СОПРОВОЖДЕНИЕ ЭКСПЕРИМЕНТА ПО АНАЛИЗУ ДАННЫХ ФОРЕКСА: успешное применение машинного обучения

Внимание. Нашел ошибку в коде, из-за которой получились отличные результаты. Весь пост аннулируется до подробного разбора полетов!
Коллеги и читатели блога!
А теперь, напомню, что мы делаем.
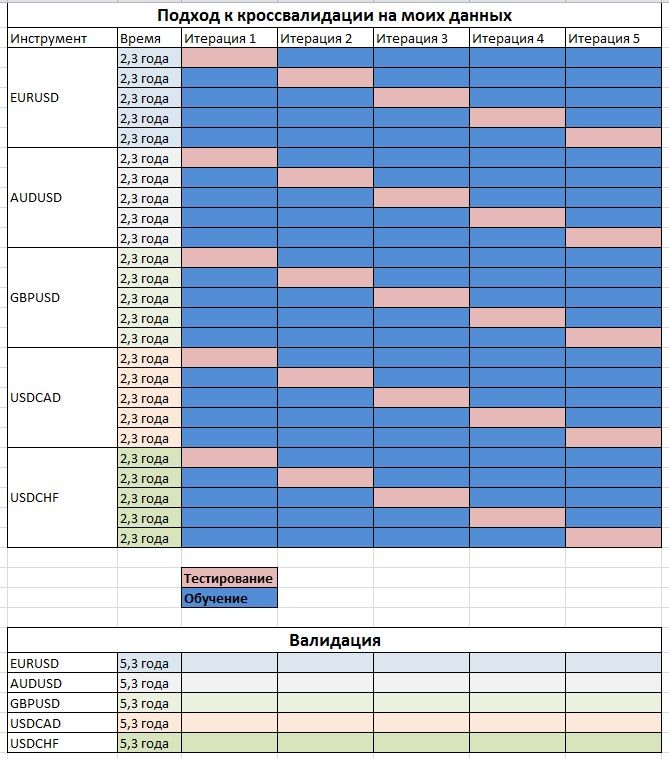
