
Approche Économétrique de l'Analyse des Graphiques

Les théories sans faits peuvent être stériles, mais les faits sans théories n'ont pas de sens.
K. Bloc
Introduction
J'entends souvent dire que les marchés sont volatils et qu'il n'y a pas de stabilité. Et cela explique pourquoi un trading réussi à long terme est impossible. Mais est-ce vrai ? Essayons d'analyser ce problème scientifiquement. Et choisissons leseconometric moyens d'analyse. Pourquoi eux ? Tout d'abord, la communauté MQL aime la précision, qui va être fournie par les mathématiques et les statistiques. Deuxièmement, cela n'a pas été décrit auparavant, si je ne me trompe pas.
Permettez-moi de mentionner que le problème du succès du trading à long terme ne peut pas être résolu en un seul article. Aujourd'hui, je vais décrire uniquement plusieurs méthodes de diagnostic pour le modèle sélectionné, qui, espérons-le, apparaîtront utiles pour une future utilisation.
En plus de cela, je ferai de mon mieux pour décrire de manière claire de la matière sèche comprenant des formules, des théorèmes et des hypothèses. Cependant, j'attends de mon lecteur qu'il soit familiarisé avec les concepts de base de la statistique, tels que : hypothèse, signification statistique, statistique (critère statistique), dispersion, distribution, probabilité, régression, auto-corrélation, etc.
1. Caractéristiques d'une Série Chronologique
Il est évident que l' objetde l'analyse est une série de prix (ses dérivés), qui est une time series.
Les économètres étudient les séries chronologiques du point de vue des méthodes fréquentielles (analyse spectrale, analyse par ondelettes) et des méthodes du domaine temporel (analyse de corrélation croisée, analyse d'auto-corrélation). L'article a été fourni au lecteur"Building Spectrum Analysis" qui décrit les méthodes de fréquence. Maintenant, je propose de jeter un œil aux méthodes du domaine temporel, à l'analyse d'auto-corrélation et à l'analyse de la variance conditionnelle en particulier.
Les modèles non linéaires décrivent mieux le comportement des price time series que les modèles linéaires. C'est pourquoi concentrons-nous sur l'étude des modèles non linéaires dans cet article.
Les séries chronologiques de prix ont des caractéristiques particulières qui ne peuvent être prises en compte que par certains modèles économétriques. Tout d’abord, de telles caractéristiques comprennent «fat tail» groupage de volatilité et effet de levier

Figure 1. Distributions avec différents aplatissements.
La figue. 1 démontre 3 distributions avec différents aplatissement (effet de pic). La distribution, dont le pic est inférieur à la distribution normale, a plus souvent des "fat tails" que les autres. Il est représenté avec la couleur rose.
Nous avons besoin d'une distribution pour afficher la densitéprobabilité de densité d'une valeur aléatoire, qui est utilisée pour le comptage des valeurs de la série étudiée.
Par groupage (depuis le groupe-paquet,concentration) de volatilité,nous voulons dire ce qui suit. Une période de forte volatilité est suivie de la même, et une période de faible volatilité est suivie de la même. Si les prix fluctuaient hier, ils le feront probablement aujourd'hui. Il y a donc inertie de la volatilité. La figue. 2 démontre que la volatilité a une forme groupée.

Figure 2. Volatilité des rendements quotidiens de l'USDJPY, son groupage.
L’effet de levierconsiste à ce que la volatilité d'un marché baissier est supérieure à celle d'un marché haussier. Il est stipulé par l'augmentation du coefficient de levier, qui dépend du rapport entre les actifs empruntés et les actifs propres, lorsque les cours des actions baissent. Cependant, cet effet s'applique au marché boursier, pas au marché des changes. Cet effet ne sera pas examiné davantage.
2. Le modèle GARCH
Ainsi,objectif principal notre est de prévoir le taux de change (prix) à l'aide d'un modèle. Les économètres utilisent des modèles mathématiques décrivant l'un ou l'autre effet qui peut être estimé en termes de quantité. En termes simples, ils adaptent une formule à un événement. Et c'est ainsi qu'ils décrivent cet événement.
