
Neuronale Netze leicht gemacht (Teil 21): Variierter Autoencoder (VAE)

Inhalt
- Einführung
- 1. Architektur des Variierten Autoencoders
- 2. Umsetzung
- 3. Tests
- Schlussfolgerung
- Liste der Referenzen
- Programme, die im diesem Artikel verwendet werden
Einführung
Wir untersuchen weiterhin Methoden des unüberwachten Lernens. Im letzten Artikel haben wir uns mit Autoencodern vertraut gemacht. Das Thema Autoencoder ist sehr umfangreich und kann nicht in einem einzigen Artikel behandelt werden. Ich möchte dieses Thema fortsetzen und Ihnen eine Modifikation des Autoencoders vorstellen — den Variierten Autoencoder.
1. Architektur des Variierten Autoencoders
Bevor wir uns mit der Architektur des Variierten Autoencoders beschäftigen, wollen wir noch einmal auf die wichtigsten Punkte zurückkommen, die wir im vorherigen Artikel herausgefunden haben.
- Ein Autoencoder ist ein neuronales Netz, das nach der Backpropagation-Methode trainiert wird.
- Jeder Autoencoder besteht aus Encoder- und Decoderblöcken.
- Die Quelldatenschicht des Encoders und die Ergebnisschicht des Decoders enthalten die gleiche Anzahl von Elementen.
- Der Encoder und der Decoder sind durch einen „Flaschenhals“ des latenten Zustands verbunden, der komprimierte Informationen über den Ausgangszustand enthält.
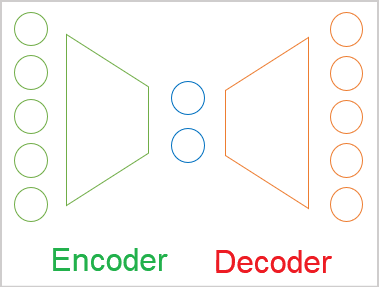
Beim Training streben wir die maximale Ähnlichkeit zwischen den Ergebnissen der Dekodierung latenter Zustände durch den Dekoder und den Originaldaten an. In diesem Fall können wir behaupten, dass die maximale Information über die ursprünglichen Daten im latenten Zustand verschlüsselt ist. Und diese Daten reichen aus, um die ursprünglichen Daten mit einiger Wahrscheinlichkeit wiederherzustellen. Der Einsatz von Autoencodern geht jedoch weit über Probleme der Datenkompression hinaus.
Nun werden wir uns mit dem Problem befassen, das bei der Verwendung von Autoencodern zur Bilderzeugung festgestellt wurde. Unsere Ausgangsdaten werden durch eine bestimmte Wolke repräsentiert. Beim Training hat unser Modell gelernt, 2 zufällig ausgewählte Objekte perfekt wiederherzustellen A und B. Einfach ausgedrückt, haben sich der Encoder und der Decoder darauf geeinigt, für das Objekt 1 A und 5 für das Objekt B im latenten Zustand. Bei der Lösung von Datenkomprimierungsproblemen ist das nicht weiter schlimm. Im Gegenteil: Die Objekte sind gut trennbar, und das Modell kann sie wiederherstellen.

Als die Forscher jedoch versuchten, mit Hilfe von Autoencodern Bilder zu erzeugen, erwies sich die Lücke in den latenten Zustandswerten zwischen zwei Objekten als Problem. Experimente haben gezeigt, dass der Decoder bei einem Wechsel der latenten Zustandswerte von Objekt A zu Objekt B in objektnahen Zonen die angezeigten Objekte mit einigen Verzerrungen wiederherstellt. Doch in der Mitte des Intervalls erzeugte der Decoder etwas, das für die ursprünglichen Daten nicht charakteristisch war.
Mit anderen Worten: Der latente Zustand von Autoencodern, in dem die Originaldaten kodiert und komprimiert werden, kann nicht kontinuierlich sein oder eine gewisse Interpolation zulassen. Dies ist das grundsätzliche Problem von Autoencodern, wenn sie auf eine bestimmte Datenerzeugung angewendet werden.
Wir werden sicherlich keine Daten generieren. Aber vergessen Sie nicht, dass sich die Welt ständig verändert. Bei der Untersuchung der Marktsituation ist die Wahrscheinlichkeit, in Zukunft ein Muster aus dem Trainingssatz mit mathematischer Genauigkeit zu erhalten, unglaublich gering. Was wir jedoch wollen, ist ein Modell, das die Marktsituation richtig behandelt und angemessene Ergebnisse liefert. Daher müssen wir eine Lösung für dieses Problem finden, sowohl für unseren Anwendungsbereich als auch für generative Modelle.
Für dieses Problem gibt es keine einfache Lösung. Eine Vergrößerung der Trainingsstichprobe und die Verwendung verschiedener Regularisierungsmethoden für latente Zustände führt zu einer Skalierung des Problems. Durch die Anwendung der Regularisierung wird beispielsweise der Abstand zwischen den Vektoren des latenten Zustands der Objekte verringert. Für unser Beispiel sind dies die Zahlen 1 und 2. Es kann aber auch ein Objekt erscheinen, das kodiert wird als 1.5. Das wird unseren Decoder verwirren. Eine größere Nähe zur Überlappung kann die Trennung von Objekten erschweren.
Eine Vergrößerung der Trainingsstichprobe hat einen ähnlichen Effekt, da jeder Zustand diskret bleibt. Außerdem führt eine Vergrößerung der Ausbildungsstichprobe zu einem Anstieg des Zeit- und Ressourcenaufwands für die Ausbildung. Gleichzeitig versucht der Autoencoder bei der Auswahl jedes einzelnen Musters der Quelldaten, den Abstand zum nächstgelegenen Nachbarzustand zu maximieren.
