ニューラルネットワークが簡単に(第63回):Unsupervised Pretraining for Decision Transformer (PDT)
Dmitriy Gizlyk | 2 4月, 2024
はじめに
Decision Transformerは、様々な実用的な問題を解決するための強力なツールです。これは主に、TransformerのAttentionメソッドを使用することによって達成されます。これまでの実験で、Transformerアーキテクチャの使用には、長時間の徹底したモデル訓練が必要であることが示されています。そのためには、ラベル付けされた訓練データを準備する必要があります。実用的な問題を解決する場合、報酬を得るのが非常に難しいことがある一方、ラベル付けされたデータは訓練セットを拡張するためにうまくスケールしません。事前訓練中に報酬を用いなければ、モデルは一般的な行動パターンを獲得することができ、後にさまざまなタスクで使用するために容易に適応させることができます。
この記事では、2023年5月に「Future-conditioned Unsupervised Pretraining for Decision Transformer」で紹介された、Pretrained Decision Transformer(PDT、事前訓練済みDecision Transformer)と呼ばれるRLの事前訓練法に触れていただきたいと思います。この方法は、報酬ラベルのないデータや、最適でないデータを使用して訓練する能力をDTに提供します。特に、この手法の著者は、まず報酬ラベルなしで以前に収集された軌跡をオフラインで訓練し、その後、オンライン相互作用を通じて目標タスクに微調整を加えるという事前訓練シナリオを考えています。
効果的な事前訓練のためには、報酬を使わずに多面的かつ普遍的な訓練シグナルを抽出できるモデルでなければなりません。事前訓練中、モデルはどの訓練信号が報酬と関連づけられるかを決定することで、報酬タスクに素早く適応しなければなりません。
PDTは、未来の軌跡の埋め込み空間と、過去の情報のみを条件とする未来の事前分布を共同で学習します。行動予測を対象の未来埋め込みに条件付けることで、PDTには「未来を推論する」能力が備わります。この能力は当然タスクに依存せず、異なるタスク仕様にも一般化できます。
下流タスクを効率的にオンラインで微調整するために、それぞれの未来の埋め込みをそのリターンに関連付けることで、フレームワークを新しい条件に簡単に適応させることができます。これは、それぞれの未来の埋め込みの報酬予測ネットワークを訓練することで実現されます。
この記事の次のセクションに進み、Pretrained Decision Transformer法について詳しく検討することをお勧めします。
1. Pretrained Decision Transformer (PDT)法
PDT法はDTの原理に基づいています。また、訪問した状態と完了した行動のシーケンスを分析した後、エージェントの行動を予測します。同時に、PDTはDTアルゴリズムに追加を導入し、ラベル付けされていないデータ、つまり返り値を分析することなく、モデルの予備訓練を可能にします。というのも、RTG(未来の報酬)はモデルによって分析されたシーケンスのメンバーの1つであり、空間におけるモデルの方向付けのためのコンパスのような役割を果たしているからです。
PDT法の著者は、RTGをある潜在状態ベクトルZに置き換えることを提案しました。この考え方は決して新しいものではありませんが、著者たちはかなり興味深い解釈を示しています。ラベルなしデータに対する予備訓練の過程で、実際には3つのモデルを訓練します。
- Actor:直前の軌跡の分析に基づいて行動予測をおこなう古典的なDT
- 目標予測モデルP(•|St):現在の状態の分析に基づいてDT目標(潜在状態Z)を予測
- Future EncoderG(•|τt+1:t+k)のモデル:「未来を見る」ことで、潜在状態Zに埋め込む
最後の2つのモデルは異なるデータを分析しますが、どちらも潜在ベクトルZを返します。これにより、現在の状態と未来の状態の間に一種のオートエンコーダが構築されます。その潜在的な状態は、DT (Actor)の目標指定として使用されます。
しかし、モデルの訓練はオートエンコーダの訓練とは異なります。まず、未来の軌跡と取った行動の間に依存関係を構築することで、Future EncoderとActorを訓練します。私たちはPDTに、ある程度の計画的視野で未来を見通すことを認めています。その後の軌跡に関する情報を潜在的な状態に圧縮します。こうすることで、モデルが未来について利用可能な情報に基づいて決断を下すことを可能にします。事前訓練では、環境的報酬によって制限されることなく、幅広い行動能力を備えたActor方策を作り上げることを期待しています。
そして、現在の状態と訓練された未来の軌道の埋め込みとの間の依存関係を探す目標予測モデルを訓練します。
このアプローチによって、報酬と目標成果を切り離すことができ、大規模で継続的な事前学習の機会が開かれます。同時に、エージェントの行動が望ましい目標から大きく逸脱した場合の一貫性のない行動の問題を軽減します。
目標予測モデルP(Z|St)の使用は、未来の潜在変数を標本化し、訓練データセットの分布を模倣した行動を生成するのに便利ですが、タスク固有のデータをエンコードするものではありません。したがって、P(Z|St)を、下流学習中に高い未来の報酬につながる未来の埋め込みデータセットに送る必要があります。
これは、リターンを最大化することを条件とした、DTの専門家としての行動を生み出すことにつながります。スカラー目標報酬を割り当ててリターン最大化方策を制御するのとは異なり、目標予測モデルP(Z|St)の分布を調整する必要があります。この分布は未知であるため、追加の報酬予測モデルF(-|Z,St)を用いて最適軌道を予測します。報酬予測モデルは、下流の訓練過程で他のすべてのモデルとともに訓練します。
事前訓練と同様に、潜在的状態を得るためにFuture Encoderを使用し、勾配を逆伝播させ、潜在的表現における報酬データの符号化を調整します。これにより、下流の学習プロセスにおいて、タスクの詳細を解決することができます。
以下は、元の記事のPretrained Decision Transformer法を視覚化したものです。
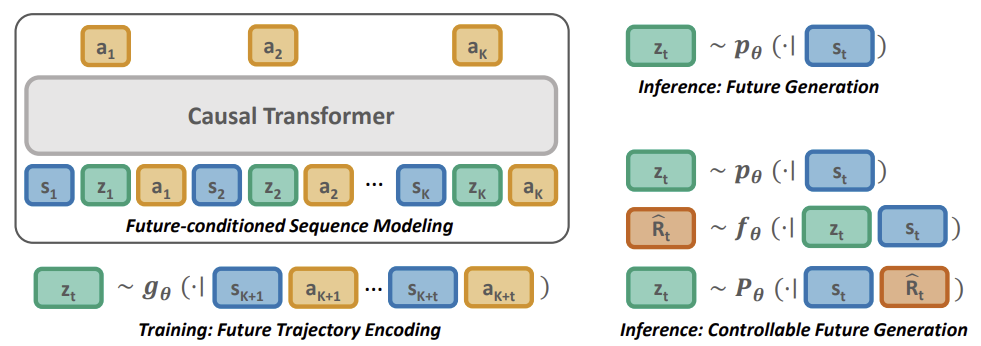
2.MQL5を使用した実装
さて、Pretrained Decision Transformer法の理論的側面について考察したので、次は実践的な部分に移り、MQL5における実装について考察します。この記事では、EAを収集する訓練データセットに焦点を当てます。以前の記事では、Decision Transformerファミリーのアルゴリズムを構築するためのいくつかの選択肢を検討しました。どれも似たような経験再生バッファを含んでいます。訓練データセットの最初の収集には、この「訓練データセット」を使用します。ここでは、前回の記事で収集した経験再生バッファを使用します。特定のモデル(Go-Exploreメソッドで実装)を参照することなく、行動の無作為標本化によって収集しました。
2.1.モデルアーキテクチャ
すでに訓練データのセットがあるので、次の段階である教師なし事前訓練に移ります。前述したように、この段階では3つのモデルを訓練します。CreateDescriptionsメソッドで収集されるモデルアーキテクチャの記述から作業を始めましょう。
bool CreateDescriptions(CArrayObj *agent, CArrayObj *planner, CArrayObj *future_embedding) { //--- CLayerDescription *descr;
パラメータに、このメソッドは3つの動的配列へのポインタを受け取り、そこにモデルのニューラル層のアーキテクチャ記述を追加します。
メソッド本体では、ローカル変数を宣言して、1つのニューラル層を記述するオブジェクトへのポインタを書き込みます。この変数には、作業中のオブジェクトへのポインタを別のブロックに「保持」します。
まず、エージェントのアーキテクチャについて説明します。この場合、Decision Transformerです。これは、軌跡の手順ごとの記述を入力として受け取り、埋め込み層の結果バッファにシーケンス全体の埋め込みを累積します。ただし、これまでの作品とは異なり、バックプロパゲーションパスの間に、誤差勾配をFuture Encoderモデルに伝搬させなければなりません。そのためには、ちょっとしたトリックを使います。ソースデータ配列全体を2つのストリームに分割します。主なデータ量は、通常通りソースデータ層のバッファを通してモデルに渡されます。未来の埋め込みは、連結層で結合される2つ目のストリームとして渡されます。ソースデータ層のバッファに供給される未処理のソースデータに関しては、バッチ正規化層を使用して正規化します。未来の埋め込みはモデルの演算結果であり、正規化せずに使用できます。
//--- if(!agent) { agent = new CArrayObj(); if(!agent) return false; } //--- Agent agent.Clear(); //--- Input layer if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBaseOCL; int prev_count = descr.count = (BarDescr * NBarInPattern + AccountDescr + TimeDescription + NActions); descr.activation = None; descr.optimization = ADAM; if(!agent.Add(descr)) { delete descr; return false; } //--- layer 1 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBatchNormOCL; descr.count = prev_count; descr.batch = 1000; descr.activation = None; descr.optimization = ADAM; if(!agent.Add(descr)) { delete descr; return false; } //--- layer 2 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronConcatenate; descr.count = prev_count + EmbeddingSize; descr.step = EmbeddingSize; descr.optimization = ADAM; descr.activation = None; if(!agent.Add(descr)) { delete descr; return false; }
1つのストリームに結合されたデータは、提示された情報を埋め込むニューラル層に供給されます。
