
Теория категорий в MQL5 (Часть 23): Другой взгляд на двойную экспоненциальную скользящую среднюю
Введение
Оперативная реализация теории категорий в MQL5 кажется сложной задачей. Доступных для изучения материалов мало. Существует множество книг, но они часто предназначены для магистрантов или аспирантов. Попытка упростить эту тему - задача не из легких, особенно учитывая, что целью является не изложение академических аргументов и теории, а скорее интерпретация и применение ее принципов к трейдерам. С этой целью мы расширим нашу тему и по-новому взглянем на простые повседневные индикаторы.
Цель данной статьи — осветить концепцию горизонтальной композиции в естественных преобразованиях. Его антоним мы рассмотрели в прошлой статье, где мы увидели, как можно вывести три функтора между двумя категориями, что подразумевает два естественных преобразования в вертикальной композиции, когда категории представляют собой такие простые наборы данных, как временные ряды цен и временные ряды скользящих средних одних и тех же цен. В этой статье мы расширим временной ряд скользящих средних по горизонтали, добавляя третью категорию скользящих средних, более известную как двойная экспоненциальная скользящая средняя. Наш вариант этого известного индикатора не использует эту формулу буквально, а скорее сглаживает скользящее среднее, будучи скользящим средним скользящего среднего. Отношения функторов аналогичны тем, которые мы имели в прошлой статье, однако у нас есть только два функтора между категориями, а не три, которые были у нас в предыдущей статье. Однако, как и в последней статье, каждый функтор между любыми двумя категориями будет иметь свой собственный период скользящего среднего, так что естественное преобразование между каждой парой функторов может помочь нам сформировать буфер временных рядов для анализа.
Значение прогнозирования волатильности в торговле, возможно, не так критично, как определение типа позиции (длинная или короткая). Тем не менее, оно дает нам возможность изучить любые потенциальные варианты использования и улучшения других существующих стратегий сигналов входа или даже создания новых, использующих его идеи. Мы много