Im Gegensatz zu unserem Modell wissen wir, dass jeder unserer diskreten Zustände für eine bestimmte Klasse von Objekten repräsentativ ist. In unserer Quelldatenwolke liegen solche Objekte nahe beieinander und sind nach einem bestimmten Verteilungsgesetz verteilt. Fügen wir dem Modell unser Vorwissen hinzu.

Aber wie können wir das Modell dazu bringen, einen ganzen Bereich von Werten anstelle eines einzelnen Wertes zurückzugeben? Beachten Sie, dass sich dieser Wertebereich in der Anzahl der diskreten Werte und deren Streuung unterscheiden kann. Dies mag Sie an Clustering-Probleme erinnern. Aber wir kennen die Anzahl der Klassen nicht. Diese Zahl kann je nach der verwendeten Datenstichprobe variieren. Wir brauchen ein allgemeineres Datenrepräsentationsmodell.
Wie bereits erwähnt, ist die Positionierung der Objekte jeder Klasse in unserer Quelldatenwolke einer gewissen Verteilung unterworfen. Die wahrscheinlich am häufigsten verwendete ist die Normalverteilung. Gehen wir also davon aus, dass jedes Merkmal im latenten Zustand am Ausgang des Encoders einer Normalverteilung entspricht. Die Normalverteilung wird durch zwei Parameter bestimmt: den mathematischen Erwartungswert und die Standardabweichung. Fordern wir unseren Encoder auf, nicht nur einen diskreten Wert für jedes Merkmal zurückzugeben, sondern zwei: den mathematischen Erwartungswert (Mittelwert) und die Standardabweichung der Verteilung, zu der das analysierte Quelldatenmuster gehört.
Aber egal, wie wir die Werte an der Ausgabe des Encoders nennen, der Decoder wird sie immer noch als Zahlen wahrnehmen. Hier kommt die Architektur des Variierten Autoencoders ins Spiel. In seiner Architektur gibt es keine direkte Übertragung von Werten zwischen Encoder und Decoder. Im Gegenteil, wir nehmen die Verteilungsparameter aus dem Encoder, entnehmen einen Zufallswert aus der angegebenen Verteilung und geben ihn in den Decoder ein. Als Ergebnis der Verarbeitung desselben Quelldatenmusters durch den Kodierer kann der Dekodierereingang also einen anderen Wertevektor aufweisen, der jedoch immer derselben Normalverteilung unterliegt.
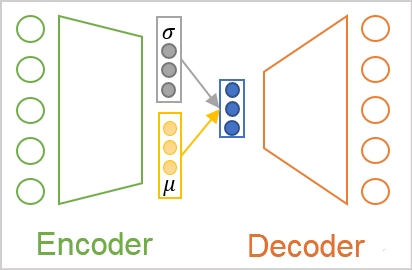
Wie Sie sehen, hat der Decodereingang bei einem solchen Vorgang immer 2 mal weniger Werte als der Encoderausgang.
Hier stellt sich jedoch das Problem des Modelltrainings. Das Modell wird mit der Backpropagation-Methode trainiert. Eine der wichtigsten Voraussetzungen für diese Methode ist die Differenzierbarkeit aller Funktionen entlang des Verlaufs des Fehlergradienten. Leider trifft dies nicht auf den Zufallszahlengenerator zu.
Aber auch dieses Problem wurde gelöst. Sehen wir uns die Eigenschaften der Normalverteilung und die Parameter, die sie beschreiben, genauer an. Die Normalverteilung ist eine mathematische Wahrscheinlichkeitsverteilung, die auf den Punkt der mathematischen Erwartung zentriert ist. 68 % der Werte liegen in einem Abstand von höchstens der Standardabweichung vom Zentrum der Verteilung. Daher verschiebt eine Änderung der mathematischen Erwartung den Mittelpunkt der Verteilung. Bei einer Änderung der Standardabweichung wird die Verteilung der Werte um den Mittelpunkt herum skaliert.
Um also einen einzelnen Wert aus einer Normalverteilung mit den gegebenen Parametern zu erhalten, können wir einen Wert für eine Standardnormalverteilung mit dem mathematischen Erwartungswert „0“ und der Standardabweichung „1“ erzeugen. Der sich daraus ergebende Wert wird dann mit der angegebenen Standardabweichung multipliziert und zu dem angegebenen mathematischen Erwartungswert addiert. Dieser Ansatz wird als Reparametrisierungs-Trick.
![]()
Daher erzeugen wir im Vorwärtsdurchlauf einen Zufallswert aus der Standardnormalverteilung und speichern ihn. Dann geben wir einen korrigierten Vektor mit den angegebenen Parametern in den Decoder ein. Im Backpropagation-Durchgang geben wir den Fehlergradienten durch leicht zu unterscheidende Additions- und Multiplikationsoperationen an den Encoder weiter. Der nicht-differenzierbare Zufallswertgenerator wird in unserem Modell nicht verwendet.
Es scheint, als hätten wir das Puzzle zusammengesetzt und alle Fallstricke umgangen. Praktische Versuche haben jedoch gezeigt, dass das Modell nicht nach unseren neuen Regeln spielen will. Anstatt komplexere Regeln mit neuen Eingaben zu lernen, reduzierte der Autoencoder die Standardabweichungsmerkmale während des Lernprozesses auf 0. Multipliziert mit 0 ist unsere Zufallsvariable wirkungslos, und der Decoder erhält einen diskreten Wert der mathematischen Erwartung als Eingabe. Indem die Standardabweichung auf 0 reduziert wird, macht das Modell alle oben genannten Bemühungen zunichte und kehrt zum Austausch diskreter Werte zwischen dem Encoder und dem Decoder zurück.
