
Análisis de clústeres (Parte I): Usando la inclinación de las líneas de indicador

Introducción
El análisis de clústeres es uno de los elementos más importantes de la inteligencia artificial. Los datos, que generalmente se muestran como tuplas (tuples) de números o puntos, se agrupan en grupos o montones. El objetivo consistirá en, asignando con éxito un punto observado a un clúster o categoría, establecer las propiedades conocidas de esa categoría para el nuevo punto observado y luego actuar en consecuencia. En este artículo, verificaremos si la inclinación del indicador puede revelar la naturaleza plana o de tendencia del mercado, y, de ser así, cómo de bien lo hace.
Numeración y denominaciones
El indicador HalfTrend, que usaremos a modo de ejemplo, está escrito en la tradición del lenguaje MQL4. El índice de las barras o velas (iB) en el gráfico de precios se cuenta partiendo de su valor más alto (rates_total), el índice de la barra más antigua hasta cero, la barra más nueva y actual. Cuando llamamos a la función OnCalculate() por primera vez después de iniciar el indicador, el valor prev_calculated es igual a cero, ya que todavía no se han realizado cálculos. En llamadas posteriores, este valor nos permitirá determinar qué barras se han calculado ya y cuáles no.
El indicador usa una línea de indicador de dos colores implementada por dos búferes de datos, up[] y down[]. Cada uno tiene su propio color. Solo uno de los dos búferes obtiene un valor mayor que cero a la vez, el segundo se establece como cero en la misma posición (el elemento de búfer con el mismo índice iB). Esto significa que no se representa.
Para que el uso posterior del análisis de clústeres con otros indicadores o programas resulte lo más sencillo posible, hemos realizado las adiciones mínimas al indicador HalfTrend. Las líneas añadidas están enmarcadas con los siguientes comentarios en el código del indicador:
//+------------------------------------------------------------------+ //| added for cluster analysis | //+------------------------------------------------------------------+ .... //+------------------------------------------------------------------+
Las funciones y los datos del análisis de clústeres al completo se incluyen en el archivo ClusterTrend.mqh adjunto al artículo. Todos los cálculos se basan en la siguiente estructura de datos para todos los clústeres:
struct __IncrStdDev { double µ, // average σ, // standard deviation max,min, // max. and min. values S2; // auxiliary variable uint ID,n; // ID and no. of values };
µ: valor promedio. σ: desviación estándar; supone la raíz de la varianza, que muestra cómo de cerca varían los valores en el clúster alrededor del promedio. Max y min: son los valores máximo y mínimo en el clúster, respectivamente. S2: es una variable auxiliar. n es el número de valores en el clúster, ID es el identificador del clúster.
Esta estructura de datos está organizada como una matriz bidimensional:
__cluster cluster[][14];
Como en MQL5 solo la primera dimensión de las matrices multidimensionales está configurada dinámicamente, le asignaremos el número de tipos de valores estudiados, lo cual nos facilitará su cambio. La segunda dimensión es el número de valores de clasificación registrados en la siguiente matriz unidimensional:
double CatCoeff[9] = {0.0,0.33,0.76,1.32,2.04,2.98,4.21,5.80,7.87};
Ambas líneas están directamente una debajo de la otra, puesto que el número de coeficientes en CatCoeff predetermina el tamaño fijo de la segunda dimensión del clúster. Debería haber 5 más. Explicaremos el motivo a continuación. Como ambas matrices se predefinen entre sí, podemos intercambiarlas fácilmente.
Solo se comprobará la diferencia entre el valor del indicador y su valor anterior: x[iB] - x[iB+1]. Esta diferencia se convierte en puntos (_Point) para que podamos comparar los diferentes instrumentos comerciales, como EURUSD con 5 decimales y XAUUSD (oro) con dos.
Tareas
A la hora de comerciar, es importante saber si el mercado está plano o en una tendencia débil o fuerte. Con el mercado en flat, deberemos comerciar desde el borde del canal cerca del indicador promedio adecuado hacia el indicador, de regreso al centro del canal, mientras que durante la tendencia, deberemos comerciar con la tendencia en dirección hacia el indicador promedio y desde el centro del canal, es decir, actuar exactamente al revés. Por consiguiente, un indicador ideal dentro del asesor debería distinguir claramente entre estos dos estados. El asesor necesita un número que muestre la acción del mercado. También necesita valores de umbral para saber si este número de indicador muestra una tendencia o un flat. Con frecuencia, parece que el análisis visual resulta suficiente para ello. No obstante, la percepción visual suele ser difícil de expresar en forma de fórmula y/o números. El análisis de clústeres es un método matemático para agrupar o categorizar datos. Nos ayudará a separar estas dos condiciones de mercado.El análisis de clústeres identifica o calcula usando la optimización:
- número de clústeres
- centros de clústeres
- asignación de puntos a solo uno de los grupos, si esto es posible (= no hay clústeres superpuestos).
- que todas las tuplas numéricas o el mayor número posible de las mismas (posiblemente excluyendo valores atípicos) se puedan asignar a un clúster,
- que el tamaño del clúster sea mínimo
- que los clústeres se superpongan lo menos posible (de lo contrario, no estará claro a qué clúster pertenece un punto),
- que el número de clústeres sea mínimo.
