
MQL5의 전자 테이블

소개
일반적으로 전자 테이블은 EXCEL과 같은 테이블 프로세서(데이터를 저장하고 처리하는 응용 프로그램)를 나타냅니다. 글에 표시된 코드는 그다지 강력하지 않지만 테이블 프로세서의 모든 기능을 구현하기 위한 기본 클래스로 사용할 수 있습니다. MQL5를 사용하여 MS Excel을 생성할 목적은 없지만 2차원 배열에서 다른 유형의 데이터로 작업하는 클래스를 구현하고 싶습니다.
그리고 제가 구현한 클래스는 성능면에서 단일 유형 데이터의 2차원 배열(데이터에 직접 액세스할 수 있음)과 비교할 수 없지만 클래스는 사용하기 편리해 보였습니다. 또한 이 클래스는 C++에서 Variant 클래스의 구현으로 간주될 수 있으며, 하나의 열로 변질된 테이블의 특정 경우입니다.
참을성이 없는 사람과 구현 알고리즘을 분석하고 싶지 않은 사람을 위해 사용 가능한 메소드에서 CTable 클래스를 설명하기 시작하겠습니다.
1. 클래스 메소드에 대한 설명
먼저 클래스에서 사용 가능한 메소드의 목적과 사용 원리에 대한 자세한 설명을 살펴보겠습니다.
1.1. 첫 번째 크기 조정
테이블 레이아웃, 열 유형 설명, TYPE[] - 행 크기와 셀 유형을 결정하는 ENUM_DATATYPE 유형의 배열입니다.
void FirstResize(const ENUM_DATATYPE &TYPE[]);
실제로 이 메소드는 매개 변수가 있는 추가 생성자입니다. 이것은 두 가지 이유로 편리합니다. 첫째, 생성자 내부의 매개변수 전달 문제를 해결합니다. 둘째, 객체를 매개변수로 전달한 다음 필요한 배열 분할을 수행할 수 있는 가능성을 제공합니다. 이 기능을 사용하면 클래스를 C++에서 Variant 클래스로 사용할 수 있습니다.
구현의 특징은 함수가 열의 첫 번째 차원과 데이터 유형을 설정함에도 불구하고 첫 번째 차원의 크기를 매개변수로 지정할 필요가 없다는 점입니다. 이 매개변수는 전달된 배열 TYPE의 크기에서 가져옵니다.
1.2. 두 번째 크기 조정
행 수를 'j'로 변경합니다.
void SecondResize(int j);
이 함수는 두 번째 차원의 모든 배열에 대해 지정된 크기를 설정합니다. 따라서 테이블에 행을 추가한다고 말할 수 있습니다.
1.3. 첫 번째 크기
이 메소드는 첫 번째 차원의 크기(행 길이)를 반환합니다.
int FirstSize();
1.4. 두 번째 크기
이 메소드는 두 번째 차원의 크기(열 길이)를 반환합니다.
int SecondSize();1.5. 가지치기 테이블
첫 번째 차원의 새 크기를 설정합니다. 변경은 시작 크기 내에서 가능합니다.
void PruningTable(int count);
실제로 함수는 행의 길이를 변경하지 않습니다. 행 길이 값을 저장하는 역할을 하는 변수 값만 다시 씁니다. 클래스에는 테이블의 초기 분할에서 설정되는 할당된 메모리의 실제 크기를 저장하는 또 다른 변수가 있습니다. 이 변수의 값 내에서 첫 번째 차원 크기의 가상 변경이 가능합니다. 이 기능은 한 테이블을 다른 테이블로 복사할 때 불필요한 부분을 잘라내기 위한 것입니다.
1.6. CopyTable
두 번째 차원의 전체 길이에서 한 테이블을 다른 테이블로 복사하는 방법:
void CopyTable(CTable *sor); 이 함수는 한 테이블을 다른 테이블로 복사합니다. 수신 테이블의 초기화를 시작합니다. 추가 생성자로 사용할 수 있습니다. 정렬 변형의 내부 구조는 복사되지 않습니다. 크기, 열 유형 및 데이터만 초기 테이블에서 복사됩니다. 이 함수는 GetPointer 함수에 의해 전달되는 매개변수로 CTable 유형의 복사된 개체 참조를 받아들입니다.
