Indicadores adaptativos

Introducción
Probablemente, todo tráder sueña con un indicador que pueda adaptarse a la situación actual del mercado. Para que él mismo determine los flats y las tendencias, y pueda tener en cuenta los cambios reales de precio. Los indicadores técnicos convencionales utilizan coeficientes constantes al procesar la señal de entrada, y estos coeficientes no dependen de ninguna forma de las características de la señal de entrada y sus cambios en el tiempo.
Los indicadores adaptativos se distinguen por la presencia de retroalimentación entre los valores de las señales de entrada y salida. Esta relación permite que el indicador se ajuste de forma independiente al procesamiento óptimo de los valores de las series temporales financieras. Dicho en palabras simples: un indicador adaptativo es un indicador lineal regular, pero sus coeficientes pueden cambiar con el tiempo dependiendo de la situación actual del mercado.
Los algoritmos de adaptación son bastante variados. La elección de un algoritmo específico depende del propósito del indicador, pero la mayoría de las veces, estos algoritmos se basan en varios métodos de mínimos cuadrados. Veamos algunos ejemplos sobre el desarrollo de un indicador adaptativo.
Primer intento
Vamos a intentar crear un indicador adaptativo. La forma más obvia de adaptar un indicador es considerar de una u otra forma sus últimos errores. Veamos cómo podemos hacer esto.
Supongamos que tenemos Indicator[i], el valor del indicador en la i-ésima barra. Entonces el error será igual a: Error[i] = price[i] - Indicator[i].
Este error se puede usar para corregir los valores del indicador en la próxima lectura. Además, podemos procesar los errores de formas diferentes. Por ejemplo, podemos tomar el promedio de los últimos errores o aplicarles un suavizado exponencial.
Veamos el aspecto de este enfoque en el gráfico. Tomaremos como base la plantilla del artículo sobre indicadores técnicos, pero vamos a hacerle algunos cambios. En primer lugar, estableceremos el número de errores para
double sum=0; for(int j=0; j<size; j++) sum=sum+coeff[j]*price[i+j];//Calculate the indicator value if(i>0) { double cur_error=price[i]-sum;//Current error if(NumErrors==0) cur_error=(error+cur_error)/2; if(NumErrors==1) error=cur_error/2; if(NumErrors>1) { for(int j=NumErrors-1; j>0; j--) errors[j]=errors[j-1]; errors[0]=cur_error; cur_error=0; for(int j=0; j<NumErrors; j++) cur_error=cur_error+errors[j]; error=cur_error/NumErrors; } } buffer[i]=sum+error;//Indicator value considering the error
Así es como se verá nuestro nuevo indicador en comparación con la media móvil simple (línea roja).
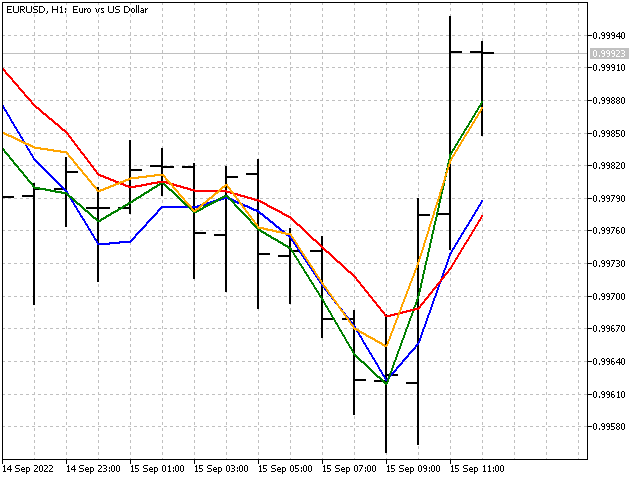
La imagen tiene buena pinta, pero ¿es nuestro indicador adaptable? Desafortunadamente, la respuesta es negativa. De hecho, tenemos un indicador lineal ordinario, pero sus coeficientes de peso se establecen implícitamente.
