
Neuronale Netze leicht gemacht (Teil 67): Nutzung früherer Erfahrungen zur Lösung neuer Aufgaben

Einführung
Verstärkungslernen basiert auf der Maximierung der Belohnung, die man von der Umgebung während der Interaktion mit ihr erhält. Es liegt auf der Hand, dass der Lernprozess eine ständige Interaktion mit der Umgebung erfordert. Die Situationen sind jedoch unterschiedlich. Bei der Lösung bestimmter Aufgaben können wir auf verschiedene Einschränkungen bei der Interaktion mit der Umgebung stoßen. Eine mögliche Lösung für solche Situationen ist die Verwendung von Offline-Algorithmen für das verstärkte Lernen. Sie ermöglichen das Trainieren von Modellen auf der Grundlage eines begrenzten Archivs von Trajektorien, die während der ersten Interaktion mit der Umgebung gesammelt wurden, solange diese verfügbar war.
Natürlich hat das Offline-Verstärkungslernen einige Nachteile. Insbesondere wird das Problem der Untersuchung der Umgebung noch akuter, da wir es mit einer begrenzten Trainingsstichprobe zu tun haben, die nicht in der Lage ist, die gesamte Vielseitigkeit der Umgebung zu berücksichtigen. Dies gilt insbesondere in komplexen stochastischen Umgebungen. Im vorigen Artikel haben wir eine der Möglichkeiten zur Lösung dieses Problems erörtert (die Methode ExORL).
Manchmal können jedoch Einschränkungen der Interaktionen mit der Umgebung entscheidend sein. Der Prozess der Umgebungserkundung kann von positiven und negativen Belohnungen begleitet sein. Negative Belohnungen können höchst unerwünscht sein und mit finanziellen Verlusten oder anderen unerwünschten Verlusten einhergehen, die Sie nicht akzeptieren können. Aber Aufgaben kommen selten aus dem Nichts. Meistens optimieren wir einen bestehenden Prozess. Und in unserem Zeitalter der Informationstechnologie kann man fast immer Erfahrungen in der Interaktion mit der zu erforschenden Umgebung bei der Lösung ähnlicher Aufgaben finden. Es ist möglich, Daten aus der realen Interaktion mit der Umgebung zu verwenden, die in gewissem Maße den erforderlichen Raum von Aktionen und Zuständen abdecken können. Experimente, bei denen solche Erfahrungen genutzt werden, um neue Aufgaben bei der Steuerung von realen Robotern zu lösen, werden in dem Artikel „Real World Offline Reinforcement Learning with Realistic Data Source“ beschrieben. Die Autoren des Artikels schlagen einen neuen Rahmen für das Training von Modellen vor: Real-ORL.
1. Real-ORL-Framework
Offline Reinforcement Learning (ORL) modelliert eine Markov-Entscheidungsumgebung. Dies setzt den Zugang zu einem vorab erstellten Datensatz in Form von Trajektorien voraus, die unter Verwendung einer oder mehrerer Verhaltensstrategien gesammelt wurden. Das Ziel von ORL ist die Verwendung eines Offline-Datensatzes zum Trainieren einer fast optimalen Strategie π zu verwenden. Im Allgemeinen gibt es keine Möglichkeit, eine optimale Strategie π* zu erlernen, da die Exploration unzureichend ist und der Trainingsdatensatz begrenzt ist. In diesem Fall versuchen wir, die beste Strategie zu finden, die auf der Grundlage des verfügbaren Datensatzes trainiert werden kann.
Die meisten Offline-Algorithmen des Reinforcement Learning beinhalten eine Form der Regularisierung oder des Konservatismus. Diese können folgende Formen annehmen, sind aber nicht auf diese beschränkt:
- Regularisierung des politischen Gradienten
- Näherungsweise dynamische Programmierung
- Lernen anhand eines Umgebungsmodells
Die Autoren des Real-ORL-Rahmens bieten keine neuen Algorithmen für die Modelltraining an. In ihrer Arbeit untersuchen sie eine Reihe von bisher repräsentativen ORL-Algorithmen und bewerten ihre Leistung auf einem physischen Roboter in realistischen Anwendungsfällen. Die Autoren des Frameworks weisen darauf hin, dass sich die in dem Artikel analysierten Lernalgorithmen hauptsächlich auf die Simulation konzentrieren, wobei ideale Datensätze, unabhängige und gleichzeitige Datensätze verwendet werden. Dieser Ansatz ist jedoch in der realen stochastischen Welt, in der Aktionen von operativen Verzögerungen begleitet werden, nicht korrekt. Dies schränkt den Einsatz von trainierten Richtlinien auf physischen Robotern ein. Es ist unklar, ob die Ergebnisse von simulierten Benchmarks oder begrenzten Gerätebewertungen auf reale Prozesse verallgemeinert werden können. Der Artikel „Real World Offline Reinforcement Learning with Realistic Data Source“ zielt darauf ab, diese Lücke zu schließen. Es werden empirische Studien mehrerer Offline-Verstärkungslernalgorithmen vorgestellt, die auf reale Lernaufgaben angewandt werden, wobei der Schwerpunkt auf der Verallgemeinerung über den Bereich des Trainingssets hinaus liegt.
Das Nachahmungslernen wiederum ist ein alternativer Ansatz zum Erlernen von Kontrollstrategien in der Robotik. Im Gegensatz zu RL, bei dem Strategien durch Optimierung der Belohnungen trainiert werden, zielt das Imitationslernen auf die Nachahmung von Expertendemonstrationen ab. In den meisten Fällen werden überwachte Lernansätze verwendet, bei denen die Belohnungsfunktion aus dem Lernprozess ausgeschlossen wird. Interessant ist auch die Kombination von Verstärkungslernen und Nachahmungslernen.
In ihrer Arbeit verwenden die Autoren des Real-ORL-Rahmens einen Offline-Datensatz, der aus den Trajektorien einer heuristischen manuellen Strategie besteht. Die Trajektorien wurden unter der Aufsicht eines Experten gesammelt und stellen einen hochwertigen Datensatz dar. Die Autoren der Methode betrachten das Offline-Nachahmungslernen (insbesondere das Klonen von Verhaltensweisen) als den grundlegenden Algorithmus in ihrer empirischen Forschung.
Um die Objektivität bei der Bewertung von Lernmethoden zu maximieren, werden in diesem Artikel vier klassische manipulative Aufgaben untersucht, die eine Reihe gängiger manipulativer Herausforderungen darstellen. Jede Aufgabe wird als MDP mit einer eindeutigen Belohnungsfunktion modelliert. Jede der untersuchten Lernmethoden wird zur Lösung aller 4 Aufgaben verwendet, wodurch alle Algorithmen unter absolut gleichen Bedingungen arbeiten.
Wie bereits erwähnt, werden die Trainingsdaten anhand einer unter Aufsicht eines Experten entwickelten Strategie erhoben. Grundsätzlich wurden die erfolgreichen Verläufe in allen vier Aufgaben gesammelt. Die Autoren des Frameworks sind der Meinung, dass das Sammeln von suboptimalen Trajektorien oder die Verzerrung von Experten-Trajektorien durch verschiedene Störgeräusche für die Robotik nicht akzeptabel ist, da verzerrtes oder zufälliges Verhalten unsicher und schädlich für den technischen Zustand der Ausrüstung ist. Gleichzeitig bietet die Verwendung von Daten, die bei verschiedenen Aufgaben gesammelt wurden, aus drei Gründen eine realistischere Umgebung für die Anwendung von Offline-Verstärkungslernen auf reale Roboter:
- Das autonome Sammeln von „zufälligen/explorativen“ Daten mit einem echten Roboter würde umfangreiche Sicherheitseinschränkungen, Überwachung und Anleitung durch Experten erfordern.
- Der Einsatz von Experten zur Aufzeichnung derartiger Zufallsdaten in großen Mengen ist weniger sinnvoll als die Erfassung aussagekräftiger Trajektorien für eine reale Aufgabe.
- Die Entwicklung aufgabenspezifischer Strategien und Stresstests der ORL-Fähigkeit auf der Grundlage eines solchen starken Datensatzes ist praktikabler als die Verwendung eines unzureichenden Datensatzes.