한 테이블을 다른 테이블로 복사하면 'sor' 샘플에 따라 새 테이블이 생성됩니다.
void CopyTable(CTable *sor,int sec_beg,int sec_end);
추가 매개변수로 위에서 설명한 기능 재정의: sec_beg - 초기 테이블 복사 시작점, sec_end - 복사 끝점(복사된 데이터의 양과 혼동하지 마십시오). 두 매개변수 모두 두 번째 차원을 나타냅니다. 데이터는 수신자 테이블의 시작 부분에 추가됩니다. 수신 테이블의 크기는 sec_end-sec_beg+1로 설정합니다.
1.7. TypeTable
'i' 열의 type_table 값(ENUM_DATATYPE 유형)을 반환합니다.
ENUM_DATATYPE TypeTable(int i)
1.8. 변경
Change() 메소드는 열 교환을 수행합니다.
bool Change(int &sor0,int &sor1);
위에서 언급했듯이 이 메소드는 열을 교환합니다(첫 번째 차원에서 작동). 정보는 실제로 이동하지 않기 때문에 함수의 동작 속도는 2차원의 크기에 영향을 받지 않습니다.
1.9. 삽입
Insert 메소드는 지정된 위치에 열을 삽입합니다.
bool Insert(int rec,int sor);
지정된 칼럼을 이동해야 하는 위치에 따라 다른 칼럼을 당기거나 푸는 기능을 수행한다는 점을 제외하고는 위에서 설명한 기능과 동일합니다. 매개변수 'rec'는 열이 이동할 포지션을 지정하고 'sor'는 열이 이동할 포지션을 지정합니다.
1.10. Variant/VariantCopy
그런 다음 '변형' 시리즈의 세 가지 기능이 제공됩니다. 테이블 처리의 변형을 기억하는 것은 클래스에서 구현됩니다.
변형은 notebook을 연상시킵니다. 예를 들어 세 번째 열을 기준으로 정렬을 수행하고 다음 처리 중에 데이터를 재설정하지 않으려면 변형을 전환해야 합니다. 처리의 이전 변형에 액세스하려면 'variant' 함수를 호출하십시오. 다음 처리가 이전 처리의 결과를 기반으로 해야 하는 경우 변형을 복사해야 합니다. 기본적으로 숫자 0을 가진 하나의 변형이 설정됩니다.
변형 설정(해당 변형이 없는 경우 'ind'까지 누락된 모든 변형과 함께 생성됨) 및 활성 변형 가져오기. 'variantcopy' 메소드는 'sor' 변형을 'rec' 변형에 복사합니다.
void variant(int ind); int variant(); void variantcopy(int rec,int sor);
변형(int ind) 메소드는 선택한 변형을 전환합니다. 메모리 자동 할당을 수행합니다. 지정된 매개변수가 이전에 지정된 매개변수보다 작으면 메모리가 재할당되지 않습니다.
variantcopy 방법을 사용하면 'sor' 변형을 'rec' 변형에 복사할 수 있습니다. 변형을 정렬하기 위해 함수가 생성됩니다. 'rec' 변형이 없으면 자동으로 변형 수를 늘립니다. 또한 새로 복사된 변형으로 전환됩니다.
1.11. SortTwoDimArray
SortTwoDimArray 메소드는 선택한 행 'i'를 기준으로 테이블을 정렬합니다.
void SortTwoDimArray(int i,int beg,int end,bool mode=false);
지정된 열을 기준으로 테이블을 정렬하는 기능입니다. 매개변수: i - 열, beg - 정렬 시작점, 끝 - 정렬 끝점(포함), 모드 - 정렬 방향을 결정하는 불 방식의 변수. mode=true인 경우 인덱스와 함께 값이 증가함을 의미합니다(인덱스가 테이블의 위에서 아래로 증가하므로 'false'가 기본값임).
