
Gradient boosting (CatBoost) en las tareas de construcción de sistemas comerciales. Un enfoque ingenuo

Introducción
El gradient boosting o potenciación del gradiente es un potente algoritmo de aprendizaje de máquinas. La esencia del método consiste en construir un conjunto de modelos débiles (por ejemplo, árboles de toma de decisiones) en los que (a diferencia del bagging) los modelos no se construyen independientemente (paralelamente), sino secuencialmente. Esto significa que el siguiente árbol aprenderá de los errores del árbol precedente, y luego se repitirá el proceso, aumentando el número de modelos débiles. De esta forma, obtendremos un modelo fuerte que puede generalizarse usando datos heterogéneos. En este experimento, se usa la biblioteca CatBoost de la compañía Yándex, como una de las más populares junto con XGboost y LightGBM.
El objetivo del artículo es mostrar la creación de un modelo basado en el aprendizaje de máquinas. Constará de las siguientes etapas:
- obtención y preprocesamiento de datos,
- entrenamiento del modelo con los datos preparados,
- simulación del modelo en un simulador de estrategias personalizado,
- traslado del modelo a MetaTrader 5.
Para preparar los datos y entrenar el modelo, se usan el lenguaje de programación Python y la biblioteca MetaTrader5.
Preparando los datos
Importamos los módulos de Python necesarios:
import MetaTrader5 as mt5 import pandas as pd import numpy as np from datetime import datetime import random import matplotlib.pyplot as plt from catboost import CatBoostClassifier from sklearn.model_selection import train_test_split mt5.initialize() # check for gpu devices is availible from catboost.utils import get_gpu_device_count print('%i GPU devices' % get_gpu_device_count())
A continuación, inicializamos las variables globales:
LOOK_BACK = 250 MA_PERIOD = 15 SYMBOL = 'EURUSD' MARKUP = 0.0001 TIMEFRAME = mt5.TIMEFRAME_H1 START = datetime(2020, 5, 1) STOP = datetime(2021, 1, 1)
Estos son los parámetros y su función, por orden:
- look_back — profundidad de la historia analizada, en barras;
- ma_period — periodo de la media móvil para calcular los incrementos de precio;
- symbol — las cotizaciones de cada símbolo deben ser cargadas desde el terminal MetaTrader 5;
- markup — tamaño del spread para el simulador personalizado;
- timeframe — marco temporal cuyos datos serán cargados;
- start, stop — intervalo de datos.
Vamos a escribir una función que se encargue de recibir los datos sin procesar y también de crear un frame de datos que contenga las columnas necesarias para entrenar el modelo:
def get_prices(look_back = 15): prices = pd.DataFrame(mt5.copy_rates_range(SYMBOL, TIMEFRAME, START, STOP), columns=['time', 'close']).set_index('time') # set df index as datetime prices.index = pd.to_datetime(prices.index, unit='s') prices = prices.dropna() ratesM = prices.rolling(MA_PERIOD).mean() ratesD = prices - ratesM for i in range(look_back): prices[str(i)] = ratesD.shift(i) return prices.dropna()
La función recibe los precios de cierre del periodo temporal indicado y calcula la media móvil; después, calcula los incrementos (la diferencia entre los precios y la media móvil). En la etapa final, se crean columnas adicionales con filas desplazadas hacia atrás según la profundidad de look_back, lo que indica la adición de características adicionales (rezagadas) al modelo.
Por ejemplo, para look_back = 10, el frame de datos contendrá 10 columnas adicionales con incrementos de precio:
>>> pr = get_prices(look_back=LOOK_BACK) >>> pr close 0 1 2 3 4 5 6 7 8 9 time 2020-05-01 16:00:00 1.09750 0.001405 0.002169 0.001600 0.002595 0.002794 0.002442 0.001477 0.001190 0.000566 0.000285 2020-05-01 17:00:00 1.10074 0.004227 0.001405 0.002169 0.001600 0.002595 0.002794 0.002442 0.001477 0.001190 0.000566 2020-05-01 18:00:00 1.09976 0.002900 0.004227 0.001405 0.002169 0.001600 0.002595 0.002794 0.002442 0.001477 0.001190 2020-05-01 19:00:00 1.09874 0.001577 0.002900 0.004227 0.001405 0.002169 0.001600 0.002595 0.002794 0.002442 0.001477 2020-05-01 20:00:00 1.09817 0.000759 0.001577 0.002900 0.004227 0.001405 0.002169 0.001600 0.002595 0.002794 0.002442 ... ... ... ... ... ... ... ... ... ... ... ... 2020-11-02 23:00:00 1.16404 0.000400 0.000105 -0.000581 -0.001212 -0.000999 -0.000547 -0.000344 -0.000773 -0.000326 0.000501 2020-11-03 00:00:00 1.16392 0.000217 0.000400 0.000105 -0.000581 -0.001212 -0.000999 -0.000547 -0.000344 -0.000773 -0.000326 2020-11-03 01:00:00 1.16402 0.000270 0.000217 0.000400 0.000105 -0.000581 -0.001212 -0.000999 -0.000547 -0.000344 -0.000773 2020-11-03 02:00:00 1.16423 0.000465 0.000270 0.000217 0.000400 0.000105 -0.000581 -0.001212 -0.000999 -0.000547 -0.000344 2020-11-03 03:00:00 1.16464 0.000885 0.000465 0.000270 0.000217 0.000400 0.000105 -0.000581 -0.001212 -0.000999 -0.000547 [3155 rows x 11 columns]
El color amarillo se indica que cada columna tiene el mismo conjunto de datos, pero con un desplazamiento. Por consiguiente, cada línea será un ejemplo individual de entrenamiento.
