
データサイエンスと機械学習(第14回):コホネンマップを使って市場で自分の道を見つける

はじめに
コホネンマップ、自己組織化マップ(SOM)、自己組織化フィーチャーマップ(SOFM)は、教師なし機械学習技法で、データの位相構造を保持したまま、高次元データセットの低次元(通常は2次元)表現を作成するために使用されます。例えば n個のオブザベーションで測定された p変数を持つデータ集合は,変数の値が似ているオブザベーションのクラスタとして表現できます。そして、これらのクラスタは、近接クラスタでのオブザベーションが遠位クラスタでのオブザベーションよりも類似した値を持つような2次元マップとして可視化できます。
コホネンマップは1980年代にフィンランドの数学者テウヴォ・コホネンによって開発されました。
概要
コホネンマップは、隣接するニューロンに接続された格子状のニューロンから構成されます。学習中、入力データがネットワークに提示され、各ニューロンは入力データとの類似度を計算します。類似度が最も高いニューロンは勝者と呼ばれ、その重みは入力データによりよく一致するように調整されます。

時間が経つにつれて、隣接するニューロンも勝者ニューロンにより近くなるように重みを調整し、その結果、マップ内のニューロンが位相幾何学的に順序付けされます。この自己組織化のプロセスにより、コホネンマップは入力データ間の複雑な関係を低次元空間で表現することができるので、データの可視化やクラスタリングに役立ちます。
学習アルゴリズム
自己組織化マップにおけるこのアルゴリズムの目的は、特定の入力パターンに対してネットワークの異なる部分が同様の反応をするようにすることです。これは、視覚、聴覚、その他の情報が人間の脳の一部でどのように扱われているかに起因しています。
このアルゴリズムが数学用語とMQL5コードに関してどのように機能するか見てみましょう。
アルゴリズムの手順
このアルゴリズムをコーディングしようとする場合、考慮すべき4つの主要な手順があります。
手順01:重み![]() を初期化します。ランダムな値が想定される場合もあります。学習率やクラスタ数などの他のパラメータもこの段階で初期化されます。
を初期化します。ランダムな値が想定される場合もあります。学習率やクラスタ数などの他のパラメータもこの段階で初期化されます。
CKohonenMaps::CKohonenMaps(matrix &matrix_, bool save_clusters=true, uint clusters=2, double alpha=0.01, uint epochs=100) { Matrix = matrix_; n = (uint)matrix_.Cols(); rows = matrix_.Rows(); m = clusters; cluster_tensor = new CTensors(m); w_matrix =matrix_utils.Random(0.0, 1.0, n, m, RANDOM_STATE); }
通常通り、パラメータはコホネンマップクラスのコンストラクタで初期化されます。
コホネンマップはデータマイニングの手法の1つです。これが、save_clusters=true というブーリアン引数で、Kohonenマップが取得したクラスタを得ることができる理由です。
手順02:各入力とそれぞれの重みとの間のユークリッド距離を計算します。
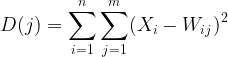
ここで
![]() = 入力ベクトル
= 入力ベクトル
![]() = 重みベクトル
= 重みベクトル
double CKohonenMaps:: Euclidean_distance(const vector &v1, const vector &v2) { double dist = 0; if(v1.Size() != v2.Size()) Print(__FUNCTION__, " v1 and v2 not matching in size"); else { double c = 0; for(ulong i=0; i<v1.Size(); i++) c += MathPow(v1[i] - v2[i], 2); dist = MathSqrt(c); } return(dist); }
この公式を適用し、すべてを明らかにするためには、コーディングやテストに役立つ簡単なデータセットが必要です。
matrix Matrix = { {1.2, 2.3}, {0.7, 1.8}, {3.6, 4.8}, {2.8, 3.9}, {5.2, 6.7}, {4.8, 5.6} }; maps = new CKohonenMaps(Matrix); //Giving our kohonen maps class data
コンストラクタが呼ばれ、重みが生成されると、以下のような出力が得られます。
CS 0 15:52:27.572 Self Organizing map (EURUSD,H1) w Matrix CS 0 15:52:27.572 Self Organizing map (EURUSD,H1) [[0.005340739158299509,0.01220740379039888] CS 0 15:52:27.572 Self Organizing map (EURUSD,H1) [0.5453352458265939,0.9172643208105716]] CS 0 15:52:27.572 Self Organizing map (EURUSD,H1) Matrix CS 0 15:52:27.572 Self Organizing map (EURUSD,H1) [[1.2,2.3] CS 0 15:52:27.572 Self Organizing map (EURUSD,H1) [0.7,1.8] CS 0 15:52:27.572 Self Organizing map (EURUSD,H1) [3.6,4.8] CS 0 15:52:27.572 Self Organizing map (EURUSD,H1) [2.8,3.9] CS 0 15:52:27.572 Self Organizing map (EURUSD,H1) [5.2,6.7] CS 0 15:52:27.572 Self Organizing map (EURUSD,H1) [4.8,5.6]]
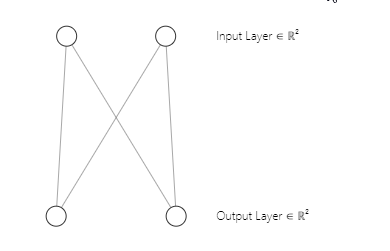
私たちのニューラルネットワークアーキテクチャが [2入力2出力] であることに気づいたかもしれません。そのため、の2x2重み行列が存在します。この行列は、最初の部分で見た以下のコード行から[nとマークされた2つの入力行列列とmとマークされた2つのクラスタ選択]を考慮して生成されました。