1.12. 퀵서치
정렬된 배열의 패턴과 동일한 첫 번째 요소를 검색합니다.
int QuickSearch(int i,long element,int beg,int end,bool mode=false);
1.13. SearchFirst
정렬된 배열의 패턴과 동일한 첫 번째 요소를 검색합니다. '요소' 패턴과 동일한 첫 번째 값의 인덱스를 반환합니다. 이 범위에서 이전에 수행된 정렬 유형을 지정해야 합니다(해당 요소가 없으면 -1을 반환함).
int SearchFirst(int i,long element,int beg,int end,bool mode=false);
1.14. SearchLast
정렬된 배열의 패턴과 동일한 마지막 요소를 검색합니다.
int SearchLast(int i,long element,int beg,int end,bool mode=false);
1.15. SearchGreat
정렬된 배열의 패턴보다 큰 가장 가까운 요소를 검색합니다.
int SearchGreat(int i,long element,int beg,int end,bool mode=false);
1.16. SearchLess
정렬된 배열에서 패턴보다 작은 가장 가까운 요소를 검색합니다.
int SearchLess(int i,long element,int beg,int end,bool mode=false);
1.17. Set/Get
Set 및 Get 함수에는 void 유형이 있습니다. 테이블이 작업하는 네 가지 유형의 데이터로 재정의됩니다. 함수는 데이터 유형을 인식하고 '값' 매개변수가 열 유형과 일치하지 않으면 할당 대신 경고를 출력합니다. 유일한 예외는 문자열 유형입니다. 입력 매개변수가 문자열 유형이면 열 유형으로 캐스트됩니다. 이 예외는 cell의 값을 받아들일 변수를 설정할 가능성이 없을 때 보다 편리한 정보 전달을 위해 만들어진 것입니다.
값을 설정하는 방법(i - 첫 번째 차원의 인덱스, j - 두 번째 차원의 인덱스).
void Set(int i,int j,long value); // setting value of the i-th row and j-th column void Set(int i,int j,double value); // setting value of the i-th row and j-th columns void Set(int i,int j,datetime value);// setting value of the i-th row and j-tj column void Set(int i,int j,string value); // setting value of the i-th row and j-th column
값을 가져오는 방법(i - 첫 번째 차원의 인덱스, j- 두 번째 차원의 인덱스).
//--- getting value void Get(int i,int j,long &recipient); // getting value of the i-th row and j-th column void Get(int i,int j,double &recipient); // getting value of the i-th row and j-th column void Get(int i,int j,datetime &recipient); // getting value of the i-th row and j-th column void Get(int i,int j,string &recipient); // getting value of the i-th row and j-th column
1.19. sGet
'j' 열과 'i' 행에서 string 유형의 값을 가져옵니다.
string sGet(int i,int j); // return value of the i-th row and j-th column
매개변수 대신 '반환' 연산자를 통해 값을 반환하는 Get 시리즈의 유일한 함수입니다. 열 유형에 관계없이 문자열 유형의 값을 반환합니다.
1.20. StringDigits
유형이 '문자열'로 캐스트되면 함수에 의해 설정된 정밀도를 사용할 수 있습니다.
void StringDigits(int i,int digits);
'double'의 정밀도를 설정하고
int StringDigits(int i);
'datetime'에서 초 표시 정밀도를 설정하려면; -1이 아닌 모든 값이 전달됩니다. 칼럼은 지정된 값을 기억하므로 정보를 표시할 때 매번 표시할 필요가 없습니다. 정보는 원래 유형으로 저장되고 출력 중에만 지정된 정밀도로 변환되기 때문에 정밀도를 여러 번 설정할 수 있습니다. 정밀도 값은 복사 시 기억되지 않으므로 새 테이블에 테이블을 복사할 때 새 테이블의 열 정밀도는 기본 정밀도에 해당합니다.
