 작업에 선을 긋고 다른 목록의 클래스 정의로 직접 진행해야 한다고 제안합니다. 예제 1-3은 스크립트 test_nodes.mq5에서 찾을 수 있습니다.
2.4 단일 연결 목록
이제 주요 목록 작업 그룹에서 단일 연결 목록의 클래스 모델을 만들 차례입니다(그림 9).

그림 9. CiSingleList 클래스 모델
CiSingleList 클래스가 CiSingleNode 유형의 노드를 사용하는 것을 쉽게 알 수 있습니다. 클래스 간의 관계 유형에 대해 말하면 다음과 같이 말할 수 있습니다.
- CiSingleList 클래스에는 CiSingleNode 클래스(구성)가 포함됩니다.
- CiSingleList 클래스는 CiSingleNode 클래스 메소드(종속성)를 사용합니다.
위의 관계에 대한 설명이 그림 10에 나와 있습니다.

그림 10 CiSingleList 클래스와 CiSingleNode 클래스의 관계 유형
새 클래스인 CiSingleList를 만들어 보겠습니다. 앞으로 글에서 사용된 다른 모든 목록 클래스는 이 클래스를 기반으로 합니다. 그게 바로 이것이 그렇게도 '풍부한 (rich)' 이유입니다.
//+------------------------------------------------------------------+ //| CiSingleList class | //+------------------------------------------------------------------+ class CiSingleList { protected: CiSingleNode *m_head; // head CiSingleNode *m_tail; // tail uint m_size; // number of nodes in the list public: //--- constructor and destructor void CiSingleList(); // default constructor void CiSingleList(int _node_val); // parameterized constructor void ~CiSingleList(); // destructor //--- adding nodes void AddFront(int _node_val); // add a new node to the beginning of the list void AddRear(int _node_val); // add a new node to the end of the list virtual void AddFront(int &_node_arr[]){TRACE_CALL(_t_flag)}; // add a new node to the beginning of the list virtual void AddRear(int &_node_arr[]){TRACE_CALL(_t_flag)}; // add a new node to the end of the list //--- deleting nodes int RemoveFront(void); // delete the head node int RemoveRear(void); // delete the node from the end of the list void DeleteNodeByIndex(const uint _idx); // delete the ith node from the list //--- checking virtual bool Find(const int _node_val) const; // find the required value bool IsEmpty(void) const; // check the list for being empty virtual int GetValByIndex(const uint _idx) const; // value of the ith node in the list virtual CiSingleNode *GetNodeByIndex(const uint _idx) const; // get the ith node in the list virtual bool SetNodeByIndex(CiSingleNode *_new_node,const uint _idx); // insert the new ith node in the list CiSingleNode *GetHeadNode(void) const; // get the head node CiSingleNode *GetTailNode(void) const; // get the tail node virtual uint Size(void) const; // list size //--- service virtual void PrintList(string _caption=NULL); // print the list virtual bool CopyByValue(const CiSingleList &_sList); // copy the list by values virtual void BubbleSort(void); // bubble sorting //---templates template<typename dPointer> bool CheckDynamicPointer(dPointer &_p); // template for checking a dynamic pointer template<typename dPointer> bool DeleteDynamicPointer(dPointer &_p); // template for deleting a dynamic pointer protected: void operator=(const CiSingleList &_sList) const; // assignment operator void CiSingleList(const CiSingleList &_sList); // copy constructor virtual bool AddToEmpty(int _node_val); // add a new node to an empty list virtual void addFront(int _node_val); // add a new "native" node to the beginning of the list virtual void addRear(int _node_val); // add a new "native" node to the end of the list virtual int removeFront(void); // delete the "native" head node virtual int removeRear(void); // delete the "native" node from the end of the list virtual void deleteNodeByIndex(const uint _idx); // delete the "native" ith node from the list virtual CiSingleNode *newNode(int _val); // new "native" node virtual void CalcSize(void) const; // calculate the list size };-->
클래스 메소드의 완전한 정의는 CiSingleList.mqh에 제공됩니다.
이 클래스를 개발하기 시작했을 때 데이터 멤버는 3개, 메소드는 몇 개 밖에 없었습니다. 하지만 이 클래스가 다른 클래스의 기초가 되었기 때문에 여러 가상 멤버 함수를 추가해야 했습니다. 이 방법에 대해서는 자세히 설명하지 않겠습니다. 이 단일 연결 목록 클래스를 사용하는 예는 스크립트 test_sList.mq5에서 찾을 수 있습니다.
추적 플래그 없이 실행하면 다음 항목이 로그에 나타납니다.
KG 0 12:58:32 test_sList (EURUSD,H1) =======List #1======= PF 0 12:58:32 test_sList (EURUSD,H1) Node #1, val=14 RL 0 12:58:32 test_sList (EURUSD,H1) Node #2, val=666 MD 0 12:58:32 test_sList (EURUSD,H1) Node #3, val=13 DM 0 12:58:32 test_sList (EURUSD,H1) Node #4, val=11 QE 0 12:58:32 test_sList (EURUSD,H1) KN 0 12:58:32 test_sList (EURUSD,H1) LR 0 12:58:32 test_sList (EURUSD,H1) =======List #2======= RE 0 12:58:32 test_sList (EURUSD,H1) Node #1, val=14 DQ 0 12:58:32 test_sList (EURUSD,H1) Node #2, val=666 GK 0 12:58:32 test_sList (EURUSD,H1) Node #3, val=13 FP 0 12:58:32 test_sList (EURUSD,H1) Node #4, val=11 KF 0 12:58:32 test_sList (EURUSD,H1) MK 0 12:58:32 test_sList (EURUSD,H1) PR 0 12:58:32 test_sList (EURUSD,H1) =======renewed List #2======= GK 0 12:58:32 test_sList (EURUSD,H1) Node #1, val=11 JP 0 12:58:32 test_sList (EURUSD,H1) Node #2, val=13 JI 0 12:58:32 test_sList (EURUSD,H1) Node #3, val=14 CF 0 12:58:32 test_sList (EURUSD,H1) Node #4, val=34 QL 0 12:58:32 test_sList (EURUSD,H1) Node #5, val=35 OE 0 12:58:32 test_sList (EURUSD,H1) Node #6, val=36 MR 0 12:58:32 test_sList (EURUSD,H1) Node #7, val=37 KK 0 12:58:32 test_sList (EURUSD,H1) Node #8, val=38 MS 0 12:58:32 test_sList (EURUSD,H1) Node #9, val=666 OF 0 12:58:32 test_sList (EURUSD,H1) QK 0 12:58:32 test_sList (EURUSD,H1)-->
스크립트는 2개의 단일 연결 목록을 채운 다음 두 번째 목록을 확장하고 정렬했습니다.
2.5 이중 연결 목록
이제 이전 유형의 목록을 기반으로 이중 연결 목록을 만들어 보겠습니다. 이중 연결 목록의 클래스 모델은 그림 11에 나와 있습니다.

그림 11 CDoubleList 클래스 모델
자손 클래스에는 훨씬 적은 수의 메소드가 포함되어 있지만 데이터 멤버는 전혀 없습니다. 다음은 CDoubleList 클래스 정의입니다.
//+------------------------------------------------------------------+ //| CDoubleList class | //+------------------------------------------------------------------+ class CDoubleList : public CiSingleList { public: void CDoubleList(void); // default constructor void CDoubleList(int _node_val); // parameterized constructor void ~CDoubleList(void){}; // destructor virtual bool SetNodeByIndex(CiSingleNode *_new_node,const uint _idx); // insert the new ith node in the list protected: virtual bool AddToEmpty(int _node_val); // add a node to an empty list virtual void addFront(int _node_val); // add a new "native" node to the beginning of the list virtual void addRear(int _node_val); // add a new "native" node to the end of the list virtual int removeFront(void); // delete the "native" head node virtual int removeRear(void); // delete the "native" tail node virtual void deleteNodeByIndex(const uint _idx); // delete the "native" ith node from the list virtual CiSingleNode *newNode(int _node_val); // new "native" node };-->
CDoubleList 클래스 메소드에 대한 전체 설명은 CDoubleList.mqh에 나와 있습니다.
일반적으로 말하면 가상 함수는 단일 연결 목록에 존재하지 않는 이전 노드에 대한 포인터의 요구 사항을 충족하기 위해서만 여기에서 사용됩니다.