Die Autoren des Real-ORL-Rahmens haben den Datensatz im Voraus eingefroren, um eine Verzerrung zugunsten der Aufgabe (oder des Algorithmus) zu vermeiden.
Um die Strategien der Agenten in allen Aufgaben zu trainieren, unterteilen die Autoren von Real-ORL jede Aufgabe in einfachere Phasen, die durch Unterziele gekennzeichnet sind. Der Agent geht in kleinen Schritten auf Teilziele zu, bis einige aufgabenspezifische Kriterien erfüllt sind. Die auf diese Weise trainierten Strategien erreichten aufgrund von Steuerungsrauschen und Tracking-Fehlern nicht die theoretisch maximal mögliche Leistung. Sie bewältigen die Aufgabe jedoch mit einer hohen Erfolgsquote und sind in ihrer Leistung mit menschlichen Vorführungen vergleichbar.
Die Autoren von Real-ORL führten Experimente durch, die mehr als 3000 Trainingstrajektorien, mehr als 3500 Auswertungstrajektorien und mehr als 270 menschliche Arbeitsstunden umfassten. Durch umfangreiche Studien haben sie herausgefunden, dass:
- Für bereichsinterne Aufgaben könnten die Algorithmen des Verstärkungslernens auf Problembereiche mit wenig Daten und auf dynamische Probleme verallgemeinert werden.
- Die Veränderung der ORL-Leistung nach der Verwendung heterogener Daten hängt von den Agenten, dem Aufgabendesign und den Dateneigenschaften ab.
- Bestimmte heterogene, aufgabenunabhängige Trajektorien können eine überlappende Datenunterstützung bieten und ein besseres Lernen ermöglichen, sodass ORL-Agenten ihre Leistung verbessern können.
- Der beste Agent für jede Aufgabe ist entweder der ORL-Algorithmus oder die Parität zwischen ORL und BC. Die in dem Artikel vorgestellten Evaluierungen zeigen, dass selbst in einem Datenmodus außerhalb der Domäne, der für die reale Welt realistischer ist, Offline-Verstärkungslernen ein effektiver Ansatz ist.
Unten sehen Sie die Visualisierung des Real-ORL-Rahmens, die von den Autoren bereitgestellt wird.
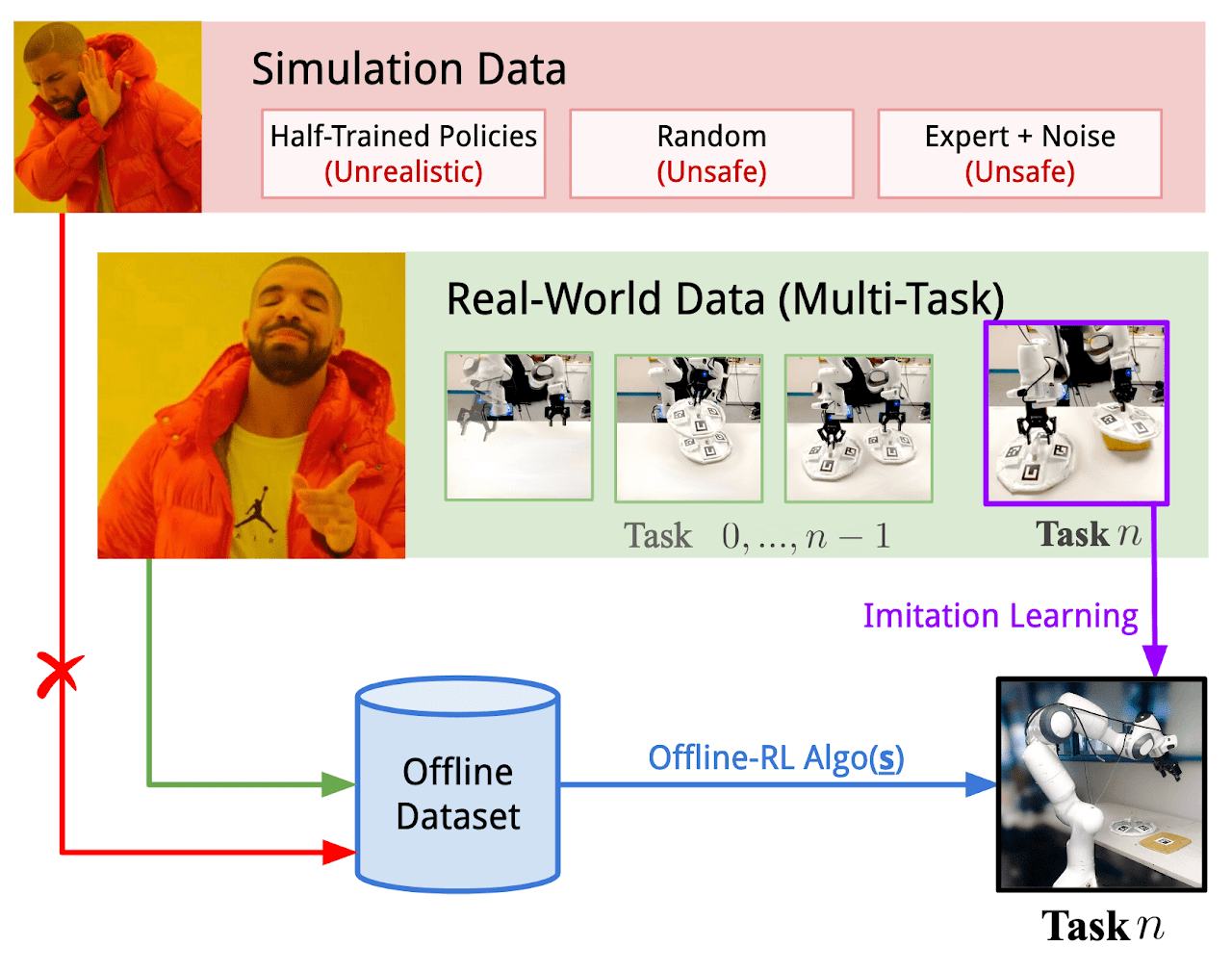
2. Implementierung mit MQL5
Der Artikel „Real World Offline Reinforcement Learning with Realistic Data Source“ bestätigt empirisch die Effektivität von Offline Reinforcement Learning Methoden zur Lösung von realen Aufgaben. Was mir jedoch auffiel, war die Verwendung von Daten über die Lösung ähnlicher Aufgaben zur Entwicklung der Agentenpolitik. Das einzige Kriterium für die Daten ist hier die Umgebung. Das heißt, der Datensatz muss als Ergebnis einer Interaktion mit der zu analysierenden Umgebung erhoben werden.
Wie können wir davon profitieren? Zumindest erhalten wir umfangreiche Informationen über die Erkundung der Umgebung, in unserem Fall der Finanzmärkte. Wir haben schon oft über eine der Hauptaufgaben des Verstärkungslernens gesprochen, nämlich die Erkundung der Umgebung. Gleichzeitig hatten wir immer eine große Menge an Informationen, die wir nicht nutzten. Ich spreche von Signalen. Im folgenden Screenshot habe ich absichtlich die Autoren und die Namen der Signale entfernt. In unserem Experiment ist das einzige Kriterium für Signale das Vorhandensein von Transaktionen während des historischen Zeitraums des Trainingszeitraums für das ausgewählte Finanzinstrument.

