Нейросети — это просто (Часть 29): Алгоритм актор-критик с преимуществом (Advantage actor-critic)
Dmitriy Gizlyk | 16 сентября, 2022
Содержание
- Введение
- 1. Сильные стороны ранее рассмотренных методов обучения с подкреплением
- 2. Алгоритм актер-критик с преимуществом
- 3. Реализация
- 4. Тестирование
- Заключение
- Ссылки
- Программы, используемые в статье
Введение
Мы продолжаем изучение методов обучения с подкреплением. В предыдущих статьях было рассказано о методах аппроксимации функции награды Q-обучение и обучения функции политики policy gradient. Каждый метод имеет свои преимущества и недостатки. И, конечно, в процессе построения и обучения своей модели нам бы хотелось максимально использовать их достоинства. В поиске методов минимизации недостатков используемых алгоритмов мы часто обращаемся к попыткам построения неких конгломератов из различных известных нам алгоритмов и методов. В данной статье мы поговорим о варианте объединения двух выше указанных алгоритмов в единый метод обучения модели, который получил название Актор-Критик с преимуществом (Advantage actor-critic).
1. Сильные стороны ранее рассмотренных методов обучения с подкреплением
Но прежде чем приступить к объединению алгоритмов, давайте вспомним их сильные и слабые стороны.
В процессе взаимодействия со Средой Агент совершает некие действия, воздействуя на Среду. При этом, в результате влияния внешних факторов и действий Агента состояния Среды изменяется. И после каждого изменения состояния Среда информирует Агента передачей некоего вознаграждения. Это вознаграждение может быть как положительным, так и отрицательным. Размер и знак вознаграждения говорит о полезности нового состояния для Агента. Природа формирования вознаграждения Агенту неизвестна. Цель Агента научиться совершать такие действия, чтобы в процессе взаимодействия со Средой получить максимально возможное вознаграждение.
Первым мы изучали алгоритм аппроксимации функции награды Q-обучение. Мы обучали нашу модель таким образом, чтобы научиться максимально точно прогнозировать предстоящую награду после совершения того или иного действия в конкретном состоянии среды. И дальше агент совершает действия, исходя из размера прогнозируемого вознаграждения и заложенной политикой поведения агента. Как правило, здесь применяется жадная или ɛ-жадная стратегия. Жадная стратегия подразумевает выбор действия с максимальным прогнозным вознаграждением. И чаще всего применяется в процессе промышленной эксплуатации агента.
Вторая, ɛ-жадная стратегия похожа на жадную стратегию не только названием. Она также подразумевает выбор действия с максимальным прогнозным вознаграждением. Но при этом допускает выбор случайного действия с вероятностью ɛ. Что применяется на стадии обучения модели для лучшего изучения среды. Ведь в противном случае, получив однажды положительное вознаграждение, модель будет постоянно повторять одно действие и не изучать другие варианты. В таком случае она так и не узнает, насколько её действие было оптимальным. Могли ли другие действия привести к большему вознаграждению. А мы хотим заставить агента максимально изучать среду. И извлекать из неё максимальную пользу.
Вполне очевидны преимущества метода Q-обучения. Модель обучается прогнозированию вознаграждения. Именно вознаграждение мы получаем от среды. И у нас есть прямая связь между значениями результатов работы модели и эталонными значениями, получаемыми от среды. В такой трактовке обучение похоже на методы обучения с учителем. При обучении модели мы использовали среднеквадратичную ошибку в качестве функции потерь.
Здесь надо обратить внимание. Обученная модель будет возвращать среднюю кумулятивную награду до конца сессии с учетом фактора дисконтирования, которую получил агент от среды после совершении конкретного действия в аналогичном состоянии среды при обучении модели. В то время, как среда возвращает награду за каждый конкретный переход в новое состояние. И здесь мы видим разрыв, который покрывается после полного прохождения эпизода Агентом.
К недостаткам алгоритма можно отнести сложность обучения модели. Помните, для обучения модели нам потребовалось введение ряда сущностей и ухищрений. Прежде всего, последовательные состояния среды сильно скоррелированы между собой. И, в большинстве случаев, отличаются лишь не значительными деталями. Прямое обучение на таких данных приведет к постоянному переобучению модели под текущее состояние с полной утратой способности к обобщению данных. Поэтому нам потребовалось создание буфера исторических данных, на которых обучалась модель. При обучении модели мы случайным образом выбирали состояния из буфера исторических данных, что позволило максимально снизить корреляцию между 2-мя состояниями, последовательно использованными для обучения.