CDoubleList 유형의 목록을 사용하는 예는 test_dList.mq5 스크립트에서 찾을 수 있습니다. 이 목록 유형과 관련된 모든 일반적인 목록 작업을 보여줍니다. 스크립트 코드에는 하나의 독특한 문자열이 포함되어 있습니다.
CiSingleNode *_new_node=new CDoubleNode(666); // create a new node of CDoubleNode type-->
기본 클래스 포인터가 하위 클래스의 개체를 설명하는 경우 이러한 구성이 상당히 수용 가능하기 때문에 오류가 없습니다. 이것은 상속의 장점 중 하나입니다.
MQL5와 С++에서 기본 클래스에 대한 포인터는 해당 기본 클래스에서 파생된 하위 클래스의 개체를 가리킬 수 있습니다. 그러나 그 반대는 무효입니다.
다음과 같이 문자열을 작성하면:
CDoubleNode*_new_node=new CiSingleNode(666);-->
컴파일러는 오류나 경고를 보고하지 않지만 프로그램은 이 문자열에 도달할 때까지 실행됩니다. 이 경우 포인터가 참조하는 유형의 잘못된 캐스팅에 대한 메시지가 표시됩니다. 후기 바인딩 메커니즘은 프로그램이 실행 중일 때만 작동하므로 클래스 간의 관계 계층을 신중하게 고려해야 합니다.
스크립트를 실행하면 로그에 다음 항목이 포함됩니다.
DN 0 13:10:57 test_dList (EURUSD,H1) =======List #1======= GO 0 13:10:57 test_dList (EURUSD,H1) Node #1, val=14 IE 0 13:10:57 test_dList (EURUSD,H1) Node #2, val=666 FM 0 13:10:57 test_dList (EURUSD,H1) Node #3, val=13 KD 0 13:10:57 test_dList (EURUSD,H1) Node #4, val=11 JL 0 13:10:57 test_dList (EURUSD,H1) DG 0 13:10:57 test_dList (EURUSD,H1) CK 0 13:10:57 test_dList (EURUSD,H1) =======List #2======= IL 0 13:10:57 test_dList (EURUSD,H1) Node #1, val=14 KH 0 13:10:57 test_dList (EURUSD,H1) Node #2, val=666 PR 0 13:10:57 test_dList (EURUSD,H1) Node #3, val=13 MI 0 13:10:57 test_dList (EURUSD,H1) Node #4, val=11 DO 0 13:10:57 test_dList (EURUSD,H1) FR 0 13:10:57 test_dList (EURUSD,H1) GK 0 13:10:57 test_dList (EURUSD,H1) =======renewed List #2======= PR 0 13:10:57 test_dList (EURUSD,H1) Node #1, val=11 QI 0 13:10:57 test_dList (EURUSD,H1) Node #2, val=13 QP 0 13:10:57 test_dList (EURUSD,H1) Node #3, val=14 LO 0 13:10:57 test_dList (EURUSD,H1) Node #4, val=34 JE 0 13:10:57 test_dList (EURUSD,H1) Node #5, val=35 HL 0 13:10:57 test_dList (EURUSD,H1) Node #6, val=36 FK 0 13:10:57 test_dList (EURUSD,H1) Node #7, val=37 DR 0 13:10:57 test_dList (EURUSD,H1) Node #8, val=38 FJ 0 13:10:57 test_dList (EURUSD,H1) Node #9, val=666 HO 0 13:10:57 test_dList (EURUSD,H1) JR 0 13:10:57 test_dList (EURUSD,H1)-->
단일 연결 목록의 경우와 마찬가지로 스크립트는 첫 번째(이중 연결) 목록을 채우고 복사하여 두 번째 목록에 전달합니다. 그런 다음 두 번째 목록의 노드 수를 늘리고 목록을 정렬하고 인쇄했습니다.
2.6 언롤링된 이중 연결 목록
이 목록 유형은 값뿐만 아니라 전체 배열을 저장할 수 있다는 점에서 편리합니다.
CiUnrollDoubleList 유형의 목록에 대한 토대를 마련해 보겠습니다(그림 12).

그림 12 CiUnrollDoubleList 클래스 모델
여기서 우리는 데이터 배열을 다룰 것이기 때문에 간접 기본 클래스 CiSingleList에 정의된 메소드를 재정의해야 합니다.
다음은 CiUnrollDoubleList 클래스 정의입니다.
//+------------------------------------------------------------------+ //| CiUnrollDoubleList class | //+------------------------------------------------------------------+ class CiUnrollDoubleList : public CDoubleList { public: void CiUnrollDoubleList(void); // default constructor void CiUnrollDoubleList(int &_node_arr[]); // parameterized constructor void ~CiUnrollDoubleList(void){TRACE_CALL(_t_flag)}; // destructor //--- virtual void AddFront(int &_node_arr[]); // add a new node to the beginning of the list virtual void AddRear(int &_node_arr[]); // add a new node to the end of the list virtual bool CopyByValue(const CiSingleList &_udList); // copy by values virtual void PrintList(string _caption=NULL); // print the list virtual void BubbleSort(void); // bubble sorting protected: virtual bool AddToEmpty(int &_node_arr[]); // add a node to an empty list virtual void addFront(int &_node_arr[]); // add a new "native" node to the beginning of the list virtual void addRear(int &_node_arr[]); // add a new "native" node to the end of the list virtual int removeFront(void); // delete the "native" node from the beginning of the list virtual int removeRear(void); // delete the "native" node from the end of the list virtual void deleteNodeByIndex(const uint _idx); // delete the "native" ith node from the list virtual CiSingleNode *newNode(int &_node_arr[]); // new "native" node };-->
클래스 메소드의 전체 정의는 CiUnrollDoubleList.mqh에 제공됩니다.
test_UdList.mq5 스크립트를 실행하여 클래스 메소드의 동작을 확인해보자. 여기서 노드 작업은 이전 스크립트에서 사용된 작업과 유사합니다. 분류 및 인쇄 방법에 대해 몇 마디 말해야 할 것입니다. 정렬 방법은 가장 작은 크기의 값 배열을 포함하는 노드가 목록의 맨 앞에 오도록 요소 수를 기준으로 노드를 정렬합니다.
인쇄 방법은 특정 노드에 포함된 배열 값의 문자열을 인쇄합니다.
스크립트를 실행하면 로그에 다음 항목이 포함됩니다.
II 0 13:22:23 test_UdList (EURUSD,H1) =======List #1======= FN 0 13:22:23 test_UdList (EURUSD,H1) List node #1, array: 55, 12, 1, 2, 11, 114, 33, 113, 14, 15, 16, 17, 18, 19, 20 OO 0 13:22:23 test_UdList (EURUSD,H1) List node #2, array: 11, 12, 13, 14, 15, 16, 17, 18, 19, 20 GG 0 13:22:23 test_UdList (EURUSD,H1) GP 0 13:22:23 test_UdList (EURUSD,H1) GR 0 13:22:23 test_UdList (EURUSD,H1) =======List #2 before sorting======= JO 0 13:22:23 test_UdList (EURUSD,H1) List node #1, array: 55, 12, 1, 2, 11, 114, 33, 113, 14, 15, 16, 17, 18, 19, 20 CH 0 13:22:23 test_UdList (EURUSD,H1) List node #2, array: 11, 12, 13, 14, 15, 16, 17, 18, 19, 20 CF 0 13:22:23 test_UdList (EURUSD,H1) List node #3, array: -89, -131, -141, -139, -129, -25, -105, -24, -122, -120, -118, -116, -114, -112, -110 GD 0 13:22:23 test_UdList (EURUSD,H1) GQ 0 13:22:23 test_UdList (EURUSD,H1) LJ 0 13:22:23 test_UdList (EURUSD,H1) =======List #2 after sorting======= FN 0 13:22:23 test_UdList (EURUSD,H1) List node #1, array: 11, 12, 13, 14, 15, 16, 17, 18, 19, 20 CJ 0 13:22:23 test_UdList (EURUSD,H1) List node #2, array: 55, 12, 1, 2, 11, 114, 33, 113, 14, 15, 16, 17, 18, 19, 20 II 0 13:22:23 test_UdList (EURUSD,H1) List node #3, array: -89, -131, -141, -139, -129, -25, -105, -24, -122, -120, -118, -116, -114, -112, -110 MD 0 13:22:23 test_UdList (EURUSD,H1) MQ 0 13:22:23 test_UdList (EURUSD,H1)-->
보시다시피 정렬 후 udList2 목록이 가장 작은 배열을 가진 노드부터 가장 큰 배열을 포함하는 노드까지 인쇄되었습니다.
