Ciência de dados e aprendizado de máquina (Parte 11): Classificador Naive Bayes e teoria da probabilidade na negociação
Omega J Msigwa | 2 junho, 2023
A quarta lei da termodinâmica diz o seguinte: se a probabilidade de sucesso não estiver próxima de um, ela estará próxima de zero.
A. Kondrashov
Introdução
Um classificador bayesiano ingênuo, também conhecido como Naive Bayes, é um algoritmo probabilístico usado em aprendizado de máquina para tarefas de classificação. O classificador é baseado no teorema de Bayes (ou fórmula de Bayes), que permite determinar a probabilidade de uma hipótese com base nas evidências disponíveis. O classificador probabilístico é um algoritmo simples, mas eficaz em diversas situações. Ele pressupõe que os atributos utilizados na classificação sejam independentes entre si. Por exemplo, se você deseja que um modelo classifique pessoas (homens e mulheres) com base na altura, tamanho do pé, peso e largura dos ombros, o modelo considerará todas essas variáveis como independentes umas das outras. Ou seja, ele não vai considerar que o tamanho do pé e a altura da pessoa estão relacionados.
Como o algoritmo não busca entender as relações entre variáveis independentes, acredito que vale a pena utilizá-lo no contexto de tomar decisões de negociação. Afinal, ninguém compreende completamente os padrões no trading. Portanto, vamos explorar como funciona o algoritmo bayesiano ingênuo.

Sem mais delongas, vamos chamar imediatamente uma instância do modelo e utilizá-la. Mais adiante, discutiremos a composição desse modelo.
Preparando dados de treinamento
Para este exemplo, escolhi 5 indicadores, a maioria dos quais são osciladores e indicadores de volume. Acredito que eles são boas variáveis para classificação e também possuem um número finito, o que os torna adequados para uma distribuição normal, que, por sua vez, é uma das ideias por trás desse algoritmo. No entanto, essa lista não é definitiva, então você pode criar seu próprio conjunto de dados e explorar diferentes indicadores e informações que sejam relevantes para você.
Vamos seguir a ordem:
matrix Matrix(TrainBars, 6); int handles[5]; double buffer[]; //+------------------------------------------------------------------+ //| Expert initialization function | //+------------------------------------------------------------------+ int OnInit() { //--- Preparing Data handles[0] = iBearsPower(Symbol(),TF, bears_period); handles[1] = iBullsPower(Symbol(),TF, bulls_period); handles[2] = iRSI(Symbol(),TF,rsi_period, rsi_price); handles[3] = iVolumes(Symbol(),TF,VOLUME_TICK); handles[4] = iMFI(Symbol(),TF,mfi_period,VOLUME_TICK ); //--- vector col_v; for (ulong i=0; i<5; i++) //Независимые переменные { CopyBuffer(handles[i],0,0,TrainBars, buffer); col_v = matrix_utils.ArrayToVector(buffer); Matrix.Col(col_v, i); } //-- Целевые переменные vector open, close; col_v.Resize(TrainBars); close.CopyRates(Symbol(),TF, COPY_RATES_CLOSE,0,TrainBars); open.CopyRates(Symbol(),TF, COPY_RATES_OPEN,0,TrainBars); for (int i=0; i<TrainBars; i++) { if (close[i] > open[i]) //price went up col_v[i] = 1; else col_v[i] = 0; } Matrix.Col(col_v, 5); //Добавляем независимую переменную в последний столбец матрицы //---
As variáveis TF, bears_period e outras são variáveis de entrada específicas que são definidas na parte superior do código acima.
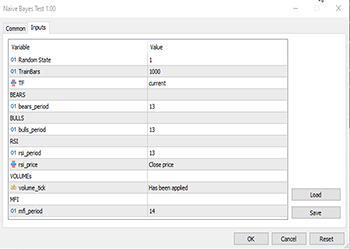
Como estamos lidando com aprendizado, foi necessário introduzir uma variável-alvo. A lógica é simples: se o preço de fechamento for maior que o preço de abertura, a variável-alvo recebe a classe 1; caso contrário, a classe é 0. É assim que obtemos o valor da variável-alvo. Abaixo está uma visão geral de como é apresentada a matriz de dados:
CS 0 13:21:15.457 Naive Bayes Test (EURUSD,H1) "Bears" "Bulls" "Rsi" "Volumes" "MFI" "Target Var" CS 0 13:21:15.457 Naive Bayes Test (EURUSD,H1) [-3.753148029472797e-06,0.008786246851970603,67.65238281791684,13489,55.24611392389958,0] CS 0 13:21:15.457 Naive Bayes Test (EURUSD,H1) [-0.002513216984025402,0.005616783015974569,50.29835423473968,12226,49.47293811405203,1] CS 0 13:21:15.457 Naive Bayes Test (EURUSD,H1) [-0.001829900272021678,0.0009700997279782353,47.33479153312328,7192,46.84320886771249,1] CS 0 13:21:15.457 Naive Bayes Test (EURUSD,H1) [-0.004718485947447171,-0.0001584859474472733,39.04848493977027,6267,44.61564654651691,1] CS 0 13:21:15.457 Naive Bayes Test (EURUSD,H1) [-0.004517273669240485,-0.001367273669240276,45.4127802340401,3867,47.8438816641815,0]
Em seguida, decidi visualizar os dados em gráficos de distribuição para verificar se eles correspondem a uma distribuição de probabilidade:





Se você quiser saber mais sobre os diferentes tipos de distribuição de probabilidade, há um artigo completo sobre isso no link.
