Redes neuronales: así de sencillo (Parte 45): Entrenando habilidades de exploración de estados

Introducción
Los algoritmos de aprendizaje por refuerzo jerárquico pueden resolver con éxito problemas bastante complejos: esto se logra dividiendo la tarea general en subtareas más pequeñas. Uno de los principales problemas en este contexto es conseguir una selección y entrenamiento correctos para las habilidades, que permitan al agente actuar con eficacia y, si es posible, gestionar al máximo el entorno para conseguir el objetivo.
Ya nos hemos familiarizado con dos algoritmos de entrenamiento de habilidades, DIAYN y DADS. En el primer caso, entrenamos habilidades con la máxima variedad de comportamientos, intentando garantizar la máxima exploración del entorno. Al mismo tiempo, nuestra intención era enseñar habilidades que no fueran útiles para nuestra tarea actual.
En el segundo algoritmo (DADS), abordamos el entrenamiento de habilidades desde la perspectiva de su impacto en el entorno. Aquí nuestro objetivo consistía en predecir la dinámica del entorno y utilizar habilidades que nos permitieran obtener el máximo beneficio de los cambios.
En ambos casos, las habilidades de la distribución anterior se utilizaban como información para el agente y se exploraban durante el proceso de entrenamiento. El uso práctico de este enfoque demuestra una cobertura insuficiente del espacio de estados. Como consecuencia, las habilidades entrenadas no pueden interactuar efectivamente con todos los estados del entorno posibles.
En este artículo, le ofrecemos familiarizarse con un método alternativo para entrenar habilidades, el método Explore, Discover and Learn (EDL). El EDL aborda el problema desde un ángulo diferente, lo cual nos permite superar el problema de la cobertura de estados limitada y posibilitar un comportamiento de los agentes más flexible y adaptativo.
1. El algoritmo "Explore, Discover and Learn" (explora, descubre y aprende)
El método EDL se presentó por primera vez en el artículo científico Explore, Discover and Learn: Unsupervised Discovery of State-Covering Skills" en agosto de 2020, y propone un enfoque que permite al agente descubrir y aprender a utilizar diferentes habilidades en un entorno sin ningún conocimiento previo de los estados y habilidades. También permite entrenar una amplia variedad de habilidades que abarcan diferentes estados, lo cual permite una exploración y aprendizaje más eficiente por parte del agente en un entorno desconocido.
El método EDL tiene una estructura fija y consta de 3 etapas principales: exploración, descubrimiento y entrenamiento de habilidades.
Comenzaremos nuestra exploración sin disponer de conocimientos previos del entorno ni habilidades necesarias. En esta etapa, deberemos crear un conjunto de entrenamiento de los estados iniciales con una cobertura máxima de varios estados correspondientes a todos los comportamientos posibles del entorno. En nuestro trabajo, usaremos un muestreo uniforme de los estados del sistema durante el periodo de entrenamiento, pero también son posibles otros enfoques, especialmente en los casos en que entrenamos modos específicos de comportamiento de los agentes. Cabe señalar que el EDL no requiere acceso a las trayectorias o acciones realizadas por la estrategia del experto, pero no excluye su uso.
En la segunda etapa, buscaremos habilidades ocultas en condiciones del entorno específicas. La idea fundamental de este método es la presencia de alguna conexión entre el estado (o espacio de estados) del entorno y la habilidad específica que el agente debe utilizar. Y tenemos que determinar dichas dependencias.
Cabe señalar que en esta etapa no tenemos ningún conocimiento sobre las condiciones del entorno, solo disponemos de una muestra de tales estados. Asimismo, carecemos de conocimientos sobre las habilidades necesarias. Al mismo tiempo, como hemos señalado antes, el método EDL implica el descubrimiento de habilidades sin supervisión. Para buscar las dependencias, el algoritmo prevé el uso de un autocodificador variacional. En la entrada y la salida del modelo, tendremos los estados del entorno, mientras que en el estado latente del autocodificador, esperaremos obtener la identificación de la habilidad latente derivada del estado actual del entorno. En este enfoque, el codificador de nuestro autocodificador creará una función de dependencia de la habilidad respecto al estado actual del entorno. El decodificador del modelo, por su parte, ejecutará la función inversa, generando una dependencia del estado respecto a la habilidad utilizada. El uso de un autocodificador variacional nos permite pasar de una correspondencia clara "estado-habilidad" a una cierta distribución de probabilidad, lo que generalmente aumenta la estabilidad del modelo en un entorno estocástico complejo.
Por ello, si no se tiene conocimiento adicional sobre los estados y habilidades, el uso del autocodificador variacional en el método EDL nos ofrecerá la oportunidad de explorar y descubrir habilidades ocultas asociadas con diferentes estados del entorno. Por su parte, la construcción de una función de dependencia entre el estado del entorno y la habilidad requerida nos permitirá en el futuro interpretar nuevos estados del entorno en un conjunto de las habilidades más relevantes.
Tenga en cuenta que en los métodos analizados anteriormente, se entrenaban primero las habilidades, mientras que el planificador buscaba después una estrategia para utilizar las habilidades ya preparadas para lograr el objetivo. El método EDL adopta el enfoque opuesto: primero construiremos las dependencias entre el estado y las habilidades, y solo entonces entrenaremos las habilidades. Esto nos permitirá lograr una mejor coincidencia de las habilidades con condiciones del entorno específicas, así como determinar qué habilidades resultan más efectivas para usar en determinadas situaciones.
