
データサイエンスと機械学習(第20回):アルゴリズム取引の洞察、MQL5でのLDAとPCAの対決

--持っているものが多ければ多いほど、見えているものは少なくなります
線形判別分析(LDA)とは
LDAは教師あり汎化機械学習アルゴリズムで、データセットのクラスを最もよく分ける特徴の線形結合を見つけることを目的としています。
主成分分析(PCA)と同様、LDAは次元削減アルゴリズムであり、これらのアルゴリズムは次元削減のための一般的な選択肢です。本連載の前の記事ですでにPCAについては説明しましたが、PCAアルゴリズムがどのようなものかを観察することから始めましょう。ディスカッションは主にPCAアルゴリズムについてです。最後に、単純なデータセットとストラテジーテスターでパフォーマンスを比較します。最後までしっかりとついてきて、データサイエンスの素晴らしさをご覧ください。
目的/理論
線形判別分析(LDA)の目的は以下の通りです。
- クラス分離可能性の最大化:LDAは、データのクラス間の分離を最大化する特徴の線形結合を見つけることを目的としています。データをこれらの識別次元に投影することで、LDAは異なるクラス間の区別を高め、分類をより効果的にするのに役立ちます。
- 次元削減:LDAは、データを低次元の部分空間に投影することで、特徴空間の次元を削減します。この次元削減は、可能な限り多くのクラス識別情報を保持しながら達成されます。特徴空間の縮小は、モデルの単純化、計算の高速化、汎化性能の向上につながります。
- クラス内のばらつきの最小化:LDAは、同じクラスに属するデータ点が変換された空間内で緊密にクラスタ化されるようにすることで、クラス内の散らばりやばらつきを最小化することを目的としています。クラス内のばらつきを抑えることで、クラス間の分離性を高め、分類モデルの頑健性を向上させます。
- クラス間のばらつきの最大化:逆にLDAは、変換された空間におけるクラス平均間の距離を最大化することで、クラス間の散らばりやばらつきを最大化しようとします。クラス内のばらつきを最小化しながらクラス間のばらつきを最大化することで、LDAはクラス間のより良い識別を達成し、より正確な分類結果につながります。
- 多クラス分類を扱う:LDAは、2つ以上のクラスが存在する多クラス分類問題を扱うことができます。すべてのクラス間の関係を同時に考慮することで、LDAはすべてのクラスを最適に分離する共通の部分空間を見つけ、高次元特徴空間における効果的な分類境界を導きます。
前提条件
線形判別分析にはいくつかの仮定があります。数千のタンパク質データセットを見て、いくつかの仮定を立てます。
- 測定は互いに独立している
- データは特徴の範囲内で正規分布している
- データセット中のクラスは同じ共分散行列を持つ
線形判別アルゴリズムのステップ
01:クラス内散布行列(SW)を計算する
各クラスの散布行列を計算します。
matrix SW, SB; //within and between scatter matrices SW.Init(num_features, num_features); SB.Init(num_features, num_features); for (ulong i=0; i<num_classes; i++) { matrix class_samples = {}; for (ulong j=0, count=0; j<x.Rows(); j++) { if (y[j] == classes[i]) //Collect a matrix for samples belonging to a particular class { count++; class_samples.Resize(count, num_features); class_samples.Row(x.Row(j), count-1); } } matrix diff = Base::subtract(class_samples, class_means.Row(i)); //Each row subtracted to the mean if (diff.Rows()==0 && diff.Cols()==0) //if the subtracted matrix is zero stop the program for possible bugs or errors { DebugBreak(); return x_centered; } SW += diff.Transpose().MatMul(diff); //Find within scatter matrix vector mean_diff = class_means.Row(i) - x_centered.Mean(0); SB += class_samples.Rows() * mean_diff.Outer(mean_diff); //compute between scatter matrix }
これらの個々の散布行列を合計して、クラス内散布行列を得ます。
02:クラス間散布行列(SB)を計算する
各クラスの平均ベクトルを計算します。
matrix SW, SB; //within and between scatter matrices SW.Init(num_features, num_features); SB.Init(num_features, num_features); for (ulong i=0; i<num_classes; i++) { matrix class_samples = {}; for (ulong j=0, count=0; j<x.Rows(); j++) { if (y[j] == classes[i]) //Collect a matrix for samples belonging to a particular class { count++; class_samples.Resize(count, num_features); class_samples.Row(x.Row(j), count-1); } } matrix diff = Base::subtract(class_samples, class_means.Row(i)); //Each row subtracted to the mean if (diff.Rows()==0 && diff.Cols()==0) //if the subtracted matrix is zero stop the program for possible bugs or errors { DebugBreak(); return x_centered; } SW += diff.Transpose().MatMul(diff); //Find within scatter matrix vector mean_diff = class_means.Row(i) - x_centered.Mean(0); SB += class_samples.Rows() * mean_diff.Outer(mean_diff); //compute between scatter matrix }
クラス間の散布行列を計算します。
