トレーディングにおける機械学習:理論、モデル、実践、アルゴトレーディング - ページ 2476 1...246924702471247224732474247524762477247824792480248124822483...3399 新しいコメント Evgeniy Ilin 2021.10.27 16:10 #24751 JeeyCi#: 同じ開発者の責任 です。私は、カオスを近似/補間する際に、本/ブログ/論文からの金融モデル(および統計的に処理された分布)を金融分析に含めることは信じていませんし、理由もないと思って います...。をさらに外挿し、出力を そう、それが基本なのです。人々は、問題への言及なしに公式やモデルを作り、普遍的なものを作ろうとし、それがすべてに適用されると素朴に考えてきたのです。なぜかみんな、ラプラス、フーリエ、テイラー、正規分布といった言葉を並べて、それを全部システムに縫い込めば、なぜかうまくいくに違いないと思いたがるのです。私は得意で、膝の上でツィオルコフスキーの公式を導き出していたのですが、誰もその方法を理解してくれず...。こんな経験をした、私。Expert Advisorで連立方程式を使って次のローソク足を予測しようと、巨大な行列を作り、行列式などを計算し、誰も持っていない、とてもクールだと思ったのですが、テストしてみると、まったくのたわごとであることが判明しました。私の予想では、次の瞬間にはマーケットの第一人者になるはずでしたが、それはおそらく5年前で、私は大学を卒業したばかりでした(ちなみに私は数学と物理にとても詳しいのです)。..まず、「何を基準にするのか」ということを自問自答し、それを人間の言葉でシンプルに答え、それを数学的な基準に置き換えていくのが正しい方法です。そのためには、元のモデルやその作り方を考える必要はないことは分かっています。しかし、端から端まで行って、モデルが正しい数値を出せば、その後はそれを理解しようとすることができます。しかし、すべてはAIに帰結し、システムが賢くなればなるほど、数学に悩まされます。私はその壁を乗り越え、仕事ではできる限り機械に任せるようにしています。 Evgeniy Ilin 2021.10.27 16:30 #24752 JeeyCi#: さっきの答えは...前回の投稿は急ぎすぎたかもしれません...。少なくとも、速度と加速度のある運動を記述する関数として、放物線から始めるべきでしょう。(この種のグラフやオプションのギリシャ語(デルタとガンマ)もどこかで見たことがあるが、思い出せないし、見つからない--必要ない--時間分析が必要だ--垂直方向ではなく、水平方向だ)。 私は、無限のデータを有限の数に圧縮できること、グラフ上に無限の点があること、たった3つの係数の式に還元できることを例として、パラボラをあげただけです。というような関数を取ることができるんですね。 a[1]*x^0+a[2]*x^1+ ....+ A [N]*X^N, これは一般にテイラー級数(関数級数)であるが, A[i] > 0 がすべての i = 1...N に対してあることを除けば, 一般に一次微分の一定の成長を与える, はっきり言って しまえば: 理想的には直線がベストですが、上で説明したような冪乗関数のファミリーを使えば、偏差を推定することができます。最終的な導関数が開始時の導関数より何倍大きくなってもよいかを指定するだけです.最終的なグラフをこのような関数に近づけて近似し、その関数に対する実際のグラフの偏差を調べることができる。 私は直線だけを使っているが、後で機能を拡張し、効率化を図り、その結果、スマートアプローチの場合には計算機設備の必要性を減らすことができるかもしれない。 Rorschach 2021.10.27 21:12 #24753 エフゲニー・イリン#: は、適切なアプローチで計算能力の必要性を低減します。 数値計算のライブラリがあれば、GPUの性能も上がるかもしれません。 Evgeniy Ilin 2021.10.28 07:41 #24754 ロールシャッハ#: 数値計算のためのライブラリがあれば、GPUの性能も上がるかもしれません。 アイデアは悪くないが、限り、私はvidyuhaのために非常に奇妙な方法でコードを記述する必要がある知っているように、すべてが少し異なって動作するように、既製のライブラリが動作する可能性は低く、ほとんどの場合、自分で記述する必要があります。ちなみに、いつか手に入れることができるかもしれません。 JeeyCi 2021.10.28 08:50 #24755 だから、いつものように、すべての差別化はMNCに帰結する......。と、このLOCから導き出されるはずのターゲット機能への未来予測全体...写真ありがとうございます...。 需給の見積もり方はとりあえず考えてみます(私にとっては未発見の規則性よりも実際の流動性の方が重要で、統計的確率を求める機械にはまだ任せられません).........。 しかし、私は、開発者の責任として、自分にとって重要な機能を選択することを忘れないようにします ...