Random Decision Forest und Reinforcement-Learning
Maxim Dmitrievsky | 9 Juli, 2018
Die abstrakte Beschreibung des Random Forest Algorithmus
Random Forest (RF) mit dem Einsatz von Bagging ist eine der leistungsfähigsten maschinellen Lernmethoden, die dem Gradienten- Boosting etwas unterlegen ist.
Random Forest besteht aus einem Komitee von Entscheidungsbäumen (auch bekannt als Klassifikationsbäume oder "CART"-Regressionsbäume zur Lösung gleichnamiger Aufgaben). Sie werden in der Statistik, im Data Mining und im maschinellen Lernen eingesetzt. Jeder einzelne Baum ist ein relativ einfaches Modell mit Zweigen, Knoten und Blättern. Die Knoten enthalten die Attribute, von denen die Zielfunktion abhängt. Dann gehen die Werte der Zielfunktion durch die Zweige zu den Blättern. Bei der Klassifizierung eines neuen Falles ist es notwendig, den Baum durch Äste zu einem Blatt hinunterzugehen und alle Attributwerte nach dem logischen Prinzip "IF-THEN" zu durchlaufen. Abhängig von diesen Bedingungen wird der Zielvariablen ein bestimmter Wert oder eine Klasse zugewiesen (die Zielvariable fällt in ein bestimmtes Blatt). Der Zweck des Aufbaus eines Entscheidungsbaums besteht darin, ein Modell zu erstellen, das den Wert der Zielvariablen in Abhängigkeit von mehreren Eingabevariablen vorhersagt.
Ein Random Forest wird durch eine einfache Abstimmung der Entscheidungsbäume mit Hilfe des Bagging-Algorithmus aufgebaut. Bagging ist ein Kunstwort aus der Wortkombination bootstrap aggregating. Dieser Begriff wurde 1994 von Leo Breiman eingeführt.
Bootstrap ist in der Statistik eine Methode der Beispielgenerierung, bei der die Anzahl der ausgewählten Objekte gleich der ursprünglichen Anzahl der Objekte ist. Aber diese Objekte werden mit Wiederholungen ausgewählt. Mit anderen Worten, das zufällig ausgewählte Objekt wird zurückgegeben und kann erneut ausgewählt werden. In diesem Fall wird die Anzahl der ausgewählten Objekte ca. 63% der Stichprobenquelle ausmachen und der Rest der Objekte (ca. 37%) wird nie in die Trainingsprobe fallen. Dieses generierte Beispiel dient zum Training der grundlegenden Algorithmen (in diesem Fall der Entscheidungsbäume). Dies geschieht auch zufällig: Zufällige Teilmengen (Stichproben) einer bestimmten Länge werden auf die ausgewählte zufällige Teilmenge von Merkmalen (Attributen) trainiert. Die restlichen 37% der Probe werden für die Prüfung der Verallgemeinerungsfähigkeit des konstruierten Modells verwendet.
Danach werden alle trainierten Bäume mit einem einfachen Voting zu einer Komposition zusammengefasst, wobei der gemittelte Fehler für alle Proben verwendet wird. Die Verwendung von Bootstrap-Aggregation reduziert den mittleren quadratischen Fehler und verringert die Varianz des trainierten Klassifikators. Der Fehler wird sich bei verschiedenen Stichproben nicht wesentlich unterscheiden. Dadurch wird das Modell weniger überangepasst, so die Autoren. Die Wirksamkeit des Baggings liegt darin, dass die grundlegenden Algorithmen (Entscheidungsbäume) an verschiedenen Stichproben trainiert werden und ihre Ergebnisse stark variieren können, während ihre Fehler bei der Abstimmung gegenseitig kompensiert werden.
Man kann sagen, dass ein Zufallswald ein Sonderfall des Baggings ist, bei dem Entscheidungsbäume als Basisfamilie verwendet werden. Gleichzeitig wird, anders als bei der konventionellen Entscheidungsbaum-Konstruktion, auf das Pruning (Beschneiden) verzichtet. Die Methode ist dafür gedacht, aus großen Datenmengen so schnell wie möglich eine Stichprobe zu konstruieren. Jeder Baum ist auf eine bestimmte Art und Weise aufgebaut. Ein Merkmal (Attribut) zum Aufbau eines Baumknotens wird nicht aus der Gesamtzahl der Merkmale ausgewählt, sondern aus deren zufälliger Untermenge. Beim Aufbau eines Regressionsmodells ist die Anzahl der Merkmale n/3. Im Falle einer Klassifizierung ist es √n. All dies sind empirische Empfehlungen und werden Dekorrelation genannt: Unterschiedliche Merkmale fallen in verschiedene Bäume, und die Bäume werden an verschiedenen Proben trainiert.
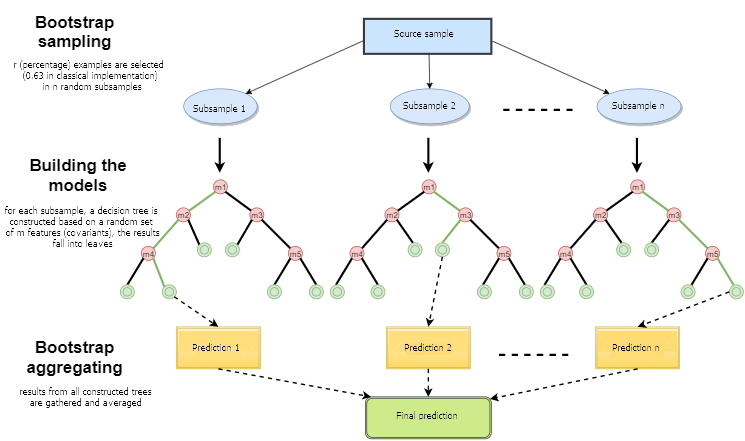
Abb. 1. Schema des Random Forest
Der Algorithmus des Random Forest erwies sich als äußerst effektiv und in der Lage, praktische Probleme zu lösen. Es bietet eine hohe Qualität der Ausbildung mit einer scheinbar großen Anzahl von Zufälligkeiten in den Prozess der Konstruktion des Modells eingeführt. Der Vorteil gegenüber anderen maschinellen Lernmodellen ist eine Out-of-Bag-Schätzung für einen Teil des Sets, der nicht in der Trainingsprobe enthalten ist. Daher ist für die Entscheidungsbäume keine Kreuzvalidierung oder Prüfung an einer einzigen Stichprobe erforderlich. Es genügt, sich auf die Out-of-Bag-Schätzung für das weitere "Tuning" des Modells zu beschränken: Auswahl der Anzahl der Entscheidungsbäume und der Regularisierungskomponente.