SB += class_samples.Rows() * mean_diff.Outer(mean_diff); //compute between scatter matrix 03:固有値と固有ベクトルを計算する
SWとSBを含む一般化固有値問題を解き、固有値とそれに対応する固有ベクトルを求めます。
matrix eigen_vectors; vector eigen_values; matrix SBSW = SW.Inv().MatMul(SB); SBSW += this.m_regparam * MatrixExtend::eye((uint)SBSW.Rows()); if (!SBSW.Eig(eigen_vectors, eigen_values)) { Print("%s Failed to calculate eigen values and vectors Err=%d",__FUNCTION__,GetLastError()); DebugBreak(); matrix empty = {}; return empty; }
識別特徴の選択
固有値を降順に並び替えます。
vector args = MatrixExtend::ArgSort(eigen_values);
MatrixExtend::Reverse(args);
eigen_values = Base::Sort(eigen_values, args);
eigen_vectors = Base::Sort(eigen_vectors, args); 変換行列を形成する上位k個の固有ベクトルを選択します。
this.m_components = extract_components(eigen_values); 線形判別分析も主成分分析も,次元削減という同じような目的を果たすので,分散やScreePlot(英語)は,PCAの記事で使用したものと同じです。
LDAクラスを拡張して、デフォルトでNULL数の成分が選択されているときに、それ自身のために成分を抽出できるようにすることができます。
if (this.m_components == NULL) this.m_components = extract_components(eigen_values); else //plot the scree plot extract_components(eigen_values);
新しい特徴空間へのデータ投影
元のデータに選択された固有ベクトルを掛け合わせ、新しい特徴空間を得ます。
this.projection_matrix = Base::Slice(eigen_vectors, this.m_components); return x_centered.MatMul(projection_matrix.Transpose());
このコードはすべてfit_transform関数内で実行されます。この関数は線形判別分析アルゴリズムの学習と準備をおこなう関数です。このクラスで新しいデータや未知のデータを扱えるようにするには、さらなる変換のための関数を追加する必要があります。
matrix CLDA::transform(const matrix &x) { if (this.projection_matrix.Rows() == 0) { printf("%s fit_transform method must be called befor transform",__FUNCTION__); matrix empty = {}; return empty; } matrix x_centered = Base::subtract(x, this.mean); return x_centered.MatMul(this.projection_matrix.Transpose()); } //+------------------------------------------------------------------+ //| | //+------------------------------------------------------------------+ vector CLDA::transform(const vector &x) { matrix m = MatrixExtend::VectorToMatrix(x, this.num_features); if (m.Rows()==0) { vector empty={}; return empty; //return nothing since there is a failure in converting vector to matrix } m = transform(m); return MatrixExtend::MatrixToVector(m); }
LDAクラスの概要
全体的なLDAクラスは以下のようになります。
enum lda_criterion //selecting best components criteria selection { CRITERION_VARIANCE, CRITERION_KAISER, CRITERION_SCREE_PLOT }; class CLDA { CPlots plt; protected: uint m_components; lda_criterion m_criterion; matrix projection_matrix; ulong num_features; double m_regparam; vector mean; uint CLDA::extract_components(vector &eigen_values, double threshold=0.95); public: CLDA(uint k=NULL, lda_criterion CRITERION_=CRITERION_SCREE_PLOT, double reg_param =1e-6); ~CLDA(void); matrix fit_transform(const matrix &x, const vector &y); matrix transform(const matrix &x); vector transform(const vector &x); };
reg_param(正則化パラメータ)は、SW行列とSB行列を正則化し、固有値とベクトルの計算誤差を少なくするのに役立つだけです。
SW += this.m_regparam * MatrixExtend::eye((uint)num_features); SB += this.m_regparam * MatrixExtend::eye((uint)num_features);
データセットへの線形判別分析の使用
人気のあるIrisデータセットにLDAクラスを適用し、その結果を観察してみましょう。
string headers; matrix data = MatrixExtend::ReadCsv("iris.csv",headers); //Read csv
これは教師あり機械学習手法であることを覚えておいてください。つまり、独立変数と目標変数を別々に収集してモデルに与える必要があります。
matrix x; vector y; MatrixExtend::XandYSplitMatrices(data, x, y);
