
Teoria das Categorias em MQL5 (Parte 18): Quadrado de naturalidade
Introdução
A teoria das categorias pode parecer muito abstrata para traders de MQL5. Até agora, nesta série de artigos, usamos uma abordagem sistêmica, preferindo morfismos para prever e classificar dados financeiros.
As transformações naturais, um conceito chave da teoria das categorias, é frequentemente percebido apenas como um mapeamento de funtores. Essa visão, embora não esteja incorreta, pode levar a alguma confusão quando se considera que um funtor vincula dois objetos, pois surge a pergunta: quais objetos uma transformação natural vincula? A resposta curta é: os dois objetos do codomínio do funtor. Neste artigo, tentaremos desvendar o que está por trás dessa definição e também incluir um exemplo de uma classe de trailing de um EA que utiliza esse morfismo para prever mudanças na volatilidade.
Usaremos duas categorias como exemplos ao ilustrar transformações naturais. Esse é o número mínimo para um par de funtores usados para definir uma transformação natural. O primeiro consistirá em dois objetos contendo valores normalizados dos indicadores. Vamos considerar os indicadores ATR e Bandas de Bollinger. A segunda categoria, que servirá como a categoria de codomínio, pois será o destino de dois funtores, incluirá quatro objetos, registrando os intervalos de preços das barras de valores que desejamos prever.
Categorias
A categoria dos valores dos indicadores é mencionada em nosso artigo apenas para ajudar a compreender os conceitos apresentados aqui. Ela desempenha um papel mínimo na previsão da volatilidade de nosso interesse, pois para alcançar esse objetivo, vamos contar principalmente com o quadrado de naturalidade (quadrado da naturalidade). No entanto, seu valor é difícil de superestimar. Na internet, há pouca informação sobre o quadrado de naturalidade. Eu recomendo consultar este post (em inglês) para obter informações adicionais.
Então, voltando à nossa categoria de domínios. Como mencionado anteriormente, ela tem dois objetos: um com valores de ATR e outro com valores das Bandas de Bollinger. Esses valores são normalizados de tal forma que os objetos tenham uma cardinalidade (tamanho) fixa. Os valores representados em cada objeto são as respectivas mudanças nos valores dos indicadores. Essas mudanças são registradas em etapas de 10% de menos 100% a mais 100%, o que significa que a cardinalidade de cada objeto é 21. Assim, eles incluem os seguintes valores:
{
-100, -90, -80, -70, -60, -50, -40, -30, -20, -10,
0,
10, 20, 30, 40, 50, 60, 70, 80, 90, 100
}
O morfismo que conecta esses objetos, elementos idênticos, combinará valores dependendo de se eles foram registrados ao mesmo tempo, atualizando assim os dados sobre as mudanças nos dois valores dos indicadores.
Esses valores de mudança de indicador poderiam ser retirados de qualquer outro indicador relacionado à volatilidade. Os princípios permanecem os mesmos. A mudança no valor do indicador é dividida pela soma dos valores absolutos das leituras anterior e atual do indicador para obter uma fração decimal. Em seguida, multiplicamos essa fração por 10 e arredondamos para zero. Depois, ela é novamente multiplicada por 10 e recebe um índice em nossos objetos descritos acima, dependendo do valor ao qual ela é equivalente.
A categoria de intervalos de barras de preço consistirá em quatro objetos, que serão o foco do quadrado de naturalidade usado na elaboração de previsões. Como nossa categoria de domínio (com mudanças de indicador) consiste em dois objetos, e temos dois funtores levando a este codomínio, segue-se que cada um desses funtores é mapeado para um objeto. Os objetos mapeados não precisam sempre ser diferentes, mas em nosso caso, para ajudar a esclarecer nossos conceitos, permitimos que cada objeto mapeado na categoria de domínio tenha seu próprio objeto de codomínio na categoria de intervalos de preço. Assim, 2 objetos multiplicados por 2 funtores resultarão em 4 objetos finais, membros de nossa categoria de codomínio.