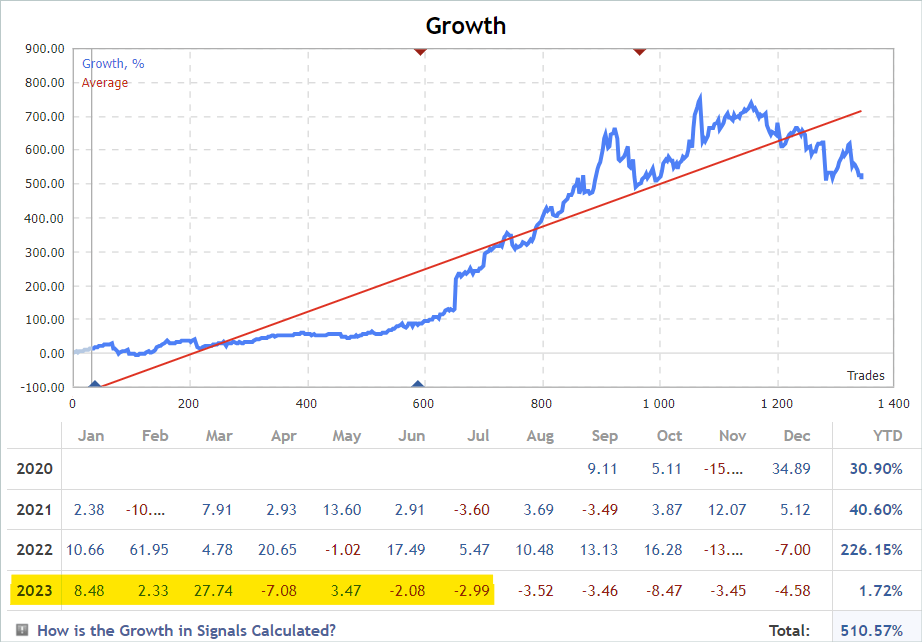
Wir trainieren Modelle für den Zeitraum der ersten 7 Monate des Jahres 2023 für das Instrument EURUSD. Diese Kriterien werden für die Auswahl der Signale herangezogen. Dabei kann es sich sowohl um kostenpflichtige als auch um kostenlose Signale handeln. Bitte beachten Sie, dass bei kostenpflichtigen Signalen ein Teil der Historie ausgeblendet wird. Allerdings sind die neuesten Angebote meist versteckt. Aber wir sind an einer veröffentlichte Historie interessiert.
Auf der Registerkarte „Konto“ prüfen wir die Vorgänge im betreffenden Zeitraum.
Auf der Registerkarte „Statistik“ werden die Operationen für das Finanzinstrument überprüft. Wir suchen jedoch nicht nach Signalen, die nur für das betreffende Instrument funktionieren. Unnötige Handelsgeschäfte werden wir später ausschließen.
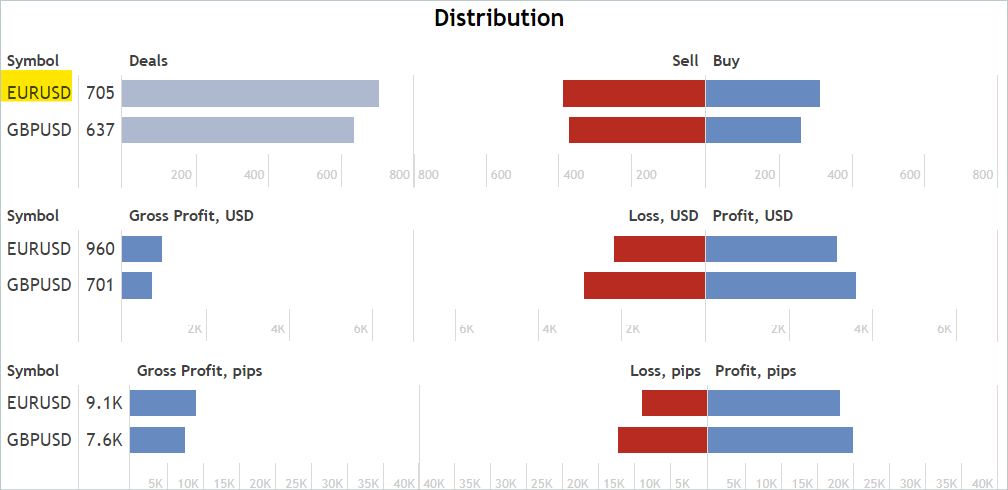
Ich stimme zu, dass dies eine eher grobe und indirekte Analyse ist. Sie garantiert nicht das Vorhandensein von Handelsgeschäften für das analysierte Finanzinstrument im gewünschten historischen Zeitraum. Aber die Wahrscheinlichkeit, dass es zu Absprachen kommt, ist recht hoch. Diese Analyse ist recht einfach und leicht durchzuführen.
Wenn wir ein passendes Signal gefunden haben, rufen wir die Registerkarte „Handelshistorie“ des Signals auf und laden eine csv-Datei mit dem Geschäftsverlauf herunter.
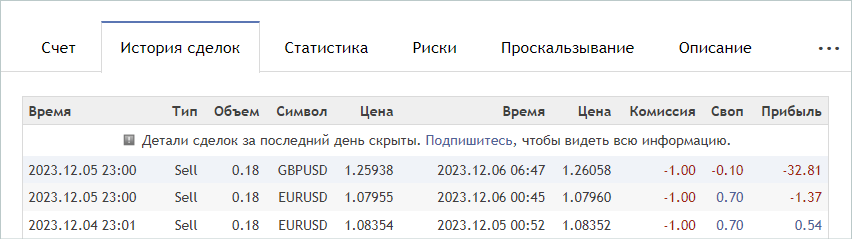

Bitte beachten Sie, dass die heruntergeladenen Dateien im gemeinsamen Ordner von MetaTrader 5 „...\AppData\Roaming\MetaQuotes\Terminal\Common\Files\“ gespeichert werden müssen. Der Einfachheit halber habe ich ein Unterverzeichnis „Signals“ angelegt und die Dateien aller Signale in „SignalX.csv“ umbenannt, wobei X die fortlaufende Nummer des gespeicherten Signalverlaufs ist.
An dieser Stelle ist anzumerken, dass der hier betrachtete Real-ORL-Rahmen die Verwendung ausgewählter Trajektorien als Erfahrung der Interaktion mit der Umgebung beinhaltet. Es verspricht keineswegs das vollständige Klonen von Trajektorien. Daher überprüfen wir bei der Auswahl der Trajektorien nicht die Korrelation (oder eine andere statistische Analyse) der Handelsgeschäfte mit den von uns verwendeten Indikatoren. Aus demselben Grund sollten Sie nicht erwarten, dass ein trainiertes Modell die Aktionen des profitabelsten oder eines anderen verwendeten Signals vollständig wiederholt.
Mit dieser Methode habe ich 20 Signale ausgewählt. Allerdings können wir die daraus resultierenden csv-Dateien nicht für das Training unserer Modelle verwenden. Wir müssen die Abschlüsse mit den historischen Kursbewegungen und den Indikatorwerten zum Zeitpunkt der Abschlüsse abgleichen und für jedes der verwendeten Signale eine Trajektorie erfassen. Wir werden diese Funktionalität im Expert Advisor „...\RealORL\ResearchRealORL.mq5“ ausführen, aber zunächst werden wir ein wenig Vorarbeit leisten.
Um jede Handelstransaktion aus dem Handelsverlauf des Signals aufzuzeichnen, erstellen wir eine Klasse CDeal. Diese Klasse ist nur für den internen Gebrauch bestimmt. Um unnötige Operationen zu vermeiden, werden wir die Wrapper für den Zugriff auf Klassenvariablen weglassen. Alle Variablen werden öffentlich deklariert.
class CDeal : public CObject { public: datetime OpenTime; datetime CloseTime; ENUM_POSITION_TYPE Type; double Volume; double OpenPrice; double StopLos; double TakeProfit; double point; //--- CDeal(void); ~CDeal(void) {}; //--- vector<float> Action(datetime current, double ask, double bid, int period_seconds); };
Klassenvariablen sind vergleichbar mit DEAL-Feldern in MetaTrader 5. Wir haben nur die Variable für den Symbolnamen weggelassen, da wir mit einem Finanzsymbol arbeiten sollen. Wenn Sie jedoch ein Modell mit mehreren Währungen erstellen, sollten Sie den Symbolnamen hinzufügen.
Beachten Sie auch, dass wir beim Handel den Stop-Loss und den Take-Profit in Form eines Preises angeben, während das Modell die Aktion des Agenten in relativen Einheiten generiert. Um Daten konvertieren zu können, speichern wir die Größe eines Symbolpunktes in der Variablen point.