#include <MALE5\Dimensionality Reduction\LDA.mqh> CLDA *lda; //+------------------------------------------------------------------+ //| Expert initialization function | //+------------------------------------------------------------------+ int OnInit() { //--- string headers; matrix data = MatrixExtend::ReadCsv("iris.csv",headers); //Read csv matrix x; vector y; MatrixExtend::XandYSplitMatrices(data, x, y); Print("Original X\n",x); lda = new CLDA(); matrix transformed_x = lda.fit_transform(x, y); Print("Transformed X\n",transformed_x); return(INIT_SUCCEEDED); }
出力
HH 0 10:18:21.210 LDA Test (EURUSD,H1) Original X IQ 0 10:18:21.210 LDA Test (EURUSD,H1) [[5.1,3.5,1.4,0.2] HF 0 10:18:21.210 LDA Test (EURUSD,H1) [4.9,3,1.4,0.2] ... ... ES 0 10:18:21.211 LDA Test (EURUSD,H1) [6.5,3,5.2,2] ML 0 10:18:21.211 LDA Test (EURUSD,H1) [6.2,3.4,5.4,2.3] EI 0 10:18:21.211 LDA Test (EURUSD,H1) [5.9,3,5.1,1.8]] IL 0 10:18:21.243 LDA Test (EURUSD,H1) DD 0 10:18:21.243 LDA Test (EURUSD,H1) Transformed X DM 0 10:18:21.243 LDA Test (EURUSD,H1) [[-1.058063221542643,2.676898315513957] JD 0 10:18:21.243 LDA Test (EURUSD,H1) [-1.060778666796316,2.532150351483708] DM 0 10:18:21.243 LDA Test (EURUSD,H1) [-0.9139922886488467,2.777963946569435] ... ... IK 0 10:18:21.244 LDA Test (EURUSD,H1) [1.527279343196588,-2.300606221030168] QN 0 10:18:21.244 LDA Test (EURUSD,H1) [0.9614855249192527,-1.439559895222919] EF 0 10:18:21.244 LDA Test (EURUSD,H1) [0.6420061576026481,-2.511057690832021…]
美しいスクリープロットもチャートに表示されました。
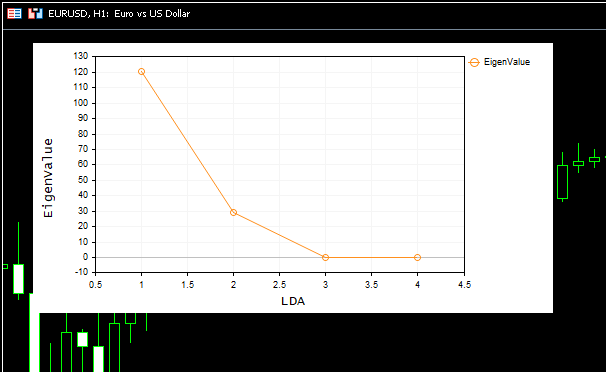
画面のプロットから、最適な成分数はエルボーポイントの2であることがわかります。これはまさに私たちのクラスが返したコンポーネントの数です。素晴らしいです。ここで、返されたコンポーネントを視覚化して、それらが特徴的かどうかを確認してみましょう。次元を削減する目的は、元のデータのすべての分散を説明する最小数のコンポーネントを取得することであることは周知のとおりなので、単純にデータの簡略化されたバージョンを置きます。
EAのコンポーネントをcsvファイルに保存し、pythonを使ってこのノートブックにプロットすることにしました。https://www.kaggle.com/code/omegajoctan/lda-vs-pca-components-iris-data
MatrixExtend::WriteCsv("iris-data lda-components.csv",transformed_x); 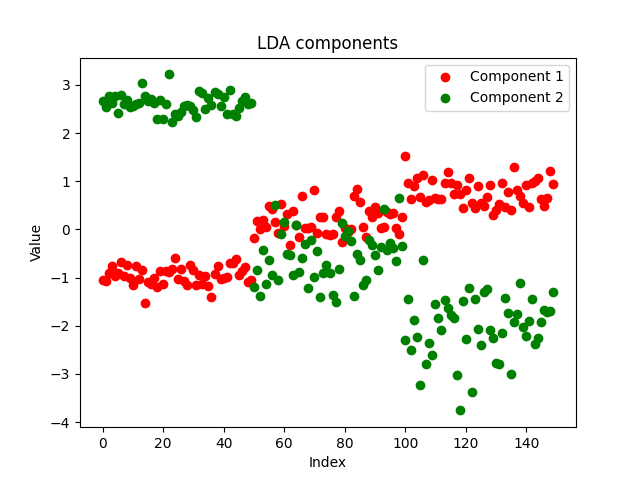
コンポーネントはきれいに見え、実装が成功したことを示しています。次に、PCAコンポーネントがどのように見えるかを見てみましょう。
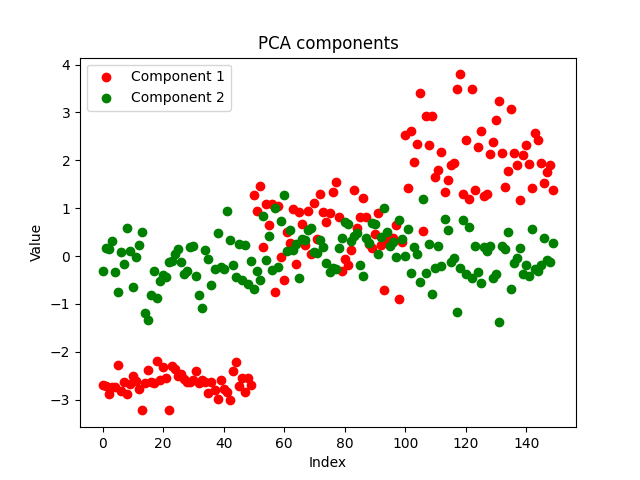
プロットを見ただけでは、どちらがより良い結果を出したかはわかりません。同じデータセットに対して同じパラメータで同じモデルを使用し、訓練と標本外テストの両方で両モデルの精度を観察してみましょう。
LDAとPCAの比較
LDAとPCAアルゴリズムからそれぞれ得られた2つの別々のデータに対して、同じパラメータを持つ決定木モデルを使用します。
#include <MALE5\Dimensionality Reduction\LDA.mqh> #include <MALE5\Dimensionality Reduction\PCA.mqh> #include <MALE5\Decision Tree\tree.mqh> #include <MALE5\Metrics.mqh> CLDA *lda; CPCA *pca; CDecisionTreeClassifier *classifier_tree; input int random_state_ = 42; input double training_sample_size = 0.7; //+------------------------------------------------------------------+ //| Expert initialization function | //+------------------------------------------------------------------+ int OnInit() { //--- string headers; matrix data = MatrixExtend::ReadCsv("iris.csv",headers); //Read csv Print("<<<<<<<< LDA Applied >>>>>>>>>"); matrix x_train, x_test; vector y_train, y_test; MatrixExtend::TrainTestSplitMatrices(data,x_train,y_train,x_test,y_test,training_sample_size,random_state_); lda = new CLDA(NULL); matrix x_transformed = lda.fit_transform(x_train, y_train); //Transform the training data classifier_tree = new