
Redes neuronales: así de sencillo (Parte 16): Uso práctico de la clusterización

Contenido
- Introducción
- 1. Aspectos teóricos del uso de los resultados de la clusterización
- 2. Usando la clusterización como una solución independiente
- 3. Usando los resultados de la clusterización como entrada
- Conclusión
- Enlaces
- Programas utilizados en el artículo.
Introducción
Los dos últimos artículos los hemos dedicado a la clusterización de datos. Pero nuestra tarea principal es aprender a utilizar todos los métodos analizados para resolver problemas prácticos específicos. En particular, nos referimos a su aplicación en el trading. Comenzando por el análisis de los métodos de aprendizaje no supervisado, hablamos de la posibilidad de usar los resultados obtenidos de forma independiente, y también como datos de entrada para otros modelos. En este artículo, le proponemos analizar los posibles usos de la clusterización de resultados.
1. Aspectos teóricos del uso de los resultados de la clusterización
Antes de pasar a la implementación práctica de ejemplos sobre el uso de los resultados de la clusterización, vamos a hablar un poco acerca de los aspectos teóricos de estos enfoques.
La primera opción a la hora de usar los resultados de la clusterización de datos es tratar de aprovecharlos al máximo para un uso práctico sin fondos adicionales. Es decir, utilizar los resultados de la clusterización como tal para tomar sus decisiones comerciales. Y aquí debemos recordar de inmediato que los métodos de aprendizaje no supervisados no se utilizan para resolver problemas de regresión. Al mismo tiempo, pronosticar el movimiento de precios más cercano constituye precisamente la tarea de la regresión. A primera vista, vemos un cierto conflicto,
pero ¿y si variamos un poco el enfoque? Teniendo en cuenta los aspectos teóricos de la clusterización, ya hemos comparado esta con la definición de patrones gráficos. Y nosotros, como en el caso de los patrones gráficos, podemos recopilar las estadísticas sobre el comportamiento del precio después de la aparición de un elemento de un grupo particular en el gráfico. Sí, eso no nos proporcionará una relación causal, pero esta no se encuentra presente en ningún modelo matemático construido con el uso de redes neuronales. Solo construimos modelos probabilísticos sin profundizar en las relaciones causa-efecto.
Para recopilar estadísticas, necesitamos un modelo de clusterización ya entrenado y datos etiquetados. Como nuestro modelo de clusterización de datos ya ha sido entrenado, la muestra con datos etiquetados podrá ser mucho más pequeña que la muestra de entrenamiento. No obstante, debería resultar suficiente para seguir siendo representativa.
A primera vista, este enfoque se parecerá a un entrenamiento supervisado, pero hay 2 diferencias esenciales:
- El tamaño de la muestra etiquetada puede ser más pequeño, ya que no existe riesgo de sobreajuste.
- Al realizar el aprendizaje supervisado, usamos un proceso iterativo con la correspondiente selección de coeficientes de peso óptimos. Y esto requiere varias épocas de entrenamiento con un gran gasto de recursos y tiempo. Para recopilar las estadísticas, la primera pasada será suficiente para nosotros. En este caso, no se realizarán correcciones al modelo.
Esperamos que la idea resulte clara: nos familiarizaremos con la implementación de este modelo un poco más tarde.
Como desventaja de esta opción, podríamos mencionar que se ignora la distancia hasta el centro del clúster. En otras palabras, tendremos el mismo resultado para los elementos cercanos al centro del clúster (por así decirlo, un patrón ideal) y los elementos en los bordes del mismo. Podemos intentar aumentar la cantidad de clústeres para reducir la distancia máxima de los elementos respecto al centro. No obstante, la efectividad de este enfoque resultará mínima, por supuesto, si hemos elegido correctamente el número de clústeres según el gráfico de la función de pérdida.
Podemos intentar resolver este problema utilizando la segunda opción de uso de los resultados de la clusterización como datos de origen del otro modelo. Sin embargo, aquí debemos entender que al transmitir el número de clúster en forma de número o vector a la entrada del segundo modelo, obtendremos un máximo de datos comparables a los resultados del método estadístico considerado anteriormente. Sin embargo, tampoco queremos incurrir en costes adicionales para obtener el mismo resultado.
Vamos a transmitir a la entrada del modelo no el número del clúster, sino el vector con la distancia a los centros de los clústeres. Al hacerlo, debemos recordar que a las redes neuronales les encantan los datos normalizados. Así que normalizamos los datos del vector de distancia con la función Softmax.
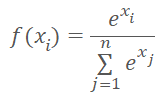
No olvidemos que Softmax se basa en el exponente, cuyo gráfico se muestra en la siguiente figura.

Ahora, vamos a pensar qué vector obtendremos como resultado de la normalización de las distancias a los centros de los clústeres con la función Softmax. Resulta bastante obvio que todas las distancias son positivas. Cuanto mayor sea la distancia, mayor resultará el exponente y más cambiará el valor de la función al darse el mismo cambio en su argumento. Por lo tanto, las distancias máximas recibirán más peso por nuestra parte. Y a medida que disminuya la distancia, disminuirán las diferencias entre los valores. Así, como resultado de la simple normalización de las distancias, obtendremos un vector que nos describirá a qué clústeres no perteneceel elemento, complicando así la selección del clúster al que pertenece el elemento. Y nos gustaría lograr la situación opuesta.
Podría parecer que para corregir la situación, simplemente tendríamos que cambiar el signo del valor de la distancia. Pero en la zona de argumentos negativos, el valor de la función exponencial se aproxima a "0". Y a medida que el argumento disminuye, la desviación de los valores de la función también tenderá a "0".
Como solución a los problemas anteriores, primero podemos normalizar las distancias en el intervalo de 0 a 1. Y luego aplicar la función Softmax a "1—X".
La elección del modelo en el que se introducen los valores normalizados dependerá del problema a resolver y se encuentra fuera del alcance de este artículo.
Y ahora que hemos analizado los principales enfoques teóricos sobre los usos de la clusterización de resultados, podemos pasar a la parte práctica de nuestro artículo.
2. Usando la clusterización como una solución independiente
Comenzaremos a trabajar en la implementación del método estadístico escribiendo el código de otro kernel KmeansStatisticen el programa OpenCL (archivo "unsupervised.cl"), que calculará las estadísticas de procesamiento de las señales para cada clúster. La organización de este proceso recuerda al entrenamiento supervisado. En realidad, necesitamos disponer de datos etiquetados, pero existe una diferencia fundamental entre este proceso y el método de propagación hacia atrás usado en anteriores artículos. Si antes optimizábamos la función del modelo para obtener resultados lo más parecidos posibles a los de referencia, ahora no cambiaremos el modelo de ninguna forma. Por el contrario, recopilaremos las estadísticas de la reacción del sistema ante la aparición de un patrón particular.