//--- layer 3 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronEmbeddingOCL; prev_count = descr.count = HistoryBars; { int temp[] = {BarDescr * NBarInPattern, AccountDescr, TimeDescription, NActions, EmbeddingSize}; ArrayCopy(descr.windows, temp); } int prev_wout = descr.window_out = EmbeddingSize; if(!agent.Add(descr)) { delete descr; return false; }
その後、データはTransformerブロックに渡されます。16個のSelf-Attentionヘッドを使用した4層の「ケーキ」を使用しました。
//--- layer 4 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronMLMHSparseAttentionOCL; prev_count = descr.count = prev_count * 5; descr.window = EmbeddingSize; descr.step = 16; descr.window_out = 64; descr.layers = 4; descr.probability = Sparse; descr.optimization = ADAM; if(!agent.Add(descr)) { delete descr; return false; }
Transformerブロックの後、安定したパターンを識別するために2つの畳み込み層を使用しました。
//--- layer 5 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronConvOCL; descr.count = prev_count; descr.window = EmbeddingSize; descr.step = EmbeddingSize; descr.window_out = EmbeddingSize; descr.optimization = ADAM; descr.activation = LReLU; if(!agent.Add(descr)) { delete descr; return false; } //--- layer 6 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronConvOCL; descr.count = prev_count; descr.window = EmbeddingSize; descr.step = EmbeddingSize; descr.window_out = 16; descr.optimization = ADAM; descr.activation = LReLU; if(!agent.Add(descr)) { delete descr; return false; }
その後に、3つの全結合層の決定ブロックが続きます。
//--- layer 7 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBaseOCL; descr.count = LatentCount; descr.optimization = ADAM; descr.activation = LReLU; if(!agent.Add(descr)) { delete descr; return false; } //--- layer 8 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBaseOCL; prev_count = descr.count = LatentCount; descr.activation = LReLU; descr.optimization = ADAM; if(!agent.Add(descr)) { delete descr; return false; } //--- layer 9 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBaseOCL; descr.count = LatentCount; descr.activation = LReLU; descr.optimization = ADAM; if(!agent.Add(descr)) { delete descr; return false; } //--- layer 10 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBaseOCL; descr.count = NActions; descr.activation = SIGMOID; descr.optimization = ADAM; if(!agent.Add(descr)) { delete descr; return false; }
モデルの出力には、エージェントの行動空間と同じ要素数を持つ全結合層があります。
次に、目標予測モデルP(Z|St)の記述を作成します。階層モデルの用語を使用すれば、Plannerと呼ぶことができます。モデルを訓練するアプローチは根本的に異なりますが、その機能は構造的に非常によく似ています。
モデルのソースデータ層への入力として、1つのパターンの過去のデータと指標値のみの記述を与えます。私たちの場合、これは1バーのみのデータです。
市場の状況を分析し、未来の状態や行動を予測するには情報が少なすぎるという点には同意します。特に、数歩先の予測について話すならなおさらです。しかし、状況を違った角度から見てみましょう。操作中は、埋め込みという形で生成された未来予測をActorの入力として与えます。その内部層は、所定の深さの履歴までデータを保存します。このような状況において、起こった変化に注意を払い、Actorの行動を調整することがより重要です。未来の埋め込みを作成する際に、より深い履歴を分析することで、局所的な変化を「ぼかす」ことができます。しかし、これは私の主観的な意見であり、Pretrained Decision Transformerアルゴリズムの要件ではありません。
if(!planner) { planner = new CArrayObj(); if(!planner) return false; } //--- Planner planner.Clear(); //--- Input layer if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBaseOCL; prev_count = descr.count = BarDescr * NBarInPattern; descr.activation = None; descr.optimization = ADAM; if(!planner.Add(descr)) { delete descr; return false; }
得られた生データは、バッチ正規化層を通して比較可能な形式に変換されます。
//--- layer 1 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBatchNormOCL; descr.count = prev_count; descr.batch = 1000; descr.activation = None; descr.optimization = ADAM; if(!planner.Add(descr)) { delete descr; return false; }
次に、モデルを複雑にしないことに決め、3層の全結合層意思決定ブロックを使用しました。
//--- layer 2 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBaseOCL; descr.count = LatentCount; descr.optimization = ADAM; descr.activation = LReLU; if(!planner.Add(descr)) { delete descr; return false; } //--- layer 3 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBaseOCL; prev_count = descr.count = LatentCount; descr.activation = LReLU; descr.optimization = ADAM; if(!planner.Add(descr)) { delete descr; return false; } //--- layer 4 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBaseOCL; prev_count = descr.count = LatentCount; descr.activation = LReLU; descr.optimization = ADAM; if(!planner.Add(descr)) { delete descr; return false; }
モデルの出力では、ベクトルサイズを埋め込みサイズまで縮小し、SoftMax関数を使用して結果を正規化します。
//--- layer 5 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBaseOCL; prev_count = descr.count = EmbeddingSize; descr.activation = None; descr.optimization = ADAM; if(!planner.Add(descr)) { delete descr; return false; } //--- layer 6 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronSoftMaxOCL; descr.count = EmbeddingSize; descr.activation = None; descr.optimization = ADAM; if(!planner.Add(descr)) { delete descr; return false; }
すでに2つのモデルのアーキテクチャソリューションを説明しました。あとはFuture Encoderの説明を加えるだけです。モデルの出力は基本的に前のモデルの出力と一致させることを意図していますが、これが顕著になるのはモデルの最後の層だけです。エンコーダのアーキテクチャはもう少し複雑です。まず、未来の埋め込みでは、ある程度深い計画を可能にします。つまり、いくつかの後続のローソク足に関する情報をソースデータ層に送り込むということです。