Tomemos por ejemplo una media móvil simple con un periodo de 3 y que promedia los últimos tres errores. Primero calcularemos los errores:
Error[1] = price[1] - (price[1] + price[2] + price[3])/3
Error[2] = price[2] - (price[2] + price[3] + price[4])/3
Error[3] = price[3] - (price[3] + price[4] + price[5])/3
Entonces la fórmula del indicador adoptará la forma:
Indicator[0] = (price[0] + price[1] + price[2])/3+(Error[1] + Error[2] + Error[3])/3 =>
Indicator[0] = (3*price[0] + 5*price[1] + 4*price[2] + 0*price[3] - 2*price[4] - 1*price[5])/9
Como resultado, hemos obtenido un indicador lineal regular. De aquí podemos extraer una conclusión simple: solo el procesamiento de errores no hace de este indicador un indicador adaptativo.
Amanecer
Un día, Pierre-Simon Laplace formuló el problema conocido como "el problema del amanecer". La esencia de dicho problema se puede formular de la forma siguiente: si hemos visto la salida del sol durante 1000 días, ¿cuál será nuestra certeza de que el sol salga por 1001-ésima vez? La tarea resulta interesante: veámosla desde el punto de vista del trading. Supongamos que hemos realizado nueve transacciones, seis de las cuales han resultado rentables. Ahora, usando esta información como base, intentemos responder a la pregunta: ¿cuál es la probabilidad de una operación rentable?
Vamos a razonar juntos. Como norma general, la probabilidad se define como la relación entre las transacciones rentables y su número total:
![]()
En nuestro ejemplo, la probabilidad será en este caso igual a 6/9. Sin embargo, iremos un paso más allá: ¿cuál será la probabilidad de ganar en una operación futura? El denominador de la fracción aumentará en uno para cualquier resultado, pero con el numerador, son posibles dos opciones: una transacción futura puede resultar rentable y no rentable. Es decir, tendremos dos opciones posibles:
![]()
Vamos a tomar el promedio de estos valores; entonces, nuestra estimación de la probabilidad de ganar será la siguiente:
![]()
que es un poco inferior al valor original de 6/9. Este método se llama suavizado de Laplace. Podemos usarlo para datos categóricos, donde las variables pueden tomar múltiples valores definidos ("éxito o fracaso" en nuestro ejemplo).
Vamos a intentar aplicar este suavizado en el indicador. Para lograr esto, haremos una pequeña suposición: vamos a asumir que hay otro precio oculto en el flujo de precios (llamémoslo imaginario), que también influirá en las lecturas del indicador.
Veamos cómo cambia la fórmula del indicador en este supuesto. Este será el aspecto de la fórmula de la media móvil simple:
![]()
Y así es como se verá la misma media con un precio imaginario:
![]()
A primera vista, todo tiene un aspecto excelente, pero hay algunas cosas negativas aquí. En primer lugar, el precio imaginario en sí mismo resultará inestable:
![]()
En segundo lugar, si movemos el precio imaginario al siguiente punto de la serie temporal, nuestro indicador se simplificará:
![]()
Esta simplificación no nos ha ayudado a estabilizar el indicador (el coeficiente con price[1] es igual a 1). Sin embargo, este fallo puede servir como base para otro indicador.
Primero, configuraremos el periodo del indicador iPeriod. Luego encontraremos los valores de SL para todo N con valores desde 1 hasta iPeriod. El siguiente paso consistirá en calcular el promedio de la suma de todos los SL. Como resultado, tendremos un indicador que mostrará un valor de precio estable. Este indicador se puede describir de la forma siguiente: un pronóstico ingenuo (lo que ha sido, será), más una tendencia lineal ligeramente debilitada.