Creando las etiquetas de entrenamiento (muestreo aleatorio)
Los ejemplos de entrenamiento son conjuntos de rasgos con sus etiquetas correspondientes. A la salida del modelo, deberá suministrarse alguna información que el modelo tendrá que aprender a predecir. Vamos a analizar un caso de clasificación binaria: el modelo predecirá la probabilidad de clasificar el ejemplo de entrenamiento como clase 0 o 1. De ahí deducimos por lógica que podemos asignar a los ceros y a los unos la dirección de las transacciones: comprar o vender. Dicho de otra forma: el modelo tiene que aprender a predecir la dirección de la transacción con unos parámetros de entorno dados (conjunto de rasgos).
def add_labels(dataset, min, max): labels = [] for i in range(dataset.shape[0]-max): rand = random.randint(min, max) if dataset['close'][i] >= (dataset['close'][i + rand]): labels.append(1.0) elif dataset['close'][i] <= (dataset['close'][i + rand]): labels.append(0.0) else: labels.append(0.0) dataset = dataset.iloc[:len(labels)].copy() dataset['labels'] = labels dataset = dataset.dropna() return dataset
La función add_labels establece de forma aleatoria (en un intervalo min, max) la duración de cada transacción, en barras. Modificando la duración máxima y mínima, podemos cambiar la frecuencia de muestro de las transacciones. Así, si el precio actual es superior al anterior en un número rand de barras hacia adelante, se tratará de una etiqueta de venta (1). En caso contrario, la etiqueta será igual a cero. Veamos qué aspecto tendrá el conjunto de datos después de aplicarle esta función:
>>> pr = add_labels(pr, 10, 25) >>> pr close 0 1 2 3 4 5 6 7 8 9 labels time 2020-05-01 16:00:00 1.09750 0.001405 0.002169 0.001600 0.002595 0.002794 0.002442 0.001477 0.001190 0.000566 0.000285 1.0 2020-05-01 17:00:00 1.10074 0.004227 0.001405 0.002169 0.001600 0.002595 0.002794 0.002442 0.001477 0.001190 0.000566 1.0 2020-05-01 18:00:00 1.09976 0.002900 0.004227 0.001405 0.002169 0.001600 0.002595 0.002794 0.002442 0.001477 0.001190 1.0 2020-05-01 19:00:00 1.09874 0.001577 0.002900 0.004227 0.001405 0.002169 0.001600 0.002595 0.002794 0.002442 0.001477 1.0 2020-05-01 20:00:00 1.09817 0.000759 0.001577 0.002900 0.004227 0.001405 0.002169 0.001600 0.002595 0.002794 0.002442 1.0 ... ... ... ... ... ... ... ... ... ... ... ... ... 2020-10-29 20:00:00 1.16700 -0.003651 -0.005429 -0.005767 -0.006750 -0.004699 -0.004328 -0.003475 -0.003769 -0.002719 -0.002075 1.0 2020-10-29 21:00:00 1.16743 -0.002699 -0.003651 -0.005429 -0.005767 -0.006750 -0.004699 -0.004328 -0.003475 -0.003769 -0.002719 0.0 2020-10-29 22:00:00 1.16731 -0.002276 -0.002699 -0.003651 -0.005429 -0.005767 -0.006750 -0.004699 -0.004328 -0.003475 -0.003769 0.0 2020-10-29 23:00:00 1.16740 -0.001648 -0.002276 -0.002699 -0.003651 -0.005429 -0.005767 -0.006750 -0.004699 -0.004328 -0.003475 0.0 2020-10-30 00:00:00 1.16695 -0.001655 -0.001648 -0.002276 -0.002699 -0.003651 -0.005429 -0.005767 -0.006750 -0.004699 -0.004328 1.0
Hemos añadido la columna labels, que contiene el número de la clase (0 o 1) para la compra y la venta, respectivamente. Ahora, cada ejemplo de entrenamiento o conjunto de rasgos (aquí tenemos 10 de ellos) tiene su propia etiqueta que indica con qué condiciones debemos comprar y con qué condiciones debemos vender (o a qué clase pertenece). El modelo debe tener la capacidad de recordar y generalizar estos ejemplos, que se analizarán más adelante.