Damit das Modell nach unseren Regeln funktioniert, müssen wir zusätzliche Regeln und Einschränkungen einführen. Zunächst geben wir unserem Modell vor, dass die mathematischen Merkmale Erwartung und Standardabweichung so weit wie möglich den Parametern der Standardnormalverteilung entsprechen sollten. Wir können dies durch Hinzufügen einer zusätzlichen Abweichungsstrafe umsetzen. Als Maß für eine solche Abweichung wurde die Kullback-Leibler-Divergenz gewählt. Wir werden uns jetzt nicht in mathematische Berechnungen vertiefen. Hier ist also das Ergebnis des Fehlers für empirische Werte, die von den Parametern der Normalverteilung abweichen. Wir werden diese Funktion verwenden, um die Werte des latenten Zustands zu regulieren. In der Praxis werden wir den Wert zum latenten Zustandsfehler addieren.

Jedes Mal, wenn das Modell bestraft wird, wenn die Parameter der Merkmale von der Referenz (in diesem Fall von der Standardverteilung) abweichen, zwingen wir das Modell dazu, die Verteilungsparameter jedes Merkmals näher an die Parameter der Standardverteilung (die mathematische Erwartung von 0 und die Standardabweichung von 1) heranzuführen.
Es muss an dieser Stelle gesagt werden, dass ein solches „Ziehen“ von Merkmalen am Ausgang des Encoders dem Hauptproblem — der Extraktion von Merkmalen einzelner Objekte — zuwiderläuft. Die hinzugefügte Regularisierung zieht alle Merkmale mit der gleichen Kraft auf die Referenzwerte. Das heißt, es wird versucht, die Parameter gleich zu machen. Gleichzeitig versucht der Decoder-Fehlergradient, die Merkmale verschiedener Objekte so weit wie möglich zu trennen. Es besteht eindeutig ein Interessenkonflikt zwischen den beiden ausgeführten Aufgaben. Das Modell muss also ein Gleichgewicht finden, um die Probleme zu lösen. Aber das Gleichgewicht wird nicht immer unseren Erwartungen entsprechen. Um diesen Gleichgewichtspunkt zu kontrollieren, werden wir einen zusätzlichen Hyperparameter in das Modell einführen. Damit wird der Einfluss der Kullback-Leibler-Divergenz auf das Gesamtergebnis kontrolliert.
2. Umsetzung
Nachdem wir die theoretischen Aspekte des Algorithmus des Variierten Autoencoders besprochen haben, können wir zum praktischen Teil übergehen. Zur Implementierung des Kodierers und des Dekodierers des Variierten Autoencoders werden wir wieder vollständig verbundene neuronale Schichten aus der zuvor erstellten Bibliothek verwenden. Um einen vollwertigen Variierter Autoencoder zu implementieren, benötigen wir einen Block, der mit dem latenten Zustand arbeitet. In diesem Block werden wir alle oben genannten Neuerungen des Variierten Autoencoders implementieren.
Um den allgemeinen Ansatz zur Organisation neuronaler Netze in unserer Bibliothek beizubehalten, werden wir den gesamten Algorithmus zur Verarbeitung latenter Zustände in eine separate neuronale Schicht verpacken CVAE. Bevor wir mit der Implementierung der Klasse fortfahren, sollten wir mehrere Kernel erstellen, um die Funktionalität auf der OpenCL-Seite des Geräts zu implementieren.
Beginnen wir mit dem Feedforward-Kernel. Wir geben in die Schicht Parameter ein, die die Normalverteilung für die latenten Zustandsmerkmale beschreiben. Es gibt jedoch einen Vorbehalt. Der mathematische Erwartungswert kann jeden beliebigen Wert annehmen. Die Standardabweichung kann jedoch nur nicht-negative Werte annehmen. Wenn wir verschiedene neuronale Schichten zur Erzeugung von Parametern verwenden, können wir verschiedene Neuronenaktivierungsfunktionen einsetzen. Unsere Bibliotheksarchitektur erlaubt jedoch nur die Erstellung von linearen Modellen. Gleichzeitig kann nur eine Aktivierungsfunktion innerhalb einer neuronalen Schicht verwendet werden.
Auch hier ist es dem Modell egal, wie der Wert aufgerufen wird. Es führt einfach die mathematischen Formeln aus. Dies ist nur für uns wichtig, da es die korrekte Konstruktion des Modells ermöglicht. Achten Sie auf die obige Formel für die Kullback-Leibler-Divergenz. Sie verwendet die Varianz und ihren Logarithmus. Die Varianz einer Verteilung ist gleich dem Quadrat der Standardabweichung und darf nur nicht-negativ sein. Sein Logarithmus kann sowohl positive als auch negative Werte annehmen. Schauen Sie sich den Graphen des natürlichen Logarithmus des quadrierten Arguments an: Der Schnittpunkt der Abszissenlinie mit dem Funktionsgraphen liegt genau bei 1. Dieser Wert ist das Ziel für die Standardabweichung. Außerdem nimmt das Funktionsargument für das Intervall der Funktionswerte von -1 bis 1 Werte von 0,6 bis 1,6 an, was unsere Erwartungen an die Standardabweichung erfüllt.

Wir werden also den Modellencodierer ANLEITEN, den mathematischen Erwartungswert und den natürlichen Logarithmus der Verteilungsvarianz auszugeben. Wir können den hyperbolischen Tangens als Aktivierungsfunktion der neuronalen Schicht verwenden, da der Bereich seiner Werte unsere Erwartungen sowohl für die mathematische Erwartung der Verteilung als auch für den Logarithmus ihrer Varianz erfüllt.