1.21. 사용 예:
#include <Table.mqh> ENUM_DATATYPE TYPE[7]= {TYPE_LONG,TYPE_LONG,TYPE_STRING,TYPE_DATETIME,TYPE_STRING,TYPE_STRING,TYPE_DOUBLE}; // 0 1 2 3 4 5 6 //7 void OnStart() { CTable table,table1; table.FirstResize(TYPE); // dividing table, determining column types table.SecondResize(5); // change the number of rows table.Set(6,0,"321.012324568"); // assigning data to the 6-th column, 0 row table.Insert(2,6); // insert 6-th column in the 2-nd position table.PruningTable(3); // cut the table to 3 columns table.StringDigits(2,5); // set precision of 5 digits after the decimal point Print("table ",table.sGet(2,0)); // print the cell located in the 2-nd column, 0 row table1.CopyTable(GetPointer(table)); // copy the entire table 'table' to the 'table1' table table1.StringDigits(2,8); // set 8-digit precision Print("table1 ",table1.sGet(2,0)); // print the cell located in the 2-nd column, 0 row of the 'table1' table. }
연산 결과는 셀(2;0)의 내용을 출력하는 것입니다. 아마 눈치채셨겠지만 복사된 데이터의 정밀도는 초기 테이블의 정밀도를 초과하지 않습니다.
2011.02.09 14:18:37 Table Script (EURUSD,H1) table1 321.01232000 2011.02.09 14:18:37 Table Script (EURUSD,H1) table 321.01232
이제 알고리즘 자체에 대한 설명으로 넘어가겠습니다.
2. 모델 선택
정보 구성에는 두 가지 방법이 있습니다. 연결된 열 구성표(이 글에서 구현)와 연결된 행 형태의 대안이 아래에 나와 있습니다.
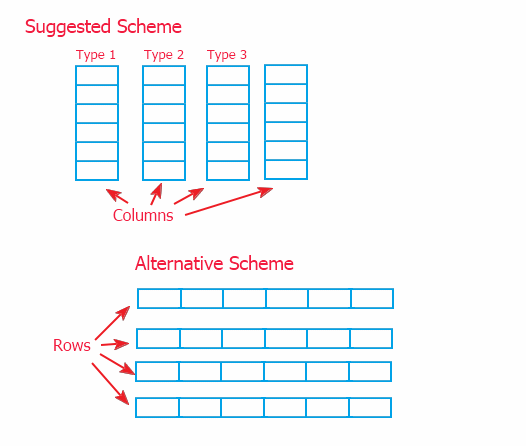
중개자를 통해 정보를 참조하기 때문에(다음에 설명되어 있음: p. 2) 상위 범위의 구현에는 큰 차이가 없습니다. 그러나 데이터를 저장하는 개체에서 낮은 범위의 데이터 방법을 구현할 수 있기 때문에 열 모델을 선택했습니다. 그리고 대체 체계는 상위 클래스 CTable의 정보로 작업하는 방법을 재정의해야 합니다. 그리고 이것은 필요한 경우 수업의 향상을 복잡하게 만들 수 있습니다.
그 때 각 체계를 사용할 수 있습니다. 제안된 방식은 데이터의 빠른 이동을 허용하고 다른 방식은 데이터 추가(정보가 테이블에 한 줄씩 더 자주 추가되기 때문에) 및 행 가져오기를 보다 빠르게 허용합니다.
구조의 배열로 테이블을 배열하는 또 다른 방법이 있습니다. 그리고 구현하기 가장 쉬운 방법이지만 상당한 단점이 있습니다. 구조는 프로그래머가 설명해야 합니다. 따라서 (소스 코드를 변경하지 않고) 사용자 정의 매개변수를 통해 테이블의 속성을 설정할 가능성을 잃게 됩니다.