Étant donné que la série chronologique analysée possède les propriétés mentionnées ci-dessus, un modèle optimal qui prend en compte ces propriétés sera un modèle non linéaire. L'un des modèles non linéaires les plus universels est le modèle GARCH model.. Comment cela peut-il nous aider ? Au sein de son corps (fonction), il prendra en compte la volatilité de la série, c'est-à-dire la variabilité dedispersion à différentes périodes d'observation. Les économètres appellent cet effet avec un terme obscur -hétéro-scédasticité (du grec - hétéro - différent, skedasis - dispersion).
Si nous examinons la formule elle-même, nous constaterons que ce modèle implique que la variabilité actuelle de la dispersion (σ2t) est affectée à la fois par les changements précédents de paramètres (ϵ2t-i)et par les estimations précédentes de la dispersion (appelées « anciennes nouvelles ») :(σ2t-i):
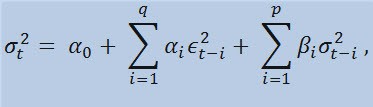
avec des limites
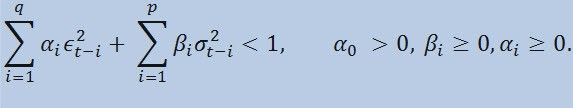
où : ϵt - innovation non-normalisées; α0 , βi , αi , q (ordre des membres ARCH ϵ2), p (ordre des membres GARCHσ2) - paramètres estimés et l’ordre de modèles.
3. Indicateur de Rendements
En fait, nous n'allons pas estimer la série de prix elle-même, mais la série de rendements. Le logarithme de la variation des prix (rendements facturés en permanence) est déterminé comme un logarithme népérien du pourcentage de rendement :
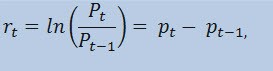
Où:
- Pt - est la valeur des séries de prix du moment t;
- Pt-1 - est la valeur de la séries de prix du moment t-1;
- pt = ln(Pt) - est le logarithme népérien Pt
En pratique, la raison principale pour laquelle il est préférable de travailler avec des rendements plutôt que de travailler avec des prix est que les rendements présentent de meilleures caractéristiques statistiques.
Créons donc un indicateur de rendements ReturnsIndicator.mq5, qui nous sera très utile. Ici, je vais me référer à l'article "Indicateurs personnalisés des débutants" qui décrit de manière compréhensible l'algorithme de création d'un indicateur. C'est pourquoi je vais vous montrer uniquement le code où la formule mentionnée est implémentée. Je pense que c'est très simple et ne nécessite aucune explication.
//+------------------------------------------------------------------+ //| Custom indicator iteration function | //+------------------------------------------------------------------+ int OnCalculate(const int rates_total, // size of the array price[] const int prev_calculated, // number of bars available at the previous call const int begin, // index of the array price[] the reliable data starts from const double& price[]) // array for the calculation itself { //--- int start; if(prev_calculated<2) start=1; // start filling ReturnsBuffer[] from the 1-st index, not 0. else start=prev_calculated-1; // set 'start' equal to the last index in the arrays for(int i=start;i<rates_total;i++) { ReturnsBuffer[i]=MathLog(price[i]/price[i-1]); } //--- return value of prev_calculated for next call return(rates_total); } //+------------------------------------------------------------------+
La seule chose que je souhaite mentionner est que la série de rendements est toujours plus petite que la série primaire de 1 élément. C'est pourquoi nous allons calculer le tableau des rendements à partir du deuxième élément, et le premier sera toujours égal à 0.
Ainsi, en utilisant l'indicateur ReturnsIndicator, nous avons obtenu une série chronologique aléatoire qui sera utilisée pour nos études.
4. Tests Statistiques
Maintenant c’est au tour des tests statistiques. Ils sont menés pour déterminer si la série chronologique présente des signes prouvant la pertinence d'utiliser l'un ou l'autre modèle. Dans notre cas, un tel modèle est le modèle GARCH.