раз использовали такой подход в предыдущих статьях. Мы постараемся объединить наши прогнозы волатильности, которые будут обрабатываться в экземпляре трейлинг-класса советника, со встроенным классом сигналов осциллятора Awesome. Читатели, как всегда, могут протестировать этот класс с другими сигналами или своими собственными стратегиями, чтобы выяснить, что им подходит лучше всего. В этой статье мы рассмотрим осциллятор Awesome.
Общие сведения
В прошлых статьях мы помимо прочего кратко рассмотрели ключевые понятия теории категорий: порядки как категории, функторы, морфизмы как функторы в особых ситуациях и, наконец, квадрат естественности, который доказывает существование естественных преобразований.
Понимание того, что подразумевается под "горизонтальной" композицией естественных преобразований в этой статье, имеет решающее значение, поскольку мы не просто имеем в виду схематическое представление естественных преобразований в двух измерениях. Рассмотрим схему ниже:
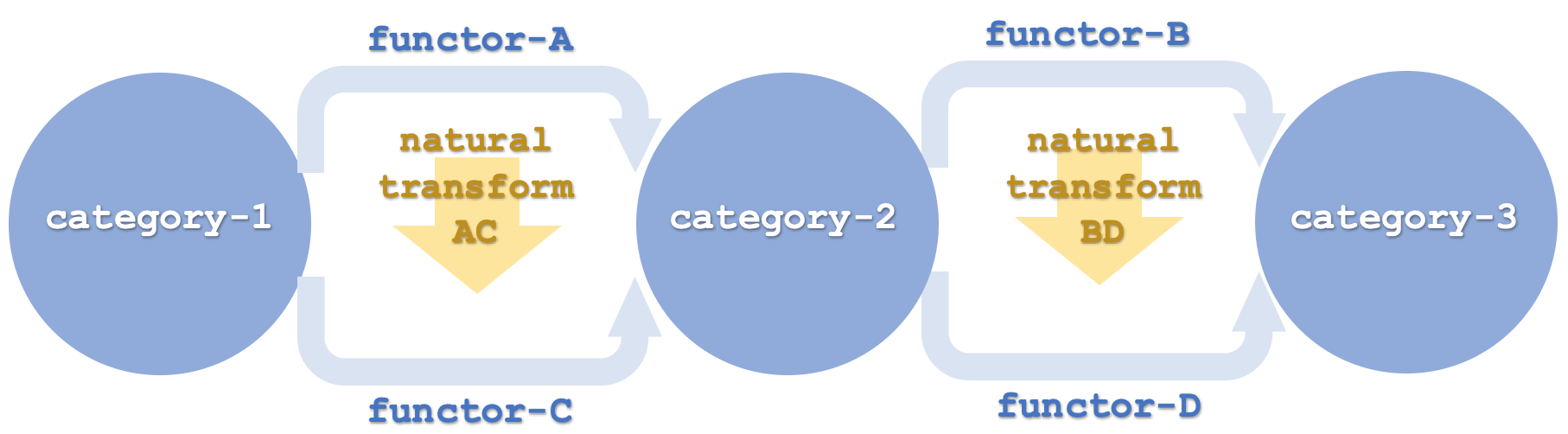
Горизонтальность здесь используется для обозначения функторов, расположенных в цепочке таким образом, что разные пары (или наборы) связаны с разными категориями доменов и кодоменов, как показано выше, где первые два функтора A и C связывают категорию-1 и категорию-2, а функторы B и D связывают категорию-2 и категорию-3. Это контрастирует с тем, что было в предыдущей статье, где все функторы связывали одну и ту же пару категорий. Даже если бы в последней статье две категории были нарисованы вертикально, что означает, что естественные преобразования проходили по горизонтали, это все равно было бы вертикальной композицией. Точно так же и здесь, даже если категории нарисованы в вертикальной последовательности, что означает, что естественные преобразования кажутся происходящими в "вертикальном" порядке, это все равно будет считаться горизонтальной композицией.
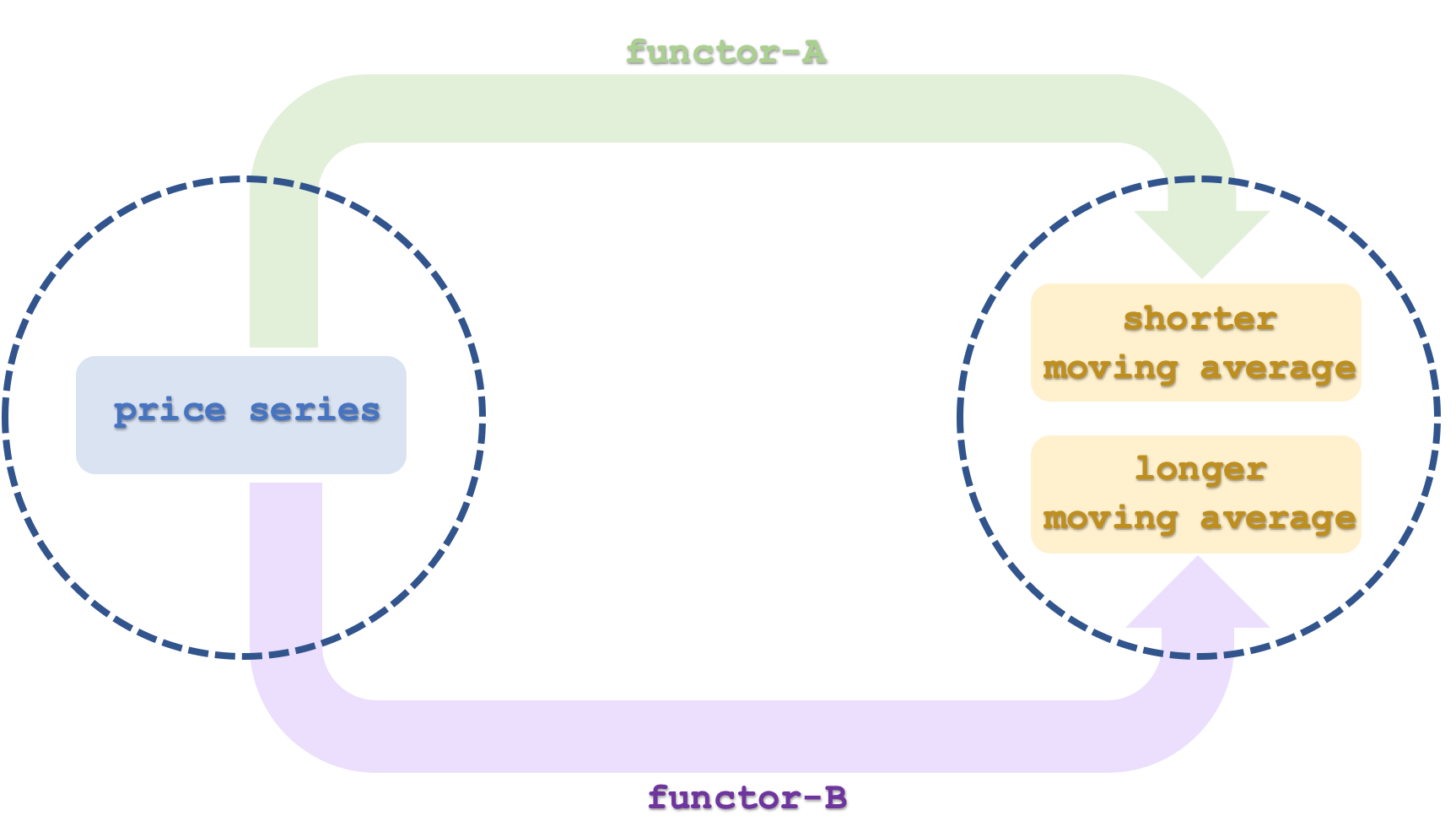
