
Datenwissenschaft und maschinelles Lernen (Teil 12): Können selbstlernende neuronale Netze Ihnen helfen, den Aktienmarkt zu überlisten?

„Ich will damit nicht sagen, dass neuronale Netze einfach sind. Man muss schon ein Experte sein, damit diese Dinge funktionieren. Aber dieses Fachwissen kommt Ihnen bei einem breiteren Spektrum von Anwendungen zugute. In gewissem Sinne fließt der gesamte Aufwand, der zuvor in die Entwicklung von Merkmalen floss, nun in die Entwicklung von Architekturen, Verlustfunktionen und Optimierungsverfahren. Die manuelle Arbeit ist auf eine höhere Abstraktionsebene gehoben worden“.
Stefano Soatto
Einführung
Wenn Sie schon länger mit Algorithmen handeln, haben Sie mit hoher Wahrscheinlichkeit schon einmal von Neuronalen Netzen gehört. Es erscheint wie der heilige Grale der Handelsroboter, aber ich bin mir nicht so sicher, weil es mehr braucht als nur das Hinzufügen von neuronalen Netzen zu einem Handels-Bot, um am Ende ein profitables System zu haben. Ganz zu schweigen davon, dass man verstehen muss, worauf man sich einlässt, wenn man neuronale Netze einsetzt, denn schon kleine Details können über Erfolg oder Misserfolg, d.h. Gewinn oder Verlust, entscheiden.

Ehrlich gesagt glaube ich, dass neuronale Netze nicht für jedermann geeignet sind, vor allem, wenn man nicht bereit ist, sich die Hände schmutzig zu machen, denn sehr oft muss man Zeit damit verbringen, die vom Modell erzeugten Fehler zu analysieren, die Eingabedaten vorzuverarbeiten und zu skalieren, und vieles mehr, worüber ich in diesem Artikel sprechen werde.
Beginnen wir diesen Artikel mit einer Definition eines künstlichen neuronalen Netzes.
Was ist ein künstliches neuronales Netz?
Einfach ausgedrückt ist ein künstliches neuronales Netz, das gewöhnlich als neuronales Netz bezeichnet wird, ein Computersystem, das sich an den neuronalen Netzen orientiert, die das Gehirn von Tieren nachbilden. Um die grundlegenden Komponenten eines neuronalen Netzes zu verstehen, lesen Sie den vorherigen Artikel dieser Serie.
In den vorangegangenen Artikeln über neuronale Netze habe ich die grundlegenden Dinge über ein neuronales Feed-Forward-Netz erklärt. In diesem Artikel werden wir uns sowohl mit dem Vorwärtsdurchlauf eines neuronalen Netzes als auch mit dem Rückwärtsdurchlauf, dem Training und dem Testen eines neuronalen Netzes befassen. Wir werden auch einen Handelsroboter erstellen, der auf allem basiert, was wir zuletzt besprochen haben, und wir werden sehen, wie unser Handelsroboter abschneidet.
In einem mehrschichtigen neuronalen Perzeptron-Netzwerk sind alle Neuronen/Knoten einer aktuellen Schicht mit den Knoten der zweiten Schicht verbunden und so weiter, für alle Schichten vom Eingang bis zum Ausgang. Dadurch sind neuronale Netze in der Lage, komplexe Zusammenhänge in den Datensätzen zu erkennen. Je mehr Ebenen Sie haben, desto besser ist Ihr Modell in der Lage, komplexe Beziehungen in den Datensätzen zu verstehen. Dies ist mit einem hohen Rechenaufwand verbunden und garantiert nicht unbedingt die Genauigkeit des Modells, insbesondere wenn das Modell zu kompliziert ist, während das Problem einfach ist.
In den meisten Fällen reicht eine einzige versteckte Schicht für die meisten Probleme aus, die man mit diesen ausgefallenen neuronalen Netzen zu lösen versucht. Deshalb werden wir ein einschichtiges neuronales Netz verwenden.
Der Vorwärtsdurchlauf
Die am Vorwärtsdurchlauf (forward pass) beteiligten Operationen sind einfach und können mit wenigen Codezeilen realisiert werden. Um Ihre neuronalen Netze flexibel zu gestalten, müssen Sie jedoch über ein solides Verständnis von Matrix- und Vektoroperationen verfügen, da diese die Bausteine neuronaler Netze und vieler Algorithmen für maschinelles Lernen sind, die wir in dieser Reihe besprechen.
Ein wichtiger Punkt ist die Art des Problems, das mit Hilfe eines neuronalen Netzes gelöst werden soll, denn unterschiedliche Probleme erfordern unterschiedliche Arten von neuronalen Netzen mit unterschiedlichen Konfigurationen und unterschiedlichen Ausgaben.
Für diejenigen, die nicht wissen, welche Arten von Problemen es gibt
- Regressionsprobleme
- Klassifizierungsprobleme
Bei Regressionsproblemen handelt es sich um die Art von Problemen, bei denen wir versuchen, kontinuierliche Variablen vorherzusagen, z. B. beim Handel versuchen wir oft, den nächsten Preispunkt vorherzusagen, auf den sich der Markt zubewegen wird. Ich empfehle die Lektüre von Linearer Regression für diejenigen, die dies noch nicht getan haben.
Diese Art von Problemen wird durch die Regression neuronaler Netze gelöst.
02: Klassifizierungsprobleme
Klassifizierungsprobleme sind die Art von Problemen, bei denen wir versuchen, diskrete/nicht kontinuierliche Variablen vorherzusagen. Beim Handel könnten wir die Signale vorhersagen, z. B. 0 bedeutet, dass der Markt nach unten geht, während 1 bedeutet, dass der Markt nach oben geht.
Diese Art von Problemen wird durch neuronale Klassifizierungsnetze oder neuronale Mustererkennungsnetze angegangen, in MATLAB werden sie als Patternnets bezeichnet
In diesem Artikel werde ich ein Regressionsproblem lösen, indem ich versuche, den nächsten Kurs, auf den sich der Markt bewegen wird, vorherzusagen.
matrix CRegNeuralNets::ForwardPass(vector &input_v) { matrix INPUT = this.matrix_utils.VectorToMatrix(input_v); matrix OUTPUT; OUTPUT = W.MatMul(INPUT); //Weight X Inputs OUTPUT = OUTPUT + B; //Outputs + Bias OUTPUT.Activation(OUTPUT, ENUM_ACTIVATION_FUNCTION(A_FX)); //Activation Function return (OUTPUT); }
Die Funktion des Vorwärtsdurchlaufs ist einfach zu lesen, aber der wichtigste Punkt, auf den Sie achten sollten, sind die Matrixgrößen bei jedem Schritt, wenn Sie versuchen, alles reibungslos zu gestalten.
matrix INPUT = this.matrix_utils.VectorToMatrix(input_v);
Dieser Teil ist erklärungsbedürftig. Da diese Funktion VectorToMatrix die Eingaben in einem Vektor entgegennimmt, müssen diese Eingaben aufgrund der bevorstehenden Matrixoperationen in einer Matrixform vorliegen.
Denken Sie immer daran:
- Die erste NN INPUT-Matrix ist eine nx1-Matrix
- Die Gewichtungsmatrix ist eine HN x n, wobei HN die Anzahl der Knoten in der aktuellen verborgenen Schicht und n die Anzahl der Eingaben aus der vorherigen Schicht oder die Anzahl der Zeilen der Eingabematrix ist.