Vamos dar uma olhada mais de perto na matriz de coeficientes de correlação de todas as variáveis independentes:
string header[5] = {"Bears","Bulls","Rsi","Volumes","MFI"}; matrix vars_matrix = Matrix; //Только независимые переменные matrix_utils.RemoveCol(vars_matrix, 5); //Удаляем целевую переменную ArrayPrint(header); Print(vars_matrix.CorrCoef(false));
Resultado:
CS 0 13:21:15.481 Naive Bayes Test (EURUSD,H1) "Bears" "Bulls" "Rsi" "Volumes" "MFI" CS 0 13:21:15.481 Naive Bayes Test (EURUSD,H1) [[1,0.7784600081627714,0.8201955846987788,-0.2874457184671095,0.6211980865273238] CS 0 13:21:15.481 Naive Bayes Test (EURUSD,H1) [0.7784600081627714,1,0.8257210032763984,0.2650418244580489,0.6554288778228361] CS 0 13:21:15.481 Naive Bayes Test (EURUSD,H1) [0.8201955846987788,0.8257210032763984,1,-0.01205084357067248,0.7578863565293196] CS 0 13:21:15.481 Naive Bayes Test (EURUSD,H1) [-0.2874457184671095,0.2650418244580489,-0.01205084357067248,1,0.0531475992791923] CS 0 13:21:15.481 Naive Bayes Test (EURUSD,H1) [0.6211980865273238,0.6554288778228361,0.7578863565293196,0.0531475992791923,1]]
Podemos observar que, com exceção da correlação entre os volumes e as demais variáveis, todas as outras variáveis apresentam uma alta correlação entre si. Em alguns casos, a correlação é bastante forte, como entre RSI e Bulls e Bears, que apresentam uma correlação de cerca de 82%. Os indicadores de Volume e MFI possuem elementos em comum, ou seja, os próprios volumes, o que explica a correlação de 62% entre eles. Como o método Naive Bayes gaussiano não explora essas razões em detalhes, vamos seguir em frente. Apenas achei interessante verificar e analisar as variáveis.
Treinamento do modelo
O treinamento do método Naive Bayes Gaussiano é simples e rápido. Vamos ver como o processo ocorre:
Print("\n---> Training the Model\n"); matrix x_train, x_test; vector y_train, y_test; matrix_utils.TrainTestSplitMatrices(Matrix,x_train,y_train,x_test,y_test,0.7,rand_state); //--- Обучение gaussian_naive = new CGaussianNaiveBayes(x_train,y_train); //Инициализация и обучение модели vector train_pred = gaussian_naive.GaussianNaiveBayes(x_train); //делаем прогнозы на обученных данных vector c= gaussian_naive.classes; //определенные в наборе данных классы metrics.confusion_matrix(y_train,train_pred,c); //анализ предсказания в матрице путаницы //---
A função TrainTestSplitMatrices divide os dados em x matrizes de treinamento e x matrizes de teste, juntamente com seus respectivos vetores-alvo. É semelhante à função train_test_split do sklearn em Python. A função principal tem a seguinte aparência:
void CMatrixutils::TrainTestSplitMatrices(matrix &matrix_,matrix &x_train,vector &y_train,matrix &x_test, vector &y_test,double train_size=0.7,int random_state=-1)
Por padrão, 70% dos dados serão alocados para os dados de treinamento, enquanto o restante será mantido como amostra de teste. Você pode ler mais sobre essa divisão de dados aqui.
O que confunde muitas pessoas nessa função é o parâmetro random_state. Na comunidade de aprendizado de máquina em Python, as pessoas frequentemente definem random_state = 42, embora, na realidade, qualquer número possa ser usado, pois esse parâmetro serve apenas para garantir que a matriz seja gerada da mesma forma aleatória a cada vez, facilitando a depuração, já que é usado um valor Random seed para gerar os números aleatórios usados para embaralhar as linhas na matriz.
Você pode observar que as matrizes de saída geradas por essa função não estão na ordem original. Existem várias discussões sobre a escolha desse número 42, por exemplo, aqui.
Aqui está o que temos como resultado deste trecho de código:
CS 0 14:33:04.001 Naive Bayes Test (EURUSD,H1) ---> Training the Model CS 0 14:33:04.001 Naive Bayes Test (EURUSD,H1) CS 0 14:33:04.002 Naive Bayes Test (EURUSD,H1) ---> GROUPS [0,1] CS 0 14:33:04.002 Naive Bayes Test (EURUSD,H1) CS 0 14:33:04.002 Naive Bayes Test (EURUSD,H1) ---> Prior_proba [0.5457142857142857,0.4542857142857143] Evidence [382,318] CS 0 14:33:04.294 Naive Bayes Test (EURUSD,H1) Confusion Matrix CS 0 14:33:04.294 Naive Bayes Test (EURUSD,H1) [[236,146] CS 0 14:33:04.294 Naive Bayes Test (EURUSD,H1) [145,173]] CS 0 14:33:04.294 Naive Bayes Test (EURUSD,H1) CS 0 14:33:04.294 Naive Bayes Test (EURUSD,H1) Classification Report CS 0 14:33:04.294 Naive Bayes Test (EURUSD,H1) CS 0 14:33:04.294 Naive Bayes Test (EURUSD,H1) _ Precision Recall Specificity F1 score Support CS 0 14:33:04.294 Naive Bayes Test (EURUSD,H1) 0.0 0.62 0.62 0.54 0.62 382.0 CS 0 14:33:04.294 Naive Bayes Test (EURUSD,H1) 1.0 0.54 0.54 0.62 0.54 318.0 CS 0 14:33:04.294 Naive Bayes Test (EURUSD,H1) CS 0 14:33:04.294 Naive Bayes Test (EURUSD,H1) Accuracy 0.58 CS 0 14:33:04.294 Naive Bayes Test (EURUSD,H1) Average 0.58 0.58 0.58 0.58 700.0 CS 0 14:33:04.294 Naive Bayes Test (EURUSD,H1) W Avg 0.58 0.58 0.58 0.58 700.0 CS 0 14:33:04.294 Naive Bayes Test (EURUSD,H1)
De acordo com o relatório de classificação da Matriz de Confusão, a precisão do modelo treinado foi de 58%. Esse relatório oferece várias informações, como a precisão, que indica o quão precisamente cada classe foi classificada (detalhes). No geral, parece que a classe 0 é classificada com maior precisão do que a classe 1. Isso é compreensível, uma vez que o modelo fez mais previsões corretas para a classe 0 em comparação com a classe 1, sem mencionar a probabilidade a priori (a probabilidade primária na amostra de dados). Neste conjunto de dados, temos as seguintes probabilidades a priori:
Prior_proba [0.5457142857142857,0.4542857142857143] Evidence [382,318]. A probabilidade a priori é calculada da seguinte forma:
Probabilidade a priori = evidência/total de eventos/resultados
No nosso caso, temos Prior Proba [382/700, 318/700]. Lembre-se de que 700 é o tamanho da amostra de treinamento resultante da divisão dos dados para reservar 70% do total de 1.000 amostras para treinamento.