Итак, наши категории — это временной ряд цен, временной ряд скользящего среднего и временной ряд двойной экспоненциальной скользящей средней. Использование двойных экспоненциальных временных рядов может создать некоторую путаницу при сравнении этой категории с категорией ценовых временных рядов. Фактически 3-я категория представляет собой двойную экспоненциальную скользящую среднюю по категории-1. Если бы мы просто взяли функторы B и D как двойное экспоненциальное скользящее среднее для объектов категории 2, то результат был бы для нас не очень полезен. В конце концов, что такое DEMA скользящей средней? Таким образом, эти функторы, по-видимому, отображают категорию 1, исходный ценовой ряд. Структуру следует воспринимать как карту скользящего среднего из категории 2. Читатель может выполнить собственные тесты соответствующим образом, поскольку полный исходный код приложен в конце этой статьи, но важно помнить об этом различии.
Категории и функторы
Итак, наша первая категория, категория-1, имеет временной ряд цен. В одной из предыдущих статей мы уже рассматривали, как порядок может быть интерпретирован как категория. Наш временной ряд здесь очень похож на линейный порядок, как указано здесь. Объектами в этой категории будут значения цены и времени в каждом интервале, что означает, что каждый объект будет иметь как минимум два элемента - цену и значение даты и времени. Морфизмы для категории будут определяться временным интервалом ряда. Они просто связывают значения цен в порядке возрастания со временем. Инструментом, временной ряд которого мы рассмотрим в этой статье, будет EURUSD.
Скользящие средние цены будут нашей категорией-2. Как и первая категория, это временной ряд, который также можно рассматривать как линейный порядок и, следовательно, как категорию. В основном он будет включать два объекта, каждый из которых представляет собой временной ряд. Первый будет сопоставлен функтором A и будет представлять собой скользящее среднее ценового ряда в период, определенный функтором A. Эта модель по существу будет иметь два периода скользящего среднего, и тот, который будет использоваться функтором A, будет более коротким из двух. Второй функтор, обозначенный C, также будет отображать временной ряд цен в категорию-2 и будет иметь более длительный период скользящего среднего, чем функтор A. Каждый из наших объектов в категории 2 представляет собой временной ряд.