En utilisantQ-test of Ljung-Box-Pierce, vérifier si les auto-corrélations de la série sont aléatoires ou s'il existe une relation. Pour cela, nous devons écrire une nouvelle fonction. Ici, par auto-corrélation j'entends une corrélation (liaison probabiliste) entre les valeurs d'une même série chronologique X (t) aux instants t1 et t2. Si les instants t1 et t2 sont adjacents (l'un suit l’autre), alors on cherche une relation entre les membres de la série et les membres de la même série décalés d'une unité de temps : x1, x2, x3, ... и x1+ 1, x2+1, x3+1, ... Un tel effet des membres déplacés est appelé un décalage (latence, retard). La valeur de décalage peut être n'importe quel nombre positif.
Maintenant, je vais faire une remarque entre parenthèses et vous parler de ce qui suit. Pour autant que je sache, ni С++, ni MQL5 n'ont de bibliothèques standard qui couvrent les calculs statistiques complexes et moyens. D’habitude, ces calculs sont effectués à l'aide d'outils statistiques spéciaux. Quant à moi, il est plus facile d'utiliser des outils tels que Matlab, STATISTICA 9, etc. pour résoudre le problème. Cependant, j'ai décidé de ne pas utiliser des bibliothèques externes, d'une part pour démontrer la puissance du langage MQL5 pour les calculs, et d'autre part... J'ai beaucoup appris par moi-même en écrivant le code MQL.
Maintenant, nous devons faire la note suivante. Pour effectuer le test Q, nous avons besoin de nombres complexes. C'est pourquoi j'ai fait la classe Complexe. Idéalement, il devrait s'appeler CComplex. Eh bien, je me suis autorisé à me détendre pendant un moment. Je suis sûr que mon lecteur est préparé et je n'ai pas besoin d'expliquer ce qu'est un numérocomplexe. Personnellement, je n'aime pas les fonctions de calcul de la transformation de Fourier publiées dans MQL5 et MQL4 ; les nombres complexes y sont utilisés de manière implicite. De plus, il existe un autre obstacle - l'impossibilité de remplacer les opérateurs arithmétiques dans MQL5. J'ai donc dû chercher d'autres approches et éviter la notation "C" standard. J'ai implémenté la classe des nombres complexes de la manière suivante :
class Complex { public: double re,im; //re -real component of the complex number, im - imaginary public: void Complex(){}; //default constructor void setComplex(double rE,double iM){re=rE; im=iM;}; //set method (1-st variant) void setComplex(double rE){re=rE; im=0;}; //set method (2-nd variant) void ~Complex(){}; //destructor void opEqual(const Complex &y){re=y.re;im=y.im;}; //operator= void opPlus(const Complex &x,const Complex &y); //operator+ void opPlusEq(const Complex &y); //operator+= void opMinus(const Complex &x,const Complex &y); //operator- void opMult(const Complex &x,const Complex &y); //operator* void opMultEq(const Complex &y); //operator*= (1-st variant) void opMultEq(const double y); //operator*= (2-nd variant) void conjugate(const Complex &y); //conjugation of complex numbers double norm(); //normalization };
Par exemple, l'opération de sommation de deux nombres complexes peut être effectuée à l'aide de la méthodeopPlus, la soustraction est réalisée à l’aide de opMinus ,etc. Si vous écrivez simplement le code c = a + b (où a, b, ñ sont des nombres complexes) alors le compilateur affichera une erreur. Mais il acceptera l'expression suivante :c.opPlus(a,b)..
Si nécessaire, un utilisateur peut étendre l'ensemble des méthodes de la classe Complex. Par exemple, vous pouvez ajouter un opérateur de division.
De plus, j'ai besoin de fonctions auxiliaires qui traitent des tableaux de nombres complexes. C'est pourquoi je les ai implémentés en dehors de la classe Complex pour ne pas cycler le traitement des éléments du tableau qu'il comporte, mais pour travailler directement avec les tableaux passés par une référence. Il existe au total trois fonctions de ce type :
- getComplexArr(renvoie un tableau bidimensionnel de nombres réels à partir d'un tableau de nombres complexes);
- setComplexArr (renvoie un tableau de nombres complexes à partir d'un tableau mono-dimensionnel de nombres réels);
- setComplexArr2(renvoie un tableau de nombres complexes à partir d'un tableau bidimensionnel de nombres réels).
Il est à noter que ces fonctions retournent des tableaux transmis par une référence. C'est pourquoi leurs corps ne comportent pas l'opérateur « retour ». Mais en raisonnant logiquement, je pense qu'on peut parler de rendement malgré le type vide.