Im Klassenkonstruktor werden wir die Variablen mit Anfangswerten füllen. Der Destruktor der Klasse bleibt leer.
void CDeal::CDeal(void) : OpenTime(0), CloseTime(0), Type(POSITION_TYPE_BUY), Volume(0), OpenPrice(0), StopLos(0), TakeProfit(0), point(1e-5) { }
Um ein Handelsgeschäft in einen Vektor von Agentenaktionen umzuwandeln, erstellen wir die Methode Action. In den Parametern werden das Datum und die Uhrzeit der aktuellen Bareröffnung, die Bid- und Ask-Preise sowie das Intervall des analysierten Zeitrahmens in Sekunden angegeben. Wir führen die Marktanalyse und alle Handelsoperationen immer bei der Eröffnung eines jeden Balkens durch.
Beachten Sie, dass der Zeitpunkt der Handelsoperationen in der Geschichte der von uns gesammelten Signale von der Eröffnungszeit des Balkens in dem von uns verwendeten Zeitrahmen abweichen kann. Wenn wir eine Position mit einem Stop-Loss oder Take-Profit innerhalb des Balkens schließen können, dann können wir eine Position nur bei der Eröffnung des Balkens eröffnen. Daher nehmen wir hier eine Annahme und eine kleine Anpassung des Preises und der Zeit für die Positionseröffnung vor: Wir eröffnen eine Position bei der Eröffnung des Balkens, wenn dieser in der Signalhistorie vor der Schließung eröffnet wird.
Dieser Logik folgend gibt die Methode im Methodencode einen Null-Vektor von Agenten-Aktionen zurück, wenn die aktuelle Zeit kleiner als die Positionseröffnungszeit unter Berücksichtigung der Anpassung oder größer als die Positionsschlusszeit ist.
vector<float> CDeal::Action(datetime current, double ask, double bid, int period_seconds) { vector<float> result = vector<float>::Zeros(NActions); if((OpenTime - period_seconds) > current || CloseTime <= current) return result;
Bitte beachten Sie, dass wir zunächst einen Nullvektor der Ergebnisse erstellen und erst dann die Zeitsteuerung implementieren und das Ergebnis zurückgeben. Dieser Ansatz ermöglicht es uns, mit dem erzeugten Nullvektor von Ergebnissen weiter zu arbeiten. Wenn es also notwendig ist, den Aktionsvektor zu füllen, füllen wir nur Elemente, die nicht Null sind.
Der Aktionsvektor wird je nach Art der Position in den Körper der switch-Anweisung eingefügt. Im Falle einer Kaufposition wird das Geschäftsvolumen in dem mit 0 indizierten Element erfasst. Dann prüfen wir, ob Take-Profit und Stop-Loss von 0 verschieden sind, und wandeln den Preis gegebenenfalls in einen relativen Wert um. Wir schreiben die resultierenden Werte in die Elemente mit den Indizes 1 bzw. 2.
switch(Type) { case POSITION_TYPE_BUY: result[0] = float(Volume); if(TakeProfit > 0) result[1] = float((TakeProfit - ask) / (MaxTP * point)); if(StopLos > 0) result[2] = float((ask - StopLos) / (MaxSL * point)); break;
Ähnliche Operationen werden für eine kurze Position durchgeführt, wobei jedoch die Indizes der Vektorelemente um 3 verschoben sind.
case POSITION_TYPE_SELL: result[3] = float(Volume); if(TakeProfit > 0) result[4] = float((bid - TakeProfit) / (MaxTP * point)); if(StopLos > 0) result[5] = float((StopLos - bid) / (MaxSL * point)); break; }
Der erzeugte Vektor wird an den Aufrufer zurückgegeben.
//--- return result; }
Wir werden alle Angebote eines Signals in der Klasse CDeals zusammenfassen. Diese Klasse wird ein dynamisches Array von Objekten enthalten, zu dem wir Instanzen der oben erstellten Klasse CDeal und 2 Methoden hinzufügen werden:
- LoadDeals zum Laden von Handelsgeschäften aus einer csv-Historiendatei;
- Action, um einen Vektor der Aktionen des Agenten zu erzeugen.
class CDeals { protected: CArrayObj Deals; public: CDeals(void) { Deals.Clear(); } ~CDeals(void) { Deals.Clear(); } //--- bool LoadDeals(string file_name, string symbol, double point); vector<float> Action(datetime current, double ask, double bid, int period_seconds); };
Im Konstruktor und Destruktor der Klasse wird das dynamische Array der Handelsgeschäfte gelöscht.
Ich schlage vor, mit der Betrachtung der Methoden der Klasse zu beginnen, indem ich den Geschäftsverlauf aus der csv-Datei LoadDeals lade. In den Methodenparametern übergeben wir den Dateinamen, den Namen des analysierten Instruments und die Punktgröße. Ich habe absichtlich den Symbolnamen in die Parameter aufgenommen, da es bei verschiedenen Brokern oft Unterschiede in den Namen der Finanzinstrumente gibt. Selbst wenn der Expert Advisor auf dem Chart des analysierten Instruments läuft, kann sein Name daher von dem in der History-Datei vereinheitlichten Signal abweichen.
bool CDeals::LoadDeals(string file_name, string symbol, double point) { if(file_name == NULL || !FileIsExist(file_name, FILE_COMMON)) { PrintFormat("File %s not exist", file_name); return false; }
Im Hauptteil der Methode wird zunächst der Dateiname und sein Vorhandensein im gemeinsamen Terminalordner überprüft. Wenn die gewünschte Datei nicht gefunden wird, wird der Nutzer informiert und die Methode mit dem Ergebnis false beendet.
bool CDeals::LoadDeals(string file_name, string symbol, double point) { if(file_name == NULL || !FileIsExist(file_name, FILE_COMMON)) { PrintFormat("File %s not exist", file_name); return false; }
Der nächste Schritt besteht darin, den Namen des angegebenen Finanzsymbols zu überprüfen. Wenn der Name nicht gefunden wird, geben Sie den Symbolnamen des Charts ein, auf dem der EA läuft.
if(symbol == NULL) { symbol = _Symbol; point = _Point; }
Nach erfolgreicher Übergabe des Kontrollblocks öffnen wir die in den Methodenparametern angegebene Datei und überprüfen sofort das Ergebnis der Operation anhand des empfangenen Handle-Wertes. Wenn die Datei aus irgendeinem Grund nicht geöffnet werden kann, informieren wir den Nutzer über den aufgetretenen Fehler und beenden die Methode mit einem negativen Ergebnis.
ResetLastError(); int handle = FileOpen(file_name, FILE_READ | FILE_ANSI | FILE_CSV | FILE_COMMON, short(';'), CP_ACP); if(handle == INVALID_HANDLE) { PrintFormat("Error of open file %s: %d", file_name, GetLastError()); return false; }
An diesem Punkt ist die Vorbereitungsphase abgeschlossen, und wir gehen dazu über, den Datenlesezyklus zu organisieren. Vor jeder Iteration der Schleife wird geprüft, ob das Ende der Datei erreicht ist.
FileSeek(handle, 0, SEEK_SET); while(!FileIsEnding(handle)) { string s = FileReadString(handle); datetime open_time = StringToTime(s); string type = FileReadString(handle); double volume = StringToDouble(FileReadString(handle)); string deal_symbol = FileReadString(handle); double open_price = StringToDouble(FileReadString(handle)); volume = MathMin(volume, StringToDouble(FileReadString(handle))); datetime close_time = StringToTime(FileReadString(handle)); double close_price = StringToDouble(FileReadString(handle)); s = FileReadString(handle); s = FileReadString(handle); s = FileReadString(handle);
Im Hauptteil der Schleife lesen wir zunächst alle Informationen für eine Transaktion und schreiben sie in lokale Variablen. Gemäß der Dateistruktur enthalten die letzten 3 Elemente die Provision, den Swap und den Gewinn für das Geschäft. Wir verwenden diese Daten nicht in unserem Kursverlauf, da die Eröffnungszeit und der Kurs von den Angaben in der Historie abweichen können. Daher können auch die Gewinnwerte unterschiedlich sein. Darüber hinaus hängen die Provisionen und Swaps von den Einstellungen des Brokers ab.