w_matrix =matrix_utils.Random(0.0, 1.0, n, m, RANDOM_STATE);明確にするために、以下にここでのコホネンマップニューラルネットワークのアーキテクチャを示します。
手順03:D(j)が最小になるように、勝者ユニットインデックスiを見つけます。簡単に言えば、単位クラスタを見つけることで、コホネンマップの競争学習における重要なテーマにたどり着きます。
競争的な学習
自己組織化マップは人工ニューラルネットワークの一種であり、バックプロパゲーションや勾配降下などのエラー訂正学習を用いて学習される他の人工ニューラルネットワークとは異なり、コホネンマップは競合学習を用いて学習されます。
競合学習では、コホネンマップのニューロンは、入力データに最も類似したニューロンとなって「勝者」になろうと互いに競争します。
学習段階では、各入力データがコホネンマップに提示され、入力データと各ニューロンの重みベクトルの類似度が計算されます。重みベクトルが入力データに最も似ているニューロンは、勝者または「ベストマッチングユニット」(BMU)と呼ばれます。
BMUは、入力データとニューロンの重みベクトル間の最小ユークリッド距離に基づいて選択されます。勝者ニューロンは、入力データにより近くなるように重みベクトルを更新します。使用される重み更新式はコホネン学習則として知られ、勝者ニューロンとその近傍ニューロンの重みベクトルを入力データに近づけます。
この手順03をコード化するには数行のコードで済みます。
vector D(m); //Euclidean distance btn clusters | Remember m is the number of clusters selected for (ulong i=0; i<rows; i++) { for (ulong j=0; j<m; j++) { D[j] = Euclidean_distance(Matrix.Row(i),w_matrix.Col(j)); } #ifdef DEBUG_MODE Print("Euc distance ",D," Winning cluster ",D.ArgMin()); #endif
常に覚えておいてほしいのは、ユークリッド距離がより小さいクラスを生成したニューロンは勝者クラスタであるということです。
競合学習により、コホネンマップは入力データ間の関係を保持しながら、入力データを低次元空間にトポロジカルに表現することを学習します。
手順04:重みを更新します。
重みは以下の式で更新することができます。
![]()
ここで
![]() = 新しい重みベクトル
= 新しい重みベクトル
![]() = 古い重みベクトル
= 古い重みベクトル
![]() = 学習率
= 学習率
![]() = 入力ベクトル
= 入力ベクトル
以下はこの式のコードです。
//--- weights update ulong min = D.ArgMin(); //winning cluster vector w_new = w_matrix.Col(min) + (alpha * (Matrix.Row(i) - w_matrix.Col(min))); w_matrix.Col(w_new, min);
特定の層のすべての重みが関与する他のタイプの人工ニューラルネットワークとは異なり、コホネンマップは特定のクラスタの重みを意識し、そのクラスタを見つけることだけに使用します。
手順を終えてアルゴリズムは完成しました。
以下は、ここまでのアルゴリズムのコード全体です。
CKohonenMaps::CKohonenMaps(matrix &matrix_, bool save_clusters=true, uint clusters=2, double alpha=0.01, uint epochs=100) { Matrix = matrix_; n = (uint)matrix_.Cols(); rows = matrix_.Rows(); m = clusters; cluster_tensor = new CTensors(m); w_matrix =matrix_utils.Random(0.0, 1.0, n, m, RANDOM_STATE); vector D(m); //Euclidean distance btn clusters for (uint epoch=0; epoch<epochs; epoch++) { double epoch_start = GetMicrosecondCount()/(double)1e6, epoch_stop=0; for (ulong i=0; i<rows; i++) { for (ulong j=0; j<m; j++) { D[j] = Euclidean_distance(Matrix.Row(i),w_matrix.Col(j)); } #ifdef DEBUG_MODE Print("Euc distance ",D," Winning cluster ",D.ArgMin()); #endif //--- weights update ulong min = D.ArgMin(); vector w_new = w_matrix.Col(min) + (alpha * (Matrix.Row(i) - w_matrix.Col(min))); w_matrix.Col(w_new, min); } epoch_stop =GetMicrosecondCount()/(double)1e6; printf("Epoch [%d/%d] | %sElapsed ",epoch+1,epochs, CalcTimeElapsed(epoch_stop-epoch_start)); } //end of training //--- #ifdef DEBUG_MODE Print("\nNew weights\n",w_matrix); #endif }
出力:
CS 0 04:13:26.617 Self Organizing map (EURUSD,H1) Euc distance [2.122748018266242,1.822857430002081] Winning cluster 1 CS 0 04:13:26.617 Self Organizing map (EURUSD,H1) Euc distance [1.434132188481296,1.100846180984197] Winning cluster 1 CS 0 04:13:26.617 Self Organizing map (EURUSD,H1) Euc distance [5.569896531530945,5.257391342266398] Winning cluster 1 CS 0 04:13:26.617 Self Organizing map (EURUSD,H1) Euc distance [4.36622216533946,4.000958814345993] Winning cluster 1 CS 0 04:13:26.617 Self Organizing map (EURUSD,H1) Euc distance [8.053842751911217,7.646959164093921] Winning cluster 1 CS 0 04:13:26.617 Self Organizing map (EURUSD,H1) Euc distance [6.966950064745546,6.499246789416081] Winning cluster 1 CS 0 04:13:26.617 Self Organizing map (EURUSD,H1) Epoch [1/100] | 0.000 Seconds Elapsed .... .... .... CS 0 04:13:26.622 Self Organizing map (EURUSD,H1) Euc distance [0.7271897806071723,4.027137175049654] Winning cluster 0 CS 0 04:13:26.622 Self Organizing map (EURUSD,H1) Euc distance [0.08133608432880858,4.734224801594559] Winning cluster 0 CS 0 04:13:26.622 Self Organizing map (EURUSD,H1) Euc distance [4.18281664576938,0.5635073709012016] Winning cluster 1 CS 0 04:13:26.622 Self Organizing map (EURUSD,H1) Euc distance [2.979092473547668,1.758946102746018] Winning cluster 1 CS 0 04:13:26.622 Self Organizing map (EURUSD,H1) Euc distance [6.664860479474853,1.952054507391296] Winning cluster 1 CS 0 04:13:26.622 Self Organizing map (EURUSD,H1) Euc distance [5.595867985957728,0.8907607121421737] Winning cluster 1 CS 0 04:13:26.622 Self Organizing map (EURUSD,H1) Epoch [100/100] | 0.000 Seconds Elapsed CS 0 04:13:26.622 Self Organizing map (EURUSD,H1) CS 0 04:13:26.622 Self Organizing map (EURUSD,H1) New weights CS 0 04:13:26.622 Self Organizing map (EURUSD,H1) [[0.75086979456201,4.028060179594681] CS 0 04:13:26.622 Self Organizing map (EURUSD,H1) [1.737580668068743,5.173650598091957]]
私たちのコホネンマップは、主行列をクラスタ化することができました。
matrix Matrix = { {1.2, 2.3}, //Into cluster 0 {0.7, 1.8}, //Into cluster 0 {3.6, 4.8}, //Into cluster 1 {2.8, 3.9}, //Into cluster 1 {5.2, 6.7}, //Into cluster 1 {4.8, 5.6} //Into cluster 1 };
しかし、この出力を提示し、プロット上で視覚化することは、見かけによらず単純な作業ではありません。2つのクラスタがあり、1つは2x2の行列、もう1つは4x2の行列です。一方は4値、もう一方は8値です。K-Meansクラスタリングの記事で、このクラスタの大きさの違いのためにクラスタを提示するのに苦労したのを覚えていらっしゃるでしょうか。
機械学習におけるテンソル
テンソルは、多次元配列内のベクトルや行列を一般化したものです。簡単に言えば、テンソルは行列とベクトルを内部に含む配列です。
# create tensor from numpy import array T = array([ [[1,2,3], [4,5,6], [7,8,9]], [[11,12,13], [14,15,16], [17,18,19]], [[21,22,23], [24,25,26], [27,28,29]], ])
テンソルは、TensorFlow、PyTorch、Kerasなどの機械学習フレームワークで使用される基本的なデータ構造です。
テンソルは、機械学習アルゴリズムにおいて、行列の乗算、畳み込み、プーリングなどの演算に使用されます。テンソルはまた、学習や推論中にニューラルネットワークの重みとバイアスを保存し、操作するためにも使用されます。全体として、テンソルは、複雑なデータの効率的な計算と表現を可能にする、機械学習における重要なデータ構造です。
Tensors.mqhライブラリをインポートしなければなりませんでした。それについては、私のGitHubウィキをお読みください。
それぞれのテンソルにクラスタを集めるのに役立つようにテンソルを加えました。