Cuantos más puntos, valores, elementos y clústeres haya, más recursos gastarán los cálculos.
La notación O
Los gastos computacionales se representan como notación O. Por ejemplo, O(n) significa que aquí el cálculo debe obtener acceso a todos los elementos n solo una vez. Ejemplos bien conocidos sobre la importancia de este valor son los valores del algoritmo de clasificación. Los más rápidos suelen ser O(nlog(n)); los más lentos son O(n²). Este criterio resultó especialmente importante para las grandes cantidades de datos en un momento en que las computadoras eran mucho menos potentes. Hoy en día, las capacidades informáticas de las computadoras son mucho más amplias, pero al mismo tiempo, en algunas áreas, la cantidad de datos también ha aumentado significativamente (análisis óptico de objetos ambientales y categorización de objetos).
El primer y más famoso algoritmo de análisis de clústeres es el método de k-medias. Este asigna n observaciones o vectores con una dimensión dc para k clústeres, minimizando las distancias (euclidianas) hasta los centros de los clústeres. Esto da como resultado un coste computacional de O(n^(dk+1)). Tenemos solo una dimensión d, que se corresponde con la diferencia del indicador respecto al valor anterior; sin embargo, la historia de precios completa, por ejemplo, las cuentas demo de MQ para velas GBPUSD D1 incluyen 7265 barras o velas (n en la fórmula). Como al principio no sabemos cuántos clústeres necesitamos, usaremos k=9 clústeres o categorías. Según esta relación, los costes serán de O(7265^(1*9+1)) o iguales a O(4,1*10^38). Mucho para cualquier computadora promedio. El método presentado aquí permite realizar la agrupación por clústeres en 16 ms, lo cual supone 454.063 valores por segundo. Al calcular las barras en GBPUSD M15 utilizando este programa, obtenemos 556 388 barras y, nuevamente, 9 clústeres. Los cálculos ocupan 140 ms o 3.974.200 valores por segundo. Los cálculos muestran que la agrupación en clústeres es incluso mejor que O(n), lo cual puede explicarse por la forma en que la terminal organiza los datos; el esfuerzo computacional para calcular el indicador también se incluye en este periodo.
Indicador
Usamos el indicador HalfTrend de MetaQuotes (adjunto al artículo). A menudo se encuentra en flat:

Nos surge entonces la siguiente pregunta: ¿existe algún umbral que indique el flat y la tendencia (sea esta alcista o bajista)? Obviamente, si la línea del indicador es horizontal, el mercado será plano. Pero, ¿a qué altura de la inclinación siguen siendo insignificantes los cambios y el mercado todavía se considera plano, y desde qué altura podemos hablar de una tendencia? Imaginemos que el asesor ve solo un número en el que se concentra la imagen completa del gráfico, pero no ve la imagen general, como podemos ver en la captura de pantalla anterior. Este problema se resuelve usando el análisis de clústeres. Pero antes de continuar, vamos primero a analizar los cambios realizados en el indicador.
Cambios del indicador
Como debemos modificar el indicador lo mínimo posible, hemos trasladado la agrupación en clústeres al archivo externo ClusterTrend.mqh, conectado al comienzo del indicador:
Obviamente, el archivo se adjunta al artículo. Pero esto solo no es suficiente. Para simplificar nuestros esfuerzos, hemos añadido la variable NumValues:
input int NumValues = 1;
Un valor 1 indica que solo se debe analizar un tipo de valor. Por ejemplo, si deseamos analizar un indicador que calcula dos promedios y queremos valorar la inclinación de ambos, así como la distancia entre ellos, NumValues deberá ser 3. Luego, la matriz usada para el cálculo se ajustará automáticamente. Si el valor es cero, no se realizará ningún análisis de clústeres. Podemos desactivar fácilmente esta carga adicional en la configuración.
Además, tenemos las variables globales:
string ShortName;
long StopWatch=0;
ShortName – nombre breve del indicador OnInit():
ShortName = "HalfTrd "+(string)Amplitude;
IndicatorSetString(INDICATOR_SHORTNAME,ShortName);
que se usará para la identificación al imprimir los resultados.
StopWatch se utiliza para seleccionar la hora. Se establece justo antes del primer valor transmitido para el análisis de clústeres y se lee después de que se impriman los resultados:
if (StopWatch==0) StopWatch = GetTickCount64();
...
if (StopWatch!=0) StopWatch = GetTickCount64()-StopWatch;
Como la mayoría de los otros indicadores, HalfTrend tiene un gran ciclo para todas las barras disponibles en la historia de precios. El indicador calcula sus valores de manera que la barra del gráfico con el índice iB = 0 contenga los precios actuales, así como los últimos recibidos, mientras que el índice más grande posible representa el comienzo de la historia de precios (las barras más antiguas). Antes del que finalice su ciclo, el valor analizado es calculado y envíado a la función de clúster para su valoración. Todo el trabajo allí está automatizado. Mostraremos los detalles más abajo.