Обучая модель на фактических данных получаемого вознаграждения от среды, мы получаем модель с низкой дисперсией данных. То есть разброс значений, возвращаемых моделью для каждого состояния, приемлемо мал. Это положительный фактор. Но вспомним, что среда возвращает вознаграждение за каждый конкретный переход. А нам необходимо максимизировать прибыль за весь обозримый период. И для её расчета необходимое полное прохождения сессии агентом. Тем не менее, благодаря использованию буфера исторических данных и добавлению модели прогнозирования будущих вознаграждений нам удалось построить алгоритм, способный дообучать модель в процессе её практического использования. Так сказать, построить процесс обучения on-line. Но за это нам пришлось заплатить погрешностью прогнозирования вознаграждения.
Дело в том, что используя вторую модель для прогнозирования будущих вознаграждений, мы прекрасно понимали и принимали риски возникновения ошибки таких прогнозов. Но каждая сделанная ошибка учитывалась при обучении модели и влияла на все последующие прогнозы. Таким образом, мы получали модель, которая способна прогнозировать результаты с малой дисперсией, но большим смещением. Этим можно пренебречь при использовании жадной стратегии. Ведь выбирая максимальное вознаграждение, мы лишь сравниваем его с остальными. Смещение или масштабирование значений в таком случае не оказывает влияние на конечный результата выбора действия.

Ну и конечно при использовании Q-обучения наша модель обучается только прогнозированию наград. Для выбора действий нам нужно указать политику (стратегию) поведения агента на стадии создания модели. А использование жадной стратегии позволяет успешно работать только в детерминированных средах. И полностью не применимо для построения стохастических стратегий.
Использование policy gradient, напротив, не требует от нас определения политики (стратегии) поведения агента на стадии создания модели. Данный метод позволяет агенту выстроить свою политику поведения, которая может быть как жадная, так и стохастическая.
Модель, обученная методом policy gradient, возвращает вероятностное распределение достижения желаемого результата при выборе того или иного действия в каждом конкретном состоянии среды.
При обучении модели мы также используем получаемые от среды вознаграждения. А для выбора оптимальной стратегии в каждом состоянии среды используется кумулятивное вознаграждение до конца сессии. Очевидно, что для обновления весов модели агенту необходимо пройти всю сессию. Наверное, это и есть основной недостаток данного метода. Мы не можем построить on-line обучение модели, так как не знаем будущих вознаграждений.
В то же время, использование фактического кумулятивного вознаграждения позволяет нам минимизировать постоянную ошибку смещение прогнозируемых данных от их реальной величины. Чем грешило Q-обучение ввиду использования прогнозных значений будущих вознаграждений.
Однако, напомню, что в policy gradient мы обучаем модель прогнозированию не ожидаемого вознаграждения, а вероятностного распределения достижения желаемого результата при совершении того или иного действия агентом в конкретном состоянии среды. И в качестве функции потерь мы используем логарифмическую функцию.
")
Для аналитического определения направления минимизации ошибки мы, как всегда, используем производную функцию потерь. В данном случае очень удобно свойство производной логарифма.

Умножая производную функции потерь на положительное вознаграждение, мы увеличиваем вероятность выбора такого действия. А при умножении производной функции потерь на отрицательное вознаграждение мы корректируем наши веса в обратном направлении. Тем самым снижая вероятность выбора такого действия. И размер вознаграждения по модулю определит шаг корректировки весов.
Как можно заметить, при обновлении матрицы весов нашей модели использование вознаграждений происходит опосредованно. Поэтому мы получаем модель, результаты которой имеют малое смещение относительно истинных данных, но довольно большую дисперсию (разброс значений).

К положительным сторонам метода можно отнести его способность к исследованию среды. Ведь если при использовании Q-обучения и ɛ-жадной стратегии мы определяли баланс исследования к эксплуатации с помощью параметра ɛ, то policy gradient использует семплирование действий из заданного распределения.