La classe des nombres complexes et des fonctions auxiliaires est décrite dans le fichier d'en-têteComplex_class.mqh.
Ensuite, lors de la réalisation des tests, nous aurons besoin de la fonction fonction d’auto-corrélation et la fonction de Transformation de Fourier. Ainsi, nous devons créer une nouvelle classe, appelons-la CFFT. EIle traitera des tableaux de nombres complexes pour les transformations de Fourier. La classe de Fourier se présente comme suit :
class CFFT { public: Complex Input[]; //input array of complex numbers Complex Output[]; //output array of complex numbers public: bool Forward(const uint N); //direct Fourier transformation bool InverseT(const uint N,const bool Scale=true); //weighted reverse Fourier transformation bool InverseF(const uint N,const bool Scale=false); //non-weighted reverse Fourier transformation void setCFFT(Complex &data1[],Complex &data2[],const uint N); //set method(1-st variant) void setCFFT(Complex &data1[],Complex &data2[]); //set method (2-nd variant) protected: void Rearrange(const uint N); // regrouping void Perform(const uint N,const bool Inverse); // implementation of transformation void Scale(const uint N); // weighting };
Il est à noter que toutes les transformations de Fourier sont effectuées avec des tableaux dont la longueur remplit la condition 2^N (où N est une puissance de deux). D’habitude, la longueur du tableau n'est pas égale à 2^N. Dans ce cas, la longueur du tableau est augmentée à la valeur de 2^N pour 2^N >= n, où n est la longueur du tableau. Les éléments ajoutés du tableau sont égaux à 0. Un tel traitement du tableau est réalisé avec le corps de la fonction autocorrà l’aide de la fonction auxiliaire nextpow2 et la fonction pow:
int nFFT=pow(2,nextpow2(ArraySize(res))+1); //power rate of two
Donc, nous avons un tableau initial dont la longueur (n) est égale à 73585, puis la fonction nextpow2 renverra la valeur 17,où 2^17 = 131072. En d'autres termes, la valeur renvoyée est supérieure à n by pow(2, ceil(log(n)/log(2))). Ensuite, nous allons calculer la valeur de nFFT : 2^(17+1) = 262144. Ce sera la longueur du tableau auxiliaire, dont les éléments de 73585 à 262143 seront égaux à zéro.
La classe de Fourier est décrite dans le fichier d'en-tête FFT_class.mqh.
Pour gagner de la place, je vais sauter la description de l'implémentation de la classe CFFT. Ceux qui sont intéressés peuvent les consulter dans le fichier inclus ci-joint. Passons maintenant à la fonction d'auto-corrélation.
void autocorr(double &ACF[],double &res[],int nLags) //1-st variant of function /* selective autocorrelation function (ACF) for unidimensional stochastic time series ACF - output array of calculated values of the autocorrelation function; res - array of observation of stochastic time series; nLags - maximum number of lags the ACF is calculated for. */ { Complex Data1[],Data21[], //input arrays of complex numbers Data2[],Data22[], //output arrays of complex numbers cData[]; //array of conjugated complex numbers double rA[][2]; //auxiliary two-dimensional array of real numbers int nFFT=pow(2,nextpow2(ArraySize(res))+1); //power rate of two ArrayResize(rA,nFFT);ArrayResize(Data1,nFFT); //correction of array sizes ArrayResize(Data2,nFFT);ArrayResize(Data21,nFFT); ArrayResize(Data22,nFFT);ArrayResize(cData,nFFT); double rets1[]; //an auxiliary array for observing the series double m=mean(res); //arithmetical mean of the array res ArrayResize(rets1,nFFT); //correction of array size for(int t=0;t<ArraySize(res);t++) //copy the initial array of observation // to the auxiliary one with correction by average rets1[t]=res[t]-m; setComplexArr(Data1,rets1); //set input array of complex numbers CFFT F,F1; //initialize instances of the CFFT class F.setCFFT(Data1,Data2); //initialize data-members for the instance