En el bloque de código justo antes del final del ciclo, deberemos asegurarnos de que el análisis de clúster con los precios históricos se realice solo una vez para cada barra, y no cada vez que llegue un nuevo precio:
//+------------------------------------------------------------------+
//| added for cluster analysis |
//+------------------------------------------------------------------+
if ( (prev_calculated == 0 && iB > 0 ) // we don't use the actual bar
|| (prev_calculated > 9 && iB == 1)) // during operation we use the second to last bar: iB = 1
{
A continuación, verificamos que esta sea la primera barra de inicialización para configurar el temporizador y restablecer los resultados anteriores (si los ha habido):
if (prev_calculated==0 && iB==limit) { // only at the very first pass/bar
StopWatch = GetTickCount64(); // start the stop whatch
if (ArraySize(Cluster) > 0) ArrayResize(Cluster,0); // in case everything is recalculated delete prev. results
}
Luego, determinamos el valor del indicador usando los índices de las barras actual iB y anterior (iB+1). Como la línea de indicador es de dos colores (ver arriba) y ha sido implementada usando dos búferes up[] y down[], uno de los cuales es siempre 0.0, y por lo tanto no se muestra, el valor del indicador será el búfer que se encuentra por encima de cero:
double actBar = fmax(up[iB], down[iB]), // get actual indi. value of bar[iB]
prvBar = fmax(up[iB+1], down[iB+1]); // get prev. indi. value
Para asegurarnos de que los valores al inicio del cálculo influyen en los resultados del análisis de clústeres (aunque el indicador no se haya calculado en absoluto), introduciremos el siguiente control de seguridad:
if ( (actBar+prvBar) < _Point ) continue; // skip initially or intermediately missing quotes
Ahora podemos transmitir la diferencia absoluta de los valores actual y anterior del indicador.
enterVal(fabs(actBar-prvBar)/_Point, // abs. of slope of the indi. line
0, // index of the value type
1.0 - (double)iB/(double)rates_total, // learning rate: use either 1-iB/rates_total or iB/rates_total whatever runs from 0 .. 1
NumValues // used for initialization (no. of value types) and if < 1 no clustering
);
¿Por qué utilizamos la diferencia absoluta fabs(actBar-prvBar) en el primer argumento? Si transmitiéramos la diferencia pura, tendríamos que determinar una cantidad de clústeres dos veces superior (para los valores mayores y menores que cero). Entonces, también resultaría relevante si un precio ha subido o bajado en general dentro de la historia de precios disponible, y eso podría distorsionar los resultados. En última instancia, lo que importa (en nuestro caso) es la intensidad de la inclinación, no su dirección. En el mercado de divisas, parece razonable suponer que los altibajos de los precios son equivalentes en cierto grado, quizás diferentes a los del mercado de valores.
El segundo argumento (0), es el índice del tipo de valor transmitido (0=primero, 1=segundo,..). Por ejemplo, con dos líneas de indicador y su diferencia, necesitaríamos establecer 0, 1 y 2 para el valor respectivo.
El tercer argumento
1.0 - (double)iB/(double)rates_total, // learning rate: use either 1-iB/rates_total or iB/rates_total whatever runs from 0 .. 1
se refiere a la tasa de aprendizaje. El índice iB va desde el valor más grande hasta 0. rates_total es el número total de todas las barras. Por consiguiente, iB/rates_total supone la relación de lo que aún no se ha calculado, y cae de casi 1 (nada calculado) a cero (todo calculado). En consecuencia, 1 menos este valor aumentará de casi 0 (todavía no se ha analizado nada) a 1 (se ha analizado todo). Explicaremos la importancia de esta relación un poco más abajo.
El último parámetro es necesario para la inicialización, así como para determinar si debemos calcular los clústeres. Si es mayor que cero, indicará (ver arriba) el número de tipos de valor, por ejemplo, de las líneas de indicador, determinando así el tamaño de la primera dimensión de la matriz global Cluster[]][] en el archivo ClusterTrend.mqh (ver arriba).
Al final de un gran ciclo a lo largo de toda la historia de precios, se muestran inmediatamente todos los resultados en la pestaña de asesores, una línea para cada categoría/clúster:
prtStdDev(_Symbol+" "+EnumToString(Period())+" "+ShortName, // printed at the beginning of each line
0, // the value type to be printed
NumValues); // if <=0 this value type is not printed
Aquí, el primer argumento se encarga de representar la información y se imprime al comienzo de cada línea; el segundo (0), muestra el tipo de indicador calculado (0=primero, 1=segundo,...). A esto le sigue NumValues. Si es igual a 0, este tipo de indicador no se muestra.