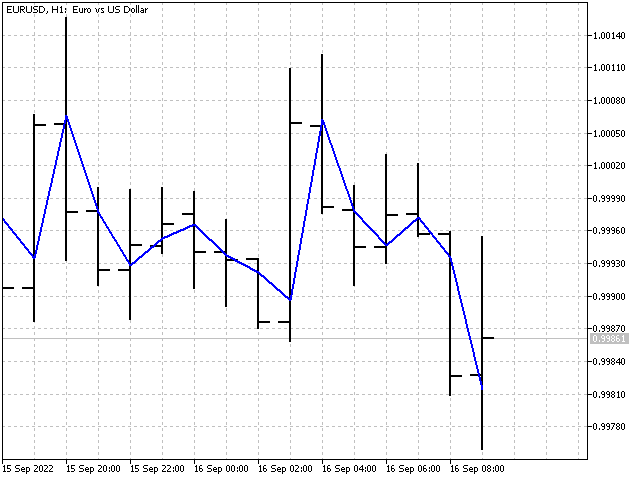
Bueno, ya tenemos el indicador. Sin embargo, no hemos conseguido la adaptación. Otro intento y otro fiasco. Vamos a tomarnos un pequeño descanso; ya intentaremos luego crear un indicador adaptativo. Bueno, o tendremos que cambiar el título del artículo.
Puesta de luna
Kozma Prutkov una vez comentó muy sabiamente: “Si te preguntan: ¿qué es más útil, el sol o la luna?, responde: la luna. Porque el sol brilla durante el día, cuando de todos modos ya hay luz; mientras que la luna brilla de noche". Veamos cómo podemos trasladar este dicho al mundo del trading.
En el suavizado de Laplace, usamos los valores de precio con los mismos coeficientes de peso, pero, ¿qué pasará si le damos ciertos pesos a los precios? En las funciones de ventana, los coeficientes de peso dependerán de la distancia entre la lectura dada y el centro de peso del indicador. Ahora lo haremos de otra forma. Primero, elegiremos un cierto valor de precio como valor central. Precisamente este valor llevará el mayor peso. Los coeficientes de peso del resto de precios dependerán de lo lejos que se encuentre el precio de este valor: cuanto más lejos, menor será su peso. Es decir, crearemos una función de ventana no en el dominio temporal, sino en el dominio del precio. Veamos el aspecto de un algoritmo de este tipo en la práctica.
double value=price[i+center],//Price value at the center max=_Point; //Maximum deviation for(int j=0; j<period; j++)//Calculate price deviations from the central one and the max deviation { weight[j]=MathAbs(value-price[i+j]); max=MathMax(max,weight[j]); } double width=(period+1)*max/period,//correct the maximum deviation from the center so that there are no zeros at the ends sum=0, denom=0; for(int j=0; j<period; j++)//calculate weight ratios for each price { if(Smoothing==Linear)//linear smoothing weight[j]=1-weight[j]/width; if(Smoothing==Quadratic)//quadratic smoothing weight[j]=1-MathPow(weight[j]/width,2); if(Smoothing==Exponential)//exponential smoothing weight[j]=MathExp(-weight[j]/width); sum=sum+weight[j]*price[i+j]; denom=denom+weight[j]; } buffer[i]=sum/denom;//indicator value
Así es como se ve nuestro indicador en el gráfico.
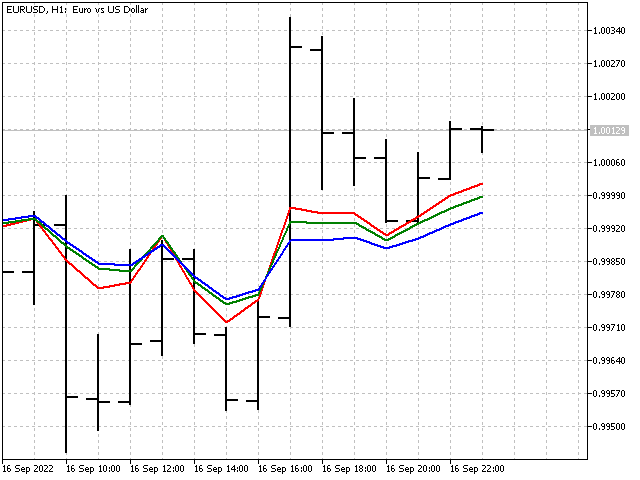
En este indicador, los coeficientes de peso cambian, pero no se puede calificar de «adaptable». Sería más correcto afirmar que este indicador se ajusta a la situación actual del mercado. El indicador adaptativo no ha funcionado para nosotros, pero hemos dado el primer paso hacia el éxito.