Die Bibliothek ALGLIB, die im Standard-Paket МetaТrader 5 enthalten ist, enthält den Random Decision Forest (RDF)-Algorithmus. Es ist eine Modifikation des ursprünglichen Random Forest Algorithmus von Leo Breiman und Adele Cutler. Dieser Algorithmus kombiniert zwei Ideen: die Verwendung eines Komitees von Entscheidungsbäumen, das das Ergebnis durch Abstimmung erhält, und die Idee, den Lernprozess zu randomisieren. Weitere Details zu Änderungen des Algorithmus finden Sie auf der Webseite des ALGLIB.
Vorteile des Algorithmus
- Hohe Lerngeschwindigkeit
- Nicht-iteratives Lernen - der Algorithmus wird in einer festen Anzahl von Operationen durchgeführt.
- Skalierbarkeit (Fähigkeit, große Datenmengen zu verarbeiten)
- Hohe Qualität der erhaltenen Modelle (vergleichbar mit neuronalen Netzwerken und Ensembles neuronaler Netzwerke)
- Keine Sensitivität gegenüber Datenspitzen durch eine Stichprobe
- Eine kleine Anzahl konfigurierbarer Parameter
- Keine Sensibilität für Skalierung von Merkmalswerten (und für monotone Transformationen im Allgemeinen) durch Auswahl von zufälligen Unterräumen
- Erfordert keine sorgfältige Konfiguration der Parameter, funktioniert sofort nach dem Auspacken. "Das "Tuning" der Parameter ermöglicht eine Erhöhung der Genauigkeit von 0,5% bis 3% je nach Aufgabe und Daten.
- Funktioniert gut mit fehlenden Daten - behält eine gute Genauigkeit, auch wenn ein großer Teil der Daten fehlt.
- Interne Bewertung der Verallgemeinerungsfähigkeit des Modells.
- Die Möglichkeit, mit Rohdaten zu arbeiten, ohne Vorverarbeitung.
Nachteile des Algorithmus
- Das konstruierte Modell nimmt viel Speicherplatz in Anspruch. Wenn ein Komitee aus K Bäumen auf Basis eines Trainingssatzes der Größe N aufgebaut ist, dann sind die Speicheranforderungen O(K-N). Für K=100 und N=1000 benötigt das von ALGLIB konstruierte Modell etwa 1 MB Speicher. Allerdings ist die Menge an RAM in modernen Computern groß genug, so dass dies kein großer Fehler ist.
- Ein trainiertes Modell arbeitet etwas langsamer als andere Algorithmen (wenn es 100 Bäume in einem Modell gibt, ist es notwendig, über alle zu iterieren, um das Ergebnis zu erhalten). Bei modernen Maschinen ist dies jedoch nicht so auffällig.
- Der Algorithmus funktioniert schlechter als die meisten linearen Methoden, wenn ein Satz viele dürftige Merkmale hat (Texte, Worttüte) oder wenn die zu klassifizierenden Objekte linear getrennt werden können.
- Der Algorithmus ist anfällig für Überanpassungen, insbesondere bei lauten Aufgaben. Ein Teil dieses Problems kann durch Einstellen des Parameters r gelöst werden. Ein ähnliches, aber ausgeprägteres Problem gibt es auch für den ursprünglichen Random Forest Algorithmus. Die Autoren behaupteten jedoch, der Algorithmus sei nicht anfällig für Überpassungen. Dieser Irrtum wird von einigen Praktikern und Theoretikern des maschinellen Lernens geteilt.
- Für Daten, die kategorische Variablen mit einer unterschiedlichen Anzahl von Ebenen enthalten, sind sie gegenüber einem Random Forest zugunsten von Merkmalen mit mehr Ebenen voreingenommen. Ein Baum wird stärker an solche Merkmale angepasst, da sie einen höheren Wert an optimierter Funktionalität (Art der Informationsgewinnung) ermöglichen.
- Ähnlich wie bei den Entscheidungsbäumen ist der Algorithmus absolut nicht extrapolierbar (dies kann aber als Plus betrachtet werden, da es bei einem Spike keine Extremwerte gibt).
Besonderheiten des Einsatzes des maschinellen Lernens im Handel
Unter den Neophyten des maschinellen Lernens gibt es einen populären Glauben, dass es eine Art Märchenwelt ist, in der Programme alles für einen Händler tun, während er einfach den erhaltenen Gewinn genießt. Das ist nur teilweise wahr. Das Endergebnis hängt davon ab, wie gut die unten beschriebenen Probleme gelöst werden.