En su totalidad, el bloque añadido tiene el aspecto que sigue:
//+------------------------------------------------------------------+ //| added for cluster analysis | //+------------------------------------------------------------------+ if ( (prev_calculated == 0 && iB > 0 ) // we don't use the actual bar || (prev_calculated > 9 && iB == 1)) // during operation we use the second to last bar: iB = 1 { if (prev_calculated==0 && iB==limit) { // only at the very first pass/bar StopWatch = GetTickCount64(); // start the stop whatch if (ArraySize(Cluster) > 0) ArrayResize(Cluster,0); // in case everything is recalculated delete prev. results } double actBar = fmax(up[iB], down[iB]), // get actual indi. value of bar[iB] prvBar = fmax(up[iB+1], down[iB+1]); // get prev. indi. value if ( (actBar+prvBar) < _Point ) continue; // skip initially or intermediately missing quotes enterVal(fabs(actBar-prvBar)/_Point, // abs. of slope of the indi. line 0, // index of the value type 1.0 - (double)iB/(double)rates_total, // learning rate: use either 1-iB/rates_total or iB/rates_total whatever runs from 0 .. 1 NumValues // used for initialization (no. of value types) and if < 1 no clustering ); } //+------------------------------------------------------------------+ } // end of big loop: for(iB = limit; iB >= 0; iB--) .. //+------------------------------------------------------------------+ //| added for cluster analysis | //+------------------------------------------------------------------+ if (prev_calculated < 1) // print only once after initialization { prtStdDev(_Symbol+" "+EnumToString(Period())+" "+ShortName, // printed at the beginning of each line 0, // the value type to be printed NumValues); // if <=0 this value type is not printed if (StopWatch!=0) StopWatch = GetTickCount64()-StopWatch; Print ("Time needed for ",rates_total," bars on a PC with ",TerminalInfoInteger(TERMINAL_CPU_CORES), " cores and Ram: ",TerminalInfoInteger(TERMINAL_MEMORY_PHYSICAL),", Time: ", TimeToString(StopWatch/1000,TIME_SECONDS),":",StringFormat("%03i",StopWatch%1000) ); } //+------------------------------------------------------------------+
Estos son todos los cambios que queríamos introducir en el indicador.
Análisis de clústeres en el archivo ClusterTrend.mqh
El archivo se encuentra en la misma carpeta que el indicador, por eso tenemos que incluirlo como ClusterTrend.mqh.
En la parte inicial existen simplificaciones relacionadas con #define. #define crash(strng) provoca deliberadamente la división entre 0, que el compilador no reconoce, porque el indicador (¿todavía?) no puede completar su propio trabajo. Al menos alert(), que notifica una especificación de dimensión incorrecta, se llama solo una vez. Debemos arreglar esto y compilar de nuevo el indicador.
Ya hemos descrito anteriormente la estructura de datos usada para este análisis.
Vamos a analizar la esencia de este enfoque.
El valor promedio y la varianza, así como el análisis de clústeres, utiliza los datos generalmente disponibles. Primero debemos recopilar los datos. A continuación, se realiza la agrupación en clústeres en uno o más ciclos. Tradicionalmente, el promedio de todos los valores anteriores (que llegan sucesivamente unos tras otros) se calcula en un segundo ciclo en los grandes datos totales para la suma. Y eso requiere mucho tiempo. Sin embargo, hemos podido encontrar un artículo de Tony Finch "Cálculo incremental del promedio ponderado y la varianza" (en inglés), en el que el autor calcula el promedio y la varianza de forma incremental, es decir, en una sola pasada sobre todos los datos, en lugar de sumar todos los datos y luego dividir la suma por el número de valores. De esta manera, el nuevo valor promedio (simple) para todos los valores anteriores, incluido el recién transmitido, se calcula usando la fórmula (4), p. 1:
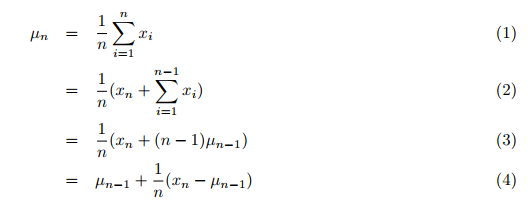
donde:
- µn = valor promedio actualizado,
- µn-1 = valor promedio anterior,
- n = número actual de valores (incluyendo el nuevo),
- xn = nuevo n-ésimo valor.
Incluso la varianza se calcula sobre la marcha, y no en un segundo ciclo después del promedio. Luego se calcula la varianza incremental (fórmulas 24, 25; p. 3):
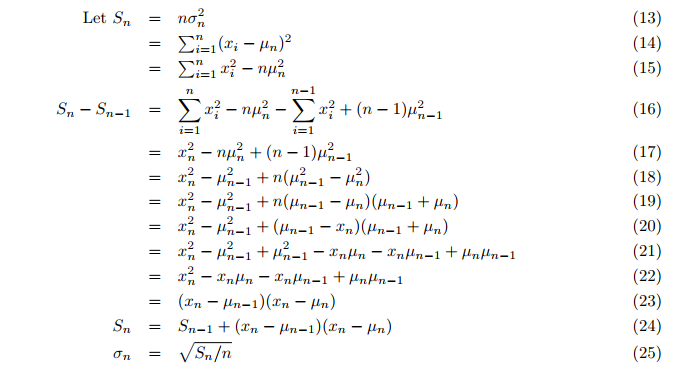
donde:
- Sn = valor actualizado de la variable auxiliar S,
- σ = varianza.
Por consiguiente, el promedio y la varianza del conjunto general se pueden calcular en una pasada, actualizando cada vez el último valor nuevo en la función incrStdDeviation(..):
Partiendo de esto, podemos usar un promedio calculado de dicha forma para realizar la clasificación después de la primera parte de los datos históricos. Podríamos preguntarnos, ¿por qué no usar simplemente una media móvil que produzca resultados útiles de forma rápida y sencilla con pocos datos? La media móvil varía. Y con fines clasificatorios, necesitaríamos un valor de comparación relativamente constante. Imaginemos que necesitamos medir el nivel del agua en un río. Está claro que el valor comparativo del nivel normal del agua no debería cambiar con la altura actual. Concretamente, durante las tendencias fuertes, las diferencias en la media móvil también aumentan, y la diferencia con este valor se vuelve innecesariamente menor. Cuando el mercado se estabiliza, el promedio también disminuye, lo cual incrementa la diferencia respecto al valor básico. Por consiguiente, necesitamos un valor muy estable que suponga el promedio del valor máximo posible.