- Die Bias-Matrix hat die gleiche Größe wie der Output einer Schicht.
Dies ist sehr wichtig zu wissen. Es wird Sie davor bewahren, eines Tages in der Ungewissheit zu ertrinken, wenn Sie versuchen, dies auf eigene Faust herauszufinden.
Ich möchte Ihnen die Architektur des neuronalen Netzes, an dem wir arbeiten, zeigen, damit Sie sich ein klares Bild davon machen können, was wir vorhaben.
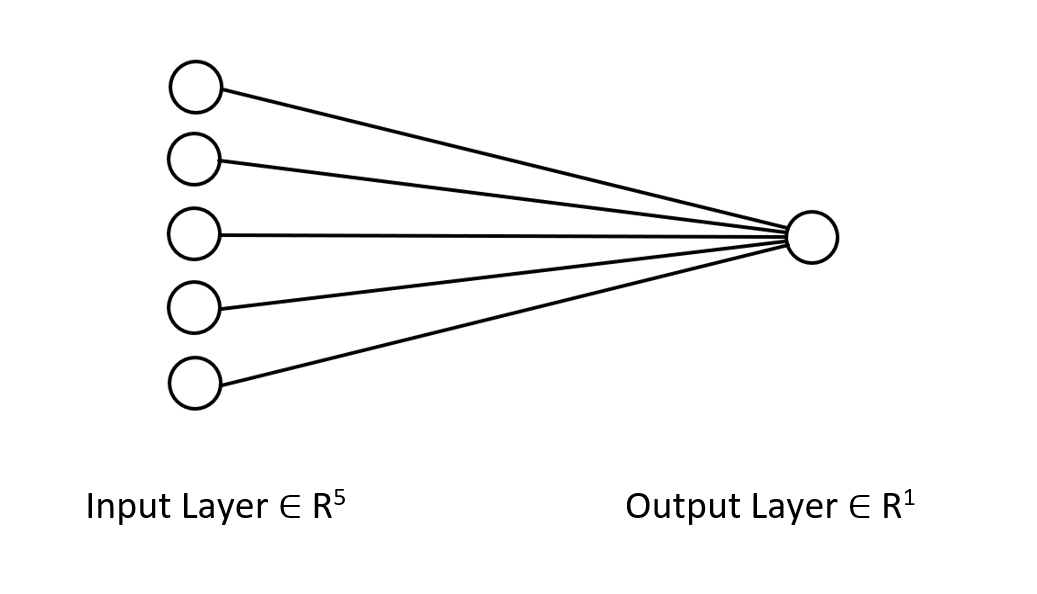
Es handelt sich nur um ein einschichtiges neuronales Netz, deshalb sehen Sie in der Funktion, die ich gerade gezeigt habe, keine Schleifen im Vorwärtsdurchlauf. Wenn Sie jedoch den gleichen Matrixansatz verfolgen und die oben erläuterten Dimensionen sicherstellen, können Sie Architekturen beliebiger Komplexität implementieren.
Sie haben den Vorwärtsdurchlauf mit der W-Matrix gesehen, nun wollen wir sehen, wie wir die Gewichte für unser Modell erzeugen können.
Generierung der Gewichte
Die Generierung der geeigneten Gewichte für das neuronale Netz ist nicht nur eine Frage der Initialisierung der Zufallswerte. Ich habe auf die harte Tour gelernt, dass ein falscher Ansatz bei der Backpropagation zu allen möglichen Problemen führen kann, die Sie bei der Fehlersuche an Ihrem hart kodierten, komplexen Code verzweifeln lässt.
Eine unsachgemäße Gewichtsinitialisierung kann den gesamten Lernprozess langwierig und zeitraubend machen. Das Netz kann in den lokalen Minima stecken bleiben und sehr langsam konvergieren.
Der erste Schritt ist die Auswahl der Zufallswerte, ich bevorzuge den Zufallswert 42.
this.W = matrix_utils.Random(0.0, 1.0,1,m_inputs, RANDOM_STATE);
Die meisten Leute landen bei diesem Schritt, sie erstellen die Gewichte und denken, das sei alles. Nachdem wir die Zufallsvariablen ausgewählt haben, müssen wir unsere Gewichte entweder mit Glorot oder He initialisieren.
Die Xavier/Glorot-Initialisierung funktioniert am besten mit Sigmoid- und tanh-Aktivierungsfunktionen, während die He-Initialisierung für RELU und seine Varianten geeignet ist.
He Initialisierung
![]()
wobei: n = Anzahl der Eingänge des Knotens.
Nachdem die Gewichte initialisiert wurden, folgte die Normalisierung der Gewichte.
this.W = matrix_utils.Random(0.0, 1.0,1,m_inputs, RANDOM_STATE); this.W = this.W * 1/sqrt(m_inputs); //He initialization
Da dieses neuronale Netz nur eine Schicht hat, gibt es nur eine einzige Matrix mit den Gewichten.
Aktivierungsfunktionen
Da es sich um ein neuronales Netz vom Typ Regression handelt, sind die Aktivierungsfunktionen dieses Netzes nur die Varianten der Regressionsaktivierungsfunktion. RELU:
enum activation { AF_ELU_ = AF_ELU, AF_EXP_ = AF_EXP, AF_GELU_ = AF_GELU, AF_LINEAR_ = AF_LINEAR, AF_LRELU_ = AF_LRELU, AF_RELU_ = AF_RELU, AF_SELU_ = AF_SELU, AF_TRELU_ = AF_TRELU, AF_SOFTPLUS_ = AF_SOFTPLUS };
Diese Aktivierungsfunktionen in Rot und viele mehr sind standardmäßig in der Standardbibliothek für Matrizen enthalten, MEHR DAZU.
Verlustfunktionen
Die Verlustfunktionen für dieses neuronale Regressionsnetz sind:
enum loss { LOSS_MSE_ = LOSS_MSE, LOSS_MAE_ = LOSS_MAE, LOSS_MSLE_ = LOSS_MSLE, LOSS_HUBER_ = LOSS_HUBER };
Es gibt weitere Aktivierungsfunktionen, die von der Standardbibliothek zur Verfügung gestellt werden, MEHR DAZU.
Backpropagation mit Delta-Regel
Die Delta-Regel ist eine Lernregel des Gradientenabstiegs zur Aktualisierung der Gewichte der Eingänge künstlicher Neuronen in einem einschichtigen neuronalen Netz. Dies ist ein Spezialfall des allgemeineren Backpropagation-Algorithmus. Für ein Neuron j mit der Aktivierungsfunktion g(x) ist die Deltaregel für das i-te Gewicht Wji des Neurons j gegeben durch:
![]()
wobei:
![]() ist eine kleine Konstante, die Lernrate genannt wird
ist eine kleine Konstante, die Lernrate genannt wird
![]() ist die Ableitung von g
ist die Ableitung von g
g(x) ist die Aktivierungsfunktion des Neurons
![]() ist die Zielausgabe
ist die Zielausgabe
![]() ist der aktuelle Ausgabe
ist der aktuelle Ausgabe
![]() ist der i-te Eingang
ist der i-te Eingang
Das ist großartig, wir haben jetzt eine Formel, wir müssen sie nur noch umsetzen, richtig? FALSCH!!!