Таким образом я графически изобразил структуру данных.
Последние 1/3 данных каждой пары идут на валидацию. Валидация начинается примерно с 23.09.2010 и заканчивается 01.02.2016.
Кроссвалидация.
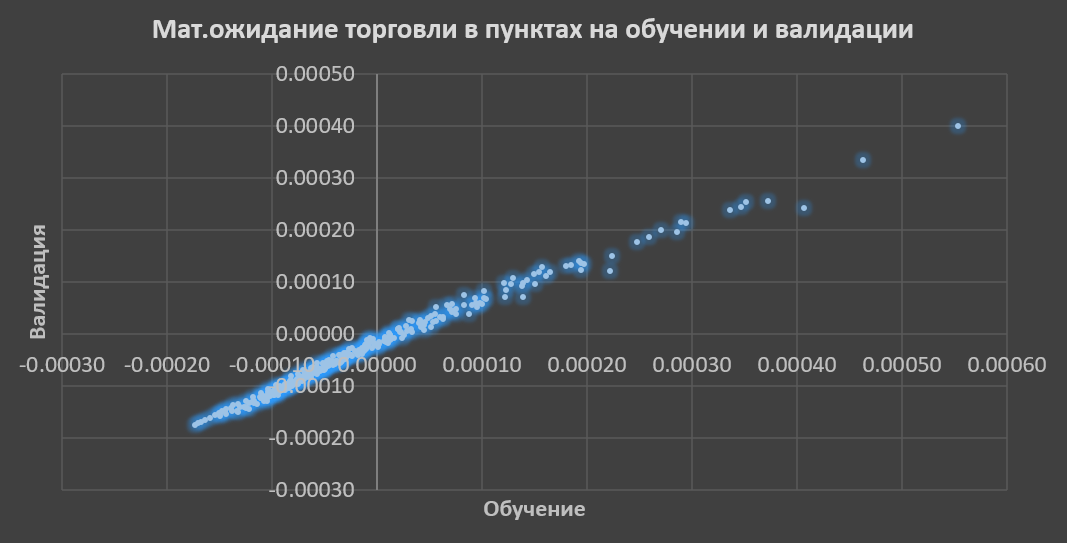
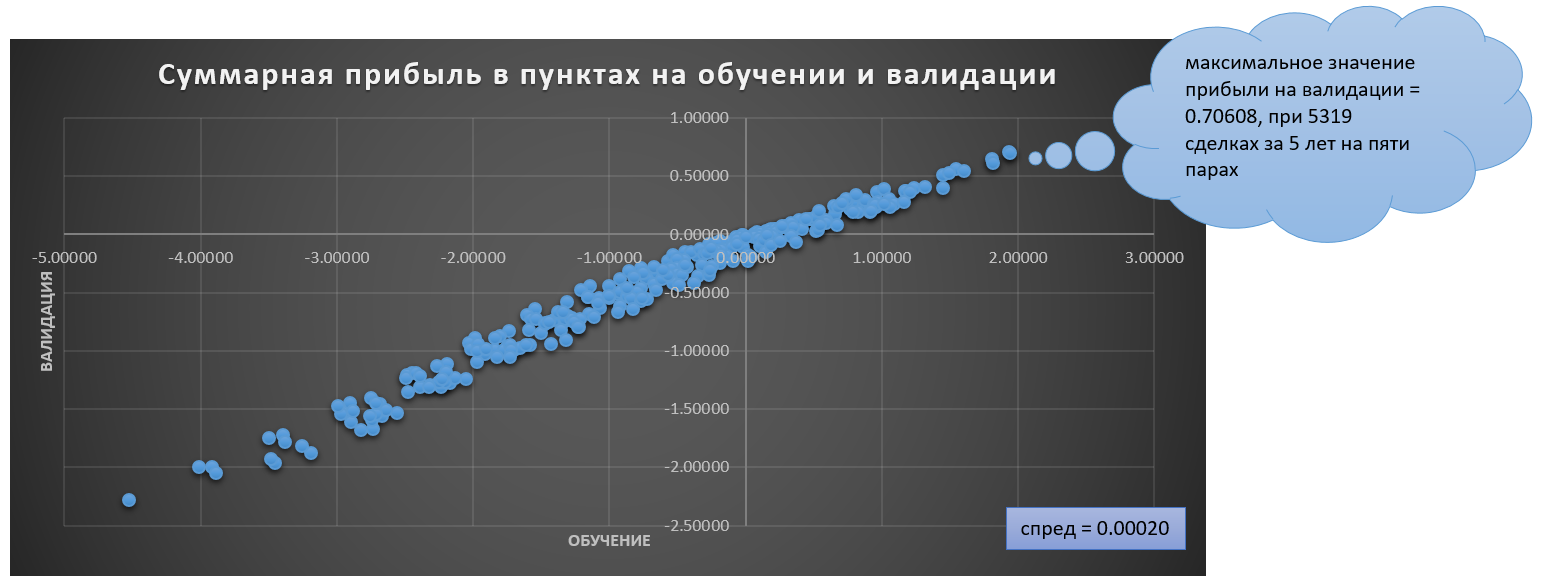
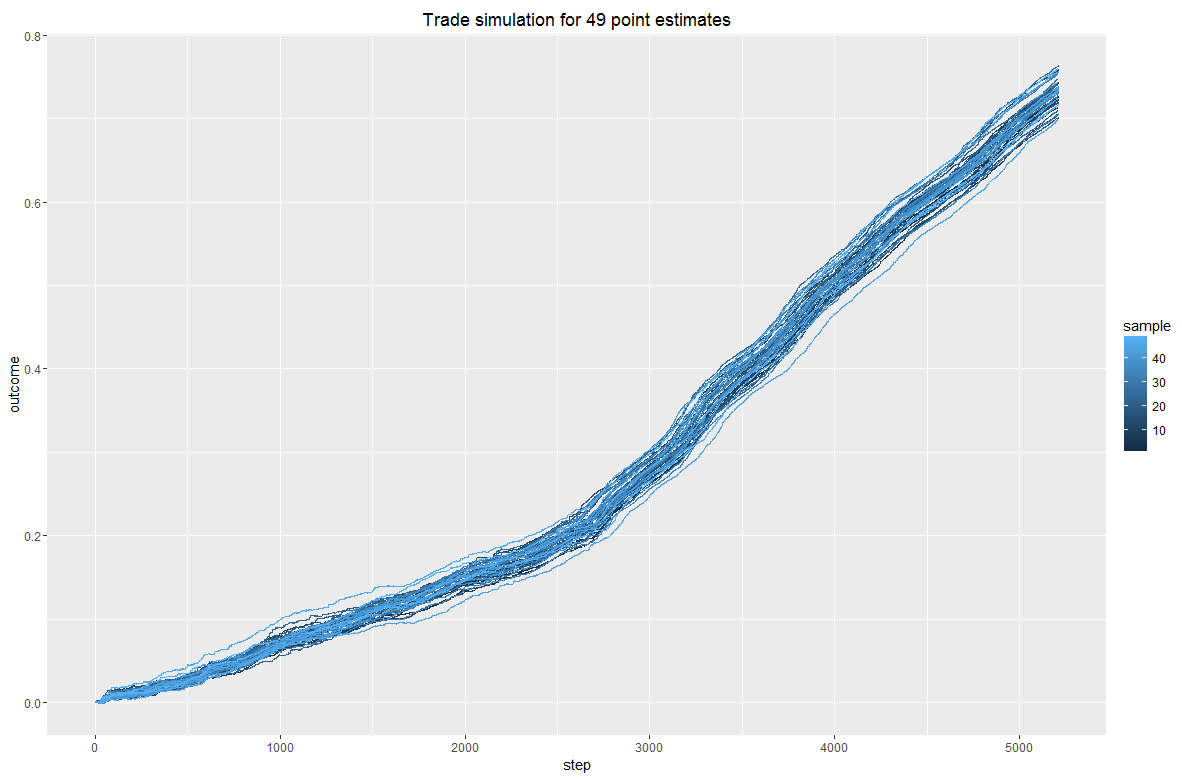
Как видно, мы в солидном плюсе.