Escribiendo un simulador personalizado
Como estamos hablando de un sistema comercial, sería positivo disponer de un simulador para las pruebas operativas del modelo. Más abajo, mostramos un ejemplo con un simulador de este tipo:
def tester(dataset, markup = 0.0): last_deal = int(2) last_price = 0.0 report = [0.0] for i in range(dataset.shape[0]): pred = dataset['labels'][i] if last_deal == 2: last_price = dataset['close'][i] last_deal = 0 if pred <=0.5 else 1 continue if last_deal == 0 and pred > 0.5: last_deal = 1 report.append(report[-1] - markup + (dataset['close'][i] - last_price)) last_price = dataset['close'][i] continue if last_deal == 1 and pred <=0.5: last_deal = 0 report.append(report[-1] - markup + (last_price - dataset['close'][i])) last_price = dataset['close'][i] return report
La función del simulador adopta un conjunto de datos y un 'etiquetado' (opcional), y luego comprueba el conjunto de datos al completo de una forma similar a la implementada en el simulador MetaTrader 5. En cada nueva barra, se comprueba la señal (etiqueta), y cuando esta cambia, la operación se invierte. Por consiguiente, la señal de venta sirve como señal para cerrar una posición de compra y abrir una posición de venta. Ahora, vamos a poner a prueba el anterior conjunto de datos:
pr = get_prices(look_back=LOOK_BACK) pr = add_labels(pr, 10, 25) rep = tester(pr, MARKUP) plt.plot(rep) plt.show()
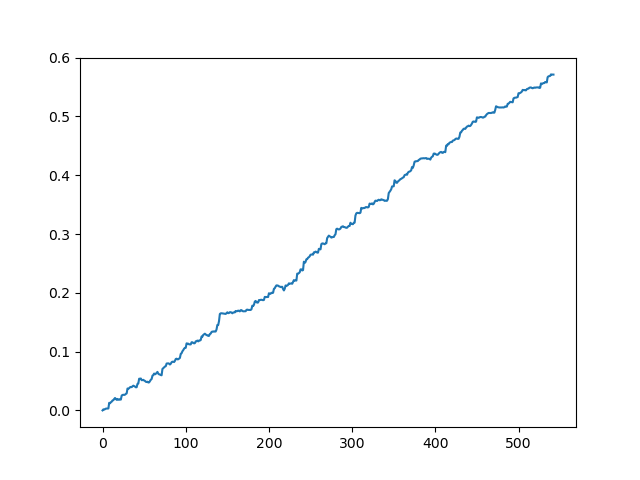
Simulamos el conjunto de datos original sin spread
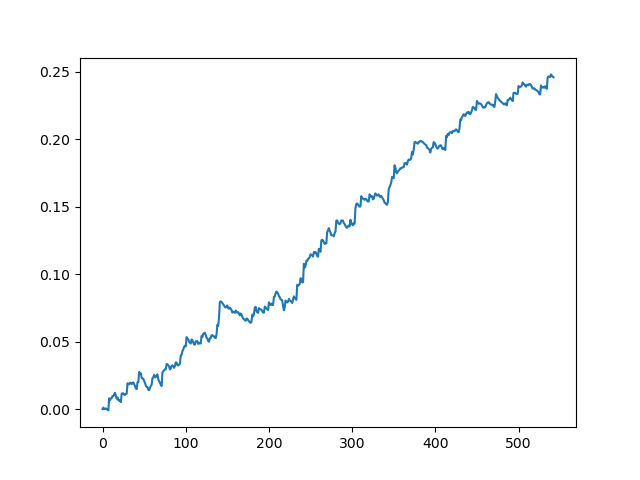
Simulación del conjunto de datos original con un spread de 70 puntos de cinco dígitos
Hemos obtenido una cierta imagen idealizada (como querríamos que fuese). Como el muestreo de etiquetas es aleatorio y depende del intervalo de los parámetros encargados de la duración mínima y máxima de las transacciones, las curvas siempre serán distintas; no obstante, todas mostrarán un buen aumento en puntos (a lo largo del eje Y) y un número distinto de transacciones (a lo largo del eje X).
Entrenando el modelo CatBoost
Vamos a pasar directamente al entrenamiento del modelo. Primero, debemos dividir el conjunto de datos en submuestras de entrenamiento y validación. Necesitamos esta separación para reducir el sobreentrenamiento del modelo. Mientras el modelo continúa aprendiendo con la submuestra de entrenamiento, minimizando el error de clasificación, el error también se mide en la submuestra de validación. Si se da una gran diferencia en estos errores, podemos decir que el modelo ha sido sobreentrenado, mientras que los valores próximos entre sí indican que el modelo se está entrenando bien.