F F.Forward(nFFT); //perform direct Fourier transformation for(int i=0;i<nFFT;i++) { Data21[i].opEqual(F.Output[i]);//assign the values of the F.Output array to the Data21 array; cData[i].conjugate(Data21[i]); //perform conjugation for the array Data21 Data21[i].opMultEq(cData[i]); //multiplication of the complex number by the one adjacent to it //results in a complex number that has only real component not equal to zero } F1.setCFFT(Data21,Data22); //initialize data-members for the instance F1 F1.InverseT(nFFT); //perform weighter reverse Fourier transformation getComplexArr(rA,F1.Output); //get the result in double format after //weighted reverse Fourier transformation for(int i=0;i<nLags+1;i++) { ACF[i]=rA[i][0]; //in the output ACF array save the calculated values //of autocorrelation function ACF[i]=ACF[i]/rA[0][0]; //normalization relatively to the first element } }
Nous avons donc calculé les valeurs ACF pour le nombre de décalages indiqué. Nous pouvons maintenant utiliser la fonction d'auto-corrélation pour le test Q. La fonction de test elle-même ressemble à ce qui suit :
void lbqtest(bool &H[],double &rets[]) /* Function that implements the Q test of Ljung-Box-Pierce H - output array of logic values, that confirm or disprove the zero hypothesis on the specified lag; rets - array of observations of the stochastic time series; */ { double lags[3]={10.0,15.0,20.0}; //specified lags int maxLags=20; //maximum number of lags double ACF[]; ArrayResize(ACF,21); //epmty ACF array double acf[]; ArrayResize(acf,20); //alternate ACF array autocorr(ACF,rets,maxLags); //calculated ACF array for(int i=0;i<20;i++) acf[i]=ACF[i+1]; //remove the first element - one, fill //alternate array double alpha[3]={0.05,0.05,0.05}; //array of levels of significance of the test /*Calculation of array of Q statistics for selected lags according to the formula: L |----| \ Q = T(T+2) || (rho(k)^2/(T-k)), / |----| k=1 where: T is range, L is the number of lags, rho(k) is the value of ACF at the k-th lag. */ double idx[]; ArrayResize(idx,maxLags); //auxiliary array of indexes int len=ArraySize(rets); //length of the array of observations int arrLags[];ArrayResize(arrLags,maxLags); //auxiliary array of lags double stat[]; ArrayResize(stat,maxLags); //array of Q statistics double sum[]; ArrayResize(sum,maxLags); //auxiliary array po sums double iACF[];ArrayResize(iACF,maxLags); //auxiliary ACF array for(int i=0;i<maxLags;i++) { //fill: arrLags[i]=i+1; //auxiliary array of lags idx[i]=len-arrLags[i]; //auxiliary array of indexes iACF[i]=pow(acf[i],2)/idx[i]; //auxiliary ACF array } cumsum(sum,iACF); //sum the auxiliary ACF array //by progressive total for(int i=0;i<maxLags;i++) stat[i]=sum[i]*len*(len+2); //fill the array Q statistics double stat1[]; //alternate of the array of Q statistics ArrayResize(stat1,ArraySize(lags)); for(int i=0;i<ArraySize(lags);i++) stat1[i]=stat[lags[i]-1]; //fill the alternate array of specified lags double pValue[ArraySize(lags)]; //array of 'p' values for(int i=0;i<ArraySize(lags);i++) { pValue[i]=1-gammp(lags[i]/2,stat1[i]/2); //calculation of 'p' values H[i]=alpha[i]>=pValue[i]; //estimation of zero hypothesis } }
Ainsi, notre fonction effectue le testQ test de Ljung-Box-Pierce et renvoie le tableau de valeurs logiques pour les décalages spécifiés. Nous devons clarifier que le test de Ljung-Box est appelé test porte-manteau ( test combiné). Cela signifie qu'un groupe de décalages jusqu'à un décalage indiqué est vérifié pour la présence d'auto-corrélation. Habituellement, l'auto-corrélation est vérifiée jusqu'au 10e, 15e et 20e décalage inclus. Une conclusion sur la présence d'auto-corrélation dans l'ensemble de la série est faite sur la base de la dernière valeur de l'élément du tableau H, c'est-à-dire du 1er au 20-ème décalage.