3. 동적 배열에서 데이터 통합
단일 동적 배열에서 다양한 유형의 데이터를 통합할 수 있으려면 배열 셀에 다른 유형을 할당하는 문제를 해결해야 합니다. 이 문제는 표준 라이브러리의 연결 목록에서 이미 해결되었습니다. 제 첫 번째 개발은 클래스의 표준 라이브러리를 기반으로 했습니다. 그러나 프로젝트를 개발하는 동안 기본 클래스 CObject를 변경해야 하는 것처럼 보였습니다.
그래서 저는 나름의 클래스를 만들기로 결정했습니다. 표준 라이브러리를 공부하지 않은 사람들을 위해 위에서 언급한 문제가 어떻게 해결되는지 설명하겠습니다. 문제를 해결하려면 상속 메커니즘을 사용해야 합니다.
class CBase { public: CBase(){Print(__FUNCTION__);}; ~CBase(){Print(__FUNCTION__);}; virtual void set(int sor){}; virtual void set(double sor){}; virtual int get(int k){return(0);}; virtual double get(double k){return(0);}; }; //+------------------------------------------------------------------+ class CA: public CBase { private: int temp; public: CA(){Print(__FUNCTION__);}; ~CA(){Print(__FUNCTION__);}; void set(int sor){temp=sor;}; int get(int k){return(temp);}; }; //+------------------------------------------------------------------+ class CB: public CBase { private: double temp; public: CB(){Print(__FUNCTION__);}; ~CB(){Print(__FUNCTION__);}; void set(double sor){temp=sor;}; double get(double k){return(temp);}; }; //+------------------------------------------------------------------+ void OnStart() { CBase *a; CBase *b; a=new CA(); b=new CB(); a.set(15); b.set(13.3); Print("a=",a.get(0)," b=",b.get(0.)); delete a; delete b; }
시각적으로 상속 메커니즘은 빗으로 표시될 수 있습니다.

클래스의 동적 객체 생성이 선언되면 기본 클래스의 생성자가 호출된다는 의미입니다. 이 정확한 속성을 통해 두 단계로 개체를 생성할 수 있습니다. 기본 클래스의 가상 함수가 재정의되므로 파생 클래스에서 다른 유형의 매개변수를 사용하여 함수를 호출할 수 있습니다.
간단한 재정의가 충분하지 않은 이유는 무엇입니까? 문제는 실행된 함수가 거대하므로 상속을 사용하지 않고 기본 클래스에서 해당 본문을 설명하면 이진 코드의 각 개체에 대해 본문의 전체 코드와 함께 사용되지 않는 함수가 생성된다는 것입니다. 그리고 상속 메커니즘을 사용하면 코드로 채워진 함수보다 훨씬 적은 메모리를 차지하는 빈 함수가 생성됩니다.
4. 배열 작업
두 번째로, 제가 표준 클래스를 사용하기를 거부하게 만든 주춧돌은 데이터에 대한 언급입니다. 저는 셀의 인덱스로 참조하는 대신 인덱스의 중간 배열을 통해 배열 셀을 간접적으로 참조하는 것을 사용합니다. 변수를 통한 직접 참조를 사용하는 경우보다 작업 속도를 낮게 규정합니다. 문제는 인덱스가 먼저 메모리에서 찾아야 하는 배열 셀보다 빠르게 작동한다는 것을 나타내는 변수입니다.
1차원 배열과 다차원 배열 정렬의 근본적인 차이점이 무엇인지 분석해 보겠습니다. 1차원 배열은 정렬하기 전에는 요소의 포지션이 무작위이고 정렬 후에는 요소가 배열됩니다. 2차원 배열을 정렬할 때 전체 배열을 정렬할 필요는 없지만 해당 열 중 하나만 정렬이 수행됩니다. 모든 행은 구조를 유지하면서 포지션을 변경해야 합니다.
여기서 행 자체는 다른 유형의 데이터를 포함하는 바인딩된 구조입니다. 이러한 문제를 해결하려면 선택한 배열의 데이터를 정렬하고 초기 인덱스의 구조를 저장해야 합니다. 이런 식으로 셀이 포함된 행을 알면 전체 행을 표시할 수 있습니다. 따라서 2차원 배열을 정렬할 때 데이터의 구조를 변경하지 않고 정렬된 배열의 인덱스 배열을 가져와야 합니다.