なお、未来に関するデータには、銘柄の値動きと指標の読みに関するデータのみを含めました。口座の状態やその後のエージェントの行動に関する情報は含めませんでした。エージェントの行動は、その方策によって決定されます。環境におけるプロセスを理解することに集中したかったのです。口座の状態には、環境から受け取った報酬に関する情報がある程度すでに含まれていますが、これはラベルなしデータの原則にやや反します。
//--- Future Embedding if(!future_embedding) { future_embedding = new CArrayObj(); if(!future_embedding) return false; } //--- future_embedding.Clear(); //--- Input layer if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBaseOCL; prev_count = descr.count = BarDescr * NBarInPattern * ValueBars; descr.activation = None; descr.optimization = ADAM; if(!future_embedding.Add(descr)) { delete descr; return false; } //--- layer 1 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBatchNormOCL; descr.count = prev_count; descr.batch = 1000; descr.activation = None; descr.optimization = ADAM; if(!future_embedding.Add(descr)) { delete descr; return false; }
前回同様、未処理の生データをバッチ正規化層に通し、比較可能な形式に変換します。
次に、4層のTransformerブロックと16個のSelf-Attentionヘッドを使用しました。この場合、Attentionブロックは個々のバー間の依存関係を分析し、計画水平線上の主な傾向を特定し、雑音成分をフィルタリングしようとします。
PDT法のロジックによれば、Actorに使用されているスキルとさらなる行動の方向性を示すべきは、未来の状態の埋め込みです。したがって、エンコーダの動作結果は、可能な限り有益で正確でなければなりません。
//--- layer 2 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronMLMHSparseAttentionOCL; prev_count = descr.count = ValueBars; descr.window = BarDescr * NBarInPattern; descr.step = 16; descr.window_out = 64; descr.layers = 4; descr.probability = Sparse; descr.optimization = ADAM; if(!future_embedding.Add(descr)) { delete descr; return false; }
Attention層に続いて、決定ブロックの全結00合層が続きます。
//--- layer 3 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBaseOCL; descr.count = LatentCount; descr.optimization = ADAM; descr.activation = LReLU; if(!future_embedding.Add(descr)) { delete descr; return false; } //--- layer 4 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBaseOCL; prev_count = descr.count = LatentCount; descr.activation = LReLU; descr.optimization = ADAM; if(!future_embedding.Add(descr)) { delete descr; return false; }
モデル出力では、上記の未来予測モデルと同様に、SoftMaxによる正規化をおこなった全結合層を使用します。
//--- layer 5 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBaseOCL; descr.count = EmbeddingSize; descr.activation = None; descr.optimization = ADAM; if(!future_embedding.Add(descr)) { delete descr; return false; } //--- layer 6 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronSoftMaxOCL; descr.count = EmbeddingSize; descr.activation = None; descr.optimization = ADAM; if(!future_embedding.Add(descr)) { delete descr; return false; } //--- return true; }
これで、事前訓練エキスパートアドバイザー(EA)のモデルアーキテクチャの説明は終わりです。ただし、EAの作業に移る前に、モデルのアーキテクチャを説明する作業を完了させたいと思います。PDT法を使用した微調整の段階で、報酬予測という別のモデルを追加することが可能であることを思い出してください。これは訓練の後の段階で追加されるものなので、別のCreateValueDescriptionsメソッドにそのアーキテクチャの説明を含めることにしました。
PDTの方法論によれば、このモデルは潜在状態と現在の状態に符号化された未来のトレンドを推定しなければなりません。分析結果に基づき、環境からの報酬を予測する必要があります。
下流の訓練プロセスの目的は、未来の埋め込みに報酬の可能性に関する情報を含めることです。したがって、事前訓練の段階と同様に、報酬予測誤差勾配をFuture Encoderモデルに渡す必要があります。ここでは、情報の流れを分離するために、上でテストしたアプローチを使用します。最初のデータストリームの1つは、現在の状態です。もう1つは、未来の埋め込みです。
今解決しなければならない2つ目の疑問は、現段階での現状把握に何が含まれているかということです。もちろん、微調整の段階では、訓練データセットからラベル付きデータを使用し、利用可能なデータの全量を含めることができます。しかし、大量の入力データはモデルを非常に複雑にし、モデル処理のコストを増大させます。現段階でこれだけのデータを使用することの効果はどうでしょうか。
その後の状態を予測するには、環境の以前の状態を分析する必要がありますが、すでに埋め込みという形で未来の状態についての情報を持っています。
エージェントの過去の行動を分析することで、使用されている方策を示すことができますが、使用されているスキルや行動方針を変更する必要性について判断を下すためには、エージェントに情報を提供する必要があります。
現在の口座状況についての情報は役に立ちます。余剰証拠金の存在は、トレンドが良好であれば追加ポジションを建てることができることを示しています。あるいは、トレンドの変化が予想され他場合、以前に建てたポジションを決済し、浮動損益を確定しなければならないことです。加えて、ポジションがなかった場合のペナルティについても覚えておく必要があります。それも報酬に影響します。
したがって、口座のステータスと未決済ポジションの現在の記述をソースデータ層にフィードします。
bool CreateValueDescriptions(CArrayObj *value) { //--- CLayerDescription *descr; //--- if(!value) { value = new CArrayObj(); if(!value) return false; } //--- Value value.Clear(); //--- Input layer if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBaseOCL; int prev_count = descr.count = AccountDescr; descr.activation = None; descr.optimization = ADAM; if(!value.Add(descr)) { delete descr; return false; }
出力はバッチ正規化層に渡されます。
//--- layer 1 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBatchNormOCL; descr.count = prev_count; descr.batch = 1000; descr.activation = None; descr.optimization = ADAM; if(!value.Add(descr)) { delete descr; return false; }
次に、連結層で2つのデータストリームを結合します。
//--- layer 2 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronConcatenate; descr.count = LatentCount; descr.step = EmbeddingSize; descr.optimization = ADAM; descr.activation = SIGMOID; if(!value.Add(descr)) { delete descr; return false; }
そして、全結合層から意思決定ブロックにデータが渡されます。
//--- layer 3 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBaseOCL; descr.count = LatentCount; descr.optimization = ADAM; descr.activation = LReLU; if(!value.Add(descr)) { delete descr; return false; } //--- layer 4 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBaseOCL; prev_count = descr.count = LatentCount; descr.activation = LReLU; descr.optimization = ADAM; if(!value.Add(descr)) { delete descr; return false; } //--- layer 5 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBaseOCL; descr.count = NRewards; descr.activation = None; descr.optimization = ADAM; if(!value.Add(descr)) { delete descr; return false; } //--- return true; }