Der konzeptionelle Ansatz ist also klar. Kommen wir nun zur Programmierung unserer Funktionen. Wir beginnen mit dem Feedforward-Kernel VAE_FeedForward. Der Kernel erhielt Zeiger auf drei Datenpuffer als Parameter. Zwei davon enthalten die Originaldaten und einer ist der Ergebnispuffer. Auf der OpenCL-Seite gibt es keinen Pseudo-Zufallszahlengenerator. Daher werden wir die Elemente der Standardverteilung auf der Seite des Hauptprogramms abfragen. Dann werden wir sie über den Puffer „random“ (Zufall) an den Feedforward-Kernel weiter.
Der zweite Quelldatenpuffer enthält die Ergebnisse des Encoders. Wie Sie wahrscheinlich schon erraten haben, werden der Vektor der mathematischen Erwartungen und der Vektor der Logarithmen der Varianz in demselben Puffer „inputs“.
Jetzt müssen wir nur noch den Trick der Neuparametrisierung im Kernelkörper implementieren. Vergessen Sie nicht, dass der Encoder anstelle der Standardabweichung den Logarithmus der Streuung liefert. Daher müssen wir, bevor wir den Trick anwenden, den Wert der Standardabweichung ermitteln.
Der Kehrwert des natürlichen Logarithmus ist die Exponentialfunktion. Mit dieser Funktion können wir die Varianz ermitteln. Durch Extraktion der Quadratwurzel der Varianz erhält man die Standardabweichung. Optional kann man mit Hilfe der Potenzeigenschaft einfach den Exponenten des halben Logarithmus der Varianz nehmen, wodurch man ebenfalls die Standardabweichung erhält.
![]()
Im Hauptteil des Feed-Forward-Kerns werden zunächst der Identifikator des aktuellen Threads und die Gesamtzahl der laufenden Threads ermittelt, die in den Quell- und Ergebnispuffern als Zeiger auf die erforderlichen Zellen dienen. Dann führen wir den Reparametrisierungs-Trick mit der Standardabweichung durch, die sich aus dem Logarithmus der Varianz ergibt. Das Ergebnis schreiben wir in das entsprechende Element des Ergebnispuffers und beenden den Kernel.
__kernel void VAE_FeedForward(__global float* inputs, __global float* random, __global float* outputs ) { uint i = (uint)get_global_id(0); uint total = (uint)get_global_size(0); outputs[i] = inputs[i] + exp(0.5f * inputs[i + total]) * random[i]; }
Der Feed-Forward-Kernel-Algorithmus ist also recht einfach. Als Nächstes organisieren wir den Backpropagation-Durchlauf auf der Kontextseite von OpenCL. Unsere latente Zustandsschicht des Variierten Autoencoders wird keine trainierbaren Parameter enthalten. Daher besteht der gesamte Backpropagation-Prozess darin, die Übertragung des Fehlergradienten vom Decoder zum Encoder zu organisieren. Dies wird im Kernel VAE_CalcHiddenGradient implementiert.
Bei der Implementierung dieses Kernels ist zu beachten, dass wir während des Feed-Forward-Durchgangs zwei Elemente aus dem Ergebnisvektor des Encoders entnommen haben und nach dem Reparametrisierungs-Trick ein Merkmal als Eingabe in den Decoder weitergegeben haben. Daher müssen wir einen Fehlergradienten vom Decoder nehmen und ihn auf zwei entsprechende Encoderelemente verteilen.
Nun, für die mathematische Erwartung ist alles einfach (beim Addieren wird der Fehlergradient vollständig auf beide Terme übertragen). Beim Varianzlogarithmus handelt es sich jedoch um die Ableitung einer komplexen Funktion.

Aber es gibt auch die andere Seite der Medaille. Damit das Modell nach unseren Regeln funktioniert, haben wir die Kullback-Leibler-Divergenz eingeführt. Und nun addieren wir den Fehlergradienten der Abweichung der Verteilungsparameter von den Referenzwerten der Standardverteilung zu dem vom Decoder erhaltenen Fehlergradienten.
Schauen wir uns die Implementierung des Kernels VAE_CalcHiddenGradient an. Der Kernel erhält als Parameter Zeiger auf vier Datenpuffer und eine Konstante. Drei der empfangenen Puffer enthalten die ursprünglichen Informationen, und ein Puffer wird für die Aufzeichnung der Ergebnisse der Gradienten und deren Weiterleitung an die Encoderebene verwendet.
- inputs — sind die Ergebnisse des Encoder-Feedforward. Der Puffer enthält mathematische Erwartungswerte und Logarithmen der Merkmalsvarianz.
- random — Werte der Standardabweichungselemente, die im Feedforward-Durchgang verwendet werden
- gradient — vom Decoder empfangene Fehlergradienten
- inp_grad — Ergebnispuffer zum Schreiben der an den Encoder übergebenen Fehlergradienten
- kld_mult — diskreter Wert des Koeffizienten des Einflusses der Kullback-Leibler-Divergenz auf das Gesamtergebnis
Im Kernelkörper ermitteln wir zunächst die Seriennummer des aktuellen Threads und die Gesamtzahl der laufenden Kernel-Threads. Diese Werte werden als Zeiger auf die erforderlichen Elemente des Eingabe- und Ergebnispuffers verwendet.
Anschließend bestimmen wir den Wert der Kullback-Leibler-Divergenz. Es ist zu beachten, dass der Abstand zwischen der empirischen Verteilung und der Referenzverteilung minimiert werden soll, d. h. er soll auf 0 reduziert werden. Dies bedeutet, dass der Fehler gleich dem Abweichungswert mit umgekehrtem Vorzeichen ist. Um unnötige Operationen zu vermeiden, entfernen wir einfach das Minuszeichen vor der Formel, die zur Bestimmung der Abweichung verwendet wird. Den Wert um den Koeffizienten des Einflusses der Divergenz passen wir auf das Ergebnis an.
Als Nächstes wird der Fehlergradient an die Encoder-Ebene weitergegeben. Hier wird die Summe der beiden Gradienten für jeden Verteilungsparameter entsprechend den Ableitungen der obigen Funktionen angegeben.