CDecisionTreeClassifier(); classifier_tree.fit(x_transformed, y_train); //Train the model using the transformed data vector preds = classifier_tree.predict(x_transformed); //Make predictions using the transformed data Print("Train accuracy: ",Metrics::confusion_matrix(y_train, preds).accuracy); x_transformed = lda.transform(x_test); preds = classifier_tree.predict(x_transformed); Print("Test accuracy: ",Metrics::confusion_matrix(y_test, preds).accuracy); delete (classifier_tree); delete (lda); //--- Print("<<<<<<<< PCA Applied >>>>>>>>>"); pca = new CPCA(NULL); x_transformed = pca.fit_transform(x_train); classifier_tree = new CDecisionTreeClassifier(); classifier_tree.fit(x_transformed, y_train); preds = classifier_tree.predict(x_transformed); //Make predictions using the transformed data Print("Train accuracy: ",Metrics::confusion_matrix(y_train, preds).accuracy); x_transformed = pca.transform(x_test); preds = classifier_tree.predict(x_transformed); Print("Test accuracy: ",Metrics::confusion_matrix(y_test, preds).accuracy); delete (classifier_tree); delete(pca); return(INIT_SUCCEEDED); }
LDAの結果
GM 0 18:23:18.285 LDA Test (EURUSD,H1) <<<<<<<< LDA Applied >>>>>>>>> MR 0 18:23:18.302 LDA Test (EURUSD,H1) JP 0 18:23:18.344 LDA Test (EURUSD,H1) Confusion Matrix FK 0 18:23:18.344 LDA Test (EURUSD,H1) [[39,0,0] CR 0 18:23:18.344 LDA Test (EURUSD,H1) [0,30,5] QF 0 18:23:18.344 LDA Test (EURUSD,H1) [0,2,29]] IS 0 18:23:18.344 LDA Test (EURUSD,H1) OM 0 18:23:18.344 LDA Test (EURUSD,H1) Classification Report KF 0 18:23:18.344 LDA Test (EURUSD,H1) QQ 0 18:23:18.344 LDA Test (EURUSD,H1) _ Precision Recall Specificity F1 score Support FF 0 18:23:18.344 LDA Test (EURUSD,H1) 1.0 1.00 1.00 1.00 1.00 39.0 GI 0 18:23:18.344 LDA Test (EURUSD,H1) 2.0 0.94 0.86 0.97 0.90 35.0 ML 0 18:23:18.344 LDA Test (EURUSD,H1) 3.0 0.85 0.94 0.93 0.89 31.0 OS 0 18:23:18.344 LDA Test (EURUSD,H1) FN 0 18:23:18.344 LDA Test (EURUSD,H1) Accuracy 0.93 JO 0 18:23:18.344 LDA Test (EURUSD,H1) Average 0.93 0.93 0.97 0.93 105.0 KJ 0 18:23:18.344 LDA Test (EURUSD,H1) W Avg 0.94 0.93 0.97 0.93 105.0 EQ 0 18:23:18.344 LDA Test (EURUSD,H1) Train accuracy: 0.933 JH 0 18:23:18.344 LDA Test (EURUSD,H1) Confusion Matrix LS 0 18:23:18.344 LDA Test (EURUSD,H1) [[11,0,0] IJ 0 18:23:18.344 LDA Test (EURUSD,H1) [0,13,2] RN 0 18:23:18.344 LDA Test (EURUSD,H1) [0,1,18]] IK 0 18:23:18.344 LDA Test (EURUSD,H1) OE 0 18:23:18.344 LDA Test (EURUSD,H1) Classification Report KN 0 18:23:18.344 LDA Test (EURUSD,H1) QI 0 18:23:18.344 LDA Test (EURUSD,H1) _ Precision Recall Specificity F1 score Support LN 0 18:23:18.344 LDA Test (EURUSD,H1) 1.0 1.00 1.00 1.00 1.00 11.0 CQ 0 18:23:18.344 LDA Test (EURUSD,H1) 2.0 0.93 0.87 0.97 0.90 15.0 QD 0 18:23:18.344 LDA Test (EURUSD,H1) 3.0 0.90 0.95 0.92 0.92 19.0 OK 0 18:23:18.344 LDA Test (EURUSD,H1) FF 0 18:23:18.344 LDA Test (EURUSD,H1) Accuracy 0.93 GD 0 18:23:18.344 LDA Test (EURUSD,H1) Average 0.94 0.94 0.96 0.94 45.0 HQ 0 18:23:18.344 LDA Test (EURUSD,H1) W Avg 0.93 0.93 0.96 0.93 45.0 CF 0 18:23:18.344 LDA Test (EURUSD,H1) Test accuracy: 0.933
LDAは訓練とテストの両方で93%の精度で安定したモデルを生成しました。
PCAの結果
MM 0 18:26:40.994 LDA Test (EURUSD,H1) <<<<<<<< PCA Applied >>>>>>>>>