Das Problem bei dieser Formel ist, dass sie, so einfach sie auch aussieht, sehr komplex ist, wenn man sie in Code umwandelt, und dass man eine Reihe von for-Schleifen programmieren muss . Die richtige Formel, die wir brauchen, ist die, die uns die Matrixoperationen zeigt. Lassen Sie mich das für Sie machen:
![]()
Wobei:
![]() = Änderung der Gewichtsmatrix
= Änderung der Gewichtsmatrix
![]() = Ableitung der Verlustfunktion
= Ableitung der Verlustfunktion
![]() = Elementweise Matrixmultiplikation/Hadamard-Produkt
= Elementweise Matrixmultiplikation/Hadamard-Produkt
![]() = Ableitung der Neuronenaktivierungsmatrix
= Ableitung der Neuronenaktivierungsmatrix
![]() = Eingabematrix.
= Eingabematrix.
Die L-Matrix hat immer die gleiche Größe wie die O-Matrix, und die sich ergebende Matrix auf der rechten Seite muss die gleiche Größe wie die W-Matrix haben. Andernfalls sind Sie aufgeschmissen.
Schauen wir uns an, wie das in Code umgewandelt aussieht.
for (ulong iter=0; iter<m_rows; iter++) { OUTPUT = ForwardPass(m_x_matrix.Row(iter)); //forward pass pred = matrix_utils.MatrixToVector(OUTPUT); actual[0] = m_y_vector[iter]; preds[iter] = pred[0]; actuals[iter] = actual[0]; //--- INPUT = matrix_utils.VectorToMatrix(m_x_matrix.Row(iter)); vector loss_v = pred.LossGradient(actual, ENUM_LOSS_FUNCTION(L_FX)); LOSS_DX.Col(loss_v, 0); OUTPUT.Derivative(OUTPUT, ENUM_ACTIVATION_FUNCTION(A_FX)); OUTPUT = LOSS_DX * OUTPUT; INPUT = INPUT.Transpose(); DX_W = OUTPUT.MatMul(INPUT); this.W -= (alpha * DX_W); //Weights update by gradient descent }
Das Gute an der Verwendung der von MQL5 bereitgestellten Matrixbibliothek anstelle von Arrays für das maschinelle Lernen ist, dass Sie sich keine Gedanken über Kalkulationen machen müssen, d. h. Sie müssen sich nicht darum kümmern, die Ableitungen der Verlustfunktion oder der Aktivierungsfunktion zu finden — nichts.
Um das Modell zu trainieren, müssen wir zwei Dinge berücksichtigen, zumindest im Moment Epochen und die Lernrate, bezeichnet als Alpha. Wenn Sie meinen vorherigen Artikel in dieser Serie über den Gradientenabstieg gelesen haben, wissen Sie, wovon ich spreche.
Epochen: Eine einzelne Epoche liegt vor, wenn der gesamte Datensatz vollständig vorwärts und rückwärts durch das Netz gelaufen ist. Mit einfachen Worten, wenn das Netz alle Daten gesehen hat. Je größer die Anzahl der Epochen ist, desto länger dauert das Training eines neuronalen Netzes, und desto besser kann es lernen.
Alpha: ist die Größe der Schritte, die der Algorithmus für den Gradientenabstieg beim Erreichen des globalen und lokalen Minimums machen soll. Alpha ist normalerweise ein kleiner Wert zwischen 0,1 und 0,00001. Je größer dieser Wert ist, desto schneller konvergiert das Netz, aber desto höher ist auch das Risiko, dass das lokale Minimum verfehlt wird.
Im Folgenden finden Sie den vollständigen Code für diese Deltaregel:
for (ulong epoch=0; epoch<epochs && !IsStopped(); epoch++) { for (ulong iter=0; iter<m_rows; iter++) { OUTPUT = ForwardPass(m_x_matrix.Row(iter)); pred = matrix_utils.MatrixToVector(OUTPUT); actual[0] = m_y_vector[iter]; preds[iter] = pred[0]; actuals[iter] = actual[0]; //--- INPUT = matrix_utils.VectorToMatrix(m_x_matrix.Row(iter)); vector loss_v = pred.LossGradient(actual, ENUM_LOSS_FUNCTION(L_FX)); LOSS_DX.Col(loss_v, 0); OUTPUT.Derivative(OUTPUT, ENUM_ACTIVATION_FUNCTION(A_FX)); OUTPUT = LOSS_DX * OUTPUT; INPUT = INPUT.Transpose(); DX_W = OUTPUT.MatMul(INPUT); this.W -= (alpha * DX_W); } printf("[ %d/%d ] Loss = %.8f | accuracy %.3f ",epoch+1,epochs,preds.Loss(actuals,ENUM_LOSS_FUNCTION(L_FX)),metrics.r_squared(actuals, preds)); }
Jetzt ist alles vorbereitet. Damit ist es an der Zeit, das neuronale Netz zu trainieren, um nur ein kleines Muster im Datensatz zu verstehen.
#include <MALE5\Neural Networks\selftrain NN.mqh> #include <MALE5\matrix_utils.mqh> CRegNeuralNets *nn; CMatrixutils matrix_utils; //+------------------------------------------------------------------+ //| Expert initialization function | //+------------------------------------------------------------------+ int OnInit() { //--- matrix Matrix = { {1,2,3}, {2,3,5}, {3,4,7}, {4,5,9}, {5,6,11} }; matrix x_matrix; vector y_vector; matrix_utils.XandYSplitMatrices(Matrix,x_matrix,y_vector); nn = new CRegNeuralNets(x_matrix,y_vector,0.01,100, AF_RELU_, LOSS_MSE_); //Training the Network //--- return(INIT_SUCCEEDED); }
Die Funktion XundYSplitMatrices zerlegt unsere Matrix in eine x- und eine y-Matrix bzw. einen Vektor.
| X Matrix | Y-Vektor |
|---|---|
| { {1, 2}, {2, 3}, {3, 4}, {4, 5}, {5, 6} } | {3}, {5}, {7}, {9}, {11} |
Die Ausbildungsergebnisse:
CS 0 20:30:00.878 Self Trained NN EA (Apple_Inc_(AAPL.O),H1) [1/100] Loss = 56.22401001 | accuracy -6.028 CS 0 20:30:00.879 Self Trained NN EA (Apple_Inc_(AAPL.O),H1) [2/100] Loss = 2.81560904 | accuracy 0.648 CS 0 20:30:00.879 Self Trained NN EA (Apple_Inc_(AAPL.O),H1) [3/100] Loss = 0.11757813 | accuracy 0.985 CS 0 20:30:00.879 Self Trained NN EA (Apple_Inc_(AAPL.O),H1) [4/100] Loss = 0.01186759 | accuracy 0.999 CS 0 20:30:00.879 Self Trained NN EA (Apple_Inc_(AAPL.O),H1) [5/100] Loss = 0.00127888 | accuracy 1.000 CS 0 20:30:00.879 Self Trained NN EA (Apple_Inc_(AAPL.O),H1) [6/100] Loss = 0.00197030 | accuracy 1.000 CS 0 20:30:00.879 Self Trained NN EA (Apple_Inc_(AAPL.O),H1) [7/100] Loss = 0.00173890 | accuracy 1.000 CS 0 20:30:00.879 Self Trained NN EA (Apple_Inc_(AAPL.O),H1) [8/100] Loss = 0.00178597 | accuracy 1.000 CS 0 20:30:00.879 Self Trained NN EA (Apple_Inc_(AAPL.O),H1) [9/100] Loss = 0.00177543 | accuracy 1.000 CS 0 20:30:00.879 Self Trained NN EA (Apple_Inc_(AAPL.O),H1) [10/100] Loss = 0.00177774 | accuracy 1.000 … … … CS 0 20:30:00.883 Self Trained NN EA (Apple_Inc_(AAPL.O),H1) [100/100] Loss = 0.00177732 | accuracy 1.000
Nach nur 5 Epochen betrug die Genauigkeit des neuronalen Netzes 100 %. Das ist eine gute Nachricht, denn dieses Problem ist sehr einfach, sodass ich ein schnelleres Lernen erwartet hatte.
