
Разрабатываем мультивалютный советник (Часть 11): Начало автоматизации процесса оптимизации
Введение
В прошлой статье мы заложили основу для легкого использования результатов, полученных при оптимизации для построения готового советника с несколькими экземплярами торговых стратегий, работающих совместно. Теперь нам не придётся прописывать вручную в коде или во входных переменных советника параметры всех используемых экземпляров. Достаточно будет сохранить строку инициализации в определённом формате в файл, или вставить её как текст в исходный код, чтобы советник смог ею воспользоваться.
Пока что формирование строки инициализации выполнялось вручную. Сейчас же, наконец, подошло время заняться реализацией процесса автоматического формирования строки инициализации советника по полученным результатам оптимизации. Вполне возможно, что в рамках данной статьи мы еще не получим полностью автоматизированного решения, но, по крайней мере, мы должны существенно продвинуться в намеченном направлении.
Постановка задачи
В общих чертах наши пожелания можно сформулировать следующим образом: мы хотим получить советник, который запускается в терминале и выполняет оптимизацию советника с одним экземпляром торговой стратегии на нескольких символах и таймфреймах. Пусть это будут символы EURGBP, EURUSD, GBPUSD и таймфреймы H1, M30, M15. Нам нужно иметь возможность выбирать из сохраненных в базе данных результатов каждого прохода оптимизации те, которые будут относиться к конкретному символу и таймфрейму (а в дальнейшем и к каким-то еще комбинациям параметров тестирования).
Из каждой группы результатов для одной комбинации символа и таймфрейма мы будем выбирать несколько самых лучших по разным критериям. Все выбранные экземпляры будем помещать в одну (пока что в одну) группу экземпляров. Затем необходимо определить множитель для группы. Этим в дальнейшем будет заниматься отдельный советник, а сейчас мы можем эту операцию проделать пока ещё вручную.
На основе выбранной группы и множителя, формируем строку инициализации, которая будет использоваться в итоговом советнике.
Понятия
Для дальнейшего использования введём несколько дополнительных понятий:
- Универсальный советник — это советник, которому мы передаём строку инициализации, после чего он готов к работе на торговом счёте. Можно сделать так, чтобы он читал строку инициализации из файла, с указанным во входных параметрах именем, или получал её из базы данных по имени и версии проекта.
- Оптимизирующий советник — это советник, который будет отвечать за выполнение всех действий по оптимизации проектов. При его запуске на графике, он будет находить в базе данных информацию о необходимых действиях по оптимизации и последовательно их выполнять. Конечным результатом его работы будет сохранённая строка инициализации для универсального советника.
- Советники этапов — это советники, которые будут непосредственно оптимизироваться в тестере. Их будет несколько, по количеству реализованных этапов. Оптимизирующий советник будет запускать эти советники на оптимизацию и отслеживать её окончание.
В рамках данной статьи ограничимся одним этапом — проведём оптимизацию параметров одиночного экземпляра торговой стратегии. Второй этап — объединение нескольких лучших экземпляров в одну группу и её нормировка, — выполним пока вручную.
В качестве универсального советника мы пока что сделаем советник, который сможет сам строить строку инициализации, выбирая из базы данных информацию о хороших экземплярах торговых стратегий.
Информацию о необходимых действиях по оптимизации в базе данных надо хранить в удобном виде. Мы должны иметь возможность относительно просто создавать подобную информацию. Оставим пока в стороне вопрос о том, каким образом эта информация будет попадать в базу данных. Удобный интерфейс можно реализовать и позже. Сейчас же главное — понять структуру этой информации и создать для неё соответствующую структуру таблиц в базе данных.
Начнём с выделения более общих сущностей, и постепенно будем опускаться до всё более простых сущностей. В конце мы должны прийти к уже созданной ранее сущности, представляющей собой информацию об одиночном проходе тестера.
Проект
На самом верхнем уровне у нас будет сущность "Проект". Это составная сущность: один проект будет состоять из нескольких этапов. Сущность "Этап" мы рассмотрим ниже. Проект характеризуется именем и версией. Может иметь некоторое описание. Проект может находиться в нескольких состояниях: "создан", "поставлен в очередь на запуск", "запущен" и "завершён". Также в этой сущности логично будет хранить полученную по результату выполнения проекта строку инициализации для универсального советника.
Для удобства использования информации из базы данных в программах на MQL5, реализуем в дальнейшем простенькую ORM, то есть создадим классы на MQL5, представляющие собой все сущности, которые мы будем хранить в базе данных.
У объектов класса для сущности "Проект" в базе данных будут храниться:
- id_project – идентификатор проекта.