#splitting on train and validation subsets X = pr[pr.columns[1:-1]] y = pr[pr.columns[-1]] train_X, test_X, train_y, test_y = train_test_split(X, y, train_size = 0.5, test_size = 0.5, shuffle=True)
Vamos a dividir los datos en dos conjuntos de diferente longitud, reubicando previamente de forma aleatoria los ejemplos de entrenamiento. A continuación, deberemos crear y entrenar el modelo:
#learning with train and validation subsets model = CatBoostClassifier(iterations=1000, depth=6, learning_rate=0.01, custom_loss=['Accuracy'], eval_metric='Accuracy', verbose=True, use_best_model=True, task_type='CPU') model.fit(train_X, train_y, eval_set = (test_X, test_y), early_stopping_rounds=50, plot=False)
El modelo adopta una serie de parámetros, pero aquí no se muestran todos. Para configurar el modelo de forma más precisa, podemos recurrir a la documentación, pero, por lo general, no resulta necesario. CatBoost funciona bien desde el primer momento, con unos ajustes mínimos.
Vamos a describir brevemente los parámetros del modelo:
- iterations — número máximo de árboles en el modelo. Dado que, con cada iteración, el modelo genera un mayor número de modelos (árboles) débiles, este parámetro deberá establecerse con cierto margen. En la práctica, para este ejemplo en particular, 1000 iteraciones resultarán suficientes e incluso excesivas.
- depth — profundidad de cada árbol. Cuanto menor sea, más basto será el modelo, reduciendo del número de transacciones a la salida. Una profundidad en el intervalo de 6-10 sería una solución óptima.
- learning_rate — magnitud de salto del gradiente; el principio es el mismo de las redes neuronales. Un intervalo de parámetros razonable sería 0.01 - 0.1. Cuanto menor sea, más tiempo se entrenará el modelo, aunque podrá encontrar una variante más adecuada.
- custom_loss, eval_metric — métrica con la que se valora el modelo. Para realizar la clasificación con la métrica clásica, será accuracy
- use_best_model — en cada salto del entrenamiento, el modelo valora la precisión, que puede variar con el tiempo. Esta bandera permite almacenar el modelo con menor error; en caso contrario, se guardará el modelo conseguido en la última iteración.
- task_type — permite entrenar el modelo en una tarjeta de vídeo, por defecto, 'CPU'. Solo será trascendente en el caso de que el volumen de datos sea muy grande, de lo contrario, en los núcleos de la tarjeta de vídeo aprenderá más despacio que en el procesador.
- early_stopping_rounds — en el modelo se incorpora el llamado detector de sobreentrenamiento (overfitting detector), que funcionará según un principio simple. Si la métrica ha dejado de disminuir/aumentar (en el caso de accuracy, de aumentar) durante el número de iteraciones establecido, el entrenamiento se interrumpirá.
Después de iniciar el entrenamiento, en la consola se mostrará el estado actual del modelo en cada iteración:
170: learn: 1.0000000 test: 0.7712509 best: 0.7767795 (165) total: 11.2s remaining: 21.5s 171: learn: 1.0000000 test: 0.7726330 best: 0.7767795 (165) total: 11.2s remaining: 21.4s 172: learn: 1.0000000 test: 0.7733241 best: 0.7767795 (165) total: 11.3s remaining: 21.3s 173: learn: 1.0000000 test: 0.7740152 best: 0.7767795 (165) total: 11.3s remaining: 21.3s 174: learn: 1.0000000 test: 0.7712509 best: 0.7767795 (165) total: 11.4s remaining: 21.2s 175: learn: 1.0000000 test: 0.7726330 best: 0.7767795 (165) total: 11.5s remaining: 21.1s 176: learn: 1.0000000 test: 0.7712509 best: 0.7767795 (165) total: 11.5s remaining: 21s 177: learn: 1.0000000 test: 0.7740152 best: 0.7767795 (165) total: 11.6s remaining: 21s 178: learn: 1.0000000 test: 0.7719419 best: 0.7767795 (165) total: 11.7s remaining: 20.9s 179: learn: 1.0000000 test: 0.7747063 best: 0.7767795 (165) total: 11.7s remaining: 20.8s 180: learn: 1.0000000 test: 0.7705598 best: 0.7767795 (165) total: 11.8s remaining: 20.7s Stopped by overfitting detector (15 iterations wait) bestTest = 0.7767795439 bestIteration = 165
En el ejemplo anterior, el detector de sobreentrenamiento se activó e interrumpió el entrenamiento en la iteración 180. Además, la consola muestra las estadísticas para la submuestra de entrenamiento (learn) y de validación (test), así como el tiempo total de entrenamiento del modelo, que fue solo de 20 segundos. En el resultado, hemos obtenido una mejor precisión en la submuestra de entrenamiento 1.0 (que se corresponde con el resultado ideal) y una precisión de 0.78 en la submuestra de validación, que no es tan buena, pero que aún se encuentra por encima de 0.5 (que se considera aleatoria). La mejor iteración es 165: precisamente este modelo se ha guardado. Ahora, podemos ponerlo a prueba en nuestro simulador:
#test the learned model p = model.predict_proba(X) p2 = [x[0]<0.5 for x in p] pr2 = pr.iloc[:len(p2)].copy() pr2['labels'] = p2 rep = tester(pr2, MARKUP) plt.plot(rep) plt.show()
X es e conjunto de datos original, pero sin etiquetas. Para disponer de las etiquetas, deberemos obtenerlas del modelo entrenado y predecir la probabilidad 'p' de pertenencia a la clase 0 o 1. Como el modelo produce probabilidades para dos clases, y solo necesitamos ceros o unos, la variable 'p2' obtendrá las probabilidades solo en la primera (dimensión cero). Asimismo, las etiquetas en el conjunto de datos original se reemplazarán con las etiquetas predichas por el modelo. Echemos un vistazo a los resultados en el simulador:
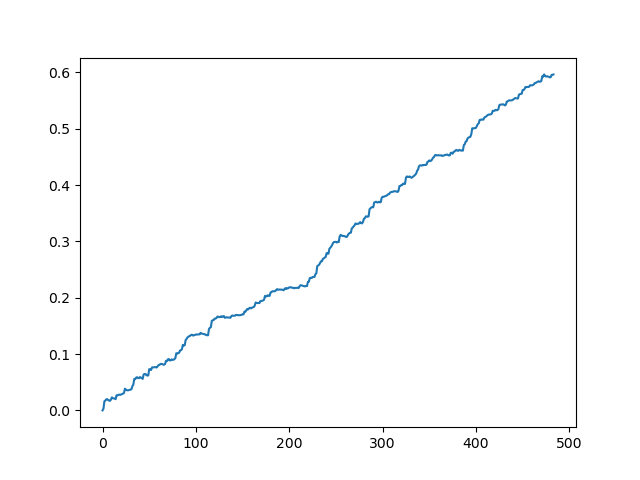
Resultado ideal después del muestreo de transacciones
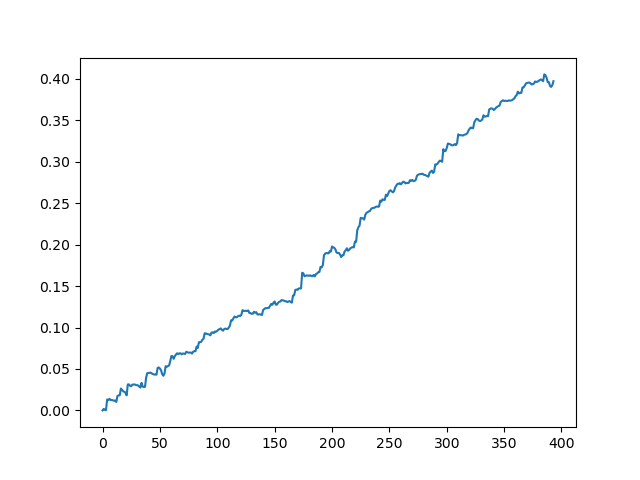
Resultado obtenido a la salida del modelo:
Como podemos ver, el modelo ha aprendido bien, es decir, no solo ha podido recordar los ejemplos de entrenamiento, sino también mostrar un resultado superior al aleatorio en el conjunto de validación. Vamos a pasar a la etapa final: la exportación del modelo y la creación de un robot comercial.
