Machine learning in trading: theory, models, practice and algo-trading - page 851
You are missing trading opportunities:
- Free trading apps
- Over 8,000 signals for copying
- Economic news for exploring financial markets
Registration
Log in
You agree to website policy and terms of use
If you do not have an account, please register
2 classes
Loaded 1 core
Setup , rfeControl = rfeControl(number = 1,repeats = 1) - reduced the time to 10-15 minutes. The changes in the results are 2 pairs of predictors swapped, but overall it looks like what the default was.
Well, here, your 10 minutes on one core is my 2 on 4, and the 2 minutes I don't remember.
I never wait for something for hours, if 10-15 minutes didn't work, then something is wrong, so spending more time won't do any good. Any optimization when building a model that lasts hours is a complete failure to understand the ideology of modeling, which says that the model should be minimally coarse and in no case as accurate as possible.
Now about the selection of predictors.
Why are you doing this and why? What problem are you trying to solve?
The most important thing in selection is trying to solve the problem of overtraining. Is your model overtrained? If not, then selection can speed up learning by reducing the number of predictors. But reducing the number is much more effective by isolating the principal components. They don't affect anything, but they can reduce the number of predictors by an order of magnitude and consequently increase the speed of model fitting.
So first: why do you need it?
I found another interesting package for sifting predictors. It is called FSelector. It offers about a dozen methods for sifting predictors, including using entropy.
I took the file with predictors and the target from here -https://www.mql5.com/ru/forum/86386/page6#comment_2534058
The estimation of the predictor by each method I showed on the graph at the end.
Blue is good, red is bad (for corrplot the results were scaled to [-1:1], for an accurate estimate see the results of calls to the functions cfs(targetFormula, trainTable), chi.squared(targetFormula, trainTable), etc.)
You can see that X3, X4, X5, X19, X20 are well evaluated with almost all methods, you can start with them, then try to add/remove more.
However, the models in rattle did not pass the test with these 5 predictors on Rat_DF2, again the miracle did not happen. I.e. even with the remaining predictors, you need to tweak model parameters, do crossvalidation, add/remove predictors yourself.
I did the same thing with CORElearn on the data from Vladimir's articles.
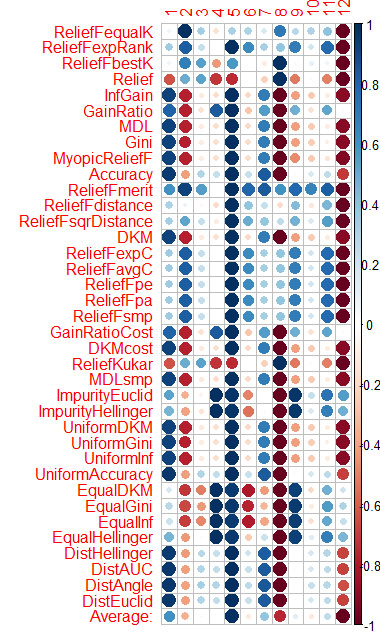
I calculated the average by columns (the bottom row is Average) and sorted by it. It's easier to perceive the total importance.
It took 1.6 minutes - and that's 37 algorithms worked. The speed is much better than Caret (16 minutes), with similar results.
I did the same thing with CORElearn using data from Vladimir's articles.
I calculated the average by columns (the bottom row Average) and sorted by it. It's easier to perceive the total importance.
It took me 1.6 minutes, which makes 37 algorithms.
So what's the bottom line??? Answered the question about the importance of predictors or not, because I do not understand a little of these pictures.
For me now there is no problem at all when building and selecting a model, I select predictors, then build 10 models on them, then mutual information selects the one that works best. And you know how to do it. It's a mental challenge!!! All right, the one who solves it is good for you!!!!!
I managed to get a set of models. And actually vporez: Which of the models is working and why??????
Or rather they are all working, but only one of them can dial. And explain why?
So what's the bottom line??? Answered the question about the importance of predictors or not, because I do not understand a little of these pictures.
For me now there is no problem at all when building and selecting a model, I select predictors, then build 10 models on them, then mutual information selects the one that works best. And you know how to do it. It's a mental challenge!!! All right, the one who solves it is good for you!!!!!
I managed to get a set of models. And actually vporez: Which of the models is working and why??????
Or rather they all work, but only one of them can dial. And explain why?
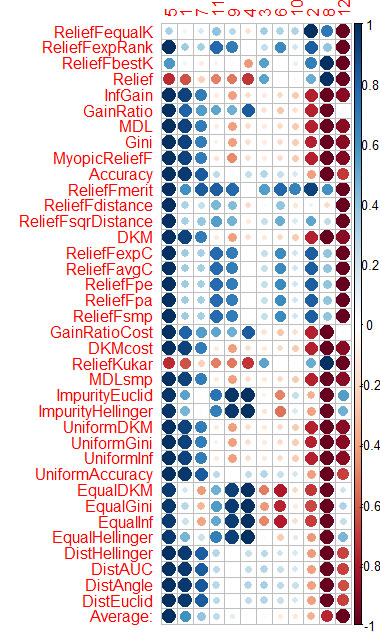
Vtreat very similarly sorts the predictors (important first)
5 1 7 11 4 10 3 9 6 2 12 8
And here's sorting by mean in CORElearn
5 1 7 11 9 4 3 6 10 2 8 12
I don't think I'll bother with predictor selection packages anymore.
So Vtreat is quite enough. Except for the fact that the interaction of predictors is not taken into account. Probably too.
I just cry when I see that you keep picking up the importance of predictors for some pieces of market history. Why? It is a profanation of statistical methods.
In practice, I checked that if you apply a predictor number 2 in the NS - the error rises from 30% to almost 50%
And on the OOS, how does the error change?
How does the error change on the OOS?
similarly. As in Vladimir's articles, the data are from there.
What if it's on a different OOS?
In practice, I checked that if you feed predictor number 2 to the NS - the error rises from 30% to almost 50%
Spit on the predictors, and feed the NS normalized time series. The NS will find the predictors itself - +1-2 layers, and there you have the predictors