Finalmente, hemos llegado a la agrupación en clústeres. Normalmente, todos los valores se usan para formar clústeres. No obstante, el cálculo incremental del valor promedio nos da otra opción: podemos usar el 50% más antiguo de los datos históricos para el promedio y el 50% más reciente para agrupar los clústeres (continuando con el promedio). Aquí denominamos tasa de aprendizaje este porcentaje (50%) en el sentido de que el promedio se "aprende" solo hasta el 50%. Aunque su cálculo no se detiene tras llegar al 50%, ahora resulta tan estable que da buenos resultados. Sin embargo, el hecho de introducir el 50% constituye esencialmente una decisión arbitraria del autor, por lo que hemos intorducido otros dos promedios de comparación: el 25% y el 75%. Estos empiezan a calcular su promedio después de alcanzar su tasa de aprendizaje. Gracias a ello, podemos ver en qué dirección se da la inclinación y cuánto ha cambiado esta.
Creando el valor promedio y los clústeres
Casi todo está controlado por la función enterVal() del archivo ClusterTrend.mqh:
//+------------------------------------------------------------------+ //| | //| enter a new value | //| | //+------------------------------------------------------------------+ // use; enterVal( fabs(indi[i]-indi[i-1]), 0, (double)iB/(double)rates_total ) void enterVal(const double val, const int iLne, const double learn, const int NoVal) { if (NoVal<=0) return; // nothing to do if true if( ArrayRange(Cluster,0)<NoVal || Cluster[iLne][0].n <= 0 ) // need to initialize setStattID(NoVal); incrStdDeviation(val, Cluster[iLne][0]); // the calculation from the first to the last bar if(learn>0.25) incrStdDeviation(val, Cluster[iLne][1]); // how does µ varies after 25% of all bars if(learn>0.5) incrStdDeviation(val, Cluster[iLne][2]); // how does µ varies after 50% of all bars if(learn>0.75) incrStdDeviation(val, Cluster[iLne][3]); // how does µ varies after 75% of all bars if(learn<0.5) return; // I use 50% to learn and 50% to develop the categories int i; if (Cluster[iLne][0].µ < _Point) return; // avoid division by zero double pc = val/(Cluster[iLne][0].µ); // '%'-value of the new value compared to the long term µ of Cluster[0].. for(i=0; i<ArraySize(CatCoeff); i++) { if(pc <= CatCoeff[i]) { incrStdDeviation(val, Cluster[iLne][i+4]); // find the right category return; } } i = ArraySize(CatCoeff); incrStdDeviation(val, Cluster[iLne][i+4]); // tooo big? it goes to the last category }
val es el valor recibido del indicador, iLine es el índice del tipo de valor, learn es la tasa de aprendizaje o la relación trabajo/historia. Finalmente, NoVal nos permite saber cuántos tipos de valores (si los hay) debemos calcular.
Primero, verificamos (NoVal<=0), es decir, si el agrupamiento en clústeres es intencional o no.
Luego, miramos (ArrayRange(Cluster,0) < NoVal), es decir, si la primera dimensión de la matriz es Cluster[][], el tamaño de los tipos de valor a calcular. De lo contrario, efectuaremos la inicialización: todos los valores se ponen a cero y el identificador es asignado por la función setStattID(NoVal) (ver a continuación).
Queremos que la cantidad de código sea pequeña y no resulte difícil de aplicar. Además, esto nos permitirá recordarlo rápidamente después de un tiempo. Así, el valor val se asigna a la estructura de datos correspondiente usando la propia función incrStdDeviation(val, Cluster[][]) y se procesa allí.
La función incrStdDeviation(val, Cluster[iLne][0]) calcula el promedio desde el primer valor hasta el último. Como ya hemos mencionado, el primer índice [iLine] denota el tipo de valor, y el segundo índice [0] indica la estructura de datos del tipo de valor a calcular. Como ya sabemos, necesitamos 5 elementos más de los que hay en la matriz estática CatCoeff[9]. Ahora podemos ver por qué:
- [0] .. [3] son necesarios para los diferentes valores promedio [0]:100%, [1]:25%, [2]:50%, [3]:75%,
- [4] .. [12] son necesarios para las 9 categorías CatCoeff[9]: 0.0, .., 7.87
- [13] es necesario como última categoría para los valores superiores a la categoría más grande CatCoeff[8] (en este caso 7.87).