В начале обучения вероятность совершения всех действий практически равны. И модель склонна к максимальному изучению среды, равновероятно выбирая то или иное действие агента. В процессе обучения модели вероятностное распределение действий меняется. Вероятность выбора прибыльных действий повышается, а убыточных — снижается. Тем самым снижается склонность модели к исследованию. И баланс смещается в сторону эксплуатации.
Надо обратить внимание ещё на один момент. Используя кумулятивное вознаграждение, мы акцентируем внимание на достижение результата в конце сессии. И при этом не оцениваем влияние каждого конкретного шага. Такой подход, к примеру, может научить нашего агента держать убыточные позиции в ожидании разворота тренда. Или совершать большое количество убыточных сделок. Убытки от которых будут перекрываться редкими прибыльными сделками, но с большой доходностью. Ведь, получив итоговую прибыль в конце сессии, модель посчитает это положительным результатом и повысит вероятность совершения таких операций. Конечно, совершение большого количества итераций призвано минимизировать этот фактор. Так как способность метода к исследованию среды должна помочь модели найти оптимальную стратегию. Но это приводит к длительному процессу обучения модели.
Подведем итоги. Модели Q-обучение обладают низкой дисперсией, но большим смещением. Policy gradient наоборот позволяет обучить модель с малым смещением и большой дисперсией. Нам бы хотелось иметь возможность обучить модель с минимальными дисперсией и смещением.
Policy gradient выстраивает целостную стратегию без учета влияния каждого отдельного шага. А нам бы хотелось получать максимальный доход на каждом шаге, что позволяет сделать Q-обучение. Вспомните про функцию Беллмана. Её использование предполагает выбор лучшего действия на каждом шаге.
Использование методов аппроксимации Q-функции требует определение политики поведения агента на стадии создания модели. Но мы предпочитаем, чтобы модель сама определяла стратегию исходя из опыта взаимодействия со средой. И, конечно, мы не хотели бы ограничиваться детерминированными стратегиями поведения. Это позволяют реализовать методы обучения политики.
И тут становится вполне очевидно желание объединить 2 метода для получения лучших результатов.
2. Алгоритм актер-критик с преимуществом
Наиболее успешными попытками объединения методов аппроксимации функции вознаграждения и обучения политик являются методы семейства Актер-Критик. Сегодня я предлагаю Вам познакомиться с алгоритмом, который назвали "Актер-Критик с преимуществом" (Advantage actor-critic).
Семейство методов актер-критик подразумевает использование двух моделей. Одна из моделей, Актер, отвечает за выбор действия агента и обучается методами аппроксимации функции политики. Вторая модель Критик обучается методами Q-обучения и оценивает выбранные Актером действия.
Первое, что мы хотели бы сделать, так это уменьшить дисперсию данных в модели политики. Давайте ещё раз посмотрим на функцию потерь нашей модели политики. Здесь мы каждый раз умножаем логарифм прогнозной вероятности совершения выбранного действия на размер кумулятивной награды с учетом дисконтирования. Значение прогнозной вероятности у нас нормализовано в диапазоне [0, 1].
![]()
Для снижения дисперсии мы можем уменьшить значение кумулятивной награды. Но мы должны это сделать таким образом, чтобы не нарушить влияние действий на общий результат. И при этом необходимо соблюсти сопоставимость данных для разных сессий обучения агента. Как вариант, мы можем отнимать всегда некую фиксированную константу или среднее вознаграждение за всю сессию.
![]()
Второе свойство, которое мы бы хотели добавить, это научить модель оценивать вклад каждого отдельного действия. На первый взгляд простая идея отказаться от кумулятивной награды и использовать для обучения только награду за текущий переход может сослужить плохую службу. Прежде всего, получение большого вознаграждение на текущем шаге не гарантирует нам такое же большое вознаграждение в будущем. Мы можем получить большое вознаграждение за переход в не выгодное состояние. Так сказать "сыр в мышеловке".