En los parámetros del kernel, transmitiremos los punteros a los 3 búferes de datos y el número total de elementos en la muestra de entrenamiento. Pero en los parámetros de este kernel, no trasmitiremos la muestra de entrenamiento. Para realizar esta funcionalidad, no necesitaremos conocer el contenido del vector de descripción del estado del sistema. En esta etapa, bastará con que sepamos a qué grupo pertenece el estado analizado del sistema. Por lo tanto, en lugar de la muestra de entrenamiento en los parámetros del kernel, trasmitiremos el puntero al vector clusters que contiene los identificadores de clúster para cada estado del sistema de la muestra de entrenamiento.
En el segundo búfer de datos originales target, se presentará un tensor que describirá la reacción del sistema después de que aparezca un patrón particular. Este tensor tendrá 3 banderas lógicas para describir la señal después de que aparezca el patrón: compra, venta, no definida. El uso de banderas hace que resulte fácil e intuitivo calcular las estadísticas de la señal, pero al mismo tiempo, limita la variabilidad de las posibles señales. Por ello, el uso de dicho método deberá cumplir con los requisitos técnicos de la tarea. En el marco de esta serie de artículos, hemos evaluado todos los algoritmos previamente analizados en cuanto a la posibilidad de determinar la formación de un fractal antes de la formación de la última vela. Como ya sabemos, se necesitan 3 velas para determinar un fractal en un gráfico. Por lo tanto, en la práctica, solo podemos determinarlo después de la formación de la tercera vela del patrón. Queremos encontrar una manera de determinar la formación de un patrón cuando solo se formen 2 velas del patrón futuro. Y, obviamente, con cierto grado de probabilidad. Para resolver este problema, nos contentaremos por completo con el uso de señales objetivo de 3 banderas para cada patrón.
También debemos decir que se pueden usar varias muestras de entrenamiento para recopilar las estadísticas de las señales después de que aparezcan los patrones, y entrenar así el modelo. Por ejemplo, podemos entrenar el modelo en un intervalo histórico lo suficientemente largo como para que el modelo pueda aprender los rasgos y características del estado del sistema analizado tanto como sea posible, marcando los datos y recopilando las estadísticas sobre el comportamiento del sistema después de la aparición de patrones en un periodo histórico más corto. Por supuesto, antes de recopilar las estadísticas, tendremos que realizar la clusterización de los patrones correspondientes. De hecho, para recopilar las estadísticas correctas, los datos deberán ser comparables.
Pero volvamos a nuestro algoritmo. Vamos a iniciar la ejecución del kernel en un espacio de tareas unidimensional. El número de hilos paralelos será igual al número de clústeres creados.
Al inicio del kernel, determinaremos el identificador del hilo actual, que nos indicará el número ordinal del clúster analizado. E inmediatamente, determinaremos el cambio en el tensor de resultados probabilísticos. Vamos a preparar las variables privadas para calcular el número de apariciones de cada señal: buy, sell, skip. Asignaremos el valor inicial "0" a cada variable.
A continuación, organizaremos un ciclo con un número de iteraciones igual al número de elementos de la muestra de entrenamiento. En el cuerpo del ciclo, primero verificaremos si el estado del sistema pertenece al clúster analizado. Y solo cuando coincidan, añadiremos los contenidos del tensor de banderas objetivo a las variables privadas correspondientes.
Entonces, para los valores objetivo, usaremos banderas que solo pueden aceptar "0" o "1". Al hacerlo, usaremos señales mutuamente excluyentes. Esto significará que es posible tener "1" en una sola bandera a la vez para cada estado individual del sistema. Gracias a esta propiedad, hemos podido renunciar a un contador aparte para el número de apariciones del patrón. En cambio, después de salir del ciclo, sumaremos las 3 variables privadas para obtener el número total de apariciones del patrón.
Ahora nos queda trasladar las sumas naturales de las señales al campo de las matemáticas probabilísticas. Para hacer esto, dividiremos el valor de cada variable privada por el número total de apariciones del patrón. Pero aquí debemos considerar algunos matices. Primero, tenemos que eliminar la posibilidad de un error crítico de división por cero. En segundo lugar, necesitaremos probabilidades reales en las que podamos confiar. Después de todo, si, por ejemplo, algún parámetro aparece solo una vez, entonces la probabilidad de tal señal será del 100%. Pero, ¿se puede confiar en tal señal? Obviamente, no. Lo más probable es que su aparición sea accidental. Por ello, para todos los patrones que se hayan encontrado menos de 10 veces, pondremos cero probabilidades para todas las señales.
__kernel void KmeansStatistic(__global double *clusters, __global double *target, __global double *probability, int total_m ) { int c = get_global_id(0); int shift_c = c * 3; double buy = 0; double sell = 0; double skip = 0; for(int i = 0; i < total_m; i++) { if(clusters[i] != c) continue; int shift = i * 3; buy += target[shift]; sell += target[shift + 1]; skip += target[shift + 2]; } //--- int total = buy + sell + skip; if(total < 10) { probability[shift_c] = 0; probability[shift_c + 1] = 0; probability[shift_c + 2] = 0; } else { probability[shift_c] = buy / total; probability[shift_c + 1] = sell / total; probability[shift_c + 2] = skip / total; } }
Después de crear el kernel en el programa OpenCL, procederemos a trabajar del lado del programa principal. Y aquí, en primer lugar, añadiremos las constantes para trabajar con el kernel creado anteriormente. Y, por supuesto, la denominación de las constantes deberá cumplir con nuestra política de nomenclatura.
#define def_k_kmeans_statistic 4 #define def_k_kms_clusters 0 #define def_k_kms_targers 1 #define def_k_kms_probability 2 #define def_k_kms_total_m 3
Después de crear las constantes, iremos a la funciónOpenCLCreate, en la que cambiaremos el número total de kernels utilizados. Y añadiremos la creación de un nuevo kernel.
COpenCLMy *OpenCLCreate(string programm) { ............... //--- if(!result.SetKernelsCount(5)) { delete result; return NULL; } //--- ............... //--- if(!result.KernelCreate(def_k_kmeans_statistic, "KmeansStatistic")) { delete result; return NULL; } //--- return result; }
Ahora deberemos organizar la llamada de este kernel del lado del programa principal.