モデルの出力では、期待報酬のベクトルが得られます。
2.2.事前訓練EA
使用するモデルのアーキテクチャを作成した後、PDT法のアルゴリズムの実装に進みましょう。まずは、事前訓練用のEA「...\PDT\Pretrain.mq5」からです。前述のように、このEAは3つのモデルの予備訓練をおこないました。Actor、Planner、Future Encoderです。
CNet Agent; CNet Planner; CNet FutureEmbedding;
EA初期化メソッドでは、まず訓練データセットを読み込みます。
//+------------------------------------------------------------------+ //| Expert initialization function | //+------------------------------------------------------------------+ int OnInit() { //--- ResetLastError(); if(!LoadTotalBase()) { PrintFormat("Error of load study data: %d", GetLastError()); return INIT_FAILED; }
事前訓練されたモデルの読み込イを試み、必要であれば、上記のアーキテクチャに従って新しいモデルを初期化します。
//--- load models float temp; if(!Agent.Load(FileName + "Act.nnw", temp, temp, temp, dtStudied, true) || !Planner.Load(FileName + "Pln.nnw", temp, temp, temp, dtStudied, true) || !FutureEmbedding.Load(FileName + "FEm.nnw", temp, temp, temp, dtStudied, true)) { CArrayObj *agent = new CArrayObj(); CArrayObj *planner = new CArrayObj(); CArrayObj *future_embedding = new CArrayObj(); if(!CreateDescriptions(agent, planner, future_embedding)) { delete agent; delete planner; delete future_embedding; return INIT_FAILED; } if(!Agent.Create(agent) || !Planner.Create(planner) || !FutureEmbedding.Create(future_embedding)) { delete agent; delete planner; delete future_embedding; return INIT_FAILED; } delete agent; delete planner; delete future_embedding; //--- }
そして、すべてのモデルを1つのOpenCLコンテキストに転送します。
//---
COpenCL *opcl = Agent.GetOpenCL();
Planner.SetOpenCL(opcl);
FutureEmbedding.SetOpenCL(opcl);
ここでは、モデルアーキテクチャに対して必要最小限の制御をおこないます。
Agent.getResults(Result); if(Result.Total() != NActions) { PrintFormat("The scope of the worker does not match the actions count (%d <> %d)", NActions, Result.Total()); return INIT_FAILED; }
Trainメソッドで実装されている予備訓練プロセスの起動を初期化します。
//--- if(!EventChartCustom(ChartID(), 1, 0, 0, "Init")) { PrintFormat("Error of create study event: %d", GetLastError()); return INIT_FAILED; } //--- return(INIT_SUCCEEDED); }
EAの初期化解除メソッドでは、訓練済みモデルを保存しなければなりません。
//+------------------------------------------------------------------+ //| Expert deinitialization function | //+------------------------------------------------------------------+ void OnDeinit(const int reason) { //--- Agent.Save(FileName + "Act.nnw", 0, 0, 0, TimeCurrent(), true); Planner.Save(FileName + "Pln.nnw", 0, 0, 0, TimeCurrent(), true); FutureEmbedding.Save(FileName + "FEm.nnw", 0, 0, 0, TimeCurrent(), true); delete Result; }
モデルの訓練プロセスはTrainメソッドで実行されます。メソッド本体では、まず経験再生バッファのサイズを決定します。
//+------------------------------------------------------------------+ //| Train function | //+------------------------------------------------------------------+ void Train(void) { int total_tr = ArraySize(Buffer); uint ticks = GetTickCount();
次に、モデル訓練プロセスのために、ネストされたループのシステムを作成しました。外部ループは、EA外部パラメータで指定された訓練反復回数に制限されます。このループの本体では、まず経験再生バッファから軌跡を標本化し、選択された軌跡に沿って別の環境状態を標本化して、学習プロセスを開始します。
bool StopFlag = false; for(int iter = 0; (iter < Iterations && !IsStopped() && !StopFlag); iter ++) { int tr = (int)((MathRand() / 32767.0) * (total_tr - 1)); int i = (int)((MathRand() * MathRand() / MathPow(32767, 2)) * MathMax(Buffer[tr].Total - 2 * HistoryBars - ValueBars, MathMin(Buffer[tr].Total, 20 + ValueBars))); if(i < 0) { iter--; continue; }
その後、DTモデルを順次訓練するためにネストされたループを実行します。
Actions = vector<float>::Zeros(NActions); for(int state = i; state < MathMin(Buffer[tr].Total - ValueBars, i + HistoryBars * 3); state++) { //--- History data State.AssignArray(Buffer[tr].States[state].state); if(!Planner.feedForward(GetPointer(State), 1, false)) { PrintFormat("%s -> %d", __FUNCTION__, __LINE__); StopFlag = true; break; }
ループの本文では、過去の値動きデータと指標の読み取り値をソースデータバッファに書き込みます。このデータは、Plannerモデルのフィードフォワードパスを実行するのに十分です。この操作が最初に実行されます。その後、Actorのソースデータバッファへの入力を続けます。口座の状態を追加します。
//--- Account description float PrevBalance = (state == 0 ? Buffer[tr].States[state].account[0] : Buffer[tr].States[state - 1].account[0]); float PrevEquity = (state == 0 ? Buffer[tr].States[state].account[1] : Buffer[tr].States[state - 1].account[1]); State.Add((Buffer[tr].States[state].account[0] - PrevBalance) / PrevBalance); State.Add(Buffer[tr].States[state].account[1] / PrevBalance); State.Add((Buffer[tr].States[state].account[1] - PrevEquity) / PrevEquity); State.Add(Buffer[tr].States[state].account[2]); State.Add(Buffer[tr].States[state].account[3]); State.Add(Buffer[tr].States[state].account[4] / PrevBalance); State.Add(Buffer[tr].States[state].account[5] / PrevBalance); State.Add(Buffer[tr].States[state].account[6] / PrevBalance);
エージェントのタイムスタンプと最後の行動を追加します。