Ahora podemos ver por qué necesitamos un promedio estable. Para encontrar una categoría o clúster, calcularemos la relación val/Cluster[iLne][0].µ. Este es el promedio general del tipo con índice iLine. Por consiguiente, los coeficientes de la matriz CatCoeff[] son los multiplicadores del promedio total si la ecuación se transforma:
pc = val/µ => pc*µ = val
Esto significa que no solo predefinimos el número de clústeres (esto es necesario para la mayoría de los métodos de agrupación en clústeres): también predefinimos las propiedades de los clústeres, lo cual resulta bastante inusual, pero precisamente por ello este método de agrupación en clústeres solo requiere una pasada, mientras que otros métodos requieren varias pasadas usando todos los datos para encontrar las propiedades óptimas de los clústeres (ver arriba). El primer coeficiente (CatCoeff [0]) es igual a cero. Lo hemos seleccionado porque el indicador HalfTrend está diseñado para ejecutar varias barras horizontalmente, por lo que la diferencia en los valores del indicador en este caso será cero. Por consiguiente, esperamos que esta categoría aumente hasta un tamaño significativo. Todas las demás denominaciones se cumplirán, siempre que:
pc <= CatCoeff[i] => val/µ <= CatCoeff[i] => val <= CatCoeff[i]*µ.
Como no podemos evitar los valores atípicos que destruirían las categorías especificadas en CatCoeff[], existe una categoría adicional para dichos valores:
i = ArraySize(CatCoeff);
incrStdDeviation(val, Cluster[iLne][i+4]); // tooo big? it goes to the last category
Evaluación y visualización de resultados
Inmediatamente después de finalizar el gran ciclo del indicador, y solo durante la primera pasada (prev_calculated <1), los resultados se imprimen en el diario de registro usando prtStdDev(), luego StopWatch se detiene y también se representa:
//+------------------------------------------------------------------+ //| added for cluster analysis | //+------------------------------------------------------------------+ if (prev_calculated < 1) { prtStdDev(_Symbol+" "+EnumToString(Period())+" "+ShortName, 0, NumValues); if (StopWatch!=0) StopWatch = GetTickCount64()-StopWatch; Print ("Time needed for ",rates_total," bars on a PC with ",TerminalInfoInteger(TERMINAL_CPU_CORES), " cores and ",TerminalInfoInteger(TERMINAL_MEMORY_PHYSICAL)," Ram: ",TimeToString(StopWatch/1000,TIME_SECONDS)); } //+------------------------------------------------------------------+
prtStdDev(..) primero muestra el encabezado con HeadLineIncrStat(pre) y luego, para cada tipo de valor (índice iLine), los 14 resultados en cada línea usando retIncrStat():
void prtStdDev(const string pre, int iLne, const int NoVal) { if (NoVal <= 0 ) return; // if true no printing if (Cluster[iLne][0].n==0 ) return; // no values entered for this 'line' HeadLineIncrStat(pre); // print the headline int i,tot = 0,sA=ArrayRange(Cluster,1), sC=ArraySize(CatCoeff); for(i=4; i<sA; i++) tot += (int)Cluster[iLne][i].n; // sum up the total volume of all but the first [0] category retIncrStat(Cluster[iLne][0].n, pre, "learn 100% all["+(string)sC+"]", Cluster[iLne][0], 1, Cluster[iLne][0].µ); // print the base the first category [0] retIncrStat(Cluster[iLne][1].n, pre, "learn 25% all["+(string)sC+"]", Cluster[iLne][1], 1, Cluster[iLne][0].µ); // print the base the first category [0] retIncrStat(Cluster[iLne][2].n, pre, "learn 50% all["+(string)sC+"]", Cluster[iLne][2], 1, Cluster[iLne][0].µ); // print the base the first category [0] retIncrStat(Cluster[iLne][3].n, pre, "learn 75% all["+(string)sC+"]", Cluster[iLne][3], 1, Cluster[iLne][0].µ); // print the base the first category [0] for(i=4; i<sA-1; i++) { retIncrStat(tot, pre,"Cluster["+(string)(i)+"] (<="+_d22(CatCoeff[i-4])+")", Cluster[iLne][i], 1, Cluster[iLne][0].µ); // print each category } retIncrStat(tot, pre,"Cluster["+(string)i+"] (> "+_d22(CatCoeff[sC-1])+")", Cluster[iLne][i], 1, Cluster[iLne][0].µ); // print the last category }
Aquí, tot += (int)Cluster[iLne][i].n es el número de valores en las categorías 4-13 sumados para obtener un valor comparativo (100%) para estas categorías. Los datos representados se muestran a continuación:
GBPUSD PERIOD_D1 HalfTrd 2 ID Cluster Num. (tot %) µ (mult*µ) σ (Range %) min - max GBPUSD PERIOD_D1 HalfTrd 2 100100 learn 100% all[9] 7266 (100.0%) 217.6 (1.00*µ) 1800.0 (1.21%) 0.0 - 148850.0 GBPUSD PERIOD_D1 HalfTrd 2 100025 learn 25% all[9] 5476 (100.0%) 212.8 (0.98*µ) 470.2 (4.06%) 0.0 - 11574.0 GBPUSD PERIOD_D1 HalfTrd 2 100050 learn 50% all[9] 3650 (100.0%) 213.4 (0.98*µ) 489.2 (4.23%) 0.0 - 11574.0 GBPUSD PERIOD_D1 HalfTrd 2 100075 learn 75% all[9] 1825 (100.0%) 182.0 (0.84*µ) 451.4 (3.90%) 0.0 - 11574.0 GBPUSD PERIOD_D1 HalfTrd 2 400000 Cluster[4] (<=0.00) 2410 ( 66.0%) 0.0 (0.00*µ) 0.0 0.0 - 0.0 GBPUSD PERIOD_D1 HalfTrd 2 500033 Cluster[5] (<=0.33) 112 ( 3.1%) 37.9 (0.17*µ) 20.7 (27.66%) 1.0 - 76.0 GBPUSD PERIOD_D1 HalfTrd 2 600076 Cluster[6] (<=0.76) 146 ( 4.0%) 124.9 (0.57*µ) 28.5 (26.40%) 75.0 - 183.0 GBPUSD PERIOD_D1 HalfTrd 2 700132 Cluster[7] (<=1.32) 171 ( 4.7%) 233.3 (1.07*µ) 38.4 (28.06%) 167.0 - 304.0 GBPUSD PERIOD_D1 HalfTrd 2 800204 Cluster[8] (<=2.04) 192 ( 5.3%) 378.4 (1.74*µ) 47.9 (25.23%) 292.0 - 482.0 GBPUSD PERIOD_D1 HalfTrd 2 900298 Cluster[9] (<=2.98) 189 ( 5.2%) 566.3 (2.60*µ) 67.9 (26.73%) 456.0 - 710.0 GBPUSD PERIOD_D1 HalfTrd 2 1000421 Cluster[10] (<=4.21) 196 ( 5.4%) 816.6 (3.75*µ) 78.9 (23.90%) 666.0 - 996.0 GBPUSD PERIOD_D1 HalfTrd 2 1100580 Cluster[11] (<=5.80) 114 ( 3.1%) 1134.9 (5.22*µ) 100.2 (24.38%) 940.0 - 1351.0 GBPUSD PERIOD_D1 HalfTrd 2 1200787 Cluster[12] (<=7.87) 67 ( 1.8%) 1512.1 (6.95*µ) 136.8 (26.56%) 1330.0 - 1845.0 GBPUSD PERIOD_D1 HalfTrd 2 1300999 Cluster[13] (> 7.87) 54 ( 1.5%) 2707.3 (12.44*µ) 1414.0 (14.47%) 1803.0 - 11574.0 Time needed for 7302 bars on a PC with 12 cores and Ram: 65482, Time: 00:00:00:016
¿Qué vemos? Vamos a pasar de una columna a otra. La primera columna contiene el símbolo, el marco temporal, el nombre del indicador y su "Amplitud" (Amplitude), como se especifica en ShortName. La segunda columna muestra el ID de cada estructura de datos. 100nnn indica que esto es solo un cálculo promedio con los últimos tres dígitos que muestran la tasa de aprendizaje (100, 25, 50 y 75). 400nnn .. 1300nnn son las categorías, grupos o montones. Aquí, los últimos tres dígitos indican la categoría o el multiplicador del promedio µ, que también se muestra en la tercera columna, Cluster, entre paréntesis. Todo esto está claro y se explica por sí solo.
Ahora viene la parte divertida. La cuarta columna muestra el número de valores en la categoría correspondiente y el porcentaje entre paréntesis. Curiosamente, el indicador se encuentra en posición horizontal la mayor parte del tiempo (categoría #4 - 2409 barras o el 66.0% de los días), es decir, comerciar en un rango podría tener éxito dos tercios del tiempo. No obstante, hubo más máximos (locales) en las categorías #8, #9 y #10, mientras que, sorprendentemente, hubo pocos valores en la categoría #5 (112, 3,1%). Y ahora este hecho puede interpretarse como una brecha entre dos valores umbral, . que nos da los siguientes valores aproximados:
si fabs(slope) < 0.5*µ => el mercado será plano, y necesitaremos comerciar en el rango
si fabs(slope) > 1.0*µ => el mercado estará en tendencia, y necesitaremos subirnos a la ola
Las primeras 4 líneas con identificadores 100nnn nos permiten valorar la estabilidad del valor µ. Como ya hemos dicho, no queremos un valor que fluctúe demasiado. Podemos ver que µ disminuye de 217,6 (pips por día) con 100100 hasta 182,1 con 100075 (para un µ dado, sólo se utiliza el último 25% de los valores), o el 16%. No es demasiado, a nuestro juicio. ¿Qué nos dice esto? La volatilidad de GBPUSD ha disminuido. El primer valor de esta categoría está fechado el 28.05.2014 00:00:00. Quizás deberíamos considerar esto.
Al calcular el promedio, la varianza σ muestra información valiosa, lo que nos lleva a la columna 6 (σ (Range %)). Esta muestra cómo de cerca están los valores individuales respecto al promedio. Para los valores distribuidos normalmente, el 68% de todos los valores está dentro de la varianza. En términos de varianza, esto significa que cuanto menor sea, más preciso (más claro) será el valor promedio. La relación σ/(máx-mín) de las dos últimas columnas se muestra entre paréntesis. También supone una medida de la calidad de la varianza y el promedio.