Para implementar esta funcionalidad, crearemos un método Statistic en nuestra clase CKmeans. En los parámetros, el nuevo método recibirá los punteros a los 2 búferes de datos: la muestra de entrenamiento y los valores de referencia. A pesar de que el conjunto de datos se parece al aprendizaje supervisado, existe una diferencia fundamental entre los enfoques. Si, durante el aprendizaje supervisado, hemos optimizado el modelo para obtener resultados óptimos, y este será un proceso iterativo repetitivo. Ahora solo recopilaremos las estadísticas en una sola pasada.
En el cuerpo del método, comprobaremos la relevancia del puntero para el búfer de valores objetivo y llamaremos al método de clusterización de las muestras de entrenamiento. Querríamos recordarle que en este caso, la muestra de entrenamiento puede diferir del modelo usado en el entrenamiento, pero deberá corresponderse con los valores objetivo.
bool CKmeans::Statistic(CBufferDouble *data, CBufferDouble *targets) { if(CheckPointer(targets) == POINTER_INVALID || !Clustering(data)) return false;
A continuación, inicializaremos el búfer para registrar los valores probabilísticos del comportamiento previsto del sistema. No usamos la expresión "respuesta al patrón" deliberadamente, porque no estamos analizando la relación causa-efecto. Esta puede ser directa o indirecta. O quizá no la haya en absoluto. Solo recopilaremos las estadísticas sobre los datos históricos.
if(CheckPointer(c_aProbability) == POINTER_INVALID) { c_aProbability = new CBufferDouble(); if(CheckPointer(c_aProbability) == POINTER_INVALID) return false; } if(!c_aProbability.BufferInit(3 * m_iClusters, 0)) return false; //--- int total = c_aClasters.Total(); if(!targets.BufferCreate(c_OpenCL) || !c_aProbability.BufferCreate(c_OpenCL)) return false;
Después de crear el búfer, cargaremos los datos necesarios en la memoria del contexto OpenCL y organizaremos el procedimiento para llamar al kernel. Aquí primero transmitiremos los parámetros del kernel, determinaremos la dimensión del espacio de tareas y los desplazamientos en cada dimensión. Después de ello, colocaremos el kernel en la cola de ejecución y leeremos el resultado de las operaciones. Durante la ejecución de las operaciones, controlaremos necesariamente el proceso en cada paso.
if(!c_OpenCL.SetArgumentBuffer(def_k_kmeans_statistic, def_k_kms_probability, c_aProbability.GetIndex())) return false; if(!c_OpenCL.SetArgumentBuffer(def_k_kmeans_statistic, def_k_kms_targers, targets.GetIndex())) return false; if(!c_OpenCL.SetArgumentBuffer(def_k_kmeans_statistic, def_k_kms_clusters, c_aClasters.GetIndex())) return false; if(!c_OpenCL.SetArgument(def_k_kmeans_statistic, def_k_kms_total_m, total)) return false; uint global_work_offset[1] = {0}; uint global_work_size[1]; global_work_size[0] = m_iClusters; if(!c_OpenCL.Execute(def_k_kmeans_statistic, 1, global_work_offset, global_work_size)) return false; if(!c_aProbability.BufferRead()) return false; //--- data.BufferFree(); targets.BufferFree(); //--- return true; }
Tras ejecutar con éxito el kernel en el búferc_aProbability, obtendremos las probabilidades de que suceda este o aquel evento después de la aparición de cada patrón. Solo tendremos que borrar la memoria y finalizar el método.
Pero el procedimiento analizado se puede atribuir al entrenamiento del modelo. Y para su uso práctico, necesitaremos obtener las probabilidades del comportamiento del sistema en tiempo real. Para hacer esto, crearemos otro métodoGetProbability. En los parámetros de este método, solo transmitiremos una muestra para la clusterización, pero es muy importante que antes de llamar al método, la matriz de probabilidad c_aProbability ya se haya formado. Por lo tanto, esto será lo primero que comprobaremos en el cuerpo del método. Luego comenzaremos a realizar la clusterización de los datos obtenidos. Y, como siempre, comprobaremos el resultado de las operaciones.
CBufferDouble *CKmeans::GetProbability(CBufferDouble *data)
{
if(CheckPointer(c_aProbability) == POINTER_INVALID ||
!Clustering(data))
return NULL;
La peculiaridad de este método es que, como resultado de su trabajo, no retornaremos un valor lógico, sino un puntero al búfer de datos. Por consiguiente, el próximo paso consistirá en crear un nuevo búfer para la recopilación de datos.
CBufferDouble *result = new CBufferDouble(); if(CheckPointer(result) == POINTER_INVALID) return result;
Estamos suponiendo que recibiremos en tiempo real los datos probabilísticos para una pequeña cantidad de registros. Y la mayoría de las veces solo para una cosa: el estado actual del sistema. Por ello, no trasladaremos más trabajo al área de cálculos paralelos. Vamos a organizar un ciclo para iterar sobre el búfer de identificadores de los clústeres de los datos estudiados. Y ya en el cuerpo del ciclo, transferiremos las probabilidades de los clústeres correspondientes al búfer de resultados.
int total = c_aClasters.Total(); if(!result.Reserve(total * 3)) { delete result; return result; } for(int i = 0; i < total; i++) { int k = (int)c_aClasters.At(i) * 3; if(!result.Add(c_aProbability.At(k)) || !result.Add(c_aProbability.At(k + 1)) || !result.Add(c_aProbability.At(k + 2)) ) { delete result; return result; } } //--- return result; }
Debemos tener en cuenta que, en el búfer de resultados, las probabilidades se ordenarán en la misma secuencia que los estados del sistema en la muestra analizada. Y si la muestra contenía datos relacionados con un clúster, se repetirán las probabilidades del comportamiento del sistema.
Para poner a prueba el método, hemos creado el asesor experto "kmeans_stat.mq5". Su código se encuentra en el archivo adjunto. Y como podemos entender por el nombre del archivo que contiene, hemos recopilado las estadísticas sobre las probabilidades de aparición de fractales después de cada patrón.
Vamos a realizar el experimento usando el modelo entrenado en el artículo anterior para 500 clústeres. Los resultados se muestran en la siguiente captura de pantalla.

Como muestran los datos presentados, el uso de este enfoque permite predecir la reacción del mercado después que surjan fractales con una probabilidad del 30-45%. Estará de acuerdo con que este es un buen resultado. Además, no hemos utilizado redes neuronales multicapa.