dat_usdchf
Для последных трех пар волатильность выше и повыше спред (надо взять не 20, а 25-30 пипсов). Поэтому на них валовый результат и процент угаданных направлений лучше. Введение повышенного спреда уменьшит МО на прикидку до 10 пунктов. Просто, чтобы понимать, что происходит.
Также есть возможность того, что машина хуже обучается на данных eurusd и audusd. Поэтому там результаты чуть похуже.
И, наконец, нужно сделать результаты статистически значимыми.
Столбцы таблицы:
- sample
- validation sample shapiro test normality p-value
- wilcoxon test p-value for difference from zero
- mean
- median
- mean dist upper 99%-tail
- mean dist lower 99%-tail
1 1.11E-65 0 0.000139 0.000095 0.000146 0.000133
2 8.55E-64 0 0.000139 0.000096 0.000145 0.000133
3 8.24E-63 0 0.000137 0.000096 0.000143 0.000131
4 3.31E-66 0 0.000139 0.000095 0.000146 0.000133
5 4.64E-66 0 0.000142 0.000097 0.000149 0.000136
6 7.08E-63 0 0.000141 0.000097 0.000147 0.000135
7 8.72E-65 0 0.000135 0.000096 0.000141 0.000129
8 4.52E-65 0 0.000139 0.000096 0.000145 0.000132
9 4.31E-64 0 0.000143 0.000102 0.000149 0.000137
10 4.53E-66 0 0.000141 0.000099 0.000147 0.000134
11 8.97E-67 0 0.000143 0.000098 0.000149 0.000136
12 2.21E-63 0 0.000139 0.000102 0.000145 0.000133
13 1.16E-63 0 0.000142 0.000099 0.000148 0.000135
14 7.82E-64 0 0.000138 0.000097 0.000144 0.000132
15 1.41E-65 0 0.000146 0.000103 0.000152 0.000140
16 8.17E-63 0 0.000135 0.000097 0.000140 0.000129
17 6.54E-65 0 0.000143 0.000099 0.000149 0.000136
18 6.70E-66 0 0.000138 0.000096 0.000144 0.000132
19 1.86E-65 0 0.000143 0.000099 0.000149 0.000136
20 1.79E-66 0 0.000142 0.000098 0.000148 0.000135
21 2.37E-62 0 0.000136 0.000099 0.000142 0.000131
22 5.51E-65 0 0.000141 0.000100 0.000147 0.000135
23 7.15E-67 0 0.000142 0.000097 0.000149 0.000136
24 1.06E-65 0 0.000144 0.000102 0.000150 0.000137