La etapa final del algoritmo consistirá en entrenar el modelo de habilidades (Agente). Aquí, el agente aprenderá una estrategia que maximizará la información mutua entre los estados y las variables ocultas. El agente se entrenará utilizando métodos de aprendizaje por refuerzo. La formación de la recompensa se estructurará de forma similar al método DADS, pero los autores del método simplificaron ligeramente la fórmula. Permítanme recordarles que en el DADS la recompensa interna del agente se formaba según la fórmula:
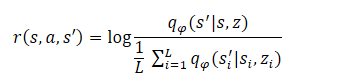
Del curso de matemáticas sabemos que
![]()
Por consiguiente:
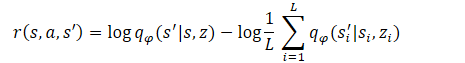
Como puede ver, el sustraendo es una constante para todas las habilidades usadas. Por lo tanto, para optimizar la política, solo podremos utilizar el minuendo. Este enfoque permite reducir el volumen de cálculos sin perder calidad en el entrenamiento del modelo.
![]()
Este paso final puede abordarse como el entrenamiento de una estrategia que imite al decodificador dentro de un proceso de decisión de Markov, es decir, una estrategia que visitará los estados que generará el decodificador para cada habilidad oculta z. Cabe señalar que la función de recompensa será fija, a diferencia de los métodos anteriores, en los que cambia continuamente dependiendo del comportamiento de la estrategia. Esto hará que el proceso de aprendizaje resulte más estable, aumentando así la convergencia de los modelos.
2. Implementación con ayuda de MQL5
Tras considerar los aspectos teóricos del método EDL, vamos a abordar la parte práctica de nuestro artículo. Antes de comenzar a implementar directamente el método usando MQL5, necesitaremos hablar un poco sobre las características de nuestra implementación.
En la sección Simulación del artículo anterior, demostramos la proximidad de los resultados del uso del vector one-hot y la distribución completa para identificar la habilidad utilizada en los datos de origen del Agente. Esto nos permitirá utilizar un enfoque u otro dependiendo de los datos que tengamos para reducir las matemáticas involucradas, lo que en general nos ofrecerá la posibilidad potencial de reducir el número de operaciones realizadas, y al mismo tiempo, de aumentar la velocidad de aprendizaje y el funcionamiento del modelo.
El segundo punto al que deberemos prestar atención es al hecho de que estamos suministrando los mismos datos iniciales a la entrada del Planificador y del Agente (los datos históricos sobre el movimiento de precios, las métricas de los indicadores y el estado del balance). Si bien es cierto que, en la entrada del Agente, el identificador de habilidad también se agrega a estos datos.
Por otro lado, al estudiar los autocodificadores, dijimos que el estado latente de un autocodificador supone una representación comprimida de sus datos originales. Es decir, al concatenar el vector de datos de origen con el vector de datos latentes del autocodificador variacional, transmitiremos los mismos datos dos veces en su representación completa y comprimida.
Si utilizamos bloques similares de procesamiento preliminar de datos originales, este enfoque podría resultar redundante, y en esta implementación, solo suministraremos el estado latente del autocodificador a la entrada del Agente, que, en esencia, ya contiene toda la información necesaria. Esto nos permitirá reducir significativamente el volumen de operaciones realizadas, y al mismo tiempo, el tiempo total de formación de modelos.
Obviamente, este enfoque solo resultará posible al utilizar datos de origen similares en la entrada del Planificador y el Agente. En principio, también son posibles otras opciones. Por ejemplo, un autocodificador puede crear dependencias solo entre datos históricos y una habilidad sin considerar el estado de la cuenta, mientras que en la entrada del agente se concatenarán el vector del estado latente del autocodificador y el vector de descripción del estado de la cuenta. No supondría un error utilizar todos los datos, como hicimos al implementar los métodos discutidos anteriormente: en su implementación, podemos experimentar con diferentes enfoques.
Todas estas decisiones se reflejan necesariamente en la arquitectura del modelo que especificamos en la función CreateDescriptions. En los parámetros del método, transmitiremos los punteros a dos arrays dinámicos que describen los modelos del planificador y del agente. Tenga en cuenta que al implementar el método EDL, no crearemos un Discriminador, ya que su función la desempeña el decodificador del autocodificador (Planificador).
bool CreateDescriptions(CArrayObj *actor, CArrayObj *scheduler) { //--- CLayerDescription *descr; //--- if(!actor) { actor = new CArrayObj(); if(!actor) return false; } //--- if(!scheduler) { scheduler = new CArrayObj(); if(!scheduler) return false; }
Primero crearemos un autocodificador variacional para el Planificador. En la entrada de este modelo, suministraremos los datos históricos y el estado de la cuenta, lo cual se reflejará en el tamaño de la capa de datos de origen. Como siempre, los datos sin procesar se procesarán previamente en una capa de normalización por lotes.