- Merkmalsauswahl
Das erste und wichtigste Problem ist die Wahl, was genau das Modell gelehrt werden soll. Der Preis wird von vielen Faktoren beeinflusst. Es gibt nur einen wissenschaftlichen Ansatz zur Untersuchung des Marktes - Ökonometrie. Es gibt drei Hauptmethoden: Regressionsanalyse, Zeitreihenanalyse und Panelanalyse. Ein weiterer interessanter Abschnitt in diesem Bereich ist die nichtparametrische Ökonometrie, die ausschließlich auf verfügbaren Daten basiert, ohne eine Analyse der Ursachen, die sie bilden. Methoden der nichtparametrischen Ökonometrie haben sich in der angewandten Forschung durchgesetzt: Dazu gehören beispielsweise Kernelmethoden und neuronale Netze. Der gleiche Abschnitt beinhaltet die mathematische Analyse nicht-numerischer Konzepte - zum Beispiel Fuzzy-Logik. Wenn Sie die maschinelle Ausbildung ernst nehmen wollen, ist eine Einführung in die ökonometrischen Methoden hilfreich. Dieser Artikel konzentriert sich auf die Fuzzy-Logik.
- Modellauswahl
Das zweite Problem ist die Wahl des Trainingsmodells. Es gibt viele lineare und nichtlineare Modelle. Deren Liste und Vergleich der Merkmale finden Sie z.B. auf der Seite Microsoft.
Zum Beispiel gibt es eine große Vielfalt an neuronalen Netzwerken. Wenn Sie sie verwenden, müssen Sie mit der Netzwerkarchitektur experimentieren und die Anzahl der Schichten und Neuronen auswählen. Gleichzeitig werden klassische neuronale Netze vom Typ MLP langsam trainiert (insbesondere das Gradientenverfahren mit konstanter Schrittweite), Experimente mit ihnen nehmen viel Zeit in Anspruch. Moderne schnell lernende Deep-Learning-Netzwerke sind derzeit in der Standardbibliothek des Terminals nicht verfügbar und die Einbindung von Drittanbieter-Bibliotheken in der DLL-Form ist nicht sehr komfortabel. Ich habe solche Pakete noch nicht ausreichend studiert.
Im Gegensatz zu neuronalen Netzen arbeiten lineare Modelle schnell, aber nicht immer gut mit der Approximation.
Random Forest hat diese Nachteile nicht. Es ist nur die Anzahl der Bäume und der Parameter r, der für den Prozentsatz der Objekte, die in die Trainingsprobe fallen, verantwortlich ist, auszuwählen. Experimente in Microsoft Azure Machine Learning Studio haben gezeigt, dass ein Random Forest in den meisten Fällen den kleinsten Vorhersagefehler in den Testdaten ergeben.
- Modellprüfung
Generell gibt es nur eine strikte Empfehlung: Je größer die Trainingsstichprobe und je aussagekräftiger die Features, desto stabiler sollte das System auf den neuen Daten sein. Bei der Lösung der Handelsaufgaben kann es jedoch zu einer unzureichenden Systemkapazität kommen, wenn die gegenseitigen Abweichungen der Prädiktoren zu gering und nicht aussagekräftig sind. Als Ergebnis wird das gleiche Signal von den Prädiktoren sowohl Kauf- als auch Verkaufssignale generieren. Das Ausgangsmodell wird in Zukunft eine geringe Verallgemeinerungsfähigkeit und damit eine schlechte Signalqualität haben. Darüber hinaus wird das Training an einer großen Probe langsam sein, so dass mehrere Läufe während der Optimierung nicht möglich sind. Bei all dem gibt es keine Garantie für ein positives Ergebnis. Hinzu kommt die chaotische Natur der Kurse, mit ihrer Nicht-Stationarität, den sich ständig ändernden Marktmustern oder (schlimmer noch) mit ihrer völligen Abwesenheit.
Auswahl der Modelltrainingsmethode
Random Forest wird verwendet, um eine Vielzahl von Regressions-, Klassifikations- und Clustering-Problemen zu lösen.
Diese Methoden können wie folgt dargestellt werden.
- Unüberwachtes Lernen. Clustering, Erkennung von Anomalien. Diese Methoden werden zur programmatischen Einteilung von Merkmalen in Gruppen mit automatisch ermittelten Unterschieden eingesetzt.
- Überwachtes Lernen. Klassifizierung und Regression. Ein Satz von zuvor bekannten Trainingsbeispielen (Labels) wird als Input gefüttert, und der Random Forest versucht, alle Fälle zu lernen (ungefähr).
- Verstärktes Lernen. Dies ist vielleicht die ungewöhnlichste und vielversprechendste Art des maschinellen Lernens, die sich von anderen abhebt. Hier findet das Lernen statt, wenn der virtuelle Agent mit der Umgebung interagiert, während der Agent versucht, die Belohnungen für Aktionen in dieser Umgebung zu maximieren. Lassen Sie uns diesen Ansatz nutzen.
Verstärktes Lernen in der Entwicklung von Handelssystemen
Stellen Sie sich vor, Sie schaffen einen Händler mit künstlicher Intelligenz. Er wird mit seiner Umgebung interagieren und eine bestimmte Antwort auf seine Aktionen von der Umgebung erhalten. So wird er beispielsweise durch profitable Geschäfte gefördert und für unrentable Geschäfte mit Geldstrafen belegt. Am Ende, nach mehreren Episoden der Interaktion mit dem Markt, wird der künstliche Händler seine eigene einzigartige Erfahrung entwickeln, die sich in sein "Gehirn" einprägen wird. Der Random Forest wird als "Gehirn" fungieren.