3. Usando los resultados de la clusterización como entrada
Vamos a proceder a la implementación de la segunda variante de uso de los resultados de la clusterización. No olvidemos que en este enfoque planeamos transmitir los resultados de la clusterización a la entrada de otro modelo como datos de entrada. En esencia, puede ser cualquier modelo que elijamos para resolver nuestro problema, incluyendo una red neuronal con uso de algoritmos de aprendizaje supervisado.
Antes, determinamos que al implementar este enfoque, los resultados de la clusterización se presentarán como un vector normalizado de distancias hasta los centros de los clústeres. Y para implementar esta funcionalidad, necesitamos crear otro kernel KmeansSoftMax en el programa OpenCL"unsupervised.cl".
Debemos decir que en el nuevo kernel no recalcularemos las distancias hasta el centro de cada clúster, porque esta función ya se está ejecutando en el kernel KmeansCulcDistance. En el nuevo KmeansSoftMax, solo normalizaremos los datos existentes.
En los parámetros del kernel, transmitiremos los punteros a los 2 búferes de datos y el número total de clústeres utilizados. Entre los búferes de datos, estará el búfer de entrada distance y el búfer de resultados softmax. Ambos búferes tienen la misma dimensionalidad y suponen una representación vectorial de una matriz cuyas filas representan los elementos individuales de la secuencia, mientras que las columnas representan los clústeres.
El kernel se iniciará en un espacio de tareas unidimensional según el número de elementos en la clusterización de la muestra. No escribimos "muestra de entrenamiento" deliberadamente, porque el uso del kernel es posible tanto en el proceso de entrenamiento del segundo modelo como en el proceso de uso comercial. Obviamente, los datos suministrados a la entrada en ambas opciones serán diferentes.
Antes de implementar el código del kernel, recordemos que en su momento cambiamos ligeramente las funciones de normalización y tomó la forma siguiente.
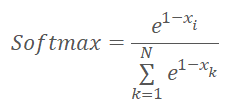
donde x es la distancia hasta el centro del clúster, normalizada en el rango de 0 a 1.
Ahora, vamos a ver la implementación de la fórmula anterior. En el cuerpo del kernel, primero determinaremos el identificador del hilo, que nos indicará el elemento analizado dentro de la secuencia. E inmediatamente determinaremos el desplazamiento en los búferes antes del comienzo del vector analizado. Debemos recordar que los tensores de los datos iniciales y los resultados tienen la misma dimensionalidad. Por consiguiente, el desplazamiento en ambos búferes será el mismo.
Luego, para normalizar las distancias en el rango de 0 a 1, necesitaremos encontrar la desviación máxima desde el centro del clúster. Aquí deberemos recordar que, a la hora de calcular las distancias, usaremos el cuadrado de las desviaciones. Esto quiere decir que todos los valores de nuestro vector de distancias serán positivos, y eso nos facilitará un poco las cosas. Ahora, declararemos la variable privada m para representar la distancia máxima y la inicializaremos con el valor del primer elemento de nuestro vector. A continuación, organizaremos un ciclo que iterará a través de todos los elementos de nuestro vector. En el cuerpo del vector, compararemos el valor de los elementos con el valor guardado y escribiremos el valor máximo en la variable.
Después de determinar el valor máximo, podremos proceder a calcular los valores exponenciales para cada elemento. Luego, calcularemos la suma de los valores exponenciales de todo el vector. Para determinar la suma, inicializaremos la variable privada sum con el valor "0". Las propias operaciones aritméticas las realizaremos directamente en el siguiente ciclo. El número de iteraciones de este ciclo será igual al número de clústeres en nuestro modelo. En el cuerpo del ciclo, primero almacenaremos en una variable privada el valor exponencial de la distancia normalizada e "invertida" hasta el centro del clúster. El valor resultante se añadirá primero a la suma y luego se transferirá al búfer de resultados. El uso de una variable privada antes de escribir los valores en el búfer se realizará para minimizar el número de accesos a la memoria global lenta.
Una vez se completen las iteraciones del ciclo, nos quedará normalizar los datos y dividir los valores exponenciales obtenidos por la suma total. Para realizar estas operaciones, crearemos otro ciclo con un número de iteraciones igual al número de clústeres. Y una vez que se complete el ciclo, saldremos del kernel.
__kernel void KmeansSoftMax(__global double *distance, __global double *softmax, inсt total_k ) { int i = get_global_id(0); int shift = i * total_k; double m=distance[shift]; for(int k = 1; k < total_k; k++) m = max(distance[shift + k],m); double sum = 0; for(int k = 0; k < total_k; k++) { double value = exp(1-distance[shift + k]/m); sum += value; softmax[shift + k] = value; } for(int k = 0; k < total_k; k++) softmax[shift + k] /= sum; }
Ya hemos completado la funcionalidad del programa OpenCL, solo nos queda añadir el código para llamar al kernel desde nuestra clase CKmeans. Actuaremos según el mismo esquema que usamos anteriormente para añadir el código de llamada al kernel anterior.
Primero, añadiremos las constantes de acuerdo con la política de nomenclatura.
#define def_k_kmeans_softmax 5 #define def_k_kmsm_distance 0 #define def_k_kmsm_softmax 1 #define def_k_kmsm_total_k 2
Después de ello, añadiremos la declaración del kernel en la función de inicialización del contexto OpenCLOpenCLCreate.
COpenCLMy *OpenCLCreate(string programm) { ............... //--- if(!result.SetKernelsCount(6)) { delete result; return NULL; } //--- ............... //--- if(!result.KernelCreate(def_k_kmeans_softmax, "KmeansSoftMax")) { delete result; return NULL; } //--- return result; }
Y, por supuesto, necesitaremos un nuevo método en nuestra clase CKmeans::SoftMax. En los parámetros, el método recibirá el puntero al búfer de datos de origen. Y como resultado del trabajo, el método retornará un búfer de resultados del mismo tamaño.
En el cuerpo del método, primero verificaremos si nuestra clase de clusterización ha sido previamente entrenada. Y, de ser necesario, inicializaremos el proceso de entrenamiento del modelo. Aquí cabe recordar que en el método de entrenamiento del modelo hemos restringido el tamaño mínimo de la muestra de entrenamiento. Por lo tanto, si el modelo aún no ha sido entrenado, deberemos proporcionar una muestra de entrenamiento suficiente en los parámetros del método. De lo contrario, el método retornará un puntero no válido al búfer de resultados. Si el modelo de clusterización de datos ya ha sido entrenado, se eliminará la restricción en el tamaño de la muestra.