2.7 순환 이중 연결 목록
이 글에서는 비선형 목록을 고려하지 않지만 우리도 함께 작업하는 것이 좋습니다. 노드를 순환적으로 연결하는 방법은 이미 위에 나와 있습니다(그림 3).
CiCircleDoubleList 클래스(그림 13)의 모델을 만들어 보겠습니다. 이 클래스는 CDoubleList 클래스.

그림 13 CiCircleDoubleList 클래스 모델
이 목록의 노드는 특정 문자(머리와 꼬리가 연결됨)로 인해 소스 기본 클래스 CiSingleList의 거의 모든 메소드를 가상으로 만들어야 합니다.
//+------------------------------------------------------------------+ //| CiCircleDoubleList class | //+------------------------------------------------------------------+ class CiCircleDoubleList : public CDoubleList { public: void CiCircleDoubleList(void); // default constructor void CiCircleDoubleList(int _node_val); // parameterized constructor void ~CiCircleDoubleList(void){TRACE_CALL(_t_flag)}; // destructor //--- virtual uint Size(void) const; // list size virtual bool SetNodeByIndex(CiSingleNode *_new_node,const uint _idx); // insert the new ith node in the list virtual int GetValByIndex(const uint _idx) const; // value of the ith node in the list virtual CiSingleNode *GetNodeByIndex(const uint _idx) const; // get the ith node in the list virtual bool Find(const int _node_val) const; // find the required value virtual bool CopyByValue(const CiSingleList &_sList); // copy the list by values protected: virtual void addFront(int _node_val); // add a new "native" node to the beginning of the list virtual void addRear(int _node_val); // add a new "native" node to the end of the list virtual int removeFront(void); // delete the "native" head node virtual int removeRear(void); // delete the "native" tail node virtual void deleteNodeByIndex(const uint _idx); // delete the "native" ith node from the list protected: void CalcSize(void) const; // calculate the list size void LinkHeadTail(void); // link head to tail };-->
전체 클래스 설명은 CiCircleDoubleList.mqh에 제공됩니다.
클래스의 몇 가지 메소드를 살펴보겠습니다. CiCircleDoubleList::LinkHeadTail() 메소드는 꼬리 노드를 머리 노드에 연결합니다. 새로운 꼬리나 머리가 있고 이전 링크가 손실되었을 때 호출되어야 합니다.
//+------------------------------------------------------------------+ //| Linking head to tail | //+------------------------------------------------------------------+ void CiCircleDoubleList::LinkHeadTail(void) { TRACE_CALL(_t_flag) this.m_head.SetPrevNode(this.m_tail); // link head to tail this.m_tail.SetNextNode(this.m_head); // link tail to head }-->
순환 단일 연결 목록을 다룬다면 이 방법이 어떨지 생각해 보십시오.
예를 들어, CiCircleDoubleList::addFront() 메소드를 고려하십시오.
//+------------------------------------------------------------------+ //| New "native" node to the beginning of the list | //+------------------------------------------------------------------+ void CiCircleDoubleList::addFront(int _node_val) { TRACE_CALL(_t_flag) CDoubleList::addFront(_node_val); // call a similar method of the base class this.LinkHeadTail(); // link head and tail }-->
메소드 본문에서 기본 클래스 CDoubleList의 유사한 메소드가 호출되는 것을 볼 수 있습니다. 이 시점에서 우리는 메소드 연산을 완료할 수 있습니다(이런 메소드는 기본적으로 여기에서 필요하지 않습니다). 한 가지만 아니라면 말입니다. 머리와 꼬리 사이의 연결이 끊어지고 목록이 없으면 순환 연결이 불가능합니다. 그래서 머리와 꼬리를 연결하는 방식을 호출해야 합니다.
순환 이중 연결 목록 작업은 test_UdList.mq5 스크립트에서 확인됩니다.
작업 및 목표 측면에서 사용된 다른 방법은 이전 예제와 동일합니다.
결과적으로 로그에는 다음 항목이 포함됩니다.
PR 0 13:34:29 test_CdList (EURUSD,H1) =======List #1======= QS 0 13:34:29 test_CdList (EURUSD,H1) Node #1, val=14 QI 0 13:34:29 test_CdList (EURUSD,H1) Node #2, val=666 LQ 0 13:34:29 test_CdList (EURUSD,H1) Node #3, val=13 OH 0 13:34:29 test_CdList (EURUSD,H1) Node #4, val=11 DP 0 13:34:29 test_CdList (EURUSD,H1) DK 0 13:34:29 test_CdList (EURUSD,H1) DI 0 13:34:29 test_CdList (EURUSD,H1) =======List #2 before sorting======= MS 0 13:34:29 test_CdList (EURUSD,H1) Node #1, val=38 IJ 0 13:34:29 test_CdList (EURUSD,H1) Node #2, val=37 IQ 0 13:34:29 test_CdList (EURUSD,H1) Node #3, val=36 EH 0 13:34:29 test_CdList (EURUSD,H1) Node #4, val=35 EO 0 13:34:29 test_CdList (EURUSD,H1) Node #5, val=34 FF 0 13:34:29 test_CdList (EURUSD,H1) Node #6, val=14 DN 0 13:34:29 test_CdList (EURUSD,H1) Node #7, val=666 GD 0 13:34:29 test_CdList (EURUSD,H1) Node #8, val=13 JK 0 13:34:29 test_CdList (EURUSD,H1) Node #9, val=11 JM 0 13:34:29 test_CdList (EURUSD,H1) JH 0 13:34:29 test_CdList (EURUSD,H1) MS 0 13:34:29 test_CdList (EURUSD,H1) =======List #2 after sorting======= LE 0 13:34:29 test_CdList (EURUSD,H1) Node #1, val=11 KL 0 13:34:29 test_CdList (EURUSD,H1) Node #2, val=13 QS 0 13:34:29 test_CdList (EURUSD,H1) Node #3, val=14 NJ 0 13:34:29 test_CdList (EURUSD,H1) Node #4, val=34 NQ 0 13:34:29 test_CdList (EURUSD,H1) Node #5, val=35 NH 0 13:34:29 test_CdList (EURUSD,H1) Node #6, val=36 NO 0 13:34:29 test_CdList (EURUSD,H1) Node #7, val=37 NF 0 13:34:29 test_CdList (EURUSD,H1) Node #8, val=38 JN 0 13:34:29 test_CdList (EURUSD,H1) Node #9, val=666 RJ 0 13:34:29 test_CdList (EURUSD,H1) RE 0 13:34:29 test_CdList (EURUSD,H1)-->
따라서 도입된 목록 클래스 간의 최종 상속 다이어그램은 다음과 같습니다(그림 14).
모든 클래스가 상속으로 관련되어야 하는지 확실하지 않지만 모든 클래스를 그대로 두기로 결정했습니다.

그림 14 목록 클래스 간의 상속
사용자 정의 목록에 대한 설명을 다룬 글의 이 섹션 아래에 선을 그리면서 비선형 목록, 곱하기 연결 목록 및 기타 그룹에 대해서는 거의 다루지 않았다는 점에 주목하고 싶습니다. 관련 정보를 수집하고 이러한 동적 데이터 구조 작업에 대한 더 많은 경험을 얻으면 다른 글을 작성하려고 합니다.
3. MQL5 표준 라이브러리의 목록
표준 라이브러리에서 사용할 수 있는 목록 클래스를 살펴보겠습니다(그림 15).
데이터 클래스에 속합니다.

그림 15 CList 클래스 모델
흥미롭게도 CList는 CObject 클래스의 자손입니다. 즉. 목록은 노드인 클래스의 데이터와 메소드를 상속합니다.
목록 클래스에는 인상적인 메소드 세트가 포함되어 있습니다. 솔직히 말해서, 저는 표준 라이브러리에서 이렇게 큰 클래스를 찾을 줄은 몰랐습니다.