예:
before sorting by the 2-nd column 4 2 3 1 5 3 3 3 6 after sorting 1 5 3 3 3 6 4 2 3 Initial array looks as following: a[0][0]= 4; a[0][1]= 2; a[0][2]= 3; a[1][0]= 1; a[1][1]= 5; a[1][2]= 3; a[2][0]= 3; a[2][1]= 3; a[2][2]= 6; And the array of indexes of sorting by the 2-nd column looks as: r[0]=1; r[1]=2; r[2]=0; Sorted values are returned according to the following scheme: a[r[0]][0]-> 1; a[r[0]][1]-> 5; a[r[0]][2]-> 3; a[r[1]][0]-> 3; a[r[1]][1]-> 3; a[r[1]][2]-> 6; a[r[2]][0]-> 4; a[r[2]][1]-> 2; a[r[2]][2]-> 3;
따라서 기호, 포지션 오픈 날짜, 이익 등으로 정보를 정렬할 수 있습니다.
많은 정렬 알고리즘이 이미 개발되었습니다. 이 개발에 가장 적합한 변형은 안정된 정렬 알고리즘입니다.
표준 클래스에서 사용하는 Quick Sorting 알고리즘은 불안정한 정렬 알고리즘을 말합니다. 그게 바로 이것이 고전적인 구현에서 우리에게 적합하지 않은 이유입니다. 그러나 빠른 정렬을 안정적인 형태로 가져온 후에도(데이터 복사 및 인덱스 배열의 추가 정렬) 빠른 정렬이 버블 정렬(가장 빠른 안정적인 정렬 알고리즘 중 하나)보다 빠른 것처럼 보입니다. 알고리즘은 매우 빠르지만 반복 사용합니다.
이것이 내가 문자열 유형의 배열로 작업할 때 칵테일 정렬을 사용하는 이유입니다(훨씬 더 많은 스택 메모리가 필요함).
5. 2차원 배열의 준비
그리고 제가 논의하고 싶은 마지막 질문은 동적 2차원 배열의 준비입니다. 이러한 배열의 준비 같은 경우 1차원 배열에 대한 클래스로 래핑을 만들고 포인터 배열을 통해 개체 배열을 호출하는 것으로 충분합니다. 즉, 배열을 생성하고 배열해야 합니다.
class CarrayInt { public: ~CarrayInt(){}; int array[]; }; //+------------------------------------------------------------------+ class CTwoarrayInt { public: ~CTwoarrayInt(){}; CarrayInt array[]; }; //+------------------------------------------------------------------+ void OnStart() { CTwoarrayInt two; two.array[0].array[0]; }
6. 프로그램의 구조
CTable 클래스의 코드는 C++ 템플릿의 대안으로 가짜 템플릿 사용 문서에 설명된 템플릿을 사용하여 작성되었습니다. 템플릿을 사용했기 때문에 이렇게 큰 코드를 빠르게 작성할 수 있었습니다. 그렇기 때문에 전체 코드를 자세히 설명하지 않겠습니다. 또한 알고리즘 코드의 대부분은 표준 클래스를 수정한 것입니다.
클래스의 일반적인 구조와 몇 가지 중요한 사항을 명확히 하는 흥미로운 기능 몇 가지를 보여드리겠습니다.

블록다이어그램의 오른쪽 부분은 주로 파생 클래스 CLONGArray, CDOUBLEArray, CDATETIMEArray 및 CSTRINGArray에 있는 재정의된 메소드가 차지합니다. 각각(비공개 섹션에 있음)에는 해당 유형의 배열이 포함됩니다. 이러한 정확한 배열은 정보에 액세스하는 모든 트릭에 사용됩니다. 위에 나열된 클래스의 메소드 이름은 공용 메소드와 동일합니다.