Si l'élément du tableau est égal àfalse, alors l'hypothèse zéro, qui stipule qu'il n'y a pas d'auto-corrélation sur les décalages précédents et sélectionnés, n'est pas rejetée. En d'autres termes, il n'y a pas d'auto-corrélation lorsque la valeur estfalse. Sinon, le test prouve la présence de l'auto-corrélation. Ainsi, une hypothèse alternative à zéro est acceptée lorsque la valeur est true.
Parfois, il arrive que des auto-corrélations ne soient pas trouvées dans des séries de rendements. Dans ce cas, pour plus d’assurance, les carrés des rendements sont testés. La décision finale d'accepter ou de rejeter l'hypothèse zéro est prise de la même manière que lors du test de la série initiale de rendements. Pourquoi utiliser les carrés des rendements ? - De cette façon, nous augmentons artificiellement l'éventuelle composante d'auto-corrélation non aléatoire de la série analysée, qui est en outre déterminée dans les limites des valeurs initiales des limites de confiance. Théoriquement, vous pouvez utiliser des carrés et d'autres puissances de rendements. Mais c'est un chargement statistique inutile, qui efface le sens des tests.
A la fin du corps de la fonction de test Q lorsque la valeur 'p' est calculée, la fonction gammp(x1/2,x2/2) est apparue. EIle permet de calculer une fonction gamma incomplète pour les éléments correspondants. En fait, nous avons besoin d'une fonction cumulative deχ2-distribution (chi-square-distribution). Mais c'est un cas particulier deGamma distribution.
Généralement, pour prouver la pertinence d'utilisation du modèle GARCH, il suffit d'obtenir une valeur positive de l'un des décalages du test Q. En plus de cela, les économètres effectuent un autre test - le test ARCH d'Engle, qui vérifie la présence d'une hétéro-scédasticité conventionnelle. Cependant, je suppose que le test Q est suffisant pour le moment. C'est le plus universel.
Maintenant, comme nous disposons de toutes les fonctions nécessaires pour réaliser le test, il faut penser à afficher les résultats obtenus à l'écran. A cet effet, j'ai écrit une autre fonction lbqtestInfo qui affiche le résultat du test économétrique sous la forme d'une fenêtre de message et le diagramme d'auto-corrélation - directement sur le graphique du symbole analysé.
Examinons le résultat par un exemple. J'ai choisi usdjpy comme premier symbole pour l'analyse. Au début, j'ouvre le graphique linéaire du symbole (par prix de clôture) et charge l'indicateur personnalisé ReturnsIndicator pour montrer la série de rendements. Le graphique est contracté au maximum pour mieux afficher le groupage de la volatilité de l'indicateur. Ensuite, j'exécute le script GarchTest.. Probablement, votre résolution de l’écran est différente de la mienne, c’est le script que vous demandera la taille souhaitée duschéma en pixels. Ma norme est 700*250.