CBufferDouble *CKmeans::SoftMax(CBufferDouble *data)
{
if(!m_bTrained && !Study(data, (c_aMeans.Maximum() == 0)))
return NULL;
En el siguiente paso, comprobaremos la validez de los punteros a los objetos utilizados. Aquí podría parecer extraño que primero llamemos al método de entrenamiento y luego verifiquemos los punteros de los objetos. De hecho, el propio método de entrenamiento tiene un bloque de controles similar. Y si siempre llamamos al método de entrenamiento del modelo antes de continuar con las operaciones, estos controles resultarían redundantes, porque repetirían los controles dentro del método de entrenamiento. Sin embargo, si usamos un modelo preentrenado, no llamaremos al método de entrenamiento con sus controles. Y la posterior ejecución de las operaciones con punteros no válidos provocará errores críticos. Por lo tanto, nos veremos obligados a repetir la comprobación de los punteros.
if(CheckPointer(data) == POINTER_INVALID || CheckPointer(c_OpenCL) == POINTER_INVALID) return NULL;
Después de comprobar los punteros, verificaremos el tamaño del búfer con los datos de origen. Este deberá contener al menos el vector de descripción del primer estado del sistema. En este caso, el número de datos en el búfer deberá ser un número múltiplo del tamaño del vector de descripción del estado del sistema.
int total = data.Total(); if(total <= 0 || m_iClusters < 2 || (total % m_iVectorSize) != 0) return NULL;
Después determinaremos la cantidad de estados del sistema que debemos distribuir entre los clústeres.
int rows = total / m_iVectorSize; if(rows < 1) return NULL;
A continuación, deberemos inicializar los búferes para calcular las distancias y normalizarlas. El algoritmo de inicialización es bastante simple. Primero verificaremos la validez del puntero al búfer y, si fuera necesario, crearemos un nuevo objeto. Después rellenaremos el búfer con valores cero.
if(CheckPointer(c_aDistance) == POINTER_INVALID) { c_aDistance = new CBufferDouble(); if(CheckPointer(c_aDistance) == POINTER_INVALID) return NULL; } c_aDistance.BufferFree(); if(!c_aDistance.BufferInit(rows * m_iClusters, 0)) return NULL;
if(CheckPointer(c_aSoftMax) == POINTER_INVALID) { c_aSoftMax = new CBufferDouble(); if(CheckPointer(c_aSoftMax) == POINTER_INVALID) return NULL; } c_aSoftMax.BufferFree(); if(!c_aSoftMax.BufferInit(rows * m_iClusters, 0)) return NULL;
Para completar el trabajo preparatorio, crearemos los búferes de datos necesarios en el contexto de OpenCL.
if(!data.BufferCreate(c_OpenCL) || !c_aMeans.BufferCreate(c_OpenCL) || !c_aDistance.BufferCreate(c_OpenCL) || !c_aSoftMax.BufferCreate(c_OpenCL)) return NULL;
Con esto completaremos el trabajo preparatorio y podremos llamar a los kernels necesarios. Para implementar la funcionalidad completa del método, tendremos que organizar la llamada secuencial de los dos kernels:
- la determinación de las distancias hasta los centros de los clústeres KmeansCulcDistance;
- la normalización de las distancias KmeansSoftMax.
El algoritmo para llamar a los kernels es bastante simple y resulta similar al utilizado en el método de uso estadístico de los resultados de clusterización descrito anteriormente. Primero, tenemos que transmitir los parámetros al kernel.
if(!c_OpenCL.SetArgumentBuffer(def_k_kmeans_distance, def_k_kmd_data, data.GetIndex())) return NULL; if(!c_OpenCL.SetArgumentBuffer(def_k_kmeans_distance, def_k_kmd_means, c_aMeans.GetIndex())) return NULL; if(!c_OpenCL.SetArgumentBuffer(def_k_kmeans_distance, def_k_kmd_distance, c_aDistance.GetIndex())) return NULL; if(!c_OpenCL.SetArgument(def_k_kmeans_distance, def_k_kmd_vector_size, m_iVectorSize)) return NULL;
Luego especificaremos la dimensionalidad del espacio de tareas y el desplazamiento en cada dimensión.
uint global_work_offset[2] = {0, 0}; uint global_work_size[2]; global_work_size[0] = rows; global_work_size[1] = m_iClusters;
Después pondremos el kernel en la cola de ejecución y leeremos los resultados de las operaciones.
if(!c_OpenCL.Execute(def_k_kmeans_distance, 2, global_work_offset, global_work_size)) return NULL; if(!c_aDistance.BufferRead()) return NULL;
A continuación, repetiremos las operaciones para el segundo kernel.
if(!c_OpenCL.SetArgumentBuffer(def_k_kmeans_softmax, def_k_kmsm_distance, c_aDistance.GetIndex())) return NULL; if(!c_OpenCL.SetArgumentBuffer(def_k_kmeans_softmax, def_k_kmsm_softmax, c_aSoftMax.GetIndex())) return NULL; if(!c_OpenCL.SetArgument(def_k_kmeans_softmax, def_k_kmsm_total_k, m_iClusters)) return NULL; uint global_work_offset1[1] = {0}; uint global_work_size1[1]; global_work_size1[0] = rows; if(!c_OpenCL.Execute(def_k_kmeans_softmax, 1, global_work_offset1, global_work_size1)) return NULL; if(!c_aSoftMax.BufferRead()) return NULL;
Finalmente, borraremos la memoria del contexto OpenCL y saldremos del método, retornando el puntero al búfer de resultados.
data.BufferFree(); c_aDistance.BufferFree(); //--- return c_aSoftMax; }
Esto completará nuestro trabajo en cuanto a los cambios en nuestra clase de clusterización con el método de k-medias CKmeans. Ya podemos pasar a la simulación con este enfoque. Para ello, crearemos el asesor experto "kmeans_net.mq5", que se creará a imagen de los asesores de los artículos sobre algoritmos de aprendizaje supervisado. El hecho es que para probar la implementación, hemos enviado los resultados de la clusterización a la entrada de un perceptrón completamente conectado con 3 capas ocultas. El código completo del asesor se encuentra en el archivo adjunto. Ahora querríamos centrarnos en la función de entrenamiento Train.