Als Nächstes wird die Übereinstimmung zwischen dem Finanzinstrument der Handelsoperation und dem in den Parametern übergebenen Finanzinstrument, das wir analysieren, überprüft. Wenn die Symbole nicht übereinstimmen, wird mit der nächsten Iteration der Schleife fortgefahren.
if(StringFind(deal_symbol, symbol, 0) < 0) continue;
Wenn für das gewünschte Finanzinstrument ein Handelsgeschäft abgeschlossen wurde, erstellen wir eine Instanz des Objekts Geschäftsbeschreibung.
ResetLastError(); CDeal *deal = new CDeal(); if(!deal) { PrintFormat("Error of create new deal object: %d", GetLastError()); return false; }
Dann füllen wir sie. Bitte beachten Sie jedoch Folgendes. Wir können leicht sparen:
- Positionsart
- Eröffnungs- und Schließzeiten
- Eröffnungspreis
- Handelsvolumen
- Größe eines Punktes
Die Stop-Loss- und Take-Profit-Kurse werden jedoch nicht in der Handelshistorie angezeigt. Stattdessen wird nur der Preis, zu dem die Position geschlossen wurde, angegeben. Wir werden hier eine recht einfache Logik anwenden:
- Wir gehen davon aus, dass die Position durch Stop-Loss oder Take-Profit geschlossen wurde.
- Wenn in diesem Fall die Position mit einem Gewinn geschlossen wurde, dann wurde sie mit Gewinnmitnahme geschlossen. Andernfalls wurde er mit Stop-Loss geschlossen. Geben wir in dem entsprechenden Feld den Schlusskurs an.
- Das gegenüberliegende Feld bleibt leer.
deal.OpenTime = open_time; deal.CloseTime = close_time; deal.OpenPrice = open_price; deal.Volume = volume; deal.point = point; if(type == "Sell") { deal.Type = POSITION_TYPE_SELL; if(close_price < open_price) { deal.TakeProfit = close_price; deal.StopLos = 0; } else { deal.TakeProfit = 0; deal.StopLos = close_price; } } else { deal.Type = POSITION_TYPE_BUY; if(close_price > open_price) { deal.TakeProfit = close_price; deal.StopLos = 0; } else { deal.TakeProfit = 0; deal.StopLos = close_price; } }
Ich habe volles Verständnis für die Risiken des Handels ohne Stop-Loss, aber gleichzeitig erwarte ich, dass diese beim nachgelagerten Training des Modells minimiert werden.
Wir fügen die erstellte Beschreibung eines Handelsgeschäfts zu einem dynamischen Array hinzu und fahren mit der nächsten Iteration der Schleife fort.
ResetLastError(); if(!Deals.Add(deal)) { PrintFormat("Error of add new deal: %d", GetLastError()); return false; } }
Wenn das Ende der Datei erreicht ist, schließen wir sie und beenden die Methode mit dem Ergebnis true.
FileClose(handle); //--- return true; }
Der Algorithmus zur Erzeugung des Aktionsvektors des Agenten ist recht einfach. Wir gehen die gesamte Reihe von Handelsgeschäften durch und rufen die entsprechenden Methoden für jedes Handelsgeschäft auf.
vector<float> CDeals::Action(datetime current, double ask, double bid, int period_seconds) { vector<float> result = vector<float>::Zeros(NActions); for(int i = 0; i < Deals.Total(); i++) { CDeal *deal = Deals.At(i); if(!deal) continue; vector<float> action = deal.Action(current, ask, bid, period_seconds);
Allerdings gibt es einige Nuancen. Wir gehen davon aus, dass in der Historie eines Signals mehrere Positionen gleichzeitig geöffnet werden können, auch solche in unterschiedliche Richtungen. Daher müssen wir die Vektoren aller Handelsgeschäfte aus dem Archiv addieren. Aber wir können nur das Volumen erhöhen. Das einfache Hinzufügen von Stop-Loss- und Take-Profit-Levels ist nicht korrekt. Denken Sie daran, dass im Aktionsvektor des Agenten Stop-Loss und Take-Profit als Verschiebung in relativen Einheiten zum aktuellen Kurs angegeben werden. Bei der Addition der Vektoren für das Stop-Loss- und das Take-Profit-Niveau wird also die maximale Abweichung berücksichtigt. Volumina, die nicht rechtzeitig geschlossen wurden, werden vom EA bei der Eröffnung einer neuen Kerze geschlossen, da wir in diesem Fall eine Abnahme des Gesamtvolumens der Gesamtposition erwarten.
result[0] += action[0]; result[3] += action[3]; result[1] = MathMax(result[1], action[1]); result[2] = MathMax(result[2], action[2]); result[4] = MathMax(result[4], action[4]); result[5] = MathMax(result[5], action[5]); } //--- return result; }
Wir übergeben den endgültigen Vektor der Agent-Aktionen an das aufrufende Programm und beenden die Methode.
Damit sind die Vorarbeiten abgeschlossen und wir können mit der Arbeit am Expert Advisor „...\RealORL\ResearchRealORL.mq5“ fortfahren. Dieser EA wurde auf der Grundlage des zuvor besprochenen EAs „...\...\Research.mq5“ erstellt und hat somit dessen Konstruktionsvorlage geerbt. Sie hat auch alle externen Parameter geerbt.
//+------------------------------------------------------------------+ //| Input parameters | //+------------------------------------------------------------------+ input ENUM_TIMEFRAMES TimeFrame = PERIOD_H1; input double MinProfit = -10000; //--- input group "---- RSI ----" input int RSIPeriod = 14; //Period input ENUM_APPLIED_PRICE RSIPrice = PRICE_CLOSE; //Applied price //--- input group "---- CCI ----" input int CCIPeriod = 14; //Period input ENUM_APPLIED_PRICE CCIPrice = PRICE_TYPICAL; //Applied price //--- input group "---- ATR ----" input int ATRPeriod = 14; //Period //--- input group "---- MACD ----" input int FastPeriod = 12; //Fast input int SlowPeriod = 26; //Slow input int SignalPeriod = 9; //Signal input ENUM_APPLIED_PRICE MACDPrice = PRICE_CLOSE; //Applied price //--- input int Agent = 1;
Gleichzeitig verwendet dieser EA kein Modell, da die Entscheidung über die Handelsoperationen bereits für uns getroffen wurde, und wir verwenden die Handelshistorie des Signals. Daher entfernen wir alle Modellobjekte und fügen ein Objekt des CDeals-Signaltransaktionsarrays hinzu.
SState sState; STrajectory Base; STrajectory Buffer[]; STrajectory Frame[1]; CDeals Deals; //--- float dError; datetime dtStudied; //--- CSymbolInfo Symb; CTrade Trade; //--- MqlRates Rates[]; CiRSI RSI; CiCCI CCI; CiATR ATR; CiMACD MACD; //--- double PrevBalance = 0; double PrevEquity = 0;
Ähnlich verhält es sich mit der EA-Initialisierungsmethode: Anstatt ein vorab trainiertes Modell zu laden, wird die Historie der Handelsoperationen geladen.
//+------------------------------------------------------------------+ //| Expert initialization function | //+------------------------------------------------------------------+ int OnInit() { //--- if(!Symb.Name(_Symbol)) return INIT_FAILED; Symb.Refresh(); //--- if(!RSI.Create(Symb.Name(), TimeFrame, RSIPeriod, RSIPrice)) return INIT_FAILED; //--- if(!CCI.Create(Symb.Name(), TimeFrame, CCIPeriod, CCIPrice)) return INIT_FAILED; //--- if(!ATR.Create(Symb.Name(), TimeFrame, ATRPeriod)) return INIT_FAILED; //--- if(!MACD.Create(Symb.Name(), TimeFrame, FastPeriod, SlowPeriod, SignalPeriod, MACDPrice)) return INIT_FAILED; if(!RSI.BufferResize(HistoryBars) || !CCI.BufferResize(HistoryBars) || !ATR.BufferResize(HistoryBars) || !MACD.BufferResize(HistoryBars)) { PrintFormat("%s -> %d", __FUNCTION__, __LINE__); return INIT_FAILED; } //--- if(!Trade.SetTypeFillingBySymbol(Symb.Name())) return INIT_FAILED; //--- load history if(!Deals.LoadDeals(SignalFile(Agent), "EURUSD", SymbolInfoDouble(_Symbol, SYMBOL_POINT))) return INIT_FAILED; //--- PrevBalance = AccountInfoDouble(ACCOUNT_BALANCE); PrevEquity = AccountInfoDouble(ACCOUNT_EQUITY); //--- return(INIT_SUCCEEDED); }
Beachten Sie, dass wir beim Herunterladen von Signaldeal-Daten anstelle des Dateinamens SignalFile(Agent) angeben. Hier verwenden wir die Makro-Substitution. Aus diesem Grund haben wir zuvor einheitliche Signaldateinamen „SignalX.csv“. Die Makrosubstitution gibt den einheitlichen Namen der Signalverlaufsdatei zurück, der den Wert des externen Parameter des Agenten als Bezeichner angibt.