//--- Time label double x = (double)Buffer[tr].States[state].account[7] / (double)(D'2024.01.01' - D'2023.01.01'); State.Add((float)MathSin(2.0 * M_PI * x)); x = (double)Buffer[tr].States[state].account[7] / (double)PeriodSeconds(PERIOD_MN1); State.Add((float)MathCos(2.0 * M_PI * x)); x = (double)Buffer[tr].States[state].account[7] / (double)PeriodSeconds(PERIOD_W1); State.Add((float)MathSin(2.0 * M_PI * x)); x = (double)Buffer[tr].States[state].account[7] / (double)PeriodSeconds(PERIOD_D1); State.Add((float)MathSin(2.0 * M_PI * x)); //--- Prev action State.AddArray(Actions);
さて、Actorのフィードフォワードパスを実行するには、未来の埋め込みだけが必要です。Plannerの結果のバッファはありますが、この段階では、訓練されていないモデルの結果は何も条件付けされていません。PDTアルゴリズムによれば、後続の状態に関する情報を読み込み、受信データの埋め込みを生成する必要があります。
//--- Target Result.AssignArray(Buffer[tr].States[state + 1].state); for(int s = 1; s < ValueBars; s++) Result.AddArray(Buffer[tr].States[state + 1].state); if(!FutureEmbedding.feedForward(Result, 1, false)) { PrintFormat("%s -> %d", __FUNCTION__, __LINE__); StopFlag = true; break; }
エンコーダの演算結果は2つ目のActorモデルに入力されます。次に、ダイレクトパスを呼び出します。
FutureEmbedding.getResults(Result); //--- Policy Feed Forward if(!Agent.feedForward(GetPointer(State), 1, false, Result)) { PrintFormat("%s -> %d", __FUNCTION__, __LINE__); StopFlag = true; break; }
使用するすべてのモデルに対してフォワードパスを実行した後、モデルの訓練を進めます。まず、Plannerモデル(未来予測)に対してバックプロパゲーション法を呼び出します。このシーケンスは、先ほどActorに入力した目標結果のベクトルの準備に関係しています。
//--- Planner Study if(!Planner.backProp(Result, NULL, NULL)) { PrintFormat("%s -> %d", __FUNCTION__, __LINE__); StopFlag = true; break; }
次に、Actorの目標リターンの準備に移ります。そのために、経験再生バッファから、既知の結果につながった行動を使用します。
//--- Policy study Actions.Assign(Buffer[tr].States[state].action); vector<float> result; Agent.getResults(result); Result.AssignArray(CAGrad(Actions - result) + result);
目標値を準備した後、Actorのバックプロパゲーションを実行し、すぐにFuture Encoderモデルに誤差勾配を通します。
if(!Agent.backProp(Result, GetPointer(FutureEmbedding)) || !FutureEmbedding.backPropGradient((CBufferFloat *)NULL)) { PrintFormat("%s -> %d", __FUNCTION__, __LINE__); StopFlag = true; break; }
その後は、操作の進捗状況をユーザーに知らせ、新しい反復に移るだけです。
//--- if(GetTickCount() - ticks > 500) { string str = StringFormat("%-15s %5.2f%% -> Error %15.8f\n", "Agent", iter * 100.0 / (double)(Iterations), Agent.getRecentAverageError()); str += StringFormat("%-15s %5.2f%% -> Error %15.8f\n", "Planner", iter * 100.0 / (double)(Iterations), Planner.getRecentAverageError()); Comment(str); ticks = GetTickCount(); } } }
ループシステムのすべての反復が完了したら、チャートのコメントフィールドを消去します。訓練結果をジャーナルに表示し、EAを終了します。
Comment(""); //--- PrintFormat("%s -> %d -> %-15s %10.7f", __FUNCTION__, __LINE__, "Agent", Agent.getRecentAverageError()); PrintFormat("%s -> %d -> %-15s %10.7f", __FUNCTION__, __LINE__, "Planner", Planner.getRecentAverageError()); ExpertRemove(); //--- }
その他のEA手法は、以前に他の記事で検討した訓練用EA「..\Study.mq5」をそのまま引き継いでいます。今はそれについては触れないことにします。プログラムの全コードは添付ファイルにあります。次の段階に進みます。
2.3.EAの微調整
事前訓練アルゴリズムの実装が完了したら、モデルの下流訓練用アルゴリズムを構築する微調整EA「...\PDT\FineTune.mq5」の作成に取り掛かます。
EAは以前のものと約9割は同じです。したがって、そのすべてのメソッドを詳細に検討することはしません。変更点だけを確認します。
この記事の理論的な部分で述べたように、この段階でのPDT法は、問題を解決するためのモデルの最適化を可能にします。つまり、ラベル付けされたデータと環境的な報酬を利用して、エージェントの方針を最適化するということです。そこで、学習プロセスに別の外部報酬予測モデルを追加します。
CNet RTG;
モデルを追加するだけで、以前のEAからのモデルの使用は変更しないことにご注意ください。
微調整EAでは、事前に訓練したモデルを読み込めない場合に、エージェント、Planner、Future Encoderのモデルを新たに作成する仕組みを残しました。そのため、ユーザーはゼロからモデルを訓練することができます。同時に、EA初期化メソッドにおける新しい外部報酬予測モデルの読み込みと、必要に応じて初期化は、別のブロックに配置されます。事前訓練から微調整に移行する際には、前回のEAで訓練したモデルを使用します。報酬予測モデルに関しては、無作為なパラメータで初期化します。
//+------------------------------------------------------------------+ //| Expert initialization function | //+------------------------------------------------------------------+ int OnInit() { //--- ........ ........ //--- if(!RTG.Load(FileName + "RTG.nnw", temp, temp, temp, dtStudied, true)) { CArrayObj *rtg = new CArrayObj(); if(!CreateValueDescriptions(rtg)) { delete rtg; return INIT_FAILED; } if(!RTG.Create(rtg)) { delete rtg; return INIT_FAILED; } delete rtg; //--- } //--- COpenCL *opcl = Agent.GetOpenCL(); Planner.SetOpenCL(opcl); FutureEmbedding.SetOpenCL(opcl); RTG.SetOpenCL(opcl); //--- RTG.getResults(Result); if(Result.Total() != NRewards) { PrintFormat("The scope of the RTG does not match the rewards count (%d <> %d)", NRewards, Result.Total()); return INIT_FAILED; } //--- ........ ........ //--- return(INIT_SUCCEEDED); }
次に、すべてのモデルを1つのOpenCLコンテキストに転送し、追加されたモデルの結果層が、分解された報酬ベクトルの次元と一致するかどうかを確認します。
また、Trainモデル訓練メソッドにもいくつかの改良が加えられました。エージェントのフィードフォワードパスの後に、報酬予測モデルのフィードフォワードパスの呼び出しを追加します。上述したように、モデルの入力には、口座の状態と未来の埋め込みを記述するベクトルを与えます。
........ ........ //--- Policy Feed Forward if(!Agent.feedForward(GetPointer(State), 1, false, Result)) { PrintFormat("%s -> %d", __FUNCTION__, __LINE__); StopFlag = true; break; } //--- Return-To-Go Account.AssignArray(Buffer[tr].States[state + 1].account); if(!RTG.feedForward(GetPointer(Account), 1, false, Result)) { PrintFormat("%s -> %d", __FUNCTION__, __LINE__); StopFlag = true; break; } ........ ........