O modelo Naive Bayes Gaussiano primeiro busca as probabilidades de ocorrência das classes no conjunto de dados e, em seguida, as utiliza para fazer previsões sobre o que pode acontecer no futuro com base no cálculo de evidências. Uma classe com evidências maiores terá uma probabilidade maior do que outra classe e, portanto, será considerada mais provável pelo algoritmo durante o treinamento e teste.. Faz sentido, não é mesmo? Essa é uma das limitações desse algoritmo, pois quando uma classe não está presente nos dados de treinamento, o modelo presume que essa classe não existe e, portanto, atribui a ela uma probabilidade zero, o que significa que não haverá previsões para essa classe nos dados de teste nem no futuro.
Teste do modelo
No teste do modelo, também não há nada complicado. Tudo o que precisamos fazer é adicionar novos dados à função GaussianNaiveBayes, que, nesse ponto, já possui os parâmetros do modelo treinado.
//--- Test Print("\n---> Testing the model\n"); vector test_pred = gaussian_naive.GaussianNaiveBayes(x_test); //подаем на вход модели тестовые данные для прогнозирования и получения предсказаний в вектор metrics.confusion_matrix(y_test,test_pred, c); //анализ тестируемой модели
Resultado
CS 0 14:33:04.294 Naive Bayes Test (EURUSD,H1) ---> Testing the model CS 0 14:33:04.294 Naive Bayes Test (EURUSD,H1) CS 0 14:33:04.418 Naive Bayes Test (EURUSD,H1) Confusion Matrix CS 0 14:33:04.418 Naive Bayes Test (EURUSD,H1) [[96,54] CS 0 14:33:04.418 Naive Bayes Test (EURUSD,H1) [65,85]] CS 0 14:33:04.418 Naive Bayes Test (EURUSD,H1) CS 0 14:33:04.418 Naive Bayes Test (EURUSD,H1) Classification Report CS 0 14:33:04.418 Naive Bayes Test (EURUSD,H1) CS 0 14:33:04.418 Naive Bayes Test (EURUSD,H1) _ Precision Recall Specificity F1 score Support CS 0 14:33:04.418 Naive Bayes Test (EURUSD,H1) 0.0 0.60 0.64 0.57 0.62 150.0 CS 0 14:33:04.418 Naive Bayes Test (EURUSD,H1) 1.0 0.61 0.57 0.64 0.59 150.0 CS 0 14:33:04.418 Naive Bayes Test (EURUSD,H1) CS 0 14:33:04.418 Naive Bayes Test (EURUSD,H1) Accuracy 0.60 CS 0 14:33:04.418 Naive Bayes Test (EURUSD,H1) Average 0.60 0.60 0.60 0.60 300.0 CS 0 14:33:04.418 Naive Bayes Test (EURUSD,H1) W Avg 0.60 0.60 0.60 0.60 300.0
Bem, o modelo se saiu um pouco melhor na amostra de teste, com uma precisão de 60%, o que é 2% maior do que a precisão dos dados de treinamento. Isso é uma boa notícia.
Modelo Naive Bayes gaussiano no testador de estratégias
O uso de modelos de aprendizado de máquina no testador de estratégias geralmente não produz resultados satisfatórios, não porque os modelos não consigam fazer previsões, mas porque geralmente analisamos o gráfico de lucro no testador de estratégias. Um modelo de aprendizado de máquina é capaz de prever para onde o mercado irá a seguir, mas isso não significa necessariamente que você obterá lucro com isso, especialmente considerando a lógica simples que utilizei para coletar e preparar nosso conjunto de dados. Vamos dar uma olhada nas amostras de dados coletadas em cada barra para o período gráfico definido no parâmetro, neste caso, PERIOD_H1 (intervalo de uma hora).
close.CopyRates(Symbol(),TF, COPY_RATES_CLOSE,0,TrainBars); open.CopyRates(Symbol(),TF, COPY_RATES_OPEN,0,TrainBars);
Coletamos 1.000 barras do período gráfico de uma hora e lemos seus valores de indicadores como variáveis independentes. Em seguida, criamos variáveis-alvo que indicam se a vela foi de alta ou não, e, nesse caso, o EA atribui a classe 1. Caso contrário, a classe é definida como 0. Esses valores são levados em consideração na função de negociação. Como nosso modelo prevê o próximo candle, as negociações são abertas a cada novo candle, enquanto as negociações anteriores são fechadas. Essencialmente, permitimos que nosso EA faça negociações em cada sinal em cada barra.
//+------------------------------------------------------------------+ //| Expert tick function | //+------------------------------------------------------------------+ void OnTick() { if (!train_state) TrainTest(); train_state = true; //--- vector v_inputs(5); //5 независимых переменных double buff[1]; //текущее значение индикатора for (ulong i=0; i<5; i++) //Независимые переменные { CopyBuffer(handles[i],0,0,1, buff); v_inputs[i] = buff[0]; } //--- MqlTick ticks; SymbolInfoTick(Symbol(), ticks); int signal = -1; double min_volume = SymbolInfoDouble(Symbol(), SYMBOL_VOLUME_MIN); if (isNewBar()) { signal = gaussian_naive.GaussianNaiveBayes(v_inputs); Comment("SIGNAL ",signal); CloseAll(); if (signal == 1) { if (!PosExist()) m_trade.Buy(min_volume, Symbol(), ticks.ask, 0 , 0,"Naive Buy"); } else if (signal == 0) { if (!PosExist()) m_trade.Sell(min_volume, Symbol(), ticks.bid, 0 , 0,"Naive Sell"); } } }
Precisamos ajustar um pouco a lógica para que essa função funcione tanto na negociação real quanto no testador de estratégias. A função CopyBuffer() e o treinamento agora estão dentro da função TrainTest(). Essa função é executada apenas uma vez na função OnTick. Você pode configurá-la para ser executada com mais frequência, o que resultará em um treinamento mais frequente do modelo. Deixo essa decisão a seu critério.
Como a função Init não é adequada para todos esses métodos copy buffer e copy rates (eles retornarão valores zero no testador de estratégias), tudo foi movido para a função TrainTest().
int OnInit() { handles[0] = iBearsPower(Symbol(),TF, bears_period); handles[1] = iBullsPower(Symbol(),TF, bulls_period); handles[2] = iRSI(Symbol(),TF,rsi_period, rsi_price); handles[3] = iVolumes(Symbol(),TF,VOLUME_TICK); handles[4] = iMFI(Symbol(),TF,mfi_period,VOLUME_TICK ); //--- m_trade.SetExpertMagicNumber(MAGIC_NUMBER); m_trade.SetTypeFillingBySymbol(Symbol()); m_trade.SetMarginMode(); m_trade.SetDeviationInPoints(slippage); return(INIT_SUCCEEDED); }
Teste único: período gráfico por hora
Realizei o teste com dados de dois meses, de 1º de janeiro de 2023 a 14 de fevereiro de 2023.