//--- Scheduler scheduler.Clear(); //--- Input layer if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBaseOCL; int prev_count = descr.count = (HistoryBars * BarDescr + AccountDescr); descr.window = 0; descr.activation = None; descr.optimization = ADAM; if(!scheduler.Add(descr)) { delete descr; return false; } //--- layer 1 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBatchNormOCL; descr.count = prev_count; descr.batch = 1000; descr.activation = None; descr.optimization = ADAM; if(!scheduler.Add(descr)) { delete descr; return false; }
Luego vendrá el bloque convolucional para reducir la dimensionalidad de los datos y extraer características específicas.
//--- layer 2 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronConvOCL; prev_count = descr.count = prev_count - 1; descr.window = 2; descr.step = 1; descr.window_out = 4; descr.activation = LReLU; descr.optimization = ADAM; if(!scheduler.Add(descr)) { delete descr; return false; } //--- layer 3 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronProofOCL; prev_count = descr.count = prev_count; descr.window = 4; descr.step = 4; if(!scheduler.Add(descr)) { delete descr; return false; } //--- layer 4 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronConvOCL; prev_count = descr.count = prev_count - 1; descr.window = 2; descr.step = 1; descr.window_out = 4; descr.activation = LReLU; descr.optimization = ADAM; if(!scheduler.Add(descr)) { delete descr; return false; } //--- layer 5 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronProofOCL; prev_count = descr.count = prev_count; descr.window = 4; descr.step = 4; if(!scheduler.Add(descr)) { delete descr; return false; }
Después tendremos tres capas completamente conectadas con una disminución gradual de la dimensionalidad. Tenga en cuenta que el tamaño de la última capa supondrá el doble del número de habilidades entrenadas. Esta es una característica distintiva de los autocodificadores variacionales. De hecho, a diferencia del autocodificador clásico, en el autocodificador variacional cada característica está representada por dos parámetros: el valor medio y la dispersión de la distribución.
//--- layer 6 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBaseOCL; descr.count = 256; descr.optimization = ADAM; descr.activation = TANH; if(!scheduler.Add(descr)) { delete descr; return false; } //--- layer 7 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBaseOCL; descr.count = 128; descr.activation = LReLU; descr.optimization = ADAM; if(!scheduler.Add(descr)) { delete descr; return false; } //--- layer 8 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBaseOCL; descr.count = 2 * NSkills; descr.activation = None; descr.optimization = ADAM; if(!scheduler.Add(descr)) { delete descr; return false; }
El truco de reparametrización (reparameterization trick) se realizará en la siguiente capa, creada específicamente para implementar el autocodificador variacional. Aquí, los parámetros también se muestrearán a partir de una distribución determinada. El tamaño de esta capa se corresponderá con el número de habilidades entrenadas.
//--- layer 9 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronVAEOCL; descr.count = NSkills; if(!scheduler.Add(descr)) { delete descr; return false; }
El decodificador se implementará como 3 capas completamente conectadas; la última de ellas no tendrá función de activación, ya que resulta difícil determinar la función de activación para datos no normalizados.
//--- layer 10 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBaseOCL; descr.count = 128; descr.optimization = ADAM; descr.activation = LReLU; if(!scheduler.Add(descr)) { delete descr; return false; } //--- layer 11 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBaseOCL; descr.count = 256; descr.optimization = ADAM; descr.activation = LReLU; if(!scheduler.Add(descr)) { delete descr; return false; } //--- layer 12 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBaseOCL; descr.count = AccountDescr; descr.optimization = ADAM; descr.activation = None; if(!scheduler.Add(descr)) { delete descr; return false; }
Tenga en cuenta que, al igual que sucede con el método anterior, no restauraremos completamente los datos originales. Después de todo, la influencia de las acciones del Agente sobre el precio de mercado del instrumento resultará insignificante. Por el contrario, el estado del balance dependerá directamente de la estrategia utilizada por el Agente. Por lo tanto, en la salida del autocodificador restauraremos solo la descripción del estado de la cuenta.
Después del planificador, crearemos la descripción de la arquitectura del agente. Como hemos mencionado antes, la capa de datos de origen del Agente se reducirá a la cantidad de habilidades entrenadas.
//--- Actor actor.Clear(); //--- Input layer if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBaseOCL; prev_count = descr.count = NSkills; descr.window = 0; descr.activation = None; descr.optimization = ADAM; if(!actor.Add(descr)) { delete descr; return false; }
Usar el estado oculto de un modelo diferente nos permitirá eliminar el bloque de preprocesamiento de datos. Por lo tanto, justo después de la capa de datos de origen tendremos un bloque de toma de decisiones con 3 capas completamente conectadas.
//--- layer 1 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBaseOCL; descr.count = 256; descr.optimization = ADAM; descr.activation = TANH; if(!actor.Add(descr)) { delete descr; return false; } //--- layer 2 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBaseOCL; descr.count = 256; descr.activation = LReLU; descr.optimization = ADAM; if(!actor.Add(descr)) { delete descr; return false; } //--- layer 3 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBaseOCL; descr.count = 256; descr.activation = LReLU; descr.optimization = ADAM; if(!actor.Add(descr)) { delete descr; return false; }
En la salida del modelo, utilizaremos un bloque con una función cuantil completamente parametrizada, lo cual nos permitirá estudiar la distribución de recompensas con mayor detalle.