Segundo intento
Tomaremos como base una función de ventana rectangular, pero haremos pequeños cambios en ella: dejaremos que los coeficientes al principio y al final de la ventana puedan cambiar. La fórmula del indicador sería entonces como sigue:
![]()
Donde, N sería el periodo del indicador, y C1 y C2 serían coeficientes adaptativos.
Supongamos que ya tenemos los valores de dichos coeficientes. Aparece un nuevo valor de precio, y junto con esto, el error del indicador puede cambiar.
![]()
Para reducir el error, necesitaremos corregir cada coeficiente con una cierta corrección R:
![]()
No hace falta decir que nos esforzaremos por garantizar que los cambios en los coeficientes reduzcan el error del indicador a cero; pero esta no será la única condición. Además, exigiremos que las correcciones R también sean pequeñas. Si se cumplen ambas condiciones, podremos esperar que el valor de los coeficientes adaptativos fluctúe alrededor de algunos valores óptimos (si los hay).
Por consiguiente, deberemos encontrar una solución al siguiente problema:
![]()
Para encontrar las correcciones R, usaremos el método de los mínimos cuadrados. Entonces, los cálculos se podrán realizar en varios pasos. Primero, calcularemos el factor de convergencia:
![]()
Así, los valores de corrección serán iguales a: R = price*Error*M.
Como consecuencia, las fórmulas de actualización de los coeficientes serán las siguientes:
![]()
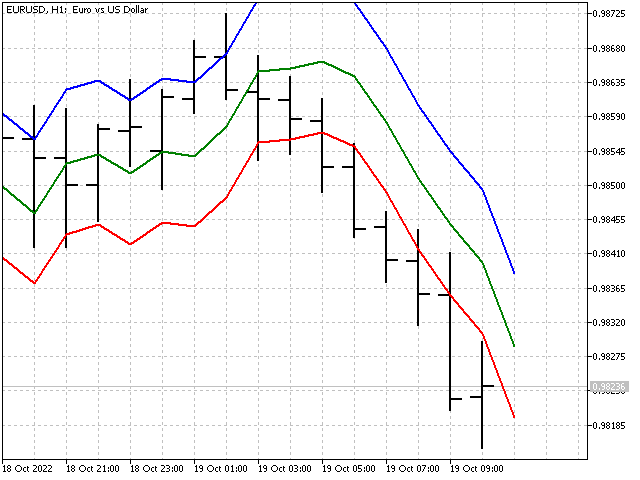
Este aspecto tendrá nuestro indicador en comparación con una media móvil simple (línea roja).
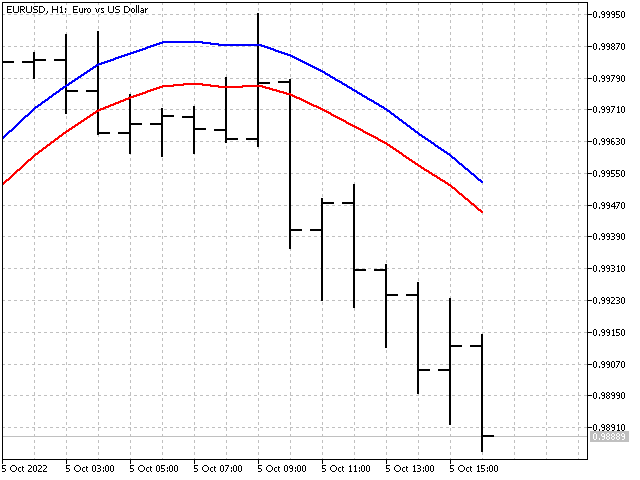
Adaptación
Con dos coeficientes sí que hemos logrado arreglárnoslas. ¿Se puede crear un indicador con todos los coeficientes adaptativos? Sí, un indicador así es posible. Los cálculos de los coeficientes de dicho indicador serán similares a los considerados en el caso anterior. La única diferencia sería el cálculo del factor de convergencia:
![]()
El parámetro P nos permitirá ajustar la tasa de cambio de los coeficientes en cada paso. Su valor deberá ser al menos de 1. Con un parámetro P pequeño, los coeficientes del indicador alcanzarán muy rápidamente sus valores óptimos. Sin embargo, los cambios en los coeficientes del indicador pueden resultar excesivos. Con un valor grande de P, los coeficientes del indicador cambiarán lentamente. En otras palabras, cuanto mayor sea P, más suave será el indicador. Por ejemplo, este será el aspecto de los indicadores con P = 1 y P = 1000.