25 4.01E-65 0 0.000147 0.000101 0.000153 0.000140
26 2.33E-64 0 0.000141 0.000098 0.000147 0.000135
27 7.85E-65 0 0.000141 0.000100 0.000147 0.000134
28 2.07E-64 0 0.000141 0.000098 0.000147 0.000134
29 2.01E-63 0 0.000140 0.000098 0.000146 0.000134
30 2.77E-64 0 0.000139 0.000098 0.000145 0.000133
31 1.43E-66 0 0.000145 0.000098 0.000151 0.000138
32 1.08E-65 0 0.000141 0.000098 0.000147 0.000134
33 3.47E-62 0 0.000136 0.000099 0.000141 0.000130
34 6.04E-67 0 0.000140 0.000096 0.000147 0.000134
35 2.32E-65 0 0.000145 0.000100 0.000152 0.000139
36 6.39E-65 0 0.000143 0.000098 0.000149 0.000137
37 1.10E-61 0 0.000141 0.000103 0.000147 0.000135
38 6.74E-63 0 0.000142 0.000100 0.000148 0.000136
39 2.54E-64 0 0.000141 0.000098 0.000147 0.000135
40 2.45E-64 0 0.000139 0.000098 0.000145 0.000133
41 6.25E-66 0 0.000141 0.000099 0.000148 0.000135
42 3.99E-66 0 0.000141 0.000097 0.000147 0.000135
43 1.35E-66 0 0.000142 0.000098 0.000148 0.000135
44 1.01E-63 0 0.000134 0.000097 0.000140 0.000128
45 1.56E-64 0 0.000139 0.000097 0.000145 0.000133
46 3.11E-66 0 0.000145 0.000103 0.000152 0.000139
47 6.11E-66 0 0.000138 0.000099 0.000144 0.000131
48 2.99E-66 0 0.000146 0.000101 0.000152 0.000139
49 1.84E-63 0 0.000138 0.000098 0.000144 0.000131
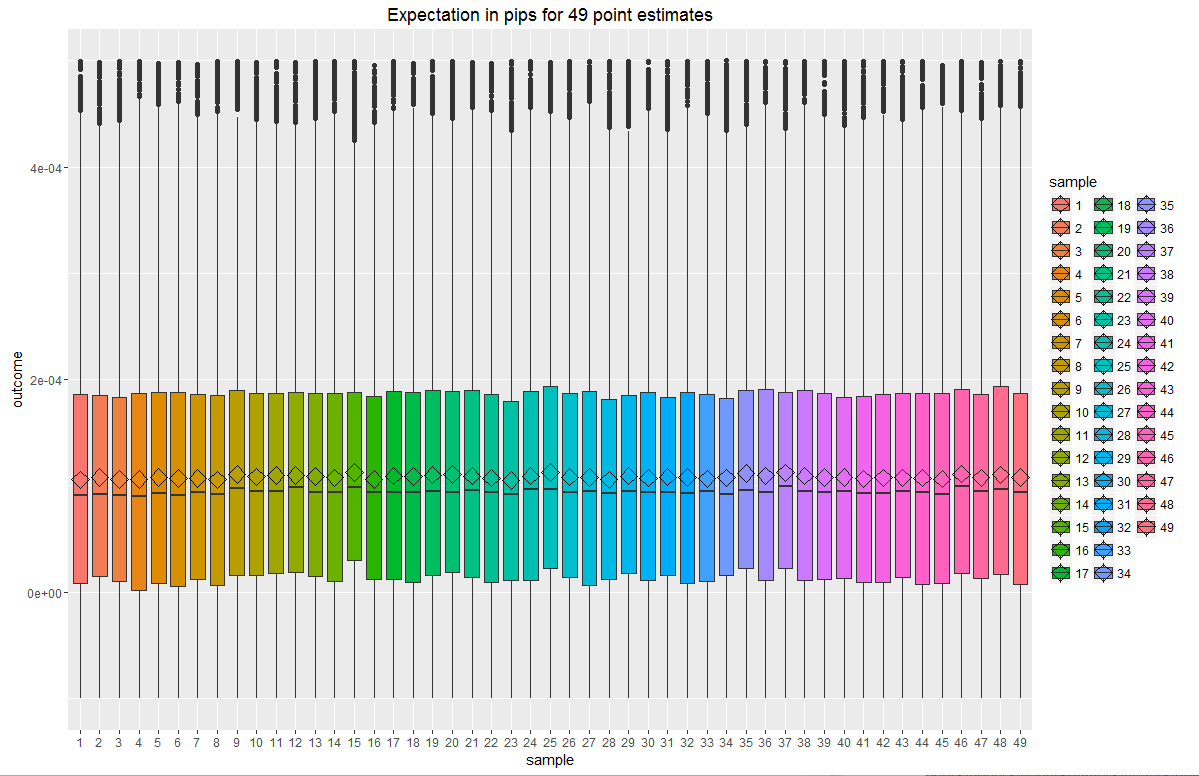
Мы проверяем исходы сделок на нормальность. Они далеко не нормальны.
Также приведем среднюю, медиану, и доверительный интервал для распределения выборочного среднего, чтобы убедиться, что нижняя граница далеко остоит от нуля.
Также я приведу для вашей информации входы, которые генерят такие картинки после обучения:
> best_inputs [1] "lag_diff_512" "lag_mean_diff_32" "lag_mean_diff_45" "lag_range_724" "lag_diff_32" [6] "lag_diff_362" "lag_sd_45" "lag_min_diff_181" "lag_range_23" "lag_range_91"
Во вложении файл с обобщенными результатами обучения и валидации.





")
")