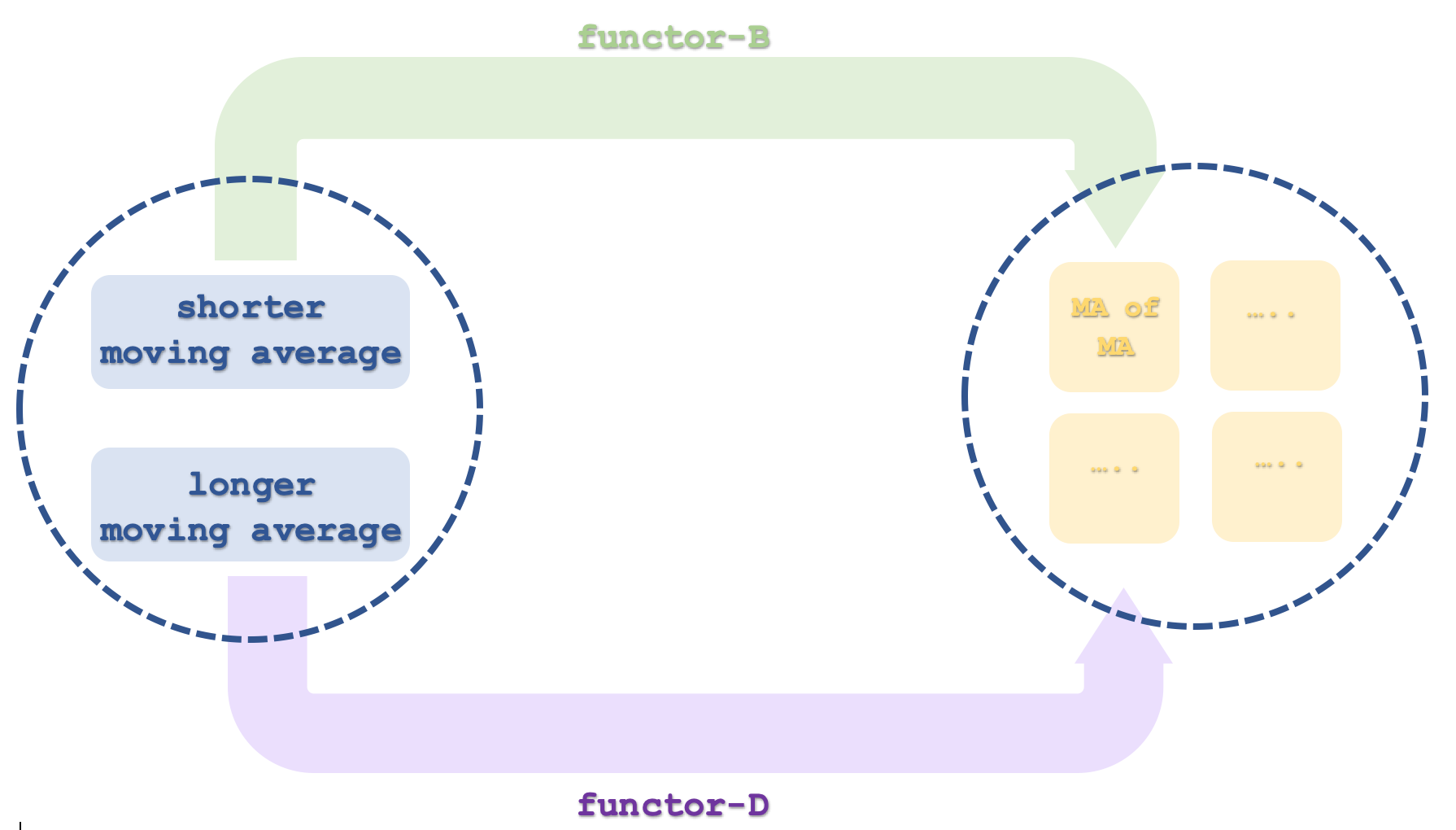
Третья и последняя категория, категория-3, будет включать четыре объекта, представляющие собой временные ряды, хотя мы будем рассматривать только 2. Каждой паре объектов (4 объекта — это 2 пары) будет сопоставлен один функтор, который вычисляет скользящее среднее скользящего среднего, чтобы получить двойное экспоненциальное скользящее среднее (DEMA). Как пояснялось выше, DEMA из кода отображает ценовой ряд категории-1, но это делается только для облегчения расчетов и не требует создания специального индикатора. Поскольку это скользящее среднее скользящего среднего, его можно рассматривать как отображение категории-2. Теперь категория-2 имеет два временных ряда скользящих средних, которые можно принять как быструю и медленную скользящую среднюю. Однако это означает, что наша категория-3 будет иметь 4 объекта, поскольку каждый из двух функторов из категории-2 сопоставляется с двумя объектами, таким образом связываясь с конкретным объектом или временным рядом.