Ahora vamos a ver si los resultados de GBPUSD D1 se repiten en los marcos temporales más pequeños, en particular en M15. Para hacerlo, simplemente cambiaremos el marco temporal del gráfico de D1 a M15:
GBPUSD PERIOD_M15 HalfTrd 2 ID Cluster Num. (tot %) µ (mult*µ) σ (Range %) min - max GBPUSD PERIOD_M15 HalfTrd 2 100100 learn 100% all[9] 556389 (100.0%) 18.0 (1.00*µ) 212.0 (0.14%) 0.0 - 152900.0 GBPUSD PERIOD_M15 HalfTrd 2 100025 learn 25% all[9] 417293 (100.0%) 18.2 (1.01*µ) 52.2 (1.76%) 0.0 - 2971.0 GBPUSD PERIOD_M15 HalfTrd 2 100050 learn 50% all[9] 278195 (100.0%) 15.9 (0.88*µ) 45.0 (1.51%) 0.0 - 2971.0 GBPUSD PERIOD_M15 HalfTrd 2 100075 learn 75% all[9] 139097 (100.0%) 15.7 (0.87*µ) 46.1 (1.55%) 0.0 - 2971.0 GBPUSD PERIOD_M15 HalfTrd 2 400000 Cluster[4] (<=0.00) 193164 ( 69.4%) 0.0 (0.00*µ) 0.0 0.0 - 0.0 GBPUSD PERIOD_M15 HalfTrd 2 500033 Cluster[5] (<=0.33) 10528 ( 3.8%) 3.3 (0.18*µ) 1.7 (33.57%) 1.0 - 6.0 GBPUSD PERIOD_M15 HalfTrd 2 600076 Cluster[6] (<=0.76) 12797 ( 4.6%) 10.3 (0.57*µ) 2.4 (26.24%) 6.0 - 15.0 GBPUSD PERIOD_M15 HalfTrd 2 700132 Cluster[7] (<=1.32) 12981 ( 4.7%) 19.6 (1.09*µ) 3.1 (25.90%) 14.0 - 26.0 GBPUSD PERIOD_M15 HalfTrd 2 800204 Cluster[8] (<=2.04) 12527 ( 4.5%) 31.6 (1.75*µ) 4.2 (24.69%) 24.0 - 41.0 GBPUSD PERIOD_M15 HalfTrd 2 900298 Cluster[9] (<=2.98) 11067 ( 4.0%) 47.3 (2.62*µ) 5.5 (23.91%) 37.0 - 60.0 GBPUSD PERIOD_M15 HalfTrd 2 1000421 Cluster[10] (<=4.21) 8931 ( 3.2%) 67.6 (3.75*µ) 7.3 (23.59%) 54.0 - 85.0 GBPUSD PERIOD_M15 HalfTrd 2 1100580 Cluster[11] (<=5.80) 6464 ( 2.3%) 94.4 (5.23*µ) 9.7 (23.65%) 77.0 - 118.0 GBPUSD PERIOD_M15 HalfTrd 2 1200787 Cluster[12] (<=7.87) 4390 ( 1.6%) 128.4 (7.12*µ) 12.6 (22.94%) 105.0 - 160.0 GBPUSD PERIOD_M15 HalfTrd 2 1300999 Cluster[13] (> 7.87) 5346 ( 1.9%) 241.8 (13.40*µ) 138.9 (4.91%) 143.0 - 2971.0 Time needed for 556391 bars on a PC with 12 cores and Ram: 65482, Time: 00:00:00:140
Obviamente, la inclinación media ahora es mucho menor. Baja de 217,6 pips por día a 18,0 pips en 15 minutos. Pero aquí también podemos ver un comportamiento similar:
si fabs(slope) < 0.5*µ => el mercado será plano, y necesitaremos comerciar en el rango
si fabs(slope) > 1.0*µ => el mercado estará en tendencia, y necesitaremos subirnos a la ola
Todo lo demás en relación con la interpretación del marco temporal de días mantiene su relevancia.
Conclusión
Usando el indicador HalfTrend como ejemplo, hemos demostrado que la categorización simple o el análisis de clústeres pueden ofrecer información muy valiosa sobre el comportamiento del indicador, que de otro modo requeriría recursos computacionales demasiado costosos. Normalmente, el promedio y la varianza se calculan en ciclos separados seguidos de ciclos adicionales para la agrupación en clústeres. Aquí hemos organizado todo en un gran ciclo que también calcula el indicador. La primera parte de los datos se usa para el entrenamiento, y la segunda para aplicar lo aprendido. Y todo esto en menos de un segundo, incluso usando una gran cantidad de datos. Esto nos permite mostrar información de forma operativa, lo cual resulta especialmente valioso para el trading.
Todo está pensado para que los usuarios puedan insertar rápida y fácilmente en su propio indicador las líneas de código necesarias para dicho análisis. Esto no solo permitirá probar si un indicador de usuario puede determinar el estado actual del mercado, sino que también ofrecerá pautas para el desarrollo posterior de ideas propias.
¿Qué es lo próximo?
En el próximo artículo, aplicaremos este enfoque a los indicadores estándar. Esto nos permitirá mirarlos de una manera nueva y ampliar su interpretación. También ofreceremos ejemplos sobre cómo proceder si deseamos usar este kit de herramientas nosotros mismos.
Traducción del inglés realizada por MetaQuotes Ltd.
Artículo original: https://www.mql5.com/en/articles/9527
- Aplicaciones de trading gratuitas
- 8 000+ señales para copiar
- Noticias económicas para analizar los mercados financieros
Usted acepta la política del sitio web y las condiciones de uso