そして,入力の正規化,確率の計算,(データが多い場合は)クラスタリング,勾配の構築,(OLSを使って)すべての谷の発見,すべての谷の正規化,共通の関数への要約,というパターンです.青くなるまで」と言ったが、マシンアシストの方が早い......。 Evgeniy Ilin#: 理想的には直線がベストですが、上で説明したようなべき乗関数のファミリーを使えば、外れ値を推定することができます。最終的な導関数が開始時の導関数より何倍大きくなるかを指定するだけです. べき乗関数の族は対数正規分布になるのでしょうか、それとも反映されるのでしょうか...愚問でしたらすみません という質問を削除した場合、答えは「ノー 」でしょう。 Evgeniy Ilin 2021.10.28 10:10 #24756 実は、あまり理解できていないんです。言い換えれば、 1)対象機能は何か、なぜそれが必要なのか? 2) 対数正規分布はなぜ必要なのですか、また、なぜ全く必要ないと思うのですか? 3) 対数正規分布であっても、関数の「ファミリー」が1つの原型関数に なることがよく理解できない。 4) 対数正規分布は何の分布か?分布の中の確率変数は何でしょうか? 5)MNCとは? 簡単な言葉で質問して、簡単な答えをもらうようにする。) JeeyCi 2021.10.28 10:31 #24757 Evgeniy Ilin#: 実は、あまり理解できていないんです。言い換えれば、 1)対象機能は何か、なぜそれが必要なのか?2) 対数正規分布はなぜ必要なのですか、また、なぜ全く必要ないと思うのですか?3) 対数正規分布であっても、関数の「ファミリー」が1つの原型関数に なることがよく理解できない。4) 対数正規分布は何の分布か?分布の中の確率変数は何でしょうか?5)MNCとは?簡単な言葉で質問して、簡単な答えを得ることができます。) 1) 出力は予測のための関数(この文脈では、ニューラルネットワークのレベルではありません) 2) 非対称性があるため(%rate*timeと買い手売り手自身によってもたらされる)。 3) ...同じ型なのだから、原型が違うはずはないだろう...おいおい、動力分布は逆依存の指標なんだな 4) 価格は確率変数である 5) 最小二乗法 もともと(私の中では)、Range(と時間軸)で「累積Debit-Credit不均衡」(これも表現が悪いですが)を判断する問題だったのですが、ここでは、学習せずに、とりあえずカウントするしかないですね......。でも、モデリングについて思い出させてくれてありがとう。 私は物理学者ではなく、生態学者です。私たちにとってはその方が簡単です(関数やモデリングはなく、分布、事実、確率を使います。リスクを評価するのは時には良いことですが、生態系は予測 しません。 mytarmailS 2021.10.28 10:33 #24758 Evgeniy Ilin#: 実は、あまり理解できていないんです。言い換えれば、 1)対象機能は何か、なぜそれが必要なのか?2) 対数正規分布はなぜ必要なのですか、また、なぜ全く必要ないと思うのですか?3) 対数正規分布であっても、関数の「ファミリー」が1つの原型関数に なることがよく理解できない。4) 対数正規分布は何の分布か?分布の中の確率変数は何でしょうか?5)MNCとは?簡単な言葉で質問してみれば、簡単な答えが返ってくるはずです(笑)。 1) ターゲットまたはフィットネス関数は、アルゴリズムの性能の定量的な尺度である。 例えば回帰学習を行う場合、ターゲット関数はアルゴリズムの誤差を計算するための関数/式であり、遺伝的アルゴリズムやその他のアルゴリズムでも同じことで、ほとんどすべてのMOアルゴリズムを最小化/最大化することができます。 https://ru.wikipedia.org/wiki/%D0%A6%D0%B5%D0%BB%D0%B5%D0%B2%D0%B0%D1%8F_%D1%84%D1%83%D0%BD%D0%BA%D1%86%D0%B8%D1%8F 5) 最小二乗法 Aleksey Nikolayev 2021.10.28 10:45 #24759 また、特徴を出力に変換する機能であるが、「目標機能」とも訳すことができる「ターゲット機能」がある。 JeeyCi 2021.10.28 13:26 #24760 -ただ、この確率を後で(役に立つ形で)どうにかできないかと考えただけです - どのようなTSでも、どのような指標でも(開発者の選択でどのような期間でもトレーニングすることで)最適化することができるのです。- 自分のインデューで最小限の誤差でエントリーできる条件を得るために... (生態学者として環境や条件を見極めて考えて いた確率とは違うものですが)。 1...246924702471247224732474247524762477247824792480248124822483...3399 新しいコメント 理由: キャンセル 取引の機会を逃しています。 無料取引アプリ 8千を超えるシグナルをコピー 金融ニュースで金融マーケットを探索 新規登録 ログイン スペースを含まないラテン文字 このメールにパスワードが送信されます エラーが発生しました Googleでログイン WebサイトポリシーおよびMQL5.COM利用規約に同意します。 新規登録 MQL5.com WebサイトへのログインにCookieの使用を許可します。 ログインするには、ブラウザで必要な設定を有効にしてください。 ログイン/パスワードをお忘れですか? Googleでログイン