Функторы и естественные преобразования
Всего естественных преобразований из этих двух пар функторов может быть 6, но поскольку мы собираемся использовать только 2 из 4 объектов категории-3, то это число будет 2. Напомним, что естественное преобразование — это разница между двумя объектами кодомена функторов. Мы легко следуем этому определению, вычитая два объекта скользящего среднего. Как мы делали в прошлой статье, каждое естественное преобразование будет фиксироваться в виде буфера временного ряда, и корреляция этих буферов поможет нам принимать решения по настройке трейлинг-стопа(ов) на открытых позициях. В прошлой статье эта корреляция между буферами естественного преобразования служила фильтром белого шума. В этой статье, поскольку нас интересует только настройка трейлинг-стопа, она снова будет служить фильтром, если по отношению к трендам скользящих средних следует применить корректировку стоп-лосса. Таким образом, отрицательный тренд с положительной корреляцией между этими буферами будет сигналом для понижения стоп-лосса на короткой позиции. Аналогичным образом, положительный тренд с достаточной корреляцией (наш порог выше нуля) будет указывать на перемещение стоп-лосса к длинным позициям, если они есть. Поэтому во многих случаях у нас не будет сигнала из-за отрицательных корреляций или из-за того, что тип открываемой позиции несовместим с генерируемым сигналом, поскольку наши решения о стоп-лоссе зависят от конкретной позиции. Как мы видели в последней статье, эту модель можно воссоздать как экземпляр класса сигналов советника и собрать в советнике с помощью Мастера, где его сигналы можно более тщательно протестировать для оценки производительности и результатов.
Прогнозирование волатильности
Таким образом, прогнозирование волатильности — это то, что делает наш экземпляр трейлинг-класса советника, как это было в нескольких статьях этой серии. Здесь мы добиваемся этого с помощью фильтра. Тренды скользящей средней должны быть подтверждены существенной корреляцией между естественными буферами трансформации. Другой подход к волатильности, который мы могли бы применить, заключается в том, чтобы иметь категорию-1 в виде ценовых диапазонов (максимумы минус минимумы). Тогда средние значения этой серии будут относиться к категории-2, а категория-3 будет ее DEMA, как мы поступаем с ценами закрытия в прилагаемом коде. Процесс во многом такой же, но этот подход может дать результаты, более адаптированные и чувствительные к волатильности.
Практическая реализация на MQL5
Настройка среды MQL5 для этой модели будет очень похожа на то, что мы рассматривали в этой серии. Как уже говорилось, экземпляр трейлинг-класса советника собирается как часть советника в Мастере MQL5. Для того, чтобы он работал или тестировался, нам необходимо сначала выбрать экземпляр класса сигнала советника в Мастере. В этой статье используется встроенный класс сигналов Awesome Oscillator. "Встроенный" здесь означает, что класс уже существует в библиотеке сигналов IDE.
Написание кода для функторов здесь не обязательно, поскольку мы можем использовать встроенные экземпляры классов скользящего среднего. Классы CiMA и CiDEMA могут легко удовлетворить потребности в скользящей средней и двойной экспоненциальной скользящей средней. Тем не менее, мы объявляем и используем экземпляры класса CObjects для обработки этих средних значений, и их объявление выглядит следующим образом:
... CObjects<double> m_o_average_a; CObjects<double> m_o_average_b; CObjects<double> m_o_average_c; CObjects<double> m_o_average_d; ...
Как и в предыдущей статье, нам потребуется инициализировать естественные буферы преобразования, поскольку возможность считывания сигналов важна с самого начала. Их размер, как и раньше, является входным параметром m_transformations, как это было в прошлой статье, поэтому этот важный шаг будет обрабатываться почти идентично тому, что мы реализовали в последней статье, с основным отличием в том, что у нас есть четыре экземпляра скользящей средней для использования в буферах. Обновление этих значений, которое также немного похоже на инициализацию, выполняется так:
//+------------------------------------------------------------------+ //| Refresh function from Natural Transformations. | //+------------------------------------------------------------------+ void CTrailingCT::Refresh(void) { if(!m_init) { Init(); } else { m_close.Refresh(-1); int _x=StartIndex(); for(int i=m_functor_ab+m_functor_ab-1;i>0;i--) { m_e_price.Let();m_e_price.Cardinality(1);m_o_prices.Get(i,m_e_price);m_o_prices.Set(i-1,m_e_price); } double _p=m_close.GetData(_x); m_e_price.Let();m_e_price.Cardinality(1);m_e_price.Set(0,_p);m_o_prices.Set(0,m_e_price); for(int i=0;i<m_transformations+1;i++) { double _a=0.0; for(int ii=i;ii<m_functor_ab+i;ii++) { _a+=m_close.GetData(_x+ii); } _a/=m_functor_ab; m_e_price.Let();m_e_price.Cardinality(1);m_e_price.Set(0,_a);m_o_average_a.Set(i,m_e_price); // double _b=0.0; for(int ii=i;ii<m_functor_cd+i;ii++) { m_e_price.Let();m_e_price.Cardinality(1);m_o_average_a.Get(i,m_e_price); double _b_i=0.0;m_e_price.Set(0,_b_i); _b+=_b_i; } _b/=m_functor_cd; m_e_price.Let();m_e_price.Cardinality(1);m_e_price.Set(0,_b);m_o_average_b.Set(i,m_e_price); // double _c=0.0; for(int ii=i;ii<m_functor_ab+i;ii++) { _c+=m_close.GetData(_x+ii); } _c/=m_functor_ab; m_e_price.Let();m_e_price.Cardinality(1);m_e_price.Set(0,_c);m_o_average_c.Set(i,m_e_price); // double _d=0.0; for(int ii=i;ii<m_functor_cd+i;ii++) { m_e_price.Let();m_e_price.Cardinality(1);m_o_average_c.Get(i,m_e_price); double _d_i=0.0;m_e_price.Set(0,_d_i); _d+=_d_i; } _d/=m_functor_cd; m_e_price.Let();m_e_price.Cardinality(1);m_e_price.Set(0,_d);m_o_average_d.Set(i,m_e_price); } for(int i=m_transformations-1;i>0;i--) { m_natural_transformations_ac[i]=m_natural_transformations_ac[i-1]; m_natural_transformations_bd[i]=m_natural_transformations_bd[i-1]; } // double _a=0.0; m_e_price.Let();m_e_price.Cardinality(1);m_o_average_a.Get(0,m_e_price);m_e_price.Get(0,_a); double _b=0.0; m_e_price.Let();m_e_price.Cardinality(1);m_o_average_b.Get(0,m_e_price);m_e_price.Get(0,_b); double _c=0.0; m_e_price.Let();m_e_price.Cardinality(1);m_o_average_c.Get(0,m_e_price);m_e_price.Get(0,_c); double _d=0.0; m_e_price.Let();m_e_price.Cardinality(1);m_o_average_d.Get(0,m_e_price);m_e_price.Get(0,_d); m_natural_transformations_ac[0]=_a-_c; m_natural_transformations_bd[0]=_b-_d; } }
Функция обновления может показаться немного сложной. Мы начинаем с обновления указателя цены закрытия, поскольку он является основой для категории-1. Прежде чем мы присвоим последнее значение единственному объекту этой категории, нам нужно сдвинуть все существующие элементы внутри этого объекта. Затем мы делаем почти то же самое с двумя объектами категории-2. Разница здесь в том, что нам нужно сначала вычислить скользящее среднее за каждый соответствующий период, и как только это будет сделано, мы присваиваем значения после сдвига значений в обоих объектах, как мы это делали в категории-1. После этого нам придется иметь дело с объектами категории-3. Их четыре, но, как уже упоминалось, для наших прогнозов мы используем только два из них. Значения этих объектов мы получим из двух объектов, которые мы только что заполнили, и, слегка изменив формулу DEMA, которая вычитает скользящее среднее скользящего среднего из двойного скользящего среднего, мы вычисляем необходимое значение - скользящую средняя скользящей средней.
Интеграция нашей модели с ежедневными ценовыми данными EURUSD для тестовых запусков выполняется после того, как наш экземпляр трейлинг-класса советника собран с помощью Мастера MQL5. Как обычно, на этот случай есть гайд. Как уже упоминалось, мы собираем этот советник с осциллятором Awesome в качестве экземпляра класса сигналов советника.
Тестирование на истории и анализ исторических данных EURUSD проводятся с 01.01.2020 по 01.01.2023. Наш отчет о тестировании с лучшими результатами оптимизации представлен ниже:

Важнейшими аспектами отчета, заслуживающими внимания, обычно являются корреляция прибыли MAE, а также период владения и корреляция прибыли. Эти два показателя обычно представлены в виде графиков в самом низу полного отчета. Выше приведено краткое изложение общих показателей, на которые следует обращать внимание.