LS 0 18:26:41.071 LDA Test (EURUSD,H1) Confusion Matrix
LJ 0 18:26:41.071 LDA Test (EURUSD,H1) [[39,0,0]
ER 0 18:26:41.071 LDA Test (EURUSD,H1) [0,34,1]
OE 0 18:26:41.071 LDA Test (EURUSD,H1) [0,4,27]]
KD 0 18:26:41.071 LDA Test (EURUSD,H1)
IL 0 18:26:41.071 LDA Test (EURUSD,H1) Classification Report
MG 0 18:26:41.071 LDA Test (EURUSD,H1)
CR 0 18:26:41.071 LDA Test (EURUSD,H1) _ Precision Recall Specificity F1 score Support
DE 0 18:26:41.071 LDA Test (EURUSD,H1) 1.0 1.00 1.00 1.00 1.00 39.0
EH 0 18:26:41.071 LDA Test (EURUSD,H1) 2.0 0.89 0.97 0.94 0.93 35.0
KL 0 18:26:41.071 LDA Test (EURUSD,H1) 3.0 0.96 0.87 0.99 0.92 31.0
ID 0 18:26:41.071 LDA Test (EURUSD,H1)
NO 0 18:26:41.071 LDA Test (EURUSD,H1) Accuracy 0.95
CH 0 18:26:41.071 LDA Test (EURUSD,H1) Average 0.95 0.95 0.98 0.95 105.0
KK 0 18:26:41.071 LDA Test (EURUSD,H1) W Avg 0.95 0.95 0.98 0.95 105.0
NR 0 18:26:41.071 LDA Test (EURUSD,H1) Train accuracy: 0.952
LK 0 18:26:41.071 LDA Test (EURUSD,H1) Confusion Matrix
FR 0 18:26:41.071 LDA Test (EURUSD,H1) [[11,0,0]
FJ 0 18:26:41.072 LDA Test (EURUSD,H1) [0,14,1]
MM 0 18:26:41.072 LDA Test (EURUSD,H1) [0,3,16]]
NL 0 18:26:41.072 LDA Test (EURUSD,H1)
HD 0 18:26:41.072 LDA Test (EURUSD,H1) Classification Report
LO 0 18:26:41.072 LDA Test (EURUSD,H1)
FJ 0 18:26:41.072 LDA Test (EURUSD,H1) _ Precision Recall Specificity F1 score Support
KM 0 18:26:41.072 LDA Test (EURUSD,H1) 1.0 1.00 1.00 1.00 1.00 11.0
EP 0 18:26:41.072 LDA Test (EURUSD,H1) 2.0 0.82 0.93 0.90 0.88 15.0
HD 0 18:26:41.072 LDA Test (EURUSD,H1) 3.0 0.94 0.84 0.96 0.89 19.0
HL 0 18:26:41.072 LDA Test (EURUSD,H1)
OG 0 18:26:41.072 LDA Test (EURUSD,H1) Accuracy 0.91
PS 0 18:26:41.072 LDA Test (EURUSD,H1) Average 0.92 0.93 0.95 0.92 45.0
IP 0 18:26:41.072 LDA Test (EURUSD,H1) W Avg 0.92 0.91 0.95 0.91 45.0
PE 0 18:26:41.072 LDA Test (EURUSD,H1) Test accuracy: 0.911 PCAは、訓練で95%の精度、テストでは91.1%の精度を提供し、より正確なモデルを生成しました。
線形判別分析(LDA)の利点
分類や次元削減タスクで広く使用されている線形判別分析(LDA)手法にはいくつかの利点があります。
- 次元削減に有用:LDAは、元の特徴をより低次元の空間に変換することで、特徴空間の次元を削減します。この削減は、より単純なモデルを導き、次元の呪いを緩和し、計算効率を向上させます。
- クラス差別情報を保持:LDAは、クラス間の分離を最大化する特徴の線形結合を見つけることを目的としています。クラス間を区別する識別情報に注目することで、LDAは変換された特徴量がクラス関連の重要なパターンと構造を保持することを保証します。
- 特徴を抽出して1ステップで分類:LDAは特徴抽出と分類を同時におこないます。クラス分離可能性を最大化する元の特徴の変換を学習するため、分類タスクに本質的に適しています。この統合されたアプローチは、より効率的で解釈しやすいモデルにつながります。
- 過剰適合に強い:LDAは、他の分類アルゴリズムに比べて、特に特徴量の数に対して標本数が少ない場合に、過剰適合を起こしにくいです。特徴空間の次元を減らし、最も識別性の高い特徴に注目することで、LDAは未知のデータにもうまく汎化できます。
- 多クラス分類に対応:LDAは当然、2つ以上のクラスを持つ多クラス分類問題にも拡張されます。これは、すべてのクラス間の関係を同時に考慮し、高次元特徴空間における効果的な分離境界を導きます。
- 計算効率が良い:LDAでは固有値問題と行列の乗算を解きますが、これは計算効率が高く、MQL5の組み込みメソッドで実装できます。このため、LDAは大規模なデータセットやリアルタイムのアプリケーションに適しています。
- 解釈が簡単:LDAから得られる変換された特徴量は解釈可能であり、データの根底にあるパターンを理解するために分析することができます。LDAによって学習された特徴の線形結合は、分類決定の原動力となる識別要因に関する洞察を提供することができます。
- 仮定がしばしば満たされる:LDAは、データが各クラス内で正規分布し、共分散行列が等しいと仮定します。実際には、これらの仮定が常に成り立つとは限りませんが、LDAは、仮定がほぼ満たされた場合でも、良好な結果を出すことができます。
線形判別分析(LDA)にはいくつかの利点がある一方で、いくつかの制限や欠点もあります。
線形判別分析(LDA)の欠点
- 特徴内でガウス分布を仮定:LDAは、各クラス内のデータが等しい共分散行列を持つ正規分布であると仮定します。この仮定に反すると、LDAは最適でない結果を出したり、収束しなかったりします。実際には、実世界のデータが非正規分布を示し、LDAの有効性が制限されることがあります。
- 外れ値の影響を受けやすい:LDAは、特に共分散行列が限られたデータから推定される場合、外れ値の影響を受けやすくなります。外れ値は、共分散行列とその結果得られる判別方向の推定に大きな影響を与え、偏った分類結果や信頼性の低い分類結果につながる可能性があります。