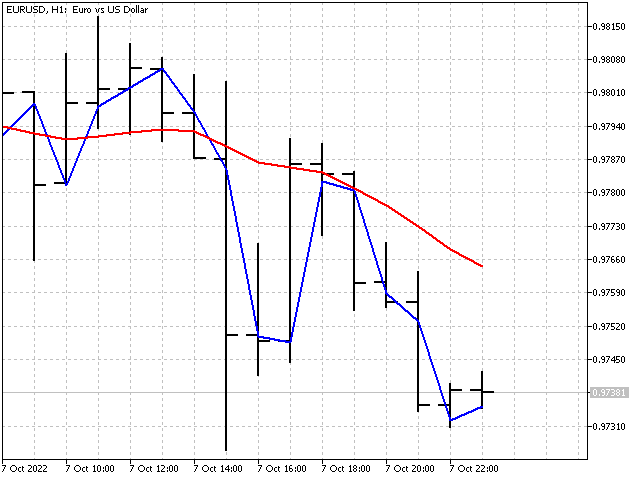
Recomendación general: establezca primero un valor del parámetro igual al periodo del indicador y luego cámbielo en una dirección u otra hasta obtener el resultado deseado.
Una característica importante de los indicadores adaptativos es su posible inestabilidad. La suma de los coeficientes de dicho indicador no será igual a uno y podrá variar según los datos de entrada. Tomaremos como ejemplo la media exponencial. La fórmula clásica tiene el aspecto siguiente: ![]() .
.
Pero la fórmula de la EMA adaptativa será así: ![]() .
.
Además, los coeficientes C1 y C2 no dependerán el uno del otro. Los coeficientes se actualizarán de la misma forma que en el indicador anterior. Solo que al realizar los cálculos, no solo se usarán los precios, sino también los valores anteriores del indicador en sí.
![]()
![]()
Entonces, los coeficientes actualizados serán iguales a:
![]()
La propia EMA adaptativa con diferentes valores del parámetro P se verá así.
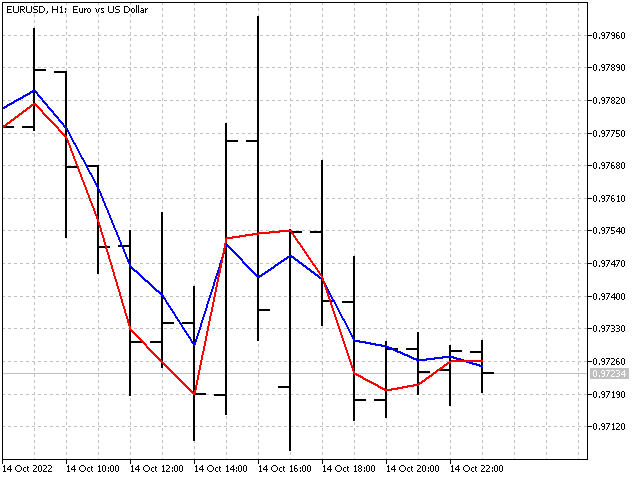
Los algoritmos de adaptación también se podrán aplicar a las funciones de ventana. Sin embargo, el resultado no será tan impresionante, ya que la adaptación se producirá gracias a un cambio en el coeficiente de normalización.