Como temos quatro objetos e não queremos duplicação, cada objeto registrará um conjunto diferente de mudanças nos intervalos de preços das barras. Para auxiliar nisso, dois funtores representarão diferentes deltas de previsão. Um funtor mapeará o intervalo de preços da barra após uma barra, e outro funtor mapeará as mudanças no intervalo de preços após duas barras. Além disso, os mapeamentos do objeto ATR se relacionarão com intervalos de preços em uma barra, enquanto os mapeamentos do objeto de Bandas de Bollinger se relacionarão com intervalos de preços em duas barras. Abaixo está o código que implementa tudo o mencionado acima:
CElement<string> _e; for(int i=0;i<m_extra_training+1;i++) { double _a=((m_high.GetData(i+_x)-m_low.GetData(i+_x))-(m_high.GetData(i+_x+1)-m_low.GetData(i+_x+1)))/((m_high.GetData(i+_x)-m_low.GetData(i+_x))+(m_high.GetData(i+_x+1)-m_low.GetData(i+_x+1))); double _c=((m_high.GetData(i+_x)-m_low.GetData(i+_x))-(m_high.GetData(i+_x+2)-m_low.GetData(i+_x+2)))/((m_high.GetData(i+_x)-m_low.GetData(i+_x))+(m_high.GetData(i+_x+2)-m_low.GetData(i+_x+2))); double _b=((fmax(m_high.GetData(i+_x),m_high.GetData(i+_x+1))-fmin(m_low.GetData(i+_x),m_low.GetData(i+_x+1))) -(fmax(m_high.GetData(i+_x+2),m_high.GetData(i+_x+3))-fmin(m_low.GetData(i+_x+2),m_low.GetData(i+_x+3)))) /((fmax(m_high.GetData(i+_x),m_high.GetData(i+_x+1))-fmin(m_low.GetData(i+_x),m_low.GetData(i+_x+1))) +(fmax(m_high.GetData(i+_x+2),m_high.GetData(i+_x+3))-fmin(m_low.GetData(i+_x+2),m_low.GetData(i+_x+3)))); double _d=((fmax(m_high.GetData(i+_x),m_high.GetData(i+_x+1))-fmin(m_low.GetData(i+_x),m_low.GetData(i+_x+1))) -(fmax(m_high.GetData(i+_x+3),m_high.GetData(i+_x+4))-fmin(m_low.GetData(i+_x+3),m_low.GetData(i+_x+4)))) /((fmax(m_high.GetData(i+_x),m_high.GetData(i+_x+1))-fmin(m_low.GetData(i+_x),m_low.GetData(i+_x+1))) +(fmax(m_high.GetData(i+_x+3),m_high.GetData(i+_x+4))-fmin(m_low.GetData(i+_x+3),m_low.GetData(i+_x+4)))); ... }
Esses objetos terão um tamanho único, pois registram apenas as mudanças atuais. Os morfismos entre eles se moverão pelo método do diagrama comutativo aplicado à projeção do intervalo de preços com uma barra para a previsão do intervalo de preços com duas barras, avançando duas barras de preço. Aprenderemos mais sobre isso quando definirmos formalmente as transformações naturais abaixo.
A relação entre os intervalos das barras de preço e os dados de mercado obtidos também é mostrada em nossa fonte acima. As mudanças registradas em cada objeto não são normalizadas, como no caso dos valores dos indicadores, mas sim as mudanças no intervalo são divididas pela soma do intervalo atual e do anterior das barras para obter um valor decimal não arredondado.
Funtores: Vinculação dos valores dos indicadores aos intervalos das barras de preço
Os funtores foram introduzidos em nossa série quatro artigos atrás, mas aqui eles são considerados como um par de duas categorias. Os funtores de completude mapeiam não apenas objetos, mas também morfismos, portanto, como nossa categoria de domínio dos valores dos indicadores tem dois objetos e um morfismo, isso significa que em nossa categoria de codomínio haverá três pontos de saída: dois do objeto e um do morfismo para cada funtor. Com dois funtores, isso resulta em seis pontos de saída em nosso codomínio.
O mapeamento de valores inteiros normalizados dos indicadores para mudanças no intervalo de preços decimais das barras (mudanças que são registradas como frações, não como valores brutos) pode ser realizado usando perceptrons multicamadas, discutidos nos últimos dois artigos. Existem muitos outros métodos ainda não explorados nesta série para criar tal mapeamento, como o método floresta aleatória, por exemplo.