エージェントのパラメータが更新された後、モデルのパラメータも更新されます。モデルの最適化アルゴリズムはほとんど同じです。モデルのバックプロパゲーションメソッドを呼び出すことで、誤差の勾配を未来の符号化モデルに伝搬し、そのパラメータを更新します。唯一の違いは目標値の違いです。このアプローチにより、エージェントの行動と受け取る外部報酬の未来の埋め込みに対する依存性を訓練することができます。
........ ........ //--- Policy study Actions.Assign(Buffer[tr].States[state].action); vector<float> result; Agent.getResults(result); Result.AssignArray(CAGrad(Actions - result) + result); if(!Agent.backProp(Result, GetPointer(FutureEmbedding)) || !FutureEmbedding.backPropGradient((CBufferFloat *)NULL)) { PrintFormat("%s -> %d", __FUNCTION__, __LINE__); StopFlag = true; break; } //--- Return To Go study vector<float> target; target.Assign(Buffer[tr].States[state + 1].rewards); result.Assign(Buffer[tr].States[state + ValueBars].rewards); target = target - result * MathPow(DiscFactor, ValueBars); Result.AssignArray(target); if(!RTG.backProp(Result, GetPointer(FutureEmbedding)) || !FutureEmbedding.backPropGradient((CBufferFloat *)NULL)) { PrintFormat("%s -> %d", __FUNCTION__, __LINE__); StopFlag = true; break; } ........ ........
これでローカルの変更は完了です。EAの完全なコードと記事で使用されたすべてのプログラムは添付ファイルで入手可能です。
2.4.訓練済みモデルをテストするEA
上述したEAでモデルを訓練した後、訓練データセットに含まれていない過去のデータを使用して、出来上がったモデルのパフォーマンスをテストする必要があります。この機能を実装するために、新しいEA「...\PDT\Test.mq5」を作成してみましょう。モデルがオフラインで訓練された上述のEAとは異なり、テストEAは環境とオンラインで相互作用します。これは、そのアルゴリズムの構築に反映されています。
OnInitEA初期化メソッドでは、まず分析した指標のオブジェクトを初期化します。
//+------------------------------------------------------------------+ //| Expert initialization function | //+------------------------------------------------------------------+ int OnInit() { //--- if(!Symb.Name(_Symbol)) return INIT_FAILED; Symb.Refresh(); //--- if(!RSI.Create(Symb.Name(), TimeFrame, RSIPeriod, RSIPrice)) return INIT_FAILED; //--- if(!CCI.Create(Symb.Name(), TimeFrame, CCIPeriod, CCIPrice)) return INIT_FAILED; //--- if(!ATR.Create(Symb.Name(), TimeFrame, ATRPeriod)) return INIT_FAILED; //--- if(!MACD.Create(Symb.Name(), TimeFrame, FastPeriod, SlowPeriod, SignalPeriod, MACDPrice)) return INIT_FAILED; if(!RSI.BufferResize(NBarInPattern) || !CCI.BufferResize(NBarInPattern) || !ATR.BufferResize(NBarInPattern) || !MACD.BufferResize(NBarInPattern)) { PrintFormat("%s -> %d", __FUNCTION__, __LINE__); return INIT_FAILED; }
取引操作オブジェクトを作成します。
//--- if(!Trade.SetTypeFillingBySymbol(Symb.Name())) return INIT_FAILED;
訓練済みモデルを読み込みます。ここでは2つのモデルのみを使用します。ActorとPlannerです。これまでのEAとは異なり、モデルの読み込み中にエラーが発生するとEAが中断されます。というのも、オンラインモデル訓練を導入していなかったからです。
//--- load models float temp; if(!Agent.Load(FileName + "Act.nnw", temp, temp, temp, dtStudied, true) || !Planner.Load(FileName + "Pln.nnw", temp, temp, temp, dtStudied, true)) { PrintFormat("Can't load pretrained model"); return INIT_FAILED; }
モデルの読み込みに成功したら、それらを1つのOpenCLコンテキストに転送し、必要最小限のアーキテクチャ制御を実行します。
Planner.SetOpenCL(Agent.GetOpenCL()); Agent.getResults(Result); if(Result.Total() != NActions) { PrintFormat("The scope of the Actor does not match the actions count (%d <> %d)", NActions, Result.Total()); return INIT_FAILED; } //--- Agent.GetLayerOutput(0, Result); if(Result.Total() != (BarDescr * NBarInPattern + AccountDescr + TimeDescription + NActions)) { PrintFormat("Input size of Actor doesn't match state description (%d <> %d)", Result.Total(), (NRewards + BarDescr * NBarInPattern + AccountDescr + TimeDescription + NActions)); return INIT_FAILED; } Agent.Clear();
メソッドの最後に、変数を初期値で初期化します。
AgentResult = vector<float>::Zeros(NActions); PrevBalance = AccountInfoDouble(ACCOUNT_BALANCE); PrevEquity = AccountInfoDouble(ACCOUNT_EQUITY); //--- return(INIT_SUCCEEDED); }
環境との相互作用のプロセスは、OnTickティック処理メソッドに実装されています。メソッド本体では、まず新しいバーのオープニングイベントの発生を確認します。なぜなら、私たちのモデルはすべて閉じられたローソク足を分析し、新しいバーがj開くと取引操作を実行するからです。
//+------------------------------------------------------------------+ //| Expert tick function | //+------------------------------------------------------------------+ void OnTick() { //--- if(!IsNewBar()) return;
次に、分析した履歴の深さに必要なデータを端末に要求します。この場合、履歴の深さとは1つのパターンの大きさを意味し、この場合は1バーです。エージェントによって分析された履歴の深さは、埋め込みの形で潜在的な状態に含まれており、各バーで再処理されることはありません。
int bars = CopyRates(Symb.Name(), TimeFrame, iTime(Symb.Name(), TimeFrame, 1), NBarInPattern, Rates); if(!ArraySetAsSeries(Rates, true)) return; //--- RSI.Refresh(); CCI.Refresh(); ATR.Refresh(); MACD.Refresh(); Symb.Refresh(); Symb.RefreshRates();