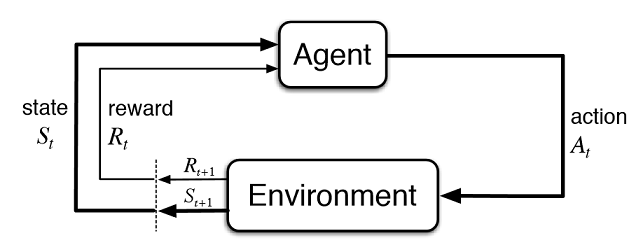
Abb. 2. Interaktion des virtuellen Händlers mit dem Markt
Abbildung 2 zeigt das Interaktionsschema des Agenten (künstlicher Händler) mit seiner Umgebung (Markt). Der Agent kann die Aktionen A zum Zeitpunkt t ausführen, während er sich im Zustand St befindet. Danach geht es in den Zustand St+1 und erhält die Belohnung Rt für die vorherige Aktion aus der Umgebung, je nachdem wie erfolgreich sie war. Diese Aktionen können t+n mal fortgesetzt werden, bis die gesamte untersuchte Sequenz (oder eine Spielepisode für den Agenten) abgeschlossen ist. Dieser Prozess kann iterativ durchgeführt werden, so dass der Agent mehrfach lernt und die Ergebnisse ständig verbessert werden.
Das Gedächtnis (oder die Erfahrung) des Agenten sollte irgendwo gespeichert werden. Die klassische Umsetzung des verstärkten Lernens erfolgt mit Hilfe von state-action Matrizen. Bei der Eingabe eines bestimmten Zustandes wird der Bearbeiter gezwungen, die Matrix für die nächste Entscheidung anzusprechen. Diese Implementierung eignet sich für Aufgaben mit einer sehr begrenzten Anzahl von Zuständen. Ansonsten kann die Matrix sehr groß werden. Daher wird die Tabelle durch einen Random Forest ersetzt:
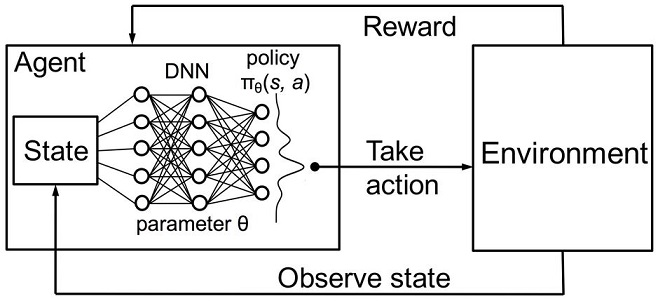
Abb. 3. Tiefes neuronales Netzwerk oder Random Forest zur Näherung der Strategie
Eine stochastisch, parametrisierte Strategie Πθ eines Agenten ist ein Satz von (s,a) Paaren, wobei θ der Vektor der Parameter für jeden Zustand ist. Die optimale Politik ist das optimale Maßnahmenpaket für eine bestimmte Aufgabe. Nehmen wir an, dass der Agent versucht, eine optimale Politik zu entwickeln. Dieser Ansatz eignet sich gut für kontinuierliche Aufgaben mit einer bisher unbekannten Anzahl von Zuständen und ist eine modellfreie Actor-Critic-Methode im Reinforcement Learning. Es gibt viele andere Ansätze für das Verstärkungslernen. Sie sind im Abschnitt "Reinforcement Learning: An Introduction" von Richard S. Sutton und Andrew G. Barto.
Software-Implementierung eines selbstlernenden Experten (Agent)
Ich strebe nach Kontinuität in meinen Artikeln, daher wird das Fuzzy-Logik-System als Agent fungieren. Im vorherigen Artikel wurde die Gaußsche Zugehörigkeitsfunktion für die Mamdani-Fuzzy-Inferenz optimiert. Dieser Ansatz hatte jedoch einen erheblichen Nachteil - der Gaußsche Wert blieb für alle Fälle unverändert, unabhängig vom aktuellen Zustand der Umgebung (Indikatorwerte). Nun gilt es, die Gaußsche Position für den "neutralen" Begriff des Fuzzy-Ausgangs "out" automatisch auszuwählen. Der Agent wird mit der Entwicklung der optimalen Politik beauftragt, indem er Werte auswählt und die Funktion des Gaußschen Zentrums annähert, abhängig von den Werten von drei Werten und im Bereich von[0;1].
Erstellen Sie in den globalen Variablen des Experten einen eigenen Zeiger auf die Zugehörigkeitsfunktion. Dies erlaubt uns, seine Parameter im Lernprozess frei zu verändern:
CNormalMembershipFunction *updateNeutral=new CNormalMembershipFunction(0.5,0.2);
Erstellen eines Random Forest und der Matrix mit den Klassenobjekten, um sie mit Werten zu versorgen.
//RDF system. Hier erstellen wir alle RF-Objekte CDecisionForest RDF; //Random Forest Objekt CMatrixDouble RDFpolicyMatrix; //Matrix für RF Ein- und Ausgaben CDFReport RDF_report; //RF-Fehlerrückgabe in diesem Objekt, um sie zu überprüfen
Die Haupteinstellungen des Random Forest werden zu den Eingabeparametern verschoben: die Anzahl der Bäume und die Regularisierungskomponente. Dies ermöglicht eine leichte Verbesserung des Modells durch Abstimmung dieser Parameter:
sinput int number_of_trees=50; sinput double regularization=0.63;
Lassen Sie uns eine Servicefunktion schreiben, um den Zustand des Modells zu überprüfen. Wenn der Zufallswald bereits für den aktuellen Zeitraum trainiert wurde, wird er für den Handel mit Signalen verwendet, und wenn nicht - initialisieren Sie die Strategie mit Zufallswerten (Handel nach dem Zufallsprinzip).