Nachdem dieses neuronale Netz nun trainiert wurde, möchte ich es mit den neuen Werten {7,8} testen. Sie und ich wissen, dass das Ergebnis 15 ist.
vector new_data = {7,8}; Print("Test "); Print(new_data," pred = ",nn.ForwardPass(new_data));
Ausgabe:
CS 0 20:37:36.331 Self Trained NN EA (Apple_Inc_(AAPL.O),H1) Test CS 0 20:37:36.331 Self Trained NN EA (Apple_Inc_(AAPL.O),H1) [7,8] pred = [[14.96557787153696]]
Es ergab ungefähr 14,97. 15 ist nur eine Verdopplung, weshalb diese zusätzlichen Werte angezeigt werden, aber wenn man auf eine signifikante Zahl von 1 aufrundet, wird die Ausgabe 15 sein. Dies ist ein Hinweis darauf, dass unser neuronales Netz jetzt in der Lage ist, selbst zu lernen. Cool
Geben wir diesem Modell einen realen Datensatz und beobachten wir, was es tut.
Bei dem Versuch, den NASDAQ(NAS 100) Index vorherzusagen, habe ich Tesla-Aktien und Apple-Aktien als unabhängige Variablen verwendet. Ich habe einmal in einem Online-Artikel von CNBC gelesen, dass es Tech-Aktien gibt, die die Hälfte des Wertes der NASDAQ ausmachen, darunter die Aktien von Apple und Tesla. In diesem Beispiel werde ich diese beiden Aktien als unabhängige Variablen für das Training des neuronalen Netzes verwenden.
input string symbol_x = "Apple_Inc_(AAPL.O)"; input string symbol_x2 = "Tesco_(TSCO.L)"; input ENUM_COPY_RATES copy_rates_x = COPY_RATES_OPEN; input int n_samples = 100; //+------------------------------------------------------------------+ //| Expert initialization function | //+------------------------------------------------------------------+ int OnInit() { matrix x_matrix(n_samples,2); vector y_vector; vector x_vector; //--- x_vector.CopyRates(symbol_x,PERIOD_CURRENT,copy_rates_x,0,n_samples); x_matrix.Col(x_vector, 0); x_vector.CopyRates(symbol_x2, PERIOD_CURRENT,copy_rates_x,0,n_samples); x_matrix.Col(x_vector, 1); y_vector.CopyRates(Symbol(), PERIOD_CURRENT,COPY_RATES_CLOSE,0,n_samples); nn = new CRegNeuralNets(x_matrix,y_vector,0.01,1000, AF_RELU_, LOSS_MSE_);
Die Art und Weise, wie mein Broker diese Symbole benennt, nämlich symbol_x und symbol_x2, kann sich von Ihrer unterscheiden. Vergessen Sie nicht, sie zu ändern und diese Symbole zur Marktbeobachtung hinzuzufügen, bevor Sie den Test-EA verwenden. Das y-Symbol ist das aktuelle Symbol des Charts. Stellen Sie sicher, dass Sie diesen EA an den NASDAQ-Chart anhängen.
Nach Ausführung des Skripts erhalte ich diese Ausgabeprotokolle:
CS 0 21:29:20.698 Self Trained NN EA (NAS100,M30) [ 1/1000 ] Loss = 353809311769.08959961 | accuracy -27061631.733 CS 0 21:29:20.698 Self Trained NN EA (NAS100,M30) [ 2/1000 ] Loss = 149221473.48209998 | accuracy -11412.427 CS 0 21:29:20.699 Self Trained NN EA (NAS100,M30) [ 3/1000 ] Loss = 149221473.48209998 | accuracy -11412.427 CS 0 21:29:20.699 Self Trained NN EA (NAS100,M30) [ 4/1000 ] Loss = 149221473.48209998 | accuracy -11412.427 CS 0 21:29:20.699 Self Trained NN EA (NAS100,M30) [ 5/1000 ] Loss = 149221473.48209998 | accuracy -11412.427 CS 0 21:29:20.699 Self Trained NN EA (NAS100,M30) [ 6/1000 ] Loss = 149221473.48209998 | accuracy -11412.427 .... .... CS 0 21:29:20.886 Self Trained NN EA (NAS100,M30) [ 1000/1000 ] Loss = 149221473.48209998 | accuracy -11412.427
Was?! Das ist es, was wir nach all den Dingen, die wir getan haben, bekommen. Solche Dinge passieren in neuronalen Netzen am häufigsten. Deshalb ist ein solides Verständnis von NNs sehr wichtig, egal welches Framework und welche Python-Bibliotheken Sie ausprobieren, solche Dinge passieren oft.
Normalisierung und Skalierung der Daten
Ich kann nicht betonen, wie wichtig dies ist, auch wenn nicht alle Datensätze die besten Ergebnisse liefern, wenn sie normalisiert werden. Wenn Sie beispielsweise diesen einfachen Datensatz normalisieren, den wir zuerst verwendet haben, um zu testen, ob dieses NN gut funktioniert, werden Sie schreckliche Ergebnisse erhalten. Das Netzwerk gibt Werte zurück, die diesen Werten entsprechen, oder noch schlimmer sind, ich habe es ausprobiert.
Es gibt viele Normalisierungstechniken. Die drei am weitesten verbreiteten von ihnen sind:
Min-Max-Skalierer
Dabei handelt es sich um eine Normalisierungstechnik, die die Werte eines numerischen Merkmals auf einen festen Bereich von [0, 1] skaliert. Die Formel lautet wie folgt:
x_norm = (x -x_min) / (x_max - x_min)
Wobei:
x = ursprünglicher Merkmalswert
x_min = ist der kleinste Wert des Merkmals
x_max = ist der höchste Wert des Merkmals
x_norm = ist der neu normierte Merkmalswert
Um die Normalisierungstechnik auszuwählen und die Daten zu normalisieren, müssen wir die pre-processing Bibliothek importieren. Die Datei ist am Ende des Artikels angefügt.
Ich habe beschlossen, die Möglichkeit zur Normalisierung der Daten in unserer Bibliothek für neuronale Netze hinzuzufügen.