- name – название проекта, будет использоваться в универсальном советнике для поиска инициализирующей строки.
- version – версия проекта, будет определяться, например, по версиям экземпляров торговых стратегий.
- description – описание проекта, произвольный текст, содержащий какие-то важные детали о проекте. Может быть пустым.
- params – строка инициализации для универсального советника, будет заполняться по завершении данного проекта. Изначально будет иметь пустое значение.
- status – статус (состояние) проекта, может принимать четыре возможных значения: Created, Queued, Processing, Done. Изначально проект создаётся со статусом Created.
В дальнейшем это список полей может быть расширен, но сейчас нам будет достаточно и такого.
Когда проект готов к запуску, то он переводится в состояние Queued. Такой перевод пока что будем осуществлять вручную. Наш советник оптимизации будет искать проекты с таким статусом и переводить их в статус Processing.
При запуске и завершении любого этапа будем проверять необходимость обновления статуса проекта. Если запускается первый этап, то проект переходит в состояние Processing. Когда завершается последний этап, то проект переходит в состояние Done. В этот момент будет заполняться значение поля params, то есть по завершении проекта мы получим строку инициализации, которую можно будет передать универсальному советнику.
Этап
Как уже было сказано, выполнение каждого проекта разбито на несколько этапов. Главной характеристикой этапа является советник, который будет запускаться в рамках данного этапа на оптимизацию в тестере (советник этапа). Также будет задаваться интервал тестирования для этапа. Этот интервал будет один и тот же для всех оптимизаций, выполняемых на данном этапе. Предусмотрим и хранение прочей информации об оптимизации (стартовый депозит, режим моделирования тиков и т.д.).
У этапа может быть указан родительский (предыдущий) этап. В этом случае выполнение этапа начнётся только после завершения родительского этапа.
У объектов этого класса в базе данных будет храниться:
- id_stage – идентификатор этапа.
- id_project – идентификатор проекта, к которому относится данный этап.
- id_parent_stage – идентификатор родительского (предыдущего) этапа.
- name – название этапа.
- expert – имя советника, запускаемого на оптимизацию в данном этапе.
- from_date – дата начала периода оптимизации.
- to_date – дата окончания периода оптимизации.
- forward_date – дата начала форвард-периода оптимизации. Может быть пустой, в этом случае форвард-режим не используется.
- прочие поля с параметрами оптимизации (стартовый депозит, режим моделирования тиков и т.д.), которые будут иметь значения по умолчанию, не требующие изменения в большинстве случаев
- status – статус (состояние) этапа, может принимать три возможных значения: Queued, Processing, Done. Изначально этап создаётся со статусом Queued.
Каждый этап, в свою очередь, состоит одной или из нескольких работ. При старте первой работы, этап переходит в состояние Processing. При завершении всех работ, этап переходит в состояние Done.
Работа
Выполнение каждого этапа состоит из последовательного выполнения всех работ, входящих в его состав. Главными характеристиками работы будет символ, таймфрейм и входные параметры советника, который оптимизируется на этапе, содержащем данную работу.
У объектов этого класса в базе данных будет храниться:
- id_job – идентификатор работы.
- id_stage – идентификатор этапа, к которому относится данная работа.
- symbol – символ (торговый инструмент) тестирования.
- period – таймфрейм тестирования.
- tester_inputs – настройки входных параметров советника для оптимизации.
- status – статус (состояние) работы, может принимать три возможных значения: Queued, Processing, Done. Изначально работа создаётся со статусом Queued.
Каждая работа будет состоять из одной или нескольких задач оптимизации. При старте первой задачи оптимизации, работа переходит в состояние Processing. При завершении всех задач оптимизации, работа переходит в состояние Done.
Задача оптимизации
Выполнение каждой работы состоит из последовательного выполнения всех всех входящих в неё задач. Главной характеристикой задачи будет критерий оптимизации. Остальные настройки для тестера задача будет наследовать от работы.
У объектов этого типа в базе данных будет храниться:
- id_task – идентификатор задачи.
- id_job – идентификатор работы, в рамках которой выполняется данная задача.
- optimization_criterion – критерий оптимизации для данной задачи.
- start_date – время начала выполнения задачи оптимизации.
- finish_date – время окончания выполнения задачи оптимизации.
- status – статус (состояние) задачи оптимизации, может принимать три возможных значения: Queued, Processing, Done. Изначально задача оптимизации создаётся со статусом Queued.
Каждая задача будет состоять из нескольких проходов оптимизации. При старте первого прохода оптимизации, задача оптимизации переходит в состояние Processing. При завершении всех проходов оптимизации, задача оптимизации переходит в состояние Done.