Plusieurs exemples de tests sont présentés dans la fig. 3.
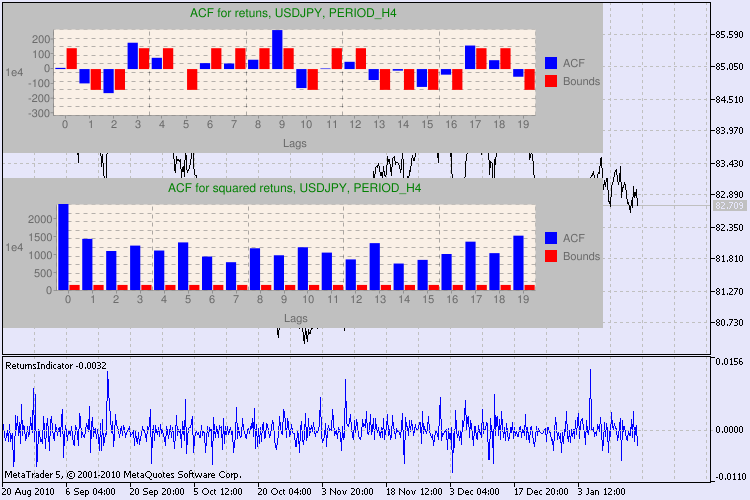
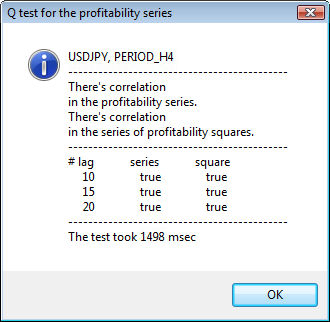
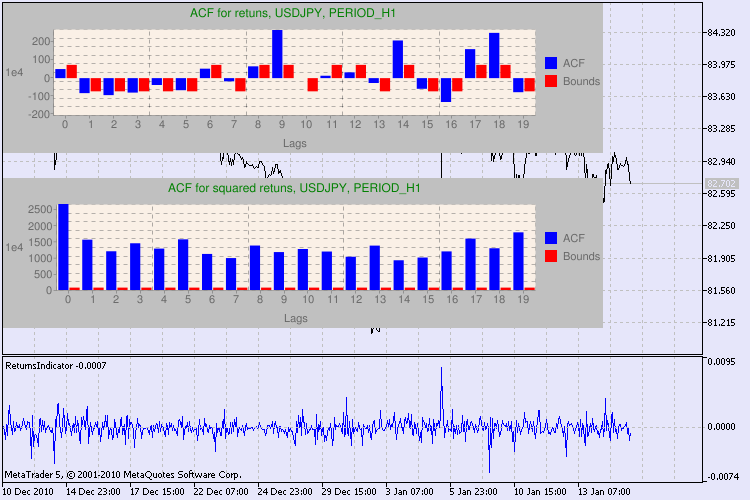
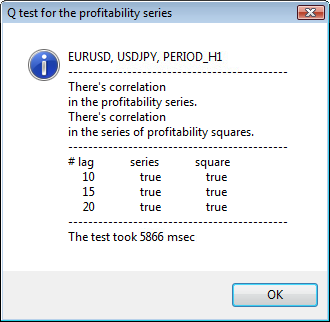
Figure 3. Le résultat du test Q et le diagramme d'auto-corrélation pour l' USDJPYpour différents intervalles de temps
Oui, j'ai beaucoup cherché une variante d'affichage du diagramme sur un graphique de symboles dans MetaTrader 5. Et j'ai décidé que la variante optimale consiste à utiliser une bibliothèque de diagrammes de dessin utilisant l'API Google Chart, qui est décrite dans l' correspondantarticle.
Comment doit-on interpréter ces informations ? Jetons un coup d’œil. La partie supérieure du graphique comporte le diagramme de la fonction d'auto-corrélation (ACF) pour la série initiale de rendements. Au premier diagramme, nous analysons la série usdjpy de la période H4. Nous pouvons constatons que plusieurs valeurs d' ACF (barres bleues) dépassent les limites (barres rouges). En d'autres termes, nous constatons une petite auto-corrélation dans la série initiale de rendements. Le schéma ci-dessous est leschéma de la fonction d'auto-corrélation (ACF) de la série decarrés de renvois du symbole spécifié. Tout y est clair, une victoire complète des barres bleues. Les diagrammes H1 sont analysés de la même manière.
Quelques mots sur la description des axes du diagramme. L'axe des x est clair ; il affiche les index des décalages. Sur l'axe des y, vous pouvez constater la valeur exponentielle, la valeur initiale de l' ACF est multipliée par. Ainsi, 1e4 signifie que la valeur initiale est multipliée par 1e4 (1e4=10000), et 1e2 signifie multiplier par 100, etc. Une telle multiplication est faite pour rendre le diagramme plus compréhensible.
La partie supérieure de la fenêtre de dialogue affiche un nom de symbole ou de paire croisée et sa période. Après eux, vous pouvez constater deux phrases qui indiquent la présence ou l'absence d'auto-corrélation dans la série initiale de rendements et dans la série de carrés de rendements. Ensuite, les 10-ème, 15-ème et 20-ème décalage sont répertoriés ainsi que la valeur de l'auto-corrélation dans la série initiale et dans la série de carrés. Une valeur relative d'auto-corrélation est affichée ici - un indicateur booléen pendant le test Q qui détermine s'il existe une auto-corrélation au niveau des indicateurs précédents et spécifiés.