기본 클래스 CBASEArray는 가상 메소드 재정의로 채워지며 CTable 클래스의 개인 섹션에서 개체 CBASEArray의 동적 배열 선언에만 필요합니다. 포인터 배열 CBASEArray는 동적 개체의 동적 배열로 선언됩니다. 객체의 최종 구성과 필요한 인스턴스의 선택은 FirstResize() 함수에서 수행됩니다. 본문에서 FirstResize()를 호출하기 때문에 CopyTable() 함수에서도 수행할 수 있습니다.
CTable 클래스는 또한 데이터 처리 방법(CTable 클래스의 인스턴스에 위치)과 Cint2D 클래스의 인덱스를 제어하는 객체의 조정을 수행합니다. 전체 조정은 재정의된 공개 메소드로 래핑됩니다.
CTable 클래스에서 자주 반복되는 재정의 부분은 매우 긴 줄이 생성되지 않도록 정의로 대체됩니다.
#define _CHECK0_ Print(__FUNCTION__+"("+(string)i+","+(string)j+")");return; #define _CHECK_ Print(__FUNCTION__+"("+(string)i+")");return(-1); #define _FIRST_ first_data[aic[i]] #define _PARAM0_ array_index.Ind(j),value #define _PARAM1_ array_index.Ind(j),recipient #define _PARAM2_ element,beg,end,array_index,mode
따라서 더 간결한 형태의 일부는 다음과 같습니다.
int QuickSearch(int i,long element,int beg,int end,bool mode=false){if(!check_type(i,TYPE_LONG)){_CHECK_}return(_FIRST_.QuickSearch(_PARAM2_));};
전처리기가 다음 줄로 대체됩니다.
int QuickSearch(int i,long element,int beg,int end,bool mode=false){if(!check_type(i,TYPE_LONG)){Print(__FUNCTION__+"("+(string)i+")");return(-1);} return(first_data[aic[i]].QuickSearch(element,beg,end,array_index,mode));};
위의 예에서 데이터 처리 메소드가 어떻게 호출되는지 명확합니다('return' 내부 부분).
저는 이미 CTable 클래스가 처리하는 동안 데이터의 물리적 이동을 수행하지 않는다고 언급했습니다. 인덱스 개체의 값만 변경합니다. 데이터 처리 방법에 인덱스 개체와 상호 작용할 수 있도록 하기 위해 모든 처리 기능에 array_index 매개 변수로 전달됩니다.
array_index 객체는 두 번째 차원 요소의 위치 관계를 저장합니다. 첫 번째 차원의 인덱싱은 CTable 클래스의 개인 영역에 선언된 aic[] 동적 배열의 책임입니다. 열의 포지션을 변경할 수 있는 가능성을 제공합니다(물론 물리적으로가 아니라 인덱스를 통해).
예를 들어 Change() 연산을 수행할 때 열의 인덱스를 포함하는 두 개의 메모리 셀만 포지션을 변경합니다. 육안으로 보기에는 두 개의 열이 움직이는 것처럼 보입니다. CTable 클래스의 기능은 문서에 꽤 잘 설명되어 있습니다(어딘가는 한 줄씩).
이제 CBASEArray에서 상속받은 클래스의 기능을 살펴봅시다. 실제로 이러한 클래스의 알고리즘은 표준 클래스에서 가져온 알고리즘입니다. 저는 그들에 대한 개념을 갖기 위해 표준 이름을 사용했습니다. 수정은 값이 직접 반환되는 표준 알고리즘과 구별되는 인덱스 배열을 사용하여 값을 간접적으로 반환하는 것으로 구성됩니다.
먼저 Quick sorting이 수정되었습니다. 알고리즘은 불안정한 범주에 속하므로 정렬을 시작하기 전에 알고리즘에 전달할 데이터 복사본을 만들어야 합니다. 데이터 변경 패턴에 따른 인덱스 객체의 동기 수정도 추가했습니다.
void CLONGArray::QuickSort(long &m_data[],Cint2D &index,int beg,int end,bool mode=0)
다음은 코드 정렬의 일부입니다.