С другой стороны, не всегда вознаграждение зависит от действия. Довольно часто можно попасть в ситуацию, когда вознаграждение в большей степени зависит от состояния среды, чем от способностей агента оценивать это состояние. К примеру, совершая сделки в направления глобального тренда Агент может переждать корректирующие тенденции против тренда и дождаться движения цены в нужном направлении. И для этого Агенту не нужно детально анализировать текущее состояния для выявления тенденций. Достаточно правильно определить глобальную тенденцию. В таком случае велика вероятность входа в позицию не по самой выгодной цене. Ведь при правильном детальном анализе можно было дождаться коррекции и войти в позицию по более выгодной цене. Но гораздо больше убытков несет риск перерастания коррекции в смену тренда. И тогда, не дождавшись разворота, открытая позиция принесет большие убытки.
Поэтому, было бы полезно сравнивать именно кумулятивное вознаграждение с неким эталонным результатом. Но где его взять? И тут на помощь нам приходит Критик. Именно с его помощью мы будем оценивать работу нашего Актера.
Идея заключается в том, что модель Критика обучается оценке текущего состояния среды. Сколько потенциально Актер может получить вознаграждения из текущего состояния до конца сессии. В то же время, Актер обучается выбирать действия, которые потенциально дадут вознаграждение больше среднего за предыдущие сессии обучения. Таким образом мы заменяем константу в формуле функции потерь выше на оценку состояния.
![]()
где V(s) - функция оценки состояния среды.
Для обучения функции оценки состояния мы используем все ту же среднеквадратичную ошибку.
![]()
Надо сказать, что на практике существуют различные подходы к построению модели с применением данного алгоритма. Мы использовать две отдельные нейронные сети. Одна для Актера, вторая - Критика. Но часто используется архитектура из одной нейронной сети с двумя выходами. Так называемая "двухголовая" нейронная сеть. В которой часть нейронных слоёв общая и отвечает за обработку исходных данных. При этом несколько слоёв принятия решения разделены по направлениям. Часть отвечает за политику модели (Актер). А вторая часть - за оценку состояния (Критик). Нельзя не согласиться, что и Актер, и Критик работают с одним состоянием среды. А значит и функцию распознавания состояния могут иметь общую.
Кроме того, существуют и реализации on-line обучения моделей Advantage actor-critic. В них, по аналогии с Q-обучением, кумулятивное вознаграждение заменяется суммой вознаграждения, полученного на последнем переходе, и оценки последующего состояния с учетом коэффициента дисконтировавния. Тогда функции потерь примут следующий вид.
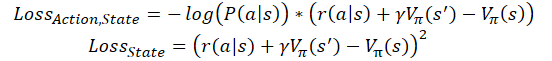
где ɣ — коэффициент дисконтирования.
Но за online обучение надо платить. Такая модель имеет большую ошибку и сложнее обучается.
3. Реализация
После ознакомления с теоретическими аспектами метода мы можем приступить к практической части данной статьи и построить процесс обучения модели средствами MQL5. Приступая к реализации описанного алгоритма, надо сказать, что данная реализация не потребует каких-либо кардинальных изменений в архитектуре построения наших моделей. Мы не будем строить 2-головую модель. А ограничимся построением 2-х отдельных нейронных сетей Актера и Критика уже существующими средствами.
Кроме того, мы не будем обучать полностью новые модели. Вместо этого мы воспользуемся 2-мя моделями из последних 2-х статей. Модель из статьи о Q-обучении мы будем использовать в качестве Критика. А модель из статьи о policy gradient будет выполнять роль Актера.
Здесь надо сказать о небольших отступления от изложенного выше теоретического материала. Модель Актера полностью соответствует требования рассматриваемого алгоритма. Но в отличии от неё, используемая нами модель Критика немного отличается от описанной выше функции оценки состояния среды. Дело в том, что оценка состояния среды не зависит от совершаемого агентом действия. Ведь стоимость состояния такова, какую максимальную выгоду может получить наш Агент из этого состояния. И если посмотреть на обученную нами ранее Q-функцию, стоимость состояния будет равна максимальному значению из вектора результатов данной функции. Однако, для корректного обучения модели мы должны будем учитывать действие, совершенное Агентом в анализируемом состоянии.