__kernel void VAE_CalcHiddenGradient(__global float* inputs, __global float* inp_grad, __global float* random, __global float* gradient, const float kld_mult ) { uint i = (uint)get_global_id(0); uint total = (uint)get_global_size(0); float kld = kld_mult * 0.5f * (inputs[i + total] - exp(inputs[i + total]) - pow(inputs[i], 2.0f) + 1); inp_grad[i] = gradient[i] + kld * inputs[i]; inp_grad[i + total] = 0.5f * (gradient[i] * random[i] * exp(0.5f * inputs[i + total]) - kld * (1 - exp(inputs[i + total]))) ; }
Wir schließen die Operationen mit dem Programm OpenCL ab und gehen zur Implementierung der Funktionalität auf der Seite des Hauptprogramms über. Wir beginnen mit der Erstellung einer neuen neuronalen Schichtklasse CVAE, die von der Neuronenschicht-Basisklasse CNeuronBaseOCL abgeleitet ist.
In dieser Klasse fügen wir eine Variable m_fKLD_Mult zur Speicherung des Kullback-Leibler-Koeffizienten für den Einfluss auf das Gesamtergebnis und die SetKLDMult Methode, um ihn festzulegen. Wir erstellen auch einen zusätzlichen Puffer m_cRandom, um Zufallswerte der Standardabweichung zu schreiben. Die Werte werden mit Hilfe der Standardbibliothek für Statistik und mathematische Operationen „Math\Stat\Normal.mqh“ ermittelt.
Um unsere Funktionalität zu implementieren, werden wir außerdem die Feedforward- und Backpropagation-Methoden außer Kraft setzen. Außerdem werden wir Methoden für die Arbeit mit Dateien außer Kraft setzen.
class CVAE : public CNeuronBaseOCL { protected: float m_fKLD_Mult; CBufferDouble* m_cRandom; virtual bool feedForward(CNeuronBaseOCL *NeuronOCL); virtual bool updateInputWeights(CNeuronBaseOCL *NeuronOCL) { return true; } public: CVAE(); ~CVAE(); virtual bool Init(uint numOutputs, uint myIndex, COpenCLMy *open_cl, uint numNeurons, ENUM_OPTIMIZATION optimization_type, uint batch); //--- virtual void SetKLDMult(float value) { m_fKLD_Mult = value;} virtual bool calcInputGradients(CNeuronBaseOCL *NeuronOCL); //--- virtual bool Save(int const file_handle); virtual bool Load(int const file_handle); //--- virtual int Type(void) const { return defNeuronVAEOCL; } };
Der Konstruktor und der Destruktor einer Klasse sind recht einfach. In der ersten setzen wir lediglich den Anfangswert unserer neuen Variablen und initialisieren die Datenpufferinstanz für die Arbeit mit einer Folge von Zufallsvariablen.
CVAE::CVAE() : m_fKLD_Mult(0.01f) { m_cRandom = new CBufferDouble(); }
Im Destruktor der Klasse löschen wir das Objekt des Puffers, das im Konstruktor erstellt wurde.
CVAE::~CVAE()
{
if(!!m_cRandom)
delete m_cRandom;
}
Die Methode zur Initialisierung der Klasseninstanz ist nicht kompliziert. Eigentlich wird fast die gesamte Funktionalität der Objektinitialisierung durch die Methode der übergeordneten Klasse implementiert. Es implementiert alle notwendigen Steuerelemente und Funktionen für die Initialisierung geerbter Objekte. Wir rufen also nur die Methode der Elternklasse in unserer Methode der Variationskodierer-Klasse auf. Nach erfolgreicher Ausführung initialisieren wir den Puffer für die Arbeit mit einer Zufallsfolge. Wir erstellen dafür einen Puffer im OpenCL-Kontextspeicher.
bool CVAE::Init(uint numOutputs, uint myIndex, COpenCLMy *open_cl, uint numNeurons, ENUM_OPTIMIZATION optimization_type, uint batch) { if(!CNeuronBaseOCL::Init(numOutputs, myIndex, open_cl, numNeurons, optimization_type, batch)) return false; //--- if(!m_cRandom) { m_cRandom = new CBufferDouble(); if(!m_cRandom) return false; } if(!m_cRandom.BufferInit(numNeurons, 0.0)) return false; if(!m_cRandom.BufferCreate(OpenCL)) return false; //--- return true; }
Beginnen wir die Implementierung der Hauptfunktionalität der Klasse mit dem Feed-Forward-Pass CVAE::feedForward. Ähnlich wie bei anderen Methoden der neuronalen Schicht erhält diese Methode in den Parametern einen Zeiger auf das Objekt der vorherigen neuronalen Schicht. Es folgt ein Kontrollblock. Sie prüft in erster Linie die Gültigkeit der Zeiger auf verwendete Objekte. Anschließend überprüfen wir die Größe der empfangenen Ausgangsdaten. Die Anzahl der Elemente im Ergebnispuffer der vorherigen Schicht muss ein Vielfaches von 2 sein und muss zweimal größer sein als der Ergebnispuffer der zu erstellenden neuronalen Schicht. Die Architektur des Variierten Autoencoders erfordert eine solche strikte Übereinstimmung. Der Encoder sollte für jedes Merkmal zwei Werte zurückgeben, die den mathematischen Erwartungswert und die Standardabweichung der Verteilung jedes Merkmals beschreiben.
bool CVAE::feedForward(CNeuronBaseOCL *NeuronOCL) { if(!OpenCL || !NeuronOCL || !m_cRandom) return false; if(NeuronOCL.Neurons() % 2 != 0 || NeuronOCL.Neurons() / 2 != Neurons()) return false;
Nach erfolgreicher Prüfung führen wir eine Stichprobe von Zufallswerten der Standardabweichung durch und übertragen deren Werte in den entsprechenden Puffer.
double random[]; if(!MathRandomNormal(0, 1, m_cRandom.Total(), random)) return false; if(!m_cRandom.AssignArray(random)) return false; if(!m_cRandom.BufferWrite()) return false;
Die erzeugten Werte übergeben wir zur weiteren Verarbeitung an den OpenCL-Kontextspeicher.