Форвард-тестирование
Если мы выполним форвард-тестирование с 2023.01.01 по 2023.08.01 с лучшими настройками из нашего бэк-теста, то получим следующие результаты:

Мы не получили желаемых результатов, что обычно означает одно из двух. Тезис нашей модели (использование трейлинг-класс) является случайным и на него нельзя положиться в торговых системах, либо мы реализовали идею с ошибками, затрагивающими порядок управления в коде нашего завершающего класса. Однакодаже если бы мы получили положительный результат, нам все равно нужно было бы провести более комплексное тестирование в течение гораздо более длительного периода. Для Форекса это может означать до двух десятилетий, и эти тесты должны включать проходы на реальных тиках. Уникальные "сигналы" корректировки трейлинг-стопа, генерируемые нашим советником, случаются нечасто, поскольку тренд скользящего среднего должен быть в направлении открытой позиции. Из-за этого эффективность трейлинг-класса недостаточно проверена на коротких тестовых окнах, одним из которых является период в три года. Кроме того, эти результаты основаны на сочетании нашего трейлинг-класса с осциллятором Awesome, но какова будет производительность в сочетании с другими сигналами на вход? Все эти и другие проблемы необходимо принимать во внимание при проведении оценки.
Тестирование на реальных данных — еще один необходимый шаг, который следует предпринять, прежде чем можно будет развернуть этот советник или его вариант, включающий в себя то, что мы здесь рассмотрели. Первым шагом в этом процессе является настройка демо-счета у вашего потенциального брокера, в идеале с тем же типом учетной записи, который вы будете использовать в реальном времени. Затем прикрепите советника к графику торгуемого символа(ов). Также неплохо было бы использовать услугу MetaQuote VPS, поскольку она требует меньше головной боли при настройке и имеет конкурентоспособную цену, но каким бы ни был выбор, необходимость мониторинга журнала советника сохраняется, так как это позволяет добиться ожидаемой производительности и необходимых торговых результатов. И MetaQuote VPS, и обычный VPS-сервер легко позволяют это сделать. Кроме того, тестовый счет в режиме реального времени должен начинаться с суммы капитала, предназначенной для использования, если тестирование окажется положительным. Наконец, еще одна хорошая идея - личный торговый журнал, особенно если представленные здесь идеи станут частью другой торговой системы, которая в той или иной форме зависит от новостей. Помните, что тестер стратегий MQL5 пока не позволяет проводить тестирование при чтении событий экономического календаря, поэтому может быть полезно регистрировать их самостоятельно, чтобы при просмотре вы могли легко оценить относительную важность каждой новости в долгосрочной перспективе.
Интерпретация результатов и принятие решения о том, что делать дальше, очень субъективны, но в качестве ориентира можно утверждать, что в системе, которая достаточно прибыльна для удовлетворения целевых требований, корреляция прибыли и MAE должна быть положительной, а период владения, а также прибыль от каждой сделки должны иметь положительную корреляцию. Последнюю метрику часто называют ожиданием, но, к сожалению, в отчетах тестера стратегий это значение не вычисляется.
Заключение
Мы увидели, как горизонтальная композиция естественных преобразований может быть полезна при прогнозировании. Прогнозы, которые мы рассматривали в этой статье, касались диапазонов ценовых баров, которые можно рассматривать как меру волатильности. Эти прогнозы были использованы, как уже несколько раз в этой серии статей, путем корректировки трейлинг-стопа открытых позиций. В то время как результаты обучения в выборке были положительными, результаты вне выборки оказались хуже. Однако эта неудача не отменяет необходимости более комплексного тестирования в течение более длительного периода времени, прежде чем можно будет вынести вердикт об эффективности системы.
Последствия этих результатов для развития торговой системы заключаются в том, что их можно сочетать с различными классами сигналов входа для получения улучшенных результатов или даже можно внести изменения в наши входные наборы данных для представления различных тестовых сценариев.
Как всегда, я приглашаю читателя изучить эти и любые другие способы внесения изменений и тестирования приложенного кода.
Ссылки
Ссылки, как всегда, в основном на статьи из Википедии. Но на этот раз есть и из Инвестопедии.
Дополнительные сведения по сборке и использованию прилагаемого кода в советнике можно найти здесь и здесь.
Перевод с английского произведен MetaQuotes Ltd.
Оригинальная статья: https://www.mql5.com/en/articles/13456
- Бесплатные приложения для трейдинга
- 8 000+ сигналов для копирования
- Экономические новости для анализа финансовых рынков
Вы принимаете политику сайта и условия использования