А теперь я предлагаю посмотреть на код реализации метода. Для обучения модели мы создадим советник с красноречивым названием "Actor_Critic.mq5". Шаблон советника был заимствован от советников из предыдущих статей. Как уже было сказано выше, мы будем использовать 2-е предварительно обученные модели. Модели обучались отдельно и сохранены в различных файлах. Поэтому, вначале мы определим файлы для загрузки моделей. В их названии явно прочитывается отсыл к упомянутым предыдущим статьям.
#define ACTOR Symb.Name()+"_"+EnumToString((ENUM_TIMEFRAMES)Period())+"_REINFORCE" #define CRITIC Symb.Name()+"_"+EnumToString((ENUM_TIMEFRAMES)Period())+"_Q-learning"
Для 2-х моделей нам потребуется 2 экземпляра класса нейронных сетей. Для прозрачности кода модели получат названия, соответствующие их роли в выстраиваемом алгоритме.
CNet Actor; CNet Critic;
В методе инициализации советника мы загружаем модели и сразу сравним размеры слоёв исходных данных и результатов. При загрузке моделей мы не можем оценить сопоставимость моделей на предмет обучения их на сопоставимых выборках. Но мы просто обязаны проверить на сопоставимость архитектур моделей. В частности, мы проверяем размер слоя исходных данных. Это даст нам уверенность, что для оценки состояния среды обе модели используют одинаковый паттерн описания состояния.
И затем мы проверяем размер слоя результатов обоих моделей, что позволит нам сравнить дискретность возможных вариантов действий агентов.
//+------------------------------------------------------------------+ //| Expert initialization function | //+------------------------------------------------------------------+ int OnInit() { //--- ................ ................ ................ //--- float temp1, temp2; if(!Actor.Load(ACTOR + ".nnw", dError, temp1, temp2, dtStudied, false) || !Critic.Load(CRITIC + ".nnw", dError, temp1, temp2, dtStudied, false)) return INIT_FAILED; //--- if(!Actor.GetLayerOutput(0, TempData)) return INIT_FAILED; HistoryBars = TempData.Total() / 12; Actor.getResults(TempData); if(TempData.Total() != Actions) return INIT_PARAMETERS_INCORRECT; if(!vActions.Resize(SessionSize) || !vRewards.Resize(SessionSize) || !vProbs.Resize(SessionSize)) return INIT_FAILED; //--- if(!Critic.GetLayerOutput(0, TempData)) return INIT_FAILED; if(HistoryBars != TempData.Total() / 12) return INIT_PARAMETERS_INCORRECT; Critic.getResults(TempData); if(TempData.Total() != Actions) return INIT_PARAMETERS_INCORRECT; //--- ................ ................ ................ //--- return(INIT_SUCCEEDED); }
При этом мы не забываем контролировать процесс выполнения операций и сохраняем необходимые данные в соответствующие переменные. В частности, мы сохраняем количество свечей одного анализируемого паттерна, которое соответствует размеру слоя исходных данных загруженных моделей.
Ну а непосредственно реализация алгоритма обучения модели осуществлялась в функции Train. В начале функции мы, как всегда, определяем диапазон обучающей выборки.
void Train(void) { //--- MqlDateTime start_time; TimeCurrent(start_time); start_time.year -= StudyPeriod; if(start_time.year <= 0) start_time.year = 1900; datetime st_time = StructToTime(start_time);
И загружаем исторические данные. При этом обязательно проверяем результат выполнения всех операций.
int bars = CopyRates(Symb.Name(), TimeFrame, st_time, TimeCurrent(), Rates); if(!RSI.BufferResize(bars) || !CCI.BufferResize(bars) || !ATR.BufferResize(bars) || !MACD.BufferResize(bars)) { ExpertRemove(); return; } if(!ArraySetAsSeries(Rates, true)) { ExpertRemove(); return; } //--- RSI.Refresh(); CCI.Refresh(); ATR.Refresh(); MACD.Refresh();
Тут же мы оцениваем количество загруженных данных и подготавливаем локальные переменные.
int total = bars - (int)(HistoryBars + SessionSize+2); //--- CBufferFloat* State; float loss = 0; uint count = 0;
Далее мы организовываем систему циклов обучения модели. Внешний цикл отсчитывает количество эпох обучения. Соответственно, в теле цикла мы определяем точку начала сессии. Которая выбирается случайным образом из загруженных исторических данных. При выборе данной точки учитывается 2 фактора. Первое, точке начала сессии должны предшествовать исторические данные, достаточные для формирования одного паттерна. И от точки начала сессии до конца обучающей выборки должно быть достаточно исторических данных для осуществления полной сессии.