#define SignalFile(agent) StringFormat("Signals\\Signal%d.csv",agent)
So können wir anschließend „...\RealORL\ResearchRealORL.mq5“ im Optimierungsmodus im MetaTrader 5 Strategietester ausführen. Die Optimierung der Parameter des Agenten ermöglicht es, dass jeder Durchgang mit seiner eigenen Signalverlaufsdatei arbeitet. Auf diese Weise werden wir in der Lage sein, mehrere Signaldateien parallel zu verarbeiten und daraus Trajektorien der Interaktion mit der Umgebung zu sammeln.
Die Interaktion mit der Umgebung ist in der Methode OnTick implementiert. Hier prüfen wir wie üblich zunächst das Eintreten des Ereignisses der Öffnung einer neuen Bar.
void OnTick() { //--- if(!IsNewBar()) return;
Falls erforderlich, laden wir Daten über historische Kursbewegungen herunter. Wir aktualisieren auch die Puffer von Objekten für die Arbeit mit Indikatoren.
int bars = CopyRates(Symb.Name(), TimeFrame, iTime(Symb.Name(), TimeFrame, 1), HistoryBars, Rates); if(!ArraySetAsSeries(Rates, true)) return; //--- RSI.Refresh(); CCI.Refresh(); ATR.Refresh(); MACD.Refresh(); Symb.Refresh(); Symb.RefreshRates();
Da es keine Modelle für die Entscheidungsfindung gibt, besteht keine Notwendigkeit, Datenpuffer zu füllen. Um jedoch Informationen in der Trajektorie der Interaktion mit der Umgebung zu speichern, müssen wir die Zustandsstruktur mit den erforderlichen Daten füllen. Zunächst werden wir Daten über die Kursentwicklung und die Leistung der Indikatoren sammeln.
float atr = 0; for(int b = 0; b < (int)HistoryBars; b++) { float open = (float)Rates[b].open; float rsi = (float)RSI.Main(b); float cci = (float)CCI.Main(b); atr = (float)ATR.Main(b); float macd = (float)MACD.Main(b); float sign = (float)MACD.Signal(b); if(rsi == EMPTY_VALUE || cci == EMPTY_VALUE || atr == EMPTY_VALUE || macd == EMPTY_VALUE || sign == EMPTY_VALUE) continue; //--- int shift = b * BarDescr; sState.state[shift] = (float)(Rates[b].close - open); sState.state[shift + 1] = (float)(Rates[b].high - open); sState.state[shift + 2] = (float)(Rates[b].low - open); sState.state[shift + 3] = (float)(Rates[b].tick_volume / 1000.0f); sState.state[shift + 4] = rsi; sState.state[shift + 5] = cci; sState.state[shift + 6] = atr; sState.state[shift + 7] = macd; sState.state[shift + 8] = sign; }
Dann geben wir Informationen über den Kontostand und die offenen Positionen ein. Wir geben auch die Eröffnungszeit des aktuellen Balkens an. Beachten Sie, dass wir in diesem Stadium nur einen Zeitwert speichern, ohne Zeitstempelharmonien zu erzeugen. So können wir die Menge der gespeicherten Daten reduzieren, ohne dass Informationen verloren gehen.
sState.account[0] = (float)AccountInfoDouble(ACCOUNT_BALANCE); sState.account[1] = (float)AccountInfoDouble(ACCOUNT_EQUITY); //--- double buy_value = 0, sell_value = 0, buy_profit = 0, sell_profit = 0; double position_discount = 0; double multiplyer = 1.0 / (60.0 * 60.0 * 10.0); int total = PositionsTotal(); datetime current = TimeCurrent(); for(int i = 0; i < total; i++) { if(PositionGetSymbol(i) != Symb.Name()) continue; double profit = PositionGetDouble(POSITION_PROFIT); switch((int)PositionGetInteger(POSITION_TYPE)) { case POSITION_TYPE_BUY: buy_value += PositionGetDouble(POSITION_VOLUME); buy_profit += profit; break; case POSITION_TYPE_SELL: sell_value += PositionGetDouble(POSITION_VOLUME); sell_profit += profit; break; } position_discount += profit - (current - PositionGetInteger(POSITION_TIME)) * multiplyer * MathAbs(profit); } sState.account[2] = (float)buy_value; sState.account[3] = (float)sell_value; sState.account[4] = (float)buy_profit; sState.account[5] = (float)sell_profit; sState.account[6] = (float)position_discount; sState.account[7] = (float)Rates[0].time;
In den Belohnungsvektor füllen wir sofort die Elemente der Auswirkung von Veränderungen im Saldo und im Eigenkapital.
sState.rewards[0] = float((sState.account[0] - PrevBalance) / PrevBalance); sState.rewards[1] = float(1.0 - sState.account[1] / PrevBalance);
Und wir speichern die Werte für den Saldo und das Eigenkapital, die wir im nächsten Balken benötigen, um die Belohnung zu berechnen.
PrevBalance = sState.account[0]; PrevEquity = sState.account[1];
Anstelle eines Vorwärtsdurchgangs des Agenten fordern wir einen Vektor mit den Aktionen aus der Handelshistorien des Signals an.
vector<float> temp = Deals.Action(TimeCurrent(), SymbolInfoDouble(_Symbol, SYMBOL_ASK), SymbolInfoDouble(_Symbol, SYMBOL_BID), PeriodSeconds(TimeFrame) );
Die Verarbeitung und Dekodierung des Aktionsvektors erfolgt nach dem zuvor erarbeiteten Algorithmus. Erstens: Wir schließen multidirektionale Volumen aus.
double min_lot = Symb.LotsMin(); double step_lot = Symb.LotsStep(); double stops = MathMax(Symb.StopsLevel(), 1) * Symb.Point(); if(temp[0] >= temp[3]) { temp[0] -= temp[3]; temp[3] = 0; } else { temp[3] -= temp[0]; temp[0] = 0; }
Wir passen dann die Kaufposition an. Bisher war es jedoch nicht möglich, eine Position zu eröffnen, ohne einen Stop-Loss oder Take-Profit festzulegen. Dies ist jetzt eine notwendige Maßnahme. Daher nehmen wir Anpassungen vor, indem wir die Schließung zuvor offener Positionen überprüfen und Stop-Loss- bzw. Take-Profit-Kurse angeben.
//--- buy control if(temp[0] < min_lot || (temp[1] > 0 && (temp[1] * MaxTP * Symb.Point()) <= stops) || (temp[2] > 0 && (temp[2] * MaxSL * Symb.Point()) <= stops)) { if(buy_value > 0) CloseByDirection(POSITION_TYPE_BUY); } else { double buy_lot = min_lot + MathRound((double)(temp[0] - min_lot) / step_lot) * step_lot; double buy_tp = (temp[1] > 0 ? NormalizeDouble(Symb.Ask() + temp[1] * MaxTP * Symb.Point(), Symb.Digits()) : 0); double buy_sl = (temp[2] > 0 ? NormalizeDouble(Symb.Ask() - temp[2] * MaxSL * Symb.Point(), Symb.Digits()) : 0); if(buy_value > 0) TrailPosition(POSITION_TYPE_BUY, buy_sl, buy_tp); if(buy_value != buy_lot) { if(buy_value > buy_lot) ClosePartial(POSITION_TYPE_BUY, buy_value - buy_lot); else Trade.Buy(buy_lot - buy_value, Symb.Name(), Symb.Ask(), buy_sl, buy_tp); } }
Ähnliche Anpassungen nehmen wir im Block für die Anpassung von Verkaufspositionen vor.