Проход оптимизации
С ними мы уже познакомились в предыдущей статье, в которой добавили автоматическое сохранение результатов всех проходов при оптимизации в тестере стратегий. Теперь мы добавим к сущности "Проход оптимизации" новое поле, содержащее идентификатор задачи, в рамках которой выполнялся данный проход.
Таким образом, у объектов этого типа в базе данных будет храниться:
- id_pass – идентификатор прохода.
- id_task – идентификатор задачи, в рамках которой выполняется данный проход.
- поля результатов прохода – группа полей для всех доступных статистик по проходу (номер прохода, количество сделок, профит-фактор и т.д.).
- params – строка инициализации с параметрами экземпляров стратегий, используемых в данном проходе.
- inputs – значения входных параметров прохода.
- pass_date. Время окончания прохода.
По сравнению с предыдущей реализацией, изменим состав сохраняемой информации о параметрах стратегий, используемых на каждом проходе. В более общем случае нам понадобится сохранить информацию о группе стратегий. Поэтому сделаем так, что и для одной стратегии будет сохраняться группа стратегий, включающая одну стратегию.
Поля статуса у прохода не будет, так как записи в эту таблицу добавляются только после совершения прохода, а не до его начала. Поэтому само наличие записи уже означает, что этот проход завершён.
Поскольку наша база данных уже существенно обогатила свою структуру, то внесём изменения в программный код, отвечающий за создание и работу с базой данных.
Создание и работа с базой данных
В процессе разработки нам придётся неоднократно пересоздавать базу данных с обновлённой структурой. Поэтому сделаем простой вспомогательный скрипт, который будет выполнять единственное действие — создавать заново базу данных и заполнять её необходимыми начальными данными. Какими именно начальными данными стоит заполнить пустую базу данных, мы рассмотрим позже.
#include "Database.mqh" int OnStart() { DB::Open(); // Открываем БД // Выполняем запросы по созданию таблиц и заполнению начальных данных DB::Create(); DB::Close(); // Закрываем БД return INIT_SUCCEEDED; }
Сохраним этот код в файле CleanDatabase.mq5 в текущей папке.
Метод создания таблиц CDatabase::Create() содержал ранее массив строк с SQL-запросами, выполняющими пересоздание одной таблицы. Теперь таблиц у нас будет побольше, поэтому хранить SQL-запросы прямо в исходном коде станет неудобно. Давайте вынесем текст всех SQL-запросов в отдельный файл, из которого они будут загружаться для выполнения внутри метода Create().
Для этого нам понадобится метод, который по имени файла будет читать из него все запросы и выполнять их:
//+------------------------------------------------------------------+ //| Класс для работы с базой данных | //+------------------------------------------------------------------+ class CDatabase { ... public: ... // Выполнение запроса к БД из файла static bool ExecuteFile(string p_fileName); }; ... //+------------------------------------------------------------------+ //| Выполнение запроса к БД из файла | //+------------------------------------------------------------------+ bool CDatabase::ExecuteFile(string p_fileName) { // Массив для чтения символов из файла uchar bytes[]; // Количество прочитанных символов long len = 0; // Если файл существует в папке данных, то if(FileIsExist(p_fileName)) { // загружаем его оттуда len = FileLoad(p_fileName, bytes); } else if(FileIsExist(p_fileName, FILE_COMMON)) { // иначе, если он есть в общей папке данных, то загружаем его оттуда len = FileLoad(p_fileName, bytes, FILE_COMMON); } else { PrintFormat(__FUNCTION__" | ERROR: File %s is not exists", p_fileName); } // Если файл загрузился, то if(len > 0) { // Преобразуем массив в строку запроса string query = CharArrayToString(bytes); // Возвращаем результат выполнения запроса return Execute(query); } return false; }
Теперь внесём изменения в метод Create(). Договоримся, что файл со схемой базы данных и начальными данными будет иметь фиксированное имя: к названию базы данных будет прибавлена строка ".schema.sql":
//+------------------------------------------------------------------+ //| Создание пустой БД | //+------------------------------------------------------------------+ void CDatabase::Create() { string schemaFileName = s_fileName + ".schema.sql"; bool res = ExecuteFile(schemaFileName); if(res) { PrintFormat(__FUNCTION__" | Database successfully created from %s", schemaFileName); } }
Теперь мы можем использовать любую среду работы с базами данных SQLite для создания в ней всех таблиц и заполнения их начальными данными. После этого мы можем сделать экспорт полученной базы данных в виде набора SQL-запросов в файл и использовать это файл в наших программах на MQL5.