for(int iter = 0; (iter < Iterations && !IsStopped()); iter ++) { int error_code; int shift = (int)(fmin(fabs(Math::MathRandomNormal(0, 1, error_code)), 1) * (total) + SessionSize);
Надо сказать, что я не стал реализовывать алгоритм on-line обучения. Так как мы обучаем модель на исторических данных. А использование полной сессии обычно даёт лучшие результаты. Но в то же время работа на рынке бесконечна. Поэтому я остановился на пакетной реализации алгоритма. В которой размер сессии ограничивается размером пакета обновления данных. И это значение указывается пользователем во внешнем параметре SessionSize.
Затем мы создаем вложенный цикл для первичного прохода сессии. В теле данного цикла мы сначала создаём объект для записи параметров описания состояния системы. И не забываем проверить результат создания нового объекта.
States.Clear(); for(int batch = 0; batch < SessionSize; batch++) { int i = shift - batch; State = new CBufferFloat(); if(!State) { ExpertRemove(); return; }
После чего сохраняем параметры текущего состояния среды. Так сказать подготовим паттерн для анализа на текущем шаге алгоритма.
int r = i + (int)HistoryBars; if(r > bars) { delete State; continue; } for(int b = 0; b < (int)HistoryBars; b++) { int bar_t = r - b; float open = (float)Rates[bar_t].open; TimeToStruct(Rates[bar_t].time, sTime); float rsi = (float)RSI.Main(bar_t); float cci = (float)CCI.Main(bar_t); float atr = (float)ATR.Main(bar_t); float macd = (float)MACD.Main(bar_t); float sign = (float)MACD.Signal(bar_t); if(rsi == EMPTY_VALUE || cci == EMPTY_VALUE || atr == EMPTY_VALUE || macd == EMPTY_VALUE || sign == EMPTY_VALUE) { delete State; continue; } //--- if(!State.Add((float)Rates[bar_t].close - open) || !State.Add((float)Rates[bar_t].high - open) || !State.Add((float)Rates[bar_t].low - open) || !State.Add((float)Rates[bar_t].tick_volume / 1000.0f) || !State.Add(sTime.hour) || !State.Add(sTime.day_of_week) || !State.Add(sTime.mon) || !State.Add(rsi) || !State.Add(cci) || !State.Add(atr) || !State.Add(macd) || !State.Add(sign)) { delete State; break; } }
Проверяем полноту сохраненных данных и вызывает метод прямого прохода модели политики.
if(IsStopped()) { delete State; ExpertRemove(); return; } if(State.Total() < (int)HistoryBars * 12) { delete State; continue; } if(!Actor.feedForward(GetPointer(State), 12, true)) { delete State; ExpertRemove(); return; }
Затем мы семплируем действие агента из полученного распределения.
Actor.getResults(TempData); int action = GetAction(TempData); if(action < 0) { delete State; ExpertRemove(); return; }
Определяем вознаграждение для выбранного действия. Надо сказать, что политика вознаграждения абсолютно не изменилась после последних экспериментов в предыдущей статье. Таким образом я планирую получить сопоставимы результаты тестирования работы метода. Что позволит сравнить влияние изменения алгоритма обучения на конечный результат работы модели, в сравнении с предыдущими тестами.
double reward = Rates[i - 1].close - Rates[i - 1].open; switch(action) { case 0: if(reward < 0) reward *= -20; else reward *= 1; break; case 1: if(reward > 0) reward *= -20; else reward *= -1; break; default: if(batch == 0) reward = -fabs(reward); else { switch((int)vActions[batch - 1]) { case 0: reward *= -1; break; case 1: break; default: reward = -fabs(reward); break; } } break; }
И сохраняем полученные значения в буферы для последующего использования в процессе обновлении весов моделей.
if(!States.Add(State)) { delete State; ExpertRemove(); return; } vActions[batch] = (float)action; vRewards[SessionSize - batch - 1] = (float)reward; vProbs[SessionSize - batch - 1] = TempData.At(action); //--- }
На этом завершаются итерации первого вложенного цикла сбора информации о сессии. И после перебора всех состояний сессии мы получим полный набор данных для обновления моделей.