Al comienzo de la función, inicializaremos un ejemplar del objeto para trabajar con el contexto de OpenCL dentro de la clase de clusterización. Y transmitiremos a nuestra clase de clusterización el puntero al objeto creado. Asegúrese, como siempre, de no olvidar comprobar el resultado de las operaciones.
void Train(datetime StartTrainBar = 0) { COpenCLMy *opencl = OpenCLCreate(cl_unsupervised); if(CheckPointer(opencl) == POINTER_INVALID) { ExpertRemove(); return; } if(!Kmeans.SetOpenCL(opencl)) { delete opencl; ExpertRemove(); return; }
Después de inicializar los objetos con éxito, determinaremos los límites del periodo de entrenamiento,
MqlDateTime start_time; TimeCurrent(start_time); start_time.year -= StudyPeriod; if(start_time.year <= 0) start_time.year = 1900; datetime st_time = StructToTime(start_time);
y también cargaremos los datos históricos. Tenga en cuenta que los datos del indicador cargados en los búferes estarán representados por series temporales. No habrá cotizaciones descargadas. Esto es importante para nosotros, ya que obtendremos la secuencia inversa de la numeración de elementos en los arrays. Por lo tanto, para poder comparar los datos, deberemos "convertir" el array de cotizaciones en una serie temporal.
int bars = CopyRates(Symb.Name(), TimeFrame, st_time, TimeCurrent(), Rates); if(!RSI.BufferResize(bars) || !CCI.BufferResize(bars) || !ATR.BufferResize(bars) || !MACD.BufferResize(bars)) { ExpertRemove(); return; } if(!ArraySetAsSeries(Rates, true)) { ExpertRemove(); return; }
RSI.Refresh(); CCI.Refresh(); ATR.Refresh(); MACD.Refresh();
Tras cargar con éxito los datos históricos, cargaremos el modelo de clusterización previamente entrenado.
int handl = FileOpen(StringFormat("kmeans_%d.net", Clusters), FILE_READ | FILE_BIN); if(handl == INVALID_HANDLE) { ExpertRemove(); return; } if(FileReadInteger(handl) != Kmeans.Type()) { ExpertRemove(); return; } bool result = Kmeans.Load(handl); FileClose(handl); if(!result) { ExpertRemove(); return; }
Y después procederemos a formar una muestra de entrenamiento y los valores objetivo.
int total = bars - (int)HistoryBars - 1; double data[], fractals[]; if(ArrayResize(data, total * 8 * HistoryBars) <= 0 || ArrayResize(fractals, total * 3) <= 0) { ExpertRemove(); return; } //--- for(int i = 0; (i < total && !IsStopped()); i++) { Comment(StringFormat("Create data: %d of %d", i, total)); for(int b = 0; b < (int)HistoryBars; b++) { int bar = i + b; int shift = (i * (int)HistoryBars + b) * 8; double open = Rates[bar].open; data[shift] = open - Rates[bar].low; data[shift + 1] = Rates[bar].high - open; data[shift + 2] = Rates[bar].close - open; data[shift + 3] = RSI.GetData(MAIN_LINE, bar); data[shift + 4] = CCI.GetData(MAIN_LINE, bar); data[shift + 5] = ATR.GetData(MAIN_LINE, bar); data[shift + 6] = MACD.GetData(MAIN_LINE, bar); data[shift + 7] = MACD.GetData(SIGNAL_LINE, bar); } int shift = i * 3; int bar = i + 1; fractals[shift] = (int)(Rates[bar - 1].high <= Rates[bar].high && Rates[bar + 1].high < Rates[bar].high); fractals[shift + 1] = (int)(Rates[bar - 1].low >= Rates[bar].low && Rates[bar + 1].low > Rates[bar].low); fractals[shift + 2] = (int)((fractals[shift] + fractals[shift]) == 0); } if(IsStopped()) { ExpertRemove(); return; } CBufferDouble *Data = new CBufferDouble(); if(CheckPointer(Data) == POINTER_INVALID || !Data.AssignArray(data)) return; CBufferDouble *Fractals = new CBufferDouble(); if(CheckPointer(Fractals) == POINTER_INVALID || !Fractals.AssignArray(fractals)) return;
Como nuestros métodos de clusterización pueden funcionar con conjuntos de datos iniciales, podemos realizar la clusterización de todo el conjunto de entrenamiento a la vez.
ResetLastError(); CBufferDouble *softmax = Kmeans.SoftMax(Data); if(CheckPointer(softmax) == POINTER_INVALID) { printf("Ошибка выполнения %d", GetLastError()); ExpertRemove(); return; }
Después de completar con éxito todas las operaciones anteriores, el búfer softmax contendrá la muestra de entrenamiento para nuestro perceptrón. También prepararemos los valores objetivo por adelantado. Así, podemos pasar al ciclo de entrenamiento del segundo modelo.
Al igual que antes, al poner a prueba los algoritmos de aprendizaje supervisado, el proceso de entrenamiento del modelo se organizará a partir de dos ciclos anidados. El ciclo externo contará las épocas de entrenamiento y la salida del ciclo se dará al suceder un evento determinado.
Primero, realizaremos un pequeño trabajo preparatorio en el que inicializaremos las variables locales necesarias.
if(CheckPointer(TempData) == POINTER_INVALID) { TempData = new CArrayDouble(); if(CheckPointer(TempData) == POINTER_INVALID) { ExpertRemove(); return; } } delete opencl; double prev_un, prev_for, prev_er; dUndefine = 0; dForecast = 0; dError = -1; dPrevSignal = 0; bool stop = false; int count = 0; do { prev_un = dUndefine; prev_for = dForecast; prev_er = dError; ENUM_SIGNAL bar = Undefine; //--- stop = IsStopped();
Y solo entonces procederemos a la organización del ciclo anidado. El número de iteraciones del ciclo anidado será igual al tamaño de la muestra de entrenamiento menos una pequeña "cola" de la zona de validación.
Debemos decir que, a pesar de que el número de iteraciones es igual al tamaño de la muestra, seguiremos eligiendo cada vez un elemento aleatorio para el proceso de aprendizaje. Lo definiremos al principio del ciclo anidado. El uso de vectores aleatorios del conjunto de entrenamiento hace que el entrenamiento del modelo resulte más uniforme.
for(int it = 0; (it < total - 300 && !IsStopped()); it++) { int i = (int)((MathRand() * MathRand() / MathPow(32767, 2)) * (total - 300)) + 300;
Según el índice del elemento seleccionado aleatoriamente, determinaremos el desplazamiento en el búfer de datos originales y copiaremos el vector necesario al búfer temporal.