CList 클래스에는 8개의 데이터 멤버가 있습니다. 몇 가지를 지적하고 싶습니다. 클래스 속성에는 현재 노드의 인덱스(int m_curr_idx)와 현재 노드에 대한 포인터(CObject* m_curr_node)가 포함됩니다. 목록이 "스마트"하다고 말할 수 있습니다. 이는 컨트롤이 현지화된 포지션을 나타낼 수 있습니다. 또한 메모리 관리 메커니즘(노드를 물리적으로 삭제하거나 단순히 목록에서 제외할 수 있음), 정렬된 목록 플래그 및 정렬 모드를 제공합니다.
메소드에 대해 말하자면 CList 클래스의 모든 메소드는 다음 그룹으로 나뉩니다.
- 속성;
- 메소드 생성;
- 메소드 추가;
- 삭제 방법;
- 항해;
- 주문 방법;
- 방법을 비교하십시오.
- 검색 방법;
- 입출력.
평소와 같이 표준 생성자와 소멸자가 있습니다.
첫 번째 포인터는 모든 포인터를 비웁니다(NULL). 메모리 관리 플래그 상태는 삭제로 설정됩니다. 새 목록이 정렬되지 않습니다.
본체에서 소멸자는 Clear() 메소드만 호출하여 노드 목록을 비웁니다. 목록 존재의 끝이 반드시 해당 요소(노드)의 "죽음"을 수반하는 것은 아닙니다. 따라서 목록 요소를 삭제할 때 설정된 메모리 관리 플래그가 클래스 관계를 구성에서 집계로 전환합니다.
set- 및 get-methods FreeMode()를 사용하여 이 플래그를 처리할 수 있습니다.
목록을 확장할 수 있는 클래스에는 Add() 및 Insert()의 두 가지 메소드가 있습니다. 첫 번째는 글의 첫 번째 섹션에서 사용된 AddRear() 메소드와 유사합니다. 두 번째 메소드는 SetNodeByIndex() 메소드와 유사합니다.
작은 예부터 시작하겠습니다. 먼저 인터페이스 클래스 CObject의 자손인 CNodeInt 노드 클래스를 생성해야 합니다. 정수 유형의 값을 저장합니다.
//+------------------------------------------------------------------+ //| CNodeInt class | //+------------------------------------------------------------------+ class CNodeInt : public CObject { private: int m_val; // node data public: void CNodeInt(void){this.m_val=WRONG_VALUE;}; // default constructor void CNodeInt(int _val); // parameterized constructor void ~CNodeInt(void){}; // destructor int GetVal(void){return this.m_val;}; // get-method for node data void SetVal(int _val){this.m_val=_val;}; // set-method for node data }; //+------------------------------------------------------------------+ //| Parameterized constructor | //+------------------------------------------------------------------+ void CNodeInt::CNodeInt(int _val):m_val(_val) { };-->
스크립트 test_MQL5_List.mq5의 CList 목록으로 작업하겠습니다.
예제 1은 목록과 노드의 동적 생성을 보여줍니다. 그런 다음 목록은 노드로 채워지고 목록을 삭제하기 전과 후에 첫 번째 노드의 값을 확인합니다.
//--- Example 1 (testing memory management) CList *myList=new CList; // myList.FreeMode(false); // reset flag bool _free_mode=myList.FreeMode(); PrintFormat("\nList \"myList\" - memory management flag: %d",_free_mode); CNodeInt *p_new_nodes_int[10]; p_new_nodes_int[0]=NULL; for(int i=0;i<ArraySize(p_new_nodes_int);i++) { p_new_nodes_int[i]=new CNodeInt(rand()); myList.Add(p_new_nodes_int[i]); } PrintFormat("List \"myList\" has as many nodes as: %d",myList.Total()); Print("=======Before deleting \"myList\"======="); PrintFormat("The 1st node value is: %d",p_new_nodes_int[0].GetVal()); delete myList; int val_to_check=WRONG_VALUE; if(CheckPointer(p_new_nodes_int[0])) val_to_check=p_new_nodes_int[0].GetVal(); Print("=======After deleting \"myList\"======="); PrintFormat("The 1st node value is: %d",val_to_check);-->
플래그를 재설정하는 문자열이 주석 처리된 상태(비활성)로 남아 있으면 로그에 다음 항목이 표시됩니다.
GS 0 14:00:16 test_MQL5_List (EURUSD,H1) EO 0 14:00:16 test_MQL5_List (EURUSD,H1) List "myList" - memory management flag: 1 FR 0 14:00:16 test_MQL5_List (EURUSD,H1) List "myList" has as many nodes as: 10 JH 0 14:00:16 test_MQL5_List (EURUSD,H1) =======Before deleting "myList"======= DO 0 14:00:16 test_MQL5_List (EURUSD,H1) The 1st node value is: 7189 KJ 0 14:00:16 test_MQL5_List (EURUSD,H1) =======After deleting "myList"======= QK 0 14:00:16 test_MQL5_List (EURUSD,H1) The 1st node value is: -1-->
myList 목록을 동적으로 삭제하면 그 안의 모든 노드도 메모리에서 삭제된다는 점에 유의하십시오.
그러나 재설정 플래그 문자열의 주석을 제거하면:
// myList.FreeMode(false); // reset flag-->로그에 대한 출력은 다음과 같습니다.
NS 0 14:02:11 test_MQL5_List (EURUSD,H1) CN 0 14:02:11 test_MQL5_List (EURUSD,H1) List "myList" - memory management flag: 0 CS 0 14:02:11 test_MQL5_List (EURUSD,H1) List "myList" has as many nodes as: 10 KH 0 14:02:11 test_MQL5_List (EURUSD,H1) =======Before deleting "myList"======= NL 0 14:02:11 test_MQL5_List (EURUSD,H1) The 1st node value is: 20411 HJ 0 14:02:11 test_MQL5_List (EURUSD,H1) =======After deleting "myList"======= LI 0 14:02:11 test_MQL5_List (EURUSD,H1) The 1st node value is: 20411 QQ 1 14:02:11 test_MQL5_List (EURUSD,H1) 10 undeleted objects left DD 1 14:02:11 test_MQL5_List (EURUSD,H1) 10 objects of type CNodeInt left DL 1 14:02:11 test_MQL5_List (EURUSD,H1) 400 bytes of leaked memory-->
머리 노드는 목록이 삭제되기 전 및 후 값을 유지한다는 것을 쉽게 알 수 있습니다. 이 경우 스크립트에 올바르게 삭제하는 코드가 포함되어 있지 않으면 삭제되지 않은 개체도 남게 됩니다.
이제 정렬 방법을 사용해 보겠습니다.
//--- Example 2 (sorting) CList *myList=new CList; CNodeInt *p_new_nodes_int[10]; p_new_nodes_int[0]=NULL; for(int i=0;i<ArraySize(p_new_nodes_int);i++) { p_new_nodes_int[i]=new CNodeInt(rand()); myList.Add(p_new_nodes_int[i]); } PrintFormat("\nList \"myList\" has as many nodes as: %d",myList.Total()); Print("=======List \"myList\" before sorting======="); for(int i=0;i<myList.Total();i++) { CNodeInt *p_node_int=myList.GetNodeAtIndex(i); int node_val=p_node_int.GetVal(); PrintFormat("Node #%d is equal to: %d",i+1,node_val); } myList.Sort(0); Print("\n=======List \"myList\" after sorting======="); for(int i=0;i<myList.Total();i++) { CNodeInt *p_node_int=myList.GetNodeAtIndex(i); int node_val=p_node_int.GetVal(); PrintFormat("Node #%d is equal to: %d",i+1,node_val); } delete myList;-->
결과적으로 로그에는 다음 항목이 포함됩니다.