Далее мы посчитаем кумулятивное дисконтированное вознаграждение для каждого состояния среды.
vectorf rewards = vectorf::Full(SessionSize, 1); rewards = MathAbs(rewards.CumSum() - SessionSize); rewards = (vRewards * MathPow(vectorf::Full(SessionSize, DiscountFactor), rewards)).CumSum(); rewards = rewards / fmax(rewards.Max(), fabs(rewards.Min()));
Тут же мы посчитаем значение функции потерь и сохраним модели при достижении лучших результатов.
loss = (fmin(count, 9) * loss + (rewards * MathLog(vProbs) * (-1)).Sum() / SessionSize) / fmin(count + 1, 10); count++; float total_reward = vRewards.Sum(); if(BestLoss >= loss) { if(!Actor.Save(ACTOR + ".nnw", loss, 0, 0, Rates[shift - SessionSize].time, false) || !Critic.Save(CRITIC + ".nnw", Critic.getRecentAverageError(), 0, 0, Rates[shift - SessionSize].time, false)) return; BestLoss = loss; }
Обратите внимание, что сохраняем модели до обновления матриц весовых коэффициентов. Ведь именно с этими параметрами модель достигла тех результатов, которые мы оценили функцией потерь. После обновления матриц модель получит обновленные параметры и результаты работы с новыми параметрами мы увидим только по завершении следующей сессии.
В заключение итераций эпохи обучения мы организовываем ещё один вложенный цикл, в котором организуем обновление параметров моделей. Здесь мы будем по порядку извлекать состояния среды из буфера и осуществлять прямой проход обоих моделей с изъятым состоянием. И, конечно, не забываем контролировать процесс выполнения операций.
for(int batch = SessionSize - 1; batch >= 0; batch--) { State = States.At(batch); if(!Actor.feedForward(State) || !Critic.feedForward(State)) { ExpertRemove(); return; }
Надо обратить внимание, что осуществление прямого прохода для каждой модели обязательно. Даже если в буферах мы сохранили все необходимые данные. Дело в том, что в процессе обратного прохода алгоритм обучения использует промежуточные данные расчетов нейронных слоёв. И для корректного распределения градиента ошибки, а вместе с ним и обновления весов, нам необходимо четкое выстраивание полной цепочки всех промежуточных значений модели для каждого состояния.
Затем мы сначала обновляем параметра Критика. И здесь можно заметить, что обновление модели относится только к действию, выбранному Агентом. При этом градиент остальных действий считается нулевым. И это отличие от ранее описанного теоретического материала вызвано именно использованием ранее обученной Q-функции, которая возвращает прогнозируемое вознаграждения в зависимости от выбранного агентом действия. Обучение функции оценки состояния, предложенное авторами метода, не зависит от совершаемого действия и не требует подобной детализации.
Critic.getResults(TempData); float value = TempData.At(TempData.Maximum(0, 3)); if(!TempData.Update((int)vActions[batch], rewards[SessionSize - batch - 1])) { ExpertRemove(); return; } if(!Critic.backProp(TempData)) { ExpertRemove(); return; }
После успешного обновления параметров Критика мы аналогичным образом обновляем параметры Актера. Здесь, как и было сказано выше, для оценки действия, выбранного Агентом, мы используем максимальное значение вектора результатов Q-функции для анализируемого состояния среды.
if(!TempData.BufferInit(Actions, 0) || !TempData.Update((int)vActions[batch], rewards[SessionSize - batch - 1] - value)) { ExpertRemove(); return; } if(!Actor.backProp(TempData)) { ExpertRemove(); return; } } PrintFormat("Iteration %d, Cummulative reward %.5f, loss %.5f", iter, total_reward, loss); }
По завершению всех итераций обновления параметров модели мы выводим информационное сообщение пользователю и переходим к следующей эпохе.
Процесс обучения моделей завершается после выполнения полного количества эпох, если раньше выполнение не будет прервано пользователем.
Comment(""); //--- ExpertRemove(); }
Операции функции завершаются очисткой поля комментариев и вызовом функции завершения работы советника.