- 非線形関係をモデル化する際の柔軟性が低い:これは、クラス間の判定境界が直線的であると仮定するためです。特徴量とクラス間の基本的な関係が非線形である場合、LDAはこれらの複雑なパターンを効果的に捕捉できない可能性があります。このような場合、非線形次元削減技術や非線形分類器の方が適しているかもしれません。
- 次元の呪いは本当:特徴数が標本数よりはるかに多い場合、LDAは次元の呪いに苦しむ可能性があります。高次元特徴空間では、共分散行列の推定は信頼性が低くなり、判別方向がデータの真の根本構造を効果的に捉えられなくなる可能性があります。
- 不均衡なクラスでの限られたパフォーマンス:LDAのパフォーマンスは、1つまたは複数のクラスの標本数が他のクラスよりも著しく少ないような不均衡なクラス分布を扱うときに低下する可能性があります。このような場合、標本数の少ないクラスは、クラス平均と共分散行列の推定において十分に表現されていない可能性があり、偏った分類結果につながります。
- 数値以外のデータはほとんど扱えない:LDAは一般的に数値データで動作するため、カテゴリー変数や数値以外の変数を含むデータセットには直接適用できない場合があります。カテゴリー変数のエンコードや、非数値データを数値表現に変換するなどの前処理が必要になる場合があり、複雑さが増し、情報が失われる可能性があります。
取引環境におけるLDAとPCAの比較
取引環境でこれらの次元削減技法を使用するには、紙のモデルを訓練およびテストするための関数を作成する必要があります。その後、訓練されたモデルを使用して、パフォーマンスの分析に役立つストラテジーテスターで予測をおこなうことができます。
この2つの方法を使って、縮小したい5つの指標をデータセットに使用します。
int OnInit() { //--- Trend following indicators indicator_handle[0] = iAMA(Symbol(), PERIOD_CURRENT, 9 , 2 , 30, 0, PRICE_OPEN); indicator_handle[1] = iADX(Symbol(), PERIOD_CURRENT, 14); indicator_handle[2] = iADXWilder(Symbol(), PERIOD_CURRENT, 14); indicator_handle[3] = iBands(Symbol(), PERIOD_CURRENT, 20, 0, 2.0, PRICE_OPEN); indicator_handle[4] = iDEMA(Symbol(), PERIOD_CURRENT, 14, 0, PRICE_OPEN); }
void TrainTest() { vector buffer = {}; for (int i=0; i<ArraySize(indicator_handle); i++) { buffer.CopyIndicatorBuffer(indicator_handle[i], 0, 0, bars); //copy indicator buffer dataset.Col(buffer, i); //add the indicator buffer values to the dataset matrix } //--- vector y(bars); MqlRates rates[]; CopyRates(Symbol(), PERIOD_CURRENT,0,bars, rates); for (int i=0; i<bars; i++) //Creating the target variable { if (rates[i].close > rates[i].open) //if bullish candle assign 1 to the y variable else assign the 0 class y[i] = 1; else y[0] = 0; } //--- dataset.Col(y, dataset.Cols()-1); //add the y variable to the last column //--- matrix x_train, x_test; vector y_train, y_test; MatrixExtend::TrainTestSplitMatrices(dataset,x_train,y_train,x_test,y_test,training_sample_size,random_state_); matrix x_transformed = {}; switch(dimension_reduction) { case LDA: lda = new CLDA(NULL); x_transformed = lda.fit_transform(x_train, y_train); //Transform the training data break; case PCA: pca = new CPCA(NULL); x_transformed = pca.fit_transform(x_train); break; } classifier_tree = new CDecisionTreeClassifier(); classifier_tree.fit(x_transformed, y_train); //Train the model using the transformed data vector preds = classifier_tree.predict(x_transformed); //Make predictions using the transformed data Print("Train accuracy: ",Metrics::confusion_matrix(y_train, preds).accuracy); switch(dimension_reduction) { case LDA: x_transformed = lda.transform(x_test); //Transform the testing data break; case PCA: x_transformed = pca.transform(x_test); break; } preds = classifier_tree.predict(x_transformed); Print("Test accuracy: ",Metrics::confusion_matrix(y_test, preds).accuracy); }
データの訓練が完了したら、LDAから始まる両手法の結果を以下に示すようにテストする必要があります。