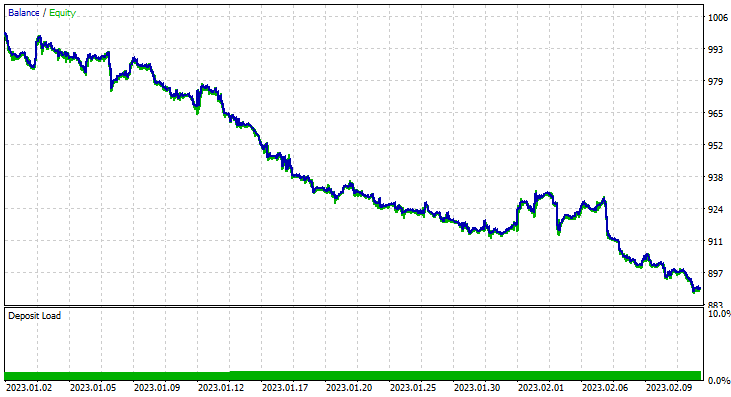
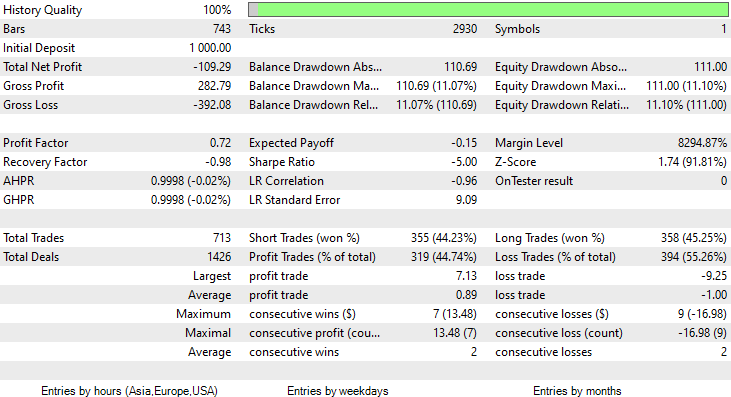
Escolhi esse período para o teste (2 meses) porque 1.000 barras de horas não representam um período de aprendizado muito extenso. São aproximadamente 41 dias, o que significa que o período de treinamento é curto, assim como o período de teste. Quando a função TrainTest() foi executada no testador, realizamos o teste em 700 barras.
O que aconteceu?
Inicialmente, o modelo impressionou durante o teste no testador de estratégias, apresentando uma precisão impressionante de 60% nos dados de treinamento.
CS 0 08:30:13.816 Tester initial deposit 1000.00 USD, leverage 1:100 CS 0 08:30:13.818 Tester successfully initialized CS 0 08:30:13.818 Network 80 Kb of total initialization data received CS 0 08:30:13.819 Tester Intel Core i5 660 @ 3.33GHz, 6007 MB CS 0 08:30:13.900 Symbols EURUSD: symbol to be synchronized CS 0 08:30:13.901 Symbols EURUSD: symbol synchronized, 3720 bytes of symbol info received CS 0 08:30:13.901 History EURUSD: history synchronization started .... .... .... CS 0 08:30:14.086 Naive Bayes Test (EURUSD,H1) 2023.01.02 01:00:00 ---> Training the Model CS 0 08:30:14.086 Naive Bayes Test (EURUSD,H1) 2023.01.02 01:00:00 CS 0 08:30:14.086 Naive Bayes Test (EURUSD,H1) 2023.01.02 01:00:00 ---> GROUPS [0,1] CS 0 08:30:14.086 Naive Bayes Test (EURUSD,H1) 2023.01.02 01:00:00 CS 0 08:30:14.086 Naive Bayes Test (EURUSD,H1) 2023.01.02 01:00:00 ---> Prior_proba [0.4728571428571429,0.5271428571428571] Evidence [331,369] CS 0 08:30:14.377 Naive Bayes Test (EURUSD,H1) 2023.01.02 01:00:00 Confusion Matrix CS 0 08:30:14.378 Naive Bayes Test (EURUSD,H1) 2023.01.02 01:00:00 [[200,131] CS 0 08:30:14.378 Naive Bayes Test (EURUSD,H1) 2023.01.02 01:00:00 [150,219]] CS 0 08:30:14.378 Naive Bayes Test (EURUSD,H1) 2023.01.02 01:00:00 CS 0 08:30:14.378 Naive Bayes Test (EURUSD,H1) 2023.01.02 01:00:00 Classification Report CS 0 08:30:14.378 Naive Bayes Test (EURUSD,H1) 2023.01.02 01:00:00 CS 0 08:30:14.378 Naive Bayes Test (EURUSD,H1) 2023.01.02 01:00:00 _ Precision Recall Specificity F1 score Support CS 0 08:30:14.378 Naive Bayes Test (EURUSD,H1) 2023.01.02 01:00:00 0.0 0.57 0.60 0.59 0.59 331.0 CS 0 08:30:14.378 Naive Bayes Test (EURUSD,H1) 2023.01.02 01:00:00 1.0 0.63 0.59 0.60 0.61 369.0 CS 0 08:30:14.378 Naive Bayes Test (EURUSD,H1) 2023.01.02 01:00:00 CS 0 08:30:14.378 Naive Bayes Test (EURUSD,H1) 2023.01.02 01:00:00 Accuracy 0.60 CS 0 08:30:14.378 Naive Bayes Test (EURUSD,H1) 2023.01.02 01:00:00 Average 0.60 0.60 0.60 0.60 700.0 CS 0 08:30:14.378 Naive Bayes Test (EURUSD,H1) 2023.01.02 01:00:00 W Avg 0.60 0.60 0.60 0.60 700.0
No entanto, posteriormente, o consultor especializado não conseguiu realizar negociações lucrativas com a precisão prometida ou próxima a ela. Abaixo estão minhas observações:
- A lógica acabou sendo cega, a estratégia está comprometendo a qualidade em prol da quantidade. A EA fez 713 negociações em dois meses. Isso é um número muito alto. Esse aspecto precisa ser alterado. Vamos treinar o modelo em um período de tempo mais longo e também negociar em períodos de tempo maiores, o que reduzirá o número de negociações realizadas.