//--- layer 4 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronFQF; descr.count = NActions; descr.window_out = 32; descr.optimization = ADAM; if(!actor.Add(descr)) { delete descr; return false; } //--- return true; }
Al igual que antes, hemos incluido la función encargada de describir la arquitectura del modelo en el archivo de inclusión "\EDL\Trajectory.mqh". Esto nos permitirá utilizar una arquitectura de modelo única en todas las etapas del método EDL.
Después de crear la arquitectura del modelo, procederemos a trabajar con los expertos para implementar el método estudiado. Primero, crearemos el asesor de la primera etapa: la Exploración. Esta funcionalidad se implementará en el asesor "EDL\Research.mq5". Debemos decir de inmediato que el algoritmo de este asesor copia casi por completo los asesores homónimos de artículos anteriores, pero también existen diferencias debidas a la arquitectura de los modelos. Concretamente, en implementaciones anteriores, el algoritmo de este asesor utilizaba únicamente un modelo de Agente cuya entrada contaba con datos iniciales y un identificador de habilidad generado aleatoriamente. En esta implementación, proporcionaremos datos históricos como entrada al planificador, y después de su pasada directa, extraeremos el estado oculto, que suministraremos a la entrada del Agente para tomar una decisión sobre la acción. El código completo del asesor y todas sus funciones se puede encontrar en el archivo adjunto.
//+------------------------------------------------------------------+ //| Expert tick function | //+------------------------------------------------------------------+ void OnTick() { //--- if(!IsNewBar()) return; //--- ........ ........ //--- if(!Scheduler.feedForward(GetPointer(State1), 1, false)) return; if(!Scheduler.GetLayerOutput(LatentLayer, Result)) return; //--- if(!Actor.feedForward(Result, 1, false)) return; int act = Actor.getSample(); //--- ........ ........ //--- }
El segundo paso del método EDL consiste en identificar las habilidades. Como hemos mencionado en la parte teórica, en esta etapa entrenaremos un autocodificador variacional. Esta funcionalidad se implementará en el asesor "StudyModel.mq5". El asesor ha sido creado usando como base los asesores de entrenamiento de modelos de artículos anteriores. Solo se han realizado cambios en el algoritmo de este método.
En la función OnInit, solo se inicializará un modelo de Planificador, pero los principales cambios se han realizado en la función de entrenamiento del modelo Train. Al comienzo de la función, como antes, declararemos las variables internas.
//+------------------------------------------------------------------+ //| Train function | //+------------------------------------------------------------------+ void Train(void) { int total_tr = ArraySize(Buffer); uint ticks = GetTickCount(); vector<float> account, reward; int bar, action;
Luego organizamos un ciclo de entrenamiento con el número de iteraciones especificadas en los parámetros externos del asesor.
//--- for(int iter = 0; (iter < Iterations && !IsStopped()); iter ++) { int tr = (int)(((double)MathRand() / 32767.0) * (total_tr - 1)); int i = (int)((MathRand() * MathRand() / MathPow(32767, 2)) * (Buffer[tr].Total - 2));
En el cuerpo del ciclo, seleccionaremos del conjunto de entrenamiento una pasada de forma aleatoria y luego uno de los estados de la pasada seleccionada. Los datos de descripción para el estado seleccionado se transferirán al búfer de datos de origen para la pasada directa de nuestro modelo. Estas iteraciones no serán diferentes de las que hemos realizado anteriormente. Permítame recordarle que completaremos la información sobre el estado de la cuenta en magnitudes relativas.
State.AssignArray(Buffer[tr].States[i].state); float PrevBalance = Buffer[tr].States[MathMax(i - 1, 0)].account[0]; float PrevEquity = Buffer[tr].States[MathMax(i - 1, 0)].account[1]; State.Add((Buffer[tr].States[i].account[0] - PrevBalance) / PrevBalance); State.Add(Buffer[tr].States[i].account[1] / PrevBalance); State.Add((Buffer[tr].States[i].account[1] - PrevEquity) / PrevEquity); State.Add(Buffer[tr].States[i].account[2] / PrevBalance); State.Add(Buffer[tr].States[i].account[4] / PrevBalance); State.Add(Buffer[tr].States[i].account[5]); State.Add(Buffer[tr].States[i].account[6]); State.Add(Buffer[tr].States[i].account[7] / PrevBalance); State.Add(Buffer[tr].States[i].account[8] / PrevBalance);
A continuación, determinaremos el beneficio por lote a partir del cambio de precio en el tamaño de la siguiente vela y guardaremos los indicadores de saldo y equidad en variables locales para realizar cálculos posteriores.