OR 0 22:47:01 test_MQL5_List (EURUSD,H1) FN 0 22:47:01 test_MQL5_List (EURUSD,H1) List "myList" has as many nodes as: 10 FH 0 22:47:01 test_MQL5_List (EURUSD,H1) =======List "myList" before sorting======= LG 0 22:47:01 test_MQL5_List (EURUSD,H1) Node #1 is equal to: 30511 CO 0 22:47:01 test_MQL5_List (EURUSD,H1) Node #2 is equal to: 17404 GF 0 22:47:01 test_MQL5_List (EURUSD,H1) Node #3 is equal to: 12215 KQ 0 22:47:01 test_MQL5_List (EURUSD,H1) Node #4 is equal to: 31574 NJ 0 22:47:01 test_MQL5_List (EURUSD,H1) Node #5 is equal to: 7285 HP 0 22:47:01 test_MQL5_List (EURUSD,H1) Node #6 is equal to: 23509 IH 0 22:47:01 test_MQL5_List (EURUSD,H1) Node #7 is equal to: 26991 NS 0 22:47:01 test_MQL5_List (EURUSD,H1) Node #8 is equal to: 414 MK 0 22:47:01 test_MQL5_List (EURUSD,H1) Node #9 is equal to: 18824 DR 0 22:47:01 test_MQL5_List (EURUSD,H1) Node #10 is equal to: 1560 OR 0 22:47:01 test_MQL5_List (EURUSD,H1) OM 0 22:47:01 test_MQL5_List (EURUSD,H1) =======List "myList" after sorting======= QM 0 22:47:01 test_MQL5_List (EURUSD,H1) Node #1 is equal to: 26991 RE 0 22:47:01 test_MQL5_List (EURUSD,H1) Node #2 is equal to: 23509 ML 0 22:47:01 test_MQL5_List (EURUSD,H1) Node #3 is equal to: 18824 DD 0 22:47:01 test_MQL5_List (EURUSD,H1) Node #4 is equal to: 414 LL 0 22:47:01 test_MQL5_List (EURUSD,H1) Node #5 is equal to: 1560 IG 0 22:47:01 test_MQL5_List (EURUSD,H1) Node #6 is equal to: 17404 PN 0 22:47:01 test_MQL5_List (EURUSD,H1) Node #7 is equal to: 30511 II 0 22:47:01 test_MQL5_List (EURUSD,H1) Node #8 is equal to: 31574 OQ 0 22:47:01 test_MQL5_List (EURUSD,H1) Node #9 is equal to: 12215 JH 0 22:47:01 test_MQL5_List (EURUSD,H1) Node #10 is equal to: 7285-->
분류가 전혀 이루어지지 않았더라도 분류 기술은 나에게 미스터리로 남아있었습니다. 이유를 설명하겠습니다. 호출 순서에 대해 자세히 설명하지 않고 CList::Sort() 메소드는 기본 클래스에서 구현되지 않은 가상 메소드 CObject::Compare()를 호출합니다. 어떠한 방식으로. 따라서 프로그래머는 정렬 방법의 구현을 스스로 처리해야 합니다.
이제 Total() 메소드에 대해 몇 마디 하겠습니다. 데이터 멤버 m_data_total이 담당하는 요소(노드)의 수를 반환합니다. 그것은 매우 간결한 방법이죠. 이 구현의 요소 수는 이전에 제안한 것보다 훨씬 빠릅니다. 실제로, 이것이 바로 매번 목록을 통과하고 노드를 세는 이유가 되는 반면에 노드를 추가하거나 삭제할 때 목록의 정확한 노드 수를 설정할 수 있습니다.
예제 3은 CList 유형과 CiSingleList 유형의 목록을 채우는 속도를 비교하여 각 목록의 크기를 가져오는 데 걸리는 시간을 계산합니다.
//--- Example 3 (nodes number) int iterations=1e7; // 10 million iterations //--- the new CList CList *p_mql_List=new CList; uint start=GetTickCount(); // starting value for(int i=0;i<iterations;i++) { CNodeInt *p_node_int=new CNodeInt(rand()); p_mql_List.Add(p_node_int); } uint time=GetTickCount()-start; // time spent, msec Print("\n=======the CList type list======="); PrintFormat("Filling the list of %.3e nodes has taken %d msec",iterations,time); //--- get the size start=GetTickCount(); int list_size=p_mql_List.Total(); time=GetTickCount()-start; PrintFormat("Getting the size of the list has taken %d msec",time); delete p_mql_List; //--- the new CiSingleList CiSingleList *p_sList=new CiSingleList; start=GetTickCount(); // starting value for(int i=0;i<iterations;i++) p_sList.AddRear(rand()); time=GetTickCount()-start; // time spent, msec Print("\n=======the CiSingleList type list======="); PrintFormat("Filling the list of %.3e nodes has taken %d msec",iterations,time); //--- get the size start=GetTickCount(); list_size=(int)p_sList.Size(); time=GetTickCount()-start; PrintFormat("Getting the size of the list has taken %d msec",time); delete p_sList;-->
이것은 제가 로그에서 얻은 것입니다.
KO 0 22:48:24 test_MQL5_List (EURUSD,H1) CK 0 22:48:24 test_MQL5_List (EURUSD,H1) =======the CList type list======= JL 0 22:48:24 test_MQL5_List (EURUSD,H1) Filling the list of 1.000e+007 nodes has taken 2606 msec RO 0 22:48:24 test_MQL5_List (EURUSD,H1) Getting the size of the list has taken 0 msec LF 0 22:48:29 test_MQL5_List (EURUSD,H1) EL 0 22:48:29 test_MQL5_List (EURUSD,H1) =======the CiSingleList type list======= KK 0 22:48:29 test_MQL5_List (EURUSD,H1) Filling the list of 1.000e+007 nodes has taken 2356 msec NF 0 22:48:29 test_MQL5_List (EURUSD,H1) Getting the size of the list has taken 359 msec-->
크기를 가져오는 방법은 CList 목록에서 즉시 작동합니다. 그건 그렇고, 목록에 노드를 추가하는 것도 매우 빠릅니다.
다음 블록(예제 4)에서는 데이터 컨테이너로서의 목록의 주요 단점 중 하나인 요소에 대한 액세스 속도에 주의를 기울일 것을 제안합니다. 문제는 목록 요소가 선형으로 액세스된다는 것입니다. CList 클래스에서는 바이너리 방식으로 액세스하므로 알고리즘의 수고가 약간 줄어듭니다.
선형적으로 검색할 때 수고는 O(N)입니다. 바이너리 방식으로 구현된 검색은 log2(N)의 수고를 초래합니다.
다음은 데이터 세트의 요소에 액세스하기 위한 코드의 예입니다.
//--- Example 4 (speed of accessing the node) const uint Iter_arr[]={1e3,3e3,6e3,9e3,1e4,3e4,6e4,9e4,1e5,3e5,6e5}; for(uint i=0;i<ArraySize(Iter_arr);i++) { const uint cur_iterations=Iter_arr[i]; // iterations number uint randArr[]; // array of random numbers uint idxArr[]; // array of indexes //--- set the arrays size ArrayResize(randArr,cur_iterations); ArrayResize(idxArr,cur_iterations); CRandom myRand; // random number generator //--- fill the array of random numbers for(uint t=0;t<cur_iterations;t++) randArr[t]=myRand.int32(); //--- fill the array of indexes with random numbers (from 0 to 10 million) int iter_log10=(int)log10(cur_iterations); for(uint r=0;r<cur_iterations;r++) { uint rand_val=myRand.int32(); // random value (from 0 to 4 294 967 295) if(rand_val>=cur_iterations) { int val_log10=(int)log10(rand_val); double log10_remainder=val_log10-iter_log10; rand_val/=(uint)pow(10,log10_remainder+1); } //--- check the limit if(rand_val>=cur_iterations) { Alert("Random value error!"); return; } idxArr[r]=rand_val; } //--- time spent for the array uint start=GetTickCount(); //--- accessing the array elements for(uint p=0;p<cur_iterations;p++) uint random_val=randArr[idxArr[p]]; uint time=GetTickCount()-start; // time spent, msec Print("\n=======the uint type array======="); PrintFormat("Random accessing the array of elements %.1e has taken %d msec",cur_iterations,time); //--- the CList type list CList *p_mql_List=new CList; //--- fill the list for(uint q=0;q<cur_iterations;q++) { CNodeInt *p_node_int=new CNodeInt(randArr[q]); p_mql_List.Add(p_node_int); } start=GetTickCount(); //--- accessing the list nodes for(uint w=0;w<cur_iterations;w++) CNodeInt *p_node_int=p_mql_List.GetNodeAtIndex(idxArr[w]); time=GetTickCount()-start; // time spent, msec Print("\n=======the CList type list======="); PrintFormat("Random accessing the list of nodes %.1e has taken %d msec",cur_iterations,time); //--- free the memory ArrayFree(randArr); ArrayFree(idxArr); delete p_mql_List; }-->
차단 작업 결과에 따라 다음 항목이 로그에 인쇄되었습니다.