CRegNeuralNets::CRegNeuralNets(matrix &xmatrix, vector &yvector,double alpha, uint epochs, activation ACTIVATION_FUNCTION, loss LOSS_FUNCTION, norm_technique NORM_METHOD)
Sie können eine Normalisierungstechnik norm_technique unter diesen auswählen;
enum norm_technique { NORM_MIN_MAX_SCALER, //Min max scaler NORM_MEAN_NORM, //Mean normalization NORM_STANDARDIZATION, //standardization NORM_NONE //Do not normalize. };
Nachdem ich die Klasse mit der hinzugefügten Normalisierungstechnik aufgerufen hatte, konnte ich eine angemessene Genauigkeit erzielen.
nn = new CRegNeuralNets(x_matrix,y_vector,0.01,1000, AF_RELU_, LOSS_MSE_,NORM_MIN_MAX_SCALER);
Ausgabe:
CS 0 22:40:56.457 Self Trained NN EA (NAS100,M30) [ 1/1000 ] Loss = 0.19379434 | accuracy -0.581 CS 0 22:40:56.457 Self Trained NN EA (NAS100,M30) [ 2/1000 ] Loss = 0.07735744 | accuracy 0.369 CS 0 22:40:56.458 Self Trained NN EA (NAS100,M30) [ 3/1000 ] Loss = 0.04761891 | accuracy 0.611 CS 0 22:40:56.458 Self Trained NN EA (NAS100,M30) [ 4/1000 ] Loss = 0.03559318 | accuracy 0.710 CS 0 22:40:56.458 Self Trained NN EA (NAS100,M30) [ 5/1000 ] Loss = 0.02937830 | accuracy 0.760 CS 0 22:40:56.458 Self Trained NN EA (NAS100,M30) [ 6/1000 ] Loss = 0.02582918 | accuracy 0.789 CS 0 22:40:56.459 Self Trained NN EA (NAS100,M30) [ 7/1000 ] Loss = 0.02372224 | accuracy 0.806 CS 0 22:40:56.459 Self Trained NN EA (NAS100,M30) [ 8/1000 ] Loss = 0.02245222 | accuracy 0.817 CS 0 22:40:56.460 Self Trained NN EA (NAS100,M30) [ 9/1000 ] Loss = 0.02168207 | accuracy 0.823 CS 0 22:40:56.460 Self Trained NN EA (NAS100,M30 CS 0 22:40:56.623 Self Trained NN EA (NAS100,M30) [ 1000/1000 ] Loss = 0.02046533 | accuracy 0.833
Ich muss auch zugeben, dass ich im 1-Stunden-Zeitrahmen nicht die gewünschten Ergebnisse erzielt habe. Das neuronale Netzwerk schien im 30-MINUTEN-Chart eine bessere Genauigkeit zu erzielen, und ich habe mir nicht die Mühe gemacht, den Grund dafür zu verstehen.
Ok, also 82,3 % Genauigkeit bei den Trainingsdaten. Das ist eine gute Genauigkeit. Lassen Sie uns eine einfache Handelsstrategie entwickeln, die dieses Netzwerk zur Eröffnung von Geschäften verwenden wird.
Der derzeitige Ansatz, den ich zum Sammeln von Daten in der Funktion OnInit verwendet habe, ist nicht zuverlässig. Ich werde die Funktion zum Trainieren der Netze erstellen und sie auf die Init-Funktion setzen. Unser Netzwerk wird nur einmal im Leben trainiert. Sie sind jedoch nicht auf diesen Weg beschränkt.
void OnTick() { //--- if (!train_nn) TrainNetwork(); //Train the network only once train_nn = true; } //+------------------------------------------------------------------+ //| | //+------------------------------------------------------------------+ void TrainNetwork() { matrix x_matrix(n_samples,2); vector y_vector; vector x_vector; x_vector.CopyRates(symbol_x,PERIOD_CURRENT,copy_rates_x,0,n_samples); x_matrix.Col(x_vector, 0); x_vector.CopyRates(symbol_x2, PERIOD_CURRENT,copy_rates_x,0,n_samples); x_matrix.Col(x_vector, 1); y_vector.CopyRates(Symbol(), PERIOD_CURRENT,COPY_RATES_CLOSE,0,n_samples); nn = new CRegNeuralNets(x_matrix,y_vector,0.01,1000, AF_RELU_, LOSS_MSE_,NORM_MIN_MAX_SCALER); }
Auch wenn diese Trainingsfunktion alles zu haben scheint, was wir brauchen, um vom Markt zu starten, ist sie doch nicht zuverlässig. Ich habe einen Test im Tages-Zeitrahmen durchgeführt und kam auf eine Genauigkeit von -77%, im H4-Zeitrahmen ergab sich eine Genauigkeit von -11234 oder so ähnlich. Als ich die Datenmenge vergrößerte und verschiedene Trainingsproben durchführte, war das neuronale Netz mit der Trainingsgenauigkeit, die es mir lieferte, inkonsistent.
Dafür gibt es viele Gründe, einer davon ist, dass unterschiedliche Probleme unterschiedliche Architekturen erfordern. Ich vermute, dass einige der Marktmuster auf verschiedenen Zeitrahmen zu komplex für dieses einschichtige neuronale Netzwerk sein könnten, da die Delta-Regel für einschichtige neuronale Netzwerke gedacht ist. Wir können das im Moment nicht beheben, also werde ich damit in einem Zeitrahmen fortfahren, in dem es mir gute Ergebnisse zu liefern scheint. Es gibt jedoch etwas, das wir tun können, um die Ergebnisse zu verbessern und dieses inkonsistente Verhalten ein wenig in den Griff zu bekommen. Damit werden die Daten mit einem zufälligen Zustand aufgeteilt.
Datensplitting ist wichtiger als Sie denken
Wenn Sie aus dem Bereich des maschinellen Lernens mit Python kommen, kennen Sie vielleicht die Funktion train_test_split aus sklearn.
Der Zweck der Aufteilung der Daten in Trainings- und Testdaten besteht nicht nur darin, die Daten aufzuteilen, sondern auch darin, den Datensatz zu randomisieren, sodass er nicht in seiner ursprünglichen Reihenfolge vorliegt. Lassen Sie es mich erklären. Da neuronale Netze und andere Algorithmen des maschinellen Lernens versuchen, die Muster in den Daten zu verstehen, kann es für die Modelle von Nachteil sein, wenn die Daten in der Reihenfolge vorliegen, in der sie extrahiert wurden, da sie die Muster aufgrund der Art und Weise, wie die Daten organisiert und angeordnet wurden, ebenfalls verstehen werden. Dies ist kein guter Weg, um die Modelle lernen zu lassen, da die Anordnung nicht so wichtig ist wie die Muster, die in den Variablen enthalten sind.
void TrainNetwork() { //--- collecting the data matrix Matrix(n_samples,3); vector y_vector; vector x_vector; x_vector.CopyRates(symbol_x,PERIOD_CURRENT,copy_rates_x,0,n_samples); Matrix.Col(x_vector, 0); x_vector.CopyRates(symbol_x2, PERIOD_CURRENT,copy_rates_x,0,n_samples); Matrix.Col(x_vector, 1); y_vector.CopyRates(Symbol(), PERIOD_CURRENT,COPY_RATES_CLOSE,0,n_samples); Matrix.Col(y_vector, 2); //--- matrix x_train, x_test; vector y_train, y_test; matrix_utils.TrainTestSplitMatrices(Matrix, x_train, y_train, x_test, y_test, 0.7, 42); nn = new CRegNeuralNets(x_train,y_train,0.01,1000, AF_RELU_, LOSS_MSE_,NORM_MIN_MAX_SCALER); vector test_pred = nn.ForwardPass(x_test); printf("Testing Accuracy =%.3f",metrics.r_squared(y_test, test_pred)); }
Nach dem Sammeln der Trainingsdaten wurde die Funktion TrainTestSplitMatrices eingeführt, wobei wobei der 42 als Zufallsanfangswert vorgegeben wurde.