//--- sell control if(temp[3] < min_lot || (temp[4] > 0 && (temp[4] * MaxTP * Symb.Point()) <= stops) || (temp[5] > 0 && (temp[5] * MaxSL * Symb.Point()) <= stops)) { if(sell_value > 0) CloseByDirection(POSITION_TYPE_SELL); } else { double sell_lot = min_lot + MathRound((double)(temp[3] - min_lot) / step_lot) * step_lot;; double sell_tp = (temp[4] > 0 ? NormalizeDouble(Symb.Bid() - temp[4] * MaxTP * Symb.Point(), Symb.Digits()) : 0); double sell_sl = (temp[5] > 0 ? NormalizeDouble(Symb.Bid() + temp[5] * MaxSL * Symb.Point(), Symb.Digits()) : 0); if(sell_value > 0) TrailPosition(POSITION_TYPE_SELL, sell_sl, sell_tp); if(sell_value != sell_lot) { if(sell_value > sell_lot) ClosePartial(POSITION_TYPE_SELL, sell_value - sell_lot); else Trade.Sell(sell_lot - sell_value, Symb.Name(), Symb.Bid(), sell_sl, sell_tp); } }
Am Ende der Methode fügen wir dem Belohnungsvektor Daten hinzu, kopieren den Aktionsvektor und übergeben die Struktur, die der Trajektorie hinzugefügt werden soll.
if((buy_value + sell_value) == 0) sState.rewards[2] -= (float)(atr / PrevBalance); else sState.rewards[2] = 0; for(ulong i = 0; i < NActions; i++) sState.action[i] = temp[i]; sState.rewards[3] = 0; sState.rewards[4] = 0; if(!Base.Add(sState)) ExpertRemove(); }
Damit ist die Überprüfung der Methoden des EA „...\RealORL\ResearchRealORL.mq5“ abgeschlossen, da die übrigen Methoden unverändert verwendet werden. Der vollständige Code des EA und aller im Artikel verwendeten Programme ist im Anhang verfügbar.
Die Autoren der Real-ORL-Methode schlagen keine neue Methode zum Erlernen der Actor-Politik vor. Für unser Experiment haben wir weder den Algorithmus zum Erlernen von Richtlinien noch die Modellarchitektur geändert. Wir gehen diesen Schritt bewusst, um die Bedingungen mit dem Training des Modells aus dem vorherigen Artikel vergleichbar zu machen. Dies wird uns letztendlich ermöglichen, die Auswirkungen des Real-ORL-Rahmens selbst auf das Ergebnis des politischen Lernens zu bewerten.
3. Tests
Oben haben wir Informationen über den Handel mit verschiedenen Signalen gesammelt und einen Expert Advisor vorbereitet, der die gesammelten Informationen in Trajektorien der Interaktion mit der Umgebung umwandelt. Nun gehen wir dazu über, die geleistete Arbeit zu testen und die Auswirkungen der ausgewählten Trajektorien auf die Trainingsergebnisse des Modells zu bewerten. In dieser Arbeit werden wir völlig neue Modelle trainieren, die mit zufälligen Parametern initialisiert werden. Im vorigen Artikel haben wir bereits trainierte Modelle optimiert.
Zunächst führen wir den EA zur Umwandlung der Signalhistorie in die Trajektorie „...\RealORL\ResearchRealORL.mq5“ aus. Wir werden den EA im vollen Optimierungsmodus laufen lassen.
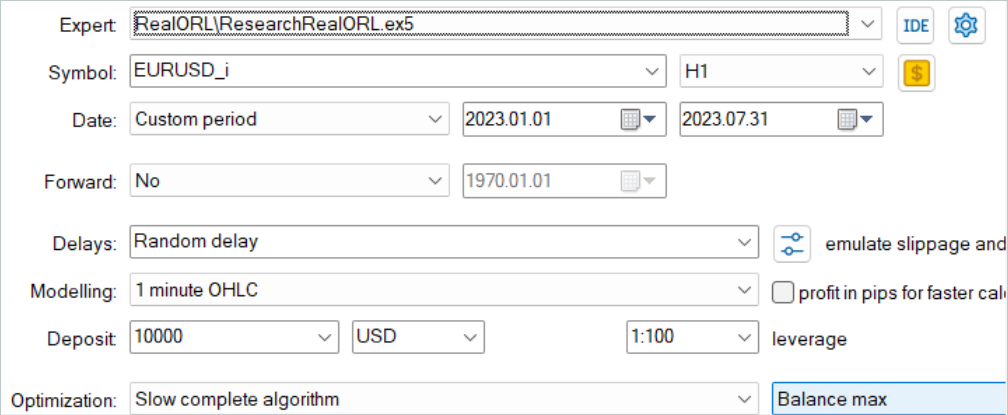
Wir werden nur einen Parameter, Agent, optimieren. Im Parameterbereich geben wir die erste und letzte ID der Signaldateien in Schritten von „1“ an.
Das Ergebnis waren einige recht interessante Trajektorien.
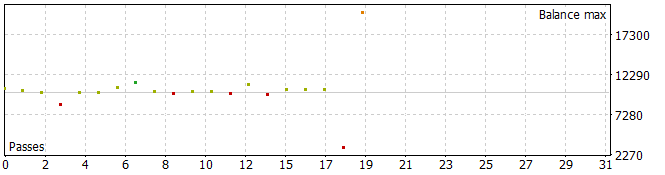
Fünf der Pässe schlossen während des analysierten Zeitraums mit einem Verlust ab, einer verdoppelte seinen Saldo.
Ein einziger Durchlauf der profitabelsten Trajektorie zeigte einen ziemlich starken Drawdown am 07.02.2023 und 25.07.2023. Ich werde nicht auf die vom Autor des Signals verwendete Strategie eingehen, da ich sie nicht kenne. Darüber hinaus ist es durchaus möglich, dass der Drawdown durch eine verfrühte Positionseröffnung verursacht wird, die durch eine Verschiebung des Positionseröffnungspunktes auf den Beginn des Balkens des analysierten Zeitrahmens hervorgerufen wird. Und natürlich führt der Einsatz von Stop-Losses, die wir absichtlich auf Null setzen, in solchen Situationen zu einer Verlustbegrenzung.
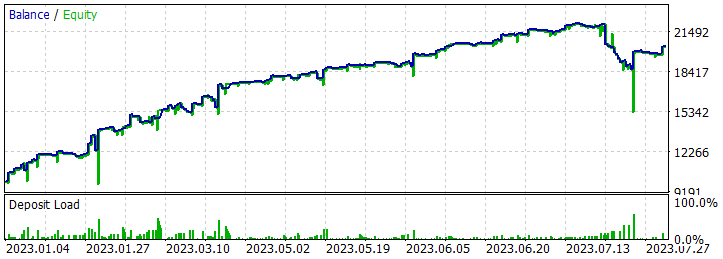
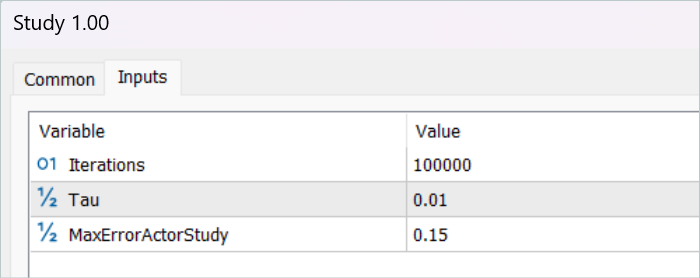
Nach dem Speichern der Trajektorien geht es an das Training des Modells. Zu diesem Zweck führen wir den EA „...\RealORL\Study.mq5“ aus.