Trasladando el modelo a MetaTrader 5
La python api de MetaTrader 5 permite comerciar directamente desde un programa Python y, por consiguiente, no será necesario portar el modelo. No obstante, querríamos poner a prueba el simulador personalizado y compararlo con el simulador de estrategias estándar. Además, la disponibilidad de un bot compilado puede resultar adecuada en muchas situaciones, incluido el uso en un VPS (en ese caso, no deberemos instalar Python). Para ello, hemos escrito una función auxiliar que guarda un modelo listo en un archivo MQH. Veamos la función:
def export_model_to_MQL_code(model):
model.save_model('catmodel.h',
format="cpp",
export_parameters=None,
pool=None)
code = 'double catboost_model' + '(const double &features[]) { \n'
code += ' '
with open('catmodel.h', 'r') as file:
data = file.read()
code += data[data.find("unsigned int TreeDepth"):data.find("double Scale = 1;")]
code +='\n\n'
code+= 'return ' + 'ApplyCatboostModel(features, TreeDepth, TreeSplits , BorderCounts, Borders, LeafValues); } \n\n'
code += 'double ApplyCatboostModel(const double &features[],uint &TreeDepth_[],uint &TreeSplits_[],uint &BorderCounts_[],float &Borders_[],double &LeafValues_[]) {\n\
uint FloatFeatureCount=ArrayRange(BorderCounts_,0);\n\
uint BinaryFeatureCount=ArrayRange(Borders_,0);\n\
uint TreeCount=ArrayRange(TreeDepth_,0);\n\
bool binaryFeatures[];\n\
ArrayResize(binaryFeatures,BinaryFeatureCount);\n\
uint binFeatureIndex=0;\n\
for(uint i=0; i<FloatFeatureCount; i++) {\n\
for(uint j=0; j<BorderCounts_[i]; j++) {\n\
binaryFeatures[binFeatureIndex]=features[i]>Borders_[binFeatureIndex];\n\
binFeatureIndex++;\n\
}\n\
}\n\
double result=0.0;\n\
uint treeSplitsPtr=0;\n\
uint leafValuesForCurrentTreePtr=0;\n\
for(uint treeId=0; treeId<TreeCount; treeId++) {\n\
uint currentTreeDepth=TreeDepth_[treeId];\n\
uint index=0;\n\
for(uint depth=0; depth<currentTreeDepth; depth++) {\n\
index|=(binaryFeatures[TreeSplits_[treeSplitsPtr+depth]]<<depth);\n\
}\n\
result+=LeafValues_[leafValuesForCurrentTreePtr+index];\n\
treeSplitsPtr+=currentTreeDepth;\n\
leafValuesForCurrentTreePtr+=(1<<currentTreeDepth);\n\
}\n\
return 1.0/(1.0+MathPow(M_E,-result));\n\
}'
file = open('C:/Users/dmitrievsky/AppData/Roaming/MetaQuotes/Terminal/D0E8209F77C8CF37AD8BF550E51FF075/MQL5/Include/' + 'cat_model' + '.mqh', "w")
file.write(code)
file.close()
print('The file ' + 'cat_model' + '.mqh ' + 'has been written to disc') En el listado, la función parece bastante caótica, pero no todo es tan complejo. La función recibe en la entrada el objeto del modelo entrenado, después de lo cual, lo guarda en el formato c++:
model.save_model('catmodel.h',
format="cpp",
export_parameters=None,
pool=None) A continuación, se crea una línea y se parsea el código c++ en mql5 con los recursos estándar del lenguaje Python:
code = 'double catboost_model' + '(const double &features[]) { \n' code += ' ' with open('catmodel.h', 'r') as file: data = file.read() code += data[data.find("unsigned int TreeDepth"):data.find("double Scale = 1;")] code +='\n\n' code+= 'return ' + 'ApplyCatboostModel(features, TreeDepth, TreeSplits , BorderCounts, Borders, LeafValues); } \n\n'
Después de realizar las manipulaciones mencionadas, insertamos la función 'ApplyCatboostModel' de la biblioteca dada, que retorna un resultado calculado en el intervalo (0; 1), basado en el modelo guardado y el vector de características transmitido.
A continuación, indicamos la ruta a la carpeta \\Include del terminal MetaTrader 5 donde se guardará el modelo. Por consiguiente, tras configurar todos los parámetros, el modelo se entrenará solo con un clic, y se guardará inmediatamente como un archivo MQH, lo cual nos viene fenomenal. Esta variante también es buena porque entrenar los modelos en Python es un clásico del género y una práctica extendida por todo el mundo.
Vamos a escribir un bot que comercie en MetaTrader 5
Después de entrenar y guardar el modelo CatBoost, tenemos que escribir un bot simple de comprobación:
#include <MT4Orders.mqh> #include <Trade\AccountInfo.mqh> #include <cat_model.mqh> sinput int look_back = 50; sinput int MA_period = 15; sinput int OrderMagic = 666; //Orders magic sinput double MaximumRisk=0.01; //Maximum risk sinput double CustomLot=0; //Custom lot input int stoploss = 500; static datetime last_time=0; #define Ask SymbolInfoDouble(_Symbol, SYMBOL_ASK) #define Bid SymbolInfoDouble(_Symbol, SYMBOL_BID) int hnd;
Incluimos el cat_model.mqh guardado y el archivo MT4Orders.mqh de fxsaber.
Debemos establecer exactamente los mismos parámetros look_back y MA_period que indicamos en el entrenamiento en el programa de Python, de lo contrario, surgirá un error.