Als Nächstes implementieren wir den Aufruf des entsprechenden Kernels. Zunächst übergeben wir Zeiger auf die vom Kernel verwendeten Datenpuffer. Beachten Sie, dass wir nur den generierten Fallpuffer an den Kontextspeicher übergeben haben. Wir gehen davon aus, dass sich alle anderen verwendeten Datenpuffer bereits im Kontextspeicher befinden. Wenn wir zuvor keine Puffer im Kontextspeicher angelegt oder Änderungen an den Pufferdaten auf der Seite des Hauptprogramms vorgenommen haben, müssen wir die Daten an den OpenCL-Kontextspeicher übergeben, bevor wir die Pufferzeiger an die Kernelparameter übergeben. Sie sollten immer daran denken, dass ein OpenCL-Programm nur auf seinem Kontextspeicher arbeitet, ohne auf den globalen Speicher des Computers zuzugreifen. Auch wenn Sie eine integrierte Grafikkarte oder die OpenCL-Bibliothek auf dem Prozessor verwenden.
if(!OpenCL.SetArgumentBuffer(def_k_VAEFeedForward, def_k_vaeff_inputs, NeuronOCL.getOutput().GetIndex())) return false; if(!OpenCL.SetArgumentBuffer(def_k_VAEFeedForward, def_k_vaeff_random, m_cRandom.GetIndex())) return false; if(!OpenCL.SetArgumentBuffer(def_k_VAEFeedForward, def_k_vaeff_outputd, Output.GetIndex())) return false;
Am Ende der Methode geben wir die Dimension der Aufgaben und den Offset für jede Dimension an und rufen die Methode auf, um den Kernel zur Ausführung einzureihen.
uint off_set[] = {0}; uint NDrange[] = {Neurons()}; if(!OpenCL.Execute(def_k_VAEFeedForward, 1, off_set, NDrange)) return false; //--- return true; }
Vergessen wir nicht, das Ergebnis bei jedem Schritt zu überprüfen.
Nach erfolgreichem Abschluss der Operationen beenden wir die Methode mit true.
Auf den Feedforward-Durchgang folgt die Backpropagation. Bisher haben wir den Rückwärtsdurchlauf mit verschiedenen Methoden umgesetzt. Zuerst haben wir calcOutputGradients, calcHiddenGradients und calcInputGradients verwendet, um die Berechnung und Weitergabe des Fehlergradienten sequentiell durch unser gesamtes Modell von der neuronalen Ausgabeschicht bis zur Eingabedatenschicht zu implementieren. Dann verwenden wir updateInputWeights, um die trainierten Parameter in Richtung des Anti-Gradienten zu ändern.
Unsere neuronale Schicht für die Arbeit mit der latenten Schicht des Variierten Autoencoders enthält keine trainierbaren Parameter. Daher werden wir die letzte Methode der Parameteroptimierung mit einem Stub überschreiben, der bei jedem Aufruf der Methode immer true zurückgibt.
Für die normale Implementierung des Backpass-Verfahrens in der Klasse müssen wir lediglich die Methode calcInputGradients umdefinieren. Obwohl die Vorwärts- und Rückwärtspassmethoden funktionell eine umgekehrte Datenflussrichtung haben, ist der Inhalt der Methoden recht ähnlich. Der Grund dafür ist, dass die Funktionalität der Algorithmen auf der OpenCL-Kontextseite implementiert ist. Auf der Seite des Hauptprogramms leisten wir nur vorbereitende Arbeit, um die Kernel aufzurufen. Sie werden nach einer einzigen Vorlage aufgerufen.
Wie bei der Feed-Forward-Methode überprüfen wir zunächst die Gültigkeit der Zeiger auf die verwendeten Objekte. Wir leiten die Daten nicht erneut an den OpenCL-Kontext weiter. Wenn Sie jedoch nicht sicher sind, dass sich alle erforderlichen Informationen im Kontextspeicher befinden, ist es besser, sie jetzt nochmal an den OpenCL-Kontextspeicher zu übergeben. Danach können wir Parameter an den Kernel übergeben.
Nach der erfolgreichen Übergabe der Parameter folgt ein Block von Operationen, um die Kernelausführung zu starten. Zunächst legeb wir die Größe der Probleme und den Versatz entlang jeder Dimension fest. Dann rufen wir die Methode auf, die den Kernel in die Ausführungswarteschlange stellt.
bool CVAE::calcInputGradients(CNeuronBaseOCL *NeuronOCL) { if(!OpenCL || !NeuronOCL) return false; //--- if(!OpenCL.SetArgumentBuffer(def_k_VAECalcHiddenGradient, def_k_vaehg_input, NeuronOCL.getOutput().GetIndex())) return false; if(!OpenCL.SetArgumentBuffer(def_k_VAECalcHiddenGradient, def_k_vaehg_inp_grad, NeuronOCL.getGradient().GetIndex())) return false; if(!OpenCL.SetArgumentBuffer(def_k_VAECalcHiddenGradient, def_k_vaehg_random, Weights.GetIndex())) return false; if(!OpenCL.SetArgumentBuffer(def_k_VAECalcHiddenGradient, def_k_vaehg_gradient, Gradient.GetIndex())) return false; if(!OpenCL.SetArgument(def_k_VAECalcHiddenGradient, def_k_vaehg_kld_mult, m_fKLD_Mult)) return false; int off_set[] = {0}; int NDrange[] = {Neurons()}; if(!OpenCL.Execute(def_k_VAECalcHiddenGradient, 1, off_set, NDrange)) return false; //--- return true; }
Wir überprüfen die Ergebnisse aller Operationen und beenden die Methode.