Последнее изменение, которое нам понадобится внести на данном этапе в класс CDatabase, связано с появившейся необходимостью выполнения запросов не только на вставку данных, но и на получение данных из таблиц. В дальнейшем весь код, отвечающий за получение данных, должен быть распределён по отдельным классам, работающим с отдельными сущностями, хранящимися в базе данных. Но пока у нас нет этих классов, обойдёмся временными мерами.
Чтение данных средствами, предоставляемыми MQL5, представляет собой более сложную задачу, чем вставка. Для получения строк результатов запроса нам нужно создать в MQL5 новый тип данных (структуру), предназначенный для получения данных именно для такого конкретного запроса. Затем нужно отправить запрос и получить хендл результата. По этому хендлу затем можно в цикле получать по одной строке из результатов запроса в переменную той самой ранее созданной структуры.
Так что в рамках класса CDababase написание универсального метода, читающего результаты произвольных запросов, извлекающих данные из таблиц, не является легко реализуемым. Поэтому поступим проще: не будем писать эту реализацию, а отдадим её на уровень выше. Для этого нам понадобится только предоставить на вышестоящий уровень хендл соединения с базой данных, который хранится в поле s_db:
//+------------------------------------------------------------------+ //| Класс для работы с базой данных | //+------------------------------------------------------------------+ class CDatabase { ... public: static int Id(); // Хендл соединения с БД ... }; ... //+------------------------------------------------------------------+ //| Хендл соединения с БД | //+------------------------------------------------------------------+ int CDatabase::Id() { return s_db; }
Сохраним полученный код в файле Database.mqh в текущей папке.
Оптимизирующий советник
Теперь мы можем приступить к созданию оптимизирующего советника. Прежде всего, нам понадобится библиотека для работы с тестером от fxsaber, точнее вот этот включаемый файл:
#include <fxsaber/MultiTester/MTTester.mqh> // https://www.mql5.com/ru/code/26132
Основную работу наш оптимизирующий советник будет выполнять периодически, по таймеру. Поэтому в функции инициализации мы создадим таймер и запустим сразу его обработчик на выполнение. Поскольку, как правило, задачи оптимизации занимают по времени десятки минут, то срабатывание таймера раз в пять секунд кажется вполне достаточным:
//+------------------------------------------------------------------+ //| Expert initialization function | //+------------------------------------------------------------------+ int OnInit() { // Создаём таймер и запускаем его обработчик EventSetTimer(5); OnTimer(); return(INIT_SUCCEEDED); }
В обработчике таймера будем проверять, свободен ли тестер в данный момент. Если да, то при наличии текущей выполняемой задачи, надо выполнить действия по её завершению. Затем получаем из базы данных идентификатор и входные параметры оптимизации для очередной задачи и запускаем её на выполнение, вызывая функцию StartTask():
//+------------------------------------------------------------------+ //| Expert timer function | //+------------------------------------------------------------------+ void OnTimer() { PrintFormat(__FUNCTION__" | Current Task ID = %d", currentTaskId); // Если советник остановлен, то удаляем таймер и самого советника с графика if (IsStopped()) { EventKillTimer(); ExpertRemove(); return; } // Если тестер свободен, то if (MTTESTER::IsReady()) { // Если текущая задача не пустая, то if(currentTaskId) { // Звершаем текущую задачу FinishTask(currentTaskId); } // Получаем количество задач в очереди totalTasks = TotalTasks(); // Если задачи есть, то if(totalTasks) { // Получаем идентификатор очередной текущей задачи currentTaskId = GetNextTask(currentSetting); // Запускаем текущую задачу StartTask(currentTaskId, currentSetting); Comment(StringFormat( "Total tasks in queue: %d\n" "Current Task ID: %d", totalTasks, currentTaskId)); } else { // Если задач нет, то удаляем советник с графика PrintFormat(__FUNCTION__" | Finish.", 0); ExpertRemove(); } } }
В функции запуска задачи мы воспользуемся методами класса MTTESTER для загрузки входных параметров в тестер и запуска тестера в режиме оптимизации. Также обновим информацию в базе данных, сохранив время запуска текущей задачи и её статус:
//+------------------------------------------------------------------+ //| Запуск задачи | //+------------------------------------------------------------------+ void StartTask(ulong taskId, string setting) { PrintFormat(__FUNCTION__" | Task ID = %d\n%s", taskId, setting); // Запускаем новую задачу оптимизации в тестере MTTESTER::CloseNotChart(); MTTESTER::SetSettings2(setting); MTTESTER::ClickStart(); // Обновляем статус задачи в базе данных DB::Open(); string query = StringFormat( "UPDATE tasks SET " " status='Processing', " " start_date='%s' " " WHERE id_task=%d", TimeToString(TimeLocal(), TIME_SECONDS), taskId); DB::Execute(query); DB::Close(); }
Функция получения очередной задачи из базы данных тоже достаточно простая. По сути в ней мы организуем выполнение одного SQL-запроса и получаем его результаты. Обратим внимание, что идентификатор очередной задачи эта функция возвращает в качестве результата, а строку с входными параметрами оптимизации она записывает в переменную setting, которая передаётся функции в качестве аргумента по ссылке:
//+------------------------------------------------------------------+ //| Получение очередной задачи оптимизации из очереди | //+------------------------------------------------------------------+ ulong GetNextTask(string &setting) { // Результат ulong res = 0; // Запрос на получение очередной задачи оптимизации из очереди string query = "SELECT s.expert," " s.from_date," " s.to_date," " j.symbol," " j.period," " j.tester_inputs," " t.id_task," " t.optimization_criterion" " FROM tasks t" " JOIN" " jobs j ON t.id_job = j.id_job" " JOIN" " stages s ON j.id_stage = s.id_stage" " WHERE t.status = 'Queued'" " ORDER BY s.id_stage, j.id_job LIMIT 1;"; // Открываем базу данных DB::Open(); if(DB::IsOpen()) { // Выполняем запрос int request = DatabasePrepare(DB::Id(), query); // Если нет ошибки if(request != INVALID_HANDLE) { // Структура данных для чтения одной строки результата запроса struct Row { string expert; string from_date; string to_date; string symbol; string period; string tester_inputs; ulong id_task; int optimization_criterion; } row; // Читаем данные из первой строки результата if(DatabaseReadBind(request, row)) { setting = StringFormat( "[Tester]\r\n" "Expert=Articles\\2024-04-15.14741\\%s\r\n" "Symbol=%s\r\n" "Period=%s\r\n" "Optimization=2\r\n" "Model=1\r\n" "FromDate=%s\r\n" "ToDate=%s\r\n" "ForwardMode=0\r\n" "Deposit=10000\r\n" "Currency=USD\r\n" "ProfitInPips=0\r\n" "Leverage=200\r\n" "ExecutionMode=0\r\n" "OptimizationCriterion=%d\r\n" "[TesterInputs]\r\n" "idTask_=%d||0||0||0||N\r\n" "%s\r\n", row.expert, row.symbol, row.period, row.from_date, row.to_date, row.optimization_criterion, row.id_task, row.tester_inputs ); res = row.id_task; } else { // Сообщаем об ошибке при необходимости PrintFormat(__FUNCTION__" | ERROR: Reading row for request \n%s\nfailed with code %d", query, GetLastError()); } } else { // Сообщаем об ошибке при необходимости PrintFormat(__FUNCTION__" | ERROR: request \n%s\nfailed with code %d", query, GetLastError()); } // Закрываем базу данных DB::Close(); } return res; }
Значения некоторых входных параметров оптимизации мы пока что для простоты указали в коде напрямую. Так, например, всегда будет использоваться депозит $10000, плечо 1:200, валюта USD и так далее. В дальнейшем, при необходимости, значения этих параметров тоже можно будет брать из базы данных.
Код функции TotalTasks(), возвращающей количество задач в очереди, очень похож на код предыдущей функции, поэтому не будем здесь его приводить.
Сохраним полученный код в файле Optimization.mq5 в текущей папке. Теперь нам надо внести еще несколько небольших правок в созданные ранее файлы, чтобы получить минимально самодостаточную систему.
СVirtualStrategy и СSimpleVolumesStrategy
В этих классах мы уберём возможность задания значения нормированного баланса стратегии и сделаем его всегда имеющим начальное значение, равное 10000. Изменяться он будет теперь только при включении стратегии в группу с заданным нормирующим множителем. Даже если мы хотим запустить один экземпляр стратегии, нам придётся добавить его одного в группу.