CKohonenMaps::CKohonenMaps(matrix &matrix_, bool save_clusters=true, uint clusters=2, double alpha=0.01, uint epochs=100) { Matrix = matrix_; n = (uint)matrix_.Cols(); rows = matrix_.Rows(); m = clusters; cluster_tensor = new CTensors(m); w_matrix =matrix_utils.Random(0.0, 1.0, n, m, RANDOM_STATE); Print("w Matrix\n",w_matrix,"\nMatrix\n",Matrix); vector D(m); //Euclidean distance btn clusters for (uint epoch=0; epoch<epochs; epoch++) { double epoch_start = GetMicrosecondCount()/(double)1e6, epoch_stop=0; for (ulong i=0; i<rows; i++) { for (ulong j=0; j<m; j++) { D[j] = Euclidean_distance(Matrix.Row(i),w_matrix.Col(j)); } #ifdef DEBUG_MODE Print("Euc distance ",D," Winning cluster ",D.ArgMin()); #endif //--- weights update ulong min = D.ArgMin(); if (epoch == epochs-1) //last iteration cluster_tensor.TensorAppend(Matrix.Row(i), min); vector w_new = w_matrix.Col(min) + (alpha * (Matrix.Row(i) - w_matrix.Col(min))); w_matrix.Col(w_new, min); //Print("New w_Matrix\n ",w_matrix); } epoch_stop =GetMicrosecondCount()/(double)1e6; printf("Epoch [%d/%d] | %sElapsed ",epoch+1,epochs, CalcTimeElapsed(epoch_stop-epoch_start)); } //end of the training //--- #ifdef DEBUG_MODE Print("\nNew weights\n",w_matrix); #endif //--- Print("\nclusters"); cluster_tensor.TensorPrint(); }
出力:
CS 0 04:13:26.624 Self Organizing map (EURUSD,H1) clusters CS 0 04:13:26.624 Self Organizing map (EURUSD,H1) TENSOR INDEX <<0>> CS 0 04:13:26.624 Self Organizing map (EURUSD,H1) [[1.2,2.3] CS 0 04:13:26.624 Self Organizing map (EURUSD,H1) [0.7,1.8]] CS 0 04:13:26.624 Self Organizing map (EURUSD,H1) TENSOR INDEX <<1>> CS 0 04:13:26.624 Self Organizing map (EURUSD,H1) [[3.6,4.8] CS 0 04:13:26.624 Self Organizing map (EURUSD,H1) [2.8,3.9] CS 0 04:13:26.624 Self Organizing map (EURUSD,H1) [5.2,6.7] CS 0 04:13:26.624 Self Organizing map (EURUSD,H1) [4.8,5.6]]
さて、クラスタはそれぞれのテンソルに格納されています。
クラスタの抽出
クラスタをCSVファイルに保存して抽出しましょう。
matrix mat= {}; if (save_clusters) for (uint i=0; i<this.cluster_tensor.TENSOR_DIMENSION; i++) { mat = this.cluster_tensor.Tensor(i); //Obtain a matrix located at I index in a cluster tensor string header[]; ArrayResize(header, (int)mat.Cols()); for (int k=0; k<ArraySize(header); k++) header[k] = "col"+string(k); if (this.matrix_utils.WriteCsv("SOM\\Cluster"+string(i+1)+".csv",mat,header)) Print("Clusters CSV files saved under the directory Files\\SOM"); }
ファイルはFiles親ディレクトリ内のSOMディレクトリに保存されます。
データの抽出は終わりましたが、コホネンマップの本質的な部分は、クラスタを視覚化し、アルゴリズムが用意してくれたマップをプロットすることです。Pythonのライブラリや他のフレームワークでは、通常Hitマップを使いますが、このライブラリではCurve plotを使います。
vector v; matrix plotmatrix(rows, m); for (uint i=0; i<this.cluster_tensor.TENSOR_DIMENSION; i++) { mat = this.cluster_tensor.Tensor(i); v = this.matrix_utils.MatrixToVector(mat); plotmatrix.Col(v, i); } this.plt.ScatterCurvePlotsMatrix("kom",plotmatrix,"Map","clusters","clusters");
出力:
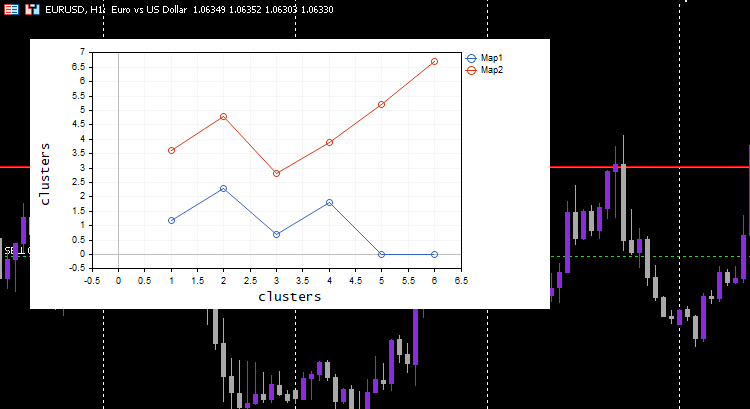
すべてがうまくいき、プロットは意図したとおりにデータをうまく視覚化できました。役立つものでアルゴリズムを試してみましょう。
クラスタリング指標値
異なる5つの移動平均指標について100本のバーを収集し、コホネンマップを使ってクラスタリングしてみましょう。これらの指標は、各指標で異なる期間を除き、同じチャート、期間、適用価格からなります。