同じ開発者の責任 です。私は、カオスを近似/補間する際に、本/ブログ/論文からの金融モデル(および統計的に処理された分布)を金融分析に含めることは信じていませんし、理由もないと思って います...。をさらに外挿し、出力を
そう、それが基本なのです。人々は、問題への言及なしに公式やモデルを作り、普遍的なものを作ろうとし、それがすべてに適用されると素朴に考えてきたのです。なぜかみんな、ラプラス、フーリエ、テイラー、正規分布といった言葉を並べて、それを全部システムに縫い込めば、なぜかうまくいくに違いないと思いたがるのです。私は得意で、膝の上でツィオルコフスキーの公式を導き出していたのですが、誰もその方法を理解してくれず...。こんな経験をした、私。Expert Advisorで連立方程式を使って次のローソク足を予測しようと、巨大な行列を作り、行列式などを計算し、誰も持っていない、とてもクールだと思ったのですが、テストしてみると、まったくのたわごとであることが判明しました。私の予想では、次の瞬間にはマーケットの第一人者になるはずでしたが、それはおそらく5年前で、私は大学を卒業したばかりでした(ちなみに私は数学と物理にとても詳しいのです)。..まず、「何を基準にするのか」ということを自問自答し、それを人間の言葉でシンプルに答え、それを数学的な基準に置き換えていくのが正しい方法です。そのためには、元のモデルやその作り方を考える必要はないことは分かっています。しかし、端から端まで行って、モデルが正しい数値を出せば、その後はそれを理解しようとすることができます。しかし、すべてはAIに帰結し、システムが賢くなればなるほど、数学に悩まされます。私はその壁を乗り越え、仕事ではできる限り機械に任せるようにしています。
さっきの答えは...前回の投稿は急ぎすぎたかもしれません...。少なくとも、速度と加速度のある運動を記述する関数として、放物線から始めるべきでしょう。(この種のグラフやオプションのギリシャ語(デルタとガンマ)もどこかで見たことがあるが、思い出せないし、見つからない--必要ない--時間分析が必要だ--垂直方向ではなく、水平方向だ)。
私は、無限のデータを有限の数に圧縮できること、グラフ上に無限の点があること、たった3つの係数の式に還元できることを例として、パラボラをあげただけです。というような関数を取ることができるんですね。
a[1]*x^0+a[2]*x^1+ ....+ A [N]*X^N, これは一般にテイラー級数(関数級数)であるが, A[i] > 0 がすべての i = 1...N に対してあることを除けば, 一般に一次微分の一定の成長を与える, はっきり言って しまえば:
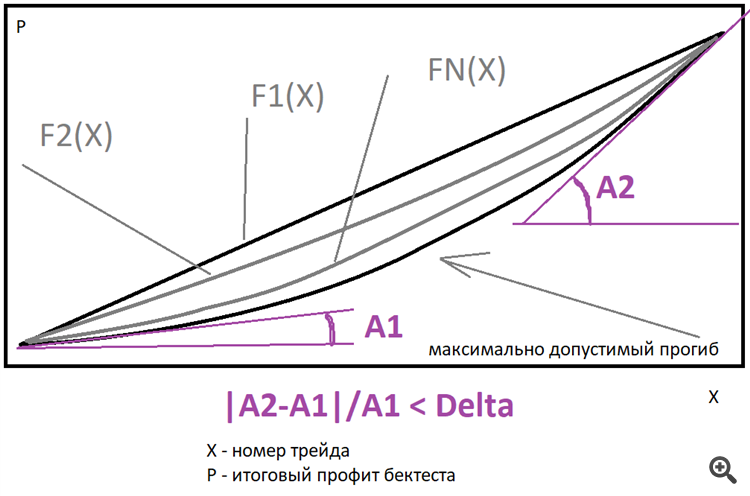
理想的には直線がベストですが、上で説明したような冪乗関数のファミリーを使えば、偏差を推定することができます。最終的な導関数が開始時の導関数より何倍大きくなってもよいかを指定するだけです.最終的なグラフをこのような関数に近づけて近似し、その関数に対する実際のグラフの偏差を調べることができる。 私は直線だけを使っているが、後で機能を拡張し、効率化を図り、その結果、スマートアプローチの場合には計算機設備の必要性を減らすことができるかもしれない。
エフゲニー・イリン#:
は、適切なアプローチで計算能力の必要性を低減します。
数値計算のライブラリがあれば、GPUの性能も上がるかもしれません。
数値計算のためのライブラリがあれば、GPUの性能も上がるかもしれません。
アイデアは悪くないが、限り、私はvidyuhaのために非常に奇妙な方法でコードを記述する必要がある知っているように、すべてが少し異なって動作するように、既製のライブラリが動作する可能性は低く、ほとんどの場合、自分で記述する必要があります。ちなみに、いつか手に入れることができるかもしれません。
だから、いつものように、すべての差別化はMNCに帰結する......。と、このLOCから導き出されるはずのターゲット機能への未来予測全体...写真ありがとうございます...。
需給の見積もり方はとりあえず考えてみます(私にとっては未発見の規則性よりも実際の流動性の方が重要で、統計的確率を求める機械にはまだ任せられません).........。
しかし、私は、開発者の責任として、自分にとって重要な機能を選択することを忘れないようにします ...そして,入力の正規化,確率の計算,(データが多い場合は)クラスタリング,勾配の構築,(OLSを使って)すべての谷の発見,すべての谷の正規化,共通の関数への要約,というパターンです.青くなるまで」と言ったが、マシンアシストの方が早い......。
理想的には直線がベストですが、上で説明したようなべき乗関数のファミリーを使えば、外れ値を推定することができます。最終的な導関数が開始時の導関数より何倍大きくなるかを指定するだけです.