... if(i<=j) { t=m_data[i]; it=index.Ind(i); m_data[i++]=m_data[j]; index.Ind(i-1,index.Ind(j)); m_data[j]=t; index.Ind(j,it); if(j==0) break; else j--; } ...
원래 알고리즘에는 Cint2D 클래스의 인스턴스가 없습니다. 다른 표준 알고리즘에도 유사한 변경 사항이 적용됩니다. 모든 코드의 템플릿을 설명하지는 않겠습니다. 코드를 개선하고 싶은 사람은 실제 유형을 템플릿으로 대체하여 실제 코드에서 템플릿을 만들 수 있습니다.
템플릿 작성을 위해 long 유형으로 작동하는 클래스의 코드를 사용했습니다. 이러한 경제 알고리즘에서 개발자는 int를 사용할 가능성이 있는 경우 불필요한 정수 사용을 피하려고 합니다. 그렇기 때문에 long 유형의 변수가 재정의된 매개변수일 가능성이 가장 높습니다. 템플릿 사용 시 '템플릿'으로 대체됩니다.
결론
이 글이 객체 지향 접근 방식을 공부하는 초보 프로그래머에게 좋은 도움이 되고 정보 작업을 더 쉽게 할 수 있기를 바랍니다. CTable 클래스는 많은 복잡한 응용 프로그램의 기본 클래스가 될 수 있습니다. 글에 설명된 방법은 데이터 작업에 대한 일반적인 접근 방식을 구현하기 때문에 엄청난 종류의 솔루션 개발의 기초가 될 수 있습니다.
게다가 이 글은 MQL5를 남용하는 것은 근거가 없음을 증명합니다. Variant 유형을 원하십니까? 여기에서는 MQL5를 통해 구현됩니다. 그러면 표준을 변경하고 언어의 보안을 약화시킬 필요가 없습니다. 행운을 빕니다!
MetaQuotes 소프트웨어 사를 통해 러시아어가 번역됨.
원본 기고글: https://www.mql5.com/ru/articles/228
 MQL5 마법사: 위험 및 자금 관리 모듈을 만드는 방법
MQL5 마법사: 위험 및 자금 관리 모듈을 만드는 방법
 MQL5 마법사: 신호 거래 모듈을 만드는 방법
MQL5 마법사: 신호 거래 모듈을 만드는 방법
 MQL5 마법사: 미결 포지션의 후행 모듈을 만드는 방법
MQL5 마법사: 미결 포지션의 후행 모듈을 만드는 방법
 차트 분석에 대한 계량학적 접근
차트 분석에 대한 계량학적 접근
니콜라이, 질문이 있습니다.
MT5에서 Excel로 이 형식으로 테이블을 작성할 수 있나요?
색상으로 강조 표시된 두 개의 매크로 열 이름("절대 데이터" 및 "상대 데이터")이 궁금합니다. 각각 3개의 셀을 결합합니다.
엑셀 셀 서식 지정과 관련하여 MQL5에서 많은 것을 원할 수도 있습니다. 하지만 만약 :-)))
"3 개의 셀 결합"이라는 단어에 어떤 물리적 의미를 부여합니까?
원칙적으로 상위 2 행이 없으면 데이터 유형이 열로 요약되므로 한 열에서 문자열과 이중을 압축하는 것은 작동하지 않지만 인쇄 할 때 수행 할 수 있습니다. 또는 테이블과 별도로 형식이 지정된 대문자 문자열을 포함하도록 클래스를 구체화할 수도 있습니다.
가장 쉬운 방법은 두 개의 테이블을 만들어 병합하는 것입니다.
"세포 3개 결합"이라는 단어에 어떤 물리적 의미를 부여하시나요?
이것이 우리가 지금 가지고있는 것입니다:
이미 가져왔으면 하는 것 ....
새 문서 MQL5의 전자 테이블이 게시되었습니다:
작성자: Николай