#include <MALE5\Neural Networks\kohonen maps.mqh> #include <MALE5\matrix_utils.mqh> CMatrixutils matrix_utils; CKohonenMaps *maps; input int bars = 100; int handles[5]; int period[5] = {10,20,30,50,100}; matrix Matrix(bars,5); //+------------------------------------------------------------------+ //| Expert initialization function | //+------------------------------------------------------------------+ int OnInit() { //--- vector v; for (int i=0; i<5; i++) { handles[i] = iMA(Symbol(),PERIOD_CURRENT,period[i],0,MODE_LWMA,PRICE_CLOSE); matrix_utils.CopyBufferVector(handles[i],0,0,bars, v); Matrix.Col(v, i); //store indicators into a matrix } maps = new CKohonenMaps(Matrix,true,2,0.01,1000); //--- return(INIT_SUCCEEDED); }
学習率/アルファ = 0.01とepochs = 1000を選択しました。以下はコホーネン マップです。
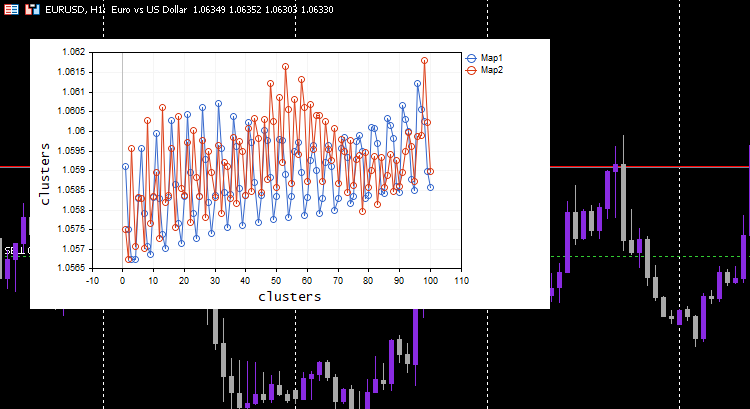
この奇妙な行動についてログを調べてみました。
CS 0 06:19:59.911 Self Organizing map (EURUSD,H1) clusters CS 0 06:19:59.911 Self Organizing map (EURUSD,H1) TENSOR INDEX <<0>> CS 0 06:19:59.911 Self Organizing map (EURUSD,H1) [[1.059108363197969,1.057514381244092,1.056754472954214,1.056739184229631,1.058300613902105] CS 0 06:19:59.911 Self Organizing map (EURUSD,H1) [1.059578181379783,1.057915286006,1.057066064352063,1.056875795994335,1.05831249905062] .... .... CS 0 06:19:59.912 Self Organizing map (EURUSD,H1) [1.063954363197777,1.061619428863266,1.061092386932678,1.060653270504107,1.059293304991227] CS 0 06:19:59.912 Self Organizing map (EURUSD,H1) [1.065106545015954,1.062409714577555,1.061610946072463,1.06098919991587,1.059488318852614…] CS 0 06:19:59.912 Self Organizing map (EURUSD,H1) TENSOR INDEX <<1>> CS 0 06:19:59.912 Self Organizing map (EURUSD,H1) [] CS 0 06:19:59.912 Self Organizing map (EURUSD,H1) CMatrixutils::MatrixToVector Failed to turn the matrix to a vector rows 0 cols 0
2番目のクラスタのテンソルは空で、アルゴリズムがそれを予測しなかったことを意味し、すべてのデータはクラスタ0に属すると予測されました。
常に変数を正規化する
これまで何度か言いましたし、これからも言い続けます。入力データの正規化は、遭遇するすべての機械学習モデルにとって不可欠です。繰り返しになりますが、正規化の重要性が重要であることがわかります。データを正規化した後の結果を見てみましょう。
Min-Max scaler正規化手法を選びました。
#include <MALE5\Neural Networks\kohonen maps.mqh> #include <MALE5\preprocessing.mqh> #include <MALE5\matrix_utils.mqh> CPreprocessing *pre_processing; CMatrixutils matrix_utils; CKohonenMaps *maps; input int bars = 100; int handles[5]; int period[5] = {10,20,30,50,100}; matrix Matrix(bars,5); //+------------------------------------------------------------------+ //| Expert initialization function | //+------------------------------------------------------------------+ int OnInit() { //--- vector v; for (int i=0; i<5; i++) { handles[i] = iMA(Symbol(),PERIOD_CURRENT,period[i],0,MODE_LWMA,PRICE_CLOSE); matrix_utils.CopyBufferVector(handles[i],0,0,bars, v); Matrix.Col(v, i); } pre_processing = new CPreprocessing(Matrix, NORM_MIN_MAX_SCALER); maps = new CKohonenMaps(Matrix,true,2,0.01,1000); //--- return(INIT_SUCCEEDED); }
今回は美しいコホネンマップがチャートに表示されました。
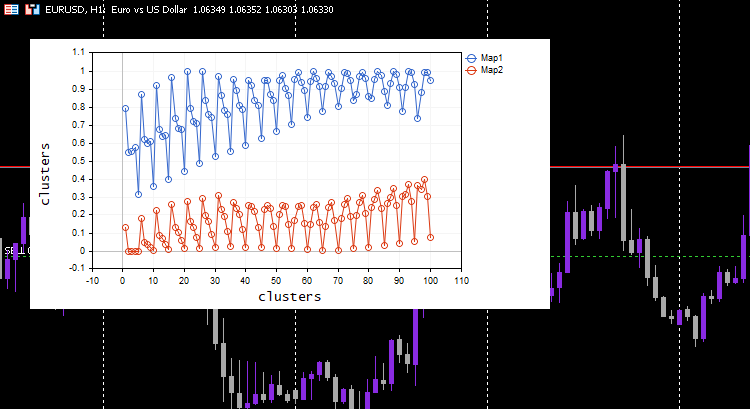
素晴らしいことですが、データを正規化するとデータはより小さな値に変換されますが、パターンを理解するためにデータをクラスター化し、抽出されたデータを他のプログラムで使用したいだけの人としては、この正規化プロセスをコアに統合する必要があります。 アルゴリズムでは、取得したクラスターが元の値になるように、データを正規化および逆正規化する必要があります。クラスタリング技術はデータを変更しないため、単にグループ化するだけです。 正規化と逆正規化のプロセスは、この前処理クラスを使用しておこなうことができます。