Damit ist die Implementierung der wichtigsten Funktionen der Klasse abgeschlossen. Aber es gibt noch eine weitere wichtige Funktion — die Arbeit mit Dateien. Daher werden wir die Funktionalität der Klasse durch diese Methoden ergänzen. Bevor wir mit dem Schreiben von Klassenmethoden fortfahren, sollten wir uns überlegen, welche Informationen wir speichern müssen, um die Leistung des Modells erfolgreich wiederherzustellen. In dieser Klasse haben wir nur eine Variable und einen Datenpuffer erstellt. Der Pufferinhalt wird bei jedem Vorwärtsdurchlauf mit Zufallswerten gefüllt. Daher besteht für uns keine Notwendigkeit, diese Daten zu speichern. Der Wert der Variablen ist ein Hyperparameter, den wir speichern müssen.
Daher wird unsere Methode zum Speichern von Objekten nur 2 Operationen enthalten:
- eine ähnliche Methode der übergeordneten Klasse aufrufen, die alle erforderlichen Kontrollen durchführt und geerbte Objekte speichert,
- den Einfluss des Hyperparameters der Kullback-Leibler-Divergenz auf das Gesamtergebnis.
bool CVAE::Save(const int file_handle) { //--- if(!CNeuronBaseOCL::Save(file_handle)) return false; if(FileWriteFloat(file_handle, m_fKLD_Mult) < sizeof(m_fKLD_Mult)) return false; //--- return true; }
Vergessen wir nicht, die Ergebnisse der Ausführung der Operation zu überprüfen. Nach erfolgreichem Abschluss aller Operationen wird die Methode mit dem Ergebnis true beendet.
Um die Leistung des Modells wiederherzustellen, werden die gespeicherten Daten aus der Datei in strikter Übereinstimmung mit der Reihenfolge des Schreibens der Daten gelesen. Zunächst rufen wir eine ähnliche Methode der Elternklasse auf. Es enthält alle erforderlichen Steuerelemente und lädt abgeleitete Objekte.
bool CVAE::Load(const int file_handle) { if(!CNeuronBaseOCL::Load(file_handle)) return false; m_fKLD_Mult=FileReadFloat(file_handle);
Nach erfolgreicher Ausführung der Methode der übergeordneten Klasse lesen wir die Hyperparameterwerte aus der Datei und schreiben sie in die entsprechende Variable. Im Gegensatz zur Methode der Datenspeicherung endet die Methode des Datenladens jedoch nicht hier. Zugegeben, es sind keine weiteren Informationen in der Datei vorhanden, die in diese Klasse geladen werden können. Um den korrekten Betrieb zu organisieren, müssen wir den Puffer jedoch so initialisieren, dass er mit Zufallsvariablen der richtigen Größe arbeitet. Wir erstellen einen Puffer mit einer Größe, die dem geladenen Puffer der aktuellen Ergebnisse der neuronalen Schicht entspricht (er wurde von der Methode der Elternklasse geladen). Wir erstellen auch den entsprechenden Puffer im OpenCL-Kontextspeicher.
if(!m_cRandom) { m_cRandom = new CBufferDouble(); if(!m_cRandom) return false; } if(!m_cRandom.BufferInit(Neurons(), 0.0)) return false; if(!m_cRandom.BufferCreate(OpenCL)) return false; //--- return true; }
Nach erfolgreichem Abschluss aller Operationen wird die Methode mit dem Ergebnis true beendet.
Damit ist die Klasse der Variierter Autoencoder für die Verarbeitung latenter Zustände abgeschlossen. Der vollständige Code aller Methoden und Klassen ist in der Anlage unten zu finden.
Unsere neue Klasse ist fertig. Aber unsere Dispatching-Klasse, die den Betrieb des neuronalen Netzes organisiert, weiß immer noch nichts darüber. Also, gehen wir zu NeuroNet.mqh und suchen die Klasse CNet.
Zunächst gehe wir zum Klassenkonstruktor und beschreiben das Verfahren zur Erstellung einer neuen neuronalen Schicht. Außerdem erhöhen wir die Anzahl der verwendeten OpenCL-Kernel und deklarieren zwei neue Kernel.
CNet::CNet(CArrayObj *Description) : recentAverageError(0), backPropCount(0) { ................. ................. //--- for(int i = 0; i < total; i++) { ................. ................. if(CheckPointer(opencl) != POINTER_INVALID) { CNeuronBaseOCL *neuron_ocl = NULL; CNeuronConvOCL *neuron_conv_ocl = NULL; CNeuronProofOCL *neuron_proof_ocl = NULL; CNeuronAttentionOCL *neuron_attention_ocl = NULL; CNeuronMLMHAttentionOCL *neuron_mlattention_ocl = NULL; CNeuronDropoutOCL *dropout = NULL; CNeuronBatchNormOCL *batch = NULL; CVAE *vae = NULL; switch(desc.type) { ................. ................. //--- case defNeuronVAEOCL: vae = new CVAE(); if(!vae) { delete temp; return; } if(!vae.Init(outputs, 0, opencl, desc.count, desc.optimization, desc.batch)) { delete vae; delete temp; return; } if(!temp.Add(vae)) { delete vae; delete temp; return; } vae = NULL; break; default: return; break; } } else for(int n = 0; n < neurons; n++) { ................. ................. } if(!layers.Add(temp)) { delete temp; delete layers; return; } } //--- if(CheckPointer(opencl) == POINTER_INVALID) return; //--- create kernels opencl.SetKernelsCount(32); ................. ................. opencl.KernelCreate(def_k_VAEFeedForward, "VAE_FeedForward"); opencl.KernelCreate(def_k_VAECalcHiddenGradient, "VAE_CalcHiddenGradient"); //--- return; }
Implementieren wir ähnliche Änderungen an der Modelllademethode CNet::Load. Ich werde den Code in diesem Artikel nicht wiederholen. Der gesamte EA-Code ist im Anhang zu finden.