次に、受信したデータをモデルに渡すためのバッファに移す必要があります。
//--- History data float atr = 0; for(int b = 0; b < NBarInPattern; b++) { float open = (float)Rates[b].open; float rsi = (float)RSI.Main(b); float cci = (float)CCI.Main(b); atr = (float)ATR.Main(b); float macd = (float)MACD.Main(b); float sign = (float)MACD.Signal(b); if(rsi == EMPTY_VALUE || cci == EMPTY_VALUE || atr == EMPTY_VALUE || macd == EMPTY_VALUE || sign == EMPTY_VALUE) continue; //--- int shift = b * BarDescr; sState.state[shift] = (float)(Rates[b].close - open); sState.state[shift + 1] = (float)(Rates[b].high - open); sState.state[shift + 2] = (float)(Rates[b].low - open); sState.state[shift + 3] = (float)(Rates[b].tick_volume / 1000.0f); sState.state[shift + 4] = rsi; sState.state[shift + 5] = cci; sState.state[shift + 6] = atr; sState.state[shift + 7] = macd; sState.state[shift + 8] = sign; } bState.AssignArray(sState.state);
受信した過去のデータは、Plannerのフィードフォワードパスを実行するのに十分です。
if(!Planner.feedForward(GetPointer(bState), 1, false)) return;
しかし、エージェントが完全に機能するためには、追加データが必要です。まず、口座状態に関する情報をバッファに追加します。
//--- Account description sState.account[0] = (float)AccountInfoDouble(ACCOUNT_BALANCE); sState.account[1] = (float)AccountInfoDouble(ACCOUNT_EQUITY); //--- double buy_value = 0, sell_value = 0, buy_profit = 0, sell_profit = 0; double position_discount = 0; double multiplyer = 1.0 / (60.0 * 60.0 * 10.0); int total = PositionsTotal(); datetime current = TimeCurrent(); for(int i = 0; i < total; i++) { if(PositionGetSymbol(i) != Symb.Name()) continue; double profit = PositionGetDouble(POSITION_PROFIT); switch((int)PositionGetInteger(POSITION_TYPE)) { case POSITION_TYPE_BUY: buy_value += PositionGetDouble(POSITION_VOLUME); buy_profit += profit; break; case POSITION_TYPE_SELL: sell_value += PositionGetDouble(POSITION_VOLUME); sell_profit += profit; break; } position_discount += profit - (current - PositionGetInteger(POSITION_TIME)) * multiplyer * MathAbs(profit); } sState.account[2] = (float)buy_value; sState.account[3] = (float)sell_value; sState.account[4] = (float)buy_profit; sState.account[5] = (float)sell_profit; sState.account[6] = (float)position_discount; sState.account[7] = (float)Rates[0].time; //--- bState.Add((float)((sState.account[0] - PrevBalance) / PrevBalance)); bState.Add((float)(sState.account[1] / PrevBalance)); bState.Add((float)((sState.account[1] - PrevEquity) / PrevEquity)); bState.Add(sState.account[2]); bState.Add(sState.account[3]); bState.Add((float)(sState.account[4] / PrevBalance)); bState.Add((float)(sState.account[5] / PrevBalance)); bState.Add((float)(sState.account[6] / PrevBalance));
次に、タイムスタンプとエージェントの最後の行動を追加します。
//--- Time label double x = (double)Rates[0].time / (double)(D'2024.01.01' - D'2023.01.01'); bState.Add((float)MathSin(2.0 * M_PI * x)); x = (double)Rates[0].time / (double)PeriodSeconds(PERIOD_MN1); bState.Add((float)MathCos(2.0 * M_PI * x)); x = (double)Rates[0].time / (double)PeriodSeconds(PERIOD_W1); bState.Add((float)MathSin(2.0 * M_PI * x)); x = (double)Rates[0].time / (double)PeriodSeconds(PERIOD_D1); bState.Add((float)MathSin(2.0 * M_PI * x)); //--- Prev action bState.AddArray(AgentResult);
別のバッファで、以前に実行されたPlannerのフィードフォワードパスの結果を受け取り、エージェントのフィードフォワードメソッドを呼び出します。
//--- Return to go Planner.getResults(Result); //--- if(!Agent.feedForward(GetPointer(bState), 1, false, Result)) return;
そして、次のバーでの操作に必要な変数を更新します。
//--- PrevBalance = sState.account[0]; PrevEquity = sState.account[1];
最初のデータ分析の第1段階は終了しました。環境との相互作用の段階に移りましょう。ここでは、エージェントのフィードフォワードパスの結果を受け取り、今後の操作のベクトルに復号します。いつものように、重複する出来高は除外し、より可能性の高い動きの方向に差を残します。
vector<float> temp; Agent.getResults(temp); //--- double min_lot = Symb.LotsMin(); double step_lot = Symb.LotsStep(); double stops = MathMax(Symb.StopsLevel(), 1) * Symb.Point(); if(temp[0] >= temp[3]) { temp[0] -= temp[3]; temp[3] = 0; } else { temp[3] -= temp[0]; temp[0] = 0; } float delta = MathAbs(AgentResult - temp).Sum(); AgentResult = temp;
そして、予測値に従って市場でのポジションを調整します。まず、ロングポジションを調整します。