CKohonenMaps::CKohonenMaps(matrix &matrix_, bool save_clusters=true, uint clusters=2, double alpha=0.01, uint epochs=100, norm_technique NORM_TECHNIQUE=NORM_MIN_MAX_SCALER) { Matrix = matrix_; n = (uint)matrix_.Cols(); rows = matrix_.Rows(); m = clusters; pre_processing = new CPreprocessing(Matrix, NORM_TECHNIQUE); cluster_tensor = new CTensors(m); w_matrix =matrix_utils.Random(0.0, 1.0, n, m, RANDOM_STATE); #ifdef DEBUG_MODE Print("w Matrix\n",w_matrix,"\nMatrix\n",Matrix); #endif vector D(m); //Euclidean distance btn clusters for (uint epoch=0; epoch<epochs; epoch++) { double epoch_start = GetMicrosecondCount()/(double)1e6, epoch_stop=0; for (ulong i=0; i<rows; i++) { for (ulong j=0; j<m; j++) { D[j] = Euclidean_distance(Matrix.Row(i),w_matrix.Col(j)); } #ifdef DEBUG_MODE Print("Euc distance ",D," Winning cluster ",D.ArgMin()); #endif //--- weights update ulong min = D.ArgMin(); if (epoch == epochs-1) //last iteration cluster_tensor.TensorAppend(Matrix.Row(i), min); vector w_new = w_matrix.Col(min) + (alpha * (Matrix.Row(i) - w_matrix.Col(min))); w_matrix.Col(w_new, min); } epoch_stop =GetMicrosecondCount()/(double)1e6; printf("Epoch [%d/%d] | %sElapsed ",epoch+1,epochs, CalcTimeElapsed(epoch_stop-epoch_start)); } //end of the training //--- #ifdef DEBUG_MODE Print("\nNew weights\n",w_matrix); #endif //--- matrix mat= {}; vector v; matrix plotmatrix(rows, m); for (uint i=0; i<this.cluster_tensor.TENSOR_DIMENSION; i++) { mat = this.cluster_tensor.Tensor(i); v = this.matrix_utils.MatrixToVector(mat); plotmatrix.Col(v, i); } this.plt.ScatterCurvePlotsMatrix("kom",plotmatrix,"Map","clusters","clusters"); //--- if (save_clusters) for (uint i=0; i<this.cluster_tensor.TENSOR_DIMENSION; i++) { mat = this.cluster_tensor.Tensor(i); pre_processing.ReverseNormalization(mat); cluster_tensor.TensorAdd(mat, i); string header[]; ArrayResize(header, (int)mat.Cols()); for (int k=0; k<ArraySize(header); k++) header[k] = "col"+string(k); if (this.matrix_utils.WriteCsv("SOM\\Cluster"+string(i+1)+".csv",mat,header)) Print("Clusters CSV files saved under the directory Files\\SOM"); } //--- Print("\nclusters"); cluster_tensor.TensorPrint(); }
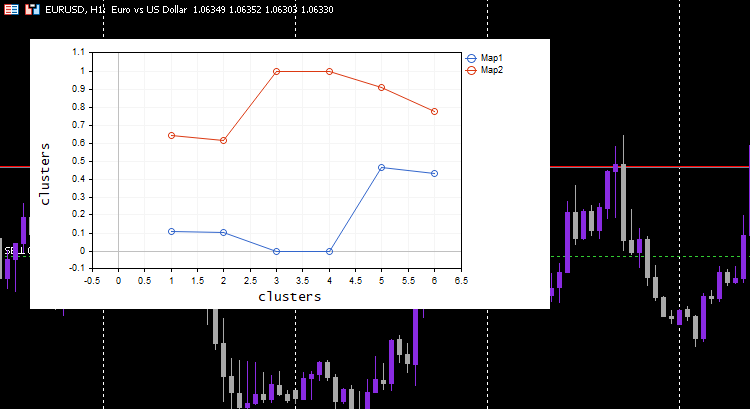
この仕組みをお見せするために、冒頭のシンプルなデータセットに戻る必要がありました。
matrix Matrix = { {1.2, 2.3}, {0.7, 1.8}, {3.6, 4.8}, {2.8, 3.9}, {5.2, 6.7}, {4.8, 5.6} }; maps = new CKohonenMaps(Matrix,true,2,0.01,1000);
出力:
CS 0 07:14:44.660 Self Organizing map (EURUSD,H1) w Matrix CS 0 07:14:44.660 Self Organizing map (EURUSD,H1) [[0.005340739158299509,0.01220740379039888] CS 0 07:14:44.660 Self Organizing map (EURUSD,H1) [0.5453352458265939,0.9172643208105716]] CS 0 07:14:44.660 Self Organizing map (EURUSD,H1) Matrix CS 0 07:14:44.660 Self Organizing map (EURUSD,H1) [[0.1111111111111111,0.1020408163265306] CS 0 07:14:44.660 Self Organizing map (EURUSD,H1) [0,0] CS 0 07:14:44.660 Self Organizing map (EURUSD,H1) [0.6444444444444445,0.6122448979591836] CS 0 07:14:44.660 Self Organizing map (EURUSD,H1) [0.4666666666666666,0.4285714285714285] CS 0 07:14:44.660 Self Organizing map (EURUSD,H1) [1,1] CS 0 07:14:44.660 Self Organizing map (EURUSD,H1) [0.911111111111111,0.7755102040816325]] CS 0 07:14:44.660 Self Organizing map (EURUSD,H1) Epoch [1/1000] | 0.000 Seconds Elapsed CS 0 07:14:44.660 Self Organizing map (EURUSD,H1) Epoch [2/1000] | 0.000 Seconds Elapsed CS 0 07:14:44.660 Self Organizing map (EURUSD,H1) Epoch [3/1000] | 0.000 Seconds Elapsed ... ... ... CS 0 07:14:44.674 Self Organizing map (EURUSD,H1) Epoch [999/1000] | 0.000 Seconds Elapsed CS 0 07:14:44.674 Self Organizing map (EURUSD,H1) Epoch [1000/1000] | 0.000 Seconds Elapsed CS 0 07:14:44.674 Self Organizing map (EURUSD,H1) CS 0 07:14:44.674 Self Organizing map (EURUSD,H1) New weights CS 0 07:14:44.674 Self Organizing map (EURUSD,H1) [[0.1937869656464888,0.8527427060068337] CS 0 07:14:44.674 Self Organizing map (EURUSD,H1) [0.1779676215121214,0.7964618795904062]] CS 0 07:14:44.725 Self Organizing map (EURUSD,H1) Clusters CSV files saved under the directory Files\SOM CS 0 07:14:44.726 Self Organizing map (EURUSD,H1) Clusters CSV files saved under the directory Files\SOM CS 0 07:14:44.726 Self Organizing map (EURUSD,H1) CS 0 07:14:44.726 Self Organizing map (EURUSD,H1) clusters CS 0 07:14:44.726 Self Organizing map (EURUSD,H1) TENSOR INDEX <<0>> CS 0 07:14:44.726 Self Organizing map (EURUSD,H1) [[1.2,2.3] CS 0 07:14:44.726 Self Organizing map (EURUSD,H1) [0.7,1.8] CS 0 07:14:44.726 Self Organizing map (EURUSD,H1) [2.8,3.899999999999999]] CS 0 07:14:44.727 Self Organizing map (EURUSD,H1) TENSOR INDEX <<1>> CS 0 07:14:44.727 Self Organizing map (EURUSD,H1) [[3.600000000000001,4.8] CS 0 07:14:44.727 Self Organizing map (EURUSD,H1) [5.2,6.7] CS 0 07:14:44.727 Self Organizing map (EURUSD,H1) [4.8,5.6]]
このプロセスは魔法のように機能します。機械学習モデルが正規化されたデータを使用するのにもかかわらず、モデルはデータをクラスタリングすることができ、まだ正規化されていない/元のデータを出すことができます。プロットされたクラスタが正規化されたデータであることに注目してください。異なる縮尺でデータをプロットするのは難しいため、これは重要です。今回、単純なテストデータセットでのクラスタのプロットは、かなり良くなりました。
コホネンマップの拡張
コホネンマップやその他のデータマイニング技術は、予測をおこなうことを主目的として作られたものではないにもかかわらず、重みである学習パラメータを持っているため、新しいデータを与えたときにクラスタを取得できるように拡張することができます。
uint CKohonenMaps::KOMPredCluster(vector &v) { vector temp_v = v; pre_processing.Normalization(v); if (n != v.Size()) { Print("Can't predict the cluster | the input vector size is not the same as the trained matrix cols"); return(-1); } vector D(m); //Euclidean distance btn clusters for (ulong j=0; j<m; j++) D[j] = Euclidean_distance(v, w_matrix.Col(j)); v.Copy(temp_v); return((uint)D.ArgMin()); } //+------------------------------------------------------------------+ //| | //+------------------------------------------------------------------+ vector CKohonenMaps::KOMPredCluster(matrix &matrix_) { vector v(n); if (n != matrix_.Cols()) { Print("Can't predict the cluster | the input matrix Cols is not the same size as the trained matrix cols"); return (v); } for (ulong i=0; i<matrix_.Rows(); i++) v[i] = KOMPredCluster(matrix_.Row(i)); return(v); }