- Desta vez, vamos reduzir as barras para treinamento, pois queremos treinar o modelo com os dados mais recentes.
Para isso, executamos a otimização no período de seis horas e obtivemos Train Bars = 80, TF = 12 hours. O teste foi realizado em dois meses de dados usando os novos parâmetros. Todos os parâmetros estão disponíveis no arquivo *set anexado no final do artigo.
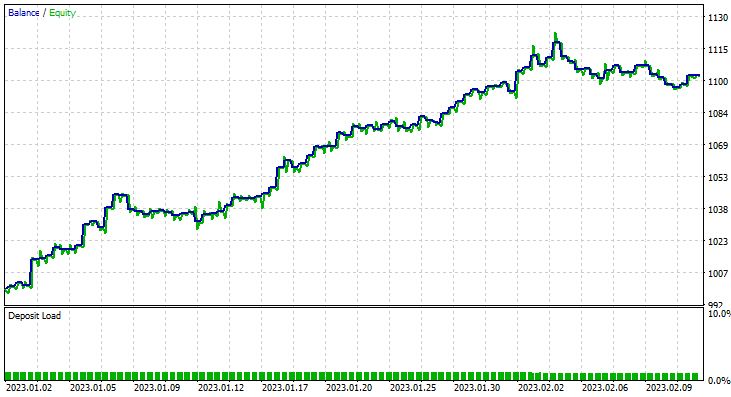
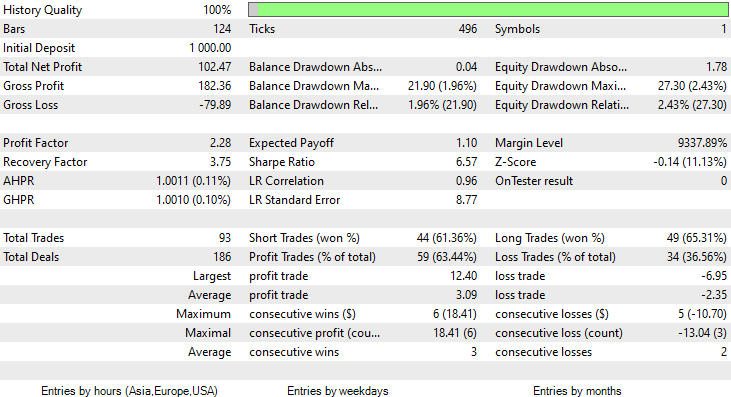
Desta vez, a precisão do modelo Naive Bayes gaussiano de aprendizado foi de 58%.
Foram realizadas 93 negociações em um período de 2 meses - isso pode ser considerado uma atividade de negociação saudável. A média foi de 2,3 negociações por dia. Desta vez, 63% das negociações feitas pelo EA Gaussian Naïve Bayes foram lucrativas. O lucro foi de 10%.
Vimos como podemos usar o modelo Naive Bayes gaussiano para tomar decisões de negociação. Agora vamos ver como ele funciona.
Teoria por trás do Naive Bayes
Não confunda com o método Naive Bayes Gaussiano.
O algoritmo é chamado de
- "Naive" (ingênuo) porque pressupõe que as variáveis/funções são independentes, o que é raro na realidade.
-
"Bayes" (bayesiano) porque é baseado no teorema de Bayes.
A fórmula do teorema de Bayes é a seguinte:
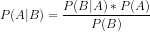
Onde:
P(A|B) é a probabilidade a posteriori da hipótese (estado) A quando o evento B é observado.
P(B|A) é a probabilidade de ocorrência do evento sob a condição de que a hipótese A seja verdadeira. Em termos simples, é a probabilidade de B dado que A é verdadeiro.
P(A) é a probabilidade a priori (incondicional) de A, ou seja, a probabilidade da hipótese antes da ocorrência do evento.
P(B) é a probabilidade marginal de ocorrência do evento.
Os termos dessa fórmula podem parecer confusos inicialmente, mas à medida que trabalharmos em nosso algoritmo, tudo ficará mais claro.
Trabalhando com o classificador
Vamos analisar um exemplo simples com uma amostra de dados meteorológicos. Observe a primeira coluna "Previsão". Primeiro, vamos entender o que está acontecendo nela e, em seguida, iremos adicionar outras colunas como variáveis independentes - é exatamente o mesmo processo.
| Previsão | Jogar tênis |
|---|---|
| Ensolarado | Nenhum |
| Ensolarado | Nenhum |
| Principalmente nublado | Sim |
| Chuva | Sim |
| Chuva | Sim |
| Chuva | Nenhum |
| Principalmente nublado | Sim |
| Ensolarado | Nenhum |
| Ensolarado | Sim |
| Chuva | Sim |
| Ensolarado | Sim |
| Principalmente nublado | Sim |
| Principalmente nublado | Sim |
| Chuva | Nenhum |
Agora, vamos fazer o mesmo no MetaEditor:
void OnStart() { //--- matrix Matrix = matrix_utils.ReadCsvEncode("weather dataset.csv"); int cols[3] = {1,2,3}; matrix_utils.RemoveMultCols(Matrix, cols); //удалим данные о температуре, влажности и ветре ArrayRemove(matrix_utils.csv_header,1,3); //удаление заголовков столбцов ArrayPrint(matrix_utils.csv_header); Print(Matrix); matrix x_matrix; vector y_vector; matrix_utils.XandYSplitMatrices(Matrix, x_matrix, y_vector); }
Observe que o Naive Bayes é adequado apenas para variáveis discretas/contínuas. Não confunda com o modelo Naive Bayes gaussiano que vimos anteriormente - ele pode lidar com variáveis contínuas, ao contrário desse modelo bayesiano ingênuo. Por isso, neste exemplo, decidi usar esse conjunto de dados específico, que contém valores discretos. Abaixo está o resultado do código mostrado acima.