JK 0 01:00:24.440 LDA Test (EURUSD,H1) GK 0 01:00:37.442 LDA Test (EURUSD,H1) Confusion Matrix QR 0 01:00:37.442 LDA Test (EURUSD,H1) [[60,266] FF 0 01:00:37.442 LDA Test (EURUSD,H1) [46,328]] DR 0 01:00:37.442 LDA Test (EURUSD,H1) RN 0 01:00:37.442 LDA Test (EURUSD,H1) Classification Report FE 0 01:00:37.442 LDA Test (EURUSD,H1) LP 0 01:00:37.442 LDA Test (EURUSD,H1) _ Precision Recall Specificity F1 score Support HD 0 01:00:37.442 LDA Test (EURUSD,H1) 0.0 0.57 0.18 0.88 0.28 326.0 FI 0 01:00:37.442 LDA Test (EURUSD,H1) 1.0 0.55 0.88 0.18 0.68 374.0 RM 0 01:00:37.442 LDA Test (EURUSD,H1) QH 0 01:00:37.442 LDA Test (EURUSD,H1) Accuracy 0.55 KQ 0 01:00:37.442 LDA Test (EURUSD,H1) Average 0.56 0.53 0.53 0.48 700.0 HP 0 01:00:37.442 LDA Test (EURUSD,H1) W Avg 0.56 0.55 0.51 0.49 700.0 KK 0 01:00:37.442 LDA Test (EURUSD,H1) Train accuracy: 0.554 DR 0 01:00:37.443 LDA Test (EURUSD,H1) Confusion Matrix CD 0 01:00:37.443 LDA Test (EURUSD,H1) [[20,126] LO 0 01:00:37.443 LDA Test (EURUSD,H1) [12,142]] OK 0 01:00:37.443 LDA Test (EURUSD,H1) ME 0 01:00:37.443 LDA Test (EURUSD,H1) Classification Report QN 0 01:00:37.443 LDA Test (EURUSD,H1) GI 0 01:00:37.443 LDA Test (EURUSD,H1) _ Precision Recall Specificity F1 score Support JM 0 01:00:37.443 LDA Test (EURUSD,H1) 0.0 0.62 0.14 0.92 0.22 146.0 KR 0 01:00:37.443 LDA Test (EURUSD,H1) 1.0 0.53 0.92 0.14 0.67 154.0 MF 0 01:00:37.443 LDA Test (EURUSD,H1) MQ 0 01:00:37.443 LDA Test (EURUSD,H1) Accuracy 0.54 MJ 0 01:00:37.443 LDA Test (EURUSD,H1) Average 0.58 0.53 0.53 0.45 300.0 OI 0 01:00:37.443 LDA Test (EURUSD,H1) W Avg 0.58 0.54 0.52 0.45 300.0 QP 0 01:00:37.443 LDA Test (EURUSD,H1) Test accuracy: 0.54
PCAは訓練では良い結果を出しましたが、テストでは少し落ちました。
GE 0 01:01:57.202 LDA Test (EURUSD,H1) MS 0 01:01:57.202 LDA Test (EURUSD,H1) Classification Report IH 0 01:01:57.202 LDA Test (EURUSD,H1) OS 0 01:01:57.202 LDA Test (EURUSD,H1) _ Precision Recall Specificity F1 score Support KG 0 01:01:57.202 LDA Test (EURUSD,H1) 0.0 0.62 0.28 0.85 0.39 326.0 GL 0 01:01:57.202 LDA Test (EURUSD,H1) 1.0 0.58 0.85 0.28 0.69 374.0 MP 0 01:01:57.202 LDA Test (EURUSD,H1) JK 0 01:01:57.202 LDA Test (EURUSD,H1) Accuracy 0.59 HL 0 01:01:57.202 LDA Test (EURUSD,H1) Average 0.60 0.57 0.57 0.54 700.0 CG 0 01:01:57.202 LDA Test (EURUSD,H1) W Avg 0.60 0.59 0.55 0.55 700.0 EF 0 01:01:57.202 LDA Test (EURUSD,H1) Train accuracy: 0.586 HO 0 01:01:57.202 LDA Test (EURUSD,H1) Confusion Matrix GG 0 01:01:57.202 LDA Test (EURUSD,H1) [[26,120] GJ 0 01:01:57.202 LDA Test (EURUSD,H1) [29,125]] KN 0 01:01:57.202 LDA Test (EURUSD,H1) QJ 0 01:01:57.202 LDA Test (EURUSD,H1) Classification Report MQ 0 01:01:57.202 LDA Test (EURUSD,H1) CL 0 01:01:57.202 LDA Test (EURUSD,H1) _ Precision Recall Specificity F1 score Support QP 0 01:01:57.202 LDA Test (EURUSD,H1) 0.0 0.47 0.18 0.81 0.26 146.0 GE 0 01:01:57.202 LDA Test (EURUSD,H1) 1.0 0.51 0.81 0.18 0.63 154.0 QI 0 01:01:57.202 LDA Test (EURUSD,H1) MD 0 01:01:57.202 LDA Test (EURUSD,H1) Accuracy 0.50 RE 0 01:01:57.202 LDA Test (EURUSD,H1) Average 0.49 0.49 0.49 0.44 300.0 IL 0 01:01:57.202 LDA Test (EURUSD,H1) W Avg 0.49 0.50 0.49 0.45 300.0 PP 0 01:01:57.202 LDA Test (EURUSD,H1) Test accuracy: 0.503
最後に、決定木モデルが提供するシグナルから簡単な取引戦略を作成することができます。