void checkBeforeLearn() { if(clear_model) { int clearRDF=FileOpen("RDFNtrees"+_Symbol+(string)_Period+".txt",FILE_READ|FILE_WRITE|FILE_CSV|FILE_ANSI|FILE_COMMON); FileWrite(clearRDF,0); FileClose(clearRDF); ExpertRemove(); return; } int filehnd=FileOpen("RDFNtrees"+ _Symbol + (string)_Period +".txt",FILE_READ|FILE_WRITE|FILE_CSV|FILE_ANSI|FILE_COMMON); int ntrees = (int)FileReadNumber(filehnd); FileClose(filehnd); if(ntrees>0) { random_policy=false; int setRDF=FileOpen("RDFBufsize"+_Symbol+(string)_Period+".txt",FILE_READ|FILE_WRITE|FILE_CSV|FILE_ANSI|FILE_COMMON); RDF.m_bufsize=(int)FileReadNumber(setRDF); FileClose(setRDF); setRDF=FileOpen("RDFNclasses"+_Symbol+(string)_Period+".txt",FILE_READ|FILE_WRITE|FILE_CSV|FILE_ANSI|FILE_COMMON); RDF.m_nclasses=(int)FileReadNumber(setRDF); FileClose(setRDF); setRDF=FileOpen("RDFNtrees"+_Symbol+(string)_Period+".txt",FILE_READ|FILE_WRITE|FILE_CSV|FILE_ANSI|FILE_COMMON); RDF.m_ntrees=(int)FileReadNumber(setRDF); FileClose(setRDF); setRDF=FileOpen("RDFNvars"+_Symbol+(string)_Period+".txt",FILE_READ|FILE_WRITE|FILE_CSV|FILE_ANSI|FILE_COMMON); RDF.m_nvars=(int)FileReadNumber(setRDF); FileClose(setRDF); setRDF=FileOpen("RDFMtrees"+_Symbol+(string)_Period+".txt",FILE_READ|FILE_WRITE|FILE_BIN|FILE_ANSI|FILE_COMMON); FileReadArray(setRDF,RDF.m_trees); FileClose(setRDF); } else Print("Starting new learn"); checked_for_learn=true; }
Wie Sie aus der Auflistung ersehen können, wird das trainierte Modell aus Dateien geladen, die Folgendes enthalten:
- Die Größe der Trainingsstichprobe,
- Die Anzahl der Klassen (1 bei einem Regressionsmodell),
- Die Anzahl der Bäume,
- Die Anzahl der Features,
- Die Anordnung der trainierten Bäume.
Das Training findet im Strategie-Tester im Optimierungsmodus statt. Nach jedem Durchlauf im Tester wird das Modell auf der neu gebildeten Matrix trainiert und in den obigen Dateien zur späteren Verwendung gespeichert:
double OnTester() { if(clear_model) return 0; if(MQLInfoInteger(MQL_OPTIMIZATION)==true) { if(numberOfsamples>0) { CDForest::DFBuildRandomDecisionForest(RDFpolicyMatrix,numberOfsamples,3,1,number_of_trees,regularization,RDFinfo,RDF,RDF_report); } int filehnd=FileOpen("RDFBufsize"+_Symbol+(string)_Period+".txt",FILE_READ|FILE_WRITE|FILE_CSV|FILE_ANSI|FILE_COMMON); FileWrite(filehnd,RDF.m_bufsize); FileClose(filehnd); filehnd=FileOpen("RDFNclasses"+_Symbol+(string)_Period+".txt",FILE_READ|FILE_WRITE|FILE_CSV|FILE_ANSI|FILE_COMMON); FileWrite(filehnd,RDF.m_nclasses); FileClose(filehnd); filehnd=FileOpen("RDFNtrees"+_Symbol+(string)_Period+".txt",FILE_READ|FILE_WRITE|FILE_CSV|FILE_ANSI|FILE_COMMON); FileWrite(filehnd,RDF.m_ntrees); FileClose(filehnd); filehnd=FileOpen("RDFNvars"+_Symbol+(string)_Period+".txt",FILE_READ|FILE_WRITE|FILE_CSV|FILE_ANSI|FILE_COMMON); FileWrite(filehnd,RDF.m_nvars); FileClose(filehnd); filehnd=FileOpen("RDFMtrees"+_Symbol+(string)_Period+".txt",FILE_READ|FILE_WRITE|FILE_BIN|FILE_ANSI|FILE_COMMON); FileWriteArray(filehnd,RDF.m_trees); FileClose(filehnd); } return 0; }
Die Funktion für die Durchführung des Handelssignals aus dem vorherigen Artikel bleibt praktisch unverändert, aber jetzt wird nach der Eröffnung einer Position folgende Funktion aufgerufen:
void updatePolicy(double action) { if(MQLInfoInteger(MQL_OPTIMIZATION)==true) { numberOfsamples++; RDFpolicyMatrix.Resize(numberOfsamples,4); RDFpolicyMatrix[numberOfsamples-1].Set(0,arr1[0]); RDFpolicyMatrix[numberOfsamples-1].Set(1,arr2[0]); RDFpolicyMatrix[numberOfsamples-1].Set(2,arr3[0]); RDFpolicyMatrix[numberOfsamples-1].Set(3,action); } }
Sie fügt einen Zustandsvektor mit den drei Indikatorwerten zur Matrix und der Ausgabewert wird mit dem aktuellen Signal aus der Mamdani-Fuzzy-Inferenz gefüllt.
Eine andere Funktion:
void updateReward() { if(MQLInfoInteger(MQL_OPTIMIZATION)==true) { int unierr; if(getLAstProfit()<0) RDFpolicyMatrix[numberOfsamples-1].Set(3,MathRandomUniform(0,1,unierr)); } }
wird jedes Mal aufgerufen, wenn eine Position geschlossen wird. Erweist sich ein Handel als unrentabel, so wird die Belohnung für den Agenten aus einer zufälligen, gleichmäßigen Verteilung ausgewählt, ansonsten bleibt die Belohnung unverändert.
Abb. 4. Gleichmäßige Verteilung zur Auswahl einer zufälligen Belohnung
So werden in der aktuellen Implementierung die gewinnbringenden Geschäfte des Agenten gefördert, und im Falle unrentabler Geschäfte ist der Agent gezwungen, eine zufällige Aktion (zufällige Position des Gaußschen Zentrums) auf der Suche nach der optimalen Lösung durchzuführen.