A continuación, comprobamos en cada barra la señal del modelo al que se transmite el vector de incremento (de la diferencia y la media móvil):
if(!isNewBar()) return; double ma[]; double pr[]; double ret[]; ArrayResize(ret, look_back); CopyBuffer(hnd, 0, 1, look_back, ma); CopyClose(NULL,PERIOD_CURRENT,1,look_back,pr); for(int i=0; i<look_back; i++) ret[i] = pr[i] - ma[i]; ArraySetAsSeries(ret, true); double sig = catboost_model(ret);
La lógica de apertura de transacciones es análoga a la lógica del simulador personalizado, pero en el estilo mql5 + MT4Orders:
for(int b = OrdersTotal() - 1; b >= 0; b--) if(OrderSelect(b, SELECT_BY_POS) == true) { if(OrderType() == 0 && OrderSymbol() == _Symbol && OrderMagicNumber() == OrderMagic && sig > 0.5) if(OrderClose(OrderTicket(), OrderLots(), OrderClosePrice(), 0, Red)) { } if(OrderType() == 1 && OrderSymbol() == _Symbol && OrderMagicNumber() == OrderMagic && sig < 0.5) if(OrderClose(OrderTicket(), OrderLots(), OrderClosePrice(), 0, Red)) { } } if(countOrders(0) == 0 && countOrders(1) == 0) { if(sig < 0.5) OrderSend(Symbol(),OP_BUY,LotsOptimized(), Ask, 0, Bid-stoploss*_Point, 0, NULL, OrderMagic); else if(sig > 0.5) OrderSend(Symbol(),OP_SELL,LotsOptimized(), Bid, 0, Ask+stoploss*_Point, 0, NULL, OrderMagic); return; }
Ponemos a prueba el bot con aprendizaje de máquinas
Tras compilar el bot, podemos ponerlo a prueba en el simulador estándar de MetaTrader 5. No debemos olvidarnos de seleccionar el periodo temporal correcto (tiene que ser igual que en el entrenamiento del modelo), así como las entradas look_back y MA_period, que también son similares a los parámetros del programa Python. Luego, comprobamos el modelo durante el periodo de entrenamiento (muestra de entrenamiento + muestra de validación):
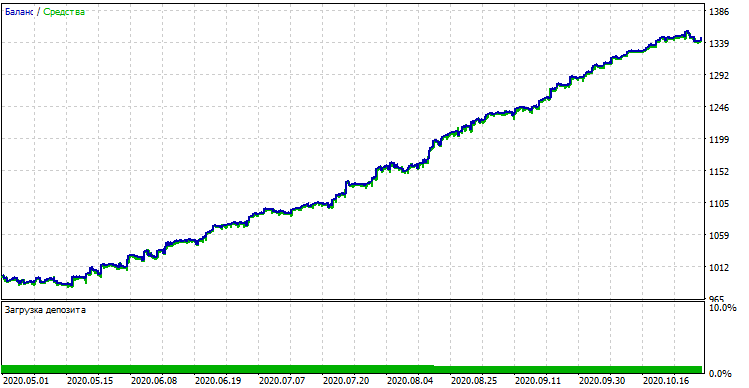
Rendimiento del modelo (muestra de entrenamiento + muestra de validación)
Si comparamos el resultado con el resultado del simulador personalizado, son iguales, salvo algunas desviaciones en los diferenciales. Ahora, vamos a probar el modelo con datos completamente nuevos, desde principios de año:
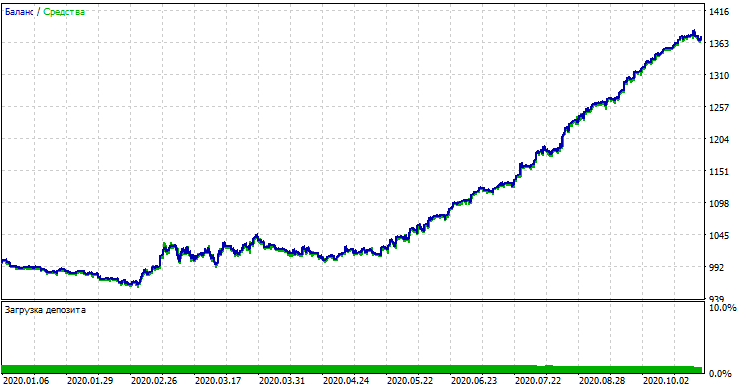
Rendimiento del modelo con los nuevos datos.
El modelo se ha comportado significativamente peor con los nuevos datos. Este resultado tan negativo está relacionado con razones objetivas que intentaremos exponer más tarde.
De los modelos ingenuos hacia los significativos (futura investigación)
Hemos titulado el artículo: "Enfoque ingenuo". Resulta ingenuo por los siguientes motivos:
- El modelo no incluye ningún dato previo sobre los patrones. La identificación de cualquier patrón se efectúa en su totalidad mediante el aumento de gradiente, cuyas posibilidades, no obstante, resultan limitadas.