TempData.Clear(); int shift = i * Clusters; if(!TempData.Reserve(Clusters)) { if(CheckPointer(Data) == POINTER_DYNAMIC) delete Data; if(CheckPointer(Fractals) == POINTER_DYNAMIC) delete Fractals; if(CheckPointer(softmax) == POINTER_DYNAMIC) delete softmax; if(CheckPointer(opencl) == POINTER_DYNAMIC) delete opencl; Comment(""); //--- ExpertRemove(); return; } for(int c = 0; c < Clusters; c++) if(!TempData.Add(softmax.At(shift + c))) { if(CheckPointer(Data) == POINTER_DYNAMIC) delete Data; if(CheckPointer(Fractals) == POINTER_DYNAMIC) delete Fractals; if(CheckPointer(softmax) == POINTER_DYNAMIC) delete softmax; if(CheckPointer(opencl) == POINTER_DYNAMIC) delete opencl; Comment(""); //--- ExpertRemove(); return; }
Después de generar el vector de datos originales, lo mandaremos a la entrada del método de pasada directa de nuestra red neuronal. Y después de realizar una pasada hacia delante con éxito, obtendremos su resultado.
if(!Net.feedForward(TempData)) { if(CheckPointer(Data) == POINTER_DYNAMIC) delete Data; if(CheckPointer(Fractals) == POINTER_DYNAMIC) delete Fractals; if(CheckPointer(softmax) == POINTER_DYNAMIC) delete softmax; if(CheckPointer(opencl) == POINTER_DYNAMIC) delete opencl; Comment(""); //--- ExpertRemove(); return; } Net.getResults(TempData);
Luego normalizaremos los resultados obtenidos utilizando la función Softmax.
double sum = 0; for(int res = 0; res < 3; res++) { double temp = exp(TempData.At(res)); sum += temp; TempData.Update(res, temp); } for(int res = 0; (res < 3 && sum > 0); res++) TempData.Update(res, TempData.At(res) / sum);
Para monitorear visualmente el proceso de aprendizaje del modelo, mostraremos el estado actual en el gráfico.
switch(TempData.Maximum(0, 3)) { case 1: dPrevSignal = (TempData[1] != TempData[2] ? TempData[1] : 0); break; case 2: dPrevSignal = -TempData[2]; break; default: dPrevSignal = 0; break; } string s = StringFormat("Study -> Era %d -> %.2f -> Undefine %.2f%% foracast %.2f%%\n %d of %d -> %.2f%% \nError %.2f\n%s -> %.2f ->> Buy %.5f - Sell %.5f - Undef %.5f", count, dError, dUndefine, dForecast, it + 1, total - 300, (double)(it + 1.0) / (total - 300) * 100, Net.getRecentAverageError(), EnumToString(DoubleToSignal(dPrevSignal)), dPrevSignal, TempData[1], TempData[2], TempData[0]); Comment(s); stop = IsStopped();
Y al final de la iteración del ciclo, llamaremos al método de pasada hacia atrás con la actualización de la matriz de pesos de nuestro modelo.
if(!stop) { shift = i * 3; TempData.Clear(); TempData.Add(Fractals.At(shift + 2)); TempData.Add(Fractals.At(shift)); TempData.Add(Fractals.At(shift + 1)); Net.backProp(TempData); ENUM_SIGNAL signal = DoubleToSignal(dPrevSignal); if(signal != Undefine) { if((signal == Sell && Fractals.At(shift + 1) == 1) || (signal == Buy && Fractals.At(shift) == 1)) dForecast += (100 - dForecast) / Net.recentAverageSmoothingFactor; else dForecast -= dForecast / Net.recentAverageSmoothingFactor; dUndefine -= dUndefine / Net.recentAverageSmoothingFactor; } else { if(Fractals.At(shift + 2) == 1) dUndefine += (100 - dUndefine) / Net.recentAverageSmoothingFactor; } } }
Después de cada época de entrenamiento, mostraremos las etiquetas gráficas en el segmento de validación. Para implementar esta funcionalidad, crearemos otro ciclo anidado. En su mayoría, las operaciones en el cuerpo del ciclo repetirán el ciclo descrito anteriormente, salvo por dos diferencias principales:
- Tomaremos los elementos en orden, y no al azar como antes.
- No realizaremos una pasada hacia atrás.
En el conjunto de validación, verificaremos cómo funciona nuestro modelo con datos nuevos sin "ajustar" el parámetro. Por lo tanto, no llamaremos a la pasada hacia atrás. Y como consecuencia, el resultado del modelo no dependerá de la secuencia de transmisión de los datos (una salvedad para los modelos recurrentes). Esto significa que no desperdiciaremos recursos en generar un número aleatorio y tomaremos secuencialmente todos los estados del sistema.
count++; for(int i = 0; i < 300; i++) { TempData.Clear(); int shift = i * Clusters; if(!TempData.Reserve(Clusters)) { if(CheckPointer(Data) == POINTER_DYNAMIC) delete Data; if(CheckPointer(Fractals) == POINTER_DYNAMIC) delete Fractals; if(CheckPointer(softmax) == POINTER_DYNAMIC) delete softmax; if(CheckPointer(opencl) == POINTER_DYNAMIC) delete opencl; Comment(""); //--- ExpertRemove(); return; }
for(int c = 0; c < Clusters; c++) if(!TempData.Add(softmax.At(shift + c))) { if(CheckPointer(Data) == POINTER_DYNAMIC) delete Data; if(CheckPointer(Fractals) == POINTER_DYNAMIC) delete Fractals; if(CheckPointer(softmax) == POINTER_DYNAMIC) delete softmax; if(CheckPointer(opencl) == POINTER_DYNAMIC) delete opencl; Comment(""); //--- ExpertRemove(); return; } if(!Net.feedForward(TempData)) { if(CheckPointer(Data) == POINTER_DYNAMIC) delete Data; if(CheckPointer(Fractals) == POINTER_DYNAMIC) delete Fractals; if(CheckPointer(softmax) == POINTER_DYNAMIC) delete softmax; if(CheckPointer(opencl) == POINTER_DYNAMIC) delete opencl; Comment(""); //--- ExpertRemove(); return; } Net.getResults(TempData);
double sum = 0; for(int res = 0; res < 3; res++) { double temp = exp(TempData.At(res)); sum += temp; TempData.Update(res, temp); } for(int res = 0; (res < 3 && sum > 0); res++) TempData.Update(res, TempData.At(res) / sum); //--- switch(TempData.Maximum(0, 3)) { case 1: dPrevSignal = (TempData[1] != TempData[2] ? TempData[1] : 0); break; case 2: dPrevSignal = -TempData[2]; break; default: dPrevSignal = 0; break; }
Añadiremos la visualización de objetos en el gráfico y saldremos del ciclo de validación.