Esta ilustração é apenas para completar o quadro e entender o que é uma transformação natural e quais são todos os seus pressupostos. Quando os traders se deparam com novos conceitos, a questão mais importante para eles é qual é a aplicação e o benefício desses conceitos. É por isso que eu declarei no início que, para nossos propósitos de previsão, nos concentraríamos no quadrado de naturalidade, que é definido exclusivamente pelos quatro objetos na categoria de codomínio. Assim, a menção à categoria do domínio de assunto e seus objetos aqui apenas ajuda a definir as transformações naturais e não auxilia em nossa aplicação específica neste artigo.
Transformações Naturais: Superando a Lacuna
Agora podemos examinar os axiomas das transformações naturais para passar à sua aplicação. Formalmente, uma transformação natural entre os funtores
F: C --> D
e
G: C --> D
é uma família de morfismos
ηA: F(A) --> G(A)
para todos os objetos A na categoria C tal que para todos os morfismos
f: A --> B
na categoria C, a seguinte diagrama comuta:
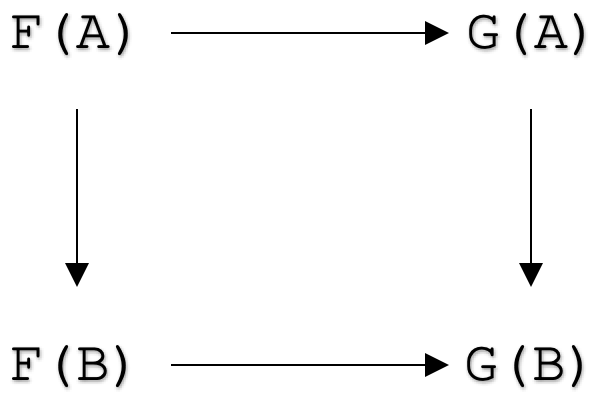
Embora haja muito material na Internet sobre transformações naturais, talvez seja útil examinar uma definição mais visual relacionada ao quadrado da naturalidade. Para isso, suponha que temos duas categorias C e D, com a categoria C tendo dois objetos X e Y, definidos como:
X = {5, 6, 7}
e
Y = {Q, R, S}
Suponha também que temos um morfismo entre esses objetos, f definido como:
f: X à Y
tal que f(5) = S, f(6) = R e f(7) = R.
Neste exemplo, dois funtores F e G entre as categorias C e D farão duas coisas simples. Vamos preparar uma lista e uma lista de listas, respectivamente. Assim, o funtor F aplicado a X terá como resultado:
[5, 6, 5, 7, 5, 6, 7, 7]
e similarmente o funtor G (lista de listas) daria:
[[5, 6], [5, 7, 5, 6, 7], [7]]
Se aplicarmos esses funtores de maneira semelhante ao objeto Y, obteremos 4 objetos na categoria de codomínio D. Eles são representados como mostrado abaixo:

Note que agora estamos focando apenas nos quatro objetos na categoria D. Como temos dois objetos em nossa categoria de domínio C, também teremos duas transformações naturais, cada uma relacionada a um objeto na categoria C. Elas são representadas abaixo:
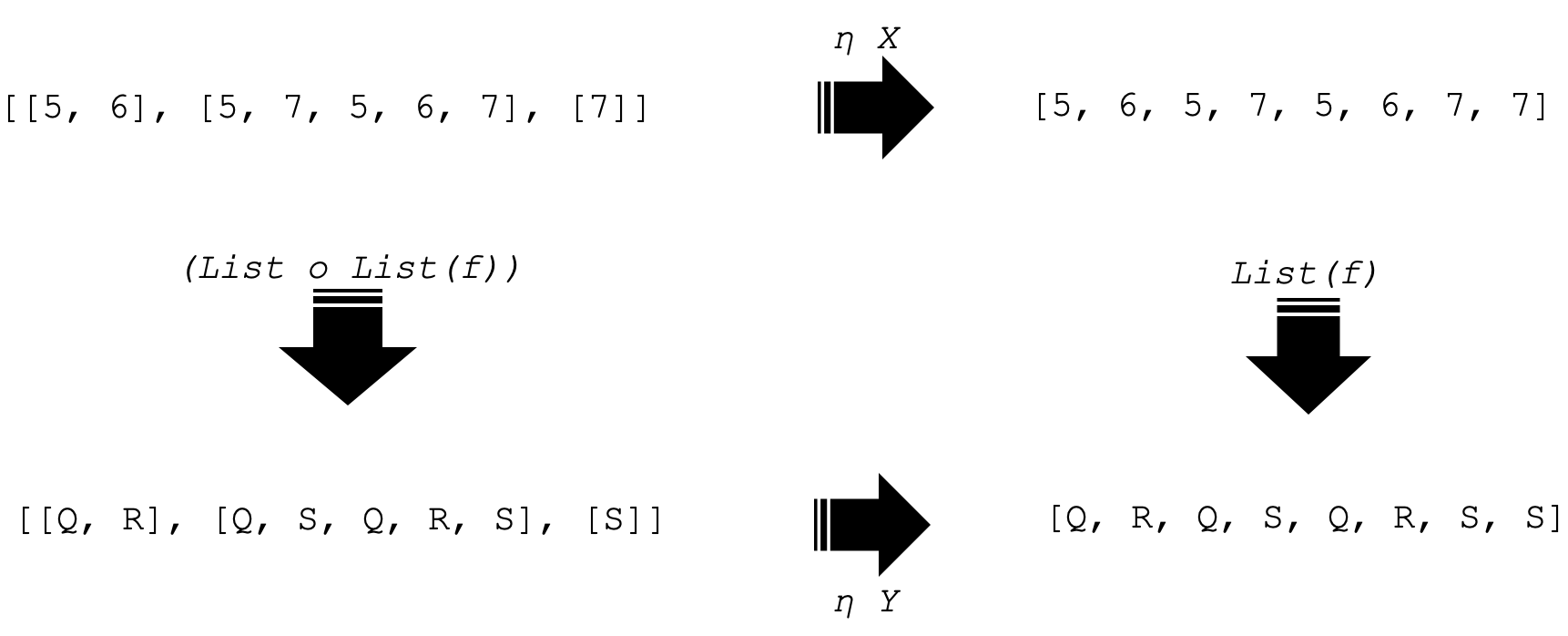
A imagem acima demonstra o quadrado de naturalidade. As setas indicam as permutações. As duas setas horizontais são nossas transformações naturais (NT) em relação a cada objeto em C, e as setas verticais são as saídas do funtor quando aplicadas ao morfismo f na categoria C para os funtores F e G.
A importância de preservar a estrutura e as relações é um aspecto-chave do NT, que pode ser facilmente ignorado, mas, apesar de sua simplicidade, é crucial. Para esclarecer nosso ponto de vista, vamos considerar um exemplo da culinária. Suponha que temos dois chefs famosos, chamemo-los A e B. Cada um deles tem uma maneira única de preparar o mesmo prato a partir de um conjunto padrão de ingredientes. Consideraríamos os ingredientes como um objeto em uma categoria mais ampla de tipos de ingredientes, e os dois pratos preparados por cada chef também pertenceriam a outra categoria mais ampla de tipos de pratos. Uma transformação natural entre os dois pratos preparados pelos nossos chefs A e B registraria os ingredientes e os preparos adicionais necessários para mudar o prato preparado pelo chef A para o prato preparado pelo chef B. Com essa abordagem, registramos mais informações e podemos verificar e ver se, por exemplo, um prato do chef C precisaria de uma NT similar para corresponder ao prato do chef B, e se não, até que ponto? Mas além da comparação, o uso da NT para obter o prato do chef B exigiria a receita do chef A, estilos e métodos de preparo. Isso significa que eles devem ser preservados. A preservação é importante também como meio de desenvolver novas receitas ou até mesmo de verificar as existentes considerando restrições dietéticas de alguém.
Aplicação: Previsão de Volatilidade
Agora, podemos considerar possíveis aplicações na previsão. Nesta série, discutimos muito a previsão de mudança nos intervalos de preços das barras. Usamos essa previsão para determinar, em primeiro lugar, se precisamos ajustar o stop móvel em posições abertas e, em segundo lugar, quanto precisamos ajustá-lo.