- El modelo usa una muestra aleatoria de transacciones, por lo que los resultados en diferentes ciclos de entrenamiento podrían ser diferentes. Esto no solo supone una desventaja, sino también una ventaja, ya que esta característica nos permite emplear la fuerza bruta.
- Durante el entrenamiento, no conocemos características del conjunto general. Nunca sabemos cómo se comportará el modelo con los nuevos datos.
Algunas posibles formas de mejorar el rendimiento del modelo serían (hablaremos de ellas en un artículo aparte):
- Elegir modelos según algún criterio externo (por ejemplo, el rendimiento con los nuevos datos)
- Nuevos enfoques sobre el muestreo de datos y el entrenamiento de modelos, apilamiento de clasificadores
- Seleccionar rasgos de diferente naturaleza basados en conocimientos y/o supuestos a priori
Conclusión
En el artículo, hemos analizado el magnífico modelo de aprendizaje de máquinas CatBoost, así como los aspectos principales relacionados con su configuración y el entrenamiento de la clasificación binaria en tareas de pronosticación de series temporales. Además, hemos entrenado y simulado un modelo que hemos trasladado al lenguaje MQL en forma de bot preparado para usar. Los programas de Python y MQL se adjuntan al artículo.
Traducción del ruso hecha por MetaQuotes Ltd.
Artículo original: https://www.mql5.com/ru/articles/8642
Advertencia: todos los derechos de estos materiales pertenecen a MetaQuotes Ltd. Queda totalmente prohibido el copiado total o parcial.
Este artículo ha sido escrito por un usuario del sitio web y refleja su punto de vista personal. MetaQuotes Ltd. no se responsabiliza de la exactitud de la información ofrecida, ni de las posibles consecuencias del uso de las soluciones, estrategias o recomendaciones descritas.
 Aprendizaje de máquinas de Yándex (CatBoost) sin estudiar Python y R
Aprendizaje de máquinas de Yándex (CatBoost) sin estudiar Python y R
 ¿Qué son las tendencias y cómo es la estructura de los mercados: de tendencia o plana?
¿Qué son las tendencias y cómo es la estructura de los mercados: de tendencia o plana?
 Uso de criptografía con aplicaciones externas
Uso de criptografía con aplicaciones externas
- Aplicaciones de trading gratuitas
- 8 000+ señales para copiar
- Noticias económicas para analizar los mercados financieros
Usted acepta la política del sitio web y las condiciones de uso
prices.dropna()Al final no funcionó. El archivo seguía conteniendo valores Nan. Se solucionó simplemente borrando líneas.
Parece que no puedo reproducir los resultados del probador de python. El MT5 tester no reproduce los resultados para el mismo periodo en python tester.
Por lo demás, he portado el modelo como se explica.
Puse cat_model.mqh y cat_trader.mql5(compilado a .ex5).
Pero los resultados son diferentes.
Aquí puedes ver el código para el modelo. Tome nota de MA_Period, Look_Back, etc. Luego mira la curva de beneficios del probador de código python. A continuación, busque en las entradas MT5, ajustes y resultados probador de estrategia.
Parece que no puedo reproducir los resultados del probador de python. El probador MT5 no está reproduciendo los resultados para el mismo período en probador de python.
Por lo demás, he portado el modelo como se explica.
Puse cat_model.mqh y cat_trader.mql5(compilado a .ex5).
Pero los resultados son diferentes.
Hola, puede haber una diferencia entre como se parseaba el modelo cuando se escribió el artículo y como ocurre ahora. CatBoost podría haber cambiado la lógica del código del modelo final en las nuevas versiones, así que tendrás que averiguarlo.
Me parece que hay una alta probabilidad de que esto pueda ser un problema.
He hecho algunos cambios:
He cambiado el código para guardar el mqh de acuerdo con el tiempo gráfico de los datos.
He cambiado el mqh para que sea diferente para cada timeframe, de forma que sea posible tener todos los timeframes entrenados y listos para usar en el EA.
Cambié el EA para utilizar todos los archivos entrenados para analizar y generar señales.
Se adjuntan todos los archivos para su revisión, si es posible.
Si pudiera mejorar el código se lo agradecería.
La estrategia y también el modelo de entrenamiento necesitan una mejora extrema, si es posible agradezco la ayuda.
He hecho algunos cambios:
He cambiado el código para guardar el mqh según el tiempo gráfico de los datos.
cambié el mqh para que sea diferente para cada tiempo gráfico, de modo que todos los tiempos gráficos puedan ser entrenados y listos para usar en el EA.
Cambié el EA para utilizar todos los archivos entrenados para analizar y generar señales.
He adjuntado todos los archivos para que los analices si es posible.
si podeis mejorar el codigo os lo agradeceria.
la estrategia y tambien el entrenamiento del modelo necesita una mejora extrema, si es posible ayuda gracias.