//--- bar = (HistoryBars - 1) * BarDescr; double cl_op = Buffer[tr].States[i + 1].state[bar]; double prof_1l = SymbolInfoDouble(_Symbol, SYMBOL_TRADE_TICK_VALUE_PROFIT) * cl_op / SymbolInfoDouble(_Symbol, SYMBOL_POINT); PrevBalance = Buffer[tr].States[i].account[0]; PrevEquity = Buffer[tr].States[i].account[1];
Tras completar el trabajo preparatorio, realizaremos la pasada directa de nuestro modelo.
if(IsStopped()) { PrintFormat("%s -> %d", __FUNCTION__, __LINE__); ExpertRemove(); break; } //--- if(!Scheduler.feedForward(GetPointer(State), 1, false)) { PrintFormat("%s -> %d", __FUNCTION__, __LINE__); ExpertRemove(); break; }
Después de ejecutar con éxito la pasada hacia adelante, tendremos que organizar la pasada inversa de nuestro modelo, y aquí necesitaremos preparar los valores objetivo de este. Y siguiendo la lógica del entrenamiento de los autocodificadores, tendríamos que utilizar como valores de destino el búfer de datos de origen, pero hemos realizado cambios en la arquitectura y la lógica de entrenamiento. En primer lugar, en la salida no generaremos un conjunto completo de características de los datos de origen, sino solo parámetros para describir el estado de la cuenta.
En segundo lugar, hemos dado un pequeño paso adelante, y nos gustaría entrenar el modelo para generar un estado de cuenta predictivo posterior. Sin embargo, no generaremos un estado de cuenta para todas las acciones posibles del agente. En la etapa de entrenamiento del modelo, podemos "mirar" la siguiente vela en la muestra de entrenamiento y realizar la acción que nos sea más beneficiosa, la que maximizaría nuestro beneficio. De esta manera, formaremos el estado de pronóstico deseado de la cuenta y lo utilizaremos como valores objetivo para la pasada inversa del modelo.
if(prof_1l > 5 ) action = (prof_1l < 10 || Buffer[tr].States[i].account[6] > 0 ? 2 : 0); else { if(prof_1l < -5) action = (prof_1l > -10 || Buffer[tr].States[i].account[5] > 0 ? 2 : 1); else action = 3; } account = GetNewState(Buffer[tr].States[i].account, action, prof_1l); Result.Clear(); Result.Add((account[0] - PrevBalance) / PrevBalance); Result.Add(account[1] / PrevBalance); Result.Add((account[1] - PrevEquity) / PrevEquity); Result.Add(account[2] / PrevBalance); Result.Add(account[4] / PrevBalance); Result.Add(account[5]); Result.Add(account[6]); Result.Add(account[7] / PrevBalance); Result.Add(account[8] / PrevBalance);
Tenga en cuenta que al definir la acción deseada introduciremos restricciones:
- beneficio mínimo para abrir la transacción,
- movimiento mínimo para cerrar la transacción (esperamos pequeñas fluctuaciones),
- antes de abrir una nueva posición, cerraremos todas las operaciones opuestas.
De esta forma, queremos formar un modelo predictivo con el comportamiento deseado.
El estado de pronóstico generado de la cuenta lo convertiremos al plano de las unidades relativas y lo transferiremos al búfer de datos. Luego realizaremos una pasada inversa de nuestro modelo.
if(!Scheduler.backProp(Result)) { PrintFormat("%s -> %d", __FUNCTION__, __LINE__); ExpertRemove(); break; } if(GetTickCount() - ticks > 500) { string str = StringFormat("%-15s %5.2f%% -> Error %15.8f\n", "Scheduler", iter * 100.0 / (double)(Iterations), Scheduler.getRecentAverageError()); Comment(str); ticks = GetTickCount(); } }
Como antes, al final de las iteraciones del ciclo, mostraremos un mensaje informativo para que el usuario supervise visualmente el proceso de entrenamiento del modelo.
Tras completar todas las iteraciones del ciclo de entrenamiento del modelo, limpiaremos el bloque de comentarios en el gráfico e iniciaremos el proceso de finalización del asesor.
Comment(""); //--- PrintFormat("%s -> %d -> %-15s %10.7f", __FUNCTION__, __LINE__, "Scheduler", Scheduler.getRecentAverageError()); ExpertRemove(); //--- }
El código completo para el asesor de entrenamiento del autocodificador variacional del planificador se puede encontrar en el archivo adjunto.
Después de determinar las dependencias entre los estados del entorno y las habilidades, deberemos entrenar a nuestro Agente con las habilidades necesarias. Esta funcionalidad la organizaremos en el asesor "EDL\StudyActor.mq5". Debemos decir de inmediato que en este asesor utilizaremos dos modelos (Planificador y Agente), pero entrenaremos solo a uno (Agente). Por lo tanto, en el método de inicialización del asesor, cargaremos previamente dos modelos, pero la finalización crítica del programa solo provocará la imposibilidad de cargar el Planificador, que ya deberá estar previamente entrenado.
//+------------------------------------------------------------------+ //| Expert initialization function | //+------------------------------------------------------------------+ int OnInit() { //--- ResetLastError(); if(!LoadTotalBase()) { PrintFormat("Error of load study data: %d", GetLastError()); return INIT_FAILED; } //--- load models float temp; if(!Scheduler.Load(FileName + "Sch.nnw", temp, temp, temp, dtStudied, true)) { PrintFormat("Error of load scheduler model: %d", GetLastError()); return INIT_FAILED; }
Si ocurre un error al cargar el modelo de Agente, iniciaremos la creación de un nuevo modelo,
if(!Actor.Load(FileName + "Act.nnw", dtStudied, true)) { CArrayObj *actor = new CArrayObj(); CArrayObj *scheduler = new CArrayObj(); if(!CreateDescriptions(actor, scheduler)) { delete actor; delete scheduler; return INIT_FAILED; } if(!Actor.Create(actor)) { delete actor; delete scheduler; return INIT_FAILED; } delete actor; delete scheduler; //--- }
y por supuesto, tras cargar o crear un nuevo modelo, comprobaremos que los tamaños de las capas neuronales de los datos de entrada se correspondan con los resultados de las operaciones realizadas por los modelos.