С полным кодом советника можно познакомиться во вложении к данной статье.
4. Тестирование
После создания советника обучения моделей мы провели полное тестирование Advantage actor-critic метода. Для начала мы запускаем процесс обучения модели. А точнее дообучения моделей из 2-х предыдущих статей.
Обучение мы осуществляли на инструменте EURUSD, таймфрейм H1 с загрузкой истории за 2 последних года. Параметры индикаторов использовались установленные по умолчанию. Можно заметить, что параметры обучения моделей используются практически без изменений на протяжении всей серии статей.
В качестве преимущества дообучения моделей из предыдущих статей можно отнести тот факт, что для проверки результатов их обучения мы можем использовать тестовые советники из предыдущей статьи. Этим я и воспользовался. После обучения модели я взял модель дообученной политики и запустил в тестере стратегий советник "REINFORCE-test.mq5" с использованием упомянутой модели. Алгоритм его построения был описан в предыдущей статье. А с полным его кодом можно познакомиться во вложении.
Ниже приведен график баланса советника в процессе тестирования. Следует отметить довольно равномерный рост баланса в процессе тестирования. Обратите внимание, что тестирование модели осуществлялась на данных, не входящих в обучающую выборку. Что говорит о состоятельности подхода для построения торговой системы. Для чистоты проверки работы именно модели все операции были совершены с фиксированным минимальным лотом без использования стоп-лосса и тейк-профита. Использование такого советника крайне не рекомендуется для реальной торговли, но хорошо демонстрирует работу обученной модели.

На ценовом графике можно заметить, как быстро закрываются убыточные сделки и немного выдерживаются прибыльные позиции. Здесь надо обратить внимание, что все операции совершаются при открытии новой свечи. При этом можно заметить несколько торговых операций совершенных практически на открытии разворотных (фрактальных) свечей.

В целом, в процессе тестирования советник продемонстрировал Профит-фактор на уровне 2.20. Доля прибыльных сделок превысила 56%. При этом средняя прибыльная сделка на 70% превысила среднюю убыточную сделку.

В то же время я должен предостеречь Вас от использования данного советника для реальной торговли, так как он создавался только для тестирования модели. Во-первых, период тестирования советника сильно мал для переноса его в реальную торговлю. Во-вторых, советник лишен всякого манименджмента и блоков управления рисками. Все торговые операции лишены стоп-лоссов и тейк-профитов, что крайне не рекомендуется для использования в реальной торговле.
Заключение
В данной статье мы познакомились с ещё одним алгоритмом методов обучения с подкреплением — Advantage actor-critic. Данный алгоритм объединяет в себе, изученные ранее подходы, Q-обучения и policy gradient в лучших их проявлениях. Что позволяет повысить планку получаемых результатов в процессе обучения моделей с подкреплением. Мы построили рассмотренный алгоритм средствами MQL5. Обучили и протестировали модель на реальных исторических данных. По результатам тестирования модель показала способность к генерированию прибыли, что позволяет делать выводы о возможности построения торговых систем с использованием данного алгоритма обучения моделей.
Надо сказать, что в текущих реалиях семейство алгоритмов Актер-Критик даёт, наверное, лучшие результаты из методов обучения с подкреплением. Тем не менее, перед использование моделей для реальной торговли необходимо их длительное обучение и тщательное тестирование. С использованием различных стресс-тестов.
Ссылки
- Asynchronous Methods for Deep Reinforcement Learning
- Нейросети — это просто (Часть 26): Обучение с подкреплением
- Нейросети — это просто (Часть 27): Глубокое Q-обучение (DQN)
- Нейросети — это просто (Часть 28): Policy gradient алгоритм
Программы, используемые в статье
| # | Имя | Тип | Описание |
|---|---|---|---|
| 1 | Actor-Critic.mq5 | Советник | Советник для обучения модели |
| 2 | REINFORCE-test.mq5 | Советник | Советник для тестирования модели в тестере стратегий |
| 3 | NeuroNet.mqh | Библиотека классов | Библиотека для организации моделей нейронных сетей |
| 4 | NeuroNet.cl | Библиотека | Библиотека кода программы OpenCL для организации моделей нейронных сетей |