Поэтому установим новое значение в конструкторе объектов класса CVirtualStrategy:
//+------------------------------------------------------------------+ //| Конструктор | //+------------------------------------------------------------------+ CVirtualStrategy::CVirtualStrategy() : m_fittedBalance(10000), m_fixedLot(0.01), m_ordersTotal(0) {}
Теперь уберём чтение последнего параметра из строки инициализации в конструкторе класса CSimpleVolumesStrategy:
//+------------------------------------------------------------------+ //| Конструктор | //+------------------------------------------------------------------+ CSimpleVolumesStrategy::CSimpleVolumesStrategy(string p_params) { // Запоминаем строку инициализации m_params = p_params; // Читаем параметры из строки инициализации m_symbol = ReadString(p_params); m_timeframe = (ENUM_TIMEFRAMES) ReadLong(p_params); m_signalPeriod = (int) ReadLong(p_params); m_signalDeviation = ReadDouble(p_params); m_signaAddlDeviation = ReadDouble(p_params); m_openDistance = (int) ReadLong(p_params); m_stopLevel = ReadDouble(p_params); m_takeLevel = ReadDouble(p_params); m_ordersExpiration = (int) ReadLong(p_params); m_maxCountOfOrders = (int) ReadLong(p_params); m_fittedBalance = ReadDouble(p_params); // Если нет ошибок чтения, то if(IsValid()) { ... } }
Сохраним сделанные изменения в файлах VirtualStrategy.mqh и CSimpleVolumesStrategy.mqh в текущей папке.
СVirtualStrategyGroup
В этом классе мы добавили новый метод, который возвращает строку инициализации текущей группы с другим подставленным значением нормирующего множителя. Это значение будет определяться только по окончании прохода тестера, поэтому сразу создать группу с правильным множителем мы не можем. По сути, мы просто подставляем в строку инициализации перед закрывающей скобкой переданное в качестве аргумента число:
//+------------------------------------------------------------------+ //| Класс группы торговых стратегий или групп торговых стратегий | //+------------------------------------------------------------------+ class CVirtualStrategyGroup : public CFactorable { ... public: ... string ToStringNorm(double p_scale); }; ... //+------------------------------------------------------------------+ //| Преобразование объекта в строку с нормировкой | //+------------------------------------------------------------------+ string CVirtualStrategyGroup::ToStringNorm(double p_scale) { return StringFormat("%s([%s],%f)", typename(this), ReadArrayString(m_params), p_scale); }Сохраним сделанные изменения в файлах VirtualStrategyGroup.mqh в текущей папке.
CTesterHandler
В классе сохранения результатов проходов оптимизации мы добавим статическое свойство s_idTask, которому будем присваивать идентификатор текущей задачи оптимизации. В методе обработки пришедших фреймов данных мы добавим его в состав значений, передаваемых в SQL-запрос на сохранение результатов в базу данных:
//+------------------------------------------------------------------+ //| Класс для обработки событий оптимизации | //+------------------------------------------------------------------+ class CTesterHandler { ... public: ... static ulong s_idTask; }; ... ulong CTesterHandler::s_idTask = 0; ... //+------------------------------------------------------------------+ //| Обработка пришедших фреймов | //+------------------------------------------------------------------+ void CTesterHandler::ProcessFrames(void) { // Открываем базу данных DB::Open(); ... // Проходим по фреймам и читаем данные из них while(FrameNext(pass, name, id, value, data)) { ... // Формируем SQL-запрос из полученных данных query = StringFormat("INSERT INTO passes " "VALUES (NULL, %d, %d, %s,\n'%s',\n'%s');", s_idTask, pass, values, inputs, TimeToString(TimeLocal(), TIME_DATE | TIME_SECONDS)); // Добавляем его в массив SQL-запросов APPEND(queries, query); } // Выполняем все запросы DB::ExecuteTransaction(queries); ... }
Сохраним полученный код в файле TesterHandler.mqh в текущей папке.
СVirtualAdvisor
И наконец, последняя правка. В классе эксперта мы добавим автоматическую нормировку стратегии или группы стратегий, которые использовались в советнике при данном проходе оптимизации. Для этого мы воссоздаём группу использованных стратегий из строки инициализации советника и затем формируем строку инициализации этой группы с другим нормирующим множителем, рассчитанным только что по результатам текущей просадки прохода:
//+------------------------------------------------------------------+ //| Обработчик события OnTester | //+------------------------------------------------------------------+ double CVirtualAdvisor::Tester() { // Максимальная абсолютная просадка double balanceDrawdown = TesterStatistics(STAT_EQUITY_DD); // Прибыль double profit = TesterStatistics(STAT_PROFIT); // Коэффициент возможного увеличения размеров позиций для просадки 10% от fixedBalance_ double coeff = CMoney::FixedBalance() * 0.1 / balanceDrawdown; // Пресчитываем прибыль в годовую long totalSeconds = TimeCurrent() - m_fromDate; double fittedProfit = profit * coeff * 365 * 24 * 3600 / totalSeconds ; // Воссоздаём группу использованных стратегий для последующей нормировки CVirtualStrategyGroup* group = NEW(ReadObject(m_params)); // Выполняем формирование фрейма данных на агенте тестирования CTesterHandler::Tester(fittedProfit, // Нормированная прибыль group.ToStringNorm(coeff) // Строка инициализации нормированной группы ); delete group; return fittedProfit; }
Сохраним изменения в файле VirtualAdvisor.mqh в текущей папке.