if(DoubleToSignal(dPrevSignal) == Undefine) DeleteObject(Rates[i + 2].time); else DrawObject(Rates[i + 2].time, dPrevSignal, Rates[i + 2].high, Rates[i + 2].low); }
Antes de completar la iteración del ciclo externo, guardaremos el estado actual del modelo y añadiremos el valor del error al archivo de dinámica de entrenamiento.
if(!stop) { dError = Net.getRecentAverageError(); Net.Save(FileName + ".nnw", dError, dUndefine, dForecast, Rates[0].time, false); printf("Era %d -> error %.2f %% forecast %.2f", count, dError, dForecast); ChartScreenShot(0, FileName + IntegerToString(count) + ".png", 750, 400); int h = FileOpen(FileName + ".csv", FILE_READ | FILE_WRITE | FILE_CSV); if(h != INVALID_HANDLE) { FileSeek(h, 0, SEEK_END); FileWrite(h, eta, count, dError, dUndefine, dForecast); FileFlush(h); FileClose(h); } } } while((!(DoubleToSignal(dPrevSignal) != Undefine || dForecast > 70) || !(dError < 0.1 && MathAbs(dError - prev_er) < 0.01 && MathAbs(dUndefine - prev_un) < 0.1 && MathAbs(dForecast - prev_for) < 0.1)) && !stop);
Después saldremos del ciclo de entrenamiento según las métricas que hayamos definido. Estas se tomarán prestadas en su totalidad de los asesores de aprendizaje supervisado.
Antes de salir del método de entrenamiento, eliminaremos los objetos creados en el cuerpo de nuestro método de entrenamiento del modelo.
if(CheckPointer(Data) == POINTER_DYNAMIC) delete Data; if(CheckPointer(Fractals) == POINTER_DYNAMIC) delete Fractals; if(CheckPointer(softmax) == POINTER_DYNAMIC) delete softmax; if(CheckPointer(TempData) == POINTER_DYNAMIC) delete TempData; if(CheckPointer(opencl) == POINTER_DYNAMIC) delete opencl; Comment(""); //--- ExpertRemove(); }
Podrá encontrar el código completo del asesor en el archivo adjunto.
Para evaluar el rendimiento del asesor experto, lo probaremos con el modelo de clusterización de 500 clústeres entrenado en el artículo anterior y utilizado en la prueba anterior. El programa de entrenamiento se muestra a continuación.

Como podemos ver, el programa de entrenamiento es bastante parejo. Para entrenar el modelo, hemos utilizado el método de optimización de parámetros Adam. Durante las primeras 20 épocas, vemos una disminución gradual en la función de pérdida relacionada con la acumulación de impulsos. Y luego se percibe una fuerte disminución en el valor de la función de pérdida hasta un cierto mínimo. Si recordamos los gráficos de entrenamiento de los modelos supervisados, las líneas discontinuas de la función de pérdida se notan con mayor frecuencia allí. Por ejemplo, a continuación le mostramos un gráfico de entrenamiento para un modelo de atención más complejo.

Al comparar los 2 gráficos presentados, podemos ver cómo la clusterización de los datos preliminares aumenta la eficiencia incluso de los modelos simples.
Conclusión
En este artículo, hemos analizado e implementado dos opciones de uso de los resultados de la clusterización en la resolución de casos prácticos. Y los resultados de las pruebas demuestran la efectividad del uso de ambos métodos. En el primer caso, tenemos un modelo simple con resultados muy claros y comprensibles, bastante transparentes. El segundo método hace que el entrenamiento del modelo resulte más rápido y fluido. Esto mejorará el rendimiento de los modelos.
Enlaces
- Redes neuronales: así de sencillo
- Redes neuronales: así de sencillo (Parte 2): Entrenamiento y prueba de la red
- Redes neuronales: así de sencillo (Parte 3): Redes convolucionales
- Redes neuronales: así de sencillo (Parte 4): Redes recurrentes
- Redes neuronales: así de sencillo (Parte 5): Cálculos multihilo en OpenCL
- Redes neuronales: así de sencillo (Parte 6): Experimentos con la tasa de aprendizaje de la red neuronal
- Redes neuronales: así de sencillo (Parte 7): Métodos de optimización adaptativos
- Redes neuronales: así de sencillo (Parte 8): Mecanismos de atención
- Redes neuronales: así de sencillo (Parte 9): Documentamos el trabajo realizado
- Redes neuronales: así de sencillo (Parte 10): Multi-Head Attention (atención multi-cabeza)
- Redes neuronales: así de sencillo (Parte 11): Variaciones de GTP
- Redes neuronales: así de sencillo (Parte 12): Dropout
- Redes neuronales: así de sencillo (Parte 13): Normalización por lotes (Batch Normalization)
- Redes neuronales: así de sencillo (Parte 14): Clusterización de datos
- Redes neuronales: así de sencillo (Parte 15): Clusterización de datos usando MQL5
Programas utilizados en el artículo.
| # | Nombre | Tipo | Descripción |
|---|---|---|---|
| 1 | kmeans.mq5 | Asesor | Asesor para el entrenamiento de modelos |
| 2 | kmeans_net.mq5 | Asesor | Asesor para probar la transmisión de datos al segundo modelo |
| 3 | kmeans_stat.mq5 | Asesor | Asesor para probar los métodos estadísticos |
| 4 | kmeans.mqh | Biblioteca de clases | Biblioteca para organizar el método de k-medias |
| 5 | unsupervised.cl | Biblioteca | Biblioteca de código del programa OpenCL para organizar el método de k-medias |
| 6 | NeuroNet.mqh | Biblioteca de clases | Biblioteca de clases para crear una red neuronal |
| 7 | NeuroNet.cl | Biblioteca | Biblioteca de código de programa OpenCL |
Traducción del ruso hecha por MetaQuotes Ltd.
Artículo original: https://www.mql5.com/ru/articles/10943
 Aprendiendo a diseñar un sistema de trading con el indicador de Acumulación/Distribución
Aprendiendo a diseñar un sistema de trading con el indicador de Acumulación/Distribución
 Aprendiendo a diseñar un sistema de trading con OBV
Aprendiendo a diseñar un sistema de trading con OBV
 Vídeo: Configuramos MetaTrader 5 y MQL5 para el comercio automatizado sencillo
Vídeo: Configuramos MetaTrader 5 y MQL5 para el comercio automatizado sencillo
 Redes neuronales: así de sencillo (Parte 15): Clusterización de datos usando MQL5
Redes neuronales: así de sencillo (Parte 15): Clusterización de datos usando MQL5
- Aplicaciones de trading gratuitas
- 8 000+ señales para copiar
- Noticias económicas para analizar los mercados financieros
Usted acepta la política del sitio web y las condiciones de uso