Der vollständige Code der Signalverarbeitungsfunktion sieht wie folgt aus:
void PlaceOrders(double ts) { if(CountOrders(0)!=0 || CountOrders(1)!=0) { for(int b=OrdersTotal()-1; b>=0; b--) if(OrderSelect(b,SELECT_BY_POS)==true) if(OrderSymbol()==_Symbol && OrderMagicNumber()==OrderMagic) switch(OrderType()) { case OP_BUY: if(ts>=0.5) if(OrderClose(OrderTicket(),OrderLots(),OrderClosePrice(),0,Red)) { updateReward(); if(ts>0.6) { lots=LotsOptimized(); if(OrderSend(Symbol(),OP_SELL,lots,SymbolInfoDouble(_Symbol,SYMBOL_BID),0,0,0,NULL,OrderMagic,Red)>0) { updatePolicy(ts); }; } } break; case OP_SELL: if(ts<=0.5) if(OrderClose(OrderTicket(),OrderLots(),OrderClosePrice(),0,Red)) { updateReward(); if(ts<0.4) { lots=LotsOptimized(); if(OrderSend(Symbol(),OP_BUY,lots,SymbolInfoDouble(_Symbol,SYMBOL_ASK),0,0,0,NULL,OrderMagic,Green)>0) { updatePolicy(ts); }; } } break; } return; } lots=LotsOptimized(); if((ts<0.4) && (OrderSend(Symbol(),OP_BUY,lots,SymbolInfoDouble(_Symbol,SYMBOL_ASK),0,0,0,NULL,OrderMagic,INT_MIN) > 0)) updatePolicy(ts); else if((ts>0.6) && (OrderSend(Symbol(),OP_SELL,lots,SymbolInfoDouble(_Symbol,SYMBOL_BID),0,0,0,NULL,OrderMagic,INT_MIN) > 0)) updatePolicy(ts); return; }
Die Funktion zur Berechnung der Mamdani-Fuzzy-Inferenz hat sich geändert. Wenn nun die Richtlinie des Agenten nicht zufällig ausgewählt wurde, wird die Berechnung der Gaußschen Position entlang der X-Achse unter Verwendung des trainierten Random Forest aufgerufen. Der Random Forest wird dem aktuellen Zustand als Vektor mit 3 Oszillatorwerten zugeführt, und das erhaltene Ergebnis aktualisiert die Gaußsche Position. Wird der EA zum ersten Mal im Optimierer ausgeführt, wird die Gaußsche Position für jeden Zustand zufällig gewählt.
double CalculateMamdani() { CopyBuffer(hnd1,0,0,1,arr1); NormalizeArrays(arr1); CopyBuffer(hnd2,0,0,1,arr2); NormalizeArrays(arr2); CopyBuffer(hnd3,0,0,1,arr3); NormalizeArrays(arr3); if(!random_policy) { vector[0]=arr1[0]; vector[1]=arr2[0]; vector[2]=arr3[0]; CDForest::DFProcess(RDF,vector,RFout); updateNeutral.B(RFout[0]); } else { int unierr; updateNeutral.B(MathRandomUniform(0,1,unierr)); } //Print(updateNeutral.B()); firstTerm.SetAll(firstInput,arr1[0]); secondTerm.SetAll(secondInput,arr2[0]); thirdTerm.SetAll(thirdInput,arr3[0]); Inputs.Clear(); Inputs.Add(firstTerm); Inputs.Add(secondTerm); Inputs.Add(thirdTerm); CList *FuzzResult=OurFuzzy.Calculate(Inputs); Output=FuzzResult.GetNodeAtIndex(0); double res=Output.Value(); delete FuzzResult; return(res); }
Training und Testen des Modells
Der Agent wird sequentiell im Optimierer trainiert. Das heißt, die Ergebnisse des vorherigen Trainings, die in Dateien geschrieben wurden, werden für den nächsten Lauf verwendet. Dazu deaktivieren Sie einfach alle Test-Agenten und die Cloud und lassen nur einen Kern übrig.
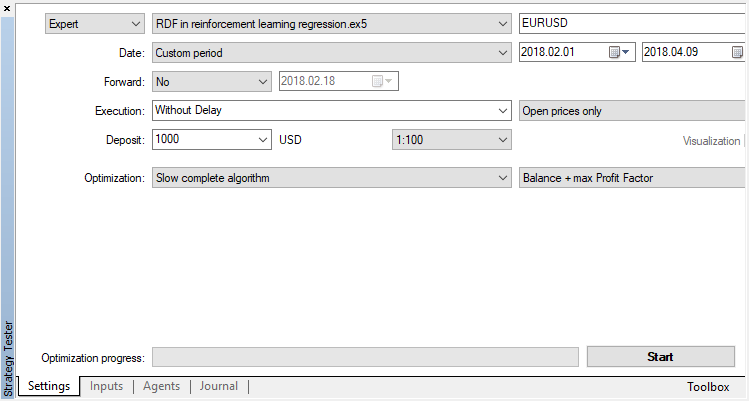
Deaktivieren Sie den genetischen Algorithmus (verwenden Sie den langsamen vollständigen Algorithmus). Das Training / Testen wird mit Open-Preis durchgeführt, da das EA explizit auf das Öffnen neuer Bars reagiert.
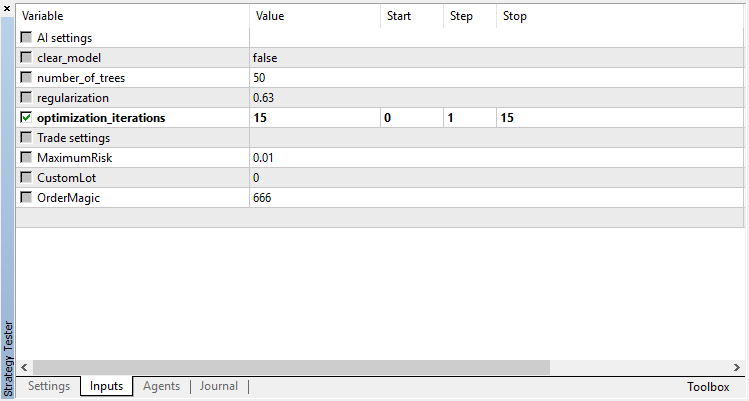
Es gibt nur einen optimierbaren Parameter - die Anzahl der Durchläufe im Optimierer. Um die Funktionsweise des Algorithmus zu demonstrieren, stellen Sie 15 Iterationen ein.