Запуск оптимизации
Всё готово к запуску оптимизации. В базе данных мы создали общим итогом 81 задачу (3 символа * 3 таймфрейма * 9 критериев). Сначала мы выбрали небольшой интервал оптимизации, длиной всего 5 месяцев, и мало возможных комбинаций оптимизируемых параметров, так как нас интересовала больше работоспособность процесса автоматического тестирования, а не сами результаты в виде найденных комбинаций входных параметров экземпляров рабочих стратегий. Выполнив несколько пробных запусков, и исправив обнаруженные мелкие недоработки, мы получили желаемое. Таблица passes была заполнена всеми результатами проходов с заполненными строками инициализации нормированных групп с одним экземпляром стратегий.
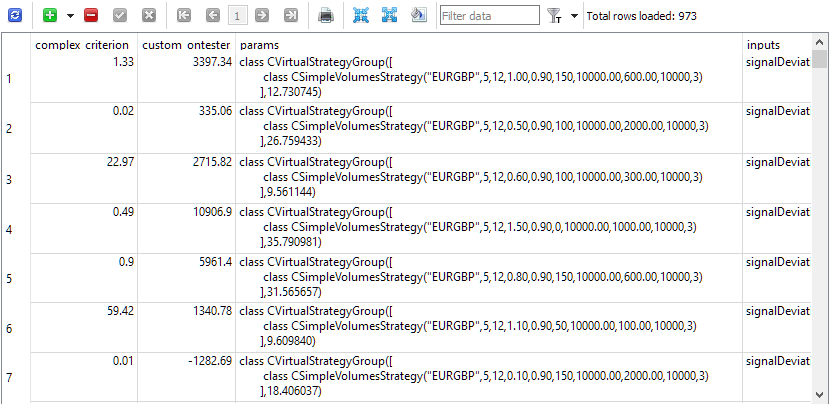
Рис. 1. Таблица passes с результатами проходов.
Когда же схема подтвердила свою работоспособность, можно уже задать ей задачу посложнее. Запустим ту же самую 81 задачу на более длительном интервале и с гораздо большим количеством комбинаций параметров. В этом случае нам придётся подождать некоторое время: 20 агентов выполняют одну задачу оптимизации примерно час. Так что при круглосуточной работе понадобится около 3 суток для завершения всех задач.
После этого проведём вручную отбор из тысяч полученных проходов самых лучших, сформировав соответствующий SQL-запрос, выбирающий такие проходы. Пока что отбор будет идти только по коэффициенту Шарпа, превышающему значение 5. Далее создадим новый советник, который будет на данном этапе играть роль универсального советника. Главная его часть — функция инициализации. В ней мы вытаскиваем из базы данных параметры выбранных лучших проходов, формируем на их основе строку инициализации эксперта и создаём его.
//+------------------------------------------------------------------+ //| Входные параметры | //+------------------------------------------------------------------+ input group "::: Управление капиталом" sinput double expectedDrawdown_ = 10; // - Максимальный риск (%) sinput double fixedBalance_ = 10000; // - Используемый депозит (0 - использовать весь) в валюте счета sinput double scale_ = 1.00; // - Масштабирующий множитель для группы input group "::: Отбор в группу" input int count_ = 1000; // - Количество стратегий в группе input group "::: Прочие параметры" sinput ulong magic_ = 27183; // - Magic input bool useOnlyNewBars_ = true; // - Работать только на открытии бара CVirtualAdvisor *expert; // Объект эксперта //+------------------------------------------------------------------+ //| Expert initialization function | //+------------------------------------------------------------------+ int OnInit() { // Устанавливаем параметры в классе управления капиталом CMoney::DepoPart(expectedDrawdown_ / 10.0); CMoney::FixedBalance(fixedBalance_); string query = StringFormat( "SELECT DISTINCT p.custom_ontester, p.params, j.id_job " " FROM passes p JOIN" " tasks t ON p.id_task = t.id_task" " JOIN" " jobs j ON t.id_job = j.id_job" " JOIN" " stages s ON j.id_stage = s.id_stage" " WHERE p.custom_ontester > 0 AND " " trades > 20 AND " " p.sharpe_ratio > 5" " ORDER BY s.id_stage ASC," " j.id_job ASC," " p.custom_ontester DESC LIMIT %d;", count_); DB::Open(); int request = DatabasePrepare(DB::Id(), query); if(request == INVALID_HANDLE) { PrintFormat(__FUNCTION__" | ERROR: request \n%s\nfailed with code %d", query, GetLastError()); DB::Close(); return 0; } struct Row { double custom_ontester; string params; int id_job; } row; string strategiesParams = ""; while(DatabaseReadBind(request, row)) { strategiesParams += row.params + ","; } // Подготавливаем строку инициализации для эксперта с группой из нескольких стратегий string expertParams = StringFormat( "class CVirtualAdvisor(\n" " class CVirtualStrategyGroup(\n" " [\n" " %s\n" " ],%f\n" " ),\n" " ,%d,%s,%d\n" ")", strategiesParams, scale_, magic_, "SimpleVolumes", useOnlyNewBars_ ); PrintFormat(__FUNCTION__" | Expert Params:\n%s", expertParams); // Создаем эксперта, работающего с виртуальными позициями expert = NEW(expertParams); if(!expert) return INIT_FAILED; return(INIT_SUCCEEDED); }
Для оптимизации мы выбрали интервал, включающий в себя два полных года: 2021 и 2022. Поэтому посмотрим, как выглядят результат универсального советника на данном интервале. Для соответствия максимальной просадки значению 10% мы подберем подходящее значение множителя scale_. Результаты тестирования универсального советника на данном интервале получились следующие:
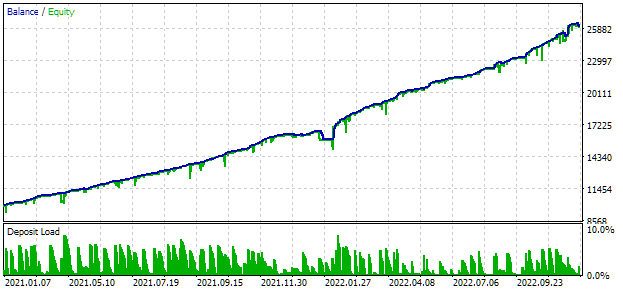
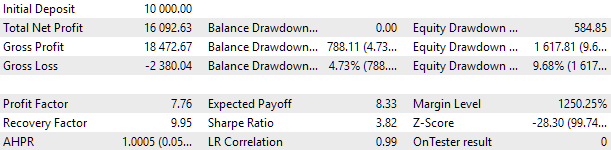
Рис. 2. Результаты тестирования универсального советника за 2021-2022 (scale_ = 2).
В работе этого советника участвовало около тысячи экземпляров стратегий. К этим результатам стоит относиться только как к промежуточным, поскольку мы пока что не выполняли многие действия, направленные на улучшение результата, которые уже рассматривались ранее. В частности, количество экземпляров стратегий по EURUSD получилось заметно больше, чем по EURGBP, из-за чего преимущества мультивалютности пока использованы слабо. Поэтому есть надежда, что потенциал улучшения ещё есть. Реализацией этого потенциала мы и займёмся в дальнейшем.
Заключение
Итак, сделан еще один важный шаг на пути к намеченной цели. Мы получили возможность автоматизировать процесс оптимизации экземпляров торговых стратегий на разных символах, таймфреймах и прочих параметрах. Теперь можно не отслеживать окончание одного запущенного процесса оптимизации, чтобы следом за ним поменять параметры и запустить следующий.
Сохранение всех результатов в базе данных позволяет не беспокоиться о возможном перезапуске оптимизирующего советника. Если по каким-то причинам оптимизирующий советник прервал свою работу, то при следующем запуске он её продолжит, начав со следующей задачи в очереди. Также мы имеем полную картину всех проходов тестера в процессе оптимизации.
Однако, есть ещё большое поле для дальнейшей работы. Мы пока что не реализовано обновление статусов этапов и проектов, реализовано только обновление статусов задач. Не рассмотрена оптимизация проектов, состоящих из нескольких этапов. Также неясно пока, как лучше реализовать промежуточную обработку данных этапов, если для неё потребуется, например, кластеризация данных. Об этом постараемся рассказать в следующих статьях.
Спасибо прочитавшим до конца, до встречи!
 Создаем простой мультивалютный советник с использованием MQL5 (Часть 6): Два индикатора RSI пересекают линии друг друга
Создаем простой мультивалютный советник с использованием MQL5 (Часть 6): Два индикатора RSI пересекают линии друг друга
- Бесплатные приложения для трейдинга
- 8 000+ сигналов для копирования
- Экономические новости для анализа финансовых рынков
Вы принимаете политику сайта и условия использования
Да, сам не ожидал, что всё так просто получится. Сначала изучал Validate, думал, что придётся что-то своё писать на его основе, но потом понял, что можно обойтись более простой реализацией.
Еще раз спасибо за отличную библиотеку!