まだ見たことのない新しいデータを与えてみましょう。どのクラスタが[0.5, 1.5]と[5.5, 6]に属するか、あなたと私は知っています。このデータはそれぞれクラスタ0と1に属します。
maps = new CKohonenMaps(Matrix,true,2,0.01,1000); //Training matrix new_data = { {0.5,1.5}, {5.5, 6.0} }; Print("new data\n",new_data,"\nprediction clusters\n",maps.KOMPredCluster(new_data)); //using it for predictions
出力:
CS 0 07:46:00.857 Self Organizing map (EURUSD,H1) new data CS 0 07:46:00.857 Self Organizing map (EURUSD,H1) [[0.5,1.5] CS 0 07:46:00.857 Self Organizing map (EURUSD,H1) [5.5,6]] CS 0 07:46:00.857 Self Organizing map (EURUSD,H1) prediction clusters CS 0 07:46:00.857 Self Organizing map (EURUSD,H1) [0,1]
コホーネンの地図は正確に予測しました。
ストラテジーテスターのコホネンマップ

このアルゴリズムは完璧に機能し、市場が上昇しているときはクラスター 0 を予測し、その逆も同様であることに気づくことができました。その意味が正しいかどうかはわかりません。動作をよく分析していないので、それはあなたにお任せします。 その場合は、ほとんどの指標がおこなうことなので、コホーネン マップを指標として使用することもできます。
コホネンマップの利点
コホネンマップには以下のような利点があります。
- 入力データと出力マップの間の非線形関係を捉える能力は、線形手法では容易に捉えられないようなデータ内の複雑なパターンや構造を扱うことができることを意味します。
- データにラベル付けすることなく、データのパターンや構造を見つけることができます。これは、ラベル付けされたデータが乏しかったり、入手にコストがかかるような状況で有用です。
- これらは、入力データを低次元空間にマッピングすることにより、入力データの次元を削減するのに役立ちます。これは、回帰や分類などの下流タスクの計算の複雑さを軽減するのに役立ちます。
- 入力データと出力マップ間のトポロジカルな関係を保持します。これは、マップ内の隣接するニューロンが、入力空間内の類似した領域に対応することを意味し、データ探索や視覚化に役立ちます。
- ノイズが大きすぎる限り、入力データのノイズや異常値に対してロバストです。
コホネンマップの欠点
- 最終的な自己組織化マップの質は、重みベクトルの初期化に影響を受けやすくなります。初期化が不十分だと、SOMは最適な解に収束しなかったり、極小値から抜け出せなくなることがあります。
- パラメータチューニングに敏感:SOMの性能は、学習率、近傍関数、ニューロン数などのハイパーパラメータの選択に影響を受けやすくなります。これらのパラメーターの調整には時間がかかり、専門知識が必要になります。
- 大規模なデータセットの場合、計算コストが高く、メモリを大量に消費します。SOMのサイズは入力データ点の数によってスケールするため、大規模なデータセットではニューロン数が多く、長い学習時間が必要になることがあります。
- 正式な収束基準がない:ニューラルネットワークのような機械学習アルゴリズムとは異なり、SOMには正式な収束基準はありません。そのため、訓練がいつ収束し、いつ訓練を中止すべきかの判断が難しくなります。
結論
コホネンマップまたは自己組織化マップ(SOM)は、トレーダーが市場で自分の道を見つけるのを助けることができる取引への革新的なアプローチです。教師なし学習を利用することで、コホネンマップは市場データのパターンと構造を特定し、トレーダーが情報に基づいた意思決定をおこなえるようにします。これまで見てきたように、コホーネンマップはデータ内の非線形関係を特定し、データをそれぞれのグループにクラスタ化することができました。ただし、トレーダーは、初期化に対する感度、正式な収束の欠如など、コホーネンマップの潜在的な欠点、および上記で説明したその他の欠点を認識しておく必要があります。全体として、コホネンマップはトレーダーのツールキットに加える価値あるものになる可能性を秘めているが、他のツールと同様、その長所と短所に注意して使用すべきです。
気をつけてください。
このアルゴリズムの開発と変更は、私のGitHubリポジトリhttps://github.com/MegaJoctan/MALE5にあります。
| ファイル | 内容と使用方法 |
|---|---|
| Self Organizing map.mq5 | この記事で取り上げたアルゴリズムをテストするためのEAファイル |
| コkohonen maps.mqh | コホネンマップアルゴリズムを含むライブラリ |
| plots.mqh | MT5でチャートにプロットを描画する関数を含むライブラリ |
| preprocessing.mqh | 入力データを正規化前処理する関数を含む。 |
| matrix_utils.mqh | MQL5における行列演算のための追加関数 |
| Tensors.mqh | テンソルを作成するためのクラスを含むライブラリ |
参考記事:
MetaQuotes Ltdにより英語から翻訳されました。
元の記事: https://www.mql5.com/en/articles/12261
警告: これらの資料についてのすべての権利はMetaQuotes Ltd.が保有しています。これらの資料の全部または一部の複製や再プリントは禁じられています。
この記事はサイトのユーザーによって執筆されたものであり、著者の個人的な見解を反映しています。MetaQuotes Ltdは、提示された情報の正確性や、記載されているソリューション、戦略、または推奨事項の使用によって生じたいかなる結果についても責任を負いません。
- 無料取引アプリ
- 8千を超えるシグナルをコピー
- 金融ニュースで金融マーケットを探索