En fin de compte, si nous constatons que l'auto-corrélation existe aux drapeaux précédent et spécifié, alors le drapeau sera égal à true, autrement - false Dans le premier cas, notre série est un "client" pour l'application du modèle GARCH non-linéaire, et dans le second cas, nous devons utiliser des modèles analytiques plus simples. Un lecteur attentif notera que la série initiale de rendements de la paire USDJPY est légèrement corrélée les unes aux autres, en particulier celle de la plus grande période. Mais la série de carrés de rendements montre une auto-corrélation.
Le temps consacré aux tests est affiché dans la partie inférieure de la fenêtre.
L'ensemble du test a été effectué à l'aide du scriptGarchTest.mq5
Conclusions
Dans mon article, j'ai décrit comment les économètres analysent les séries chronologiques, ou pour être plus précis, comment ils entament leurs études. Au cours de celle-ci, j'ai dû écrire de nombreuses fonctions et coder plusieurs types de données (par exemple, des nombres complexes). L'estimation visuelle d'une série initiale donne probablement à peu près le même résultat que l'estimation économétrique. Cependant, nous avons convenu de n'utiliser que des méthodes précises. Vous savez, un bon médecin peut établir un diagnostic sans utiliser une technologie et une méthodologie complexes. Mais de toute façon, ils étudieront le patient avec soin et minutie.
Qu'obtenons-nous de l'approche décrite dans l'article? L'utilisation des modèles GARCH non linéaires permet de représenter formellement la série analysée du point de vue mathématique et de créer une prévision pour un nombre spécifié d'étapes. En outre, cela nous aidera à simuler le comportement des séries aux périodes de prévision et à tester n’importe quel Expert Advisor prêt à l'emploi en utilisant les informations prévues.
Emplacement des fichiers:
| # | Fichier | Chemin : |
|---|---|---|
| 1 | ReturnsIndicator.mq5 | %MetaTrader%\MQL5\Indicators |
| 2 | Complex_class.mqh | %MetaTrader%\MQL5\Include |
| 3 | FFT_class.mqh | %MetaTrader%\MQL5\Include |
| 4 | GarchTest.mq5 | %MetaTrader%\MQL5\Scripts |
Les fichiers et la description de la bibliothèque google_charts.mqh et Libraries.rar peuvent être téléchargés depuis l’article précédemment mentionné .
Bibliographie utilisée pour l'article :
- Analysis of Financial Time Series, Ruey S. Tsay, , 2e édition, 2005. - 638 pp.
- Les séries chronologiques économétriques appliquées,Walter Enders, John Wiley & Sons, 2eme Edition, 1994. - 448 pp.
- Bollerslev, T., R. F. Engle et DB Nelson. "Modèles ARCH." Manuel d’économétrie. Vol. 4, chapitre 49, Amsterdam : Elsevier Science B.V.
- Boîte, GE P., G. M. Jenkins et GC Reinsel. Analyse des Séries Chronologiques: Prévision et Contrôle. 3e éd. Upper Saddle River, New Jersey : Prentice-Hall, 1994.
- Recettes numériques en C, L'art de l'informatique scientifique, 2e édition, WH Presse, BP Flannery, SA Teukolsky, W. T. Vetterling, 1993. - 1020 p.
- Gene H. Golub, Charles F. Van Loan. Calculs matriciels, 1999.
- Porshnev S. V. « Calculs mathématiques. Série de conférences", S.Pb, 2004.
Traduit du russe par MetaQuotes Ltd.
Article original : https://www.mql5.com/ru/articles/222
 Assistant MQL5 : Comment Créer un Module de Signaux de Trading
Assistant MQL5 : Comment Créer un Module de Signaux de Trading
 Les indicateurs des tendances micro, moyenne et principale
Les indicateurs des tendances micro, moyenne et principale
 Tableaux Électroniques en MQL5
Tableaux Électroniques en MQL5
 Création d’Expert Advisors Multiples sur la base de Modèles de Trading
Création d’Expert Advisors Multiples sur la base de Modèles de Trading
- Applications de trading gratuites
- Plus de 8 000 signaux à copier
- Actualités économiques pour explorer les marchés financiers
Vous acceptez la politique du site Web et les conditions d'utilisation