CS 0 12:59:37.386 Naive Bayes theory script (EURUSD,H1) "Outlook" "Play" CS 0 12:59:37.386 Naive Bayes theory script (EURUSD,H1) [[0,0] CS 0 12:59:37.386 Naive Bayes theory script (EURUSD,H1) [0,0] CS 0 12:59:37.386 Naive Bayes theory script (EURUSD,H1) [1,1] CS 0 12:59:37.386 Naive Bayes theory script (EURUSD,H1) [2,1] CS 0 12:59:37.386 Naive Bayes theory script (EURUSD,H1) [2,1] CS 0 12:59:37.386 Naive Bayes theory script (EURUSD,H1) [2,0] CS 0 12:59:37.386 Naive Bayes theory script (EURUSD,H1) [1,1] CS 0 12:59:37.386 Naive Bayes theory script (EURUSD,H1) [0,0] CS 0 12:59:37.386 Naive Bayes theory script (EURUSD,H1) [0,1] CS 0 12:59:37.386 Naive Bayes theory script (EURUSD,H1) [2,1] CS 0 12:59:37.386 Naive Bayes theory script (EURUSD,H1) [0,1] CS 0 12:59:37.386 Naive Bayes theory script (EURUSD,H1) [1,1] CS 0 12:59:37.386 Naive Bayes theory script (EURUSD,H1) [1,1] CS 0 12:59:37.386 Naive Bayes theory script (EURUSD,H1) [2,0]]
Agora, vamos encontrar a probabilidade a priori em nosso construtor de classe NaïveBayes:
CNaiveBayes::CNaiveBayes(matrix &x_matrix, vector &y_vector) { XMatrix.Copy(x_matrix); YVector.Copy(y_vector); classes = matrix_utils.Classes(YVector); c_evidence.Resize((ulong)classes.Size()); n = YVector.Size(); if (n==0) { Print("--> n == 0 | Naive Bayes class failed"); return; } //--- vector v = {}; for (ulong i=0; i<c_evidence.Size(); i++) { v = matrix_utils.Search(YVector,(int)classes[i]); c_evidence[i] = (int)v.Size(); } //--- c_prior_proba.Resize(classes.Size()); for (ulong i=0; i<classes.Size(); i++) c_prior_proba[i] = c_evidence[i]/(double)n; #ifdef DEBUG_MODE Print("---> GROUPS ",classes); Print("Prior Class Proba ",c_prior_proba,"\nEvidence ",c_evidence); #endif }
Resultado
CS 0 12:59:37.386 Naive Bayes theory script (EURUSD,H1) ---> GROUPS [0,1] CS 0 12:59:37.386 Naive Bayes theory script (EURUSD,H1) Prior Class Proba [0.3571428571428572,0.6428571428571429] CS 0 12:59:37.386 Naive Bayes theory script (EURUSD,H1) Evidence [5,9]
A probabilidade a priori [Sim, Não] é aproximadamente [0,36, 0,64].
Agora, suponhamos que queiramos saber a probabilidade de uma pessoa jogar tênis em um dia ensolarado. Para isso, faremos o seguinte:
P(Yes | Sunny) = P(Sunny | Yes) * P(Yes) / P(Sunny)
Mais detalhes em português simples:
A probabilidade de alguém jogar em um dia ensolarado = quantas vezes provavelmente estava ensolarado e alguém jogou tênis * quantas vezes as pessoas jogaram tênis em termos de probabilidade / quantas vezes era um dia ensolarado em termos de probabilidade.
P(Sol | Sim) = 2/9
P(Yes) = 0.64
P(Sunny) = 5/14 = 0.357
No total, temos P(Yes | Sunny) = 0.333 x 0.64 / 0.357 = 0.4
Quanto à probabilidade (No| Sunny), ela pode ser calculada da seguinte forma: 1 - probabilidade Yes = 1 - 0,5972 = 0,4027. É simples assim, mas vamos dar uma olhada nessa parte também.
P(No|Sunny) = (3/5) x 0.36 / (0.357) = 0.6
No código, é assim:
vector CNaiveBayes::calcProba(vector &v_features) { vector proba_v(classes.Size()); //вектор для возврата if (v_features.Size() != XMatrix.Cols()) { printf("FATAL | Can't calculate probability, features columns size = %d is not equal to XMatrix columns =%d",v_features.Size(),XMatrix.Cols()); return proba_v; } //--- vector v = {}; for (ulong c=0; c<classes.Size(); c++) { double proba = 1; for (ulong i=0; i<XMatrix.Cols(); i++) { v = XMatrix.Col(i); int count =0; for (ulong j=0; j<v.Size(); j++) { if (v_features[i] == v[j] && classes[c] == YVector[j]) count++; } proba *= count==0 ? 1 : count/(double)c_evidence[c]; //не считаем, если нет достаточно доказательств } proba_v[c] = proba*c_prior_proba[c]; } return proba_v; }
O vetor de probabilidade fornecido por essa função para tempo ensolarado:
2023.02.15 16:34:21.519 Naive Bayes theory script (EURUSD,H1) Probabilities [0.6,0.4]
Exatamente como esperávamos. No entanto, atenção, essa função não nos fornece as probabilidades. Vou explicar. Quando há apenas duas classes no conjunto de dados de previsão, nesse cenário o resultado é uma probabilidade. Por outro lado, a saída dessa função precisa ser verificada em termos de probabilidade. Isso é bastante simples:
Nós somamos o vetor resultante dessa função e, em seguida, dividimos cada elemento pela soma total. O vetor resultante serão os valores reais de probabilidade que, quando somados, resultarão em um.
probability_v = v[i]/probability_v.Sum()
Esse pequeno processo é realizado dentro da função NaiveBayes(), que prevê o resultado da classe ou da classe com a maior probabilidade de todas:
int CNaiveBayes::NaiveBayes(vector &x_vector) { vector v = calcProba(x_vector); double sum = v.Sum(); for (ulong i=0; i<v.Size(); i++) //преобразуем значения в вероятности v[i] = NormalizeDouble(v[i]/sum,2); vector p = v; #ifdef DEBUG_MODE Print("Probabilities ",p); #endif return((int)classes[p.ArgMax()]); }
E é isso. O algoritmo bayesiano ingênuo é simples assim. Agora vamos nos concentrar no algoritmo Naive Bayes gaussiano que usamos no início deste artigo.
Método Naive Bayes Gaussiano
O método Naive Bayes gaussiano pressupõe que os recursos sigam uma distribuição normal. Isso significa que, se os preditores forem variáveis contínuas em vez de variáveis discretas, presume-se que esses valores sejam extraídos da distribuição gaussiana.