void TrainTestSplitMatrices(matrix &matrix_,matrix &x_train,vector &y_train,matrix &x_test, vector &y_test,double train_size=0.7,int random_state=-1)
Marktprognosen in Echtzeit
Um Echtzeit-Vorhersagen über die Ontick-Funktion zu machen, muss es einen Code geben, der Daten sammelt und sie in den Eingangsvektor einer Vorwärtsdurchgangsfunktion eines neuronalen Netzes einfügt.
void OnTick() { //--- if (!train_nn) TrainNetwork(); //Train the network only once train_nn = true; vector x1, x2; x1.CopyRates(symbol_x,PERIOD_CURRENT,copy_rates_x,0,1); //only the current candle x2.CopyRates(symbol_x2,PERIOD_CURRENT,copy_rates_x,0,1); //only the current candle vector inputs = {x1[0], x2[0]}; //current values of x1 and x2 instruments | Apple & Tesla matrix OUT = nn.ForwardPass(inputs); //Predicted Nasdaq value double pred = OUT[0][0]; Comment("pred ",OUT); }
Jetzt kann unser neuronales Netz Vorhersagen machen. Versuchen wir, sie für den Handel zu nutzen. Hierfür werden wir eine Strategie entwickeln.
Handelslogik
Die Handelslogik ist einfach: Wenn der vom neuronalen Netz vorhergesagte Kurs über dem aktuellen Kurs liegt, wird ein Kaufgeschäft mit einem Take-Profit in Höhe des vorhergesagten Kurses mal einem bestimmten Eingabewert als Take-Profit eröffnet und umgekehrt für Verkaufsgeschäfte. Bei jedem Handel wird ein Stop-Loss bei bestimmten Gewinnmitnahmepunkten mal einem bestimmten, als Stop-Loss gekennzeichneten Eingabewert gesetzt. Unten sehen Sie, wie die Dinge in MetaEditor aussehen.
stops_level = (int)SymbolInfoInteger(Symbol(),SYMBOL_TRADE_STOPS_LEVEL); Lots = SymbolInfoDouble(Symbol(),SYMBOL_VOLUME_MIN); spread = (double)SymbolInfoInteger(Symbol(), SYMBOL_SPREAD); MqlTick ticks; SymbolInfoTick(Symbol(), ticks); if (MathAbs(pred - ticks.ask) + spread > stops_level) { if (pred > ticks.ask && !PosExist(POSITION_TYPE_BUY)) { target_gap = pred - ticks.bid; m_trade.Buy(Lots, Symbol(), ticks.ask, ticks.bid - ((target_gap*stop_loss) * Point()) , ticks.bid + ((target_gap*take_profit) * Point()),"Self Train NN | Buy"); } if (pred < ticks.bid && !PosExist(POSITION_TYPE_SELL)) { target_gap = ticks.ask - pred; m_trade.Sell(Lots, Symbol(), ticks.bid, ticks.ask + ((target_gap*stop_loss) * Point()), ticks.ask - ((target_gap*take_profit) * Point()), "Self Train NN | Sell"); } }
Das ist unsere Logik. Mal sehen, wie sich der EA auf dem MT5 schlägt.
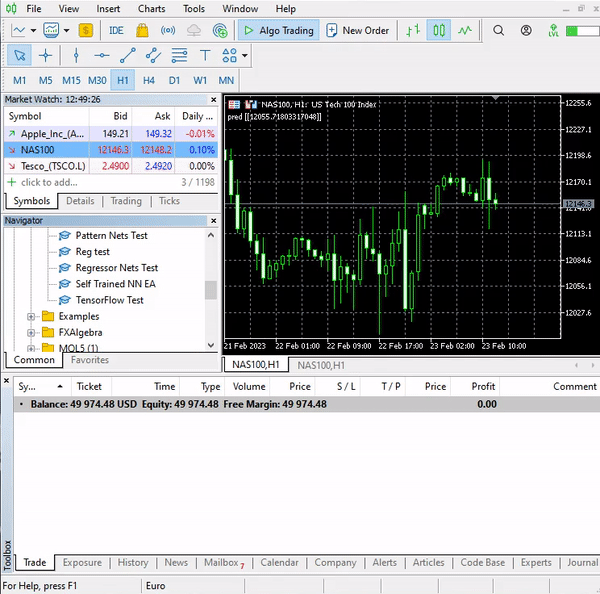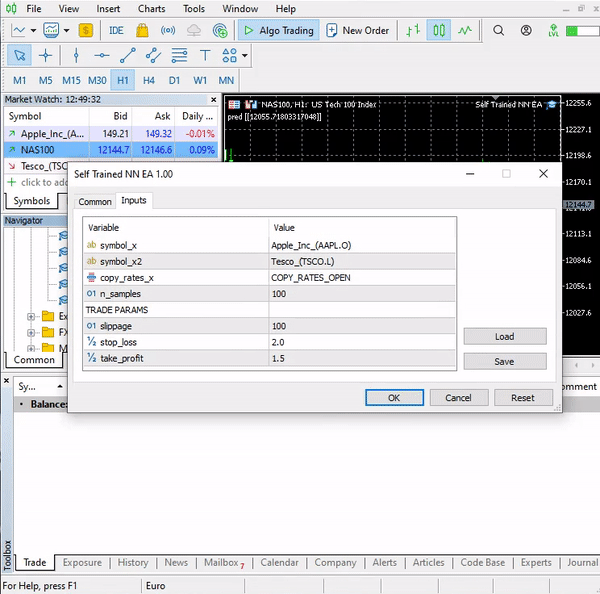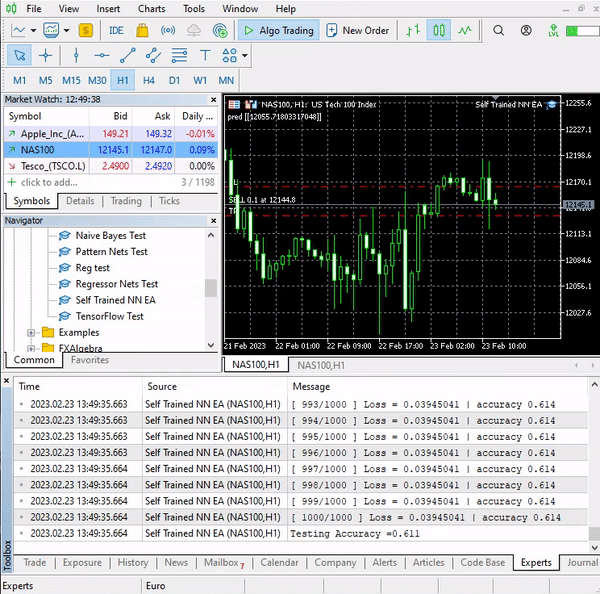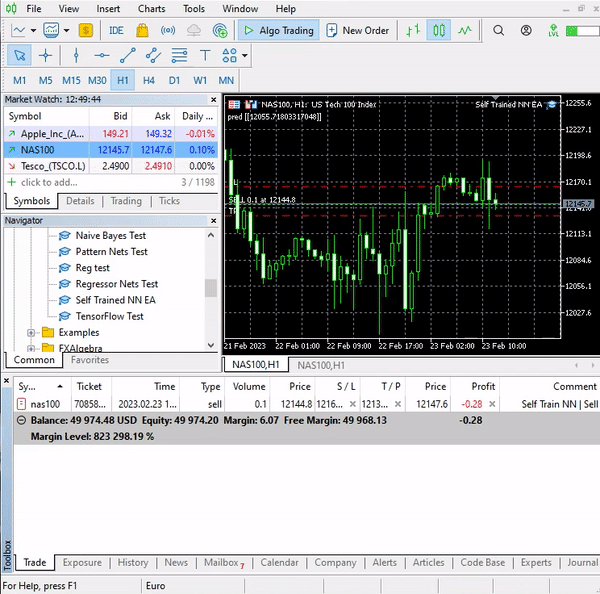
Dieser einfache Expert Advisor kann nun selbständig Handel treiben. Im Moment können wir seine Leistung noch nicht beurteilen, dafür ist es noch zu früh. Kommen wir nun zum Strategietester.