MR 0 22:51:22 test_MQL5_List (EURUSD,H1) QL 0 22:51:22 test_MQL5_List (EURUSD,H1) =======the uint type array======= IG 0 22:51:22 test_MQL5_List (EURUSD,H1) Random accessing the array of elements 1.0e+003 has taken 0 msec QF 0 22:51:22 test_MQL5_List (EURUSD,H1) IQ 0 22:51:22 test_MQL5_List (EURUSD,H1) =======the CList type list======= JK 0 22:51:22 test_MQL5_List (EURUSD,H1) Random accessing the list of nodes 1.0e+003 has taken 0 msec MJ 0 22:51:22 test_MQL5_List (EURUSD,H1) QD 0 22:51:22 test_MQL5_List (EURUSD,H1) =======the uint type array======= GO 0 22:51:22 test_MQL5_List (EURUSD,H1) Random accessing the array of elements 3.0e+003 has taken 0 msec QN 0 22:51:22 test_MQL5_List (EURUSD,H1) II 0 22:51:22 test_MQL5_List (EURUSD,H1) =======the CList type list======= EP 0 22:51:22 test_MQL5_List (EURUSD,H1) Random accessing the list of nodes 3.0e+003 has taken 16 msec OR 0 22:51:22 test_MQL5_List (EURUSD,H1) OL 0 22:51:22 test_MQL5_List (EURUSD,H1) =======the uint type array======= FG 0 22:51:22 test_MQL5_List (EURUSD,H1) Random accessing the array of elements 6.0e+003 has taken 0 msec CF 0 22:51:22 test_MQL5_List (EURUSD,H1) GQ 0 22:51:22 test_MQL5_List (EURUSD,H1) =======the CList type list======= CH 0 22:51:22 test_MQL5_List (EURUSD,H1) Random accessing the list of nodes 6.0e+003 has taken 31 msec QJ 0 22:51:22 test_MQL5_List (EURUSD,H1) MD 0 22:51:22 test_MQL5_List (EURUSD,H1) =======the uint type array======= MO 0 22:51:22 test_MQL5_List (EURUSD,H1) Random accessing the array of elements 9.0e+003 has taken 0 msec EN 0 22:51:22 test_MQL5_List (EURUSD,H1) MJ 0 22:51:22 test_MQL5_List (EURUSD,H1) =======the CList type list======= CP 0 22:51:22 test_MQL5_List (EURUSD,H1) Random accessing the list of nodes 9.0e+003 has taken 47 msec CR 0 22:51:22 test_MQL5_List (EURUSD,H1) KL 0 22:51:22 test_MQL5_List (EURUSD,H1) =======the uint type array======= JG 0 22:51:22 test_MQL5_List (EURUSD,H1) Random accessing the array of elements 1.0e+004 has taken 0 msec GF 0 22:51:22 test_MQL5_List (EURUSD,H1) KR 0 22:51:22 test_MQL5_List (EURUSD,H1) =======the CList type list======= MK 0 22:51:22 test_MQL5_List (EURUSD,H1) Random accessing the list of nodes 1.0e+004 has taken 343 msec GJ 0 22:51:22 test_MQL5_List (EURUSD,H1) GG 0 22:51:22 test_MQL5_List (EURUSD,H1) =======the uint type array======= LO 0 22:51:22 test_MQL5_List (EURUSD,H1) Random accessing the array of elements 3.0e+004 has taken 0 msec QO 0 22:51:24 test_MQL5_List (EURUSD,H1) MJ 0 22:51:24 test_MQL5_List (EURUSD,H1) =======the CList type list======= NP 0 22:51:24 test_MQL5_List (EURUSD,H1) Random accessing the list of nodes 3.0e+004 has taken 1217 msec OS 0 22:51:24 test_MQL5_List (EURUSD,H1) KO 0 22:51:24 test_MQL5_List (EURUSD,H1) =======the uint type array======= CP 0 22:51:24 test_MQL5_List (EURUSD,H1) Random accessing the array of elements 6.0e+004 has taken 0 msec MG 0 22:51:26 test_MQL5_List (EURUSD,H1) ER 0 22:51:26 test_MQL5_List (EURUSD,H1) =======the CList type list======= PG 0 22:51:26 test_MQL5_List (EURUSD,H1) Random accessing the list of nodes 6.0e+004 has taken 2387 msec GK 0 22:51:26 test_MQL5_List (EURUSD,H1) OG 0 22:51:26 test_MQL5_List (EURUSD,H1) =======the uint type array======= NH 0 22:51:26 test_MQL5_List (EURUSD,H1) Random accessing the array of elements 9.0e+004 has taken 0 msec JO 0 22:51:30 test_MQL5_List (EURUSD,H1) NK 0 22:51:30 test_MQL5_List (EURUSD,H1) =======the CList type list======= KO 0 22:51:30 test_MQL5_List (EURUSD,H1) Random accessing the list of nodes 9.0e+004 has taken 3619 msec HS 0 22:51:30 test_MQL5_List (EURUSD,H1) DN 0 22:51:30 test_MQL5_List (EURUSD,H1) =======the uint type array======= RP 0 22:51:30 test_MQL5_List (EURUSD,H1) Random accessing the array of elements 1.0e+005 has taken 0 msec OD 0 22:52:05 test_MQL5_List (EURUSD,H1) GS 0 22:52:05 test_MQL5_List (EURUSD,H1) =======the CList type list======= DE 0 22:52:05 test_MQL5_List (EURUSD,H1) Random accessing the list of nodes 1.0e+005 has taken 35631 msec NH 0 22:52:06 test_MQL5_List (EURUSD,H1) RF 0 22:52:06 test_MQL5_List (EURUSD,H1) =======the uint type array======= FI 0 22:52:06 test_MQL5_List (EURUSD,H1) Random accessing the array of elements 3.0e+005 has taken 0 msec HL 0 22:54:20 test_MQL5_List (EURUSD,H1) PD 0 22:54:20 test_MQL5_List (EURUSD,H1) =======the CList type list======= FN 0 22:54:20 test_MQL5_List (EURUSD,H1) Random accessing the list of nodes 3.0e+005 has taken 134379 msec RQ 0 22:54:20 test_MQL5_List (EURUSD,H1) JI 0 22:54:20 test_MQL5_List (EURUSD,H1) =======the uint type array======= MR 0 22:54:20 test_MQL5_List (EURUSD,H1) Random accessing the array of elements 6.0e+005 has taken 15 msec NE 0 22:58:48 test_MQL5_List (EURUSD,H1) FL 0 22:58:48 test_MQL5_List (EURUSD,H1) =======the CList type list======= GE 0 22:58:48 test_MQL5_List (EURUSD,H1) Random accessing the list of nodes 6.0e+005 has taken 267589 msec-->
목록 요소에 대한 임의 액세스는 목록 크기가 커질수록 더 많은 시간이 소요됨을 알 수 있습니다(그림 16).

그림 16 배열 및 목록 요소에 대한 임의 액세스에 소요된 시간
이제 데이터를 저장하고 로드하는 방법을 살펴보겠습니다.
기본 목록 클래스 CList에는 이러한 메소드가 포함되어 있지만 가상입니다. 따라서 예제를 사용하여 작동을 테스트하려면 몇 가지 준비가 필요합니다.
자손 클래스 CIntList를 사용하여 CList 클래스 기능을 상속해야 합니다. 후자는 새 요소 CIntList::CreateElement()를 생성하는 방법이 하나뿐입니다.
//+------------------------------------------------------------------+ //| CIntList class | //+------------------------------------------------------------------+ class CIntList : public CList { public: virtual CObject *CreateElement(void); }; //+------------------------------------------------------------------+ //| New element of the list | //+------------------------------------------------------------------+ CObject *CIntList::CreateElement(void) { CObject *new_node=new CNodeInt(); return new_node; }-->
또한 파생된 노드 유형 CNodeInt에 가상 메소드 CNodeInt::Save() 및 CNodeInt::Load()를 추가해야 합니다. 이들은 각각 CList::Save() 및 CList::Load() 멤버 함수에서 호출됩니다.
결과적으로 예는 다음과 같습니다(예제 5).