//--- Actor.getResults(Result); if(Result.Total() != NActions) { PrintFormat("The scope of the actor does not match the actions count (%d <> %d)", NActions, Result.Total()); return INIT_FAILED; } Actor.SetOpenCL(Scheduler.GetOpenCL()); Actor.SetUpdateTarget(MathMax(Iterations / 100, 10000)); //--- Scheduler.getResults(Result); if(Result.Total() != AccountDescr) { PrintFormat("The scope of the scheduler does not match the account description (%d <> %d)", AccountDescr, Result.Total()); return INIT_FAILED; } //--- Actor.GetLayerOutput(0, Result); int inputs = Result.Total(); if(!Scheduler.GetLayerOutput(LatentLayer, Result)) { PrintFormat("Error of load latent layer %d", LatentLayer); return INIT_FAILED; } if(inputs != Result.Total()) { PrintFormat("Size of latent layer does not match input size of Actor (%d <> %d)", Result.Total(), inputs); return INIT_FAILED; }
Tras cargar e inicializar con éxito los modelos, y también tras pasar todos los controles, inicializaremos el evento para comenzar el proceso de entrenamiento del modelo y finalizaremos la operación de la función de inicialización del asesor.
//--- if(!EventChartCustom(ChartID(), 1, 0, 0, "Init")) { PrintFormat("Error of create study event: %d", GetLastError()); return INIT_FAILED; } //--- return(INIT_SUCCEEDED); }
El proceso de entrenamiento del Agente se organiza en el método Train. La primera parte del método incluye la selección de la pasada, el estado y la propagación del planificador, como se ha descrito anteriormente, y se transferirá sin cambios a este asesor. Por tanto, nos saltaremos este bloque y procederemos directamente a organizar la pasada directa de nuestro agente. Aquí todo resultará bastante sencillo. Solo extraeremos el estado latente del autocodificador y transmitiremos los datos recibidos a la entrada de nuestro Agente. No se olvide de controlar el proceso de ejecución de las operaciones.
//+------------------------------------------------------------------+ //| Train function | //+------------------------------------------------------------------+ void Train(void) { ........ ........ //--- if(!Scheduler.GetLayerOutput(LatentLayer, Result)) { PrintFormat("%s -> %d", __FUNCTION__, __LINE__); ExpertRemove(); break; } //--- if(!Actor.feedForward(Result, 1, false)) { PrintFormat("%s -> %d", __FUNCTION__, __LINE__); ExpertRemove(); break; }
Tras completar con éxito las operaciones de pasada directa, deberemos organizar una pasada inversa a través de nuestro modelo de agente. Como ya hemos dicho en el bloque teórico, el entrenamiento de agentes se realizará mediante métodos de aprendizaje por refuerzo, por lo que deberemos organizar la formación de recompensas por las acciones generadas durante la pasada directa. El método EDL implica entrenar al Agente según las recompensas generadas por el Discriminador. En este caso, su función la desempeñará el decodificador del autocodificador del planificador. Sin embargo, nos hemos desviado ligeramente del método del principio de formación de recompensas propuesto por los autores, lo cual en general no contradice la ideología del método.
Como hemos mencionado antes, durante el entrenamiento del autocodificador, utilizaremos el estado calculado deseado de nuestra cuenta, considerando las restricciones introducidas. Ahora recompensaremos el comportamiento del agente que nos acerque lo más posible al resultado deseado, y como medida entre el estado deseado y el previsto de nuestro balance, utilizaremos la métrica euclidiana de la distancia entre dos vectores, y para que la máxima recompensa la reciba la acción que nos acerque lo más posible al estado deseado, multiplicaremos la distancia resultante por “-1” como recompensa.
Este enfoque nos permitirá organizar un ciclo y rellenar las recompensas para todas las acciones posibles del Agente, y no solo para una acción individual. Esto generalmente aumentará la estabilidad y el rendimiento del proceso de entrenamiento del modelo.
Scheduler.getResults(SchedulerResult); ActorResult = vector<float>::Zeros(NActions); for(action = 0; action < NActions; action++) { reward = GetNewState(Buffer[tr].States[i].account, action, prof_1l); reward[0] = reward[0] / PrevBalance - 1.0f; reward[3] = reward[2] / PrevBalance; reward[2] = reward[1] / PrevEquity - 1.0f; reward[1] /= PrevBalance; reward[4] /= PrevBalance; reward[7] /= PrevBalance; reward[8] /= PrevBalance; reward=MathPow(SchedulerResult - reward, 2.0); ActorResult[action] = -reward.Sum(); }
Tras completar el ciclo de iteración de todas las acciones posibles del Agente, obtendremos un vector de distancias desde los estados calculados después de cada posible acción del Agente hasta el estado deseado predicho por nuestro autocodificador. Permítame recordarle que hemos escrito las distancias con el signo opuesto. Por lo tanto, nuestra distancia máxima será máximamente negativa, o simplemente el valor mínimo. Si restamos este valor mínimo a cada elemento del vector, pondremos a cero la recompensa por la acción que nos aleje del resultado deseado, y trasladaremos todas las demás recompensas al ámbito de los valores positivos sin cambiar su estructura.