Tomemos como base el indicador LWMA con un periodo de 5. Podemos escribir su fórmula escribir así: ![]() .
.
Donde C es un cierto coeficiente de normalización. En los casos habituales, el valor de este coeficiente es constante y se puede calcular de antemano. Ahora permitiremos la posibilidad de que este cambie en una u otra dirección.
Primero necesitaremos calcular la suma ponderada: ![]() .
.
Entonces, el valor ajustado del coeficiente de normalización se podrá encontrar mediante la fórmula:
![]()
Este enfoque puede ser útil para indicadores con un periodo corto. Durante periodos largos, la influencia de la adaptación y el parámetro P resultará casi imperceptible.
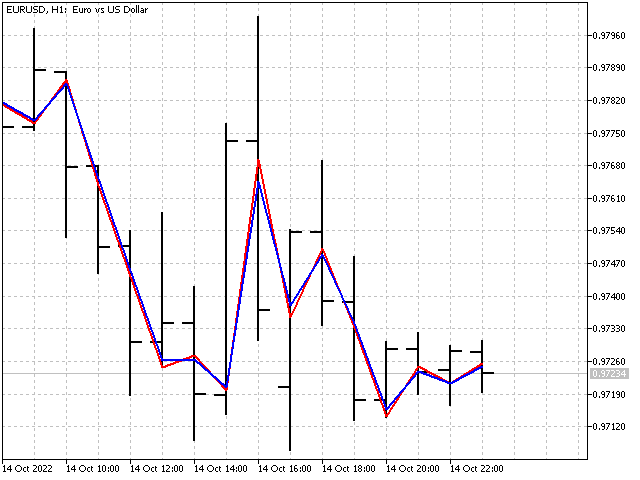
Basándonos en los indicadores adaptativos, podemos crear toda una variedad de osciladores. Por ejemplo, así es como se verá el indicador adaptativo CCI.
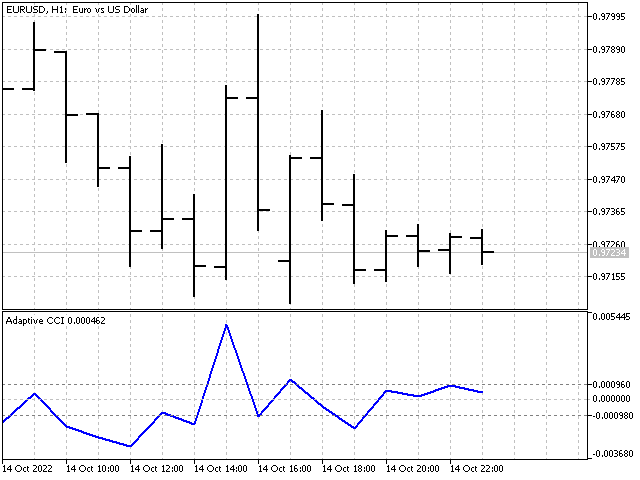
Predicción lineal
Construir un indicador adaptativo resulta similar en muchos aspectos a resolver un problema de predicción lineal. De hecho, si usamos la diferencia entre el valor del indicador y el precio futuro (en relación con el mismo indicador) como error, entonces el indicador adaptativo se convertirá en predictivo.
Vamos a tomar los precios opencomo ejemplo. Entonces la fórmula del indicador y el valor del error serán como vemos:
![]()
![]()
Todos los demás cálculos se realizan según fórmulas que ya nos son familiares. Lo único que añadiremos a este indicador será el cálculo del error de predicción media. Como resultado, obtendremos el valor pronosticado del precio open para la barra con un índice -1.
Predicción probabilística lineal
La tarea de la predicción lineal también se puede expresar como una ecuación de movimiento de precios. En el mundo físico, todo parece bastante simple: si conocemos la posición actual de un punto, su velocidad y su aceleración, entonces no resultará difícil predecir su posición en un momento próximo. Pero con los movimientos de precio tendremos que sudar un poco.