//--- Example 5 (saving list data) //--- the CIntList type list CList *p_int_List=new CIntList; int randArr[1000]; // array of random numbers ArrayInitialize(randArr,0); //--- fill the array of random numbers for(int t=0;t<1000;t++) randArr[t]=(int)myRand.int32(); //--- fill the list for(uint q=0;q<1000;q++) { CNodeInt *p_node_int=new CNodeInt(randArr[q]); p_int_List.Add(p_node_int); } //--- save the list to the file int file_ha=FileOpen("List_data.bin",FILE_WRITE|FILE_BIN); p_int_List.Save(file_ha); FileClose(file_ha); p_int_List.FreeMode(true); p_int_List.Clear(); //--- load the list from the file file_ha=FileOpen("List_data.bin",FILE_READ|FILE_BIN); p_int_List.Load(file_ha); int Loaded_List_size=p_int_List.Total(); PrintFormat("Nodes loaded from the file: %d",Loaded_List_size); //--- free the memory delete p_int_List;-->
차트에서 스크립트를 실행하면 다음 항목이 로그에 추가됩니다.
ND 0 11:59:35 test_MQL5_List (EURUSD,H1) As many as 1000 nodes loaded from the file.-->
따라서 우리는 CNodeInt 노드 유형의 데이터 멤버에 대한 입력/출력 메소드의 구현을 보았습니다.
다음 섹션에서는 MQL5로 작업할 때 문제를 해결하기 위해 목록을 사용하는 방법의 예를 볼 것입니다.
4. MQL5에서 목록 사용의 예
이전 섹션에서 표준 라이브러리 클래스 CList의 메소드를 고려할 때 몇 가지 예를 들었습니다.
이제 목록을 사용하여 특정 문제를 해결하는 경우를 살펴보겠습니다. 그리고 여기서 다시 한 번 목록의 이점을 컨테이너 데이터 유형으로 지적할 수 없습니다. 목록의 유연성을 활용하여 코드 작업을 보다 효율적으로 만들 수 있습니다.
4.1 그래픽 개체 다루기
차트에서 프로그래밍 방식으로 그래픽 개체를 생성해야 한다고 상상해 보세요. 다양한 이유로 차트에 나타날 수 있는 다른 개체일 수 있습니다.
일단 목록이 그래픽 개체로 상황을 분류하는 데 도움이 되었던 것을 기억합니다. 그리고 이 추억을 당신과 공유하고 싶습니다.
지정된 조건으로 세로선을 만드는 작업이 있었습니다. 조건에 따라 수직선은 경우에 따라 길이가 달라지는 주어진 시간 간격에 대한 제한 역할을 했습니다. 즉, 간격이 항상 완전히 형성되지는 않았습니다.
저는 EMA21의 동작을 연구하고 있었고 이를 위해 통계를 수집해야 했습니다.
저는 특히 이동 평균의 기울기 길이에 관심이 있었습니다. 예를 들어, 하향 이동에서 시작점은 수직선이 그려지는 이동 평균의 음의 이동(즉, 가치 감소)을 등록하여 식별되었습니다. 그림 17은 촛대가 열렸을 때 EURUSD, H1에 대해 2013년 9월 5일 16:00으로 식별된 지점을 보여줍니다.

그림 17 하향 구간의 첫 번째 지점
하락 움직임의 끝을 암시하는 두 번째 점은 이동 평균의 양의 움직임, 즉 가치 증가를 등록함으로써 역 원리에 따라 식별되었습니다(그림 18).

그림 18 하향 구간의 두 번째 지점
따라서 목표 간격은 2013년 9월 5일 16:00부터 2013년 9월 6일 17:00까지였습니다.
다른 간격을 식별하는 시스템은 더 복잡하거나 더 간단할 수 있습니다. 이것은 요점이 아닙니다. 중요한 것은 그래픽 개체로 작업하고 통계 데이터를 동시에 수집하는 이 기술이 목록의 주요 이점 중 하나인 구성의 유연성을 포함한다는 사실입니다.
현재 예제의 경우 먼저 2개의 그래픽 "수직선" 개체를 담당하는 CVertLineNode 유형의 노드를 만들었습니다.
클래스 정의는 다음과 같습니다.
//+------------------------------------------------------------------+ //| CVertLineNode class | //+------------------------------------------------------------------+ class CVertLineNode : public CObject { private: SVertLineProperties m_vert_lines[2]; // array of structures of vertical line properties uint m_duration; // frame duration bool m_IsFrameFormed; // flag of frame formation public: void CVertLineNode(void); void ~CVertLineNode(void){}; //--- set-methods void SetLine(const SVertLineProperties &_vert_line,bool IsFirst=true); void SetDuration(const uint _duration){this.m_duration=_duration;}; void SetFrameFlag(const bool _frame_flag){this.m_IsFrameFormed=_frame_flag;}; //--- get-methods void GetLine(SVertLineProperties &_vert_line_out,bool IsFirst=true) const; uint GetDuration(void) const; bool GetFrameFlag(void) const; //--- draw the line bool DrawLine(bool IsFirst=true) const; };-->
기본적으로 이 노드 클래스는 프레임을 설명합니다(여기서는 두 개의 수직선 내에 제한된 수의 촛대로 해석됨). 프레임 제한은 수직선 속성, 지속 시간 및 형성 플래그의 몇 가지 구조로 표시됩니다.
표준 생성자 및 소멸자 외에도 클래스에는 여러 설정 및 가져오기 메소드와 차트에 선을 그리는 메소드가 있습니다.
내 예에서 수직선(프레임)의 노드는 하향 이동의 시작을 나타내는 첫 번째 수직선과 상향 이동의 시작을 나타내는 두 번째 수직선이 있을 때 형성되는 것으로 간주할 수 있음을 상기시켜 드리겠습니다.
Stat_collector.mq5 스크립트를 사용하여 차트의 모든 프레임을 표시하고 지난 2,000개 바에서 특정 기간 제한에 해당하는 노드(프레임)의 수를 세었습니다.
설명을 위해 모든 프레임을 포함할 수 있는 4개의 목록을 만들었습니다. 첫 번째 목록에는 최대 5개의 촛대 수, 두 번째는 최대 10개, 세 번째는 최대 15개, 네 번째는 무제한 수의 프레임이 포함되었습니다.
NS 0 15:27:32 Stat_collector (EURUSD,H1) =======List #1======= RF 0 15:27:32 Stat_collector (EURUSD,H1) Duration limit: 5 ML 0 15:27:32 Stat_collector (EURUSD,H1) Nodes number: 65 HK 0 15:27:32 Stat_collector (EURUSD,H1) OO 0 15:27:32 Stat_collector (EURUSD,H1) =======List #2======= RI 0 15:27:32 Stat_collector (EURUSD,H1) Duration limit: 10 NP 0 15:27:32 Stat_collector (EURUSD,H1) Nodes number: 15 RG 0 15:27:32 Stat_collector (EURUSD,H1) FH 0 15:27:32 Stat_collector (EURUSD,H1) =======List #3======= GN 0 15:27:32 Stat_collector (EURUSD,H1) Duration limit: 15 FG 0 15:27:32 Stat_collector (EURUSD,H1) Nodes number: 6 FR 0 15:27:32 Stat_collector (EURUSD,H1) CD 0 15:27:32 Stat_collector (EURUSD,H1) =======List #4======= PS 0 15:27:32 Stat_collector (EURUSD,H1) Nodes number: 20-->
그 결과 다음과 같은 차트를 얻었다(그림 19). 편의상 두 번째 수직 프레임 라인은 파란색으로 표시됩니다.
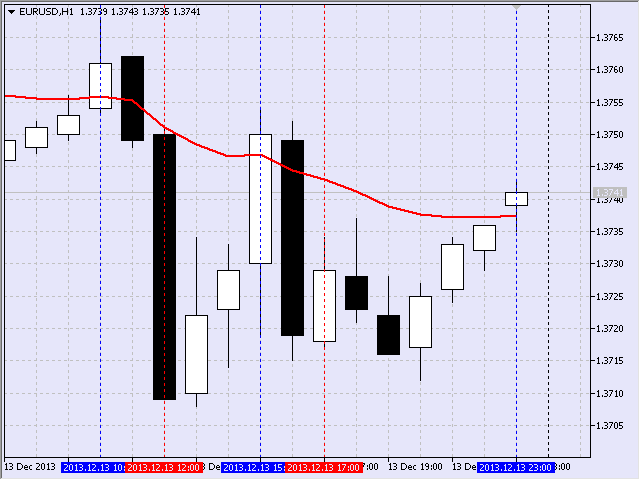
그림 19 프레임 표시
흥미롭게도 마지막 프레임은 2013년 12월 13일 금요일 마지막 시간에 형성되었습니다. 지속 시간이 6시간이었기 때문에 두 번째 목록에 포함되었습니다.