Das primäre Training wurde nur mit Trajektoriedaten durchgeführt, die aus den Ergebnissen des Signalbetriebs gewonnen wurden. Ich muss zugeben, dass ein Wunder nicht geschehen ist. Die Ergebnisse des Modells nach dem ersten Training waren weit von den gewünschten Ergebnissen entfernt. Die trainierte Strategie generierte einen Verlust sowohl für den Trainingszeitraum in den ersten 7 Monaten des Jahres 2023 als auch für das historische Testintervall im August 2023. Aber ich würde nicht von der Unwirksamkeit des vorgeschlagenen Real-ORL-Rahmens sprechen. Die ausgewählten 20 Trajektorien sind weit entfernt von den 3000 Trajektorien, die von den Autoren des Frameworks verwendet wurden. Diese 20 Trajektorien decken nicht einmal einen kleinen Teil der Vielfalt der möglichen Aktionen des Agenten ab.
Bevor das Training fortgesetzt wurde, wurden dem Puffer der Trainingstrajektorien mit Hilfe des EA „...\RealORL\Research.mq5“ weitere Daten hinzugefügt. Dieser EA-Advisor führt Durchläufe mit Entscheidungsfindung auf der Grundlage der zuvor trainierten Strategie des Agenten aus. Die Erkundung der Umgebung erfolgt dank der Stochastizität des latenten Zustands und der Politik des Agenten. Zwei Stochastiken sorgen für eine ziemlich große Vielfalt an Aktionen des Agenten, die es ihm ermöglichen, die Umgebung zu erkunden. Wenn die Politik des Agenten lernt, nehmen beide Stochastizitäten aufgrund einer Abnahme der Varianz der einzelnen Parameter ab. Dies macht die Handlungen des Agenten vorhersehbarer und bewusster.
Wir fügen dem Puffer 200 neue Trajektorien hinzu und wiederholen das Modelltraining.
Dieses Mal war der Trainingsprozess für die Agentenpolitik recht langwierig. Ich musste den Erfahrungswiedergabepuffer viele Male mit dem EA „...\RealORL\Research.mq5“ aktualisieren, bevor ich eine rentable Police erhielt. Bitte beachten Sie, dass wir bei der Aktualisierung des Erfahrungswiederholungspuffers, nachdem dieser vollständig gefüllt ist, die verlustreichsten (gewinnärmsten) Trajektorien durch profitablere ersetzen. Daher haben wir nur Trajektorien ersetzt, die mit dem EA „...\RealORL\Research.mq5“ gesammelt wurden. Die Trajektorien der Signale blieben aufgrund ihrer allgemeinen Rentabilität ständig im Erfahrungswiedergabepuffer.
Wie bereits erwähnt, ist es mir durch langes Training gelungen, eine Strategie zu entwickeln, die in der Lage ist, auf dem Trainingsset Gewinne zu erzielen. Darüber hinaus war die daraus resultierende Politik in der Lage, die gewonnenen Erfahrungen auf neue Daten zu verallgemeinern. Dies wird durch den Gewinn an historischen Daten über den Trainingszeitraum hinaus belegt.


Ausgehend von den historischen Daten der Teststichprobe tätigte der Agent 131 Transaktionen, von denen 48,85 % mit Gewinn abgeschlossen wurden. Der maximale Gewinn ist fast 10 % niedriger als der maximale Verlust (379,89 bzw. 398,49). Gleichzeitig ist der durchschnittliche Gewinn 40 % höher als der durchschnittliche Verlust. Daraus ergibt sich für den Testzeitraum ein Gewinnfaktor von 1,34 und ein Erholungsfaktor von 0,94.
Es ist auch festzustellen, dass zwischen 70 Kauf- und 61 Verkaufs-Transaktionen nahezu Parität besteht. Dies zeigt, dass der Agent in der Lage ist, lokale Trends aufzuzeigen und nicht nur dem globalen Trend zu folgen.
Schlussfolgerung
In diesem Artikel haben wir das Real-ORL-Framework besprochen, das wir aus der Robotik kennen. Die Autoren des Frameworks führen in ihrer Arbeit recht umfangreiche empirische Untersuchungen mit einem echten Roboter durch, die es ihnen ermöglichen, die folgenden Schlussfolgerungen zu ziehen:
- Für bereichsinterne Aufgaben könnten die Algorithmen des Verstärkungslernens auf Problembereiche mit wenig Daten und auf dynamische Probleme verallgemeinert werden.
- Die Veränderung der ORL-Leistung nach der Verwendung heterogener Daten hängt von den Agenten, dem Aufgabendesign und den Dateneigenschaften ab.
- Bestimmte heterogene, aufgabenunabhängige Trajektorien können eine überlappende Datenunterstützung bieten und ein besseres Lernen ermöglichen, sodass ORL-Agenten ihre Leistung verbessern können.
- Der beste Agent für jede Aufgabe ist entweder der ORL-Algorithmus oder die Parität zwischen ORL und BC. Die in dem Artikel vorgestellten Evaluierungen zeigen, dass selbst in einem Datenmodus außerhalb der Domäne, der für die reale Welt realistischer ist, Offline-Verstärkungslernen ein effektiver Ansatz ist.
In unserer Arbeit prüfen wir die Möglichkeit, den vorgeschlagenen Rahmen für den Einsatz auf den Finanzmärkten zu nutzen. Insbesondere die von den Autoren des Real-ORL-Rahmens vorgeschlagenen Ansätze ermöglichen es uns, die Historie eines breiten Spektrums verschiedener auf dem Markt vorhandener Signale zu nutzen, um Modelle zu trainieren. Um die Vielfalt der Umgebung zu maximieren, benötigen wir jedoch eine große Anzahl von Trajektorien. Daher wäre es notwendig, so viele verschiedene Trajektorien wie möglich zu sammeln. Die Verwendung von nur 20 Trajektorien in dieser Arbeit kann wahrscheinlich als Fehler angesehen werden. Die Autoren von Real-ORL haben in ihrer Arbeit mehr als 3000 Trajektorien verwendet.
Ich persönlich bin der Meinung, dass die Methode für das anfängliche Training von Modellen verwendet werden kann und sollte und einen Vorteil gegenüber dem Sammeln von zufälligen Trajektorien hat. Es reicht jedoch nicht aus, nur „eingefrorene“ Trajektoriedaten zu verwenden, um eine optimale Agentenpolitik zu entwickeln. Es ist schwierig, von der kleinen Anzahl der von mir ausgewählten Trajektorien ernsthafte Ergebnisse zu erwarten. Aber auch die Autoren der Methode waren in ihrer Arbeit nicht in der Lage, die theoretisch maximal möglichen Ergebnisse zu erzielen. Darüber hinaus sind die Informationen über Signale begrenzt und erlauben es nicht, alle Risiken zu berücksichtigen. Die Signale enthalten zum Beispiel keine Informationen über Stop-Loss und Take-Profits. Das Fehlen dieser Daten erschwert eine umfassende Bewertung und Kontrolle der Risiken. Daher erfordert ein Modell, das anhand von Signaltrajektorien trainiert wurde, eine weitere Feinabstimmung anhand zusätzlicher Trajektorien, die unter Berücksichtigung der vortrainierten Strategie gewonnen wurden.
Referenzen
Programme, die im diesem Artikel verwendet werden
| # | Name | Typ | Beschreibung |
|---|---|---|---|
| 1 | Research.mq5 | EA | Beispielsammlung EA |
| 2 | ResearchRealORL.mq5 | EA | EA zum Sammeln von Beispielen mit der Real-ORL-Methode |
| 3 | ResearchExORL.mq5 | EA | EA für die Sammlung von Beispielen mit der ExORL-Methode |
| 4 | Study.mq5 | EA | Trainings-EA des Agenten |
| 5 | Test.mq5 | EA | Modeltest-EA |
| 6 | Trajectory.mqh | Klassenbibliothek | Struktur der Systemzustandsbeschreibung |
| 7 | NeuroNet.mqh | Klassenbibliothek | Eine Bibliothek von Klassen zur Erstellung eines neuronalen Netzes |
| 8 | NeuroNet.cl | Code Base | Die Bibliothek des Programmcodes von OpenCL |
Übersetzt aus dem Russischen von MetaQuotes Ltd.
Originalartikel: https://www.mql5.com/ru/articles/13854
- Freie Handelsapplikationen
- Über 8.000 Signale zum Kopieren
- Wirtschaftsnachrichten für die Lage an den Finanzmärkte
Sie stimmen der Website-Richtlinie und den Nutzungsbedingungen zu.