//--- buy control if(temp[0] < min_lot || (temp[1] * MaxTP * Symb.Point()) <= stops || (temp[2] * MaxSL * Symb.Point()) <= stops) { if(buy_value > 0) CloseByDirection(POSITION_TYPE_BUY); } else { double buy_lot = min_lot + MathRound((double)(temp[0] - min_lot) / step_lot) * step_lot; double buy_tp = Symb.NormalizePrice(Symb.Ask() + temp[1] * MaxTP * Symb.Point()); double buy_sl = Symb.NormalizePrice(Symb.Ask() - temp[2] * MaxSL * Symb.Point()); if(buy_value > 0) TrailPosition(POSITION_TYPE_BUY, buy_sl, buy_tp); if(buy_value != buy_lot) { if(buy_value > buy_lot) ClosePartial(POSITION_TYPE_BUY, buy_value - buy_lot); else Trade.Buy(buy_lot - buy_value, Symb.Name(), Symb.Ask(), buy_sl, buy_tp); } }
反対方向にも同じ操作を繰り返します。
//--- sell control if(temp[3] < min_lot || (temp[4] * MaxTP * Symb.Point()) <= stops || (temp[5] * MaxSL * Symb.Point()) <= stops) { if(sell_value > 0) CloseByDirection(POSITION_TYPE_SELL); } else { double sell_lot = min_lot + MathRound((double)(temp[3] - min_lot) / step_lot) * step_lot;; double sell_tp = Symb.NormalizePrice(Symb.Bid() - temp[4] * MaxTP * Symb.Point()); double sell_sl = Symb.NormalizePrice(Symb.Bid() + temp[5] * MaxSL * Symb.Point()); if(sell_value > 0) TrailPosition(POSITION_TYPE_SELL, sell_sl, sell_tp); if(sell_value != sell_lot) { if(sell_value > sell_lot) ClosePartial(POSITION_TYPE_SELL, sell_value - sell_lot); else Trade.Sell(sell_lot - sell_value, Symb.Name(), Symb.Bid(), sell_sl, sell_tp); } }
環境との相互作用の結果に基づいて構造を構成し、それを軌跡として保存します。この軌跡は、後にモデル方策の最適化のために経験再生バッファに追加されます。
//--- int shift = BarDescr * (NBarInPattern - 1); sState.rewards[0] = bState[shift]; sState.rewards[1] = bState[shift + 1] - 1.0f; if((buy_value + sell_value) == 0) sState.rewards[2] -= (float)(atr / PrevBalance); else sState.rewards[2] = 0; for(ulong i = 0; i < NActions; i++) sState.action[i] = AgentResult[i]; if(!Base.Add(sState)) ExpertRemove(); }
これで、MQL5を使用したPretrained Decision Transformer法の実装に関する調査は終わりです。使用されたすべてのプログラムの完全なコードは、添付ファイルでご覧ください。
3.テスト
検討した方法の実装が完了したら、モデルを訓練し、過去のデータでその性能をテストする必要があります。例によって、最もボラティリティの高い商品の1つであるEURUSDとH1時間枠を使用して、モデルの訓練とテストをおこなっています。モデルは2023年の最初の7ヶ月間の過去データで訓練されています。訓練済みモデルの性能をテストするため、2023年8月からの過去データを使用しました。
モデルの予備訓練を開始する前に、訓練データセットを収集する必要があります。前述したように、ここでは前回の記事の訓練データセットを使用します。詳しくはその記事をお読みください。訓練データセットのコピーを作成し、「PDT.bd」として保存しました。
その後、事前訓練EAをリアルタイムで起動しました。
すべてのモデル訓練EAはオンラインチャート上で動作します。しかし、すべての訓練プロセスは、取引操作を実行せずにオフラインでおこなわれます。
この段階では辛抱強く待つ必要があります。事前訓練にはかなり時間がかかます。コンピュータを1日以上起動したままにしていました。
次に微調整のプロセスに移ります。このメソッドの著者は、オンライン学習について語っています。ストラテジーテスターで、短いダウンストリーム訓練と訓練区間でのテストを交互におこないました。しかし、まず最初に、以前に収集した訓練データセットを使用してモデルを「ウォームアップ」する必要がありました。
微調整の期間には、下流の訓練とテストを数十回繰り返す必要があり、これにも時間と労力がかかりました。
しかし、学習結果はあまり期待できるものではありませんでした。訓練の結果、最小ロットで取引するモデルを手に入れました。過去のある部分では、バランスラインは明確な上昇傾向を示していました。また、明らかに落ち込んでいるところもありました。一般的に、訓練データでも新しいセットでも、モデルの結果は0に近くなりました。
肯定的な側面には、得られた経験を新しいデータに転送するモデルの機能が含まれます。これは、訓練セットの履歴データセットと次の履歴区間でのテスト結果の比較可能性によって確認されます。さらに、利益が出た取引の規模は、負けた取引の規模よりもかなり大きいことがわかります。両履歴データセグメントにおいて、平均的な勝ち取引のサイズが最大損失を上回っていることが観察されます。ただし、すべてのプラス面は、利益が出ている取引の割合の低さによって相殺されています。


2023年8月の履歴データ(新しいデータ)でモデルをテストしたところ、モデルは18件の取引を約定しました。そのうち39%だけが利益を計上しています。同時に、最大利益の取引は11.26であり、最大損失の4.76のほぼ3倍です。平均利益は5.15ドル、平均損失は3.19ドルでした。テスト期間のプロフィットファクターは1.03でした。
当然ながら、収益性の高い取引の割合を増やすためには、得られた結果をさらに分析し、モデルを微調整する必要があります。この方法は可能性を示していますが、長期のモデル訓練が必要です。
結論
本稿では、Pretrained Decision Transformer (PDT)法を紹介しました。PDT法は、Decision Transformer強化訓練のための教師なし事前訓練アルゴリズムを提供します。PDTは、モデル訓練中の未来の状態に関する知識に基づき、訓練データから豊富な事前知識を抽出することができます。PDTが未来の各機会に対応するリターンを関連付け、予測される報酬が最大のものを選択するように、この知識はモデル下流の訓練中にさらに微調整され、調整されます。それが最適な決断を下す助けとなります。
しかし、PDTは、先に議論したDTやODTに比べて、より多くの訓練時間と計算資源を必要とするため、利用可能な資源が限られているため、実際には課題につながる可能性があります。さらに、モデルを訓練するという目的は、訓練される行動の多様性とその一貫性の間にトレードオフを生み出します。この手法の著者による実際の実験によると、最適な値は特定のデータセットに依存します。また、未来の状態の符号化を改善するために、さらなる技術を適用することもできます。
私はこの方法の著者たちの結論に同意せざるを得ません。私たちの実践的な経験は、それを十分に裏付けています。モデルの訓練は非常に時間がかかり、手間のかかるプロセスです。エージェントのスキルを最大限に伸ばすには、かなり大規模な訓練データセットが必要です。もちろん、事前訓練にはラベルの付いていないデータを使用するので、データ収集はより簡単になります。しかし、データを収集し、処理し、モデルを訓練するためのリソースを確保できるかどうかという問題があります。
参照文献
記事で使用されているプログラム
| # | 名前 | 種類 | 詳細 |
|---|---|---|---|
| 1 | Faza1.mq5 | EA | コレクションEAの例 |
| 2 | Pretrain.mq5 | EA | 事前訓練EA |
| 3 | FineTune.mq5 | EA | EAの微調整 |
| 4 | Test.mq5 | EA | モデルテストEA |
| 5 | Trajectory.mqh | クラスライブラリ | システム状態記述の構造 |
| 6 | NeuroNet.mqh | クラスライブラリ | ニューラルネットワークを作成するためのクラスのライブラリ |
| 7 | NeuroNet.cl | コードベース | OpenCLプログラムコードライブラリ |