Vamos relembrar a distribuição normal
A distribuição normal é uma distribuição contínua de probabilidade que é simétrica em relação à sua média. A maioria das observações se concentra em torno de um pico central, e as probabilidades dos valores mais distantes da média diminuem igualmente em ambas as direções. Valores extremos em ambas as caudas da distribuição são considerados improváveis.

Essa curva de probabilidade em forma de sino é tão eficaz que é considerada uma das ferramentas mais úteis na análise estatística. Ela mostra que há uma probabilidade aproximada de 34% de encontrar algo dentro de um desvio padrão da média e uma probabilidade de 34% de encontrar algo no outro lado da curva da distribuição normal. Isso significa que a probabilidade de encontrar um valor que esteja a um desvio padrão da média em ambos os lados é de aproximadamente 68%. Se você quiser saber mais detalhes sobre isso, recomendo ler aqui.
A partir dessa distribuição normal/Gaussiana, precisamos encontrar a função de densidade de probabilidade. Ela é calculada usando a seguinte fórmula:
![]()
Onde:
μ - valor médio
𝜎 - desvio padrão
x - valor de entrada
Como isso faz parte do algoritmo Naive Bayes gaussiano, vamos escrever o código correspondente.
class CNormDistribution { public: double m_mean; //присваем значение среднего double m_std; //присваиваем значение дисперсии CNormDistribution(void); ~CNormDistribution(void); double PDF(double x); //функция плотности вероятности }; //+------------------------------------------------------------------+ //| | //+------------------------------------------------------------------+ CNormDistribution::CNormDistribution(void) { } //+------------------------------------------------------------------+ //| | //+------------------------------------------------------------------+ CNormDistribution::~CNormDistribution(void) { ZeroMemory(m_mean); ZeroMemory(m_std); } //+------------------------------------------------------------------+ //| | //+------------------------------------------------------------------+ double CNormDistribution::PDF(double x) { double nurm = MathPow((x - m_mean),2)/(2*MathPow(m_std,2)); nurm = exp(-nurm); double denorm = 1.0/(MathSqrt(2*M_PI*MathPow(m_std,2))); return(nurm*denorm); }
Construindo um modelo Naive Bayes gaussiano
O construtor da classe Gaussian Naïve Bayes é semelhante ao construtor da classe Naïve Bayes. Portanto, não vou mostrar nem explicar o código do construtor aqui. Abaixo está nossa função principal responsável pelo cálculo da probabilidade.
vector CGaussianNaiveBayes::calcProba(vector &v_features) { vector proba_v(classes.Size()); //вектор для возврата if (v_features.Size() != XMatrix.Cols()) { printf("FATAL | Can't calculate probability, features columns size = %d is not equal to XMatrix columns =%d",v_features.Size(),XMatrix.Cols()); return proba_v; } //--- vector v = {}; for (ulong c=0; c<classes.Size(); c++) { double proba = 1; for (ulong i=0; i<XMatrix.Cols(); i++) { v = XMatrix.Col(i); int count =0; vector calc_v = {}; for (ulong j=0; j<v.Size(); j++) { if (classes[c] == YVector[j]) { count++; calc_v.Resize(count); calc_v[count-1] = v[j]; } } norm_distribution.m_mean = calc_v.Mean(); //назначаем нормальному распределению Гаусса norm_distribution.m_std = calc_v.Std(); #ifdef DEBUG_MODE printf("mean %.5f std %.5f ",norm_distribution.m_mean,norm_distribution.m_std); #endif proba *= count==0 ? 1 : norm_distribution.PDF(v_features[i]); //не считаем, если нет достаточно доказательств } proba_v[c] = proba*c_prior_proba[c]; //превращение плотности вероятности в вероятность #ifdef DEBUG_MODE Print(">> Proba ",proba," prior proba ",c_prior_proba); #endif } return proba_v; }
Vamos ver como esse modelo se comporta na prática.
Vamos usar uma amostra de dados de gênero como exemplo.
| Altura (pés) | Peso (libras) | Tamanho do pé (polegadas) | Sexo (0 - masculino, 1 - feminino) |
|---|---|---|---|
| 6 | 180 | 12 | 0 |
| 5.92 | 190 | 11 | 0 |
| 5.58 | 170 | 12 | 0 |
| 5.92 | 165 | 10 | 0 |
| 5 | 100 | 6 | 1 |
| 5.5 | 150 | 8 | 1 |
| 5.42 | 130 | 7 | 1 |
| 5.75 | 150 | 9 | 1 |
//--- гауссовский наивный байес Matrix = matrix_utils.ReadCsv("gender dataset.csv"); ArrayPrint(matrix_utils.csv_header); Print(Matrix); matrix_utils.XandYSplitMatrices(Matrix, x_matrix, y_vector); gaussian_naive = new CGaussianNaiveBayes(x_matrix, y_vector);
Resultado:
CS 0 18:52:18.653 Naive Bayes theory script (EURUSD,H1) ---> GROUPS [0,1] CS 0 18:52:18.653 Naive Bayes theory script (EURUSD,H1) CS 0 18:52:18.653 Naive Bayes theory script (EURUSD,H1) ---> Prior_proba [0.5,0.5] Evidence [4,4]
Como 4 dos 8 eram do gênero masculino e os outros 4 do gênero feminino, a probabilidade de o modelo prever o gênero masculino ou feminino é de 50-50.
Vamos tentar o modelo com novos dados de uma pessoa que tem 5,3 de altura, pesa 140 e tem um tamanho de pé de 7,5. Você e eu entendemos que é provável que essa pessoa seja uma mulher.
vector person = {5.3, 140, 7.5}; Print("The Person is a ",gaussian_naive.GaussianNaiveBayes(person));
Resultado:
2023.02.15 19:14:40.424 Naive Bayes theory script (EURUSD,H1) The Person is a 1
Ótimo, a previsão acabou sendo correta - é uma mulher.
Testar o modelo Naive Bayes gaussiano também é relativamente simples. Basta passar a matriz na qual o modelo foi treinado e medir a precisão das previsões usando a matriz de confusão.