A implementação do quadrado de naturalidade como uma ferramenta chave nesta tarefa será realizada com o uso de perceptrons multicamadas (MLP), como foi nos nossos dois últimos artigos, com a diferença de que aqui esses MLPs são construídos em torno de permutações (square commutation). Isso nos permite verificar nossas previsões, pois qualquer dois passos podem fornecer uma previsão. Os quatro cantos do quadrado refletem diferentes previsões em algum ponto futuro da mudança no intervalo de nossas barras de preço. À medida que avançamos para o canto D, olhamos mais para o futuro, com o canto A prevendo a mudança de intervalo apenas para a próxima barra. Isso significa que, se conseguirmos treinar MLPs que conectem todos os quatro cantos, usando a mudança de intervalo para a barra de preço mais recente, seremos capazes de fazer previsões muito além de uma única barra.
Os passos necessários para aplicar nossas NTs para obter uma previsão são mostrados na lista abaixo:
//+------------------------------------------------------------------+ //| NATURAL TRANSFORMATION CLASS | //+------------------------------------------------------------------+ class CTransformation { protected: public: CDomain<string> domain; //codomain object of first functor CDomain<string> codomain;//codomain object of second functor uint hidden_size; CMultilayerPerceptron transformer; CMLPBase init; void Transform(CDomain<string> &D,CDomain<string> &C) { domain=D; codomain=C; int _inputs=D.Cardinality(),_outputs=C.Cardinality(); if(_inputs>0 && _outputs>0) { init.MLPCreate1(_inputs,hidden_size+fmax(_inputs,_outputs),_outputs,transformer); } } // void Let() { this.codomain.Let(); this.domain.Let(); }; CTransformation(void){ hidden_size=1; }; ~CTransformation(void){}; };
Primeiramente, temos a classe NT mencionada acima. Quanto à definição aleatória, poderíamos esperar que ela incluísse uma instância dos dois funtores que ela conecta. Isso é aplicável, mas aumentaria significativamente a quantidade de código. O momento chave em NT são duas áreas representadas por funtores. São eles que são destacados.
//+------------------------------------------------------------------+ //| NATURALITY CLASS | //+------------------------------------------------------------------+ class CNaturalitySquare { protected: public: CDomain<string> A,B,C,D; CTransformation AB; uint hidden_size_bd; CMultilayerPerceptron BD; uint hidden_size_ac; CMultilayerPerceptron AC; CTransformation CD; CMLPBase init; CNaturalitySquare(void){}; ~CNaturalitySquare(void){}; };
O quadrado de naturalidade, cujo diagrama é mostrado acima, também terá sua classe, representada por instâncias da classe NT. Seus quatro cantos, expressos pelas letras A, B, C e D, são objetos capturados pela classe de domínio, e apenas dois de seus morfismos serão MLP diretos, enquanto os outros dois são reconhecidos como NT.
Implementação prática no MQL5
A implementação prática no MQL5, considerando nosso uso de MLP, inevitavelmente encontrará problemas, principalmente, como treinamos e armazenamos o que aprendemos (os pesos da rede). Diferentemente dos dois últimos artigos, nesta os pesos do treinamento não são armazenados de forma alguma, o que significa que em cada nova coluna é gerada e treinada uma nova instância de cada um dos quatro MLP. Isso é realizado por meio de uma função de atualização, conforme mostrado abaixo:
//+------------------------------------------------------------------+ //| Refresh function for naturality square. | //+------------------------------------------------------------------+ double CTrailingCT::Refresh() { double _refresh=0.0; m_high.Refresh(-1); m_low.Refresh(-1); int _x=StartIndex(); // atr domains capture 1 bar ranges // bands' domains capture 2 bar ranges // 1 functors capture ranges after 1 bar // 2 functors capture ranges after 2 bars int _info_ab=0,_info_bd=0,_info_ac=0,_info_cd=0; CMLPReport _report_ab,_report_bd,_report_ac,_report_cd; CMatrixDouble _xy_ab;_xy_ab.Resize(m_extra_training+1,1+1); CMatrixDouble _xy_bd;_xy_bd.Resize(m_extra_training+1,1+1); CMatrixDouble _xy_ac;_xy_ac.Resize(m_extra_training+1,1+1); CMatrixDouble _xy_cd;_xy_cd.Resize(m_extra_training+1,1+1); CElement<string> _e; for(int i=0;i<m_extra_training+1;i++) { ... if(i<m_extra_training+1) { _xy_ab[i].Set(0,_a);//in _xy_ab[i].Set(1,_b);//out _xy_bd[i].Set(0,_b);//in _xy_bd[i].Set(1,_d);//out _xy_ac[i].Set(0,_a);//in _xy_ac[i].Set(1,_c);//out _xy_cd[i].Set(0,_c);//in _xy_cd[i].Set(1,_d);//out } } m_train.MLPTrainLM(m_naturality_square.AB.transformer,_xy_ab,m_extra_training+1,m_decay,m_restarts,_info_ab,_report_ab); ... // if(_info_ab>0 && _info_bd>0 && _info_ac>0 && _info_cd>0) { ... } return(_refresh); }
A função de atualização acima treina MLPs, inicializados com pesos aleatórios, apenas no último preço do bar. Claramente, isso será insuficiente para outros sistemas de negociação ou implementações de código geral, no entanto, o parâmetro de entrada m_extra_training, cujo valor padrão zero é mantido para nossos propósitos de teste, pode ser ajustado para aumentar, a fim de proporcionar um teste mais completo antes de fazer previsões.
O uso do parâmetro para treinamento adicional inevitavelmente criará um sobrecarga de desempenho do Expert Advisor e, de fato, destaca por que a leitura e escrita de pesos durante o treinamento foram evitadas neste artigo.
Vantagens e limitações
Se realizarmos testes no EURUSD no intervalo diário de 01.08.2022 a 01.08.2023, uma das nossas melhores corridas dará o seguinte resultado:


Se realizarmos os testes com as mesmas configurações em um período não otimizado (no nosso caso, o período de um ano antes do nosso intervalo de testes), obteremos resultados negativos, que não refletem o desempenho apresentado no relatório acima. Como pode ser visto, todo o lucro foi obtido por meio da ativação dos stop-loss.
Comparado com as abordagens que usamos anteriormente nesta série para prever a volatilidade, este método, sem dúvida, requer mais recursos e claramente necessita de mudanças na maneira como definimos nossos quatro objetos no quadrado de naturalidade para possibilitar o avanço durante períodos não otimizados.
Conclusão
Em resumo, o conceito-chave discutido aqui é as transformações naturais. Elas são importantes para conectar categorias ao fixar a diferença entre um par de funtores paralelos que conectam categorias. Os exemplos de uso discutidos aqui focaram na previsão de volatilidade usando o quadrado de naturalidade, no entanto, outras aplicações possíveis incluem a geração de sinais de entrada e saída, bem como a determinação do tamanho da posição. Além disso, vale mencionar que neste artigo e ao longo desta série, não realizamos nenhum teste preliminar com as configurações otimizadas obtidas. Portanto, é provável que eles não funcionem "fora da caixa" (ou seja, na forma como o código é fornecido), mas podem funcionar após algumas modificações, por exemplo, combinando as ideias apresentadas com outras estratégias que o leitor possa aplicar. É por isso que o uso de masterclasses MQL5 se mostra útil, pois facilita isso.
Referências
Referências para artigos na Wikipedia e no site stackexchange.com.
Notas sobre os aplicativos
Coloque o arquivo SignalCT_16_.mqh na pasta MQL5\include\Expert\Signal\, e o arquivo ct_16.mqh em MQL5\include\.
Você também pode achar úteis as recomendações fornecidas aqui sobre como montar um EA usando o assistente. Como mencionado no artigo, não usei trailing stop e margem fixa para gestão de capital. Ambos fazem parte da biblioteca MQL5. Como sempre, o objetivo do artigo não é apresentar a você o Santo Graal, mas sim oferecer uma ideia que você pode adaptar para sua própria estratégia.
Traduzido do Inglês pela MetaQuotes Ltd.
Artigo original: https://www.mql5.com/en/articles/13200
- Aplicativos de negociação gratuitos
- 8 000+ sinais para cópia
- Notícias econômicas para análise dos mercados financeiros
Você concorda com a política do site e com os termos de uso