Ergebnisse des Strategietesters
Es gibt immer Herausforderungen, die mit der Ausführung von Algorithmen des maschinellen Lernens durch den Strategietester verbunden sind, da Sie sicherstellen müssen, dass die Algorithmen reibungslos und schnell laufen und Sie dabei auch noch Gewinne erzielen.
Ich habe einen Test von 2023.01.01 bis 2023.02.23 auf einem 4-Stunden-Chart auf der Grundlage von realen Ticks durchgeführt. Ich habe für diesen Test jüngste Ticks verwendet, da ich vermute, dass sie von viel besserer Qualität sind, als wenn ich sie über viele Jahre und Monate vorher laufen lasse.
Da ich die Funktion, mit der unser Modell trainiert wird, so eingestellt habe, dass sie beim allerersten Tick eines Testlebenszyklus ausgeführt wird, war der Prozess des Trainings und Testens des Modells sofort abgeschlossen. Schauen wir uns erst einmal an, wie das Modell abgeschnitten hat, bevor wir uns die Charts und alles, was der Strategietester bietet, ansehen.
CS 0 15:50:47.676 Tester NAS100,H4 (Pepperstone-Demo): generating based on real ticks CS 0 15:50:47.677 Tester NAS100,H4: testing of Experts\Advisors\Self Trained NN EA.ex5 from 2023.01.01 00:00 to 2023.02.23 00:00 started with inputs: CS 0 15:50:47.677 Tester symbol_x=Apple_Inc_(AAPL.O) CS 0 15:50:47.677 Tester symbol_x2=Tesco_(TSCO.L) CS 0 15:50:47.677 Tester copy_rates_x=1 CS 0 15:50:47.677 Tester n_samples=200 CS 0 15:50:47.677 Tester = CS 0 15:50:47.677 Tester slippage=100 CS 0 15:50:47.677 Tester stop_loss=2.0 CS 0 15:50:47.677 Tester take_profit=2.0 CS 3 15:50:49.209 Ticks NAS100 : 2023.02.21 23:59 - real ticks absent for 2 minutes out of 1379 total minute bars within a day CS 0 15:50:51.466 History Tesco_(TSCO.L),H4: history begins from 2022.01.04 08:00 CS 0 15:50:51.467 Self Trained NN EA (NAS100,H4) 2023.01.03 01:00:00 [ 1/1000 ] Loss = 0.14025037 | accuracy -1.524 CS 0 15:50:51.468 Self Trained NN EA (NAS100,H4) 2023.01.03 01:00:00 [ 2/1000 ] Loss = 0.05244676 | accuracy 0.056 CS 0 15:50:51.468 Self Trained NN EA (NAS100,H4) 2023.01.03 01:00:00 [ 3/1000 ] Loss = 0.04488896 | accuracy 0.192 CS 0 15:50:51.468 Self Trained NN EA (NAS100,H4) 2023.01.03 01:00:00 [ 4/1000 ] Loss = 0.04114715 | accuracy 0.259 CS 0 15:50:51.468 Self Trained NN EA (NAS100,H4) 2023.01.03 01:00:00 [ 5/1000 ] Loss = 0.03877407 | accuracy 0.302 CS 0 15:50:51.469 Self Trained NN EA (NAS100,H4) 2023.01.03 01:00:00 [ 6/1000 ] Loss = 0.03725228 | accuracy 0.329 CS 0 15:50:51.469 Self Trained NN EA (NAS100,H4) 2023.01.03 01:00:00 [ 7/1000 ] Loss = 0.03627591 | accuracy 0.347 CS 0 15:50:51.469 Self Trained NN EA (NAS100,H4) 2023.01.03 01:00:00 [ 8/1000 ] Loss = 0.03564933 | accuracy 0.358 CS 0 15:50:51.470 Self Trained NN EA (NAS100,H4) 2023.01.03 01:00:00 [ 9/1000 ] Loss = 0.03524708 | accuracy 0.366 CS 0 15:50:51.470 Self Trained NN EA (NAS100,H4) 2023.01.03 01:00:00 [ 10/1000 ] Loss = 0.03498872 | accuracy 0.370 CS 0 15:50:51.662 Self Trained NN EA (NAS100,H4) 2023.01.03 01:00:00 [ 1000/1000 ] Loss = 0.03452066 | accuracy 0.379 CS 0 15:50:51.662 Self Trained NN EA (NAS100,H4) 2023.01.03 01:00:00 Testing Accuracy =0.717
Die Trainingsgenauigkeit lag bei 37,9 %, aber die Testgenauigkeit betrug 71,7 %. WAS?!
Ich bin mir nicht sicher, was genau falsch ist, aber ich vermute die Qualität des Trainings. Achten Sie stets darauf, dass Ihre Trainings- und Testdaten eine angemessene Qualität aufweisen, denn jede Lücke in den Daten könnte zu einem anderen Modell führen. Da wir auch beim Strategietester gute Ergebnisse erzielen wollen, müssen wir sicher sein, dass die Backtesting-Ergebnisse aus dem guten Modell hervorgehen, in dessen Erstellung wir viel Energie investiert haben.
Am Ende des Strategietesters waren die Ergebnisse nicht überraschend, die Mehrheit der von diesem EA eröffneten Positionen endete mit Verlusten von 78,27%.
Da wir die Stop-Loss- und Take-Profit-Ziele noch nicht optimiert haben, halte ich es für eine gute Idee, diese Werte und andere Parameter zu optimieren.
Ich habe eine kurze Optimierung durchgeführt und die folgenden Werte ermittelt. copy_rates_x: COPY_RATES_LOW, n_samples: 2950, Slippage: 1, Stop loss: 7.4, Take profit: 5.0.