ActorResult = ActorResult - ActorResult.Min();
En este caso, no utilizaremos SoftMax deliberadamente. Después de todo, el paso al ámbito de las probabilidades preservará solo la estructura y neutralizará la influencia de la propia distancia del resultado deseado, mientras que esta influencia resultará de gran importancia en el proceso de construcción de una estrategia general.
Además, debemos tener en cuenta que los estados previstos del autocodificador no se corresponden completamente con la estocasticidad real del entorno. Por ello, es importante evaluar la calidad de la predicción del autocodificador. La calidad del aprendizaje de un agente dependerá en última instancia de la correspondencia entre los estados predichos del autocodificador y los estados de entorno reales con los que interactúa el agente.
También querría recordarle que al construir su estrategia, el Agente tiene en cuenta no solo la recompensa actual, sino también la posibilidad total de obtener una recompensa antes del final del episodio, y en este caso, usaremos el modelo objetivo (Target Net) para determinar el coste del siguiente estado. Esta funcionalidad ya está implementada en el modelo de función cuantil totalmente parametrizado, pero para que funcione normalmente, necesitaremos transmitir el siguiente estado del sistema al método de pasada inversa.
En este caso, primero deberemos realizar una pasada directa del autocodificador utilizando el siguiente estado del sistema del búfer de reproducción de experiencia.
State.AssignArray(Buffer[tr].States[i+1].state); State.Add((Buffer[tr].States[i+1].account[0] - PrevBalance) / PrevBalance); State.Add(Buffer[tr].States[i+1].account[1] / PrevBalance); State.Add((Buffer[tr].States[i+1].account[1] - PrevEquity) / PrevEquity); State.Add(Buffer[tr].States[i+1].account[2] / PrevBalance); State.Add(Buffer[tr].States[i+1].account[4] / PrevBalance); State.Add(Buffer[tr].States[i+1].account[5]); State.Add(Buffer[tr].States[i+1].account[6]); State.Add(Buffer[tr].States[i+1].account[7] / PrevBalance); State.Add(Buffer[tr].States[i+1].account[8] / PrevBalance); //--- if(!Scheduler.feedForward(GetPointer(State), 1, false)) { PrintFormat("%s -> %d", __FUNCTION__, __LINE__); ExpertRemove(); break; }
Solo entonces podremos extraer una representación comprimida del siguiente estado del sistema partiendo del estado latente del autocodificador, y luego ya realizar una pasada inversa de nuestro Agente.
if(!Scheduler.GetLayerOutput(LatentLayer, Result)) { PrintFormat("%s -> %d", __FUNCTION__, __LINE__); ExpertRemove(); break; } State.AssignArray(Result); Result.AssignArray(ActorResult); if(!Actor.backProp(Result,DiscountFactor,GetPointer(State),1,false)) { PrintFormat("%s -> %d", __FUNCTION__, __LINE__); ExpertRemove(); break; }
A continuación, informaremos al usuario sobre el progreso del proceso de entrenamiento del Agente y pasaremos a la siguiente iteración del ciclo.
if(GetTickCount() - ticks > 500) { string str = StringFormat("%-15s %5.2f%% -> Error %15.8f\n", "Actor", iter * 100.0 / (double)(Iterations), Actor.getRecentAverageError()); Comment(str); ticks = GetTickCount(); } }
Tras completar el proceso de entrenamiento del Agente, limpiaremos el campo de comentarios e iniciaremos el proceso de finalización del asesor.
Comment(""); //--- PrintFormat("%s -> %d -> %-15s %10.7f", __FUNCTION__, __LINE__, "Actor", Actor.getRecentAverageError()); ExpertRemove(); //--- }
Podrá encontrar el código completo del asesor en el archivo adjunto.
3. Simulación
Hemos probamos la eficacia del enfoque usando datos históricos de los primeros 4 meses de 2023 del instrumento EURUSD. Como siempre, hemos utilizado el marco temporal H1. Los parámetros de todos los indicadores se han utilizado por defecto. En primer lugar, hemos recopilado una base de datos con ejemplos de 50 pasadas, entre las cuales se encuentran pasadas rentables y no rentables. Permítame recordarle que antes buscábamos utilizar únicamente pasadas rentables. Haciendo esto, queríamos enseñar habilidades que pudieran generar ganancias. En este caso, hemos añadido varias pasadas no rentables a la base de datos de ejemplos para demostrar estados no rentables al modelo. Después de todo, en el comercio real debemos aceptar el riesgo de sufrir reducciones, pero nos gustaría tener una estrategia para salir de ellas con pérdidas mínimas.
A continuación, entrenaremos los modelos. Primero el autocodificador y luego el agente.
El funcionamiento del modelo entrenado se ha puesto a prueba en el simulador de estrategias utilizando datos históricos de mayo de 2023. Estos datos no se han incluido en el conjunto de entrenamiento y nos permiten probar el rendimiento de los modelos con datos nuevos.