CS 0 19:21:22.951 Naive Bayes theory script (EURUSD,H1) Confusion Matrix CS 0 19:21:22.951 Naive Bayes theory script (EURUSD,H1) [[4,0] CS 0 19:21:22.951 Naive Bayes theory script (EURUSD,H1) [0,4]] CS 0 19:21:22.951 Naive Bayes theory script (EURUSD,H1) CS 0 19:21:22.951 Naive Bayes theory script (EURUSD,H1) Classification Report CS 0 19:21:22.951 Naive Bayes theory script (EURUSD,H1) CS 0 19:21:22.951 Naive Bayes theory script (EURUSD,H1) _ Precision Recall Specificity F1 score Support CS 0 19:21:22.951 Naive Bayes theory script (EURUSD,H1) 0.0 1.00 1.00 1.00 1.00 4.0 CS 0 19:21:22.951 Naive Bayes theory script (EURUSD,H1) 1.0 1.00 1.00 1.00 1.00 4.0 CS 0 19:21:22.951 Naive Bayes theory script (EURUSD,H1) CS 0 19:21:22.951 Naive Bayes theory script (EURUSD,H1) Accuracy 1.00 CS 0 19:21:22.951 Naive Bayes theory script (EURUSD,H1) Average 1.00 1.00 1.00 1.00 8.0 CS 0 19:21:22.951 Naive Bayes theory script (EURUSD,H1) W Avg 1.00 1.00 1.00 1.00 8.0
A precisão do treinamento é de 100%! Nosso modelo pode classificar se uma pessoa é homem ou mulher usando todos os dados como amostra de treinamento.
Vantagens dos classificadores bayesianos ingênuos e gaussianos
- Esses são alguns dos algoritmos de aprendizado de máquina mais simples e rápidos usados para classificar conjuntos de dados.
- Podem ser usados tanto para classificação binária quanto para classificação multiclasse.
- Apesar de sua simplicidade, eles geralmente têm um desempenho melhor na classificação multiclasse do que a maioria dos outros algoritmos.
- São a ferramenta mais popular para tarefas de classificação de texto.
Desvantagens desses classificadores
Embora o algoritmo de classificação bayesiana ingênuo seja simples e eficiente para classificação, ele possui algumas limitações e desvantagens a serem consideradas.
Naive Bayes
- A suposição de independência. A abordagem Naive Bayes pressupõe que todas as características são independentes umas das outras, o que nem sempre é verdade na prática. Essa suposição pode levar a uma redução na precisão da classificação se as características estiverem fortemente dependentes umas das outras.
- Esparsidade dos dados. O Naive Bayes depende de ter um número adequado de exemplos de treinamento para cada classe, a fim de estimar com precisão as probabilidades a priori da classe e as probabilidades condicionais. Se os dados de treinamento forem muito escassos, as estimativas podem ser imprecisas e a classificação pode ser ineficiente.
- Sensibilidade a características irrelevantes. O método Naive Bayes trata todas as características da mesma forma, independentemente de sua relevância para a tarefa de classificação. Isso pode levar a uma classificação inferior se características irrelevantes estiverem incluídas no conjunto de dados. No entanto, é difícil argumentar que algumas características no conjunto de dados são mais importantes do que outras.
- Incapacidade de lidar com variáveis contínuas. A abordagem Naive Bayes pressupõe que todas as características sejam discretas ou categóricas e não consegue lidar diretamente com variáveis contínuas. Para usar o Naive Bayes com variáveis contínuas, os dados devem ser discretizados, o que pode resultar na perda de informações e redução da precisão da classificação.
- Expressividade limitada. O algoritmo Naive Bayes pode modelar apenas limites de decisão lineares, o que pode ser insuficiente para problemas de classificação mais complexos. Isso pode resultar em desempenho inferior se o limite de decisão não for linear.
- Desbalanceamento de classes. O método Naive Bayes pode ter um desempenho inferior quando a distribuição de exemplos entre as classes é altamente desbalanceada, pois isso pode resultar em estimativas tendenciosas das probabilidades a priori da classe e más estimativas das probabilidades condicionais para a classe minoritária. Se não houver evidências suficientes, a classe pode não ser prevista de forma alguma.
Método Naive Bayes gaussiano
O método Naive Bayes gaussiano apresenta as mesmas desvantagens mencionadas anteriormente e duas desvantagens adicionais:
- Sensibilidade a valores atípicos. O método Naive Bayes gaussiano pressupõe que as características seguem uma distribuição normal, o que significa que valores extremos ou valores atípicos podem ter um impacto significativo nas estimativas de média e variância. Isso pode levar a um desempenho de classificação ruim se o conjunto de dados contiver valores atípicos.
- Não é adequado para funções com caudas pesadas. O método Naive Bayes gaussiano pressupõe que as características tenham uma distribuição normal com variância finita. No entanto, se houver caudas pesadas, como a distribuição de Cauchy, o algoritmo pode ter um desempenho ruim.
Considerações finais
Para que um modelo de aprendizado de máquina forneça resultados em um testador de estratégias, é necessário mais do que apenas treinar o modelo. É preciso buscar um bom desempenho e procurar obter um gráfico de lucro em ascensão. Às vezes, não é necessário executar o próprio modelo de aprendizado de máquina no testador de estratégias, pois, para alguns modelos, os testes exigirão recursos computacionais significativos. No entanto, você certamente precisará usar o testador por outras razões, como a otimização dos volumes de negociação, períodos gráficos, etc. É necessário realizar uma análise cuidadosa da lógica antes de decidir iniciar a negociação em tempo real em qualquer modo.
Cumprimentos.
Acompanhe o desenvolvimento do assunto no meu repositório do GitHub em https://github.com/MegaJoctan/MALE5
| Arquivo | Conteúdo e uso |
|---|---|
| Naive Bayes.mqh | Contém classes de modelos Naive Bayes |
| Naive Bayes theory script.mq5 | Script para testar a biblioteca |
| Naive Bayes Test.mq5 | EA para negociação com base nos modelos estudados |
| matrix_utils.mqh | Contém funções de matriz adicionais |
| metrics.mqh | Contém funções para analisar o desempenho de modelos de aprendizado de máquina, como uma matriz de confusão |
| naive bayes visualize.py | Script Python para desenhar gráficos de distribuição para todas as variáveis independentes usadas no modelo |
| gender datasets.csv & weather dataset.csv | Amostras de dados usadas como exemplos neste artigo |
Aviso: Este artigo se destina apenas a fins educacionais. Negociar é uma atividade arriscada e você deve estar ciente de todos os riscos envolvidos. O autor não se responsabiliza por quaisquer perdas ou danos decorrentes do uso dos modelos discutidos neste artigo. Nunca arrisque mais dinheiro do que você pode perder sem se prejudicar!