4.2 가상 거래 다루기
틱 흐름에서 하나의 기기와 관련하여 여러 독립적인 전략을 구현하는 Expert Advisor를 만들어야 한다고 상상해 보십시오. 실제로는 하나의 도구에 대해 한 번에 하나의 전략만 실행할 수 있다는 것이 분명합니다. 다른 모든 전략은 가상적입니다. 따라서 거래 아이디어를 테스트하고 최적화하기 위한 목적으로만 구현할 수 있습니다.
여기에서는 일반적인 거래, 특히 MetaTrader 5 터미널과 관련된 기본 개념에 대한 자세한 설명을 제공하는 기본 문서를 참조해야 합니다. "MetaTrader 5의 주문, 포지션 및 거래" .
따라서 이 문제를 풀 때 MetaTrader 5 환경에서 일반적으로 사용되는 거래 개념, 거래 개체 관리 시스템 및 거래 개체에 대한 정보를 저장하는 방법론을 사용한다면 가상 데이터베이스를 만드는 것을 생각해야 할 것입니다.
개발자는 모든 거래 개체를 주문, 포지션, 거래 및 내역 주문으로 분류한다는 점을 상기시켜 드리겠습니다. 비평가는 '거래 대상'이라는 용어가 저자 자신에 의해 여기에서 사용되었음을 알아차릴 수 있습니다. 이것은 사실입니다...
가상 거래에서 유사한 접근 방식을 사용하고 가상 주문, 가상 포지션, 가상 거래 및 가상 기록 주문과 같은 가상 거래 개체를 얻을 것을 제안합니다.
저는 이 주제가 더 심도 있고 더 자세한 논의의 가치가 있다고 생각합니다. 그 동안 글의 주제로 돌아가서 목록을 포함한 컨테이너 데이터 유형이 가상 전략을 구현할 때 프로그래머의 삶을 더 쉽게 만들 수 있다고 말하고 싶습니다.
자연스럽게 거래 서버 측에 있을 수 없는 새로운 가상 포지션을 생각해 보십시오. 이것은 그것에 대한 정보가 터미널 측에 저장되어야 함을 의미합니다. 여기서 데이터베이스는 여러 목록으로 구성된 목록으로 나타낼 수 있으며 그 중 하나는 가상 포지션의 노드를 포함합니다.
개발자의 접근 방식을 사용하면 다음과 같은 가상 거래 클래스가 있습니다.
Class/Group | 설명 |
C가상주문 | 가상 보류 주문 작업을 위한 클래스 |
CVirtualHistoryOrder | 가상 "내역" 주문을 위한 클래스 |
CVirtual포지션 | 가상 열린 포지션 작업을 위한 클래스 |
CVirtual딜 | 가상 "내역" 딜 작업을 위한 클래스 |
CVirtual거래 | 가상 거래 작업을 수행하기 위한 클래스 |
표 1. 가상 거래 클래스
저는 가상 거래 클래스의 구성에 대해 논의하지 않을 것입니다. 그러나 아마도 표준 거래 클래스의 모든 또는 거의 모든 방법을 포함할 것입니다. 개발자가 사용하는 것은 주어진 거래 객체 자체의 클래스가 아니라 해당 속성의 클래스라는 점에 주목하고 싶습니다.
알고리즘에서 목록을 사용하려면 노드도 필요합니다. 따라서 가상 거래 객체의 클래스를 노드에 래핑해야 합니다.
가상 열린 포지션의 노드가 CVirtualPositionNode 유형이라고 가정합니다. 이 유형의 정의는 초기에 다음과 같을 수 있습니다.
//+------------------------------------------------------------------+ //| Class CVirtualPositionNode | //+------------------------------------------------------------------+ class CVirtualPositionNode : public CObject { protected: CVirtualPositionNode *m_virt_position; // pointer to the virtual function public: void CVirtualPositionNode(void); // default constructor void ~CVirtualPositionNode(void); // destructor };-->
이제 가상 포지션이 열리면 가상 포지션 목록에 추가할 수 있습니다.
또한 가상 거래 개체로 작업하는 이 접근 방식은 데이터베이스가 랜덤 액세스 메모리에 저장되기 때문에 캐시 메모리를 사용할 필요가 없다는 점에 주목하고 싶습니다. 물론 다른 저장 매체에 저장되도록 정렬할 수 있습니다.
결론
이 글에서는 목록과 같은 컨테이너 데이터 유형의 장점을 보여주려고 했습니다. 하지만 단점을 언급하지 않고는 갈 수 없었습니다. 여하튼 이 정보가 OOP 전반, 특히 기본 원리 중 하나인 다형성(Polymorphism)을 공부하시는 분들께 도움이 되었으면 합니다.
파일 위치:
제 생각에는 프로젝트 폴더에 파일을 만들어 저장하는 것이 가장 좋습니다. 예: %MQL5\Projects\UserLists. 여기에 모든 소스 코드 파일을 저장했습니다. 기본 디렉토리를 사용하는 경우 일부 파일의 코드에서 포함 파일 지정 방법(따옴표를 꺾쇠 괄호로 대체)을 변경해야 합니다.
| # | 파일 | 위치 | 설명 |
|---|---|---|---|
| 1 | CiSingleNode.mqh | %MQL5\Projects\UserLists | 단일 연결 목록 노드의 클래스 |
| 2 | CDoubleNode.mqh | %MQL5\Projects\UserLists | 이중 연결 목록 노드의 클래스 |
| 3 | CiUnrollDoubleNode.mqh | %MQL5\Projects\UserLists | 언롤링된 이중 연결 목록 노드의 클래스 |
| 4 | test_nodes.mq5 | %MQL5\Projects\UserLists | 노드 작업 예제가 있는 스크립트 |
| 5 | CiSingleList.mqh | %MQL5\Projects\UserLists | 단일 연결 목록의 클래스 |
| 6 | CDoubleList.mqh | %MQL5\Projects\UserLists | 이중 연결 목록의 클래스 |
| 7 | CiUnrollDoubleList.mqh | %MQL5\Projects\UserLists | 언롤링된 이중 연결 목록의 클래스 |
| 8 | CiCircleDoublList.mqh | %MQL5\Projects\UserLists | 순환 이중 연결 목록의 클래스 |
| 9 | test_sList.mq5 | %MQL5\Projects\UserLists | 단일 연결 목록으로 작업하는 예제가 있는 스크립트 |
| 10 | test_dList.mq5 | %MQL5\Projects\UserLists | 이중 연결 목록 작업 예제가 있는 스크립트 |
| 11 | test_UdList.mq5 | %MQL5\Projects\UserLists | 언롤링된 이중 연결 목록으로 작업하는 예제가 있는 스크립트 |
| 12 | test_CdList.mq5 | %MQL5\Projects\UserLists | 순환 이중 연결 목록으로 작업하는 예제가 있는 스크립트 |
| 13 | test_MQL5_List.mq5 | %MQL5\Projects\UserLists | CList 클래스 작업 예제가 있는 스크립트 |
| 14 | CNodeInt.mqh | %MQL5\Projects\UserLists | 정수형 노드의 클래스 |
| 15 | CIntList.mqh | %MQL5\Projects\UserLists | CNodeInt 노드의 목록 클래스 |
| 16 | CRandom.mqh | %MQL5\Projects\UserLists | 난수 생성기의 클래스 |
| 17 | CVertLineNode.mqh | %MQL5\Projects\UserLists | 수직선 프레임을 처리하기 위한 노드 클래스 |
| 18 | Stat_collector.mq5 | %MQL5\Projects\UserLists | 통계 수집 예제가 있는 스크립트 |
참조:
- A. Friedman, L. Klander, M. Michaelis, H. Schildt. C/C++ 주석이 달린 아카이브. Mcgraw-Hill Osborne Media, 1999. 1008페이지.
- V.D. Daleka, A.S. Derevyanko, O.G. Kravets, L.E. Timanovskaya. 데이터 모델 및 구조. 학습 가이드. Kharkov, KhGPU, 2000. 241쪽(러시아어).
MetaQuotes 소프트웨어 사를 통해 러시아어가 번역됨.
원본 기고글: https://www.mql5.com/ru/articles/709
 MQL5 Cookbook - MQL5의 다중 통화 Expert Advisor 및 대기 중인 주문 작업
MQL5 Cookbook - MQL5의 다중 통화 Expert Advisor 및 대기 중인 주문 작업