void OnTick() { //--- if (!train_once) //call the function to train the model once on the program lifetime { TrainTest(); train_once = true; } //--- vector inputs(indicator_handle.Size()); vector buffer; for (uint i=0; i<indicator_handle.Size(); i++) { buffer.CopyIndicatorBuffer(indicator_handle[i], 0, 0, 1); //copy the current indicator value inputs[i] = buffer[0]; //add its value to the inputs vector } //--- SymbolInfoTick(Symbol(), ticks); if (isnewBar(PERIOD_CURRENT)) // We want to trade on the bar opening { vector transformed_inputs = {}; switch(dimension_reduction) //transform every new data to fit the dimensions selected during training { case LDA: transformed_inputs = lda.transform(inputs); //Transform the new data break; case PCA: transformed_inputs = pca.transform(inputs); break; } int signal = (int)classifier_tree.predict(transformed_inputs); double min_lot = SymbolInfoDouble(Symbol(), SYMBOL_VOLUME_MIN); SymbolInfoTick(Symbol(), ticks); if (signal == -1) { if (!PosExists(MAGICNUMBER, POSITION_TYPE_SELL)) // If a sell trade doesnt exist m_trade.Sell(min_lot, Symbol(), ticks.bid, ticks.bid+stoploss*Point(), ticks.bid - takeprofit*Point()); } else { if (!PosExists(MAGICNUMBER, POSITION_TYPE_BUY)) // If a buy trade doesnt exist m_trade.Buy(min_lot, Symbol(), ticks.ask, ticks.ask-stoploss*Point(), ticks.ask + takeprofit*Point()); } } }
始値モードで2023年1月から2024年2月まで、両手法をシンプルなストラテジーに適用してテストしてみました。
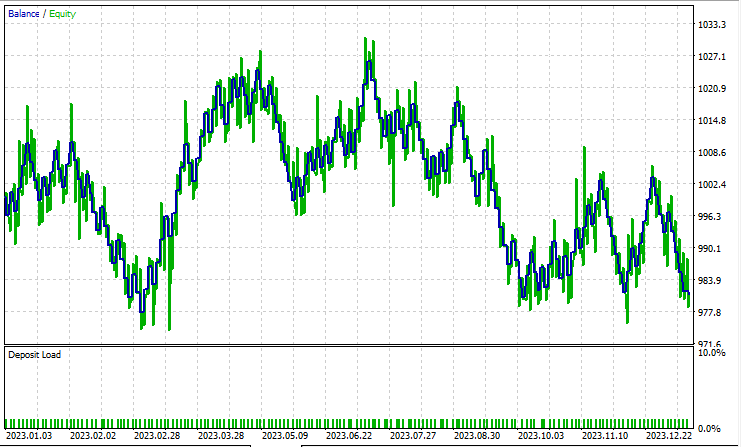
線形判別分析(LDA)のテスト
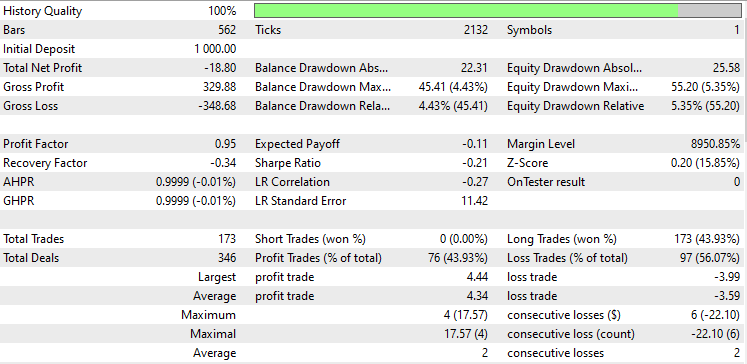
主成分分析(PCA)のテスト
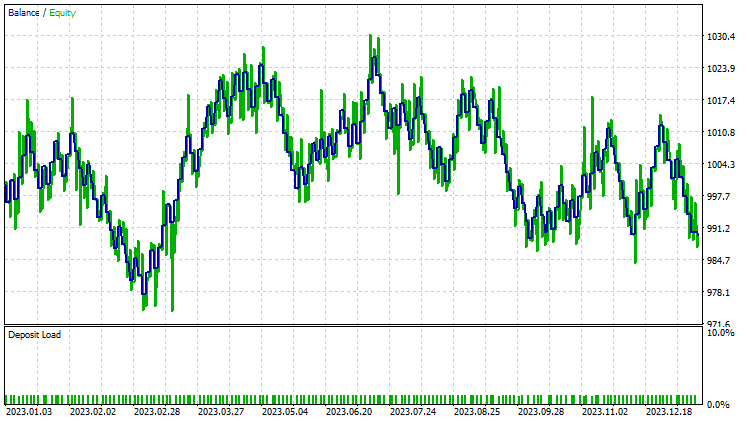
LDAはPCAよりも8ドル多く損失を出し、ほぼ同様のパフォーマンスを示しました。ストラテジーテスターは、MQL5トレーダーがデータサイエンティストの視点から見るものですが、これらの次元削減技術は、特にビッグデータを扱う場合、変数を単純化することが主な仕事であるため、あまり関係がありません。また、このEAをストラテジーテスターで実行した際、行列メソッドとベクトルメソッドの未解明なバグに起因する計算の矛盾をいくつか経験したことを説明しなければなりません。途中でエラーや障害に遭遇した場合は、意味のある結果が得られるまでプログラムを何度か実行してください。
この連載を読まれている方は、先の記事でおこなったように、この2つの手法でなぜ変換したデータをスケーリングしないのかと疑問に思われるかもしれません。
機械学習モデルのためにPCAやLDAのデータを正規化する必要があるかどうかは、データセットの特性、使用するアルゴリズム、目的によって異なります。以下、考慮すべき点をいくつか挙げます。
- PCA変換:この2つは、元の特徴の共分散行列を操作し、データの最大分散を捕らえる直交成分(主成分)を見つけます。これら2つの手法で得られた変換データは、これらの主成分から構成されます。
- PCAまたはLDAの前の正規化:特に特徴量のスケールや単位が異なる場合は、PCAまたはLDAを実行する前に元の特徴量を正規化するのが一般的です。正規化によって、すべての特徴が共分散行列に等しく寄与するようになり、スケールの大きな特徴が主成分を支配するのを防ぐことができます。
- PCAまたはLDA後の正規化;PCAから変換されたデータを正規化する必要があるかどうかは、機械学習アルゴリズムの特定の要件と変換された特徴の特性に依存します。ロジスティック回帰やk近傍法のようないくつかのアルゴリズムは、特徴量のスケールの違いに敏感で、PCAやLDAの後でも、正規化された特徴量の恩恵を受けるかもしれません。
- 私たちが導入した決定木やランダムフォレストのような他のアルゴリズムは、特徴スケールの影響を受けにくく、PCA後の正規化を必要としない場合があります。
- 正規化が解釈可能性に与える影響:PCA後の正規化は、主成分の解釈可能性に影響を与える可能性があります。主成分に対する元の特徴の寄与を理解することに興味がある場合、変換されたデータを正規化すると、これらの関係が不明瞭になる可能性があります。
- パフォーマンスへの影響:正規化したデータと正規化しない変換データの両方で実験し、モデルのパフォーマンスへの影響を評価します。場合によっては、正規化によって収束が良くなったり、汎化が改善されたり、訓練が速くなったりすることもありますが、ほとんど効果がないこともあります。
機械学習モデルの開発を追跡し、本連載で説明されている多くのことは、このGitHubレポに掲載されています。
添付ファイル:
| ファイル | 説明/用途 |
|---|---|
| tree.mqh | 決定木分類モデルを含む |
| MatrixExtend.mqh | 行列操作のための追加関数 |
| metrics.mqh | MLモデルのパフォーマンスを測定するための関数とコード |
| preprocessing.mqh | 生の入力データを前処理して機械学習モデルの使用に適したものにするためのライブラリ |
| base.mqh | pcaとldaのベースライブラリで、これら2つのライブラリのコーディングを簡単にするための関数を含む |
| pca.mqh | 主成分分析ライブラリ |
| lda.mqh | 線形判別分析ライブラリ |
| plots.mqh | ベクトルと行列をプロットするためのライブラリ |
| lda vs pca script.mq5 | pcaとldaアルゴリズムを紹介するスクリプト |
| LDA Test.mq5 | ほとんどのコードをテストするための主なEA |
| iris.csv | 一般的な虹彩データセット |
MetaQuotes Ltdにより英語から翻訳されました。
元の記事: https://www.mql5.com/en/articles/14128
- 無料取引アプリ
- 8千を超えるシグナルをコピー
- 金融ニュースで金融マーケットを探索