Debemos decir que los primeros resultados han sido peores de lo que esperábamos. Los resultados positivos incluyen una distribución bastante uniforme de las habilidades utilizadas en la muestra de prueba, pero aquí terminan los resultados positivos de nuestras pruebas. Tras varias iteraciones de entrenamiento del autocodificador y del agente, todavía no hemos podido obtener un modelo capaz de generar ganancias en el conjunto de entrenamiento. Aparentemente el problema reside en la incapacidad del autocodificador para predecir estados con suficiente precisión. Como resultado, la curva de balance se encuentra lejos del resultado deseado.
Para probar nuestra suposición, hemos creado un asesor alternativo de entrenamiento de agentes, "EDL\StudyActor2.mq5". La única diferencia entre la opción alternativa y la comentada anteriormente es el algoritmo para generar la recompensa. También hemos utilizado un ciclo para predecir los cambios en el estado de la cuenta. Solo que esta vez hemos usado el indicador de cambio de balance relativo como recompensa.
ActorResult = vector<float>::Zeros(NActions); for(action = 0; action < NActions; action++) { reward = GetNewState(Buffer[tr].States[i].account, action, prof_1l); ActorResult[action] = reward[0]/PrevBalance-1.0f; }
El agente que hemos entrenado usando la función de recompensa modificada ha mostrado un aumento bastante regular en la rentabilidad durante todo el periodo de prueba.


Debemos señalar que el agente ha sido entrenado con un enfoque modificado para generar recompensas sin reentrenar el autocodificador ni cambiar la arquitectura del propio agente. Es decir, el entrenamiento de ambos agentes se ha realizado íntegramente en condiciones comparables, y solo una revisión de los enfoques para la formación de la recompensa ha permitido aumentar la eficacia del modelo. Esto confirma una vez más la importancia de elegir correctamente la función de recompensa, que juega un papel clave en los métodos de aprendizaje por refuerzo.

Conclusión
En este artículo, hemos presentado otro método para enseñar habilidades, el llamado Explore, Discover and Learn (EDL). El algoritmo presentado permite al agente explorar el entorno y descubrir nuevas habilidades sin conocer previamente las condiciones o habilidades requeridas. Esto resulta posible gracias al uso de un autocodificador variacional, que permite encontrar dependencias entre los estados del entorno y las habilidades requeridas.
En la primera etapa del método se realiza una exploración del entorno. Asimismo, se forma una muestra de entrenamiento de estados con una cobertura máxima de varios estados correspondientes a diversos comportamientos. Luego, utilizando un autocodificador variacional, hemos buscado las dependencias entre estados y habilidades. El estado latente del autocodificador sirve como representación comprimida de los estados y también como una especie de identificador de la habilidad requerida. El decodificador y el codificador del modelo forman las funciones de dependencia entre estados y habilidades.
El agente se entrena en el marco tratando de obtener el estado predicho por el autocodificador. Los estados predictivos proporcionados por el autocodificador carecen de la estocasticidad inherente al entorno real, lo cual aumenta la estabilidad y la velocidad de aprendizaje del agente. Al mismo tiempo, esto supone un obstáculo para el enfoque, dado que el rendimiento del modelo depende en gran medida de la calidad de la predicción del estado por parte del autocodificador. Esto es lo que se ha demostrado durante el proceso de prueba.
Hoy en día, los mercados financieros suponen entornos bastante complejos y estocásticos, difíciles de predecir, e invertir en ellos sigue siendo muy arriesgado. Lograr resultados positivos en el trading solo resulta posible cumpliendo estrictamente una estrategia mesurada y equilibrada.
Enlaces
Programas usados en el artículo
| # | Nombre | Tipo | Descripción |
|---|---|---|---|
| 1 | Research.mq5 | Asesor | Asesor de recopilación de datos |
| 2 | StudyModel.mq5 | Asesor | Asesor de entrenamiento del modelo de autocodificador |
| 3 | StudyActor.mq5 | Asesor | Asesor de entrenamiento del agente |
| 4 | StudyActor2.mq5 | Asesor | Asesor alternativo de entrenamiento del agente (función de recompensa modificada) |
| 5 | Test.mq5 | Asesor | Asesor para la prueba de modelos |
| 6 | Trajectory.mqh | Biblioteca de clases | Estructura de descripción del estado del sistema. |
| 7 | FQF.mqh | Biblioteca de clases | Biblioteca de clases de organización de modelos completamente parametrizada |
| 8 | NeuroNet.mqh | Biblioteca de clases | Biblioteca de clases para crear una red neuronal |
| 9 | NeuroNet.cl | Biblioteca | Biblioteca de código de programa OpenCL |
| 10 | VAE.mqh | Biblioteca de clases | Biblioteca de clases de capa latente del autocodificador variacional |
Traducción del ruso hecha por MetaQuotes Ltd.
Artículo original: https://www.mql5.com/ru/articles/12783
 Iniciamos MetaTrader VPS por primera vez: instrucciones paso a paso
Iniciamos MetaTrader VPS por primera vez: instrucciones paso a paso
- Aplicaciones de trading gratuitas
- 8 000+ señales para copiar
- Noticias económicas para analizar los mercados financieros
Usted acepta la política del sitio web y las condiciones de uso