Anschließend fügen wir in den Methoden CLayer::CreateElement und CLayer::Load die Zeiger auf die neue Klasse hinzu.
Schließlich ergänzen wir noch neue Klassenzeiger zu den Dispatcher-Methoden der neuronalen Basisschicht CNeuronBaseOCL FeedForward, calcHiddenGradients und UpdateInputWeights.
Nachdem wir alle notwendigen Ergänzungen vorgenommen haben, können wir mit der Implementierung und Prüfung des Modells beginnen. Der gesamte Code aller Klassen und Methoden befindet sich in der Anlage.
3. Tests
Um die Funktionsweise des Variierten Autoencoders zu testen, werden wir das Modell aus den vorherigen Artikeln verwenden. Speichern Sie ihn in einer neuen Datei „vae.mq5“. In diesem Modell lieferte der Encoder 2 Werte auf der 5. neuronalen Schicht. Um den Betrieb des Variierten Autoencoders richtig zu organisieren, habe ich die Schichtgröße am Encoderausgang auf 4 Neuronen erhöht. Ich habe auch unsere neue neuronale Schicht eingefügt, die mit dem latenten Zustand des Variierten Autoencoders als 6. Neuron. Das Modell wurde mit EURUSD-Daten und dem H1-Zeitrahmen trainiert, ohne dass die Parameter geändert wurden. Als Zeitraum für die Modellbildung wurden die letzten 15 Jahre herangezogen. Die folgende Abbildung zeigt eine vergleichende Grafik der Lerndynamik von mehrschichtigen und variierenden Autokodierern.

Wie Sie sehen können, zeigte der Variierter Autoencoder nach den Ergebnissen des Modelltrainings während des gesamten Trainingszeitraums einen deutlich geringeren Datenwiederherstellungsfehler. Darüber hinaus zeigte der Variierter Autoencoder eine höhere Dynamik bei der Fehlerreduzierung.
Auf der Grundlage der Testergebnisse können wir schließen, dass Variations-Auto-Coder bei der Lösung des Problems der Extraktion von Zeitreihenmerkmalen am Beispiel der EURUSD-Preisdynamik ein großes Potenzial für die Extraktion individueller Musterbeschreibungsmerkmale haben.
Schlussfolgerung
In diesem Artikel haben wir uns mit dem Variierter Autoencoder-Algorithmus vertraut gemacht. Wir haben eine Klasse zur Implementierung eines Algorithmus für den Variierten Autoencoder entwickelt. Wir haben auch ein Testtraining des Variations-Auto-Encoder-Modells mit realen historischen Daten durchgeführt. Die Testergebnisse zeigen die Konsistenz des Variierten Autoencoder-Modells, wenn es als vorläufiges Training für Modelle verwendet wird, die einzelne Merkmale zur Beschreibung der Marktsituation extrahieren sollen. Die Ergebnisse eines solchen Trainings können zur Erstellung von Handelsmustern verwendet werden, die mit Methoden des überwachten Lernens weiter trainiert werden können.
Liste der Referenzen
- Neuronale Netze leicht gemacht (Teil 14): Datenclustering
- Neuronale Netze leicht gemacht (Teil 15): Datenclustering mit MQL5
- Neuronale Netze leicht gemacht (Teil 16): Praktische Anwendung des Clustering
- Neuronale Netze leicht gemacht (Teil 17): Dimensionsreduktion.
- Neuronale Netze leicht gemacht (Teil 18): Assoziationsregeln
- Neuronale Netze leicht gemacht (Teil 19): Assoziationsregeln mit MQL5
- Neuronale Netze leicht gemacht (Teil 20): Autokodierer
- Tutorial on Variational Autoencoders
- Intuitively Understanding Variational Autoencoders
- Tutorial - What is a variational autoencoder?
Programme, die im diesem Artikel verwendet werden
| # | Name | Typ | Beschreibung |
|---|---|---|---|
| 1 | vae.mq5 | EA | Autoencoder eines lernenden Expert Advisors |
| 2 | vae2.mq5 | EA | EA zur Vorbereitung von Daten für die Visualisierung |
| 3 | VAE.mqh | Klassenbibliothek | Klassenbibliothek des Variierten Autoencoders für latente Schichten |
| 4 | NeuroNet.mqh | Klassenbibliothek | Eine Bibliothek von Klassen zur Erstellung eines neuronalen Netzes |
| 5 | NeuroNet.cl | Code Base | OpenCL-Programmcode-Bibliothek |
Übersetzt aus dem Russischen von MetaQuotes Ltd.
Originalartikel: https://www.mql5.com/ru/articles/11206
 Neuronale Netze leicht gemacht (Teil 22): Unüberwachtes Lernen von rekurrenten Modellen
Neuronale Netze leicht gemacht (Teil 22): Unüberwachtes Lernen von rekurrenten Modellen
 Experimente mit neuronalen Netzen (Teil 2): Intelligente Optimierung neuronaler Netze
Experimente mit neuronalen Netzen (Teil 2): Intelligente Optimierung neuronaler Netze
- Freie Handelsapplikationen
- Über 8.000 Signale zum Kopieren
- Wirtschaftsnachrichten für die Lage an den Finanzmärkte
Sie stimmen der Website-Richtlinie und den Nutzungsbedingungen zu.