Die Optimierungsergebnisse des Modells Regression (mit einer Ausgabevariablen) werden nachfolgend dargestellt. Beachten Sie, dass das trainierte Modell in einer Datei gespeichert wird, so dass nur das Ergebnis des letzten Laufs gespeichert wird.
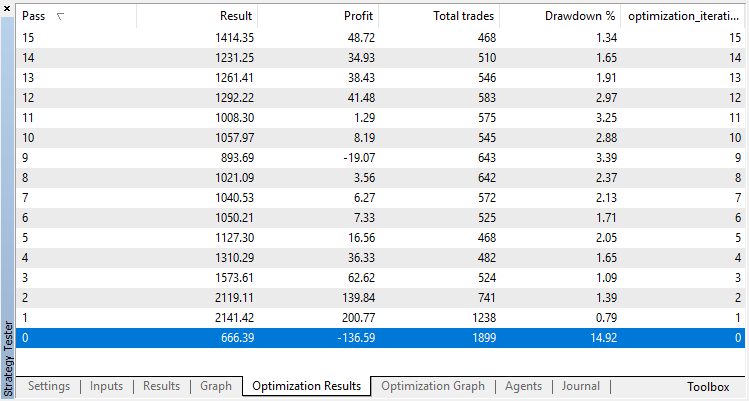
Der Durchgang Null entspricht der Zufallspolitik des Agenten (erster Durchlauf), so dass er wohl den größten Verlust verursachen wird. Der erste Lauf erwies sich im Gegenteil als der produktivste. Nachfolgende Varianten brachten keinen Gewinn, sondern stagnierten. Nach dem 15. Lauf sieht die Wachstumstabelle daher wie folgt aus:
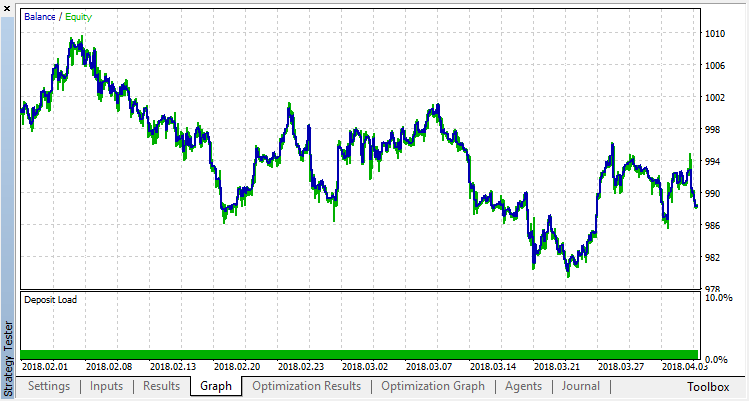
Lassen Sie uns das gleiche Experiment für das Modell Klassifikation durchführen. In diesem Fall werden die Belohnungen in 2 Klassen eingeteilt - positiv und negativ.
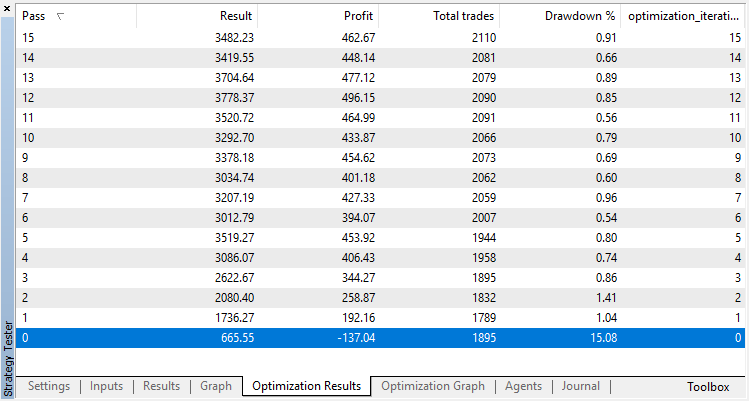
Die Klassifizierung erfüllt diese Aufgabe viel besser. Zumindest gibt es ein stabiles Wachstum ab dem Durchgang Null, der der Zufallspolitik entspricht, bis zum 15., wo das Wachstum gestoppt wurde und die Politik um das Optimum herum zu schwanken begann.