べき乗関数の族は対数正規分布になるのでしょうか、それとも反映されるのでしょうか...愚問でしたらすみません
という質問を削除した場合、答えは「ノー 」でしょう。
実は、あまり理解できていないんです。言い換えれば、
1)対象機能は何か、なぜそれが必要なのか?
2) 対数正規分布はなぜ必要なのですか、また、なぜ全く必要ないと思うのですか?
3) 対数正規分布であっても、関数の「ファミリー」が1つの原型関数に なることがよく理解できない。
4) 対数正規分布は何の分布か?分布の中の確率変数は何でしょうか?
5)MNCとは?
簡単な言葉で質問して、簡単な答えをもらうようにする。)
実は、あまり理解できていないんです。言い換えれば、
1)対象機能は何か、なぜそれが必要なのか?
2) 対数正規分布はなぜ必要なのですか、また、なぜ全く必要ないと思うのですか?
3) 対数正規分布であっても、関数の「ファミリー」が1つの原型関数に なることがよく理解できない。
4) 対数正規分布は何の分布か?分布の中の確率変数は何でしょうか?
5)MNCとは?
簡単な言葉で質問して、簡単な答えを得ることができます。)
1) 出力は予測のための関数(この文脈では、ニューラルネットワークのレベルではありません)
2) 非対称性があるため(%rate*timeと買い手売り手自身によってもたらされる)。
3) ...同じ型なのだから、原型が違うはずはないだろう...おいおい、動力分布は逆依存の指標なんだな
4) 価格は確率変数である
5) 最小二乗法
もともと(私の中では)、Range(と時間軸)で「累積Debit-Credit不均衡」(これも表現が悪いですが)を判断する問題だったのですが、ここでは、学習せずに、とりあえずカウントするしかないですね......。でも、モデリングについて思い出させてくれてありがとう。 私は物理学者ではなく、生態学者です。私たちにとってはその方が簡単です(関数やモデリングはなく、分布、事実、確率を使います。リスクを評価するのは時には良いことですが、生態系は予測 しません。
実は、あまり理解できていないんです。言い換えれば、
1)対象機能は何か、なぜそれが必要なのか?
2) 対数正規分布はなぜ必要なのですか、また、なぜ全く必要ないと思うのですか?
3) 対数正規分布であっても、関数の「ファミリー」が1つの原型関数に なることがよく理解できない。
4) 対数正規分布は何の分布か?分布の中の確率変数は何でしょうか?
5)MNCとは?
簡単な言葉で質問してみれば、簡単な答えが返ってくるはずです(笑)。
1) ターゲットまたはフィットネス関数は、アルゴリズムの性能の定量的な尺度である。
例えば回帰学習を行う場合、ターゲット関数はアルゴリズムの誤差を計算するための関数/式であり、遺伝的アルゴリズムやその他のアルゴリズムでも同じことで、ほとんどすべてのMOアルゴリズムを最小化/最大化することができます。
https://ru.wikipedia.org/wiki/%D0%A6%D0%B5%D0%BB%D0%B5%D0%B2%D0%B0%D1%8F_%D1%84%D1%83%D0%BD%D0%BA%D1%86%D0%B8%D1%8F
5) 最小二乗法
- どのようなTSでも、どのような指標でも(開発者の選択でどのような期間でもトレーニングすることで)最適化することができるのです。- 自分のインデューで最小限の誤差でエントリーできる条件を得るために...
(生態学者として環境や条件を見極めて考えて いた確率とは違うものですが)。