Sabemos el valor del precio. La velocidad y la aceleración son, hablando en términos matemáticos, la primera y la segunda derivada. Las reemplazaremos con un análogo discreto: las diferencias divididas del orden correspondiente. Los coeficientes de las diferencias divididas se pueden tomar de la línea correspondiente del triángulo de Pascal, solo será necesario cambiar los signos delante de cada coeficiente. Así, obtendremos:
1*open[0] -1*open[1] – análogo discreto de velocidad;
1*open[0] -2*open[1] +1*open[2] – análogo discreto de aceleración.
Entonces la ecuación de movimiento de precios se puede expresar de la forma siguiente:
open[0] + (open[0] – open[1]) + (open[0] – 2*open[1] + open[2]).
Añadimos los coeficientes adaptativos a esta ecuación y como resultado obtendremos:
open[-1] = open[0] + c1*(open[0] – open[1]) + c2*(open[0] – 2*open[1] + open[2]).
Abrimos los paréntesis y agrupamos los coeficientes. Entonces la ecuación tomará la forma siguiente:
open[-1] = (1 + с1 + с2)*open[0] + (-c1 – 2*с2)*open[1] + c2*open[2].
Recuerde que los coeficientes de un indicador estable deberán encontrarse en el rango de -1 a +1. Entonces, necesitaremos resolver el siguiente sistema de desigualdades:
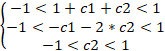
Como resultado, tendremos tres opciones posibles:
![]()
![]()
![]()
Ahora podremos elegir los valores de los coeficientes y usarlos en el indicador.
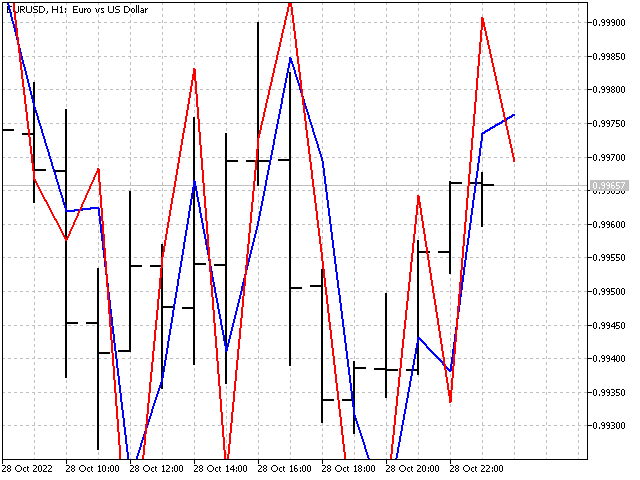
Obviamente, el uso de diferencias de un orden superior ofrecerá más opciones posibles e influirá favorablemente en el aspecto del indicador.
Conclusión
El uso de algoritmos de adaptación permite conseguir indicadores bastante inusuales. Su principal ventaja consiste en el ajuste automático a la situación actual del mercado, mientras que las desventajas incluyen un aumento en el número de parámetros de control, cuya selección puede requerir algo de tiempo. Por otra parte, los indicadores adaptativos pueden cambiar en un rango muy amplio, lo cual puede ofrecer nuevos enfoques al análisis técnico.
Traducción del ruso hecha por MetaQuotes Ltd.
Artículo original: https://www.mql5.com/ru/articles/11627
 Aprendizaje automático y Data Science (Parte 8): Clusterización con el método de k-medias en MQL5
Aprendizaje automático y Data Science (Parte 8): Clusterización con el método de k-medias en MQL5
 Aprendiendo a diseñar un sistema de trading con Fractals
Aprendiendo a diseñar un sistema de trading con Fractals
- Aplicaciones de trading gratuitas
- 8 000+ señales para copiar
- Noticias económicas para analizar los mercados financieros
Usted acepta la política del sitio web y las condiciones de uso