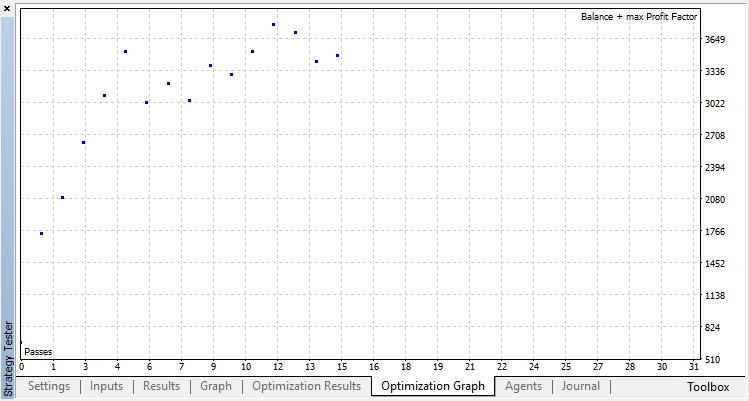
Das Endergebnis der Ausbildung des Agenten:
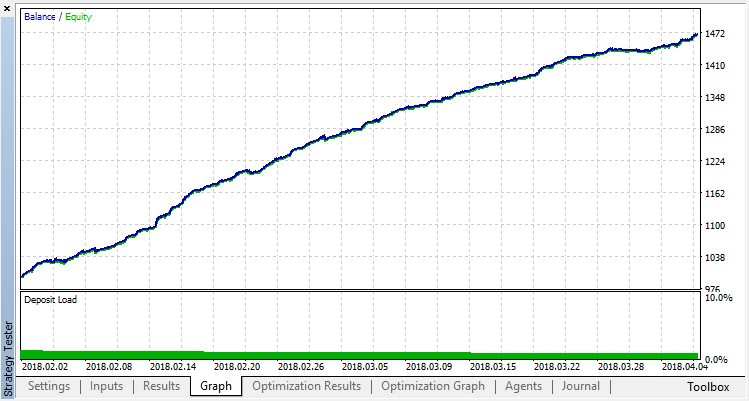
Überprüfen Sie die Ergebnisse des Systembetriebs an einer Probe außerhalb des Trainingsdaten. Das Modell war stark überangepasst:
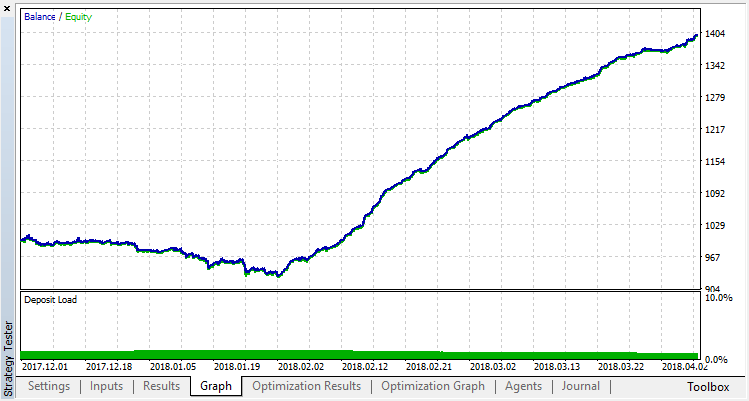
Lassen Sie uns versuchen, die Überanpassung zu beseitigen. Setzen Sie den Parameter r (Regularisierung) auf 0,25: nur 25% der Probe werden im Training verwendet. Verwenden Sie den gleichen Trainingsbereich.
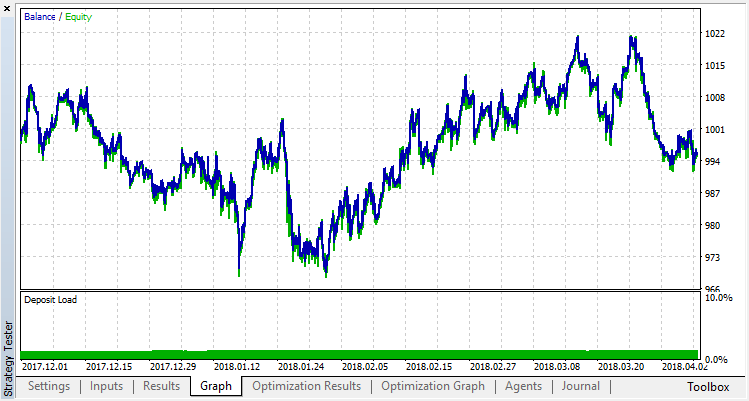
Das Modell hat schlechter gelernt (es gibt jetzt mehr Rauschen), aber es war nicht möglich, die globale Überanpassung zu beseitigen. Diese Regularisierungsmethode ist natürlich nur für stationäre Prozesse geeignet, bei denen sich die Regelmäßigkeiten im Laufe der Zeit nicht ändern. Ein weiterer offensichtlicher negativer Faktor sind die 3 Oszillatoren am Eingang des Modells, die zudem miteinander korrelieren.
Zusammenfassung des Artikels
Ziel war es, die Möglichkeiten aufzuzeigen, einen Random Forest zur Annäherung an eine Funktion zu nutzen. In diesem Fall war die Funktion der Indikatorwerte ein Kauf- oder Verkaufssignal. Außerdem wurden zwei Arten des überwachten Lernens berücksichtigt - Klassifizierung und Regression. Für das Lernen mit bisher unbekannten Trainingsbeispielen, die während des Optimierungsprozesses automatisch ausgewählt wurden, wurde ein nicht standardisierter Ansatz angewandt. Der Prozess ähnelt im Allgemeinen einer konventionellen Optimierung im Tester (Cloud), wobei der Algorithmus in wenigen Iterationen konvergiert, ohne dass man sich um die Anzahl der optimierten Parameter kümmern muss. Das ist ein klarer Vorteil des angewandten Ansatzes. Nachteil des Modells ist eine starke Tendenz zur Überpassung, wenn die Strategie falsch gewählt wird, was einer Überoptimierung der Parameter entspricht.
Aus Tradition werde ich mögliche Wege zur Verbesserung der Strategie aufzeigen (schließlich ist die aktuelle Umsetzung nur ein grober Rahmen).
- Erhöhung der Anzahl der optimierten Parameter (Optimierung der Mehrfachmitgliedschaft).
- Hinzufügen verschiedener signifikanter Prädiktoren.
- Anwendung verschiedener Methoden, um den Agenten zu belohnen.
- Erstellen mehrerer konkurrierender Agenten, um den Raum für Varianten zu vergrößern.
Die Quelldateien des selbstlernenden Experten sind unten angehängt.
Damit der Experte kompilieren werden kann und dann arbeitet, ist es notwendig, die Bibliothek MT4Orders und die aktualisierte Bibliothek Fuzzy herunterzuladen.