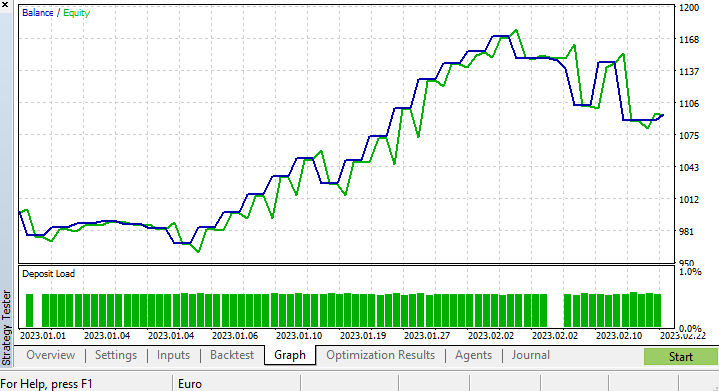
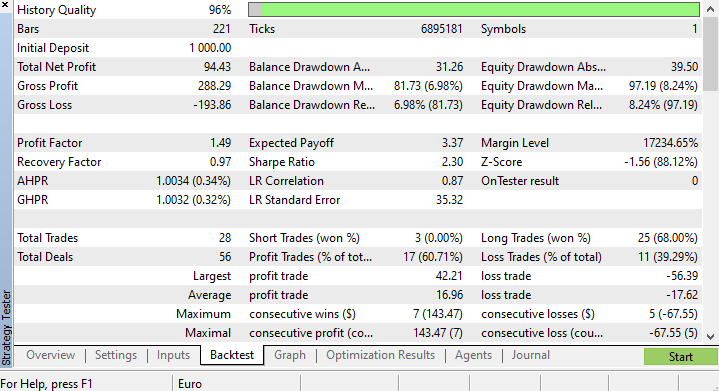
Diesmal ergab das Modell zu Beginn des Strategietesters eine Trainingsgenauigkeit von 61,5 % und eine Testgenauigkeit von 63,5 %. Das scheint akzeptabel zu sein.
CS 0 17:11:52.100 Self Trained NN EA (NAS100,H4) 2023.01.03 01:00:00 [ 1000/1000 ] Loss = 0.05890808 | accuracy 0.615 CS 0 17:11:52.101 Self Trained NN EA (NAS100,H4) 2023.01.03 01:00:00 Testing Accuracy =0.635
Abschließende Überlegungen
Die Delta-Regel gilt für einschichtige neuronale Netze des Regressionstyps, denken Sie daran. Trotz der Verwendung eines einschichtigen neuronalen Netzes haben wir gesehen, wie es aufgebaut und verbessert werden kann, wenn die Dinge nicht gut laufen. Ein einschichtiges neuronales Netz ist lediglich eine Kombination von linearen Regressionsmodellen, die als Team zusammenarbeiten, um ein bestimmtes Problem zu lösen. Zum Beispiel:
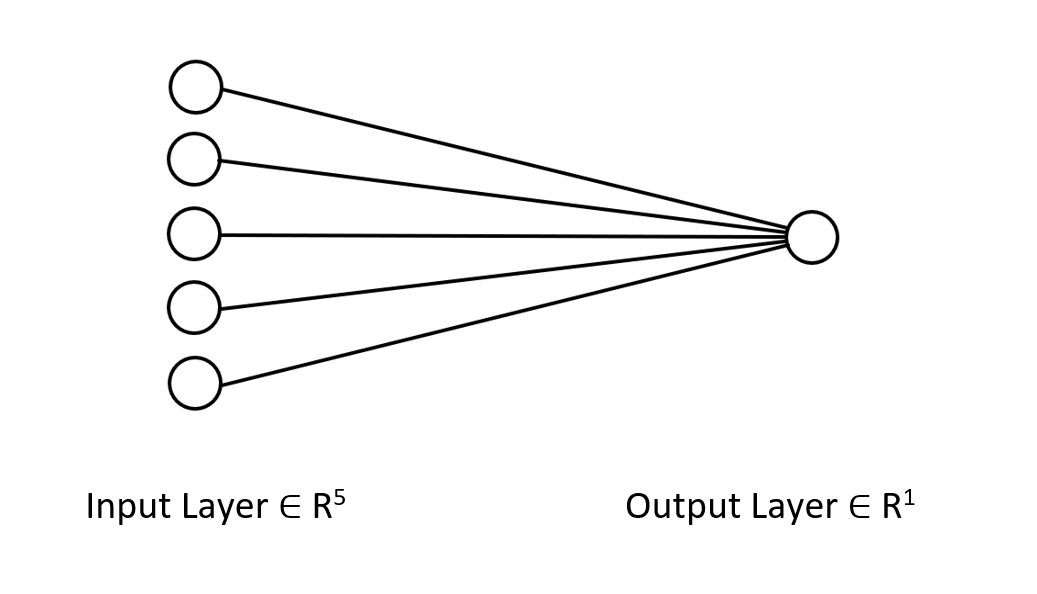
Man kann es als 5 lineare Regressionsmodelle betrachten, die sich mit demselben Problem befassen. Es ist erwähnenswert, dass dieses neuronale Netz nicht in der Lage ist, komplexe Muster in den Variablen zu erkennen, seien Sie also nicht überrascht, wenn dies nicht der Fall ist. Wie bereits erwähnt, ist die Delta-Regel der Baustein des allgemeinen Backpropagation-Algorithmus, der für weitaus komplexere neuronale Netze beim Deep Learning verwendet wird.
Der Grund, warum ich ein neuronales Netz aufgebaut habe, während ich mich selbst anfällig für Fehler gemacht habe, ist, dass ich einen Punkt erklären möchte, damit Sie verstehen, dass neuronale Netze zwar in der Lage sind, Muster zu lernen, dass man aber auf kleine Details achten und viele Dinge richtig machen muss, damit es überhaupt funktioniert.
Mit freundlichen Grüßen.
Verfolgen Sie die Entwicklung dieser Bibliothek und vieler anderer ML-Modelle in diesem Repo https://github.com/MegaJoctan/MALE5
Tabelle der Anhänge:
| Datei | Inhalt & Verwendung |
|---|---|
| metrics.mqh | Enthält Funktionen zur Messung der Genauigkeit von Modellen neuronaler Netze. |
| preprocessing.mqh | Enthält Funktionen zur Skalierung und Aufbereitung der Daten für Modelle neuronaler Netze |
| matrix_utils.mqh | Zusätzliche Funktionen zur Matrixmanipulation |
| selftrain NN.mqh | Die wichtigste Include-Datei, die selbstlernende neuronale Netze enthält |
| Self Train NN EA.mq5 | Ein EA zum Testen der selbst trainierten neuronalen Netze |
Referenzartikel:
-
Matrix Utils, Erweiterung der Funktionalität der Standardbibliothek für Matrizen und Vektoren
-
Datenwissenschaft und maschinelles Lernen (Teil 06): Gradientenverfahren
Haftungsausschluss: Dieser Artikel ist nur für Bildungszwecke gedacht. Der Handel ist ein riskantes Spiel; Sie sollten sich des damit verbundenen Risikos bewusst sein. Der Autor haftet nicht für Verluste oder Schäden, die durch die Anwendung der in diesem Artikel beschriebenen Methoden verursacht werden können. Riskieren Sie nur das Geld, das Sie sich leisten können zu verlieren.
Übersetzt aus dem Englischen von MetaQuotes Ltd.
Originalartikel: https://www.mql5.com/en/articles/12209
- Freie Handelsapplikationen
- Über 8.000 Signale zum Kopieren
- Wirtschaftsnachrichten für die Lage an den Finanzmärkte
Sie stimmen der Website-Richtlinie und den Nutzungsbedingungen zu.
Eine gute Demo, um die Möglichkeit des Selbsttrainings (Tuning) von ML EA zu zeigen.
Dies ist noch in den frühen Tagen von MQL ML. Hoffentlich werden im Laufe der Zeit immer mehr Menschen MALE5 nutzen. Ich freue mich auf seine Reife.
Wie speichern und laden Sie das Netz?